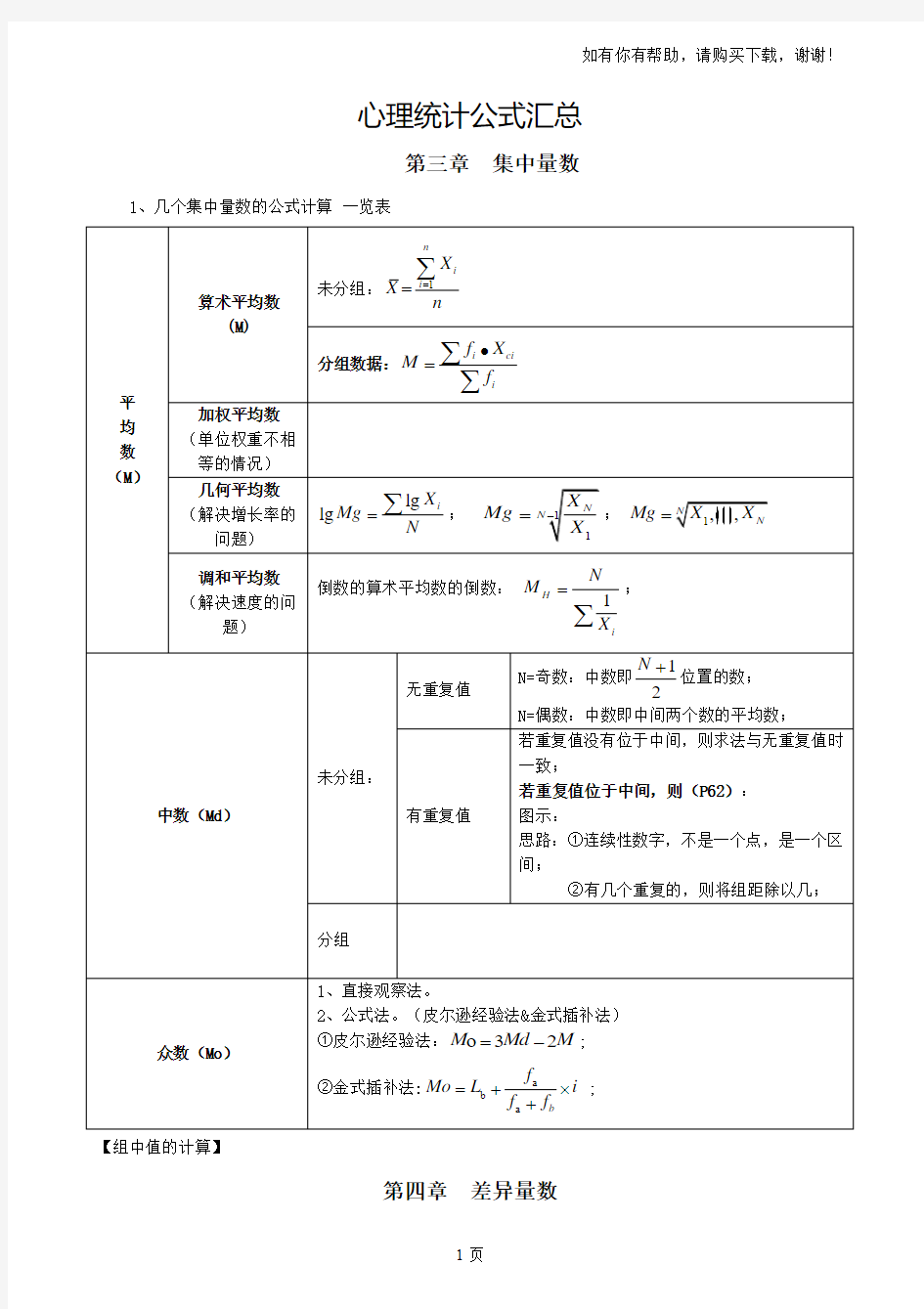

心理统计公式汇总
第三章集中量数1、几个集中量数的公式计算一览表
平均数(M)
算术平均数
(M)
未分组:1
=
n
i
i
X
X
n
=
∑
分组数据:i ci
i
f X
M
f
?
=
∑
∑
加权平均数
(单位权重不相
等的情况)
几何平均数
(解决增长率的
问题)
lg
lg i
X
Mg
N
=
∑
;1
1
N
N
X
Mg
X
-
=;
1
,,
N
N
Mg X X
=
调和平均数
(解决速度的问
题)
倒数的算术平均数的倒数:
1
H
i
N
M
X
=
∑
;
中数(Md)
未分组:
无重复值
N=奇数:中数即
1
2
N+
位置的数;
N=偶数:中数即中间两个数的平均数;
有重复值
若重复值没有位于中间,则求法与无重复值时
一致;
若重复值位于中间,则(P62):
图示:
思路:①连续性数字,不是一个点,是一个区
间;
②有几个重复的,则将组距除以几;
分组
众数(Mo)
1、直接观察法。
2、公式法。(皮尔逊经验法&金式插补法)
①皮尔逊经验法:o32
M Md M
=-;
②金式插补法:a
b
a b
f
Mo L i
f f
=+?
+
;
【组中值的计算】
第四章差异量数
百分位数(点) 100b
p b
P
N F P L i f
?-=+?; 百分等级
未分组:(10050)
100R R P N
-=-
分组:()100
[]b R b f X L P F N i
-=
?+ 四分位差
31
=
2
Q Q Q -; (Q3与Q1即P25与P75) 平均差
未分组:..i
i
X
A D n
n
X x
-=
=
∑∑
分组:..f
x
A D n
=
∑;(IxI 为各组中点值对平均数离差的绝对值)
方差与 标准差
未分组:①
2
2
2
()s
X X N
N
x
-=
=
∑∑;
②原始数据代入:
2
2
2
2
2
2
()
(
)s
N N
X
X X X
N
N
-=
-=
∑∑∑∑
分组:
2
2
2
()c f X X f
N
N
x
s
-=
=
∑
∑
总方差与总标准差:
2
2
2;()i
i
i i
T
i T
i i
N s
N d s
d X
X N
+=
=-∑∑∑
标准差
的应用 差异
系数
标准
分数
第五章 相关关系
相关系数
适用资料
公式
积差相关(皮尔逊)①成对的数据(≥30对);
②连续变量;③正态双变
量;④线性关系;
r
x y
xy
N s s
=
∑
(N为成对数,x、y为离均差);
原始值代入:
22
22
()()
X Y
XY
N
r
N N
X Y
X Y
-
=
-?-
∑∑
∑
∑∑
∑∑
等级相关斯皮尔曼
等级相关
(两列)
两列具有线性关系的等级
或顺序变量;
1、等级差数法:
2
2
6
=1
(1)
r R
N
D
N
-
-
∑
(D为对偶等级之差)
2、等级序数法:
4
3
=(1)
1(1)
r X Y
R
N
N N N
R R
??
