《x86汇编语言:从实模式到保护模式》勘误表
- 格式:doc
- 大小:38.00 KB
- 文档页数:2

ASM:《X86汇编语⾔-从实模式到保护模式》第11章:进⼊保护模式★PART1:进⼊保护模式1. 全局描述符表(Global Descriptor Table,GDT)32位保护模式下,如果要使⽤⼀个段,必须先登记,登记的信息包括段的起始地址,段的界限和各种访问属性,如果偏移地址超过了段的界限,就会引发异常中断。
和⼀个段有关的信息需要8个字节来描述,这被称为段的描述符(Segement Descriptor),每个段都需要⼀个描述符,为了存放描述符,需要在内存中开辟⼀段空间。
这些描述符集中存放,构成了⼀个描述符表。
为了跟踪全局描述符表,处理器内部有⼀个48位的寄存器,称为全局描述符寄存器(GDTR)。
这个寄存器分为两个部分,前16位为全局描述表的边界,后32位为全局描述表的线性基地址。
GDT的界限是16位的,所以GDT的最⼤是216字节,⼜因为⼀个描述符是8个字节的,所以最多可以定义8192个描述符。
因为进⼊保护模式之前,是实模式,实模式只能访问最多1MB的内存,所以GDT通常都是定义在1MB以下的内存范围中,允许进⼊保护模式之后换个地⽅定义GDT。
因为在进⼊保护模式之前处理器初始化为实模式,同样的,主引导程序是在0x0000:0x7c00这个地⽅加载的,⽽主引导程序最⼤也就512字节,所以我们把GDT放在主引导程序之后,也就是0x7e00后⾯,GDT的界限可以到0x17DFF(64KB最⼤)。
栈段寄存器SS被初始化为0x0000,栈是向下拓展的,我们可以把SP段定义到0x7c00处,然后向下拓展(要注意⼤⼩不能太⼤,因为BIOS数据区和中断向量表都在下⾯)。
描述符不是由⽤户程序⾃⼰创建的,都是由操作系统创建的,如果⽤户程序对段的访问超过了操作系统所规定的范围,或者访问了⼀个不属于它的段,那么这些操作都会被处理器阻⽌。
2. 32位保护模式下GDT每个位置的定义每个描述符在GDT占8个字节,每个位置及其定义见下图:在32位保护模式下,如果未开始页功能,那么段地址就是物理地址,注意描述符段保存器的段界限和基地址是不连续的(其实是为了兼容80286)。

实模式与保护模式在是模式下,16位寄存器需要用“段:偏移”这种方法才能达到1MB的寻址能力,如今我们有了32位寄存器,一个寄存器就可以寻址4GB的空间,是不是从此段值就被抛弃了?,在新的政策下地址仍然用“段:偏移”这样的形式来表示,只不过保护模式下的“段”的概念发生了根本性的变化,是模式下段值还是可以看成地址的一部分的,段值为XXXXh表示以XXXX0h开始的一段内存,而保护模式下虽然段值仍然由原来的16位的CS,DS等寄存器表示,但此时它仅仅变成了一个索引,这个索引指向一个数据结构的一个表项,表项中详细定义了段的起始地址,界限,属性等内容这个数据结构就是GDT(global description table)在Protected Mode下,一个重要的必不可少的数据结构就是GDT(Global Descriptor Table)。
为什么要有GDT?我们首先考虑一下在Real Mode下的编程模型:在Real Mode下,我们对一个内存地址的访问是通过Segment:Offset的方式来进行的,其中Segment是一个段的Base Address,一个Segment的最大长度是64 KB,这是16-bit系统所能表示的最大长度。
而Offset则是相对于此Segment Base Address的偏移量。
Base Address+Offset就是一个内存绝对地址。
由此,我们可以看出,一个段具备两个因素:Base Address和Limit(段的最大长度),而对一个内存地址的访问,则是需要指出:使用哪个段?以及相对于这个段Base Address的Offset,这个Offset应该小于此段的Limit。
当然对于16-bit系统,Limit不要指定,默认为最大长度64KB,而 16-bit的Offset也永远不可能大于此Limit。
我们在实际编程的时候,使用16-bit段寄存器CS(Code Segment),DS (Data Segment),SS(Stack Segment)来指定Segment,CPU将段积存器中的数值向左偏移4-bit,放到20-bit的地址线上就成为20-bit的Base Address。

80X86保护模式及其编程(⼀)80x86系统寄存器和系统指令1、标志寄存器(EFLAGS)标志寄存器EFLAGS的标志位含义如下图:TF 位8是跟踪标志(Trace flag),当设置该位时可为调试操作启动单步执⾏⽅式。
复位时则禁⽌单步执⾏。
在单步执⾏⽅式下,处理器会在每个指令执⾏后产⽣⼀个调试异常,这样我们可以观察执⾏程序在每条指令执⾏后的状态。
IOPL 位13-12时I/O特权级(I/O Privilege Level)字段。
该字段指明当前运⾏程序或任务的I/O特权级别IOPL。
当前任务或程序的CPL必须⼩于这个IOPL才能访问I/O地址空间。
只有当CPL位特权级0时,程序才可以使⽤POPF或IRET指令修改这个字段,IOPL也是控制对IF标志修改的机制之⼀NT 位14是嵌套任务标志(Nested Task)。
它控制着被中断任务和调⽤任务之间的链接关系。
在使⽤CALL指令、中断或异常执⾏任务调⽤时,处理器会设置该标志,在通过IRET指令从⼀个任务返回时,处理器会检查并修改这个NT标志。
