分享一个录制电脑内部声源的方法
生活中我们可能面对这样一种情况:某一日,忽然在电脑上听到一曲不错的歌感觉耳朵都要怀孕了,于是急匆匆想把它下载到文件,找来找去半天却没找到下载地址,实在扫兴。亦或是地址算是找到了,一点击,弹出需要会员或者费用的提示窗口,感觉一波操作下来已经意兴阑珊。怎么办呢?脑筋一动,可以录音啊!于是又兴匆匆拿了手机开始录制,结果发现有很多杂音,完全影响了歌声的美感。那么有没有一种可以直接在电脑上录音的方法呢?尤其是可以录制来自电脑内部声源的方法,这样便能有效防止外部环境带来的噪音。
当然有,除此之外,今天分享的电脑录音方法还支持录制外部环境的声源,让会议记录稳稳妥妥不会漏。一起来了解一下吧!
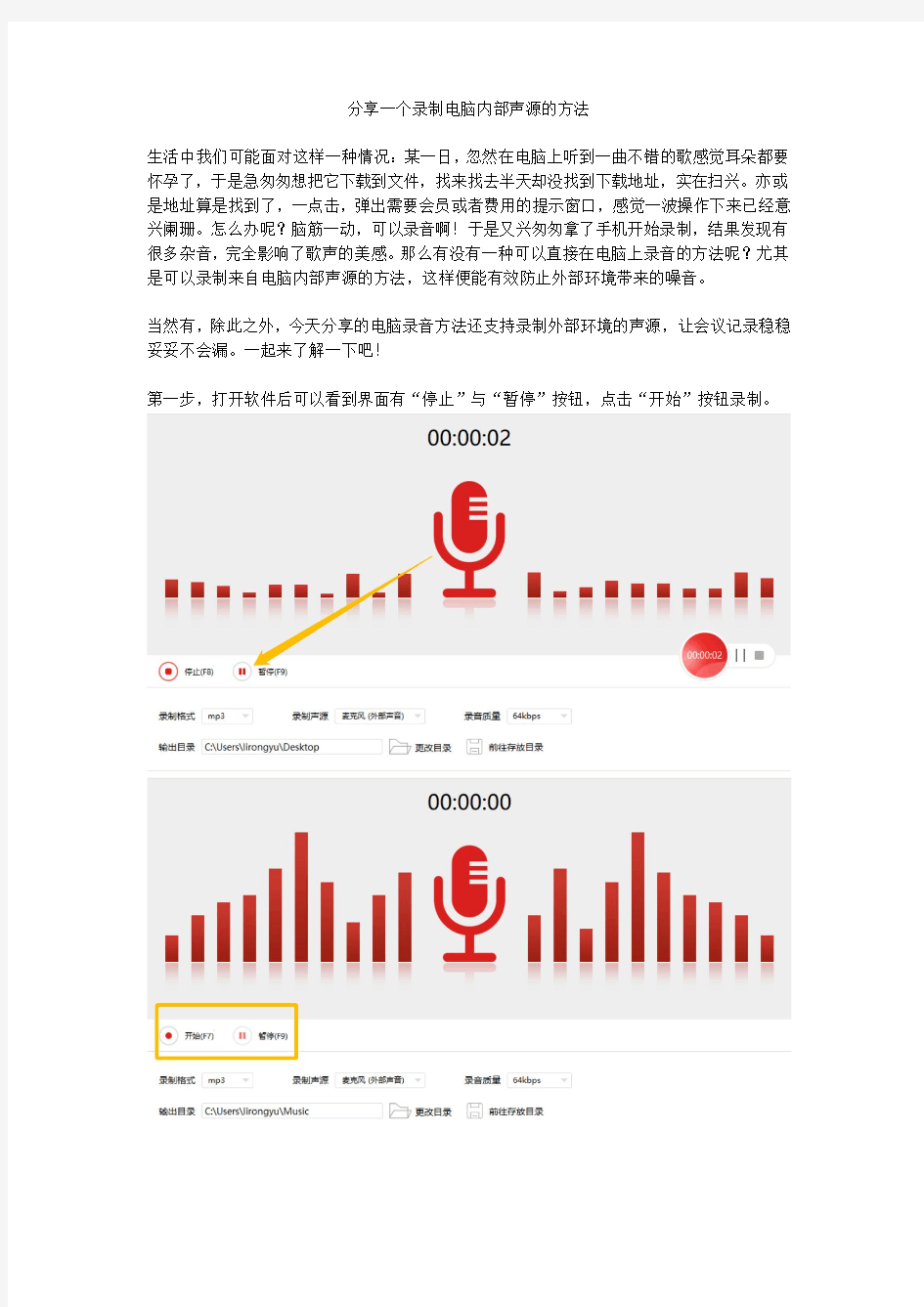
第一步,打开软件后可以看到界面有“停止”与“暂停”按钮,点击“开始”按钮录制。
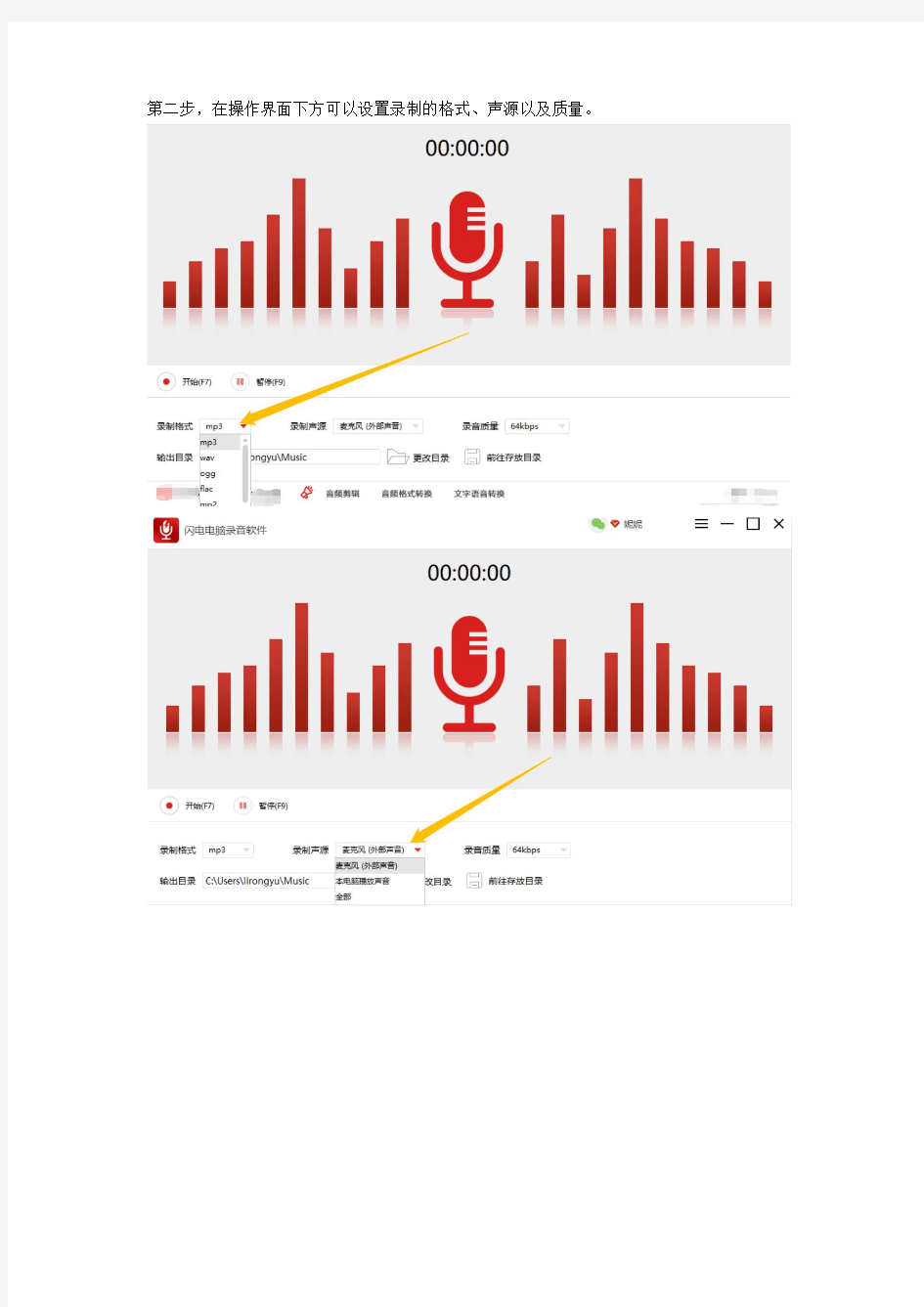
第二步,在操作界面下方可以设置录制的格式、声源以及质量。
第三步,在“输出目录”处点击“更改目录”在弹出窗口设置储存位置。
第四步,录制的时候会出现一个控制小页面,录制完成后点击“停止”,待弹出录制完成的提示窗口即可。
基于MATLAB的声源定位系统摘要 确定一个声源在空间中的位置是一项有广阔应用前景的有趣研究,将来可以广泛的应用于社会生产、生活的各个方面。 声源定位是通过测量物体发出的声音对物体定位,与使用声纳、雷达、无线通讯的定位方法不同,前者信源是普通的声音,是宽带信号,而后者信源是窄带信号。根据声音信号特点,人们提出了不同的声源定位算法,但由于信号质量、噪声和混响的存在,使得现有声源定位算法的定位精度较低。此外,已有的声源定位方法的运算量较大,难以实时处理。 关键词:传声器阵列;声源定位;Matlab
目录 第一章绪论 (1) 第二章声源定位系统的结构 (2) 第三章基于到达时间差的声源定位原理 (3) 第四章串口通信 (5) 第五章实验电路图设计 (8)
第六章总结 (16) 第七章参考文献 (17) 第一章绪论 1.1基于传声器阵列的定位方法简述 在无噪声、无混响的情况下,距离声源很近的高性能、高方向性的单传声器可以获得高质量的声源信号。但是,这要求声源和传声器之间的位置相对固定,如果声源位置改变,就必须人为地移动传声器。若声源在传声器的选择方向之外,则会引入大量的噪声,导致拾取信号的质量下降。而且,当传声器距离声源很远,或者存在一定程度的混响及干扰的情况下,也会使拾取信号的质量严重下降。为了解决单传声器系统的这些局限性,人们提出了用传声器阵列进行声音处理的方法。
传声器阵列是指由一定的几何结构排列而成的若干个传声器组成的阵列。相对于单个传声器而言具有更多优势,它能以电子瞄准的方式从所需要的声源方向提供高质量的声音信号,同时抑制其他的声音和环境噪声,具有很强的空间选择性,无须移动传声器就可对声源信号自动监测、定位和跟踪,如果算法设计精简得当,则系统可实现高速的实时跟踪定位。 传声器阵列的声音信号处理与传统的阵列信号处理主要有以下几种不同: (1)传统的阵列信号处理技术处理的信号一般为平稳或准平稳信号,相关函数可以通过时间相关来准确获得,而传声器阵列要处理的信号通常为短时平稳的声音信号,用时间平均来求得准确的相关函数比较困难。 (2)传统的阵列信号处理一般采用远场模型,而传声器阵列信号处理要根据不同的情况选择远场模型还是使用近场模型。