
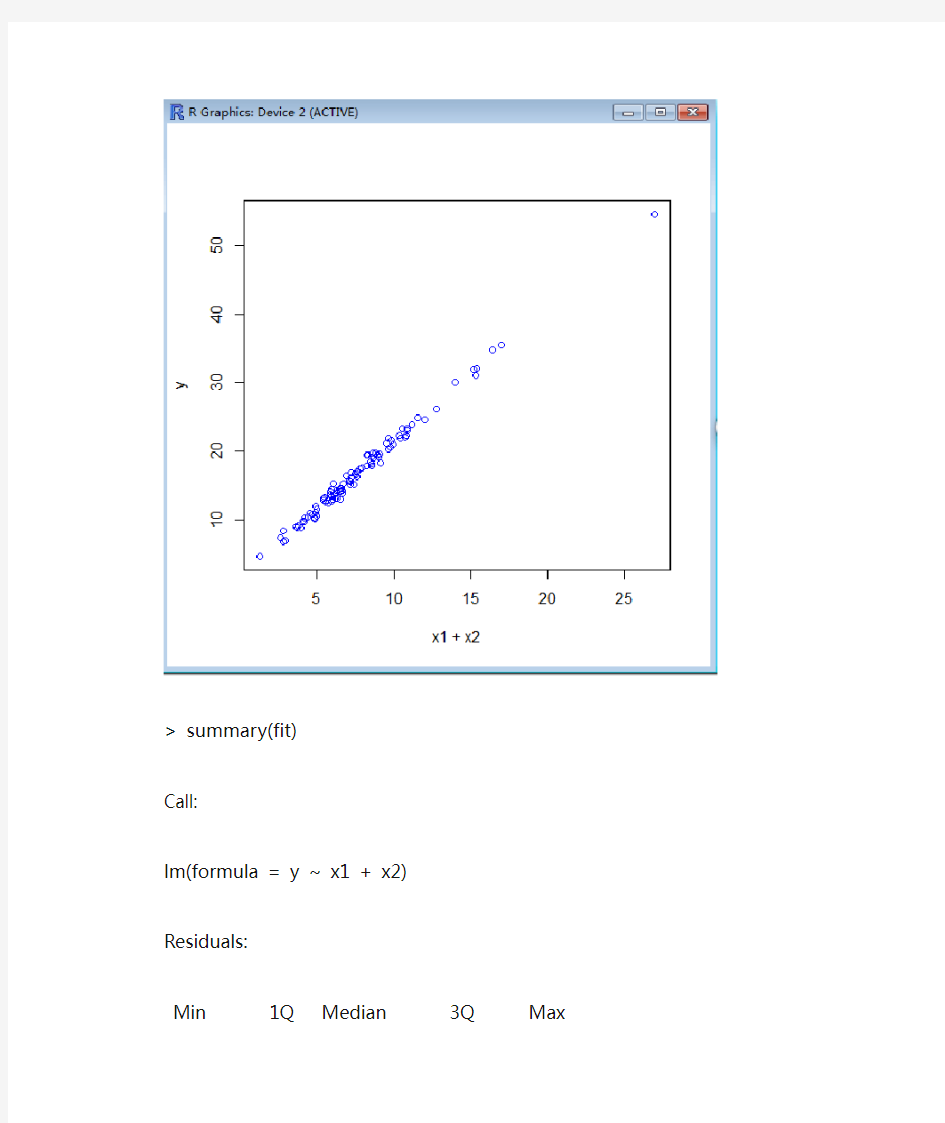
自编R程序计算判定系数
> x1=rchisq(100,6)
> x2=rnorm(100,2,1)
> err=rnorm(100,0,0.5)
> y=2.5+2*x1+1.5*x2+err
> plot(x1+x2,y,col=4)
> lm(y~x1+x2)
> fit=lm(y~x1+x2)
> summary(fit)
Call:
lm(formula = y ~ x1 + x2)
Residuals:
Min 1Q Median 3Q Max -1.30115 -0.32732 0.05836 0.26329 1.20733
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.53643 0.15610 16.25 <2e-16 ***
x1 1.99801 0.01415 141.18 <2e-16 ***
x2 1.48427 0.06030 24.61 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.5009 on 97 degrees of freedom
Multiple R-squared: 0.9953, Adjusted R-squared: 0.9952
F-statistic: 1.018e+04 on 2 and 97 DF, p-value: < 2.2e-16
有上述回归分析可知:判定系数R^2=0.9953 调整后的R^2为0.9952 下面自己编程进行验证:
> RSS=sum(fit$residuals^2)
> RSS
[1] 24.33994
> TSS=var(y)*(length(y)-1)
[1] 5131.309
> ESS=TSS-RSS
> ESS
[1] 5106.97
> r_squared=ESS/TSS
> r_squared
[1] 0.9952566
> adjustedr_squared=1-(1-r_squared)*(length(y)-1)/(length(y)-2)
> adjustedr_squared
[1] 0.9952082
由此可见0.9952566≈0.9953
0.9952082≈0.9952
则r_squared =Multiple R-squared
adjustedr_squared= Adjusted R-squared
Test<-function(RE,Y)
+ { RSS=sum(RE)
+ TSS=var(Y)*(length(Y)-1)
+ ESS=TSS-RSS
+ r_squared=ESS/TSS
+ return(r_squared)}
> Test(r,y)
相关系数是变量之间相关程度的指标。样本相关系数用r表示,总体相关系数用ρ表示,相关系数的取值一般介于-1~1之间。相关系数不是等距度量值,而只是一个顺序数据。计算相关系数一般需大样本. 相关系数又称皮(尔生)氏积矩相关系数,说明两个现象之间相关关系密切程度的统计分析指标。 相关系数用希腊字母γ表示,γ值的范围在-1和+1之间。 γ>0为正相关,γ<0为负相关。γ=0表示不相关; γ的绝对值越大,相关程度越高。 两个现象之间的相关程度,一般划分为四级: 如两者呈正相关,r呈正值,r=1时为完全正相关;如两者呈负相关则r呈负值,而r=-1时为完全负相关。完全正相关或负相关时,所有图点都在直线回归线上;点子的分布在直线回归线上下越离散,r的绝对值越小。当例数相等时,相关系数的绝对值越接近1,相关越密切;越接近于0,相关越不密切。当r=0时,说明X和Y两个变量之间无直线关系。 相关系数的计算公式为<见参考资料>. 其中xi为自变量的标志值;i=1,2,…n;■为自变量的平均值, 为因变量数列的标志值;■为因变量数列的平均值。 为自变量数列的项数。对于单变量分组表的资料,相关系数的计算公式<见参考资料>. 其中fi为权数,即自变量每组的次数。在使用具有统计功能的电子计算机时,可以用一种简捷的方法计算相关系数,其公式<见参考资料>. 使用这种计算方法时,当计算机在输入x、y数据之后,可以直接得出n、■、∑xi、∑yi、∑■、∑xiy1、γ等数值,不必再列计算表。 简单相关系数: 又叫相关系数或线性相关系数。它一般用字母r 表示。它是用来度量定量变量间的线性相关关系。 复相关系数: 又叫多重相关系数
相 关 系 数 r AB 的 计 算 公 式 的 推 导 设 A i 、 B i 分别表示证券 A 、证券 B 历史上各年获得的收益率; A 、 B 分别表示证券 A 、证券 B 各 年获得的收益率的平均数; P i 表示证券 A 和证券 B 构成的投资组合各年获得的收益率,其他符号的含义 同上。 