Linux下编译AVRO动态库操作说明
功能:Linux下编译AVRO动态库
编译环境:
VMware? Workstation 7.1.4
CentOS-5.6-x86_64
需要准备的源码和文件:(分别从官网下载即可)
avro-cpp-1.7.1.tar.gz
boost_1_50_0.tar.gz
cmake-2.8.9-Linux-i386.tar.gz
第一步:编译boost(因为AVRO依赖boost库)
进入boost_1_50_0目录,执行命令:
./bootstrap.sh
执行完毕,在这个目录下会多出几个文件,其中一个是bjam,再执行命令:
./bjam --toolset=gcc --includedir=/usr/local/include --libdir=/usr/local/lib/boost install 这个命令执行时间较长,大概要20分钟
成功后,会在上述所示目录下生成对应的include和lib。
至此,2条命令就把boost编译完了,简单吧?
第二步:编译AVRO.
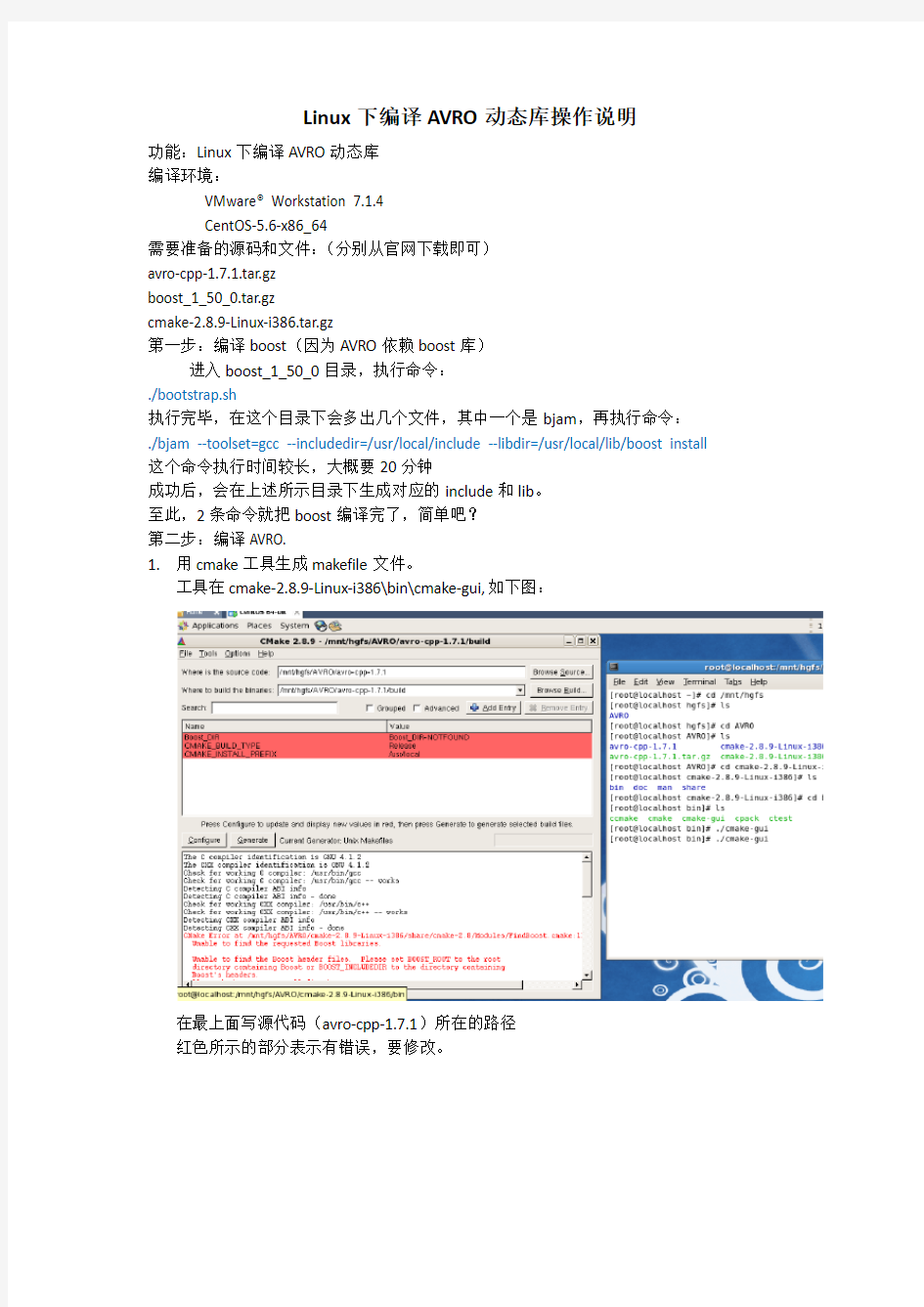
1.用cmake工具生成makefile文件。
工具在cmake-2.8.9-Linux-i386\bin\cmake-gui,如下图:
在最上面写源代码(avro-cpp-1.7.1)所在的路径
红色所示的部分表示有错误,要修改。
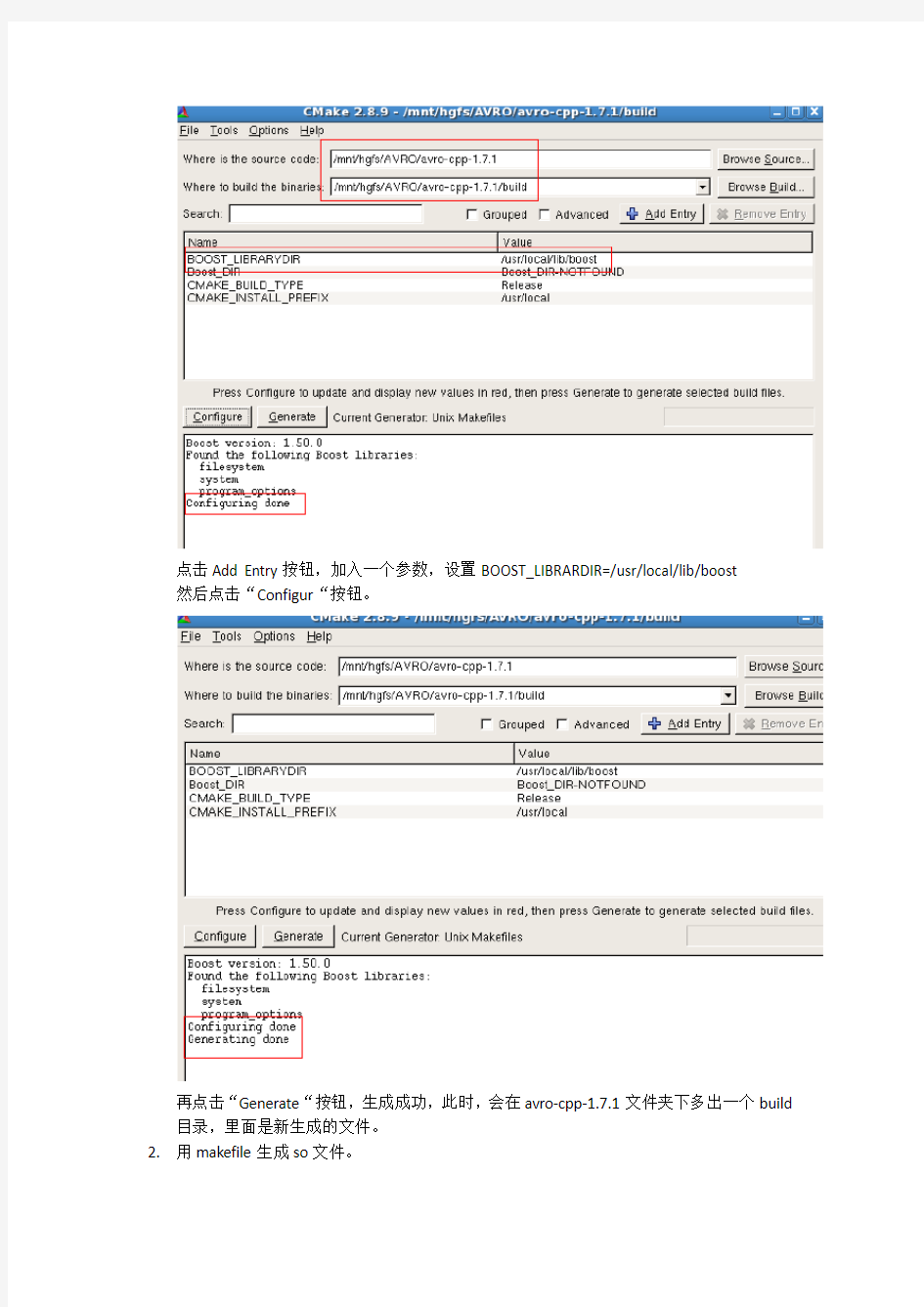
点击Add Entry按钮,加入一个参数,设置BOOST_LIBRARDIR=/usr/local/lib/boost
然后点击“Configur“按钮。
再点击“Generate“按钮,生成成功,此时,会在avro-cpp-1.7.1文件夹下多出一个build 目录,里面是新生成的文件。
2.用makefile生成so文件。
这里就更清楚了,进入avro-cpp-1.7.1\build目录,执行make命令:
期间,出现如图红色所示的错误,不知道什么原因,把avro-cpp-1.7.1拷到其他目录如/usr/local下就可以了。
生成so文件成功。
