Web搜索引擎设计和实现分析
- 格式:doc
- 大小:185.50 KB
- 文档页数:32

基于Web标准的网页设计的分析与实现张勇【摘要】生活中处处是标准,我们可以试想生活中没有标准的样子-即便是一颗小小的螺丝钉也可能无法找到合适的.经验告诉我们一个行业的发展总是经历一个由无序竞争到规范的发展过程,Web页面设计也同样经历了这样一个过程.文章详细叙述了Web标准产生的原因,及Web标准的组成与实现方法.【期刊名称】《安阳师范学院学报》【年(卷),期】2011(000)002【总页数】4页(P28-31)【关键词】web标准;浏览器;DIV+CSS;XHTML【作者】张勇【作者单位】宿州职业技术学院计算机信息系,安徽宿州234101【正文语种】中文【中图分类】TP393.092早在1997年,有一个通用的惯例,Netscape浏览器使用Javascript,IE使用Jscript (一种类似于Javasrcipt的脚本语言)。
Javasrcipt只能运行在Netscape,而微软的ActiveX和Jscript只能运行在 IE。
1997年下半年的时候,Netscape和 IE都推出了4.0版本浏览器,他们各自吹嘘自己的浏览器有强大的Dhtml(动态的html),但他们的浏览器完全不兼容,更不用说不知名的浏览器了,而且Netscape和IE跟他们3.0的版本也无法兼容,对于项目开发者来说,想让自己的网站在几个不同版本的浏览器中同时使用的话就要做几个不同的版本,同时每个功能都要做几个不同的版本去适应不同的浏览器,这样造成项目开发成本至少增加了25%左右;所以一些开发者限制他们的网站只适应其中一个版本的浏览器。
而且网站随时面临着过时的命运和被淘汰的怪圈。
这种情况在那个Web传统网站的旧时代非常普遍,因为许多东西都没有真正意义上的一个标准,Web网站开发显得非常混乱。
当时的网景和IE的浏览器大战就是个最好的例子,因为当时的浏览器没有统一的标准可以遵守,大家都使用自己私有的标准,加上当时的浏览器支持非常劣质的CSS1.0,所以没有一个有效的方法可以解决浏览器之间的兼容性问题。


基于人工智能的智能问答搜索引擎设计与实现智能问答搜索引擎是一种基于人工智能技术的应用程序,旨在通过自动回答用户提出的问题,为用户提供准确、高效的信息查询和解答服务。
本文将详细介绍基于人工智能的智能问答搜索引擎的设计与实现。
一、智能问答搜索引擎的设计1. 数据收集与处理:智能问答搜索引擎的核心在于准确的问题解答和信息查询。
为了实现这一目标,首先需要收集和整理大量的问题和答案数据。
可以利用网络爬虫技术从互联网上收集相关问题的数据,并对这些数据进行去重、分类和标注,建立问题与答案的对应关系。
2. 自然语言处理:智能问答搜索引擎需要具备对用户问题的理解和答案的生成能力。
这就需要利用自然语言处理技术对用户提问进行分析,提取问题的关键信息。
可以采用词法分析、句法分析、语义分析等技术来处理用户问题,将问题转换为计算机能够理解和处理的形式。
3. 知识库构建:为了回答用户提出的问题,智能问答搜索引擎需要建立一个知识库,存储大量的问题和答案。
可以结合领域专家的知识,将知识库分为不同的主题或领域,以便更精确地回答用户的问题。
知识库的构建可以采用手工编写、半自动标注、数据挖掘等方式。
4. 排序与答案生成:在用户提问后,智能问答搜索引擎需要根据用户问题的关键信息,在知识库中检索出相关的问题和答案。
可以使用信息检索技术,例如倒排索引和向量空间模型,对用户问题和知识库中的问题进行匹配,根据匹配度为问题和答案进行排序。
然后,通过生成算法,从知识库中选取最相关的答案,返回给用户。
5. 用户界面设计:智能问答搜索引擎的用户界面应该简洁明了,方便用户输入问题和查看答案。
可以采用搜索框和分类标签的形式,用户可以通过输入问题或选择相应的标签来进行查询。
另外,还可以提供问题补全功能,根据用户输入的部分问题,自动推荐可能的问题选项,提高查询的准确性和效率。
二、智能问答搜索引擎的实现1. 自然语言处理技术的应用:实现一个智能问答搜索引擎需要使用自然语言处理技术对用户问题进行分析和处理。