2 = 1A n 1 2 = 1B n 1 2 1 P = 1 n = 1 n 1 = 1 n 1 = 1 n 1 = 1 n 1 =A 2 A × =A 2 2 A A ( A i A) 2 (B i B) 2 (P i 1 P i ) 2 n 1 [( A A A i A B B i ) ( A A A i A B B i )]2 n [( A A A i A B B i ) (A A A A B B)] 2 [ A A ( A i A) A B (B i B)] 2 [ 2 ( A i ) 2 2 ( B i B ) 2 2 A A A B ( A i )( B )] A A A A B A B i ( A i A) 2 A B 2 × ( B i B) 2 2A A A B [( A i A)( B i B)] n 1 n 1 n 1 2 2 2A A A B [( A i A)( B i B)] A B B n 1 对照公式( 1)得: ( A i A) 2 (B i B) 2 = × n × r AB n 1 1 ∴ r AB = [( A i A)( B i B)] ( A i A)2 (B i B) 2 这就是相关系数 r AB 的计算公式。 投资组合风险分散化效应的内在特征 1. 两种证券构成的投资组合为最小方差组合(即风险最小)时各证券投资比例的测定 公式( 1)左右两端对 A A 求一阶导数,并注意到 A B =1—A A : 2 2 2 A B r AB ( P )′=2A A A -2(1 -A A ) B + 2 (1 - A A ) A B r AB -2A A 令 ( P 2 )′=0 并简化,得到使 P 2 取极小值的 A A : 2 B r AB A A = B A ( 3) 2 2 2 A B r AB A B 式中,0 ≤ A A ≤ 1, 否则公式( 3)无意义。
附件1: 差异系数测算说明 一、测算范围 差异系数测算的对象为县域内义务教育阶段学校,包括小学、一贯制学校、初级中学、完全中学,不含省(市)直属学校、民办学校、小学教学点、特殊教育学校和职业学校。其中九年一贯制学校按照“一个小学生:一个初中生=1:1.1”的比例对五项办学条件进行拆分,将小学部、初中部占有部分分别作为小学、初中数据;完全中学按照“一个初中生:一个高中生=1:1.2”的比例进行拆分,将初中部占有部分作为单独一所初中学校数据;十二年一贯制学校,按照“一个小学生:一个初中生:一个高中生=1:1.1:1.32”的比例进行拆分,将其小学部、初中部占有部分分别作为小学、初中数据。 二、测算指标及数据提取来源 县域内义务教育校际间均衡评估,依据国家教育事业统计数据进行差异系数的测算。 差异系数测算涉及8项指标,分别为生均教学及辅助用房、生均体育运动场馆面积、生均教学仪器设备值、每百名学生拥有计算机台数、生均图书册数、师生比、生均高于规
定学历教师数、生均中级及以上专业技术职务教师数。 “学生”均指“具有学籍并在本学年初进行学籍注册的学生”。数据提取来源为教育事业统计报表中的“基础基312小学学生数”表 [行01,列4]、“基础基313初中学生数”表[行01,列3]和“基础基314高中学生数”表[行01,列3]。 (1)生均教学及辅助用房面积 “教学及辅助用房面积”指学校中教室、实验室、图书室、微机室和语音室面积之和(不含体育馆面积)。 数据提取来源:“基础基512表中小学校舍情况”表,[行04,列1]减去[行10,列1]。 (2)生均体育运动场馆面积 “体育运动场馆面积”指学校中的体育馆面积和运动场地面积之和,运动场地面积指学校专门用于室外体育运动并有相应设施所占用的土地面积。 数据提取来源:体育馆面积取“基础基512表中小学校舍情况”表,[行10,列1];运动场地面积取“基础基522表中小学占地面积及其他办学条件”表,[行01,列3]。 (3)生均教学仪器设备值 “教学仪器设备值”指学校固定资产中用于教学、实验等仪器设备的资产值。 数据提取来源:“基础基522表中小学占地面积及其他
线性回归方程中的相关系数r r=∑(Xi-X的平均数)(Yi-Y平均数)/根号下[∑(Xi-X平均数)^2*∑(Yi-Y平均数)^2]
R2就是相关系数的平方, R在一元线性方程就直接是因变量自变量的相关系数,多元则是复相关系数 判定系数R^2 也叫拟合优度、可决系数。表达式是: R^2=ESS/TSS=1-RSS/TSS 该统计量越接近于1,模型的拟合优度越高。 问题:在应用过程中发现,如果在模型中增加一个解释变量,R2往往增大 这就给人一个错觉:要使得模型拟合得好,只要增加解释变量即可。 ——但是,现实情况往往是,由增加解释变量个数引起的R2的增大与拟合好坏无关,R2需调整。 这就有了调整的拟合优度: R1^2=1-(RSS/(n-k-1))/(TSS/(n-1)) 在样本容量一定的情况下,增加解释变量必定使得自由度减少,所以调整的思路是:将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响: 其中:n-k-1为残差平方和的自由度,n-1为总体平方和的自由度。 总是来说,调整的判定系数比起判定系数,除去了因为变量个数增加对判定结果的影响。R = R接近于1表明Y与X1,X2 ,…,Xk之间的线性关系程度密切; R接近于0表明Y与X1,X2 ,…,Xk之间的线性关系程度不密切 相关系数就是线性相关度的大小,1为(100%)绝对正相关,0为0%,-1为(100%)绝对负相关 相关系数绝对值越靠近1,线性相关性质越好,根据数据描点画出来的函数-自变量图线越趋近于一条平直线,拟合的直线与描点所得图线也更相近。 如果其绝对值越靠近0,那么就说明线性相关性越差,根据数据点描出的图线和拟合曲线相差越远(当相关系数太小时,本来拟合就已经没有意义,如果强行拟合一条直线,再把数据点在同一坐标纸上画出来,可以发现大部分的点偏离这条直线很远,所以用这个直线来拟合是会出现很大误差的或者说是根本错误的)。 分为一元线性回归和多元线性回归 线性回归方程中,回归系数的含义 一元: Y^=bX+a b表示X每变动(增加或减少)1个单位,Y平均变动(增加或减少)b各单位多元: Y^=b1X1+b2X2+b3X3+a 在其他变量不变的情况下,某变量变动1单位,引起y平均变动量 以b2为例:b2表示在X1、X3(在其他变量不变的情况下)不变得情况下,X2每变动1单位,y平均变动b2单位 就一个reg来说y=a+bx+e a+bx的误差称为explained sum of square e的误差是不能解释的是residual sum of square
