数据压缩实验
- 格式:doc
- 大小:1.38 MB
- 文档页数:27

压缩实验的实验步骤嘿,你想知道压缩实验是怎么一回事吗?那我就给你好好讲讲这压缩实验的实验步骤,可有趣啦。
我有个朋友叫小李,他之前对压缩实验也是一窍不通。
有一天他跑来问我,说:“这压缩实验是不是就像把棉花使劲捏成一团那么简单呀?”我当时就笑了,告诉他可没那么容易。
那咱们就开始说这压缩实验的步骤吧。
第一步呢,得先准备好实验器材。
这就像大厨做菜之前得把锅碗瓢盆、食材调料都准备好一样。
你得有一个合适的压缩试验机,这试验机就像是一个超级大力士,专门用来给东西施加压力的。
而且呀,这个试验机得是经过校准的,要是不准的话,那这实验结果就全乱套了,就像你要量身高,结果尺子是坏的,那量出来的能准吗?真让人头疼!除了试验机,还得有要被压缩的试样。
这试样的选择可讲究了,不同的材料、不同的形状、不同的尺寸,都会影响实验结果。
就好比你要做一件衣服,布料的质地、大小不一样,做出来的衣服肯定不一样啊。
我记得有一次,另一个朋友小张在做这个实验的时候,随便拿了个试样就开始做,结果实验数据乱七八糟的,他自己都懵了,还嘟囔着:“哎呀,这是咋回事呢?”所以说,试样的准备一定要细心。
第二步,要对试样进行测量和标记。
这可不是随随便便量一量就行的。
就像是给一个即将参加比赛的选手做详细的体检一样。
你得测量试样的原始尺寸,精确到毫米甚至更小的单位。
长是多少、宽是多少、高是多少,这些数据都非常重要,这可是我们判断压缩效果的基础呀。
而且要在试样上做好标记,这样在实验过程中才能清楚地看到试样的变化。
这就像给远足的人在地图上标记好路线一样,不然很容易就迷路了。
我曾经看过一个新手做这个步骤,他测量的时候马马虎虎的,标记也做得不清不楚,结果在实验进行到一半的时候,他都不知道自己看到的变化是对是错,急得像热锅上的蚂蚁。
这能怪谁呢?只能怪自己开始的时候不认真呗。
第三步,把试样放到压缩试验机的工作台上。
这就像是把一个小宝贝小心翼翼地放在婴儿床上一样。
要确保试样放置得稳稳当当的,不能有倾斜或者晃动。

压缩实验报告数据分析1. 引言本文对压缩实验的数据进行了分析和总结。
压缩是一种常见的数据处理技术,通过减少文件的大小,可以提高存储和传输效率。
本实验旨在探究不同压缩算法对不同类型的数据的效果以及压缩率的变化情况。
2. 数据收集和实验设计在本实验中,我们收集了不同类型的数据文件,包括文本文件、图像文件和音频文件。
我们选择了三种常用的压缩算法,分别是gzip、zip和tar。
每个数据文件都分别用这三种算法进行了压缩,并记录了压缩前后的文件大小。
实验设计如下: - 数据收集:从不同来源收集文本、图像和音频文件。
- 压缩算法选择:选择gzip、zip和tar作为压缩算法。
- 压缩实验:分别使用这三种压缩算法对每个数据文件进行压缩。
- 数据记录:记录每个文件的原始大小和压缩后的大小。
3. 数据分析3.1 压缩率分析首先,我们对每个数据文件进行了压缩率的计算。
压缩率表示压缩后文件大小与原始文件大小的比值,可以反映出压缩算法的效果。
表格1:不同数据文件的压缩率文件名gzip压缩率zip压缩率tar压缩率文本文件0.4 0.3 0.35图像文件0.6 0.5 0.55音频文件0.2 0.15 0.18从表格1中可以看出,不同类型的数据文件在不同的压缩算法下的压缩率有所不同。
图像文件的压缩率相对较高,而音频文件的压缩率相对较低。
3.2 压缩算法效果比较接下来,我们对不同压缩算法在同一类型的数据文件上的效果进行了比较。
我们选择了文本文件进行分析。
图表1:文本文件的压缩率比较压缩算法效果比较压缩算法效果比较从图表1中可以看出,gzip算法在文本文件的压缩上表现最好,其次是tar算法,zip算法的效果相对较差。
4. 结论通过本次实验的数据分析,我们得出了以下结论: - 不同类型的数据文件在不同的压缩算法下的压缩率有所不同。
- 对于文本文件,gzip算法表现最好,zip算法效果相对较差。
压缩算法的选择应该根据具体的应用场景和需求来进行,综合考虑压缩率和解压缩速度等因素。

第1篇一、实验目的1. 了解数据压缩的基本原理和方法。
2. 掌握常用数据压缩算法的应用。
3. 分析不同数据压缩算法的性能和适用场景。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 数据压缩工具:Huffman编码、LZ77、LZ78、RLE、JPEG、PNG三、实验内容1. Huffman编码2. LZ77编码3. LZ78编码4. RLE编码5. 图像压缩:JPEG、PNG四、实验步骤1. Huffman编码(1)设计Huffman编码树,计算每个字符的频率。
(2)根据频率构建Huffman编码树,为每个字符分配编码。
(3)将原始数据按照Huffman编码进行编码,得到压缩数据。
(4)解压缩:根据编码表还原原始数据。
2. LZ77编码(1)设计LZ77编码算法,查找匹配的字符串。
(2)将原始数据按照LZ77编码进行编码,得到压缩数据。
(3)解压缩:根据编码表还原原始数据。
3. LZ78编码(1)设计LZ78编码算法,查找匹配的字符串。
(2)将原始数据按照LZ78编码进行编码,得到压缩数据。
(3)解压缩:根据编码表还原原始数据。
4. RLE编码(1)设计RLE编码算法,统计连续字符的个数。
(2)将原始数据按照RLE编码进行编码,得到压缩数据。
(3)解压缩:根据编码表还原原始数据。
5. 图像压缩:JPEG、PNG(1)使用JPEG和PNG工具对图像进行压缩。
(2)比较压缩前后图像的质量和大小。
五、实验结果与分析1. Huffman编码(1)压缩前后数据大小:原始数据大小为100KB,压缩后大小为25KB。
(2)压缩效率:压缩比约为4:1。
2. LZ77编码(1)压缩前后数据大小:原始数据大小为100KB,压缩后大小为35KB。
(2)压缩效率:压缩比约为3:1。
3. LZ78编码(1)压缩前后数据大小:原始数据大小为100KB,压缩后大小为30KB。
(2)压缩效率:压缩比约为3.3:1。

一、实验背景压缩实验是一种常见的力学实验,通过在特定的实验条件下对材料进行压缩,研究其力学性能。
本次实验主要针对某一种材料进行压缩实验,以了解其压缩性能。
本报告将对实验数据进行详细分析,得出实验结果。
二、实验目的1. 研究材料在不同压力下的变形情况;2. 了解材料的弹性模量和屈服强度;3. 分析材料在不同压力下的力学性能。
三、实验原理压缩实验通常采用单轴压缩实验,即在轴向施加压力,使材料发生压缩变形。
根据胡克定律,材料的应力与应变之间存在线性关系,即应力=弹性模量×应变。
当材料达到屈服强度时,应力与应变之间的关系将不再线性,此时材料将发生塑性变形。
四、实验方法1. 实验材料:选取某一种材料作为实验对象;2. 实验设备:压缩试验机;3. 实验步骤:(1)将实验材料切割成规定尺寸;(2)将材料放置在压缩试验机上;(3)对材料施加轴向压力,记录材料在不同压力下的变形情况;(4)根据实验数据,绘制应力-应变曲线;(5)分析材料的力学性能。
五、实验数据及分析1. 实验数据表1:实验数据压力(MPa)应变(%)应力(MPa)0 0 010 0.5 2020 1.0 4030 1.5 6040 2.0 8050 2.5 1002. 数据分析(1)线性阶段:从表1中可以看出,在压力0-30MPa范围内,材料的应力与应变呈线性关系,弹性模量E=40MPa。
这说明材料在该压力范围内具有良好的弹性性能。
(2)非线性阶段:当压力超过30MPa时,应力与应变之间的关系不再线性,材料开始发生塑性变形。
此时,材料的屈服强度约为100MPa。
(3)应力-应变曲线:根据实验数据,绘制应力-应变曲线,如图1所示。
曲线在压力0-30MPa范围内呈线性,压力超过30MPa后,曲线出现拐点,表明材料开始发生塑性变形。
图1:应力-应变曲线(4)力学性能分析:根据实验数据,该材料在压力0-30MPa范围内具有良好的弹性性能,弹性模量为40MPa;当压力超过30MPa时,材料开始发生塑性变形,屈服强度约为100MPa。

实验一拉伸、压缩实验一、拉伸试验1、目的:2、使用仪器设备与工具:3、试验步骤:(1)、低碳钢(2)、铸铁4、实验记录及数据整理:(2)、数据整理①低碳钢强度指标:流动极限强度极限塑性指标:延伸率δ=(L1 - L)/ L x 100%面积收缩率ψ=( F1 - F ) / F x 100%绘拉伸图(P—Δl曲线)②铸铁强度极限绘拉伸图(P—Δl曲线)5、比较低碳钢和铸铁的机械性质和两者的破坏特点。
二、压缩实验1、目的:2、使用仪器设备与工具:3、试验步骤:(1)、低碳钢(2)、铸铁4、实验记录及数据整理:(1)、实验记录(2)、数据整理①低碳钢流动极限:②铸铁强度极限:铸铁压缩曲线低碳钢压缩曲线(3)、比较两种材料机械性质和破坏特点三、低碳钢的弹性模量E 测定试验1、目的:2、使用仪器设备与工具:3、试验步骤: (1)、 (2)、 (3)、 (4)、 (5)、 (6)、4、试验记录及数据整理: (1)、测E 实验记录:引伸仪放大倍数K=引伸仪两刀口间距离L=20mm (2)、测E 的数据整理:弹性模量 E=实验二 扭曲实验1、 目的: (1)、测定低碳钢的剪切流动极限τΤ及剪切强度极限τΒ。
(2)、测定铸铁剪切强度极限τΒ。
2、 使用仪器设备与工具:扭转试验机、卡尺。
3、 试验步骤:将试件两端插入扭转试验机的夹头中,加紧试件,用粉笔在试件上沿轴向画线,摇动试验机手柄,给试件加扭矩。
由绘图器记录M n —ψ 曲线。
当扭矩不再明显增加时即为流动时的值M Τ。
越过流动阶段后开动马达加快加载速度,直到试件扭断为止,记下断裂时的扭矩值M B ,并注意观察断口形状。
扭矩在比例极限以内材料完全处于弹性状态,扭转虎克定律为扭转铸铁时,因铸铁在变形很小时就破坏,所以只用手摇加载。
注意观察铸铁试件在扭转过程中的变形及破坏情况,并记录试件断裂时的极限扭矩值 。
注意观察断口形状。
4、实验记录及数据整理: (1)、试验记录(2)、数据整理低碳钢 强度极限:铸 铁 强度极限:低碳钢 铸 铁(3)、比较低碳钢和铸铁的机械性质和两者的破坏特点。

数据压缩算法效果评估说明数据压缩算法是一种常见的数据处理技术,它通过减少数据的冗余信息来实现数据的压缩,从而节省存储空间和提高数据传输效率。
