esper
- 格式:docx
- 大小:711.64 KB
- 文档页数:68

1.我明白了。
--yo lo se2.我不干了! --yo dimito3. 放手! --sueltame4. 我也是。
--yo tambien5. 天哪! --dios mio6. 不行! --no puede7. 来吧(赶快) --rapido8. 等一等。
-espera momento -9. 我同意。
--acepta10. 还不错。
- -bueno11. 还没。
-todavia no-12. 再见。
--adios13. 闭嘴! --callete o callarse14. 再见。
--adios15. (为什么不呢?) --como no17.安静点! - -silencio18. 振作起来! -inspirar19做得好! --bien trabajo21. 多少钱? --cuando cuesta22. 我饱了。
-- ya llena23. 我回来了。
-ya regreso24. 我迷路了。
-- me perdido25. 我请客。
--es mi cuenta26. 我也一样。
yo tambien -27. 这边请。
-qiu paso28. 您先。
-- tu primero29. 祝福你! -- felicitar30. 跟我来。
--ven comigo31. 休想! (算了!) --es final32. 祝好运! --buena suerte33. 我拒绝! --yo negar34. 我保证。
--yo prometer36 慢点! --mas lento37. 保重! --cuidado uste38. (伤口)疼。
-doler39. 再试试。
-proba otra vez40.当心。
--cuidado41. 有什么事吗? --que paso?42. 注意! --cuidado!43干杯(见底)! --salud!44. 不许动! --no mover45. 猜猜看? -imaginar46. 我怀疑。
![[要略]罕见英文姓氏](https://uimg.taocdn.com/c57c30c477a20029bd64783e0912a21615797f42.webp)
常见英文姓氏常见英文姓氏.txt年轻的时候拍下许多照片,摆在客厅给别人看;等到老了,才明白照片事拍给自己看的。
当大部分的人都在关注你飞得高不高时,只有少部分人关心你飞得累不累,这就是友情!姓Admirind/阿德米林德Aerum/阿埃鲁姆Akvum/阿克乌姆Ambrofaltkhawsen/安布罗法尔特克豪森Ameblo/阿梅布洛Amik/阿米克Amomian/阿莫米安Arbar/阿尔巴尔Barbarkor/巴尔巴尔科尔Bier/比埃尔Bird/比尔德Biterlif/比特尔利夫Bondno/邦德诺Bravul/布拉乌尔Burlu/布尔卢Butik/布蒂克Celum/蔡卢姆Chener/切内尔Chipen/奇彭Delolmo/德洛尔莫Devum/德乌姆Domet/多梅特Ehhum/埃胡姆Emilan/埃米兰Enhhoran/恩霍兰Esper/埃斯佩尔Estrum/埃斯特鲁姆Fajrer/法伊雷尔Famili/法米利Fesanan/费萨南Filopator/菲洛帕托尔Fiskan/菲斯坎Flugil/弗卢吉尔Garan/加兰Geralan/格拉兰Gimik/吉米克Glaving/格拉温格Grinhilt/格林希尔特Gust/古斯特Gharden/扎尔登Hakil/哈基尔Hark/哈尔克Haska/哈斯卡Heldan/海尔丹Herb/赫尔布Homar/霍马尔Horbek/霍尔贝克Hhorum/霍鲁姆Inkuj/因奎Interes/因特雷斯Irlan/伊尔兰Ivens/伊文斯Jablich/亚布利奇Jagu/亚古Jarum/亚鲁姆Junul/尤努尔Jhurnal/茹尔纳尔Kamino/卡米诺Kandeling/坎德林格Kanjas/卡尼亚斯Karlan/卡尔兰Klub/克卢布Kodlar/科德拉尔Korjas/科里亚斯Kovert/科维尔特Kradan/克拉丹Kredeblo/克雷德布洛Kruf/克鲁夫Kudril/库德里尔Kuirej/库伊雷Kunul/库努尔Kuvan/库万Kvarop/克瓦罗普Laget/拉格特Lamris/拉姆里斯Land/兰德Libret/利布雷特Loghej/洛哲伊Lumstel/卢姆斯特尔Makavel/马卡维尔Maksipes/马克西佩斯Marban/马尔班Marist/马里斯特Marsaus/马尔萨乌斯Marum/马鲁姆Mehhkaprad/梅赫卡普拉德Memorind/梅莫林德Montum/蒙图姆Montril/蒙特里尔Nakan/纳坎Nomum/诺穆姆Oktoped/奥克托佩德Ostum/奥斯图姆Paner/帕内尔Panum/帕努姆Pentium/彭蒂乌姆Pentrist/彭特里斯特Pepian/佩皮安Pilk/皮尔克Piruj/皮鲁伊Pluming/普卢明格Plumuj/普卢穆伊Pluver/普卢维尔Pomuj/波穆伊Preghej/普雷哲伊Pulver/普尔维尔Rafnil/拉夫尼尔Ralfan/拉尔凡Rastagan/拉斯塔甘Razil/拉齐尔Regnestrum/雷格内斯特鲁姆Regum/雷古姆Richul/里楚尔Rukspin/鲁克斯平Sabler/萨布雷尔Saghulo/萨朱尔Sagum/萨古姆Saist/萨伊斯特Skatol/斯卡托尔Stelum/斯特卢姆Suker/苏克尔Shlosil/施洛西尔Shuist/舒伊斯特Tander/坦德尔Terikan/特里坎Tipum/蒂普姆Traman/特拉曼Tranchil/特兰奇尔Travis/特拉维斯Urbum/乌尔布姆Vendej/温德伊Verdajh/维尔达日Verum/维鲁姆Vilanan/维拉南Vinberuj/温贝鲁伊Vishon/碧声Vort/沃尔特Zerkos/泽尔科斯Zijat/齐亚特Zorajan/佐拉扬adamsandersonarnoldbakerbellcampbellcartercecilcharleschristiandale david clark clive cook duncan eddy edward evelyn fergus garcia gary george gerard giles green griffin hall harris hill jackson james ja joyce keith kirk lee leonard leslie lester lewismaymurphynelsonoliverowenpercypetersquickraphaelrodneyroserupertscottshelleysmithtaylortuenerwalkerwarrenWilliamsSmith仍为美国第一大姓,次是Johnson,Williams,Brown,Jones,Miller,Davis,Garcia,Rodriguez和Wilson。

500 引言复杂事件处理(Complex Event Process)是一组已定义的工具和技术,用于分析和控制驱动现代分布式信息系统的一系列相互关联的复杂事件[1]。
决策支持系统有很多种形式,其中一种就包括复杂事件处理,从简单事件流中推导出复杂决策是CEP提供的基本能力。
简单事件可能触发系统中的状态转换,通过与预定义的事件模式进行对比,可以了解复杂事件的关系。
复杂事件处理引擎将外部收集到的事件流作为输入,并对其进行连续和及时的处理,以关注更高层次的事件中发生了什么。
例如:网络入侵检测系统实时分析网络流量,以确定可能的攻击;环境检测应用处理来自传感器网络的原始数据,以确定污染的程度[2]。
复杂事件处理技术可以作为一种解决方法广泛应用在决策支持,大数据分析等领域。
1 Esper介绍Esper是一种用于复杂事件处理(CEP)和流分析的引擎[3],具有可扩展性强,内存效率高,内存计算,低延迟,高吞吐,实时流处理的特点,用于在线和离线数据的事件分析。
Esper提供了一种事件处理语言(EPL),它是一种用于处理基于时间的高频事件数据的声明性语言,实现和扩展sq l标准,并支持针对事件和时间的丰富表达式。
同时,Esper可以在单机和分布式环境中运行,不依赖外部环境。
Esper能够应用在业务过程管理和自动化、金融、网络和应用程序监控以及传感器网络等领域。
1.1 EPL事件是已经发生的事实,新的事件只能够添加到事件流中,而不能从事件流中移除。
在Esper中,流(Stream)是CEP的主要构建模块。
Esper引擎中的计算执行是以事件流作为基础,并使用标准表达式描述关注的事件模式,在Esper中,标准表达式称为事件处理语言(Event Processing Language)。
EPL语句允许指定关注的事件模式,并将其部署到Esper复杂事件处理引擎上,Esper将流定义为按时间排序的事件序列。
首先,将简单事件流输入到Esper引擎中;随后,Esper引擎执行一系列转换,以确定是否满足感兴趣的事件模式(例如:用于检测违反某条规则)。

教程简介Esper是一个事件流处理(ESP)和事件关联引擎(CEP的,复杂事件处理)。
Esper的目标是针对实时事件驱动架构(EDA)。
当Esper监测到事件流中又符合条件的时间发生时,即可触发Plain Old Java Objects(POJO)编写的自定义操作。
当数百万数量级的事件同时发生时,我们不可能使用普通的关系型数据库来存储和查询,Esper正是专为这样的大批量关联事件而设计的。
Esper提供一个定制的事件处理语言(EPL),允许的条件表达丰富的事件,相关性,可能跨越时间窗,从而减少开发工作需要设置一个系统,可以对复杂的情况作出反应。
Esper是一个轻量级的Java编写的内核是完全纳入任何Java进程,JEE应用服务器或基于Java 的企业服务总线嵌入的。
它使应用程序的过程中收到的消息或事件的大量快速发展。
介绍事件流和复杂事件信息是至关重要的作出明智的决定。
这是真实的在现实生活中,而且在计算,并在几个领域,如金融,欺诈检测,商业智能或战场的运作,特别是关键。
从信息流中的消息或事件的形式不同的来源,如给在特定的时间内股票价格对国家的暗示。
这就是说,看着那些离散事件是毫无意义的时间最多。
交易者需要看一段时间内的股票走势可能与其他信息在恰当的时间,最好的交易相结合。
虽然离散事件时看了一个又一个可能是毫无意义的,事件流 - 这是一个无限集合的事件 - 被认为在一个滑动窗口,进一步密切相关,是很有意义的,并用最小的延迟反应对他们是至关重要的有效行动和竞争优势。
简介Esper关系数据库或如JMS消息为基础的系统使之真正难以对付的时空数据和实时查询。
事实上,数据库查询,返回需要明确的有意义的数据,不适合推动,因为它变化的数据。
JMS的系统是无状态的,需要开发人员的时间和实施自己的聚合逻辑。
相比之下,Esper引擎提供了一个更高的抽象与才智,可以被看作是一个数据库天翻地覆式:不是存储数据和运行对存储的数据查询,Esper允许应用程序存储数据的查询和运行通过。

一,概述关系型数据用来查询相对静态的数据,如果执行一些复杂的查询,要降低查询的频度。
传统关系型数据库普遍将数据存储在硬盘(也有内存数据库),它的检索性能受限于硬盘访问性能。
受制于关系型数据库的设计,如果频繁查询数据来实现实时统计则需要在较短时间内构建多次查询语句(SQL),每次检索都耗时较长,关系型数据库会成为系统瓶颈。
总而言之,传统关系型数据库并不适合每秒成百上千次的查询统计。
Esper引擎可以使用类似于SQL的EPL语句来构建处理模型,处理每秒几万到几十万的实时数据的查询统计。
它的工作有点像倒过来的关系型数据库,它不需要像数据库那样存储数据,而是先构建查询语句,引擎依据这些处理模型实时的输出符合的结果。
而关系型数据要查询语句提交后才会输出结果。
Esper除核心jar包之外还有诸如io,jdbc,jmx等jar。
本文只讲解核心的前几章基础知识。
二,例子先看一个Epser处理实时数据的例子:收集某网站的实时用户访问日志(accesslog),数据字段如下:ip(访客ip)、time(访问时间)、url(页面地址)、httpcode(状态码)、agent(浏览器头信息)、sizeinbytes(数据大小)、等等。
场景1,分析1小时(周期)产生的状态码数量:select httpcode,count(*) as hz from accesslog.win:time_batch(1 hour) group by httpcode otder by hz desc;场景2,分析1小时(周期)访客对url的访问频率:select ip,url,count(*) as hz from accesslog.win:time_batch(1 hour) group by ip,url order by hz desc;场景3,找到可能危险的请求(状态码403 404),分析1小时(周期)访客对url的访问频率:select ip,url,count(*) as hz from accesslog(httpcode in(403,404)).win:time_batch(1 hour) group by ip,url order by hz desc;注:三个例子使用了时间批量窗口,它会收集此时间间隔数据一起统计,周期内只输出一次结果(这样更像是关系型数据库的输出形式),以便于理解。


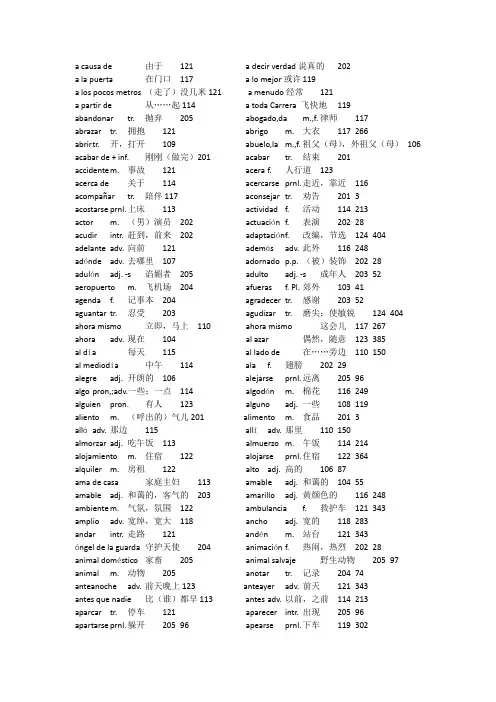
a causa de 由于121 a decir verdad说真的202a la puerta 在门口117 a lo mejor或许 119a los pocos metros (走了)没几米121 a menudo经常121a partir de 从……起114 a toda Carrera 飞快地119abandonar tr. 抛弃205 abogado,da m.,f. 律师117abrazar tr. 拥抱121 abrigo m. 大衣117 266abrir t r. 开,打开109 abuelo,la m.,f. 祖父(母),外祖父(母)106 acabar de + inf. 刚刚(做完)201 acabar tr. 结束201accidente m. 事故121 acera f. 人行道123acerca de 关于114 acercarse prnl. 走近,靠近116acompañar tr. 陪伴117 aconsejar tr. 劝告201 3acostarse prnl. 上床113 actividad f. 活动114 213actor m. (男)演员202 actuación f. 表演202 28acudir intr. 赶到,前来202 adaptación f. 改编,节选124 404 adelante adv. 向前121 además adv. 此外116 248adónde adv. 去哪里107 adornado p.p. (被)装饰202 28adulón adj. -s 谄媚者205 adulto adj. -s 成年人203 52 aeropuerto m. 飞机场204 afueras f. Pl. 郊外103 41agenda f. 记事本204 agradecer tr. 感谢203 52aguantar tr. 忍受203 agudizar tr. 磨尖;使敏锐124 404 ahora mismo 立即,马上110 ahora mismo 这会儿117 267ahora adv. 现在104 al azar 偶然,随意123 385al día 每天115 al lado de 在……旁边110 150al mediodía 中午114 ala f. 翅膀202 29alegre adj. 开朗的106 alejarse prnl. 远离205 96algo pron,;adv.一些;一点114 algodón m. 棉花116 249alguien pron. 有人123 alguno adj. 一些108 119aliento m. (呼出的)气儿201 alimento m. 食品201 3alláadv. 那边115 allíadv. 那里110 150almorzar adj. 吃午饭113 almuerzo m. 午饭114 214 alojamiento m. 住宿122 alojarse prnl. 