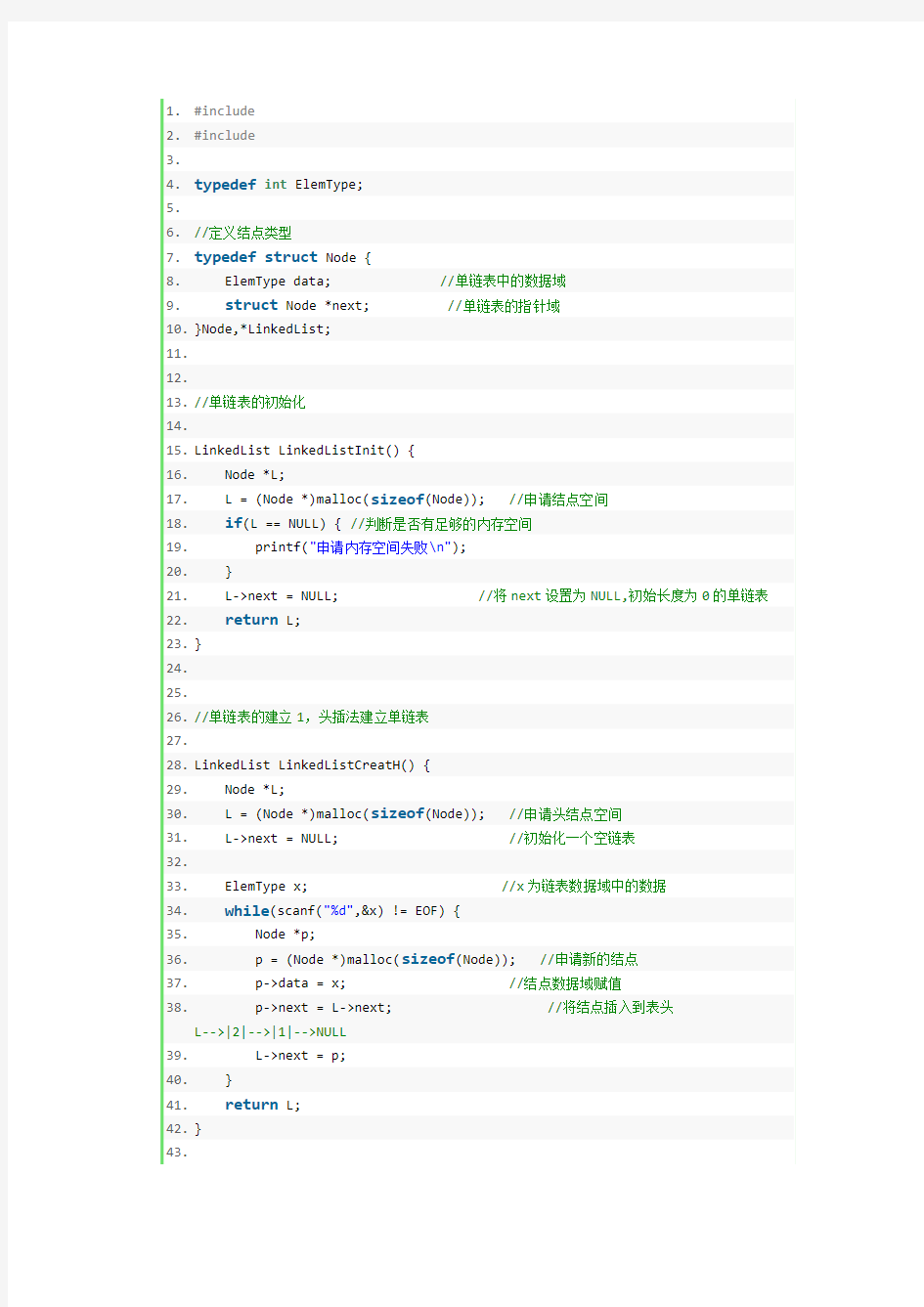
1.#include
2.#include
3.
4.typedef int ElemType;
5.
6.//定义结点类型
7.typedef struct Node {
8. ElemType data; //单链表中的数据域
9.struct Node *next; //单链表的指针域
10.}Node,*LinkedList;
11.
12.
13.//单链表的初始化
14.
15.LinkedList LinkedListInit() {
16. Node *L;
17. L = (Node *)malloc(sizeof(Node)); //申请结点空间
18.if(L == NULL) { //判断是否有足够的内存空间
19. printf("申请内存空间失败\n");
20. }
21. L->next = NULL; //将next设置为NULL,初始长度为0的单链表
22.return L;
23.}
24.
25.
26.//单链表的建立1,头插法建立单链表
27.
28.LinkedList LinkedListCreatH() {
29. Node *L;
30. L = (Node *)malloc(sizeof(Node)); //申请头结点空间
31. L->next = NULL; //初始化一个空链表
32.
