第七节计数数据统计分析的SPSS操作
对于计数数据的统计分析,SPSS提供了不同的分析和检验方法,从总体上来说,大致可以分为:用于比率差异的非参数二项检验,用于离散型变量配合度检验的卡方检验、用于连续型变量配合度检验的单样本K-S检验和正态图检验法和用于独立性检验的列联表分析等,这一节我们简单介绍如何通过SPSS操作解决这些常见的计数数据分析的统计问题。
一、二项分布的非参数检验方法
我们常常需要检验一个事件在特定条件下发生的概率是否与已知结论相同,如某地区出生婴儿的性别比例是否与通常男女各半的结论相符,或在一次抽样中,男女两性所占的比例是否与原先设计好的比例相符。此时即可用二项分布(Binomial)方法进行检验。下面结合具体数据说明Binomial方法在检验比率差异时的应用。
1.数据
所用数据文件为SPSS目录下之GSS93 subset.sav。这里我们将该数据文件另寸为“8-6-1.sav”。该文件中有一变量SEX,是回答者的性别,我们想检验这些回答者的性别是否各占一半。
2.理论分析
从上面数据来看,我们的目的是检验数据中男生和女生所占的比例是否相等,这等价于检验男生所占的比例是否等于0.5,可以用比例检验的方法进行检验。在SPSS中对应于二项分布的检验(Binomial Test)过程。
3.二项分布检验过程
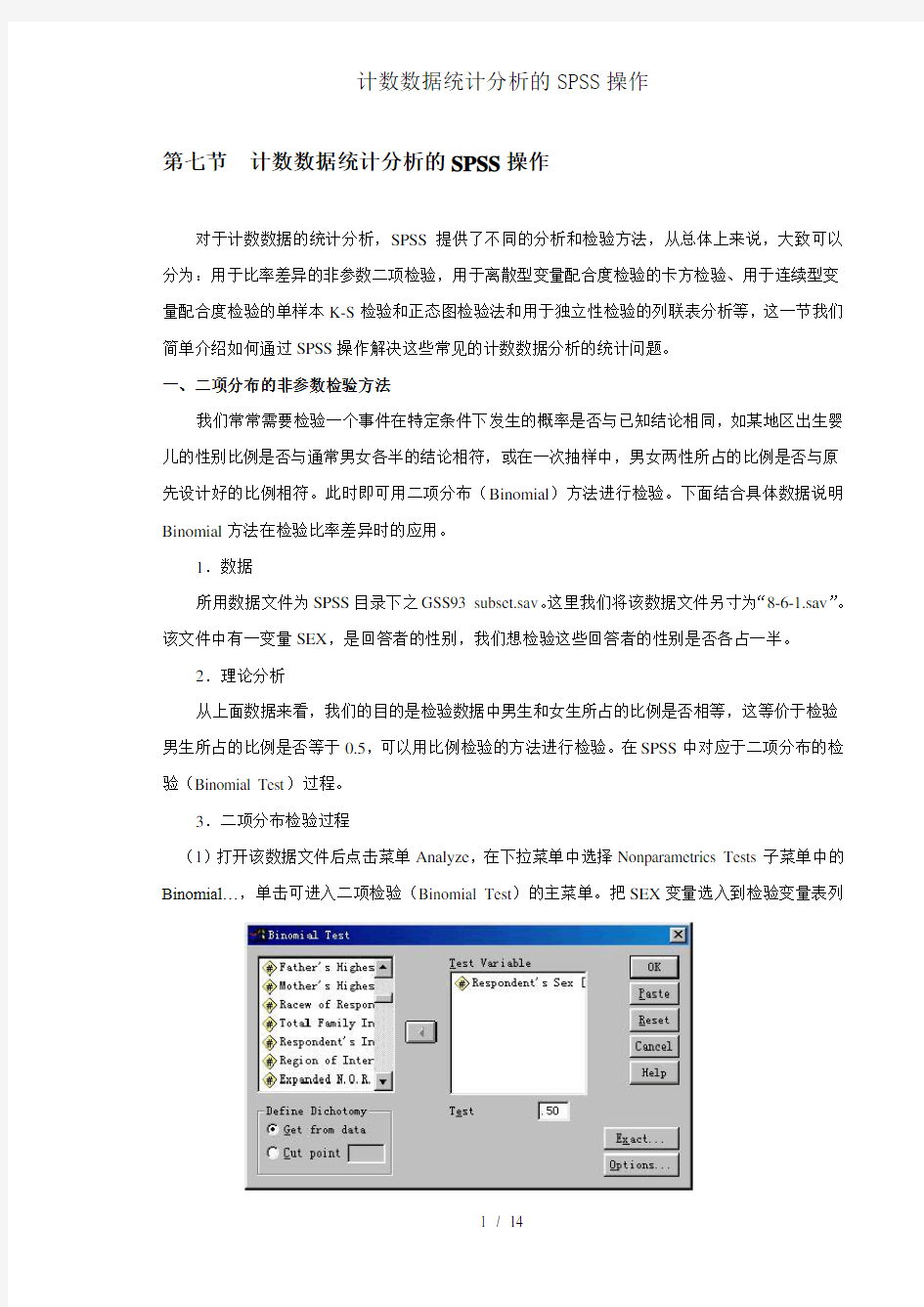
(1)打开该数据文件后点击菜单Analyze,在下拉菜单中选择Nonparametrics Tests子菜单中的Binomial…,单击可进入二项检验(Binomial Test)的主菜单。把SEX变量选入到检验变量表列
中,其他选项请保持默认(图8-1)。
图8-1:二项分布检验主对话框
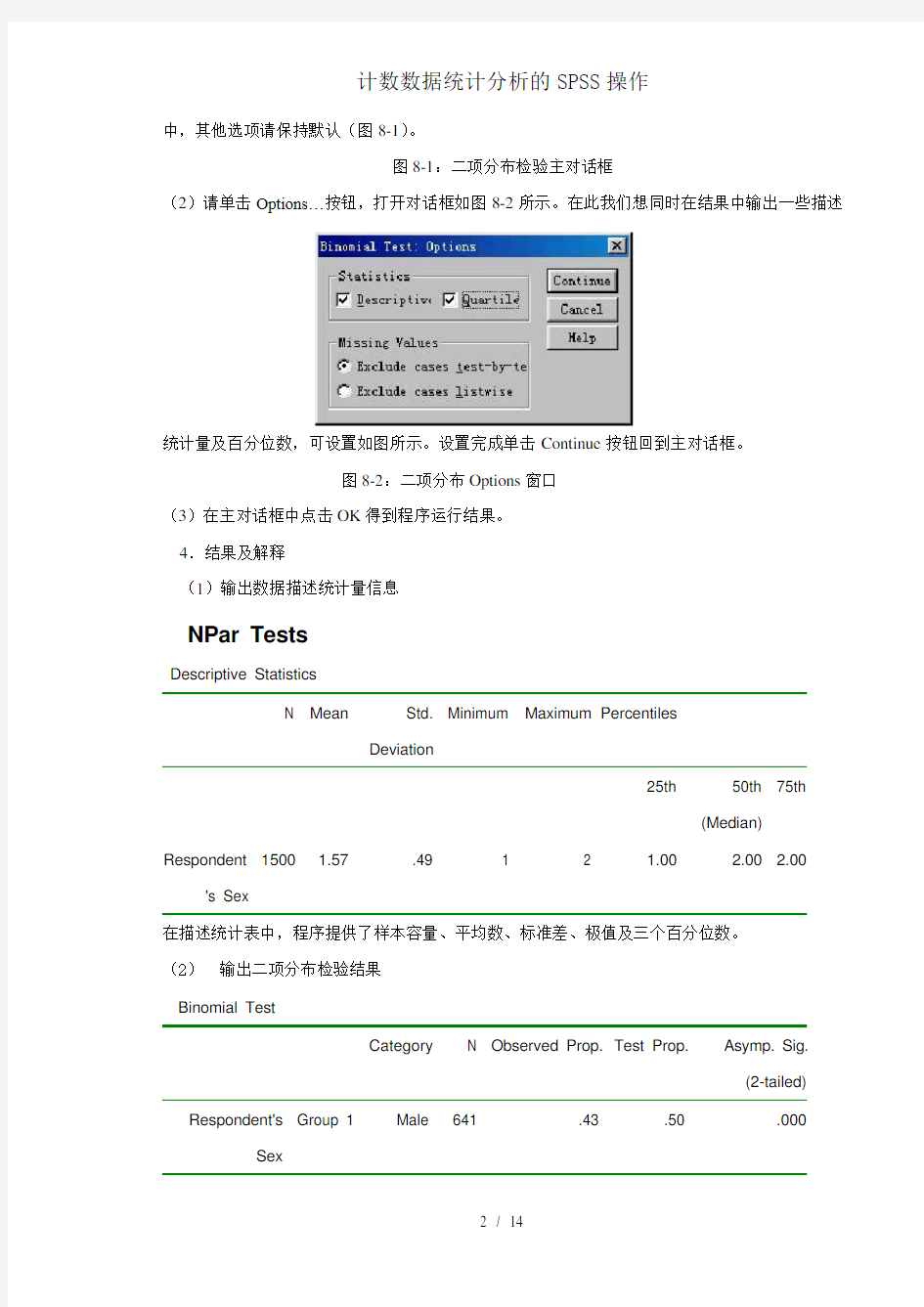
(2)请单击Options…按钮,打开对话框如图8-2所示。在此我们想同时在结果中输出一些描述
统计量及百分位数,可设置如图所示。设置完成单击Continue 按钮回到主对话框。 图8-2:二项分布Options 窗口 (3)在主对话框中点击OK 得到程序运行结果。 4.结果及解释
(1)输出数据描述统计量信息 NPar Tests Descriptive Statistics
N
Mean
Std. Deviation
Minimum Maximum Percentiles
25th
50th (Median)
75th Respondent 's Sex
1500
1.57
.49
1
2
1.00
2.00 2.00
在描述统计表中,程序提供了样本容量、平均数、标准差、极值及三个百分位数。 (2) 输出二项分布检验结果 Binomial Test
Category
N Observed Prop. Test Prop.
Asymp. Sig. (2-tailed)
Respondent's Sex
Group 1
Male
641
.43
.50
.000
Group 2 Female 859 .57
Total 1500 1.00
a Based on Z Approximation.
在Binomial Test表中,所检验变量的有关信息,如男女两性的数目及比例,最后一项是双侧检验的显著性水平值。本例数据检验结果表明:男生组的人数641,在总人数中所占的比例为0.43,假设的总体比例为0.5,双侧检验的显著性小于.05,所以我们可以说男女两性回答者比例相同的假设不能成立,从表中可以看出,女性被试远多于男性被试(女生人数859人,所占比例0.57)。5.非对称二项分布的检验
也可以用该程序来检验样本数据分布是否来自非对称分布的二项总体。以刚才我们用过的数据为例,假如在调查设计时,调查者想控制被试性别比例(男:女)为4:6,在调查结束后分析数据资料中的性别比例是否与原先所设想的一致。操作如下:打开Binomial对话框,设置如下图8-3所示(指定检验的概率值为0.40):
图8-3:非对称二项分布比率定义