?-+
??
-+
??
∑
3、出现相同等级时:
其中,
3
2
-N
=
12X
N
x C
-
∑∑;2(1)
12
X
n n
C-
=
∑∑
(N为成对数据数目,n为各列变量相同等级数)
肯德尔等级相
关(多列)
肯德尔W系数(和谐系数):
①K个评分人评N个对象,
分析K个评分人的一致性
程度;
②同一个人先后K次评价
N个对象,分析其前后一致
性;
1、基本公式:
23
s
1
()
12
W
K N N
=
-
;(K为评价者数,N
为被评对象数)
2
i
22
123(1)
(1)1
N
W
K N N N
R+
=-
--
∑
; (
i
R为评价对象获得的K
个评价者给的等级之和,
22
2
()
()i i
i i
R R
s R R
N N
=-=-
∑∑
∑∑);
2、相同等级时:
23
s
=
1
()
12
W
K N N K T
--∑
;其中,s的意义同上,T如
下:
3
12
n n
T
-
=
∑∑;(n为相同等级数)
位值平均数计算公式 1、众数:是一组数据中出现次数最多的变量值 组距式分组下限公式:002 110m m d L M ??+??+= 0m L :代表众数组下限; 1100--=?m m f f :代表众数组频数—众数组前一组频数 0m d :代表组距; 1200+-=?m m f f :代表众数组频数—众数组后一组频数 2、中位数:是一组数据按顺序排序后,处于中间位置上的变量值。 中位数位置2 1+=n 分组向上累计公式:e e e e m m m m e d f S f L M ?-∑+=-12 e m L 代表中位数组下限; 1-e m S :代表中位数所在组之前各组的累计频数; e m f 代表中位数组频数; e m d 代表组距 3、四分位数:也称四分位点,它是通过三个点将全部数据等分为四部分,其中每部分包含 25%,处在25%和75%分位点上的数值就是四分位数。 其公式为:4 11+=n Q 212+=n Q (中位数) 4)1(33+=n Q 实例 数据总量: 7, 15, 36, 39, 40, 41 一共6项 Q1 的位置=(6+1)/4=1.75 Q2 的位置=(6+1)/2=3.5 Q3的位置=3(6+1)/4=5.25 Q1 = 7+(15-7)×(1.75-1)=13, Q2 = 36+(39-36)×(3.5-3)=37.5, Q3 = 40+(41-40)×(5.25-5)=40.25 数值平均数计算公式 1、简单算术平均数:是将总体单位的某一数量标志值之和除以总体单位。 其公式为:n x n x x x X n ∑=??++=21 2、加权算术平均数:受各组组中值及各组变量值出现的频数(即权数f )大小的影响,
心理统计学公式总结 一、集中量 1.算术平均数:X??X X??fXNNNi ?n1)2fmd? 2.中位数:Md?Lmd?( 3.众数:M??3Md?2X 4.加权算术平均数:XW? 5.几何平均数:Xg? 6.调和平均数:XH? 二、差异量 1.四分差:QD?N?WX ?W X1X2?XN N1?XQ3?Q1 2 2X?X?2.平均差:MD?N3.标准差:?X?? N24.方差:?2X? ?N5.差异系数:CV??XX100% 6.百分等级分数:PR??Fb???f(X?Lb)?100?N i?7.标准分数:Z? X?X?X 三、相关量1.积差相关系数:r??XY?nXY n?x?y6?D2n(n2?1) 2.斯皮尔曼等级相关系数:rR?1?2?23.肯德尔和谐系数:rW? 式中:SSR??R? 123nK(n?n)12SSR4.点二列相关系数:rpb?Xp?Xq?tpq 5.二列相关系数:
rb?Xp?Xqpq ?tY6.多系列相关系数:rs??[(Y?Y)X] (Y?Y)??pLH2LHt7.四分相关系数:rt?cos(180?bc1?ad) 8.Φ相关系数:r??ad?bc(a?b)(a?c)(b?d)(c?d) 9.列联相关系数:c? 四、推断统计?2 N??2XXn?X1.二项分布概率:P?Cpq n2.二项分布平均数:??np 3.二项分布标准差:??npq Ne12??(X??)22?24.正态分布曲线:Y??2? 5.标准正态分布曲线:Y?e?Z22 6.平均数抽样分布标准误:?X??n??Xn?1 五、总体平均数的显著性检验 1.?已知:Z?X??? nX??2.?未知但n>30:Z??X n?1 3.?未知但n≤30:t?X???Xn?1 六、平均数差异的显著性检验 1.相关大样本:Z?X1?X2?2X1??2X2 ?2r?X1?X2n?1 df?n?1 2.相关小样本:t?X1?X2?2X1??2X2?2r?X1?X2n?13.独立大样本:Z?X1?X2?2X1n14.独立小样本:t???2X2
若n为奇数,则Md为第「个数 2 X n X n 1 若n 为偶数,则Md 2- 2 b.有重复数据 b1.重复数没有位于数列中间 方法与无重复数一样 b2.重复数位于数列中间若重复数的个数为奇数若重复个数为偶数 先将数据从小到大(从大到小)排列 三、众数 a.皮尔逊经验公式:分布近似正态探M。:3Md -2X 算术平均数、中位数、众数三者的关系探 在正态分布中:X=Md=M O 四分位差:a未分组数据Q =Q^ Q1 2 b分组数据2 f——Xi Qi = 1* --------- j------ X i 二?平均差— 1. 原始数据计算公式:氷D _》X_X n If Xc-乂2. 次数分布表计算公式:AD = ----------------- n 三.方差和标准差的定义式:探 S2 原始数据导出公式 、算术平均数 1.原始数据计算公式探 X i n 1 X X n 2.简捷公式 1—— X = AM x' n 、中位数(中数) 1.原始数据计算法探 a.无重复数据一.全距R (又称极差):探R = Xmax — Xmin P 百分位数的计算方法:I Pp为所求的第P个百分位数 Lb为百分位数所在组的精确下限 f为百分位数所在组的次数 Fb为小于Lb的各组次数的和 N为总次数 i为组距 百分等级:P R -10°F b f(x 一Lb) R n [ b i 」 在负偏态分布中:X ::: Md ::: M O 四、其它集中量数 1. 加权平均数(Mw)探 W t X, + Xj + - + W,X n 2. 几何平均数(Mg)探 M g 7 X i X2 X n 3、调和平均数 (MH)____________ 1 丄(丄+丄』 N V X1X2X3X4 'X i S2 1X 2 次数分布表计算公式 S2 、fg-X)2 n 导出公式 、2 If X c2代f X c f > = - n i n 丿 If X f(X ci-X)2 n 2 在正偏态分布中: X Md M O