GCC 支持了许多不同的语言,包括C、C++、Ada、Fortran、Objective C,Perl、Python 和Ruby,甚至还有Java。 Linux 内核和许多其他自由软件以及开放源码应用程序都是用 C 语言编写并使用GCC 编译的。 编译C++程序: -c 只编译不连接 g++ file1 -c -o file1.o g++ file2 -c -o file2.o g++ file1.o file.o -o exec g++ -c a.cpp 编译 g++ -o a a.o 生成可执行文件 也可以g++ -o a a.cpp直接生成可执行文件。 1. 编译单个源文件 为了进行测试,你可以创建“Hello World”程序: #include
# ./hello Hello wordl! 在默认情况下产生的可执行程序名为a.out,但你通常可以通过gcc 的“-o”选项来指定自己的可执行程序名称。 2. 编译多个源文件 源文件message.c包含一个简单的消息打印函数: #include
Linux 下编译C程序 admin , 2010/03/05 12:55 , linux , 评论(0) , 阅读(76020) , Via 本站原创 GCC 支持了许多不同的语言,包括 C、C++、Ada、Fortran、Objective C,Perl、Python 和 Ruby,甚至还有Java。 Linux 内核和许多其他自由软件以及开放源码应用程序都是用 C 语言编写并使用 GCC 编译的。 编译C++程序: -c 只编译不连接 g++ file1 -c -o file1.o g++ file2 -c -o file2.o g++ file1.o file.o -o exec g++ -c a.cpp 编译 g++ -o a a.o 生成可执行文件 也可以 g++ -o a a.cpp直接生成可执行文件。 1. 编译单个源文件 为了进行测试,你可以创建“Hello World”程序: #include
选项来指定自己的可执行程序名称。 2. 编译多个源文件 源文件message.c包含一个简单的消息打印函数: #include
实验二Linux基本操作 编写c源程序并用编译运行 【需求】 在当前目录下创建新文件,用vi编辑器一段简单代码,代码要求在屏幕上输出文字“Hello Linux!”; 用gcc编译文件,并运行,查看输出结果,若结果错误,请根据提示修改; 【系统及软件环境】 操作系统:Virtualbox,Fedora 13 【实验配置文件及命令】 1.配置文件: 2