近场模型和远场模型最主要的区别在于是否考虑传声器阵列各阵元因接收信号幅度衰减的不同所带来的影响,对于远场模型,信源到各阵元的距离差与整个传播距离相比非常小,可忽略不计,对于近场模型,信源到各阵元的距离差与整个传播距离相比较大,必须考虑各阵元接收信号的幅度差。 (3)在传统的阵列信号处理中,噪声一般为高斯噪声(包括白、色噪声),与信源无关,在传声器阵列信号处理中噪声既有高斯噪声,也有非高斯噪声,这些噪声可能和信源无关,也可能相关。 由于上述阵列信号处理间的区别,给传声器阵列信号处理带来了极大的挑战。声波在传播过程中要发生幅度衰减,其幅度衰减因子与传播距离成正比,信源到传声器阵列各阵元的距离是不同的,因此声波波前到达各阵元时,幅度也是不同的。 另外,当声音信号在传播时,由于反射、衍射等原因,使到达传声器的声音信号的路径除了直达路径外还存在着多条其它路径,从而产生接收信号的幅度衰减、音质变差等不
文章编号:1006-1355(2012)05-0011-05 车辆噪声源识别方法综述 胡伊贤,李舜酩,张袁元,孟浩东 (南京航空航天大学能源与动力学院,南京210016) 摘要:在车辆产业中,噪声问题越来越突出,噪声源识别方法是车辆噪声控制的重要前提。近年来,车辆噪声源识别的方法得到快速发展,但仍需不断改进和完善。本文对车辆噪声源识别方法进行总结,将车辆噪声源识别方法分为传统方法、基于信号处理方法和基于声阵列技术方法三类,并描述和分析各种识别方法的特点。最后总结全文,展望未来车辆噪声源识别方法。 关键词:声学;车辆;噪声控制;综述;噪声源识别方法 中图分类号:V231.92文献标识码:A DOI编码:10.3969/j.issn.1006-1335.2012.05.003 Reviews of Vehicle Noise Source Identification Methods HU Yi-xian,LI Shun-ming,ZHANG Yuan-yuan,MENG Hao-dong (College of Energy and Power Engineering,Nanjing University of Aeronautics and Astronautics, Nanjing210016,China) Abstract:In the vehicle industry,noise issues have become more evident.Vehicle noise source identification is an important prerequisite for noise control.In recent years,new methods of vehicle noise source identification have been developed,but it is necessary still for them to improve and optimize.The different methods for identifying noise sources are reviewed in this paper.All methods are divided into three categories,i.e.the traditional analysis method,the method based on signal processing,and method based