(1)方法一: 在指标设置的时候,加设“完成难度”这一项指标,并赋予一定的权重。比如,公司对销售人员考核指标的设置比较严格,难以完成,而对后勤人员的考核比较宽松。在这种情况下销售人员“完成难度”一项就可以得到较高的分数,而后勤人员得分较低,从而使总体得分更为客观。 (2)方法二: 这种方法是将“完成难度”以“难度系数”的形式单独设立,与考核的结果相乘,来进行修正。比如,某个员工的考核得分为80分,其指标完成的难度系数为1.2,则其最终得分为80*1.2=96分。也可以考虑将每一项目标指标都设置“难度系数”。 (1)方法一: 设立公司的整体绩效基准分(可以是全体员工绩效考核的平均数),对各部门的考核均值和员工的考核得分进行部门差异调整,具体设公司整体绩效基准分为A,如员工绩效考核实际得分为B,该员工所在部门绩效考核平均分为C.则部门差异分及为D=C-A,根据部门差异调整员工绩效考核得分为B1=B-D,员工绩效考核系数可以相应的定为B2= B1/A.这种调整方法是假定部门绩效均维持在一致的水
平上,使部门间绩效相尽的员工考核得分接近,而部门内部则仍保持原由的业绩差异结构。 示例: 某员工甲,绩效考核得分为90分,部门考核平均分为80分,公司基准分为75分,则该员工调整后得分为B1=B-D=B-(C-A)=90-(80-75)=85分。其绩效考核系数可确定为B2= B1/A=85/75=1.13. 与甲同部门的员工乙,绩效考核得分为80分,则调整后考核得分为:B1=80-(80-75)=75分,其绩效考核系数为B2= B1/A=75/75=1. 与甲不同部门的但业绩相近的员工丙,由于部门经理对考核标准把握比较严格,绩效考核得分为80分,其所在部门的平均分为70分,则调整后考核得分为:B1=80-(70-75)=85分,其绩效考核系数为B2= B1/A=85/75=1.13. (2)方法二: 在实行部门考核的公司,为了体现部门绩效与员工绩效的一致性,还可以按以下办法进行调整: 第一,可将部门绩效赋予一定的权重作为员工考核的指标。比如设部门考核在员工考核中占有20%的比重,那么调整后的员工考核得分应为:
Spss电脑实验-第六节(3)线性相关系数的计算 https://www.doczj.com/doc/8e11704693.html,更新时间:2006-1-19 21:11:30 关注指数:7992 Ⅲ.线性相关系数的计算 1. 线性相关的概念 如果各统计指标是定量数据,要了解它们间的关系密切程度,可用线性相关分析。 例如:大家都知道的糖尿病病人,它靠胰岛素来治疗。现测量20 名糖尿病病人(以ID 来编号)血中的血糖值(y)、胰岛素值(x1)和生长激素值(x2)。我们即可分析 y、x1 和x2 间的两两/ 双变量间的线性关系。数据见下面的程序文件CorreRegre2.sps 的例*2。 2. 线性相关计算的所用命令 用SPSS Analyze 菜单中的子菜单Correlate,其中的Bivariate 对话框即可计算两两/ 双变量间的线性相关系数r 及其显著性。这是通常最常见、最常用的情况。 本例所用程序文件名为CorreRegre2.sps 中的例*2。(例*2 中还有用于偏相关系数与距离相关系数的计算命令,详后)。 ---------------------------------------------------------------- *2. Prof. Zhang Weng-Tong: SPSS 11, P.273-277:. DATA LIST FREE /ID y x1 x2. BEGIN DATA. 1 12.21 15.20 9.51 2 14.54 16.70 11.43 3 12.27 11.90 7.53 4 12.04 14.00 12.17 5 7.88 19.80 2.33 6 11.10 16.20 13.52 7 10.43 17.00 10.07 8 13.32 10.30 18.89 9 19.59 5.90 13.14 10 9.05 18.70 9.63 11 6.44 25.10 5.10 12 9.49 16.40 4.53 13 10.16 22.00 2.16 14 8.38 23.10 4.26 15 8.49 23.20 3.42 16 7.71 25.00 7.34 17 11.38 16.80 12.75 18 10.82 11.20 10.88 19 12.49 13.70 11.06 20 9.21 24.40 9.16 END DATA. CORRELATIONS /VARIABLES=y x1 x2 /PRINT=TWOTAIL NOSIG. NONPAR CORR /VARIABLES=y x1 x2 /PRINT=SPEARMAN TWOTAIL NOSIG.
