CUDA 工程配置
- 格式:pdf
- 大小:509.03 KB
- 文档页数:4

CUDA4.1 VS2008 配置今天总算把cuda的环境搭建好了。
在此记录一下平台搭建的过程。
首先需要安装VS 2008。
然后从英伟达官网上下载开发包、驱动和工具包。
保证驱动和开发包、工具包均为同一版本。
我下载的是4.1的最新版本。
即cudatoolkit_4.1.28_win_32.msi 、devdriver_4.1_winxp_32_286.19_general.exe、gpucomputingsdk_4.1.28_win_32.exe 。
然后开始安装,首先装好对应的驱动,其次装工具包,最后装开发包。
工具包的路径是默认的,即C:\Program Files\NVIDIA GPU ComputingToolkit\CUDA\v4.1\,而开发包可以更改路径,我选择的路径是D:\NVIDIA Corporation\NVIDIA GPU Computing SDK 4.1\。
装好之后,需要配置VS 2008。
首先需要将C:\Program Files\NVIDIA GPU ComputingToolkit\CUDA\v4.1\extras\visual_studio_integration\rules路径下面的4个rules文件拷贝到VS安装路径下面的VC\VCProjectDefaults 中,这样就可以在VS 2008中打开位于D: \ProgramData \NVIDIA Corporation\NVIDIA GPU Computing SDK4.1\C\src 的工程样例了。
为了显示关键字高亮,需要将D:\ C:\ProgramData\NVIDIACorporation\NVIDIA GPU Computing SDK4.1\C\doc\syntax_highlighting\visual_studio_8下面的usertype.dat拷贝到VS安装路径下面的Common7\IDE目录中。

第一课:CUDA的安装配置(Win8.164位NVIDIAGT705VS2012)捣鼓了一天,终于把环境搭建好了,测试代码也运行成功。
期间遇到了一些问题,甚至觉得是操作系统的问题,想着要不要换个操作系统。
吃中饭的时候,认真思考了一下,觉得不能半途而废,win8.1肯定是没问题的,事实证明我是对的。
下面是配置的详细步骤:step 1:首先当然是要有Visual Studio啦如果你是学生,可以到Microsoft DreamSpark的官网下载,完全免费。
step 2:根据操作系统的类型下载最新版本的CUDA(现在是CUDA 7),网址是:/cuda-downloads。
如果你注册了CUDA社区的账号还可以下载先行版呢。
step 3:下载完了当然是安装啦,安装步骤就不用说了吧。
选择自己喜欢的目录然后安装吧。
step 4:安装完毕后,可以看到系统中多了CUDA_PATH和CUDA_PATH_V6_0两个环境变量,接下来,还要在系统中添加以下几个环境变量:CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v7.0CUDA_LIB_PATH = %CUDA_PATH%\lib 64CUDA_BIN_PATH = %CUDA_PATH%\binCUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib 64然后,在系统变量PATH的末尾添加:;%CUDA_LIB_PATH%;%CUDA_BIN_PATH%;%CUDA_SDK_LIB_ PATH%;%CUDA_SDK_BIN_PATH%;step 5:重启计算机使环境变量生效step 6:打开VS2012建立一个空的Win32控制台项目step 7:右键点击源文件 => 添加 => 新建项,然后选择NVIDIA CUDA 7.0 => Code => CUDA C/C++ Filestep 8:右键项目=> 生成自定义,在弹出的对话框中勾选“ CUDA 7.0 xxx” 选项。
VS2010 CUDA 5.5 Win7 64位配置以及项目创建配置一.安装CUDA5.5以及配置VS助手1、安装之前必须确认自己电脑的GPU支持CUDA。
在设备管理器中找到显示适配器(Display adapters),找到自己电脑的显卡型号,如果包含在/object/cuda_gpus.html的列表中,说明支持CUDA。
安装CUDA之前最好检查一下自己电脑的显卡驱动版本,版本过老的话,需要更新。
有时候安装完毕CUDA之后,运行6中的deviceQuery程序时会出错,请优先考虑显卡驱动的问题。
2、下载NVIDIA CUDA Toolkit( /content/cuda/cuda-downloads.html),本人下载的是desktop版本win64CUDA5.0以上已经将ToolKit和SDK等整合在了一起,因此只需下载一个安装文件即可。
3、首先确认自己已经安装Visual Studio 2010 后再安装助手Visual Assist X。
这里Visual Assist X 对于使用CUDA 不是必须的,但为了使程序编写更为方便,这里推荐安装。
4、CUDA的默认安装目录为:C:\Program Files\NVIDIA GPU Computing Toolkit\ 这里推荐使用默认的安装路径,不需更改。
5、安装完成后,在系统变量环境里面会发现新添加了两个环境变量CUDA_PATHC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.5CUDA_PATH_V5_5C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.5且在系统变量的path也会自动添加C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.5\bin;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.5\libnvvp;C:\Program Files (x86)\NVIDIA Corporation\PhysX\Common;6、此时CUDA已经安装成功。