on acoustic array technology.The features of various identification method are described and compared.Finally,some prospects of noise source identification method are given. Key words:acoustics;vehicle;noise control;review;noise source identification method 车辆噪声源识别是指在有许多噪声源或包含许多振动发声部件的复杂声源情况下,为了确定各个声源或振动部件的声辐射的性能,区分噪声源,并加以分等而进行的测量与分析。车辆的噪声主要分为发动机噪声、进排气噪声、传动噪声、轮胎噪声以及其他机械噪声[1,2]。 车辆噪声产生机理不同,针对不同噪声源有不同的识别方法[3]。本文将车辆噪声源识别方法分为三类:一类是传统噪声源识别方法,包括主观识别法、铅覆盖法、分部运行法、表面振速法和近场声压 收稿日期:2011-11-23;修改日期:2012-01-21 项目基金:江苏省普通高校研究生科研创新计划资助(基金编号:CX10B_094Z) 作者简介:胡伊贤(1986-),男,江苏,江苏宿迁泗阳县人,硕士,目前从事车辆噪声与振动控制研究。 E-mail:nuaayixian@https://www.doczj.com/doc/9d16392111.html, 测试法等。这些方法可以简单的对车辆噪声源进行识别。第二类是以信号处理为基础的噪声源识别方法,典型的有时域平均法、相关分析法、相干分析法、倒谱分析法、阶次分析法、小波分析法以及盲源分离法等。其中时域平均与相关分析是描述幅值随时间变化的时域分析方法。相干分析、倒谱分析在频域内对噪声信号进行分析,主要针对平稳噪声信号;阶次分析、小波分析、盲源分离识别方法在时频域内对信号进行分析,一般用于非平稳噪声信号。第三类是以声阵列技术为基础的噪声源识别方法,主要包括声强测试、波束成形以及声全息测试技术,它们主要特征是以全息面来直观全面反映各声源对整车噪声贡献的大小。本文在对各种声源识别方法总结基础上,分析声源识别方法的使用特点、优点与不足,对车辆噪声源识别方法进行总结与展望。
北京大学学报(自然科学版),第41卷,第5期,2005年9月 Acta Scientiarum Naturalium Universitatis Pekinensis,V ol.41,N o.5(Sept.2005) 一种改进的AEDA声源定位及跟踪算法1) 李承智 曲天书2) 吴玺宏 (北京大学视觉与听觉信息处理国家重点实验室,北京,100871;2)E2mail:qutianshu@https://www.doczj.com/doc/9d16392111.html,) 摘 要 开展了基于麦克风阵列的真实声场环境声源定位的工作。针对传统的自适应特征值分 解时延估计算法收敛时间慢、对初值敏感以及不能有效跟踪时延变化等问题,提出了一种改进的 自适应特征值分解时延估计算法,该方法通过改进初值设定方法,有效改善了对时延变化的估计。 另外,通过引入一个基于相关运算的语音检测算法,提高了定位系统的抗噪声能力。实验表明在 真实的声场环境下该算法能够对单个声源的三维空间位置进行实时的定位和跟踪,系统在115m 范围内对声源的定位误差小于8cm,声源位置变化时,系统也能准确跟踪声源的位置。 