住宿122 364alquiler m. 房租122 alto adj. 高的106 87ama de casa 家庭主妇113 amable adj. 和蔼的104 55amable adj. 和蔼的,客气的203 amarillo adj. 黄颜色的116 248 ambiente m. 气氛,氛围122 ambulancia f. 救护车121 343amplio adv. 宽绰,宽大118 ancho adj. 宽的118 283andar intr. 走路121 andén m. 站台121 343ángel de la guarda 守护天使204 animación f. 热闹,热烈202 28animal doméstico 家畜205 animal salvaje 野生动物205 97 animal m. 动物205 anotar tr. 记录204 74 anteanoche adv. 前天晚上123 anteayer adv. 前天121 343antes que nadie 比(谁)都早113 antes adv. 以前,之前114 213aparcar tr. 停车121 aparecer intr. 出现205 96apartarse prnl. 躲开205 96 apearse prnl. 下车119 302apenas adv. 几乎不120 apetecer tr. 想望,渴望116 248apetito m. 胃口201 aplaudir tr. 鼓掌,喝彩202 29 aprender tr. 学,学习108 apretado p.p. 拥挤,紧凑204 74 aproximar(se) tr.,prnl. 使靠近;靠近124 apunte m. 笔记120 325apuro m. 难处,困难处境124 árbol m. 树118 283armario m. 衣柜105 arquitectónico adj. 建筑的123 385 arrancar tr. 拔除124 arriba adv. 上边118 284arroz m. 稻子,大米,米饭115 artículo m. 商品112 183ascensor m. 电梯119 asearse prnl. 洗漱113 195asíadv. 这样113 asiático,ca m.,f. 亚洲人;亚洲的122 364 asiento m. 座位117 asistente,ta m.,f. 家庭服务员119 303asistir tr.,intr. 服侍;出席119 asno m. 驴子124 404asociación f. 协会204 asombrar(se) tr.;prnl. 使吃惊;吃惊123 asustado p.p. 被惊吓205 atardecer intr.;m. 黄昏降临,黄昏122 364 atareado p.p. 忙碌的,多事的119 atasco m. 堵塞121 343atención f. 注意203 atender tr. 注意,关注201 3 atentamente adv. 专心致志124 atraído p.p. 被吸引202 28atravesar tr. 穿过122 auscultar tr. 听诊110 150auténtico adj. 真正的,正宗的202 autobús m. 公共汽车110 150 autopista f. 高速公路121 avanzar intr. 前进121 343avería f. 故障,损伤121 avisar tr. 通知121 343ayudar tr. 帮助113 azul adj. 蓝色的105 73bailar tr.,intr. 跳舞117 bajar intr. 下去121 343bajo adj. 矮的106 balcón m. 阳台118 284baloncesto m. 篮球201 barato adj. 便宜的112 183barba f.(下巴和两鬓的)胡须202 barrer tr. 扫203 52barro m. 泥203 barroco adj. 巴罗克式的123 385 bastante adj. 相当的114 bastar intr. 足够203 52beber tr. 喝109 beca f. 奖学金122 364biblioteca f. 图书馆111 bibliotecario,ria m.,f. 图书管理员111 170 bicicleta f. 自行车110 bienvenida f. 欢迎117 266 bienvenido adj. 受欢迎的117 bigote m. 胡子202 29blanco adj. 白色的105 blanco,a m.,f. 白人122 364blusa f. 女士衬衣106 boca f. 嘴124 405bolígrafo m. 圆珠笔204 bonito adj. 漂亮的104 55bosque m. 森林122 botella tr. 瓶子117 267brazo m. 胳膊201 breve adj. 短暂的114 214brindis m. 敬酒,干杯117 bromear intr. 开玩笑204 73buitre m. 兀鹫205 buscar tr. 寻找111 170busto m. 半身塑像123 cabeza f. 头123 386cada vez que 每次122 caer intr. 落下,掉下205 96caja f. 付款处116 calcetín m. 袜子105 73calentar(se) tr.,prnl. 加热117 calidad f. 质量116 248cálido adj. 温暖的119 calle f. 街道116 248calorm. 热201 caluroso a dj. 炎热的119 303calzar tr. 穿(鞋)116 cama f. 床103 41cambiar intr. 变化,改换114 caminar tr. 走路123 386camisa f. 男衬衣105 campesino,na m.,f. 农民122 364campo m. 农村,田野113 cansado adj. 累,疲倦204 73cantante m.,f. 歌手,歌唱家102 cantar tr. 唱歌109 138carne f. 肉115 carnet m. (身份,学生)证123 386 carnicero,ra m.,f. 屠夫124 caro adj. 贵的116 248casco m. 蹄甲124 casi adv. 几乎115 230castellamo m. 卡斯蒂利亚语117 catorce num. 十四105 73ceder tr. 让(座位等)121 celebración f. 庆祝活动202 28 celebrar tr. 庆祝,举行202 cena f. 晚饭114 214cenar tr. 吃晚饭113 centro m. 中心103 41 centrocepillar tr. 刷114 cerca de 在……附近103 41 cerca de cerca f. 栅栏124 cereal m. 粮食116 249cerrar tr. 关112 cesar intr. 终止202 28champúm. 洗头膏,香波116 chaqueta f. 外衣105 73chiste m. 笑话122 chocante adj. 另人奇怪的203 51cielo m. 天204 cierto adj. 确实的113 196cinco num. 五103 cincuenta num. 五十106 87 cirujano,na m.,f. 外科医生201 claro adv. 当然了109clavar tr. 钉进,扎进124 clemencia f. 宽容,仁慈124 404coca-cola f. 可口可乐117 coche m. 轿车110 150cocina f. 厨房103 cocinar tr. 作饭,烹饪122 364cocinero,ra m.,f. 厨师102 coger tr. 拿起;乘坐119 302cojear intr. 一雀一拐124 cojo adj. 雀,拐124 405cola f. (购物等)排的队121 colegio mayor 学生公寓122 364 colegio m. 学校112 colgar tr. 悬挂117 266colocado p.p. 摆放118 comedia f. 剧,喜剧202 29comedor m. 餐厅,食堂118 comentar tr. 评论108 119comenzar t r. 开始114 comer tr.,intr. 吃饭109 137comida f. 食品107 comisaría f. 警察局121 343como túquieras 随你的便117 cómodo adj. 舒适的116 248compartirtr. 共享122 complicado adj. 复杂的123 386 comportamiento m. 举止,行为203 compra f. 买112 183comprar tr. 采购,买107 comprender tr. 懂得,明白120 324con frecuencia 经常118 con mucho gusto 很高兴,很乐意120 325 conceder tr. 给予203 conducir tr. 通向;引导;驾驶118 283 conferencia f. 报告会,讲座120 confianza f. 信任203 51confundir t r. 弄混120 conocer tr. 认识,了解,知道115 231 conseguir t r. 得到,弄到123 consejo m. 劝告,忠告203 51considerar tr. 认为203 consultorio m. 诊(所,室)201 3 contar tr. 讲述;数数122 contento adj. 满意,高兴204 73 contestar tr. 回答108 continuar tr. 继续205 96convenir intr. 对(某人)合适120 324conversar i ntr. 谈话,交谈117 267correr intr. 跑119 302cosa f. 东西112 183costilla f. 肋骨,排骨201 4costumbre f. 习惯115 231coz f. 踢(一下)124 405creer tr. 相信110 150crema f. 奶油,润肤膏116 249cruel adj. 残忍的124 404cruzar tr. 穿过123 385cuaderno m. 练习本120 325cualquier adj. 任何一个119 302cuanto antes 尽快,尽早119 302cuántos adj. 多少105 73cuántos adv. 什么时候111 170cuarto de baño 卫生间109 137cuarto m. 一刻钟111 170cuarto num. 第四120 324cubano,na 古巴人101 6 Cubano,na cubierto m. (整套)餐具(刀、叉、匙)115 231 cubrir tr. 覆盖118 284cuchara f. 勺儿,汤匙115 231cuchillo m. 刀115 231cueca f. 一种智利民间舞202 29cuento m. 故事122 364cuervo m. 乌鸦205 96cuidado m. 小心,注意121 344cultivar tr. 种植122 364cultura f. 文化120 324cultural adj. 文化的202 29curar tr. 治愈201 4cursillo m. 短期讲习班120 324curso m. 学年,课程122 364danza f. 舞蹈202 29dar tr. 给109 137darse prisa 赶紧,赶快120 325de acuerdo 同意,行117 267de compras 购物,买东西116 248de inmediato 立即205 96de modo que 因此122 364de ninguna manera 绝对不203 52de pie 站着117 267de pronto 突然205 96de repente 突然121 343deber m. 责任204 74deber tr. 该,欠116 248deber tr. 应该,想必114 213débil adj. 弱,虚弱201 4decidir tr. 决定121 343decir tr. 说109 137dejar tr. 放;搁下110 150 delante adv. 前面118 284demás adj 其他的121 343 demasiado adv. 太,过于117 267 demostración f. 展示202 29dentro de 在……之内111 170dentro adv. 里面105 73 dependiente m.,f. 售货员116 248 deporte m. 体育活动114 214 derecho,cha adj. 右边118 284 desaparecer intr. 消失205 96 desayunar intr. 吃早饭113 195 desayuno m. 早饭113 195descansar intr. 休息107 104 desconocido p.p. 陌生的;陌生人123 385 descubrir tr. 发现204 74desde luego 当然,自然120 324 desde prep. 从……起120 324 desear tr. 想,要,希望115 231 desesperante adj. 令人绝望的121 343 despedirse prnl. 告别,告辞201 3 despertar t r. 叫醒113 195después adv. 然后,以后108 119detalle m. 细节204 73devolver tr. 归还111 170devorar tr. 吞食124 405dicho y hecho 说干就干123 386 dictar tr. 口述,口授120 324dieciséis num. 十六106 87diente m. 牙齿114 213diez num. 十104 55diferencia f. 区别114 214 diferente adj. 不同,有级别的114 213difícil adj. 难的108 119dificultad f. 困难120 324 directamente adv. 直接118 284 disculpar tr. 原谅204 74discutir tr. 讨论109 138disfrazado f. 化了装的202 29 disfrutar tr. 享用202 28distinguir tr. 区分,辨别118 284distribución f. 分布,分配,布局118 284 distribuído p.p. 分布118 284diverso adj. 各种各样的120 324divertirse prnl. 娱乐,消遣122 364dividir tr. 分开,分为118 284doce n um. 十二104 55doler intr. (某部位)疼201 3dolor m. 疼痛201 4domingo m. 星期天107 104don Quijote 堂.吉诃德123 385dormir tr. 睡觉109 138dormitorio m. 卧室103 41drama m. 戏剧202 29ducharse prnl. 淋浴113 196durar intr. 持续114 214echar siesta 睡午觉114 214echarse prnl. 躺下205 96económico adj. 经济的204 74Ecuador 厄瓜多尔117 267edad f. 年龄203 51edificio m. 楼房112 183efectivamente adv. 确实如此113 196 efectuar tr. 开展,实行114 213eficaz adj. 有效201 4ejercicio m. 练习120 324elegante adj. 优雅,漂亮205 96elogiar tr. 赞扬203 51empezar tr. 开始113 195empleado,da m.,f. 