
实验1—X M L的语法
实验日期:2015.3.9 实验室:204信息管理实验室
学号:姓名:何瑞班级:计科5班
实验目的
1.安装并学习如何使用XMLSPY集成开发环境完成XML相关的开发工作。
2.熟悉和掌握XML规范的基本内容,包括XML声明、注释、处理指令、元素、
属性、CDATA段、预定义实体、命名空间的使用,以及如何进行XML文档
良构和有效性验证;能够灵活地使用XML层次数据来表示各种信息。
实验环境
1.硬件
2.软件:XMLSpy2011
实验原理
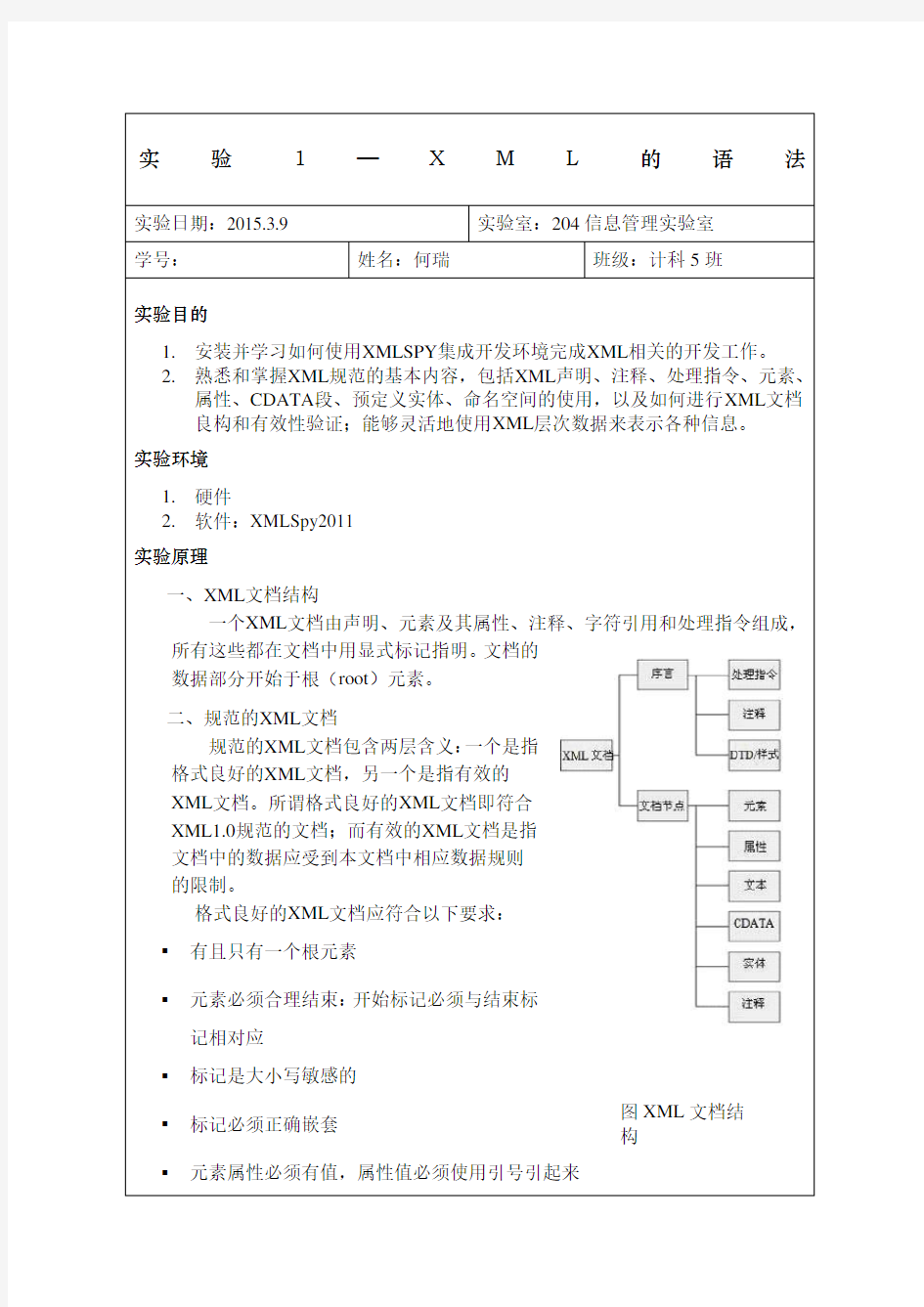
一、XML文档结构
一个XML文档由声明、元素及其属性、注释、字符引用和处理指令组成,所有这些都在文档中用显式标记指明。文档的
数据部分开始于根(root)元素。
二、规范的XML文档
规范的XML文档包含两层含义:一个是指
格式良好的XML文档,另一个是指有效的
XML文档。所谓格式良好的XML文档即符合
XML1.0规范的文档;而有效的XML文档是指
文档中的数据应受到本文档中相应数据规则
的限制。
格式良好的XML文档应符合以下要求:
?有且只有一个根元素
?元素必须合理结束:开始标记必须与结束标
记相对应
?标记是大小写敏感的
?标记必须正确嵌套
?元素属性必须有值,属性值必须使用引号引起来图XML文档结构
编译原理语法分析实验报告 - 班级:XXX 学号:XXX 姓名:XXX 年月日 1、摘要: 用递归子程序法实现对pascal的子集程序设计语言的分析程序 2、实验目的: 通过完成语法分析程序,了解语法分析的过程和作用 3、任务概述 实验要求:对源程序的内码流进行分析,如为文法定义的句子输出”是”否则输出”否”,根据需要处理说明语句填写写相应的符号表供以后代码生成时使用 4、实验依据的原理 递归子程序法是一种自顶向下的语法分析方法,它要求文法是LL(1)文法。通过对文法中每个非终结符编写一个递归过程,每个过程的功能是识别由该非终结符推出的串,当某非终结符的产生式有多个候选式时,程序能够按LL(1)形式唯一地确定选择某个候选式进行推导,最终识别输入串是否与文法匹配。 递归子程序法的缺点是:对文法要求高,必须满足LL(1)文法,当然在某些语言中个别产生式的推导当不满足LL(1)而满足LL(2)时,也可以采用多向前扫描一个符号的办法;它的另一个缺点是由于递归调用多,所以速度慢占用空间多,尽管这样,它还是许多高级语言,例如PASCAL,C等编译系统常常采用的语法分析方法。
为适合递归子程序法,对实验一词法分析中的文法改写成无左递归和无左共因子的,,,如下: <程序>?<程序首部><分程序>。 <程序首部>?PROGRAM标识符; <分程序>?<常量说明部分><变量说明部分><过程说明部分> <复合语句> <常量说明部分>?CONST<常量定义><常量定义后缀>;|ε <常量定义>?标识符=无符号整数 <常量定义后缀>?,<常量定义><常量定义后缀> |ε <变量说明部分>?VAR<变量定义><变量定义后缀> |ε <变量定义>?标识符<标识符后缀>:<类型>; <标识符后缀>?,标识符<标识符后缀> |ε <变量定义后缀>?<变量定义><变量定义后缀> |ε <类型>?INTEGER | LONG <过程说明部分>?<过程首部><分程序>;<过程说明部分后缀>|ε <过程首部>?PROCEDURE标识符<参数部分>; <参数部分>?(标识符: <类型>)|ε <过程说明部分后缀>?<过程首部><分程序>;<过程说明部分后缀>|ε <语句>?<赋值或调用语句>|<条件语句>|<当型循环语句>|<读语句> |<写语句>|<复合语句>|ε <赋值或调用语句>?标识符<后缀> <后缀>?:=<表达式>|(<表达式>)|ε <条件语句>?IF<条件>THEN<语句> <当型循环语句>?WHILE<条件>DO <语句> <读语句>?READ(标识符<标识符后缀>)
实验室常用溶液及试剂配制 一、实验室常用溶液、试剂的配制-------------------------------------------------------1 表一普通酸碱溶液的配制 表二常用酸碱指示剂配制 表三混合酸碱指示剂配制 表四容量分析基准物质的干燥 表五缓冲溶液的配制 1、氯化钾-盐酸缓冲溶液 2、邻苯二甲酸氢钾-氢氧化钾缓冲溶液 3、邻苯二甲酸氢钾-氢氧化钾缓冲溶液 4、乙酸-乙酸钠缓冲溶液 5、磷酸二氢钾-氢氧化钠缓冲溶液 6、硼砂-氢氧化钠缓冲溶液 7、氨水-氯化铵缓冲溶液 8、常用缓冲溶液的配制 二、实验室常用标准溶液的配制及其标定-----------------------------------------------4 1、硝酸银(C AgNO3=0.1mol/L)标准溶液的配制 2、碘(C I2=0.1mol/L)标准溶液的配制 3、硫代硫酸钠(C Na2S2O3=0.1mol/L)标准溶液的配制 4、高氯酸(C HClO4=0.1mol/L)标准溶液的配制 5、盐酸(C HCl=0.1mol/L)标准溶液的配制 6、乙二胺四乙酸二钠(C EDTA =0.1mol/L)标准溶液的配制 7、高锰酸钾(C K2MnO4=0.1mol/L)标准溶液的配制 8、氢氧化钠(C NaOH=1mol/L)标准溶液的配制 三、常见物质的实验室试验方法 ----------------------------------------------------------6 1、柠檬酸(C6H8O7·H2O) 2、钙含量测定(磷酸氢钙CaHPO4、磷酸二氢钙Ca(H2PO4)2·H2O、钙粉等) 3、氟(Fˉ)含量的测定 4、磷(P)的测定 5、硫酸铜(CuSO4·5H2O) 6、硫酸锌(ZnSO4·H2O) 7、硫酸亚铁(FeSO4·H2O) 8、砷 9、硫酸镁(MgSO4) 四、维生素检测--------------------------------------------------------------------------------8 1、甜菜碱盐酸盐 2、氯化胆碱
学号107 成绩 编译原理上机报告 名称:编写递归下降语法分析器 学院:信息与控制工程学院 专业:计算机科学与技术 班级:计算机1401班 姓名:叶达成 2016年10月31日
一、上机目的 通过设计、编制、调试一个递归下降语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,掌握常用的语法分析方法。通过本实验,应达到以下目标: 1、掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法。 2、掌握词法分析的实现方法。 3、上机调试编出的词法分析程序。 二、基本原理和上机步骤 递归下降分析程序实现思想简单易懂。程序结构和语法产生式有直接的对应关系。因为每个过程表示一个非终结符号的处理,添加语义加工工作比较方便。 递归下降分析程序的实现思想是:识别程序由一组子程序组成。每个子程序对应于一个非终结符号。 每一个子程序的功能是:选择正确的右部,扫描完相应的字。在右部中有非终结符号时,调用该非终结符号对应的子程序来完成。 自上向下分析过程中,如果带回溯,则分析过程是穷举所有可能的推导,看是否能推导出待检查的符号串。分析速度慢。而无回溯的自上向下分析技术,当选择某非终结符的产生时,可根据输入串的当前符号以及各产生式右部首符号而进行,效率高,且不易出错。 无回溯的自上向下分析技术可用的先决条件是:无左递归和无回溯。 无左递归:既没有直接左递归,也没有间接左递归。 无回溯:对于任一非终结符号U的产生式右部x1|x2|…|x n,其对应的字的首终结符号两两不相交。 如果一个文法不含回路(形如P?+ P的推导),也不含以ε为右部的产生式,那么可以通过执行消除文法左递归的算法消除文法的一切左递归(改写后的文法可能含有以ε为右部的产生式)。 三、上机结果 测试数据: (1)输入一以#结束的符号串(包括+—*/()i#):在此位置输入符号串例如:i+i*i# (2)输出结果:i+i*i#为合法符号串 (3)输入一符号串如i+i*#,要求输出为“非法的符号串”。 程序清单: #include
. 编译原理实验专业:13级网络工程
语法分析器1 一、实现方法描述 所给文法为G【E】; E->TE’ E’->+TE’|空 T->FT’ T’->*FT’|空 F->i|(E) 递归子程序法: 首先计算出五个非终结符的first集合follow集,然后根据五个产生式定义了五个函数。定义字符数组vocabulary来存储输入的句子,字符指针ch指向vocabulary。从非终结符E函数出发,如果首字符属于E的first集,则依次进入T函数和E’函数,开始递归调用。在每个函数中,都要判断指针所指字符是否属于该非终结符的first集,属于则根据产生式进入下一个函数进行调用,若first集中有空字符,还要判断是否属于该非终结符的follow集。以分号作为结束符。 二、实现代码 头文件shiyan3.h #include
#include int a=0; cout<<"按1结束程序"< 1DEPC水(1‰) 1000ml 水 1ml DEPC 根据需要确定要配的体积,泡实验器具的DEPC水静止4小时后备用,泡24小时。配液体的DEPC水37℃过夜,送至高压,然后配相关溶液。 20.1M tris(ph 7.5) 12.114g tris 1000ml DEPC水 用HCL调ph至7.5,高压备用。 3 4%PFA的配制(ph 7.0)40g PFA 1000ml 0.1m tris(DEPC水配制高压) 将溶液持续加热至60℃左右,搅拌之至完全溶解,注意温度不要超过65℃,否则PFA降解失效。 30.2% 甘油/0.1M tris 20ml 甘油 980ml 0.1Mtris 4 20XSSC Nacl 175.3g (ph 7.0)柠檬酸钠88.2g DEPC水1000ml 分别稀释至2XSSC和0.2XSSC备用 5 HEPES 溶液HEPES 23.8g (ph6.8-8.0)DEPC H2O 100ml 6 50X Denhaldt′s 液 聚蔗糖(Ficoll 400)0.2g 聚乙烯吡咯烷酮(polyvinypyrrolidone) 0.2g 牛血清蛋白(BSA)0.2g DEPC 水20ml 7 预杂交buffer Deinoized formanmid 5ml 20X SSC 1.5ml 1M HEPES 0.5ml 50X Denhanldt′s液1ml 龟精DNA 0.6ml(4ug/ul) DEPC水 1.4ml 龟精DNA 要先95℃10-15min加热变性,随即冰浴。