
https://www.doczj.com/doc/8f15600480.html,
微博爬虫如何爬取数据
微博上有大量的信息,很多用户会有采集微博信息的需求,对于不会写爬虫的小白来说可能是一件难事。本文介绍一个小白也可以使用的工具是如何爬取数据的。
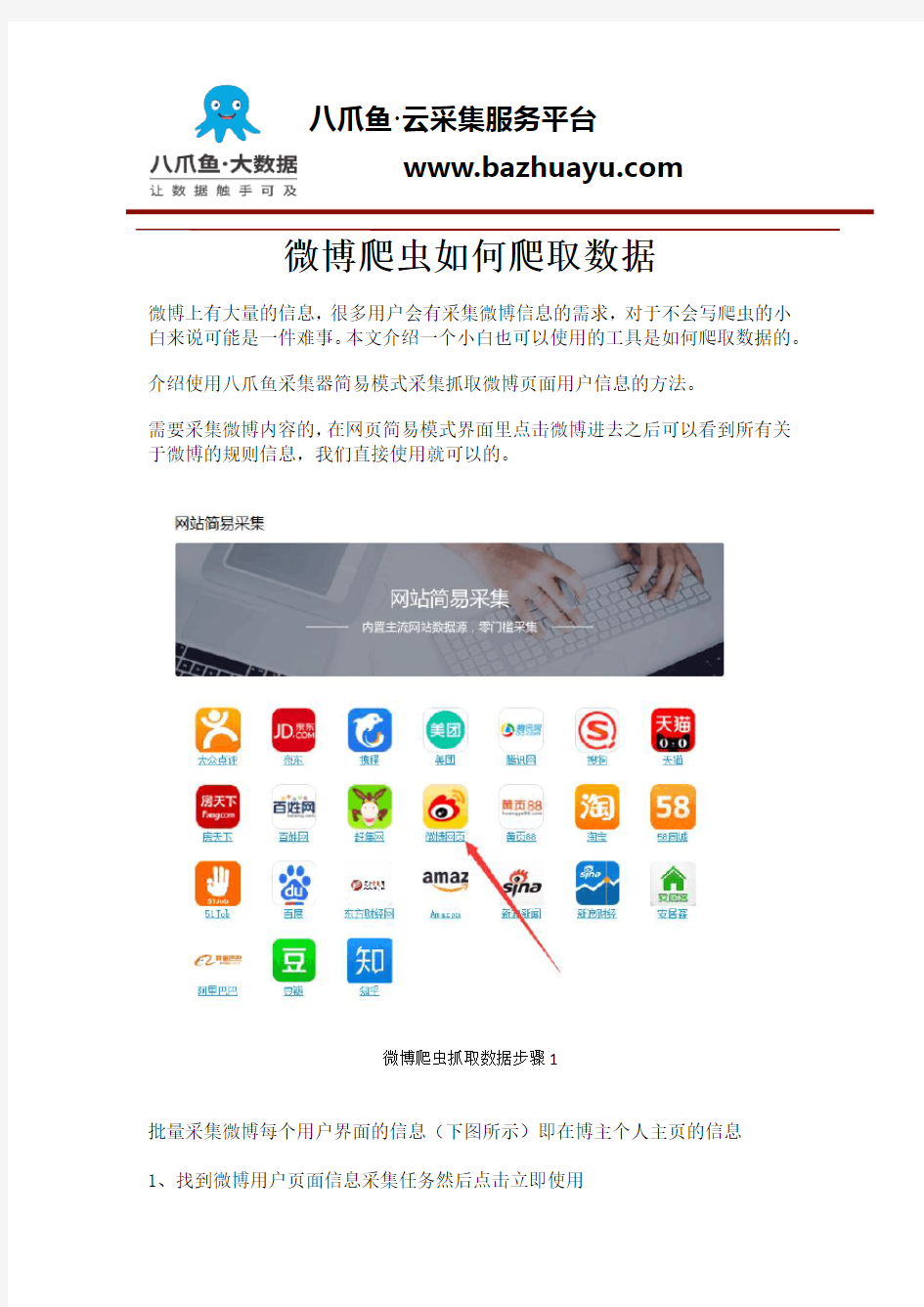
介绍使用八爪鱼采集器简易模式采集抓取微博页面用户信息的方法。
需要采集微博内容的,在网页简易模式界面里点击微博进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。
微博爬虫抓取数据步骤1
批量采集微博每个用户界面的信息(下图所示)即在博主个人主页的信息
1、找到微博用户页面信息采集任务然后点击立即使用
https://www.doczj.com/doc/8f15600480.html,
微博爬虫抓取数据步骤2
2、简易采集中微博用户页面信息采集的任务界面介绍
查看详情:点开可以看到示例网址;
任务名:自定义任务名,默认为微博用户页面信息采集;
任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组;
网址:用于填写博主个人主页的网址,可以填写多个,用回车分隔,一行一个,将鼠标移动到?号图标和任务名顶部文字均可以查看详细的注释信息;
示例数据:这个规则采集的所有字段信息。
https://www.doczj.com/doc/8f15600480.html,
微博爬虫抓取数据步骤3
3、任务设置示例
例如要采集与相关的微博消息
在设置里如下图所示:
任务名:自定义任务名,也可以不设置按照默认的就行
任务组:自定义任务组,也可以不设置按照默认的就行
网址:从浏览器中直接复制博主个人主页的网址,此处以“人民日报”和“雷军”为例。示例网址:https://www.doczj.com/doc/8f15600480.html,/rmrb?is_all=1
https://www.doczj.com/doc/8f15600480.html,/leijun?refer_flag=1001030103_&is_all=1
设置好之后点击保存
https://www.doczj.com/doc/8f15600480.html,
微博爬虫抓取数据步骤4
保存之后会出现开始采集的按钮
微博爬虫抓取数据步骤5
https://www.doczj.com/doc/8f15600480.html,
4、选择开始采集之后系统将会弹出运行任务的界面
可以选择启动本地采集(本地执行采集流程)或者启动云采集(由云服务器执行采集流程),这里以启动本地采集为例,我们选择启动本地采集按钮。
微博爬虫抓取数据步骤6
5、选择本地采集按钮之后,系统将会在本地执行这个采集流程来采集数据,下
图为本地采集的效果
https://www.doczj.com/doc/8f15600480.html,
微博爬虫抓取数据步骤7
6、采集完毕之后选择导出数据按钮即可,这里以导出excel2007为例,选择这
个选项之后点击确定
微博爬虫抓取数据步骤8
https://www.doczj.com/doc/8f15600480.html, 7、然后选择文件存放在电脑上的路径,路径选择好之后选择保存
微博爬虫抓取数据步骤9
8、这样数据就被完整的导出到自己的电脑上来了
微博爬虫抓取数据步骤10
https://www.doczj.com/doc/8f15600480.html,
https://www.doczj.com/doc/8f15600480.html,
网络爬虫工作原理 1 聚焦爬虫工作原理及关键技术概述 网络爬虫是一个自动提取网页的程序,它为搜索引擎从Internet网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。 相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题: (1) 对抓取目标的描述或定义; (2) 对网页或数据的分析与过滤; (3) 对URL的搜索策略。 抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。 2 抓取目标描述 现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征、基于目标数据模式和基于领域概念3种。 基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。根据种子样本获取方式可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标注的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。现有的聚焦爬虫对抓取目标的描述或定义可以分为基于目标网页特征,基于目标数据模式和基于领域概念三种。 基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。具体的方法根据种子样本的获取方式可以分为:(1)预先给定的初始抓取种子样本;(2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等;(3)通过用户行为确定的抓取目标样例。其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。 基于目标数据模式的爬虫针对的是网页上的数据,所抓取的数据一般要符合一定的模式,或者可以转化或映射为目标数据模式。