使⽤POPF/POPFD指令也可以修改这个标志,但是在应⽤程序中改变这个标志的状态会产⽣不可意料的异常RF 位16时恢复标志(Resume Flag)。
该标志⽤于控制处理器对断点指令的响应。
当设置时,这个标志会临时禁⽌断点指令产⽣调试异常;当标志复位时,则断点指令将会产⽣异常。
RF的主要功能是允许调试异常后重⾏执⾏⼀条指令。
当调试软件使⽤IRETD指令返回被中断程序之前,需要设置堆栈上EFLAGS内容中的RF标志,以防⽌指令断点造成另⼀个异常,处理器会在指令返回之后⾃动清除该标志,从⽽再次允许指令断点异常。
VM位17是虚拟-8086⽅式标志,当设置该标志时,新开启虚拟-8086⽅式,当复位该标志时,则回到保护模式内存管理寄存器处理器提供了4个内存管理寄存器(GDTR、LDTR、IDTR和TR),⽤于指定分段内存管理所使⽤的系统表的基地址,其中包含有分段机制的重要信息。


第十章IA3210.1 IA-32架构的基本执行环境10.1.1 寄存器的扩展在16位处理器内,有8个通用寄存器AX、BX、CX、DX、SI、DI、BP和SP,其中,前4个还可以拆分成两个独立的8位寄存器来用,即AH、AL、BH、BL、CH、CL、DH和DL。
为了在汇编语言程序中使用经过扩展(Extend)的寄存器,需要给它们命名,它们的名字分别是EAX、EBX、ECX、EDX、ESI、EDI、ESP和EBP。
可以在程序中使用这些寄存器,即使是在实模式下:mov eax,0xf0000005mov ecx,eaxadd edx,ecx但是,就像以上指令所示的那样,指令的源操作数和目的操作数必须具有相同的长度,个别特殊用途的指令除外。
因此,像这样的搭配是不允许的,在程序编译时,编译器会报告错误:mov eax,cx ;错误的汇编语言指令如果目的操作数是32位寄存器,源操作数是立即数,那么,立即数被视为32位的:mov eax,0xf5 ;EAX←0x000000f532位通用寄存器的高16位是不可独立使用的,但低16位保持同16位处理器的兼容性。
因此,在任何时候它们都可以照往常一样使用:mov ah,0x02mov al,0x03add ax,si可以在32位处理器上运行16位处理器上的软件。
但是,它并不是16位处理器的简单增强。
事实上,32位处理器有自己的32位工作模式,在本书中,32位模式特指32位保护模式。
在这种模式下,可以完全、充分地发挥处理器的性能。
同时,在这种模式下,处理器可以使用它全部的32根地址线,能够访问4GB内存。
10.1.2 基本的工作模式8086具有16位的段寄存器、指令指针寄存器和通用寄存器(CS、SS、DS、ES、IP、AX、BX、CX、DX、SI、DI、BP、SP),因此,我们称它为16位的处理器。
尽管它可以访问1MB的内存,但是只能分段进行,而且由于只能使用16位的段内偏移量,故段的长度最大只能是64KB。

Linux0.11——从实模式到保护模式综述最近在阅读Linux 0.11的源码时,对于setup.s⽂件中设置GDT表的部分不是很理解,后来经过刘国军⽼师的指点,结合赵炯博⼠的《Linux内核完全注释》的第四章《80X86保护模式及其编程》,对于保护模式有了⼀些粗浅的了解和认识。
备忘。
本⽂章主要讲解保护模式的寻址机制与setup.s中的切换部分。
保护模式保护模式运⾏在80286及其之后的所有CPU上,但是为了保证向前兼容性,正常的CPU在启动时并不会默认进⼊保护模式,⽽是会进⼊实模式,随后通过⼀系列设定转⼊保护模式。
在16位实模式下,CPU寻址时使⽤16位段寄存器的内容乘以16当作段基地址,加上16位段偏移地址形成20位的物理地址,所以最⼤寻址仅为1MB字节,最⼤段长度64KB。
在实模式下,所有的段都是可以任意访问的,即任意读、写和执⾏。
虽然在80286点CPU上已经出现了保护模式,但是其寄存器的位宽仍然是16位,只不过其地址线由20位扩⼤到了24位,寻址空间随即扩⼤到了16MB。
真正的32位保护模式出现在80386上,其地址总线和寄存器都是32位宽的,因此寻址空间扩⼤到了4GB。
保护模式下,CPU寻址主要有两种模式,⼀是分段模式,⼆是分段和分页相结合,分页⽆法单独出现。
保护模式的分段模式为每⼀段增加了段属性来限制⽤户程序对内存中⼀些段的操作。
在全局描述符表(GDT)中,每个段的表项存储了⼀个段的基本属性,例如段的基地址、段的界限、段的类型(代码段、数据段)、段的执⾏权限等。
分页模式的出现使得程序员可以编写远远⼤于内存的程序⽽⽆需担⼼内存的容量,在该模式下,内存被划分为“页”存储,磁盘的⼀部分⽤作虚拟内存,当应⽤程序执⾏时需要的某些代码或数据所在的页不在内存中时,CPU就会产⽣⼀个缺页异常,从磁盘中将所需的页调⼊内存中后恢复执⾏,在应⽤程序看来,所需的代码或数据仿佛⼀直存在内存上。
重要数据结构在保护模式中,有⼏个长得很像的名字⼀直是我们⼼头噩梦:GDT、GDTR、LGDT、LDT、LDTR、LLDT……事实上,并不是那么难区分。

保护模式的主要数据结构分段机制段描述符在保护模式下,把有关一个段的信息,即段基址、限长(段的字节数)、类型、访问权限及其他属性信息存放在一个8字节长的数据结构中,这种数据结构称为段描述符,简称描述符。
描述符有两种类型:非系统段描述符和系统段描述符。
后面将具体给出这两种描述符的格式及各字段的功能定义。
