An Automated Approach for Constructing Road Network Graph from Multispectral Images
- 格式:pdf
- 大小:5.73 MB
- 文档页数:13
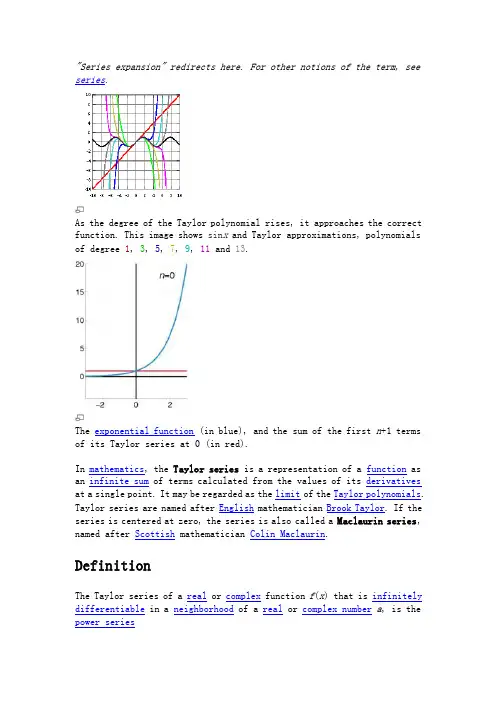
"Series expansion" redirects here. For other notions of the term, see series.As the degree of the Taylor polynomial rises, it approaches the correct function. This image shows sin x and Taylor approximations, polynomials of degree 1, 3, 5, 7, 9, 11 and 13.The exponential function (in blue), and the sum of the first n+1 terms of its Taylor series at 0 (in red).In mathematics, the Taylor series is a representation of a function as an infinite sum of terms calculated from the values of its derivativesat a single point. It may be regarded as the limit of the Taylor polynomials. Taylor series are named after English mathematician Brook Taylor. If the series is centered at zero, the series is also called a Maclaurin series, named after Scottish mathematician Colin Maclaurin.DefinitionThe Taylor series of a real or complex function f(x) that is infinitely differentiable in a neighborhood of a real or complex number a, is the power serieswhich in a more compact form can be written aswhere n! is the factorial of n and f (n)(a) denotes the n th derivative of f evaluated at the point a; the zeroth derivative of f is defined to be f itself and (x−a)0 and 0! are both defined to be 1.Often f(x) is equal to its Taylor series evaluated at x for all x sufficiently close to a. This is the main reason why Taylor series are important.In the particular case where a= 0, the series is also called a Maclaurin series.[edit] ExamplesThe Maclaurin series for any polynomial is the polynomial itself. The Maclaurin series for (1 −x)−1 is the geometric seriesso the Taylor series for x−1 at a = 1 isBy integrating the above Maclaurin series we find the Maclaurin series for −log(1 −x), where log denotes the natural logarithm:and the corresponding Taylor series for log(x) at a = 1 isThe Taylor series for the exponential function e x at a = 0 isThe above expansion holds because the derivative of e x is also e x and e0 equals 1. This leaves the terms (x− 0)n in the numerator and n! in the denominator for each term in the infinite sum.[edit] ConvergenceThe sine function (blue) is closely approximated by its Taylor polynomial of degree 7 (pink) for a full period centered at the origin.The Taylor polynomials for log(1+x) only provide accurate approximations in the range −1 < x≤ 1. Note that, for x > 1, the Taylor polynomials of higher degree are worse approximations.Taylor series need not in general be convergent, but often they are. The limit of a convergent Taylor series of a function f need not in generalbe equal to the function value f(x), but often it is. If f(x) is equal to its Taylor series in a neighborhood of a, it is said to be analytic in this neighborhood. If f(x) is equal to its Taylor series everywhere it is called entire. The exponential function e x and the trigonometric functions sine and cosine are examples of entire functions. Examples of functions that are not entire include the logarithm, the trigonometric function tangent, and its inverse arctan. For these functions the Taylor series do not converge if x is far from a.Taylor series can be used to calculate the value of an entire function in every point, if the value of the function, and of all of its derivatives, are known at a single point. Uses of the Taylor series for entire functions include:1.The partial sums (the Taylor polynomials) of the series can be usedas approximations of the entire function. These approximations are good if sufficiently many terms are included.2.The series representation simplifies many mathematical proofs.Pictured on the right is an accurate approximation of sin(x) around the point a = 0. The pink curve is a polynomial of degree seven:The error in this approximation is no more than |x|9/9!. In particular, for |x| < 1, the error is less than 0.000003.In contrast, also shown is a picture of the natural logarithm function log(1 + x) and some of its Taylor polynomials around a = 0. These approximations converge to the function only in the region −1 < x≤ 1; outside of this region the higher-degree Taylor polynomials are worse approximations for the function. This is similar to Runge's phenomenon.Taylor's theorem gives a variety of general bounds on the size of the error in R n(x) incurred in approximating a function by its n th-degree Taylor polynomial.[edit] HistoryThe Greek philosopher Zeno considered the problem of summing an infinite series to achieve a finite result, but rejected it as an impossibility: the result was Zeno's paradox. Later, Aristotle proposed a philosophicalresolution of the paradox, but the mathematical content was apparently unresolved until taken up by Democritus and then Archimedes. It was through Archimedes's method of exhaustion that an infinite number of progressive subdivisions could be performed to achieve a finite result.[1] Liu Hui independently employed a similar method a few centuries later.[2]In the 14th century, the earliest examples of the use of Taylor series and closely-related methods were given by Madhava of Sangamagrama.[3] Though no record of his work survives, writings of later Indian mathematicians suggest that he found a number of special cases of the Taylor series, including those for the trigonometric functions of sine, cosine, tangent, and arctangent. The Kerala school of astronomy and mathematics further expanded his works with various series expansions and rational approximations until the 16th century.In the 17th century, James Gregory also worked in this area and published several Maclaurin series. It was not until 1715 however that a general method for constructing these series for all functions for which they exist was finally provided by Brook Taylor[4], after whom the series are now named.The Maclaurin series was named after Colin Maclaurin, a professor in Edinburgh, who published the special case of the Taylor result in the 18th century.[edit] PropertiesThe function e−1/x²is not analytic at x= 0: the Taylor series is identically 0, although the function is not.If this series converges for every x in the interval (a−r, a + r) and the sum is equal to f(x), then the function f(x) is said to be analytic in the interval(a−r, a+ r). If this is true for any r then the function is said to be an entire function. To check whether the series converges towards f(x), one normally uses estimates for the remainder term of Taylor's theorem. A function is analytic if and only if it can be represented as a power series; the coefficients in that power series are then necessarily the ones given in the above Taylor series formula.The importance of such a power series representation is at least fourfold. First, differentiation and integration of power series can be performed term by term and is hence particularly easy. Second, an analytic function can be uniquely extended to a holomorphic function defined on an open disk in the complex plane, which makes the whole machinery of complex analysis available. Third, the (truncated) series can be used to compute function values approximately (often by recasting the polynomial into the Chebyshev form and evaluating it with the Clenshaw algorithm).Fourth, algebraic operations can often be done much more readily on the power series representation; for instance the simplest proof of Euler's formula uses the Taylor series expansions for sine, cosine, and exponential functions. This result is of fundamental importance in such fields as harmonic analysis.Another reason why the Taylor series is the natural power series for studying a function f is given by the probabilistic interpretation of Taylor series. Given the value of f and its derivatives at a point a, the Taylor series is in some sense the most likely function that fits the given data.Note that there are examples of infinitely differentiable functions f(x) whose Taylor series converge, but are not equal to f(x). For instance, the function defined pointwise by f(x) = e−1/x² if x≠ 0 and f(0) = 0 is an example of a non-analytic smooth function. All its derivatives at x = 0 are zero, so the Taylor series of f(x) at 0 is zero everywhere, even though the function is nonzero for every x≠ 0. This particular pathology does not afflict Taylor series in complex analysis. There, the area of convergence of a Taylor series is always a disk in the complex plane (possibly with radius 0), and where the Taylor series converges, it converges to the function value. Notice that e−1/z²does not approach 0 as z approaches 0 along the imaginary axis, hence this function is not continuous as a function on the complex plane.Since every sequence of real or complex numbers can appear as coefficients in the Taylor series of an infinitely differentiable function defined onthe real line, the radius of convergence of a Taylor series can be zero.[5] There are even infinitely differentiable functions defined on the real line whose Taylor series have a radius of convergence 0 everywhere.[6]Some functions cannot be written as Taylor series because they have a singularity; in these cases, one can often still achieve a series expansion if one allows also negative powers of the variable x; see Laurent series. For example, f(x) = e−1/x² can be written as a Laurent series.[edit] List of Taylor series of some common functionsSee also List of mathematical seriesThe cosine function in the complex plane.An 8th degree approximation of the cosine function in the complex plane.The two above curves put together.Several important Maclaurin series expansions follow.[7] All these expansions are valid for complex arguments .Exponential function:Natural logarithm:Finite geometric series:Infinite geometric series:Variants of the infinite geometric series:Square root:Binomial series (includes the square root for α = 1/2 and the infinite geometric series for α = −1):with generalized binomial coefficientsTrigonometric functions:where the B s are Bernoulli numbers.Hyperbolic functions:Lambert's W function:The numbers B k appearing in the summation expansions of tan(x) and tanh(x) are the Bernoulli numbers. The E k in the expansion of sec(x) are Euler numbers.[edit] Calculation of Taylor seriesSeveral methods exist for the calculation of Taylor series of a large number of functions. One can attempt to use the Taylor series as-is and generalize the form of the coefficients, or one can use manipulations such as substitution, multiplication or division, addition or subtraction of standard Taylor series to construct the Taylor series of a function, by virtue of Taylor series being power series. In some cases, one can also derive the Taylor series by repeatedly applying integration by parts. Particularly convenient is the use of computer algebra systems to calculate Taylor series.[edit] First exampleCompute the 7th degree Maclaurin polynomial for the function.First, rewrite the function as.We have for the natural logarithm (by using the big O notation)and for the cosine functionThe latter series expansion has a zero constant term, which enables us to substitute the second series into the first one and to easily omit terms of higher order than the 7th degree by using the big O notation:Since the cosine is an even function, the coefficients for all the odd powers x, x3, x5, x7, . . . have to be zero.[edit] Second exampleSuppose we want the Taylor series at 0 of the function.We have for the exponential functionand, as in the first example,Assume the power series isThen multiplication with the denominator and substitution of the series of the cosine yieldsCollecting the terms up to fourth order yieldsComparing coefficients with the above series of the exponential function yields the desired Taylor series[edit] Taylor series as definitionsClassically, algebraic functions are defined by an algebraic equation, and transcendental functions (including those discussed above) are defined by some property that holds for them, such as a differential equation. For example the exponential function is the function which is everywhere equal to its own derivative, and assumes the value 1 at the origin. However, one may equally well define an analytic function by its Taylor series.Taylor series are used to define functions in diverse areas of mathematics. In particular, this is true in areas where the classical definitions of functions break down. For example, using Taylor series, one may defineanalytical functions of matrices and operators, such as the matrix exponential or matrix logarithm.In other areas, such as formal analysis, it is more convenient to work directly with the power series themselves. Thus one may define a solution of a differential equation as a power series which, one hopes to prove, is the Taylor series of the desired solution.[edit] Taylor series in several variablesThe Taylor series may also be generalized to functions of more than one variable withFor example, for a function that depends on two variables, x and y, the Taylor series to second order about the point (a, b) is:where the subscripts denote the respective partial derivatives.A second-order Taylor series expansion of a scalar-valued function of more than one variable can be compactly written aswhere is the gradient and is the Hessian matrix. Applyingthe multi-index notation the Taylor series for several variables becomesin full analogy to the single variable case.[edit] See also∙Taylor's theorem∙Linear approximation∙Power series∙Laurent series∙Holomorphic functions are analytic— a proof that a holomorphic function can be expressed as a Taylor power series ∙Newton's divided difference interpolation∙Difference engine∙Mean value theorem[edit] Notes1.^ Kline, M. (1990) Mathematical Thought from Ancient to Modern Times.Oxford University Press. pp. 35-37.2.^Boyer, C. and Merzbach, U. (1991) A History of Mathematics. John Wileyand Sons. pp. 202-203.3.^"Neither Newton nor Leibniz - The Pre-History of Calculus and CelestialMechanics in Medieval Kerala". MAT 314. Canisius College. Retrieved on 2006-07-09.4.^ Taylor, Brook, Methodus Incrementorum Directa et Inversa [Direct andReverse Methods of Incrementation] (London, 1715), pages 21-23(Proposition VII, Theorem 3, Corollary 2). Translated into English inD. J. Struik, A Source Book in Mathematics 1200-1800 (Cambridge,Massachusetts: Harvard University Press, 1969), pages 329-332.5.^ Exercise 12 on page 418 in Walter Rudin, Real and Complex Analysis.McGraw-Hill, New Dehli 1980, ISBN 0-07-099557-56.^ Exercise 13, same book7.^ Most of these can be found in (Abramowitz & Stegun 1970).。

移民火星计划作文作文英语In the not-so-distant future, humanity stands on the brink of a monumental leap; the colonization of Mars. This essay will delve into the intricacies of the Mars Immigration Project, exploring its scientific, technological, and social implications.The Scientific Frontier:Mars has long captivated the imaginations of scientists and the public alike. The red planet's similarities to Earth, such as its day length and the presence of water, make it an ideal candidate for colonization. The Mars Immigration Project aims to establish a sustainable human presence on the planet, which would require a deep understanding of Martian geology, climate, and potential resources.Technological Marvels:The project hinges on cutting-edge technologies that are yet to be fully realized. Spacecraft capable of transporting humans and the necessary equipment to Mars must be developed. These crafts must be efficient, reliable, and capable of sustaining life during the long journey. Upon arrival, advanced robotics and automated systems will be essential for constructing habitats and infrastructure.Sustainable Living:The establishment of a self-sufficient colony is paramount. Scientists are researching ways to utilize Martian soil andresources for agriculture and construction. Energy production will likely rely on solar and nuclear power, given Mars' distance from the Sun and the potential for nuclear reactors.The Human Element:The psychological and physiological effects of long-termspace travel and living in a Martian environment cannot be understated. Astronauts will need to be carefully selectedand trained to cope with the isolation, confinement, and the unique challenges of life on Mars. Medical facilities and research into Martian health will be crucial.International Collaboration:The Mars Immigration Project transcends national boundaries.It is a venture that requires the collaboration of nations, pooling resources, knowledge, and expertise. This endeavor could serve as a model for global cooperation in tackling humanity's most pressing challenges.Ethical Considerations:As we venture into this new frontier, ethical questions arise. How will we respect and preserve the Martian environment?What are the implications for the rights and responsibilities of those who choose to leave Earth behind? These arequestions that must be addressed as we move forward.The Future Awaits:The Mars Immigration Project is not just about survival; it's about growth and exploration. It represents the next chapterin human evolution, where we become a multi-planetary species. The journey to Mars is fraught with challenges, but it alsoholds the promise of incredible discoveries and a legacy that will inspire generations to come.In conclusion, the Mars Immigration Project is a beacon of human ambition, a testament to our innate desire to explore and to push the boundaries of what is possible. As we look to the stars, we also look to our future, and the potential for a new home beyond our own planet.。