在“系统-分配光驱”里选择“” 查看安装源挂载位置 df命令,可查看到虚拟光驱挂载点 返回结果为:/media/Fedora 13 i386 DVD 使用安装源 安装的文件为RPM安装包,所在位置为安装光盘中的“Packages”目录下,可用“cd” 命令进入此目录 cd /media/ Fedora 13 i386 DVD/Packages 由于“Fedora 13 i386 DVD”名字中有空格,若直接输入,则会提示找不到此目录,可用“tab”键自动补全 【方法】cd /media/F
①打开你是boost_1_37_0文件夹 ②打开tools/jam/src ③点击build.bat 稍等一下会生成一个新的文件夹,打开里面有一个bjam.exe,复制它然后将它粘 贴到boost_1_37_0文件夹里面 然后打开vc2005的命令行:开始->所有程序->visualstudio 2005->visual sudio tools->命令提示(也就是那个黑色doc的标志) (许多人用cmd 那个doc命令,许多情况下是不行的,我就试过) 假如你的boost文件夹在E:/boost_1_37_0; 那么可以这样打命令: 1 E:然后回车 2 cd boost_1_37_0 然后回车 3 bjam.exe 然后回车 你的boost库就开始编译了,时间很长~ 剩下的别人也说得较为清楚,呵呵,;-), 我玩boost很久了,从1.34开始就一直玩,很不错 4 回答者:a_xr13800 - 二级 2009-1-7 22:01 我来评论>>提问者对于答案的评价: 谢谢哦 相关内容 ? boost 1_33_1 在VC6.0上的安装出现问题 2006-12-17 ? 1.0 bar boost是什么意思 2009-2-7 ? 笔记本《上、下、左、右,》键不起作用调不成boost引导顺序,怎样装系 统啊 2010-5-12 ? 联想Y460 I3 intel turbo boost technology device驱动装不了,是什么原 因 3 2010-8-1 ? 我的主板是技嘉770t-us3 装了easy tune 6 可是找不到easy boost 2010-4-28 等待您来回答更多 ?2回答为什么不用卫星来测控嫦娥二号? ?2回答xyhhdh商业理财 ?0回答最近刚买的房子,走的是商业贷款,现交完订金,马上就去交首付款,我... ?0回答用VS2008 新建一个MFC单文档工程,菜单里的改变应用程序外观是怎么实现... ?1回答visual studio 2008 SP1里有STL吗?? ?2回答各位编程爱好者,请帮我看看这道C语言题,将中缀表达式转化为后缀表达... ?2回答请问高手,汉武大帝第七集里贵妃们玩的什么游戏???