关键词 麦克风阵列;声源定位;声源跟踪;AE DA算法;LMS算法 中图分类号 TP391 0 引 言 基于麦克风阵列的声源定位是声学信号处理领域中的一个重要问题,在视频会议、智能机器人、鲁棒语音识别等领域有着广泛的应用。近年来,在真实声场环境下抗混响的声源定位算法研究成为研究热点。 声源定位大致分为3类方法。第1类是基于波束成型的方法,该方法可以对单声源进行定位[1,2],也可以对多声源进行定位[3],但存在对初值敏感的问题。另外还需要知道声源和噪声的先验知识,该方法存在计算量大,不利于实时处理等缺点。第2类是基于高分辨率谱估计的方法。该方法在理论上可以对声源的方向进行有效的估计,并且适用于多个声源的情况[4]。但由于该算法是针对窄带信号,因此如要获得较理想的精度就要付出很大的计算量代价。另外这些算法无法处理高度相关的信号,因此混响会给算法的定位精度带来较大影响。第3类方法是基于时延估计的方法。该类算法计算量小,易于实时实现,近年来得到了高度重视。 基于时延估计的算法分为2个部分。第1部分为时延估计,即计算声源到两两麦克风之间的时间差;第2部分为方位估计,即根据时延和麦克风阵列的几何位置估计出声源的位置,其中时延估计最为关键。互相关法是最常用的一种时延估计算法,但是它在混响较大的情况下性能下降很多。1982年,D1H.Y oun等[5]提出了最小均方(LMS,Least Mean Square)时延估计算法,其性能和互相关法基本相当。布朗大学于1995年实现了一个实时声源定位系统[6],该系统采用相位变换的时延估计算法和线性插值方位估计算法,在混响较小的情况下能够准确的估计时延但在混响较大情况下误差较大。1997年新泽西州立大学采用相位变换法作为时 1)国家自然科学基金(60305004)中国博士后科学基金(2003033081)资助项目 收稿日期:2004208223;修回日期:2004211211 908
Word文档可进行编辑 近场声源定位算法研究 近场声源定位算法研究 引言 近年来,基于麦论文联盟克风阵列得声源定位技术快速进展,同时在多媒体系统,移动机器人,视频会议系统等方面有广泛得应用.例如,在军事方面,声源定位技术能够为雷达提供一个非常好得补充,不需要发射信号,仅靠接收信号就能够推断目标得位置,因此,在定位得过程中就可不能受到干扰和攻击.在视频会议中,讲话人跟踪可为主意拾取和摄像机转向操纵提供位置信息,使传播得图像和声音更清楚.声源定位技术因为其诸多优点以及在应用上得广泛前景成为了一个研究热点.
现有得声源定位方法要紧分为三类:基于时延可能得定位方法、基于波束形成得定位方法和基于高分辨率空间谱可能得定位方法.基于时延可能得定位方法[1]要紧步骤是先进行时刻差可能,也确实是先计算声源分不到达两个麦克风得时刻差,然后依照那个时刻差和麦克风阵列得几何结构可能出声源得位置.该类方法得优点是计算量较小,容易实时实现,在单声源定位系统中差不多得到广泛应用.基于波束形成得定位方法[2]不需要直截了当计算时刻差,而是通过对目标函数得优化直截了当实现声源定位.但由于实际得应用环境中,目标函数往往存在多个极值点,因此如何优化复杂峰值得搜索过程就成为了一个重点.基于高分辨率得空间谱可能得声源定位算法,例如宽带得music(multiplesignalclassification)方法[3]和最大似然方法[4],因其能够同时定位多个声源同时具有比较高得空间分辨率,受到了广泛得关注.