2.加权算术平均数 X =- X h X 3调和平均数: 式中: m = Xf , f X 统计学原理常用公式汇总 第2章统计整理 a ) 组距=上限—下限 b ) 组中值=(上限+下限)—2 c ) 缺下限开口组组中值=上限-1/2邻组组距 d ) 缺上限开口组组中值=下限+1/2邻组组距 e ) 组数k=1+3.322Lg n n 为数据个数 第3章综合指标 i. 相对指标 1.结构相对指标=各组(或部分)总量/总体总量 2?比例相对指标=总体中某一部分数值/总体中另一部分数值 3?比较相对指标=甲单位某指标值/乙单位同类指标值 4. 强度相对指标=某种现象总量指标/另一个有联系而性质不 同的现象总量指标 5. 计划完成程度相对指标=实际数/计划数 =实际完成程度(%) /计划规定的完成程度(%) ii. 平均指标 1.简单算术平均数:; 丄 iii. 标志变动度 1.全距=最大标志值-最小标志值 加权 或 ? f ? Xf ? Xf
3.标准差系数:”= iiii抽样推 断 1.抽样平均误差: 重复抽样: p(1 P) n 不重复抽样: 2 ( 1 2.抽样极限误差 3.重复抽样条件下: 平均数抽样时必要的样本数目 n 成数抽样时必要的样本数目不重复抽样条件下: t2 2 2- x t2P(1 p) 平均数抽样时必要的样本数目第4 章动态数列分析一、平均发展水平的计算方法:(1)由总量指标动态数列计算序时平均数 ①由时期数列计算 a a n Nt2 2 N 2x t2 2 ②由时点数列计算 在间断时点数列的条件下计算: 若间断的间隔相等,则米用“首末折半法”计算。公式为: 1 1 a i a2 a n a. 1 a 2—— n 1 若间断的间隔不等,则应以间隔数为权数进行加权平均计算。公式为:
统计学常用公式汇总 项目三 统计数据的整理与显示 组距=上限-下限 a) 组中值=(上限+下限)÷2 b) 缺下限开口组组中值=上限-邻组组距/2 c) 缺上限开口组组中值=下限+1/2邻组组距 例 按完成净产值分组(万元) 10以下 缺下限: 组中值=10—10/2=5 10—20 组中值=(10+20)/2=15 20—30 组中值=(20+30)/2=25 30—40 组中值=(30+40)/2=35 40—70 组中值=(40+70)/2=55 70以上 缺上限:组中值=70+30/2=85 项目四 统计描述 i. 相对指标 1. 结构相对指标=各组(或部分)总量/总体总量 2. 比例相对指标=总体中某一部分数值/总体中另一部分数值 3、 比较相对指标=甲单位某指标值/乙单位同类指标值 4、 动态相对指标=报告期数值/基期数值 5、 强度相对指标=某种现象总量指标/另一个有联系而性质不同的现 象总量指标 6、 计划完成程度相对指标K =计划数实际数 =% %计划规定的完成程度实际完成程度 7、 计划完成程度(提高率):K=%10011?++计划提高百分数 实际提高百分数 计划完成程度(降低率):K=%10011?--计划提高百分数 实际提高百分数 ii. 平均指标 1、简单算术平均数: 2、加权算术平均数 或
iii. 变异指标 1. 全距=最大标志值-最小标志值 2、标准差: 简单σ= ; 加权 σ= 成数的标准差(1) p p p σ=- 3、标准差系数: 项目五 时间序列的构成分析 一、平均发展水平的计算方法: (1)由总量指标动态数列计算序时平均数 ①由时期数列计算 n a a ∑= ②由时点数列计算 在连续时点数列的条件下计算(判断标志按日登记):∑∑=f af a 在间断时点数列的条件下计算(判断标志按月/季度/年等登记): 若间断的间隔相等,则采用“首末折半法”计算。公式为: 1 212 1121-++++=-n a a a a a n n 若间断的间隔不等,则应以间隔数为权数进行加权平均计算。公式为: ∑ --++++++=f f a a f a a f a a a n n n 11232121222 (2) (选用)由相对指标或平均指标动态数列计算序时平均数 基本公式为: b a c = 式中:c 代表相对指标或平均指标动态数列的序时平均数; a 代表分子数列的序时平均数; b 代表分母数列的序时平均数;
第1章统计与统计数据 一、学习指导 统计学是处理和分析数据的方法和技术,它几乎被应用到所有的学科检验领域。本章首先介绍统计学的含义和应用领域,然后介绍统计数据的类型及其来源,最后介绍统计中常用的一些基本概念。本章各节的主要内容和学习要点如下表所示。 概念:统计学,描述统计,推断统计。 统计在工商管理中的应用。 统计的其他应用领域。 概念:分类数据,顺序数据,数值型数据。 不同数据的特点。 概念:观测数据,实验数据。 概念:截面数据,时间序列数据。 统计数据的间接来源。 二手数据的特点。 概念:抽样调查,普查。 数据的间接来源。 数据的收集方法。 调查方案的内容。 概念。抽样误差,非抽样误差。 统计数据的质量。 概念:总体,样本。 概念:参数,统计量。 概念:变量,分类变量,顺序变量,数值 型变量,连续型变量,离散型变量。 二、主要术语 1.统计学:收集、处理、分析、解释数据并从数据中得出结论的科学。 2.描述统计:研究数据收集、处理和描述的统计学分支。 3.推断统计:研究如何利用样本数据来推断总体特征的统计学分支。 4.分类数据:只能归于某一类别的非数字型数据。 5.顺序数据:只能归于某一有序类别的非数字型数据。 6.数值型数据:按数字尺度测量的观察值。 7.观测数据:通过调查或观测而收集到的数据。 8.实验数据:在实验中控制实验对象而收集到的数据。 9.截面数据:在相同或近似相同的时间点上收集的数据。 10.时间序列数据:在不同时间上收集到的数据。