姓名:雨田河南大学rjxy 班级:XXXX 实验二Linux基本操作 实验二Linux基本操作 编写c源程序并用编译运行 【需求】 ◆在当前目录下创建新文件t.c,用vi编辑器一段简单代码,代码要求在屏幕上输出 文字“Hello Linux!”; ◆用gcc编译t.c文件,并运行,查看输出结果,若结果错误,请根据提示修改;【系统及软件环境】 操作系统:Virtualbox,Fedora 13 【实验配置文件及命令】 1.配置文件: 2.命令:touch、rpm、gcc、./等
进入Linux操作系统,应用程序-> 系统工具-> 终端,输入命令:su 输入密码切换到root超级用户。 1.在当前目录建立一个新的目录test:$ mkdir test 在test目录下建立文件t.c :$touch t.c 3编辑程序源代码:vi t.c 首先按下键盘的“i”键,字符界面下方出现“insert”提示字符,此时输入以下代码: #include "stdio.h" int main() { printf("Hello Linux!\n"); return 0; } 4 保存退出:先按下“Esc”键,然后按下“shift”和“:”键,界面上出现冒号,然后输入“xq!”或者“x”对代码保存退出。 5 由于系统默认没有安装C语言编译程序,下面进行安装gcc 程序; 此处不再赘述,以下引用实验指导书: 1.gcc的安装 (1)查看gcc是否安装 rpm –q gcc (2)指定安装源 在“系统-分配光驱”里选择“Fedora-13-i386-DVD.iso” (3)查看安装源挂载位置 df命令,可查看到虚拟光驱挂载点 返回结果为:/media/Fedora 13 i386 DVD (4)使用安装源 安装的文件为RPM安装包,所在位置为安装光盘中的“Packages”目录下,可用“cd”命令进入此目录 cd /media/ Fedora 13 i386 DVD/Packages ★由于“Fedora 13 i386 DVD”名字中有空格,若直接输入,则会提示找不到此目录,可用“tab”键自动补全 【方法】cd /media/F
ICU编译(VS2010): ICU提供了unicode和国际化支持,目前的版本是 4.8.1。ICU的主页是https://www.doczj.com/doc/947202263.html,/。 (1). 下载 可以从https://www.doczj.com/doc/947202263.html,/projects/icu/files/下载源代码版本。4.8.1是VS2010的,4.4.2才是VS2008的,如果是2010要做转换。 (2). 编译 ICU的编译比较简单,打开ICU源代码目录下的source\allinone\allinone.sln,需要转换到VS2008格式,直接转换即可。然后,选择release,Rebuild Solution即可。 (3). 测试 将编译出来的bin目录加入到系统的PATH目录中去。然后,重新打开allinone.sln工程。需要通过测试的项目 1. cintltst项目 2. intltest项目 3. iotest 分别设置成启动项目,运行即可。 2. bzip bzip的主页是https://www.doczj.com/doc/947202263.html,/,从https://www.doczj.com/doc/947202263.html,/downloads.html下面下载源代码包即可,boost直接使用源代码来进行编译。 3. zlib zlib的主页是https://www.doczj.com/doc/947202263.html,/,https://www.doczj.com/doc/947202263.html,/projects/gnuwin32/files/zlib/从该网页下面下载源代码包即可,boost直接使用源代码来进行编译。 4. python python的主页是https://www.doczj.com/doc/947202263.html,/,下载python的2.5.2版本,安装即可。boost默认是会编译python,并且会自动寻找python的安装目录。 ICU编译(MinGW): 还未成功编译
linux下使用gcc命令编译代码 初学时最好从命令行入手,这样可以熟悉从编写程序、编译、调试和执行的整个过程。编写程序可以用vi/vim(个人觉得vim比vi好用)或其它编辑器编写。编译则使用gcc命令。要往下学习首先就得熟悉gcc命令的用法。 gcc命令提供了非常多的命令选项,但并不是所有都要熟悉,初学时掌握几个常用的就可以了,到后面再慢慢学习其它选项,免得因选项太多而打击了学习的信心。 一. 常用编译命令选项 假设源程序文件名为test.c 1. 无选项编译链接 用法:#gcc test.c 作用:将test.c预处理、汇编、编译并链接形成可执行文件。这里未指定输出文件,默认输出为a.out。编译成功后可以看到生成了一个a.out的文件。在命令行输入./a.out 执行程序。./表示在当前目录,a.out为可执行程序文件名。 2. 选项 -o 用法:#gcc test.c -o test 作用:将test.c预处理、汇编、编译并链接形成可执行文件test。-o选项用来指定输出文件的文件名。输入./test执行程序。 3. 选项 -E 用法:#gcc -E test.c -o test.i 作用:将test.c预处理输出test.i文件。 4. 选项 -S 用法:#gcc -S test.i 作用:将预处理输出文件test.i汇编成test.s文件。 5. 选项 -c 用法:#gcc -c test.s 作用:将汇编输出文件test.s编译输出test.o文件。 6. 无选项链接 用法:#gcc test.o -o test 作用:将编译输出文件test.o链接成最终可执行文件test。输入./test执行程序。 7. 选项-O 用法:#gcc -O1 test.c -o test 作用:使用编译优化级别1编译程序。级别为1~3,级别越大优化效果越好,但编译时间越长。输入./test执行程序。 8.编译使用C++ std库的程序 用法:#gcc test.cpp -o test -lstdc++ 作用:将test.cpp编译链接成test可执行文件。-lstdc++指定链接std c++库。