职工103 41 empresario,ria m.,f. 企业家113 196en ... honor (de) 为(某人)举行204 74 en eso 此时205 96en memoria de 纪念碑123 385 encantado p.p. 十分高兴117 266 encender tr. 点燃203 52encontrar t r. 找到111 170enfermedad f. 疾病201 3enfermero,ra m.,f. 护士102 23enfermo adj. 病了108 119enfurecerse prnl. 发怒203 52enjuto adj. 干瘦201 4enorme adj. 巨大的118 284ensalada f. 沙拉,凉菜115 231 enseguida f. 马上,立刻118 283 enseñar tr. 教117 267enseñar tr. 教203 52ensuciar tr. 弄脏203 52entender tr. 懂得,明白119 303entero adj. 整个的122 364entonces adv. 于是,那么113 196entrada f. 进入,入口,门票123 386 entrar intr. 进入113 195entre prep. 在……之间112 183 entregar tr. 交,给110 150entregar tr. 交给204 74entrevista f. 会见204 74equipaje m. 行李204 73erigido p.p. 竖立,矗立123 385eructar intr. 打嗝201 3escaparate m. 橱窗116 248escribir tr. 写109 138escritor,ra m.,f. 作家118 284 escuchar tr. 听121 343escuela f. 学校104 55Esopo 伊索124 404espacio m. 空间118 283espalda f. 脊背201 4especial adj. 特别的123 386especie f. 种类122 364espera f. 等待121 343esperar tr. 等待,希望109 137espina f. 刺124 405esposo,sa m.,f. 丈夫,妻子102 23esquina f. 拐角121 343estación f. 火车站119 303estación f. 季节114 213estante m. 书柜104 55estilo m. 风格123 385estómago m. 胃,肚子201 3estorbar tr. 碍事203 52éstos,tas pron. 这些,这几位102 23 estrella f. 星星204 73estudiante m.,f. 学生102 23 estudiante estudiar tr. 学习107 104estudio m. 书房,写字间118 284 examen m. 考试119 303examinar tr. 检查124 405excelente adj. 极好的,优秀的119 303 exclamar intr. 惊呼205 96excusar(se) tr.,prnl. 原谅;致歉121 343 explicar tr. 解释,讲解108 119 exposición f. 展览123 386 extranjero adj. 外国的120 324 extremo m. 端,极端118 284fábrica f. 工厂103 41 fábricafábula f. 寓言124 404fácilmente adv. 容易地116 248 facultad f. 系107 104faltar intr. 缺201 3fama f. 名声124 404familia f. 家,家庭104 55 farmacia f. 药店110 150feliz adj. 幸福,满意205 96feo adj. 难看的105 73feroz adj. 凶猛的,凶狠的124 405 ferroviario adj. 铁路的119 303fiebre f. 发烧110 150fiesta f. 节日,庆祝聚会121 343 fijarse prnl. 注视202 29fila f. 行列118 284fin m. 终结;末尾116 248fingir(se) tr.,prnl. 假装124 404flaco a dj. 瘦201 4flamenco m. 吉普赛舞117 267flor f. 花118 283folklore m. 民俗,民间艺术202 29folklórico f. 民间(艺术)的202 29 fondo m. 深处,底部,尽头118 284 foto f. 照片106 87fotocopia f. 影印件204 74frasco m. 小瓶116 249 frecuentemente adv. 经常地115 230 fregar tr. 擦洗203 52frente f. 前额201 3fresco adj. 新鲜,凉爽201 3frío m. 冷117 266fruta f. 水果115 231fruto m. 果实118 283fuente f. 泉水,喷泉122 364fuerte adj. 强壮的,有力的106 87 funcionario,ria m.,f. 公务员103 41garaje m. 车库121 343garganta f. 咽喉201 3garra f. 爪子124 404gastroscopia f. 胃镜检查201 4gente f. 人,人们114 213golosina f. 零食;美味205 96gótico adj. 歌特式的123 385Goya 戈雅123 386grado m. 级,度201 3grande adj. 大的104 55gratis adv. 免费123 386grave adj. 严重201 3gripe f. 感冒110 150gris adj. 灰色的116 248gritar intr. 喊叫203 52grupo m. 班,组108 119grupo m. 小组204 73guardar cama 卧床(休息)201 3guardar tr. 保存109 137Guatemala 危地马拉120 325guía m.,f. 导游;导游手册123 386guitarra f. 吉他202 29gustar intr. 喜欢,爱好115 231haber intr. 有103 41habitación f. 房间104 55hábito m. 习惯203 51habla f. 言语202 29hablar intr. 谈,聊天107 104hacer el favor 请,劳驾116 248hacer la cama 整理床铺113 195hacer pregunta 提问题108 119hacer tr. 做,干107 104hacia prep. 向119 302hambre f. 饥饿204 73hasta prep. 直到113 196hay que 应该,必须108 119herido p.p. 受伤的121 343hermano,na m.,f. 兄弟,姐妹102 23 hermano,na hijo,a m.,f. 儿子,女儿103 41hinchado p.p. 肿胀124 405hispánico adj. 西班牙语(国家)的120 324Hispanoamérica f. 西班牙语美洲117 266 hispanohablante adj. 讲西班牙语的120 324 historia f. 历史204 74hola interj. 喂,你好110 150hombre m. 男人104 55Honduras 洪都拉斯120 325horario m. 作息时间,时刻表114 213hortaliza f. (种在园子里的)蔬菜122 364hostal m. 客店122 364hotel m. 旅馆,饭店122 364huerto m. 园子122 364huevo m. 鸡蛋115 230huir intr. 逃跑124 404húmedo adj. 潮湿的119 303idea f. 主意,想法123 386idea f. 主意,想法204 74igual que 跟……一样114 214importante adj. 重要的120 324importar intr. 对(某人)要紧或有关120 325incluso adv. 甚至114 214indigestión f. 消化不良201 3indispuesto p.p. 不舒服201 3indumentaria f. 服装,服饰202 29infancia f. 童年122 364ingenio tr. 才智,才能124 404inmenso adj. 广阔的123 386inmortal adj. 不朽的123 385insistir intr. 坚持203 52instrucción f. 指示,说明204 74inteligente adj. 聪明的112 183intenso adj. 密集的,紧张的118 284intentar tr. 试图205 96interés m. 兴趣,利益205 96interesante adj. 有趣的104 55interesar(se) tr.,prnl. 使感兴趣,对……感兴趣120 324 internacional adj. 国际的122 364interpretado p.p. (由)表演的202 29intérprete m.,f. 译员(口译)204 73invierno m. 冬天113 195invitar tr. 邀请117 266inyección f. 注射201 3izquierdo,da adj. 左边118 283jabón (una pastilla de) m. 肥皂(一块)116 249 jardín m. 花园112 183joven adj. 年轻的104 55jueves m. 星期四107 104jugar intr. 玩122 364junto a 靠近……的115 231junto con 跟……一起115 230junto adj. 一起113 195 justoadj.,adv. 正义的;恰好118 284lápiz m. 铅笔104 55lástima 遗憾120 324 latinoamericano adj. 拉丁美洲的120 324 lavabo m. 卫生间109 137lavarse prnl. 洗脸114 213lección f. 课108 119leche f. 奶,乳汁115 230 lector,ra m.,f. 读者111 170lejos de 离……远107 104lengua f. 舌头;语言201 3 lentamente adv. 慢慢地122 364león,na m.,f. 狮子205 97levantarse prnl. 起床113 195libre adj. 自由的,空的115 231libro m. 书104 55ligero adj. 轻,清淡201 3limitado p.p. 有限的120 324limitarse prnl. 限于203 52limpiar tr. 打扫,清洁113 195limpio adj. 干净的106 87lío m. 麻烦204 73listo adj. 停当,好了113 195literatura f. 文学120 324llamarse prnl. 叫……名字101 6 llamarse llave f. 钥匙109 137llegar intr. 到达119 302llevar tr. 送,带110 150llevarse prnl. 带走109 137llorar intr. 哭205 96lluvioso adj. 多雨的119 303lobo m. 狼124 404lomo m. 后腰201 4luminosidad f. 光亮202 28lunes m. 星期一107 104 madrugada f. 清晨119 303 madrugador adj. 早起的119 303 madrugar i ntr. 早起119 303maestro,tra m.,f. 教师104 55maleta f. 箱子204 73malo adj. 坏的106 87maltratado p.p. 受虐待的124 405malvado adj. 坏心眼的205 96mañana adv. 明天111 171mañana f. 上午111 170manera f. 方式115 230mapa m. 地图123 386marchar intr. 行进123 386mariachis m. 墨西哥的一种民间乐曲及其乐队202 28 marido m. 丈夫117 267marinera f. 一种秘鲁民间舞202 29martes m. 星期二107 104más allá再过去一点118 283más adv. 更,更加112 183máscara f. 面具202 29mayor adj. 老的,年龄大的106 87me llamo 我叫102 23 me llamomecánico,ca m.,f. 机械师103 41 mecánico,camedia f. 半111 170medianoche f. 半夜113 196medicina f. 药110 150medicina f. 药201 3médico,ca m.,f. 医生102 23 médico,camejor dicho 确切地说119 303melodía f. 曲调,旋律202 29menos adv. 差111 171mercado m. 市场107 104merecer(se) tr.,prnl. 应该得到124 405mes m. 月111 170mesa f. 桌子103 41 mesamesilla f. 小桌,茶几118 284mestizo,a m.,f. 印欧混血种122 364meter(se) t r.,prnl. 塞进;钻进117 267meterse de 滥竽充数干某事124 405metro m. 地铁119 303metro m. 公尺,米118 283mexicano,na adj. -s 墨西哥的,墨西哥人202 28México 墨西哥202 29miedo m. 害怕124 404mientras conj. 与……同时122 364miércoles m. 星期三107 104minuto m. 分钟110 150mío adj. 我的109 137mirar tr. 看望115 231mismo adj. 同一个115 230modelo m. 模样,样式116 248molestar tr. 打扰117 267molestia f. 打搅204 74molesto adj. 讨厌,烦人201 3mono,na m.,f. 猴子205 97monumento m. 纪念碑123 385moreno adj. (皮肤)黑的106 87mostrador m. 柜台116 248mostrar tr. 展示,拿给……看116 248mover tr. 动124 404muchacho,cha m.,f. 男孩,女孩108 119mucho gusto 很高兴,很荣幸117 266mueble m. 家具118 284muerto p.p. 死人121 343mujer f. 女儿,妇女106 87mulato,a m.,f. 黑白混血种122 364Museo del Prado 普拉多博物馆123 386museo m. 博物馆123 385música f. 音乐202 28nadar intr. 游泳122 364nadie pron. 没有(人),谁也(不,没)119 303 nariz f. 鼻子201 3natural adj. 自然的204 74necesitar tr. 需要110 150negar tr. 否定,否认203 52negro adj. 黑色的105 73negro,a m.,f. 黑人122 364neo-clásico adj. 新古典主义的123 385ni conj. 也不,甚至不115 230no es para tanto 不至于如此123 386no sólo ...sino también 不仅……而且113 196 nocturno adj. 