2020年11月25日第4卷第22期现代信息科技Modern Information TechnologyNov.2020 Vol.4 No.22收稿日期:2020-10-15基金项目:江西省教育厅科学技术研究项目(GJJ207803);江西省高等学校教学改革研究课题(JXJG-19-77-2)站长工具平台“搜一搜”的设计与实现——基于Python+PHP+Elasticsearch 语言邱慧玲,王鹰汉(上饶职业技术学院,江西 上饶 334109)摘 要:个人站长是目前大学生创业的主流方法,使用站长工具是网站运营的必备技能。
文章着重探讨了站长工具平台——“搜一搜”的建设,在分析市面上已有站长工具缺点的基础上,对“搜一搜”平台进行了具体的系统分析,最终设计并建立了一个更加适合高校学生使用的新平台,旨在为新站长们节约学习成本,提供清晰的运营流程,明确适合个人网站的优化方向,助力大学生创业。
关键词:站长工具;Elasticsearch ;关键词;PHP中图分类号:TP393.092;TP391.3 文献标识码:A文章编号:2096-4706(2020)22-023-04Design and Implementation of Webmaster Tool Platform “Souyisou”——Based on Python + PHP + Elasticsearch LanguageQIU Huiling ,WANG Yinghan(Shangrao Vocational & Technical College ,Shangrao 334109,China )Abstract :Personal webmaster is the mainstream method for college students to start a business ,and the use of webmaster tool isa necessary skill for website operation. This paper focuses on the construction of the webmaster tool platform ——“souyisou ”,based onthe analysis of the shortcomings of the existing webmaster tools in the market ,a specific systematic analysis of the “souyisou ” platform is carried out ,a new platform which is more suitable for college students is designed and established ,which aims to save learning costs for new webmasters ,provide a clear operation process ,clarify the optimization direction for personal websites ,and help college students start their own businesses.Keywords :webmaster tool ;Elasticsearch ;keyword ;PHP0 引 言“大众创业、万众创新”的新时代开启以来,高校纷纷建立创业学院,为学生创新创业提供资金、场地、学业等多方位支持及优惠政策,极大激发了高校学生的创业积极性,并取得了一些成绩。

语义网搜索引擎设计与实现语义网搜索引擎是一种基于Web语义这种机器可读的语言进行搜索的搜索引擎。
与传统的搜索引擎不同,语义网搜索引擎更加侧重于语义的理解和表达,可以实现更加精准、智能的搜索结果。
本文将从设计和实现两个方面来探讨语义网搜索引擎的相关问题。
一、设计语义网搜索引擎1. 语义理解的重要性语义网搜索引擎的设计首先需要考虑如何对语义进行理解。