这里所说的非系统段即应用程序段,也就是通常的代码段、数据段和堆栈段;而系统段包括任务状态段(Task State Segment,TSS)和各种门,另外,局部描述符表(下面即将介绍)也是一种系统段。
任务状态段是多任务系统中的一种特殊数据结构,它对应一个任务的各种信息。
所谓门,实际上是一种特殊的段描述符。
有4种不同类型的门,即调用门、任务门、中断门及陷阱门。
调用门用来改变任务或者程序的特权级別;任务门像个开关一样,用来执行任务切换;中断门和陷阱门用来指出中断服务程序的同入口。
描述符表为了査找和识别,把系统中的描述符按线性表的形式来组织,即构成描述符表。
描述符表的每一项就是一个描述符。
描述符表由操作系统建立,并由操作系统维护和管理。
有三种类型的描述符表:全局描述符表(Global Descriptor Table,GDT)、局部描述符表(Local Descriptor T able,LDT)和中断描述符表(Interrupt Descriptor Table,IDT)。
全局描述符表GDT含有可供系统中所有任务使用的段描述符。
另外,系统把每个局部描述符表也看成一种特殊的段,并分别赋予描述符,所以,GDT中还包含各个局部描述符表LDT的描述符;还有,如上所述,任务状态段TSS也是一种系统段,该段对应的描述符称为TSS描述符,TSS描述符也放在GDT中。
也就是说,GDT中除了含有可供所有任务使用的全局描述符外,还包含有LDT描述符和TSS 描述符。
局部描述符表LDT只含有与系统中某一个给定任务相关联的描述符。
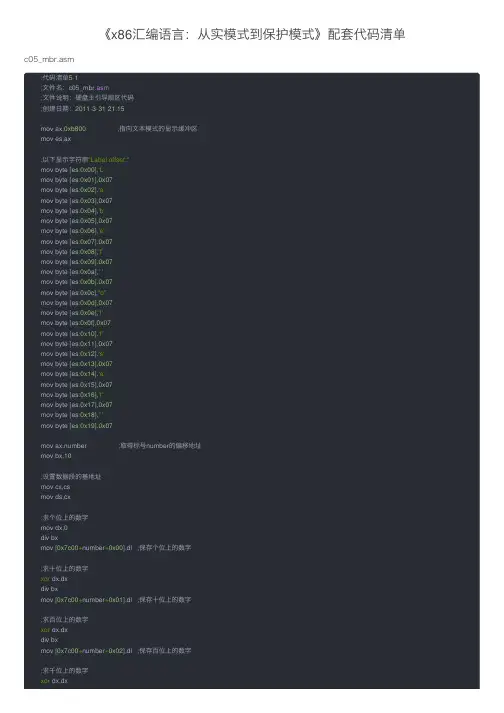
《x86汇编语⾔:从实模式到保护模式》配套代码清单c05_mbr.asm;代码清单5-1;⽂件名:c05_mbr.asm;⽂件说明:硬盘主引导扇区代码;创建⽇期:2011-3-3121:15mov ax,0xb800;指向⽂本模式的显⽰缓冲区mov es,ax;以下显⽰字符串"Label offset:"mov byte [es:0x00],'L'mov byte [es:0x01],0x07mov byte [es:0x02],'a'mov byte [es:0x03],0x07mov byte [es:0x04],'b'mov byte [es:0x05],0x07mov byte [es:0x06],'e'mov byte [es:0x07],0x07mov byte [es:0x08],'l'mov byte [es:0x09],0x07mov byte [es:0x0a],' 'mov byte [es:0x0b],0x07mov byte [es:0x0c],"o"mov byte [es:0x0d],0x07mov byte [es:0x0e],'f'mov byte [es:0x0f],0x07mov byte [es:0x10],'f'mov byte [es:0x11],0x07mov byte [es:0x12],'s'mov byte [es:0x13],0x07mov byte [es:0x14],'e'mov byte [es:0x15],0x07mov byte [es:0x16],'t'mov byte [es:0x17],0x07mov byte [es:0x18],':'mov byte [es:0x19],0x07mov ax,number ;取得标号number的偏移地址mov bx,10;设置数据段的基地址mov cx,csmov ds,cx;求个位上的数字mov dx,0div bxmov [0x7c00+number+0x00],dl ;保存个位上的数字;求⼗位上的数字xor dx,dxdiv bxmov [0x7c00+number+0x01],dl ;保存⼗位上的数字;求百位上的数字xor dx,dxdiv bxmov [0x7c00+number+0x02],dl ;保存百位上的数字div bxmov [0x7c00+number+0x03],dl ;保存千位上的数字;求万位上的数字xor dx,dxdiv bxmov [0x7c00+number+0x04],dl ;保存万位上的数字;以下⽤⼗进制显⽰标号的偏移地址mov al,[0x7c00+number+0x04]add al,0x30mov [es:0x1a],almov byte [es:0x1b],0x04mov al,[0x7c00+number+0x03]add al,0x30mov [es:0x1c],almov byte [es:0x1d],0x04mov al,[0x7c00+number+0x02]add al,0x30mov [es:0x1e],almov byte [es:0x1f],0x04mov al,[0x7c00+number+0x01]add al,0x30mov [es:0x20],almov byte [es:0x21],0x04mov al,[0x7c00+number+0x00]add al,0x30mov [es:0x22],almov byte [es:0x23],0x04mov byte [es:0x24],'D'mov byte [es:0x25],0x07infi: jmp near infi ;⽆限循环number db 0,0,0,0,0times 203 db 0db 0x55,0xaac06_mbr.asmjmp near