33. ElemType x; //x为链表数据域中的数据
34.while(scanf("%d",&x) != EOF) {
35. Node *p;
36. p = (Node *)malloc(sizeof(Node)); //申请新的结点
37. p->data = x; //结点数据域赋值
38. p->next = L->next; //将结点插入到表头
L-->|2|-->|1|-->NULL
39. L->next = p;
40. }
41.return L;
42.}
43.
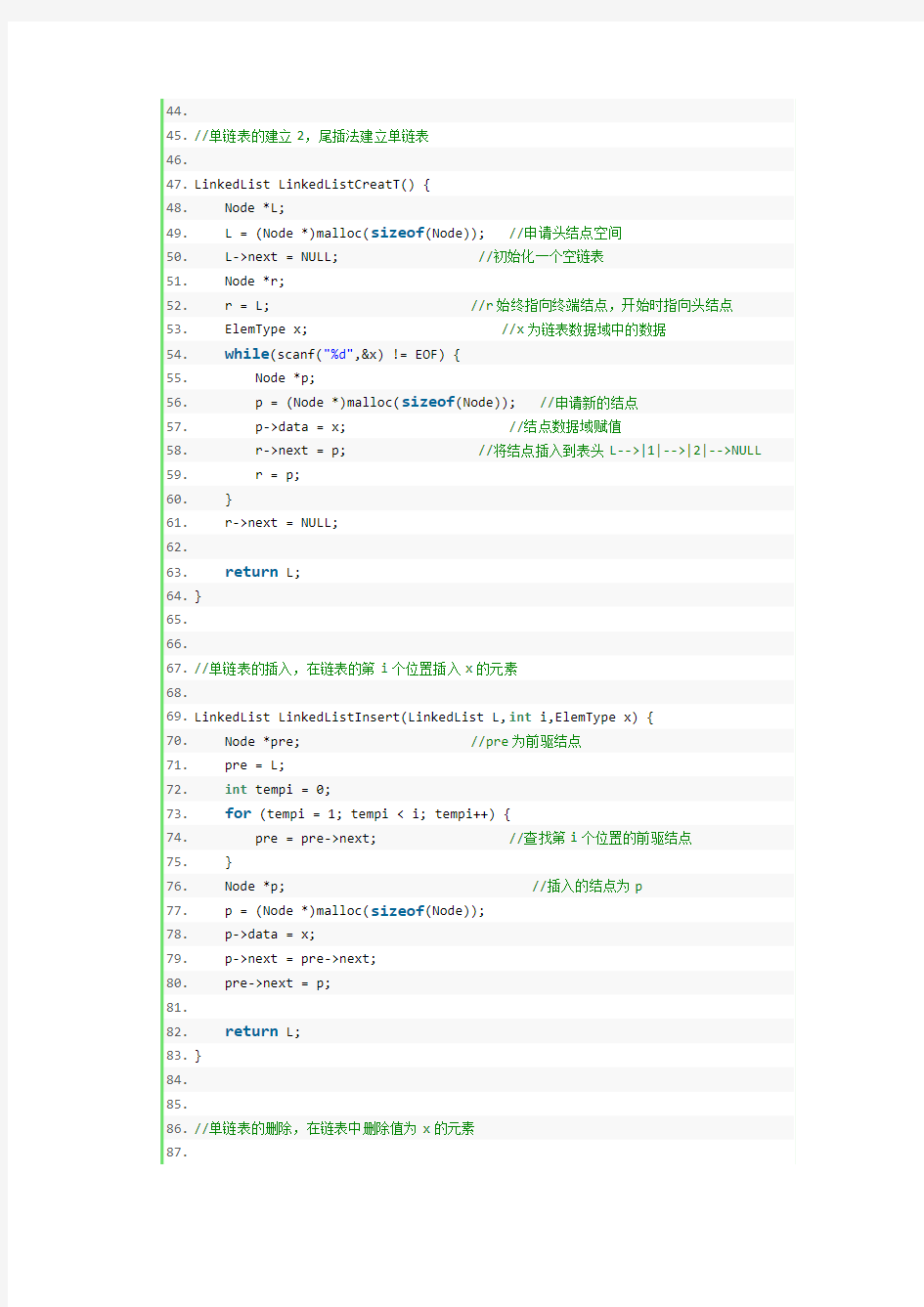
44.
45.//单链表的建立2,尾插法建立单链表
46.
47.LinkedList LinkedListCreatT() {
48. Node *L;
49. L = (Node *)malloc(sizeof(Node)); //申请头结点空间
50. L->next = NULL; //初始化一个空链表
51. Node *r;
52. r = L; //r始终指向终端结点,开始时指向头结点
53. ElemType x; //x为链表数据域中的数据
54.while(scanf("%d",&x) != EOF) {
55. Node *p;
56. p = (Node *)malloc(sizeof(Node)); //申请新的结点
57. p->data = x; //结点数据域赋值
58. r->next = p; //将结点插入到表头L-->|1|-->|2|-->NULL
59. r = p;
60. }
61. r->next = NULL;
62.
63.return L;
64.}
65.
66.