用户可以自行检验程序运行的结果。
如果用户指定分析的变量中含有三个或更多的变量值,在定义二分值时,需要选择Cut point 项,并在后面的方框中填入一个分界点,该分界点必须小于最大变量值,大于最小变量值。小于或等于分界点的值形成第一项,大于分界点的值将形成第二项。此时请注意如果指定检验概率值,它所对应的将是第一项的概率值。请用户自行检验该程序。
二、配合度的检验
(一)、离散变量配合度检验——单样本2检验
这种方法可用于离散型变量的配合度检验,分析实际频数与理论频数是否一致。它要求至少有一个变量,变量值为几个固定值,即一个因素多项分类的情况。
1.数据
采用SPSS文件夹中的CARS.SA V数据为例,具体说明这一方法的应用。CARS.SA V数据文件中有一变量为origin,变量值为1、2、3三个整数,分别代表三个地区,这三个整数出现的总次数是405。我们现在欲检验这三个地区所出现的频率是否与预期的270、65、70一致。将该数据文件另存为“8-6-2.sav”。
2.理论分析
从上面数据来看,我们的主要目的是检验三个地区的实际观测频率与理论假设的270、65、70是否存在差异,属于离散变量配合度检验的问题,应用卡方检验。
3.单样本2检验过程和结果
(1)请单击主菜单Analyze / Nonparametric Tests / Chi-S quare…,可进入单样本2检验的主对话框。从左边变量表列中把指定分析的地区变量选入到右边检验变量表中去,在下面Expected values 中选择Values一项,并分别把理论次数填入到小方框中,并点击Add按钮完成设置。如果我们欲检验的理论次数各组相等,则可以直接选择All categories eaqual项即可。在Expected range项中保持默认选择项即Get from data。如果我们只想使用一部分按大小顺序排列的数据来进行分析,就可以选择Use specified range,并指定数据的下限与上限。本例设置如下图11-1所示:
图11-1
(2)E xact…按钮可以保持默认选项。Options…按钮允许用户指定输出结果是否包括描述性统计量,以及对缺失值的处理方法。因与前面所讲述的用法相同,在此不再赘述。点击Continue返回主对话框。
(3)在主对话框中点击OK,得到输出结果。
4.结果及解释
(1)描述统计量表列出了变量名、样本容量、平均数、标准差、最小值、最大值。
Descriptive Statistics
N Mean Std. Deviation Minimum Maximum
Country of Origin 405 1.57 .80 1 3
(2)实际观测数与理论次数对照表列出了每个变量值的实际频数与理论次数及差值。
Country of Origin
Observed N Expected N Residual
American 253 270.0 -17.0
European 73 65.0 8.0
Japanese 79 70.0 9.0
Total 405
本例中,美国(American)实际观测次数253人,理论期望次数270人,实际观测次数与理论次数的差异为-17;欧洲(European)实际观测次数73人,理论期望次数65人,实际观测次数与理论次数的差异为8;日本(Japanese)实际观测次数79人,理论期望次数70人,实际观测次数与理论次数的差异为9。
(3)2检验表列出了2值,自由度及显著性水平值。在这种基于渐近分布的检验方法中,显著性水平小于0.05 即可认为实际次数与理论次数差异显著,否则差异不显著。
Test Statistics a
Country of Origin
Chi-Square 3.212
df 2
Asymp. Sig. .201
a 0 cells (.0%) have expected frequencies less than 5. The minimum expected cell frequency is 65.0.
