第二章习题
2.1
(1)各国人均寿命和按购买力平均计算的人均GDP(X1)的关系
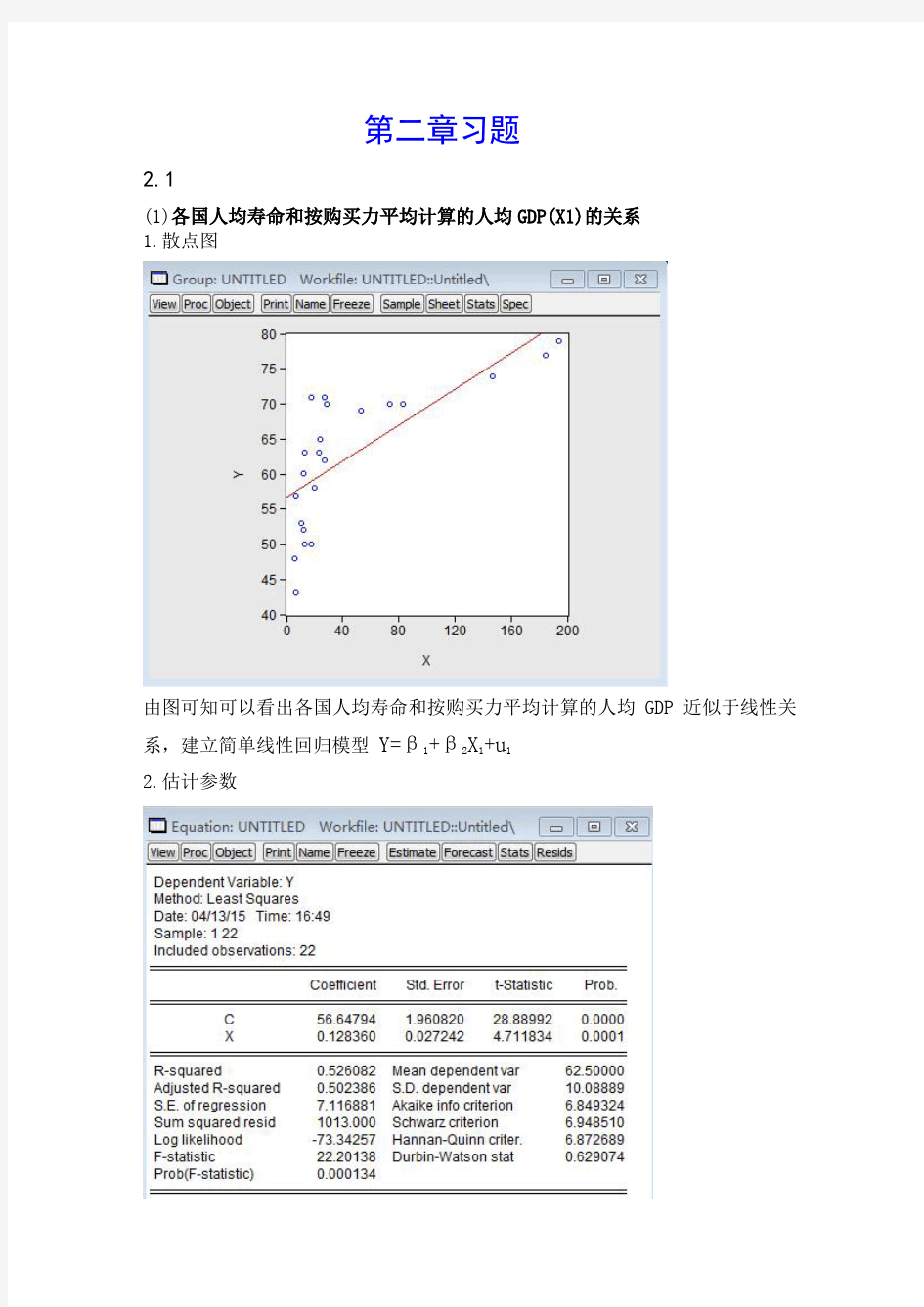
1.散点图
由图可知可以看出各国人均寿命和按购买力平均计算的人均GDP近似于线性关系,建立简单线性回归模型Y=β1+β2X1+u1
2.估计参数
Y=56.6479+0.12836X1
(1.96082)(0.027242)
t=(28.88992) (4.711834)
R2=0.526082 F=22.2.138 n=22
各国人均寿命和成人识字率(X2)的关系
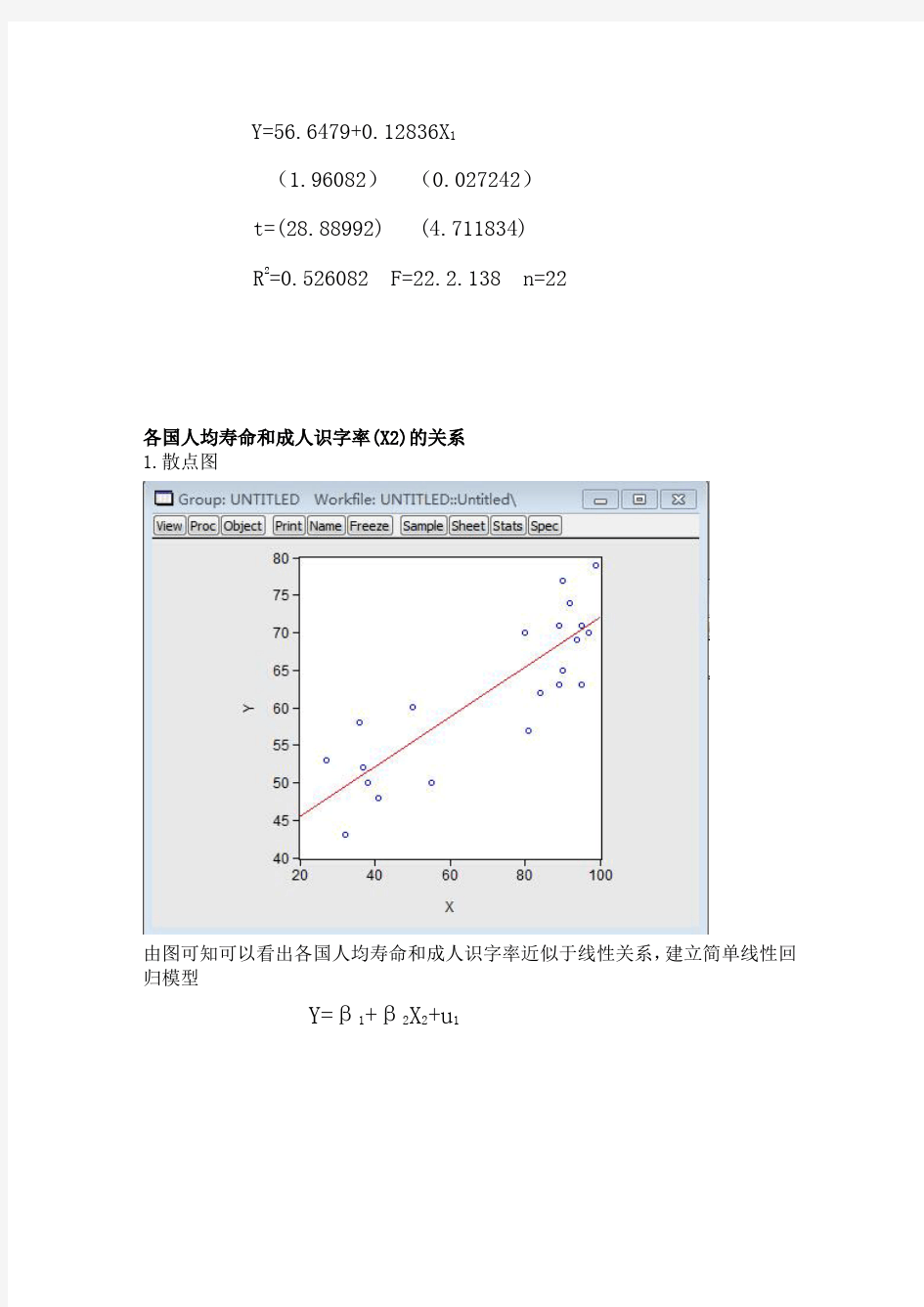
1.散点图
由图可知可以看出各国人均寿命和成人识字率近似于线性关系,建立简单线性回归模型
Y=β1+β2X2+u1
2.估计参数
Y=38.79424+0.331971X2
(3.532079)(0.046656)
t=(10.9834) (7.115308)
R2=0.716825 F=50.62761 n=22
各国人均寿命和一岁儿童育苗接种率(X3)的关系
1.散点图
由图可知可以看出各国人均寿命和一岁儿童育苗接种率近似于线性关系,建立简单线性回归模型
Y=β1+β2X3+u1
2.估计参数
Y=31.79956+0.387276X3
(2)①关于人均寿命和按购买力平均计算的人均GDP
R2=0.526082:说明所建模型整体上对样本数据拟合较好
t(β1)=4.711834 > t0.025(20)=2.086:人均GDP对人均寿命有显著影响
②关于人均寿命与成人识字率模型
R2=0.716825:说明所建模型整体上对样本数据拟合较好
t(β1)=7.115308 > t0.025(20)=2.086:成人识字率对人均寿命有显著影响
③关于人均寿命与一岁儿童疫苗的模型
R2=0.537929:说明所建模型整体上对样本数据拟合较好
t(β1)=4.825285>t0.025(20)=2.086
2.2(1)
Y =-154.3063+0.176124x
(39.08196) (0.004072)
t=(-3.948274) (43.25639)
R2=0.983702 F=1871.115 n=33
经济意义:生产总值每增加1亿元,财政预算总收入增加0.176124亿元
(2)①进行点预测
Y=5481.6617
②进行区间预测
∑x i2=∑(Xi—X)2=δ2x(n—1)
=7608.0212×(33—1)=1852223.473
(X f —X)2=(32000—6000.441)2
=675977068.2
当X f =32000时,将相关数据代入计算得到:5481.6617+2.0395×175.2325×2
675977068.3
1852223.47+
331 =5481.6617+64.9649
即Yf 的置信区间为(5481.6617—64.9649,5481.6617+64.9649) (3)
lnY=-1.918289+0.980275lnx
可决系数为0.963442,说明所建模型整体上对样本数据拟合较好。 t 检验:t (β2)=28.58268>t 0.025(31)=2.0395,对斜率系数的显著性检验表明,全省生产总值对财政预算总收入有显著影响
经济意义:全省生产总值每增长1%,财政预算总收入增长0.980275%
(1)因为C=50+0.6Y ,所以当Y f =1000时
C=50+0.6×1000=650元
(2)在95%的置信概率下消费支出C 平均值的预测区间 根据公式可知平均值预测区间为
[Y f -t 2
ασ
2∑12
X f i x X n )(+-,Y f +t 2
α
σ
2
2∑12
X f i x X n )(+-]
其中,Y f =650,t 2
α(10)=2.23,σ
2
=2Σe 2
i
- n =10
300=30, 2
X f )(-X =(1000-800)2=40000
∑x i 2=∑(Xi —X )2
=8000
所以:Y f -t 2
α
σ
2∑12
X f i x X n )(+-=650-2.23×30×
8000
40000
121+
置信区间为[650-12.3491,650+12.3491] (3)在95%的置信概率下消费支出C 个别值的预测区间
[Y f -t 2
ασ
2∑112
X f i x X n )(++-,Y f +t 2
α
σ
2
2∑12
X f i x X n )(+-]
Y f -t 2
α
σ
2∑112
X f i x X n )(++-=650-2.23×30×8000
400001211++
置信区间为[650-13.5093,650+13.5093]
(1)
散点图
由图可知可以看出建造单位成本和建筑面积近似于线性关系,建立简单线性回归模型
Y=β1+β2X+u1
估计参数
Y=1845.475-64.184X
(2)建筑面积每增加1万平方米,建筑单位成本每平方米减少64.18400元(3)点预测:当x=4.5 y=1556.647
区间预测
∑x i 2=∑(Xi —X )2=δ2x(n —1)=1.9894192
×(12—1)=43.5357 (X f —X)2
=(4.5—3.523333)2
=0.95387843
当X f =4.5时,将相关数据代入计算得到:
1556.647+2.228×31.73600×0.95387843