https://www.doczj.com/doc/8f15600480.html, 微博数据抓取方法详细步骤 很多朋友想要采集微博上面的有用信息,对于繁多的信息量,需要手动的复制,粘贴,修改格式吗?不用这么麻烦!教你一键收集海量数据。 本文介绍使用八爪鱼采集器简易模式采集抓取新浪微博的方法。 需要采集微博内容的,在网页简易模式界面里点击微博进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。 新浪微博数据抓取步骤1 采集在微博首页进关键词搜索后的信息以及发文者的关注量,粉丝数等(下图所示)即打开微博主页进行登录后输入关键词进行搜索,采集搜索到的内容以及进入发文者页面采集关注量,粉丝数,微博数。
https://www.doczj.com/doc/8f15600480.html, 1、找到微博网页-关键词搜索规则然后点击立即使用 新浪微博数据抓取步骤2 2、简易模式中微博网页-关键词搜索的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为微博网页-关键词搜索 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组用户名:请填写您的微博账号 密码:请填写微博账号的登录密码 关键词/搜索词:用于搜索的关键词,只支持填写一个 翻页次数:设置采集多少页,由于微博会封账号,限制翻页1-50页 将鼠标移动到?号图标和任务名顶部文字均可以查看详细的注释信息。示例数据:这个规则采集的所有字段信息。
https://www.doczj.com/doc/8f15600480.html, 新浪微博数据抓取步骤3 3、任务设置示例 例如要采集与十九大相关的微博消息 在设置里如下图所示: 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 用户名:请填写您的微博账号,必填 密码:请填写微博账号的登录密码,必填 关键词/搜索词:用于搜索的关键词,此处填写“十九大” 翻页次数:设置采集多少页,此处设置2页 设置好之后点击保存
如何抓取网页数据,以抓取安居客举例 互联网时代,网页上有丰富的数据资源。我们在工作项目、学习过程或者学术研究等情况下,往往需要大量数据的支持。那么,该如何抓取这些所需的网页数据呢? 对于有编程基础的同学而言,可以写个爬虫程序,抓取网页数据。对于没有编程基础的同学而言,可以选择一款合适的爬虫工具,来抓取网页数据。 高度增长的抓取网页数据需求,推动了爬虫工具这一市场的成型与繁荣。目前,市面上有诸多爬虫工具可供选择(八爪鱼、集搜客、火车头、神箭手、造数等)。每个爬虫工具功能、定位、适宜人群不尽相同,大家可按需选择。本文使用的是操作简单、功能强大的八爪鱼采集器。以下是一个使用八爪鱼抓取网页数据的完整示例。示例中采集的是安居客-深圳-新房-全部楼盘的数据。 采集网站:https://https://www.doczj.com/doc/8f15600480.html,/loupan/all/p2/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
如何抓取网页数据,以抓取安居客举例图1 2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
如何抓取网页数据,以抓取安居客举例图2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,以建立一个翻页循环
如何抓取网页数据,以抓取安居客举例图3 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里的第一个楼盘信息区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
如何抓取网页数据,以抓取安居客举例图4 2)系统会自动识别出页面中的其他同类元素,在操作提示框中,选择“选中全部”,以建立一个列表循环
网络爬虫技术 网络机器人 1.概念: 它们是Web上独自运行的软件程序,它们不断地筛选数据,做出自己的决定,能够使用Web获取文本或者进行搜索查询,按部就班地完成各自的任务。 2.分类: 购物机器人、聊天机器人、搜索机器人(网络爬虫)等。 搜索引擎 1.概念: 从网络上获得网站网页资料,能够建立数据库并提供查询的系统。 2.分类(按工作原理): 全文搜索引擎、分类目录。 1> 全文搜索引擎数据库是依靠网络爬虫通过网络上的各种链接自动获取大量 网页信息内容,并按一定的规则分析整理形成的。(百度、Google) 2> 分类目录:按目录分类的网站链接列表而已,通过人工的方式收集整理网 站资料形成的数据库。(国内的搜狐) 网络爬虫 1.概念: 网络爬虫也叫网络蜘蛛,它是一个按照一定的规则自动提取网页程序,其会自动的通过网络抓取互联网上的网页,这种技术一般可能用来检查你的站点上所有的链接是否是都是有效的。当然,更为高级的技术是把网页中的相关数据保存下来,可以成为搜索引擎。 搜索引擎使用网络爬虫寻找网络内容,网络上的HTML文档使用超链接连接了起来,就像织成了一张网,网络爬虫也叫网络蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序将这个网页抓下来,将内容抽取出来,同时抽取超链接,作为进一步爬行的线索。网络爬虫总是要从某个起点开始爬,这个起点叫做种子,你可以告诉它,也可以到一些网址列表网站上获取。
现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征、基于目标数据模式和基于领域概念3种。 基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。根据种子样本获取方式可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如Y ahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标注的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。 一些算法的介绍 1> 网页分析算法