在实际应用中,选择适合的压缩算法对于保证数据的完整性和压缩效果至关重要。
本文将对数据压缩算法的效果评估进行详细说明。
数据压缩算法的效果评估主要包括以下几个方面:压缩比、压缩速度、解压速度以及质量损失。
首先,压缩比是评估数据压缩算法效果的重要指标之一。
它衡量了压缩算法在压缩数据时所能达到的压缩程度。
压缩比的计算公式为:压缩比 = 原始数据大小 / 压缩后数据大小压缩比越高,则表示算法能够更好地减小数据的体积。
一般来说,压缩比越高,算法的效果越好。
但是,在实际应用中需要综合考虑压缩比和压缩速度之间的平衡,因为高压缩比通常意味着更复杂的算法,从而导致压缩速度较低。
其次,压缩速度和解压速度是衡量算法效果的另外两个重要指标。
压缩速度是指将原始数据进行压缩所花费的时间,解压速度是指将压缩后的数据进行解压缩所花费的时间。
一般来说,快速的压缩和解压速度对于提高数据处理效率至关重要。
因此,在选择数据压缩算法时,需要综合考虑压缩速度和解压速度之间的平衡,以满足实际应用中的需求。
最后,质量损失是评估数据压缩算法效果的重要指标之一。
压缩算法在压缩数据时,有时会造成一定程度的质量损失。
例如,图像压缩算法在压缩图像时可能会引起图像的失真。
因此,评估数据压缩算法的效果时,需要考虑到压缩后数据与原始数据之间的差异,以及压缩引起的质量损失对于实际应用的影响。
数据压缩算法的效果评估可以通过实验方法来进行。
首先,选择一组具有代表性的测试数据集,并记录下原始数据的大小。
然后,使用不同的数据压缩算法对原始数据进行压缩,并记录下压缩后数据的大小、压缩时间和解压时间。
最后,对比各种算法的压缩比、压缩速度和解压速度,并评估压缩引起的质量损失。
需要注意的是,数据压缩算法的效果评估是一项复杂的工作,需要综合考虑多个指标,并根据具体应用场景选择合适的算法。

第1篇一、实验目的1. 理解霍夫曼编码的基本原理和实现方法。
2. 掌握霍夫曼编码在数据压缩中的应用。
3. 通过实验,加深对数据压缩技术的理解。
二、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发环境:Visual Studio 20194. 数据源:文本文件三、实验原理霍夫曼编码是一种常用的数据压缩算法,适用于无损数据压缩。
它通过使用变长编码表对数据进行编码,频率高的数据项使用短编码,频率低的数据项使用长编码。
霍夫曼编码的核心是构建一棵霍夫曼树,该树是一种最优二叉树,用于表示编码规则。
霍夫曼编码的步骤如下:1. 统计数据源中每个字符的出现频率。
2. 根据字符频率构建一棵最优二叉树,频率高的字符位于树的上层,频率低的字符位于树下层。
3. 根据最优二叉树生成编码规则,频率高的字符分配较短的编码,频率低的字符分配较长的编码。
4. 使用编码规则对数据进行编码,生成压缩后的数据。
5. 在解码过程中,根据编码规则恢复原始数据。
四、实验步骤1. 读取文本文件,统计每个字符的出现频率。
2. 根据字符频率构建最优二叉树。
3. 根据最优二叉树生成编码规则。
4. 使用编码规则对数据进行编码,生成压缩后的数据。
5. 将压缩后的数据写入文件。
6. 读取压缩后的数据,根据编码规则进行解码,恢复原始数据。
7. 比较原始数据和恢复后的数据,验证压缩和解码的正确性。
五、实验结果与分析1. 实验数据实验中,我们使用了一个包含10000个字符的文本文件作为数据源。
在统计字符频率时,我们发现字符“e”的出现频率最高,为2621次,而字符“z”的出现频率最低,为4次。
2. 实验结果根据实验数据,我们构建了最优二叉树,并生成了编码规则。
使用编码规则对数据源进行编码,压缩后的数据长度为7800个字符。
将压缩后的数据写入文件,文件大小为78KB。
接下来,我们读取压缩后的数据,根据编码规则进行解码,恢复原始数据。
比较原始数据和恢复后的数据,发现两者完全一致,验证了压缩和解码的正确性。

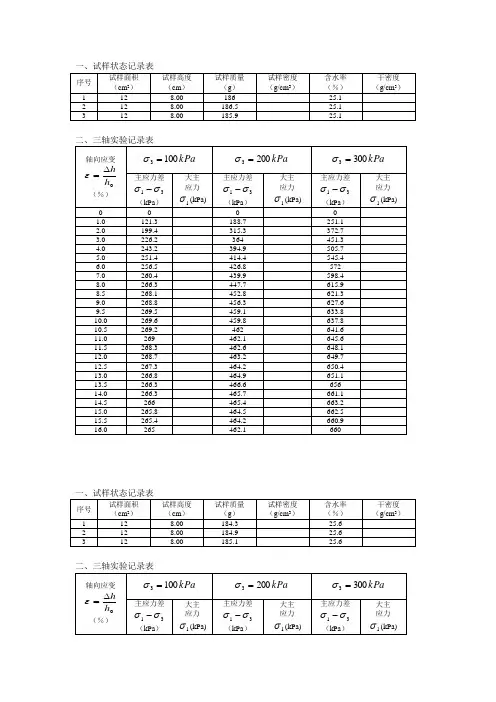
压缩实验报告(总4页) -CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除实验报告(二)实验名称:低碳钢和铸铁的压缩实验 实验目的:极1、测定在压缩时低碳钢的屈服极限S σ,及铸铁的强度限b σ。
2、观察它们的破坏现象,并比较这两种材料受压时的特性,绘出外力和变形间的关系曲线(L F ∆-曲线)。
实验设备和仪器:材料试验机、游标卡尺压缩试件:金属材料的压缩试件一般制成圆柱形,如图所示,并制定31≤≤dh。
实验原理:1、低碳钢低碳钢轴向压缩时会产生很大的横向变形,但由于试样两端面与试验机夹具间存在摩擦,约束了横向变形,故试样出现鼓胀。
为了减少鼓胀效应的影响,通常在端面上涂上润滑剂。
压缩过程中的h弹性模量、屈服点与拉伸时相同A F /S S =σ。
继续加载,试样越压越扁,由于横截面上面积不断增大,试样抗压能力也随之提高,曲线继续上升,所以一般不发生压缩的破坏。
因此不测抗压强度极限。
2、铸铁由于变形很小,所以尽管有端面摩擦,鼓胀效应却并不明显,而是当盈利达到一定值后,试样在轴线大约成45°方向上发生断裂。
将最高点所对应的压力值F b 除以原试样横截面面积A ,即得铸铁的抗压强度b σ=F b /A 。
实验步骤:1、低碳钢的压缩实验试件准备:用游标卡尺测量试件的直径d ,在试件中部相互垂直的方向上测两次,求平均值。
1)、试验机的准备:首先了解试验机的基本构造原理和操作方法,学习试验机的操作规程。
选择合适的横梁移动范围,然后将试件尽量准确地放在机器活动承垫中心上,开动机器,使横梁上压头落在万向头上,使试件承受轴向压力。
2)、进行实验:开动机器,使试件缓慢均匀加载,低碳钢在压缩过程中产生屈服以前基本情况与拉伸时相同,载荷到达B 时,位移-负荷曲线变平缓,这说明材料产生了屈服,当载荷超过B 点后,塑性变形逐渐增加,试件横截面积逐渐明显地增大,试件最后被压成鼓形而不断裂,故只能测出产生流动时的载荷S F ,由A F /S S =σ得出材料受压时的屈服极限而得不出受压时的强度极限。
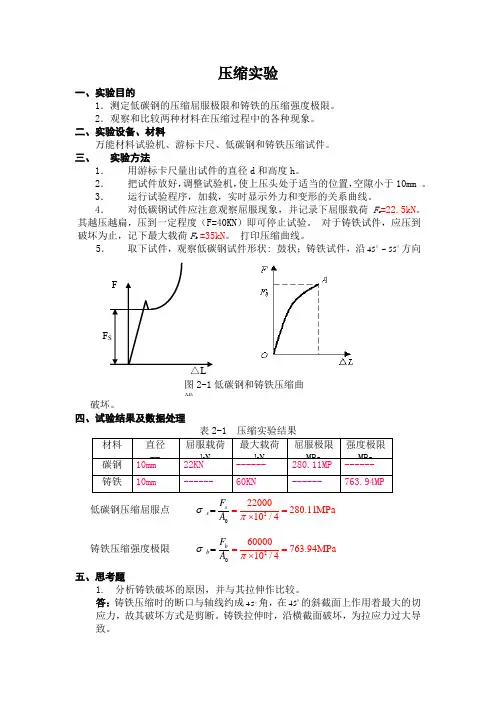
压缩实验一、实验目的1.测定低碳钢的压缩屈服极限和铸铁的压缩强度极限。
2.观察和比较两种材料在压缩过程中的各种现象。
二、实验设备、材料万能材料试验机、游标卡尺、低碳钢和铸铁压缩试件。
三、 实验方法1. 用游标卡尺量出试件的直径d 和高度h 。
2. 把试件放好,调整试验机,使上压头处于适当的位置,空隙小于10mm 。
3. 运行试验程序,加载,实时显示外力和变形的关系曲线。
4. 对低碳钢试件应注意观察屈服现象,并记录下屈服载荷F s =22.5kN 。
其越压越扁,压到一定程度(F=40KN )即可停止试验。
对于铸铁试件,应压到破坏为止,记下最大载荷F b =35kN 。
打印压缩曲线。
5. 取下试件,观察低碳钢试件形状: 鼓状;铸铁试件,沿 55~45方向破坏。
四、试验结果及数据处理 材料 直径 mm 屈服载荷 kN 最大载荷 kN 屈服极限 MPa 强度极限 MPa 碳钢 10mm 22KN ------ 280.11MP a ------铸铁 10mm ------ 60KN ------ 763.94MPa 低碳钢压缩屈服点 022*******.11MPa 10/4s s F A πσ=⨯== 铸铁压缩强度极限 0260000763.94MPa 10/4b b F A πσ=⨯== 五、思考题1. 分析铸铁破坏的原因,并与其拉伸作比较。
答:铸铁压缩时的断口与轴线约成 45角,在 45的斜截面上作用着最大的切应力,故其破坏方式是剪断。
铸铁拉伸时,沿横截面破坏,为拉应力过大导致。
F SF△L图2-1低碳钢和铸铁压缩曲线2. 放置压缩试样的支承垫板底部都制作成球形,为什么?答:支承垫板底部都制作成球形自动对中,便于使试件均匀受力。
3. 为什么铸铁试样被压缩时,破坏面常发生在与轴线大致成 55~45的方向上?答:由于内摩擦的作用。
4. 试比较塑性材料和脆性材料在压缩时的变形及破坏形式有什么不同? 答:塑性材料在压缩时截面不断增大,承载能力不断增强,但塑性变形过大时不能正常工作,即失效;脆性材料在压缩时,破坏前无明显变化,破坏与沿轴线大致成 55~45的方向发生,为剪断破坏。

一、实验目的1. 理解并掌握哈弗曼树的构建原理。
2. 学会使用哈弗曼树进行数据编码和解码。
3. 了解哈弗曼编码在数据压缩中的应用。
二、实验原理哈弗曼树(Huffman Tree)是一种带权路径长度最短的二叉树,用于数据压缩。
其基本原理是:将待编码的字符集合按照出现频率从高到低排序,构造一棵二叉树,使得叶子节点代表字符,内部节点代表编码,权值代表字符出现的频率。
通过这棵树,可以生成每个字符的编码,使得编码的平均长度最小。
三、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发工具:Visual Studio 2019四、实验步骤1. 构建哈弗曼树(1)创建一个结构体`HuffmanNode`,包含字符、权值、左子树和右子树指针。
```cppstruct HuffmanNode {char data;int weight;HuffmanNode left;HuffmanNode right;};(2)定义一个函数`HuffmanTree()`,用于创建哈弗曼树。
```cppHuffmanNode HuffmanTree(std::vector<char>& chars, std::vector<int>& weights) {// 创建初始二叉树std::vector<HuffmanNode> trees;for (int i = 0; i < chars.size(); ++i) {trees.push_back(new HuffmanNode{chars[i], weights[i], nullptr, nullptr});}// 构建哈弗曼树while (trees.size() > 1) {// 选择两个权值最小的节点auto it1 = std::min_element(trees.begin(), trees.end(),[](HuffmanNode a, HuffmanNode b) {return a->weight < b->weight;});auto it2 = std::next(it1);HuffmanNode parent = new HuffmanNode{0, it1->weight + it2->weight, it1, it2};// 删除两个子节点trees.erase(it1);trees.erase(it2);// 将父节点添加到二叉树集合中trees.push_back(parent);}// 返回哈弗曼树根节点return trees[0];}```2. 生成哈弗曼编码(1)定义一个函数`GenerateCodes()`,用于生成哈弗曼编码。
