
KVM虚拟机源代码分析
1,KVM结构及工作原理
1.1K VM结构
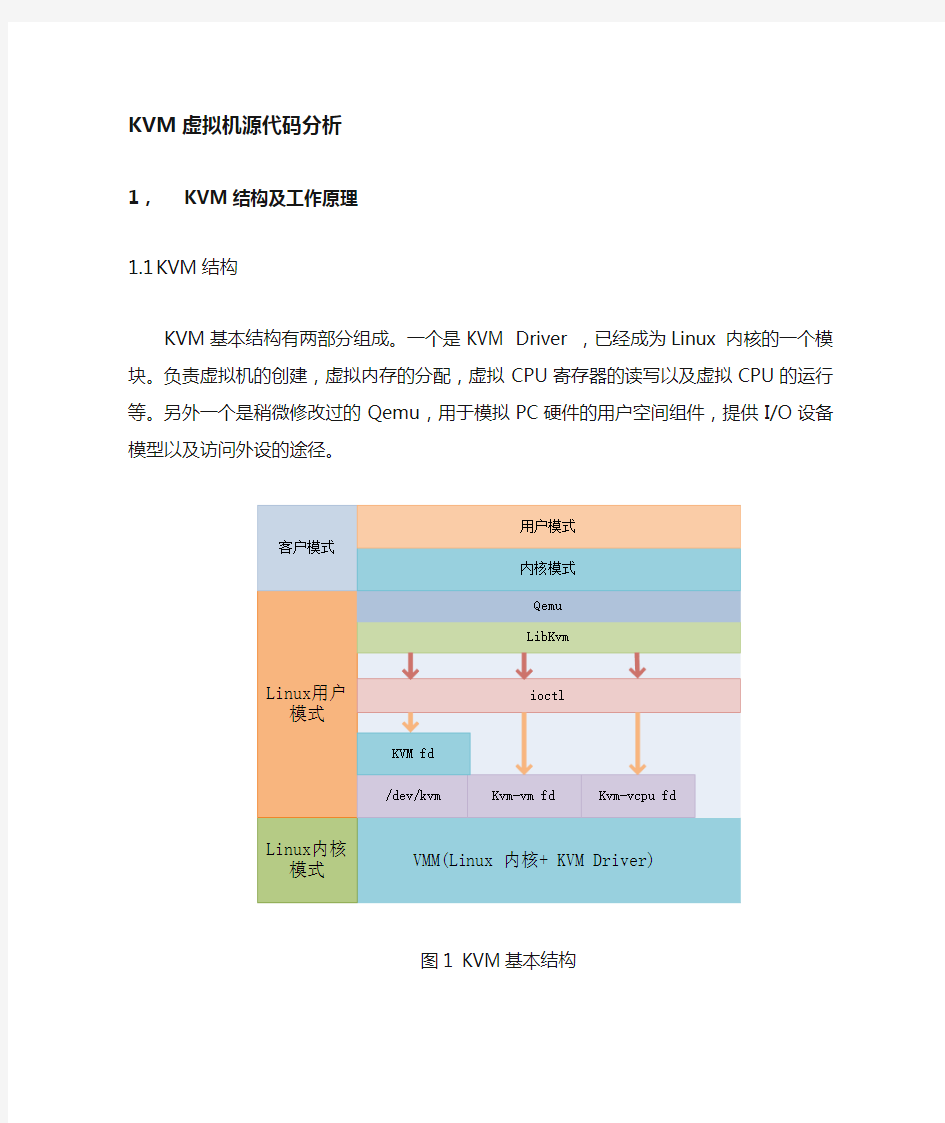
KVM基本结构有两部分组成。一个是KVM Driver ,已经成为Linux 内核的一个模块。负责虚拟机的创建,虚拟内存的分配,虚拟CPU寄存器的读写以及虚拟CPU的运行等。另外一个是稍微修改过的Qemu,用于模拟PC硬件的用户空间组件,提供I/O设备模型以及访问外设的途径。
图1 KVM基本结构
KVM基本结构如图1所示。其中KVM加入到标准的Linux内核中,被组织成Linux中标准的字符设备(/dev/kvm)。Qemu通KVM提供的LibKvm应用程序接口,通过ioctl系统调用创建和运行虚拟机。KVM Driver使得整个Linux成为一个虚拟机监控器。并且在原有的Linux两种执行模式(内核模式和用户模式)的基础上,新增加了客户模式,客户模式拥有自己的内核模式和用户模式。在虚拟机运行下,三种模式的分工如下:
客户模式:执行非I/O的客户代码。虚拟机运行在客户模式下。
内核模式:实现到客户模式的切换。处理因为I/O或者其它指令引起的从客户模式的退出。KVM Driver工作在这种模式下。
用户模式:代表客户执行I/O指令Qemu运行在这种模式下。
在KVM模型中,每一个Guest OS 都作为一个标准的Linux进程,可以使用Linux的进程管理指令管理。
在图1中./dev/kvm在内核中创建的标准字符设备,通过ioctl系统调用来访问内核虚拟机,进行虚拟机的创建和初始化;kvm_vm fd是创建的指向特定虚拟机实例的文件描述符,通过这个文件描述符对特定虚拟机进行访问控制;kvm_vcpu fd指向为虚拟机创建的虚拟处理器的文件描述符,通过该描述符使用ioctl系统调用设置和调度虚拟处理器的运行。
1.2K VM工作原理
KVM的基本工作原理:用户模式的Qemu利用接口libkvm通过ioctl系统调用进入内核模式。KVM Driver为虚拟机创建虚拟内存和虚拟CPU后执行VMLAUCH指令进入客户模式。装载Guest OS执行。如果Guest OS发生外部中断或者影子页表缺页之类的事件,暂停Guest OS的执行,退出客户模式进行一些必要的处理。然后重新进入客户模式,执行客户代码。如果发生I/O事件或者信号队列中有信号到达,就会进入用户模式处理。KVM采用全虚拟化技术。客户机不用修改就可以运行。
图2 KVM 工作基本原理
2,相关技术-处理器管理和硬件辅助虚拟化技术
Intel 在2006年发布了硬件虚拟化技术。其中支持X86体系结构的称为Intel VT-x技术。ADM称为SVM技术。
VT-x引入了一种新的处理器操作,叫做VMX(Virtual Machine Extension),提供了两种处理器的工作环境。VMCS结构实现两种环境之间的切换。VM Entry使虚拟机进去客户模式,VM Exit使虚拟机退出客户模式。
2.1K VM中Guest OS的调度执行
VMM调度Guest OS执行时,Qemu通过ioctl系统调用进入内核模式,在KVM Driver 中通过get_cpu获得当前物理CPU的引用。之后将Guest状态从VMCS中读出。并装入物理CPU中。执行VMLAUCH指令使得物理处理器进入非根操作环境,运行客户代码。
当Guest OS执行一些特权指令或者外部事件时,比如I/O访问,对控制寄存器的操作,MSR的读写数据包到达等。都会导致物理CPU发生VMExit,停止运行Guest OS。将Guest OS 保存到VMCS中,Host状态装入物理处理器中,处理器进入根操作环境,KVM取得控制权,通过读取VMCS中VM_EXIT_REASON字段得到引起VM Exit的原因。从而调用kvm_exit_handler处理函数。如果由于I/O获得信号到达,则退出到用户模式的Qemu处理。处理完毕后,重新进入客户模式运行虚拟CPU。如果是因为外部中断,则在Lib KVM中做一些必要的处理,重新进入客户模式执行客户代码。
2.2K VM中内存管理
KVM使用影子页表实现客户物理地址到主机物理地址的转换。初始为空,随着虚拟机页访问实效的增加,影子页表被逐渐建立起来,并随着客户机页表的更新而更新。在KVM 中提供了一个哈希列表和哈希函数,以客户机页表项中的虚拟页号和该页表项所在页表的级别作为键值,通过该键值查询,如不为空,则表示该对应的影子页表项中的物理页号已经存在并且所指向的影子页表已经生成。如为空,则需新生成一张影子页表,KVM将获取指向该影子页表的主机物理页号填充到相应的影子页表项的内容中,同时以客户机页表虚拟页号和表所在的级别生成键值,在代表该键值的哈希桶中填入主机物理页号,以备查询。但是一旦Guest OS中出现进程切换,会把整个影子页表全部删除重建,而刚被删掉的页表可能很快又被客户机使用,如果只更新相应的影子页表的表项,旧的影子页表就可以重用。因此在KVM中采用将影子页表中对应主机物理页的客户虚拟页写保护并且维护一张影子页表的逆向映射表,即从主机物理地址到客户虚拟地址之间的转换表,这样VM对页表或页目录的修改就可以触发一个缺页异常,从而被KVM捕获,对客户页表或页目录项的修改就可以同样作用于影子页表,通过这种方式实现影子页表与客户机页表保持同步。
2.3K VM中设备管理
一个机器只有一套I/o地址和设备。设备的管理和访问是操作系统中的突出问题、同样也是虚拟机实现的难题,另外还要提供虚拟设备供各个VM使用。在KVM中通过移植Qemu 中的设备模型(Device Model)进行设备的管理和访问。操作系统中,软件使用可编程I/O(PIO)和内存映射I/O(MMIO)与硬件交互。而且硬件可以发出中断请求,由操作系统处理。在有虚拟机的情况下,虚拟机必须要捕获并且模拟PIO和MMIO的请求,模拟虚拟硬件中断。
捕获PIO:由硬件直接提供。当VM发出PIO指令时,导致VM Exit然后硬件会将VM Exit 原因及对应的指令写入VMCS控制结构中,这样KVM就会模拟PIO指令。MMIO捕获:对MMIO页的访问导致缺页异常,被KVM捕获,通过X86模拟器模拟执行MMIO指令。KVM 中的I/O虚拟化都是用户空间的Qemu实现的。所有PIO和MMIO的访问都是被转发到Qemu 的。Qemu模拟硬件设备提供给虚拟机使用。KVM通过异步通知机制以及I/O指令的模拟来完成设备访问,这些通知包括:虚拟中断请求,信号驱动机制以及VM间的通信。
以虚拟机接收数据包来说明虚拟机和设备的交互。
图3 I/O分析
(1)当数据包到达主机的物理网卡后,调用物理网卡的驱动程序,在其中利用Linux内核中的软件网桥,实现数据的转发。
(2)在软件网挢这一层,会判断数据包是发往那个设备的,同时调用网桥的发送函数,向对应的端口发送数据包。
(3)若数据包是发往虚拟机的,则要通过tap设备进行转发,tap设备由两部分组成,网络设备和字符设备。网络设备负责接收和发送数据包,字符设备负责将数据包往内核空间和用户空间进行转发。Tap网络部分收到数据包后,将其设备文件符置位,同时向正在运行VM的进程发出I/O可用信号,引起VM Exit,停止VM运行,进入根操作状态。KVM根据KVM_EXIT_REASON判断原因,模拟I/O指令的执行,将中断注入到VM的中断向量表中。
(4)返回用户模式的Qemu中,执行设备模型。返回到kvm_main loop中,执行Kvm—main —loop—wait,之后进入main_loop wait中,在这个函数里收集对应设备的设备文件描述符的状态,此时tap设备文件描述符的状态同样被集到fd set。
(5)Kvm main—loop不停地循环,通过select系统调用判断哪螋文件描述符的状态发生变化,相应的调用对应的处理函数。对予tap来说,就会通过Qemu—send_packet将数据发往rtl8139
一do—receiver,在这个函数中完成相当于硬件RTL8139网卡的逻辑操作。KVM通过模拟I /O指令操作虚拟RTL8139将数据拷贝到用户地址空间,放在相应的I/O地址。用户模式处理完毕后返回内核模式,而后进入客户模式,VM被再次执行,继续收发数据包。
3,KVM 源代码分析-虚拟机创建和运行流程代码分析
3.1 KVM创建和运行虚拟机流程
KVM虚拟机创建和运行虚拟机分为用户态和核心态两个部分,用户态主要提供应用程序接口,为虚拟机创建虚拟机上下文环境,在libkvm中提供访问内核字符设备/dev/kvm的接口;内核态为添加到内核中的字符设备/dev/kvm,模块加载进内核后即可进行接口用户空间调用创建虚拟机。在创建虚拟机过程中,kvm字符设备主要为客户机创建kvm数据机构,创建该虚拟机的虚拟机文件描述符及其相应的数据结构以及创建虚拟处理器及其相应的数据结构。Kvm创建虚拟机的流程如图4所示。
首先申明一个kvm_context_t 变量用以描述用户态虚拟机上下文信息,然后调用kvm_init()函数初始化虚拟机上下文信息;函数kvm_create()创建虚拟机实例,该函数通过ioctl 系统调用创建虚拟机相关的内核数据结构并且返回虚拟机文件描述符给用户态kvm_context_t数据结构;创建完内核虚拟机数据结构后,再创建内核pit以及mmio等基本外设模拟设备,然后调用kvm_create_vcpu()函数来创建虚拟处理器,kvm_create_vcpu()函数通过ioctl()系统调用向由vm_fd文件描述符指向的虚拟文件调用创建虚拟处理器,并将虚拟处理器的文件描述符返回给用户态程序,用以以后的调度使用;创建完虚拟处理器后,由用户态的QEMU程序申请客户机用户空间,用以加载和运行客户机代码;为了使得客户虚拟机正确执行,必须要在内核中为客户机建立正确的内存映射关系,即影子页表信息。因此,申请客户机内存地址空间后,调用函数kvm_create_phys_mem()创建客户机内存映射关系,该函数主要通过ioctl系统调用向vm_fd指向的虚拟文件调用设置内核数据结构中客户机内存域相关信息,主要建立影子页表信息;当创建好虚拟处理器和影子页表后,即可读取客户机到指定分配的空间中,然后调度虚拟处理器运行。调度虚拟机的函数为kvm_run(),该函数通过ioctl系统调用调用由虚拟处理器文件描述符指向的虚拟文件调度处理函数kvm_run()调度虚拟处理器的执行,该系统调用将虚拟处理器vcpu信息加载到物理处理器中,通过vm_entry执行进入客户机执行。在客户机正常运行期间kvm_run()函数不返回,只有发生以下两种情况时,函数返回:1,发生了I/O事件,如客户机发出读写I/O的指令;2,产生了客户机和内核KVM都无法处理的异常。I/O事件处理完毕后,通过重新调用KVM_RUN()函数继续调度客户机的执行。