语义理解是指通过自然语言的表达和上下文信息来解析语义的过程。
语义理解是非常重要的,因为语义网的本质在于构建机器可读的语言,其目的就是帮助机器能够自动理解这种语言。
2. 元数据的应用语义网搜索中的元数据是指与Web内容相关的信息,包括作者、摘要、关键词、主题等等。
元数据可以在语义网中为内容增加附加信息,从而提供更加深入、详细的搜索结果,帮助用户更好地找到自己想要的信息。
因此,在语义网搜索引擎设计过程中,需要对元数据的应用进行深入探讨,以提高搜索结果的准确性和可用性。
3. 计算机语言的使用语义网采用的是一种基于计算机语言的形式化语言,该语言可以轻松地为数据附加元数据,表达数据之间的关系,从而实现数据的自动分析和推理。
因此,语义网搜索引擎设计需要涉及计算机语言的使用,帮助机器能够更好地理解和理解语言,提高搜索结果的准确性和可用性。
二、实现语义网搜索引擎1. 知识表示和推理知识表述是语义网搜索引擎的核心,它建立在基于Web的知识库上。
知识库是指包含了一些基本概念、实体、属性和关系的数据库,这些概念可以用来描述语义网中的各种内容。
推理是指通过推理算法对知识库中的数据进行分析,推出更加深入、具体的信息,从而实现更加智能、准确的搜索结果。
2. Web服务技术的应用Web服务是一种为Web应用程序和机器之间提供通信机制的技术。
Web服务可以使不同的应用程序之间可以互操作,实现信息的共享和交换。
在语义网搜索引擎实现过程中,Web服务技术可以帮助搜索引擎更好地处理搜索请求,组织和查询知识库中的数据,从而提高搜索结果的准确性和可用性。

搜索引擎实验实验报告网址:/以谷歌搜索引擎为例:一、搜索引擎简介搜索引擎(search engine)是指根据一定的策略、运用特定的计算机程序搜集互联网上的信息,在对信息进行组织和处理后,并将处理后的信息显示给用户,是为用户提供检索服务的系统。
现在的搜索引擎有百度、谷歌、雅虎、搜狗、迅雷等等。
下面介绍下谷歌的工作原理:Google采用了两个重要的特性,因此而获取了准确的查询结果:第一,Google利用网页的链接结构计算出每个网页的等级排名,这就是所谓的PageRank;第二,Google利用了链接提供的信息进一步改善搜索结果。
Google使用两个探测器来抓取网站上的内容:Freshbot和Deepbot。
深度探测器(Deepbot)每月出击一次,受访内容在Google的主要索引之中。
刷新探测器(Freshbot)是持续不断地发现新的内容,例如新的网站、论坛、博客等。
看起来,Google是发现了一个新的网页,之后再频繁地再访,来看看是否还有什么新的更新。
如果有,这个新网站就会被加入到刷新探测器的名单中进行访问。
刷新探测器取得的结果是汇总在一个单独的数据库里。
每一次刷新探测器进行新的一轮循环的时候都被重写。
刷新探测器和Google的主要索引是合在一起提供搜索结果的。
Google的操作模式收集---->采编/索引---->反馈的工作程序。
事实上,搜索引擎包括以下几个元素。
抓取状态:搜索引擎派出探测器到互联网上不知疲倦地搜集网页。
网页仓库:搜索来的网页要集中在一个地方存储,等候索引处理。
索引整理:将网页分门别类,进行压缩,等候进行索引编类,而未压缩的原始网页资料被删除掉。
索引状态:将压缩后的网页编目在不同的索引之下。
问询状态:将用户问询所用的白话转换成搜索引擎读的懂的计算机语言,来咨询各个索引求得相关答案。
排名状态:搜索引擎将相关答案根据一定的标准以列表的形式排列给用户。
搜索引擎认为最好的答案被推荐在首位,较次的排列随后,以此类推。


校园网Web搜索引擎的设计与实现引言随着校园网建设的迅速发展,校园网内的信息内容正在以惊人的速度增加着。
如何更全面、更准确地获取最新、最有效的信息已经成为我们把握机遇、迎接挑战和获取成功的重要条件。
目前虽然已经有了像Google、百度这样优秀的通用搜索引擎,但是它们并不能适用于所有的情况和需要。
对学术搜索、校园网的搜索来说,一个公平的排序结果是非常重要的。