67.//单链表的插入,在链表的第i个位置插入x的元素
68.
69.LinkedList LinkedListInsert(LinkedList L,int i,ElemType x) {
70. Node *pre; //pre为前驱结点
71. pre = L;
72.int tempi = 0;
73.for (tempi = 1; tempi < i; tempi++) {
74. pre = pre->next; //查找第i个位置的前驱结点
75. }
76. Node *p; //插入的结点为p
77. p = (Node *)malloc(sizeof(Node));
78. p->data = x;
79. p->next = pre->next;
80. pre->next = p;
81.
82.return L;
83.}
84.
85.
86.//单链表的删除,在链表中删除值为x的元素
87.
88.LinkedList LinkedListDelete(LinkedList L,ElemType x)
89.{
90. Node *p,*pre; //pre为前驱结点,p为查找的结点。
91. p = L->next;
92.while(p->data != x) { //查找值为x的元素
93. pre = p;
94. p = p->next;
95. }
96. pre->next = p->next; //删除操作,将其前驱next指向其后继。
97. free(p);
98.return L;
99.}
100.
101.
102.int main() {
103. LinkedList list,start;
104. printf("请输入单链表的数据:");
105. list = LinkedListCreatH();
106.for(start = list->next; start != NULL; start = start->next) { 107. printf("%d ",start->data);
108. }
109. printf("\n");
110.int i;
111. ElemType x;
112. printf("请输入插入数据的位置:");
113. scanf("%d",&i);
114. printf("请输入插入数据的值:");
115. scanf("%d",&x);
116. LinkedListInsert(list,i,x);
117.for(start = list->next; start != NULL; start = start->next) { 118. printf("%d ",start->data);
119. }
120. printf("\n");
121. printf("请输入要删除的元素的值:");
122. scanf("%d",&x);
123. LinkedListDelete(list,x);
124.for(start = list->next; start != NULL; start = start->next) { 125. printf("%d ",start->data);
126. }
127. printf("\n");
128.
129.return 0;
130.}
单链表的创建、插入和删除 (数据结构) ——SVS #include
Status DeleteList_Link(LinkList L,int i,ElemType e) //删除链表{ LinkList q,p=L;int j=0; while(p->next&&j
专题二算法的效率 评价一个算法的效率主要是考察算法执行时间的情况。可以在相同的规模下,根据执行时间的长短来评价一个算法的优劣。一个算法的好坏对计算机的效能影响有多大呢?我们来做这样一个比较,假设有两台计算机分别是计算机A和计算机B,计算机A的运算处理速度比计算机B大约快50倍。以求解“百钱买百鸡”(“鸡翁一,值钱五,鸡母一,值钱三,鸡雏三,值钱一。百钱买百鸡。问鸡翁、母、雏各几何?”)为例子,设鸡翁为x只,鸡母为y只,鸡雏为z只。算法A:把公鸡、母鸡、小鸡的枚举范围都是1~100;算法B:经粗略计算公鸡的枚举范围为1~20,母鸡的枚举范围为1~33,而小鸡的枚举范围应是100-x-y。在计算机A上运行算法A程序,在计算机B上运行算法B程序,两台计算机谁先把结果运算出来呢? 算法A的程序代码如下: For x = 1 To 100 For y = 1 To 100 For z = 1 To 100 If (x+y+z=100) And (5* x + 3 * y + z/3 = 100) Then List1.AddItem Str(x) + " " + Str(y) + " " + Str(z) End If Next z Next y Next x 算法B程序代码如下: For x = 1 To 20 For y = 1 To 33 Z=100-x-y If 5* x +3* y + z/3 = 100 Then List1.AddItem Str(x) + " " + Str(y) + " " + Str(z) End If Next y Next x 运算结果是计算机B先把结果运算出来。为什么会这样呢?我们来分析一下,算法A 需要执行100×100×100=1000000次内循环,而算法B只需要执行20×33=660次内循环,虽然计算机A比计算机B快50多倍,但还是计算机B先求得计算结果。 一个好的算法可以算得更快。