startmytext db 'L',0x07,'a',0x07,'b',0x07,'e',0x07,'l',0x07,' ',0x07,'o',0x07,\'f',0x07,'f',0x07,'s',0x07,'e',0x07,'t',0x07,':',0x07number db 0,0,0,0,0start:mov ax,0x07c0;设置数据段基地址mov ds,ax ;ds寄存器⼀般保存数据段基地址mov ax,0xb800;设置附加段基地址mov es,ax ;这⾥附加段指向显存位置,存放在es寄存器中cld ;将⽅向标志位DF清零,以指⽰传送是负⽅向的,与此相对应的指令是stdmov si,mytext ;movsw指令原始数据串需要存放在ds:si位置,⽬的地址为es:di,因为ds⽬前指⽰的是当前代码段基地址地址,因此只要把偏移mytext存⼊si寄存器即可mov di,0;当前es指⽰显存起始位置,因此只要把偏移0存⼊di即可mov cx,(number-mytext)/2;实际上等于13,cx作为计数器,每进⾏⼀次rep指令cx-1rep movsw ;⼀次传送⼀个字(两个字节);得到标号所代表的偏移地址mov ax,number ;此代码⽬的旨在显⽰number的偏移地址;计算各个数位mov bx,ax ;bx指向当前number偏移地址mov cx,5;循环次数mov si,10;除数digit:xor dx,dx ;dx(被除数⾼16位)清零div si ;除法mov [bx],dl ;保存数位;为什么这⾥不⽤加0x7c00了?inc bx ;bx⾃加1,指向下⼀个内存单元,number⼀共定义了5个字节内存单元loop digit;显⽰各个数位mov bx,numbermov si,4show:mov al,[bx+si];从后往前显⽰add al,0x30mov ah,0x04mov [es:di],axadd di,2dec sijns show ;上⼀条指令符号位为SF=0(结果为⾮负)时跳转mov word [es:di],0x0744jmp near $ ;⽆限循环times 510-($-$$) db 0;512字节减去之后两个db指令=510字节,$当前指令偏移,$$当前代码段起始位置,填充字节0(db 0)db 0x55,0xaac07_mbr.asmjmp near startmessage db '1+2+3+...+100='start:mov ax,0x7c0;设置数据段的段基地址mov ds,axmov ax,0xb800;设置附加段基址到显⽰缓冲区mov es,ax;以下显⽰字符串mov si,messagemov di,0mov cx,start-message@g:mov al,[si];因为这是硬盘主引导扇区代码,因此被加载到0x7c00,[si]=[ds:si],就是相对于代码段开头的相对偏移,这个相对偏移就是标签message的值mov [es:di],alinc di ;di⽤做显存段地址的相对偏移,字符内容信息放在低⼀个字节mov byte [es:di],0x07inc di ;字符显⽰信息放在⾼⼀个字节inc si ;si⽤作寻址字符串相对偏移loop @g;以下计算1到100的和xor ax,ax ;清空ax寄存器,存放结果mov cx,1@f:add ax,cxinc cx ;cx做累加器cmp cx,100jle @f ;⼩于等于时跳转;以下计算累加和的每个数位xor cx,cx ;设置堆栈段的段基地址mov ss,cxmov sp,cx ;堆栈段指针和段基址都在0x0000处,堆栈段从⾼地址向低地址⽣长mov bx,10xor cx,cx@d:inc cx ;压栈中⽤cx记录⼀共压⼊栈元素个数,以便之后出栈时能及时停⽌popxor dx,dx ;被除数[dx:ax]div bx ;除数bxor dl,0x30;余数在dx中,但是余数最多到9,因此在dl中就够了,加0x30得到ASCII码push dx ;dx中只有dl有意义,但是压栈的单位必须是字(两个字节)cmp ax,0jne @d ;循环跳出时,结果5050每⼀位被放在栈中;以下显⽰各个数位@a:pop dx ;出栈,栈顶元素是千位,百位,⼗位,个位mov [es:di],dlinc dimov byte [es:di],0x07inc diloop @a8086寻址⽅式总结:1.寄存器寻址 :mov ax,cx2.⽴即寻址 :add bx,0xf000 (⽬的操作数⽴即数寻址,源操作数寄存器寻址)3.直接寻址 :mov ax,[0x5c0f]4.基址寻址:利⽤基址寄存器bx/bp中的值作为偏移地址,其中bx默认段寄存器为ds(数据段),bp默认段寄存器为ss(堆栈段)。