在本例中,对应的卡方统计量的值为3.212(2=3.212),对应的自由度为2(df=2),显著性水平值为0.201>0.05,故可认为实际次数与理论次数无差异。
(二).连续型变量的配合度检验——正态分布的检验
有时在执行统计分析前,需要确定样本是否来自一个正态分布的总体。在此我们介绍一种非参数检验的方法及相应的图形检验法。
1.单样本的K-S检验
(1)数据我们仍以SPSS目录下的数据文件GSS93 subset.sav(或盘中文件8-6-1.sav)为例,我们欲检验educ变量值是否来自正态分布的总体。
(2)变量受教育程度可以看成是一个连续型的变量,要检验其分布是否为正态分布属于配合度检验的问题,可以用单样本的K-S检验。
(3)操作过程
①单击主菜单Analyze/Nonparametrics Test / 1-Sample K-S…,进入主对话框,请设置如下图8-4
所示:
图8-4: 单样本的柯尔莫哥洛夫—斯米诺夫检验主对话框程序所能检验的四种分布:Normal(正态分布)、Uniform(均匀分布)、Poisson(普阿松分布)和Exponedtial(指数分布)。
②单击Exact…可进入选择检验方法的对话框,如下图8-5所示:
图8-5:K—S检验的Exact选项
Asymptotic only 是一种基于渐近分布的显著性水平的检验指标,通常显著性水平小于0.05则认为显著,适于大样本,如果样本过小或分布不好,该指标的适用性会降低。
Monte Carlo 精确显著性水平的无偏估计,适用于样本过大无法使用渐近方法估计显著性水平的情况,可以不必依赖渐近方法的假设前提。
Exact 精确计算观测结果的概率值,通常小于0.05即被认为显著,表明行变量与列变量之间存在相关。同时允许用户键入每次检验的最长时间限制,可以键入1到9,999,999,999之间的数字,但只要一次检验超过指定时间的30分钟,就应该使用Monte Carlo方法。
注:只要有可能,程序会提供显著性水平的精确值,而不是Monte Carlo估计值。
③单击Options按钮可以进入对话框。选择是否输出描述统计量和百分位数,以及以缺失值的处理,由于与以前所用过的程序相差无几,所以在此不赘述。
④在主对话框点击OK得到程序执行结果。
(4)结果及解释
①描述统计量信息
Descriptive Statistics
N Mean Std.
Minimum Maximum Percentiles
Deviation
75th
25th 50th
(Median) Highest Year
1496 13.04 3.07 0 20 12.00 12.00 15.75 of School
Completed
描述统计量表列指定检验变量的标签、样本容量、平均数、标准差、最大值、最小值及三个百分位数。
②单样本的K-S检验结果
One-Sample Kolmogorov-Smirnov Test
Highest Year of School Completed
N 1496 Normal Parameters Mean 13.04
Std. Deviation 3.07 Most Extreme Differences Absolute .163
Positive .134
Negative -.163 Kolmogorov-Smirnov Z 6.317 Asymp. Sig. (2-tailed) .000
a Test distribution is Normal.
b Calculated from data.
上表中输出了指定检验变量的正态参数,包括平均数与标准差,极端差的最大绝对值、正值及负值,K-S Z值,双侧检验的显著性水平。由于渐近方法所检验的显著性水平小于0.05,所以变量educ的值并非来自一个正态分布的总体。
2.检验正态分布的图形
(1)Q-Q正态检验图
为了更形象地说明这一种结果,我们还将介绍一种图形检验方法。仍以K-S检验所用数据文件和分析变量为例。
Q-Q正态检验图的操作过程如下:单击主菜单Graphs/Q-Q…,请保持对话框如下图8-6所示的设置(即把欲检验的变量选入到指定变量表列中去,在Test Distribution选项中选择Normal 即正态分布检验,其他设置保持默认):
图8-6:Q-Q图定义窗口
单击完成后输出两个统计图如下所示。图8-7为正态分布Q-Q检验图,横坐标为实际观测值按从小到大的顺序排列,纵坐标为正态分布下的期望值。如果实际观测值取自正态分布的总体,那么图中所示的落点应该分布在趋势线的附近,并且应该表现出一定的集中趋势,即平均数附近应该聚集较多的落点,越靠近两个极端落点越少。现在图中落点的分布尽管呈现出线性状态,但由于没有表现出集中趋势,所以可以判断它并非正态分布或接近正态分布。
E x p e c t e d N o r m a l V a l u e
图8-7:正态分布Q-Q 检验图
D e v i a t i o n f r o m N o r m a l
图8-8为无趋势正态检验图
图8-8为无趋势正态检验图,它以实际观测值为横坐标,以实际观测值与期望值的差为纵坐标。在符合正态分布的情况下,图中的落点应该分布在中央横线的附近,甚至完全落到这条横线上,而且也应表现出集中在平均数周围的趋势。现在图中所示的落点分布离散性较大,不符合正态分布标准,所以我们可以说该样本属非正态分布。从这个图中,我们还可以发现极端值的存在,例如图中离中央线最远的几个落点,都落在下方,表明样本数据中存在极端小的观测值,这时,需要检查数据录入是否有误。如果变量分布明显地呈现非正态,在进行一些要求正态分布前提下的分析以前,应当考虑对数据进行必要的变换。 (2)P-P 正态检验图
单击主菜单Graphs/P-P…,进入主对话框。设置与Q-Q 程序相同,它的输出图形也与Q-Q 极相似,唯一不同之处在于图形的横纵坐标都变成了累加百分比,横坐标为实际观测值的累加百分比,纵坐标为假定正态分布下有累加百分比。是否接近正态分布的判断标准与Q-Q 输出图相同。
三.独立性检验——列联表分析
列联表分析可以为我们提供每类的实际观测值、理论值、所占百分比、及差异检验结果。
1.数据
仍以SPSS文件夹中的数据文件GSS93 subset.sav(或盘中文件“”8-6-1.sav)为例,在此数据中,有两个变量为income4(家庭年收入)与degree(学历)。这两个变量都是按人为标准划分的定性变量(用户可以双击变量名,并在Labels按钮中看到变量值及其标签说明)。现在我们想知道这两个变量之间是否存在关联,也就是说学历是否在年收入的不同分类上存在差异,反之亦然。
2.理论分析
如果要研究的两个变量都具有两项或更多的分类值,如体育项目的划分、人种的划分,或只是研究者按一定的标准分为不同的类别,如优、良、中、差,这种定性数据(或计数数据)之间关系(是指一个变量的不同分类在另一变量分类上是否存在差异,或者说两个变量是否相互关联)的研究通常使用列联表分析。在分析过程中由于主要根据2分布进行,所以又常称其为2检验。
3.操作过程
(1)单击主菜单Analyze / Descriptive Statistics / Crosstabs…可进入列联表分析的主对话框。从左边变量表列中把指定分析的两个变量degree与income4分别选到到右边Row与Column框中,如图8-9所示:
图8-9:Crosstabs…主对话窗口
(2)为了检验两个变量是否关联,我们需要对其进行检验。这一步可以通过Statistics按钮
进行。单击该按扭可进入其设置对话框。一般我们都需要输出2值及其检验结果,同时,在Nominal组中,我们还发现可以选择列联相关系数C,即Contingency coefficient,这是检验R×C 表品质相关常用的一个指标。完成设置如下图8-10所示:
图8-10:Crosstabs…统计量输出选择窗口
(3)SPSS在列联表时,允许用户自己控制表中的输出内容。该项设置可以单击主菜单中Cells 按钮来进行。打开它的对话框如图8-11所示,可以看到共有三组可选项,下面具体说明:·Counts 次数