一、软件研发工程师 工作职责: -负责核心产品功能和架构开发 -负责核心技术算法的研究、实现和优化 -负责前瞻技术的跟踪调研和产品创新 需要的技能: -深刻理解计算机数据结构和算法设计,精通C/C++、Java、PHP中至少一门编程语言 -了解windows、unix、linux等主流操作系统原理,熟练运用系统层支持应用开发 二、移动软件研发工程师 工作职责: -开发移动互联网应用产品或框架 -移动应用核心技术研发 -学习和研究移动客户端新技术 -根据开发过程中的体验对产品提出改进建议 -配合市场等其他部门,提供产品相关技术支持 需要的技能: -精通一门常用编程语言(C/C++/Java/Objective C) -对数据结构和算法设计有较为深刻的理解 -熟悉手机研发平台(Android/iPhone/windows phone 7等)者优先 -熟悉HTML/WML/CSS等相关规 -熟悉Javascript与DOM规 -熟悉webkit或其他任意一种浏览器核 -熟悉HTML5编程技术 -熟悉Linux操作系统 -熟悉数据库原理和技术,熟练使用SQL -熟悉TCP/IP,HTTP,HTTPS等网络协议优先
三、Web前端研发工程师 工作职责: -各产品Web前端研发 -各产品易用性改进和界面技术优化 -Web前沿技术研究和新技术调研 需要的技能: -精通JavaScript、Ajax等Web开发技术 -精通HTML/XHTML、CSS等网页制作技术,熟悉页面架构和布局 -熟悉W3C标准,对表现与数据分离、Web语义化等有深刻理解 -具有Mobile WEB/WAP、HTML5/CSS3、nodejs、Flash开发经验 -精通一种模板语言(Smarty、Velocity、Django等) -熟悉Linux平台,掌握一种后端开发语言(PHP/Java/C/C++/python等) -有前端性能优化经验 -具有一定的软件工程意识,对数据结构和算法设计有充分理解 四、机器学习/数据挖掘工程师 工作职责: -研究数据挖掘或统计学习领域的前沿技术,并用于实际问题的解决和优化 -大规模机器学习算法研究及并行化实现,为各种大规模机器学习应用研发核心技术 -通过对数据的敏锐洞察,深入挖掘产品潜在价值和需求,进而提供更有价值的产品和服务,通过技术创新推动产品成长 需要的技能: -具有以下一个或多个领域的理论背景和实践经验:机器学习/数据挖掘/深度学习/信息检索/自然语言处理/机制设计/博弈论 -至少精通一门编程语言,熟悉网络编程、多线程、分布式编程技术,对数据结构和算法设计有较为深刻的理解 -良好的逻辑思维能力,对数据敏感,能够发现关键数据、抓住核心问题 -熟悉文本分类、聚类、机器翻译,有相关项目经验 -熟悉海量数据处理、最优化算法、分布式计算或高性能并行计算,有相关项目经验
核心板linux内核编译及驱动模块编译步骤 一、内核编译: 1,拷贝开发板linux系统源代码(linux-2.6.30)到ubuntu的任意位置,打开终端,进入linux-2.6.30目录,输入命令:cp arch/arm/configs/sbc6045_defconfig .config 回车 2,输入命令:make menuconfig 回车,若提示以下界面 *** Unable to find the ncurses libraries or the *** required header files. *** 'make menuconfig' requires the ncurses libraries. *** *** Install ncurses (ncurses-devel) and try again. *** 输入命令:sudo apt-get install libncurses5-dev 回车,安装ncurses 3,安装完成后,输入命令:make menuconfig 回车,进入配置选项界面,按需修改,目前未修改。 4,输入命令:make uImage 回车,若提示Can't use 'defined(@array)',修改kernel/timeconst.pl 文件中 373行,if (!defined(@val))改为if (!@val) ,重新执行make uImage命令。 二、驱动模块编译(若从未编译过内核,需要先编译内核): 1,将编写好到源文件(如:cgc-pio.c)拷贝到linux-2.6.30/drivers/char/目录 2,修改linux-2.6.30/drivers/char/目录下到Makefile文件,增加一行,内容为:obj-m += xxx.o,如:obj-m += cgc-pio.o 3,打开linux终端,进入linux-2.6.30目录,输入命令:make modules 回车,完成后在linux-2.6.30/drivers/char/目录下会产生对应到.ko文件(如:cgc-pio.ko)。
Articles from LinkSprite学习中心 Linux ALSA声卡驱动之四:Control设备的创建 2014-03-08 17:03:48 z ou, baoz hu Control接口 Cont rol接口主要让用户空间的应用程序(alsa-lib)可以访问和控制音频codec芯片中的多路开关,滑动控件等。对于Mixer(混音)来说,Cont rol接口显得尤为重要,从ALSA 0.9.x版本开始,所有的mixer工作都是通过cont rol接口的API来实现的。 ALSA已经为AC97定义了完整的控制接口模型,如果你的Codec芯片只支持AC97接口,你可以不用关心本节的内容。