《x86汇编语⾔:从实模式到保护模式》检测点和习题答案检测点1.1:按顺序分别为:13 15 78 255 128 56091检测点1.2:按顺序分别为:1000 1010 1100 1111 11001 1000000 1100100 11111111 1111101000 1111111111111111 100000000000000000000检测点1.3:按顺序分别为:8 10 11 12 13 14 15 16 31 1741 1022 4092 65535检测点1.4:按顺序分别为:8 a c f 19 40 64 ff 3e8 ffff 100000检测点1.5:1.按顺序分别为:11 1010 1100 1111 100000 111111 1011111110 1111111111111111 100111111100000001011101 11111001100111111111110111111112.按顺序分别为:1/1 11/3 0101/5 111/7 1001/9 1011/A 1101/D 1111/F 0/0 10/2 100/4 110/6 1000/8 1100/C 1110/E检测点1.6:1.4092/111111111100 2.27B6100/10011110110110000100000000第1章习题:1.5 C =15D=1111B =12D=1100B =10D=1010B =8H=1000B =11D=1011B =14D=1110B =16D=10000B 2.12 10101 10001111 1000000000 1FF检测点2.1:1.(2) (16) (4) (32) 2. (7) (8) 最⾼位 3. (00) (0F) (8) (00、02、04、06、08、0A、0C、0E) 双字时,是00、04、08、0C检测点2.2:A3D8H检测点2.3:1.8 (AX BX CX DX SI DI BP SP) (AH AL BH BL CH CL DH DL) 2.(A) (C) (D F) 3.(A B C D F)第2章习题:1. 64个 2. 25BC0H~35BBFH检测点3.1:1.(略) 2. (B) (A) (C)第3章习题:1. 00H、35H、40H 2. 49H(即73个字节)检测点4.1:1.(0) (0) (1) (0) (0) (1) 2. (A B C)检测点4.2:1.(略) 2. (略) 3.应在屏幕克上⾓显⽰a、s、m三个字母检测点5.1:1.(0xB8000) (0xB800) (0xF9E) (0x27) (0x48) 2. (E F G H J L) A错误的原因是企图向8位寄存器传送16位字; B错误的原因是向段寄存器传送⽴即数; C错误的原因是通过8位寄存器AL向段寄存器传送; D错误的原因是未指⽰内存操作数的长度; I错误的原因是两个寄存器不匹配; K错误的原因是在两个内存单元之间传送。

ASM:《X86汇编语⾔-从实模式到保护模式》第8章:实模式下硬盘的访问,程序重定位和加载第⼋章是⼀个⾮常重要的章节,讲述的是实模式下对硬件的访问(这⼀节主要讲的是硬盘),还有⽤户程序重定位的问题。
现在整理出来刚好能和保护模式下的⽤户程序定位作⼀个对⽐。
★PART1:⽤户程序的重定位,硬盘的访问1. 分段、段的汇编地址和段内汇编地址NASM编译器使⽤汇编指令“SECTION”或者“SEGMENT”来定义段。
他的⼀般格式是SECTION 段名称或者SEGMENT段名称(段名称不能重复),另外NASM对段没有数量的限制,⼀个程序可以有很多的代码段和数据段。
Intel处理器要求段在内存中的其是物理地址起码是16字节对齐的,⽽NASM 提供了段的修饰符align,使每⼀个段可以16字节对齐或者32字节对齐,⽐如所谓段的汇编地址其实就是段内第⼀个元素(数据,指令)的汇编地址,16字节对齐的意思是所有段⾸的汇编地址都要可以被16整除,如果存在⼀个段要求16字节对齐,⽽这个段的前⼀个段长度不够使当前段不能16字节对齐,那么编译器会⾃动将前⼀个段补0来使这⼀个段满⾜16字节对齐。
NASM编译器提供以下形式section.段名称.start来获得段的汇编地址,⽐如:另外段还可以加⼀个vsart修饰符,因为在NASM编译器中,即使你定义了⼀个段,段的汇编地址就是段内第⼀个元素的汇编地址,但是在引⽤某个标号的时候(包括section.段名称.start),这个标号的汇编地址还是从整个程序的开头开始计算的,⽽不是对段⾸的偏移。
不过再加了vsart=0的时候,段内所有标号的地址都是相对于当前段⾸的偏移了(当然也可以设定为其他数值,标号的偏移值是在这个值的基础上加上与段⾸的偏移地址。
)2. ⽤户程序头部加载⼀个⽤户程序需要⼀个加载器(在实模式下),⽽加载器是不知道⽤户程序⾥⾯具体的结构和功能的,⼀个程序想要运⾏,那么这个程序就要满⾜运⾏环境的⼀些约定俗成的条件,也就是程序哪些部分要怎么写是固定的,现在我们在MBR加载⼀个程序也是⼀样的,只要⽤户程序在某些部分满⾜⼀些条件,我们的加载器就可以识别并加载它。

摘自“/rosetta/article/details/8933200”64KB-4GB-64TB?我记得大学的汇编课程、组成原理课里老师讲过实模式和保护模式的区别,在很多书本上也有谈及,无奈本人理解和感悟能力实在太差,在很长一段时间里都没真正的明白它们的内含,更别说为什么实模式下最大寻址空间为1MB?段的最大长度不超过64KB?而保护模式下为啥最大寻址能力就变成了64TB?每个段最大也达4GB?更甚者分段和分页这两个高深的概念像我这种菜鸟怎么也理解不了啊!寻址能力都达64TB了,为啥我的电脑内存只有2GB呢?其实不用纠结于这事,这64TB就是所谓的虚拟地址空间,也叫逻辑地址空间,它能够寻址这么多,只是它有这个能力,并不代表你的内存就要装这么大,你内存比它小再多也不会影响你工作,反过来,要是它的寻址能力只有1MB,而你有2GB的内存,那么那1.9GB就没有实际用处了,这就太浪费资源了。