另外,由于互联网上信息量之巨,远远超出哪怕是最大的一个搜索引擎可以完全收集的能力范围。
因此,本着整合校园网资源的目的,为方便广大师生对校园网信息的获取和使用,设计并实现了一个灵活、可配置、具有良好可扩展性的校园网搜索引擎。
1. 搜索引擎的发展在国内很多基于主题领域的小型搜索引擎得到很好的发展。
例如一些音乐搜索引擎以及医药方面的搜索都有很好的应用;在越来越多的学校、企业、比较大型的网站如BBS都开始建立了自己的搜索引擎。
在国外,比较著名的有美国教育资源信息搜索的AskERIC,实现医药文献搜索的Highwire等。
Google公司在2007年决定向小型网站提供专门的搜索服务。
这些都表明,小型专用的搜索引擎将在人们获取Web信息中发挥更重要的作用[1]。
在小型搜索引擎快速发展的同时,越来越多的人致力于研究和发展这些小型搜索引擎开发技术,Lucene和Nutch是其中的代表成果。
Lucene是一个高性能、纯Java的全文检索引擎,完全免费、开源。
Lucene几乎适合于任何需要全文检索的应用,尤其是跨平台的应用。
Lucene为Nutch提供了文本索引和查询服务的API,而Nutch在Lucene的基础上实现了网页收集与搜索[2]。
小型搜索引擎与通用搜索引擎相比有很多优点,由于它本身的信息量小,它不可能取代通用搜索引擎。
但是,它是对通用搜索的很好的补充。
随着Web上信息的进一步扩大,小型搜索引擎也将会进一步发展,其中已经引起人们关注的垂直搜索引擎在未来的搜索将发挥更大的作用。

面向语义的Web搜索引擎的设计与实现随着互联网的发展,我们使用搜索引擎的频率越来越高。
现有的搜索引擎大多基于文本匹配,即搜索关键词与网页文本的匹配度。
但这种方式往往不能很好地满足用户需求,因为搜索词可能有多种含义,同一个词在不同领域可能有不同的解释。
为了解决这个问题,语义技术被引入到搜索引擎中。
语义搜索引擎可以更好地理解用户查询的意图,将查询需要的信息组织起来,并以更符合用户意图的方式呈现给用户。
下面将讨论如何设计和实现一个面向语义的Web搜索引擎。
1. 知识图谱与语义标记知识图谱是指用来表示概念之间关系的语义图谱。
它可以帮助我们更好地理解用户查询的含义,实现搜索结果的个性化推荐和排序。
语义标记可以将文本内容中的词汇与知识图谱中的概念进行匹配。
这样一来,搜索引擎就可以将文本内容与知识图谱进行匹配,从而更好地理解用户查询的含义。
例如,用户查询“罗伯特·德尼罗”,搜索引擎可以通过语义标记将该查询与知识图谱中的“电影演员”等相关概念进行匹配,从而得出更符合用户需求的搜索结果。
2. 多模态搜索随着互联网的发展,图片、视频等多媒体形式的信息也越来越丰富。
面向语义的Web搜索引擎应该支持跨模态的搜索。
例如,用户输入一个图片文件,在搜索引擎的搜索结果中显示与图片相关的信息。
多模态搜索涉及到的技术包括图像识别、声音识别等。
通过应用这些技术,搜索引擎可以更好地理解用户需求,提供更有针对性的搜索结果。
3. 结果排序针对用户查询,搜索引擎可以通过多种算法进行排序,以提供更符合用户需求的搜索结果。
例如,搜索结果可以按照与用户查询的相似度排序,或者按照搜索内容的权重进行排序等。
排序算法的选择应该考虑用户需求和实际效果,例如,用户喜欢看的细节,如果排序规则不符合此要求,就可能使用户对搜索引擎的满意度降低。
4. 思考过程的开放性任何一种搜索方法都是基于某种模型的,假设您的模型完美无瑕,那么查询结果的效果将非常有保障。

Web图像检索系统原型设计和实现摘要计算机处理能力的日益增强,因特网技术的广泛普及和网络带宽不断提高,大量的图像信息不断产生,如何从这些海量图像数据中搜索人们感兴趣并有效利用这些图像,成为迫切需要解决的问题.本设计介绍了在web中检索图像的基本概念和常用的重要技术,并简要阐述了它们的基本概念、原理,说明了目前这一领域的发展现状。
本文介绍了图像的特征:颜色特征、纹理特征和形状特征,和以图像内容特征为基础的Web图检索原理。
最后以基于内容的图像检索为重点,利用Matlab对Web图像检索系统进行了模拟和验证。