Case Study: Unearthing Success Stories and Learning Valuable Lessons In the realm of business, education, and various other fields, case studies serve as powerful tools for understanding realworld scenarios and extracting meaningful insights. A case study delves into the details of aparticular situation, allowing us to analyze the context, identify challenges, and uncover the strategies that led to success or failure. Let's explore some key aspects of case studies and how they can benefit us.Embracing the Depth of Human ExperienceThe Art of ProblemSolvingLessons in AdaptabilityChange is the only constant, and case studies are a testament to this adage. They showcase how individuals and groups adapt to shifting circumstances, often demonstrating remarkable flexibility and resourcefulness. By examining these instances of adaptation, we can learn how to be more agile in our own lives and careers, ready to pivot when the winds of change blow.The Power of ReflectionCase studies also serve as a mirror, reflecting our own values, biases, and assumptions. They invite us to question our preconceived notions and consider alternative perspectives. This reflective practice is crucial for personal growth and for developing a more empathetic understanding of the world around us.Inspiring ActionFinally, case studies are a call to action. They inspire us to apply the lessons learned to our own contexts, to experiment with new approaches, and to strive for excellence. They remind us that every challenge presents an opportunity for growth, and that success is often the result of a willingness to learn from the experiences of others.Unlocking the Potential for Future InnovationAs we delve deeper into the world of case studies, we uncover a treasure trove of knowledge that can spark future innovation. These detailed accounts of past endeavors are not merely historical records; they are blueprints for constructing new ideas and strategies. Here's how case studies continue to shape our approach to innovation: Identifying Patterns for Predictive InsightsFostering a Culture of Continuous LearningThe study of case histories fosters a culture of continuous learning within organizations and educationalinstitutions. It encourages individuals to seek out new information, to question the status quo, and to remain curious about the world around them. This culture of learning is a fertile ground for innovation, as it keeps minds open to new possibilities and solutions.Facilitating CrossDisciplinary CollaborationEnhancing Critical Thinking SkillsGuiding Ethical DecisionMakingEthics play a pivotal role in innovation, and case studies often explore the ethical dimensions of decisions. They provide a framework for understanding the consequences of our actions on various stakeholders and society at large. By examining the ethical implications within case studies, we are better equipped to innovate responsibly and sustainably.In essence, case studies are not just a retrospective look at what has been; they are a forwardlooking tool that can guide us toward a future rich with innovation. They are a reminder that the past is a stepping stone to the future, and that learning from history, we can create a more dynamic and prosperous tomorrow.。

The Growth Challenge增长的挑战Executives and managers within almost every business today, both within the Private and Public sectors complain about the difficulties in achieving one or more of the following objectives:执行官和经理们整天忙于公务,在自己或公共的部门中抱怨达成以下或者更多目标的困难性1.How to develop a market focused growth strategy that has a high probability to benecessary and sufficient for achieving and sustaining the required growth rate financial targets set by their shareholders.1. 怎样发展一个关注市场的增长战略,这样的战略可以确保公司达到以及位置股东所设定的财务增长目标。
2. How to Achieve and maintain total synchronization between departmental goals, measurements and projects with the overall business strategy in a way that will align priorities and focus and prevent ¡°local optimization¡± and ¡°silo thinking¡±2. 怎样可以达到以及维持部门目标,绩效,项目与总体商业策略的同步性,从而可以调整优先级及关注程度,以及避免局部最优化。

请求外教帮助指导英语的作文范文全文共3篇示例,供读者参考篇1Dear English Tutor,I am writing to you today to request your assistance in improving my English writing skills. As an international student, mastering written English has been one of my greatest challenges. While I have made significant progress in my spoken English through daily practice and immersion, composingwell-structured and coherent essays remains a formidable task for me.My primary struggle lies in effectively organizing my thoughts and ideas into a logical and cohesive piece of writing. Often, I find myself grappling with the proper flow and structure of an essay, leading to disjointed and potentially confusing passages. Additionally, I sometimes struggle to convey my intended meaning accurately, which can undermine the overall clarity and impact of my writing.Another area where I seek your guidance is in refining my vocabulary and sentence construction. While I have a decentgrasp of English grammar, I frequently find myself relying on overly simplistic vocabulary or repetitive sentence structures, which can make my writing feel dull and monotonous. I aspire to achieve a more sophisticated and engaging writing style, one that captivates the reader and effectively communicates my ideas.Furthermore, I would greatly appreciate your input on developing a stronger argumentative voice in my essays. Often, I find myself presenting information in a neutral or passive manner, rather than asserting a clear stance or position. I recognize the importance of crafting persuasive arguments and supporting them with well-reasoned evidence, but I struggle to strike the right balance between objectivity and advocacy.Beyond these specific areas of concern, I am eager to learn from your expertise and experience in teaching English writing. Your guidance on techniques for brainstorming, outlining, drafting, and revising essays would be invaluable. I am particularly interested in strategies for conducting thorough research, integrating sources effectively, and ensuring that my writing adheres to academic conventions and standards.I understand that improving my English writing skills will require consistent effort and dedication on my part. However,with your support and guidance, I am confident that I can overcome these challenges and develop into a more proficient and confident writer. Your insights and feedback will be instrumental in helping me refine my writing abilities and better prepare me for academic and professional pursuits in an English-speaking environment.I am deeply grateful for your time and consideration. I look forward to the opportunity to work with you and benefit from your expertise. Please let me know if you require any additional information or if there is a specific time that would be convenient for us to discuss my writing goals and develop a plan for improvement.Thank you for your assistance.Sincerely,[Your Name]篇2Dear Mr. Jenkins,First of all, I want to express my sincere gratitude for your dedication to teaching us English. Your engaging lessons and patient guidance have been invaluable in helping me improvemy English skills. However, as I approach the upcoming English composition assignment, I find myself in need of your expert assistance.Writing a well-structured and coherent essay in English has always been a challenge for me. Despite my best efforts, I often struggle to articulate my thoughts clearly and effectively. The thought of composing a compelling piece that adheres to the conventions of English writing fills me with trepidation.One of my primary concerns is organizing my ideas in a logical and cohesive manner. While I may have a wealth of thoughts and insights to share, I sometimes find it difficult to present them in a structured and easy-to-follow format. I tend to jump from one point to another without proper transitions, which can make my writing appear disjointed and confusing.Additionally, I often encounter difficulties in using appropriate vocabulary and idiomatic expressions. Although I have a decent grasp of English grammar, I struggle to convey my intended meaning with the precise words and phrases that would make my writing more engaging and impactful. I find myself defaulting to simpler, more literal expressions, which can make my writing sound dull and lacking in nuance.Another area where I could use your guidance is in developing a strong thesis statement and supporting arguments. Crafting a clear and compelling thesis that encapsulates the central idea of my essay is a skill I have yet to master. Furthermore, I frequently struggle to provide convincing evidence and examples to back up my claims, weakening the overall persuasiveness of my writing.Beyond these specific concerns, I also worry about adhering to the conventions of English academic writing. Proper formatting, citation styles, and adherence to stylistic guidelines are aspects that often elude me, potentially compromising the professionalism and credibility of my work.I understand that improving one's writing skills is a gradual process that requires consistent practice and feedback. That is why I am reaching out to you, Mr. Jenkins, for your invaluable guidance and support. Your expertise and experience in teaching English composition would be an immense asset in helping me overcome these challenges.I would be incredibly grateful if you could spare some time to review my drafts and provide constructive feedback. Your insights into areas where I need improvement, as well as suggestions for how to strengthen my writing, would beinvaluable. Additionally, if you could provide me with resources or exercises specifically tailored to address my weaknesses, it would greatly aid my learning process.Furthermore, if you have the availability, I would deeply appreciate the opportunity to schedule one-on-one sessions with you. During these sessions, we could discuss my work in greater depth, allowing you to provide personalized guidance and address any specific questions or concerns I may have.I am fully committed to improving my English writing skills and am willing to put in the necessary effort and dedication. With your expert guidance and my unwavering determination, I am confident that I can overcome these challenges and produce a composition that not only meets the assignment requirements but also showcases my growth as a writer.Thank you, Mr. Jenkins, for considering my request. I eagerly await your response and look forward to the opportunity to work closely with you on this important endeavor.Sincerely,[Your Name]篇3Dear English Teacher,I am writing to you today to seek your valuable guidance and expertise in improving my English writing skills. As an international student, mastering the art of written expression in English is crucial for my academic and professional success. However, I find myself encountering several challenges that hinder my progress in this area.Firstly, I struggle with organizing my thoughts and ideas in a coherent and logical manner. Often, my writing feels disjointed, and my arguments lack flow and clarity. I find it challenging to structure my essays effectively, transitioning smoothly between paragraphs and maintaining a consistent train of thought throughout the piece. Guidance on proper essay structure and techniques for coherent writing would be invaluable.Secondly, I experience difficulties in expressing myself with precision and clarity. Despite having a decent grasp of vocabulary, I sometimes struggle to convey my intended meaning accurately. I tend to use imprecise language or convoluted sentences, which can obscure the central message I aim to convey. Improving my ability to articulate my thoughts concisely and precisely would greatly enhance the quality of my writing.Furthermore, I often find myself grappling with issues related to grammar, punctuation, and style. While I have studied the rules of English grammar extensively, applying them consistently in my writing remains a challenge. Unfamiliar with the nuances of academic writing conventions, I frequently make errors in punctuation and stylistic choices, which can detract from the overall quality of my work. Guidance in these areas would be immensely beneficial.Additionally, I struggle with developing and supporting my arguments effectively. While I may have interesting ideas or perspectives to share, I often find it challenging to provide solid evidence, examples, or logical reasoning to substantiate my claims. This weakness can undermine the persuasiveness and credibility of my writing. Instruction on techniques for constructing well-supported and convincing arguments would be invaluable.Moreover, I face difficulties in adopting an appropriate tone and voice for different writing contexts. Whether it's an academic essay, a formal report, or a creative piece, I sometimes struggle to strike the right balance and adapt my writing style to suit the specific purpose and audience. Guidance on how to modulate my tone and voice effectively would be greatly appreciated.Lastly, I often find the revision and editing process to be daunting. While I recognize the importance of proofreading and refining my work, I sometimes struggle to identify and address weaknesses in my writing。

英国小说英文作文模板Title: Crafting a Template for Writing English Essays on British Novels。
Introduction:In the realm of English literature, British novels stand as towering pillars of storytelling prowess, often exploring intricate themes, complex characters, and societal issues. Crafting an essay on such novels requires a structured approach that delves into the narrative, characters, themes, and the socio-historical context. This essay will provide a template for constructing insightful English essays on British novels.1. Introduction:Begin with a captivating opening sentence or quote related to the novel under discussion.Provide essential background information about the author and the novel.Introduce the central themes or issues explored in the novel.2. Plot Summary:Offer a concise summary of the plot, outlining the major events and developments.Avoid excessive detail but ensure key plot points are covered.Use present tense when narrating the plot events to create immediacy.3. Character Analysis:Analyze the main characters in depth, discussing their personalities, motivations, and development throughout the novel.Provide textual evidence to support character analysis.Explore the relationships between characters and their significance in the narrative.4. Themes and Symbols:Identify and discuss the prominent themes explored in the novel, such as love, power, identity, or social class.Examine how these themes are developed and conveyed through the storyline and character interactions.Analyze symbolic elements in the novel and their deeper meanings.5. Socio-Historical Context:Situate the novel within its socio-historicalcontext, discussing relevant events, ideologies, orcultural movements of the time.Explore how the author's background and historical circumstances influenced the creation of the novel.Consider the novel's relevance and resonance with contemporary issues or concerns.6. Literary Techniques:Analyze the author's use of literary techniques such as symbolism, imagery, foreshadowing, or narrative structure.Discuss how these techniques contribute to the overall effectiveness of the novel and enhance its themes and meanings.Provide specific examples from the text toillustrate the application of these techniques.7. Critical Evaluation:Offer a balanced critique of the novel, highlighting its strengths and weaknesses.Engage with different interpretations and critical perspectives on the novel.Formulate your own opinion on the novel's significance and enduring impact.8. Conclusion:Summarize the key points discussed in the essay, emphasizing the novel's significance within the broader context of English literature.Offer some final thoughts on the enduring relevance or cultural significance of the novel.End with a thought-provoking closing statement that leaves a lasting impression on the reader.Conclusion:Constructing an effective English essay on a British novel requires a systematic approach that encompasses plot analysis, character study, thematic exploration, socio-historical context, literary analysis, and critical evaluation. By following this template, students can develop insightful essays that demonstrate a deep understanding of the novel and its place within theliterary canon.。

An Implementation of FP-Growth Algorithm Based on High Level DataStructures of Weka-JUNG Framework1Shui Wang*Corresponding author,2Le Wang1Software School, Nanyang Institute of Technology, seawan@2School of Innovation Experiment, Dalian University of Technology, wangleboro@doi:10.4156/jcit.vol5. issue9.30AbstractFP-Growth is a classical data mining algorithm; most of its current implementations are based on programming language's primitive data types for their data structures; this leads to poor readability & reusability of the codes. Weka is an open source platform for data mining, but lacks of the ability in dealing with tree-structured data; JUNG is a network/graph computation framework. Starting from the analysis on Weka's foundation classes, builds a concise implementation for FP-Growth algorithm based on high level object-oriented data objects of the Weka-JUNG framework; comparison experiments against Weka's built-in Apriori implementation are carried out and its correctness is verified. This implementation has been published as an open source Google Code project.Keywords: FP-Growth Algorithm, Frequent Itemset Mining, Weka, JUNG1. IntroductionFP-growth (frequent pattern growth) [1] uses an extended prefix-tree (FP-tree) structure to store the database in a compressed form. It adopts a divide-and-conquer approach to decompose both the mining tasks and the databases. It uses a pattern fragment growth method to avoid the costly process of candidate generation and testing used by Apriori.Weka [2] is an open source data mining framework, integrates multiple algorithms for classification, clustering, association rule, etc, and supports abundant data I/O and visualization functionalities. But it lacks the ability to support tree-structured data type directly, and up to version 3.6 it has not implemented FP-Growth algorithm [5]. In its data mining monograph [3], information about Weka's internal data structure or data processing work flow is still insufficient; this makes it difficult to build customized algorithm based on this platform.JUNG [6][9] is a universal graph/network framework; its functionality includes construction, computation and visualization of graphs, trees and forests.FP-growth implementations based on primitive data types of programming languages lack reusable high-level data structures such as tree, itemset etc., and therefore are hard to read or migrate, or to modify for customized algorithms.This paper analyzes the basic data structure and fundamental classes of both the Weka and JUNG frameworks, gives a concise implementation for FP-Growth algorithm based on high level object-oriented data objects of the two frameworks, and compares its result against Weka's build-in Apriori implementation to verify its correctness, provides a "cloneable" template for data mining programmers to build their own algorithms on this integrated platform.2. Related workAlthough there're lots of papers discussing various derivatives or improvements of the FP-Growth algorithm, only a few of them talked about the implementation details beyond the skeleton description of the algorithm itself. Some student implementations can be found such as in [11], but usually they are poor documented and not general applicable, and/or without thorough testing. This situation makes it difficult for learners to study/research existing coding methods - they have to begin from scratch even if they just want to make a small modification to the original algorithm.Xinyu Wang et al [12] tested 3 different approaches for constructing the tree node: the vector approach, the linked list approach and the binary tree