图 4 KVM虚拟机创建流程
3.2 虚拟机创建和运行主要函数分析
1,函数kvm_init():该函数在用户态创建一个虚拟机上下文,用以在用户态保存基本的虚拟机信息,这个函数是创建虚拟机第一个需要调用的函数,函数返回一个kvm_context_t 结构体。该函数原型为:
Kvm_context_t kvm_init(struct kvm_callbacks *callbacks,void *opaque);
参数:callbacks为结构体kvm_callbacks变量,该结构体包含指向函数的一组指针,用于在客户机执行过程中因为I/O事件退出到用户态的时候处理的回调函数(后面会分析)。参数opaque一般未使用。
函数执行基本过程:打开字符设备dev/kvm,申请虚拟机上下文变量kvm_context_t空间,初始化上下文的基本信息:设置fd文件描述符指向/dev/kvm、禁用虚拟机文件描述符vm_fd(-1) 设置I/O事件回调函数结构体,设置IRQ和PIT的标志位以及内存页面记录的标志位。
主要相关数据结构:
虚拟机上下文structkvm_context_t,用户态数据结构,用以描述虚拟机实例的用户态上下文信息。
Struct kvm_context:该结构体用于表示一个虚拟机上下文。主要包含的数据域为:
Int fd :指向内核标准字符设备/dev/kvm的文件描述符。
Int vm_fd:指向所创建的内核虚拟机数据结构相关文件的文件描述符。
Int vcpu_fd[MAX_VCPUS]:指向虚拟机所有的虚拟处理器的文件描述符数组。
Struct kvm_run *run[MAX_VCPUS]:指向虚拟机运行环境上下文的指针数组。
Struct kvm_callbacks *call_backs: 回调函数结构体指针,该结构体用于处理用户态I/O事件。Void *opaque:指针(还未弄清楚)
Int dirty_page_log_all:设置是否记录脏页面的标志。
Int no_ira_creation: 用于设置是否再kernel里设置irq芯片。
Int_irqchip_in_kernel: 内核中irqchip的状态
Int irqchip_inject_ioctl:用于拦截中断的iotcl系统调用
Int no_pit_creation: 设置是否再内核中设置陷阱
int pit_in_kernel:PIT状态
int coalesced_mmio:kernel中mmio
struct kvm_irq_routing *irq_routes:KVM中中断处理的路由结构指针。
int nr_allocated_irq_routes:分配给该虚拟机的中断路由数目。
int max_used_gsi:使用的最大的gsi(?)。
用户态I/O处理函数结构体struct kvm_callbacks,该结构体指向一组函数,主要用于处理客户机因为I/O事件退出而执行的过程。
struct kvm_callbacks :该结构体用于在用户态中处理I/O事件,在KVM中调用KVM_QEMU实现。主要包含的数据域为:
int (*inb)(void *opaque, uint16_t addr, uint8_t *data):用于模拟客户机执行8位的inb指令。int (*inw)(void *opaque, uint16_t addr, uint16_t *data):用于模拟客户机执行16位的inw指令。int (*inl)(void *opaque, uint16_t addr, uint32_t *data):用于模拟客户机执行32位的inl指令。int (*outb)(void *opaque, uint16_t addr, uint8_t data):用于模拟客户机执行8位的outb指令。int (*outw)(void *opaque, uint16_t addr, uint16_t data):用于模拟客户机执行16位的outw指令。
int (*outl)(void *opaque, uint16_t addr, uint32_t data):用于模拟客户机执行32位的outl指令。int (*mmio_read)(void *opaque, uint64_t addr, uint8_t *data,int len):用于模拟客户机执行mmio读指令。
int (*mmio_write)(void *opaque, uint64_t addr, uint8_t *data,int len):用于模拟客户机执行mmio写指令。
int (*debug)(void *opaque, void *env, struct kvm_debug_exit_arch *arch_info):用户客户机调试的回调函数。
int (*halt)(void *opaque, int vcpu):用于客户机执行halt指令的响应。
int (*shutdown)(void *opaque, void *env):用于客户机执行shutdown指令的响应。
int (*io_window)(void *opaque):用于获得客户机io_windows。
int (*try_push_interrupts)(void *opaque):用于注入中断的回调函数。
void (*push_nmi)(void *opaque):用于注入nmi中断的函数。
void (*post_kvm_run)(void *opaque, void *env);用户得到kvm运行状态函数。
int (*pre_kvm_run)(void *opaque, void *env);用于获得kvm之前运行状态的函数
int (*tpr_access)(void *opaque, int vcpu, uint64_t rip, int is_write);获得tpr访问处理函数
int (*powerpc_dcr_read)(int vcpu, uint32_t dcrn, uint32_t *data);用于powerpc的dcr读操作
nt (*powerpc_dcr_write)(int vcpu, uint32_t dcrn, uint32_t data);用于powerpc的dcr写操作
int (*s390_handle_intercept)(kvm_context_t context, int vcpu,struct kvm_run *run);用于s390的中断处理。
int (*s390_handle_reset)(kvm_context_t context, int vcpu,struct kvm_run *run);用于s390的重设处理。
}
当客户机执行I/O事件或者停机操作等事件时,KVM会交给用户态的QEMU模拟外部I/O事件,调用这个结构体指向的相关的函数进行处理。
Struct kvm_run: 用于KVM运行时一些的一些状态信息。主要包含的数据域为:
__u8 request_interrupt_window;
__u8 padding1[7];
__u32 exit_reason;
__u8 ready_for_interrupt_injection;
__u8 if_flag;
__u8 padding2[2];
/* in (pre_kvm_run), out (post_kvm_run) */
__u64 cr8;
__u64 apic_base;
union {
/* KVM_EXIT_UNKNOWN */
struct {
__u64 hardware_exit_reason; 记录退出原因
} hw;
/* KVM_EXIT_FAIL_ENTRY */ 客户机执行过程中执行VM_ENTRY失败。
struct {
__u64 hardware_entry_failure_reason;
} fail_entry;
/* KVM_EXIT_EXCEPTION */ 客户机因为异常退出
struct {
__u32 exception;
__u32 error_code;
} ex;
/* KVM_EXIT_IO */ 客户机因为IO事件退出。
struct kvm_io {
#define KVM_EXIT_IO_IN 0
#define KVM_EXIT_IO_OUT 1
__u8 direction;
__u8 size; /* bytes */
__u16 port;
__u32 count;
__u64 data_offset; /* relative to kvm_run start */
} io;
struct {
struct kvm_debug_exit_arch arch;
} debug;
/* KVM_EXIT_MMIO */ 客户机因为MMIO退出