11.抽样调查:从总体中随机抽取一部分单位作为样本进行调查,并根据样本调查结果来推 断总体特征的数据收集方法。 12.普查:为特定目的而专门组织的全面调查。 13.总体:包含所研究的全部个体(数据)的集合。 14.样本:从总体中抽取的一部分元素的集合。 15.样本容量:也称样本量,是构成样本的元素数目。 16.参数:用来描述总体特征的概括性数字度量。 17.统计量:用来描述样本特征的概括性数字度量。 18.变量:说明现象某种特征的概念。 19.分类变量:说明事物类别的一个名称。 20.顺序变量:说明事物有序类别的一个名称。 21.数值型变量:说明事物数字特征的一个名称。 22.离散型变量:只能取可数值的变量。 23.连续型变量:可以在一个或多个区间中取任何值的变量。 四、习题答案 1.D 2.D 3.A 4.B 5.A 6.D 7.C 8.B 9.A 10.A 11.C、12.C 13.B 14.A 15.C 16.D 17.C 18.A 19.C 20.D 21.A 22.C 23.C 24.B 25.D 26.C 27.B 28.D 29.A 30.D 31.A 32.B 33.C 34.A 35.A 36.A 37.D 38.B 39.B 40.C 41.C 42.D 43.C 44.D 45.A 46.B 47.C 48.A 49.C 50.D 51.A 52.C 53.D 54.A 55.B
《心理统计学》作业 本课程作业由两部分组成。第一部分为“客观题部分”,由15个选择题组成,每题1分,共15分。第二部分为“主观题部分”,由绘制图表题和计算题题组成,共15分。作业总分30分,将作为平时成绩记入课程总成绩。 一、选择题(每题1分) 1 按两个以上品质分组的统计表是:D A 简单表 B 相关表 C 双向表 D 复合表 2 若描述统计事项随时间的变化其总体指标的变化趋势,应该使用:C A 次数分布多边图B依存关系曲线图 C 动态曲线图D次数分布直方图 3 按照数据的获得方式,找出下列数据中与其他不同类型的数据:D A 80斤 B 80升 C 80米D80条 4 测量数据的下实限是:D A B 10.005 C D. 5按测量数据实限的规定, 组限a~b的实际代表范围应是:D A 开区间 B 闭区间C左开右闭 D 左闭右开 6 绘制次数分布多边图时,其横轴的标数是:B A 次数B组中值 C 分数D上实限 7 编制次数分布表最关键的两个步骤是:A A 求全距与定组数 B 求组距与定组限 C 求中值与划记D记录次数与核对 8 将一组数据中的每个数据都加上10,则所得平均数比原平均数:A A 多10 B多,但具体多少无法知道 C 相等D多10 数据个数 9 已知有10个数据的平均数是12,另外20个数据的平均数是9,那么全部数据的平均数应为:B A 9 B 10 C 11 D 12 10 某校1990年在校学生为880人,1992年在校学生为1760人。那么从1990年到1992年在校人数平均增长率为:B
A % B % C 126% D 26% 11 可否用几何平均数求平均下降速度及平均下降率。A A 两者都可以 B 可以求平均下降速度但不能求平均下降率 C两者都不可以D可以求平均下降率但不能求平均下降速度 12 下面哪种情况用差异系数比较数据的离散程度比较适合D A 单位相同,标准差相差较大 B单位相同,标准差相差较小 C单位相同,平均数相差较小 D单位相同,无论平均数相差大小 13 一组数据44,45,48,52,60,64,65,89,83,65,87,66,67,81,80,68,79,72,79,73的四分差为:B A B 8.75 C D 62 14 某班语文期末考试,语文平均成绩为82分,标准差为分;数学平均成绩为75分,标准差为分;外语成绩为66分,标准差为8分,问哪一科成绩的离散程度最大C A 语文 B 数学 C 外语 D 无法比较 15某校抽取45名五年级学生参加市统一组织的数学竞赛,成绩如下表: 问用什么作为起差异量的代表值合适B A 标准差 B 四分差 C 差异量数D标准分数 二、制表绘图题(每题3分)
第三章集中量数 一、算术平均数 1.原始数据计算公式※ 121 1n n i i X X X X X n n =+++==∑ 2.简捷公式 二、中位数(中数) 1. 原始数据计算法※ a. 无重复数据 b.有重复数据 b1.重复数没有位于数列中间 方法与无重复数一样 b2.重复数位于数列中间 若重复数的个数为奇数 若重复个数为偶数 先将数据从小到大(从大到小)排列 三、众数 a. 皮尔逊经验公式:分布近似正态※ 算术平均数、中位数、众数三者的关系※ 在正态分布中: 在正偏态分布中: 在负偏态分布中: 四、其它集中量数 1. 加权平均数(Mw)※ 2. 几何平均数(Mg)※ 3、调和平均数(MH) 第四章离散量数 一.全距 R (又称极差):※ R =Xmax -Xmin 百分位数的计算方法: Pp 为所求的第P 个百分位数 Lb 为百分位数所在组的精确下限 f 为百分位数所在组的次数 Fb 为小于Lb 的各组次数的和 N 为总次数 i 为组距 百分等级: 四分位差:a 未分组数据 b 分组数据 二.平均差 1. 原始数据计算公式:※ 2. 次数分布表计算公式: 三.方差和标准差的定义式:※ 原始数据导出公式 次数分布表计算公式 导出公式 个数为第 则为奇数若2 1 ,+n Md n 2 ,1 22 ++= n n X X Md n 则为偶数若X n X ∑=1' 1x n AM X ∑+=X Md M o 23-≈O M Md X ==O M Md X >>O M Md X < 统计学原理常用公式汇总 第2章统计整理 a)组距=上限-下限 b)组中值=(上限+下限)÷2 c)缺下限开口组组中值=上限-1/2邻组组距 d)缺上限开口组组中值=下限+1/2邻组组距 e)组数k=1+3.322Lg n n为数据个数 第3章综合指标 i.相对指标 1.结构相对指标=各组(或部分)总量/总体总量 2.