我的工作是Web图像检索系统原型的架构和检索界面的设计和实现,利用matlab gui设计系统界面以实现图像的检索功能。
关键字:Web图象检索,特征提取,Matlab GUIAbstractWith the capacity of computer increasing , Internet technology is popular more and more。
A mass of image data informations is produced constantly,so image retrieval becomes a urgent problem.Firstly, the basic concept of Web image retrieval and some technologys are introduced in the paper; secondly we describes the image features:color feature,texton feafure,shape feafure. the theory of Web image retrieval is based on these content features. Meanwhile ,several important image retrieval algorithms are introduced and compared in the paper. Finally, we made experiment on Matlab for web image retrieval 。
本科毕业设计题目:基于网络爬虫的搜索引擎设计与实现系别:专业:计算机科学与技术班级:学号:姓名:同组人:指导教师:教师职称:协助指导教师:教师职称:摘要本文从搜索引擎的应用出发,探讨了网络蜘蛛在搜索引擎中的作用和地住,提出了网络蜘蛛的功能和设计要求。
在对网络蜘蛛系统结构和工作原理所作分析的基础上,研究了页面爬取、解析等策略和算法,并使用Java实现了一个网络蜘蛛的程序,对其运行结果做了分析。
关键字:爬虫、搜索引擎AbstractThe paper,discussing from the application of the search engine,searches the importance and function of Web spider in the search engine.and puts forward its demand of function and design.On the base of analyzing Web Spider’s system strtucture and working elements.this paper also researches the method and strategy of multithreading scheduler,Web page crawling and HTML parsing.And then.a program of web page crawling based on Java is applied and analyzed.Keyword: spider, search engine目录摘要 (1)Abstract (2)一、项目背景 (4)1.1搜索引擎现状分析 (4)1.2课题开发背景 (4)1.3网络爬虫的工作原理 (5)二、系统开发工具和平台 (5)2.1关于java语言 (5)2.2 Jbuilder介绍 (6)2.3 servlet的原理 (6)三、系统总体设计 (8)3.1系统总体结构 (8)3.2系统类图 (8)四、系统详细设计 (10)4.1搜索引擎界面设计 (10)4.2 servlet的实现 (12)4.3网页的解析实现 (13)4.3.1网页的分析 (13)4.3.2网页的处理队列 (14)4.3.3 搜索字符串的匹配 (14)4.3.4网页分析类的实现 (15)4.4网络爬虫的实现 (17)五、系统测试 (25)六、结论 (26)致谢 (26)参考文献 (27)一、项目背景1.1搜索引擎现状分析互联网被普及前,人们查阅资料首先想到的便是拥有大量书籍的图书馆,而在当今很多人都会选择一种更方便、快捷、全面、准确的方式——互联网.