均衡发展计算差异系数填表说明表内数据单位:用房面积单位(㎡)、体育场单位(㎡)、教学仪器单位(万元)、计算机(台)、图书(册)、师生比(教师数)、规定学历(教师数)、职称(教师数)。 (1)“生均建筑面积”,省定标准为小学生均不低于5.2㎡,初中生均不低于 6.4㎡;全寄宿制生均初中、小学分别不低于13.13、15.31㎡。 小学生均:(6班8.25㎡、12班6.8㎡、18班5.9㎡、24班5.5㎡、30班5.2㎡、36班5㎡)。初中生均(12班7.9㎡、18班7.1㎡、24班6.7㎡、30班6.4㎡、36班6㎡)。 (2)运动场地: (一)非完全小学。设置60米直跑道田径场地一块和200平方米游戏场地一块。 (二)完全小学体育场地配置要求见表5。 表5 完全小学体育场地配置要求 (三)初级中学体育场地配置要求见表7。
表7 初级中学体育场地配置要求 注:1.300米以上的环形田径场应包括100米的直跑道,200m的环形田径场应至少包括60米直跑道。 2.田径场内应设置1~2个沙坑(长5~6米、宽2.75~4米,助跑道长 25~45米)。环形田径场内应设置为足球场所。 3.器械场地学校可根据实际条件进行集中或分散配备。 4.因受地理环境限制达不到标准的山区学校,可因地制宜建设相应的体育 活动场地。 (3)“小学(初中)数学、科学(理科)仪器”,根据我省《实施办法》规定,省定标准:小学、初中均为《河南省中小学教育技术装备标准(试行)》第一种配备方案规定标准。 小学科学实验室:(1个标准实验室)一、台凳4万元,二、仪器柜30个,2.4万元。三、小学科学、数学仪器6万元,总计:12.4万元。 小学科学实验室配备标准:6-18班1个实验室,24-36班2个实验室。 初中理化生实验室:(1个标准理化生实验室)一、物理台凳4万元,化学、生物台凳各4.5万元,计13万元。二、仪器柜91个,7.3万元。三、理化生、数学、地理仪器24万元,总计:44.3万元。 初中理化生实验室配备标准:12-18班3个实验室,24班4个实验室,30班5个实验室,36班6个实验室。
05修正系数计算方法及表格 注:各地区标准不同 综合用地修正系数体系 一、综合用地深度修正 综合用地路线价深度修正系数表 二、综合用地宽深比修正综合用地路线价宽深比修正系数表 三、综合用地容积率修正
注:当容积率W 2.0时,容积率修正系数为1,当容积率〉10?0,容积率修正系数为1.978四、综合用地使用年期修正
五、综合用地街角地修正分两种情况: 1.旁街附设有路线价时,街角地修正计算公式为:地价二正街地价+旁街地价X 修正系数 综合用地路线价街角地修正系数表 2.若街角地只有正街路线价而无旁街路线价,则旁街的影响按下列公式计算:地价二正街地价 +正街地价x 修正系数 综合用地路线价街 角地无旁街路线价修正系数表 六、两面临街地修正 对两面临街的宗地,釆用“重叠价值法”即划分高价街与低价街影响范围的分界点(亦称合致点) ,以 合致线(合致点的连接线)将宗地分为两部分,各部分按其所面临的路线价分别计算地价,然后加总。其计算公式如下: V 二(Uh x dVh x fh ) + (U1 x dVl x fl ) 其中:V ------- 待估宗地地价 佈 ------ 高价街路线价 dVh ——高价街临街深度修正系数 fh ------- 高价街步行街宽深度修正系数 U1 ------ 低价街路线价 dVl ------- 低价街临街深度修正系数 fl ——低价街临街宽深比修正系数 高、低价街临街深度修正系数根据高、低价街的影响深度确定。 高价街路线价 高价街影响深度二 ------------------------------------------- X 全部深度 高价街路线价+低价街路线价 低价街路线价 低价街影响深度二? 舟价街路线价+低价街路线价 X 全部深度
实用标准 文档大全基准地价修正系数表及说明表的编制 基准地价修正系数表是采用替代原理,建立基准地价、宗地地价及其影响因素之间的相关关系,编制出基准地价在不同因素条件下修正为宗地地价的系数体系,以便能在宗地条件调查的基础上,按对应的修正系数,快速、高效、及时地评估出宗地地价。 一、基准地价修正幅度值的计算 以土地级别为单位,以各级别中最高、最低定级因素总分值所对应的单元地价作为上、下限值,分别与相应级别的基准地价相减,得到上调或下调的最高值。计算公式如下: 上调幅度计算公式: F1=[(I nh—I ib)/I ib]×100% (10-1)下调幅度计算公式: F2=[(I nb—I nl)/I ib]×100% (10-2)式中:F1 --基准地价上调最大幅度; F2 --基准地价下调最大幅度; I ib --级别基准地价; I nh --级别单元总分上限值所对应的地价; I nl --级别单元总分下限值所对应的地价。 根据前述确定的单元总分值、基准地价评估结果及其关系模型,按公式9-1、9-2可以计算出各类各级基准地价修正幅度值。结果见表10-4、10-5、10-6。 表10-4 商业用地基准地价最大上调、下调幅度计算表
二、因素修正系数值的计算及修正系数表及说明表的编制 (一)因素修正系数值计算 根据确定的影响各类用地价格的因素及其权重值,采用下式计算各因素的修正值: F1i=F1×W i(10-3) F2i=F2×W i(10-4)
式中:F1i—某一因素的上调幅度;F2i—某一因素的下调幅度; F1—基准地价上调幅度;F2—基准地价下调幅度; W i—某一因素对宗地地价的影响权重。 (二)因素修正系数及指标说明表的编制 根据基准地价修正幅度的计算结果,在按公式10-3、10-4计算因素修正幅度值的基础上,按优、较优、一般、较劣、劣等5个层次设定修正幅度值,分地类按级别编制修正系数表。 在此基础上,进一步编制影响因素修正系数条件指标表。因素修正系数指标说明表是对各层次的修正系数对应的地价影响因素状态条件所做的描述,通常以在一定区域或土地级别围地价影响因素的最佳状态指标、平均状态指标、最差状态指标分别对应着优、一般、劣等层次的修正系数。利用土地定级中各影响因素的评价结果,在进行统计分析的基础上,编制影响因素修正系数条件指标表,结果见表10-7~36。