比例相对指标=总体中某一部分数值/总体中另一部分数值 3.比较相对指标=甲单位某指标值/乙单位同类指标值 4.强度相对指标=某种现象总量指标/另一个有联系而性质不 同的现象总量指标 5.计划完成程度相对指标=实际数/计划数 =实际完成程度(%)/计划规定的完成程度(%) ii.平均指标 1.简单算术平均数: 2.加权算术平均数或 3调和平均数: ? ? = f X f X h 1 1 式中:, h Xf Xf m X X m f Xf X X m m Xf f X ==== == ??? ??? iii.标志变动度 1.全距=最大标志值-最小标志值 2.标准差: 简单σ= ;加权σ= 3.标准差系数: iiii 抽样推断 1. 抽样平均误差: 重复抽样: n x σ μ= n p p p ) 1(-= μ 不重复抽样: )1(2 N n n x - = σμ 2.抽样极限误差 x x t μ=? 3.重复抽样条件下: 平均数抽样时必要的样本数目 2 22x t n ?= σ 成数抽样时必要的样本数目2 2)1(p p p t n ?-= 不重复抽样条件下: 平均数抽样时必要的样本数目 2222 2σσt N Nt n x +?= 第4章 动态数列分析 一、平均发展水平的计算方法: (1)由总量指标动态数列计算序时平均数 ①由时期数列计算 n a a ∑= ②由时点数列计算 在间断时点数列的条件下计算: 若间断的间隔相等,则采用“首末折半法”计算。公式为: 1 212 11 21-++++=-n a a a a a n n Λ 若间断的间隔不等,则应以间隔数为权数进行加权平均计算。公式为: 统计学主要计算公式(第三章) 1 11 1k i i k i i k i k i i i f f f f ====?? ? ???? ? ? ?? ? ? ???? ?? ?∑ ∑ ∑ ∑ ∑ N i i=1i i 一、算术平x 简单x=N x 均数加权x=频数权数x=x 1i i H i i i i m m x m m x x = = ∑∑∑∑二、调和平均数 ? = ?? ? ? =?? G G 简单x 三、几何平均数加权x 11/2/2m e m m e m f S M L i f f S M U i f -+?-=+ ??? ? -?=-???∑∑下限公式四、中位数上限公式 1012 20 12d M L i d d d M U i d d ? =+??+?? ?=-??+? 下限公式五、众数上限公式 () ()x x x x f f AD AD ? -?? ? -??? ∑ ∑∑六、平均差简单=N 加权= σ σ σ σ ??? ???? ??? ??? ????? ??? 七、标准差简单加权 简捷公式 简单 加权 100%100% AD AD V x V x σσ ? ??? ? ???? 平均差系数=八、离散系数标准差系数= 统计学主要计算公式(第五章) ( )( ) 11n n s s t t n αα α α αα σ σ μμμμμμ--?±±?? ?? ±±?? ? ?±±??22 22 22 一、参数估计(随机抽样)1.总体均值估计-单总体 正态总体,方差已知 =x z =x z 正态总体,方差未知=x =x 非正态总体,足够大=x z =x z 心理统计公式汇总 心理学考研分为:心理学学硕和心理学专硕(又称“应用心理硕士”、“心理专硕”)。心理学学硕和心理学专硕考试科目不同,但是都会考察到心理学统计,(部分自主命题院校不考察心理学统计,考生需要提前了解院校信息。)无论是对本专业还是跨专业心理学考研的同学而言,心理学统计始终是比较难懂的一块。博仁教育老师为考生分章节整理出心理学统计公式,方便考生进行复习与记忆。 第三章集中量数 1、几个集中量数的公式计算一览表 【组中值的计算】 第四章差异量数 第五章相关关系 第六章概率分布 1、几个基本概念 (1)概率:表明随机事件出现的可能性大小的客观指标。 (2)后验概率(统计概率): 先验概率(古典概率): (3)概率分布:对随机变量取值的概率分布的情况用数学方法(函数)描述。 2、概率的基本性质: ※概率的公理系统: 任何一个随机事件的概率都是非负的; 在一定条件下必然发生的必然事件概率为1; 在一定条件下必然不发生的事件,即不可能事件的概率为0. ※概率的加法定理 ※概率的乘法定理 3、概率的分布类型划分 4、几个重要分布 ★正态分布 (1)特征: ①正态分布的形式是对称的,对称轴是经过平均数的垂线。 ②正态分布的中央点即平均数最高,然后逐渐向两侧下降;曲线形式先向内弯,再向外弯,拐点位于正负1个标准差处,曲线两端向基线无线靠近,但不相交。 ③正态曲线下面积为1。 ④正态分布是一族分布。平均数决定其位置,标准差决定其形态。标准差越小,曲线越狭高。 ⑤正态分布中各差异量数值间有固定比率。 ⑥正态曲线下,标准差和概率(面积)有一定的数量关系。 (2)正态分布表的利用 ①已知Z分数求概率p,即已知标准分数求面积。 ②已知概率P求Z分数。 ③已知概率或Z求概率密度y,即曲线的高。【直接查表即可。注意已知的y是位于中间部分,还是两尾。】 (3)次数分布是否为正态的检验方法 (4)正态分布理论在测验中的应用 ①化等级评定为测量数据 ②标准测验题目的难易度 ③在能力分组或等级评定时确定人数 ④测验分数的正态化 二项分布(贝努里分布) (1)几个重要概念理解 心理统计公式汇总 第三章集中量数1、几个集中量数的公式计算一览表 平均数(M) 算术平均数 (M) 未分组:1 = n i i X X n = ∑ 分组数据:i ci i f X M f ? = ∑ ∑ 加权平均数 (单位权重不相 等的情况) i i i W X Mw W ? = ∑ ∑ 几何平均数 (解决增长率的 问题) lg lg i X Mg N = ∑ ;1 1 N N X Mg X - =; 1 ,, N N Mg X X = 调和平均数 (解决速度的问 题) 倒数的算术平均数的倒数: 1 H i N M X = ∑ ; 中数(Md) 未分组: 无重复值 N=奇数:中数即 1 2 N+ 位置的数; N=偶数:中数即中间两个数的平均数; 有重复值 若重复值没有位于中间,则求法与无重复值时 一致; 若重复值位于中间,则(P62): 图示: 思路:①连续性数字,不是一个点,是一个区 间; ②有几个重复的,则将组距除以几; 分组d() 2 b b Md N i M L F f =+-? 