夜间的119 303normal adj. 正常的203 51nota f. 记号,符号;分数119 303notable adj. 显著的115 230notar tr. 感到,觉察202 28noviembre m. 十一月119 302novio,via m.,f. (男、女)朋友203 51nuera f. 媳妇117 267nuestro adj. 我们的103 41 nuestronueve num. 九104 55nuevo adj. 新的104 55numeral cardinal 指量数词112 184número m. 号码111 170número m. 节目117 267obra f. 作品123 386observar tr. 观察205 96occidental adj. 西方的115 231Occidente m. 西方115 230ocho num. 八103 42octubre m. 十月117 266ocupado p.p. 忙;被占用116 248ocupado p.p. 忙碌,忙于113 196ocuparse prnl. 忙于(做某事)113 195ocurrir intr. 发生119 303ocurrírsele (a uno) algo 突发奇想124 404 oficina f. 办公室103 41oficio m. 行当124 405oído m. 听觉;耳朵120 324olfatear tr. 闻,嗅205 96olvidadizo adj. 健忘204 74olvidar tr. 忘记203 52once n um. 十一104 55operación f. 手术201 4oportunidad f. 机会202 29ordenado a dj. 整齐的106 87ordenar tr. 命令;整理119 303ordenar tr. 整理203 52oreja f. 耳朵124 404orilla f. 岸边122 364oscuro adj. 暗的,深(色)的116 248oso,sa 熊205 96otoño m. 秋天118 283otro adj. 另一个113 195pagar tr. 付款116 248país m. 国度,国家114 213palabra f. 词108 119Palacio Imperial 故宫123 386palacio m. 宫殿123 386palillo m. 小棍儿;筷子115 230pan m. 面包115 230Panamá巴拿马117 267panameño,ña m.,f. 巴拿马人101 6 Panameño,ña pantalón m. 裤子105 73papagayo m. 鹦鹉205 97papel m. 纸111 170paquete m. 包裹203 52para prep. 为了107 104parada f. (市内)车站121 343parcela f. (一小块)田地122 364parecer intr. 像是;使觉得116 248pareja f. 双,对202 28parque m. 公园123 385parte f. 部分,地方114 213pasajero,ra m.,f. 乘客121 343pasar tr. 递给111 170pasar tr. 过,度过109 137pasear intr. 散步116 248pasión f. 激情202 29paso m. 步201 3pasta de dientes (un tubo de) 牙膏(一筒)116 249 pastar tr.,intr. 放牧,(牲畜)吃草124 404pastilla f. 药片110 150pata f. 蹄子124 405patio m. 院子118 283pato,ta m.,f. 鸭子205 97pecho m. 胸部,胸脯201 4pedazo m. 块205 96pedir tr. 请求,要求;点菜115 231pedir tr. 求借111 170peinarse prnl. 梳头114 213peine m. 梳子116 249pelear intr. 打架203 52película f. 电影109 137peligro m. 危险205 96peligroso adj. 危险的203 52peluquero,ra m.,f. 理发师106 87pena f. 痛苦,遗憾116 248pensar tr. 想113 196perder tr. 失去122 364perdón m. 对不起204 73perdonar tr. 原谅117 267perfecto adj. 完美的201 4periódico m. 报纸104 55permitir tr. 允许117 266persona f. (每个)人115 231personal m.;adj. 人事;个人的119 302Perú秘鲁120 325peruano,na adj. -s 秘鲁的,秘鲁人202 29pescado m. (捕获供食用的)鱼115 231 piano m. 钢琴118 284pico m. 鸟喙205 96pie m. 脚124 405pierna f. 腿201 4pieza f. 零件;一(段、件等)202 29 piscina f. 游泳池118 283planeta m. 行星,星球123 386plano m. 平面图123 386planta 花草;楼层118 283plato m. 盘子;(每道)菜115 230plaza f. 广场123 385plazoleta f. 小广场121 344pluma f. 钢笔104 55plumaje m. 羽毛205 96pobre adj. 穷,可怜205 96poco a poco 慢慢地121 344poder tr. 能够108 119poesía f. 诗202 29poeta m. 诗人202 29policía m.,f. 警察121 343político adj. 政治的204 74poner tr. 放置,安放115 231ponerse en camino 上路121 343por ejemplo 比如114 213por escrito 笔头的119 303por favor 请,劳驾115 231por fin 终于204 73por la mañana 上午114 214por la tarde 下午108 119por lo menos 至少120 324por último 最后115 231por prep. 为,代替115 231posgrado m. 研究生班120 324postre m. 饭后甜食115 231prado m. 草地124 404precio m. 价钱116 248precipitarse prnl. 匆忙(做某事)204 74 precisamente adv. 恰恰是121 343 precisamente adv. 正是204 74preciso adj. 必须;精确的121 343 preferir tr. 喜欢,偏爱114 214pregunta f. 问题108 119preguntar tr. 发问,提问题116 248preocuparse prnl. 担忧201 3preparar tr. 准备113 195presentar tr. 介绍117 266prestar tr. 出借111 170primavera f. 春天118 283primero adj. 第一114 214primero adv. 首先108 119primo,ma m.,f. 表兄弟,表姐妹107 104 principal adj. 主要的118 283principio m. 开始;原则123 386prisa f. 急事,着急109 137probar(se) tr.,prnl. 试,试(衣物)116 248 producir tr. 发生,产生121 343profesor,ra m.,f. 教师,老师107 104 programa m. 纲领;节目203 52prohibir tr. 禁止121 344propio adj. 自己的115 231prórroga f. 延长122 364próximo adj. 下一个119 303pueblo m. 人民;村镇121 343puerta f. 门109 137pues a dv. 那么116 248puesto m. 小摊123 386pulso m. 脉搏201 3puqueño adj. 小的104 55quéva 哪里,哪哟113 196quedarse prnl. 留下,剩下116 248quehacer m. 事情,家务113 196querer tr. 想,希望109 137queso m. 奶酪205 96quince num. 十五105 73quitar(se) t r.,prnl. 去掉;脱下117 266 rapidez f. 快,迅速119 302rápido adv. 快113 195raza f. 种族,人种122 364razón f. 道理,理智124 405recepción f. 接待,招待会204 74receta f. 处方110 150recetar tr. 开处方,开药110 150recibir tr. 接受;接待118 284recién adv. 新近地121 343recitar tr. 朗诵202 29recoger tr. 拣起205 96reconocer tr. 认出,承认202 29recordar tr. 记忆,记住114 213 recorrido m. 走(一圈,一趟)202 29 recreo m. 休憩114 214regalo m. 礼物203 52regar tr. 浇水203 52regatear intr. 讨价还价203 52 regresar intr. 回来,返回113 195reír intr. 笑205 96remedio m. 办法;药剂119 303 remedio m. 药;办法201 4repartir tr. 分摊122 364repaso m. 复习112 183 representar tr. 代表;表演117 267 resfriado m. 着凉,感冒201 3 resignado p.p. 忍耐121 344resistir intr. 抵抗,抗拒124 404 resolver tr. 解决204 73responder tr. 回答124 405 responsible adj. -s 负责人204 74 restaurante m. 饭馆115 231 resultar intr. 结果是……123 386retraso m. 迟到119 303reunirse prnl. 会集,聚集113 196revista f. 杂志104 55revoluvión f. 革命204 74rígido adj. 僵硬的,严格的122 364río m. 河122 364ritmo m. 节奏202 29rojo adj. 红色的106 87romper tr. 弄破,打破116 248ropa f. 衣服105 73rubio adj. 金黄色的106 87ruido m. 噪声203 52sábado m. 星期六107 104saber tr. 知道109 138sabroso adj. 可口的205 96sacar tr. 取出116 248sala de estar 起居室,客厅118 284 sala f. 厅103 41 salasalario m. 工资203 51salir tr. 离开,出去113 195saltar intr. 跳124 405salud f. 身体115 230saludable adj. 健康的122 364Sancho Panza 桑丘.潘沙123 385se llama (他,她,您)叫……名字101 6 se llama secar tr. (晒,晾)干201 3seco adj. 干的,干燥的119 303secundario adj. 中级的113 195seguir tr.,intr. 继续121 343según prep. 根据114 213segundo adj. 第二个115 230segundo m. 秒111 171seguro adv. 肯定,保准113 196seis num. 六103 42semana f. 星期108 119señal f. 记号;迹象205 96señalar tr. 指出123 386sencillamente adv. 简单地203 51sencillo adj. 简单的,单纯的117 267señor,ra m.,f. 先生,女士104 55señorita f. 小姐110 150sentarse prnl. 坐下115 231sentir tr. 感觉;抱歉116 248separar tr. 分开118 284septiembre m. 九月116 248ser m. 生灵,人123 386servir de 充当204 73servir(se) tr.,prnl. 服务;进餐115 230setenta y ocho n um. 七十八106 87sevillanas f. Pl. 塞维利亚舞117 267siempre adv. 永远,总是113 196siete n um. 七103 42silla f. 椅子104 55simpático a dj. 和蔼可亲的104 55sin prep. 没有,不115 230situación f. 形势;位置204 74situado p.p. 位于118 284sobre todo 尤其,特别是116 248sobre m. 信封202 28sobrino,a m.,f. 侄子(女),外甥(女)117 267social adj. 社会的118 284sofá m. 沙发103 41 sofásol m. 太阳122 364solertr. 惯常(做某事)122 364sombrero m. 大沿帽202 29sonar tr. 响117 266sopa f. 汤115 230sorpresa f. 惊喜,惊奇122 364subir intr.,tr. 上去,运上去119 302sucio adj. 脏的106 87sudar intr. 出汗201 3sudor m. 汗水201 3suelo m. 地面205 96suerte f. 运气121 343sujetar tr. 固定,抓住203 52superior adj. 高级的120 324suplicar tr. 哀求205 96suponer tr. 设想203 51suyo adj. 他的;他们的;您的109 137tableta f. 药片201 3tacón m. 鞋跟116 248también adv. 同样,也106 87tan ... como 跟……一样114 214tango m. 探戈202 29tanto adv. 如此,这样113 196tapado p.p. 塞住201 3tardar intr. 耽搁,花费(时间)121 343tarde adv. 晚,迟112 183tarde f. 下午114 214taxi m. 出租车119 302taxista m. 出租车司机106 87téde jazmín 茉莉花茶117 266teatral adj. 舞台的,戏剧的202 29telefonear tr. 打电话203 51televisión f. 电视113 196televisor m. 电视机203 52tema m. 题目120 324templado adj. 温和的119 303templo m. 庙宇,寺院204 74temprano adv. 早112 183tenedor m. 叉115 231tener ganas 想,有愿望120 324tener mucho que hacer 有许多事情要做113 196 tener que 必须,应该108 119tener tr. 有108 119tercero num. 第三120 324termómetro m. 温度计201 3terrible adj. 可怕的121 343testigo m. 证人121 343tiempo m. 时间114 214tienda f. 商店112 183timbre m. 