1下载相关软件1.1.CUDA driver 、 CUDA toolkit 、 CUDA SDKvidia 的官网上可以下载得到 CUDA driver 、 CUDA toolkit 、 CUDA SDK code samples 等CUDA 环境相关文件,例如目前的最新版 3.2 的下载地址是/object/cuda_3_2_downloads.html。
注意选择对应的操作系统和操作系统位数。
1.2. CUDA VS Wizard 以及Visual Assist X.CUDA VS Wizard 可以使我们更加方便的在VS 中添加CUDA 项目。
在/projects/cudavswizard/可以得到CUDA VS Wizard ,注意选择对应的操作系统位数,否则将有可能出现”Err source: CreatcustomProject” 等错误信息。
Visual Assist X在网上可以下载到,可能需要破解按照文档说明进行即可。
2.安装相应的N卡驱动我们得到一个文件名如devdriver_3.2_ winvista- win7_32_253.05_ general.exe的显卡驱动安装文件。
选择安装路径开始安装(如果选择了非默认路径会有提示是否改回默认路径)。
在安装的过程中可能会有数次黑屏及分辨率调整的过程。
3. 按顺序安装 CUDA toolkit、CUDA SDK安装目录要记清,可以改成好找的目录。
4. 安装 CUDA VS Wizard及Visual Assist XVisual Assist X需要破解,“C:\AllUsers\Administrator\AppData\Local \Microsoft\VisualStudio\10.0\Extensions\Whole Tomato Software\Visual Assist X”里的VA_X.dll替换成破解后的文件(可以下载到)。

VS2012与CUDA6.5配置新建项目-NVIDIA CUDA 6.5-CUDA 6.5 Runtime,输入方案名称,项目路径放于D:\CUDA\CUDAsdk\0_Simple,建立需要的.cpp及.cu文件打开项目属性进行配置1)配置属性-常规输出目录:..\bin\win32\$(Configuration)\中间目录:$(Platform)/$(Configuration)/字符集:使用多字节字符集2)配置属性-调试-命令:..\bin\win32\$(Configuration)\cppIntegration.exe3)V C++目录-包含目录D:\CUDA\CUDAsdk\common\inc;$(IncludePath)4)C/C++选项4.1 常规-附加包含目录./;$(CudaToolkitDir)/include;../../common/inc;4.2预处理器定义WIN32;_MBCS;%(PreprocessorDefinitions)4.3代码生成-运行库:多线程调试(/MTd)5)CUDA C/C++选项5.1 Common-Additional Include Directories:./;../../common/inc5.2 Device-Code Generation:compute_11,sm_11;compute_20,sm_20;compute_30,sm_30;compute_35,sm_35;co mpute_37,sm_37;compute_50,sm_50;5.3 HostPreprocessor Definitions:WIN32Runtime Library:Multi-Threaded Debug (/MTd)6)链接器选项6.1常规输出文件:$(OutDir)/cppIntegration.exe附加库目录:$(CudaToolkitLibDir);6.2输入cudart_static.lib;kernel32.lib;user32.lib;gdi32.lib;winspool.lib;comdlg32.lib;advapi32. lib;shell32.lib;ole32.lib;oleaut32.lib;uuid.lib;odbc32.lib;odbccp32.lib;%(AdditionalDe pendencies)6.3优化链接代码时间生成:默认设置。
1下载相关软件1.1.CUDA driver 、 CUDA toolkit 、 CUDA SDKvidia 的官网上可以下载得到 CUDA driver 、 CUDA toolkit 、 CUDA SDK code samples 等CUDA 环境相关文件,例如目前的最新版 3.2 的下载地址是/object/cuda_3_2_downloads.html。
注意选择对应的操作系统和操作系统位数。
1.2. CUDA VS Wizard 以及Visual Assist X.CUDA VS Wizard 可以使我们更加方便的在VS 中添加CUDA 项目。
在/projects/cudavswizard/可以得到CUDA VS Wizard ,注意选择对应的操作系统位数,否则将有可能出现”Err source: CreatcustomProject” 等错误信息。
Visual Assist X在网上可以下载到,可能需要破解按照文档说明进行即可。
2.安装相应的N卡驱动我们得到一个文件名如devdriver_3.2_ winvista- win7_32_253.05_ general.exe的显卡驱动安装文件。
选择安装路径开始安装(如果选择了非默认路径会有提示是否改回默认路径)。
在安装的过程中可能会有数次黑屏及分辨率调整的过程。
3. 按顺序安装 CUDA toolkit、CUDA SDK安装目录要记清,可以改成好找的目录。
4. 安装 CUDA VS Wizard及Visual Assist XVisual Assist X需要破解,“C:\AllUsers\Administrator\AppData\Local \Microsoft\VisualStudio\10.0\Extensions\Whole Tomato Software\Visual Assist X”里的VA_X.dll替换成破解后的文件(可以下载到)。
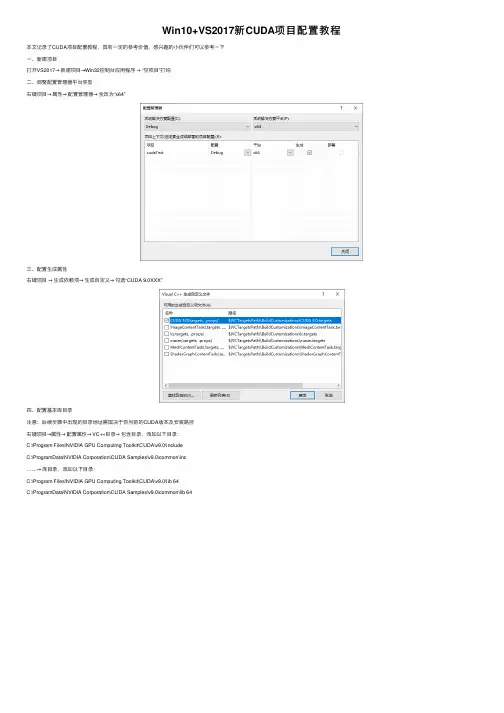