众数(Mo) 1、直接观察法。 2、公式法。(皮尔逊经验法&金式插补法) ①皮尔逊经验法:o32 M Md M =-; ②金式插补法:a b a b f Mo L i f f =+? + ; 【组中值的计算】 第四章 差异量数 百分位数(点) 100b p b P N F P L i f ?-=+?; 百分等级 未分组:(10050) 100R R P N -=- 分组:()100 []b R b f X L P F N i -= ?+ 四分位差 31 = 2 Q Q Q -; (Q3与Q1即P25与P75) 平均差 未分组:..i i X A D n n X x -= = ∑∑ 分组:..f x A D n = ∑;(IxI 为各组中点值对平均数离差的绝对值) 方差与 标准差 未分组:① 2 2 2 ()s X X N N x -= = ∑∑; ②原始数据代入:2 2 2 2 2 2 () ()s N N X X X X N N -= -= ∑∑∑∑ 分组: 2 2 2 ()c f X X f N N x s -= = ∑ ∑ 2 2 s ()f i N fd d N = -?∑∑ 总方差与总标准差: 2 2 2;()i i i i T i T i i N s N d s d X X N += =-∑∑∑ 标准差 的应用 差异 系数 100%s CV X = ? 标准 分数 X X x Z s s -= = 第五章 相关关系 统计学主要计算公式(第三章) 统计学主要计算公式(第五章) 010220102001001111221012221 22((((1,1)(1,1)(H H Z Z H H H Z Z H H H Z Z H H H F n n F F n n H S F S ααααασσσσχσσσσσσσσσσσσσ-?≠≥??>≥??<≤??≠--≤≤--22220022222002222002222224.方差检验(正态总体) 单总体: :=:拒绝双侧)(n-1)S =:=:拒绝单侧):=:拒绝单侧) 两方差之比检验 :=:拒绝=011112001111210(1,1)((1,1)(H H F F n n H H H F F n n H αασσσσσσσσ-???>≥--??<≤--??222222222222双侧):=:拒绝单侧):=:拒绝单侧) 统计学主要计算公式(第六章) 统计学主要计算公式(第七章) 统计学主要计算公式(第八章) d L d U 2 4-d U 4-d L d 01'201201101???????(1)(1)(1)t t t t t t t t t y y b b t y y b b t b t y ab b b y y a y a a a a -???=+???=++???=?? =++++=+-=-+-t t-1t t-1t-2t-n t+1t t 六、时间序列预测 一阶差分大致相同,趋势外推法模型测定二阶差分大致相同, (同回归模型)y 环比发展速度大体相同,y 自回归预测y (同回归模型) y y y 移动平均n 指数平滑y =ay y y 201(1)(1)n a a a a ++-++-t-1t-2t-n-1 y y 统计学主要计算公式(第九章) 心理统计常用公式总结 1 、组数K (总体分布为正态)(N 为数据个数,K 取近似整数) 2 、算术平均数 3 、中数 4 、众数 5 、加权平均数 ,其中W i 为权数 ,其中为各小组的平均数,n i 为各小组人数 6 、几何平均数 ,其中n 为数据个数,X i 为数据的值 7 、调和平均数 8 、方差与标准差 , 其中 9 、变异系数,其中S 为标准差,M 为平均数 10 、标准分数,其中X 为原始数据,为平均数,S 为标准差 11 、全距R =最大数-最小数 12 、平均差 13 、四分差 ,其中L b 为该四分点所在组的精确下限, F b 为该四分点所在组以下的累加次数, 和为该四分点所在组的次数,i 为组距,N 为数据个数 14 、积差相关 基本公式:,其中 , ,N 为成对数据的数目,S x 、S y 分别为X 和Y 的标准差 变形: 差法公式: 用估计平均数计算: 用相关表计算: 15 、斯皮尔曼等级相关 ,其中 D 为各对偶等级之差 直接用等级序数计算:,其中R X 、R Y 分别为二变量各等级数有相同等级时: 16 、肯德尔等级相关 有相同等级: 17 、点二列相关,其中是两个二分变量对偶的连续变量的平均数,p 、q 是二分变量各自所占的比率,p+q=1 ,S t 是连续变量的标准差 18 、二列相关 ,其中S T 与是连续变量的标准差与平均数,y 为P 的正态曲线的高度 19 、多系列相关 ,其中P i 为每系列的次数比率,y 1 为每一名义变量下限的正态曲线高度,y h 为每一名义变量上线的正态曲线高度, 为每一名义变量对偶的连续变量的平均数,S t 为连续变量的标准差 20 、总体为正态,σ 2 已知: 21 、总体为正态,σ 2 未知: 22 、 23 、 24 、 心理统计学重要知识点 WTD standardization office【WTD 5AB- WTDK 08- WTD 2C】 《心理统计学》重要知识点 第二章 统计图表 简单次数分布表的编制:Excel 数据透视表 列联表(交叉表):两个类别变量或等级变量的交叉次数分布,Excel 数据透视表 直方图(histogram ):直观描述连续变量分组次数分布情况,可用Excel 图表向导的柱形图来绘制 散点图(Scatter plot ):主要用于直观描述两个连续性变量的关系状况和变化趋向。 条形图(Bar chart ):用于直观描述称名数据、类别数据、等级数据的次数分布情况。 简单条形图:用于描述一个样组的类别(或等级)数据变量次数分布。 复式条形图:用于描述和比较两个或多个样组的类别(或等级)数据的次数分布。 