43.6357+121=1556.647+478.1231 即Yf 的置信区间为(1556.647—478.1231, 1556.647+478.1231)
2.5
没有截距项的过原点的回归模型为:Yi=β2Xi+ui
Σ
ei 2
=Σ(Yi-2
?βXi)2
求偏导 2
2
?β
σσΣei =2Σ(Yi-2?βXi )(-Xi )=-2ΣeiXi
令 2
2?β
σσΣei =0,得2?
β=
2
i i
i X Y X ΣΣ
而有截距项的回归为2?
β=
2
i i
i x y x ΣΣ 对于过原点的回归,根据最小二乘的原则 Σei=0不成立,ΣeiXi=0成立
且Var(2?β)=
2
2
xi Σσ 2
?σ
=1
Σe 2
i - n 而有截距项的回归为 Var(2?β)=
22
xi Σσ , 2?σ=2
Σe 2
i
- n
第2章 一元线性回归模型 一、单项选择题 1、变量之间的关系可以分为两大类__________。 A 函数关系与相关关系 B 线性相关关系和非线性相关关系 C 正相关关系和负相关关系 D 简单相关关系和复杂相关关系 2、相关关系是指__________。 A 变量间的非独立关系 B 变量间的因果关系 C 变量间的函数关系 D 变量间不确定性的依存关系 3、进行相关分析时的两个变量__________。 A 都是随机变量 B 都不是随机变量 C 一个是随机变量,一个不是随机变量 D 随机的或非随机都可以 4、表示x 和y 之间真实线性关系的是__________。 A 01???t t Y X ββ=+ B 01()t t E Y X ββ=+ C 01t t t Y X u ββ=++ D 01t t Y X ββ=+ 5、参数β的估计量?β 具备有效性是指__________。 A ?var ()=0β B ?var ()β为最小 C ?()0β β-= D ?()ββ-为最小 6、对于01??i i i Y X e ββ=++,以σ?表示估计标准误差,Y ?表示回归值,则__________。 A i i ??0Y Y 0σ∑ =时,(-)= B 2 i i ??0Y Y σ∑=时,(-)=0 C i i ??0Y Y σ∑=时,(-)为最小 D 2 i i ??0Y Y σ∑=时,(-)为最小 7、设样本回归模型为i 01i i ??Y =X +e ββ+,则普通最小二乘法确定的i ?β的公式中,错误的是__________。 A ()() () i i 1 2 i X X Y -Y ?X X β--∑∑= B ()i i i i 1 2 2 i i n X Y -X Y ?n X -X β ∑∑∑∑∑= C i i 1 2 2 i X Y -nXY ?X -nX β ∑∑= D i i i i 1 2x n X Y -X Y ?β σ ∑∑∑= 8、对于i 01i i ??Y =X +e ββ+,以?σ表示估计标准误差,r 表示相关系数,则有__________。 A ?0r=1σ =时, B ?0r=-1σ =时, C ?0r=0σ =时, D ?0r=1r=-1σ =时,或 9、产量(X ,台)与单位产品成本(Y ,元/台)之间的回归方程为?Y 356 1.5X -=,这说明__________。 A 产量每增加一台,单位产品成本增加356元 B 产量每增加一台,单位产品成本减少1.5元 C 产量每增加一台,单位产品成本平均增加356元 D 产量每增加一台,单位产品成本平均减少1.5元
计量经济学(第四版)习题参考答案 潘省初
第一章 绪论 试列出计量经济分析的主要步骤。 一般说来,计量经济分析按照以下步骤进行: (1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项? 为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。 什么是时间序列和横截面数据? 试举例说明二者的区别。 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。 横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。 估计量和估计值有何区别? 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。在一项应用中,依据估计量算出的一个具体的数值,称为估计值。如Y 就是一个估计量,1 n i i Y Y n == ∑。现有一样本,共4个数,100,104,96,130,则 根据这个样本的数据运用均值估计量得出的均值估计值为 5.1074 130 96104100=+++。 第二章 计量经济分析的统计学基础 略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间 N S S x = = 4 5= 用 =,N-1=15个自由度查表得005.0t =,故99%置信限为 x S t X 005.0± =174±×=174± 也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH 备择假设 120:1≠μH 检验统计量 () 10/2510/25 X X μσ-Z == == 查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH 备择假设 : 2500:1≠μH ()100/1200.83?480/16 X X t μσ-= === 查表得 131.2)116(025.0=-t 因为t = < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