Linux mysql5.7.13安装教程 本文实例为大家分享了Linuxmysql5.7.13安装教程,供大家参考,具体内容如下 1、准备 cmake-3.6.0.tar.gz bison-3.0.4.tar.gz mysql-5.7.13.tar.gz (s://dev.mysql./get/Downloads/MySQL-5.7/mysql-5.7.13.tar.g z) 2、安装cmake和bison 首先可以查看下是否安装了cmake #rpm-qa|grepcmake#tarzxvfcmake-3.6.0.tar.gz#cdcmake-3.6.0#. /bootstrap#make&&makeinstall#tarzxvfbison-3.0.4.tar.gz#cdbi son-3.0.4#./configure#make&&makeinstall 3、安装Mysql [root@localhostsrc]#tar-zxvfmysql-5.7.13.tar.gz[root@localh ostsrc]#cdmysql-5.7.13[root@localhostmysql-5.7.13]#cmake-DC MAKE_INSTALL_PREFIX=/usr/local/mysql-DMYSQL_UNIX_ADDR=/usr/ local/mysql/mysql.sock-DDEFAULT_CHARSET=gbk-DDEFAULT_COLLAT ION=gbk_chinese_ci-DWITH_INNOBASE_STORAGE_ENGINE=1-DWITH_AR
Linux下源码编译mysql-5.7.14 基础环境 RHEL6.5X64 mysql-5.7.14.tar.gz mysql-5.7.14-boost.tar.gz #经测试此软件包不需要额外boost-1.59.0依赖库所以上面mysql-5.7.14可以省略 配置网络yum源以Centos6.5源为例 [root@zlf~]#wget -O /etc/yum.repos.d/CentOS-Base.repo https://www.doczj.com/doc/947202263.html,/repo/Centos-6.repo [root@zlf~]#sed -i 's/$releasever/6/g' /etc/yum.repos.d/CentOS-Base.repo [root@zlf~]#yum clean all [root@zlf~]#yum list 安装必要的依赖库以及升级cmake #cmake版本要求在2.8以上 [root@zlf~]#yum -y install gccgcc-c++ autoconfautomakezlib* libxml* ncurses-devellibtool-ltdl-devel* make cmake 移除系统自带mysql以及mysql-boost库 [root@zlf~]#yum –y remove mysql boost* 创建服务文件夹方便安装管理 [root@zlf~]#mkdir /server [root@zlf~]#cd /server 上传软件包 [root@zlfserver]#tar zxvf mysql-5.7.14.tar.gz && tar zxvf mysql-5.7.14-boost.tar.gz
FSDK_LoadImageFromFile 从文件中载入一副图像,并且为该图像提供一个内部的句柄。 函数原型int FSDK_LoadImageFromFile(HImage*Image,char*FileName); Image是指向一个HImage类型变量的指针,用来接收为该图像文件分配的内部句柄。FileName所要载入文件的文件名,FaceSDK支持JPG,PNG,BMP三种图像文件格式。如果函数调用成功返回FSDKE_OK,否则返回FSDKE_FAILED。 FSDK_SaveImageToFile 把图像保存到文件中去,在保存jpg类型文件的时候,可以通过函数 FSDK_SetJpegCompressionQuality()来设置图像的压缩质量。 函数原型int FSDK_SaveImageToFile(HImage Image,char*FileName); Image为要保存图像的内部句柄。 FileName是图像文件要保存的文件名。 如果函数调用成功返回FSDKE_OK,否则返回FSDKE_FAILED。 FSDK_LoadImageFromBuffer 从缓冲区中载入一副图像,并且为该图像分配一个内部句柄。该函数建议图像数据按照-top-to-bottom顺序。并且相邻行之间ScaleLine字节。该函数一共支持一下几种图像模式. Mode Name Meaning FSDK_IMAGE_GRAYSCALE_8BIT8位的灰度图像
FSDK_IMAGE_COLOR_24BIT24位的彩色图像(R,G,B顺序) FSDK_IMAGE_COLOR_32BIT32位的彩色图像带有alpha通道(R,G,B,alpha顺序) 这个函数在.NET框架下并不支持,建议用FSDK_LOADIMAGEFROMHBITMAP()函数代替。 函数原型int FSDK_LoadImageFromBuffer(HImage*Image,unsigned char*Buffer,int Width,int Height,int ScanLine,FSDK_IMAGEMODE ImageMode); Image为图像分配的内部句柄 Buffer图像缓冲区 Width图像宽度 Height图像高度 ScanLine扫描线宽度 FSDK_IMAGEMODE所使用的图像模式。 FSDK_GetImageBufferSize 返回相应的缓冲区大小,以存贮相应图像。 函数原型int FSDK_GetImageBufferSize(HImage Image,int*BufSize, FSDK_IMAGEMODE ImageMode); Image所要检测的图像的内部句柄。 BufSize用以接收缓冲区大小的一个指向整形变量的指针。 FSDK_IMAGEMODE所要检测图像的色彩模式,貌似三种…… 如果函数调用成功返回FSDKE_OK