杂交buffer分装后-20℃保存。 8Washing buffer (ph7.5) maleic acid 5.8g NACL 4.4g Tween(吐温) 1.5ml 定容至500ml溶质浓度最后分别为0.1M maleic acid 0.15M nacl 0.3% Tween 9Maleic acid buffer (ph7.5) Maleic acid 5.8g Nacl 4.4g 定容至500ml 溶质的浓度最后分别为0.1M maleic acid 0.15M nacl 10Detection buffer 学士后Java阶段测试-U1单元-笔试试卷1 考试时间 60分钟 选择题(共50题,每题2分,满分100分) 1) 在Java类中,使用以下()声明语句来定义公有的int型常量MAX。 A. public int MAX = 100; B. final int MAX = 100; C. public static int MAX = 100; D. public static final int MAX = 100; 2) 在Java中,下列关于方法重载的说法中错误的是()(多选)。 A. 方法重载要求方法名称必须相同 B. 重载方法的参数列表必须不一致 C. 重载方法的返回类型必须一致 D. 一个方法在所属的类中只能被重载一次 3) 给定Java代码如下所示,在横线处新增下列()方法,是对cal方法的重 载。(多选) public class Test{ public void cal(int x, int y, int z) {} ________________ } A. public int cal(int x, int y, float z){ return 0; } B. public int cal(int x, int y, int z){ return 0; } C. public void cal(int x, int z){ } D. public void cal(int z, int y, int x){ } 4) 在Java中,下面对于构造函数的描述正确的是()。 A. 类必须显式定义构造函数 B. 构造函数的返回类型是void C. 构造函数和类有相同的名称,并且不能带任何参数 D. 一个类可以定义多个构造函数 5) 下面Java代码的运行结果是()。 class Penguin { private String name=null; // 名字 private int health=0; // 健康值 private String sex=null; // 性别 public void Penguin() { health = 10; sex = "雄"; System.out.println("执行构造方法。"); 词法分析 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 3.1 主程序示意图: 扫描子程序主要部分流程图 其他 词法分析程序的C语言程序源代码: // 词法分析函数: void scan() // 数据传递: 形参fp接收指向文本文件头的文件指针; // 全局变量buffer与line对应保存源文件字符及其行号,char_num保存字符总数。 void scan() { char ch; int flag,j=0,i=-1; while(!feof(fp1)) { ch=fgetc(fp1); flag=judge(ch); printf("%c",ch);//显示打开的文件 if(flag==1||flag==2||flag==3) {i++;buffer[i]=ch;line[i]=row;} else if(flag==4) {i++;buffer[i]='?';line[i]=row;} else if(flag==5) {i++;buffer[i]='~';row++;} else if(flag==7) continue; else cout<<"\n请注意,第"< 上海电力学院 编译原理 课程实验报告 实验名称:实验三自下而上语法分析及语义分析 院系:计算机科学和技术学院 专业年级: 学生姓名:学号: 指导老师: 实验日期: 实验三自上而下的语法分析 一、实验目的: 通过本实验掌握LR分析器的构造过程,并根据语法制导翻译,掌握属性文法的自下而上计算的过程。 二、实验学时: 4学时。 三、实验内容 根据给出的简单表达式的语法构成规则(见五),编制LR分析程序,要求能对用给定的语法规则书写的源程序进行语法分析和语义分析。 对于正确的表达式,给出表达式的值。 