Observed 实际观测频数
Expected 理论次数
·Percentages 百分比
Row 横行次数百分比
Column 纵列次数百分比
Total 总共
·Resduals残差
Unstandardized 残差,实际次数与理论次数之差。
Standardized 标准化残差,残差除以其标准误,又称Pearson残差,其均值为0,准差为1。
Adj. Standardized 调整标准化残差
图8-11:Crosstabs…单元格输出选择窗口
点击Continue,返回主对话框。
(4)在主对话框中点击OK,得到程序运行结果。
4.结果及解释
(1)文件中观测量的概括描述列出了有效观测量、缺失值及全部观测量的个数和百分比。Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent INCOME4 Total Family Income
* DEGREE RS Highest Degree
1496 99.7% 4 .3% 1500 100.0%
上表显示,总的观测为1500个,有效样本1496个,占99。7%,缺失值4个,占0。3%。
(2)R C表表中列出了两个变量每项分类,由用户指定输出的内容,如实际次数与理论次数。INCOME4 Total Family Income * DEGREE RS Highest Degree Crosstabulation
DEGREE RS Highest Degree Total
0 Less than HS 1 High
school
2 Junior
college
3
Bachelor
4
Graduate
INCOME4
Total
Family
Income
1.00
24,999 or
less
Count 196 315 25 39 9 584
Expected
Count
108.9 304.5 35.1 91.3 44.1 584.0
2.00
25,000 to
39,999
Count 28 175 21 58 18 300
Expected
Count
55.9 156.4 18.0 46.9 22.7 300.0
3.00
40,000 to
59,999
Count 16 121 23 52 18 230
Expected
Count
42.9 119.9 13.8 36.0 17.4 230.0
4.00
60,000 or
more
Count 39 169 21 85 68 382
Expected
Count
71.2 199.2 23.0 59.8 28.9 382.0
Total Count 279 78 96
Expected
Count
279.0 780.0 90.0 234.0 113.0 1496.0
(3)2检验表列出了三种2值及其显著性水平,若显著性水平小于临界值如0.05 ,则表明两变量互相关联,但不反映两变量的关联强度及方向。在表的下方还附有单元格的理论次数小于5的个数及百分比,以及单元格的最小理论次数。已有研究者建议当最小理论次数小于1或超过20%的单元格的理论次数小于5的时候不应选择该项,也有研究者建议所有单元格的理论次数都应大于或等于5。为了达到这样的要求,在条件不具备的时候应该考虑对分类项目进行合并处理。
Chi-Square Tests
Value df Asymp. Sig. (2-sided)
Pearson Chi-Square 264.299 12 .000
Likelihood Ratio 266.638 12 .000
Linear-by-Linear Association 194.175 1 .000
N of Valid Cases 1496
a 0 cells (.0%) have expected count less than 5. The minimum expected count is 13.84.
本例中数据检验结果表明:3个统计量的值检验结果都达到了显著水平,说明检验的两个变量之间存在显著的关联。
(4)两变量的相关系数表列出了名义变量间的品质相关系数及显著性水平。
Symmetric Measures
Value Approx. Sig.
Nominal by Nominal Contingency Coefficient .387 .000
N of Valid Cases 1496
a Not assuming the null hypothesis.
b Using the asymptoti
c standar
d error assuming th
e null hypothesis.
在此C=0.387,虽然相关不是很高,但检验结果表明足以达到相关的显著性水平。
学生姓名:肖浩鑫学号:31407371 一、实验项目名称:实验报告(三) 二、实验目的和要求 (一)变量间关系的度量:包括绘制散点图,相关系数计算及显著性检验; (二)一元线性回归:包括一元线性回归模型及参数的最小二乘估计,回归方程的评价及显著性检验,利用回归方程进行估计和预测; (三)多元线性回归:包括多元线性回归模型及参数的最小二乘估计,回归方程的评价及显著性检验等,多重共线性问题与自变量选择,哑变量回归; 三、实验内容 企业编号产量(台)生产费用(万元)企业编号产量(台)生产费用(万元) 1 40 130 7 84 165 2 42 150 8 100 170 3 50 155 9 116 167 4 5 5 140 10 125 180 5 65 150 11 130 175 6 78 154 12 140 185 (1)绘制产量与生产费用的散点图,判断二者之间的关系形态。 (2)计算产量与生产费用之间的线性相关系数,并对相关系数的显著性进行检验(),并说明二者之间的关系强度。 地区人均GDP(元)人均消费水平(元) 北京22460 7326 辽宁11226 4490 上海34547 11546 江西4851 2396 河南5444 2208 贵州2662 1608 陕西4549 2035
(1)绘制散点图,并计算相关系数,说明二者之间的关系。 (2)人均GDP作自变量,人均消费水平作因变量,利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。 (3)计算判定系数和估计标准误差,并解释其意义。 (4)检验回归方程线性关系的显著性() (5)如果某地区的人均GDP为5000元,预测其人均消费水平。 (6)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 航空公司编号航班正点率(%)投诉次数(次) 1 81.8 21 2 76.6 58 3 76.6 85 4 75.7 68 5 73.8 74 6 72.2 93 7 71.2 72 8 70.8 122 9 91.4 18 10 68.5 125 (1)用航班正点率作自变量,顾客投诉次数作因变量,估计回归方程,并解释回归系数的意义。(2)检验回归系数的显著性()。 (3)如果航班正点率为80%,估计顾客的投诉次数。 4. 某汽车生产商欲了解广告费用(x)对销售量(y)的影响,收集了过去12年的有关数据。通过计算得到下面的有关结果: 方差分析表 变差来源df SS MS F Significance F 回归 2.17E-09 残差40158.07 —— 总计11 1642866.67 ——— 参数估计表 Coefficients 标准误差t Stat P-value Intercept 363.6891 62.45529 5.823191 0.000168 X Variable 1 1.420211 0.071091 19.97749 2.17E-09 (1)完成上面的方差分析表。 (2)汽车销售量的变差中有多少是由于广告费用的变动引起的?