https://www.doczj.com/doc/8f15600480.html, 本文介绍使用八爪鱼7.0采集新浪微博博主信息的方法(以艺术分类为例)采集网站: 使用功能点: ●翻页元素设置 ●列表内容提取 相关采集教程: 新浪微博数据采集 豆瓣电影短评采集 搜狗微信文章采集 步骤1:创建采集任务 1)进入主界面选择,选择自定义模式
https://www.doczj.com/doc/8f15600480.html, 微博博主信息采集方法以及详细步骤图1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 微博博主信息采集方法以及详细步骤图2
https://www.doczj.com/doc/8f15600480.html, 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容 微博博主信息采集方法以及详细步骤图3 步骤2:设置翻页步骤 创建翻页循环,设置翻页元素 1)页面下拉到底部,找到“下一页”按钮,点击选择“循环点击下一页”
https://www.doczj.com/doc/8f15600480.html, 微博博主信息采集方法以及详细步骤图4 2)设置翻页步骤:打开流程图,点击“循环翻页”步骤,在右侧点击“自定义” 微博博主信息采集方法以及详细步骤图5 注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
https://www.doczj.com/doc/8f15600480.html, 3)如图选择好翻页点击元素的xpath ,点击“确定”,完成翻页步骤的设置 微博博主信息采集方法以及详细步骤图 6 步骤3:采集博主信息 选中需要采集列表中的信息框,创建数据提取列表 1)如图,移动鼠标选中博主信息栏,右键点击,选择“选中子元素” 微博博主信息采集方法以及详细步骤图7
https://www.doczj.com/doc/8f15600480.html, 2)然后点击“选中全部” 微博博主信息采集方法以及详细步骤图8 注意:鼠标点击“X”,即可删除不需要字段。 微博博主信息采集方法以及详细步骤图9
网络爬虫详解 一、爬虫技术研究综述 引言 随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine),例如传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,如: (1) 不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。 (2) 通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。 (3) 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频/视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。 (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。 为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫(general purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。 1 聚焦爬虫工作原理及关键技术概述 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件,如图1(a)流程图所示。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,如图1(b)所示。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。 相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题: (1) 对抓取目标的描述或定义; (2) 对网页或数据的分析与过滤; (3) 对URL的搜索策略。 抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。
https://www.doczj.com/doc/8f15600480.html, 新浪微博数据抓取详细教程 本文介绍使用八爪鱼采集器简易模式采集抓取新浪微博的方法。 需要采集微博内容的,在网页简易模式界面里点击微博进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。 新浪微博数据抓取步骤1 采集在微博首页进关键词搜索后的信息以及发文者的关注量,粉丝数等(下图所示)即打开微博主页进行登录后输入关键词进行搜索,采集搜索到的内容以及进入发文者页面采集关注量,粉丝数,微博数。 1、找到微博网页-关键词搜索规则然后点击立即使用
https://www.doczj.com/doc/8f15600480.html, 新浪微博数据抓取步骤2 2、 简易模式中微博网页-关键词搜索的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为微博网页-关键词搜索 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 用户名:请填写您的微博账号 密码:请填写微博账号的登录密码 关键词/搜索词:用于搜索的关键词,只支持填写一个 翻页次数: 设置采集多少页,由于微博会封账号,限制翻页1-50页 将鼠标移动到?号图标和任务名顶部文字均可以查看详细的注释信息。 示例数据:这个规则采集的所有字段信息。