对于错误的表达式,给出出错位置。 四、实验方法 采用LR分析法。 首先给出S-属性文法的定义(为简便起见,每个文法符号只设置一个综合属性,即该文法符号所代表的表达式的值。属性文法的定义可参照书137页表6.1),并将其改造成用LR分析实现时的语义分析动作(可参照书145页表6.5)。 接下来给出LR分析表。 然后程序的具体实现: ● LR分析表可用二维数组(或其他)实现。 ●添加一个val栈作为语义分析实现的工具。 ●编写总控程序,实现语法分析和语义分析的过程。 注:对于整数的识别可以借助实验1。 五、文法定义 简单的表达式文法如下: (1)E->E+T (2)E->E-T (3)E->T (4)T->T*F (5)T->T/F (6)T->F (7)F->(E) (8)F->i 状态ACTION(动作)GOTO(转换) i + - * / ( ) # E T F 0 S5 S4 1 2 3 1 S6 S1 2 acc 2 R 3 R3 S7 S13 R3 R3 3 R6 R6 R6 R6 R6 R6 4 S 5 S4 8 2 3 5 R8 R8 R8 R8 R8 R8 6 S5 S4 9 3 7 S5 S4 10 8 S6 R12 S11 9 R1 R1 S7 S13 R1 R1 10 R4 R4 R4 R4 R4 R4 11 R7 R7 R7 R7 R7 R7 12 S5 S4 14 3 13 S5 S4 15 14 R2 R2 S7 S13 R2 R2 15 R5 R5 R5 R5 R5 R5 五、处理程序例和处理结果例 示例1:20133191*(20133191+3191)+ 3191# 编译原理实验报告 实验名称:编写语法分析分析器实验类型: 指导教师: 专业班级: 学号: 电子邮件: 实验地点: 实验成绩: 一、实验目的 通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。 1、选择最有代表性的语法分析方法,如LL(1) 语法分析程序、算符优先分析程序和LR分析分析程序,至少选一题。 2、选择对各种常见程序语言都用的语法结构,如赋值语句(尤指表达式)作为分析对象,并且与所选语法分析方法要比较贴切。 二、实验过程 编写算符优先分析器。要求: (a)根据算符优先分析算法,编写一个分析对象的语法分析程序。读者可根据自己的能力选择以下三项(由易到难)之一作为分析算法中的输入: Ⅰ:通过构造算符优先关系表,设计编制并调试一个算法优先分析程序Ⅱ:输入FIRSTVT,LASTVT集合,由程序自动生成该文法的算符优先关系矩阵。 Ⅲ:输入已知文法,由程序自动生成该文法的算符优先关系矩阵。(b)程序具有通用性,即所编制的语法分析程序能够使用于不同文法以及各种输入单词串,并能判断该文法是否为算符文法和算符优先文法。 (c)有运行实例。对于输入的一个文法和一个单词串,所编制的语法分析程序应能正确地判断,此单词串是否为该文法的句子,并要求输出分析过程。 三、实验结果 算符优先分析器: 测试数据:E->E+T|T T->T*F|F F->(E)|i 实验结果:(输入串为i+i*i+i) 四、讨论与分析 自下而上分析技术-算符优先分析法: 算符文法:一个上下无关文法G,如果没有且没有P→..QR...(P ,Q ,R属于非终结符),则G是一个算符文法。 FIRSTVT集构造 1、若有产生式P →a...或P →Qa...,则a∈FIRSTVT(P)。 2、若有产生式P→...,则FIRSTVT(R)包含在FIRSTVT(P)中。由优先性低于的定义和firstVT集合的定义可以得出:若存在某个产生式:…P…,则对所有:b∈firstVT(P)都有:a≦b。 构造优先关系表: 1、如果每个非终结符的FIRSTVT和LASTVT集均已知,则可构造优先关系表。 2、若产生式右部有...aP...的形式,则对于每个b∈FIRSTVT(P)都有 语法分析器的设计 一、实验内容 语法分析程序用LL(1)语法分析方法。首先输入定义好的文法书写文件(所用的文法可以用LL(1)分析),先求出所输入的文法的每个非终结符是否能推出空,再分别计算非终结符号的FIRST集合,每个非终结符号的FOLLOW集合,以及每个规则的SELECT集合,并判断任意一个非终结符号的任意两个规则的SELECT 集的交集是不是都为空,如果是,则输入文法符合LL(1)文法,可以进行分析。对于文法: G[E]: E->E+T|T T->T*F|F F->i|(E) 分析句子i+i*i是否符合文法。 二、基本思想 1、语法分析器实现 语法分析是编译过程的核心部分,它的主要任务是按照程序的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行词法检查,为语义分析和代码生成作准备。这里采用自顶向下的LL(1)分析方法。 语法分析程序的流程图如图5-4所示。 语法分析程序流程图 该程序可分为如下几步: (1)读入文法 (2)判断正误 (3)若无误,判断是否为LL(1)文法 (4)若是,构造分析表; (5)由句型判别算法判断输入符号串是为该文法的句型。 