linux下可执行文件分析
- 格式:doc
- 大小:123.50 KB
- 文档页数:14
浅析Linux下core文件当我们的程序崩溃时,内核有可能把该程序当前内存映射到core文件里,方便程序员找到程序出现问题的地方。
最常出现的,几乎所有C程序员都出现过的错误就是“段错误”了。
也是最难查出问题原因的一个错误。
下面我们就针对“段错误”来分析core文件的产生、以及我们如何利用core文件找到出现崩溃的地方。
何谓core文件当一个程序崩溃时,在进程当前工作目录的core文件中复制了该进程的存储图像。
core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。
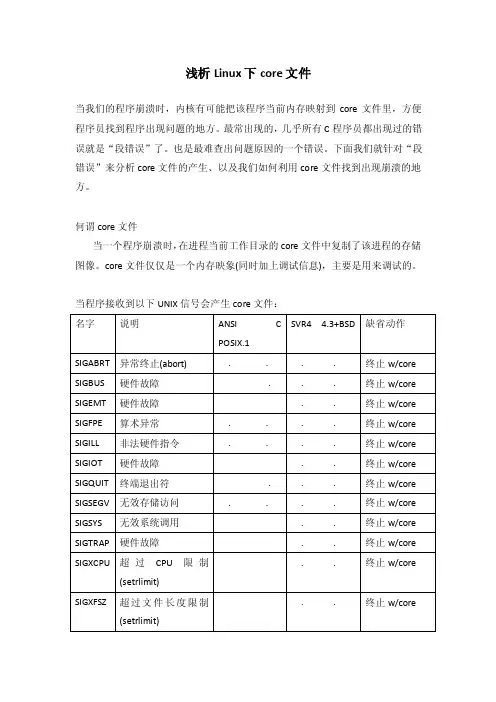
当程序接收到以下UNIX信号会产生core文件:在系统默认动作列,“终止w/core”表示在进程当前工作目录的core文件中复制了该进程的存储图像(该文件名为core,由此可以看出这种功能很久之前就是UNIX功能的一部分)。
大多数UNIX调试程序都使用core文件以检查进程在终止时的状态。
core文件的产生不是POSIX.1所属部分,而是很多UNIX版本的实现特征。
UNIX第6版没有检查条件(a)和(b),并且其源代码中包含如下说明:“如果你正在找寻保护信号,那么当设置-用户-ID命令执行时,将可能产生大量的这种信号”。
4.3 + BSD 产生名为core.prog的文件,其中prog是被执行的程序名的前1 6个字符。
它对core文件给予了某种标识,所以是一种改进特征。
表中“硬件故障”对应于实现定义的硬件故障。
这些名字中有很多取自UNIX早先在DP-11上的实现。
请查看你所使用的系统的手册,以确切地确定这些信号对应于哪些错误类型。
下面比较详细地说明这些信号。
SIGABRT 调用abort函数时产生此信号。
进程异常终止。
SIGBUS 指示一个实现定义的硬件故障。
SIGEMT 指示一个实现定义的硬件故障。
EMT这一名字来自PDP-11的emulator trap 指令。
SIGFPE 此信号表示一个算术运算异常,例如除以0,浮点溢出等。

Linux下如何查找可执⾏⽂件Linux下的可执⾏⽂件Linux下如何查找可执⾏⽂件,作为⼀个Linux⼩菜刚刚有了这个问题,在windows中,可以通过后缀名判断是否是可执⾏⽂件,⽐如.exe,.bat等是可执⾏⽂件,但是在Linux下呢?Linux下不能简单根据⽂件后缀判断是否可执⾏。
linux下判断⼀个⽂件是否可执⾏,关键看是否有可执⾏权限,⽐如:在终端中输⼊:,会列出类似于下的列表:-rwxrwxr-x 1 bingyue bingyue 48141 Jul 17 02:50 redis-trib.rb*-rw-rw-r-- 1 bingyue bingyue 2163 Aug 5 23:34 release.cdrwxrwxr-x 2 bingyue bingyue 4096 Jul 22 20:03 Documents以下⾯输出为例,下划线区域说明了⽂件的权限,包括可读、可写、可执⾏等等。
10个字符确定不同⽤户能对⽂件⼲什么:第⼀个字符代表⽂件(-)、⽬录(d),链接(l)其余字符每3个⼀组(rwx),读(r)、写(w)、执⾏(x),分别说明⽂件所有者(User)、⽂件所有者所在的⽤户组其他⽤户(Group)、其他组⽤户(Others)对该⽂件拥有的权限。
第⼀组rwx:⽂件所有者的权限是读、写和执⾏第⼆组rwx:与⽂件所有者同⼀组的⽤户的权限是读、写和执⾏第三组r-x:不与⽂件所有者同组的其他⽤户的权限是读和执⾏,不能写另外有部分⽂件也可以通过后缀名判断,⽐如redhat中,凡是.rpm格式的都能在redhat中执⾏,debian中.deb格式的在debianlinux中能直接执⾏。
如何查找可执⾏⽂件使⽤ls -F|grep "*"Ubuntu下也可以使⽤ll | grep "*"ll不是linux下⼀个基本的命令,可以认为是ls -l的⼀个别名。

操作系统第⼆次实验报告——Linux创建进程及可执⾏⽂件结构分析0 个⼈信息张樱姿201821121038计算18121 实验⽬的熟练Linux创建进程fork操作。
2 实验内容在服务器上⽤VIM编写⼀个程序:⼀个进程创建两个⼦进程。
查看进程树查看进程相关信息3 实验报告 3.1编写程序创建两个⼦进程1 #include<sys/types.h>2 #include<stdio.h>3 #include<unistd.h>45int main(){6 pid_t cpid1 = fork(); //创建⼦进程178if(cpid1<0){9 printf("fork cd1 failed\n");10 }11else if(cpid1==0){12 printf("Child1:pid: %d, ppid: %d\n",getpid(),getppid());13 }14else{15 pid_t cpid2 = fork(); //创建⼦进程216if(cpid2<0){17 printf("fork cd2 failed\n");18 }19else if(cpid2==0){20 printf("Child2:pid: %d, ppid: %d\n",getpid(),getppid());21 }22else{23 printf("Parent: pid :%d\n",getpid());24 }25 }26 }编译运⾏后的结果:3.2打印进程树 添加sleep函数以挂起进程,⽅便打印进程树:1 #include<sys/types.h>2 #include<stdio.h>3 #include<unistd.h>45int main(){6 pid_t cpid1 = fork();78if(cpid1<0){9 printf("fork cd1 failed\n");10 }11else if(cpid1==0){12 printf("Child1:pid: %d, ppid: %d\n",getpid(),getppid());13 sleep(30); //挂起30秒14 }15else{16 pid_t cpid2 = fork();17if(cpid2<0){18 printf("fork cd2 failed\n");19 }20else if(cpid2==0){21 printf("Child2:pid: %d, ppid: %d\n",getpid(),getppid());22 sleep(30); //挂起30秒23 }24else{25 printf("Parent: pid :%d\n",getpid());26 sleep(60); //挂起60秒27 }28 }29 }pstree -p pid #打印进程树 3.3 解读进程相关信息 3.3.1 解释执⾏ps -ef后返回结果中每个字段的含义 ps -ef输出格式 :UID PID PPID C STIME TTY TIME CMDUID: User ID,⽤户ID。