如果说互联网是一个知识宝库,那么搜索引擎就是打开知识宝库的一把钥匙.搜索引擎是随着WEB信息的迅速增加,从1995年开始逐渐发展起来的技术,用于帮助互联网用户查询信息的搜索工具.搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的.目前搜索引擎已经成为倍受网络用户关注的焦点,也成为计算机工业界和学术界争相研究、开发的对象.目前较流行的搜索引擎已有Google, Yahoo, Info seek, baidu等. 出于商业机密的考虑, 目前各个搜索引擎使用的Crawler 系统的技术内幕一般都不公开, 现有的文献也仅限于概要性介绍. 随着W eb 信息资源呈指数级增长及Web 信息资源动态变化, 传统的搜索引擎提供的信息检索服务已不能满足人们日益增长的对个性化服务的需要, 它们正面临着巨大的挑战. 以何种策略访问Web, 提高搜索效率, 成为近年来专业搜索引擎网络爬虫研究的主要问题之一。
基于Web的计算机专业人才培养需求分析系统的设计和实现摘要:系统采用B/S模式,利用深度优先搜索策略对招聘网站信息进行采集、加工、索引,提出基于探索性分析的时序数据挖掘方法,采用线性回归技术建立数学模型,对未来计算机专业需求状况进行分析预测,为专业人才培养方案的确定提供了重要的依据和解决方案。
关键词:人才培养;数据搜索;线性回归;分析预测0 引言目前全国各高校普遍开办计算机类专业,而计算机技术发展迅速,如果不建立快速的反映机制,教学内容和培养目标很容易过时,从而不符合社会对人才的需求。
20世纪90年代以来,伴随着Internet应用的逐渐普及和发展,因特网上的信息资源正在呈几何级数增长。
在人才需求方面,网络上的信息十分丰富,一些著名人才招聘网站更是定期发布全国企事业单位的人才需求信息。
这就给各高校教学改革一个启示:开发基于Web的计算机专业人才培养的需求分析系统,该系统可以搜集当前人才需求信息,对未来一段时间内社会对专业人才的需求作出分析预测。
在此基础上建立岗位——能力——知识——课程关联模型,合理地确定专业人才的能力结构、知识结构、课程体系,从而确定专业人才的培养方案。
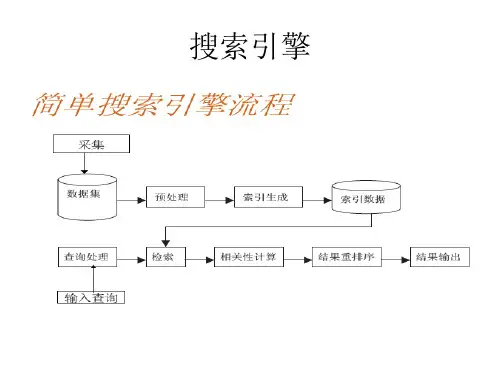
1 Web数据搜索引擎概述搜索引擎指对WWW站点资源和其它资源进行索引和检索的一类检索系统机制。
搜索引擎是由数据采集、数据加工、查询服务三个模块组成。
目前各种各样的中西文搜索引擎有十几种或更多,每个搜索引擎都有其各自的特点,有的以查询速度快见长,有的以数据库容量大占优,但总而言之,一个优秀的搜索引擎应具有以下几个特点:①支持全文检索(Full Text Search):用户能够对各网站的每篇文章中的每个词进行搜索。
世界上最典型的全文搜索引擎为Digital公司的Altavista;②支持分类查询:世界上最具代表性的目录式分类搜索引擎是Yahoo网站。
分类搜索引擎的优点是将信息系统分门别类。
它可以提供给用户选定类的信息,尤其适合“希望了解某一方面/类信息,并不局限某个关键字”的用户;③能够区分搜索结果的相关性:搜索引擎应能够找到与搜索要求相对应的站点,并将其相关程度将搜索结果排序。
Web搜索引擎设计和实现分析引言---- 随着Internet的飞速发展,人们越来越依靠网络来查找他们所需要的信息,但是,由于网上的信息源多不胜数,也就是我们经常所说的"Rich Data, Poor Information"。
所以如何有效的去发现我们所需要的信息,就成了一个很关键的问题。
为了解决这个问题,搜索引擎就随之诞生。
---- 现在在网上的搜索引擎也已经有很多,比较著名的有AltaVista, Yahoo, InfoSeek, Metacrawler, SavvySearch 等等。