而实际上这个64TB也没有什么实际意义,因为32位的地址总线能寻址的线性地址空间和物理地址空间都是2^32=4GB。
这个64TB是怎么出来的,稍后揭晓。
实模式与保护模式的来历我们先来说一下为什么有实模式和保护模式的区别。
最早期的8086 CPU只有一种工作方式,那就是实模式,而且数据总线为16位,地址总线为20位,实模式下所有寄存器都是16位。
而从80286开始就有了保护模式,从80386开始CPU数据总线和地址总线均为32位,而且寄存器都是32位。
但80386以及现在的奔腾、酷睿等等CPU为了向前兼容都保留了实模式,现代操作系统在刚加电时首先运行在实模式下,然后再切换到保护模式下运行。
再来区别下几个基本概念:逻辑地址、线性地址和物理地址。
这些概念一时没领会没关系。
继续往下看。
三种地址逻辑地址:即逻辑上的地址,实模式下由“段基地址+段内偏移”组成;保护模式下由“段选择符+段内偏移”组成。
线性地址:逻辑地址经分段机制后就成线性地址,它是平坦的;如果不启用分页,那么此线性地址即物理地址。
前沿:今年的前些时候,在杂志的一篇文章看到如下一句:―掌握汇编,仍是高手必经之路‖。
然而在实际的学习中,汇编往往因为其应用太难而被初学者忽视。
熟悉汇编语言,将是自己在软件调试时的―倚天剑‖,重要性实不言而喻。
也有很多在学习的过程中几次三番,最终退却。
希望这一篇文章可以与你一起,重拾汇编这把双刃剑。
文档转载请注明―天衣有缝‖原创。
0.本文讲述汇编语言的基础知识,寻址方式,指令系统,宏汇编,结构化程序设计,堆栈,函数,中断等知识1.汇编简介:汇编语言是一种符号语言,比机器语言容易理解和掌握,也容易调试和维护。
但是,汇编语言源程序要翻译成机器语言程序才可以由计算机执行。
这个翻译的过程称为―汇编‖,这种把汇编源程序翻译成目标程序的语言加工程序称为汇编程序。
汇编语言虽然较机器语言直观,但仍然烦琐难懂。
于是人们研制出了高级程序设计语言。
高级程序设计语言接近于人类自然语言的语法习惯,与计算机硬件无关,易被用户掌握和使用。
汇编语言的特点:(1)汇编语言与处理器密切相关。
(2)汇编语言程序效率高。
(3)编写汇编语言源程序比编写高级语言源程序烦琐。
(4)调试汇编语言程序比调试高级语言程序困难。
汇编语言的主要应用场合:(1)程序执行占用较短的时间,或者占用较小存储容量的场合。
(2)程序与计算机硬件密切相关,程序直接控制硬件的场合。
(3)需提高大型软件性能的场合。
(4)没有合适的高级语言的场合。
2.数值数据:数值数据分为有符号数和无符号数。
无符号数最高位表示数值,而有符号数最高位表示符号。
有符号数有不同的编码方式,常用的是补码。
n位二进制数能够表示的无符号整数的范围是:0 ≤I ≤ 2n-1n位二进制数能够表示的有符号整数的范围是:-2(n-1)≤ I ≤+2(n-1)-1ASCII码:标准ASCII码用7位二进制数编码,共有128个。
计算机存储器基本单位为8位,ASCII码的最高位通常为0,通信时,最高位用作奇偶校验位。
第十章IA3210.1 IA-32架构的基本执行环境10.1.1 寄存器的扩展在16位处理器内,有8个通用寄存器AX、BX、CX、DX、SI、DI、BP和SP,其中,前4个还可以拆分成两个独立的8位寄存器来用,即AH、AL、BH、BL、CH、CL、DH和DL。
为了在汇编语言程序中使用经过扩展(Extend)的寄存器,需要给它们命名,它们的名字分别是EAX、EBX、ECX、EDX、ESI、EDI、ESP和EBP。
可以在程序中使用这些寄存器,即使是在实模式下:mov eax,0xf0000005mov ecx,eaxadd edx,ecx但是,就像以上指令所示的那样,指令的源操作数和目的操作数必须具有相同的长度,个别特殊用途的指令除外。
因此,像这样的搭配是不允许的,在程序编译时,编译器会报告错误:mov eax,cx ;错误的汇编语言指令如果目的操作数是32位寄存器,源操作数是立即数,那么,立即数被视为32位的:mov eax,0xf5 ;EAX←0x000000f532位通用寄存器的高16位是不可独立使用的,但低16位保持同16位处理器的兼容性。
因此,在任何时候它们都可以照往常一样使用:mov ah,0x02mov al,0x03add ax,si可以在32位处理器上运行16位处理器上的软件。
但是,它并不是16位处理器的简单增强。
事实上,32位处理器有自己的32位工作模式,在本书中,32位模式特指32位保护模式。
在这种模式下,可以完全、充分地发挥处理器的性能。
同时,在这种模式下,处理器可以使用它全部的32根地址线,能够访问4GB内存。
10.1.2 基本的工作模式8086具有16位的段寄存器、指令指针寄存器和通用寄存器(CS、SS、DS、ES、IP、AX、BX、CX、DX、SI、DI、BP、SP),因此,我们称它为16位的处理器。
尽管它可以访问1MB的内存,但是只能分段进行,而且由于只能使用16位的段内偏移量,故段的长度最大只能是64KB。
ASM:《X86汇编语⾔-从实模式到保护模式》第14章:保护模式下的特权保护和任务概述★PART1:32位保护模式下任务的隔离和特权级保护 这⼀章是全书的重点之⼀,这⼀张必须要理解特权级(包括CPL,RPL和DPL的含义)是什么,调⽤门的使⽤,还有LDT和TSS的⼯作原理(15章着重讲TSS如何进⾏任务切换)。
1. 任务,任务的LDT和TSS 程序是记录在载体上的指令和数据,其正在执⾏的⼀个副本,叫做任务(Task)。