Win10+VS2017新CUDA项⽬配置教程本⽂记录了CUDA项⽬配置教程,具有⼀定的参考价值,感兴趣的⼩伙伴们可以参考⼀下⼀、新建项⽬打开VS2017→新建项⽬→Win32控制台应⽤程序→ “空项⽬”打钩⼆、调整配置管理器平台类型右键项⽬→属性→配置管理器→全改为“x64”三、配置⽣成属性右键项⽬→⽣成依赖项→⽣成⾃定义→勾选“CUDA 9.0XXX”四、配置基本库⽬录注意:后续步骤中出现的⽬录地址需取决于你当前的CUDA版本及安装路径右键项⽬→属性→配置属性→ VC++⽬录→包含⽬录,添加以下⽬录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\includeC:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0\common\inc……→库⽬录,添加以下⽬录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\lib 64C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0\common\lib 64五、配置CUDA静态链接库路径右键项⽬→属性→配置属性→链接器→常规→附加库⽬录,添加以下⽬录:$(CUDA_PATH_V9_0)\lib\$(Platform)六、选⽤CUDA静态链接库右键项⽬→属性→配置属性→链接器→输⼊→附加依赖项,添加以下库:cublas.lib;cublas_device.lib;cuda.lib;cudadevrt.lib;cudart.lib;cudart_static.lib;cufft.lib;cufftw.lib;curand.lib;cusolver.lib;cusparse.lib;nppc.lib;nppial.lib;nppicc.lib;nppicom.lib;nppidei.lib;nppif.lib;nppig.lib;nppim.lib;nppis 以上为 “第三步” 中添加的库⽬录 “C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\lib 64” 中的库!注意:kernel32.lib;user32.lib;gdi32.lib;winspool.lib;comdlg32.lib;advapi32.lib;shell32.lib;ole32.lib;oleaut32.lib;uuid.lib;odbc32.lib;odbccp32.lib;%(AdditionalDependencies)这些库为原有!七、配置源码⽂件风格右键源⽂件→添加→新建项→选择 “CUDA C/C++ File”右键 “xxx.cu" 源⽂件→属性→配置属性→常规→项类型→设置为“CUDA C/C++”⼋、测试程序#include "cuda_runtime.h"#include "device_launch_parameters.h"#include <stdio.h>int main() {int deviceCount;cudaGetDeviceCount(&deviceCount);int dev;for (dev = 0; dev < deviceCount; dev++){int driver_version(0), runtime_version(0);cudaDeviceProp deviceProp;cudaGetDeviceProperties(&deviceProp, dev);if (dev == 0)if (deviceProp.minor = 9999 && deviceProp.major == 9999)printf("\n");printf("\nDevice%d:\"%s\"\n", dev, );cudaDriverGetVersion(&driver_version);printf("CUDA驱动版本: %d.%d\n", driver_version / 1000, (driver_version % 1000) / 10);cudaRuntimeGetVersion(&runtime_version);printf("CUDA运⾏时版本: %d.%d\n", runtime_version / 1000, (runtime_version % 1000) / 10);printf("设备计算能⼒: %d.%d\n", deviceProp.major, deviceProp.minor);printf("Total amount of Global Memory: %u bytes\n", deviceProp.totalGlobalMem);printf("Number of SMs: %d\n", deviceProp.multiProcessorCount);printf("Total amount of Constant Memory: %u bytes\n", deviceProp.totalConstMem);printf("Total amount of Shared Memory per block: %u bytes\n", deviceProp.sharedMemPerBlock);printf("Total number of registers available per block: %d\n", deviceProp.regsPerBlock);printf("Warp size: %d\n", deviceProp.warpSize);printf("Maximum number of threads per SM: %d\n", deviceProp.maxThreadsPerMultiProcessor);printf("Maximum number of threads per block: %d\n", deviceProp.maxThreadsPerBlock);printf("Maximum size of each dimension of a block: %d x %d x %d\n", deviceProp.maxThreadsDim[0],deviceProp.maxThreadsDim[1],deviceProp.maxThreadsDim[2]);printf("Maximum