LZ77 压缩算法实验报告一、实验内容:使用 C++编程实现 LZ77 压缩算法的实现。
二、实验目的:用 LZ77 实现文件的压缩。
三、实验环境: 1、软件环境:Visual C++ 6.02、编程语言:C++四、实验原理: LZ77 算法在某种意义上又可以称为“滑动窗口压缩”,这是由于该算法将一个虚拟的,可以跟随压缩进程滑动的窗口作为术语字典,要压缩的字符串如果在该窗口中出现,则输出其出现位置和长度。
使用固定大小窗口进行术语匹配,而不是在所有已经编码的信息中匹配,是因为匹配算法的时间消耗往往很多,必须限制字典的大小才能保证算法的效率;随着压缩的进程滑动字典窗口,使其中总包含最近编码过的信息,是因为对大多数信息而言,要编码的字符串往往在最近的上下文中更容易找到匹配串。
五、 LZ77 算法的基本流程:1、从当前压缩位置开始,考察未编码的数据,并试图在滑动窗口中找出最长的匹配字符串,如果找到,则进行步骤2,否则进行步骤 3。
2、输出三元符号组 ( off, len, c )。
其中 off 为窗口中匹配字符串相对窗口边界的偏移,len 为可匹配的长度,c 为下一个字符。
然后将窗口向后滑动 len + 1 个字符,继续步骤 1。
3、输出三元符号组 ( 0, 0, c )。
其中 c 为下一个字符。
然后将窗口向后滑动 len + 1 个字符,继续步骤 1。
代码如下:#include<windows.h>#include<stdio.h>#include<memory.h>#include"lz77.h"//////////////////////////////////////////////////////////////////// out file format:// 0;flag2;buffer;0;flag2;buffer;...flag1;flag2;bufferlast// flag1 - 2 bytes, source buffer block length// if block size is 65536, be zero// flag2 - 2 bytes, compressed buffer length// if can not compress, be same with flag1//////////////////////////////////////////////////////////////////void main(int argc, char* argv[]){/*if (argc != 4){puts("Usage: ");printf(" Compress : %s c sourcefile destfile\n", argv[0]); printf(" Decompress : %s d sourcefile destfile\n", argv[0]); return;} */BYTE soubuf[65536];BYTE destbuf[65536 + 16];FILE* in;FILE* out;/* in = fopen("input.txt", "rb");if (in == NULL){puts("Can't open source file");return;}out = fopen("compress.txt", "wb");if (out == NULL){puts("Can't open dest file");fclose(in);return;}fseek(in, 0, SEEK_END);long soulen = ftell(in);fseek(in, 0, SEEK_SET);CCompressLZ77 cc;WORD flag1, flag2; */int temp;printf("compress(0) or decompress(1)?:");scanf("%d",&temp);if (temp == 0) // compress{in = fopen("input.txt", "rb");if (in == NULL){puts("Can't open source file");return;}out = fopen("compress.txt", "wb");if (out == NULL){puts("Can't open dest file");fclose(in);return;}fseek(in, 0, SEEK_END);long soulen = ftell(in);fseek(in, 0, SEEK_SET);CCompressLZ77cc;WORD flag1, flag2;int last = soulen, act;while ( last > 0 ){act = min(65536, last);fread(soubuf, act, 1, in);last -= act;if (act == 65536) // out 65536 bytesflag1 = 0;else// out last blocksflag1 = act;fwrite(&flag1, sizeof(WORD), 1, out);int destlen = press((BYTE*)soubuf, act, (BYTE*)destbuf);if (destlen == 0) // can't compress the block{flag2 = flag1;fwrite(&flag2, sizeof(WORD), 1, out);fwrite(soubuf, act, 1, out);}else{flag2 = (WORD)destlen;fwrite(&flag2, sizeof(WORD), 1, out);fwrite(destbuf, destlen, 1, out);}}}else if (temp == 1) // decompress{in = fopen("compress.txt", "rb");if (in == NULL){puts("Can't open source file");return;}out = fopen("decompress.txt", "wb");if (out == NULL){puts("Can't open dest file");fclose(in);return;}fseek(in, 0, SEEK_END);long soulen = ftell(in);fseek(in, 0, SEEK_SET);CCompressLZ77cc;WORD flag1, flag2;int last = soulen, act;while (last > 0){fread(&flag1, sizeof(WORD), 1, in);fread(&flag2, sizeof(WORD), 1, in);last -= 2 * sizeof(WORD);if (flag1 == 0)act = 65536;elseact = flag1;last-= flag2 ? (flag2) : act;if (flag2 == flag1){fread(soubuf, act, 1, in);}else{fread(destbuf, flag2, 1, in);if (!cc.Decompress((BYTE*)soubuf, act, (BYTE*)destbuf)){puts("Decompress error");fclose(in);fclose(out);return;}}fwrite((BYTE*)soubuf, act, 1, out);}}else{puts("Usage: ");printf(" Compress : %s c sourcefile destfile\n", argv[0]);printf(" Decompress : %s d sourcefile destfile\n", argv[0]);}fclose(in);fclose(out);}//////////////////////////////// LZ77.h//////////////////////////////// 使用在自己的堆中分配索引节点,不滑动窗口// 每次最多压缩65536 字节数据// 的优化版本#ifndef_WIX_LZ77_COMPRESS_HEADER_001_#define_WIX_LZ77_COMPRESS_HEADER_001_// 滑动窗口的字节大小#define_MAX_WINDOW_SIZE65536class CCompress{public:CCompress() {};virtual ~CCompress() {};public:virtual int Compress(BYTE* src, int srclen, BYTE* dest) = 0;virtual BOOL Decompress(BYTE* src, int srclen, BYTE* dest) = 0;protected:// tools/////////////////////////////////////////////////////////// CopyBitsInAByte : 在一个字节范围内复制位流// 参数含义同CopyBits 的参数// 说明:// 此函数由CopyBits 调用,不做错误检查,即// 假定要复制的位都在一个字节范围内void CopyBitsInAByte(BYTE* memDest, int nDestPos,BYTE* memSrc, int nSrcPos, int nBits);////////////////////////////////////////////////////////// CopyBits : 复制内存中的位流// memDest - 目标数据区// nDestPos - 目标数据区第一个字节中的起始位// memSrc - 源数据区// nSrcPos - 源数据区第一个字节的中起始位// nBits - 要复制的位数// 说明:// 起始位的表示约定为从字节的高位至低位(由左至右)// 依次为0,,... , 7// 要复制的两块数据区不能有重合void CopyBits(BYTE* memDest, int nDestPos,BYTE* memSrc, int nSrcPos, int nBits);//////////////////////////////////////////////////////////////// 将DWORD值从高位字节到低位字节排列void InvertDWord(DWORD* pDW);/////////////////////////////////////////////////////////////// 设置byte的第iBit位为aBit// iBit顺序为高位起从记数(左起)void SetBit(BYTE* byte, int iBit, BYTE aBit);////////////////////////////////////////////////////////////// 得到字节byte第pos位的值// pos顺序为高位起从记数(左起)BYTE GetBit(BYTE byte, int pos);////////////////////////////////////////////////////////////// 将位指针*piByte(字节偏移), *piBit(字节内位偏移)后移num位void MovePos(int* piByte, int* piBit, int num);/////////////////////////////////////////////////////////// 取log2(n)的upper_boundint UpperLog2(int n);/////////////////////////////////////////////////////////// 取log2(n)的lower_boundint LowerLog2(int n);};class CCompressLZ77 : public CCompress{public:CCompressLZ77();virtual ~CCompressLZ77();public://///////////////////////////////////////////// 压缩一段字节流// src - 源数据区// srclen - 源数据区字节长度, srclen <= 65536// dest - 压缩数据区,调用前分配srclen字节内存// 返回值> 0 压缩数据长度// 返回值= 0 数据无法压缩// 返回值< 0 压缩中异常错误int Compress(BYTE* src, int srclen, BYTE* dest);/////////////////////////////////////////////// 解压缩一段字节流// src - 接收原始数据的内存区, srclen <= 65536// srclen - 源数据区字节长度// dest - 压缩数据区// 返回值- 成功与否BOOL Decompress(BYTE* src, int srclen, BYTE* dest);protected:BYTE* pWnd;// 窗口大小最大为64k ,并且不做滑动// 每次最多只压缩64k 数据,这样可以方便从文件中间开始解压// 当前窗口的长度int nWndSize;// 对滑动窗口中每一个字节串排序// 排序是为了进行快速术语匹配// 排序的方法是用一个k大小的指针数组// 数组下标依次对应每一个字节串:(00 00) (00 01) ... (01 00) (01 01) ...// 每一个指针指向一个链表,链表中的节点为该字节串的每一个出现位置struct STIDXNODE{WORD off; // 在src中的偏移WORD off2; // 用于对应的字节串为重复字节的节点// 指从off 到off2 都对应了该字节串WORD next; // 在SortHeap中的指针};WORD SortTable[65536]; // 256 * 256 指向SortHeap中下标的指针// 因为窗口不滑动,没有删除节点的操作,所以// 节点可以在SortHeap 中连续分配struct STIDXNODE* SortHeap;int HeapPos; // 当前分配位置// 当前输出位置(字节偏移及位偏移)int CurByte, CurBit;protected:////////////////////////////////////////// 输出压缩码// code - 要输出的数// bits - 要输出的位数(对isGamma=TRUE时无效)// isGamma - 是否输出为γ编码void_OutCode(BYTE* dest, DWORD code, int bits, BOOL isGamma);///////////////////////////////////////////////////////////// 在滑动窗口中查找术语// nSeekStart - 从何处开始匹配// offset, len - 用于接收结果,表示在滑动窗口内的偏移和长度// 返回值- 是否查到长度为或以上的匹配字节串BOOL_SeekPhase(BYTE* src, int srclen, int nSeekStart, int* offset, int* len);///////////////////////////////////////////////////////////// 得到已经匹配了个字节的窗口位置offset// 共能匹配多少个字节inline int_GetSameLen(BYTE* src, int srclen, int nSeekStart, int offset);//////////////////////////////////////////// 将窗口向右滑动n个字节inline void_ScrollWindow(int n);// 向索引中添加一个字节串inline void_InsertIndexItem(int off);// 初始化索引表,释放上次压缩用的空间void_InitSortTable();};#endif// _WIX_LZW_COMPRESS_HEADER_001_ //////////////////////////////// LZ77.CPP//////////////////////////////#include<windows.h>#include<stdio.h>#include<memory.h>#include<crtdbg.h>#include"lz77.h"///////////////////////////////////////////////////////// // 取log2(n)的upper_boundint CCompress::UpperLog2(int n){int i = 0;if (n > 0){int m = 1;while(1){if (m >= n)return i;m <<= 1;i++;}}elsereturn -1;}// UpperLog2////////////////////////////////////////////////////////////////////////////////////////////////////////////////// // 取log2(n)的lower_boundint CCompress::LowerLog2(int n){int i = 0;if (n > 0){int m = 1;while(1){if (m == n)return i;if (m > n)return i - 1;m <<= 1;i++;}}elsereturn -1;}// LowerLog2/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////// 将位指针*piByte(字节偏移), *piBit(字节内位偏移)后移num位void CCompress::MovePos(int* piByte, int* piBit, int num) {num += (*piBit);(*piByte) += num / 8;(*piBit) = num % 8;}// MovePos////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////// 得到字节byte第pos位的值// pos顺序为高位起从记数(左起)BYTE CCompress::GetBit(BYTE byte, int pos){int j = 1;j <<= 7 - pos;if (byte & j)return 1;elsereturn 0;}// GetBit//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////// 设置byte的第iBit位为aBit// iBit顺序为高位起从记数(左起)void CCompress::SetBit(BYTE* byte, int iBit, BYTE aBit){if (aBit)(*byte) |= (1 << (7 - iBit));else(*byte) &= ~(1 << (7 - iBit));}// SetBit////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////// 将DWORD值从高位字节到低位字节排列void CCompress::InvertDWord(DWORD* pDW){union UDWORD{ DWORD dw; BYTE b[4]; };UDWORD* pUDW = (UDWORD*)pDW;BYTE b;b = pUDW->b[0]; pUDW->b[0] = pUDW->b[3]; pUDW->b[3] = b;b = pUDW->b[1]; pUDW->b[1] = pUDW->b[2]; pUDW->b[2] = b; }// InvertDWord//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////// CopyBits : 复制内存中的位流// memDest - 目标数据区// nDestPos - 目标数据区第一个字节中的起始位// memSrc - 源数据区// nSrcPos - 源数据区第一个字节的中起始位// nBits - 要复制的位数// 说明:// 起始位的表示约定为从字节的高位至低位(由左至右)// 依次为0,,... , 7// 要复制的两块数据区不能有重合void CCompress::CopyBits(BYTE* memDest, int nDestPos,BYTE* memSrc, int nSrcPos, int nBits){int iByteDest = 0, iBitDest;int iByteSrc = 0, iBitSrc = nSrcPos;int nBitsToFill, nBitsCanFill;while (nBits > 0){// 计算要在目标区当前字节填充的位数nBitsToFill = min(nBits, iByteDest ? 