国内也建立了很多的搜索引擎,比如:搜狐、新浪、北极星等等,当然由于它们建立的时间不长,在信息搜索的取全率和取准率上都有待于改进和提高。
---- Alta Vista是一个速度很快的搜索引擎,由于它强大的硬件配置,使它能够做及其复杂的查询。
它主要是基于关键字进行查询,它漫游的领域有Web和Usenet。
支持布尔查询的"AND","OR"和"NOT",同时还加上最相近定位" NEAR",允许通配符和"向后"搜索(比如:你可以查找链接到某一页的所有Web站点)。
你可以决定是否对搜索的短语加上权值,在文档的什么部位去查找它们。
能够进行短语查询而不是简单的单词查询的优点是很明显的,比如,我们想要查找一个短语"to be or not to be",如果只是把它们分解成单词的话,这些单词都是属于Stop Word,这样这个查询就不会有任何结果,但是把它当作一个整体来查询,就很容易返回一些结果,比如关于哈姆雷特或者是莎士比亚等等的信息。
系统对查询结果所得到的网页的打分是根据在网页中所包含的你的搜索短语的多少,它们在文档的什么位置以及搜索短语在文档内部之间的距离来决定的。
同时可以把得到的搜索结果翻译成其他的语言。
---- Exite是称为具有"智能"的搜索引擎,因为它建立了一个基于概念的索引。
当然,它所谓的"智能"是基于对概率统计的灵活应用。
它能够同时进行基于概念和关键字的索引。
它能够索引Web,Usenet和分类的广告。
支持"AND"," OR","NOT"等布尔操作,同时也可以使用符号"+"和"-"。
缺点是在返回的查询结果中没有指定网页的尺寸和格式。
---- InfoSeek是一个简单但是功能强大的索引,它的一个优点是有一个面向主题搜索的可扩展的分类。
你可以把你的搜索短语和相似的分类目录的主题短语相互参照,而那些主题短语会自动加到你的查询中去。
使你的搜索有更好的主题相关性。
同时它也支持对图象的查询。
它能够漫游Web,Usenet,Usenet FAQs等等。
不支持布尔操作,但是可以使用符号"+"和"-"(相当于"AND"和"NOT")---- Yahoo实际上不能称为是一个搜索引擎站点,但是它提供了一个分层的主题索引,使你能够从一个通常的主题进入到一个特定的主题,Yahoo对Web进行了有效的组织和分类。
比如你想要建立一个网页,但是你不知道如何操作,为了在Yahoo上找到关于建立网页的信息,你可以先在Yahoo上选择一个主题:计算机和Internet,然后在这个主题下,你可以发现一些子主题,比如:Web网页制作,CGI编程,JAVA,HTML,网页设计等,选择一个和你要找的相关的子主题,最终你就可以得到和该子主题相关的所有的网页的链接。
也就是说,如果你对要查找的内容属于哪个主题十分清楚的话,通过目录查询的方法要比一般的使用搜索引擎有更好的准确率。
你可以搜索Yahoo的索引,但是事实上,你并没有在搜索整个Web。
但是Yahoo提供了选项使你可以同时搜索其他的搜索引擎,比如:Alta V ista。
但是要注意的是Yahoo实际上只是对Web的一小部分进行了分类和组织,而且它的实效性也不是很好。
---- 搜索引擎的基本原理是通过网络机器人定期在web网页上爬行,然后发现新的网页,把它们取回来放到本地的数据库中,用户的查询请求可以通过查询本地的数据库来得到。
如yahoo每天会找到大约500万个新的网页。
---- 搜索引擎的实现机制一般有两种,一种是通过手工方式对网页进行索引,比如yahoo的网页是通过手工分类的方式实现的,它的缺点是Web的覆盖率比较低,同时不能保证最新的信息。
查询匹配是通过用户写入的关键字和网页的描述和标题来进行匹配,而不是通过全文的匹配进行的。
第二种是对网页进行自动的索引,象AltaVista则是完全通过自动索引实现的。
这种能实现自动的文档分类,实际上采用了信息提取的技术。
但是在分类准确性上可能不如手工分类。
---- 搜索引擎一般都有一个Robot定期的访问一些站点,来检查这些站点的变化,同时查找新的站点。