https://www.doczj.com/doc/8f15600480.html, 新浪微博数据抓取步骤3 3、任务设置示例 例如要采集与十九大相关的微博消息 在设置里如下图所示: 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 用户名:请填写您的微博账号,必填 密码:请填写微博账号的登录密码,必填 关键词/搜索词:用于搜索的关键词,此处填写“十九大” 翻页次数:设置采集多少页,此处设置2页 设置好之后点击保存
https://www.doczj.com/doc/8f15600480.html, 网站爬虫如何爬取数据 大数据时代,用数据做出理性分析显然更为有力。做数据分析前,能够找到合适的的数据源是一件非常重要的事情,获取数据的方式有很多种,最简便的方法就是使用爬虫工具抓取。今天我们用八爪鱼采集器来演示如何去爬取网站数据,以今日头条网站为例。 采集网站: https://https://www.doczj.com/doc/8f15600480.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式” 网站爬虫如何爬取数据图1
https://www.doczj.com/doc/8f15600480.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站爬虫如何爬取数据图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.doczj.com/doc/8f15600480.html, 网站爬虫如何爬取数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定
https://www.doczj.com/doc/8f15600480.html, 网站爬虫如何爬取数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量
https://www.doczj.com/doc/8f15600480.html, 网站爬虫如何爬取数据图5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”
微博内容提取 摘要 随着近年来微博等社交软件的使用人数日益增多,微博的隐私发展也成为人们日益关注的问题,然而由于微博没有固定的格式约束使得在微博的研究过程中有一些无意义的“噪音”的干扰,本文主要是为了完成微博的“噪音”过滤问题,实现一个小软件,来将新浪微博等微博中下载到本地的微博来进行过滤,去除其中的噪音,提取出纯净的页面内容,主要工作包括以下几个方面: (1)字符串的查找函数与分割函数的实现。 (2)多个文件的查找的函数的实现。 (3)固定字符串的即表情“噪音”的过滤实现。 (4)具有一定正则文法的“噪音”的过滤实现。 关键字:中文微博,微博,过滤,噪音,正则
Microblogging content extraction Author: Liudi Tutor: Yangkexin Abstract With recent years the number of micro-blog using social software is increasing, the development of micro-blog privacy has become a growing concern,However, due to the micro blog there is no fixed format constraint makes the interference of some meaningless "noise" in the research process of micro blog. the purpose of this paper is to complete the "noise" micro-blog filtering problem, the realization of a small software, to be used for filtering the download to the Sina micro-blog micro-blog etc., remove the noise, extract the page content is pure, the main work includes the following aspects: (1) the search function and the function of the string segmentation. (2) the implementation of the search function for multiple files (3) the filter of the expression "noise" of the fixed string. (4) the filter of a certain regular grammar "noise" of the fixed string. Keywords: Chinese micro-blog,micro-blog,filtering ,noise ,regular
https://www.doczj.com/doc/8f15600480.html, 如何抓取网页数据 很多用户不懂爬虫代码,但是却对网页数据有迫切的需求。那么怎么抓取网页数据呢? 本文便教大家如何通过八爪鱼采集器来采集数据,八爪鱼是一款通用的网页数据采集器,可以在很短的时间内,轻松从各种不同的网站或者网页获取大量的规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑,规范化,摆脱对人工搜索及收集数据的依赖,从而降低获取信息的成本,提高效率。 本文示例以京东评论网站为例 京东评价采集采集数据字段:会员ID,会员级别,评价星级,评价内容,评价时间,点赞数,评论数,追评时间,追评内容,页面网址,页面标题,采集时间。 需要采集京东内容的,在网页简易模式界面里点击京东进去之后可以看到所有关于京东的规则信息,我们直接使用就可以的。