相 关 系 数 r AB 的计算公式的推导 设A i 、B i 分别表示证券A 、证券B 历史上各年获得的收益率;A 、B 分别表示证券A 、证券B 各年获得的收益率的平均数;P i 表示证券A 和证券B 构成的投资组合各年获得的收益率,其他符 号的含义同上。 2 A σ=1 1-n 2)(∑-A A i 2 B σ=1 1-n )(B B i -∑2 2 P σ= 12)1(-i i P P 公式(1)左右两端对A A 求一阶导数,并注意到A B =1—A A : (2P σ)′=2 A A 2A σ-2 (1-A A )2B σ+2 (1-A A )B A σσ r AB -2A A B A σσ r AB 令 (2P σ)′= 0 并简化,得到使2 P σ取极小值的A A : A A =AB B A B A AB B A B r r σσσσσσσ22 22-+- … …………………………………(3) 式中, 0≤A A ≤1,否则公式(3)无意义。 由于使(2P σ)′=0的A A 值只有一个,所以据公式(3)计算出的A A 使2 P σ为最小值。
以上分析清楚地说明:对于证券A和证券B,只要它们的系数r AB 适当小(r AB 的“上限”的 计算,本文以下将进行分析),由证券A和证券B构成的投资组合中,当投资于风险较大的证券B 的资金比例不超过按公式(3)计算的(1—A A ),会比将全部资金投资于风险较小的证券A的方 差(风险)还要小;只要投资于证券B的资金在(1—A A )的比例范围内,随着投资于证券B的资 金比例逐渐增大,投资组合的方差(风险)会逐渐减少;当投资于证券B的资金比例等于(1—A A )时,投资组合的方差(风险)最小。这种结果有悖于人们的直觉,揭示了风险分散化效应的内在特征。按公式(3)计算出的证券A和证券B的投资比例构成的投资组合称为最小方差组合,它是证券A和证券B的各种投资组合中方差(亦即风险)最小的投资组合。
如何理解参数的修正系数? 统计修正系数计算时,公式括号中的正负号如何选择?不利组合具体情况下怎么考虑?除了抗剪强度取负值外,还有那些指标通常取负值或那些指标可以取负值?另外,统计修正系数一般情况下在0.75-1之间,如果计算出来是负数或大于1,是不是计算结果就不能用了呢? 对于岩土参数的统计规范有规定,对于原住测试该怎么统计呢,是按照规范的公式,还是按平均值-1.645σ? 答复: 《岩土工程勘察规范》(GB50021-2001)给出了岩土参数标准值φk 的计算公式: 式中正负号的选用取决于指标的性质,如对于抗剪强度指标,应取负号。为什么对抗剪强度标准这样的参数需要取负号呢?什么指标需要取正号呢?这还必须从概率统计的基本原理说起。 统计修正系数是对土性指标的平均值因变异性而进行的修正,平均值乘以修正系数以后称为标准值,标准值是具有概率意义的代表性数值或者称为取用值。 岩土参数的标准值是岩土工程设计的基本代表值,是岩土参数的可靠性估值。对岩土设计参数的估计,实质上是对总体平均值作置信区间估计。在勘察工作中取土试样或者作原位测试测定岩土的性状和行为,其目的是希望了解岩土体的总体的性状和行为,取土试验或作测试工作是一种抽样的手段,而非目的。抽样所得的子样,包括试验的结果和原位测试的结果都是抽样得到的子样,这些子样并非我们的终极目标。例如,我们取土作三轴试验,求得的强度指标仅是所取的土样的性状,这些指标在多大程度上反映了整个土层的实际性状呢?我们感兴趣的不是几筒土样,而是整个土层,需要了解的是整个土层强度的平均趋势,也就是需要了解强度指标的总体。如何从子样的数据中得出关于总体的结论呢?这种方法在统计学中称为统计推断,就是从有限的样品的结果出发来估计总体的特征,从特殊的抽样数据来推断一般的总体特征的方法。 在采用统计学区间估计理论基础上,可以得到的关于参数总体平均值置信区间的单侧置信界限值:
设A i 、B i 分别表示证券A 、证券B 历史上各年获得的收益率;A 、B 分别表示证券A 、证券B 各年获得的收益率的平均数;P i 表示证券A 和证券B 构成的投资组合各年获得的收益率,其他符号的含义同上。 2 A σ= 11 -n 2)(∑-A A i 2 B σ=1 1-n )(B B i -∑2 2 P σ=11-n 2)1(∑∑-i i P n P =2)](1 )[(11i B i A i B i A B A A A n B A A A n +-+-∑∑ =2)]()[(1 1 B A A A B A A A n B A i B i A +-+-∑ =2)]()([1 1 B B A A A A n i B i A -+--∑ =)])((2)()([1 122 22B B A A A A B B A A A A n i i B A i B i A --+-+--∑ =A 2 A × 2 2 1 )(B i A n A A +--∑× 1 )] )([(21 )(2 ---+ --∑∑n B B A A A A n B B i i B A i =A 1 )])([(22 2 2 2---? ++∑n B B A A A A A i i B A B B A A σσ 对照公式(1)得: = 1 )(2 --∑n A A i × 1 )(2 --∑n B B i × r AB ∴ r AB = ∑∑∑-?---2 2 ) ()()] )([(B B A A B B A A i i i i 这就是相关系数r AB 的计算公式。 投资组合风险分散化效应的内在特征 1.两种证券构成的投资组合为最小方差组合(即风险最小)时各证券投资比例的测定 公式(1)左右两端对A A 求一阶导数,并注意到A B =1—A A : (2 P σ)′=2 A A 2 A σ-2 (1-A A )2 B σ+2 (1-A A )B A σσ r AB -2A A B A σσ r AB 令 (2 P σ)′= 0 并简化,得到使2 P σ取极小值的A A : AB B A i i r n B B A A σσ =---∑1 )])([(