linux下的三种可执⾏⽂件格式的⽐较linux下的三种可执⾏⽂件格式的⽐较本⽂讨论了 UNIX/LINUX 平台下三种主要的可执⾏⽂件格式:a.out(assembler and link editor output 汇编器和链接编辑器的输出)、COFF(Common Object File Format 通⽤对象⽂件格式)、ELF(Executable and Linking Format 可执⾏和链接格式)。
⾸先是对可执⾏⽂件格式的⼀个综述,并通过描述 ELF ⽂件加载过程以揭⽰可执⾏⽂件内容与加载运⾏操作之间的关系。
随后依此讨论了此三种⽂件格式,并着重讨论 ELF ⽂件的动态连接机制,其间也穿插了对各种⽂件格式优缺点的评价。
最后对三种可执⾏⽂件格式有⼀个简单总结,并提出作者对可⽂件格式评价的⼀些感想。
可执⾏⽂件格式综述相对于其它⽂件类型,可执⾏⽂件可能是⼀个操作系统中最重要的⽂件类型,因为它们是完成操作的真正执⾏者。
可执⾏⽂件的⼤⼩、运⾏速度、资源占⽤情况以及可扩展性、可移植性等与⽂件格式的定义和⽂件加载过程紧密相关。
研究可执⾏⽂件的格式对编写⾼性能程序和⼀些⿊客技术的运⽤都是⾮常有意义的。
不管何种可执⾏⽂件格式,⼀些基本的要素是必须的,显⽽易见的,⽂件中应包含代码和数据。
因为⽂件可能引⽤外部⽂件定义的符号(变量和函数),因此重定位信息和符号信息也是需要的。
⼀些辅助信息是可选的,如调试信息、硬件信息等。
基本上任意⼀种可执⾏⽂件格式都是按区间保存上述信息,称为段(Segment)或节(Section)。
不同的⽂件格式中段和节的含义可能有细微区别,但根据上下⽂关系可以很清楚的理解,这不是关键问题。
最后,可执⾏⽂件通常都有⼀个⽂件头部以描述本⽂件的总体结构。
相对可执⾏⽂件有三个重要的概念:编译(compile)、连接(link,也可称为链接、联接)、加载(load)。
源程序⽂件被编译成⽬标⽂件,多个⽬标⽂件被连接成⼀个最终的可执⾏⽂件,可执⾏⽂件被加载到内存中运⾏。

Linux系统下的ELF文件分析摘要:随着linux系统的发展,elf成了十分重要的可执行文件格式。
本文介绍了eIf文件的格式,并在此基础上分析出eIf文件的特性。
关键词:elf文件:平台相关PIC1.引言ELF(Executable and Linkable Format)IN可执行连接文件格式.是LinuxSVR4和Solaris2,0默认的目标文件格式,目前标准接口委员会TIS已将ELF标准化为一种可移植的目标文件格式,运行于32一bitIntel体系微机上,可与多种操作系统兼容。
分析elf文件有助于理解一些重要的系统概念,例如程序的编译和链接,程序的加载和运行等2.ELF文件格式2.1 ELF文件的类型ELF文件主要有三种类型(1)可重定位文件包含了代码和数据.可与其它ELF文件建立一个可执行或共享的文件:(2)可执行文件时可直接执行的程序:(3)共享目标文件包括代码和数据,可以在两个地方链接。
第一,连接器可以把它和其它可重定位文件和共享文件一起处理以建立另一个ELF文件;第二,动态链接器把它和一个可执行文件和其它共享文件结合在一起建立一个进程映像。
2.2 ELF文件的组织ELF文件参与程序的连接(建立一个程序)和程序的执行(运行一个程序),编译器和链接器将其视为节头表(section headertable)描述的一些节(section)的集合,而加载器则将其视为程序头表(program header table)描述的段(segment)的集合,通常一个段可以包含多个节。
可重定位文件都包含一个节头表.可执行文件都包含一个程序头表。
共享文件两者都包含有。
为此,ELF文件格式同时提供了两种看待文件内容的方式,反映了不同行为的不同要求。
2.3文件头EIF头在在程序的开始部位,作为引路表描述整个ELF的文件结构,其信息大致分为四部分:一是系统相关信息,二是目标文件类型,三是加载相关信息,四是链接相关信息其中系统相关信息包括elf文件魔数(标识elf文件),平台位数,数据编码方式,elf头部版本,硬件平台e machine,目标文件版本e_version,处理器特定标志e ftags:这些信息的引入极大增强了elf文件的可移植性使交叉编译成为可能。

Linux命令行中的文件比较和合并技巧在Linux命令行中,文件比较和合并是常见的操作。
通过使用一些特定的命令和技巧,可以方便地进行文件比较和合并,以满足不同的需求。
本文将介绍一些常用的Linux命令行中的文件比较和合并技巧。
1. 文件比较技巧:1.1 文件内容比较:使用diff命令可以比较两个文件的内容差异。
通过在命令行中输入以下命令,可以列出两个文件之间的差异:```bashdiff file1.txt file2.txt```1.2 忽略空格和空行:有时候文件中的空格和空行对比较结果没有太大意义,可以使用-d参数来忽略它们,如下所示:```bashdiff -d file1.txt file2.txt```1.3 比较目录:如果需要比较两个目录下的文件差异,可以使用-d 参数结合-r参数来递归比较两个目录的文件:```bashdiff -dr dir1 dir2```2. 文件合并技巧:2.1 合并文件内容:使用cat命令可以合并多个文件的内容。
通过在命令行中输入以下命令,可以将多个文件的内容合并到一个新文件中:```bashcat file1.txt file2.txt > merged.txt```2.2 合并目录下的文件:如果需要合并一个目录下的所有文件,可以使用find命令结合cat命令来实现。
以下命令会将目录dir下所有的txt文件内容合并到一个新文件中:```bashfind dir -name "*.txt" -exec cat {} + > merged.txt```2.3 合并有序文件:如果需要将多个有序的文件按照顺序合并,可以使用sort命令结合cat命令来实现。