size of each dimension of a grid: %d x %d x %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]);printf("Maximum memory pitch: %u bytes\n", deviceProp.memPitch);printf("Texture alignmemt: %u bytes\n", deviceProp.texturePitchAlignment);printf("Clock rate: %.2f GHz\n", deviceProp.clockRate * 1e-6f);printf("Memory Clock rate: %.0f MHz\n", deviceProp.memoryClockRate * 1e-3f);printf("Memory Bus Width: %d-bit\n", deviceProp.memoryBusWidth);}return 0;}输出结果:以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。

浅析CUDA编译流程与配置方法CUDA是一种并行计算编程平台和应用程序编程接口(API),由NVIDIA公司开发而成。
它允许开发人员使用C/C++编写高性能的GPU加速应用程序。
CUDA编程使用了一种特殊的编译流程,并且需要进行相关的配置才能正确地使用。
本文将对CUDA编译流程和配置方法进行浅析。
CUDA编译流程可以分为以下几个步骤:1.源代码编写:首先,开发人员需要根据自己的需求,使用CUDAC/C++语言编写并行计算的代码。
CUDA代码中包含了主机端代码和设备端代码。
主机端代码运行在CPU上,用于管理GPU设备的分配和调度工作;设备端代码运行在GPU上,用于实际的并行计算。
2.配置开发环境:在进行CUDA编程之前,需要正确地配置开发环境。
开发环境包括安装适当的CUDA驱动程序和CUDA工具包,并设置相应的环境变量。
此外,还需要选择合适的GPU设备进行开发。
3.编译主机端代码:使用NVCC编译器编译主机端代码。
NVCC是一个特殊的C/C++编译器,它能够处理包含CUDA扩展语法的代码。
主机端代码编译后会生成可执行文件,该文件在CPU上运行,负责分配和调度GPU设备的工作。
4.编译设备端代码:使用NVCC编译器编译设备端代码。
设备端代码编译后会生成CUDA二进制文件,该文件会被主机端代码加载到GPU设备上进行并行计算。
在编译设备端代码时,需要根据GPU架构选择适当的编译选项,以充分发挥GPU性能。
5.运行程序:将生成的可执行文件在CPU上运行,主机端代码会将设备端代码加载到GPU上进行并行计算。
在程序运行期间,主机端代码可以通过调用CUDAAPI来与GPU进行数据传输和任务调度。
配置CUDA开发环境的方法如下:2. 设置环境变量:CUDA安装完成后,需要将相关的路径添加到系统的环境变量中。
具体来说,需要将CUDA安装目录下的bin和lib64路径添加到系统的PATH变量中,以便系统能够找到CUDA相关的可执行文件和库文件。

cuda配置Visual Studio 2010 中CUDA 4.0的安装与配置安装环境:Win7 64位系统,Geforce GT 430显卡安装前提:Visual Studio 2010Visual Assist X安装步骤:1,Nvidia显卡驱动,装275.33版,这是最新版本驱动,初次安装为了少出错,最好安装⽐较新版本的驱动。
2,Cuda Toolkit 4.0安装,CUDA 4.0的新特性可以参见其Release Notes,其中包括了本⽂将要介绍的Thrust库。
3,CUDA Tools SDK 4.0安装,默认安装路径可能是C:\ProgramData\NVIDIA Corporation\NVIDIA GPU Computing SDK 4.0,记这个路径为SDK_PATH.4,Parallel Nsight 2.0安装,这个⼯具可以将GPU通⽤计算集成进Microsoft Visual Studio,能够对使⽤CUDA C,OpenCL, DirectCompute, Direct3D,和 OpenGL的应⽤程序进⾏调试和分析。
现在可以⽤VS打开CUDA SDK的例⼦了,在这之前,两个⼯具库可以先⽣成⼀下。
a.使⽤VS2010打开SDK_PATH \ c\common\cutil vs2010.sln,VS2010 选“Build|BatchBuild…”,“Select All”,⽣成所有配置需要的lib.如果遇到“Can not open sourcefile …”的错误,把⽂件夹的只读属性去掉。
⽬的:⽣成各配置需要的cutilxx[D].lib XX:32 /64 [D]debug模式lib存放的位置:SDK_PATH \ c\common\lib\(win32|X64)b.同上⽅法,打开SDK_PATH\share\ shrUtils_vs2010.sln 选“Build|Batch Build…”⽬的:⽣成各配置需要的shrUtilxx.lib XX:32 /64 [D]debug模式lib存放的位置:SDK_PATH\share\lib\(Win32|x64)注:这个项⽬编译时会提⽰有两个.cpp找不到,直接把他们从项⽬⾥移去即可。