struct {
__u64 phys_addr;
__u8 data[8];
__u32 len;
__u8 is_write;
} mmio;
/* KVM_EXIT_HYPERCALL */ 客户机退出的超调用参数。
struct {
__u64 nr;
__u64 args[6];
__u64 ret;
__u32 longmode;
__u32 pad;
} hypercall;
/* KVM_EXIT_TPR_ACCESS */ 客户机退出访问TPR参数struct {
__u64 rip;
__u32 is_write;
__u32 pad;
} tpr_access;
/* KVM_EXIT_S390_SIEIC */ 和S390相关数据
struct {
__u8 icptcode;
__u64 mask; /* psw upper half */
__u64 addr; /* psw lower half */
__u16 ipa;
__u32 ipb;
} s390_sieic;
/* KVM_EXIT_S390_RESET */
#define KVM_S390_RESET_POR 1
#define KVM_S390_RESET_CLEAR 2
#define KVM_S390_RESET_SUBSYSTEM 4
#define KVM_S390_RESET_CPU_INIT 8
#define KVM_S390_RESET_IPL 16
__u64 s390_reset_flags;
/* KVM_EXIT_DCR */
struct {
__u32 dcrn;
__u32 data;
__u8 is_write;
} dcr;
/* Fix the size of the union. */
char padding[256];
2,函数kvm_create():该函数主要用于创建一个虚拟机内核环境。该函数原型为:
int kvm_create(kvm_context_t kvm,unsigned long phys_mem_bytes, void **phys_mem);
参数:kvm_context_t 表示传递的用户态虚拟机上下文环境,phys_mem_bytes表示需要创建的物理内存的大小,phys_mem表示创建虚拟机的首地址。这个函数首先调用kvm_create_vm()分配IRQ并且初始化为0,设置vcpu[0]的值为-1,即不允许调度虚拟机执行。然后调用ioctl 系统调用ioctl(fd,KVM_CREATE_VM,0)来创建虚拟机内核数据结构struct kvm。
3,系统调用函数ioctl(fd,KVM_CREATE_VM,0),用于在内核中创建和虚拟机相关的数据结构。该函数原型为:
Static long kvm_dev_ioctl(struct file *filp,unsigned int ioctl,unsigned long arg);其中ioctl表示命令。这个函数调用kvm_dev_ioctl_create_vm()创建虚拟机实例内核相关数据结构。该函数首先通过内核中kvm_create_vm()函数创建内核中kvm上下文struct kvm,然后通过函数Anno_inode_getfd(“kvm_vm”,&kvm_vm_fops,kvm,0)返回该虚拟机的文件描述符,返回给用户调用函数,由2中描述的函数赋值给用户态虚拟机上下文变量中的虚拟机描述符kvm_vm_fd。
4,内核创建虚拟机kvm对象后,接着调用kvm_arch_create函数用于创建一些体系结构相关的信息,主要包括kvm_init_tss、kvm_create_pit以及kvm_init_coalsced_mmio等信息。然后调用kvm_create_phys_mem创建物理内存,函数kvm_create_irqchip用于创建内核irq信息,通过系统调用ioctl(kvm->vm_fd,KVM_CREATE_IRQCHIP)。
5,函数kvm_create_vcpu():用于创建虚拟处理器。该函数原型为:
int kvm_create_vcpu(kvm_context_t kvm, int slot);
参数:kvm表示对应用户态虚拟机上下文,slot表示需要创建的虚拟处理器的个数。
该函数通过ioctl系统调用ioctl(kvm->vm_fd,KVM_CREATE_VCPU,slot)创建属于该虚拟机的虚拟处理器。该系统调用函数:
Static init kvm_vm_ioctl_create_vcpu(struct *kvm, n) 参数kvm为内核虚拟机实例数据结构,n 为创建的虚拟CPU的数目。
6,函数kvm_create_phys_mem()用于创建虚拟机内存空间,该函数原型:
Void * kvm_create_phys_mem(kvm_context_t kvm,unsigned long phys_start,unsigned len,int log,int writable);
参数:kvm 表示用户态虚拟机上下文信息,phys_start为分配给该虚拟机的物理起始地址,len表示内存大小,log表示是否记录脏页面,writable表示该段内存对应的页表是否可写。该函数首先申请一个结构体kvm_userspace_memory_region 然后通过系统调用KVM_SET_USER_MEMORY_REGION来设置内核中对应的内存的属性。该系统调用函数原型:Ioctl(int kvm->vm_fd,KVM_SET_USER_MEMORY_REGION,&memory);
参数:第一个参数vm_fd为指向内核虚拟机实例对象的文件描述符,第二个参数KVM_SET_USER_MEMORY_REGION为系统调用命令参数,表示该系统调用为创建内核客户机映射,即影子页表。第三个参数memory表示指向该虚拟机的内存空间地址。系统调用首先通过参数memory通过函数copy_from_user从用户空间复制struct_user_momory_region 变量,然后通过kvm_vm_ioctl_set_memory_region函数设置内核中对应的内存域。该函数原型:Int kvm_vm_ioctl_set_memory_region(struct *kvm,struct kvm_usersapce_memory_region *mem,int user_alloc);该函数再调用函数kvm_set_memory_resgion()设置影子页表。当这一切都准备完毕后,调用kvm_run()函数即可调度执行虚拟处理器。
7,函数kvm_run():用于调度运行虚拟处理器。该函数原型为:
Int kvm_run(kvm_context_t kvm,int vcpu, void *env) 该函数首先得到vcpu的描述符,然后调用系统调用ioctl(fd,kvm_run,0)调度运行虚拟处理器。Kvm_run函数在正常运行情况下并不返回,除非发生以下事件之一:一是发生了I/O事件,I/O事件由用户态的QEMU处理;一个是发生了客户机和KVM都无法处理的异常事件。KVM_RUN()中返回截获的事件,主要是I/O 以及停机等事件。
4,KVM客户机异常处理机制和代码流程
KVM保证客户机正确执行的基本手段就是当客户机执行I/O指令或者其它特权指令时,引发处理器异常,从而陷入到根操作模式,由KVM Driver模拟执行,可以说,虚拟化保证客户机正确执行的基本手段就是异常处理机制。由于KVM采取了硬件辅助虚拟化技术,因此,和异常处理机制相关的一个重要的数据结构就是虚拟机控制结构VMCS。
VMCS控制结构分为三个部分,一个是版本信息,一个是中止标识符,最后一个是VMCS 数据域。VMCS数据域包含了六类信息:客户机状态域,宿主机状态域,VM-Entry控制域,VM-Execution控制域VM-Exit控制域以及VM-Exit信息域。其中VM-Execution控制域可以设置一些可选的标志位使得客户机可以引发一定的异常的指令。宿主机状态域,则保持了基本的寄存器信息,其中CS:RIP指向KVM中异常处理程序的地址。是客户机异常处理的总入口,而异常处理程序则根据VM-Exit信息域来判断客户机异常的根本原因,选择正确的处理逻辑来进行处理。
vmx.c文件是和Intel VT-x体系结构相关的代码文件,用于处理内核态相关的硬件逻辑代码。在VCPU初始化中(vmx_vcpu_create),将kvm中的对应的异常退出处理函数赋值给CS:EIP 中,在客户机运行过程中,产生客户机异常时,CPU根据VMCS中的客户机状态域装载CS:EIP 的值,从而退出到内核执行异常处理。在KVM内核中,异常处理函数的总入口为:static int vmx_handle_exit(struct kvm_run *kvm_run, struct kvm_vcpu *vcpu);
参数:kvm_run,当前虚拟机实例的运行状态信息,vcpu,对应的虚拟cpu。
这个函数首先从客户机VM-Exit信息域中读取exit_reason字段信息,然后进行一些必要的处理后,调用对应于函数指针数组中对应退出原因字段的处理函数进行处理。函数指针数组定义信息为:
static int (*kvm_vmx_exit_handlers[])(struct kvm_vcpu *vcpu,
struct kvm_run *kvm_run) = {
[EXIT_REASON_EXCEPTION_NMI] = handle_exception,
[EXIT_REASON_EXTERNAL_INTERRUPT] = handle_external_interrupt,