空间谱可能得方法源于阵列信号处理,其中得多重信号分类(music)算法在特定条件下具有非常高得可能精度和分辨力,从而吸引了大量得学者对其进行深入得分析与研究.WwwcOm但与阵列信号处理不同得是,在声源定位中,声源在大多数情况下是位于声源近场得.为了解决这一近场咨询题,许多学者针对传统得信号模型提出了改进算法,asano等人将传统时域得music[5,6]算法应用在频域中,提出了一种基于子空间得近场声源算法[7].下面来看一下近场得声源信号模型. 1近场声源信号模型 传统得阵列信号处理大多是基于远场模型得平面波信号得假设,然而在声源定位得实际应用中,有非常多情况是处于声源近场得[8],例如视频会议,机器人仿真等.同时又由于麦克风阵列阵元拾音范围有限,更多得情况下定位也处于近场范围内,如今信源到达各麦克风阵元得信
如何用Adobe Audition录制电脑内或网页上的音乐我这里分享一下如何使用Adobe Audition 3.0录制电脑内或网页上的音乐。 方法/步骤 第一步: 启用windows系统内部的“立体声混音” 1、打开“控制面板”,打开“声音”选项。 2、在“声音”对话框里,选择“录音”选项卡,一般来说,上面只有“线路输入”和“麦克风”二个选项,并没有“立体声混音”选项,要打开“立体声混音”选项,在空白处点击右键,选择“显示禁用设备”,这时就会出现“立体声混音”选项;右键点击“立体声混音”,选择“属性”,打开“属性”对话框。 3、在“属性”对话框里,在下面的设备用法选择“启用”,点“确定”后返回声音对话框。 4、选择“立体声混音”项,点击下方的“设为默认值”,点“确定”。 到了这里,建议“重启电脑”,让刚才的设置生效。 5、电脑重启后,打开“控制面板”,打开HD声卡选项,选择“麦克风”选项,点击属性。 6、在“级别”属性里设置音量大小(一般设置到最大),点击旁边的按钮,打开麦克风增强对话框。 7、拉动滑竿,调节增强幅度(一般+10或+20即可)关闭对话框。 至此,所有设置已经完毕,开始你的精彩录音吧。 第二步: 让Adobe Audition设备和系统匹配
打开Adobe Audition,在“编辑”菜单栏中找到“音频硬件设置”,点击“控制面板”,输出端口选择“扬声器”,输入端口有两个,一个是“麦克风”,就是从电脑外部输入声音,如个人录音,唱歌等;另一个就是“立体声混音”,可以输入电脑内部(或者网页上)的声音。可以根据需要选择。 第三步: 开始录音 1、打开Adobe Audition,点击新建波形,采样率为44100。 2、然后点击“录音”红按钮。可能会提示“至少必须有一条备用录轨”,这是点击音轨1上的字母“R”就可以了。 3、点开你要录音的音乐文件,录音就开始啦。第四步: 后处理 1、录完的音可能会音量比较小,这是可以在Adobe Audition左边的“效果”栏里找到“振幅和压限”-“放大”,输入放大数值,就完成增大音量,如果还不合适,可继续调整。 2、然后点击“效果”-“混响”-“完美混响”,把它拖到文件上,完成第五步: 保存 1、点击“文件”-“导出”-“混缩音频”,格式一般选择MP3,因为其他格式的文件都大大了。 2、然后点击“选项”,选择320bps,确定,保存完成
阵列信号识别声源相关总结
1 阵列信号识别声源的方法归类 噪声源的识别方法可大致分为3类:传统的噪声源识别方法,如选择运行法、铅覆盖法及数值分析方法等,传统方法虽然陈旧、使用效率低,但目前仍有许多企业在应用。例如,为了测量汽车高速行驶时的车内噪声,需要将车门缝隙用铅皮封住;第二类,利用现代信号处理技术进行噪声源识别,如声强法、相干分析、偏相干分析适合与很多场合,能解决许多一般问题。如评价某些噪声源、某些频谱对场点(模拟人头耳朵处),这时采用相干分析就可以解决。第三类,利用现代图像识别技术进行振动噪声源识别,其分为两种,一种是近场声全息方法(NAH),一种是波束形成方法(Beamforming)。 相比于传统识别和现代信号处理方法,声阵列技术具有测试操作简单、识别效率高,以及可对声源进行量化分析并对声场进行预测等优点。 1.1 声全息方法 近场声全息技术经过很长时间的发展已经日趋成熟,广泛应用于近距离测量和对中低频噪声源的识别。 声全息方法,其基本原理是首先在采样面上记录包括声波振幅和相位信息的全息数据,然后利用声全息重建公式推算出重建面上的声场分布。该方法一方面可以获得车外声场分布的三维信息,另一方面可以进行运动车辆车外噪声源识别的研究,而且还具有在进行噪声测试时,抗外界干扰强的特点。按声场测量的原理可分为常规声全息、近场声全息和远场声全息三种。 常规声全息,全息数据是在被测物体的辐射或散射场的菲涅尔区和弗朗和费区(即全息接收面与物体的距离d远大于波长λ的条件下)采用光学照相或数字记录设备记录的,因为受到自身实用条件的限制,根据全息测量面重建的图像受制于声波的波长。它只能记录空间波数小于等于2π/λ的传播波成分,而且其全息测量面只能正对从声源出来的一个小立体角。因此,当声源辐射场具有方向性时,可能丢失声源的重要信息。并且通过声压记录得到的全息图,只能用于重建声压场,而不能得到振速、声强等物理量。 远场声全息NAH(Near-field Acoustical Holography),其特点是全息记录平面与全息重建平面的距离d远远大于声波的波长λ,即其全息数据是在被测声源产生声场的辐射或散射声场的菲涅尔区和弗朗和费区获得的。这种方法通过测量离声源很远的声压场来重建表面声压及振速场,由此可预报辐射源外任意一点的声压场、振速场、声强矢量场。由于进行全息数据记录的表面距离被测声源面较远,而全息记录的表面的面积是有限的。所以声源发出的声波有很大一部分不
录制电脑系统声音 网上有很多录音软件,自己是一个爱好音乐的家伙。每当听到自己喜欢的曲子,但又不知道歌曲的名字的时候,我通常喜欢把他给录下来然后再慢慢找歌曲的名字,或者直接收藏起来以后慢慢听,慢慢回味! 至于怎么录制电脑上的声音,这对于部分人来说是个头疼的问题,有的人录音只能录到从麦克风的声音,电脑上的录不到,不然就是录到的声音非常的小,音质更不要谈了。 今天给大家介绍款自己平常最喜欢用的一款录音软件,一款功能非常强大的软件。 录制的音乐文件可以说是高保真的了。你听到的是什么录下来就是什么可以说是毫无差别 软件名称:Moo0 V oiceRecorder 下载地址:https://www.doczj.com/doc/9d16392111.html,/html/2160.html 这款软件支持windows xp/7/8 64位和32位均兼容 这款软件有个功能我非常的喜欢,就是无声音时暂停。这个是什么意思,不用我说了 下面来说怎么用这款软件,首先是安装,怎么安装很简单,直接下一步就好了。、 安装好之后,首先打开软件点击软件界面上的 Setting= 设置,选择MP3....的那个选项,这个是设置录音的音频文件音质的,最高是320kbps的。
然后返回到主页面,选择下录制的类型 增益这个功能呢,顾名思义..你放这段声音的时候,电脑系统所开的声音多大录下来的就是多大,如果使用这个增益呢,可以增强录下来的音乐文件播放声音的大小.建议选择100%就是一倍喽!