全区可采:全部或基本全部可采; 大部分可采:局部可采~全区可采; 局部可采:有1/3左右分布比较集中的面积。 零星可采:面积很小,或分布零星,不便或不能被开发利用。 厚度:全层厚度、纯煤厚度、采用厚度(即估算厚度)。 全层厚度:包括夹矸,但不包括岩浆岩。用于研究煤层沉积环境、赋存规律、煤层对比。 采用厚度:即估算厚度,用于煤层可采程度评价(全区可采、大部分可采、局部可采)和估算资源储量。
钻孔控制可采、局部可采煤层情况一览表表4-2-3
一、采用厚度与全层厚度的区别 采用厚度主要用于煤层可采程度评价和估算煤层的资源量。 在研究煤层的沉积环境、赋存规律、煤层对比时,以考虑煤层的全层厚度为宜。 二、含煤系数: 含煤系数= 各煤层平均煤厚之和 ×100% 地层总厚度 三、可采煤层的煤厚与平均煤厚: 可采煤层的煤厚与平均煤厚应包括夹矸在内,因为在研究煤层的沉积环境、赋存规律、煤层对比时,以考虑煤层的全层厚度为宜。沉缺点、冲刷点、火侵点煤厚为0,当有岩浆岩夹矸时,应将岩浆岩夹矸扣除在外。 三、可采煤层的可采性指数(Km 为小数,一般取小数点后两位): 可采性指数(Km )= 可采点数(n ′) 见煤点数(n ) n ——井田内参与煤厚评价的见煤点总数(不包括沉缺、冲刷、火侵,要求分布均匀,有代表性) n ′——煤层采用厚度≥最低可采厚度的见煤点数 注:沉缺点、冲刷点、火侵点为非见煤点,不参与统计 四、可采煤层的煤厚变异系数(r 为百分数,一般取不保留小数): (注:这里用的煤厚是指的煤层全厚度) %100?=M S r M ——井田内的平均煤厚 S ——均方差 煤层平均厚度公式 n M M M M M n ++++= 321 1 ) (1 2 --= ∑=n M M S n i i
2009年度中国大陆地区城市薪酬差异系数报告 一、城市薪酬差异系数的概念 中国是一个幅员广阔、地大物博的国家,各地经济发展水平有着较大的差距。受经济发展不同水平的影响和限制,各地区间薪酬水平有着较大的差距。为鼓励员工接受在中国境内的流动,企业针对不同的地区、不同的城市制定不同的薪酬方案。为帮助 企业更加直观、准确的了解中国各地的薪酬水平以及之 间的差异,太和顾问特制定城市薪酬差异系数(CDI)的 概念。 城市薪酬差异系数(CDI),将有利于企业在制定薪酬 政策时寻找到更加贴近于本地实际情况的薪资数字。由 于所在的不同城市生活水平有着较大的差别,公司向员 工发放的薪酬其单位货币的实际购买能力有着较大的差 别。而一家公司在实际制定薪酬政策、确定整体薪资定 位及制定具体岗位的薪酬给付水平时,除了考察市场薪 酬信息以外,还必须结合上述谈及的本地区实际状况进 行调整。 二、城市薪酬差异系数的计算方法 城市薪酬差异系数是根据太和顾问每年在中国大陆地区内开展的薪酬调研收集到的数据为主要依据,参考国家、各城市、各地区统计局公布的社会平均工资,并且利用统计模型找出与城市薪酬差异高度相关的反应城市经济发展水平的指标,它们是国内城市GDP、各地区居民消费价格指数、社会消费品零售额、城镇居民人均可支配收入、城乡居民储蓄年末余额、职工工资总额等重要指标,这些指标的选取具有一定的代表性及可操作性;最后参考各地人均消费水平,以年度现金总收入为计算口径,综合计算得出的。 选取影响城市差异系数因素的统计模型: Y=β 0+β i X i+ε 其中,Y是薪酬数据,X i是影响薪酬的变量因素(如国内城市GDP、各地区CPI等),β0,βi是该模型的估计系数,ε是模型的估计误差。 最终选取的指标是太和顾问的薪酬调研数据、国家统计局发布的社会平均工资、国内城市GDP、各地区居民消费价格指数、社会消费品零售额、城镇居民人均可支配收入、城乡居民储蓄年末余额、职工工资总额共8个指标。 太和顾问在计算城市薪酬差异系数时,将北京设定为基准薪酬水平城市,其他各城市、区域将以北京为参考依据进行对比计算,从而得出当地的薪酬差异系数。当然,太和顾问也可以根据企业的实际需要,以企业要求的城市设为基准薪酬水平城市,从而计算出城市薪酬差异系数。 因此,城市薪酬差异系数的计算公式可以理解为: F(CDI)=f(X i)
第三章附录:相关系数r的计算公式的推导 -CAL-FENGHAI.-(YICAI)-Company One1
相关系数r AB 的计算公式的推导 设A i 、B i 分别表示证券A 、证券B 历史上各年获得的收益率;A 、B 分别表示证券A 、证券B 各年获得的收益率的平均数;P i 表示证券A 和证券B 构成的投资组合各年获得的收益率,其他符号的含义同上。 2 A σ=1 1-n 2)(∑-A A i 2 B σ=1 1-n )(B B i -∑2 2 P σ=11-n 2)1(∑∑-i i P n P =2)](1 )[(11i B i A i B i A B A A A n B A A A n +-+-∑∑ =2)]()[(1 1 B A A A B A A A n B A i B i A +-+-∑ =2)]()([1 1 B B A A A A n i B i A -+--∑ =)])((2)()([1122 22B B A A A A B B A A A A n i i B A i B i A --+-+--∑ =A 2 A × 22 1 )(B i A n A A +--∑× 1 )] )([(21 )(2 ---+ --∑∑n B B A A A A n B B i i B A i =A 1 )])([(22222 ---? ++∑n B B A A A A A i i B A B B A A σσ 对照公式(1)得: = 1 )(2 --∑n A A i × 1 )(2 --∑n B B i × r AB ∴ r AB = ∑∑∑-?