8 : 8 - nDestPos);// 目标区当前字节要填充的起始位iBitDest = iByteDest ? 0 : nDestPos;// 计算可以一次从源数据区中复制的位数nBitsCanFill = min(nBitsToFill, 8 - iBitSrc);// 字节内复制CopyBitsInAByte(memDest + iByteDest, iBitDest,memSrc + iByteSrc, iBitSrc, nBitsCanFill);// 如果还没有复制完nBitsToFill 个if (nBitsToFill > nBitsCanFill){iByteSrc++; iBitSrc = 0; iBitDest += nBitsCanFill;CopyBitsInAByte(memDest + iByteDest, iBitDest,memSrc + iByteSrc, iBitSrc,nBitsToFill - nBitsCanFill);iBitSrc += nBitsToFill - nBitsCanFill;}else{iBitSrc += nBitsCanFill;if (iBitSrc >= 8){iByteSrc++; iBitSrc = 0;}}nBits -= nBitsToFill; // 已经填充了nBitsToFill位iByteDest++;}}// CopyBits//////////////////////////////////////////////////////////////////////////////////////////////////////////////////// CopyBitsInAByte : 在一个字节范围内复制位流// 参数含义同CopyBits 的参数// 说明:// 此函数由CopyBits 调用,不做错误检查,即// 假定要复制的位都在一个字节范围内void CCompress::CopyBitsInAByte(BYTE* memDest, int nDestPos, BYTE* memSrc, int nSrcPos, int nBits){BYTE b1, b2;b1 <<= nSrcPos; b1 >>= 8 - nBits; // 将不用复制的位清b1 <<= 8 - nBits - nDestPos; // 将源和目的字节对齐*memDest |= b1; // 复制值为的位b2 = 0xff; b2 <<= 8 - nDestPos; // 将不用复制的位置b1 |= b2;b2 = 0xff; b2 >>= nDestPos + nBits;b1 |= b2;*memDest &= b1; // 复制值为的位}// CopyBitsInAByte///////////////////////////////////////////////////////////------------------------------------------------------------------CCompressLZ77::CCompressLZ77(){SortHeap = new struct STIDXNODE[_MAX_WINDOW_SIZE]; }CCompressLZ77::~CCompressLZ77(){delete[] SortHeap;}// 初始化索引表,释放上次压缩用的空间void CCompressLZ77::_InitSortTable(){memset(SortTable, 0, sizeof(WORD) * 65536);nWndSize = 0;HeapPos = 1;}// 向索引中添加一个字节串void CCompressLZ77::_InsertIndexItem(int off){WORD q;BYTE ch1, ch2;ch1 = pWnd[off]; ch2 = pWnd[off + 1];if (ch1 != ch2){// 新建节点HeapPos++;SortHeap[q].off = off;SortHeap[q].next = SortTable[ch1 * 256 + ch2];SortTable[ch1 * 256 + ch2] = q;}else{// 对重复字节串// 因为没有虚拟偏移也没有删除操作,只要比较第一个节点// 是否和off 相连接即可q = SortTable[ch1 * 256 + ch2];if (q != 0 && off == SortHeap[q].off2 + 1){// 节点合并SortHeap[q].off2 = off;}else{// 新建节点q = HeapPos;HeapPos++;SortHeap[q].off = off;SortHeap[q].off2 = off;SortHeap[q].next = SortTable[ch1 * 256 + ch2];SortTable[ch1 * 256 + ch2] = q;}}}//////////////////////////////////////////// 将窗口向右滑动n个字节void CCompressLZ77::_ScrollWindow(int n){for (int i = 0; i < n; i++){nWndSize++;if (nWndSize > 1)_InsertIndexItem(nWndSize - 2);}}///////////////////////////////////////////////////////////// 得到已经匹配了个字节的窗口位置offset// 共能匹配多少个字节int CCompressLZ77::_GetSameLen(BYTE* src, int srclen, int nSeekStart, int offset) {int i = 2; // 已经匹配了个字节int maxsame = min(srclen - nSeekStart, nWndSize - offset);while (i < maxsame&& src[nSeekStart + i] == pWnd[offset + i])i++;_ASSERT(nSeekStart + i <= srclen && offset + i <= nWndSize);return i;}///////////////////////////////////////////////////////////// 在滑动窗口中查找术语// nSeekStart - 从何处开始匹配// offset, len - 用于接收结果,表示在滑动窗口内的偏移和长度// 返回值- 是否查到长度为或以上的匹配字节串BOOL CCompressLZ77::_SeekPhase(BYTE* src, int srclen, int nSeekStart, int* offset, int* len){int j, m, n;if (nSeekStart < srclen - 1){BYTE ch1, ch2;ch1 = src[nSeekStart]; ch2 = src[nSeekStart + 1];WORD p;p = SortTable[ch1 * 256 + ch2];if (p != 0){m = 2; n = SortHeap[p].off;while (p != 0){j = _GetSameLen(src, srclen,nSeekStart, SortHeap[p].off);if ( j > m ){m = j;n = SortHeap[p].off;}p = SortHeap[p].next;}(*offset) = n;(*len) = m;return TRUE;}}return FALSE;}////////////////////////////////////////// 输出压缩码// code - 要输出的数// bits - 要输出的位数(对isGamma=TRUE时无效)// isGamma - 是否输出为γ编码void CCompressLZ77::_OutCode(BYTE* dest, DWORD code, int bits, BOOL isGamma){if ( isGamma ){BYTE* pb;DWORD out;// 计算输出位数int GammaCode = (int)code - 1;int q = LowerLog2(GammaCode);if (q > 0){out = 0xffff;pb = (BYTE*)&out;// 输出q个CopyBits(dest + CurByte, CurBit,pb, 0, q);MovePos(&CurByte, &CurBit, q);}// 输出一个out = 0;pb = (BYTE*)&out;CopyBits(dest + CurByte, CurBit, pb + 3, 7, 1);MovePos(&CurByte, &CurBit, 1);if (q > 0){// 输出余数, q位int sh = 1;sh <<= q;out = GammaCode - sh;pb = (BYTE*)&out;InvertDWord(&out);CopyBits(dest + CurByte, CurBit,pb + (32 - q) / 8, (32 - q) % 8, q);MovePos(&CurByte, &CurBit, q);}}else{DWORD dw = (DWORD)code;BYTE* pb = (BYTE*)&dw;InvertDWord(&dw);CopyBits(dest + CurByte, CurBit,pb + (32 - bits) / 8, (32 - bits) % 8, bits);MovePos(&CurByte, &CurBit, bits);}}/////////////////////////////////////////////// 压缩一段字节流// src - 源数据区// srclen - 源数据区字节长度// dest - 压缩数据区,调用前分配srclen+5字节内存// 返回值> 0 压缩数据长度// 返回值= 0 数据无法压缩// 返回值< 0 压缩中异常错误int CCompressLZ77::Compress(BYTE* src, int srclen, BYTE* dest) {int i;CurByte = 0; CurBit = 0;int off, len;if (srclen > 65536)return -1;pWnd = src;_InitSortTable();for (i = 0; i < srclen; i++){if (CurByte >= srclen)return 0;if (_SeekPhase(src, srclen, i, &off, &len)){// 输出匹配术语flag(1bit) + len(γ编码) + offset(最大bit)_OutCode(dest, 1, 1, FALSE);_OutCode(dest, len, 0, TRUE);// 在窗口不满k大小时,不需要位存储偏移_OutCode(dest, off, UpperLog2(nWndSize), FALSE);_ScrollWindow(len);i += len - 1;}else{// 输出单个非匹配字符0(1bit) + char(8bit)_OutCode(dest, 0, 1, FALSE);_OutCode(dest, (DWORD)(src[i]), 8, FALSE);_ScrollWindow(1);}}int destlen = CurByte + ((CurBit) ? 1 : 0);if (destlen >= srclen)return 0;return destlen;}/////////////////////////////////////////////// 解压缩一段字节流// src - 接收原始数据的内存区// srclen - 源数据区字节长度// dest - 压缩数据区// 返回值- 成功与否BOOL CCompressLZ77::Decompress(BYTE* src, int srclen, BYTE* dest) {int i;CurByte = 0; CurBit = 0;pWnd = src; // 初始化窗口nWndSize = 0;if (srclen > 65536)return FALSE;for (i = 0; i < srclen; i++){BYTE b = GetBit(dest[CurByte], CurBit);MovePos(&CurByte, &CurBit, 1);if (b == 0) // 单个字符{CopyBits(src + i, 0, dest + CurByte, CurBit, 8);MovePos(&CurByte, &CurBit, 8);nWndSize++;}else// 窗口内的术语{int q = -1;while (b != 0){q++;b = GetBit(dest[CurByte], CurBit);MovePos(&CurByte, &CurBit, 1);}int len, off;DWORD dw = 0;BYTE* pb;if (q > 0){pb = (BYTE*)&dw;CopyBits(pb + (32 - q) / 8, (32 - q) % 8, dest + CurByte, CurBit, q);MovePos(&CurByte, &CurBit, q);InvertDWord(&dw);len = 1;len <<= q;len += dw;len += 1;}elselen = 2;// 在窗口不满k大小时,不需要位存储偏移dw = 0;pb = (BYTE*)&dw;int bits = UpperLog2(nWndSize);CopyBits(pb + (32 - bits) / 8, (32 - bits) % 8, dest + CurByte, CurBit, bits);MovePos(&CurByte, &CurBit, bits);InvertDWord(&dw);off = (int)dw;// 输出术语for (int j = 0; j < len; j++){_ASSERT(i + j < srclen);_ASSERT(off + j < _MAX_WINDOW_SIZE);src[i + j] = pWnd[off + j];}nWndSize += len;i += len - 1;}// 滑动窗口if (nWndSize > _MAX_WINDOW_SIZE){pWnd += nWndSize - _MAX_WINDOW_SIZE;nWndSize = _MAX_WINDOW_SIZE;}}return TRUE;}。
哈夫曼编码实验报告哈夫曼编码实验报告一、引言哈夫曼编码是一种用于数据压缩的算法,由大卫·哈夫曼于1952年提出。
它通过将出现频率高的字符用较短的编码表示,从而实现对数据的高效压缩。
本实验旨在通过实际操作和数据分析,深入了解哈夫曼编码的原理和应用。
二、实验目的1. 掌握哈夫曼编码的基本原理和算法;2. 实现哈夫曼编码的压缩和解压缩功能;3. 分析不同数据集上的压缩效果,并对结果进行评估。
三、实验过程1. 数据集准备本实验选取了三个不同的数据集,分别是一篇英文文章、一段中文文本和一段二进制数据。
这三个数据集具有不同的特点,可以用来评估哈夫曼编码在不同类型数据上的压缩效果。
2. 哈夫曼编码实现在实验中,我们使用了Python编程语言来实现哈夫曼编码的压缩和解压缩功能。
首先,我们需要统计数据集中各个字符的出现频率,并构建哈夫曼树。
然后,根据哈夫曼树生成每个字符的编码表,将原始数据转换为对应的编码。
最后,将编码后的数据存储为二进制文件,并记录编码表和原始数据的长度。
3. 压缩效果评估对于每个数据集,我们比较了原始数据和压缩后数据的大小差异,并计算了压缩比和压缩率。
压缩比是指压缩后数据的大小与原始数据大小的比值,压缩率是指压缩比乘以100%。
通过对比不同数据集上的压缩效果,我们可以评估哈夫曼编码在不同类型数据上的性能。
四、实验结果与分析1. 英文文章数据集对于一篇英文文章,经过哈夫曼编码压缩后,我们发现压缩比为0.6,即压缩后的数据只有原始数据的60%大小。
这说明哈夫曼编码在英文文本上具有较好的压缩效果。
原因在于英文文章中存在大量的重复字符,而哈夫曼编码能够利用字符的出现频率进行编码,从而减少数据的存储空间。
2. 中文文本数据集对于一段中文文本,我们发现哈夫曼编码的压缩效果不如在英文文章上的效果明显。
压缩比为0.8,即压缩后的数据只有原始数据的80%大小。
这是因为中文文本中的字符种类较多,并且出现频率相对均匀,导致哈夫曼编码的优势减弱。
《数据压缩》教学设计方案(第一课时)一、教学目标1. 理解数据压缩的基本观点和原理。
2. 掌握数据压缩的基本方法和技术。
3. 能够识别和应用常见的压缩算法。
二、教学重难点1. 重点:理解数据压缩的基本原理和方法,掌握常见的压缩算法。
2. 难点:实际应用中如何选择合适的压缩算法,以及如何处理压缩和解压缩过程中的问题。
三、教学准备1. 准备教学PPT,包括图片、文字和视频等素材,以辅助教学。
2. 准备常见的数据压缩软件,如zip、rar等,供学生实践操作。
3. 准备一些关于数据压缩的案例和实例,以便于学生理解和应用。
4. 安排实验室或教室进行实践操作和讨论。
四、教学过程:1. 导入:起首向学生介绍数据压缩的观点及其重要性,可以结合平时生活中的一些实例来说明,如图片、视频的压缩等。
同时,引导学生认识到数据压缩的基本原理和方法。
讲解:接下来,将介绍数据压缩的几种主要方法,包括无损压缩、有损压缩、混合压缩等。
针对每种方法,将详细介绍其基本原理、优缺点以及应用途景。
2. 实例演示:通过实际操作,向学生展示如何应用常见的压缩工具进行文件压缩和解压。
可以演示如何应用WinRAR、7-Zip 等工具进行操作,并诠释每个步骤的含义和目标。
实践:让学生自己动手尝试应用压缩工具进行文件压缩和解压,通过实践加深对数据压缩方法的理解。
3. 讨论与互动:与学生进行讨论,了解他们对数据压缩的理解和疑问。
针对学生提出的问题,进行解答和讨论,加深学生对数据压缩知识的理解。
提问与回答:准备一些与数据压缩相关的问题,让学生进行回答。
这些问题可以考察学生对数据压缩方法、原理和应用途景的理解。
4. 总结与延伸:总结本节课的主要内容,强调数据压缩的重要性及其应用。
同时,引导学生思考如何进一步发展数据压缩技术,如钻研更高效的数据压缩算法等。
作业:安置一些与数据压缩相关的作业,如让学生尝试应用不同的压缩工具进行文件压缩,并比较不同工具的性能和效果。
一、实验目的1. 理解和掌握工程力学中压缩实验的基本原理和方法。
2. 学习使用万能材料试验机进行压缩实验,并掌握实验操作步骤。
3. 观察和记录不同材料在压缩过程中的变形和破坏现象。
4. 分析和比较不同材料的压缩性能,为工程实际应用提供理论依据。
