
《编译原理上机实验指导》
实验一词法分析
1实验目的
设计编制并调试一个词法分析程序,加深对构造词法分析器的原理和技术理解与应用。
2实验要求
选择一种计算机高级程序语言子语言,运用恰当的词法分析技术线路,设计和实现其子语言的词法分析器。语言选择,建议为《计算机程序设计》课程所采用的语言。技术线路建议如下两种之一:正则式T NFA^DFQ min DFQ程序设计和正则文法宀NFA T DFA T min DFA T程序设计。分析器输出结果存入到磁盘文件中。具有出错处理功能。
选择子语言方法举例。以教材选取的PASCAL语言为例,确定其子语言涉及的单
词类如下:
(1)关键字
begi n end if the n while do
(2)运算符和界符
:=+ —* / <<=<>>>==;() : #
(3)标识符
正则式:ID=letter(letter|digit)*
(4)整型常数
正则式:NUM= digit(digit)*
3算法设计
(1)单词种别码设计
单表
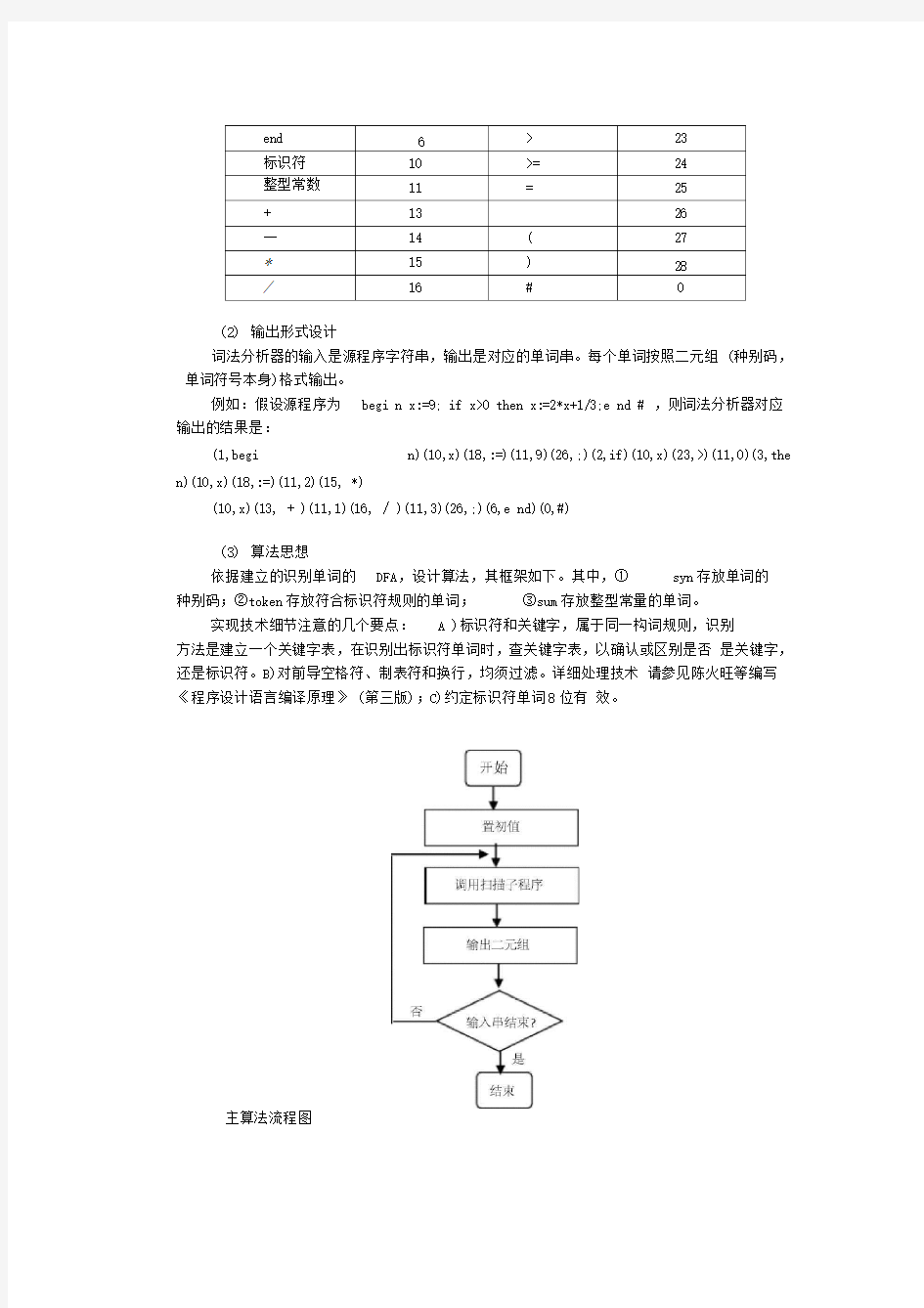
(2)输出形式设计
词法分析器的输入是源程序字符串,输出是对应的单词串。每个单词按照二元组 (种别码,单词符号本身)格式输出。
例如:假设源程序为begi n x:=9; if x>0 then x:=2*x+1/3;e nd # ,则词法分析器对应
输出的结果是:
(1,begi n)(10,x)(18,:=)(11,9)(26,;)(2,if)(10,x)(23,>)(11,0)(3,the n)(10,x)(18,:=)(11,2)(15, *)
(10,x)(13, + )(11,1)(16, / )(11,3)(26,;)(6,e nd)(0,#)
(3)算法思想
依据建立的识别单词的DFA,设计算法,其框架如下。其中,①syn存放单词的
种别码;②token存放符合标识符规则的单词;③sum存放整型常量的单词。
实现技术细节注意的几个要点: A )标识符和关键字,属于同一构词规则,识别
方法是建立一个关键字表,在识别出标识符单词时,查关键字表,以确认或区别是否是关键字,还是标识符。B)对前导空格符、制表符和换行,均须过滤。详细处理技术请参见陈火旺等编写《程序设计语言编译原理》 (第三版);C)约定标识符单词8位有效。
主算法流程图
扫描子程序流程图
4程序框架
#in clude
#in clude
void sca nn er(void);
char prog[8],toke n[ 8],ch;
int syn ,p,m,sum;
char *rwtab[6]={ begin ” if ” “hen ” while ” do ” end"};
void mai n(void){
p=0;
printf( \n please in put stri ng:\n ”;
do{
sca nn er();
switch(s yn){
case 11:输出“整型数的二元组";break;
case ―:输出"错误";break;
default:输出"其它单词的二元组";
}
} while(s yn);
}
void sca nn er(void){
for(m=0,n=0;n<8;n++) token[n]=NULL;
ch=读取下一个字符;
while(ch== ' ')ch=读取下一个字符;
if(ch 是字符){
while(ch 是字符或数字符号){