圆形图(circle graph )、饼图(pie graph ):用于直观描述类别数据或等级数据的分布情况。 线形图(line graph ):用于直观描述不同时期的发展成就的变化趋势; 第三章 集中量数 ● 集中趋势和离中趋势是数据分布的两个基本特征。 ● 集中趋势:就是数据分布中大量数据向某个数据点集中的趋势。 ● 集中量数:描述数据分布集中趋势的统计量数。 ● 离中趋势:是指数据分布中数据分散的程度。 ● 差异量数:描述数据分布离中趋势(离散程度)的统计量数 ● 常用的集中量数有:算术平均数、众数(M O )、中位数(M d ) 1.算术平均数(简称平均数,M 、X 、Y ):n x X i ∑ = Excel 统计函数AVERAGE 算术平均数的重要特性: (1)一组数据的离均差(离差)总和为0,即0)(=-∑x x i (2)如果变量X 的平均数为X ,将变量X 按照公式bx a y +=转换为Y 变量后, 那么,变量Y 2.中位数(median ,M d ):在一组有序排列的数据中,处于中间位置的数值。中 位数上下的数据出现次数各占50%。 3.众数(mode ,M O ):一组数据中出现次数最多的数据。 4.算术平均数、中数、众数之间的关系。 《统计学原理》常用公式汇总及计算题目分析 第一部分常用公式 第三章统计整理 a)组距=上限-下限 b)组中值=(上限+下限)÷2 c)缺下限开口组组中值=上限-1/2邻组组距 d)缺上限开口组组中值=下限+1/2邻组组距 第四章综合指标 i.相对指标 1.结构相对指标=各组(或部分)总量/总体总量 2.比例相对指标=总体中某一部分数值/总体中另一部分数值 3.比较相对指标=甲单位某指标值/乙单位同类指标值 4.强度相对指标=某种现象总量指标/另一个有联系而性质不同的现 象总量指标 5.计划完成程度相对指标=实际数/计划数 =实际完成程度(%)/计划规定的完成程度(%) ii.平均指标 1.简单算术平均数: 2.加权算术平均数或 iii.变异指标 1.全距=最大标志值-最小标志值 2.标准差: 简单σ= ;加权σ= 3.标准差系数: 第五章抽样估计 1.平均误差: 重复抽样: 不重复抽样: 2.抽样极限误差 3.重复抽样条件下: 平均数抽样时必要的样本数目 成数抽样时必要的样本数目 4.不重复抽样条件下: 平均数抽样时必要的样本数目 第七章相关分析 1.相关系数 2.配合回归方程y=a+bx 3.估计标准误: 第八章指数分数 一、综合指数的计算与分析 (1)数量指标指数 此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。 ( - ) 此差额说明由于数量指标的变动对价值量指标影响的绝对额。 (2)质量指标指数 此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。 ( - ) 此差额说明由于质量指标的变动对价值量指标影响的绝对额。 加权算术平均数指数= 加权调和平均数指数= (3)复杂现象总体总量指标变动的因素分析 相对数变动分析: = × 绝对值变动分析: 第一章绪论 1.名词解释 随机变量:在统计学上,把取值之前不能预料取到什么值的变量称之为随机变量 总体:又称为母全体、全域,指据有某种特征的一类事物的全体 样本:从总体中抽取的一部分个体,称为总体的一个样本 个体:构成总体的每个基本单元称为个体 次数:指某一事件在某一类别中出现的数目,又成为频数,用f表示 频率:又称相对次数,即某一事件发生的次数被总的事件数目除,亦即某一数据出现的次数被这一组数据总个数去除。频率通畅用比例或百分数表示概率:又称机率。或然率,用符号P表示,指某一事件在无限的观测中所能预料的相对出现的次数,也就是某一事物或某种情况在某一总体中出现的比率统计量:样本的特征值叫做统计量,又叫做特征值 参数:总体的特性成为参数,又称总体参数,是描述一个总体情况的统计指标 观测值:在心理学研究中,一旦确定了某个值,就称这个值为某一变量的观测值,也就是具体数据 2.何谓心理与教育统计学?学习它有何意义 心理与教育统计学是专门研究如何运用统计学原理和方法,搜集。整理。分析心理与教育科学研究中获得的随机数据资料,并根据这些数据资料传递的信息,进行科学推论找出心理与教育活动规律的一门学科。 3.选用统计方法有哪几个步骤? 首先要分析一下试验设计是否合理,即所获得的数据是否适合用统计方法去处理,正确的数量化是应用统计方法的起步,如果对数量化的过程及其意义没有了解,将一些不着边际的数据加以统计处理是毫无意义的 其次要分析实验数据的类型,不同数据类型所使用的统计方法有很大差别,了解实验数据的类型和水平,对选用恰当的统计方法至关重要 第三要分析数据的分布规律,如总体方差的情况,确定其是否满足所选用的统计方法的前提条件 4.什么叫随机变量?心理与教育科学实验所获得的数据是否属于随机变量 随机变量的定义:①率先无法确定,受随机因素影响,成随机变化,具有偶然性和规律性②有规律变化的变量 5.怎样理解总体、样本与个体? 总体N:据有某种特征的一类事物的全体,又称为母体、样本空间,常用N表示,其构成的基本单元为个体。特点:①大小随研究问题而变(有、无限)②总体性质由组成的个体性质而定 样本n:从总体中抽取的一部分交个体,称为总体的一个样本。样本数目用n表示,又叫样本容量。特点:①样本容量越大,对总体的代表性越强②样本不同,统计方法不同 总体与样本可以相互转化。 个体:构成总体的每个基本单元称为个体。有时个体又叫做一个随机事件或样本点 统计学主要计算公式(第三章) 1 11 1k i i k i i k i k i i i f f f f ====?? ? ???? ? ? ?? ? ? ???? ?? ?∑ ∑ ∑ ∑ ∑ N i i=1i i 一、算术平x 简单x=N x 均数加权x=频数权数x=x 1i i H i i i i m m x m m x x = = ∑∑∑∑二、调和平均数 ? = ?? ? ? =?? G G 简单x 三、几何平均数加权x 11/2/2m e m m e m f S M L i f f S M U i f -+?-=+ ??? ? -?