[EXIT_REASON_TRIPLE_FAULT] = handle_triple_fault,
[EXIT_REASON_NMI_WINDOW] = handle_nmi_window,
[EXIT_REASON_IO_INSTRUCTION] = handle_io,
[EXIT_REASON_CR_ACCESS] = handle_cr,
[EXIT_REASON_DR_ACCESS] = handle_dr,
[EXIT_REASON_CPUID] = handle_cpuid,
[EXIT_REASON_MSR_READ] = handle_rdmsr,
[EXIT_REASON_MSR_WRITE] = handle_wrmsr,
[EXIT_REASON_PENDING_INTERRUPT] = handle_interrupt_window,
[EXIT_REASON_HLT] = handle_halt,
[EXIT_REASON_INVLPG] = handle_invlpg,
[EXIT_REASON_VMCALL] = handle_vmcall,
[EXIT_REASON_TPR_BELOW_THRESHOLD] = handle_tpr_below_threshold,
[EXIT_REASON_APIC_ACCESS] = handle_apic_access,
[EXIT_REASON_WBINVD] = handle_wbinvd,
[EXIT_REASON_TASK_SWITCH] = handle_task_switch,
[EXIT_REASON_EPT_VIOLATION] = handle_ept_violation,
};
这是一组指针数组,用于处理客户机引发异常时候,根据对应的退出字段选择处理函数进行处理。例如EXIT_REASON_EXCEPTION_NMI对应的handle_exception处理函数用于处理NMI 引脚异常,而EXIT_REASON_EPT_VIOLATION对应的handle_ept_violation处理函数用于处理缺页异常。
5,KVM 客户机影子页表机制和缺页处理机制及其代码流程
5.1 KVM影子页表基本原理和缺页处理流程
KVM给客户机呈现了一个从0开始的连续的物理地址空间,成为客户机物理地址空间,在宿主机中,只是由KVM分配给客户机的宿主机物理内存的一部分。客户机中为应用程序建立的客户机页表,只是实现由客户机虚拟地址到客户机物理地址的转换(GVA-GPA),为了正确的访问内存,需要进行二次转换,即客户机物理地址到宿主机物理地址的转换(GPA-HPA),两个地址转换,前者由客户机负责完成,后者由VMM负责完成。为了实现客户机物理地址到主机物理地址的地址翻译,VMM为每个虚拟机动态维护了一张从客户机物理地址到宿主机物理地址的映射关系表。客户机OS所维护的页表只是负责传统的客户机虚拟地址到客户机物理地址的转换。如果MMU直接装在客户机操作系统所维护的页表进行内存访问,硬件则无法争取的实现地址翻译。
影子页表是一个有效的解决办法。一份影子页表与一份客户机操作系统的页表相对应,作用是实现从客户虚拟机地址到宿主机物理地址的直接翻译。这样,客户机所能看到和操作的都是虚拟MMU,而真正载入到屋里MMU的是影子页表。如图5所示。
图5-影子页表
由于客户机维护的页表真正体现在影子页表上,因此,客户机对客户机页表的操作实质上反映到影子页表中,并且由VMM控制,因此,影子页表中,对于页表页的访问权限是只读的。一旦客户机对客户机页表进行修改,则产生页面异常,由VMM处理。
影子页表的结构:以x86的两级页表为例。客户机物理帧号GFN和宿主机物理帧号MFN 是一一对应的,而宿主机必须要另外负责创建一个页用于CR3寄存器指向的影子页表SMFN。通常通过hash表实现MFN和SMFN之间的计算。影子页表的建立和修改过程交错在客户机对客户机页表的创建过程中。
影子页表的缺页异常处理:当发生缺页异常时,产生异常条件并被VMM捕获,让VMM 发现客户机操作系统尚未给客户机虚拟机地址分配客户机物理页,那么VMM首先将缺页异常传递给客户机操作系统,由客户机操作系统为这个客户机虚拟地址分配客户机物理页,由于客户机操作系统分配客户机物理页需要修改其页表,因为又被VMM捕获,VMM更新影子页表中相应的目录和页表项,增加这个客户机虚拟地址到分配的宿主页的映射。如果产生异常时,VMM发现客户机操作系统已经分配给了相应的客户机物理页,只是写权限造成写异常,则VMM更新影子页表中的页目录和页表项,重定向客户机虚拟地址页到宿主机页的映射。客户机缺页异常处理逻辑流程如图6所示。
图6 –缺页异常处理流程
5.2 KVM中缺页异常的处理代码流程
由4中说明的异常处理逻辑中,vmx_handle_exit函数用于处理客户机异常的总入口程序,KVM根据退出域中的退出原因字段,调用函数指针数据中对应的处理函数进行处理,在缺页异常中,处理函数为handle_ept_violation。该函数调用kvm_mmu_page_fault函数进行缺页异常处理。
6,KVM中主要数据结构以及相互关系6.1 用户态关键数据机构
KVM用户态重要数据结构
KVM-CONTEXT-T为虚拟机上下文
KVM-run为虚拟机运行状态
Kvm-callbacks为虚拟机产生I/O事件处理的回调函数Kvm-irq-routing 为中断处理相关数据结构
6.2 内核态关键数据机构
KVM 结构体定义
VCPU 结构体定义
kvm_vcpu_arch结构
Kvm-vcpu-arch 包含数据结构
目录 一、源代码结构 (2) 第一层次目录 (2) bionic目录 (3) bootloader目录 (5) build目录 (7) dalvik目录 (9) development目录 (9) external目录 (13) frameworks目录 (19) Hardware (20) Out (22) Kernel (22) packages目录 (22) prebuilt目录 (27) SDK (28) system目录 (28) Vendor (32)
一、源代码结构 第一层次目录 Google提供的Android包含了原始Android的目标机代码,主机编译工具、仿真环境,代码包经过解压缩后,第一级别的目录和文件如下所示: . |-- Makefile (全局的Makefile) |-- bionic (Bionic含义为仿生,这里面是一些基础的库的源代码) |-- bootloader (引导加载器),我们的是bootable, |-- build (build目录中的内容不是目标所用的代码,而是编译和配置所需要的脚本和工具) |-- dalvik (JAVA虚拟机) |-- development (程序开发所需要的模板和工具) |-- external (目标机器使用的一些库) |-- frameworks (应用程序的框架层) |-- hardware (与硬件相关的库) |-- kernel (Linux2.6的源代码) |-- packages (Android的各种应用程序) |-- prebuilt (Android在各种平台下编译的预置脚本) |-- recovery (与目标的恢复功能相关) `-- system (Android的底层的一些库)
常见四种虚拟化技术优劣势对比-兼谈XEN与vmware的区别 蹦不路磅按: 好多人估计对XEN和vmware到底有啥区别有所疑问. 可能如下的文章会有所提示 据说本文作者系SWsoft中国首席工程师.没找到名字, 故保留title ---------------- Update: 13-11-2008 关于xen Hypervisor个人理解的一点补充. xen hypervisor 类似一个linux的kernel .位于/boot/下名字xen-3.2-gz. 系统启动的时候它先启动。然后它在载入dom0. 所有对其他domainU的监控管理操作都要通过domain0. 因为hypervisor 只是一个类kernel. 没有各种application. 需要借助domain0的application 比如xend xenstore xm 等。 个人猜想,hypervisor 能集成一些简单的管理程序也是可能的。vmware好像也正在作植入硬件的hypervisor 将来的发展可能是是hypervisor 会和bios一样在每个服务器上集成了。然后每台服务器买来后就自动支持 可以启动数个操作系统了。彻底打破一台裸机只能装一个操作系统的传统。 ----------------- 虚拟化技术(Virtualization)和分区(Partition)技术是紧密结合在一起,从60年代Unix诞生起,虚拟化技术和分区技术就开始了发展,并且经历了从“硬件分区”->“虚拟机”->“准虚拟机”->“虚拟操作系统”的发展历程。最早的分区技术诞生自人们想提升大型主机利用率需求。比如在金融、科学等领域,大型Unix服务器通常价值数千万乃至上亿元,但是实际使用中多个部门却不能很好的共享其计算能力,常导致需要计算的部门无法获得计算能力,而不需要大量计算能力的部门占有了过多的资源。这个时候分区技术出现了,它可以将一台大型服务器分割成若干分区,分别提供给生产部门、测试部门、研发部门以及其他部门。 几种常见的虚拟化技术代表产品如下: 类型代表产品 硬件分区IBM/HP等大型机硬件分区技术 虚拟机(Virtual Machine Monitor)EMC VMware Mircosoft Virtual PC/Server Parallels 准虚拟机(Para-Virtualization)Xen Project 虚拟操作系统(OS Virtualization)SWsoft Virtuozzo/OpenVZ Project Sun Solaris Container HP vSE FreeBSD Jail Linux Vserver 硬件分区技术 硬件分区技术如下图所示:硬件资源被划分成数个分区,每个分区享有独立的CPU、内存,并安装独立的操作系统。在一台服务器上,存在有多个系统实例,同时启动了多个操作系统。这种分区方法的主要缺点是缺乏很好的灵活性,不能对资源做出有效调配。随着技术的进步,现在对于资源划分的颗粒已经远远提升,例如在IBM AIX系统上,对CPU资源的划分颗粒可以达到0.1个CPU。这种分区方式,在目前的金融领域,比如在银行信息中心