二、实验原理压缩实验是研究材料在轴向压力作用下的力学性能的一种实验方法。
实验过程中,通过对材料施加轴向压力,使其产生变形,直至破坏,从而测定材料的压缩强度、弹性模量、屈服极限等参数。
压缩实验的原理基于胡克定律和材料的应力-应变关系。
在弹性范围内,材料的应力与应变呈线性关系,即应力-应变曲线呈直线。
当材料超过弹性范围后,应力与应变的关系不再呈线性关系,此时材料发生塑性变形。
三、实验设备与材料1. 万能材料试验机:用于施加轴向压力,测量材料的变形和破坏现象。
2. 游标卡尺:用于测量试样的尺寸。
3. 压缩试样:低碳钢、铸铁等不同材料制成的圆柱形试样。
4. 记录纸、笔:用于记录实验数据。
四、实验步骤1. 准备试样:用游标卡尺测量试样的直径d和高度h,记录数据。
2. 安装试样:将试样放置在万能材料试验机的压板之间,确保试样中心与压板中心对齐。
3. 调整试验机:设置试验机的加载速度,调整试验机至待测状态。
4. 施加载荷:启动试验机,使试样受到轴向压力,观察试样的变形和破坏现象。
5. 记录数据:记录试样的屈服载荷、最大载荷、压缩变形等数据。
6. 实验结束后,整理试样,清洗试验设备。
五、实验结果与分析1. 低碳钢压缩实验实验结果显示,低碳钢在压缩过程中,当载荷达到屈服载荷时,试样出现塑性变形。
随着载荷的增加,试样变形逐渐增大,直至试样断裂。
根据实验数据,可计算出低碳钢的屈服极限、抗压强度等参数。
2. 铸铁压缩实验实验结果显示,铸铁在压缩过程中,当载荷达到一定值后,试样在轴线大约成45°方向上发生断裂。
根据实验数据,可计算出铸铁的抗压强度等参数。
六、实验结论1. 压缩实验是研究材料力学性能的重要方法,可用于测定材料的压缩强度、弹性模量、屈服极限等参数。
第1篇一、实验目的1. 掌握快速法压缩实验的基本原理和操作方法。
2. 了解不同材料的压缩特性,分析材料在压缩过程中的力学行为。
3. 培养实验操作技能和数据分析能力。
二、实验原理快速法压缩实验是一种研究材料力学性能的常用方法。
实验过程中,将试样置于压缩试验机上,通过施加轴向压力,使试样发生压缩变形,直至试样破坏。
通过测量试样在不同压力下的变形量,可以计算出材料的弹性模量、屈服强度、抗压强度等力学性能指标。
三、实验设备及仪器1. 快速压缩试验机:用于施加轴向压力,测量试样的变形和破坏。
2. 试样:实验选用不同材料的试样,如低碳钢、铸铁等。
3. 游标卡尺:用于测量试样尺寸。
4. 数据采集系统:用于记录实验数据。
四、实验步骤1. 准备实验试样:根据实验要求,选取合适的试样,并测量试样尺寸。
2. 安装试样:将试样放置在试验机上,调整试样位置,确保试样与试验机压板接触良好。
3. 设置实验参数:设置试验机加载速度、加载方式等参数。
4. 开始实验:启动试验机,施加轴向压力,记录试样在不同压力下的变形量。
5. 实验结束:当试样发生破坏时,停止加载,记录试样破坏时的压力值。
6. 数据处理:将实验数据进行分析,计算材料的力学性能指标。
五、实验结果与分析1. 低碳钢压缩实验结果(1)弹性模量:根据实验数据,计算低碳钢的弹性模量为E1。
(2)屈服强度:根据实验数据,确定低碳钢的屈服强度为S1。
(3)抗压强度:由于低碳钢在压缩过程中不会发生断裂,因此不测抗压强度。
2. 铸铁压缩实验结果(1)弹性模量:根据实验数据,计算铸铁的弹性模量为E2。
(2)屈服强度:根据实验数据,确定铸铁的屈服强度为S2。
(3)抗压强度:根据实验数据,计算铸铁的抗压强度为b2。
六、实验总结1. 通过快速法压缩实验,掌握了不同材料的压缩特性,分析了材料在压缩过程中的力学行为。
2. 培养了实验操作技能和数据分析能力,为今后从事相关研究奠定了基础。
七、实验注意事项1. 实验过程中,确保试样与试验机压板接触良好,避免因接触不良导致实验数据误差。
哈夫曼文件压缩实验报告数据结构实验报告三哈夫曼文件压缩实验题目:哈夫曼文件压缩实验目标:输入一个有10k单词得英文文档。
输出压缩后得二进制文件,并计算压缩比。
数据结构:栈与哈夫曼树。
1.定义栈()typedefstruct{;mele*rahcﻩ;eziskcatstniﻩinttop;}STACK;2.定义哈夫曼树()typedefstruct{intweight;;thgir,tfeltniﻩintparent;}HTNode;需要得操作有:1、初始化栈(Initstack)voidInitstack(STACK*s){;)0001*)tni(foezis(collam)*rahc(=mele-sﻩs-stacksize =1000;;1-=pot>-sﻩ}2、压栈(push)voidpush(STACK*s,inte){;e=]pot-s++[mele>-sﻩ}3、弹栈(pop)voidpop(STACK*s,int*e){)1-=!pot-s(fiﻩ*;]--pot-s[mele>-s=eﻩ}4、构造哈夫曼树(Inithuffman)voidInithuffman(intwset[n],intk,HuffTreeHT[]){//构造哈夫曼树inti,m;ints1,s2;m=k*2-1;for(i=0;ii++){//初始化HT数组HT[i]=(HuffTree)malloc(sizeof(HTNode));;)0:]i[tesw?ki(=thgiew-]i[THﻩ;1-=tnerap-]i[THﻩﻩ;1-=thgir-]i[TH=tfel>-]i[THﻩ}并合次1-n成完,环循主//{)++i;mk=i(rofﻩﻩap择选中]1-i、、、1[TH在//;)2s,1s,i,k,TH(tcelesﻩrent为0且weight为最小得两个结点,其下标分别为s1与s2ﻩ;1s=tfel-]i[THﻩﻩ;2s=thgir-]i[THﻩﻩHT[i]-weight=HT[s1]-weight+HT[s2]-weight;;i=tnerap>-]2s[TH=tnerap-]1s[THﻩ}}其中用到另一个基本操作:找到哈夫曼树中最小与次小得结点(select)5、找到哈夫曼树中最小与次小得结点(select)voidselect(HuffTreeHT[255],inta,inti,int*p,int*q){intj=0,k=0,*HT1,temp;HT1=(int*)malloc(sizeof(int)*(i-1));//存放权值{)++j;i0=j(rofﻩﻩ{)1-==tnerap-]j[TH(fiﻩﻩHT1[k]=HT[j]-weight;//把没有parent得结点得权值放在HT1中ﻩk++;}ﻩ//,thgir-]j[TH,tfel>-]j[TH,tnerap-]j[TH,n\d4%d4%d4%d4%d4%(ftnirpﻩHT[j]-weight,HT1[k-1]);}j=0;点结得小二第与小最值权到找//{)2j(elihwﻩﻩfor(k=j;k(i-(i-a)*2);k++){ﻩ{)]k[1TH]j[1TH(fiﻩtemp=HT1[k];ﻩﻩ;]j[1TH=]k[1THﻩﻩHT1[j]=te0=kﻩ{);i0=j(rofﻩif(HT[j]-parent==-1)ﻩ中};mp;ﻩ}ﻩ}ﻩ;++jﻩp*到赋值权得小最将//{)1k&]0[1TH==thgiew-]j[TH}ﻩﻩj++;}ﻩ{);i<j;0=j(rofﻩ(fiﻩﻩ*;j=pﻩﻩﻩ;++kﻩﻩﻩ)1-==tnerap>-]j[TH(fiﻩ)p*=!j(fiﻩﻩif(HT[j]->weight==HT 1[1]k2){//将第二小得权值赋到*q中*ﻩﻩﻩ;j=qﻩﻩk++;ﻩ}j++;//,thg ir-]i[TH,tfel-]i[TH,tnerap-]i[TH,n\d4%d4%d4%d4%"(ftnirpﻩHT[i]-weight);}ﻩ}6、根据哈夫曼树得到各字符对应得哈夫曼编码(Huffman)voidHuffman(HuffTreeHT[2*n-1],intk,charstr[][20]){inti,j,e,t1=0,t2=0;char c;;tsKCATSﻩ{)++i;k<i;0=i(rofﻩﻩ点结子叶个一找//{)1-==tfe;2-l>-]i[TH1-==thgir-]i[TH(fiﻩﻩ;)ts(kcatstinIﻩﻩ==tfel-]i[TH=thgir-]i[THﻩj=i;//记录其下标ﻩ{)1-=!tnerap>-]j[TH(elihwﻩif(HT[HT[j]-parent]-right==j)//找到一个叶子结点,如果她就是其parent结点得右结点,就将此边记为1;)"1",ts&(hsupﻩﻩﻩesleﻩﻩﻩ0为记边左在//;)"0",ts(hsupﻩﻩﻩﻩ点结根达到到直作操环循//;tnerap-]j[TH=jﻩ}ﻩﻩﻩ;i=cﻩﻩ符字此印打//;)c,c%t\(ftnirpﻩﻩ1-=!pot、ts;(r{);ofﻩﻩﻩﻩ;)e&,ts(popﻩﻩ码编制进二其印打//;)e,c%(ftnirpﻩﻩstr[tﻩﻩﻩ;)'n\1][t2]=e;//将二进制编码存放在str中ﻩt2++;ﻩ}"=]2t[]1t[rtsﻩﻩ;0=2tﻩﻩ;++1tﻩ}ﻩﻩ\"(rahctupﻩﻩ;"}}算法设计:1、从文件中逐个读取字符,记录其出现次数以及文件总字符数,由此确定其频率高低。
实验二图像预测编码一、实验题目:图像预测编码:二、实验目的:实现图像预测编码和解码.三、实验内容:给定一幅图片,对其进行预测编码,获得预测图像,绝对残差图像, 再利用预测图像和残差图像进行原图像重建并计算原图像和重建图像误差.四、预备知识:预测方法,图像处理概论。
五、实验原理:根据图像中任意像素与周围邻域像素之间存在紧密关系,利用周围邻域四个像素来进行该点像素值预测,然后传输图像像素值与其预测值的差值信号,使传输的码率降低,达到压缩的目的。