嵌入式Linux内核编译步骤和经验 5.tar.xz,并且顺利的编译安装成功了,上电重启都OK的。不过,我使用的.config配置文件,是Fedora 13自带内核的配置文件,即/lib/modules/`uname -r`/build/.config d) 如果你是移植Linux到嵌入式系统,则还要再下载安装交叉编译工具链。 例如,你的目标单板CPU可能是arm或mips等cpu,则安装相应的交叉编译工具链。安装后,需要将工具链路径添加到PATH环境变量中。例如,你安装的是arm工具链,那么你在shell中执行类似如下的命令,假如有类似的输出,就说明安装好了。 [root@localhost linux-2.6.33.i686]# arm-linux-gcc --version arm-linux-gcc (Buildroot 2010.11) 4.3.5Copyright (C) 2008 Free Software Foundation, Inc.This is free software; see the source for copying conditions. There is NOwarranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. 注:arm的工具链,可以从这里下载:回复“ARM”即可查看。 二、设置编译目标 在配置或编译内核之前,首先要确定目标CPU架构,以及编译时采用什么工具链。这是最最基础的信息,首先要确定的。 如果你是为当前使用的PC机编译内核,则无须设置。 否则的话,就要明确设置。 这里以arm为例,来说明。 有两种设置方法(): a) 修改Makefile 打开内核源码根目录下的Makefile,修改如下两个Makefile变量并保存。 ARCH := armCROSS_COMPILE := arm-linux- 注意,这里cross_compile的设置,是假定所用的交叉工具链的gcc程序名称为arm-linux-gcc。如果实际使用的gcc名称是some-thing-else-gcc,则这里照葫芦画瓢填some-thing-else-即可。总之,要省去名称中最后的gcc那3个字母。
主机环境:ubuntu10.04 lts X64_64bit 编译器:arm gnu tools for Xilinx 参考网址:https://www.doczj.com/doc/947202263.html,/zynq-tools(这个网址的内容真的需要更新了) 详细步骤:以下操作均在root用户下进行,官方参考网址的东西仅是“参考”的 1,下载交叉编译器 在ubuntu里下载arm-2010.09-62-arm-xilinxa9-linux-gnueabi.bin安装文件,网址:https://https://www.doczj.com/doc/947202263.html,/GNUToolchain/kbentry62,放到
创新采用bcrypt算法的淘京币,目前已经迭代第二个版本0.9.2,新版本解决了同步较慢的问题,同时完美支持新人拷贝最新block,实现秒同步的强力功能, 新人可以直接从官方下载最新block(目前为8500,官方每隔几天更新一次),拷贝到Tjcoin数据目录覆盖,即可实现秒开秒同步。 通过这个版本,解决了淘京币一直以来让人鄙视的同步速度问题,淘京币的技术帝也能够有空来回复下淘京币的研发过程。 特开此贴,告诉您山寨币是怎么来的,需要需要怎么制作,纯抄袭和创新的币区别在哪里,让您擦亮眼睛,透过现象,看到技术价值的本质。 您甚至也可以通过本帖尝试子自己去制作一个山寨币。 1.纯抄袭的山寨币制作流程(通常是以BTC或者LTC为基础架构,两者类似,此处以LTC为例) 前提:最好你得要懂编程,不懂的话难度比较大,当然只要你专研,不懂也还是能做出来的,BTC和LTC均是C++源码; 第一步:准备编译环境。 代码都是需要编译的,因此需要准备编译环境和工具,您需要下载mingw(仿linux环境编译工具)、qtcreator和对应的sdk,下载boost1.5.0(需要依赖库)、openssl、伯克利db、miniupnp;配置好系统环境变量,qt环境,使用mingw编译boost库(这个需要编译大概2个小时),openssl、伯克利db、miniupnp等文件,编译命令在ltc源代码里的mingw-unix文件里有详细说明。 整个过程,如果是熟练的程序猿大概3天能够准备好,不懂的人恐怕要折腾很久。 第二步:编译widows钱包. 从github下ltc源代码。此处以0.8.5的版本为内核。在qtcreator内打开该项目工程,配置好pro文件,配置好编译器,开始编译,此时您并没有修改过任何代码,甚至连参数都没有调整,编译出来的就是莱特币的客户端,甚至可以直接使用。 整个过程,熟悉的预计也是3天能成功编译出。不懂的同样要折腾很久,各种编译不过。第三布:调整参数,生成属于你的山寨币。 还是在qtcreator打开各个源文件,找到对应的地方调整参数即可,如在main.cpp调整每块出币数,总产量,调整难度,修改创世hash,减产时间,增加检查点等等,将原本莱特币的跑p2p端口9333端口修改,自己指定某个端口(比如指定为9999),看到这里大家可以发现,这里只要你摸清楚了在哪里改,无非是改个数值,甚至不需要阅读代码。