approach. They found that (upon their testingdatasets), contrary to common beliefs, the vector approach had the best performance. However, a vector is not a "natural" way to manifest a tree, and nor the "binary tree" approach.C. Borgelt [13] gave a C implementation of the FP-Growth algorithm, with his own specialized memory allocation management module. The initial FP-tree is built as a simple list of integer arrays. This list is sorted lexicographically and can be turned into an FP-tree with a recursive procedure. The proposed 2 projecting approaches do not need parent-too-child pointers, so the structure of tree node can be more compact. Despite this implementation's technical merits, its C coding style and complex data structures make it difficult to be used as educational purpose or fast application prototype building.Zi-guang Sun [14] discussed an implementation approach using STL (Standard Template Library) in C++ programming language. He argued that STL's "set" data type was implemented with a black-red tree with O(logN) searching time complexity, and could help boost the performance when constructing the header table & FP-trees despite its relatively higher memory cost. Although high-level data types were used in this implementation, these types were not intuitive.The purpose of this paper is to provide an intuitive, concise source code implementation for the FP-Growth algorithm, using high-level data types (with affordable performance loss of course), to make it easy to be adopted for education or application prototype building.3. High-level data types and functions in Weka & JUNG framework3.1. Weka's layered data structureTo deal with data transactions in a unified way, Weka provides several data types to serve this purpose; these data objects can be analogized to database terms such as transaction, table, record and field; they can be categorized into several layers as follows [4]:(1) DataSource: the source where we obtain the data; usually a data file;(2) Instances: the collection of data transactions, or database;(3) Instance: a single transaction, or record;(4) Item: a unique value for a field; this is an abstract class, its subclass such as NominalItem or NumericalItem should be used in practice for nominal items or numerical items respectively.Association rule mining uses NominalItem as its data structure; the built-in "equals()" function is used to determine where two items belong to the same field (i.e. getAttribute()returns the same value) and their values (or precisely, the index of their values) are also the same. Note that the frequency (or "support") of the two items are not compared. Item's innate "compareTo()" function compares their frequencies and attribute name with descending order, that is, the natural order of Items is the descending order on their frequencies.In Weka, an Item's "value" is represented by an "index" of the value domain; the real meaning of this index can only be obtained by referencing the underlying Attribute object. Class "Attribute" contains attribute information of a data field, including its name and value domain;e.g., suppose the attribute's value domain is {"Li", "Wang", "Zhang"}, a nominal item with a value index of 0 corresponds to "Li", and a value index of 1 corresponds to "Wang".Besides the above mentioned 4 layers of data objects, an "ItemSet" object represents the collection of one or more data items; its inner structure is an array of integers, each of which represents the value index of one item; the size of this array is the length of this itemset.Apriori-like algorithms use horizontal representation for transactions, in which the basic data element is "Instance" (aka transaction or record); FP-Growth algorithm uses vertical presentation of data, i.e., it uses data "Items" to construct the FP-trees; its implementation requires the ability of tree computation.3.2. Tree computation in JUNGJUNG has powerful support for network/graph computation & visualization functionalities [6]; Tree and Forest are special cases of Graph, and JUNG provides dedicated APIs for them. A straight-forward implementation of Tree interface is "DelegateTree", which is in fact a subclass derived from DirectedGraph. Core methods of this class include:addVertex(V vertex): add a vertex as the root node.●addChild(E edge, V parent, V child): add a child node under vertex "parent"; the "edge"object must be specified.●getPath(V vertex): get all the vertices from root to node "vertex".The idea of this paper is this: use Weka's NominalItem data object as JUNG Tree's node element, to code a concise implement for the FP-Growth algorithm.4. Constructing the header tableA "Header Table" in FP-Growth algorithm is a map from an item to its total support; the map is sorted in descending order of support. In the construction of a header table, operations such as searching, inserting, modifying and deleting of a certain item in the map is required; and to ensure the efficiency of these operations, a data structure that supports fast retrieval of data item (such as hashtable or tree) is required.Also, because the map should be sorted in descending order of support, mechanism that supports automatic sorting should be enforced on this map. We choose Apache's TreeBidiMap [7] to do this trick. TreeBidiMap establishes a bi-directional map between the key and the value elements. Bi-direction means that the key and the value are exchangeable: you can seek the value corresponding to a specified key, and you can also seek a key corresponding to a specified value: both operations should be performed efficiently.These features of the TreeBidiMap class requires that both key and value should be comparable (i.e., implement the Comparable interface and overload the compareTo() method) and there should be a 1-to-1 relationship between all keys and values. Because the support of different items might be the same, so we define a customized HeaderCount class with an attribute of random value to impose the 1-to-1 relationship between items and supports.Figure 1 is the class used in header table representing an item's support; the "link" attribute is the link table required by FP-Growth algorithm. So we can define the header table as: TreeBidiMap<HeaderCount, NominalItem>Note that here we use the HeaderCount object as the "key" of the map merely for the convenience of coding; for a bi-directional map, key and value are exchangeable.TreeBidiMap is one of the collection classes in “Apache Commons”project [8]; it is a bi-direction tree structure implemented using the red-black tree approach, and comparison operation is performed during its construction, so all the nodes should implement Comparable interface. Detailed structure of the NominalItem class is discussed in the next section.Data type 1: header table:class HeaderCount implements Comparable<HeaderCount> {int count = 1;//total supportdouble random = Math.random();Vector<NominalItem> link = new Vector<NominalItem>();public int compareTo(HeaderCount arg0) {if (arg0 == this) return 0;long r = count - arg0.count;if (r < 0) return 1;else if (r > 0) return -1;else {//impose "unequal" for different objectsreturn (random <= arg0.random) ? 1 : -1;}}}Figure 1. Class HeaderCount for the header table5. Constructing FP-treesThere are two types of data stored in an FP-tree: items and supports. Items that come from different transactions but belong to the same field and with the same value may share one node(if they have common prefix) or reside on different nodes; but JUNG framework do not allow different nodes to be "equal", so the "item" object in a FP-Growth implementation must satisfy the following two conditions:(1) It must be able to distinguish between items that has the same attribute and value but from different transactions.(2) It must also be able to identify the above mentioned items to be a special kind of "equal".Because the NominalItem class only overloads Item's equals() method in which its attribute is compared, it can not distinguish items from different transactions; so we define a new class for nominal items named "OrderedNominalItem", with a "serial" property indicating its transaction id; equals() method is also rewritten to ensure its effectiveness when constructing a JUNG Tree object with OrderedNominalItem nodes.In the construction process of the header tables (data type is TreeBidiMap) and FP-Trees (data type is DelegateTree of JUNG), comparative operations are performed when adding or deleting nodes. The original compareTo()method only compares item's frequency & attribute's name; this strategy gives an "equal" result for those items that belong to the same field (attribute) but with different values. So our comparison strategy is: compare item's frequency, name of attribute and item value consecutively, as shown in Figure 2.Condition (2) is met by method equalsWithoutOrder(), in which comparison is made without involving the serial property; this method is called when seeking a specified item in a collection when only the item's attribute & value are compared, see seekItemInCollection() method in class FpTree [8]; this seeking operation is needed when adding a new node to the existing FP-tree.Data type 2: comparator of OrderedNominalItem:public boolean equals(Object o) {if (serial != ((OrderedNominalItem) o).serial)return false;return super.equals(o);}public int compareTo(Item o) {OrderedNominalItem comp = (OrderedNominalItem) o;// 1. first, frequencyif (comp.getFrequency() < m_frequency) {return -1;}if (comp.getFrequency() > m_frequency) {return 1;}// 2. then, by nameint c = m_().compareTo(comp.getAttribute().name());if (c != 0)return -1 * c;// 3. last, by valueif (m_valueIndex < comp.getValueIndex())return 1;else if (m_valueIndex > comp.getValueIndex())return -1;elsereturn 0;}Figure 2. Comparator used in OrderedNominalItem6. Algorithm descriptionUsing the high-level data types in Weka and JUNG framework along with data objects from Apache Collections, the computation process of FP-Growth algorithm can have a simple description.Figure 3 is the work flow of the initial process on transaction database; it constructs the first FP-tree and header table with two scans. From this point on, the mining process becomes mining on FP-trees. Figure 3. Initial process for transaction databaseThe main mining method is defined as mineDbtree(dbTree, dbHeader); it is a recursive function with two basic steps:(1) Traverse the header table and construct subtrees;(2) Mine the subtree (with recursive function call to mineDbtree());Each subtree is a new transaction database, we can handle it with just the same way we handle the original database:(1) First scan, construct header table;(2) For each transaction, sort its items in header table's order;(3) Second scan, construct transaction tree;(4) Mine the resulted transaction tree (recursive call to mineDbtree ).This process is demonstrated in Figure 4.Figure 4. Mining process on subtreesMining the transaction tree comprises two main steps:(1) Obtaining the subtree corresponding to the header table items (getSubtree ).(2) Mining the resulted subtree (mineSubtree ).Although the actual code may seem a little different, but the idea inside getSubtree() is quite simple: traverse the link table and get all the branches corresponding to each item; each branch is obtained by simply invoke:List<OrderedNominalItem> branch = tree .getPath(link item );Algorithm 1: construction of the initial fp-tree://1.Initialization:Initialize instances object from a data source (e.g. a file);//2.First Scan, create initial header table:For each instance in instances :Split it into items (OrderedNominalItem objects)Construct header table (data type: TreeBidiMap<HeaderCount, OrderedNominalItem>)Delete unfrequent items from header table//3.Second scan, create initial FP-Tree and link table:Construct dbTree;(data type: DelegateTree<OrderedNominalItem, Long>)Construct link table(data type:Vector)//4.now do the mining on dbTtreemineDbtree(dbTree, dbHeader)Algorithm 2: mining sub-tree:mineSubtree(Vector<List<OrderedNominalItem>>subtree) {//1. Traverse subtree build header tableTreeBidiMap<HeaderCount, OrderedNominalItem>header;//2. Sort items in transaction//3. Rebuild transaction treeDelegateTree<OrderedNominalItem, Long> fptree;//4. Mine the resulted treemineDbtree(fptree, header);After removing its root & leaf node, branch is a list of nodes that consists one transaction of the subtree. All such branches form a new transaction database, which can be mined recursively using mineDbtree. Recursion termination condition: the resulting subtree is empty.Mining process of the subtree is illustrated in Figure 5.Algorithm 3: mining transaction-tree:mineDbtree(dbtree, dbheader) {Vector<List<OrderedNominalItem>> subtree;HeaderCount headerItem = stKey();// traverse from the tail of the header tablewhile (headerItem != null) {// 1. get subtree for this itemsubtree = getSubtree(dbtree, headerItem);// if subtree is null, go to nextif (subtree == null) {headerItem =dbheader.previousKey(headerItem);continue;}// 2. subtree miningmineSubtree(subtree);// next item in header tableheaderItem =dbheader.previousKey(headerItem);}}Figure 5. Mining the transaction tree7. Implementation and experimentsThe approach described in this paper has been implemented and published as an open source project on Google Code™; the project URL is:/p/weka-jung-fpgrowth/JUNG & Weka's supporting package that is needed for compiling can be download at [5][9]; the Apache Collections support is included in JUNG package.We created a simple GUI (see Figure 6) for testing different data sets. The favorite type for the data file is "arff" which is the standard in Weka [5], while other types such as "csv" are also supported.As shown in Figure 6, button "Read Datafile" loads data from a file into a DataSource object and parses it to an Instances object; button "Apriori->FP" uses the Weka's built in Apriori algorithm to find all the frequent patterns, and button "Show FP" lists these patterns in the window. "FP-Tree" is our implementation: it applies the FP-Growth algorithm upon the above mentioned Instances and shows the results.Experiments have been performed to check its correctness; data sets used in these experiments are downloaded from UCI Machine Learning Repository [10]. The computer that runs the experiments has a software environment of Windows XP and JDK 1.6.0_14 with a hardware configuration of Intel® Core2 Duo CPU (2.8GHz) & 3GB memory. Source code compilation is done with MyEclipse V7.5.Because we only want to check the correctness (instead of performance) of this implementation, a simple comparison with the result of the built-in Apriori algorithm should suffice. Table 1 is the testing result on the classical "Breast Cancer" dataset, and clearly it out performs the Apriori implementation (which is also a Weka based program), and Figure 6 is the runtime screen shot of this test for the minimum support value setting to 0.5. We have not tested our implementation against FP-Growth's C++ implementations because we consider there is no comparability between these two approaches and the overhead of our complex data objects is obvious.Figure 6. A graphic user interface of our implementationTable 1. Runtime Comparison with Weka-Apriori ImplementationMini Sup Apriori(ms) FP-Tree/JUNG-Weka(ms)0.5 156 630.2 375 780.1 906 2190.02 overflow 15948. Conclusion and discussionUtilizing the combined framework of Weka and JUNG, together with other high-level data types from Apache Collections, algorithms (such as FP-Growth) that need sophisticated data structures (such as trees, graphs etc) could be implemented concisely with less effort and yet higher reusability; the overhead on complex data objects and its downside impact on runtime efficiency can be overlooked when human labor cost is a more important factor.This implementation does not use Weka's built-in NominalItem data type directly as JUNG tree's node class, because from experiments we find that if the internal attribute such as m_frequency is changed via its public method then this object will no longer be considered as a composing node of the tree; this odd behavior forced the customized OrderedNominalItem class to have a redundant data attribute for the item's support, and the course of this remains further study.Utilizing the high-level data types of JUNG has other benefits: JUNG provides powerful visualization functionalities, which can be used to present graphical illustration of the mining results such as needed when dealing with visualization requirements [15]. In fact, setting the boolean variable "showtrees" to "true" will cause our program to visualize all FP-trees it create, one example of such trees is shown in Figure 7.Thoughts on further research work include implementing other algorithms that need tree computation and visualization, such as the "cluster first" strategy proposed in [16], and text mining for mind map [17].Figure 7. Visualization of an FP-tree9. References[1]Jiawei Han, Jian Pei, Yiwen Yin, and Runying Mao, “Mining frequent patterns without candidategeneration”, Data Mining and Knowledge Discovery, vol. 8, no. 1, pp.53-87, 2004.[2]Mark Hall, Eibe Frank, Geoffrey Holmes, Bernhard Pfahringer, Peter Reutemann, Ian H. Witten,“The WEKA Data Mining Software: An Update”, SIGKDD Explorations, vol.11, no. 1, 2009. [3]Eibe Frank, Ian H. Witten. Data Mining: Practical Machine Learning Tools and Techniques[M].Morgan Kaufmann, 2005.[4]Guang-li Yu, Ying Zhan and Shui Wang, “Analysis on Weka Foundation Classes and AlgorithmExtending Method”, Journal of Nanyang Institute of Technology, vol. 1, no. 6, pp. 9-11, 2009. [5]Weka (Machine Learning Group at University of Waikato). Data mining with open sourcemachine learning software in Java [/~ml/weka/]. Accessed in Sep.2010.[6]Shui Wang, Yu-jun Ma, “Introduction to JUNG: Network/Graph Computation Framework on Javaplatform”. (to be published).[7]Apache Software Foundation. Apache Commons [/collections/].Accessed in Sep 2010.[8]Shui Wang, Le Wang. Source code of this paper [/p/weka-jung-fpgrowth/downloads/]. 2010.[9]Joshua O'Madadhain, Danyel Fisher, Tom Nelson et al. Java Universal Network/GraphFramework [/]. Accessed in Sep 2010.[10]Frank, A. & Asuncion, A. UCI Machine Learning Repository [/ml]. Irvine,CA: University of California, School of Information and Computer Science. Accessed in Sep 2010.[11]CSDN, Java source for FP-Growth [/source/665781]. Accessed in Sep2010.[12]Xinyu Wang, Xiaoping Du, Kunqing Xie, “Research on Implementation of the FP-GrowthAlgorithm”, Computer Engineering and Applications, vol. 40, no. 9, pp. 174-176, 2004. (in Chinese).[13]C. Borgelt. An implementation of the FP-growth algorithm. In Proceeding of OSDM 2005, pp.1-5,2005.[14]Zi-guang Sun, “Analysis and implementation of the algorithm of FP-growth”, Journal of GuangxiInstitute of Technology, vol. 16,no. 3, pp. 64-67, 2004. (in Chinese).[15]Jinlong Wang, Can Wen, Shunyao Wu, Huy Quan Vu , “A Visual Mining System for ThemeDevelopment Evolution Analysis of Scientific Literature”, JDCTA: International Journal of Digital Content Technology and its Applications, vol. 4, no. 3, pp. 21-23, 2010.[16]Lilin FAN, “Research on Classification Mining Method of Frequent Itemset”, JCIT: Journal ofConvergence Information Technology, vol. 5, no. 8, pp. 71-77, 2010.[17]Shui Wang, Le Wang, “Mindmap-NG: A novel framework for modeling effective thinking”, InProceeding of the 3rd IEEE International Conference on Computer Science and Information Technology (ICCSIT), vol.2, pp.480-483, July 2010.。