第二章主要公式 资料地址:https://www.doczj.com/doc/8a5402588.html,/jl 1、回归模型概述 (1)相关分析与回归分析 经济变量之间的关系:函数关系、相关关系 相关关系:单相关和复相关,完全相关、不完全相关和不相关,正相关与负相关,线性相关和负相关,线性相关和非线性相关。 相关分析: ——总体相关系数XY ρ= ——样本相关系数()() n i i XY X X Y Y r --= ∑ ——多个变量之间的相关程度可用复相关系数和偏相关系数度量 回归分析:相关关系 + 因果关系 (2)随机误差项:含有随机误差项是计量经济学模型与数理经济学模型的一大区别。 (3)总体回归模型 总体回归曲线:给定解释变量条件下被解释变量的期望轨迹。 总体回归函数:(|)()i i E Y X f X = 总体回归模型:(|)()i i i i i Y E Y X f X μμ=+=+ 线性总体回归模型:011,2,...,i i i Y X i n ββμ=++= (4)样本回归模型 样本回归曲线:根据样本回归函数得到的被解释变量的轨迹。 (线性)样本回归函数: 01???i i Y X ββ=+ (线性)样本回归模型:01???i i i Y X e ββ=++ 2、一元线性回归模型的参数估计 (1)基本假设 ① 解释变量:是确定性变量,不是随机变量 var()0i X = ② 随机误差项:零均值、同方差,在不同样本点之间独立,不存在序列相关等 ()01,2,...,i E i n μ== 2var()1,2,...,i i n μσ==
cov(,)0;,1,2,...,i j i j i j n μμ=≠= ③ 随机误差项与解释变量:不相关 cov(,)01,2,...,i i X i n μ== ④ (针对最大似然法和假设检验)随机误差项: 2~(0,)1,2,...,i N i n μσ= ⑤ 回归模型正确设定。 【前四条为线性回归模型的古典假设,即高斯假设。满足古典假设的线性回归模型称为古典线性回归模型。】 (2)参数的普通最小二乘估计(OLS ) 目标:21 min n i i e =∑ 对于一元线性回归模型:011,2,...,i i i Y X i n ββμ=++= 正规方程组: 011 011 ?? 2[()]0??2[()]0n i i i n i i i i Y X X Y X ββββ==?--+=????--+=??∑∑ 解得: 011 112 211??()()?()n n i i i i i i n n i i i i Y X X X Y Y x y X X x βββ====?=-???--?==??-?? ∑∑∑∑ (3)最大似然估计(ML ) 对于一元线性回归模型:011,2,...,i i i Y X i n ββμ=++= 重要的基本假设: 2~(0,)1,2,...,cov(,)0;,1,2,...,var()01,2,...,i i j i N i n i j i j n X i n μσμμ?=? =≠=?? ==? 得到:2 01~(,)1,2,...,i i Y N X i n ββσ+= 【且cov(,)0;,1,2,...,i j Y Y i j i j n =≠=,这个对最大似然法的估计很重要】 则目标:12,,...,n Y Y Y 的联合概率密度最大,即
271 APPENDIX E SOLUTIONS TO PROBLEMS E.1 This follows directly from partitioned matrix multiplication in Appendix D. Write X = 12n ?? ? ? ? ? ???x x x , X ' = (1'x 2'x n 'x ), and y = 12n ?? ? ? ? ? ??? y y y Therefore, X 'X = 1 n t t t ='∑x x and X 'y = 1 n t t t ='∑x y . An equivalent expression for ?β is ?β = 1 11n t t t n --=??' ???∑x x 11n t t t n y -=??' ??? ∑x which, when we plug in y t = x t β + u t for each t and do some algebra, can be written as ?β= β + 1 11n t t t n --=??' ???∑x x 11n t t t n u -=??' ??? ∑x . As shown in Section E.4, this expression is the basis for the asymptotic analysis of OLS using matrices. E.2 (i) Following the hint, we have SSR(b ) = (y – Xb )'(y – Xb ) = [?u + X (?β – b )]'[ ?u + X (?β – b )] = ?u '?u + ?u 'X (?β – b ) + (?β – b )'X '?u + (?β – b )'X 'X (?