什么样的算法是好算法呢?通常从时间复杂度和空间复杂度两方面来评价,在这里我们主要讨论时间复杂度。通常我们把算法的基本操作执行的次数作为算法的时间量度T(n)=O(f(n)),表示随着规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称时间复杂度,估算时按该算法对各种输入情况的平均值来考虑。在最坏情况下的复杂度和平均情况下的复杂度是评估算法两种衡量标准。 在排序算法中,我们学习了冒泡排序和交换排序,这两种算法的效率如何呢?下面我们来进行讨论。算法的基本操作主要是比较语句和交换两个变量值的赋值语句。冒泡排序(bubble sort)是在一列数据中把较小的数据逐次向上推移的一种技术,它和气泡从水中往上冒的情况有些类似,它把待排序的n个元素的数组看成是垂直堆放的一列数据,从最下面的一个元素起,自下而上地比较相邻两个元素中的数据,将较小的数据换到上面的一个元素中。当第一遍加工完成时,最小的数据已经上升为第一个元素的数据。然后对余下的n-1
数组作为存放同类数据的集合,给我们在程序设计时带来很多的方便,增加了灵活性。但数组也同样存在一些弊病。如数组的大小在定义时要事先规定,不能在程序中进行调整,这样一来,在程序设计中针对不同问题有时需要3 0个大小的数组,有时需要5 0个数组的大小,难于统一。我们只能够根据可能的最大需求来定义数组,常常会造成一定存储空间的浪费。我们希望构造动态的数组,随时可以调整数组的大小,以满足不同问题的需要。链表就是我们需要的动态数组。它是在程序的执行过程中根据需要有数据存储就向系统要求申请存储空间,决不构成对存储区的浪费。 链表是一种复杂的数据结构,其数据之间的相互关系使链表分成三种:单链表、循环链表、双向链表,下面将逐一介绍。 7.4.1 单链表 图7 - 3是单链表的结构。 单链表有一个头节点h e a d,指向链表在内存的首地址。链表中的每一个节点的数据类型为结构体类型,节点有两个成员:整型成员(实际需要保存的数据)和指向下一个结构体类型节点的指针即下一个节点的地址(事实上,此单链表是用于存放整型数据的动态数组)。链表按此结构对各节点的访问需从链表的头找起,后续节点的地址由当前节点给出。无论在表中访问那一个节点,都需要从链表的头开始,顺序向后查找。链表的尾节点由于无后续节点,其指针域为空,写作为N U L L。 图7 - 3还给出这样一层含义,链表中的各节点在内存的存储地址不是连续的,其各节点的地址是在需要时向系统申请分配的,系统根据内存的当前情况,既可以连续分配地址,也可以跳跃式分配地址。 看一下链表节点的数据结构定义: struct node { int num; struct node *p; } ; 在链表节点的定义中,除一个整型的成员外,成员p是指向与节点类型完全相同的指针。在链表节点的数据结构中,非常特殊的一点就是结构体内的指针域的数据类型使用了未定义成功的数据类型。这是在C中唯一规定可以先使用后定义的数据结构。 ?单链表的创建过程有以下几步: 1 ) 定义链表的数据结构。 2 ) 创建一个空表。 3 ) 利用m a l l o c ( )函数向系统申请分配一个节点。 4 ) 将新节点的指针成员赋值为空。若是空表,将新节点连接到表头;若是非空表,将新 节点接到表尾。 5 ) 判断一下是否有后续节点要接入链表,若有转到3 ),否则结束。 ?单链表的输出过程有以下几步 1) 找到表头。
数据结构课程设计报告 搜索算法效率比较的设计 专业 计算机科学与技术 学生姓名 Xxxxx 班级 Xxxx 学 号 Xxxx 指导教师 Xxx 完成日期 2016年6月16日
目录 1.设计题目 (3) 2.设计目的及要求 (3) 2.1.目的 (3) 2.2.要求 (3) 3.设计内容 (3) 4.设计分析 (4) 4.1.空间复杂度 (5) 4.2非递归线性搜索设计 (5) 4.3递归线性搜索 (5) 4.4二叉搜索设计 (6) 5.设计实践 (7) 5.1非递归线性搜索模块设计 (7) 5.2递归线性搜索模块设计 (7) 5.3二叉搜索模块设计 (7) 5.4.主程序模块设计 (8) 6测试方法 (10) 7.程序运行效果 (11) 8.设计心得 (12)
搜索算法效率比较的设计 1.设计题目 给定一个已排序的由N个整数组成的数列{0,1,2,3,……,N-1},在该队列中查找指定整数,并观察不同算法的运行时间。考虑两类算法:一个是线性搜索,从某个方向依次扫描数列中各个元素;另一个是二叉搜索法。要完成的任务是:分别用递归和非递归实现线性搜索;分析最坏情况下,两个线性搜索算法和二叉搜索算法的复杂度;测量并比较这三个方法在N=100,500,1000,2000,4000,6000,8000,10000时的性能。 2.设计目的及要求 2.1.目的 (1)需要同学达到熟练掌握C语言的基本知识和技能; (2)基本掌握面向对象程序设计的基本思路和方法; (3)能够利用所学的基本知识和技能,解决简单的程序设计问题;2.2.要求 学生必须仔细阅读数据结构,认真主动完成课设的要求,有问题及时主动通过各种方式与教师联系沟通;要发挥自主学习的能力,充分利用时间,安排好课设的时间计划,并在课设过程中不断检测自己计划完成情况;独立思考,课程设计中各任务的设计和调试哦要求独立完成,遇到问题可以讨论,可以通过同学间相互讨论而解决。 3.设计内容 任何程序基本上都是要用特定的算法来实现的。算法性能的好坏,直接决定了所实现程序性能的优劣。此次对有关算法设计的基本知识作了简单的介绍。针对静态查找问题,以搜索算法的不同实现,并对非递归线性搜索算法、递归线性搜索算法和二叉搜索算法这三种方法进行了比较和分析。 算法是为求解一个问题需要遵循的、被清楚地指定的简单指令的集合。解决一个问题,可能存在一种以上的算法,当这些算法都能正确解决问题时,算法需要的资源量将成为衡量算法优良度的重要度量,列如算法所需的时间、空间等。算法是对问题求解过程的一种描述,是为解决一个问题或一类问题给出的一个正确的,有限长的操作序列。 由于查找一个数的过程,无论运用哪种算法对于电脑来说速度都是非常快的,都爱1ms之内,无法用计时函数测试出来。所以为了能够直观准确地表示出各个算法间的差异,此程序用了循环查找的方法,具体的思想是:先随机生成3000