---2 2 ) ()()])([(B B A A B B A A i i i i 这就是相关系数r AB 的计算公式。 投资组合风险分散化效应的内在特征 1.两种证券构成的投资组合为最小方差组合(即风险最小)时各证券投资比例的测定 公式(1)左右两端对A A 求一阶导数,并注意到A B =1—A A : (2P σ)′=2 A A 2A σ-2 (1-A A )2B σ+2 (1-A A )B A σσ r AB -2A A B A σσ r AB 令 (2P σ)′= 0 并简化,得到使2P σ取极小值的A A : A A =AB B A B A AB B A B r r σσσσσσσ22 22 -+- … …………………………………(3) AB B A i i r n B B A A σσ =---∑1 )])([(
利用Excel 对相关系数的计算 计量检定要求客观、公正、科学、准确、可靠。当计量检定过程都按要求完成后,还得严格的按照规程给定的公式进行计算。一些比较繁琐的计算对于计量工作者来说既耗时也容易出错,常常需要反复计算来验证数据的准确性,这在数据后期处理过程中占用了大量的时间和人力。 以相关系数的计算为例,测量质量浓度为2.0、4.0、6.0、8.0、10.0g/L 的标准溶液的吸光度值分别为0.168、0.335、0.507、0.675、0.837Abs ,假如直接用给定的公式进行计算显得相当复杂,本文在此不再加以赘述。 ??? ? ??? ?- ??????? ?- - = ∑∑∑∑∑ ∑∑N y y N x x N y x xy r 2 22 2 )()( (1) r ——相关系数,x ——浓度,y ——吸光度值, N ——各浓度点数 为了更好地解决计算中遇到的实际问题,利用Excel 自带的函数公式、图表向导等功能或者自己编辑计算公式进行计算,使得一些比较繁琐的计算变得更简单、快捷、准确。 方法1:图表向导法 第一步:打开Microsoft Excel 新建工作簿,在A1:A5,B1:B5分别输入浓度值和吸光度值。 图1所示
图1 第二步:选中A1:B5,选择“插入→图表”,在图表类型(c):选择“XY散点图”,子图表类型(T):选择“平滑线散点图”。图2所示 图2 第三步:单击下一步,下一步,得到图表选项图。图3所示
图3 第四步:单击图三所示的“完成”,得到散点系列。图4所示 图4 第五步:选中散点系列,右键→添加趋势线,类型:选择“线性(L)”,选项:选择“显示公式(E)”、“显示R平方值(R)”。图5、图6所示
三种常用的不同变量之间相关系数的计算方法 1.定类变量之间的相关系数. 定类变量之间的相关系数,只能以变量值的次数来计算,常用λ系数法, 其计算公式为: (3.2.12) 式中,为每一类x中y分布的众数次数;为变量y各分类次数的众数次数;n为总次数。一般来说,λ系数在0~1之间取值,值越大表明相关程度越高。 例如,性别与对吸烟的态度资料见表3—2。 表3—2 性别与对吸烟态度 态度y 性别x 男女合计(Fy) 容忍反对37 15 8 42 45 57 合计(Fx)52 50 102 从y的分布来看,对吸烟的态度众数是“反对”,众数次数为57,即=57。再从x的每 一个分组(男、女)中y的次数分布来看,男性中y的分布众数是“容忍”,次数为37(f1m);女性中y的分布众数是“反对”,次数为42(f2m);总次数为102(n)。于是, 从计算结果可知,性别与对吸烟态度的相关程度为0.49,属于中等相关。 2.定序变量之间的相关系数
定序变量之间的相关测量常用Gamma系数法和Spearman系数法。Gamma系数法计算公式为: (3.2.13) 式中,G为系数;Ns为同序对数目;Nd为异序对数目。 所谓序对是指表明高低位次的两两配对,如果一对个案在变量x,y的分类表现位次一致,则为同序对;如果位次相反,则为异序对。 G系数取值在—1--十1之间。G=1,表示完全正相关;G=-1,表示完全负相关;G=0,表示完全不相关;-1 相关系数r AB 的计算公式的推导 设A i 、B i 分别表示证券A 、证券B 历史上各年获得的收益率;A 、B 分别表示证券A 、证券B 各年获得的收益率的平均数;P i 表示证券A 和证券B 构成的投资组合各年获得的收益率,其他符号的含义同上。 2 A σ=11 -n 2)(∑-A A i 2B σ=11-n )(B B i -∑2 2 P σ=11-n 2)1(∑∑-i i P n P =2)](1 )[(11i B i A i B i A B A A A n B A A A n +-+-∑∑ =2)]()[(11 B A A A B A A A n B A i B i A +-+-∑ =2)]()([11 B B A A A A n i B i A -+--∑ =)])((2)()([1 122 22B B A A A A B B A A A A n i i B A i B i A --+-+--∑ =A 2A × 22 1 ) (B i A n A A +--∑× 1 )] )([(21 )(2 ---+ --∑∑n B B A A A A n B B i i B A i =A 1 )] )([(22222 ---? ++∑n B B A A A A A i i B A B B A A σσ 对照公式(1)得: = 1 )(2 --∑n A A i × 1 )(2 --∑n B B i × r AB ∴ r AB = ∑∑∑-?---2 2 ) ()()] )([(B B A A B B A A i i i i 这就是相关系数r AB 的计算公式。 投资组合风险分散化效应的内在特征 1.