β – b ). But by the first order conditions for OLS, X '?u = 0, and so (X '?u )' = ?u 'X = 0. But then SSR(b ) = ?u '?u + (?β – b )'X 'X (?β – b ), which is what we wanted to show. (ii) If X has a rank k then X 'X is positive definite, which implies that (?β – b ) 'X 'X (?β – b ) > 0 for all b ≠ ?β . The term ?u '?u does not depend on b , and so SSR(b ) – SSR(?β) = (?β– b ) 'X 'X (?β – b ) > 0 for b ≠?β. E.3 (i) We use the placeholder feature of the OLS formulas. By definition, β = (Z 'Z )-1Z 'y = [(XA )' (XA )]-1(XA )'y = [A '(X 'X )A ]-1A 'X 'y = A -1(X 'X )-1(A ')-1A 'X 'y = A -1(X 'X )-1X 'y = A -1?β . (ii) By definition of the fitted values, ?t y = ?t x β and t y = t z β. Plugging z t and β into the second equation gives t y = (x t A )(A -1?β ) = ?t x β = ?t y . (iii) The estimated variance matrix from the regression of y and Z is 2σ(Z 'Z )-1 where 2σ is the error variance estimate from this regression. From part (ii), the fitted values from the two
第一章导论 一、单项选择题 1-6: CCCBCAC 二、多项选择题 ABCD;ACD;ABCD 三.问答题 什么是计量经济学? 答案见教材第3页 四、案例分析题 假定让你对中国家庭用汽车市场发展情况进行研究,应该分哪些步骤,分别如何分析?(参考计量经济学研究的步骤) 第一步:选取被研究对象的变量:汽车销售量 第二步:根据理论及经验分析,寻找影响汽车销售量的因素,如汽车价格,汽油价格,收入水平等 第三步:建立反映汽车销售量及其影响因素的计量经济学模型 第四步:估计模型中的参数; 第五步:对模型进行计量经济学检验、统计检验以及经济意义检验; 第六步:进行结构分析及在给定解释变量的情况下预测中国汽车销售量的未来值为汽车业的发展提供政策实施依据。 第二章简单线性回归模型 一、填空题 1、线性、无偏、最小方差性(有效性),BLUE。 2、解释变量;参数;参数。 3、随机误差项;随机误差项。 二、单项选择题 1-4:BBDA;6-11:CDCBCA 三、多项选择题 1.ABC; 2.ABC; 3.BC; 4.ABE; 5.AD; 6.BC 四、判断正误: 1. 错; 2. 错; 3. 对; 4.错; 5. 错; 6. 对; 7. 对; 8.错 五、简答题: 1.为什么模型中要引入随机扰动项? 答:模型是对经济问题的一种数学模型,在模型中,被解释变量是研究的对象,解释变量是其确定的解释因素,但由于实际问题的错综复杂,影响被解释变量的因素中,除了包括在模型中的解释变量以外,还有其他一些因素未能包括在模型中,但却影响被解释变量,我们把这类变量统一用随机误差项表示。随机误差项包含的因素有:
班级:金融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAW sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出一个模型,容许u的方差在男女之间有所不同。这个方差不应该取决于其他因素。 在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u方差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。所以,当方差在male=1时,即为男性时,结果为δ0+δ1;当为女性时,结果为δ0。 将sleep对totwork,educ,age,age2,yngkid和male进行回归,回归结果如下: (ⅱ)利用SLEEP75.RAW的数据估计异方差模型中的参数。u的估计方差对于男人和女人而言哪个更高? 由截图可知:u2=189359.2?28849.63male+r