比较两对算法的效率 考虑问题1:已知不重复且已经按从小到大排好的m个整数的数组A[1..m](为简单起见。还设m=2 k,k是一个确定的非负整数)。对于给定的整数c,要求寻找一个下标i,使得A[i]=c;若找不到,则返回一个0。 问题1的一个简单的算法是:从头到尾扫描数组A。照此,或者扫到A的第i个分量,经检测满足A[i]=c;或者扫到A的最后一个分量,经检测仍不满足A[i]=c。我们用一个函数Search来表达这个算法: Function Search (c:integer):integer; Var J:integer; Begin J:=1; {初始化} {在还没有到达A的最后一个分量且等于c的分量还没有找到时, 查找下一个分量并且进行检测} While (A[i]
几种字符串哈希HASH算法的性能比较 2011年01月26日星期三 19:40 这不就是要找hash table的hash function吗? 1 概述 链表查找的时间效率为O(N),二分法为log2N,B+ Tree为log2N,但Hash链表查找的时间效率为O(1)。 设计高效算法往往需要使用Hash链表,常数级的查找速度是任何别的算法无法比拟的,Hash 链表的构造和冲突的不同实现方法对效率当然有一定的影响,然而Hash函数是Hash链表最核心的部分,本文尝试分析一些经典软件中使用到的字符串 Hash函数在执行效率、离散性、空间利用率等方面的性能问题。 2 经典字符串Hash函数介绍 作者阅读过大量经典软件原代码,下面分别介绍几个经典软件中出现的字符串Hash函数。 2.1 PHP中出现的字符串Hash函数 static unsigned long hashpjw(char *arKey, unsigned int nKeyLength) { unsigned long h = 0, g; char *arEnd=arKey+nKeyLength; while (arKey < arEnd) { h = (h << 4) + *arKey++; if ((g = (h & 0xF0000000))) { h = h ^ (g >> 24); h = h ^ g; } } return h; } 2.2 OpenSSL中出现的字符串Hash函数 unsigned long lh_strhash(char *str) { int i,l; unsigned long ret=0; unsigned short *s; if (str == NULL) return(0); l=(strlen(str)+1)/2; s=(unsigned short *)str; for (i=0; i ret^=(s[i]<<(i&0x0f)); return(ret);
单链表的插入和删除实验日志 指导教师刘锐实验时间2010 年10 月11 日 学院数理专业数学与应用数学 班级学号姓名实验室S331-A 实验题目:单链表的插入和删除 实验目的:了解和掌握线性表的逻辑结构和链式存储结构,掌握单链表的基本算法及相关的时间性能分析。 实验要求:建立一个数据域定义为字符串的单链表,在链表中不允许有重复的字符串;根据输入的字符串,先找到相应的结点,后删除之。 实验主要步骤: 1、分析、理解程序(相关程序见附录) 。 2、调试程序,并设计输入字符串数据(如:aa, bb , cc , dd, ee,#),测试程序的如下功能: 不允许重复字符串的插入;根据输入的字符串,找到相应的结点并删除。 3、修改程序: (1)增加插入结点的功能。 (2)将建立链表的方法改为头插入法。 实验结果: 1、不允许重复字符串的插入功能结果如下:
3、删除和插入结点的功能如下:
心得体会: 通过这次实验我学会了单链表的建立和删除,基本了解了线性表的逻辑结构和链式存储结构,掌握了单链表的基本算法,使我受益匪浅。在调试程序的过程中,遇见了一系列的问题,后来在同学的帮助下,修改了几个语句后,终于把它给调试出来了。有时候一个标点符号的问题就可能导致程序无法运行。所以在分析调试程序的时候一定要仔细。 附加程序代码: 1、调试之后的程序如下(其中蓝色字体部分为修改过的): #include"stdio.h" #include"string.h" #include"stdlib.h" #include"ctype.h" typedef struct node //定义结点 { char data[10]; //结点的数据域为字符串 struct node *next; //结点的指针域 }ListNode; typedef ListNode * LinkList; // 自定义LinkList单链表类型 LinkList CreatListR1(); //函数,用尾插入法建立带头结点的单链表ListNode *LocateNode(); //函数,按值查找结点