以下命令会按照文件名的顺序将文件内容合并到一个新文件中:```bashcat $(ls -v file*.txt) > merged.txt```3. 文件对比和合并工具:除了基本的命令行工具外,还有一些强大的文件对比和合并工具可供使用:3.1 Meld:Meld是一款简单易用的图形化文件比较和合并工具。

linux obj dump 用法Linux objdump 用法详解Linux objdump 是一个非常强大的命令行工具,用于分析目标文件或可执行文件,可以显示文件的各个节(section)的详细信息,如代码段、数据段等。
本篇文章将详细介绍objdump 命令的使用方法,从基础到高级逐步回答。
第一步:安装objdump在Linux 系统上,objdump 命令通常属于binutils 软件包的一部分。
大多数常见的Linux 发行版都默认安装了binutils,所以无需额外安装。
如果你的系统中没有安装binutils,则可以使用以下命令来安装:bashsudo apt-get install binutils根据你使用的Linux 发行版可能不同,安装命令也会有所不同。
请根据你的系统选择正确的安装命令。
第二步:基本语法和用法objdump 命令的基本语法如下:bashobjdump [options] objfile...其中objfile 是指定要分析的目标文件或可执行文件的文件名。
options 表示objdump 命令的选项参数,我们将在后面的内容中详细介绍。
以下是一些常用的选项参数:- `-d` 或`disassemble`:显示反汇编代码。
- `-s` 或`full-contents`:显示所有节的内容。
- `-t` 或`syms`:显示符号表信息。
- `-h` 或`section-headers`:显示所有节的头信息。
- `-r` 或`reloc`:显示重定位表。
- `-x` 或`all-headers`:显示所有头信息。
- `-l` 或`line-numbers`:显示源代码行号信息。
下面我们将逐个选项参数进行详细讲解。
- 反汇编代码(-d 或disassemble)使用`-d` 或`disassemble` 选项参数可以将目标文件或可执行文件中的机器码反汇编为可读的汇编代码。
例如,要将一个名为`test.o` 的目标文件反汇编,可以执行以下命令:bashobjdump -d test.o该命令将会输出test.o 中所有节的反汇编代码。

可执行目标文件详解可执行目标文件是计算机程序经过编译后生成的文件,在操作系统中直接可以执行的文件格式。
可执行目标文件是由机器指令、数据和符号表组成的。
机器指令是代码段中的指令,数据是数据段中的数据。
符号表中记录了程序中的各个符号的地址信息,用于链接时进行符号解析。
可执行目标文件的格式有多种,常见的有 ELF、PE、Mach-O 等。
这些不同的可执行目标文件格式在一些方面有所不同,但是它们都包含以下几个部分:1. 标头:包含了一些基本属性,如程序入口地址、段的数量、各段的偏移和大小等等。
2. 代码段:里面存储了程序的机器指令,是可执行程序的核心部分。
3. 数据段:里面存储了程序需要的数据,如字符串、数组、结构等等。
4. 符号表:记录程序中的符号,包括函数名、变量名称等等,用于链接时进行符号的解析。
5. 重定位表:记录程序中需要重定位的地址信息,是实现程序重定位的重要数据。
6. 调试信息:包含了程序的调试信息,如变量的值、函数的调用栈等等。
在 Linux 下,可执行目标文件的格式一般是 ELF (Executable and Linkable Format)。
ELF 文件的结构相对简单,易于使用,常用的工具有 objdump、nm、readelf 等等。
这些工具可以帮助开发者查看和调试可执行目标文件,对于检测程序中可能存在的安全漏洞、调试程序等等都是非常有用的工具。
在 Windows 下,可执行目标文件的格式一般是 PE (Portable Executable)格式。
PE 文件的结构相对复杂,但是它支持 Windows 下的多种可执行文件(如 .dll 文件等),是 Windows 下的主要可执行目标文件格式。
在 macOS 下,可执行目标文件的格式一般是 Mach-O (Mach object)格式。
Mach-O 文件的结构与 ELF 不同,但是它支持 macOS 下的各种可执行文件(如 .dylib 文件、.app 文件等),是 macOS 下的主要可执行目标文件格式。

Linux下分析bin⽂件的10种⽅法这世界有10种⼈,⼀种⼈懂⼆进制,另⼀种⼈不懂⼆进制。
——鲁迅⼤家好,我是良许。
⼆进制⽂件是我们⼏乎每天都需要打交道的⽂件类型,但很少⼈知道他们的⼯作原理。
这⾥所讲的⼆进制⽂件,是指⼀些可执⾏⽂件,包括你天天要使⽤的 Linux 命令,也是⼆进制⽂件的⼀种。
Linux 系统给我们提供了⾮常多⽤于分析⼆进制⽂件的⼯具,不管你在 Linux 下从事的是何种⼯作,知道这些⼯具也会让你对你的系统更加了解。
在本⽂中,将介绍⼏种最常⽤的⽤于分析⼆进制⽂件的⼯具及命令,这些⼯具在⼤部分发⾏版⾥可以直接使⽤,如果不能直接⽤的话,可以⾃⾏安装。
filefile 命令⽤于分析⽂件的类型。
如果你需要分析⼆进制⽂件,可以⾸先使⽤ file 命令来切⼊。
我们知道,在 Linux 下,⼀切皆⽂件,但并不是所有的⽂件都具有可执⾏性,我们还有各种各样的⽂件,⽐如:⽂本⽂件,管道⽂件,链接⽂件,socket⽂件,等等。
在对⼀个⽂件进⾏分析之前,我们可以⾸先使⽤ file 命令来分析它们的类型。
当然除此之外,我们还可以看到⼀些其它信息。
$ file /bin/pwd/bin/pwd: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=0d264bacf2adc568f0e21cbcc9576df434c44380, strippedlddldd 命令可以⽤于分析可执⾏⽂件的依赖。
我们使⽤ file 命令来分析⼀个可执⾏⽂件的时候,有时候可以看到输出中有dynamically linked这样的字眼。
这个是啥意思呢?⼤部分程序,都会使⽤到第三⽅库,这样就可以不⽤重复造轮⼦,节约⼤量时间。
最简单的,我们写C程序代码的话,肯定会使⽤到libc或者glibc库。