铃117 266tío,a m.,f. 伯,叔,舅;姨,姑,舅妈107 104 tipico adj. 典型的122 364titular(se) t r.,prnl. 题为202 29título m. 题目111 170tomar el pulso 号脉110 150tomar tr. 拿起;(此处)吃114 213trabajar intr. 劳动107 104trabajo m. 工作114 213tradicional adj. 传统的201 4traer t r. 带来111 170tráfico m. (市内)交通121 343tragedia f. 悲剧202 29tranquilamente adv. 安安静静地124 404 tranquilo adj. 安静的122 364tras prep. 在……之后115 230trasladar(se) tr.,prnl. 搬动;搬家118 284trece num. 十三105 73treinta num. 三十106 87tren m. 火车119 303trigal m. 麦田122 364túnel m. 地道121 343turista m.,f. 旅游者123 386último adj. 最后的114 214un poco más 较……多一点114 213un rato 一会儿119 303universidad f. 大学107 104urgente adj. 紧急的117 267vagón m. 车厢119 303vanidoso adj. 好虚荣的205 96variar intr. (有所)不同203 51vaso m. 杯子115 230vecino m. 邻居112 183veinte num. 二十106 87veintena f. 二十来个120 324veinticinco num. 二十五106 87veintidós num. 二十二106 87veintiuno num. 二十一106 87velada f. 晚会202 28vender tr. 卖112 183Venezuela 委内瑞拉117 267venir intr. 来109 137ventana f. 窗户115 231ventanal m. 落地窗118 284ver tr. 看,看望108 119verano m. 夏天118 283verdad f. 真理,事实109 137 verdadero adj. 真正的202 29verdura f. 蔬菜,青菜115 231vestíbulo m. 前厅204 74vestirse prnl. 穿衣113 195vez f. 次,回115 230viajar intr. 旅行118 284viaje m. 旅行204 73vida f. 生命,生活205 96viejo a dj. 老,旧202 28viento m. 风201 3viernes m. 星期五107 104visita f. 拜访,来访117 266 visitante m.,f. 来访者,参观者123 386 vivir intr. 居住109 137vivo adj. 活着205 96vocabulario m. 词汇(量)120 324 volumen m. (音)量203 52volver + inf. 重新(做某事)114 214 volver intr. 回来110 150vuelta f. 一圈123 385vuestro adj. 你们的103 41 vuestroya que 既然118 283ya adv. 现在,已经109 137yerno m. 女婿117 267zapatería f. 鞋店116 248zona f. 区域,地区118 284zorro,rra m.,f. 狐狸205 96。

Esper简介1. CEP(Complex Event Processing, 复杂事件处理)事件(Event)⼀般情况下指的是⼀个系统中正在发⽣的事,事件可能发⽣在系统的各个层⾯上,它可以是某个动作,例如客户下单,发送消息,提交报告等,也可以是某种状态的改变,例如温度的变化,超时等等。
通过对这些事件进⾏分析,可以提取出其中有效的信息。
根据维基百科的定义,事件处理(Event processing)指的是跟踪系统中发⽣的事件,分析事件中的信息并从中得到某种结论。
⽽复杂事件处理,则是结合多个事件源中的事件,从中推断出更加复杂的情况下的事件。
由此可见,CEP的⽬的包括:(1)识别所需要的事件;(2)快速地对这些事件进⾏处理。
通常情况下,我们想要利⽤CEP达到的⽬的是掌握当前的某种情况或者说状态,因此CEP感兴趣的不是事件本⾝给出的信息,⽽是通过这些信息所能推导出的某种结论,通过CEP,我们能够让这些事件变得有意义。
要实现⼀个CEP引擎,需要考虑的事情包括:(1)吞吐量;(2)低延迟,从事件到达到事件被处理,不能有太⼤的延迟;(3)复杂的逻辑处理,CEP需要能够对事件进⾏较为复杂的操作,例如,检测事件之间的相关性,过滤,加窗,连接等。
2. EsperEsper是⼀个开源的复杂事件处理引擎,它的⽬的是让⽤户能够通过它提供的接⼝,构建⼀个⽤于处理复杂事件的应⽤程序。
从Esper的架构图中,可以看出,Esper主要包括了三个部分:Input adapter,Esper engine,Output adapter。
2.1 Input adapter & Output adapter输⼊适配器和输出适配器的主要⽬的是接收来⾃不同事件源的事件,并向不同的⽬的地输出事件。
⽬前,Esper提供的适配器包括File Input and Output adpter, Spring JMS Input and Output Adapter, AMQP Input and Output Adapter, Kafka Adapter等等。

和凉宫春日的忧郁学英语单词学习英语单词是每个学习者必经的过程,尤其对于喜欢日本文化的人来说,掌握一些日常用语和关键词汇可以更好地理解动漫、电影和小说。
而对于喜欢《凉宫春日的忧郁》的粉丝来说,学英语单词也可以成为一个有趣的过程。
本文将介绍一些实用的英语单词,这些单词与凉宫春日的故事情节和角色息息相关。
1. Brigade(萌燃部队)这是凉宫春日的小说和动画作品中的核心团队,也是主人公加入的社团。
在英语中,"brigade"这个词表示一个组织或单位,特指军队中的一个分队或者任务小组。
通过学习这个词汇,我们可以了解到"brigade"的英文意思,并将它与故事情节联系起来。
2. Haruhi Suzumiya(凉宫春日)首先,我们可以学习主角凉宫春日的名字。
"Haruhi"是个常用的日本女性名字,但在英文中并没有特定的对应。
因此,我们可以直接用英文拼写"H-a-r-u-h-i"来表达。
3. Mysterious(神秘的)在凉宫春日的故事中,凉宫本人以及她遇到的事情都充满着神秘的色彩。
"Mysterious"一词在英文中是形容词,意思是有神秘感的、未解之谜的。
我们可以用这个词来描述凉宫春日及相关情节。
4. Time traveler(时空旅行者)凉宫春日系列作品中涉及了很多关于时空旅行的概念和情节。
"Time traveler"这个词在英语中表示穿越时空的人。
通过学习这个词,我们可以更好地理解凉宫春日中的时间跳跃和故事发展。
5. Esper(超能力者)在凉宫春日中,有一个角色叫做长门有希,她是一个具有超能力的人。
"Esper"这个词在英语中表示超能力者,通常用来描述那些拥有特殊能力的人。
通过了解这个词汇,我们可以更好地理解角色的特点及剧情的发展。
6. Alien(外星人)除了超能力者,凉宫春日系列作品中还涉及到"alien"这个词。

Vocabulário de português para ensino universitário A1、àentrada de 在...入口2、A seguir 接下来,紧接着3、àvontade 随意地,自由的4、Abafado 闷的,憋闷的5、Abril 四月6、Abrir 打开7、Abundante 丰富的,大量的8、Acabar 做完,结束9、Acção 行动,动作10、Aceitar 接收11、Acender 开灯,点燃火12、Achar 认为,觉得13、Acidente 事故14、Acontecer 发生15、Actor 男演员16、Actriz 女演员17、Administrativo行政的18、Adorar 酷爱,非常喜欢19、Adormecer 入睡20、Advogado 律师21、África 非洲22、África de sul 南非23、Africano 非洲人,非洲的24、Agenda 记事本25、Agora 现在26、Agosto 八月27、Agradável 舒适的,宜人的,愉悦的28、Água 水29、Aguentar 忍受,承受30、Aí那里31、Ainda 还,任然,ainda bem 还好,幸好32、Ajudar 帮助33、Álcool 酒精34、Aldeia 村子,村庄35、Alegre 快乐的,高兴的36、além de 除了...之外37、Alemanha 德国,almão,almã,德语,德国人38、Algo 某事39、Alguém 有人,某人40、Algum 某些,某个41、Ali 那儿,那里42、Alma 心灵,灵魂43、Almoçar 吃午饭44、Almoço 午餐,午饭45、Alto 高的46、Altura 高度,neste altura 现在,此刻,眼下47、Alugado 租的48、Aluno 学生49、Amar 爱50、Amarelo 黄色的,黄色51、Ambiente 环境52、Ambos 两者,两个人53、Ameno 舒适的,令人愉快的54、América do sul 南美55、Americano 每周的,美国的,美国人56、Amigo 朋友57、Ananás 菠萝58、Andar 层,行走,步行59、Angola 安哥拉60、Angolano 安哥拉人61、Animado 有生气的,活跃的62、Aniversário 周年,生日63、Ano 年,岁,ano novo chinês 春节64、Ante ontem 前天65、Antes de 在...之前66、Antigamento 以前,从前67、Antigo 古老的68、Antipático 不友好,不友善的69、Anual 一年的,每年的70、Ao passo que 而71、Aos quadrados 格子的72、Apagar 熄灭,擦拭,使消失73、Aparelho 仪器,装置,器械,aparelho de DVD DVD机74、Apartamento 公寓,单元房75、Apenas 仅仅,只是76、Aprender 学习,学会77、Apresentador 节目主持人78、Apresnetar 表现,体现,介绍79、Aquário 水族馆,水瓶座80、Aquecimento 加热,变暖,暖气81、Aquele,aquela那,那个82、Aqui 这儿,这里83、Aquilo 那,那个,那事儿84、Ar 空气,ar condicionado 空调85、Árabe 阿拉伯语,阿拉伯人,阿拉伯人的86、Argentina 阿根廷,argentino 阿根廷人的87、Árido 干旱的88、Armário 柜子,储物柜89、Arquitecto 建筑师90、Arranjar 找到,获得,修理,收拾,打扮91、Arroz 米,米饭92、Árvore 树93、Às bolinhas 小圆点儿的94、Às riscas 条纹的95、Ásia 亚洲96、Asiático 亚洲的,亚洲人97、Assim 这样,如此98、Associação 协会99、Assunto 问题,食物,事情100、Até直到101、Aula 课102、Austrália 澳大利亚,Australiano 澳大利亚的,澳大利亚人的103、Avó奶奶,外婆,avô 爷爷,外公104、Azul 蓝色B105、Badminton 羽毛球运动106、Bairro 街区,城区107、Baixo 低的,矮的108、Balança 平衡,天秤座109、Balão 气球110、Bancário 银行职员111、Banco 银行112、Banda larga 宽带113、Bandeira 旗帜114、Banqueiro 银行家115、Bar 酒吧116、Barba 胡须117、Barril (石油)桶118、Basquetebal 篮球运动119、Bastante 相当120、Bater 打,敲击,bater àporta 敲门121、Beber 喝122、Bebida 饮料,bêbado 喝醉123、Bem 好,很,非常124、Biblioteca 图书馆125、Bigode 小胡子126、Bisavô 曾祖父,bisavó曾祖母127、Bisneta 曾孙女,bisneto 曾孙128、Bissau 比绍129、Blusa 女士衬衣130、Boa 好的131、Boi 公牛,水牛132、Boletim 简报,通报(定期出版的)133、Bolo 蛋糕134、Bolo-rei 圣诞节蛋糕135、Bom 好的136、Bombeiro 消防员137、Bonito 漂亮的138、Bota 靴子139、Branco 白色,白色的140、Brasil 巴西141、Brasileiro巴西人,巴西的142、Brasília 巴西利亚143、Bronzeado 古铜色的,黝黑的144、Buffet/bufê自助餐C145、Cabeleireiro 理发师146、Cabelo 头发147、Cabo verde 佛得角148、Cabo-verdiano 佛得角人149、Cachecol 围巾150、Cada 每个,cada vez mais 越来越151、Cadeira 椅子152、Caderno 笔记本153、Café咖啡154、Caixa 盒子155、Calado 沉默的,不爱说话的156、Calça 裤子(calças)157、Calmo 平静的,安静的158、Calor 热159、Cama 床160、Camisa 男士衬衣161、Camisola 毛衣162、Campo 场地,场所,campo de jogos 操场163、Camponês 农民164、Campus 校园165、Canadá加拿大166、Canadiano 加拿大人167、Canal 频道168、Candeeiro 台灯169、Caneta 钢笔170、Cantão 广州171、Canar 唱歌172、Cantina 食堂,餐厅173、Cantor 歌手,歌星174、Cão 狗175、Capital 首都,省会176、Capitão 船长177、Capricórnio 摩羯座178、Cara 脸179、Característica 特点,特色180、Caranguejo 螃蟹,巨蟹座181、Careca 秃顶的182、Carnaval 狂欢节183、Carneiro 绵阳,白羊座184、Caro 贵的185、Carro 小汽车186、Carta 信,carta de jogo扑克牌187、Cartão 卡片,cartão de aniversário 生日卡片188、Carteira 课桌,钱包189、Casa 房子,casa de banho 卫生间190、Casaco 上衣,外套191、Casado 结婚的,已婚的,ser casado com 与某人结婚192、Casal 夫妇193、Castanho 褐色的,棕色的194、Catorze 14195、Cavalo 马196、Cedo 早197、Celebrar 庆祝198、Cem 100,cento e dois 102,cento e um 101199、Centro 中心,中央,centro comercial 商场,商业中心200、Cerca de 约,将近201、Céu 天空202、Chá茶叶203、Chamar-se 名字是204、Chão 地面205、Chato 讨厌的206、Chegar 到达,chegar atrasado a 迟到207、China 中国,chinês 中国人的208、Chorar 哭泣209、Chover 下雨210、Chuva 雨水211、Cidadão 公民212、Cidade 城市213、Científico 科学的214、Cinco 5215、Cinema 电影院216、Cinquenta 50217、Cinzento 灰色的,灰色218、Civil 