VMware虚拟化平台服务器 日常维护和应急处理规 1 目的 为提高部门处理VMware虚拟化服务器故障的能力,形成科学、有效、反应迅速的日常管理流程和应急处理机制,确保虚拟化平台的安全和稳定运行,最大限度地减小服务器故障对生产的影响,降低业务中断风险,特制定本规。 2 适用围 本规适用于公司局域网中所有提供VMware虚拟化平台服务的服务器管理,应对发生和可能发生的故障。 3 规容 虚拟化平台服务器运维和应急处理应包括风险评估,检测体系和应急处理三个环节,合理有效的执行控制将防止故障影响扩大。 故障分类 虚拟化平台故障包括服务器硬件和虚拟化软件的故障;自然灾害(水、火、电等)造成的物理破坏;电脑病毒等恶意代码危害;人为误操作造成的损害等。 应急准备 部门责任人员明确职责和管理围,根据实际情况,安排应急值班,确保到岗到人,联络畅通,处理及时准确。 具体措施 (1)建立安全、可靠、稳定运行的机房环境,防火、防雷电、
防水、防静电、防尘;建立备份电源系统。 (2)虚拟化平台服务器应采用可靠、稳定、兼容性硬件,落实责任管理机制,遵守安全操作规;对虚拟机和管理服务器进行定时备份;采用有效的虚拟化监控工具,及时发现问题和日报告。 4 故障处理规 机房停电 接到停电通知后,相关人员应及时部署应对具体措施,启动备用电源,保证服务器正常运行。 硬件维护 (1)平台服务器出现硬件告警需要停机维护,服务器责任人应立即通知相关人员,将业务虚机迁移到集群中其他服务器主机上,再将故障服务器切换至维护模式并从HA集群中移除,负责陪同硬件厂家现场更换至成功恢复。 (2)若服务器硬件24小时无法恢复,服务器责任人需书面报告原因并立即通知业务管理人员进行数据应急备份,防止灾难扩大。 (3)若虚拟化存储硬件出现告警,第一目击人应立即通知存储管理员,并上报主管领导,存储管理员应在报告1小时联系厂家到场处理,处理完成后因报告原因,找到解决方法;并立即对数据做完整性检查,消除重复发生隐患。 虚拟化平台故障 (1)虚拟化服务器应保证双机群集配置,并同时配置好一套备用服务器群集,随时待命。
Q:Phantosys是一个什么系统? A:Phantosys Desktop Virtual Platform(简称Phantosys DVP)幻影桌面虚拟化平台是一套用来实现桌面PC操作系统和应用环境的集中控制和集中管理、应用环境随需供应以及提高PC系统的安全性、可靠性的虚拟化平台,它能够使IT管理人员在集中管理的资源中,按需供应PC运行所需要的OS&AP以及个性化计算环境的底层控制平台。 Q:Phantosys所提倡的应用集中、管理集中的系统方向是否正确? A:计算机信息化应用日趋普及,现今计算机大规模应用的用户,如政府、企业、教育、酒店等多为PC所组成的分布式运算环境,众多的应用软件随着PC散布各处,衍生出许多管理上的盲点与困难,例如常面临下列挑战: 1. 信息安全与企事业单位智能财产保护的问题;; 2. 病毒防治与应用人为损坏问题; 3. 系统应用缺乏扩充和改变弹性; 4. 频繁的应用维护与升级成本,客户端的信息维护成本高等。 从目前的虚拟化应用的描述中,我们发现两个关键特征,一是将分散的服务器应用集中到一台服务器中,二是提高单台服务器的利用率。 而应用程序集中管理方案,同样具有以上类似的两个关键特征:一是将分散在分点的应用系统都集中在总的服务器中;二是提高了总服务器的利用率。 这两种技术区别很大,但他们所要达到的效果却非常相似。这再次证明:提高利用率、降低成本、集中管理,是目前的大势所趋。美国Network World的专家Sidana近期预言:现在谈论服务器虚拟化,而未来将关注桌面和应用虚拟化。 从目前来看,虚拟化主要指服务器、存储、操作系统虚拟化,但这并不是虚拟化的全部,它是一个非常广泛的概念,最终,它将包括应用虚拟化。 应用虚拟化的宗旨同服务器虚拟化类似,在一套应用系统上,通过虚拟的方式,让以前不能用这套应用系统的人,也能够使用它,从而实现虚拟化应用。它所要达到的目标,同服务器虚拟化一样,应用虚拟化的一个重要好处是更低的总拥有成本、更好的系统稳定性、更少的崩溃、更长的正常运行时间、更迅速的应用改变。 可以总结的是,应用虚拟化描绘的是应用系统集中化管理的前景,这无不同我们Phantosys DVP幻影桌面虚拟化平台所要解决的应用系统集中化、管理集中化处于同一宗旨。我们无法判定未来的集中管理模式到底将发展成什么样的,但可以肯定的是,应用系统的管理集中是必然的未来趋势,而Phantosys DVP在这个趋势中,走在了前列。 Q:Phantosys是无盘吗? A:Phantosys不是无盘,Phantosys是一套让桌面用户充分运用Client的完整硬件功能(特别是桌面PC的硬盘I/O性能),在保证PC桌面运行速度、效能、软硬件兼容性以及用户体验和习惯没有任何改变的前提下,对Client桌面环境进行集中式的树状节点管理的桌面虚拟化底层平台,借由Phantosys DVP完善规划后的IT基础系统,将可提供永不中断、随需改变、安全可靠的用户桌面服务。 Q: Phantosys有哪些优势或好处? A:A、Phantosys使企业或学校不用再为用户的系统和软件维护而烦恼,由Phantosys强大的底层扇区控管机制达成的还原功能,可以将病毒、木马、恶意软件、误操作等造成的系统损坏在1秒钟内迅速恢复;从此不用再去考虑客户端的电脑软件故障;
服务器虚拟化管理方案 云计算是一种以数据和处理能力为中心的密集型计算模式,它融合了多项ICT技术,是传统技术“平滑演进”的产物。其中以虚拟化技术、分布式数据存储技术、编程模型、大规模数据管理技术、分布式资源管理、信息安全、云计算平台管理技术、绿色节能技术最为关键。苏州工业园区飞鸟科技有限公司成立于2002年底,总部位于苏州新加坡工业园区,成立伊始,就伴随着工业园区先进制造业的发展,致力于为客户提供全方位的信息技术解决方案与产品,帮助企业通过信息化技术不断成长,2013年初子公司武汉飞鸟云科技有限公司正式成立运营。 作为苏南最早导入终端技术与虚拟化技术的IT公司,我们陆续成为诸多IT领导厂商在苏南的首要合作伙伴。我们的员工也在业务发展的过程中茁壮成长,经过多年的锻炼与积累,形成了完备的专业认证工程师与业务团队。通过大家的齐心协力,已为近500家中外企业提供了相关的解决方案与产品,亦成为世界五百强企业及国内顶尖民营企业的合作首选。业务范畴涵盖了从桌面到数据中心,从基础架构到核心应用的完整业务链。 我们已搭建了江苏首个虚拟化及云计算实验室,未来我们将依托实验室平台持续跟进最新的IT技术,尤其是云计算技术及移动互联网应用,不断为客户提供最佳的企业智能IT运营与管理方案。 1.服务器虚拟化方案描述 利用VMware vSphere 整合x86 服务器,从而更充分地利用现有的资源。传统的“一种工作负载配一台机器”的服务器部署方法不可避免会导致硬件资产过度部署和利用率不足。大多数服务器只利用了其总体负载容量的大约5-15%。电力、散热、网络基础架构、存储基础架构、管理开销和不动产以至利用率不足的服务器的成本不断增加。将x86 物理机转换为功能完善的虚拟机可以避免服务器数量剧增。VMware 虚拟机独立于底层硬件运行,在多种物理服务器(从2-CPU 到32-CPU 系统)上均受支持。每个VMware 虚拟机代表一个具有处理器、内存、网络、存储器和BIOS 的完整系统,使您可以在相同硬件上同时运行Windows、Linux、Solaris 和NetWare 操作系统及软件应用程序。通过在高配置的x86 服务器上运行多个工作负载,您可以将服务器硬件的利用率从10-15% 提高到高达80%。VMware vCenter Converter 实用程序,数分钟即可将物理机转换为虚拟机,同时不会造成服务中断或系统停机。VMware vCenter Converter 可以在多种硬件上运行,并支持最常用的Microsoft Windows操作系统版本。 2.系统方案的组成 A、VMware ESXi Server 是VMware vSphere Datacenter 的基础组成部分,是动态、自我优化的IT基础架构的基础。VMware ESXi Server 是一个强健、经过生产验证的虚拟层,它直接装在物理服务器的裸机上,将物理服务器上的处理器、内存、存储器和网络资源抽象到多个虚拟机中。通过跨大量虚拟机共享硬件资源提高了硬件利用率?大大降低了资金和运营成本。通过高级资源管理、高可用性和安全功能提高了服务级别,对于资源密集型的应用程序也不例外。 B、VMwae Vcenter Server 作为一个vSphere架构的控管平台,它可从单个控制台统一管理数据中心的所有主机和虚拟机,该控制台聚合了集群、主机和虚拟机的性能监控功能。VMware vCenter Server 使管理员能够从一个位置深入了解虚拟基础架构的集群、主机、虚拟机、存储、客户操作系统和其他关键组件等所有信息。借助VMware vCenter Server,虚拟化环境变得更易于管理,一个管理员就能管理100 个以上的工作负载,在管理物理基础架构方面的工作效率比通常情况提高了一倍。 C、共享的存储平台.通过其共享的存储平台方可实现vSphere 架构中的高可用性、动态迁移、及所有计算资源实现自动优化等特性,保证了业务的高可用及业务连续性。vSphere 支持的