Gender Educational Level (years)N Valid 474474Missing 00关于某公司474名职工综合状况的统计分析报告 1、 数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id (职工编号),gender(性别),bdate(出生日期),edcu (受教育水平程度),jobcat (职务等级),salbegin (起始工 资),salary (现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss 统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。2、 数据分析 1、 频数分析。基本的统计分析往往从频数分析开始。通过频数分析 能够了解变量的取值状况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu (受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女 性别分布进行频数分析,结果如下: Gender FrequencyPercent Valid Percent Cumulative Percent Valid Female 21645.645.645.6 Male 258 54.4 54.4 100.0 Total 474100.0100.0 上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表 : Educational Level (years) Valid Cumulative
10.11统计分析软件&SPSS建立数据 目录 10.11统计分析软件&SPSS建立数据 (1) 10.25数据加工作图 (1) 11. 08绘图解答&描述性分析: (3) 2.描述性统计分析: (4) 四格表卡方检验:(检验某个连续变量的分布是否与某种理论分布一致,如是否符合正态分布) (7) 第七章非参数检验 (10) 1.单样本的非参数检验 (11) (1)卡方检验 (11) (2)二项分布检验 (12) 2.两独立样本的非参数检验 (13) 3.多独立样本的非参数检验 (16) 4.两相关样本的非参数检验 (16) 5.多相关样本的非参数检验 (18) 第五章均值检验与T检验 (20) 1.Means过程(均值检验)( (20) 4. 单样本T检验 (21) 5. 两独立样本T检验 (22) 6.两配对样本T检验 (23) 第六章方差分析 (25) 单因素方差分析: (25) 多因素方差分析: (29) 10.25数据加工作图 1.Excel中随机取值:=randbetween(55,99) 2.SPSS中新建数据,一列40个,正态分布随机数:先在40那里随便输入一个数表示选择40个可用的,然后按一下操作步骤: 3.排序:个案排秩
4.数据选取:数据-选择个案-如果条件满足: 计算新变量: 5.频次分析:分析-统计描述-频率
还原:个案-全部 6.加权: 还原 7.画图: 11. 08绘图解答&描述性分析:1.课后题:长条图
2.描述性统计分析: (1)频数分析:
(2)描述性分析: 描述性统计分析没有图形功能,也不能生成频数表,但描述性分析可以将原始数据转换成标准化得分,并以变量形式存入数据文件中,以便后续分析时应用。 操作: 分析—描述性分析:然后对结果进行筛选,去掉异常值,就得到标准化的数据: 任何形态的数据经过Z标准化处理之后就会是正态分布的<—错误!标准化是等比例缩放的,不会改变数据的原始分布状态, (3)探索分析:(检验是否是正态分布:茎叶图、箱图) 实例:
计算机与信息技术学院专业实习报告 学校:商丘师范学院 专业:信息管理与信息系统年级:2012 姓名:亚慧 学号:121112015 时间:2015.09
《统计分析与SPSS的应用》 实习报告 专业实习题目:数据处理与分析 一.实习目的 1.初步了解探索数据分析的基本方法和思路 2.掌握问题的研究思路及方法 3.掌握统计分析软件实现这些方法的步骤和原理 4.熟悉SPSS操作系统,掌握数据管理界面的简单的操作; 5.熟悉SPSS结果窗口的常用操作方法,掌握输出结果在文字处理软件中的使用方法。 6.掌握常用统计图(线图、条形图、饼图、散点、直方图等)的绘制方法;熟悉描述性统计图的绘制方法; 7.熟悉描述性统计图的一般编辑方法。掌握相关分析的操作,对显著性水平的基本简单判断。二.实习要求 1.遵守学校实习纪律和学校的各项规章制度 2.服从领导和指导老师的实习安排、虚心接受指导老师的安排 3.不得冒名顶替,否则严肃处理 4.按时上下课,不得缺席 5.掌握SPSS软件的基本操作、数据分析的基本功能和基本步骤 6.掌握对SPSS所分析的各项数据的理解、数据分析的基本方法和思路 7.掌握工作中如何进行数据的收集、整理以及统计分析报告的撰写的方法。 8.掌握相关关系的含义,并准确应用,熟练掌握绘制散点图的具体操作 9.掌握线性回归分析的主要目标、及具体操作。 三.实习任务 (一)下列表为数据处理所有表格和数据 信管12-1成绩表 学号性别计算机 网络 管理信 息系统 统计 学 市场营 销学 现代管 理学 运筹学 信息资 源管理 英语上 学期 英语 下学 期 大三 综合 成绩 121112001 女82.00 90.00 79.00 82.00 84.00 85.30 81.00 74 75 89.5
应用统计s p s s分析报 告 TYYGROUP system office room 【TYYUA16H-TYY-TYYYUA8Q8-
学生姓名:肖浩鑫学号: 一、实验项目名称:实验报告(三) 二、实验目的和要求 (一)变量间关系的度量:包括绘制散点图,相关系数计算及显着性检验; (二)一元线性回归:包括一元线性回归模型及参数的最小二乘估计,回归方程的评价及显着性检验,利用回归方程进行估计和预测; (三)多元线性回归:包括多元线性回归模型及参数的最小二乘估计,回归方程的评价及显着性检验等,多重共线性问题与自变量选择,哑变量回归; 三、实验内容 企业编号产量(台)生产费用(万 元)企业编号产量(台)生产费用(万 元) 1 40 130 7 84 165 2 42 150 8 100 170 3 50 155 9 116 167 4 5 5 140 10 125 180 5 65 150 11 130 175 6 78 154 12 140 185 (2)计算产量与生产费用之间的线性相关系数,并对相关系数的显着性进行检验(),并说明二者之间的关系强度。 2. 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数 地区人均GDP(元)人均消费水平(元) 北京22460 7326 辽宁11226 4490 上海34547 11546 江西4851 2396 河南5444 2208 贵州2662 1608 陕西4549 2035 (2)人均GDP作自变量,人均消费水平作因变量,利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。
(3)计算判定系数和估计标准误差,并解释其意义。 (4)检验回归方程线性关系的显着性() (5)如果某地区的人均GDP为5000元,预测其人均消费水平。 (6)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 3. 随机抽取10家航空公司,对其最近一年的航班正点率和顾客投诉次数进行调查, 航空公司编号航班正点率(%)投诉次数(次) 1 21 2 58 3 85 4 68 5 74 6 93 7 72 8 122 9 18 10 125 系数的意义。 (2)检验回归系数的显着性()。 (3)如果航班正点率为80%,估计顾客的投诉次数。 4. 某汽车生产商欲了解广告费用(x)对销售量(y)的影响,收集了过去12年的有关数据。通过计算得到下面的有关结果: 变差来源df SS MS F Significance F 回归 残差—— 总计11——— Coefficients标准误差t Stat P-value Intercept X Variable 1 (2)汽车销售量的变差中有多少是由于广告费用的变动引起的? (3)销售量与广告费用之间的相关系数是多少? (4)写出估计的回归方程并解释回归系数的实际意义。 (5)检验线性关系的显着性(a=)。 5. 随机抽取7家超市,得到其广告费支出和销售额数据如下