Pyinstaller打包详解---⽣成windows、linux下的整包可执⾏⽂件1、原理及作⽤:pyinstaller⾃⾝打包的流程:读取编写好的python脚本,分析其中调⽤的模块和库,然后收集这些⽂件的副本(包括Python的解释器)。
最后把副本与脚本,可执⾏⽂件等放在⼀个⽂件夹中,或者可选的封装在⼀个可执⾏⽂件中。
我们可以将⾃⼰的python代码打包成⼀个可执⾏⽂件。
起到代码保护和封装的作⽤。
2、打包流程:简略描述Pyinstall的打包流程:①下载好Pyinstaller之后,②拷贝上述spec⽂件并增删⾃⼰的⼯程代码路径(或使⽤pyi-makespec main.py命令⽣成.spec⽂件)③执⾏ pyinstaller main.spec④在dist中,检验⽣成的 main可执⾏⽂件2-1、安装pyinstallerpip install pyinstaller2-2、拷贝main.spec⽂件我们⽤main.spec⽂件记录打包需要的⽂件依赖等,pyinstaller参数的本质可认为是 .spec⽂件中的配置属性。
main.spec⽂件可按照类型直接在internet中拷贝模板即可,之后进⾏修改。
(下⽂有模板⽰例)以camera_stress_test_tool_main⼯具为例:将下⾯模板的camera_stress_test_tool_main.spec⽂件拷贝⾄和 main.py同⽬录下(亦可⽤pyi-makespec main.py⽣成 .spec⽂件,需注意按需使⽤参数)-F, –onefile打包⼀个单个⽂件-D, –onedir打包多个⽂件,在dist中⽣成很多依赖⽂件,适合以框架形式编写⼯具代码,我个⼈⽐较推荐这样,代码易于维护-K, –tk在部署时包含 TCL/TK-a, –ascii不包含编码.在⽀持Unicode的python版本上默认包含所有的编码.-d, –debug产⽣debug版本的可执⾏⽂件-w,–windowed,–noconsole使⽤Windows⼦系统执⾏.当程序启动的时候不会打开命令⾏(只对Windows有效)-c,–nowindowed,–console使⽤控制台⼦系统执⾏(默认)(只对Windows有效)pyinstaller -c xxxx.pypyinstaller xxxx.py –console-s,–strip可执⾏⽂件和共享库将run through strip.注意Cygwin的strip往往使普通的win32 Dll⽆法使⽤.-X, –upx如果有UPX安装(执⾏Configure.py时检测),会压缩执⾏⽂件(Windows系统中的DLL也会)(参见note)-o DIR, –out=DIR 指定spec⽂件的⽣成⽬录,如果没有指定,⽽且当前⽬录是PyInstaller的根⽬录,会⾃动创建⼀个⽤于输出(spec和⽣成的可执⾏⽂件)的⽬录.如果没有指定,⽽当前⽬录不是PyInstaller的根⽬录,则会输出到当前的⽬录下.-p DIR, –path=DIR 设置导⼊路径(和使⽤PYTHONPATH效果相似).可以⽤路径分割符(Windows使⽤分号,Linux使⽤冒号)分割,指定多个⽬录.也可以使⽤多个-p参数来设置多个导⼊路径,让pyinstaller⾃⼰去找程序需要的资源–icon=<FILE.ICO>将file.ico添加为可执⾏⽂件的资源(只对Windows系统有效),改变程序的图标 pyinstaller -i ico路径 xxxxx.py –icon=<FILE.EXE,N>将file.exe的第n个图标添加为可执⾏⽂件的资源(只对Windows系统有效)-v FILE, –version=FILE将verfile作为可执⾏⽂件的版本资源(只对Windows系统有效)-n NAME, –name=NAME可选的项⽬(产⽣的spec的)名字.如果省略,第⼀个脚本的主⽂件名将作为spec的名字camera_stress_test_tool_main.spec⽂件模板⽰例:(模板为单⽂件⽰范)# -*- mode: python ; coding: utf-8 -*-block_cipher = Nonea = Analysis(['main.py','./cfg/__init__.py','./cfg/setting.py','./comm/__init__.py','./comm/logger.py','./comm/utils.py','./handler/__init__.py','./handler/invite_handler.py','./handler/sip_parse_handler.py','./handler/subscribe_handler.py','./my_thread/__init__.py','./my_thread/alarm.py','./my_thread/audio_media.py','./my_thread/audio_media_rtp.py','./my_thread/broadcast.py','./my_thread/my_sip_epoll.py','./my_thread/timer.py','./my_thread/video_media.py','./redis_utils/__init__.py','./redis_utils/redis_keys.py','./redis_utils/redis_work.py','./__init__.py','./device.py','./std/ietf/__init__.py','./std/ietf/rfc1035.py','./std/ietf/rfc2198.py','./std/ietf/rfc2396.py','./std/ietf/rfc2617.py','./std/ietf/rfc2833.py','./std/ietf/rfc3261.py','./std/ietf/rfc3489.py','./std/ietf/rfc5658.py','./std/ietf/rfc6455.py','./std/ietf/rfc7064.py','./std/ietf/rfc7065.py','./std/itu_t/__init__.py','./std/w3c/__init__.py','./std/w3c/simplexml.py','./std/__init__.py'],pathex=['./'],binaries=[],datas=[],hiddenimports=[],hookspath=[],runtime_hooks=[],excludes=[],win_no_prefer_redirects=False,win_private_assemblies=False,cipher=block_cipher,noarchive=False)pyz = PYZ(a.pure, a.zipped_data,cipher=block_cipher)exe = EXE(pyz,a.scripts,a.binaries,a.zipfiles,a.datas,[],name='main',debug=False,bootloader_ignore_signals=False,strip=False,upx=True,upx_exclude=[],runtime_tmpdir=None,console=True )2-3、修改main.spec⽂件⼀般来说,我们需要在“Analysis”这个item中,加⼊打包的代码的路径,(此处需注意路径相关依赖,与创建spec的路径相对应,⼀般在main.py⽂件基础上找,可写绝对及相对路径)。

16测试技术学报2004年6月立映射表,缩小两个系统之间的差异。
系统的基本实现原理可概括为图l。
图l系统原理性框架3实现方案3.1程序加载加载并运行程序是Linux进程管理的一个重要部分,也是Linux和UNⅨ系统间实现二进制兼容的关键。
为了使UNⅨ可执行程序能够在Linll)【上运行,必须对Linu】【内核做相应的扩展,.使之能够兼容IMX系统的二进制文件格式,包括COFF、XOUT和ELF等。
1)COFF文件格式分析通用对象文件格式(Commono场ectFileFo咖at,COFF)是一种常用的二进制文件格式,它用于目标文件、库文件和可执行文件。
最初由UNlX跚咖mV引入并作为标准可执行程序的格式,已经广泛地应用在L刀ⅥX和Windows等操作系统上。
Lin麟内核不支持COFF格式,要实现与UNIX系统的二进制兼容,首先要解决如何正确地加载UNlX系统中cOFF格式的目标文件。
为了实现兼容,首先分析了COFF格式的可执行文件的格式。
COFF文件中共有8种数据:文件头、可选头、段落头、段数据、重定位表、行号表、符号表和字符串表。
文件头中包含[]幻数,给出COFF文件的格式。
口COFF文件中的段落数。
口时间戳,描述文件的建立时间。
口符号表在该文件中从文件头开始的的偏移量。
口符号表中符号记录的个数。
口可选头的长度,通常它的值是0。
口COFF文件的类型及文件的内容等信息。
2)UNl)(可执行文件的加载UNIX常用的文件格式有三种:ELF、COFF和xOUT,Linux内核只能识别ELF的文件格式。
在实现与uNIx二进制兼容时,要考虑如何处理后两种格式。
即使ELF格式的可执行文件,两者的格式也不完全相同。
因此,对LinuX内核中的这一部分也要做相应的修改,使之能适应于UNIX系统的ELF二进制代码。
在Linux系统中,执行一个程序时,要先创建一个进程,该进程调用eXecve()系统调用,加载和执行该程序。
MagicLinux开发入门指南(二)MagicLinux开发总部2.4 让这个新的gcc环境能够真正的工作起来编译器、连接器、程序库都创建好了,可以开始创建MagicLinux 了吧?呵呵,不行!这个新的gcc环境还没有真正工作起来呢。
不信,我们做一个实验试试。
编写一个最简单的C代码:#echo 'main(){}' > ttt.c#gcc ttt.c#readelf -l a.out看看结果,是不是有一行类似下面的内容:[Requesting program interpreter:/lib/ld-linux.so.2]这是不对的。
readelf是分析elf可执行文件(Linux下可执行文件的格式)格式的工具,-l选项是用来显示可执行文件各段头内容的,通过它可以了解一个可自行文件的依赖关系。
上面的结果表明新的gcc产生的可执行文件还是依赖于你现有系统的ld-linux.os.2,这是glibc的一部分。
这是为什么?该怎么办?问题在创建binutils是就已经作了一些解决,但是还没有完全解决。
回想一下,在安装完binutils后,还做了如下操作:#make -C ld clean#make -C ld LIB_PATH=/toolchain/lib#cp -v ld/ld-new /toolchain/bin创建了一个ld-new,而且还复制到了/toolchain/bin下,这个ld-new就是关键,执行下面操作:#mv -v /toolchain/bin/{ld,ld-old}#mv -v /toolchain/$(gcc -dumpmachine)/bin/{ld,ld-old}#mv -v /toolchain/bin/{ld-new,ld}#ln -sv /toolchain/bin/ld /toolchain/$(gcc -dumpmachine)/bin/ld这就使得接下来创建的程序都使用/toolchain/lib中的程序库了。
制作可执行的JAR文件包及jar命令详解常常在网上看到有人询问:如何把java 程序编译成 .exe 文件。
通常回答只有两种,一种是制作一个可执行的JAR 文件包,然后就可以像.chm 文档一样双击运行了;而另一种是使用JET 来进行编译。
但是JET 是要用钱买的,而且据说JET 也不是能把所有的Java 程序都编译成执行文件,性能也要打些折扣。
所以,使用制作可执行JAR 文件包的方法就是最佳选择了,何况它还能保持Java 的跨平台特性。
下面就来看看什么是JAR 文件包吧:1. JAR 文件包JAR 文件就是Java Archive File,顾名思意,它的应用是与Java 息息相关的,是Java 的一种文档格式。
JAR 文件非常类似ZIP 文件--准确的说,它就是ZIP 文件,所以叫它文件包。
JAR 文件与ZIP 文件唯一的区别就是在JAR 文件的内容中,包含了一个META-INF/MANIFEST.MF 文件,这个文件是在生成JAR 文件的时候自动创建的。