ch 拼到token ;
ch=读取下一个字符;
}
token[m++]= '\0';回退一个输入字符;syn=10;
for(n=0;n<6;n++) if(strcmp(token,rwtab[n])==0){syn=n;break;} }else if(ch 是字符){
while(ch 是数字符号){
sum=sum*10+ch; '0';
ch=读取下一个字符;
}
回退一个输入字符;syn=11;
}else
switch(ch){
case ‘<':m=0;token[m++]=ch; ch= 读取下一个字符;
if(ch== '>'){
syn=21; token[m++]=ch;
}else if(ch== '='){
syn=22; token[m++]=ch;
}else
{syn=20; 回退一个输入字符;} break;
case ‘> ': m=0;token[m++]=ch; ch= 读取下一个字符;
if(ch== '='){
syn=24; token[m++]=ch;
}else
{syn=23; 回退一个输入字符;} break;
case ‘:' : m=0;token[m++]=ch; ch= 读取下一个字符;
if(ch== '='){
syn=18; token[m++]=ch;
}else
{syn=25; 回退一个输入字符;} break;
case ' + ': syn=13; token[0]=ch; break;
case ‘-' : syn=14; token[0]=ch; break;
case ‘* ': syn=15; token[0]=ch; break;
case ‘/':syn=16; token[0]=ch; break;
case ‘# ': syn=0; token[0]=ch; break;
default : syn=-1;
实验二语法分析
1实验目的
设计编制并调试一个语法分析程序,加深对构造自顶向下的语法分析器的原理和技术理解与应用。
2实验要求
简单语言至少包括赋值语句和复合语句,其中表达式至少包括算术表达式。设计语言文法,运用递归下降分析技术,设计和实现语法分析器。具有出错处理功能。
选择子语言方法举例。以教材选取的PASCAL 语言为例,确定其子语言涉及的语法,以扩充的BNF 方法描述如下:
(1)<程序>T bengin <语句串>end
(2)<语句串>T<语句>{;<语句>}
(3)<语句>T<赋值语句>
(4)<赋值语句>T<标识符> :=<表达式>
(5)<表达式>T<项> { + <项> | —<项>}
(6)<项>T<因子> { * <项> | / <项>}
(7)<因子>T<标识符> |整型常数| (<表达式>)
3算法设计
语法分析器的输入是由词法分析器从源程序字符串中分离输出的单词串,如果源
程序字符串是文法正确的句子,则输出" success",否则,输出"error”。
例如:( 1 )输入: begin a:=9;x:=2*3;b:=a+x end #
输出: success
( 2)输入: begin a:=9;x:=2*3;b:=a+x #
输出: error
主程序和每个非终结符(语法单位)对应的递归子程序的算法流程图如下。这里注意的是A)词法分析器(seaner)作为子程序,由语法分析器调用,即系统选择的是词法分析和语法分析一趟的方案;B) 约定每个非终结符(语法单位)对应的递归子程序进入时,均已读入一个单词。