元器件交易网ML6554PRODUCT SPECIFICATIONPin ConfigurationPin DescriptionPin Name Function1V DD Digital supply voltage2PV DD1 Voltage supply for internal power transistors 3V L1 Output voltage/ inductor connection 4P GND1 Ground for output power transistors 5P GND2 Ground for output power transistors 6V L2 Output voltage/inductor connection 7PV DD2 Voltage supply for internal power transistors 8D GND Digital ground 9V DD Digital supply voltage10V FB Input for external compensation feedback 11VREF IN Input for external reference voltage 12SHDN Shutdown active low. CMOS input level 13AGND Ground for internal reference voltage divider 14VREF OUT Reference voltage output15V CCQVoltage reference for internal voltage divider 16AV CCAnalog voltage supply元器件交易网PRODUCT SPECIFICATIONML6554Absolute Maximum RatingsAbsolute maximum ratings are those values beyond which the device could be permanently damaged. Absolute maximum ratings are stress ratings only and functional device operation is not implied.Operating ConditionsElectrical CharacteristicsUnless otherwise speci fied, AV CC = V DD = PV DD = 3.3V ±10%, T A = Operating T emperature Range (Note 1) Notes1.Limits are guaranteed by 100% testing, sampling, or correlation with worst-case test conditions.2.Infinite heat sink ParameterMin.Max.Units PV DD4.5V Voltage on Any Other PinGND – 0.3V IN + 0.3V Average Switch Current (I AVG ) 3.0A Junction Temperature150°C Storage Temperature Range-65150°C Lead Temperature (Soldering, 10 sec)150°C Thermal Resistance ( θJC )(Note 2)2°C/W Output Current, Source or Sink3.0AParameterMin.Max.Units Temperature Range, CU suffix 070°C Temperature Range, IU suffix -40+85°C PV DD Operating Range 2.0 4.0V V CCQ Operating Range1.44.0VSymbol Parameter ConditionsMin.Typ. Max.UnitsSwitching Regulator V TT Output Voltage, SSTL_2(See Figure 1)I OUT = 0, V REF = open V CCQ = 2.3V 1.12 1.15 1.18V V CCQ = 2.5V 1.22 1.25 1.28V V CCQ = 2.7V 1.32 1.35 1.38V I OUT = ±3A, V REF = openV CCQ = 2.3V 1.09 1.15 1.21V V CCQ = 2.5V 1.19 1.25 1.31V V CCQ = 2.7V 1.28 1.35 1.42V VREF OUTInternal Resistor DividerI OUT = 0V CCQ = 2.3V 1.139 1.15 1.162V V CCQ = 2.5V 1.238 1.25 1.263V V CCQ = 2.7V 1.337 1.35 1.364V Z INV REF Reference Pin InputImpedanceVCCQ = 0100k Ω Switching Frequency650kHz ∆ V OFFSET Offset Voltage V TT – VREF OUTAV CC = 2.5V No Load VCCQ = 2.5–2020mV Supply I Q Quiescent CurrentI OUT = 0, no loadV CCQ = 2.5VI VCCQ 610µA I AVCC0.5 1.0mA I AVCC SD 0.20.5mA I VDD0.25 1.0mA I VDD SD 0.2 1.0mA I PVDD100250µA Buffer IREFOutput Load Current3mA元器件交易网元器件交易网ML6554PRODUCT SPECIFICATIONPRODUCT SPECIFICATION ML6554ML6554PRODUCT SPECIFICATIONFigure 3. Alternate Application CircuitAn alternate application circuit for the ML6554 is shown in Figure 3. The number of external components is reduced compared to the circuit in Figure 2. This is achieved by replacing four, 0.1µF bypass capacitors with one, low ESR, 10µF ceramic capacitor placed right next to U1. Two 100Ωresistors are also eliminated. High value, surface-mount MLC capacitors were not available when the original appli-cation circuit (Figure 2) was developed. Both application circuits offer the same electrical performance but that shown in Figure 2 has a reduced bill-of-materials. Table 2 shows the recommended parts list for the circuit of Figure 3.PRODUCT SPECIFICATION ML6554ML6554PRODUCT SPECIFICATIONFigure 6. Top SilkFigure 7. Top LayerFigure 8. Bottom LayerPRODUCT SPECIFICATION ML6554ML6554PRODUCT SPECIFICATIONTable 1. Recommend Parts List for SSTL-2 Termination Circuit in Figure 2.Table 2. Recommend Parts List for Figure 3.Item Qty DescriptionManufacturer / Part Number Designator Resistors12100Ω1210 SMD Panasonic/ERJ-8ENF1000V R1, R2211k Ω 1210 SMD Panasonic/ERJ-8ENF1001V R532100k Ω1210 SMD Panasonic/ERJ-8ENF1003V R3, R4Capacitors430.1µF 1210 Film SMD Panasonic/ECV3VB1E104K Panasonic/ECU-V1H104KBW C2, C8, C951820µF 2V Solid Elect. SMD Sanyo/2SV820M Os Con C162330µF Tant 6.3V 100m ΩAVX/TPSE337M006R0100C5, C6711nF 1210 Film SMD Panasonic/ECU-V1H102KBM C7820.1µF 0805 Film Panasonic/ECJ-2VF1C104Z C3, C4ICS91ML6554 Bus Terminator Power SOP Package ML6554CU or ML6554IUU1Magnetics1013.3µH 5A inductor SMDCoilcraft/D03316P-332HC Pulse Eng./ P0751.332T Gowanda/SMP3316-331M XFMRS inc./XF0046-S4L1Other111Scope probe socket Tektronics/131-4353-00TP112112 Pin breakaway strip Sullins/PTC36SAAN (36 PINS)I/O, standoffsItem Qty DescriptionManufacturer / Part Number Designator Resistors12100k Ω 0805 SMD Panasonic/ERJ-8ENF1000V R1, R3211k Ω 0805 SMD Panasonic/ERJ-8ENF1000V R2Capacitors310.1µF, 1210 Film SMD Panasonic/ECV3VB1E104K Panasonic/ECU-V1H104KBW C241820µF 2V Solid Elect. SMD Sanyo/2SV820M Os Con C152330µF Tant 6.3V 100m ΩAVX/TPSE337M006R0100C5, C6611nF 1210 Film SMD Panasonic/ECU-V1H102KBM C47110µF 6.3V Ceramic TDK/C2012X5R0J106M C3ICS81ML6554 Bus Terminator Power SOP Package ML6554CU or ML6554IUU1Magnetics913.3µH 5A inductor SMDCoilcraft/D03316P-332HC Pulse Eng./ P0751.332T Gowanda/SMP3316-331M XFMRS inc./XF0046-S4L1Other101Scope probe socket Tektronics/131-4353-00TP111112 Pin breakaway strip Sullins/PTC36SAAN (36 PINS)I/O, standoffsFigure 12. Test Board Layout for ΘJA vs. Airflow Table 3. Termination Solutions Summary By Buss TypeBus Description DrivingMethod VDDQ VTT V REFFairchildSolutionsIndustrySystemComponentsGTL+GunningTransceiverBus Plus Open Drain5v or 3.3VNote 101.5V±10%Note121.0V±2%Note 11ML6554CU;Mode: V REFInput = 1.5V,V CC = 5V300 to 500MHzProcessor;PC Chipsets;GTLP 16xxxBuffers;Fairchild,Texas Instr.SSTL_2Series StubTerminatedLogic for 2V SymmetricDrive,SeriesResistance2.5V±10%0.5x(V DDQ)±3%2.5V ML6554CUor ML6553CS;Mode: V REFInput = Floatingor Forced,V CC = 3.3VSSTL SDRAM;Hitachi,Fujitsu,NEC, Micro,MitsubishiRAMBUS RAMBUSSignalingLogic Open Drain NoneSpecified2.5V 2.0V ML6553CS;Mode: V REFInput = Open,V CC = V DDQnDRAM,RAMBUS,Intel, ToshibaLV-TTL Low VoltageTTL Logic orPECL or3.3V VME SymmetricDrive3.3±10%V DDQ/2 3.3V ML6553CS;Mode: V REFInput = Open,VCC = VDDQProcessors orbackplanes;LV-TTLSDRAM,EDO RAMDISCLAIMERFAIRCHILD SEMICONDUCTOR RESERVES THE RIGHT TO MAKE CHANGES WITHOUT FURTHER NOTICE TO ANY PRODUCTS HEREIN TO IMPROVE RELIABILITY, FUNCTION OR DESIGN. FAIRCHILD DOES NOT ASSUME ANY LIABILITY ARISING OUT OF THE APPLICATION OR USE OF ANY PRODUCT OR CIRCUIT DESCRIBED HEREIN; NEITHER DOES IT CONVEY ANY LICENSE UNDER ITS PATENT RIGHTS, NOR THE RIGHTS OF OTHERS.LIFE SUPPORT POLICYFAIRCHILD’S PRODUCTS ARE NOT AUTHORIZED FOR USE AS CRITICAL COMPONENTS IN LIFE SUPPORT DEVICES OR SYSTEMS WITHOUT THE EXPRESS WRITTEN APPROVAL OF THE PRESIDENT OF FAIRCHILD SEMICONDUCTOR CORPORATION. As used herein:1.Life support devices or systems are devices or systemswhich, (a) are intended for surgical implant into the body, or (b) support or sustain life, or (c) whose failure to perform when properly used in accordance with instructions for use provided in the labeling, can be reasonably expected to result in significant injury of the user.2. A critical component is any component of a life supportdevice or system whose failure to perform can bereasonably expected to cause the failure of the life support device or system, or to affect its safety or effectiveness.。

循迹小车制作英语作文Building a Line Follower RobotLine follower robots are autonomous vehicles that are designed to follow a predefined path marked by a line or track. These robots use sensors to detect the line and adjust their movement accordingly to stay on the designated path. The process of designing and constructing a line follower robot can be an engaging and educational experience, allowing individuals to explore the principles of robotics, electronics, and programming.The first step in building a line follower robot is to understand the basic components and their functions. At the core of the robot is a microcontroller, which serves as the "brain" of the system. The microcontroller is responsible for processing sensor inputs, making decisions, and controlling the robot's movement. Commonly used microcontrollers for line follower robots include Arduino, Raspberry Pi, and various microcontrollers from manufacturers like Atmel, Texas Instruments, and Microchip.The sensors used in a line follower robot are typically infrared (IR) sensors or reflective sensors. These sensors are positioned on the underside of the robot and are used to detect the line or track. When the sensor detects the line, it sends a signal to the microcontroller, which then adjusts the robot's movement accordingly. The numberof sensors used can vary, with some designs incorporating a single sensor and others using multiple sensors to improve the robot's tracking accuracy.The robot's movement is typically controlled by a set of motors, such as DC motors or stepper motors, which are connected to the microcontroller. The microcontroller sends signals to the motors to control the speed and direction of the robot's movement. In a basic line follower robot, the motors are often connected to the robot's wheels, allowing it to move forward, backward, and turn as neededto follow the line.In addition to the core components, a line follower robot may also include additional features or components to enhance its capabilities. For example, some robots may incorporate a display or LED indicators to provide visual feedback on the robot's status or performance. Others may include wireless communication modules, such as Bluetooth or Wi-Fi, to enable remote control or data transmission.The software or programming aspect of a line follower robot is crucial, as it determines the robot's behavior and decision-making process. The microcontroller's programming is typically done using a programming language such as C, C++, or Arduino's own programming language. The code must be designed to read the sensor inputs, interpret the line's position, and send appropriate commands to the motors to keep the robot on the designated path.One of the key challenges in building a line follower robot is ensuring that the robot can accurately follow the line, even in the presence of variations or obstacles. This may require fine-tuning the sensor placement, adjusting the motor control algorithms, and implementing advanced techniques like proportional-integral-derivative (PID) control or adaptive algorithms.Beyond the technical aspects, building a line follower robot can also be a valuable learning experience. It allows individuals to develop skills in problem-solving, critical thinking, and hands-on engineering. The process of designing, constructing, and programming the robot can foster a deeper understanding of robotics, electronics, and computer science principles.Moreover, line follower robots can be used in a variety of applications, such as automated guided vehicles (AGVs) in industrial settings, educational demonstrations, or even as part of roboticscompetitions and challenges. These applications can further inspire and motivate individuals to continue exploring the field of robotics and seek new opportunities for innovation.In conclusion, building a line follower robot is a rewarding and educational endeavor that allows individuals to apply their knowledge of electronics, programming, and engineering to create a functional autonomous vehicle. By understanding the core components, designing the mechanical and electrical systems, and developing the software, individuals can gain valuable hands-on experience and contribute to the growing field of robotics.。

人教版八年级上册英语基础训练第一单元达标测试Embarking on the journey of learning a new language opens up a world of opportunities. As students of the eighth grade begin their exploration of English, they encounter a variety of themes that not only enhance their linguistic skills but also broaden their cultural horizons. The first unit of the People's Education Press textbook for eighth grade serves as an introduction to this adventure, laying the foundation for a solid understanding of English.The unit starts with the basics of grammar, an essential building block for constructing clear and correct sentences. Understanding subjects, predicates, and objects allows students to form simple sentences, which is the first step in communication. As they progress, they learn about the different types of sentences: declarative, interrogative, imperative, and exclamatory, each serving a unique purpose in expression.Vocabulary is another cornerstone of language learning. This unit introduces students to a carefully selected set of words that are both practical and relevant to their daily lives. Through various exercises, students practice using these new words in context, enhancing their ability to remember and apply them.Pronunciation and intonation are also covered, with audio resources providing models for students to imitate. Accurate pronunciation is crucial, as it affects the clarityof communication. Intonation, the rise and fall of the voice in speaking, conveys emotions and attitudes, adding depth to the spoken word.Cultural insights are woven throughout the unit, offering glimpses into the English-speaking world. These cultural tidbits not only make the learning process more interesting but also help students develop a global perspective.The unit includes a range of activities designed to cater to different learning styles. Visual learners benefit from the colorful illustrations and charts, auditory learners fromthe listening exercises, and kinesthetic learners from the role-play and group work. This multimodal approach ensures that every student has the chance to engage with the material in a way that suits them best.Assessment is an integral part of the learning process, and the unit concludes with a test that measures students' understanding of the material covered. This test is not just a means of evaluation but also a tool for reflection, allowing students to identify their strengths and areas for improvement.In conclusion, the first unit of the eighth-grade English textbook is more than just a collection of lessons; it is a carefully crafted experience designed to ignite a passion for the English language. Through a blend of grammar, vocabulary, pronunciation, cultural knowledge, and diverse activities, students are equipped with the tools they need to communicate effectively and to continue their journey of language learning with confidence and enthusiasm.This document, adhering to the guidelines provided, aims to encapsulate the essence of the first unit, ensuring that the content is accurate, lively, concise, and logically connected, thus reflecting a high standard of document quality without deviating from the topic at hand. 。

学报Journal of China Pharmaceutical University2021,52(1):20-3020自组装型树形分子在生物医学领域的研究进展史康洁1,陈家轩1,2,刘潇璇1*,彭玲2**(1中国药科大学,天然药物活性组分与药效国家重点实验室,药物科学研究院高端药物制剂与材料研究中心,南京210009;2法国国家科学院马赛纳米交叉科学研究中心,艾克斯马赛大学,法国马赛13188)摘要树形分子因其具有独特的树枝状分子结构以及多价协同作用等特性在生物医学领域具有广阔的应用前景。
然而树形分子合成繁琐费时、纯化困难,使得大规模制备高代无缺陷的树形分子困难重重。
为了克服这一困难,研究人员提出了一种基于自组装的方法构建树形分子的策略,即利用低代的两亲性树形分子自组装构建非共价超分子树形分子,用以模拟高代共价树形分子。
本文介绍超分子树形分子的研究及其在生物医学领域的应用,例如输送小分子抗肿瘤药物、核酸治疗试剂和分子造影剂等,并通过一些代表性的实例展现超分子树形分子的应用前景与挑战。
关键词聚酰胺-胺类树形分子;自组装型树形分子;树形分子合成;药物递送;基因递送中图分类号R944文献标志码A文章编号1000-5048(2021)01-0020-11doi:10.11665/j.issn.1000-5048.20210103引用本文史康洁,陈家轩,刘潇璇,等.自组装型树形分子在生物医学领域的研究进展[J].中国药科大学学报,2021,52(1):20–30. Cite this article as:SHI Kangjie,CHEN Jiaxuan,LIU Xiaoxuan,et al.Self-assembling dendrimers for biomedical applications[J].J China Pharm Univ,2021,52(1):20–30.Self-assembling dendrimers for biomedical applicationsSHI Kangjie1,CHEN Jiaxuan1,2,LIU Xiaoxuan1*,PENG Ling2**1State Key Laboratory of Natural Medicines,Center of Advanced Pharmaceuticals and Biomaterials,China Pharmaceutical University, Nanjing210009,China;2Interdisciplinary Center of Nanoscience of Marseille,Aix-Marseille University,CNRS,Marseille13188, FranceAbstract Dendrimers,a special class of synthetic polymers known for their well-defined ramified structures and unique multivalent cooperativity,hold great promise for various biomedical applications.However,prepara⁃tion of defect-free dendrimers of high-generation on a large scale remains challenging because of the tedious and time-consuming synthesis as well as difficult purification.To overcome these limitations,an alternative strategy based on self-assembling approach has been developed to construct supramolecular dendrimers using small amphiphilic dendrimer-building units.By virtue of the amphiphilic nature,these small dendrimer-building units self-assemble and form large non-covalent supramolecular dendritic structures that mimic high-generation cova⁃lent dendrimers.Here,we present a brief overview of the supramolecular dendrimers developed in our group for the delivery of nucleic acid therapeutics,anticancer drug and imaging agents.Key words poly(amidoamine)dendrimer;self-assembling dendrimers;dendrimer synthesis;drug delivery;gene delivery收稿日期2020-06-02通信作者*Tel:************E-mail:xiaoxuanliucpu@**Tel:0033-6-17248164E-mail:ling.peng@univ-amu.fr基金项目国家自然科学基金资助项目(No.50773127,No.81701815);国家重点研发计划“政府间国际科技创新合作/港澳台科技创新合作”重点专项资助项目(No.2018YFE0117800);江苏省自然科学基金资助项目(No.BK20170734);江苏省“高层次创新创业人才引进计划”资助项目;中国药科大学天然药物活性组分与药效国家重点实验室资助项目(No.SKLN⁃MZZ202007);法国外交部埃菲尔奖学金、法国国家癌症防治联盟资助项目第52卷第1期史康洁,等:自组装型树形分子在生物医学领域的研究进展This work was supported by the National Natural Science Foundation of China (No.50773127,No.81701815),the Key Program for International S&T Cooperation Projects of China (No.2018YFE0117800),the Natural Science Foundation of Jiangsu Province (No.BK20170734),the Program for Jiangsu Province Innovative Research Talents,the State Key Laboratory of Natural Medicines at ChinaPharmaceutical University (No.SKLNMZZ202007),Bourse d'Excellence Eiffel and Ligue Nationale Contre le Cancer1树形分子1978年,Buhleier 等[1]第一次合成了树枝状分子,又称为“级联分子”。