举个例子,如果我们具有如下目录结构的一些文件:==`-- test`-- Test.class把它压缩成ZIP 文件test.zip,则这个ZIP 文件的内部目录结构为:test.zip`-- test`-- Test.class如果我们使用JDK 的jar 命令把它打成JAR 文件包test.jar,则这个JAR 文件的内部目录结构为:test.jar|-- META-INF|`-- MANIFEST.MF`-- test`--Test.class2. 创建可执行的JAR 文件包制作一个可执行的JAR 文件包来发布你的程序是JAR 文件包最典型的用法。
Java 程序是由若干个 .class 文件组成的。
这些 .class 文件必须根据它们所属的包不同而分级分目录存放;运行前需要把所有用到的包的根目录指定给CLASSPATH 环境变量或者java 命令的-cp 参数;运行时还要到控制台下去使用java 命令来运行,如果需要直接双击运行必须写Windows 的批处理文件(.bat) 或者Linux 的Shell 程序。
Linux命令高级技巧使用objdump和readelf查看可执行文件信息在Linux系统中,objdump和readelf是两个常用的命令,用于查看可执行文件(二进制文件)的详细信息。
通过使用这两个命令,我们可以深入了解可执行文件的结构、函数、符号表等相关信息,有助于我们进行程序分析和调试。
本文将介绍如何使用objdump和readelf命令来查看可执行文件的高级技巧。
一、使用objdump查看可执行文件信息objdump命令是GNU Binutils工具集中的一个重要组成部分,它可以用于反汇编可执行文件,显示可执行文件的各个节(section)的内容。
下面是一些常用的objdump命令选项:1. objdump -h <可执行文件名>:显示可执行文件的节表信息。
该命令会列出可执行文件中各个节的起始偏移地址、大小等信息。
2. objdump -S <可执行文件名>:显示可执行文件的源代码和汇编代码。
该命令会将可执行文件中的机器码和源代码进行关联,并以汇编代码的形式显示出来,便于分析。
3. objdump -t <可执行文件名>:显示可执行文件的符号表。
符号表中包含了可执行文件中定义和引用的函数、变量等符号信息。
除了上述常用选项外,objdump还提供了很多其他有用的选项,可以根据实际需求进行选择。
二、使用readelf查看可执行文件信息readelf是GNU Binutils工具集中的另一个重要工具,它可以用于查看和分析可执行文件的各个节的信息,以及可执行文件的头部信息。
下面是一些常用的readelf命令选项:1. readelf -h <可执行文件名>:显示可执行文件的头部信息。
头部信息包含了可执行文件的类型、入口地址、节表偏移等重要信息。
2. readelf -S <可执行文件名>:显示可执行文件的节表信息。
节表信息包含了可执行文件中各个节的起始地址、大小、访问属性等详细信息。
Linux可执行文件格式•Elf 也就是“Executable and Linking Format.”•Elf 起源于Unix,经改进应用于FreeBSD和Linux等现有类Unix操作系统。
•微软的PE格式也学习了ELF格式的优点。
•ELF文档服务于在不同的操作系统上目标文件的创建或者执行文件的开发。
它分以下三个部分:•“目标文件”描述了ELF目标文件格式三种主要的类型。
•“程序装载和动态连接”描述了目标文件的信息和系统在创建运行时程序的行为。
•“C 语言库”列出了所有包含在libsys中的符号、标准的ANSIC和libc的运行程序,还有libc运行程序所需的全局的数据符号。
三种主要类型:•一个可重定位文件(relocatable file)保存着代码和适当的数据,用来和其他的目标文件一起来创建一个可执行文件或者是一个共享文件。
•一个可执行文件(executable file)保存着一个用来执行的程序,该文件指出了exec(BA_OS)如何来创建程序进程映象。
•一个共享目标文件(shared object file)保存着代码和合适的数据,用来被下面的两个链接器链接。
第一个是链接编辑器,可以和其他的重定位和共享目标文件来创建另一个目标文件。
第二个是动态链接器,联合一个可执行文件和其他的共享目标文件来创建一个进程映象。
ELF头•#define EI_NIDENT 16•typedef struct {•unsigned char e_ident[EI_NIDENT];•Elf32_Half e_type;•Elf32_Half e_machine;•Elf32_Word e_version;•Elf32_Addr e_entry;•Elf32_Off e_phoff;•Elf32_Off e_shoff;•Elf32_Word e_flags;•Elf32_Half e_ehsize;•Elf32_Half e_phentsize;•Elf32_Half e_phnum;•Elf32_Half e_shentsize;•Elf32_Half e_shnum;•Elf32_Half e_shstrndx;•} Elf32_Ehdr;节•一个目标文件的节头表可以让我们定位所有的节。
Linux命令高级技巧使用ldd命令进行动态链接库依赖查看在Linux系统中,ldd命令是一种非常有用的工具,它可以帮助我们查看可执行文件或共享库文件所依赖的动态链接库。
在本文中,我们将探讨ldd命令的用法和一些高级技巧。
一、ldd命令简介ldd是Linux系统中的一个工具,用于打印可执行文件或共享库文件所依赖的动态链接库。
该命令可以帮助我们了解一个程序在运行时所需要的动态链接库文件,便于分析和解决依赖问题。
二、ldd命令的基本用法要使用ldd命令,只需在终端中输入ldd,后跟要查看依赖的可执行文件或共享库文件的路径。
例如,我们要查看一个可执行文件的依赖关系,可以使用以下命令:$ ldd /path/to/executable-file命令执行后,ldd将会列出该可执行文件所依赖的全部动态链接库文件的路径。
对于每个链接库文件,ldd还会显示其版本号和一些其他信息。
三、查看共享库的加载地址除了显示依赖的动态链接库文件路径外,ldd还可以显示动态链接库的加载地址。
加载地址是操作系统在运行时将二进制文件加载到内存中的地址。
在某些情况下,了解共享库的加载地址可以帮助我们调试和优化程序。
要查看共享库的加载地址,可以使用-l选项加上可执行文件或共享库文件的路径:$ ldd -l /path/to/executable-file命令执行后,ldd将会列出可执行文件或共享库文件的详细信息,包括加载地址。
四、使用ldd分析共享库依赖问题在开发和部署过程中,我们经常会遇到共享库缺失或不匹配的问题。