PyTorchCUDA环境配置及安装的步骤(图⽂教程)⽬录Pytorch版本介绍安装NVIDIA显卡驱动程序确认项⽬所需torch版本安装CUDA下载安装安装cuDNN下载安装安装PyTorch在线安装离线安装确认环境是否配置成功参考及引⽤Pytorch版本介绍torch:1.6CUDA:10.2cuDNN:8.1.0安装 NVIDIA 显卡驱动程序⼀般电脑出⼚/装完系统会⾃动安装显卡驱动如果有可直接进⾏下⼀步下载链接选择和⾃⼰显卡相匹配的显卡驱动下载安装确认项⽬所需torch版本# pip install -r requirements.txt# base ----------------------------------------Cythonmatplotlib>=3.2.2numpy>=1.18.5opencv-python>=4.1.2pillowPyYAML>=5.3scipy>=1.4.1tensorboard>=2.2torch>=1.6.0torchvision>=0.7.0tqdm>=4.41.0# coco ----------------------------------------# pycocotools>=2.0# export --------------------------------------# packaging # for coremltools# coremltools==4.0# onnx>=1.7.0# scikit-learn==0.19.2 # for coreml quantization# extras --------------------------------------# thop # FLOPS computation# seaborn # plotting例如此项⽬需求torch>=1.6在PyTorch官⽹查看与之匹配的CUDA版本这⾥可以从conda命令看出 torch1.6 可以安装10.2版本的CUDAtorch与CUDA版本⼀定要匹配!安装 CUDANVIDIA控制⾯板 -> 帮助 -> 系统信息 -> 组件查看NVCUDA.DLL 后的参数本机是10.2//如果更新了显卡驱动这⾥参数可能会变⾼下载的CUDA版本可以低于这⾥显⽰的参数但是⼀定要与torch版本匹配下载//上⾯的链接默认下载的是最新版本的CUDA要下载之前版本的CUDA在上述下载页⾯下滑然后点击 ”CUDA早期版本档案”或者直接点击跳转选择CUDA Toolkit 10.2选择对应操作系统版本然后点击Download !Installer Type⼀定要选exe(local)安装安装完成在Terminal输⼊以下命令nvcc -V安装cuDNN下载链接选择和操作系统以及CUDA相匹配的cuDNN版本例如我刚才安装了CUDA10.2 这⾥选择安装解压下载的zip把解压得到的⽂件夹内的bin、include、lib⽬录下的dll⽂件与h⽂件分别复制到相应的CUDA的安装⽬录下默认安装⽬录分别为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\binC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\includeC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib安装PyTorch在线安装在PyTorch官⽅链接上查看相应安装命令例如我要安装CUDA10.2版本的torch1.6 对应的conda命令是# CUDA 10.2conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.2 -c pytorch !在线安装速度很慢可以选择下⾯离线安装的⽅法离线安装whl下载链接选择对应CUDA、Python、操作系统、torch版本的whl例如我要安装CUDA10.2、Python3.8、torch1.6 版本的whl应下载例如我要安装CUDA10.2、Python3.8、torchvision0.7 版本的whl 应下载然后在conda环境中安装pip install torch-1.6.0-cp38-cp38-win_amd64.whlpip install torchvision-0.7.0-cp38-cp38-win_amd64.whl安装完成确认环境是否配置成功import torchprint(torch.__version__)print(torch.cuda.is_available())如上所⽰环境配置成功参考及引⽤到此这篇关于PyTorch CUDA环境配置及安装的步骤(图⽂教程)的⽂章就介绍到这了,更多相关PyTorch CUDA配置及安装内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。

I. 安装CUDA 软件包首先安装CUDA 软件包,可以从NVIDIA 官方网站上下载,我选择的是当前的最新版本4.0. 需要下载的东西有3 个,分别是:• 开发驱动(cudatoolkit_4.0.17_win_32.msi)• 工具包(devdriver_4.0_winvista-win7_32_275.33_notebook.exe)• SDK 样例代码(gpucomputingsdk_4.0.19_win_32.exe)需要注意的问题是,这三个工具的版本号一定要匹配、还有就是要跟自己的操作系统和硬件匹配。
网址: /cuda-toolkit-40比如笔记本电脑应选择带有notebook 字样的下载,64 位系统的要选择64 位版本。
下载完成后进行安装,过程比较简单,一路下一步即可。
安装完驱动后需要重启电脑。
II. 安装IDE安装IDE,我选择的是Visual Studio 2008 Team System SP1.(狗狗搜索到的)安装完这些软件后,我们可以开始创建一个CUDA 的程序了。
网上有很多手动配置工程的方法,非常繁琐。
我们基本上都会使用更加自动化的工具:CUDA VS Wizard,这个安装后会在VS 中显示CUDA 的项目模板。
免去了繁琐的手工配置。
这个工具的项目主页是:/projects/cudavswizard/版本为:CUDA_VS_Wizard_W32.2.2.beta1.zip下载的时候一定要根据自己系统的版本来选择32 位还是64 位的版本。
如果操作系统是32 位的,却安装了64 位版本的Wizard,在vs 中创建cuda project 时就会出错。
III. 配置环境安装好Wizard,剩下的工作就比较简单了。
在VS 中建立一个CUDA 工程,按照默认为Console application, 不要选择EmptyProject,建好后直接编译。
顺利的话应该可以编译通过。