3000字服装设计外文文献篇一:服装设计外文文献翻译文献出处:Sukumar N, Gnanavel P, Ananthakrishnan T. Effect of Seams on Drape of Fabrics [J]. African Research Review, 20xx, 3(3):62-72.原文Effect of Seams on Drape of FabricsSukumar ;Gnanavel. P. , Ananthakrishnan, T.AbstractDrape of the fabric is its ability to hang freely in graceful folds when some area of it is supported over a surface and the rest is unsupported. Drape is a unique property that allows a fabric to be bent in more than in one direction, When two-dimensional fabric are converted to three-dimensional garment form. In the present study, the effects of sewing of different seam were selected on different fabric and their behaviors were studied. In this study drape of ten fabrics are analyzed with three types of seams and three stitch densities. Sample without seam is a control sample and drape of seamed samples are compared with control sample to analyze the drape behavior of seamed fabrics. This paper presents a fundamental drape analysis of seamed fabrics using drape meter. Drape behavior is determined in terms of drape coefficient. The effect of seams on the drape coefficient and Drape profile has been made. Drape coefficients significantly differs between the fabrics and also between the seam stitch density combinations. Investigating drape on seamed fabrics can improve fabric end use application.Key words: drape, computer aided design, seam, stitch densityIntroductionDrape is an important property that decides the gracefulness of any garment as it is relates to aesthetics of garments (Kaushal Raj sharma and B.K. Behera. 20xx). The mechanical properties of fabrics were firststudied during the late 19th century by German researchers working on developing airships (Postle, 1998). Drape ability has been regarded as a quantitative characteristic of cloth, and several devices as well as virtual systems have been developed to measure it (Booth, 1968; Jeong, 1998; Stylios and Wan, 1999). Instruments for measuring drape ability have been developed by Chu et al.(1950) and later by Cusick (1965, 1968) using a parallel light source that reflects the drape shadow of a circular specimen from hanging disc into a piece of ring paper at present numerous instruments, ranging from a simple cantilever bending tester to a dynamic drape tester developed for measuring fabric drape. During recent years, the investigation of fabric drape has attracted the attention of many researchers because of the attempts to realize the clothing Computer aided design (CAD) system by introducing the fabric properties, in which fabric drape is the key element. It is obvious that fabrics have to be sewn together for a garment to be formed. The seams of a garment affect the fabric drape greatly (Matsudaira, M. and Yang, M. 2000). It is uealistic to realize the appearance of a garment system without the consideration of seams and the methods of assembling of fabrics into garments (Jinlian Hu et al, 1997).When a fabric is draped; it can bend in one or more directions. Curtains and drapes usually bend in one direction, whereas garments and upholstery exhibit acomplex three-dimensional form with double curvature. Hence, fabric drape is a complex mathematical problem involving large deformations under low stresses (Postle, 1993).A plain seam the most typical seam found extensively in apparel is the simplest type in which a single row of lock stitches joins two pieces of fabrics together. Thus, investigating the effect of a plain seam on fabric drape has a significant value for both the textile and clothingindustries. The quantified drapeability of a fabric into a dimensionless value called a “Drape coefficient”, which is defined as the percent of the area from an angular ring of fabric covered by a vertical projection of the draped fabric (Brand R.H.1964). “Drape co efficient (DC)” the main parameter used to quantify fabric drape (Narahari Kenkare and Traci May-Plumlee. 20xx). Though useful, it is insufficient to characterize complex forms such as garments. Stylios and Zhu, 1997 considered that the drape coefficient by itself did not capture the full aesthetic quality of the drape of a fabric.Drape profile of fabrics with seams provide guidance for garment designs and producers in the apparel industry and improve the understanding of drape properties corresponding to different seam features (Fourt.L and Hollies.N.R.S.1970). Furthermore, we expect that the results will be useful in predicting garment drape with clothing CAD systems.Different types of seams are used in garment making and also wide stitch densities are employed. Once the fabric is joined with seams possibly its drape configuration would vary.The product range of textile industry has extended to the garments. Mass production of operational systems and automated sewing is making more and more presence, it is very essential to understand to the change in properties the fabric under goes once it is seamed. This study is an attempt to understand the effects of seams on the drape of fabrics, which is one of key characteristics for apparels and certain draperies.Types of SeamThe types of seams were selected and in each type, three stitch densities were employed. Fabrics were sewn along the warp and weft direction on a 35cm square side. Control sample for the test is a piece with no seams. This resulted in 9 treatment combinations.(1) Plain Seam (S1)This is the most common seam used in the garment industry. This is easy to make and pliable. It is normally suitable for all types of garments. And, it is suitable for curved locations like armhole. To make this seam we have to place two pieces of fabrics to be joined together right sides facing, matching the seam lines, and we should stitch the seam exactly on the seam line.(2) Welt Seam (S2)For constructing this, we should stitch the plan seam and press both seam allowances to one side. Then the inside seam allowance is trimmed to ”. Then top stitching is done on the right side of the garment by catching the wider seam allowance. This type is normally used on heavy coats.(3) French seam (S3)The French seam is stitched twice once from the right side and once from the wrong side. It is the classic seam for sheers and looks best if the finished widt h is” or less. To form this seam, with wrong sides of the fabric together, we should stitch 3/8” from the edge on the right side of the fabric. The seam allowance in trimmed to 1/8” and the seam is pressed well. Then the right sides are folded together with stitched line exactly on the edge of the fold and pressed again. Then the stitches are made” from the fold.ConclusionA study on effect of seams on the drape coefficient Drape profile is been made. Three types of seams namely three stitch densities 5, 4 and 3 per centimeter has been employed. Ten fabric verities containing different fibres weaves are analyzed. Drape coefficients significantly differs between the fabrics also between the seam stitch density combination.The Drape Coefficient alone may not give a clean idea of real drape. For this purpose the drape profiles were generated with the help of radii measures. The drape profile has clearly indicating shapes that takes place with the seams put on. Seamed fabrics have generally shown more stabilized pattern compared to control samples.Sateen weave followed by BHC MAT weave has shown highly symmetrical patterns. The seam has markedly improved drape profile of honeycomb fabric. Polyester, Polyester/Viscous fabrics have registered better drape profiles than Polyester/Cotton fabrics. Both the cotton gray casement has shown agreeable drape篇二:服装设计中的创意性灵感外文文献翻译文献出处:Mete, Fatma. “The creative role of sources of inspiration in clothing design.” International Journal of Clothin g Science and Technology 18.4 (20xx): 278-293.原文The creative role of sources of inspiration in clothing designFatma MeteAbstract:Purpose - To assess the creative role of sources of inspiration in visual clothing design. It aims to analyse simple, general accounts of observed design behaviour and early stages of the clothing design process, what is the nature of design inspiration, how sources of inspiration are gathered and how they affect the creativity and originality in clothing design.Design/methodology/approach - A progressive series of empirical studies looking at ready-to-wear clothing design has been undertaken; in situ observation, semi-structured interviews and constrained and semi-constrained design tasks. This empirical approach used ethnographic observational methods, which is effective in situations whereconventional knowledge acquisition methods are insufficient, when broad understanding of an industry is needed, as in the fashion industry, not just a case study of a single individual or company.Findings - Identifies the major types of idea sources in clothing design and provides information about each source. Recognises that these sources of inspiration help designers to create design elements and principles of individual designs. In order to foster originality, sources of inspiration play a powerful role throughout the creative stage of design process, and also in the early stages of fashion research and strategic collection planning.Originality/value - This paper highlights the role of sources of inspiration and its effect in creativity and originality in the clothing design process. Offers practical help to clothing designers and design-led clothing companies.Keywords: Fashion design, Clothing, Creative thinking, Design calculations, DesignmanagementIntroductionSources of inspiration and its personal interpretation, visually and technically, play an important role in the design process, in increasing creativity. Clothing design studies and the creative role of design inspiration, during the early informal and actual clothing design processes is open to scientific investigation like aesthetically driven designs in other domains.Studying creative fashion design as process and product is seen more problematic than other design-led industries, as the interaction between the design elements and principles, material properties, adaptation and modification of design inspiration are complex. Clothing design, as a variety of aesthetic and functional design processes, shares manycharacteristics of engineering design process.Research and observation are critically important in the fashion business. By researching and observing, designers gather background information for design, including studying current and future fashion trends and try to predict what the majority of their customers will want in the foreseeable future. In order to keep up with the changing world of fashion, fashion awareness should become second nature to every clothing designer.Design and clothing as a visual and tactile sensory designIt is well known that design is two things: process and product, as verb and noun. As design problem solution process, it is researching, setting the source of inspiration, planning, organizing to meet a goal, carrying out according to a particular purpose and creating. As product it is the end result, an intended arrangement that is the outcome of that process or plan.Clothing is an example of applied design, even the most exciting, original idea must show awareness of its practical purpose and environment. We realise that some art is pure, “art for art’s sake” but most creations in the daily world are for a practical purpose and use. Design as process is planning to meet a goal, and thus applies to everything intentionally created for a purpose. The steps and order of the process areessentially the same regardless of the end product. These steps are very similar to management as a planning process.Design as man made product and service falls into two major categories: sensory and behavioural. Sensory design is perceived through the senses, and is classified as visual, auditory, olfactory, tactile and gustatory. Behavioural design is planned action. Many products, however, include aspects of both, because design may be perceived through the senses andthen interpreted behaviourally. A fashion show, for example, include both sensory and behavioural designs.Research methodology and findingsThe importance of source of inspiration and their role in creative clothing design has been little understood and, therefore, rarely received attention in this industry. [6],[7], [8] Eckert and Stacey (1998, 2000, 2003) studied knitwear design case, which shares many characteristics of complex engineering projects and as an example of “practical design” in a fast moving and highly competitive manufacturing industry. Their work included a large ethnographic study of the knitwear industry, which produced a detailed design process model and an analysis of the causes of communication problems within design teams. [15] M?kirinne-Croft et al. (1996) tried to explain the fashion design process in terms of quantum mechanics and psychoanalysis and see design creativity as the ultimate mystery; their description of the design process is simplistic.The author has undertaken a progressive series of empirical studies, based on observation and interviews, looking at ready-to-wear (RTW) clothing design; in situ observation, semi-structured interviews and constrained and semi-constrained design tasks. This empiric approach combines ethnographic observational methods with the knowledge analysis techniques of artificial intelligence. It is effective in situations where conventional knowledge acquisition methods are insufficient, when broad understanding of an industry is needed as in the fashion industry, not just a case study of a single individual or company.In this research, the creative role of sources of inspiration in visual clothing design by novice and expert clothing designers was assessed through empiricalresearch. As subjects, 16 talented clothing designers, 11university-level fashion design students in Fashion Design Department at Dokuz Eylul University and five professional designers participated in the experiment carried out in this research. The first group of subjects included advanced fashion design students, seven talented students selected from the third and fourth year of undergraduate studies, and also four students of postgraduate studies, who also works as a free lance or part time assistant designers in the clothing industry. The second group was composed of five professional designers with a minimum of 5 years of experience in clothing industry. Sources of inspiration in clothing designWhere does the fashion designer get ideas and inspiration for new styles? The answer is everywhere and everything. Anything visual and tactile, in fact sensual, can be a source of inspiration for a garment. Through television, the designer experiences all the wonders of the entertainment world. In films, the designer is exposed to the influences of all the arts, and lifestyles throughout the world. Because consumers are exposed to movies through international distribution, films prime their audiences to accept new fashions inspired by the costumes. Museum exhibits, art shows, world happenings, expositions, theatres, music, dance and world travel are all sources of design inspiration to fashion designers. The fashions of the past are also a rich source of design inspiration. While always alert to the new and exciting, fashion designers never lose sight of the past, they use old things in new ways.As stated the inspiration for a garment within a collection or for an entire collection can come from an infinite variety of sources. Sources of inspiration are often linked to the social “spirit of the times” also called the “zeitgeist”. Understanding the state of current fashion and searching for ideas and sources of inspiration involves looking at art objects and books, going on trips to places like Paris and Milan, visitingmuseums, watching people on streets and going on country walks. Designers are most creative when they are directly exposed to the sources of ideas. On the other hand, it has been observed in the fashion industry that there are two fundamental approaches in the creative clothing design processes:(1) material, thus fabric, inspired clothing design process; and(2) conceptual clothing design process, such as several themes originated from the universe of arts, nature or products.It is known that the high-fashion “name” designers typically develop a concept, also called theme, for their collection in order to be more creative and original.The major types of idea sources in design-led industries are previous products, artifacts, natural objects and phenomena. In case of clothing design, garments, fabrics and trims as previous products, play an important role in sources of inspiration. Although, there is a broad recognition that much of the design proceeds by modification of previous ideas, in case of fabric inspired clothing design, designers search for new forms and styles with newly developed or invented materials. For example, the development of elasthen fabrics, such as Lycra, inspired designers to figure-hugging silhouettes.ConclusionsAnything visual and tactile, in fact sensual, can be a source of inspiration in fashion design. Design ideas do not simply materialize out of thin air. First, the designer does careful research, but what makes a designer’s collection special and original is his or her unique interpretation of design sources. Therefore, in order to be more creative and original the sources of inspiration play an important role in clothing design.Research and awareness are the key to creativity. Designers must learnmost of all to keep their eyes open, to develop their skills of observation, to absorb visual ideas, blend them and translate them into clothes that their customers will like. The design process shows that realistic observation of outside influences and needs, extensive research and awareness and logical thinking and order, remove a great deal of the supposed “mystery” of design or creativity. One who thoroughly understands design as product and process and has mastered the use of appropriate materials and adaptation techniques can be “creative” and can translate the source into reality as a successful fashion product. Sources of inspiration are used at the early stages of design and throughout the篇三:课题_服装设计外文翻译服装设计外文翻译CoutureSewingUnitedStates Technique Claire B.Shaeffer Printed originallypublished TauntonPress,Inc. Chapter4.Edge Finishes Hems,Facings BindingsUnless finished someway, garmentravel lookincomplete. edges—theneckline; verticalfrontcanbecome edges jackets,coats manyblouses; jackets distinctive, decorative elements design.Threefinishes usedextensively couture:hems,facings edgefinish depends manythings—the shape edgebeing finished; its position type,design garment;current fashion trends; individualwearer bottomedge asymmetrical,curved, scalloped otherwiseunusually shaped, facing.Even when twodifferent edges requireslightly different finishes tailoredgarment would require very different finishing from eveninggown, even similar designs vorked dissimilarfabrics would dictate finishes suitable eachfabric. Although hems, facings alledge finishes, each has slightlydifferent function. Hems generallyused loweredges garmentsection manyhelp garmenthangattractively addingweight edge.Facings, otherhand, verticaledges garments.Bindings can upper,lower