三、核心思想 该分析程序有15部分组成: (1)首先定义各种需要用到的常量和变量; (2)判断一个字符是否在指定字符串中; (3)读入一个文法; (4)将单个符号或符号串并入另一符号串; (5)求所有能直接推出&的符号; (6)求某一符号能否推出‘& ’; (7)判断读入的文法是否正确; (8)求单个符号的FIRST; (9)求各产生式右部的FIRST; (10)求各产生式左部的FOLLOW; (11)判断读入文法是否为一个LL(1)文法; (12)构造分析表M; (13)句型判别算法; (14)一个用户调用函数; (15)主函数; 下面是其中几部分程序段的算法思想: 1、求能推出空的非终结符集 Ⅰ、实例中求直接推出空的empty集的算法描述如下: void emp(char c){ 参数c为空符号 char temp[10];定义临时数组 int i; for(i=0;i<=count-1;i++)从文法的第一个产生式开始查找 { if 产生式右部第一个符号是空符号并且右部长度为1, then将该条产生式左部符号保存在临时数组temp中 将临时数组中的元素合并到记录可推出&符号的数组empty中。 } Ⅱ、求某一符号能否推出'&' int _emp(char c) { //若能推出&,返回1;否则,返回0 int i,j,k,result=1,mark=0; char temp[20]; temp[0]=c; temp[1]='\0'; 存放到一个临时数组empt里,标识此字符已查找其是否可推出空字 如果c在可直接推出空字的empty[]中,返回1 for(i=0;;i++) { if(i==count) return(0); 找一个左部为c的产生式 j=strlen(right[i]); //j为c所在产生式右部的长度 if 右部长度为1且右部第一个字符在empty[]中. then返回1(A->B,B可推出空) if 右部长度为1但第一个字符为终结符,then 返回0(A->a,a为终结符) else 实验室常用生化试剂配方 1.常用抗生素配制以及使用说明(参考链霉菌室操作手册2019版) 抗生素 英文名称及缩写 抗性基因 贮藏液浓度(mg/ml) 100 25(无水乙醇配) 50 25 50 50 25(DMSO配) 100 50 35 25(0.15M NaOH配) 50(DMSO配) 50 50 MM 使用终浓度(μg/ml)链霉菌 2CM YEME 大肠杆菌 LA或LB 氨苄青霉素氯霉素潮霉素卡那霉素壮观霉素链霉素硫链丝菌素红霉素阿泊拉霉素紫霉素萘锭酮酸 TMP Ampicillin, Amp bla Chloramphenicol, Cml Hygromycin, Hyg Kanamycin, Km Spectinomycin, Spc Streptomycin, Str Thiostrepton, Thio Erythomycin, Ery Apramycin, Am Viomycin,Vio Nalidixic acid Trimethoprim cat hyg aac/aph aadA str tsr ermE aac(3)IV vph -* 10 10 2 5 10 5 100 10 -- 25 25 20 25 10 - 50 ------ 2.5 - 5 50-100 25 - 25 50 25 25 20 10-30 注意事项: (1) –表示无记录或不能使用,贮存液除特别说明外均用无菌水配制,配制过程请 确保抗生素粉末充分溶解混匀后再分装; (2)Km 和Am有交叉抗性,同时具有这两种抗性基因时应适当提高抗生素的量,并 设置阴性对照; (3)Hyg、Vio易见光分解,配制好后应用锡箔纸包好,使用过程中建议避光操作。有些抗生素需要在低盐的环境(如DNA培养基)下筛选效率较高,如Hyg, Km, Vio (4)用无菌水配制的抗生素需在超净工作台内用0.22 μm一次性过滤器过滤除菌并 分装;氯霉素、TMP、硫链丝菌素可以在超净工作台外配制分装,无需过滤除菌,但需确 保配制贮存液所用溶剂(无水乙醇、DMSO)未遭受污染,建议配制氯霉素时使用新的无水 乙醇,不要使用抽提质粒或总DNA时用的无水乙醇,以防止污染;DMSO,即二甲亚砜,易 挥发,有剧毒; (5)长期不用的抗生素请置于-20℃保存,抗生素粉末按照使用说明一般置于4℃保存,经常使用时可以暂置于4℃保存; (6)抗生素的实际使用浓度请结合实验经验进行适当调整; (7)配制抗生素时应尽量一次性称取抗生素粉末,配制过程中建议穿工作服,戴一次 性橡胶手套及口罩,及时清理称量配制抗生素时使用的台面及器具,以避免抗生素及溶剂 对自身的损伤及对工作环境的污染。 注意事项: (1)表中所列酶均可以用无菌水配制,也可以用相应的缓冲液配制,缓冲液配制方法 参考《分子克隆实验指南(第3版)》: 蛋白酶 K缓冲液:50 mM Tris(pH 8.0),1.5 mM 乙酸钙; RNase A缓冲液:TE (pH 7.6):10 mM Tris-HCl,1 mM EDTA;溶菌酶缓冲液:10 mM Tris-HCl(pH 8.0); (2) RNase A配制好后沸水浴处理5 min,取出贮存RNase A后首次使用时也需沸水 浴处理5 min后再使用; (3)制备原生质体时使用的溶菌酶配制时需过滤除菌,其他情况一般无需过滤除菌; (4)所有酶均应在-20℃保存,使用过程中避免反复冻融,配制过程中尽量避免外界 污染。 (1)IPTG用无菌水配制,0.22μm一次性滤膜过滤除菌,分装保存于-20℃; 《编译原理》 实验报告 姓名:余同庆 班级:软件1005班 学号: 3902100509 日期: 2012-6-7 中南大学软件学院 2012年06月 第一部分词法分析 词法分析程序设计与实现 一、实验目的 加深对词法分析器的工作过程的理解;加强对词法分析方法的掌握;能够采用一种编程语言实现简单的词法分析程序;能够使用自己编写的分析程序对简单的程序段进行词法分析。 二、实验内容 自定义一种程序设计语言,或者选择已有的一种高级语言,编制它的词法分析程序。词法分析程序的实现可以采用任何一种编程语言和编程工具。 从输入的源程序中,识别出各个具有独立意义的单词,即关键字、标识符、常数、运算符、界符。并依次输出各个单词的内部编码及单词符号自身值。(遇到错误时可显示“Error”,然后跳过错误部分继续显示) 三、实验要求 1.对单词的构词规则有明确的定义; 2.编写的分析程序能够正确识别源程序中的单词符号; 3.识别出的单词以<种别码,值>的形式保存在符号表中,正确设计和维护 符号表; 4.对于源程序中的词法错误,能够做出简单的错误处理,给出简单的错误 提示,保证顺利完成整个源程序的词法分析; 四、程序设计思路 这里以开始定义的C语言子集的源程序作为词法分析程序的输入数据。在词法分析中,自文件头开始扫描源程序字符,一旦发现符合“单词”定义的源程序字符串时,将它翻译成固定长度的单词内部表示,并查、填适当的信息表。经过词法分析后,源程序字符串(源程序的外部表示)被翻译成具有等长信息的单词串(源程序的内部表示),并产生两个表格:常数表和标识符表,它们分别包含了源程序中的所有常数和所有标识符。 1.定义部分:定义常量、变量、数据结构。 2.初始化:从文件将源程序全部输入到字符缓冲区中。 3.取单词前:去掉多余空白。 4.取单词:利用实验一的成果读出单词的每一个字符,组成单词,分析类 Java语言学习笔记 1、java基础语法 1.1组成元素: 1.1-1标识符: (1)作用:起名字,变量、方法、源文件, (2)标识符规则:只能由字母、数字、_、$组成,数字不能打头,java 支持汉字,不推荐使用汉字,尽量见名知意,java严格区分大小写 1.1-2关键字:也叫保留字,系统保留的标示符,系统赋予关键字特殊的语法含义,我们不能将关键字当做普通的标示符使用,只能使用系统赋予的语法编程 1.1-3数据类型: (1)作用: ①、对变量类型严格控制; ②、对不同类型变量内存空间进行分配 (2)基本类型: ①、整数类型: a、byte占8位,[-128,127] b、short占16位,[-2^15,2^15-1] c、int占32位,[-2^31,2^31-1] d、java中整数默认是int类型,如果一个整数超过了int的范围则需要在其后加L(l)将int数据转换为long e、long占64位,[-2^63,2^63-1] f、int a = 5; java中整数支持2进制,8进制和16进制 a、2进制整数用0b开头 b、8进制整数用0开头 c、16进制整数用0x开头 d、0x11~~16= a,b,c,d,e,f ②、小数类型:也叫浮点型 a、浮点型数据有精度的区分 float:单精度浮点型,精确位数为6到8位,小数点不占位数。 double:双精度浮点型,精确位数为14到16位。 java中小数默认是double类型,所以必须在使用float时需要在数据后加F(f)将double转换成float类型。 ③、字符类型: java采用的是unicode编码方式,使用两个字节对所有字符进行编码范围为[0,65535] (字符编码有:ascii、gbk、gb2312、gb18030、big5、iso-8859-1) char表示单个字符,使用 ' ' 括起来,汉字也是字符 转义字符:\; \\:表示\ ;\t:表示tab;\r:表示回车;\n:表示换行。 windows中enter键就是\r\n表示回车换行,linux中使用\n表示换行 (3)引用类型: ①、类(后面会补充) ②、接口(后面会补充) 实验二语法分析器 一、实验目的 通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练学生掌握开发应用程序的基本方法。有利于提高学生的专业素质,为培养适应社会多方面需要的能力。 二、实验内容 ◆根据某一文法编制调试LL (1 )分析程序,以便对任意输入的符号串 进行分析。 ◆构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分 析程序。 ◆分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号 以及LL(1)分析表,对输入符号串自上而下的分析过程。 三、LL(1)分析法实验设计思想及算法 ◆模块结构: (1)定义部分:定义常量、变量、数据结构。 (2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等); (3)控制部分:从键盘输入一个表达式符号串; (4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。 四、实验要求 1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。 2、如果遇到错误的表达式,应输出错误提示信息。 3、对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG (2)G->+TG|—TG (3)G->ε (4)T->FS (5)S->*FS|/FS (6)S->ε (7)F->(E) (8)F->i 输出的格式如下: 五、实验源程序 LL1.java import java.awt.*; import java.awt.event.*; import javax.swing.*; import javax.swing.table.DefaultTableModel; import java.sql.*; import java.util.Vector; public class LL1 extends JFrame implements ActionListener { /** * */ private static final long serialVersionUID = 1L; JTextField tf1; JTextField tf2; JLabel l; JButton b0; JPanel p1,p2,p3; JTextArea t1,t2,t3; JButton b1,b2,b3; 昆明理工大学信息工程与自动化学院学生实验报告 (2011 —2012 学年第 1 学期) 课程名称:编译原理开课实验室: 445 2011年 12 月 19日年级、专业、 班 计科093 学号200910405310 姓名孙浩川成绩 实验项目名称语法分析器指导教师严馨 教 师评语 该同学是否了解实验原理: A.了解□ B.基本了解□ C.不了解□ 该同学的实验能力: A.强□ B.中等□ C.差□ 该同学的实验是否达到要求: A.达到□ B.基本达到□ C.未达到□ 实验报告是否规范: A.规范□ B.基本规范□ C.不规范□ 实验过程是否详细记录: A.详细□ B.一般□ C.没有□ 教师签名: 年月日 一、实验目的及内容 实验目的:编制一个语法分析程序,实现对词法分析程序所提供的单词序列进行语法检 查和结构分析。 实验内容:在上机(一)词法分析的基础上,采用递归子程序法或其他适合的语法分析方法,实现其语法分析程序。要求编译后能检查出语法错误。 已知待分析的C语言子集的语法,用EBNF表示如下: <程序>→main()<语句块> <语句块> →‘{’<语句串>‘}’ <语句串> → <语句> {; <语句> }; <语句> → <赋值语句> |<条件语句>|<循环语句> <赋值语句>→ID=<表达式> <条件语句>→if‘(‘条件’)’<语句块> <循环语句>→while’(‘<条件>’)‘<语句块> <条件> → <表达式><关系运算符> <表达式> <表达式> →<项>{+<项>|-<项>} <项> → <因子> {* <因子> |/ <因子>} <因子> →ID|NUM| ‘(’<表达式>‘)’ <关系运算符> →<|<=|>|>=|==|!= 二、实验原理及基本技术路线图(方框原理图或程序流程图) 1、以下为一个名为的文件,要使其编译和运行,在屏幕上显示“你好” 。哪句有错误? { ① ([] ){ ② ("你好"); ③ } } A.①有错 B.②有错 C.③有错 D.没有错 2、源文件和编译后的文件扩展名分别为 A、和 B、和 C、和 D、和 3. 下列正确编写入口点语句的是 A. ([] ) B. ([] ) C. ([] ) D. ([] ) 4、下列声明变量方式正确的是 A. 1 12345; B. 12 154; C. ’’; D. 0; 5、下列程序能正确执行的是 A. { ([] ) { (“!”); } } B. { ([] ) { (“!”) } } C. { ([] ) { (“!”); } } D. { ([] ); { (“!”); } } 6、新建一个文件存放在E盘文件夹,下列语法在命令模式中正 确是 A.切换源文件所在目录: \d B.用命令编译源文件: C.在命令模式下命令执行时生成文件 D.运行程序: 7、以下变量名合法的是 A. B. 2 C. D. 8、下列对数组进行初始化错误的是: A.[] {1,2,3,4,5}; B.[] []{1,2,3,4,5}; C.[] [5]; D.