平民,百姓219、Claro 明亮的,浅色的,当然220、Clássico 经典的,古典的221、Clima 气候222、Coelho 兔子223、Coimbra 科英布拉224、Coisa 东西,事情225、Colega 同事,同学226、Colheita 收获,收成227、Colocar 摆,放,安置228、Colorido 彩色的229、Coluna 音箱230、Com 与,跟231、Com certeza 当然可以,没问题232、Combinar 约定,商定233、Começar 开始234、Comédia 喜剧235、Comer 吃236、Cômico 喜剧的,滑稽的237、Comida 食物238、Como 如何,怎样,像,如同239、Complicado 复杂的240、Compota 果酱241、Compra 买,购买242、Comprar 购买243、Comprido 长的244、Computador 电脑,computador portátil 手提电脑245、Comum 共同的,常见的246、Concerto音乐会247、Concordar 同意,赞同248、Confortável 舒服的,舒适的249、Conhecer 认识,熟悉250、Conhecido 知名的251、Conjunto 整体,套252、Conseguir 能够253、Construção 建筑,Construção civil 土木建筑254、Contente 高兴的255、Continente 大洲,大陆256、Conversação 会话,交谈257、Conversar 聊天258、Convidar 邀请259、Convite 邀请260、Cor 颜色,色彩261、Cor-de-laranja 橙色的262、Cor-de-rosa 粉红色,玫瑰色263、Coreano 韩国人,韩语264、Coreia 韩国265、Correr 跑步266、Cortar 切,切割267、Cortina 窗帘268、Costumar 习惯,经常269、Cozido 煮的270、Cozinha 厨房271、Cizinheiro 厨师272、Crer 相信273、Criança 小孩,孩子274、Criar 抚养,养育275、Cultura文化276、Cumprimentar 问候,打招呼277、Cunhada 大姑子,大姨子,嫂子278、Cunhado 大伯,大舅,姐夫279、Curso 课程280、Curto 短的281、Custar 花费D282、Daqui a pouco 一会儿283、Dar 给284、Data 日期285、De...a 从...到...286、De acordo com 根据287、Debaixo de 在...下面288、Décimo 第十289、De facto 确实,的确290、Deitar-se 躺下,睡觉291、Deles 他们的292、Dentista 牙医293、Departamento 系294、Depois 然后,之后,depois de 在...之后295、Depressa 快速296、Descansar 休息297、Descar 下降,下车298、Desculpa 原谅,宽恕,pedir desculpa 不好意思,请求原谅299、Desejar 祝愿300、Deserto 沙漠301、Despedir-se 告别,辞别302、Despertar 醒来,惊醒303、Desporto 体育304、Deus 上帝,meu deus 我的天哪!305、Dez 10306、Dezanove 19307、Dezasseis 16308、Dezassete 17309、Dezembro 十二月310、Dezoito 18311、Dia 白天,dia de aniversário 生日312、Dicionário 字典,词典313、Diferente 不同,ser diferente de 与...不同的314、Diferir 不同,有差别315、Difícil 难的,困难的316、Dinheiro 钱317、Directamente 直接318、Directo 直接的319、Director 主任,厂子,director geral 总经理320、Disciplina 课程,科目321、Distinto 有区别的,截然不同的322、Divertir-se 玩,娱乐323、Divorciado 离婚的324、Dizer 说,告诉325、Documentário 纪录片326、Doente 病的327、Dois 2328、Doméstica 家的,家里的,trabalho doméstica 家务329、Domingo 星期天330、Donde 哪儿331、Dor 疼,痛332、Dormir 睡觉333、Dormitório 宿舍334、Dourado 金黄色的335、Doze 12336、Dr.(doutor),Dra(doutora)先生,女士337、Dragão 龙338、Drama 悲剧339、Durante 在...期间340、Duzentos 200E341、Economia 经济学342、Economista 经济学家343、Edifício 楼房,大厦344、educação física 体育课345、Egipto 埃及346、Egípcio 埃及人,埃及的347、Elegante 精神的,帅的,优雅的348、Elevador 电梯349、Em baixo 在下面350、Em cima de 在...的上面351、Em frente de在对面,352、Em ponto 整点353、Em seguida 随后,挨着354、Empregado 雇员,empregado de mesa 餐厅服务员,empregado de balcão 售货员,empregado de limpeza 清洁工355、Emprego 职业,工作,就业356、Empresa 公司,empresa de entretenimento 娱乐公司,empresa de tradução 翻译公司357、Empresário 企业家358、Encantador 迷人的,讨人喜欢的359、Encontrar 遇见,碰见,找到,相遇,处于....的境地360、Endiabrado 顽皮的,淘气的361、Enfeitar 装饰,装点362、Enfermeira 女护士363、Engenheiro 工程师364、Enorme 巨大的,庞大的365、Enquanto 而,enquanto que,在...的时候,与...同时366、Ensinar 教,教授367、Entrar 进入,进来,进去368、Entre 在....之间369、Entregar 交,提交370、Equipa 队371、Escola 学校372、Escorpião 蝎子,天蝎座373、Escrever 写,书写374、Escrita 文字,书面的东西375、Escritório 办公室,escritório de advogados 律师事务所376、Escultura 雕刻,雕塑377、Escuro 暗色的,深色的378、Espaço 空间379、Espaçoso 宽敞的380、Espanha 西班牙381、Espanhol 西班牙人,西班牙语,西班牙的382、Especial 特殊的,特别的383、Esperto 机敏的,精明的384、Esposa 妻子,夫人385、Esquadra 警署,派出所386、Esqui 滑雪运动387、Estação 季节,estação de chuvas 雨季,estação de seca 旱季388、Estante 书架389、Estatal 国有的390、Este 东,东方的391、Estrangeiro 外国人,国外,外国的392、Estrela 星星393、Estudante 学生394、Estudar 学习395、estúdio de cinéma 电影厂396、Estudioso 勤奋的397、Estudo 学习,研究398、Estúpido 笨的,蠢的399、Europa 欧洲400、Europeu 欧洲的401、Exacto 正确的,对的402、Exame 考试403、Experiente 有经验的404、Exportação 出口405、Extensivo 延伸的,扩展的406、Extenso 广阔的407、Extremo 末端,极端,尽头408、Extrovertido 外向的F409、Fábrica 工厂410、Fácil 容易的411、Faculdade 系,院(大学的)412、Fado 法多(葡萄牙民歌)413、Falador 爱说话的,多话的414、Falar 讲415、Faltar 缺,差416、Família 家庭417、Fantástico 非常棒的,绝妙的418、Farol 等他419、Fato 西服420、Favorável 有利的,有益的,ser favorável a 对...有利的,对...有帮助的421、Fazer 做,fazer anos 过生日422、Feio 难看的,丑的423、Feira 集市424、Felicidade 幸福425、Feliz 幸福的426、Felizmente 幸运的427、Féria 假期428、Feriado 节假日429、Festa 聚会430、Fevereiro 二月431、Fiambre 冷餐肉432、Ficar (em)位于,坐落于433、Ficção 小说434、Filha 女儿435、Filme 电影436、Fim-de-semana 周末437、Fita 带子,丝带,纸条438、Fixo 固定的439、Flor 花朵440、Fome 饥饿441、Fora,外面,fora de442、Forma 形式443、Forte 强壮的444、Fraco 弱的(身体),差的(学习)445、França 法国,francês 法国人,法语446、Fresco 新鲜的,凉爽的447、Frio 冷的448、Friorento 怕冷的449、Funcionário 职员,funcionário público 公务员450、Futebal 足球451、Gabinete 办公室452、Galo 公鸡454、Garrafa 瓶子455、Gelado 冰冻的456、Gelo 冰457、Gémeo 双胞胎,孪生的458、Genro 女婿459、Gente 人,人们460、Geração 代,辈461、Geral 总的,全面的,de forma geral 总体来说462、Gerente 经理463、Ginástica 体操464、Giratório 旋转的,cadeira giratório a 转椅465、Giro 有意思,好玩,que giro 真有意思,真好玩466、Global 全球的467、Gordo 胖的,肥胖的468、Gostar 喜欢469、Governo 政府470、Gozar 享受471、Gramática 语法472、Gramatical 语法的473、Grande 伟大的474、Grau 度,度数476、Guarda-chuva 雨伞477、Gaurda-costas 保镖478、Guarda-fato 衣柜479、Guardar 收藏,存放480、Guarda-roupa 衣柜481、Guarda-sol 太阳伞482、Guerra 战争H483、Habitante 居民484、Hábito 习惯485、Habituado 习惯的,estar habituado a 习惯于486、Harmonioso 和谐的,和睦的487、Haver 有488、História 历史489、Hoje 今天490、Homem 男人491、Hora 小时,a horas 准点492、Horário 时间表,课程表493、Hospital 医院494、Hotel 宾馆,酒店495、Húmido 潮湿的I496、Idade 年龄497、Ideia 主意,想法498、Igual 一样的499、Imenso 非常,很,巨大的500、Importação 进口501、Importante 重要的502、Índia 印度503、Indiano 印度的,印度人的504、Individual 单人的,cama individual 单人床505、Indizível 不可言喻的,难以形容的506、Inglaterra 英国507、Inglês 英语,英国人508、Inteligente 聪明的509、Interessante 有趣的510、Interior 内部,里面,内地511、Internet 因特网512、Intérprete 口译议员513、Introvertido 内向的514、Inveja 羡慕,嫉妒,ter inveja de 羡慕,嫉妒... 515、Inverno 冬天516、Ir 去,ir para a cama 睡觉517、Irmã 姐妹518、Irmão 兄弟,irmão mais novo 弟弟,irmão mais velho 哥哥519、Isso 那,那个520、Isto 这,这个521、Itália 意大利J522、Já已经523、Janeiro 一月524、Janela 窗户525、Jantar 晚餐,吃晚饭526、Japão 日本527、Japonês 日语,日本人528、Jardim 花园529、Jeans 牛仔裤530、Jogar 打,玩,下(棋牌类运动)531、Jogo 游戏532、Jornal 报纸533、Jornalista 记者534、Julho 七月535、Junho 六月536、Junto 一起的L537、Lá那儿,那里538、Laboratório 实验室539、Lado 边,侧,ao lado de 在...旁边540、Lago 湖,湖泊541、Lápis 铅笔542、Laranja 橙子543、Latino-americano 拉丁美洲的,拉丁美洲人544、Lavar 洗,洗涤545、Leão 狮子,狮子座546、Leccionar 教,教授547、Leite 牛奶548、Leitura 阅读,leitura extensiva 泛读549、Lentes de contacto 隐形眼镜550、Lento 缓慢的551、Ler 看,读552、Leste 东,东方的553、Letra 字母,文科554、Levantar 抬起,举起,起床,levantar a mesa 收拾桌子555、Levar 带上556、Licenciatura 本科557、Ligar 开,接通558、Limpo 清洁的,干净的559、Lindo 美丽的,漂亮的560、Língua 语言561、Liso 直的562、Litoral 沿海的563、Livre 自由的,空闲的564、Livro 书565、Logo 马上,立刻566、Loiro 金发的567、Loja商店568、Longe 远的,longe de 离...