=-???∑∑下限公式四、中位数上限公式 1012 20 12d M L i d d d M U i d d ? =+??+?? ?=-??+? 下限公式五、众数上限公式 ()()x x x x f f AD AD ? -?? ? -??? ∑∑∑六、平均差简单= N 加权= σ σ σ σ ??? ???? ??? ??? ????? ??? 七、标准差简单加权 简捷公式 简单 加权 100% 100% AD AD V x V x σσ ? ??? ? ???? 平均差系数=八、离散系数标准差系数= 统计学主要计算公式(第五章) ( ) ( ) 11n n t t n αα αα αα μμμμμμ--?±±?? ?? ±±?? ? ?±±??22 22 22 一、参数估计(随机抽样)1.总体均值估计-单总体 正态总体,方差已知 =x z =x z 正态总体,方差未知=x =x 非正态总体,足够大=x z =x z 0272《心理统计学》2016年6-7月期末考试指导 一、考试说明 本课程闭卷考试,满分100分,考试时间90分钟。可能的考试题型包括: 1、单项选择题 2、判断题 3、简答题 4、计算题 5、综合应用题 二、重点复习内容 (一)绪论 1、心理学统计学的内容:描述统计、推论统计、实验设计。其中,描述统计的指标包括数据的集中趋势,数据的离散趋势和数据间的相关 2、数据的种类 按照测量的水平,可以划分为称名变量、等级变量、等距变量和比率变量。 (1)称名变量,是指根据事物的某一特征,用来划分、区别事物的不同种类所形成的变量。这类数码并无数量和序列的含义,不能进行数量化分析,不能做加减乘除的运算。 (2)等级变量,在对事物进行分类过程中,依据事物某种属性程度的大小排列顺序形成的变量。等级变量既无相等单位,也无绝对零,不同组的等级变量间不能进行加减乘除的运算。(3)等距变量,是指在观测标识事物某一特定属性时,具有相对参照点、有相等单位的变量。可以进行加减运算,但是由于等距变量的参照点是相对的,即无绝对零点,因此不能进行乘除的运算。例如,测量温度的℃。 (4)比率变量,是指既有相等单位又有绝对零参照点的变量,如身高、体重、反应时、各种感觉阈值的物理量等。这类变量可以进行加减乘除的运算。 (二)统计图表 1、次数分布表:各种次数分布的列表形式和图示形式。次数分布包括简单次数分布、分组次数分布、相对次数分布、累积次数分布等。 2、编制次数分布表的步骤 (1)求全距:从最大值的数据中减去最小值的数据,所得差数就是全距。用符号R表示(2)定组数 (3)求组距:指每一组的间距,用符号i表示。 (4)定组限:指各组数据在数值上的起点值和终点值。 (5)求组中值:各组实际上限数值与实际下限数值的中点数值,即上、下限数值的平均值。(6)归类划记:将原始观测值按照一定的顺序逐一归组。 (7)记录各组次数(f)。 (8)核对,抄录新表。 3、连续变量的单位是无限的,例如整数180的实上限和下限分别为179.5和180.5,而测量数据8.35的下实限是8.345。 4、累加次数分布表:如果想知道某个数值以下或以上的数据的数目,就要用累加次数。 5、次数分布图:编制次数分布表与绘制次数分布图,对于了解一组数据的分布情况,平均水平,差异情况等非常有用。由于数据的性质不同,有时实验结果的次数分布图上会出现双峰。 (三)集中量数 集中量数主要用来描述一组数据的集中趋势,常用的代表性的集中量数有算术平均数、中数、众数。 1、算术平均数:又称平均数,是集中量数中性能最好的一个统计量,一般用M表示。 《统计学原理》常用公式汇总 组距=上限-下限组中值=(上限+下限)÷2 缺下限开口组组中值=上限-1/2邻组组距缺上限开口组组中值=下限+1/2邻组组距 111平均指标 1.简单算术平均数: 2.加权算术平均数 或 iii.变异指标 1.全距=最大标志值-最小标志值 2.标准差: 简单σ= ;加权σ= 3.标准差系数: 第五章抽样估计 1.平均误差:重复抽样: 不重复抽样: 2.抽样极限误差 3.重复抽样条件下:平均 数抽样时必要的样本数目 成数抽样时必要的样本数目 4.不重复抽样条件下:平均数抽样时必要的样本数目 第七章相关分析 1.相关系数 2.配合回归方程y=a+bx 3.估计标准误: 第八章指数分数一、综合指数的计算与分析 (1)数量指标指数 此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。 ( - ) 此差额说明由于数量指标的变动对价值量指标影响的绝对额。 (2)质量指标指数 此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。 ( - ) 此差额说明由于质量指标的变动对价值量指标影响的绝对额。 加权算术平均数指数= 加权调和平均数指数= (3)复杂现象总体总量指标变动的因素分析 相对数变动分析: = × 绝对值变动分析: - = ( - )×( - ) 第九章动态数列分析 一、平均发展水平的计算方法: (1)由总量指标动态数列计算序时平均数 ①由时期数列计算 ②由时点数列计算 在间断时点数列的条件下计算: a.若间断的间隔相等,则采用“首末折半法”计算。公式为: b.若间断的间隔不等,则应以间隔数为权数进行加权平均计算。公式为: (2)由相对指标或平均指标动态数列计算序时平均数 基本公式为: 式中:代表相对指标或平均指标动态数列的序时平均数; 代表分子数列的序时平均数; 代表分母数列的序时平均数; 逐期增长量之和累积增长量 二. 平均增长量=─────────=───────── 逐期增长量的个数逐期增长量的个数 (1)计算平均发展速度的公式为: (2)平均增长速度的计算 平均增长速度=平均发展速度-1(100%)统计学原理常用公式汇总
统计学主要计算公式72485
心理统计公式汇总
心理统计公式汇总
统计学主要计算公式
心理统计常用公式总结
心理统计学重要知识点
最新《统计学原理》常用公式汇总及计算题目分析
现代心理与教育统计学课后题完整版78975
统计学主要计算公式
0272《心理统计学》2016年6-7月期末考试指导.
统计学常用公式汇总
相关主题
文本预览