偶尔有良心的会去阅读代码,了解原理,用心维护。 再然后,全文搜索litcoin,改成你自己名字,比如diaosicoin之类的,想怎么取名就怎么取名,然后再res文件夹里替换掉logo等图片; 最后编译,通过,产生个新币,剩下的就是发布新币,建立官网、Q群,甚至都不需要测试!!!这是最为关键的,我们都知道一个新的软件诞生是需要经过长时间的测试,但是纯抄袭的山寨币不需要,为什么?因为它根本就没有改过功能,只改了数值和图片,相当于btc和ltc早就帮它测试过了,直接发布,绝对不会有问题~ 然后从github上下载现成的挖矿工具(通常支持sha和scrypt算法)、矿池,再改名字编译下,部署起,也同样直接就可以用了,剩下的就是如何说服别人用你的币了。 总得来看,如果是熟练的程序员,第一次接触这个,只是纯粹抄袭,改名字后发布,我
Boost库学习指南和说明文档 作者:刘刚email:ganghust@https://www.doczj.com/doc/947202263.html, 个人主页:https://www.doczj.com/doc/947202263.html,2007年11月17号 Boost中文站 Boost库是一个经过千锤百炼、可移植、提供源代码的C++库,作为标准库的后备,是C++标准化进程的发动机之一。Boost库由C++标准委员会库工作组成员发起,在C++社区中影响甚大,其成员已近2000人。Boost库为我们带来了最新、最酷、最实用的技术,是不折不扣的“准”标准库。本站主要介绍Boost相关的中文技术文档。 Boost入门 boost库简介 Windows和Solaris上Boost安装和编译 走进Boost(Boost使用入门) Boost编程技术 C++Boost Thread线程编程指南 Boost中文文档 C++Boost Assign文档 C++Boost Regex文档
C++Boost Array文档 Boost源码剖析 Boost源码剖析之:型别分类器—type_traits Boost源码剖析之:泛型指针类any之海纳百川 Boost源码剖析之:增强的std::pair——Tuple Types Boost库学习指南和说明文档 (1) Boost入门 (1) Boost编程技术 (1) Boost中文文档 (1) Boost源码剖析 (2) C++Boost学习资源列表 (3) C++Boost库简介 (3) Windows和Solaris上Boost安装和编译 (5) 0前言 (5) 1下载Boost+解包(略) (6) 2编译jam (6) 3设置环境变量 (6) 4编译Boost (7) 走进Boost[Boost使用入门] (8) 0摘要 (8)
linux下编译boost 原文出处:https://www.doczj.com/doc/947202263.html,/archives/148 工作平台:Fedora 12 获取boost库 Linux下官方提供了两个压缩版本: boost_1_43_0.tar.bz2 boost_1_43_0.tar.gz 找到其中一个Unix/Linux包的直接下载地址,然后输入下列命令 sudo wget https://www.doczj.com/doc/947202263.html,/project/boost/boost/1.43.0/boost_1_43_0.tar.gz?use_mirror= cdnetworks-kr-1 解压 tar -zxvf boost_1.43.0.tar.gz 进入解压目录 cd boost_1_43_0 编译安装 使用下面的命令创建boost自己的编译工具bjam(目的是保证Boost在任何平台上都能用bjam编译),类似于GNU Make。 ./bootstrap.sh --prefix=/home/usrname/boost_1_43_0/boost_install boost将被安装到/boost_install目录下,不知名prefix将默认安装到/usr/local/include和/usr/local/lib下。 建议先查看下帮助文档,了解些默认选项,命令为 ./bjam –help .bjam命令的格式为:bjam [options] [properties] [targets] 常用选项(Options)和属性(Properties)的说明,一般带有–前缀的关键词为option,没有的则为property。 –show-libraries 显示需要编译才能使用的库列表 –build-type=minimal|complete –build-type=minimal为默认值,此时在Linux下只编译生成release版的动态链接C运行库(C++标准库)的多线程静态库和动态库。 –build-type=complete,在Unix/linux下要编译多个变体(debug或release,多线程或单线程,静态库或动态库,https://www.doczj.com/doc/947202263.html, 静态链接或动态链接C运行库/C++标准库)。不建议全部编译,费时还费空间,提倡按需编译。 –layout=versioned|tagged|system 决定需要编译的库名及头文件的地址目录名的生成策略。默认Windows下–layout=versioned,Linux下–layout=system。 当同时编译多个版本时,最好设置–layout=versioned或–layout=tagged,否则编译多半会失败,原因是有的版本同时编译若不指定命名策略,可能在输出到指定目录的时候造成命名冲突。 注:–build-type=complete时,不需要设置此属性。但指定variant=debug,release等属性时,须确保–layout=versioned或–layout=tagged。