远569、Lua 月亮570、Lúsofono 讲葡萄牙语的571、Luva 手套572、Luz 灯,灯光M573、Macaco 猴子574、Macau 澳门575、Madeira 木材576、Mãe 妈妈577、Magro 瘦的578、Maio 五月579、Maior 更大的580、Mais 更,更加581、Maneira 方法582、Manhã 上午,de manhã 上午583、Manteiga 黄油584、Mão 手585、Março 三月586、Marido 丈夫587、Mas 但是,可是588、Materno 母亲的589、Mau 坏的,不好的590、Medicina 医学591、Médico 医生592、Médio 中等的593、Meio 一半的594、meio-dia 中午595、Melhor 更好的596、Membro 成员597、Memorizar 记住,背598、Menor 更小的599、Menos 更少的600、Mentira 谎话,假话601、Mês 月,seis meses 半年602、Mesa 桌子,mesa baixo 茶几,mesa de cabecaira 床头柜,mesa de jantar 餐桌603、Mesmo 正好,恰好604、Meteorológico 气象的,boletim Meteorológico 天气预报605、Metro米,metro quadrado 平方米606、Meu,minha 我607、Mil 千608、Mínimo 最小的,最低的609、Minuto 分钟610、Misto 混合的611、Moça 女孩,姑娘612、Moçanbicano 莫桑比克人,moçambique莫桑比克613、Mochila 双肩背包614、Moço 小伙子615、Modo 方式616、Momento 时刻,片刻,neste momento 现在,目前617、Morar 居住618、Moreno 皮肤黝黑的619、Motorista 司机620、Móvel 移动621、Muito很多的,大量的622、Muito prazer 很高兴认识你623、Mulher 女子,妻子624、Mundial 世界的625、Música 音乐626、Mutuamente 相互,彼此N627、Nacional 全国的628、Nacionalidade 国籍629、Nada 没有什么,nada de especial 没什么特别的,de nada 不客气630、Nadar 游泳631、Não...nem 既不,也不632、...sóo/mas também 不仅,而且633、Nascer 出生634、Natal 出生的,圣诞的635、Natural 自然的636、Navegar 航行637、Negativo 零下的,消极的638、Negócio 业务,生意639、Negro 黑色的,黑种人640、Nem 甚至没有,并不是641、Nenhum 没有任何一个642、Neto孙子643、Nevar 下雪644、Neve雪645、Nevoeiro 雾646、No entanto 然而,不过647、Noite 晚上,ànoite 晚上648、Nome 名字649、Nono 第九650、Nora 儿媳妇651、Nordeste 东北,东北的652、Normal 正常653、Normalmente 一般,通常654、Noroeste 西北,西北的655、Norte 北,北方656、Norte-americano 北美洲的,美国的657、Nosso,nossa 我们的658、Novamente 再次659、Nove 9660、Novecentos 900661、Novembro 十一月662、Noventa 90663、Novo 新的,de novo 重新664、Nublado 多云的665、Número 数字,号码,número de telefone 电话号码666、Nunca 从不,决不667、Nuvem 云O668、O qual 这个,那个,669、Origado 谢谢670、Obrigatório 必须的,强制性的671、Óculos 眼镜,óculos de sol 太阳镜,óculos escuros 墨镜672、Oeste 西,西方673、Oferecer 送,赠送674、Oficial 官方的675、Oitavo 第八,oitenta 80,oitocentos 800,676、Olho 眼睛677、Onde 哪儿678、Ondulado 波浪形的679、Ontem 昨天680、Onze 11681、Opcional 选择性的,可挑选的682、Operário 工人683、Oportunidade 机会,机遇684、Óptimo 很好的685、Oralidade 口语686、Oralmente 口头地687、Órfão 孤儿688、Organismo governamental 政府机关689、Órgão 器官690、Outono 秋天691、Outro 别的,其它的692、Outubro 十月693、Ouvir 听,听见694、Oval 椭圆的695、Ovo 鸡蛋,ovo cozido 煮鸡蛋P696、Paciente 有耐心的697、Pago 报酬的,支付的698、Pai 爸爸699、País 国家700、Palavra 单词701、Palma 手掌,掌声702、Pão 面包703、Papel 纸704、Par 对,双705、Parabéns 祝贺,恭喜706、Parecer 像,看起来像707、Parede 墙,墙壁708、Parte 部分709、Passado 过去的710、Passar 过,度过的,经过711、Passear 散步,逛街712、Pasta 文件夹,公文包713、Paterno 父亲的714、Patinar 滑冰715、Patrão 老板716、Pedido 请求,恳求,fazer um pedido 许一个愿717、Pedir 请求,要求718、Peixe 鱼,双鱼座719、Pele 皮肤720、Pelo menos 至少721、Pena 遗憾722、Pensão 公寓723、Pensar 想,打算724、Pequeno-almoço 早餐725、Perder 失去726、Perguntar 问727、Perto 附近,perto...de 距离...近728、Pessoa 人,pessoa de idade 上了年纪的人729、Piano 钢琴730、Pior 更差的,更坏的731、Pluviosodade 降雨量732、Poder 可以733、Pois 对,是,因为734、Polícia 警察735、Policial 警察的,侦探的736、Popular 受欢迎的737、Pôr 摆,放,pôr a mesa 摆桌子738、Por exemplo 比如,例如739、Por isso 因此,所以740、Por volta de 在...点钟左右741、Porco 猪742、Porque 为什么743、Porta 门744、Portátil 手提的,便携式的745、Portugal 葡萄牙746、Português 葡萄牙语,葡萄牙人747、Possível 可能的748、Pouco 少的,um pouco 一点儿749、Praia 沙滩,海滩750、Prateado 银灰色的751、Prática 练习,实践752、Precioso 珍贵的,宝贵的753、Precisar 需要754、Preciso 需要的755、Prédio 大楼756、Preferir 偏爱,宁可,宁愿757、Preguiçoso 懒惰的758、Prenda 礼物,礼品759、Preocupar 使担心760、Preparação 准备761、Preparar 准备762、Presente 礼物763、Presidente 主席764、Preto 黑色的765、Prima 表姐妹766、Primavera 春天的767、Primeiro 第一768、Primo 表兄弟769、Privado 私人的770、Privativo 专有的771、Problema 问题772、Procurado 需求的773、Professor 老师774、Profissão 职业775、Projecto 项目776、Província 省777、Próximo 下一个的778、Público 公共的Q779、Quadrado 方形的,正方形的780、Quadro preto 黑板781、Quando 当782、Quanto多少783、Quarenta 40784、Quarta-feira 星期三785、Quartel dos bombeiros 消防队786、Quarto 卧室,房间,一刻钟,第四787、Quase 几乎788、Quatro 4789、Quatrocentos 400790、Queijo 奶酪791、Quem 谁,那个人792、Quente 热的793、Querer想,愿意794、Querido 可爱的795、Quinhentos 500796、Quinta-feira 星期四797、Quinto 第五798、Quinze 15799、Quotidiano 日常的R800、Ralhar 责骂,斥责801、Rapariga 姑娘,女孩子802、Rapaz 小伙子,男孩子803、Rato 老鼠804、Realmente 真正的,确实805、Receber 收到806、Recepcionista 接待员,前台807、Reciprocamente 相互,彼此808、Redondo 圆的809、Região 地区810、Regra 规则,规律811、Regressar 返回812、Rejeitar 拒绝813、Relação 关系814、Relativamente 相对的815、Relatório 报告816、Relógio 钟,表817、rés-do-chão 底层818、Restaurant 餐厅,餐馆819、Resto 剩余的820、Reunião 会议821、Reunir-se 团聚822、Rio de janeiro 里约热内卢823、Rítmico 有节奏的824、Romântico 浪漫的825、Roupa 衣服826、Roxo 紫色的827、Rua 街,道路828、Rússia 俄罗斯S829、Sábado 星期六830、Saber 知道831、Saco 袋子832、Sagitário 射手座833、Saia 裙子834、Sair 出来,出去835、Sala 厅,堂,sala de aula 教室,sala de estar 客厅,sala de jantar餐厅836、salão de beleza 发廊837、Salva 鼓掌,uma salva de palmas 鼓掌838、Salvar 拯救839、Sande 三明治840、Sapato皮鞋841、Satisfeito 满意的,满足的,estar satisfeito 满意842、Saudável 健康的843、Saúde 健康,estar com boa saúde 身体好844、Seco 干旱845、Secretaria 秘书处846、Secretária 秘书,写字台847、Secundário 次要的,escola secundária 中学848、Segunda-feira 星期一849、Segundo 秒,第二,根据850、Seis 6,seiscentos 600851、Semana 周,星期852、Semestre 学期853、semi-árido 半干旱的854、Sempre 总是,永远855、Senhor 先生,o senhor 您856、Senhora 女士,a senhora 您857、Senhorio 房东858、Sentimental 感情丰富的859、Sentir 感受,感到860、Separado 分开的861、Ser 是862、Serpente 蛇863、Servir 服务864、Sessenta 60865、Sesta 午觉866、Sete 7867、Setecentos 700868、Setembro 九月869、Setenta 70870、Sétimo 第七871、Sexta-feira 星期五872、Sexto 第六873、Significado 意义,含义874、Signo 生肖,属相875、Silêncio 沉默,em silêncio 静静的876、Sim是877、Simpático 友善的,和气的878、Sobre 关于,有关879、Sobretudo 特别,尤其,大衣880、Sobrinha 侄女881、Sobrinho 侄儿882、Sócio 合伙人883、Sofá沙发884、Sogra 岳母,婆婆885、Sogro 岳父,公公886、Sol 太阳,阳光887、Solteiro 单身的,未婚的888、Sopa 汤,sopa de arroz 大米粥889、Sopro 气,de um sopro 一口气890、Sozinho 单独的,独自的891、Sub-director 副主任892、Sudeste 东南,东南方893、Sudoeste 西南,西南方894、Sueste 东南,东南方895、Sugerir 提议,建议896、Sujo 脏的897、Sul 难,南方898、Sul-africano 南非人899、Sumo 果汁,sumo de laranja 橙汁900、Supermercado 超市901、Surpresa 惊讶T902、Também 也903、Tanto 同样多的,一样多904、Tão 如此,这样905、Tarde 下午,迟,àtarde 下午906、Taxista 出租车司机907、Teatro 剧院,戏院908、Técnico 技术员909、Telefonar 打电话910、Telefone 电话911、Telefónico 电话的,cartão telefónico 电话卡912、Telemóvel 移动电话913、Televisão 电视台914、Televisor 电视机915、Temperado 温和的,气温适中的916、Temperatura 气温,温度,temperatura mínima 最低气温,temperatura máxima 最高气温,temperatura média 平均气温917、Tempo 天气,tempo livre 业余时间,闲暇时光918、Tênis 网球,tênis de mesa 乒乓球919、Ter 有,ter de/que 必须920、terça-feira 星期二921、Terceiro 第三922、Terminar 完成,结束923、Terra 土地,地球terra natal 家乡924、Território 国土,领土925、Terror 恐怖,恐惧926、Teste 测试,927、Texto 文章928、Tigre 老虎929、Tio 叔叔,舅舅,伯伯,姑父930、Tipo 类型931、Tirar 拿出,取出,拍照片932、Tocar 演奏,吹啦弹奏乐器933、Todo 所有的,全部的934、Tomar 吃早餐,喝茶935、Torrada 吐司936、Total 全部,总计,no total 总计,总共937、Touro 斗牛,金牛座938、Trabalhador 勤奋的,勤劳的939、Trabalhar 工作940、Trabalho 工作941、Tradutor 翻译942、Transportadora 运输公司943、Trazer 带来944、Três 3,treze 13,trezentos 300,trinta 30 945、Triste 伤心的,忧郁的946、Tropical 热带的947、T-shirt948、Tudo 所有,一切949、Tufão 台风950、Turma 班级U951、Último 最后的952、Único 唯一的,filho único 独生子953、Unidade 单元954、Unido 团结的955、Universidade 大学956、Universitário 大学的957、Usar 用,使用958、Útil 有用的,dia útil 工作日V959、Varanda 阳台960、Vário 好几个961、Vela 蜡烛962、Velho 老的,旧的963、Vendedor 商贩964、Vender 卖965、Vento 风966、Ventoinha 电风扇967、Ver 看,看到968、Verão 夏天,夏季969、Verdade 真实,真相,na verdade 事实上970、Verde 绿色的971、Vermelho 红色的972、Vestido 连衣裙,estar vestido com 穿着...的衣服973、Vestir-se 穿衣服974、Vez 次,回,às vezes 有时,em vez de 替代975、Viagem 旅行,旅途976、Viajar 旅游977、Vice-presidente 副主席978、Vida 生活979、Vigésimo 第二十980、Vinda 来981、Vinho 葡萄酒982、Vinte 20,vinte e um 21983、Violino 小提琴984、Vir 来985、Virgem 处女座986、Visita 参观,访问987、Visitar 看望,拜访988、Vista 风光,风景989、Viver 生活990、Vileibol 排球991、Volta 圈,转圈àvolta de 在...周围992、Voltar 回来,回去993、Vosso,vossa 你们的994、Voto 祝福,祝愿,选票995、Xadrez 国际象棋996、Yoga 瑜伽997、Zero 0998、Zona 地区999、Zona climática 气候带1000、Zona temperada 温带1001、Zona tropical 热带1002、Zona subtropical 亚热带。
Esper学习之⼗EPL语法(六)2014是新的⼀年,正好也是本⼈的本命年。
既然是本命年,看来今年也是本⼈兴旺之年了。
开了个⼩玩笑,同时也祝各位同⾏今年少调bug多涨⼯资,这才是最实际的。
年前的最后⼀篇说的是⼦查询和join,基本上epl的⼤部分简单语法都说完了。