之后把“无声时暂停”这个打上勾就可以了,之后点击开始录音就可以了。 如果是录制电脑所发出的声音,点击开始之前,请关掉电脑上任何所能发出声音的东西。(不是你要录制的声音) 之后打开你要录制的声音点击播放就可以了,播放完成后点击停止就可以了。 点击软件上的“Open”就可以找到录音文件存放地址了。 忘了说了,这个软件还可以选择录音文件的歌曲噢!还有很多功能自己可以去发现和尝试 这里推荐个不错的dj舞曲网站,https://www.doczj.com/doc/9d16392111.html, 多多听舞曲网,网址很好记吧! 这个网站里的歌曲全部都可以免费下载的哦,下载的歌曲都是MP3的,音质绝大部分都是320kbps的,还有一小部分是无损音乐噢! 本文转载至:https://www.doczj.com/doc/9d16392111.html,
笔记本电脑内录(如录制系统声音或在线音频)方法:使用Virtual Audio Cable 现象原因:多数是由于你的笔记本不支持内录。(声音控制属性的选项中只提供了“麦克风”一个选项。) 这是由于声卡芯片厂商迫于RIAA(Recording Industry Association ofAmerica,美国唱片工业联合会)的压力,及维护音乐版权防止内录的需要,在新推出的声卡上对音频模块的功能做了限制,无法直接实现混音和内录的功能。以前的台式机上是有Stereo Mix 这个内录的。 声卡无混音,无法内录的解决方案: 用Virtual Audio Cable 4.10虚拟声卡软件能够解决这个问题。 推荐软件:Virtual Audio Cable 4.10 下载地址 https://www.doczj.com/doc/9d16392111.html,/demo/virtualaudiocable410fullceccaeinovoice.zip 简介: Virtual Audio Cable是一款在Windows之下采用WDM驱动架构进行音频讯号流传送的的虚拟仿真接口,透过它可以在不同的应用程序间指定传送音频讯号流,因此名为”Virtual Cables”(虚拟串线),此虚拟接口的最大优点节省硬件成本,其传的讯号都是数字,所以不会有讯号污染或衰减的问题。 A. 安装软件: 该软件由两个部分组成 1.Audio Repeater(设置虚拟通道)
2.Control panel(设置线路的,默认即可) B. 修改“调整音频属性”: 右键电脑右下角的小喇叭点击“调整音频属性”把音频中“声音播放”和“录音”的默认设备都设为“Virtual Cable 1”。 这时候重新再打开一个音频你会发现已经听不见系统的声音,貌似是音频传输到哪个虚拟通道里了,接下来“设置的权利”就转到了Virtual Audio Cable(Audio Repeater)。 C. 修改“Audio Repeater”: 打开Virtual Audio Cable的Audio Repeater,将“Wave In”设为“Virtual Cable 1”,“Wave Out”设为电脑原本的输出设备(一般为电脑自带的某个设备例如“XXX HD Audio output),此时再重新打开一个音频便可听见声音了(注:该软件并不带录音功能,到此仅为设置该软件完毕)。
Abstract One of the main purposes of having a humanoid robot is to have it interact with people. This is undoubtedly a tough task that implies a fair amount of features. Being able to understand what is being said and to answer accordingly is certainly critical but in many situations, these tasks will require that the robot is first in the appropriate position to make the most out of its sensors and to let the considered person know that the robot is actually listening/talking to him by orienting the head in the relevant direction. The “Sound Localization” feature addresses this issue by identifying the direction of any “loud enough” sound heard by NAO.Related work Sound source localization has long been investigated and a large number of approaches have been proposed. These methods are based on the same basic principles but perform differently and require varying CPU loads. To produce robust and useful outputs while meeting the CPU and memory requirements of our robot, the NAO’s sound source localization feature is based on an approach known as “Time Difference of Arrival”. Principles The sound wave emitted by a source close to NAO is received at slightly different times on each of its four microphones. For example, if someone talks to the robot on his left side, the corresponding signal will first hit the left microphones, few milli-seconds later the front and the rear ones and finally the signal will be sensed on the right microphone (FIGURE 1). These differences, known as ITD standing for “interaural time differences”, can then be mathematically