verticaledges, they’reused most often replacefacings rather than hems. Facings can separatesections finishcurvedshapededges. whenused onlyslightly curved, nothingmore than widehem allowance, whichcase they’re called extended facings. Both hems onlyone side—usually garment.Bindings, separatestrips garmentedgeBecause finishboth materialstakes sides backseat garmentattractively.desiredresults, edges alwaysfinished simplestmethod onemost often used ready-to-wearconstruction homesewing. Whatever finishingmethod, hems, facings bindingscan sewnentirely machinework.. handwork visible finishedproduct, however, handwork used traditionalcouture garment. FACINGS Facings, like hems, garment.Unlike hems, which hang free garment’shang more than its overall shape, faced edges frequently fit body’scurves subtlyaffect garment’ssilhouette. Used garmentopenings, curved edges shapededges like jacket lapels, facings contribute significantly overallimpression well-constructedgarment. threetypes facings:extended, shaped bias.Two biasfacings—are cut separately from sewnfrom self-fabric lightweightlining fabrics. extendedfacing garmentsection like plainhem course,self-fabric. extendedfacing nothingmore than 2-in.hem sewnexactly like plainhem (see pp. 63-64). When garmentedge length-wisegrain, extendedfacing duplicates slightcurve,facingcan’t duplicate mayhave eased,stretched edgesmoothly. extendedfacing usedextensively couturebecause foldededge moresupple than seamededgesbetter.stabilizedso Edges biasfacings extendedfacings itsnameoftenusedalwaysused consequentlydrapes generallyinterfaced suggests, originalshape shapedfacing ususllyduplicates look, edgesintended crisp,constructedintricatelyshaped edges like scallopedhem. biasfacing stripcut truebias. Because doesn’tduplicate facingmust itself edge.Bias facings madefrom lightweight fabrics producenarrow, inconspicuous facings. cousture,more than one type oftenused singlegarment singleedge. pinkgazar dress shown above, example,has extended facings frontneckline backopening backopening shapedfacings frontnecklineshapedfacings backneckline. Similarly, p.60has shapedfacing upperhalf frontedge extendedfacing lowerhalf edge.Before applying any kind facing,examine garment’sfit determinewhether edgeneeds staytape (see pp. 49-50) interfaced(see 68).Once you’ve handled youcan proceed facingyou’ve chosen. SHAPED FACINGS Shaped facings can machine.Both types couture,while only machine applications machineapplication course,faster, sometimesmore difficultfacingso fitssmoothly, sometimesvisible garmentedge. instructionsbelow applyingshaped facings machine,refer yourfavorite sewing manual.) directionsfocus necklinefacings because they’re most frequently used coutureworkrooms. However, directionscan otheredges waistbands,armholes, applied pockets, collars garmentlinings. facingcan madeany time after neckedge stabilizedappropriately design.Facings can cutfrom originalgarment pattern edgewasn’t changed during fittingprocess, garmentitself can serve pattern.When thread-tracedneckline can correspondingstitching line finishedneckline can also guidewhen you’re applying hand.Neck facings can severalshapes. Two mostpopular traditionalcirclular shape, which measures evendistance all around from rectangularshape, which extends armscyeseams. When largershape facingedges can seamlines,holding them smooth facingshadow may alsolessobtrusive largershape, depending obviousdisadvantage additionalfabric introduced shoulderarea, which may give bulkyappearance. One solution reducingsome seamlines1/2 originalpositions. alwaysaligned correspondinggarment seamlines, homesewing. lessfamiliar rectangular facing. caneasily circularfacing, Start selectingsome scraps from your garment fabric backfacingsunless whichcase use lighter,firmly woven material facings.Rectangular pieces preferablebecause you’recutting rectangularfacing high,round neckline back,begin onelarge rectangle about 16 frontfacing twosmaller ones about backfacings. When applying garmentedge before making facingso youcan use finished,do so before starting freeedge lieflat. Trim seamallowance around garmentneck wrongside. Baste generous1/5 seamallowance’s tendency curlaround neck,snip shallow cuts rawedge every inch necklineseam allowance lie flat(as shown wrongside up, place necklineover pressingcushion pressjust necklineedge. yourfingers, gently try rawedge. necessary,trim edgefurther firmlywoven fabrics lessstabble fabrics. seamallowance still doesn’t lie flat, clip rawedge short,closely spaced snips up bastingstitches around neckedge. Use loosecatchstitch seamallowance garmenthas neither, sew carefully so stitchesdo rightside garment.Cut eachsection faced.Before proceeding, decide whether relacating shoulderseams bulk.After relacating youdecide doso, begin wrongsides together, grainlinestogether centerfront itsfacing. garmentneckline curved, whenworn, smooth place,pinning yougo. When you get shoulderseams, smooth frontfacing over seamsso seamallowances flat.Pin。
Proceedings of the AUVSI's Unmanned Systems North America 2005, June 2005, Baltimore, MD.A Framework For Autonomy Levels For Unmanned Systems(ALFUS)Hui-Min Huang i, Kerry Pavek ii, Brian Novak iii, James Albus i, Elena Messina i 1IntroductionRapid evolution of mobile robotic technology is witnessed by the fact that unmannedvehicles have begun to be fielded in many problem areas ranging from homeland security and battlefield support to Mars exploration. Military and civilian agencies continue toexpand the roles that unmanned systems (UMS) may serve. As government agenciescontinue to specify UMS capabilities for future applications, there are increasingdemands for a facilitating common framework. The demands include a commonterminology for characterizing the UMS requirements and standard metrics for evaluating the autonomous capability of the UMS. Individual government agencies have begun the efforts toward building facilitating frameworks. The Department of Defense JointProgram Office (JPO), the U.S. Army Maneuver Support Center, and the NationalInstitute of Standards and Technology (NIST) have, in separate but related efforts,described levels of robotic behaviors for the Army Future Combat Systems (FCS)program [1, 2, 3]. The Air Force Research Laboratory (AFRL) has established anAutonomous Control Levels (ACL) [4] scale. The Army Science Board has described aset of levels of autonomous behavior [5]. Central to these efforts is the concept ofautonomy levels for the UMS. It is extremely beneficial that these and other agenciesleverage each other’s efforts and aim at a government and industry-wide consistent andstandard approach.Recognizing the benefits and the needs, in July 2003 an initiative was launched toassemble key representative practitioners from U.S. Departments of Commerce (DoC),Defense (DoD), Energy (DoE), and Transportation (DoT) (and their supportingcontractors). This group assembled at NIST and formed the Autonomy Levels ForUnmanned Systems(ALFUS) Ad Hoc Work Group to address the autonomy issue.2Requirement AnalysisAs the technological frontier for unmanned systems has expanded, the potentialapplications for their use have also expanded. These technological and applicationexpansions have complicated the users’iv problem in articulating both the potential for,and requirements associated with, the use of UMS. A common means by which toarticulate both capabilities and requirements is essential to the ability of the useri National Institute of Standards and Technology, Gaithersburg, Maryland 20899-8230 { hui-min.huang, james.albus,elene.messina }@; /; phone: 301 975 {3427, 3418, 3510}; Fax: 301 990 9688.ii Titan Corporation, U.S. Army Unit of Action Mounted Battle Laboratory, Contractor; phone: 502-624-8783;Kerry.Pavek@.iii Army Tank-Automotive Research, Development & Engineering Center (TARDEC); Phone: 586-574-5913;NovakB@.iv The term user is used in a broad sense, covering operators, their supervisors, the UMS acquirers, etc.community to adequately express its needs, and allows for the establishment of a “language” that is understood by all facets of the acquisition community.The expansion in capabilities (and therefore potential operational application) from simple tele-operated systems that perform a specific task within a well defined environment to more complex, autonomous or semi-autonomous systems that perform multiple tasks in complex environments has evolved several means by which disparate “User communities” articulate their needs. The DoD “Joint User” community has struggled for years to find a common method of articulating its requirements given the wide range of operational and organizational contexts across the services. The disparate missions and use of UMS within other government agencies (DoT, DoE, DoC, NASA, etc.) have also complicated intelligent comparison of and dialog about UMS capabilities. To best capitalize on limited funding, cross-fertilization of ideas, experiences and technology among cross-agency efforts is seen as essential and would be enhanced by a common baseline for discussion.The User community, therefore, has articulated two major thrusts/needs:• A common vernacular that could be used to articulate capabilities (common set of definitions). This facilitates comparisons between systems/capabilities,and allows for disparate organizations to intelligently discuss issuessurrounding the use of Unmanned Systems capabilities within theiroperational constructs.• A means by which to articulate the amount of autonomy required/expected from an Unmanned System. This would facilitate interactions between theUsers, Research and Development agencies, and Materiel Developers.The variety of autonomous systems currently envisioned for use by government and non-government entities makes a common set of terminology and definitions paramount. It also provides a challenge to the determination of the proper metrics to apply so that these definitions and metrics can be universally utilized in all the UMS vehicle domains: aerial (UAV), ground (UGV), underwater (UUV), surface (USV), etc. The end result of the creation of a common vernacular would be to enhance the common understanding of terms which would, in turn, be a key enabler for intelligent dialog and collaboration amongst disparate organizations.In terms of defining autonomy, the User community sees two levels of need. At an executive level, there is a need to provide a means by which to easily articulate requirements. This would provide a means of common communication between the User and Material Developer in expressing requirements, but would also provide an easy to understand method of explaining autonomy requirements to decision makers. At a more technical level, the User community sees a need for a tool by which interactions between the User, Material Developer, Industry, and the Test Community can be made easier. This tool could then be used to articulate system-specific, specification-level detail and provide a framework for the testing/verification of autonomy.The combination of common terms and definitions and a means to define autonomy are seen as key enablers for the interaction and cooperation amongst Users and Developers of UMS. This has the potential of increasing the ability of disparate organizations (across the government and industry) to interact and collaborate in the development of UMS technologies facilitating cost savings and knowledge sharing.3Work Group Objectives, Plan, and ApproachThe overall objectives for the work group are to produce:•Standard terms and definitions to facilitate characterizing the levels of autonomy for unmanned systems.•Metrics, methods, and processes for evaluating and measuring the autonomy of unmanned systems.The development plan for the Group contains the following phases:•Phase 1, Development of Framework ContentDevelop the core technical content of the ALFUS framework. This effort will be an iterative process between a top-down approach for constructing the genericframework and a bottom-up approach for evaluating the framework conceptsthrough use-case experiments with selected application programs.•Phase 2, Enhancement and Evolution of the Frameworko Investigate and develop testing and validation plans and methods. Generalize the framework further by experiments in additional domains.o Revise and upgrade the framework based on user feedback. Expand metrics as testing and measurement technologies advance. For example, continuedresearch efforts may produce measurement methods for certain metrics thatare currently hard to measure, such as workload for a robotic operator.•Phase 3, Expansion. Investigate expansion of the ALFUS framework to a generic performance metrics framework for unmanned systems (“PerMFUS”).The planned migration path of the work group effort is:•Start as a government only user effort.•Include the contractors for the selected use case programs once the critical elements of the Framework have been established, during Phase 1.•Open to industry, during Phase 2.•Migrate to a U.S. or international standards development organization (SDO), during Phase 2.4ParticipationThe government organizations and programs that are represented in the ALFUS work group include:DoD:•Aviation Applied Technology Directorate (AATD)* v•Air Force Research Laboratory (AFRL)v Asterisks denote U.S. Army.•Aviation and Missile Research, Development and Engineering Center (AMRDEC)*•Army Research Laboratory (ARL)*•Communication-Electronics Research Development & Engineering Center (CERDEC)*•Defense Advanced Research Projects Agency (DARPA)•Maneuver Support Center (MANCEN)*•Naval Air System Command Naval Air System Command (NAVAIR)•Naval Sea System Command (NAVSEA)•Naval Research Laboratory (NRL)•The Office of the Secretary of Defense/ Joint Project Office (OSD/JPO)•Tank-Automotive Research, Development & Engineering Center (TARDEC)* •Training and Doctrine Command (TRADOC) Systems Manager Future Combat System (TSM FCS)*•TRADOC Unit of Action Maneuver Battlelab (UAMBL)*DoC – National Institute of Standards and Technology (NIST)DoE – Headquarter (HQ), Idaho National Engineering and Environmental Lab (INEEL) DoT – Federal Highway Administration (FHWA)The work group has identified FCS as its first use case. Therefore, the FCS Lead System Integrator (LSI), namely, the Boeing and SAIC companies and their subcontractors are also represented in the work group.Each of these entities has identified a need for autonomy level definitions.5ALFUS FrameworkNine workshops have been conducted, so far, in an effort to develop the ALFUS framework. The accomplishments include:5.1Formulated the ALFUS FrameworkWe envision that a generic autonomy level framework should include:• A set of terms and definitions for UMS that facilitates communications on the UMS autonomy requirements and capabilities.• A Detailed Model for the autonomy levels that includes sets of identified metrics used for evaluating the autonomy levels for UMSs.• A Summary (or Executive) Model that defines an autonomy scale from zero or one through ten. This scale can be used for describing the UMS autonomy levels at a high level of abstraction.We further envision that this generic framework is to be instantiated for various UMS programs specific ALFUS models. The resulting ALFUS framework [6] is illustrated in Figure 1.Generic ALFUSFrameworkProgram Specific ALFUS FrameworksFigure 1: ALFUS Framework5.2 Established the metrics sets for the Detailed ModelMission Complexity*EMIdecoyFigure 2: ALFUS Detailed ModelThe ALFUS framework Detailed Model contains the following defining concepts:• UMS autonomy concerns multiple technical areas. Task complexity andadaptability to environment are among the key aspects.• The nature of UMSs’ collaboration with human operators, such as the levelsof involvement and types of interaction is important to the autonomycapability.• Performance factors, such as mission success rate, response time, precision,resolution, and allowed latencies affect a UMS’s autonomy levels [7].The ALFUS Detailed Model is shown in Figure 2. In this three-axis model, theautonomy level is determined by the complexity of the missions that a UMS is able to perform, the degrees of difficulty of the environments within which the UMS canperform the missions, and the levels of operator interaction that are required toperform the missions. Note that we used curved lines to connect the three scores foreach of the illustrated vehicles to indicate that users might use some complex algorithms, as opposed straightforward, weighted-average ones, to determine the vehicles’ resulting autonomy levels. The curve lines also imply that they may beused to define maximum capabilities, i.e., the UMSs can perform at any combinationof complexity/difficulty/independence that lies on or below the surfaces.Mission complexity could be measured with the metrics of: levels of subtasking, decision making, and collaboration, knowledge and perception requirements,planning and execution performance, etc. Human independence level (HI) can be measured with the metrics of: interaction time and frequencies, operator workload,skill levels, robotic initiation, etc. Environmental difficulty can be measured through obstacle size, density, and motion, terrain types, urban traffic characteristics, ability to recognize friends/foe/bystanders, etc. Work is underway to define measuring scalesfor the metrics. Priorities will be set to include the metrics in various versions of the framework.5.3Established a process model for ALFUSFigure 3 depicts how the autonomy levels for a UMS can be evaluated in the ALFUS framework. We outline the process as the following:•An identified mission is decomposed, via an adopted method, to generate a task structure covering from the mission to the lowest level skills. This is shown onthe top of Figure 3, from left to right. An earlier paper describes some of thecurrent concepts [8]. The NIST 4D/RCS [9] architecture may provide a viablemethod. However, modifications might be needed to suit the purposes ofautonomy level analysis.•The decomposed subtasks or skills should be assigned relative weights (labeled as “task weight” in the Figure) in terms of their criticality to the performance of theparent tasks or missions.•The metrics should be reviewed and relative weights (labeled as “metric weight”in the Figure) should be assigned based on the particular focuses or requirements that the applying program has established. Non-applicable metrics are weightedzero.•As shown in the MC row in the Figure, tasks and skills are evaluated and scored against each of the metrics. A composite score for each task is obtained through a weighted average (or a different integration method if the user prefers) of all theindividual metric scores. The “task/skill complexity” box depicts the result.Note that “additional constraints,” such as inter-metric dependence, couldconceivably affect the metric scores. This issue will be further developed in thefuture.