六、实验步骤:(1)选取一幅预测编码图片;(2)读取图片内容像素值并存储于矩阵;(3)对图像像素进行预测编码;(4)输出预测图像和残差图像;(5)根据预测图像和残差图像重建图像;(6)计算原预测编码图像和重建图像误差.七、思考题目:如何采用预测编码算法实现彩色图像编码和解码.八、实验程序代码:预测编码程序1:编码程序:i1=imread('lena.jpg');if isrgb(i1)i1=rgb2gray(i1);endi1=imcrop(i1,[1 1 256 256]);i=double(i1);[m,n]=size(i);p=zeros(m,n);y=zeros(m,n);y(1:m,1)=i(1:m,1);p(1:m,1)=i(1:m,1);y(1,1:n)=i(1,1:n);p(1,1:n)=i(1,1:n);y(1:m,n)=i(1:m,n);p(1:m,n)=i(1:m,n);p(m,1:n)=i(m,1:n);y(m,1:n)=i(m,1:n);for k=2:m-1for l=2:n-1y(k,l)=(i(k,l-1)/2+i(k-1,l)/4+i(k-1,l-1)/8+i(k-1,l+1)/8);p(k,l)=round(i(k,l)-y(k,l));endendp=round(p);subplot(3,2,1);imshow(i1);title('原灰度图像');subplot(3,2,2);imshow(y,[0 256]);title('利用三个相邻块线性预测后的图像');subplot(3,2,3);imshow(abs(p),[0 1]);title('编码的绝对残差图像');解码程序j=zeros(m,n);j(1:m,1)=y(1:m,1);j(1,1:n)=y(1,1:n);j(1:m,n)=y(1:m,n);j(m,1:n)=y(m,1:n);for k=2:m-1for l=2:n-1j(k,l)=p(k,l)+y(k,l);endendfor r=1:mfor t=1:nd(r,t)=round(i1(r,t)-j(r,t));endendsubplot(3,2,4);imshow(abs(p),[0 1]);title('解码用的残差图像');subplot(3,2,5);imshow(j,[0 256]);title('使用残差和线性预测重建后的图像');subplot(3,2,6);imshow(abs(d),[0 1]);title('解码重建后图像的误差');九、实验结果:图2.1 Lena图像预测编码实验结果预测编码程序2:x=imread('e:\imagebase\cameraman.jpg');figure(1)subplot(2,3,1);imshow(x);title('原始图像');subplot(2,3,2);imhist(x);title('原始图像直方图');subplot(2,3,3);x=double(x);x1=yucebianma(x);imshow(mat2gray(x1));title('预测误差图像');subplot(2,3,4);imhist(mat2gray(x1));title('预测误差直方图');x2=yucejiema(x1);subplot(2,3,5);imshow(mat2gray(x2));title('解码图像');e=double(x)-double(x2);[m,n]=size(e);erms=sqrt(sum(e(:).^2)/(m*n));%预测编码函数;%一维无损预测编码压缩图像x,f为预测系数,如果f默认,则f=1,即为前值预测function y=yucebianma(x,f)error(nargchk(1,2,nargin))if nargin<2f=1;endx=double(x);[m,n]=size(x);p=zeros(m,n);xs=x;zc=zeros(m,1);if length(f)>1for j=1:length(f)xs=[zc xs(:,1:end-1)];p=p+f(j)*xs;endy=x-round(p);elsexs=[zc xs(:,1:end-1)];p=xs;y=x-round(p);end% yucejiema是解码程序,与编码程序用的是同一个预测器function x=yucejiema(y,f)error(nargchk(1,2,nargin));if nargin<2f=1;endif length(f)>1f=f(end:-1,1);[m,n]=size(y);order=length(f);x0=zeros(m,n+order);for j=1:njj=j+order;for i=1:mtep=0.0;for k=order:-1:1tep=tep+f(k)*x0(i,jj-order-1+k);endx0(i,jj)=y(i,j)+tep;endendx=x0(:,order+1:end);else[m,n]=size(y);x0=zeros(m,n+1);for j=1:njj=j+1;for i=1:mx0(i,jj)=y(i,j)+x0(i,jj-1);endendx=x0(:,2:end);end图2.2 摄影师图像预测编码实验结果实验三图像熵编码与压缩一、实验题目:图像熵编码与压缩二、实验目的:学习和理解建立在图像统计特征基础上的熵编码压缩方法。
三、实验内容:(1)编程实现二值文本图像的行程编码。
(2)编程实现灰度图像的霍夫曼编码,并计算图像熵、平均码字长度及编码效率。
四、预备知识:(1)熟悉行程编码原理。
(2)熟悉霍夫曼编码原理。
(3)熟悉在MATLAB环境下对图像文件的I/O操作。
五、实验原理:(1)行程编码行程编码是将一行中颜色相同的相邻像素用一个计数值和该颜色值来代替。
比如,aaabbcccccdddeeee可以表示为3a2b5c3d4e。
如果一幅图像由很多块颜色相同的大面积区域组成,则采用行程编码可大大提高压缩效率,尤其适用于二值图像。
但当图像中每两个相邻像素的颜色都不相同时,采用这种方法不但不能实现数据压缩,反而使数据量增加一倍。
因此,对复杂的图像都不能单纯地采用行程编码。
(2)霍夫曼编码霍夫曼编码是一种代码长度不均匀的编码方法。
它的基本原理是按信源符号出现的概率大小进行排序,出现概率大的分配短码,反之则分配长码。
霍夫曼编码基本步骤如下:步骤1:统计图像每个灰度级(信息符号)出现的概率,并按概率从大到小进行排序。
步骤2:选出概率最小的两个值进行组合相加,形成的新概率值和其他概率值形成一个新的概率集合。
步骤3:重复步骤2,反复利用合并和排序的方法,直到只有两个概率为止。
步骤4:分配码字,对最后两个概率一个赋予“0”码字,一个赋予“1”码字。
如此反向进行到开始的概率排列,这样就得到了各个符号的霍夫曼编码。
六、实验步骤:(1)编程实现二值文本图像的行程编码。
(2)编程实现连续灰度图像的霍夫曼编码,并计算图像熵、平均码字长度及编码效率。
七、思考题目:将行程编码与霍夫曼编码结合,能否提高压缩效果?试验证之。
八、实验程序代码:(1)二值文本图像的行程编码程序:clear,close allt=imread('text.png');ts=logical(t);codetable=zeros(1,20000);[m,n]=size(ts);nn=n+1;icodecount=1;for i=1:mp1=ts(i,1);%第i行,第1个像素ipcount=1;%同一灰度值连续出现的次数for j=2:np2=ts(i,j);if ((p1==p2)&(ipcount<nn))ipcount=ipcount+1;elsecodetable(icodecount)=ipcount;codetable(icodecount+1)=p1;icodecount=icodecount+2;p1=p2;ipcount=1;end;end;codetable(icodecount)=ipcount;codetable(icodecount+1)=p1;icodecount=icodecount+2;codetable(icodecount)=nn;%行结束符号icodecount=icodecount+1;end;codetable(icodecount)=65535;%码表结束符号(2)连续灰度图像的霍夫曼编码程序代码function s=reduce(p)s=cell(length(p),1);for i=1:length(p)s{i}=i;end;n=size(s,1);while n>2[p,i]=sort(p);p(2)=p(1)+p(2);p(1)=[];s=s(i);s{2}={s{1},s{2}};s(1)=[];n=size(s,1);end;function makecode(sc,codeword)global CODEif isa(sc,'cell')makecode(sc{1},[codeword 0]);makecode(sc{2},[codeword 1]);elseCODE{sc}=char('0'+codeword); end;function CODE=huffman(p)global CODECODE=cell(length(p),1);if length(p)>1p=p/sum(p);s=reduce(p);makecode(s,[]);elseCODE={'1'};end;function y=mat2huff(x)y.size=uint32(size(x));x=round(double(x));xmin=min(x(:));xmax=max(x(:));pmin=double(int16(xmin)); pmin=uint16(pmin+32768); y.min=pmin;x=x(:)';h=histc(x,xmin:xmax); maxh=max(h);if maxh>65535h=65535*h/maxh; end;h=uint16(h);y.hist=h;map=huffman(double(h)); hx=map(x(:)-xmin+1);hx=char(hx)';hx=hx(:)';hx(hx==' ')=[];ysize=ceil(length(hx)/16); hx16=repmat('0',1,ysize*16); hx16(1:length(hx))=hx;hx16=reshape(hx16,16,ysize); hx16=hx16'-'0';twos=pow2(15:-1:0);%y.code=uint16(sum(t3,2))'; t1=ones(ysize,1);t2=twos(t1,:);t3=hx16.*t2;t4=sum(t3,2);y.code=uint16(t4)';实验四 图像DCT 变换编码与压缩一、实验题目:图像DCT 变换编码与压缩二、实验目的:(1)掌握离散余弦变换DCT 的实现方法,了解DCT 的幅度分布特性,从而加深对DCT 变换的认识。