[] [5]{1,2,3,4,5}; 9、下列程序存在语法错误的是 A. 0; (<10;){ ; (i); } B. ( 0<10); (i); (;;){ (i); } C. ( 0<10) (i); D. 0; 10、下列代码执行的结果是: ( 0<10){ (20){ ; (i); } ("a"); 实验室药品的取用和溶液的配制 1 固体试剂的取用规则 (1)要用干净的药勺取用。用过的药勺必须洗净和擦干后才能再使用,以免沾污试剂。 (2)取用试剂后立即盖紧瓶盖。 (3)称量固体试剂时,必须注意不要取多,取多的药品,不能倒回原瓶。 2 液体试剂的取用规则 (1)从滴瓶中取液体试剂时,要用滴瓶中的滴管,滴管绝不能伸入所用的容器中,以免接触器壁而沾污药品。从试剂瓶中取少量液体试剂时,则需要专用滴管。装有药品的滴管不得横置或滴管口向上斜放,以免液体滴入滴管的胶皮帽中。 (2)使用胶头滴管“四不能”:不能伸入和接触容器内壁,不能平放和倒拿,不能随意放置,未清洗的滴管不能吸取别的试剂。 (3)配制一定物质的量溶液时,溶解或稀释后溶液应冷却再移入容量瓶。 (4)配制一定物质的量浓度溶液,要引流时,玻璃棒的上面不能靠在容量瓶口,而下端则应靠在容量瓶刻度线下的内壁上(即下靠上不靠,下端靠线下)。 (5)容量瓶不能长期存放溶液,更不能作为反应容器,也不能互用。(一般用于配制标准溶液的容量瓶最好专用) 3 溶液的配制 (1)配制溶质质量分数一定的溶液 计算:算出所需溶质和水的质量。把水的质量换算成体积。如溶质是液体时,要算出液体的体积。 称量:用天平称取固体溶质的质量;用量筒量取所需液体、水的体积。 溶解:将固体或液体溶质倒入烧杯里,加入所需的水,用玻璃棒搅拌使溶质完全溶解。(2)配制一定物质的量浓度的溶液 计算:算出固体溶质的质量或液体溶质的体积。 称量:用托盘天平称取固体溶质质量,用量筒量取所需液体溶质的体积。 溶解:将固体或液体溶质倒入烧杯中,加入适量的蒸馏水用玻璃棒搅拌使之溶解,冷却到室温后,将溶液引流注入容量瓶里。 转移:用适量蒸馏水将烧杯及玻璃棒洗涤2-3 次,将洗涤液注入容量瓶,振荡,使溶液混合均匀。 编译原理语法分析器实验报告 西安邮电大学 编译原理实验报告 学院名称:计算机学院 学生姓名:高宏伟 实验名称:语法分析器的设计与实现班级:计科1405班学号:04141152 时间:2017年5月12日 把SELECT (i)存放到temp中结果返回1; 1.构建好的预测分析表 2.语法分析流程图 一.实验结果 正确运行结果: 错误运行结果: 二.设计技巧和心得体会 这次实验编写了一个语法分析方法的程序,但是在LL(1)分析器的编写中我只达到了最低要求,就是自己手动输入的select集,first集,follow集然后通过程序将预测分析表构造出来,然后自己编写总控程序根据分析表进行分析。 通过本次试验,我能够设计一个简单的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。 还能选择最有代表性的语法分析方法,如LL(1) 语法分析程序、算符优先分析 程序和LR分析分析程序。 三.源代码 package com.LL1; import java.util.ArrayDeque; import java.util.Deque; /** * LL1文法分析器,已经构建好预测分析表,采用Deque实现 * Created by HongWeiPC on 2017/5/12. */ public class LL1_Deque { //预测分析表 private String[][] analysisTable = new String[][]{ {"TE'", "", "", "TE'", "", ""}, {"", "+TE'", "", "", "ε", "ε"}, {"FT'", "", "", "FT'", "", ""}, {"", "ε", "*FT'", "", "ε", "ε"}, {"i", "", "", "(E)", "", ""} }; //终结符 private String[] VT = new String[]{"i", "+", "*", "(", ")", "#"}; //非终结符 private String[] VN = new String[]{"E", "E'", "T", "T'", "F"}; //输入串strToken private StringBuilder strToken = new StringBuilder("i*i+i"); //分析栈stack private Deque常用实验试剂配制
Java基础语法考试题
编译原理词法分析和语法分析报告 代码(C语言版)
编译原理实验三-自下而上语法分析及语义分析.docx
编译原理-语法分析-算符优先文法分析器
编译原理语法分析器实验
实验室常用生化试剂配方
编译原理实验报告
Java基础学习(基础语法)
编译原理 语法分析器 (java完美运行版)
昆明理工大学 编译原理 实验二 语法分析器
Java基础语法测试题(1)---答案
实验室药品的取用和溶液的配制
编译原理语法分析器实验报告
相关主题
文本预览