. 实验一、单链表的插入和删除 一、目的 了解和掌握线性表的逻辑结构和链式存储结构,掌握单链表的基本算法及相关的时间性能分析。 二、要求: 建立一个数据域定义为字符串的单链表,在链表中不允许有重复的字符串;根据输入的字符串,先找到相应的结点,后删除之。 三、程序源代码 #include"stdio.h" #include"string.h" #include"stdlib.h" #include"ctype.h" typedef struct node //定义结点 { char data[10]; //结点的数据域为字符串 struct node *next; //结点的指针域 }ListNode; typedef ListNode * LinkList; // 自定义LinkList单链表类型 LinkList CreatListR1(); //函数,用尾插入法建立带头结点的单链表
ListNode *LocateNode(); //函数,按值查找结点 void DeleteList(); //函数,删除指定值的结点void printlist(); //函数,打印链表中的所有值 void DeleteAll(); //函数,删除所有结点,释放内存 //==========主函数============== void main() { char ch[10],num[10]; LinkList head; head=CreatListR1(); //用尾插入法建立单链表,返回头指针printlist(head); //遍历链表输出其值 printf(" Delete node (y/n):");//输入“y”或“n”去选择是否删除结点scanf("%s",num); if(strcmp(num,"y")==0 || strcmp(num,"Y")==0){ printf("Please input Delete_data:"); scanf("%s",ch); //输入要删除的字符串 DeleteList(head,ch); printlist(head); } DeleteAll(head); //删除所有结点,释放内存 } //==========用尾插入法建立带头结点的单链表
————————————————————————————————————————————————————————————————————共有三套系统。。对排序算法的效率比较。。———————————————————————————————————————————————————————————————————— 第一个 008#include 数据结构作业: 计科1301 张睿算法目的:实现在一个线性单链表中插入一个新的元素 设计思路:构建一个线性单链表,获得头指针。输入想要插入新元素的位置,和想要插入的元素。通过头指针找到相应位置,插入元素,输出插入了新元素的链表。 设计方案: 1、单链表的类型定义: typedef int ElemType; typedef int Status; typedef struct LNode{ ElemType data; struct LNode *next; }LNode,*LinkList; 2、构建单链表: void creatlist(LinkList &L) { int x,k; LinkList p; printf("输入想要插入的链表的长度:\n"); scanf("%d",&x); L=(LinkList)malloc(sizeof(LNode)); L->next=NULL; printf("输入%d个元素:",x); for(k=x;k>0;--k) { p=(LinkList)malloc(sizeof(LNode)); scanf("%d",&p->data); p->next=L->next; L->next=p; } } 3、插入新元素: Status ListINsert_L(LinkList &L,int i,ElemType &e) {LinkList p,s; p=L; int j=0; while(p&&j 单链表的插入和删除实验报告 一、目的: 了解和掌握线性表的逻辑结构和链式存储结构,掌握单链表的基本算法及相关的时间性能分析。 二、要求: 建立一个数据域定义为字符串的单链表,在链表中不允许有重复的字符串;根据输入的字符串,先找到相应的结点,后删除之。 三、实验内容: 1、分析、理解程序。 程序的主要功能是实现对数据域为字符串的单链表的建立、查找、删除、插入和浏览。 其中链表的建立为头插入法。 链表建立示意图: (a)、删除hat: (b)、插入charu: 2、修改程序: 1)增加插入结点的功能。 如在jat后插入charu,程序运行结果为: 2)将建立链表的方法改为头插入法。 程序源代码: ===================main.cpp===================== #include LinkList L; L=CreateList(); //用尾插入法建立单链表,返回头指针 PrintList(L); //遍历链表输出其值 printf(" Delete node (y/n):"); //输入"y"或"n"去选择是否删除结点 scanf("%s",num); if(strcmp(num,"y")==0 || strcmp(num,"Y")==0) { printf("Please input Delete_data:"); scanf("%s",ch); //输入要删除的字符串 DeleteList(L,ch); PrintList(L); } printf("the position after:"); scanf("%s",ch1); InsertList(L,ch1); PrintList(L); FreeAll(L); //删除所有结点,释放内存 } ===================linkList.cpp===================== #include "linkList.h" #include 单链表的定义及基本操作 一、实验目的、意义 (1)理解线性表中带头结点单链表的定义和逻辑图表示方法。 (2)熟练掌握单链表的插入,删除和查询算法的设计与实现。 (3)根据具体问题的需要,设计出合理的表示数据的链表结构,并设计相关算法。 二、实验内容及要求 说明1:本次实验中的链表结构均为带头结点的单链表。 说明2: 学生在上机实验时,需要自己设计出所涉及到的函数,同时设计多组输入数据并编写主程序分别调用这些函数,调试程序并对相应的输出作出分析;修改输入数据,预期输出并验证输出的结果,加深对有关算法的理解。 具体要求: 建立单链表,完成链表(带表头结点)的基本操作:建立链表、插入、删除、查找、输出;其它基本操作还有销毁链表、将链表置为空表、求链表的长度、获取某位置结点的内容、搜索结点。 三、实验所涉及的知识点 数据结构、C语言语法函数、结构体类型指针、单链表(建表、初始化链表、求表长、插入、删除、查询算法)等。 四、实验结果及分析 (所输入的数据及相应的运行结果,运行结果要有提示信息,运行结果采用截图方式给出。) 五、总结与体会 (调试程序的心得与体会,若实验课上未完成调试,要认真找出错误并分析原因等。) 调试程序时,出现了许多错误。如:结构体类型指针出错,忽略了释放存储空间,对头插法建表、尾插法建表不熟悉等。另外还有一些语法上的错误。由于对所学知识点概念模糊,试验课上未能完成此次上机作业。后来经过查阅教材,浏览网页等方式,才完成试验。这次试验出现错误最重要的原因就是对课本知识点理解不深刻以及编写代码时的粗心。以后要都去练习、实践,以完善自己的不足。 六、程序清单(包含注释) //单链表 实验报告 课程名称数据结构 姓名 学号 专业班级 指导教师 目录 第二章线性表的查找、插入、删除 (1) 1.1顺序表的查找 (1) 1.2顺序表的插入 (2) 1.3顺序表的删除 (4) 单链表的建立、插入、删除 (6) 2.1 单链表的建立(尾插法) (6) 2.2 单链表的插入 (8) 2.3 单链表的删除 (10) 第三章栈 (14) 3.1链栈 (14) 3.2 顺序栈 (16) 3.3队列 (18) 3.4杨辉三角 (20) 第四章串 (23) 4.1字符串的建立 (23) 4.2顺序串的插入 (25) 1.线性表的查找、插入、删除 1.1顺序表的查找 程序: #include 1 数据结构课程设计 算法分析:搜索算法效率比较 专业 Xxxx 学生姓名 xxxx 班级 xxxxx 学 号 xxxxxxxxxxx 目录 1 设计题目 (1) 2 设计分析 (2) 3 设计实现 (3) 4测试方法 (6) 5测试结果 (7) 6 设计小结 (7) 1.设计题目 给定一个已排序的由N个整数组成的数列{0,1,2,3,……,N-1},在该队列中查找指定整数,并观察不同算法的运行时间。 考虑两类算法:一个是线性搜索,从某个方向依次扫描数列中各个元素;另一个是二叉搜索法。 要完成的任务是: 分别用递归和非递归实现线性搜索; 分析最坏情况下,两个线性搜索算法和二叉搜索算法的复杂度; 测量并比较这三个方法在N=100,500,1000,2000,4000,6000,8000,10000时的性能。 3 2.设计分析 5 在实际测试中,当程序运行时间太快,会无法获得实际运行时间。为了避免这种情 况,可以将同一操作运行K 遍,得到1秒以上的时间,再将结果除以重复次数K 得到平均时间。若单重循环还不能达到目的,可用多重嵌套循环解决。 3 设计实现 #include 单链表的基本操作 #include r->next=p->next; p->next=r; } void puter(linklist linker) { linklist p; p=linker->next; while(p!=NULL) { printf("%c ",p->ch); p=p->next; } } void delet(linklist head ,int i) { int j=0; linklist r,p; p=head->next; while(p&&j 一,常用推荐系统算法总结1、Itemcf (基于商品的协同过滤) 这个算法是cf中的一种,也是当今很多大型网站都在采用的核心算法之一。对于商城网站(以Amazon为代表,当然也包括京东那种具有搞笑特色的推荐系统在内),影视类推荐,图书类推荐,音乐类推荐系统来说,item的增长速度远不如user的增长速度,而且item之间的相似性远不如user之间的相似性那么敏感,所以可以在离线系统中将item的相似度矩阵计算好,以供线上可以近乎即时地进行推荐。因为这种方法靠的是item之间的相关性进行推荐,所以推荐的item一般都和喜欢的item 内容或者特性高度相似,很难推荐出用户潜在喜欢的item,多样性也比较差。 2、Usercf (基于用户的协同过滤) 这个是cf中的另外一种,它的主要特色是可以发现和用户具有同样taste的人,有句俗话叫做观其友知其人,大概也是这个道理吧。找到用户的相似用户,通过相似用户喜欢的item推荐给该用户。因为用户的相似用户群还是比较敏感的,所以要频繁地计算出用户的相似用户矩阵,这样的话运算量会非常大。