CentOS6.0操作系统下CUDA环境配置首先到英伟达的官网上下载必须得软件,包括和操作系统及Tesla卡对应的驱动NVIDIA-Linux-x86_64-270.41.19.run和cudatoolkit(cudatoolkit_4.0.17_linux_64_rhel6.0.run)及cudasdk(gpucomputingsdk_4.0.17_linux.run)显卡驱动安装1首先要关闭图形界面网上看到的方法是ctrl+alt+F1进入命令行,然后输入sudo service gdm stop不过这个方法好像不太管用,所以我们还是用下边的方法吧用su命令切换到root用户下su密码用vi打开inittab文件vi /etc/inittab打开后进入insert模式a(按完a后最底下一行回显示insert)到该文件的最后一行,修改启动的默认模式选项,就是把最后一行的5改成3就行按Esc退出insert模式(最底下的INSERT消失)保存修改并退出vi :wq重新启动reboot -h now这回出来的就是没有图形界面只有黑框框的命令行界面的linux了2 安装驱动在终端进入驱动程序所在目录输入sudo sh NVIDIA-Linux-x86_64-270.41.19.run装好之后要把那个inittab改回来,不然就看不到图形界面了,方法跟上边一样,就是把3改成5就好了cudatoolkit安装我们装的系统是CentOS6.0,与之匹配的cudatoolkit版本是 4.0,就是cudatoolkit_4.0.17_linux_64_rhel6.0.run首先执行指令sudo sh cudatoolkit_3.1_linux_32_ubuntu9.10.run,之后一路回车对环境变量进行配置,执行sudo gedit ~/.bashrc打开文件,在最后添加两行代码:export PATH=$PATH:/usr/local/cuda/binexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64如果是64位系统,上面这句后面加64使用nvcc –V来查看版本号,如果正确则CUDA安装正确cudasdk安装安装之前要保证你的gcc和g++能够使用,gcc和g++,且其版本与你的系统、toolkit、sdk 匹配进入到存放gpucomputingsdk_4.0.17_linux.run的目录下执行sh gpucomputingsdk_4.0.17_linux.run命令,安装过程中注意安装文件的路径,防止装完后找不到文件安装完了之后进入到你安装的文件夹下,进入NVIDIA_GPU_Computing_SDK中的C文件夹下的src文件夹中,选中一个你想要编译的项目打开,在该项目的目录下输入make 命令进行编译,如果成功的话会在NVIDIA_GPU_Computing_SDK/C/bin/linux/release目录下生成可执行文件,进到该目录下输入./ 命令来执行编译好的文件并查看结果。
cuda的安装与配置简介先安装nvidia驱动,然后安装cuda查看显卡型号lspci | grep -i nvidia查看NVIDIA驱动版本sudo dpkg --list | grep nvidia-*N卡驱动安装有以下三种nvidia驱动安装⽅式.集成驱动管理和安装sudo add-apt-repository ppa:graphics-drivers/ppasudo apt-get update通过System Settings->SoftWare & Updates->Additional Drivers 切换安装,推荐安装⾼版本的驱动, 例如410使⽤apt-get install安装sudo add-apt-repository ppa:graphics-drivers/ppasudo apt-get updatesudo apt-get install nvidia-410 nvidia-settings nvidia-prime官⽅驱动编译安装(不太推荐)注:驱动安装后要重启电脑sudo reboot验证安装是否成功查看驱动版本和显卡属性:nvidia-smi查看显卡占⽤情况在终端中输⼊watch -n 10 nvidia-smi注:每隔10秒刷新⼀次终端删除nvidia驱动sudo apt-get --purge remove nvidia-*注意事项有的电脑需要在4.4.168的内核上安装驱动,否则重启后循环进⼊登录界⾯。
cuda安装CUDA Toolkit推荐安装cuda9.0或cuda10.0,⾸先安装cuda,然后安装相应的补丁。
选择Linux -> x86_64 -> Ubuntu -> 16.04 -> runfile(local) 或者deb(local)runfile安装sudo chmod +x cuda_10.0.130_410.48_linux.runsudo ./cuda_10.0.130_410.48_linux.runcat /usr/local/cuda/version.txt注: EULA⽂档阅读, 点击space键会⼀页⼀页翻过,那么阅读完⽂档仅需⼏秒钟即可。
开始接触CUDA,我安装好后完全不知道怎么运行demo,当然也没有见到详细的安装说明。
下面说说我的经验。
Platform:Win XP64IDE:VS20081 获取可访问以下网址:/object/cuda_get.html共需下载3个应用程序,分别是:1>CUDA Driver2>CUDA Toolkit3>CUDA SDK code samples可以选择合适的操作系统,例如我选的是WIN XP 64-bit。
2 安装a)其中CUDA Driver是为了使CUDA和硬件交互,CUDA 2.2中驱动文件版本是185.85,我原来的显卡驱动是17*.*,所以需要安装升级。
b)接下来安装Toolkit,里面是一些头文件和库,nVidia的编译器,还有帮助文档。
安装后,会自动在系统的环境变量里注册路径CUDA_BIN_PATH (defaults to C:\CUDA\bin) contains the compiler executables and runtime libraries.CUDA_INC_PATH (defaults to C:\CUDA\include) contains the include files needed to compile CUDA programs.CUDA_LIB_PATH (defaults to C:\CUDA\lib) contains the libraries needed for linking CUDA codes.c)然后安装SDK,里面有很多示例和模版,可以参照。