如果⼀个程序有多个副本正在内存中运⾏,那么他对应多个任务,每⼀个副本都是⼀个任务。
为了有效地在任务之间进⾏隔离,处理器建议每个任务都应该具有他⾃⼰的描述符表,称为局部描述符表LDT(Local Descriptor Table)。
LDT和GDT⼀样也是⽤来储存描述符的,但是LDT是只属于某个任务的。
每个任务是有的段,都应该在LDT中进⾏描述,和GDT不同的是,LDT的0位也是有效的,也可以使⽤。
LDT可以有很多个(有多少个任务就有多少个LDT),处理器使⽤局部描述符寄存器(LDT Register: LDTR)。
在⼀个多任务的系统中,会有很多任务在轮流执⾏,正在执⾏中的那个任务,称为当前任务(Current Task)。
因为LDTR只有⼀个,所以他⽤于指向当前任务的LDT,当发⽣任务切换(会在15章讲),LDTR会被⾃动更新成新的任务的LDT,和GDTR⼀样,LDTR包含了32位线性基地址字段和16位段界限。
以指⽰当前LDT的位置和⼤⼩。
如果要访问LDT中的⼀个描述符,和访问GDT的时候是差不多的,也是要向段寄存器传输⼀个16位的段选择⼦,只是和指向GDT的选择⼦不同,指向LDT的选择⼦的TI位是1。
因为索引号只能是13位的,所以每个LDT所能容纳的描述符个数为213,也就是8192个。
⼜因为每个描述符是8个字节,所以LDT最⼤长度是64KB。
同时,为了保存任务的状态,并且在下次重新执⾏的时候恢复他们,每个任务都应该⽤⼀个额外的内存区域保存相关信息,这就叫做任务状态段(Task State Segment: TSS)。
实模式、保护模式2009-06-07 17:18参考了百度百科中关于实模式的讨论:/view/404433.htm及/toening/blog/item/d8d927d403bdfdc350da4b6d.html和/trueailei/blog/item/b8faa413a22c57d7f7039e4d.html实模式、保护模式、虚拟模式都是X86中的概念。
从寻址方式来说,CPU中的IP(EIP)中存放虚地址,把虚地址转换到物理地址,各个模式有各自的转换方式。
实模式下,虚地址到实地址转换:DS段寄存器左移4位与偏移地址相加,得到物理地址,寻址1M。
保护模式下,虚地址到实地址转换经过MMU(内存管理单元),也就是分段与分页机制,寻址4G。
保护有两层含义:1、任务间保护:多任务操作系统中,一个任务不能破坏另一个任务的代码,这是通过内存分页以及不同任务的内存页映射到不同物理内存上来实现的。
2、任务内保护:系统代码与应用程序代码虽处于同一地址空间,但系统代码具有高优先级,应用程序代码处于低优先级,规定只能高优先级代码访问低优先级代码,这样杜绝用户代码破坏系统代码。
这是通过段式管理来实现,4G虚拟内存中,代码数据和堆栈各占有一个段,段是一个独立有意义的内存单元,有基地址和边界以及本段的优先级,windows系统有两个优先级,Ring0(高优先级)或Ring3(低优先级),系统代码段和数据段属于Ring0,不能被用户代码(Ring3)访问。
实模式:16bit的8086处理器标志着IntelX86王朝的开始,并且引入了一个重要概念——段。
8086处理器地址总线扩展到 20位,但算术逻辑运算单元(ALU)宽度即数据总线却只有16位,也就是直接运算的指针长度是16位的。
为支持1M寻址空间,引入分段的方法。
为支持分段8086CPU设置四个16bit段寄存器:CS、DS、SS、ES,对应于地址总线中的高16位。
寻址时,段寄存器*0x10+偏移地址=物理地址。
80x86保护模式系列教程(1)保护方式简介一.保护方式简介80386有三种工作方式:实模式,保护模式和虚拟8086模式。
本文介绍保护方式下的80386及相关的程序设计内容。
实模式下的80386寄存器,寻址方式和指令等基本概念,除特别说明外在保护方式下仍然保持。
尽管实方式下80386的功能要大大超过其先前的处理器(8086/8088,80186,80286),但只有在保护方式下, 8038 6才能真正发挥更大的作用。
在保护方式下,全部32条地址线有效,可寻址高达4G字节的物理地址空间;扩充的存储器分段管理机制和可选的存储器分页管理机制,不仅为存储器共享和保护提供了硬件支持,而且为实现虚拟存储器提供了硬件支持;支持多任务,能够快速地进行任务切换和保护任务环境;4个特权级和完善的特权检查机制,既能实现资源共享又能保证代码和数据的安全和保密及任务的隔离;支持虚拟8086方式,便于执行8086程序。
<一>存储管理机制为了对存储器中的程序及数据实现保护和共享提供硬件支持,为了对实现虚拟存储器提供硬件支持,在保护方式下,80386不仅采用扩充的存储器分段管理机制,而且提供可选的存储器分页管理机制。
这些存储管理机制由803 86存储管理部件MMU实现。
1.目标80386有32根地址线,在保护方式下,它们都能发挥作用,所以可寻址的物理地址空间高达4G字节。
在以8038 6及其以上处理器为CPU的PC兼容机系统中,把地址在1M以下的内存称为常规内存,把地址在1M 以上的内存称为扩展内存。
80386还要对实现虚拟存储器提供支持。
虽然与8086可寻址的1M字节物理地址空间相比,80386可寻址的物理地址空间可谓很大,但实际的微机系统不可能安装如此达的物理内存。
所以,为了运行大型程序和真正实现多任务,必须采用虚拟存储器。