•Composite scores for the higher-level tasks or missions can be obtained similarly through the weighted averages of the subtask scores, as the corresponding boxesin the Figure depict.•The UMS autonomy levels can be determined by the vehicle’s overall mission scores.ALFUS DETAILED MODEL EVALUATION PROCESSMCHIEDFigure 3: ALFUS evaluation process5.4 Published the terminologyThis report [10], as shown in Figure 4, includes such terms as UMS, autonomy, levels of fusion, levels of perception, etc., which are needed to address the UMS capability and requirement issues. We adopted and modified existent definitions when feasible.Figure 4: ALFUS Terminology Publication5.5 Began prototyping a tool for evaluating the autonomy levels for UMSAn autonomy level evaluation software tool is being implemented based on the ALFUS process model and Detailed Model. An earlier paper [8] described the concept in detail.5.6 Began defining the Summary/Executive ModelThe Summary Model (or Executive Model) for ALFUS devises a linear scale, zero through ten or one through ten, together with definitions and concise descriptors, to be used to represent the level of autonomy of a UMS. This model is envisioned to serve the conceptual, common reference purposes.Figure 5 depicts the general trend of the metric scores, in terms of mission complexity, environmental difficulty, and human-robot interaction, along the Summary/ExecutiveModel scale. In general, the more a robot is able to see, learn, think, plan, and act independently or collaboratively (in this case, the team operates independently) to achieve assigned, complex goals in difficult environments, the higher the level of autonomy score.5.7Established a web site./projects/autonomy_levels/ was established to facilitate interaction and information sharing within the UMS community.Figure 5: ALFUS Summary Model Overall Concept6SummaryWe have reported the latest concepts for the Autonomy Levels for Unmanned Systems (ALFUS) framework. It is recognized that autonomy level is an extremely complex issue. Therefore, the work group still faces major technical challenges that lie ahead, including:1.Refine and prioritize the metrics. Identify overlaps and conflicts among themalong the three axes and provide resolutions.2.Provide standard measuring scales for the metrics.3.Generate high-level definitions for the autonomy levels for the Summary orExecutive Model.4.Devise methods and plans for testing and validating UMSs’ autonomy levels.5.Establish domain-specific autonomy level models for selected programs.We anticipate holding frequent workshops to address these issues to complete, apply, and expand the ALFUS framework.AcknowledgementThe entire ALFUS ad hoc work group participants contribute to the ALFUS framework. Charles Bishop, Technical Fellow, Boeing Company proposed and conceptualized the autonomy level evaluation software tool, a critical ALFUS product, and currently leadsthe development effort. Woody English, Systems Engineer, SAIC, leads the Environmental Difficulty metrics group.The NIST ALFUS project is partially funded by the Department of Homeland Security, U.S. Army Research Laboratory, Charles Shoemaker, Funding Manager, and NIST Internal Funding.Company/Product DisclaimerCertain commercial products or company names are identified in this paper to describe our study adequately. In no case does such identification imply recommendation or endorsement by the National Institute of Standards and Technology, nor does it imply that the products or names identified are necessarily the best available for the purpose. References1/activities_new/FY2003%20Joint%20Robotics%20Master%20Plan.pdf2 Knichel, David, Position Presentation for the Maneuver Support Center, Directorate of Combat Development, U.S. Army, the First Federal Agencies Ad Hoc Working Group Meeting for the Definition of the Autonomy Levels for Unmanned Systems, Gaithersburg, MD, July, 18, 2003.3 James Albus, Position Presentation for National Institute of Standards and Technology, Intelligent Systems Division, the First Federal Agencies Ad Hoc Working Group Meeting for the Definition of the Autonomy Levels for Unmanned Systems, Gaithersburg, MD, July, 18, 2003.4 Bruce T. Clough, “Metrics, Schmetrics! How The Heck Do You Determine A UAV’s Autonomy Anyway?” Proceedings of the Performance Metrics for Intelligent Systems Workshop, Gaithersburg, Maryland, 2002.5 Army Science Board, Ad Hoc Study on Human Robot Interface Issues, Arlington, Virginia, 2002.6Hui-Min Huang et al., “Autonomy Measures for Robots,” Proceedings of the 2004 ASME International Mechanical Engineering Congress & Exposition, Anaheim, California, November 20047 Hui-Min Huang, Elena Messina, James Albus, “Autonomy Level Specification for Intelligent Autonomous Vehicles: Interim Progress Report,” 2003 PerMIS Workshop, Gaithersburg, MD.8 Huang, H.M. et al., “Autonomy Levels for Unmanned Systems (ALFUS) Framework: An Update” the 2005 SPIE Defense and Security Symposium, Orlando, Florida, March 2005.9 Barbera, Anthony et al., “Software Engineering for Intelligent Control Systems” KI Journal Special Issue on AI and Software Engineering, Germany, March 2004.10Autonomy Levels for Unmanned Systems Framework, Volume I: Terminology, Version 1.1, Huang, H. Ed., NIST Special Publication 1011, National Institute of Standards and Technology, Gaithersburg, MD, September 2004.。
专利名称:DIGITAL FLEXURAL MATERIALS发明人:CHEUNG, Kenneth,GERSHENFELD, Neil, Adam申请号:US2013/054034申请日:20130807公开号:WO2014/025944A3公开日:20140605专利内容由知识产权出版社提供专利附图:摘要:Digital flexural materials are kits of discrete parts that can be assembled into a lattice structure to produce functionally useful assemblies. Digital flexural materials enable design of materials with many small and inexpensive flexures that combine in alattice geometry that permits deformation without compromising the strength of the assembly. The number of types of parts in a kit is small compared to the total number of parts. A product constructed from digital flexural materials comprises a set of discrete units that are assembled into the structure according to a lattice geometry, with a majority of the units being reversibly connected to at least two other units in the set according to the lattice geometry, and wherein, in response to loading of the structure, a reversible deformation of at least part of the structure occurs. An automated process may be employed for constructing a product from digital flexural materials.申请人:MASSACHUSETTS INSTITUTE OF TECHNOLOGY地址:02139 US国籍:US代理人:HENDERSON, Norma, E.更多信息请下载全文后查看。
An Automated Approach for Constructing Road NetworkGraph from Multispectral ImagesWeihua Sun a and David W.Messinger aa Chester F.Carlson Center for Imaging Science,Rochester Institute of Technology,Rochester,NY,USAABSTRACTWe present an approach for automatically building a road network graph from multispectral WorldView II images in suburban and urban areas.In this graph,the road parts are represented by edges and their connectivity by vertices.This approach consists of an image processing chain utilizing both high-resolution spatial features as well as multiple band spectral signatures from satellite images.Based on an edge-preservingfiltered image,a two-pass spatial-spectralfloodfill technique is adopted to extract a road class map.This technique requires only one pixel as the initial training set and collects spatially adjacent and spectrally similar pixels to the initial points as a second level training set for a higher accuracy asphalt classification.Based on the road class map,a road network graph is built after going through a curvilinear detector and a knowledge based system.The graph projects a logical representation of the road network in an urban image.Rules can be made tofilter salient road parts with different width as well as ruling out parking lots from the asphalt class map.This spatial spectral joint approach we propose here is capable of building up a road network connectivity graph and this graph laysa foundation for further road related tasks.1.INTRODUCTIONRoad network extraction from satellite images has become an active and important research area in recent decades.The extracted road network can be used for several applications such as providing road layout for constructing geographic information systems(GIS)or corrections for existing GIS database.1–3The road net-work can also be used for image registration,4change detection5as well as vehicle detection.6The availability of accurate high resolution multispectral images delivered by the new generation of sensors has provided the potential to discriminate very subtle details in urban scenes.The WorldView-2Satellite delivers8-band images covering the visible and near infrared(400-1040nm)wavelengths with a2.0meter ground spatial resolution. These images provide us rich spatial and spectral information and can be utilized for road network extraction.The study of road detection can be dated back three decades ago and a number of approaches have been proposed to tackle the problem.Mena3surveyed the techniques for automated road extraction and extensively reviewed the related approaches.While a number of techniques can be used to facilitate the task of road extraction,it often requires a series of processing to export thefinal road network from the input of aerial images. With the increase in complexity of the road network,this task entails an integrated system incorporating both low-level image-based recognition techniques as well as higher-level knowledge.Image-based recognition often involves obtaining initial road candidates based on features in images.Under this category,line-based approaches are often explored since roads are mostly linear or curvilinear structures. Baumgartner et al.7built a multi-resolution aerial image set and extracted lines from low resolution images; similarly Couloigner and Ranchin8took a multi-resolution approach using wavelet transform tofind street strips. Jin and Davis9also employed a multi-scale approach by thresholding spectral Normalized Difference Vegetation Index to locate road pixels for suburban areas.Mena and Malpica10evaluated the texture statistics to produce a binary road segmentation.Shao et al.11used a fast linear detector and non maximum suppression to extract road centerlines on high contrast road pixels with increased performance.Besides linear features,road intersections are another signature in road networks.Koutaki and Uchimura12considered matching a binary road image with a group of prior shape models to identify intersections.Morphological operators are also extensively used, Ref.[10,13,14]obtained road centerlines using a skeleton operator from a segmented binary road image.Ref.9 developed a directional morphological operations to separate roads from dark or bright building and parking lots Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XVIII,edited by Sylvia S. Shen, Paul E. Lewis, Proc. of SPIE Vol. 8390, 83901W · © 2012 SPIECCC code: 0277-786X/12/$18 · doi: 10.1117/12.918692$##""! #Figure1:Theflowchart for the road network extraction system.in city block scenes.Recently Mnih and Hinton performed a neural network approach to detect road structure under different occulsions.15Active contour or snake model16is a frequently used method for road network extraction.Ziplock ribbon active contour derived from the snake model is used to bridge gaps on road network blocked by shadows.17Song et al.18also succeeded in road conflation using active contours together with existing geospatial vector road data. The active contour model is known to be sensitive to initialization and thus require a high level of confidence in initial estimation.Alternatively a grouping or tracing scheme is also possible to bridge the gaps from the initial estimates.Baumgartner et al7used a line fusion technique by iteratively relaxing the maximum length of the gap to be bridged.Hu and Tao19employed a probabilistic geometric relationship model to hierarchically group line segments.Amini et al.13also utilized collinearity and spline interpolation to group and refine their detection results.Hu et al.20traces the road footprint using a spoke-wheel operator from road seedings and such operator is capable of tracing both straight and highly curved roads.Contextual information is also employed for assistance in road detection.Jin and Davis9proposed using different algorithms for urban and suburban scenes to take advantage of their individual characteristics.Mena14performed topological pruning of erroneous road branches using superposition of an existing GIS building layer.In this paper,we design a systematic workflow incorporating novel algorithms applied to the problem of road network extraction.We use multispectral WorldView2images for detection since they contain rich spectral and spatial information.The algorithm follows theflowchart illustrated in Figure1.Firstlyfiltering21is applied to reduce the noise and enhance the important edges;next a spectralfloodfilling technique is used to produce a binary asphalt image.Road-like structures are then extracted using a curvilinear detector based on template matching;these structures are then processed by a knowledge-based system.The extracted road network is finally presented with its centerline position as well as width and orientation information and can be easily converted to a vectorized shapefile for processing with GIS packages.The remainder of this paper is organized as follows:the spectralfloodfilling is introduced in Section2and the curvilinear detector is detailed in Section3.The experimental results on a set of scenes are shown in Section 4.Finally we present our discussion in Section5.2.FLOOD FILLING FOR MSIThefirst step for road network extraction is to properly determine the connected asphalt pixels in satellite images.A conventional approach is to perform a supervised classification where an adequate amount of trainingsamples are needed to properly separate different classes.These methods would often require training samples not only for the asphalt,but for vegetation,waters,concrete,soil etc.as well.In addition,classification is often carried out solely in the spectral space so the spatial information is completely ignored.Thefloodfilling procedure is a widely used approach in region growing and segmentation for binary,grayscale or RGB images.22Floodfilling requires one or several seed points.It iterativelyfills the neighboring pixels by merging those possessing similar digital count values.The process resembles aflooding pattern sprung from a specific spot.In this paper,thefloodfilling is extended for processing multispectral or hyperspectral images; thefilling is carried out by comparing spectral similarity.In our case,two spectral similarity metrics are used, namely the spectral angle mapper(SAM)and the spectral Euclidean distance(ED).23SAM for two spectralvectors v1and v2is defined asSAM( v1, v2)=cos−1(v1· v2| v1|×| v2|)(1)where·indicates the inner product.SAM basically computes a normalized correlation between two vectors. Spectral ED is defined asED( v1, v2)=|| v1− v2||.(2) Thefilling proceeds only if both SAM and ED between the neighboring pixels are smaller than the predefined thresholds.This ensures thefilled areas touch the boundaries of the roads.The technique supersedes the conventional classification method in that it only requires minimal training of only one or several seed points;it also takes into account the spatial continuity for road pixels.In most cases,a de-noising process is carried out to improve image quality and remove noise and clutter.In this paper,a trilateralfiltering process21is employed tofilter the spectral image.This technique is derived from the conventional bilateralfilters24and it can reduce small clutter across the image while keeping edges with strong contrast.Thefloodfill only gives one connected area given one seed.While the road network is generally connected, it is often not the case in real images.Several seed points may be needed in order to correctly identify all these areas.Alternatively,we design a two-step approach to locate asphalt pixels in the entire image using limited seeds.Thefirst step is to grow a connected area using a given seed;then we apply a Gaussian Maximum Likelihood classifier(GML)23on the entire image using the connected area as a training set.The high-fidelity pixels are used as seeds for a second-passfilling to ensure most of the asphalt pixels are obtained.The genericfloodfilling process performs a significant amount of neighbor comparison,many of which are often repeated thus a number of optimization schemes have been proposed and well programmed in most image processing toolboxes;yet these toolboxes are mostly designed only for black-white or RGB images.However,one can still optimize the multispectralfilling process by utilizing functions in these toolboxes.This is made possible by computing a joint SAM edge and ED edge map using provided thresholds;a binaryfloodfilling,which is available in most toolboxes,can then be carried out.The optimized multispectralfloodfill approach features a two step process,first a comparison of SAM and/or ED with the seed pixels is performed across the image and is quantized to binary images using predefined thresholds such that spectrally similar pixels are marked as1and others as0.The process is carried out for each seed pixel respectively and combined using an OR operation.This rules out all the pixels that are not similar to any of the seed pixels and the output is a similarity binary map.Next we mark spectral edge pixels on this binary map as zeros.While several approaches can achieve this,25,26an edge pixel can be simply determined by comparing itself to its neighbors.To be specific,SAM and/or ED is calculated with the north,west,north-west pixels respectively and is marked as an edge pixel if any of results is larger than the thresholds;pixels in other directions are not considered to avoid the unnecessary repetition.These edge pixels are marked as zeros on the binary map;then the binaryfloodfill from the seed pixels can be carried out on this image using 4-way connectivity to obtain the connected part.Results from the optimizedfloodfilling process will depend on the specific definition of the multispectral edge.While the results may be somehow different than the generic algorithm,they are essentially very similar and can well satisfy our need for initial road detection.3.CUR VILINEAR STRUCTURE DETECTIONUsingfloodfilling,a binary asphalt map is produced;yet urban and suburban scenes contain a number of structures that are built using asphalt other than roads.A curvilinear detection technique is often required to separate roads from other objects such as parking lots or building rooftops.In this paper,we follow a strategy similar to Ref.