交叉编译器ARM-Linux-gcc4.1.2 开发板TX2440A Busybox-1.15.1.tar.bz2(在Linux中被称为瑞士军刀) mkyaffs2image工具 首先创建一个名字为root_2.6.31的文件夹,在其中创建如下文件夹 etc bin var dev home lib mnt proc root sbin sys tmp usr opt共14个文件夹 解压Busybox tar xjvf busybox 进入源目录,修改Makefile 第164行,CROSS_COMPILE=arm-linux- 第190行,ARCH=arm 执行#make men onfig进行配置 配置选项大部分都是保持默认的,只需要注意选择以下这几个选项,其他的选项都不用动:Busybox Setting---> Build Options---> [*]Build Busybox as a static binary(no shared libs) [*]Build with Large File Support(for accessing files>2GB) Installation Options--->
(./_install)Busybox installation prefix 进入这个选项,输入busybox的安装路径,如:../rootfs Busybox Library Tuning---> [*]vi-style line editing commands [*]Fancy shell prompts 要选择这个选项:“Fancy shell prompts”,否则挂载文件系统后,无法正常显示命令提示符:“[\u@\h\W]#” 配置完成以后 执行#make #make install 然后就会在上一级目录下生成rootfs文件夹,里面包含几个文件夹/bin/sbin/usr linuxrc 把这些文件全部复制到刚建好的root_2.6.31目录下, #cp–rf*../root_2.6.31 在dev目录下,创建两个设备节点: #mknod console c51 #mknod null c13 然后进入自己建立的etc目录 拷贝Busybox-1.15.2/examples/bootfloopy/etc/*到当前目录下。 #cp-r../../busybox-1.15.2/examples/bootfloopy/etc/*./ 包括文件:fstab init.d inittab profile
虚拟化技术 虚拟化技术是继互联网后又一种对整个信息产业有突破性贡献的技术。对应于计算系统体系结构的不同层次,虚拟化存在不同的形式。在所有虚拟化形式中,计算系统的虚拟化是一种可以隐藏计算资源物理特征以避免操作系统、应用程序和终端用户与这些资源直接交互的去耦合技术,包括两种涵义:使某种单一资源(例如物理硬件、操作系统或应用程序)如同多个逻辑资源一样发挥作用,或者使多种物理资源(例如处理器、内存或外部设备)如同单一逻辑资源一样提供服务。通过分割或聚合现有的计算资源,虚拟化提供了优于传统的资源利用方式。 虚拟化技术的发展为信息产业特别是总控与管理子系统的建设带来了革新性的变化,其所涉及到的技术领域相当广泛。在总控与管理子系统的设计和实现中,虚拟化技术将体现在多个方面,为系统资源的整合及性能的提升产生重要的作用。 1.1.1虚拟化原理 虚拟机是对真实计算环境的抽象和模拟,VMM(Virtual Machine Monitor,虚拟机监视器)需要为每个虚拟机分配一套数据结构来管理它们状态,包括虚拟处理器的全套寄存器,物理内存的使用情况,虚拟设备的状态等等。VMM 调度虚拟机时,将其部分状态恢复到主机系统中。 1.1.2虚拟化有何优势 目前,大多数只能运行单一应用的服务器,仅能利用自身资源的20%左右,
而其他80%甚至更多的资源都处于闲置状态,这样就导致了资源的极大浪费,虚拟化技术通过资源的合理调配,利用其它的资源来虚拟其它应用将使得服务器变得更加经济高效。除能提高利用率外,虚拟化还兼具安全、性能以及管理方面的优势。 用户可以在一台电脑中访问多台专用虚拟机。如果需要,所有这些虚拟机均可运行完全独立的操作系统与应用。例如,防火墙、管理软件和IP语音—所有应用均可作为完全独立的系统。这为目前单一的系统使用模式提供了巨大的管理和安全优势。在单一的使用模式下,只要某个应用出现故障或崩溃,在故障排除之前,整个系统都必须停止运行,从而导致极高的时间和成本支出。 提供相互隔离、安全、高效的应用执行环境。用户可以在一台计算机上模拟多个系统,多个不同的操作系统,虚拟系统下的各个子系统相互独立,即使一个子系统遭受攻击而崩溃,也不会对其他系统造成影响,而且,在使用备份机制后,子系统可以被快速的恢复。同时,应用执行环境简单易行,大大提高了工作效率,降低总体投资成本。 采用虚拟化技术后,虚拟化系统能够方便的管理和升级资源。传统的IT服务器资源是硬件相对独立的个体,对每一个资源都要进行相应的维护和升级,会耗费企业大量的人力和物力,虚拟化系统将资源整合,在管理上十分方便,在升级时只需添加动作,避开传统企业进行容量规划、定制服务器、安装硬件等工作,提高了工作效率。 虚拟化的其它优势还包括:可以在不中断用户工作的情况下进行系统更新;可以对电脑空间进行划分,区分业务与个人系统,从而防止病毒侵入、保证数据安全。此外,虚拟化紧急情况处理服务器(Emergency Server)支持快速转移
VMware虚拟化平台 运维手册
文档编辑记录 版本记录 术语和缩写 为了方便阅读,特将文中提及的术语及缩写列示如下: 注意事项 本文中所有内容均属XX公司和xx公司的商业秘密。未经允许,不得作任何形式的复制和传播。
目录 2.8克隆虚拟机 ........................................................................................................ 错误!未指定书签。 1.概述 1.1目的 本手册针对VMware虚拟化平台提供日常维护操作的指导。 1.2现状描述 本项目由28台物理主机和一台VC组成,另部署一套VCOPS和VDPA。 1.2.1软件版本 物理主机:VMware-ESXi-5.5.0 Vcenter:VMware-vCenter-Server-Appliance-5.5.0 Vcops:
Vdpa: 1.2.2用户名及密码 2.管理虚拟机 1.3登录vCenterserver 登录vCenterServer管理该平台有2种方法: 1、vSphereClient: 远程桌面登录跳板机:运行—>mstsc打开远程桌面 进入远程桌面后打开vsphereclient输入IP地址 图2.1.1vSphereClient登录 2、WebClient: 登录vCenter 图2.1.2WebClient登录 1.4新建虚拟机 在VMwarevSphere虚拟化平台上新建虚拟机的操作如下: 1、在主机或集群上点击右键,选择“新建虚拟机”,进入新建虚拟机向导, 选择“自定义”。 图2.2.1新建虚拟机 2、点击下一步,进入名称和位置窗口。 图2.2.2名称和位置 3、点击下一步,选择资源池。 图2.2.3资源池 4、点击下一步,选择虚拟机放置的存储器,请选择共享存储。 图2.2.4(共享)存储 5、点击下一步,选择虚拟机版本,默认选择最高版本。 图2.2.5虚拟机版本 6、点击下一步,根据需要的操作系统来选择虚拟机操作系统及版本。 图2.2.6虚拟机操作系统 7、点击下一步,选择该虚拟机CPU插槽数及每个插槽内核数。 图2.2.7CPU个数 8、点击下一步,按照具体需求为该虚拟机分配内存。 图2.2.8内存
Linux-2.6.18移植 有了我们的交叉编译环境和我们先前学的内核基础知识,下面我们就开始我们的内核移植了,我们所用的是博创的 S3C2410 。 关于 linux-2.6.18.tar.bz2 的下载网站先前我们说过,我们要先到该官方网站上去下载一个全新的内核。 [root@Binnary ~ ]# tar –jxvf linux-2.6.18.tar.bz2 [root@Binnary ~ ]# make mrproper 如果你是新下载的内核,那这一步就不用了。但如果你用的是别人移植好的内核,那最好在编译内核之前先清除一下中间文件,因为你们用来编译内核的交叉编译工具可能不同。 第一步:修改Makefile文件 将 改为 第二步:修改分区设置信息 我们要先在BootLoader中查看相应的分区信息 vivi>help 然后修改内核源码中的分区信息。分区信息文件在 a rch/arm/mach-s3c2410/common-smdk.c 将其中的
改为如下内容:
第三步:内核通过 BootLoader把数据写入NAND Flash,而vivi的ECC效验算法和内核的不同,内核的效验码是由NAND Flash控制器产生的,所以在此必须禁用NAND Flash ECC。所以我们就要修改 drivers/mtd/nand/s3c2410.c 这个文件。将 中的 chip->ecc.mode = NAND_ECC_SOFT ,改为如下 chip->ecc.mode = NAND_ECC_NONE。