20546.36 (27296.36) 由于male 的系数为负,所以u 的估计方差对女性而言更大。 (ⅲ)u 的方差是否对男女而言有显著不同? 因为male 的 t 统计量为?1.06,所以统计不显著,故u 的方差是否对男女而言并没有显著不同。 C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利用HPRICE 1.RAW 中的数据得到方程(8.17)的异方差—稳健的标准误。讨论其与通常的标准误之间是否存在任何重要差异。 ● 先进行一般回归,结果如下: ● 再进行稳健回归,结果如下: 由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms 29.48 0.00064 0.013 (9.01) 37.13 0.00122 0.018 [8.48] n = 88, R 2=0.672 比较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较大。而sqrft 的稳健标准误也比通常的大,但相差不大,bdrms 的稳健标准误比通常的要小些。 (ⅱ)对方程(8.18)重复第(ⅰ)步操作。 n =706,R 2=0.0016
第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间__________的关系,用__________性的数学方程加以描述。 3.经济数学模型是用__________描述经济活动。 4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。 5.计量经济学模型包括__________和__________两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即__________、____________________、____________________。 7.确定理论模型中所包含的变量,主要指确定__________。 8.可以作为解释变量的几类变量有__________变量、__________变量、__________变量和__________变量。 9.选择模型数学形式的主要依据是__________。 10.研究经济问题时,一般要处理三种类型的数据:__________数据、__________数据和__________数据。 11.样本数据的质量包括四个方面__________、__________、__________、__________。 12.模型参数的估计包括__________、__________和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是__________检验、__________检验、__________检验和__________检验。 14.计量经济模型的计量经济检验通常包括随机误差项的__________检验、__________检验、解释变量的__________检验。 15.计量经济学模型的应用可以概括为四个方面,即__________、__________、__________、__________。 16.结构分析所采用的主要方法是__________、__________和__________。 二、单选题: 1.计量经济学是一门()学科。 A.数学 B.经济
第二章案例分析 一、研究的目的要求 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我们研究的对象是各地区居民消费的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2002年截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 从2002年《中国统计年鉴》中得到表2.5的数据: 表2.52002年中国各地区城市居民人均年消费支出和可支配收入
第七章 课后练习答案 7.1 (1)已知:96.1%,951,25,40,52/05.0==-===z x n ασ。 样本均值的抽样标准差79.0405== = n x σ σ (2)边际误差55.140 5 96.12/=? ==n z E σ α 7.2 (1)已知:96.1%,951,120,49,152/05.0==-===z x n ασ。 样本均值的抽样标准差14.249 15== = n x σ σ (2)边际误差20.449 1596.12 /=? ==n z E σ α (3)由于总体标准差已知,所以总体均值μ的95%的置信区间为 20.412049 1596.11202 /±=? ±=±n z x σ α 即()2.124,8.115 7.3 已知:96.1%,951,104560,100,854142/05.0==-===z x n ασ。 由于总体标准差已知,所以总体均值μ的95%的置信区间为 144.16741104560100 8541496.11045602 /±=? ±=±n z x σ α 即)144.121301,856.87818( 7.4 (1)已知:645.1%,901,12,81,1002/1.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的90%的置信区间为: 974.181100 12645.1812 /±=? ±=±n s z x α 即)974.82,026.79(