https://www.doczj.com/doc/8f15600480.html, 京东评价采集步骤1 采集京东商品评论(下图所示)即打开京东主页输入关键词进行搜索,采集搜索到的内容。 1、找到京东商品评论规则然后点击立即使用
https://www.doczj.com/doc/8f15600480.html, 京东评价采集步骤2 2、简易模式中京东商品评论的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为京东商品评论 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 商品评论URL列表:提供要采集的网页网址,即商品评论页的链接。每个商品的链接必须以#comment结束,这个链接可以在商品列表点评论数打开后进行复制。或者自己打开商品链接后手动添加,如果没有这个后缀可能会报错。多个商品评论输入多个商品网址即可。 将鼠标移动到?号图标可以查看详细的注释信息。 示例数据:这个规则采集的所有字段信息。
https://www.doczj.com/doc/8f15600480.html, 微信文章抓取工具详细使用方法 如今越来越多的优质内容发布在微信公众号中,面对这些内容,有些朋友就有采集下来的需求,下面为大家介绍使用八爪鱼抓取工具去抓取采集微信文章信息。 抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。 采集网站:https://www.doczj.com/doc/8f15600480.html,/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
https://www.doczj.com/doc/8f15600480.html, 微信文章抓取工具详细使用步骤1 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/8f15600480.html, 微信文章抓取工具详细使用步骤2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”
https://www.doczj.com/doc/8f15600480.html, 微信文章抓取工具详细使用步骤3 2)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮 微信文章抓取工具详细使用步骤4
https://www.doczj.com/doc/8f15600480.html, 3)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮” 微信文章抓取工具详细使用步骤5 4)页面中出现了 “八爪鱼大数据”的文章搜索结果。将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
https://www.doczj.com/doc/8f15600480.html, 微信文章抓取工具详细使用步骤6 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里第一篇文章的区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
网络爬虫基本原理 网络爬虫根据需求的不同分为不同种类: 1. 一种是爬取网页链接,通过url链接得到这个html页面中指定的链接,把这 些链接存储起来,再依次以这些链接为源,再次爬取链接指向html页面中的链接……如此层层递归下去,常用的方法是广度优先或者深度优先,根据爬取层次需求不同而选择不同的方法达到最优效果,爬虫的效率优化是一个关键。搜索引擎的第一个步骤就是通过爬虫得到需要索引的链接或数据,存放于数据库,然后对这些数据建立索引,然后定义查询语句,解析查询语句并利用检索器对数据库里的数据进行检索。 2. 一种是爬取数据信息,如文本信息、图片信息等,有时需要做数据分析,通 过某种手段来获取数据样本以供后续分析,常用的方法是爬虫获取指定数据样本或利用现有的公共数据库。本文的微博爬虫和新闻数据爬取都属于第二种类,根据自定义搜索关键字爬取微博信息数据。 3. 对于网络爬虫原理,其实并不复杂。基本思路是:由关键字指定的url把所 有相关的html页面全抓下来(html即为字符串),然后解析html文本(通常是正则表达式或者现成工具包如jsoup),提取微博文本信息,然后把文本信息存储起来。 重点在于对html页面源码结构的分析,不同的html需要不同的解析方法;还有就是长时间爬取可能对IP有影响,有时需要获取代理IP,甚至需要伪装浏览器爬取。(主要是针对像新浪等这些具有反扒功能的网站,新闻网站一般不会有这样的情况)。 对于微博,通常情况下是必须登录才能看到微博信息数据(比如腾讯微博),但是有的微博有搜索机制,在非登录的情况下可以直接通过搜索话题来查找相关信息(如新浪微博、网易微博)。考虑到某些反爬虫机制,如果一个账号总是爬取信息可能会有些影响(比如被封号),所以本文采用的爬虫都是非登录、直接进入微博搜索页面爬取。这里关键是初始url地址。 网络爬虫是搜索引擎抓取系统的重要组成部分。爬虫的主要目的是是将互联网上的网页下载到本地形成一个活互联网内容的镜像备份。这篇博客主要对爬虫及抓取系统进行一个简单的概述。 一、网络爬虫的基本结构及工作流程 通用的网络爬虫的框架如图所示:
网络爬虫 摘要随着互联网的日益壮大,搜索引擎技术飞速发展。搜索引擎已成为人们在浩瀚的网络世界中获取信息必不可少的工具,利用何种策略有效访问网络资源成为专业搜索引擎中网络爬虫研究的主要问题。文章介绍了搜索引擎的分类及其工作原理.阐述了网络爬虫技术的搜索策略,对新一代搜索引擎的发展趋势进行了展望。 关键词网络爬虫;策略;搜索引擎 概念: 网络爬虫也叫网络蜘蛛,它是一个按照一定的规则自动提取网页程序,其会自动的通过网络抓取互联网上的网页,这种技术一般可能用来检查你的站点上所有的链接是否是都是有效的。当然,更为高级的技术是把网页中的相关数据保存下来,可以成为搜索引擎。 搜索引擎使用网络爬虫寻找网络内容,网络上的HTML文档使用超链接连接了起来,就像织成了一张网,网络爬虫也叫网络蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序将这个网页抓下来,将内容抽取出来,同时抽取超链接,作为进一步爬行的线索。网络爬虫总是要从某个起点开始爬,这个起点叫做种子,你可以告诉它,也可以到一些网址列表网站上获取。 网络爬虫的构成及分类 网络爬虫又被称为做网络蜘蛛、网络机器人,主要用于网络资源的收集工作。在进行网络舆情分析时,首要获取舆情信息内容,这就需要用到网络爬虫(蜘蛛程序)这个工具,它是一个能自动提取网页内容的程序,通过搜索引擎从互联网上爬取网页地址并抓取相应的网页内容,是搜索引擎(Search Engine)的重要组成部分。 一个典型的网络爬虫主要组成部分如下: 1. URL 链接库,主要用于存放爬取网页链接。 2. 文档内容模块,主要用于存取从Web 中下载的网页内容。 3. 文档解析模块,用于解析下载文档中的网页内容,如解析PDF,Word,HTML 等。 4. 存储文档的元数据以及内容的库。 5. 规范化URL 模块,用于把URL 转成标准的格式。 6. URL 过滤器,主要用于过滤掉不需要的URL。 上述模块的设计与实现,主要是确定爬取的内容以及爬去的范围。最简单的例子是从一个已知的站点抓取一些网页,这个爬虫用少量代码就可以完成。然而在实际互联网应用中,可能会碰到爬去大量内容需求,就需要设计一个较为复杂的爬虫,这个爬虫就是N个应用的组成,并且难点是基于分布式的。 网络爬虫的工作原理 传统网路爬虫的工作原理是,首先选择初始URL,并获得初始网页的域名或IP 地址,然后在抓取网页时,不断从当前页面上获取新的URL 放入候选队列,直到满足停止条件。聚焦爬虫(主题驱动爬虫)不同于传统爬虫,其工作流程比较复杂,首先需要过滤掉跟主题不相关的链接,只保留有用的链接并将其放入候选URL 队列。然后,根据搜索策略从候选队列中选择下一个要抓取的网页链接,并重复上述过程,直到满足终止条件为止。与此同时,将所有爬取的网页内容保存起来,并进行过滤、分析、建立索引等以便进行性检索和查询。总体来讲,网络爬虫主要有如下两个阶段: 第一阶段,URL 库初始化然后开始爬取。
https://www.doczj.com/doc/8f15600480.html, 微博爬虫一天可以抓取多少条数据 微博是一个基于用户关系信息分享、传播以及获取的平台。用户可以通过WEB、WAP等各种客户端组建个人社区,以140字(包括标点符号)的文字更新信息,并实现即时分享。 微博作为一种分享和交流平台,十分更注重时效性和随意性。微博平台上产生了大量的数据。而在数据抓取领域,不同的爬虫工具能够抓取微博数据的效率是质量都是不一样的。 本文以八爪鱼这款爬虫工具为例,具体分析其抓取微博数据的效率和质量。 微博主要有三大类数据 一、博主信息抓取 采集网址:https://www.doczj.com/doc/8f15600480.html,/1087030002_2975_2024_0 采集步骤:博主信息抓取步骤比较简单:打开要采集的网址>建立翻页循环(点击下一页)>建立循环列表(直接以博主信息区块建立循环列表)>采集并导出数据。 采集结果:一天(24小时)可采集上百万数据。
https://www.doczj.com/doc/8f15600480.html, 微博爬虫一天可以抓取多少条数据图1 具体采集步骤,请参考以下教程:微博大号-艺术类博主信息采集 二、发布的微博抓取 采集网址: 采集步骤:这类数据抓取较为复杂,打开网页(打开某博主的微博主页,经过2次下拉加载,才会出现下一页按钮,因而需对步骤,进行Ajax下拉加载设置)>建立翻页循环(此步骤与打开网页步骤同理,当翻到第二页时,同样需要经过2次下来加载。因而也需要进行Ajax下拉加载设置)>建立循环列表(循环点击每条微博链接,以建立循环列表)>采集
https://www.doczj.com/doc/8f15600480.html, 并导出数据(进入每条微博的详情页,采集所需的字段,如:博主ID、微博发布时间、微博来源、微博内容、评论数、转发数、点赞数)。 采集结果:一天(24小时)可采集上万的数据。 微博爬虫一天可以抓取多少条数据图2 具体采集步骤,请参考以下教程:新浪微博-发布的微博采集 三、微博评论采集 采集网址: https://https://www.doczj.com/doc/8f15600480.html,/mdabao?is_search=0&visible=0&is_all=1&is_tag=0&profile_fty pe=1&page=1#feedtop 采集步骤:微博评论采集,采集规则也比较复杂。打开要采集的网页(打开某博主的微博主
https://www.doczj.com/doc/8f15600480.html, 如何利用八爪鱼爬虫抓取数据 听说很多做运营的同学都用八爪鱼采集器去抓取网络数据,最新视频,最热新闻等,但还是有人不了解八爪鱼爬虫工具是如何使用的。 所以本教程以百度视频为例,为大家演示如何采集到页面上的视频,方便工作使用。 常见场景: 1、遇到需要采集视频时,可以采集视频的地址(URL),再使用网页视频下载器下载视频。 2、当视频链接在标签中,可切换标签进行采集。 3、当视频链接在标签中,也可采集源码后进行格式化数据。 操作示例: 采集要求:采集百度视频上综艺往期视频 示例网址:https://www.doczj.com/doc/8f15600480.html,/show/list/area-内地+order-hot+pn-1+channel-tvshow 操作步骤: 1、新建自定义采集,输入网址后点击保存。
https://www.doczj.com/doc/8f15600480.html, 注:点击打开右上角流程按钮。