两种证券构成的投资组合为最小方差组合(即风险最小)时各证券投资比例的测定 公式(1)左右两端对A A 求一阶导数,并注意到A B =1—A A : (2 P σ)′=2 A A 2A σ-2 (1-A A )2 B σ+2 (1-A A )B A σσ r AB -2A A B A σσ r AB 令 (2P σ)′= 0 并简化,得到使2 P σ取极小值的A A : AB B A i i r n B B A A σσ =---∑1 )])([( 2009年度中国大陆地区城市薪酬差异系数报告一、城市薪酬差异系数的概念 中国是一个幅员广阔、地大物博的国家,各地经济发展水平有着较大的差距。受经济发展不同水平的影响和限制,各地区间薪酬水平有着较大的差距。为鼓 励员工接受在中国境内的流动,企业针对不同的地区、 不同的城市制定不同的薪酬方案。为帮助企业更加直观、 准确的了解中国各地的薪酬水平以及之间的差异,太和 顾问特制定城市薪酬差异系数(CDI)的概念。 城市薪酬差异系数(CDI),将有利于企业在制定薪 酬政策时寻找到更加贴近于本地实际情况的薪资数字。由于所在的不同城市生活水平有着较大的差别,公司向员工发放的薪酬其单位货币的实际购买能力有着较大的差别。而一家公司在实际制定薪酬政策、确定整体薪资定位及制定具体岗位的薪酬给付水平时,除了考察市场薪酬信息以外,还必须结合上述谈及的本地区实际状况进行调整。 二、城市薪酬差异系数的计算方法 城市薪酬差异系数是根据太和顾问每年在中国大陆地区内开展的薪酬调研收集到的数据为主要依据,参考国家、各城市、各地区统计局公布的社会平均工资,并且利用统计模型找出与城市薪酬差异高度相关的反应城市经济发展水平的指标,它们是国内城市GDP、各地区居民消费价格指数、社会消费品零售额、城镇居民人均可支配收入、城乡居民储蓄年末余额、职工工资总额等重要指标,这些指标的选取具有一定的代表性及可操作性;最后参考各地人均消费水平,以年度现金总收入为计算口径,综合计算得出的。 选取影响城市差异系数因素的统计模型: Y=β 0+β i X i+ε 其中,Y是薪酬数据,X i是影响薪酬的变量因素(如国内城市GDP、各地区CPI等),β 0,β i 是该模型的 估计系数,ε是模型的估计误差。 最终选取的指标是太和顾问的薪酬调研数据、国家统计局发布的社会平均工资、国内城市GDP、各地区居民消费价格指数、社会消费品零售额、城镇居民人均可支配收入、城乡居民储蓄年末余额、职工工资总额共8个指标。 太和顾问在计算城市薪酬差异系数时,将北京设定为基准薪酬水平城市,其他各城市、区域将以北京为参考依据进行对比计算,从而得出当地的薪酬差异系数。当然,太和顾问也可以根据企业的实际需要,以企业要求的城市设为基准薪酬水平城市,从而计算出城市薪酬差异系数。 因此,城市薪酬差异系数的计算公式可以理解为: F(CDI)=f(X i) 注:薪酬差异指数将有利于各地区的公司寻找到更加贴近与本地实际情况的薪资数字,帮助公司按照本地区的薪资差异指数进行有效的数据转换,从而更加精确的计算各地薪资给付金额。 三、2009年度全国主要城市薪酬差异系数 义务教育均衡发展差异系数计算方法及数据来源 生均教学及辅助用房面积、生均体育运动场馆面积、生均教学仪器设备值、每百名学生拥有计算机台数、生均图书册数、师生比、生均高于规定学历教师数、生均中级及以上专业技术职务教师数8项指标 (一)差异系数计算方法: 差异系数也叫变异系数或离散系数,是一组数据的标准差与其均值之 比。当考虑到学校规模对均衡程度的影响时,其计算公式表示为: S CV X ??= ??? ,CV 为差异系数,s 为标准差,X 为全县平均数。 式中, S =, i X 表示区县均衡指标体系 中第i 个学校(初中或小学)某个指标值,i i i X x P =, i x 为该指标第i 个学校的原始值,i P 为第i 个学校(初中或小学)的在校生数;X 表示该指标的区县平均值,其中1n i N i X x P ==∑, N P 为区县内所有 初中(或小学)学校的在校生数,1N n i i P P == ∑。 (二)数据提取来源: 计算小学、初中差异系数的相关数据可从教育事业统计报表中提取。独立设置的小学数据在《基础教育学校(机构)统计报表(小学)》,独立设置的初中、完全中学数据在《基础教育学校(机构)统计报表(中学)》,九年一贯制学校、十二年一贯制学校数据在《基础教育学校(机构)统计报 表(九年一贯制学校、十二年一贯制学校)》。 1. 学生 指标说明:具有学籍并在本学年初进行学籍注册的学生。 数据提取来源:小学(包括独立设置的小学、一贯制学校的小学部,下同)学生数据提取来源为教育事业统计报表中的“基础基312小学学生数”表,[行01,列4]。初中(包括独立设置的初中、一贯制学校的初中部、完全中学的初中部,下同)学生数据提取来源为教育事业统计报表中的“基础基313初中学生数”表,[行01,列3]。 2.教学及辅助用房面积 指标说明:学校中教室、实验室、图书室、微机室、语音室面积之和。 数据提取来源:教育事业统计报表中的“基础基512中小学校舍情况”表,教学及辅助用房面积减去体育馆面积,[行04,列1]-[行10,列1]。 3. 体育运动场馆面积 指标说明:学校中的体育馆面积和运动场地面积之和,运动场地面积指学校专门用于室外体育运动并有相应设施所占用的土地面积。 数据提取来源:体育馆面积在教育事业统计报表中的“基础基512中小学校舍情况”表,[行10,列1];运动场地面积在教育事业统计报表中的“基础基522中小学占地面积及其他办学条件”表,[行01,列3]。 4. 教学仪器设备值 指标说明:学校固定资产中用于教学、实验等仪器设备的资产值。 数据提取来源:教育事业统计报表中的“基础基522中小学占地面积及其他办学条件”表,[行01,列9]。 5.计算机台数 指标说明:计入学校固定资产的用于教学用的台式、笔记本计算机。第三章附录相关系数r 的计算公式的推导
地区城市薪酬差异系数报告
义务教育均衡发展差异系数计算方法及数据来源
相关主题
文本预览