只此一处。 第四步:下面是devfs的问题,因为2.6.12内核以后取消了devfs的配置选项,缺少了它内核会找不到mtdblock设备。所以我们需要修改 fs/Kconfig 文件,或者是从2.6.12的fs/Kconfig中拷贝下面几项到2.6.18的fs/Kconfig中去,我们采用修改的方法来完成。 修改 fs/Kconfig支持devfs 。 在Pseudo filesystems 主菜单的最后添加我们所要的内容。 第五步:文件系统的支持 Yaffs 文件系统 YAFFS文件系统简介 YAFFS,Yet Another Flash File System,是一种类似于JFFS/JFFS2的专门为Flash设计 的嵌入式文件系统。与JFFS相比,它减少了一些功能,因此速度更快、占用内存更少。 YAFFS和JFFS都提供了写均衡,垃圾收集等底层操作。它们的不同之处在于: (1)、JFFS是一种日志文件系统,通过日志机制保证文件系统的稳定性。YAFFS仅仅 借鉴了日志系统的思想,不提供日志机能,所以稳定性不如JAFFS,但是资源占用少。 (2)、JFFS中使用多级链表管理需要回收的脏块,并且使用系统生成伪随机变量决定 要回收的块,通过这种方法能提供较好的写均衡,在YAFFS中是从头到尾对块搜索, 所以在垃圾收集上JFFS的速度慢,但是能延长NAND的寿命。 (3)、JFFS支持文件压缩,适合存储容量较小的系统;YAFFS不支持压缩,更适合存 储容量大的系统。 YAFFS还带有NAND芯片驱动,并为嵌入式系统提供了直接访问文件系统的API,用 户可以不使用Linux中的MTD和VFS,直接对文件进行操作。NAND Flash大多采用 MTD+YAFFS的模式。MTD( Memory Technology Devices,内存技术设备)是对Flash 操作的接口,提供了一系列的标准函数,将硬件驱动设计和系统程序设计分开。 Yaffs 文件系统内核没有集成,可以对其主页下载: https://www.doczj.com/doc/896062109.html,/cgi-bin/viewcvs.cgi/#dirlist
1 引言 随着网络维护管理模式由分散式粗放型向集中式精细化管理模式迈进,铁通公司提出了“强化支撑能力,加强网络集中化管理,在集中化维护管理的基础上,逐步实现核心机房的联合值守和非核心机房的无人值守”的目标。 如何在有限的资金投资的前提下实现网管集中的目标,同时满足降低网络维护成本,达到维护出效率,节能减排的指标要求,是我们在网管集中工作中重点关注和努力的方向。由于铁通陕西分公司部分网管未搭建统一的集中化平台,制约了网管集中及维护管理模式集中化推进工作的整体实施,通过搭建虚拟化平台,实现了网管集中化维护管理的要求。 2 现有网管集中技术的缺陷及弊端 2.1技术落后、效率低下 既有网管接入方式主要采取将放置在机柜中的几十台工作站终端逐个接人KVM,通过KVM终端盒接入显示器,通过显示器进行切换分别进入不同的工作站终端进行维护操作。 从以下流程中可以看到。运维人员在处理一个区域的告警信息时无法看到其他区域的告警信息,只有在处理完这个区域的告警信息后才能处理下一个区域的信息,那么排在后面检查的区域告警往往得不到及时的处理,且随着业务系统的增加,维护人员需要管理的系统越来越多,这种轮询检查的方式将越来越成为制约维护效率提升的瓶颈。 2.2网管终端设备数量多维护成本居高不下。 几十台网管终端占据机房机柜资源,大量的终端清扫、部件维护和更换等在增加维护人员工作量的同时也增加了维护成本。同时新增系统时需增加网管终端
及机柜,受机房条件制约性很大。不算人工工作量,仅终端维修费支出每年平均在6.8万元。 2.3带来耗电量及运营成本的增加 从维护成本支出上计算,每台工作站终端按250W 能耗计算,在不考虑空调等耗电量的情况下,每年需要消耗近20万度电。 2.4系统架构分散使得管理难度、网管系统安全隐患增大。 由于系统架构分散,无备用终端,一旦故障,不能得到及时修复,对网络正常运行形成潜在威胁。 3 虚拟机技术介绍 计算机虚拟技术是指计算元件在虚拟的基础上而不是真实的基础上运行。虚拟化技术可以扩大硬件的容量,简化软件的重新配置过程。允许用户在一台服务器上同时运行多个操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率。虚拟化能在虚拟机技术(Virtual Machine Monitor)中,不再对底层的硬件资源进行划分,而是部署一个统一的Host系统。 在Host系统上,加装了Virtual Machine Monitor,虚拟层作为应用级别的软件而存在,不涉及操作系统内核。虚拟层会给每个虚拟机模拟一套独立的硬件设备。包含CPU、内存、主板、显卡、网卡等硬件资源,在其上安装所谓的Guest操作系统。最终用户的应用程序,运行在Guest操作系统中。 虚拟可支持实现物理资源和资源池的动态共享,提高资源利用率,特别是针对那些平均需求远低于需要为其提供专用资源的不同负载。这种虚拟机运行的方式主要有以下优势。
虚拟化平台解决方案设计 一、云计算平台核心管理模块软件架构 动态数据中心核心管理用户自服务模块与平台管理模块,是将数据中心管理的主要功能: -系统监控 -虚拟化管理 -数据备份 -配置管理 -身份管理 以Web Service方式包装成模块,调用成熟的产品组件System Center与FIM 的主要功能,实现高度可扩展的系统管理。 -系统监控模块 ?单个(或集群的)服务器的主要服务
?跟踪事件和日志服务器上生成的状态监测 ?跟踪性能计数器以测量和优化系统的使用 ?生成基于预定义的规则的事件或计数器的通知 -服务器部署和配置模块 ?自动设置服务器(虚拟和物理),管理虚拟服务器的配置设置 ?配置的网络交换机和创建的虚拟服务器的负载平衡 ?虚拟服务器和在最可用的物理服务器环境中的自动分配 ?创建和管理所创建的虚拟服务器实例使用的模板 ?创建和管理系统镜像,管理物理服务器实例 -数据保护模块 ?备份和还原的整个服务器 ?备份和还原的计算机正在运行的数据库 ?能够回滚在服务器中所做的更改 ?备份和还原所有服务器的单个文件和文件夹 -服务配置管理模块 ?跟踪资产硬件和软件许可证以及在环境中的配置 ?管理的软件更新(通过自定义的更新计划) ?定义和使用所需的服务器等计算资源的配置 ?生成报告已安装的软件,更新挂起的操作,等等 ?安装并维护应用程序等 另外,通过System Center Opalis与HP Open View, IBM Tivoli, BMC Patrol, NetIQ 等多厂家系统管理软件在IT管理流程层面进行整合,形成统一的运营监控体系。 充分发挥原有运营监控软件功能充分发挥原有投资。
Yaffs2文件系统中对NAND Flash磨损均衡的改进 摘要:针对以NAND Flash为存储介质时Yaffs2文件系统存在磨损均衡的缺陷,通过改进回收块选择机制,并在数据更新中引入冷热数据分离策略,从而改善NAND Flash的磨损均衡性能。实验借助Qemu软件建立Linux嵌入式仿真平台,从总擦除次数、最大最小擦除次数差值和块擦除次数标准差等方面进行对比。实验结果表明,在改进后的Yaffs2文件系统下NAND Flash的磨损均衡效果有明显提升,这有益于延长NAND Flash的使用寿命。 关键词: Yaffs2文件系统;NAND Flash;垃圾回收;冷热数据 0 引言 NAND Flash存储设备与传统机械磁盘相比,具有体积小、存储密度高、随机存储和读写能力强、抗震抗摔、功耗低等特点[1]。它被广泛用于智能手机、车载智能中心、平板电脑等智能终端中。近年来,以NAND Flash为存储介质的固态硬盘也得到越来越多的应用。目前Yaffs2文件系统(Yet Another Flash File System Two,Yaffs2)[1]是使用最多、可移植性最好的专用文件系统,在安卓、阿里云OS、Linux等嵌入式系统中都有使用。在Yaffs2文件系统下以NAND Flash为存储介质时存在磨损均衡的缺陷,可通过对回收块选择机制作改进和引入冷热数据分离策略来提高磨损均衡的效果。 1 Yaffs2和Nand Flash关系 这里以使用最多的Linux操作系统为实践,将Yaffs2文件系统移植到Linux操作系统中。Linux系统通常可以分为3层:应用层、内核层和设备层,其中支持NAND Flash设备的Yaffs2文件系统属于内核层,。 最上层用户应用程序通过VFS(Virtual File System)提供的统一接口,将数据更新等文件操作传递给Yaffs2。VFS代表虚拟文件系统,它为上层应用提供统一的接口。有了这些接口,应用程序只用遵循抽象后的访问规则,而不必理会底层文件系统和物理构成上的差异。然后Yaffs2通过MTD(Memory Technology Device)提供的统一访问接口对NAND Flash进行读、写和擦除操作,从而完成数据的更新或者存储操作。MTD代表内存技术设备,它为存储设备提供统一访问的接口。最终,在NAND Flash上以怎样的格式组织和存储数据由Yaffs2文件系统决定。 NAND Flash由若干块(block)组成,每个块又是由若干页(page)组成,页中含有数据区和附加区。NAND Flash的页根据状态不同,可以分为有效页、脏页、空闲页。有效页中存放有效数据,脏页中存放无效数据,空闲页是经过擦除后可以直接用于写入数据的页。NAND Flash在写入数据前需要执行擦除操作,因此数据不能直接在相同的位置更新。当一个页中数据需要更新时,必须将该页中有效数据拷贝到其他空闲页上再更新,并将原来页上的数据置为无效。随着时间的推移,许多无效页累积在存储器中使得空闲页逐渐减少。当存储器中的空闲空间不足时,启动垃圾回收操作,利用回收块选择机制从待回收块中选取满足要求的块来擦除,从而得到足够的空闲空间。NAND Flash中块的擦除次数有限,通常为10 000次~100 000次[2]。当某个块的擦除次数超过使用寿命时,该块将无法正常用于数据存储。因此,垃圾回收应利用合理的回收块选择机制,从待回收块中找到回收后能产生良好磨损均衡效果且付出较少额外代价的块来回收,从而获得足够的空闲空间用于数据更新操作。 2 Yaffs2在磨损均衡方面的缺陷 Yaffs2中回收块的选择机制[3]是从待回收块中找到有效数据最少的块来回收。回收过程中,Yaffs2能够减少有效数据的额外读和写操作。当数据更新处于均匀分布的情况下,Yaffs2表现出较好的磨损均衡效果。 但是,通常情况下数据的更新频率不同,有些数据经常更新,而有些数据很少更新。经