使用ldd命令可以帮助我们分析共享库的依赖关系,从而解决这些问题。
假设我们的程序无法启动,并显示缺少某个共享库文件。
我们可以使用ldd命令查看该程序所依赖的动态链接库文件,以确定缺失的共享库以及其路径。
例如:$ ldd /path/to/executable-file命令执行后,ldd将会列出该程序所依赖的动态链接库文件的路径。
linux下nm命令的使⽤linux下强⼤的⽂件分析⼯具 -- nm什么是nmnm命令是linux下⾃带的特定⽂件分析⼯具,⼀般⽤来检查分析⼆进制⽂件、库⽂件、可执⾏⽂件中的符号表,返回⼆进制⽂件中各段的信息。
⽬标⽂件、库⽂件、可执⾏⽂件⾸先,提到这三种⽂件,我们不得不提的就是gcc的编译流程:预编译,编译,汇编,链接。
⽬标⽂件 :常说的⽬标⽂件是我们的程序⽂件(.c/.cpp,.h)经过预编译,编译,汇编过程⽣成的⼆进制⽂件,不经过链接过程,编译⽣成指令为:gcc(g++) -c file.c(file.cpp)将⽣成对应的file.o⽂件,file.o即为⼆进制⽂件库⽂件:分为静态库和动态库,这⾥不做过多介绍,库⽂件是由多个⼆进制⽂件打包⽽成,⽣成的.a⽂件,⽰例:ar -rsc liba.a test1.o test2.o test3.o将test1.o test2.o test3.o三个⽂件打包成liba.a库⽂件可执⾏⽂件:可执⾏⽂件是由多个⼆进制⽂件或者库⽂件(由上所得,库⽂件其实是⼆进制⽂件的集合)经过链接过程⽣成的⼀个可执⾏⽂件,对应windows下的.exe⽂件,可执⾏⽂件中有且仅有⼀个main()函数(⽤户程序⼊⼝,⼀般由bootloader指定,当然也可以改),⼀般情况下,⼆进制⽂件和库⽂件中是不包含main()函数的,但是在linux下⽤户有绝对的⾃由,做⼀个包含main函数的库⽂件也是可以使⽤的,但这不属于常规操作,不作讨论。
上述三种⽂件的格式都是⼆进制⽂件。
为什么要⽤到nm在上述提到的三种⽂件中,⽤编辑器是⽆法查看其内容的(乱码),所以当我们有这个需求(例如debug,查看内存分布的时候)去查看⼀个⼆进制⽂件⾥包含了哪些内容时,这时候就将⽤到⼀些特殊⼯具,linux下的nm命令就可以完全胜任(同时还有objdump和readelf⼯具,这⾥暂不作讨论)。
怎么使⽤nm如果你对linux下的各种概念还算了解的话,就该知道⼀般linux下的命令都会⾃带⼀些命令参数来满⾜各种应⽤需求,了解这些参数的使⽤是使⽤命令的开始。
本文讨论了UNIX/LINUX 平台下三种主要的可执行文件格式:a.out(assembler and link editor output 汇编器和链接编辑器的输出)、COFF(Common Object File Format 通用对象文件格式)、ELF(Executable and Linking Format 可执行和链接格式)。
首先是对可执行文件格式的一个综述,并通过描述ELF 文件加载过程以揭示可执行文件内容与加载运行操作之间的关系。
随后依此讨论了此三种文件格式,并着重讨论ELF 文件的动态连接机制,其间也穿插了对各种文件格式优缺点的评价。
最后对三种可执行文件格式有一个简单总结,并提出作者对可文件格式评价的一些感想。
可执行文件格式综述相对于其它文件类型,可执行文件可能是一个操作系统中最重要的文件类型,因为它们是完成操作的真正执行者。
可执行文件的大小、运行速度、资源占用情况以及可扩展性、可移植性等与文件格式的定义和文件加载过程紧密相关。
研究可执行文件的格式对编写高性能程序和一些黑客技术的运用都是非常有意义的。
不管何种可执行文件格式,一些基本的要素是必须的,显而易见的,文件中应包含代码和数据。
因为文件可能引用外部文件定义的符号(变量和函数),因此重定位信息和符号信息也是需要的。
一些辅助信息是可选的,如调试信息、硬件信息等。
基本上任意一种可执行文件格式都是按区间保存上述信息,称为段(Segment)或节(Section)。
不同的文件格式中段和节的含义可能有细微区别,但根据上下文关系可以很清楚的理解,这不是关键问题。
最后,可执行文件通常都有一个文件头部以描述本文件的总体结构。
相对可执行文件有三个重要的概念:编译(compile)、连接(link,也可称为链接、联接)、加载(load)。
源程序文件被编译成目标文件,多个目标文件被连接成一个最终的可执行文件,可执行文件被加载到内存中运行。
因为本文重点是讨论可执行文件格式,因此加载过程也相对重点讨论。
下面是LINUX平台下ELF文件加载过程的一个简单描述。
1:内核首先读ELF文件的头部,然后根据头部的数据指示分别读入各种数据结构,找到标记为可加载(loadable)的段,并调用函数mmap()把段内容加载到内存中。
在加载之前,内核把段的标记直接传递给mmap(),段的标记指示该段在内存中是否可读、可写,可执行。
显然,文本段是只读可执行,而数据段是可读可写。
这种方式是利用了现代操作系统和处理器对内存的保护功能。
著名的Shellcode(参考资料17)的编写技巧则是突破此保护功能的一个实际例子。
2:内核分析出ELF文件标记为PT_INTERP 的段中所对应的动态连接器名称,并加载动态连接器。
现代LINUX 系统的动态连接器通常是/lib/ld-linux.so.2,相关细节在后面有详细描述。
3:内核在新进程的堆栈中设置一些标记-值对,以指示动态连接器的相关操作。
4:内核把控制传递给动态连接器。
5:动态连接器检查程序对外部文件(共享库)的依赖性,并在需要时对其进行加载。
6:动态连接器对程序的外部引用进行重定位,通俗的讲,就是告诉程序其引用的外部变量/函数的地址,此地址位于共享库被加载在内存的区间内。
动态连接还有一个延迟(Lazy)定位的特性,即只在"真正"需要引用符号时才重定位,这对提高程序运行效率有极大帮助。
7:动态连接器执行在ELF文件中标记为 .init 的节的代码,进行程序运行的初始化。
在早期系统中,初始化代码对应函数_init(void)(函数名强制固定),在现代系统中,则对应形式为void__attribute((constructor))init_function(void){……}其中函数名为任意。
8:动态连接器把控制传递给程序,从ELF 文件头部中定义的程序进入点开始执行。
在a.out 格式和ELF格式中,程序进入点的值是显式存在的,在COFF 格式中则是由规范隐含定义。