(2)已知:96.1%,951,12,81,1002/05.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的95%的置信区间为: 352.281100 1296.1812 /±=? ±=±n s z x α 即)352.83,648.78( (3)已知:58.2%,991,12,81,1002/05.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的99%的置信区间为: 096.381100 1258.2812 /±=? ±=±n s z x α 即)096.84,940.77( 7.5 (1)已知:96.1%,951,5.3,25,602/05.0==-===z x n ασ。 由于总体标准差已知,所以总体均值μ的95%的置信区间为: 89.02560 5.39 6.1252 /±=? ±=±n z x σ α 即)89.25,11.24( (2)已知:33.2%,981,89.23,6.119,752/02.0==-===z s x n α。 由于75=n 为大样本,所以总体均值μ的98%的置信区间为: 43.66.11975 89.2333.26.1192 /±=? ±=±n s z x α 即)03.126,17.113( (3)已知:645.1%,901,974.0,419.3,322/1.0==-===z s x n α。 由于32=n 为大样本,所以总体均值μ的90%的置信区间为: 283.0419.332 974.0645.1419.32 /±=? ±=±n s z x α 即)702.3,136.3(
第二章 回归模型思考与练习参考答案 2.1参考答案 ⑴答:解释变量为确定型变量、互不相关(无多重共线性);随机误差项零的值、同方差、非自相关;解释变量与随机误差项不相关。 现实经济中,这些假定难以成立。要解决这些问题就得对古典回归理论做进一步发展,这就产生了现代回归理论。 ⑵答:总体方差是总体回归模型中随机误差项i ε的方差;参数估计误差则属于样本回归模型中的概念,通常是指参数估计的均方误。参数估计的均方误为 MSE ()i i b b ?=E ()2?i i b b -=D ()i b ?=()[]ii u 12-'χχσ 即根据参数估计的无偏线,参数估计的均方误与其方差相等。而参数估计的方差又源于总体方差。因此,参数估计误差是总体方差的表现,总体方差是参数估计误差的根源。 ⑶答:总体回归模型 ()i i i x y E y ε+= 样本回归模型i i i e y y +=? i ε是因变量y 的个别值i y 与因变量y 对i x 的总体回归函数值() i x y E 的偏差;i e 为因变量y 的观测值i y 与因变量y 的样本回归函数值i y ?的偏差。 i e 在概念上类似于i ε,是对i ε的估计。 对于既定理论模型,OLS 法能使模型估计的拟和误差达最小。但或许我们可选择更理想的理论模型,从而进一步提高模型对数据的拟和程度。 ⑷答:2R 检验说明模型对样本数据的拟和程度;F 检验说明模型对总体经济关系的近似程度。 ()()()k k n R R k n Model Total k Model k m Error k Model F 111122--?-=---=--= 由02>??R F 可知,F 是2R 的单调增函数。对每一个临界值?F ,都可以找到一个2?R 与之对应,当22?>R R 时便有?>F F 。 ⑸答:在古典回归模型假定成立的条件下,OLS 估计是所有的线形无偏估计量中的有效估计量。 ⑹答:如果模型通过了F 检验,则表明模型中所有解释变量对被解释变量的影响显著。但这并不说明多个解释变量的影响都是显著的。建模开始时,常根据先验知识尽可能找出影响被解释变量的所有因素,这样就可能会选择不重要的因素作为解释变量。对单个解释变量的显著性检验可以剔除这些不重要的影响因素。 ⑺答:考虑两个经济变量y 与x ,及一组观测值(){},,2,1,,n i y x i i =。
DATA SET HANDBOOK Introductory Econometrics: A Modern Approach, 4e Jeffrey M. Wooldridge This document contains a listing of all data sets that are provided with the fourth edition of Introductory Econometrics: A Modern Approach. For each data set, I list its source (wherever possible), where it is used or mentioned in the text (if it is), and, in some cases, notes on how an instructor might use the data set to generate new homework exercises, exam problems, or term projects. In some cases, I suggest ways to improve the data sets. Special thanks to Edmund Wooldridge, who provided valuable assistance in updating the page numbers for the fourth edition. 