华中师范大学网络教育学院 《SPSS统计软件》练习题库及答案(本科) 一、选择题(选择类) (A)1、在数据中插入变量的操作要用到的菜单是: A Insert Variable; B Insert Case; C Go to Case; D Weight Cases (C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是: A Sort Cases; B Select Cases; C Compute; D Categorize Variables (C)3、Transpose菜单的功能是: A 对数据进行分类汇总; B 对数据进行加权处理; C 对数据进行行列转置; D 按某变量分割数据 (A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明: A. 按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别; B. 三种城市身高没有差别的可能性是0.043; C. 三种城市身高有差别的可能性是0.043; D. 说明城市不是身高的一个影响因素 (B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异; B 服用某种药物前后病情的改变情况; C 服用药物和没有服用药物的病人身体状况的差异; D性别和年龄对雇员薪水的影响 二、填空题(填空类) 6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。 7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。 8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。 三、名词解释(问答类) 9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。 10、Chi-Square test:卡方检验,它是非参数检验的一种方法,来检验变量的几个取值所占百分比是否和我们期望的比例没有统计学差异。比如我们在人群中抽取了一个样本,可以用该方法来分析四种血型所占的比例是否相同(都是25%),或者是否符合我们所给出的一个比例(如分别为10%、30%、40%和20%)。 四、简答题(问答类) 11、用SPSS对数据进行分析的基本流程是什么? 答:(1)、将数据输入SPSS,并保存; (2)、进行必要的预分析(分布图、均数标准差等的描述等),以确定应采用的检验方法; (3)、按题目要求进行统计分析; (4)、保存和导出分析结果。 12、对数据进行方差分析时,Univariate菜单和Multivariate菜单最大的区别是什么? 答:当因变量只有一个时,使用Univariate菜单,当因变量不止一个时,使用Multivariate菜单。 13、简述SPSS打开其它格式数据的几种方法? 答:(1)、直接打开:选择菜单File==>Open==>Data或直接单击快捷工具栏上的打开按钮; (2)、使用数据库查询打开:选择菜单File==>Open Database==>New Query,根据向导打开数据; (3)、使用文本向导读入文本文件:选择菜单File==>Read Text Data
目录 一、研究背景及其意义 (3) 二、研究方案 (3) 研究目标 (3) 研究内容 (4) 研究方法 (4) 三、科学技术与经济发展的关系分析 (4) 科技投入 (4) 科技产出 (5) 经济发展 (7) 小结 (7) 四、科学技术与经济发展的模型分析 (8) 模型假设 (8) 符号说明 (8) 信度与相关性分析 (8) 因子分析 (9)
回归分析 (10) 五、结论 (13) 附录: (14) 科学技术与经济发展的关系 一、研究背景及其意义 十九大报告指出:创新是引领发展的第一动力,是建设现代化经济体系的战略支撑。要瞄准世界科技前沿,强化基础研究,实现前瞻性基础研究、引领性原创成果重大突破。加强应用基础研究,拓展实施国家重大科技项目,突出关键共性技术、前沿引领技术、现代工程技术、颠覆性技术创新,为建设科技强国、质量强国、航天强国、网络强国、交通强国、数字中国、智慧社会提供有力支撑。加强国家创新体系建设,强化战略科技力量。深化科技体制改革,建立以企业为主体、市场为导向、产学研深度融合的技术创新体系,加强对中小企业创新的支持,促进科技成果转化。倡导创新文化,强化知识产权创造、保护、运用。培养造就一大批具有国际水平的战略科技人才、科技领军人才、青年科技人才和高水平创新团队。 而科技作为创新的重要引领者和实践者,对于建设创新型国家起着重要作用。科技进步是经济发展与社会发展的强大推动力。邓小平同志曾指出;"科学技术是第一生产力";江泽民同志也曾指出:"科学技术是第一生产力,而且是先进生产力的集中体现和主要标志。科学技术的突飞猛进,给世界生产力和人类经济发展带来了极大的推动,未来的科学发展还将产生新的重大飞跃"。在当今这个信息化和全球化加速的时代,科技进步对经济社会发展的促进作用越来越显着,科技进步成为生产力水平的首要决定因素,是国家或区域竞争力的重要源泉。近年来,随着我国经济增长方式的转变,科技支撑和引领经济社会发展的作用越来越强,无论是国家还是区域都需要通过依靠科技进步来促进经济社会发展。科技进步考核有效地促进了科教兴国、可持续发展和人才强国战略的落实,使科技促进经济杜会发展的能力逐步提升。
SPSS 统计分析练习题目 -2012-10-26 学号:________________________ 姓名:___________________________ (注:将本文件以学号+姓名.doc 的形式另存为一个文件,例2008144154葛爽.doc ,然后以附件形式发送至 all689@https://www.doczj.com/doc/8a10786146.html, ,时间截止到2012年10月31日。没有指明数据文件名称的题目需自行在SPSS 中建立数据文件并录入相应数据,回答问题时应将SPSS 中的主要输出结果粘贴于答案中。) 1.一所国际新闻学校每年从各大高校中招募刚刚毕业的本科生参加培训,进而作为记者参加新闻工作。大多数刚刚毕业的学生以前没有任何做记者的经验,所以在正式成为一名记者之前,必须进行一段时间的学习,作为职业的预备课程。该国际新闻学校于是设计了两种培训方案: 方案A :学生参加为期15周的全天课程听课学习,随后参加预备课程考试; 方案B :学生直接先参加6个月的记者实习,再进行为期15周的全天课程听课学习,最后进行预备课程考试。 为了评估两种方案各自的有效性,学校随机选出了20名学生参加实验。事前还根据他们的文学等相关学科的成绩对这20人进行了分组,20人分成10组,每组中2人的成绩相近,然后随机地将2人分配去参加方案A 和方案B 的培训。 下表是这20人预备课程本学期的成绩单: 1 2 3 4 5 6 7 8 9 10 A 50 68 72 54 42 60 56 72 63 61 B 62 62 58 74 60 66 64 64 78 66 请问上面的数据是否证明了先参加实践对提高平均测试分数的效果显著? Independent Samples Test 1.843.1911.54518.140.60006239921373013731.5455.331.143.6000623993098710987 Equal varia Equal varia assumed X F Sig.vene's Test f ality of Varian t df g. (2-taile Mean ifferenc td. Erro ifferenc Lower Upper 5% Confiden nterval of the Difference t-test for Equality of Means 因p=0.140>0.05,故不能证明先参加实践对提高平均测试分数的效果显著。 2.早在1990年,美国巴维利亚的6个省报道了他们的婴儿死亡率(每1000名活着出生的婴儿的死亡数)以及母乳喂养率(母乳喂养婴儿的比例)的数据如下: 省号码 死亡率(每1000名婴儿中的死亡人数) 母乳喂养率(%) 1 250 60 2 320 30 3 170 90 4 300 60 5 270 40
SPSS统计分析案例 一、我国城镇居民现状 近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。 二、我国居民消费结构的横向分析 第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。随着收入的增加,衣着支出比重呈现先上升后下降的走势。事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。第四,医
疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。可以看出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动需,促进我国的经济发展方面有着重大的现实意义。 三、我国居民消费结构的纵向分析 进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费质量和消费结构都发生了明显的变化。城镇居民在食品、衣着、家庭设备用品三项支出在消费支出中的比重呈现明显的下降趋势,其中食品类支出比重降幅最大;衣着类有所下降;家庭设备用品类下降幅度不是很大。与此同时,医疗保健、交通通讯、文化娱乐教育服务、居住及杂项商品支出在消费支出中的比例均有上升,富裕阶段的消费特征开始显现。 四、我国城镇居民消费结构及趋势的统计分析