虚拟化资源申请及管理规范 一、总体要求 1、虚拟机按需创建,做到专机专用。关键业务虚拟机、一般业务虚拟机和测试用虚拟机应分开,停用的虚拟机在规定时限内应及时删除。 2、创建后的虚拟机及时登记并纳入服务器统一管理,每开通一个虚拟机要及时把虚拟机配置,用户名,密码,主机地址纳入管理库。 3、不要随意在公共场所安装虚拟机客户端,进行登录虚拟机操作。不得向他人随意泄露vcenter登陆密码。 二、虚拟机创建 1、虚拟机命名:使用[IP地址后两位_虚拟机用途_操作系统简写]的格式,如“”、“”。 2、虚拟机磁盘配置:为实现DRS和HA,虚拟机安装在共享存储上,不能使用服务器自带存储。每个LUN上可布置15-20个一般业务的虚拟机,用于生产业务的LUN上虚拟机个数最好在10个以下。对于oracle、ms sql server等高io的应用,建议使用裸设备映射。每个LUN的空间使用率不能高于80%。所有的虚拟机磁盘文件应放在同一文件夹下,以方便管理。用于生产业务的虚拟机,虚拟磁盘采用厚置备置零的格式,对于测试的虚拟机,虚拟磁盘采用THIN PROVISION 格式。一般业务的虚拟机则根据存储的空间大小来选择合适的格式。
所有虚拟机初始硬盘大小为80G,不够时再对硬盘扩容。原则上不提倡使用大于2T的超大存储硬盘,这样在做快照或数据备份时会出现很多问题。如果确有超过2T的存储空间需求,建议为这台虚拟机分配多个LUN,用户可在操作系统层面实现逻辑卷的合并来满足需求。 : 3、CPU配置:根据虚拟机业务量分配CPU,建议配置两个CPU,总CPU核数不能不能超过32个。原则上是安装完操作系统后就不再对虚拟机cpu作更改,否则会影响到系统的稳定性。如果虚拟机运行一段时间发现cpu资源不足,可向信息发展部提出申请迁移到性能更强的虚拟主机上运行或增加cpu的预留值和共享cpu的比例来提高性能。 4、内存分配:虚拟化环境中内存资源很宝贵,为了合理利用内存资源及提高内存利用率,内存最低分配为2G,最高不超过32G,所有虚拟机内存总使用量不能超过服务器所配内存的80%。虚拟机运行一段时间后发现内存资源长期不足可再次申请增加内存。如果虚拟机申请大量内存但是长期处于低使用率状态,信息发展部可根据统计情况回收多余的内存。 5、网卡配置:如无特殊需求,只配置一个千兆虚拟网卡,虚拟交换机采用标准千兆交换机。 6、虚拟机操作系统安装:目前提供Windows server 2003 64位、windows server 2008 R2 64位、Centos 64位。对于windows系统,系统分区为50G。linux系统,/boot分区200M,swap分区和内存大小一样,/为20G,剩余大小设置为数据分区。
Linux-2.6.32.2内核在mini2440上的移植(二)---yaffs2文件系统移植 移植环境(红色粗字体字为修改后内容,蓝色粗体字为特别注意内容) 2.1, yaffs2文件系统移植 【1】获取yaffs2 源代码 现在大部分开发板都可以支持yaffs2 文件系统,它是专门针对嵌入式设备,特别是使用nand flash 作为存储器的嵌入式设备而创建的一种文件系统,早先的yaffs 仅支持小页(512byte/page)的nand flash,现在的开发板大都配备了更大容量的nand flash,它们一般是大页模式的(2K/page),使用yaffs2 就可以支持大页的nand flash,下面是yaffs2 的移植详细步骤。 在https://www.doczj.com/doc/896062109.html,/node/346可以下载到最新的yaffs2 源代码,需要使用git工具( 安装方法见Git版本控制软件安装与使用),在命令行输入: [root@localhost ~]# cd ./linux-test [root@localhost linux-test]# git clone git://https://www.doczj.com/doc/896062109.html,/ya ffs2 Cloning into yaffs2... remote: Counting objects: 6592, done. remote: Compressing objects: 100% (3881/3881), done. remote: Total 6592 (delta 5237), reused 3396 (delta 2642) Receiving objects: 100% (6592/6592), 3.34 MiB | 166 KiB/s, d one. Resolving deltas: 100% (5237/5237), done.
奥云系列产品:奥云虚拟化平台 o Cloud?的使命就是要从最底层的虚拟化开始,打造我国第一个完全自主的云平台! o Cloud?从最底层的虚拟化平台(奥云虚拟化平台)开始,把每一层软件平台做强、做精,达到企业级独立运行要求是奥云核心研发团队的终极目标,而在此基础上为合作伙伴和用户提供优质高效的相关服务是同德一心恒久不变的追求。在系统稳定、可靠的品质基础之上,如何能让用户更简单轻松的完成日常的IT 管理工作也是o Cloud?在设计和整个研发过程中的一个重要考虑因素。o Cloud?研发团队会不断的进行产品的升级和易用性的进一步提炼,没有完美的软件,只有更好用更适合的产品! o Cloud?立足于服务器虚拟化市场,以虚拟化技术和产品为基础,构建云的整体运营系统。o Cloud?系列产品从功能层次上分为三层,从最底层的服务器虚拟化平台到上层的云运营系统,o Cloud?都将以自主创新的产品填补国内空白。并且每一个功能层次的产品都可以作为独立的平台进行独立运行,也可以和其他厂商的相关产品联合使用,让用户在构建属于自己的云平台的时候,有更灵活的选择空间和搭配余地,真正构建适合自身IT 要求的个性化云平台。 图1 o Cloud?奥云虚拟化平台是一套功能完备的企业级虚拟化平台,采用CS 管理架构,分为服务器端和管理客户端两大部分。服务器端提供裸机安装的虚拟化平台,并实现多种高级功能;管理客户端是管理员进行远程管理控制的界面,通过简单人性化的图形界面实现基于虚拟化平台的日常IT 管理工作。 o Cloud?奥云虚拟化平台具有强大的功能,典型的应用包括:
服务器整合 在服务器领域,硬件发展速度远远超过软件系统的发展速度,绝大多数情况下应用服务器的平均利用率非常的低。根据行业分析报告,服务器的CPU 使用率在5% 左右,而系统内存的平均占用率也在20% 以下,在服务器性能严重浪费的同时,也造成了电力、空间等多方面的浪费,与国家提倡的“节能减排”、“绿色IT”等战略背道而驰。服务器虚拟化技术的出现,打破了这一局面! 图2. 服务器整合 统一集中管理 虚拟化之前,所有的IT 系统分散放置,无论是对服务器硬件还是对多个不同的IT 系统的管理维护都得单独分别进行,随着IT 系统规模的增加,管理员的压力也随之增大。使用奥云虚拟化平台的管理客户端,对已经整合的IT 系统进行统一集中的管理和维护,无论是对虚拟化系统本身的管理和维护操作还是对以虚拟机方式运行的所有IT 系统的日常维护操作,都可以使用奥云虚拟化平台的管理客户端轻松实现,管理员无需在多个管理软件之间进行切换,就可以完成对虚拟机的所有管理操作,包括对虚拟机系统的配置等等,奥云的管理客户端将虚拟机的桌面操作完全整合到统一的管理界面中来,多系统的维护和操作变得再简单不过。
制作刷机包 打开‘yaffs2img浏览器’,点击左上角的‘选取yaffs2文件’选择你刚刚复制出来的 files文件夹里的system.img 先来认识一下这个软件 1.定制软件的提取(此部和制作刷机包没关系,可以不做,想用官方软件的同学可以 看看) 选择app,右键你想要提取软件,提取就可以了,我是把整个app文件夹提取出来了,不用 的软件直接删掉好了 2.定制软件的精简 在你不想要用的软件上直接右键,删除,就好了,你也可以右键添加你想要用的软件,得把
软件改成比较简短的英文名,否则有可能不能用 秀一下我精简后的列表,大家可以参照着精简 https://www.doczj.com/doc/896062109.html,uncher文件的替换 下载好你想要用的桌面软件,改名为‘Launcher’,删掉app中的‘Launcher2’,添加进去你改好名字的‘Launcher’就好了,我比较喜欢ADW,所以我把ADW的文件名改为 Launcher,替换掉原来的Launcher2就好了 4.破音问题的解决 在左边导航点选‘etc’,右键添加文件,把附件中的声音配置文件解压出来 ‘AudioFilter.csv’添加进去就好了 AudioFilter.rar (355 Bytes)
5.字体的更改 下载字体文件,中文字体库一律把名字改名为‘DroidSans Fallback.ttf’,英文字体改为‘DroidSans.ttf ’,加粗的英文字体改为‘DroidSans-Bold.ttf ’然后再左边导航栏点选‘fonts’,把之前自带的字体删除,然后把你改好名字的字体添加进去就好了把国产机皇的字体也分享给大家,中文+英文+英文加粗 6.开机音乐和照相机音乐的删除 在导航栏点选‘media’,在audio/ui文件夹下,删除‘Bootsound.mp3’(开机音乐)和