401K.RAW Source:L.E. Papke (1995), “Participation in and Contributions to 401(k) Pension Plans: Evidence from Plan Data,”Journal of Human Resources 30, 311-325. Professor Papke kindly provided these data. She gathered them from the Internal Revenue Service’s Form 5500 tapes. Used in Text: pages 64, 80, 135-136, 173, 217, 685-686 Notes: This data set is used in a variety of ways in the text. One additional possibility is to investigate whether the coefficients from the regression of prate on mrate, log(totemp) differ by whether the plan is a sole plan. The Chow test (see Section 7.4), and the less restrictive version that allows different intercepts, can be used. 401KSUBS.RAW Source: A. Abadie (2003), “Semiparametric Instrumental Variable Estimation of Treatment Response Models,”Journal of Econometrics 113, 231-263. Professor Abadie kindly provided these data. He obtained them from the 1991 Survey of Income and Program Participation (SIPP). Used in Text: pages 165, 182, 222, 261, 279-280, 288, 298-299, 336, 542 Notes: This data set can also be used to illustrate the binary response models, probit and logit, in Chapter 17, where, say, pira (an indicator for having an individual retirement account) is the dependent variable, and e401k [the 401(k) eligibility indicator] is the key explanatory variable.
第二章 简单线性回归模型 一、单项选择题(每题2分): 1、回归分析中定义的( )。 A 、解释变量和被解释变量都是随机变量 B 、解释变量为非随机变量,被解释变量为随机变量 C 、解释变量和被解释变量都为非随机变量 D 、解释变量为随机变量,被解释变量为非随机变量 2、最小二乘准则是指使( )达到最小值的原则确定样本回归方程。 A 、1 ?()n t t t Y Y =-∑ B 、1?n t t t Y Y = -∑ C 、?max t t Y Y - D 、21 ?()n t t t Y Y =-∑ 3、下图中“{”所指的距离是( )。 A 、随机误差项 B 、残差 C 、i Y 的离差 D 、?i Y 的离差 4、参数估计量?β是i Y 的线性函数称为参数估计量具有( )的性质。 A 、线性 B 、无偏性 C 、有效性 D 、一致性 5、参数β的估计量β? 具备最佳性是指( )。 A 、0)?(=βVar B 、)? (βVar 为最小 C 、0?=-ββ D 、)? (ββ-为最小 6、反映由模型中解释变量所解释的那部分离差大小的是( )。 A 、总体平方和 B 、回归平方和 C 、残差平方和 D 、样本平方和 7、总体平方和TSS 、残差平方和RSS 与回归平方和ESS 三者的关系是( )。 X 1?β+ i Y
A 、RSS=TSS+ESS B 、TSS=RSS+ESS C 、ESS=RSS-TSS D 、ESS=TSS+RSS 8、下面哪一个必定是错误的( )。 A 、 i i X Y 2.030? += ,8.0=XY r B 、 i i X Y 5.175?+-= ,91.0=XY r C 、 i i X Y 1.25? -=,78.0=XY r D 、 i i X Y 5.312?--=,96.0-=XY r 9、产量(X ,台)与单位产品成本(Y ,元/台)之间的回归方程为?356 1.5Y X =-,这说明( )。 A 、产量每增加一台,单位产品成本增加356元 B 、产量每增加一台,单位产品成本减少1.5元 C 、产量每增加一台,单位产品成本平均增加356元 D 、产量每增加一台,单位产品成本平均减少1.5元 10、回归模型i i i X Y μββ++=10,i = 1,…,n 中,总体方差未知,检验 010=β:H 时,所用的检验统计量1 ? 1 1?βββS -服从( )。 A 、)(22 -n χ B 、)(1-n t C 、)(12-n χ D 、)(2-n t 11、对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值的( )。 