实验三SPSS基本统计分析 一.实验目的和要求 1.掌握频数分析; 2.掌握计算基本描述统计量; 3.掌握交叉分组下的频数分析和各种相关性检验; 4.掌握多选项分析; 5.掌握比率分析。 二.实验的基本方法和内容 1. 频数分析 操作步骤:参阅教材第63、64、65页。 2. 基本描述统计量 操作步骤:参阅教材第68、69、70、71页。 3. 交叉分组下的频数分析 操作步骤:参阅教材第73、74、75、76、77、78、79、80、81、82、83、84、85页。 4. 多选项分析 操作步骤:参阅教材第85、86、87、88、89、90页。 5. 比率分析 操作步骤:参阅教材第91、92页。 6. 实验内容: (一)验证性实验 (1)教材第65页“商品房购买意向的调查数据分析” (2)教材第71“商品房购买意向的调查数据分析” (3)教材第79“商品房购买意向的调查数据分析” (4)教材第90“商品房购买意向的调查数据分析” (5)教材第92“保险业务的保费收入占全部业务保费收入的比例情况” (二)实践性实验 (1)对“文科成绩”的数据文件作如下统计整理: 1.利用频数分析功能,分别对“文科成绩7”中“及格次数”变量和“文科成绩9”中的“value
range ”变量,要求绘制频数分布表和频数分布图,其中频数分布表中的内容按变量值的升序输出,频数分布图前者采用饼状图,后者采用带有分布曲线的直方图,二者均输出百分比数据。最后将输出结果保存为“文科成绩7-1”和“文科成绩9-1”。 2. 对“文科成绩5.1”的spss 文件,利用描述统计功能,统计第一、第二及第三次考试成 绩的最大值,最小值,区间范围,平均值,标准差,方差,峰度,偏度等统计量的数值, 要求三个变量的输出内容按均值升值的顺序排列。最后将输出结果保存为“文科成绩5.1-1”。并配文字对数据做出以适当的分析。 3. 如何在同一个输出结果中同时输出不同学院的“第三次考试成绩”的各种基本 描述统计量,并对不同学院的学生考试成绩情况进行深入比较。 (2)调查100名健康大学生的血清总蛋白含量(g%)如下表: 1.利用描述统计功能从集中趋势、分散程度、偏斜程度、有无异常值等方面分析血清蛋白含量这个变量的分布状况。 2.原始数据进行算术处理:已知最小值为6.430,最大值为8.430,全距为2.000,故可要求分成5组,试作分组后的频数分析,并给出带有正态曲线的直方图。 7.43 7.88 6.88 7.80 7.04 8.05 6.97 7.12 7.35 8.05 7.95 7.56 7.50 7.88 7.20 7.20 7.20 7.43 7.12 7.20 7.50 7.35 7.88 7.43 7.58 6.50 7.43 7.12 6.97 6.80 7.35 7.50 7.20 6.43 7.58 8.03 6.97 7.43 7.35 7.35 7.58 7.58 6.88 7.65 7.04 7.12 8.12 7.50 7.04 6.80 7.04 7.20 7.65 7.43 7.65 7.76 6.73 7.20 7.50 7.43 7.35 7.95 7.35 7.47 6.50 7.65 8.16 7.54 7.27 7.27 6.72 7.65 7.27 7.04 7.72 6.88 6.73 6.73 6.73 7.27 7.58 7.35 7.50 7.27 7.35 7.35 7.27 8.16 7.03 7.43 7.35 7.95 7.04 7.65 7.27 7.72 8.43 7.50 7.65 7.04 (3)对某城市家庭的社会经济调查中,美国某调查公司想确定家庭的家庭拥有量与汽车拥有量是否独立。该公司对10000户家庭组成的简单随机样本进行调查,获得如下资料。 现问: 1汽车用有量与量与电话拥有量是否独立?(01.0=α) 2请根据列联表特征,选择卡方统计量以外的检验方法分析行列变量之间的关联强度和关联方向。
精选范文、公文、论文、和其他应用文档,希望能帮助到你们! SPSS简单数据分析报告
目录 一、数据样本描述 (4) 二、要解决的问题描述 (4) 1 数据管理与软件入门部分 (4) 1.1 分类汇总 (4) 1.2 个案排秩 (5) 1.3 连续变量变分组变量 (5) 2 统计描述与统计图表部分 (5) 2.1 频数分析 (5) 2.2 描述统计分析 (5) 3 假设检验方法部分 (5)
3.1 分布类型检验 (5) 3.1.1 正态分布 (5) 3.1.2 二项分布 (6) 3.1.3 游程检验 (6) 3.2 单因素方差分析 (6) 3.3 卡方检验 (6) 3.4 相关与线性回归的分析方法 (6) 3.4.1 相关分析(双变量相关分析&偏相关分析) (6) 3.4.2 线性回归模型 (6) 4 高级阶段方法部分 (6) 三、具体步骤描述 (7) 1 数据管理与软件入门部分 (7) 1.1 分类汇总 (7) 1.2 个案排秩 (8) 1.3 连续变量变分组变量 (10) 2 统计描述与统计图表部分 (11) 2.1 频数分析 (11) 2.2 描述统计分析 (14) 3 假设检验方法部分 (16) 3.1 分布类型检验 (16) 3.1.1 正态分布 (16) 3.1.2 二项分布 (17)
3.1.3 游程检验 (18) 3.2 单因素方差分析 (22) 3.3 卡方检验 (24) 3.4 相关与线性回归的分析方法 (26) 3.4.1 相关分析 (26) 3.4.2 线性回归模型 (28) 4 高级阶段方法部分 (32) 4.1 信度 (32) 一、数据样本描述 本次分析的数据为某公司474名职工状况统计表,其中共包含11个变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用SPSS统计软件,对变量进行统计分析,以了解该公司职工总体状况,并分析职工受教育程度、起始工资、现工资的分布特点及相互间的关系。 二、要解决的问题描述 1 数据管理与软件入门部分 1.1 分类汇总 以受教育水平程度为分组依据,对职工的起始工资和现工资进行数据
SPSS统计分析结课报告 居民收入水平与经济发展的关系 姓名: 学号: 班级: 学院: 日期:
目录 一、研究背景及其意义 (3) 二、研究方案 (3) 2.1 研究目标 (3) 2.2 研究内容 (3) 2.3 研究方法 (3) 2.4 数据来源 (3) 三、居民收入水平与经济发展的关系分析 (3) 3.1 居民收入水平 (3) 3.2 经济发展 (5) 3.3 小结 (6) 四、科学技术与经济发展的模型分析 (6) 五、结论 (10)
一、研究背景及其意义 居民收入是指一个国家物质生产部门的劳动者在一定时期内创造的价值总和。人均国民收入这一指标能大体反映一国的经济发展水平。党的十九大报告指出,必须始终把人民利益摆在至高无上的地位,让改革发展成果更多更公平惠及全体人民,朝着实现全体人民共同富裕不断迈进。报告在论述提高保障和改善民生水平,加强和创新社会治理部分中,特别强调要提高就业质量和人民收入水平。 二、研究方案 2.1研究目标 党的十九大报告把2020年实现全面建成小康社会目标之后的第二个百年奋斗目标,按照2035年基本实现社会主义现代化和本世纪中叶建成社会主义现代化强国,分两步或两个阶段进行安排。在描述第一步目标时,报告指出,“人民生活更为宽裕,中等收入群体比例明显提高,城乡区域发展差距和居民生活水平差距显著缩小,基本公共服务均等化基本实现,全体人民共同富裕迈出坚实步伐”。报告描述的第二步目标,是到本世纪中叶,富强民主文明和谐美丽的社会主义现代化强国建成时,“全体人民共同富裕基本实现,我国人民将享有更加幸福安康的生活”。 本文利用相关的数据,力争较全面地反映居民收入与经济发展之间的关系,为相关政策制定的提供借鉴,为我国相关工作的有效开展提供支持。 2.2研究内容 由于区域数据相对而言比较残缺、难收集,因此报告从国民居民收入水平数据分析方面与我国经济发展之间的关系进行理论分析。 2.3研究方法 本文在采用了一元线性回归的知识,对居民收入水平和区域经济发展进行研究分析。 2.4数据来源 本研究所采用的数据主要来源于国家统计局、各大信息网站等,数据权威性较高,其中2017-2018年部分数据有缺失,通过各数据网站进行了部分补充,但真实性和准确性有待考证。 三、居民收入水平与经济发展的关系分析 3.1居民收入水平
SPSS简单数据统计分析报告
目录 一、数据样本描述 (4) 二、要解决的问题描述 (4) 1 数据管理与软件入门部分 (4) 1.1 分类汇总 (4) 1.2 个案排秩 (5) 1.3 连续变量变分组变量 (5) 2 统计描述与统计图表部分 (5) 2.1 频数分析 (5) 2.2 描述统计分析 (5)
3 假设检验方法部分 (5) 3.1 分布类型检验 (5) 3.1.1 正态分布 (5) 3.1.2 二项分布 (6) 3.1.3 游程检验 (6) 3.2 单因素方差分析 (6) 3.3 卡方检验 (6) 3.4 相关与线性回归的分析方法 (6) 3.4.1 相关分析(双变量相关分析&偏相关分析) (6) 3.4.2 线性回归模型 (6) 4 高级阶段方法部分 (6) 三、具体步骤描述 (7) 1 数据管理与软件入门部分 (7) 1.1 分类汇总 (7) 1.2 个案排秩 (8) 1.3 连续变量变分组变量 (10) 2 统计描述与统计图表部分 (11) 2.1 频数分析 (11) 2.2 描述统计分析 (14) 3 假设检验方法部分 (16) 3.1 分布类型检验 (16) 3.1.1 正态分布 (16)