安装后进入\NVIDIA CUDA SDK\common文件夹,将Release.sln(2005)或Release_vc90.sln(2008)编译。
新生成的.lib和.dll会在\NVIDIA CUDASDK\common\lib里。
3 使用以Visual Studio 2008 TeamSuite为例:1)文本编辑由于CUDA使用的源文件是.cu文件,因此默认情况下VS不会识别它里面的语法,会把它当成普通的txt文件。
使用VS2005进行cuda开发收藏设置基本环境下载相关的软件:显卡驱动、CUDA Toolkit、CUDA SDK,如果你显卡支持CUDA,请先安装支持CUDA的显卡驱动,之后安装CUDA Toolkit(现在叫CUDA,假设安装在d:\programming\cuda\toolkit目录下),之后安装SDK(假设安装在d:\programming\cuda\sdk 目录下),一般来说安装完后,相应的环境变量都已设置好,包括CUDA_BIN_PATH,CUDA_INC_PATH,CUDA_LIB_PATH等。
配置VisualStudio环境(语法高亮,VA设置等)语法高亮:将d:\programming\cuda\sdk\doc\syntax_highlighting\visual_studio_8里面的usertype.dat文件copy到Microsoft Visual Studio 8\Common7\IDE目录下面(如果已经存在,就追加到原来的后面)。
设置VS2005环境:进入Tools|Options|Projects and Solutions|VC++Directories 添加:Include files:d:\programming\cuda\toolkit\include和d:\programming\cuda\sdk\common\inc Library files:d:\programming\cuda\toolkit\lib和d:\programming\cuda\sdk\common\lib Source files:d:\programming\cuda\sdk\common\src进入VC++ Project Settings:C/C++ File extensions:添加*.cu,在Text editor-File extension:添加cu 对应editor到Microsoft VC++ editor。
目前支持CUDA的显卡下表列出了支持CUDA 的设备的多处理器数量和计算能力:多处理器数量计算能力GeForce GTX 280 30 1.3GeForce GTX 260 24 1.3GeForce 9800 GX2 2×16 1.1GeForce 9800 GTX 16 1.1GeForce 8800 Ultra, 8800 GTX 16 1.0GeForce 8800 GT 14 1.1GeForce 9600 GSO, 8800 GS, 8800M12 1.1GTXGeForce 8800 GTS 12 1.0GeForce 9600 GT, 8800M GTS 8 1.1GeForce 9500 GT, 8600 GTS, 8600 GT,4 1.18700M GT, 8600M GT, 8600M GSGeForce 8500 GT, 8400 GS, 8400M GT,2 1.18400M GSGeForce 8400M G 1 1.1Tesla S1070 4×30 1.3Tesla C1060 30 1.3Tesla S870 4×16 1.0Tesla D870 2×16 1.0Tesla C870 16 1.0Quadro Plex 1000 Model S4 4×16 1.0Quadro Plex 1000 Model IV 2×16 1.0Quadro FX 5600 16 1.0Quadro FX 3700 14 1.1Quadro FX 3600M 12 1.1Quadro FX 4600 12 1.0Quadro FX 1700, FX 570, NVS 320M, FX1600M,4 1.1FX 570MQuadro FX 370, NVS 290, NVS 140M,2 1.1NVS 135M, FX 360MQuadro FX 370M ,Quadro NVS 130M 1 1.1查看自己的电脑拥有那一款GPU的方法:适用于Windows平台的计算机:1.右击桌面。
CUDA 工程配置
by vampirefa n
1.安装
VS2008+VS2008 SP1(工具Parallel Nsight需要)
CUDA Driver(对应的或最新的显卡驱动)
CUDA Toolkit (3.2以上)
GPU Computing SDK (3.2以上)
安装完成后确认计算机的环境变量
CUDA_BIN_PATH %CUDA_PATH%\bin
CUDA_INC_PATH %CUDA_PATH%\include
CUDA_LIB_PATH %CUDA_PATH%\lib\x64 (64位和32位的有点不同)
CUDA_PATH C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v3.2\ CUDA_PATH_V3_2 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v3.2\ CUDA_PATH_V4_0 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v4.0\ NVSDKCOMPUTE_ROOT C:\ProgramData\NVIDIA Corporation\NVIDIA GPU Computing SDK 3.2
2.简单测试
运行GPU Computing SDK中Device Query示例程序,运行良好。
3.编译测试
打开GPU Computing SDK中Device Query示例程序的源代码,编译运行。
遇到错误:
[错误fatal error LNK1181: 无法打开输入文件”cutil32D.lib”]
解决办法:
打开\NVIDIA GPU Computing SDK 3.2\shared中shrUtils_vc90程序,批生成
打开\NVIDIA GPU Computing SDK 3.2\C\common中Release_vc90程序,批生成
重新编译运行Device Query示例程序的源代码,编译成功,运行正常。
4.建立工程
新建一个空的Win32控制台应用程序工程。
将Device Query示例程序的源代码deviceQuery.cpp加入工程。
4.1右键工程->自定义生成规则->选择一个CUDA API作为生成规则
4.2右键工程->属性->配置属性
->C/C++->常规->附加包含目录
$(CUDA_PATH)/include;./;$(NVSDKCOMPUTE_ROOT)/C/common/inc;$(NVSDKCOMPUTE_ROOT)/ shared/inc
->C/C++->代码生成->运行库
设置为多线程调试(/MTd)
->链接器->常规->附加库目录
$(CUDA_PATH)/lib/$(PlatformName); $(NVSDKCOMPUTE_ROOT)/C/common/lib; $(NVSDKCOMPUTE_ROOT)/shared/lib
->链接器->输入->附加依赖项
cudart.lib cutil32D.lib shrUtils32D.lib
4.3编译运行此工程
运行结果和示例相同。
5.建立带有MFC的工程
5.1建立VC++中CLR中的Windows窗体应用程序
5.2将已有的工程源代码加入到工程中
5.3自定义生成规则->选择一个CUDA API作为生成规则
5.4工程属性
->通用属性->框架和引用
确认引用库完整
->配置属性->常规->公共语言运行是支持
公共语言运行时支持(/clr)
->C/C++->常规->附加包含目录
$(CUDA_PATH)/include;./;$(NVSDKCOMPUTE_ROOT)/C/common/inc;$(NVSDKCOMPUTE_ROOT)/ shared/inc
->C/C++->优化
禁用(/Od)
->C/C++->预处理器->预处理器定义
WIN32;_DEBUG;_CONSOLE
->C/C++->代码生成->运行库
多线程调试DLL (/MDd)
->C/C++->预编译头
不使用预编译头
->链接器->常规->启用增量链接
否(/INCREMENTAL:NO)
->链接器->常规->附加库目录
$(CUDA_PATH)/lib/$(PlatformName); $(NVSDKCOMPUTE_ROOT)/C/common/lib; $(NVSDKCOMPUTE_ROOT)/shared/lib
->链接器->输入->附加依赖项
cudart.lib cutil32D.lib
->链接器->系统
控制台(/SUBSYSTEM:CONSOLE)
->链接器->高级->入口点
把main删掉
->链接器->高级->随机基址
禁用映像随机化(/DYNAMICBASE:NO)
->链接器->高级->数据执行保护(DEP)
默认值
CUDA Runtime API->Host->Optimization
Disabled (/Od)
CUDA Runtime API->Host->Runtime Library
Multi-Threaded Debug DLL (/MDd)
CUDA Runtime API->Host->Basic Runtime Checks
Both (/RTC1, equiv. to /RTCsu)
5.5编译运行此工程
运行结果和预期相同。
6.使用Parallel Nsight双机调试
6.1安装
在已有的CUDA环境下安装Parallel Nsight 2.0
参看官方User Manual
/ParallelNsight/2.00/UserGuide/HTML/webframe.html
6.2远程调试配置
工程属性->CUDA Runtime API->GPU->Generate GPU Debug Information
是(-G0)
Monitor->General->WDDM TDR enabled
false
Monitor->Analysis->Report Directory
和调试机工作目录相同
Monitor->Security->General->Enable secure server
false
Target Machine->Launch Options->Connection name
监视机计算机名称
7.可能遇到的错误
●【fatal error C1083: 无法打开包括文件:“shrUtils.h”】
没有在C/C++附加库目录中加入CUDA头文件目录
●【fatal error LNK1104: 无法打开文件“glut32.lib”】
没有在链接器附加库目录中加入CUDA库目录
●【error LNK2019: 无法解析的外部符号_shrLogEx,该符号在函数_main 中被引用】类
似错误
没有在链接器输入的附加依赖项中加入cudart.lib cutil32D.lib shrUtils32D.lib库文件
●【fatal error C1189: #error : ERROR: XMM intrinsics not supported in the pure mode!】
配置属性->公共语言运行是支持设置有问题
●【error LNK2005: "public: __thiscall std::basic_string<char,struct std::char_traits<char>,class
std::allocator<char> >::~basic_string<char,struct std::char_traits<char>,class std::allocator<char> >(void)"
(??1?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@std@@QAE@XZ) 已经在msvcprtd.lib(MSVCP90D.dll) 中定义】类似错误
8.必要更改的参数选项
CUDA Runtime API->GPU->GPU Architecture
GPU的计算能力
其他一些参数选项。