A 、i C (消费)i I 8.0500+=(收入) B 、di Q (商品需求)i I 8.010+=(收入)i P 9.0+(价格) C 、si Q (商品供给)i P 75.020+=(价格) D 、i Y (产出量)6.065.0i K =(资本)4 .0i L (劳动) 12、进行相关分析时,假定相关的两个变量( )。 A 、都是随机变量 B 、都不是随机变量 C 、一个是随机变量,一个不是随机变量 D 、随机或非随机都可以 13、假设用OLS 法得到的样本回归直线为i i i e X Y ++=2 1 ??ββ ,以下说法不正确的是( )。 A 、∑=0i e B 、),(Y X 一定在回归直线上 C 、Y Y =? D 、0),(≠i i e X COV 14、对样本的相关系数γ,以下结论错误的是( )。 A 、γ越接近0,X 和Y 之间的线性相关程度越高
计量经济学课后习题答案
业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、 预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒等关系。 三、简答题 ⒈什么是计量经济学?它与统计学的关系是怎样的? 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与
第二章练习题及参考解答 2.1 为研究中国的货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相互依存关系,分析表中1990年—2007年中国货币供应量(M2)和国内生产总值(GDP )的有关数据: 表2.9 1990年—2007年中国货币供应量和国内生产总值(单位:亿元) 资料来源:中国统计年鉴2008,中国统计出版社 对货币供应量与国内生产总值作相关分析,并说明相关分析结果的经济意义。 练习题2.1 参考解答: 计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为: 计算方法: XY n X Y X Y r -= 或 ,()()X Y X X Y Y r --= 计算结果: M2 GDP M2 1 0.996426148646 GDP 0.996426148646 1 经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性
相关程度相当高。 2.2 为研究美国软饮料公司的广告费用X与销售数量Y的关系,分析七种主要品牌软饮料公司的有关数据 表2.10 美国软饮料公司广告费用与销售数量 资料来源:(美) Anderson D R等. 商务与经济统计.机械工业出版社.1998. 405 绘制美国软饮料公司广告费用与销售数量的相关图, 并计算相关系数,分析其相关程度。能否在此基础上建立回归模型作回归分析? 练习题2.2参考解答 美国软饮料公司的广告费用X与销售数量Y的散点图为 说明美国软饮料公司的广告费用X与销售数量Y正线性相关。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为 x 4036.147857.21y ?+= (96.9800)(1.3692) t= (-0.131765) (10.5200) 9568.02=R F=110.6699 S.E=92302.73 D.W=1.4389 经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。 2.3 为了研究深圳市地方预算内财政收入与国内生产总值的关系,得到以下数据: 表2.11 深圳市地方预算内财政收入与国内生产总值
1.最小二乘法对随机误差项u作了哪些假定?说明这些假定条件的意义。 答:假定条件: (1)均值假设:E(u i)=0,i=1,2,…; (2)同方差假设:Var(u i)=E[u i-E(u i)]2=E(u i2)=σu2 ,i=1,2,…; (3)序列不相关假设:Cov(u i,u j)=E[u i-E(u i)][u j-E(u j)]=E(u i u j)=0,i≠j,i,j=1,2,…; (4)Cov(u i,X i)=E[u i-E(u i)][X i-E(X i)]=E(u i X i)=0; (5)u i服从正态分布, u i~N(0,σu2)。 意义:有了这些假定条件,就可以用普通最小二乘法估计回归模型的参数。 2.阐述对样本回归模型拟合优度的检验及回归系数估计值显著性检验的步骤。 答:样本回归模型拟合优度的检验:可通过总离差平方和的分解、样本可决系数、样本相关系数来检验。 回归系数估计值显著性检验的步骤: (1)提出原假设H0 :β1=0; (2)备择假设H1 :β1≠0; (3)计算t=β1/Sβ1; (4)给出显著性水平α,查自由度v=n-2的t分布表,得临界值tα/2(n-2); (5)作出判断。如果|t|
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分 析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒 等关系。 三、简答题 ⒈什么是计量经济学?它与统计学的关系是怎样的? 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从经济理论和经济模型出发进行计量经济分析的过程,也是对经济理论证实或证伪的过程。这些是以处理数