之前有朋友问我epl怎么和数据库交互,正好今天这篇就是来专门解释这个问题。
但是要提醒各位,本篇只是说明了在epl中如何与数据库交互,并且只能算是简单的交互。
⽽⾼级的⽤法会在esperio⾥有详细的指导(esperio的⽂档可在esper的官⽹找到)。
在esper的⽂档中,epl访问数据库的配置放在了⽐较靠后的位置,不过为了⽅便各位学习,这⾥会先说明和数据库交互的相关配置,然后再说epl怎么访问数据库。
配置⽂件在官⽅esper包的etc⽂件夹下,⼤家可以参考着学习。
1.连接数据库a.JNDI获取连接配置如下:[html]view plaincopy1.2.3.e ="com.myclass.CtxFactory"/>4.="iiop://localhost:1050"/ >5.6.database-reference的name是要连接的数据库名字,其余的配置可参考JNDI 的⽂档使⽤⽅法:[java]view plaincopy1.if (envProperties.size() > 0) {2.initialContext = new InitialContext(envProperties);3.} else {4.initialContext = new InitialContext();5.}6.DataSource dataSource = (DataSource) initialContext.lookup(lookupName);7.Connection connection = dataSource.getConnection();更多内容可参考JNDI的⽂档b.从连接池获取连接配置如下:(以dbcp为例)[html]view plaincopy1.2.3.4.5.6.7.8.9.10.11.相同的配置可以使⽤esper的api达到同样的效果。
python cep用法-回复Python中的CEP用法CEP,即复杂事件处理(Complex Event Processing),是一种处理和分析实时数据流的技术。
Python提供了一些强大的库和工具,使得在Python中使用CEP变得更加简单和高效。
在本文中,我们将逐步介绍Python中的CEP用法,并且探讨如何应用CEP来处理和分析实时数据。
第一步:了解CEP的基本概念和原理在开始之前,我们需要了解CEP的基本概念和原理。
CEP可以被定义为一种通过检测和分析数据流中的事件来推断高级事件的技术。
一个事件可以是任何类型的数据,例如传感器读数、日志信息或用户行为记录。
CEP引擎可以通过定义规则和模式来检测和匹配事件,从而推断出更高级的事件或情境。
第二步:安装CEP库Python中有一些主要的CEP库可以用于处理和分析实时数据流。
其中最受欢迎的是Esper和Siddhi。
在本文中,我们将以Esper为例来展示CEP的用法。
要安装Esper库,请使用以下命令:pip install esper第三步:导入所需的库和模块在使用CEP之前,我们需要导入一些必要的库和模块。
首先,我们需要导入Esper库:from esper import esper然后,我们还可能需要导入其他一些常用的Python库,如numpy、pandas等,以便更方便地处理和分析数据。
第四步:定义事件在CEP中,事件可以是任何类型的数据。
在Python中,我们可以通过定义一个类来表示一个事件。
例如,假设我们要处理传感器的读数数据,我们可以定义一个类来表示这个事件:class SensorReading:def __init__(self, sensor_id, value, timestamp):self.sensor_id = sensor_idself.value = valueself.timestamp = timestamp在这个例子中,我们定义了一个SensorReading类,它有三个属性:sensor_id、value和timestamp。
暂停更新三个多月,转眼间就2014年了。
年底相信都是大家最忙碌的时候,我也不例外,以至于真的是没腾出手来继续更新,好在年初这段时间可以休息一阵了,所以赶着这段时间空闲就多写点吧。
本来想先写view,pattern这些常用的内容以满足大部分人的需求,但是考虑到这些章节有涉及到前面章节的知识,所以我觉得基础还是要学的,不能还没学会走就想跑,否则可能会摔得很惨哦。
本篇的内容主要包括了Subquery(也就是子查询)和Join,内容不少,但是不难,基本上和sql差不太多。
1.SubqueryEPL里的Subquery和sql的类似,是否比sql的用法更多我不得而知,毕竟本人是sql菜鸟,只在where语句里用过子查询。
废话不多说,先上几个Subquer 的简单用法:子查询结果作为外部事件的属性[plain]view plaincopy1.select assetId, (select zone from ZoneClosed.std:lastevent()) as lastClosed from RFIDEvent上面的例子是说返回当前RFIDEvent的assetId属性值和最新ZoneClosed事件的zone属性值,且以lastClosed作为zone的别名。
子查询关联外部事件的属性[plain]view plaincopy1.select * from RfidEvent as RFID where 'Dock 1' = (select name from Zones.std:unique(zoneId) where zoneId = RF ID.zoneId)子查询语句中的where条件可以应用RFID的属性,即内部的zoneId=RFID.zoneId[plain]view plaincopy1.select zoneId, (select name from Zones.std:unique(zoneId)where zoneId = RFID.zoneId) as name from RFIDEvent关联外部事件属性的同时也可以作为外部事件的属性返回。
ESPER构建大数据量实时分析引擎ESPER是一个实时数据分析引擎,并不是一个实时数据分析系统。
引擎和系统之间有很大的差别。
它无法作为一套完整独立的实时分析系统来使用它有以下几个缺点:(1)数据安全:ESPER引擎内部都是内存操作,一旦重启会丢失。
这里就涉及到一个日志failover的问题,那这个目前尚不在ESPER的处理范围内,需要自己来处理。
(2)高并发数据:ESPER引擎并没有做分布式框架,大量数据的分布式处理需要自己想办法来解决。
ESPER也有Enterprise版本、HA版本,据官方介绍这两个版本比较安全可靠,但由于这两个版本不开源、且收费,也未去做相应的研究在开源的esper基础上也可以自己搭建一套完整的实时数据分析系统。
先说说我的需求吧,目前有个实时数据流平台,能推送JSON格式的数据过来,每种格式的数据有各自不同的tag。
实时数据可以推送到MQ服务器,希望通过配置不同的EPL语句得到分析的结果,并将结果也输出都MQ服务器中。
由于数据量比较大,所有数据往单台服务器上推肯定是不现实的,因此需要对数据进行切分,实现分析引擎的水平扩展。
下面是我初步设计的架构图对各个模块简单说明一下:三、Scheduler:调度模块key就是select 语句后面的那些字段该模块编码不复杂,重点在于EPL语句的合理性六、Summary模块这个是对分布式运算的结果进行合并的模块,类似于Hadoop中的Reducer 这不是个现成的模块,需要自己来实现,主要功能是把各个ESPER引擎分布计算的日志进行聚合运算,实现sum,count,加减乘除等响应计算方法就可以了。
最好把输出结果发送到MQ队列中。
这里有两个个问题(1)因为是分布式运算,多个时间段的数据在到达Summary模块的时间先后顺序不一致,因此需要再ESPER推送到Summary的时候加入一个ID,只将相同ID的统计消息进行聚合运算。
(2)虽然说都是近5秒的数据,但是这个时间如果按照机器时间来算的话就很难办了,因为你5秒内收集到的数据可能是apache10s内的日志。
虽然是实时分析系统,但也可能会出现这种情况,可能是由于(1)网络延迟(2)程序刚启动的时间内大量历史日志发送过来(3)统计系统负载高造成延迟,很难说一定能完全match上。
上一篇博客也提到了ESPER的时间窗口不是由系统时间控制,而是由应用程序控制,我们可以使用PlainEvent中的时间来推动时间窗口的运作。
要实现这一点就需要保证MQ中的消息在时间上是有序的,如果是多台机器上采集到的日志无法保证完全有序至少可以保证单台机器的日志由于。
在Distributor时可以根据机器名来做拆分,将一台机器上采集到的日志发送到一个ESPER引擎来实例来处理。
这样做就可以保证ESPER引擎的时间窗口和日志的时间相匹配。
从而实现精确的实时统计分析效果。
结论最后我们来说一下ESPER的性能情况,什么时候需要用到上面说的那种架构ESPER单节点的处理能力还是不错的,官方网站有个性能测试报告,在双2GHZ CPU的Intel系统测试环境下,处理50万+个事件/s;在VWAP基准测试中在有1000语句的情况下,引擎延时平均小于3微妙(在10微妙时超过99%的预测准确率)---最高时有70Mb/s流量并占用85%的CPU资源/display/ESPER/Esper+performance单节点的处理能力是很强的,目前50万事件/s的产品日志估计不多见,还是可以满足绝大部分的产品应用情况的。
如果没有超过50万/s事件的需求,可以不需要使用分布式运算,仅仅在Distributor时对不同的type调配到某个ESPER 就可以了,还可以省略Summary模块。
而上述这套框架是为了满足超过50万事件/s的产品,单台ESPER处理能力不足的时候使用的。
1.1介绍CEP和事件流分析Esper引擎是为了满足对事件进行分析并做出反应等这些应用需求而产生的。
这些应用要求事实或接近事实处理事件(或消息)。
有时候是为了应对复杂事件处理(CEP)和事件流分析的。
关键要考虑这些类型应用的(高)吞吐量、(低)响应时间和需求逻辑的复杂程度(复杂计算)。
esper可以用在股票系统、风险监控系统等等要求实时性比较高的系统中。
1.2 CEP和关系数据库关系型数据库不适合每秒成百上千的数据量的查询内存数据库与比传统的关系数据库相比,有更好的查询性能,更适合处理CEP应用。
1.3 专注于CEP的Esper 引擎这个Esper引擎工作起来有点像数据库的倒置。
Esper 引擎允许应用存储查询并运行数据通过,来代替存储数据并且执行查询存储数据的工作方式。
esper提供两种机制来处理事件:1、Esper提供了一个事件模式语言去指定基于表达式的事件模式匹配。
这个模式匹配引擎是通过一个状态机来实现的。
这个事件处理的方法匹配期望存在的队列或者不存在的事件或者事件的组合。
它包括以时间为基础的各个事件之间的关系。
2、Esper还提供事件流查询。
这个样可以使事件流分析CEP应用的需求。
事件流查询提供窗口、聚合、连接和分析的函数来处理事件流。
这些查询是通过EPL 语句来实现的。
EPL用于视图。
视图表示需要将构造的数据放入到一个事件流中并且去驱动数据的流动。
在数据流动的过程中对数据进行处理,来得到我们最后所需要的结果。
下面是在网上找到的资料,觉得总结的挺好的:Esper提供这两种方法作为互补是通过相同的API来实现的1.4事件驱动应用服务器(Event Driven Application Server)事件驱动应用服务器是一种新型的服务器,为每秒需要处理超过100,000个事件的服务器提供一个运行时和多种支撑基础设施服务(如传输、安全、事件日志、高可靠性和连接器等)。
除了事件处理以外,事件驱动服务器还可以将事件信息和长时间存在的数据(通常从关系数据库查询中获取)结合起来,以及在事件流上执行临时的关联关系和匹配操作。
事件系统(Event System)存在两个概念,可使之与消息传送系统(Messaging System)区分开来:1、事件流处理(Event Stream Processing,ESP)——检测事件数据流,分析出那些符合条件的事件,然后通知监听器2、复杂事件处理(Complex Event Processing,CEP)——可以监察各事件间的模式全功能的事件驱动服务器尚需数年时间方可实现,但现在开发者就可通过来自Codehaus的Esper,在独立应用、Java企业级应用和Spring应用中实现事件驱动架构。
Esper的1.0版本(InfoQ曾报道过)是在2006年6月发布的,它是一个轻量级、可嵌入的ESP和CEP的开源实现。
把Esper集成到独立应用中其实很简单。
步骤如下:1、获取一个Esper引擎实例2、生成一个Statement(用Esper的查询语言)3、使用引擎注册这个Statement4、生成一个Listener(通过实现一个Java接口,该接口在Statement所得值为true会被触发),并把它跟Statement绑定起来事件能以Java对象、XML或Map的形式展现,当它们通过系统的时候,系统会评估Statement的值,并执行Listener中的逻辑。
Esper查询语言提供了丰富的语法,这些语法可以表达复杂的临时逻辑,此外还有如下的一些特征:1、事件过滤2、滑动窗口和聚集(计算在最近30秒内所有报告的有意义的信息)3、分组窗口和对输出率的限制(获取最近10分钟内每个区域的信息数量)4、连接和外连接(允许事件流之间的连接)5、与历史数据或引用数据集成(访问关系型数据库)6、生成所有Statement都可以访问的虚拟流官网的英文简介如下:/products/esper.php在官网上借两张图来加深一下理解:分类: 事件系统epser是CEP开源(企业版不免费)实现的一种,epser提供的事件模式和视图两种机制实际上在底层都是视图化的处理,相比其他SODBASE CEP, Streambase等CEP引擎的内核机制的完备性上还是比较弱的,epser存在事件漏报的情况。
最近一直有同事跟我说目前开发的数据流平台仅仅只是把数据推送过来作用不大。
希望最好能够连数据分析也一起做了,告诉他们结果就好。
这样的需求一般交给数据分析组去做就好了,不过了解了一下现在只有离线分析,最快也只能半小时统计一次,实时分析这块还没有实现。
去搜了下,看看有哪些开源的实时分析引擎可以用。
之前先看了下storm,twitter做的,大公司大品牌,完全开源,看上去的确不错。
但是看了一下功能,相当于是一个实时hadoop,只能帮你计算,但是怎么算还得你自己写程序,离贴一张esper官网上的结构图,方便大家了解esper的结构接下来对上述结构图进行详细的解释让大家加深对ESPER的了解win:time(3 sec)就是定义了3秒的时间窗口,avg(price)就是统计了3win:length(10)就是定义了10个Event的,avg(price)就是统计了最近10个的OrderEvent对象的price的平均值钻研一下他的内部实现方式。
先来看一张时间窗口模式的图他仅保留最近时间窗口的对象内容,但是每个Event到来都会触发一次事件窗口也基本类似。
贴得比较乱简单解释一下,ScheduledThreadPoolExecutor.scheduleAtFixedRate固定每100ms (可配置)运行一次,并且通过计算延迟future.getDelay来确保计时精确,接下来通过发送一个CurrentTimeEvent来推送时间前进100+delay(ms),也就是说ESPER中的时间不是完全受机器时间控制的,而是通过发送时间批量模式的操作图如下上图的时间窗口大小为4s,他会在4s的窗口时间到达以后才将窗口中的内容一配置一下总体来说,ESPER的EPL功能非常强大,而且基本和SQL类似,入门容易,构造一个实时数据分析系统比较简单,且维护成本低,新应用进来只需要简单配置一下EPL语句就可以了,方便快捷,对大部分的系统还是比较适合的。
由于项目需要,我开始了学习Esper的任务。
刚开始觉得他是个很高级的东西,学了一段时间后发现他确实是很高级的东西。
不过貌似在国内的应用很少,网上都查不到什么资料的,所以我觉得在博客里写一下自己的学习的收获,一是总结所学知识点,二是分享给更多的学习者,毕竟好东西不能这样被埋没了。
今天就先来简单介绍一下Esper是什么玩意儿。
说到Esper,不得不说一下CEP。
CEP即Complex Event Process,中文意思就是“复杂事件处理”。