https://www.doczj.com/doc/8f15600480.html, 2、创建循环翻页,找到采集页面中下一页按钮,点击,执行“循环点击下一页”。 在流程中的点击翻页勾选Ajax加载数据,时间设置2-3秒。
https://www.doczj.com/doc/8f15600480.html, 3、创建循环点击列表。点击第一张图片,选择“选中全部”(由于标签可能不同,会导致无法选中全部,可以继续点击没被选中的图片) 继续选择循环点击每个元素
https://www.doczj.com/doc/8f15600480.html, 4、进入详情页后,点击视频标题(从火狐中可以看到视频链接在A标签中,如图所示),所以需要手动更换到相应的A标签。 手动更换为A标签:
https://www.doczj.com/doc/8f15600480.html, 更换为A标签后,选择“选中全部”,将所有视频标题选中,此时就可以采集视频链接地址。 5、所有操作设置完毕后,点击保存。然后进行本地采集,查看采集结果。
https://www.doczj.com/doc/8f15600480.html, 微博上面有很多我们想要收集的信息,有没有什么简单的方法做到一键收集提取呢。当然是有的,本文介绍使用八爪鱼7.0采集新浪微博数据的方法,供大家学习参考。 采集网站: https://https://www.doczj.com/doc/8f15600480.html,/1875781361/FhuTqwUjk?from=page_1005051875781361_profile&wvr=6&m od=weibotime&type=comment#_rnd1503315170479 使用功能点: ●Ajax滚动加载设置 ●分页列表详情页内容提取 步骤1:创建采集任务 1)进入主界面选择,选择自定义模式
https://www.doczj.com/doc/8f15600480.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 采集新浪微博数据图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.doczj.com/doc/8f15600480.html, 采集新浪微博数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)在页面打开后,当下拉页面时,会发现页面有新的数据在进行加载
https://www.doczj.com/doc/8f15600480.html, 采集新浪微博数据图4 所以需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 采集新浪微博数据图5 2)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,
https://www.doczj.com/doc/8f15600480.html, python抓取网页数据的常见方法 很多时候爬虫去抓取数据,其实更多是模拟的人操作,只不过面向网页,我们看到的是html在CSS样式辅助下呈现的样子,但爬虫面对的是带着各类标签的html。下面介绍python抓取网页数据的常见方法。 一、Urllib抓取网页数据 Urllib是python内置的HTTP请求库 包括以下模块:urllib.request 请求模块、urllib.error 异常处理模块、urllib.parse url解析模块、urllib.robotparser robots.txt解析模块urlopen 关于urllib.request.urlopen参数的介绍: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url参数的使用 先写一个简单的例子:
https://www.doczj.com/doc/8f15600480.html, import urllib.request response = urllib.request.urlopen(' print(response.read().decode('utf-8')) urlopen一般常用的有三个参数,它的参数如下: urllib.requeset.urlopen(url,data,timeout) response.read()可以获取到网页的内容,如果没有read(),将返回如下内容 data参数的使用 上述的例子是通过请求百度的get请求获得百度,下面使用urllib的post请求 这里通过https://www.doczj.com/doc/8f15600480.html,/post网站演示(该网站可以作为练习使用urllib的一个站点使用,可以 模拟各种请求操作)。 import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
搜索引擎蜘蛛采用什么抓取策略 搜索引擎蜘蛛简称爬虫,它的主要目的是抓取并下载互联网的网页到本地,同时与切词器、索引器一起共同对网页内容进行分词处理,建立索引数据库,促使最终形成用户查询的结果。即使对于商业搜索引擎来说,想要抓取互联网的所有网页也是一件很困难的事情,百度为什么没有Google强大?首先百度对于互联网上信息的抓取量与Google是无法相比的;其次对于爬虫的抓取速度和抓取效率也跟不上Google,这些不是说解决就能解决的,一些技术上的问题很可能会很长时间都无法获得解决。 虽然搜索引擎很难抓取到互联网上的所有网页,但是这也是它必然的目标,搜索引擎会尽量增加抓取数量。那么搜索引擎抓取采用的策略都有什么呢? 目前主要流行的策略有四个:宽度优先遍历策略、Partial PageRank策略、OPIC策略策略、大站优先策略。 一、宽度优先遍历策略 如图所示,宽度优先遍历策略就是将下载完成的网页中发现的链接逐一直接加入待抓取URL,这种方法没有评级网页的重要性,只是机械性地将新下载的网页中URL提取追加入待抓取URL。