3.1.2 二项分布 (17) 3.1.3 游程检验 (18) 3.2 单因素方差分析 (22) 3.3 卡方检验 (24) 3.4 相关与线性回归的分析方法 (26) 3.4.1 相关分析 (26) 3.4.2 线性回归模型 (28) 4 高级阶段方法部分 (32) 4.1 信度 (32) 一、数据样本描述 本次分析的数据为某公司474名职工状况统计表,其中共包含11个变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用SPSS统计软件,对变量进行统计分析,以了解该公司职工总体状况,并分析职工受教育程度、起始工资、现工资的分布特点及相互间的关系。 二、要解决的问题描述 1 数据管理与软件入门部分 1.1 分类汇总
SPSS 专业技术词汇、短语的中英文对照索引% of cases 各类别所占百分比 1-tailed单尾的 1Independent Samples 两个独立样本的检验 2 Related Samples 两个相关样本检验 2-tailed双尾的 3-D (=dimensional) 三维-->三维散点图 A Above 高于 Absolute 绝对的-->绝对值 Add 加,添加 Add Cases 合并个案 Add cases from...从……加个案 Add Variables 合并变量 Add variables from... 从……加变量 Adj.(=adjusted)standardized 调整后的标准化残差 Aggregate 汇总-->分类汇总 Aggregate Data 对数据进行分类汇总 Aggregate Function 汇总函数 Aggregate Variable需要分类汇总的变量 Agreement协议 Align 对齐-->对齐方式 Alignment 对齐-->对齐方式 All 全部,所有的 All cases所有个案 All categories equal 所有类别相等 All other values所有其他值 All requested variables entered 所要求变量全部引入 Alphabetic 按字母顺序的-->按字母顺序列表 Alternative 另外的,备选的 Analysis by groups is off 分组分析未开启 Analyze 分析-->统计分析 Analyze all cases, do not create groups 分析全部个案,不建立分组 Annotation 注释 ANOVA Table ANOVA表 ANOVA table and eta (对分组变量)进行单因素方差分析并计算其η值 Apply 应用 Apply Data Dictionary 应用数据字典 Apply Dictionary 应用数据字典 Approximately 大约 Approximately X% of all cases从所有个案中随机选择约X%的个案
SPSS 数据分析报告 学生姓名:李婷 学号:0904100223 专业:统计学 班级:统计0902 指导教师:朱钰 完成日期:2011年12月17日
目录 一.数据简介 ........................................................................................... 错误!未定义书签。二.数据分析 .. (3) 三.描述性分析 (5) 四.探索性分析 (6) 1.交叉分析 (6) 2.茎叶图 (7) 3 p-p 图分析 (11) 五.证实性分析 (12) 1.相关分析 (12) 2.回归分析 (13) 3.参数检验 (15) (1)单样本T检验 (16) (2)独立样本T检验 ............................................................. 错误!未定义书签。
关于某地区361个人旅游情况统计分析报告 一、数据介绍: 此数据来源于https://www.doczj.com/doc/8a10786146.html,/publications/jse/jse_data_archive.htm 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、频数分析: 基本的统计分析往往从频数分析开始。通过频数分地区359个人旅游基本状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性况的基本分布。 首先,对该地区的男女性别分布进行频数分析,结果如下 表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为44.8%和55.2%,该公司职工男女数量差距不大,女性略多于男性。
第三章 1、利用习题二第6题数据,采用SPSS数据筛选功能将数据分成两份文件。其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。 第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。 第二份文件:选取数据数据——选择个案——随机个案样本——输入70。 2、利用习题二第6题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。 排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。 3、利用习题二第4题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。 计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。 4、利用习题二第4题的完整数据,计算每个学生课程的平均分以及标准差。同时,计算男生和女生各科成绩的平均分。 方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定 5、利用习题二第6题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。 根据存款金额排序,观察其最大值与最小值,算出组数和组距。转换——重新编码为其他变量——将存款金额作为输出变量——定义输出变量的名称及标签——设定旧值和新值. 6、在习题二第6题数据中,如果认为调查中“今年的收入比去年增加”且“预计未来一两年收入仍会增加”的人是对自己收入比较满意和乐观的人,请利用SPSS的计数和数据筛选功能找到这些人。 转换——对个案的值计数——设定目标变量及标签——将“今年的收入比去年增加”和“预计未来一两年收入仍会增加”两个变量选中——定义值。 7、对习题二第5题数据,选择恰当的加权变量进行加权处理进而还原为原始数据为后续分析做准备。 数据——加权个案——点击加权个案——将人数作为频率变量——确定。 第四章
SPSS与数据统计分析期末论文影响学生对学校服务满意程度的因素分析
一、数据来源 本次数据主要来源自本校同学,调查了同学们年级、性别、助学金申请情况、生源所在地、学院、毕业学校、游历情况、家庭情况、升高、体重、近视程度、学习时间、经济条件、兴趣、对学校各方面的评价、与对学校总评价以及建议等共41条信息,共收集数据样本724条。我们将运用SPSS,对变量进行频数分析、样本T检验、相关分析等手段,旨在了解同学们对学校提供的满意程度与什么因素有关。 二、频数分析 可靠性统计 克隆巴赫 Alpha 项数 .985 62 对全体数值进行可信度分析
本次数据共计724条,首先从可靠性统计来看,alpha值为0.985,即全体数据绝大部分是可靠的,我们可以在原始数据的基础上进行分析与处理。 其中,按年级来看,绝大多数为大二学生填写(占了总人数的67.13%),之后分别依次为大二(23.76%)、大四(4.14%)、大一(4.97%)。而从专业来看,占据了数据绝大多数样本所在的学院为机械、材料、经管、计通。 三、数据预处理 拿到这份诸多同学填写的问卷之后,我们首先应对一些数据进行处理,对于数据的缺失值处理,由于我们对本份调查的分析重点方面是关于学生的经济情况的,因此对于确实的部分数据,升高、体重、近视度数、感兴趣的事等无关项我们均不需要进行缺失值的处理,而我们可能重点关注的每月家里给的钱、每月收入以及每月支出,由于其具有较强主观性,如果强行处理缺失值反而会破坏数据的完整性,因此我们筛去未填写的数据,将剩余数据当作新的样本进行分析。 而对于一些关键的数据,我们需要做一些必要的预处理,例如一些调查项,我们希望得到数值型变量,但是填写时是字符型变量,我们就应该新建一个数字型变量并将数据复制,以便后续分析。同时一些与我们分析相关的缺省值,一些明显可以看出的虚假信息,我们都需要先进行处理。而具体预处理需要怎么做,这将会在其后具体分析时具体给出。