从上面的描述可以看出,加载文件最重要的是完成两件事情:加载程序段和数据段到内存;进行外部定义符号的重定位。
重定位是程序连接中一个重要概念。
我们知道,一个可执行程序通常是由一个含有main() 的主程序文件、若干目标文件、若干共享库(Shared Libraries)组成。
(注:采用一些特别的技巧,也可编写没有main 函数的程序,请参阅参考资料2)一个 C 程序可能引用共享库定义的变量或函数,换句话说就是程序运行时必须知道这些变量/函数的地址。
在静态连接中,程序所有需要使用的外部定义都完全包含在可执行程序中,而动态连接则只在可执行文件中设置相关外部定义的一些引用信息,真正的重定位是在程序运行之时。
静态连接方式有两个大问题:如果库中变量或函数有任何变化都必须重新编译连接程序;如果多个程序引用同样的变量/函数,则此变量/函数会在文件/内存中出现多次,浪费硬盘/内存空间。
比较两种连接方式生成的可执行文件的大小,可以看出有明显的区别。
回页首a.out 文件格式分析a.out 格式在不同的机器平台和不同的UNIX 操作系统上有轻微的不同,例如在MC680x0 平台上有6 个section。
下面我们讨论的是最"标准"的格式。
a.out 文件包含7 个section,格式如下:exec header(执行头部,也可理解为文件头部)text segment(文本段)data segment(数据段)text relocations(文本重定位段)data relocations(数据重定位段)symbol table(符号表)string table(字符串表)执行头部的数据结构:struct exec {unsigned long a_midmag; /* 魔数和其它信息*/unsigned long a_text; /* 文本段的长度*/unsigned long a_data; /* 数据段的长度*/unsigned long a_bss; /* BSS段的长度*/unsigned long a_syms; /* 符号表的长度*/unsigned long a_entry; /* 程序进入点*/unsigned long a_trsize; /* 文本重定位表的长度*/unsigned long a_drsize; /* 数据重定位表的长度*/};文件头部主要描述了各个section 的长度,比较重要的字段是a_entry(程序进入点),代表了系统在加载程序并初试化各种环境后开始执行程序代码的入口。
这个字段在后面讨论的ELF 文件头部中也有出现。
由a.out 格式和头部数据结构我们可以看出,a.out 的格式非常紧凑,只包含了程序运行所必须的信息(文本、数据、BSS),而且每个section 的顺序是固定的。
这种结构缺乏扩展性,如不能包含"现代"可执行文件中常见的调试信息,最初的UNIX 黑客对a.out 文件调试使用的工具是adb,而adb 是一种机器语言调试器!a.out 文件中包含符号表和两个重定位表,这三个表的内容在连接目标文件以生成可执行文件时起作用。
在最终可执行的 a.out 文件中,这三个表的长度都为0。
a.out 文件在连接时就把所有外部定义包含在可执行程序中,如果从程序设计的角度来看,这是一种硬编码方式,或者可称为模块之间是强藕和的。
在后面的讨论中,我们将会具体看到ELF格式和动态连接机制是如何对此进行改进的。
a.out 是早期UNIX系统使用的可执行文件格式,由AT&T 设计,现在基本上已被ELF 文件格式代替。
a.out 的设计比较简单,但其设计思想明显的被后续的可执行文件格式所继承和发扬。
可以参阅参考资料16和阅读参考资料15源代码加深对a.out 格式的理解。
参考资料12讨论了如何在"现代"的红帽LINUX运行 a.out 格式文件。
回页首COFF 文件格式分析COFF 格式比a.out 格式要复杂一些,最重要的是包含一个节段表(section table),因此除了 .text,.data,和 .bss 区段以外,还可以包含其它的区段。
另外也多了一个可选的头部,不同的操作系统可一对此头部做特定的定义。
COFF 文件格式如下:File Header(文件头部)Optional Header(可选文件头部)Section 1 Header(节头部)………Section n Header(节头部)Raw Data for Section 1(节数据)Raw Data for Section n(节数据)Relocation Info for Sect. 1(节重定位数据)Relocation Info for Sect. n(节重定位数据)Line Numbers for Sect. 1(节行号数据)Line Numbers for Sect. n(节行号数据)Symbol table(符号表)String table(字符串表)文件头部的数据结构:struct filehdr{unsigned short f_magic; /* 魔数*/unsigned short f_nscns; /* 节个数*/long f_timdat; /* 文件建立时间*/long f_symptr; /* 符号表相对文件的偏移量*/long f_nsyms; /* 符号表条目个数*/unsigned short f_opthdr; /* 可选头部长度*/unsigned short f_flags; /* 标志*/};COFF 文件头部中魔数与其它两种格式的意义不太一样,它是表示针对的机器类型,例如0x014c 相对于I386 平台,而0x268 相对于Motorola 68000系列等。
当COFF 文件为可执行文件时,字段f_flags 的值为F_EXEC(0X00002),同时也表示此文件没有未解析的符号,换句话说,也就是重定位在连接时就已经完成。
由此也可以看出,原始的COFF 格式不支持动态连接。
为了解决这个问题以及增加一些新的特性,一些操作系统对COFF 格式进行了扩展。
Microsoft 设计了名为PE(Portable Executable)的文件格式,主要扩展是在COFF 文件头部之上增加了一些专用头部,具体细节请参阅参考资料18,某些UNIX 系统也对COFF 格式进行了扩展,如XCOFF(extended common object file format)格式,支持动态连接,请参阅参考资料5。
紧接文件头部的是可选头部,COFF 文件格式规范中规定可选头部的长度可以为0,但在LINUX 系统下可选头部是必须存在的。