[27]to obtain an initial set of curvilinear pixels.A set of curvilinear detectors with different width and direction form afilter bank and eachfilter in the bank is convoluted with the binary map.The detectors take the form of long rectangular shapes and are defined asf(x)=12wr×⎧⎨⎩1|x|<w2−w2r w2≤|x|<w2+r0|x|≥w2+r(3)where w is the length of the short rectangle edge and is representative of the road width and l is the length of the long edge;the region between w2and w2+r is designed to capture the edge response so that the template gives maximum response when correlated with two parallel edges with asphalt pixelsfilled in between separated by w. It should be noted that the non-asphalt pixels in the binary image should be mapped to-1before convolution. It is also possible to use smooth varying kernels yet we found Eq.3produces best results.It is worth mentioning that the proper choice of r is important for the detection.r is expressed as the relaxed space to correlate with road boundaries.If r is too narrow,the template may not properly capture the road boundary.While it is possible to choose a higher value,the space occupied by r may overlap with other asphalt structures such as parallel roads or parking lots on urban scenes;the overlap may decrease the matching response and produce false negatives.In our experiment,r is set to2to produce most stable responses.We have also normalized the maximum possible response for differentfilters so that the matching response across different filters can be compared.This is necessary since we need to determine the most likely width and orientation for each pixel.A maximum response score map can be obtained afterfiltering;the corresponding width and direction are also recorded.High response score indicates higher possibility for road structure.Non-maximum suppression and hysteresis thresholding are employed in order to obtain the centerline of the road structure.This guarantees a thin representation of the road.The detector produces adequate accuracy for simple road structures.Yet it generates high responses not only for road segments,but also for long edges of large parking lots and tight house complex forming a line. The detector produces a large amount of false alarms for scenes abundant of such interference.In addition, the detector misses a few places when the road is merged with a roadside parking lot or partially occluded by overhead trees.In these scenarios,we use a follow-up knowledge-based system to further increase the overall detection accuracy.The knowledge-based system segments the initial road network into logical parts using the geometric and contextual connectivity and applies a set of rules to eliminate the erroneous segments.The details of the knowledge based system are described in Ref.[28].4.EXPERIMENTAL RESULTSThe proposed approach has been applied to a set of scenes.First we demonstrate the process in details using the Trona scene;then the results and analysis for other scenes are presented.4.1The Trona SceneThe Trona scene consists of a small town in Trona,California.An RGB image of the scene from the WorldView-2 sensor is shown in Figure2.The roads are generally straight but appear to have varying color.Wefirst remove the noise from the image using trilateralfiltering21with a SAM threshold of0.1and an ED of100considering the WorldView-2image has a dynamic range of11bit(2048).Due to the nature of this joint spatio-spectral filtering,the resultant image appears to be much less noisy and the road edges stand out as shown in Figure3a. Two pixels on the road are manually selected to startfloodfilling for obtaining all the asphalt pixels.These two pixels are marked by red dots in Figure3a and the resultant binary asphalt map from thefloodfill is shown in Figure3b.Figure2:RGB bands of the Trona Scene.(a)RGB bands offiltered Trona Scene.(b)Asphalt map fromfloodfill.Figure3:Thefloodfill process on the Trona scene,it comprises two steps:first a trilateralfiltering and next a multispectralfloodfill.(a)Response from the curvilinear detectors.Brighter val-ues indicate higher response thus more likely to be roadsegments.(b)The initial guess of the road centerline after non-maximum suppression and hysteresis thresholding.Figure 4:The curvilinear detection process on the Tronascene.Figure 5:Two types of false alarms produced from the curvilinear detectors.The left panel illustrates the case when a portion of the main road is obscured by the surrounding while the right panel shows a case where consecutive houses produce false alarms.In each panel,the top-left is the RGB image;the top-right is the binary asphalt map;the lower-left is the response from the curvilinear detector and the lower-right is the centerline produced by thresholding.Following the flood filling,the curvilinear detector is applied.The matching process produces higher responses (Figure 4a)when the signature of road is prominent.Then the initial road centerline can be obtained using non-maximum suppression and hysteresis thresholding as shown in Figure 4b.The lower and upper thresholds for hysteresis thresholding are 0.4and 0.6respectively.It can be seen that the curvilinear detector performs well on this scene and has extracted most of the major road pixels,but it also produces a number of false alarms on consecutive houses.The detector also misses one part on the major road where the curvilinear signature is weakened by its surroundings.These two cases are shown in Figure 5.To eradicate such false alarms,it is necessary to seek the high-level knowledge-based recognition approach.The knowledge-based system is advantageous in its ability to process segments instead of pixels.The curvilinear detector produces 7339pixels as potential centerline pixels,yet the knowledge-based system only needs to process 107segments,making the computation much more efficient.The final result (Figure 6)demonstrates that the entire system performs very well on this scene.The system not only detects almost all the road centerlines in the scene but can recover the full road structure as well using the width and orientation information from the curvilinear detector.It missed only one road on the bottom andFigure6:Knowledge-based system applied to the detection of the road network.Figure7:RGB band for RIT scene.The red dot on the top left parking lot is the seed pixel forfloodfilling. this is because the road edge is obscured and it is not well picked by thefloodfill.4.2The RIT Campus SceneThe RIT campus scene was collected in June2009from the WorldView-2sensor.It displays the main campus of Rochester Institute of Technology and the RGB bands are shown in Figure7.The RIT campus scene is challenging in that it contains large parking lots and curved roads.It also has overhead trees blocking portions of the road.We use the GIS database from Monroe County Government as truth data for comparison.The GIS database also has some inconsistencies with the image due to recent constructions on the campus.Only one pixel is chosen forfloodfilling and it is shown by the red dot in Figure7.The results are shown in Figure8.We can see the detector successfully detects all the major roads surrounding the main campus even though they are curved.It missed a few small circles since they do not possess any curvilinear features.One interesting aspect is that the detector also identifies the parking lanes as roads,which are not present in the truth data.However, we would argue that such detection as correct since they follow the general definition of road and also appears in many other GIS database such as Google Maps.In order to obtain the accuracy statistics of our detection,the GIS data is projected into the image intrinsic space,connected using linear interpolation,and dilated to be5pixels wide to avoid mis-registration.Detection is marked as a hit when it overlaps with the dilated truth data;otherwise it is marked as a false alarm.To obtain the miss rate,we carry out a similar procedure by dilating the detected road centerline and count the pixels outside the dilated region.The hit rate is computed as the fraction of the hit pixels falling within all(a)Floodfill result(b)Extracted road network(c)Truth data(d)Extracted centerline.Figure8:Results for the RIT scene.pixels from the truth and the miss rate as the fraction of the missed pixels within all pixels from the truth;the false alarm rate is calculated as the fraction of false alarm pixels within all detected pixels.Table1describes the detection rates for the following scenes in the Rochester area.The hit rate for the RIT campus scene is78.63%, the false alarm rate is37.98%and the miss rate is21.37%.The high false alarm rate is because of the absence of the parking lanes in the truth data.In addition,many roads in the truth data do not manifest any curvilinear features or have been reallocated such as the bright road at the center of the image.However,the detector still produces relatively accurate results based on visual inspection.4.3The Mall SceneThe Mall Scene is a complex scene.Again,ground truth was obtained from the GIS database from Monroe County Government.It contains not only roads with different width and orientation,but also many interference factors such as large parking lots and small road side parking lots.The road side parking lots break the curvilinearity of roads thus those parts could not be detected using the curvilinear detector.For example,an upper part of the main vertical road in Figure9a(marked in the blue box)is contiguous to a roadside parking.Furthermore the complexity of the scene leads to more false alarms.The RGB bands of the scene are shown in Figure9a and the results in Figure9.Our method successfully detected the main road even with the interference from roadside parking lots.It detected two major rail tracks that are absent from the truth data;this is due to the2-meter resolution of theimage.At such resolution,the railroad track appears to be the same as regular road and it is even beyond(a)RGB image.(b)Floodfill results.(c)Curvilinear detection results.(d)Truth data(e)Final detection Results(f)Extracted centerlineFigure9:Results for the Mall scene.In(a),the red dots indicate the seeds forfloodfilling.Two rail tracks are also detected by our method due to the resolution of the image.Figure10:RGB bands of the Residential Area Scene(left),RGB bands of the trilateralfiltered image(right) with noise removed,the red dots indicate the seeds forfloodfilling.Scene Name Coverage Hit Rate Miss Rate False Alarm RateRIT Campus1.06k m278.63%21.37%37.98%Mall2.79k m284.77%15.23%44.24%Mall(w/o rail track)87.84%12.16%34.26%Residential1.52k m298.21% 1.79%13.22%Table1:Accuracy statistics on the test scenes.the recognition of visual inspection.For a complex scene like the mall,the knowledge-based system plays an important role in refining the results from the curvilinear detector by merging segments logically and removing small segments.The curvilinear detector produces18475road centerline pixels.It is initially segmented to have 486parts and reduced to332grouped segments.Thefinal pruned road centerline only contains54segments.4.4The Residential Area SceneThe residential area scene is a portion of a suburban area in Henrietta New York and is shown in Figure10. Ground truth is again acquired from the aforementioned GIS database.The scene contains several road types including highway entrance/exit and a residential house complex.Several factors make it a complex scene.The width of the roads changes in the scene,it contains a curved ramp at highway entrances as well as width varying exists.The road color varies from light gray to dark black and overhead trees cover portions of the roads.Many of the rooftops in the scene are built with materials spectrally similar to asphalt and this is confirmed by the floodfill map in Figure11.Furthermore,the consecutive houses often form a line that triggers false positives for the curvilinear detector.Despite the complexity of the scene,the detection still can yield high accuracy.The overall hit rate is98.21% with a miss rate of1.79%and a false alarm rate of13.22%.The system can correctly identify the highly curved highway entrance,the main road as well as the small roads in the residential complex.It is also able to avoid most of the false alarms from the house rows and overcome the partial occlusion of trees.5.DISCUSSIONIn this paper,we present an integrated road extraction system.The system works on high-resolution WorldView-2images and comprises three major steps.It obtains the asphalt pixels using spatial-spectral jointfloodfill technique and the pixels are fed into a template-matching based curvilinear detector;a knowledge-based system is then employed to segment and prune the road network.This approach works well on several scenes and has been shown to generate high accuracy;on particular scenes such as residential areas,the hit rate can reach as high as98.21%.The accuracies are summarized in Table1.A Matlab GUI was created to provide a user interface for road extraction.The main control panel consists of four sections in correspondence with steps of the algorithm.The options are stored as a structure object and(a)Floodfill result(b)Extracted road network(c)Truth data(d)Extracted road network.Figure11:Results for the residential area scene.can be edited outside the program;a number of options can also be edited on the control panel and two windows provide previews of the scenes.The algorithm has some drawbacks at special road structures such as very short segments or circles since the curvilinear detector cannot produce sufficient responses.In several cases,the detector produces false positives on very long buildings and false negatives on roads with faint edges.However,the algorithm works well in general on diverse road structures.It has been shown to produce high accuracy results in complex and diversely structured scenes.The algorithm can overcome partial occlusions from overhead trees or cars and interference from roadside parking lots.Our paper only includes the most basic rules but the algorithm can be made more robust by adding more rules for grouping or pruning according to the scene characteristics.However one caveat is that although added rules can achieve higher accuracy on one particular scene,they may produce more unwarranted error on others. It is often necessary to evaluate the rules before deployment to achieve higher overall accuracy.6.ACKNOWLEDGMENTThe authors are grateful to DigitalGlobe for generously providing the WorldView-2imagery and the Monroe County Government for providing the GIS road database.Special thanks to Nina Raqueno for processing theGIS road database.This work is supported by Department of Energy grant number DE-NA0000444.REFERENCES[1]Baumgartner,A.,Steger,C.,Wiedemann,C.,Mayer,H.,Eckstein,W.,and Ebner,H.,“Update of roads ingis from aerial imagery:Verification and multi-resolution extraction,”International Archives of Photogram-metry and Remote Sensing31,53–58(1996).[2]Straub,B.,Wiedemann,C.,and Heipke,C.,“Towards the automatic interpretation of images for gis update,”International Archives of Photogrammetry and Remote Sensing33(B2;PART2),525–532(2000).[3]Mena,J.B.,“State of the art on automatic road extraction for gis update:a novel classification,”PatternRecognition Letters24(16),3037–3058(2003).[4]Ton,J.and Jain,A.,“Registering landsat images by point matching,”Geoscience and Remote Sensing,IEEE Transactions on27,642–651(sep1989).[5]Volker and Walter,“Object-based classification of remote sensing data for change detection,”ISPRS Journalof Photogrammetry and Remote Sensing58(3-4),225–238(2004).[6]Jin,X.and Davis,C.H.,“Vehicle detection from high-resolution satellite imagery using morphologicalshared-weight neural networks,”Image and Vision Computing25(9),1422–1431(2007).[7]Baumgartner,A.,Steger,C.,Mayer,H.,Eckstein,W.,and Ebner,H.,“Automatic road extraction basedon multi-scale,grouping,and context,”Photogrammetric Engineering&Remote Sensing65(7),777–785 (1999).[8]Couloigner,I.and Ranchin,T.,“Mapping of urban areas:A multiresolution modeling approach for semi-automatic extraction of streets,”Photogrammetric engineering and remote sensing66(7),867–874(2000).[9]Jin,X.and Davis,C.H.,“An integrated system for automatic road mapping from high-resolution multi-spectral satellite imagery by information fusion,”Information Fusion6(4),257–273(2005).[10]Mena,J.and Malpica,J.,“An automatic method for road extraction in rural and semi-urban areas startingfrom high resolution satellite imagery,”Pattern Recognition Letters26(9),1201–1220(2005).[11]Yuanzheng,S.,Bingxuan,G.,Xiangyun,H.,and Liping,D.,“Application of a fast linear feature detector toroad extraction from remotely sensed imagery,”Selected Topics in Applied Earth Observations and Remote Sensing,IEEE Journal of4(3),626–631(2011).[12]Koutaki,G.and Uchimura,K.,“Automatic road extraction based on cross detection in suburb,”Computa-tional Imaging II5299(1),337–344,SPIE(2004).[13]Amini,J.,Saradjian,M.R.,Blais,J.A.R.,Lucas,C.,and Azizi,A.,“Automatic road-side extractionfrom large scale imagemaps,”International Journal of Applied Earth Observation and Geoinformation4(2), 95–107(2002).[14]Mena,J.B.,“Automatic vectorization of segmented road networks by geometrical and topological analysisof high resolution binary images,”Knowledge-Based Systems19(8),704–718(2006).[15]Mnih,V.and Hinton,G.,“Learning to detect roads in high-resolution aerial images,”in[Computer Vision–ECCV2010],Daniilidis,K.,Maragos,P.,and Paragios,N.,eds.,Lecture Notes in Computer Science6316, 210–223,Springer Berlin/Heidelberg(2010).[16]Kass,M.,Witkin,A.,and Terzopoulos,D.,“Snakes-active contour models,”International Journal ofComputer Vision1(4),321–331(1987).[17]Laptev,I.,Mayer,H.,Lindeberg,T.,Eckstein,W.,Steger,C.,and Baumgartner,A.,“Automatic extractionof roads from aerial images based on scale space and snakes,”Machine Vision and Applications12(1),23–31 (2000).[18]Wenbo,S.,Keller,J.M.,Haithcoat,T.L.,and Davis,C.H.,“Automated geospatial conflation of vectorroad maps to high resolution imagery,”Image Processing,IEEE Transactions on18(2),388–400(2009). [19]Hu,X.and Tao,V.,“Automatic extraction of main road centerlines from high resolution satellite imageryusing hierarchical grouping,”Photogrammetric Engineering and Remote Sensing73(9),1049(2007). [20]Jiuxiang,H.,Razdan,A.,Femiani,J.C.,Ming,C.,and Wonka,P.,“Road network extraction and inter-section detection from aerial images by tracking road footprints,”Geoscience and Remote Sensing,IEEE Transactions on45(12),4144–4157(2007).[21]Sun,W.and Messinger,D.W.,“Trilateralfilter on multispectral imagery for classification and segmenta-tion,”in[Algorithms and Technologies for Multispectral,Hyperspectral,and Ultraspectral Imagery XVII], 8048(1),80480Y,SPIE(2011).。