虚拟存储器是一种软硬件结合的技术,用于提供比在计算机系统中实际可以使用的物理主存储器大得多的存储空间。
8.2 用户程序的结构8.2.1 分段、段的汇编地址和段内汇编地址处理器的工作模式是将内存分成逻辑上的段,指令的获取和数据的访问一律按“段地址:偏移地址”的方式进行。
NASM编译器使用汇编指令“SECTION”或者“SEGMENT”来定义段。
它的一般格式是SECTION段名称SEGMENT段名称align子句理论上,如果不考虑段的对齐方式,那么段data1的汇编地址是0,段data2的汇编地址是1,段data3的汇编地址是2。
段的汇编地址其实就是段内第一个元素(数据、指令)的汇编地址。
在段data1中声明和初始化的0x55位于汇编地址0x00000000处。
编译器将0x00000010作为段data2的汇编地址,并在两个段之间填充15字节的0x00段data3的汇编地址就是0x00000020(十进制的32)。
段data3只有1字节8.2.2 用户程序头部用户程序实际上定义了7个段,分别是第7行定义的段header、第27行定义的段code_1、第163行定义的段code_2、第173行定义的段data_1、第194行定义的段data_2、第201行定义的段stack和第208行定义的段trail。
第7行:SECTION header vstart=0用户程序头部起码要包含以下信息。
①用户程序的尺寸,即以字节为单位的大小。
②应用程序的入口点,包括段地址和偏移地址。
第11、12行,依次声明并初始化了入口点的偏移地址和段地址。
代码段code_1是在代码清单8-2的第27行定义的:SECTION code_1 align=16 vstart=0③段重定位表。
8.3 加载程序(器)的工作流程8.3.1 初始化和决定加载位置第6行,加载器程序的一开始声明了一个常数(const):app_lba_start equ 100常数是用伪指令equ声明的,它的意思是“等于”。
本语句的意思是,用标号app_lba_start 来代表数值100,app_lba_start equ 500用equ声明的数值不占用任何汇编地址,也不在运行时占用任何内存位置。
1,第42页,检测点4.2,第1题。
本程序有误,正确的内容是:(由网易邮箱读者'小小鸟'、QQ读者'闪耀'、'流星梦'和'二玉'发现)
mov ax,0xb800
mov ds,ax
mov byte [0x00],'a'
mov byte [0x02],'s'
mov byte [0x04],'m'
jmp $
times 510-($-$$) db 0
db 0x55,0xaa
2,第52页,第24行,正确的内容是:(由QQ读者'闪耀'发现)
mov ax,[0x02] ;按字操作
3,第53页,第4行,正确的内容是:(由QQ读者'tome'发现)
mov [0x02],bl
4,第65、80、94、129、138页中,需要更正和明确loop指令、短转移指令jmp short、相对近转移指令jmp near和相对近调用指令call near的操作数计算方法和执行过程。
(由网易邮箱读者'小小鸟'、QQ读者'艾小羊'提出)
首先,这些指令的操作数都是相对于目标位置处的偏移量。
但需要指出的是,偏移量的计算方法取决于实际的编译器,书中所说的“用目标位置处的汇编地址减去当前指令的汇编地址,再减去当前指令的长度”,不应算错。
其次,处理器的执行过程严格地说,是非IA-32架构的组成部分。
因此,除了结果是确定的,各步骤的先后次序取决于处理器的设计。
历史上,指令的执行过程有不同的解释和说法。
但本书对这些指令执行过程的解释比较模糊和武断。
为严谨起见,再统一描述如下:在以上指令的编译阶段,编译器用目标位置处的汇编地址减去当前指令的下一条指令的汇编地址,结果做为操作数;处理器在执行一条指令时,指令指针寄存器IP会自动指向下一条指令。
因此,当以上指令执行时,IP的内容就是下一条指令的偏移地址。
处理器用IP的内容加上指令的操作数(如果是call near指令,还要压入IP的内容),并用该值取代IP中的原有内容。
5,第79页,检测点6.1。
正确的内容是:(由QQ读者'闪耀'发现)
选择填空:MOVSB指令每次传送一个(),MOVSW指令每次……
6,第86页,第26行:(由QQ读者'闪耀'发现)
原指令为“idiv bl”,正确的是“idiv bx”
7,第92页,检测点6.4,第2题,(由QQ读者'闪耀'发现)
中间一句的正确内容是:“AX的内容等于BX的内容时,转移到标号lbz处执行;”8,第101页,7.5.2节。
本节第10行:(由QQ读者'闪耀'发现)
正确的内容是:“……为了方便,源程序第50行,直接将DL中的余数……。
”
9,第104页,7.5.4节。
本节第12行。
(由QQ读者'闪耀'发现)
正确的内容是:mov ax,cs
10,第136页,倒数第11行。
(由QQ读者'闪耀'发现)
正确的内容是:第四种指令格式和第三种类似,只是……
11,第137页,倒数第14行。
(由QQ读者'tome发现)
正确的内容是:如图8-15所示。
12,第144页,8.4.6小节内第2行。
少了一个字。
应当是“为此,需要首先识别出它们。
”
13,第152页,倒数第3行。
(由QQ读者'闪耀'发现)
应改为“那么它每个引脚IR0~IR7所对应的中断号分别为0x08~0x0F。
”
14,第155页,图9-4。
(由QQ读者'艾小羊'提出)
改为下图:。