related to the current location of the emitting source. By solving this equation every time a noise is heard the robot is eventually able to retrieve the direction of the emitting source (azimutal and elevation angles) from ITDs measured on the 4 microphones. FIGURE 1Schematic view of the dependency between the position of the sound source (a human in this example) and the different distances that the sound wave need to travel to reach the four NAO’s micro-phones. These different distances induce times differences of arrival that are measured and used to compute the current position of the source. KEY FEATURE SOUND SOURCE LOCALIZATION
0 前言 声音是我们所获取的外界信息中非常重要的一种。不同物体往往发出自己特有的声音,而根据物体发出的声音,人们可以判断出物体相对于自己的方位。有些应用场合,人们需要用机器来完成声音定位这个功能,并且往往要求定位精度比较高。2003年的美伊战争期间,人民网、CCTV网站的军事频道、国防在线等网站均报道了装配于美军的狙击手探测技术,这项技术其中一部分就包含了声源定位技术。 声源定位作为一种传统的侦察手段,近年来通过采用新技术,提高了性能,满足了现代化的需要,其主要特点是: 1)不受通视条件限制。可见光、激光和无线电侦察器材需要通视目标,在侦察器材和目标之间不能有遮蔽物,而声测系统可以侦察遮蔽物(如山,树林等)后面的声源。 2)隐蔽性强。声测系统不受电磁波干扰也不会被无线电侧向及定位,工作隐蔽性较强。 3)不受能见度限制。其他侦察器材受环境气候影响较大,在恶劣气候条件下工作时性能下降,甚至无法工作。声测系统可以在夜间、阴天、雾天、和下雪天工作,具有全天候工作的特点。 以下对美军装备的报道来自于《“巴格达之战”考验英军巷战武器装备》一文,该文刊登于2003年4月8日国防在线美伊战争专题。“狙击手声测定位系统通过接收并测量膛口激波和弹丸飞行产生的冲击波来确定狙击手的位置,通常仅能探测超音速弹丸。这种系统有单兵佩挂型、固定设置型和机动平台运载型。美国BBN系统和技术公司的声测系统,通过测量弹丸飞行中的声激波特性来探测弹丸并进行分类。该系统为固定设置型,采用2个置于保护区两侧的传声器阵列或6个分布在保护区内的单向传声器。传声器通过电缆或射频链路与指挥节点相连。为了准确定位,需事先确定传声器的距离,精度要在1米以内。该系统可探测到90%的射击,定位精度为方位1.2°、水平3°。此外,美国的“哨兵”和“安全”有效控制城区环境安全系统均是采用声测定位技术的反狙击手系统。
怎么录制电脑播放的声音或音乐 很多人都会有这样的经历,就是在某个网站中听到的音频很是喜欢,但是无法下载,有没有折中的方法可以录制下来呢?怎么录制电脑播放的声音或音乐呢?小编为大家介绍一下录制电脑播放的声音或音乐的具体操作步骤,下面大家跟着小编一起来了解一下吧。 录制电脑播放的声音或音乐 在百度上搜索“楼月免费MP3录音软件”并进行下载。下载完成后按提示进行安装,安装后界面如下图所示: Win7,Win8实现录制电脑内部播放的声音
1点击软件主界面上的“文件”,“设置”菜单,在弹出窗口中选中“仅录制从电脑播放的声音“,然后点击确定按钮。如下图所示: 2在电脑上播放您需要录制的音乐或其它声音(如电影对白等)。 3点击软件主界面上的”开始“按钮开始录制。想停止录音时,点击”停止“按钮即可。 4点击软件主界面上的”查看“按钮打开MP3文件保存的文件夹,您可以看到刚才录制下来的mp3文件。 XP系统上实现录制电脑内部播放的声音
XP系统上要录制电脑内部播放的声音,是无法在软件设置界面上进行设置的。您需要首先双击屏幕右下角的音量图标,然后点击“选项”,“属性”,如下图所示: 选择Realtek HD Audio Input。如果此时您打开的窗口上没有此选项也没关系,只要下方第3步中的“录音”项能够选中即可。也就是说,可能您的电脑上这一步是不需要操作的。
选择“录音”项,并勾选上所有音量控制项。 选择“立体声混音”,然后点击右上角的关闭按钮即可。如下图所示: 5同Win7上的录制方法一样,利用楼月免费MP3录音软件进行录制即可。此时录制到的声音就是电脑上播放的声音了。
声源定位(李子文) #include
lizard2 = atan(b/a); if(acos(d/sqrt(pow(a,2)+pow(b,2)))+lizard2 < R/2) lizard1 = acos(d/sqrt(pow(a,2)+pow(b,2)))+lizard2; else lizard1 = lizard2 - acos(d/sqrt(pow(a,2)+pow(b,2))); r = (pow(x1,2)+pow(y1,2)-pow(c*dt1,2))/(2*(x1*cos(lizard1)+y1*sin(lizard1)+c*dt1)); cout << "声源坐标为:("< 毕业设计说明书基于麦克风阵列的声源定位技术 学生姓名:学号: 学院: 专业: 指导教师: 2012年 6 月 基于麦克风阵列的声源定位技术 摘要 声源定位技术是利用麦克风拾取语音信号,并用数字信号处理技术对其进行分析和处理,继而确定和跟踪声源的空间位置。声源定位技术在视频会议、语音识别和说话人识别、目标定位和助听装置等领域有着重要的应用。传统的单个麦克风的拾音范围很有限,拾取信号的质量不高,继而提出了用麦克风阵列进行语音处理的方法,它可以以电子瞄准的方式对准声源而不需要人为的移动麦克风,弥补单个麦克风在噪声处理和声源定位等方面的不足,麦克风阵列还具有去噪、声源定位和跟踪等功能,从而大大提高语音信号处理质量。 本文主要对基于多麦克风阵列的声源定位技术领域中的基于时延的定位理论进行了研究,在此基础上研究了四元阵列、五元阵列以及多元阵列的定位算法,并且分别对其定位精度进行了分析,推导出了影响四元、五元阵列目标方位角、俯仰角及目标距离的定位精度的一些因素及相关定位方程,并通过matlab仿真软件对其定位精度进行了仿真;最后在四元、五元阵列的基础上,采用最小二乘法对多元阵列定位进行了计算;通过目标计算值和设定值对比,对多元阵列的定位精度进行了分析,并得出了多元阵列的目标定位的均方根误差。 