而且这个算法往往推荐出来的item很多都是大家都喜欢的比较hot的item,有的时候它提供的结果并不是个性化,反而成了大众化的推荐了。用这种算法的web应用一般都是item更新频繁,比如提供资讯类服务的应用(以“指阅”为代表的),或者笑话类推荐(以“冷笑话精选”为代表的)。当然这种算法的一个中间产物-----用户相似度矩阵是一个很有用的东西,社交类的网站可以利用这个中间产物来为用户提供相同品位的好友推荐。 3、Content_based(基于内容的推荐) 基于内容的推荐,很大程度上是在进行文本挖掘。web应用提供的内容或者爬取的内容在推给用户之前可以做一些挖掘,比如资讯类的应用,将抓取到的资讯,通过文本分析那一套算法提取出每篇资讯的关键词,以及统计频次和逆向文档频率来聚类或者笨一点地话计算出资讯的相似度矩阵,即共同的key words越多,两篇资讯的相似度越高。当你的用户很少很少,你的显式反馈数据非常非常少的时候,你可以根据用户的浏览或者搜索等等各种行为,来给用户进行推荐。再猥琐一点的话,你可以在用户刚刚注册好你的应用的时候,给他一些提问,比如让他输入一些感兴趣的话题啊,或者对以前看过的电影打分什么的。(当然这些电影都是你从各个簇中随机选取的,要足够多样性)这个算法它好就好在,不需要拿到用户--项目的评分矩阵,只需要知道用户喜欢什么,就可以很快速地推荐给用户十分相关的item。这个算法需要每天都要根据你抓取的资讯,不断地计算item之间的相似性。这个算法有个好处在于可以从容应对上面的两个算法其实都很难应对的问题,就是如果你想推出一个新的item,因为没有一个人有对这个new item的评分,所以上述的两个算法不可能推荐新的东西给你,但你可以用基于内容的算法将新的item计算出它属于哪个类,然后时不时地推出你的新item,这点对于商城尤其重要。 4、Knn(邻近算法) K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k 个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法 单链表的建立查找插入删除 数学与计算机学院计算机系实验报告 课程名称:数据结 构 年级:2011 实验成绩: 指导教师:黄襄念姓名: abraham 实验教室:6A-412 实验名称:单链表的建立/查找/插入/删除学号:实验日期: 2012/12/16 实验序号:实验1 实验时间:6:40 —9:50 实验学时:4 撰写说明:填写上面相关栏目,须作相应修改。 仔细阅读:最后“六、提交文档要求”有关说明。 一、实验目的 1.熟悉掌握链表的创建、链表的常用算法:如查找节点,删除节点,插 入节点等等。 二、实验环境 1. 操作系统:Windows XP 2. 开发软件:VC++6.0 三、实验内容 ●程序功能 本程序完成了以下功能: 1.可以逐个添加英文字到链中。 2.可以删除链中的任意一元素而保持其他元素整体不变。 3.可以查找链表中的任意一个元素,只要输入该元素在链表中 的位置,就可以查找到该元素。 4.可以在该链表中插入任意一个元素不改变整体的顺序,输入 你要插入的位置即可。 ●数据结构 本程序中使用的数据结构(若有多个,逐个说明): 1.它的优缺点 1)能将物理地址散乱的链接在一起,更好的利用空间,可 以动态的申请空间,如使用数组未必能申请到连续的空间但是用链表就可以解决这个问题。 2)能快速的删除节点,和增添节点。 2.逻辑结构图 3.存储结构图Head m 开始 创建链插 入 节 删 除 节 查 找 节结束 Num Num 4.存储结构的C/C++ 语言描述 typedef struct node { char data; struct node *next; }link; ●算法描述(结合流程图或伪代码描述算法,若无可略) 本程序中采用的算法(若有多个,逐个说明) 1.算法名称:创建链表 2.算法原理或思想 通过申请一个结构体指针,在用结果体指针申请一个空间,在输入信息后用前一个节点的Next指针将增加的结点与前面的结点链接,如此重复操作,就形成一个链表。 3.算法特点(优缺点,与可选或同类算法作对比) 与数组相比较,是不连续的,它能随意的添加结点你需要多少就添加多少不会浪费多余的空间也不用提前去预测需要多少空间而其他的要考虑通用性,就必须申请较大的空间,而造成空间的浪费。 ●程序说明 1.系统流程图(各个函数或类的调用流程图) 《数据结构》课程实验 实验报告 题目:内部排序算法效率比较平台的设计与实现 专业:计算机科学与技术 班级: 姓名: 学号: 完成日期: 一、试验内容 各种内部排序算法的时间复杂度分析结果只给出了算法执行时间的阶,或大概执行时间。设计和实现内部排序算法效率比较平台,通过随机的数据比较各算法的关键字比较次数和关键字移动次数,以取得直观的感受。 二、试验目的 掌握多种排序方法的基本思想,如直接插入、冒泡、简单选择、快速、堆、希尔排序等排序方法,并能够用高级语言实现。 三、源程序代码 #include #include for(j=le-1;j>i;j--){ bj=bj+1;q=strcmp(b[i].key,b[j].key); if(q==1){ a=b[i]; b[i]=b[j]; b[j]=a; jh=jh+3; }; }; }; cout<<"冒泡法:"<单链表插入新元素
单链表的插入和删除实验报告
单链表的定义及其基本操作技巧
数据结构线性表单链表的查找,插入,删除
【数据结构】搜索算法效率比较
单链表的建立及插入删除操作-c语言
常用系统算法总结及性能比较
单链表的建立查找插入删除
数据结构实验排序算法效率比较平台
相关主题
文本预览