这种策略属于搜索引擎早期采用的抓取策略,效果很好,以后的新策略也都以这个为基准的。 上图遍历抓取路径:A-B-C-D-E-F G H I 二、Partial PageRank策略 Partial PageRank策略借鉴了PageRank算法的思想,对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL 队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。 通常搜索引擎会采取每当新下载网页达到一个N值后,就将所有下载过的网页计算一个新的PageRank(非完全PageRank值),然后将待抓取URL跟这个进行重新排序。这种方法的争议很大,有人说比宽度优先遍历策略的效果:也有人说这样与PageRank的完整值差别很大,依托这种值的排序不准确。 三、OPIC策略 OPIC策略更像是Partial PageRank策略进行的改进。OPIC策略与Partial PageRank策略大体结构上相同,类似与PageRank评级的网页重要性,每个网页都会有一个10分,然后分别传递给网页上的链接,最后10分清空。通过网页获得的分值高低,评级一个网页的重要性,优先下载获得评分高的URL。这种策略不需要每次都要对新抓取URL进行重新计算分值。
1引言 近年来,社交网络的发展引人注目,参考文献[1]介绍了社交网络的发展现状及趋势。目前,约有一半的中国网民通过社交网络沟通交流、分享信息,社交网络已成为覆盖用户最广、传播影响最大、商业价值最高的Web2.0业务。微博作为一种便捷的媒体交互平台,在全球范围内吸引了数亿用户,已成为人们进行信息交流的重要媒介,用户可以通过微博进行信息记录和交流、娱乐消遣以及社会交往等[2]。 Twitter自2006年由Williams E等人联合推出以来,发展迅猛。Twitter作为一种结合社会化网络和微型博客的新型Web2.0应用形式正风靡国外,其应用涉及商业、新闻教育等社会领域,已成为网络舆论中最具有影响力的一种[3]。 基于微博API的分布式抓取技术 陈舜华1,王晓彤1,郝志峰1,蔡瑞初1,肖晓军2,卢宇2 (1.广东工业大学计算机学院广州510006;2.广州优亿信息科技有限公司广州510630) 摘要:随着微博用户的迅猛增长,越来越多的人希望从用户的行为和微博内容中挖掘有趣的模式。针对如何对微博数据进行有效合理的采集,提出了基于微博API的分布式抓取技术,通过模拟微博登录自动授权,合理控制API的调用频次,结合任务分配控制器高效地获取微博数据。该分布式抓取技术还结合时间触发和内存数据库技术实现重复控制,避免了数据的重复爬取和重复存储,提高了系统的性能。本分布式抓取技术具有可扩展性高、任务分配明确、效率高、多种爬取策略适应不同的爬取需求等特点。新浪微博数据爬取实例验证了该技术的可行性。 关键词:新浪微博;爬取策略;分布式爬取;微博API doi:10.3969/j.issn.1000-0801.2013.08.025 A Distributed Data-Crawling Technology for Microblog API Chen Shunhua1,Wang Xiaotong1,Hao Zhifeng1,Cai Ruichu1,Xiao Xiaojun2,Lu Yu2 (1.School of Computers,Guangdong University of Technology,Guangzhou510006,China; 2.Guangzhou Useease Information Technology Co.,Ltd.,Guangzhou510630,China) Abstract:As more and more users begin to use microblog,people eagerly want to dig interesting patterns from the microblog data.How to efficiently collect data from the service provider is one of the main challenges.To address this issue,a distributed crawling solution based on microblog API was present.The distributed crawling solution simulates microblog login,automatically gets authorized,and control the invoked frequency of the API with a task controller.A time trigger method with memory database was also proposed to avoid extra trivial data duplication and improve efficiency of the system.In the distributed framework,the crawling tasks can be assigned to distributed clients independently,which ensures the high scalability and flexibility of the crawling procedure.The feasibility of the crawler technology according to Sina microblog instance was verified. Key words:Sina microblog,crawling strategy,distributed crawl,microblog API 运营创新论坛 146