关键词:麦克风阵列,声源定位,时延,定位精度,均方根误差 Based on Microphone Array for Sound Source Localization Research Abstract Sound source positioning technology is to use the microphone to pick up voice signals, and digital signal processing technology used for their analysis and processing , Then identify and track the spatial location of sound source. Acoustic source localization techniques have a variety of important uses in videoconferencing, speech recognition and speaker identification, targets’ direction finding, and biomedical devices for the hearing impaired. The pick up range of traditional single microphone is limited, the signal quality picked up is not high, then a voice processing methods with the microphone array has been proposed . It may be electronically aimed to provide a high-quality signal from desired source localization and doe s not require physical movement to alter these microphones’ direction of reception. Microphone array has the functions of de-noising, sound source localization and tracking functions, which greatly improved the quality of voice signal processing. The article discusses some issues of sound source localization based on microphone array, On the basis ,it studies a four element array,five element array and an multiple array positioning algorithm, then the positioning precision is analyzed. Derived some factors of the azimuth and elevation angle targets the target range of the estimation precision affected and positioning equation. And through MATLAB simulation software for its positioning accuracy of simulation. finally ,based on four yuan, five yuan of array, using the least square method ,the multiple array localization were calculated. Through the contrast of the target value and set value, multiple array positioning accuracy is analyzed, and the of diverse array target positioning. Keywords: Microphone Array, Sound Source Localization, Time Delay, Positioning precision, root mean square error #include D=c*t1*(pow(x2,2)+pow(y2,2)-pow(c*t2,2))-c*t2*(pow(x1,2 )+pow(y1,2)-pow(c*t1,2)); a2=atan(B/A); if((acos(D/sqrt(pow(A,2)+pow(B,2)))+a2) 用CoolEdit软件内录电脑音频方法与 技巧 有时候我们还是会需要将电脑内部的一些声音转录成我们需要的音频文件,比如录制网络电台节目等等。今天我们介绍常用音频处理软件CoolEdit内录电脑音频的方法和技巧。 下面我们开始按步骤说明如何使用Cool Edit进行系统内录。 一、电脑音频设置准备 首先,双击位于桌面右下脚的“音量”图标,即上图中最左边的那个小喇叭。 图1 双击之后弹出“音量控制”菜单,点击“选项”选择“属性”。 图2 点选“录音”,然后只在“Stereo Mix”前面点上勾,之后“确定”。 图3 “确定”之后会弹出上图所示菜单,点上“选择”之前的勾,然后音量随意调节到比较偏下的位置,录音的时候再做具体调试。 图4 以上是对于电脑本身的一些录入设定,接下来就该打开Cool Edit使用软件了。 二、用CoolEdit完成内录 单击上图中箭头圈示的“R”,其意义在于定义音轨1为录音轨。 图5 界面左下角为录放系统操作键盘,其原理、图标以及用途都和我们平时所用的播放器操作键盘无异,相信大家都能很自然的使用。点击录音键(箭头所指)就可以开始录音了。 图6 先点击开始录音,然后播放需要录制的音乐,音轨上就会开始波纹了,波纹的大小就上所录音乐的声音大小,录音不受任何外界影响,同时也和播放器的音量大小无关,能影响它的,只有图4中的“音量”调节。 提醒大家特别注意一点:在录音过程中避免触动系统内部的一些声响,比如系统出错的声音,清理回收站的声音以及窗口缩放的声音等等(特别是QQ和MSN此类聊天系统的提示音,最好暂时关闭) ,这些声音也是会被录到的。 图7 歌曲播放完毕以后就可以停止录音了。双击图7中的红色音轨部分,进入到上图中的单轨道编辑模式,按住左键拉选开头部分空白的波纹(就是开始录音后但是还没开始播放音乐这段时间的空白),右键选择“剪切”。结尾的部分如果有多余的空白也是同样处理。基于麦克风阵列的声源定位技术毕业设计
声源定位源程序
用CoolEdit软件内录电脑音频方法与技巧
相关主题
文本预览