一般站点有一个robot.txt文件用来说明服务器不希望Robot访问的区域,Robot 都必须遵守这个规定。
如果是自动索引的话,Ro bot在得到页面以后,需要对该页面根据其内容进行索引,根据它的关键字的情况把它归到某一类中。
页面的信息是通过元数据的形式保存的,典型的元数据包括标题、IP地址、一个该页面的简要的介绍,关键字或者是索引短语、文件的大小和最后的更新的日期。
尽管元数据有一定的标准,但是很多站点都采用自己的模板。
文档提取机制和索引策略对Web搜索引擎的有效性有很大的关系。
高级的搜索选项一般包括:布尔方法或者是短语匹配和自然语言处理。
一个查询所产生的结果按照提取机制被分成不同的等级提交给用户。
最相关的放在最前面。
每一个提取出来的文档的元数据被显示给用户。
同时包括该文档所在的URL地址。
---- 另外有一些关于某一个主题的专门的引擎,它们只对某一个主题的内容进行搜索和处理,这样信息的取全率和精度相对就比较高。
---- 同时,有一类搜索引擎,它本身不用Robot去定期的采集网页。
象SavvySearch 和MetaCrawler是通过向多个搜索引擎同时发出询问并对结果进行综合返回给用户实现搜索功能。
当然实际上象SavvySearch能够对各个搜索引擎的功能进行分析和比较,根据不同的用户查询提交给不同的搜索引擎进行处理,当然用户自己也可以指定利用哪一个搜索引擎。
---- 一个优秀的搜索引擎必须处理以下几个问题:1 网页的分类2 自然语言的处理3 搜索策略的调度和协作4 面向特定用户的搜索。
所以很多搜索引擎不同程度的使用了一些人工智能的技术来解决这些方面的问题。
---- 二、网络Spider的实现描述---- 现在有很多文章对Web引擎做了大量的介绍和分析,但是很少有对它们的实现做一个详细的描述,这里我们主要来介绍一个具有基本功能的Web引擎的实现。
本文,我们以类C++语言的形式来描述Web引擎如何采集网页并存放到数据库中的过程。
同时描述了如何根据用户输入的关键字查询数据库并得到相关网页的过程。
---- 2.1数据库结构---- 首先,我们要建立一个数据库表用来存放我们得到的网页。
这里一般需要建立如下的表:---- 1.字典表的建立,事实上这里是用文档中有意义的单词和它们的出现频率来代表一个文档。
---- 该表(WordDictionaryTbl)主要要包括三个字段,主要是用来存放和一个网页相关的单词的情况url_id 对每一个URL的唯一的ID号word 该URL中的经过stem的单词intag 该单词在该网页中的出现的次数---- 2.存储每一个URL信息的表---- 该表(URLTbl)中主要的关键字段有:rec_id 每一条记录的唯一的ID号status 得到该URL内容的状态,比如HTTP_STATUS_TIMEOUT表示下载网页的最大允许超时url URL的字符串名称content_type 内容的类型last_modified 最新的更改时间title 该URL的标题docsize 该URL的文件的尺寸last_index_time 最近一次索引的时间next_index_time 下一次索引的时间tag 对于网页,用来表示它的类型,比如:是text,或者是html,或者是图片等等hops 得到文件时候的曾经失败的次数keywords 对于网页,和该网页相关的关键字description 对于网页,指网页的内容的描述lang 文档所使用的语言---- 3.因为网页中有很多单词是一些介词和语气助词或者是非常常用的常用词,它们本身没有多少意义。
比如:英语中的about,in,at,we,this等等。
中文中的如"和","一起","关于"等等。
我们统一的把它们称为停止词(stop word)。
所以我们要建立一个表,来包括所有这些停止词。
该表(StopWordTbl)主要有两个字段。
word char(32) 表示那些停止词lang char(2) 表示所使用的语言---- 4.我们要建立一个关于robot的表,我们在前面说过,所有的网站一般都有一个robot.txt文件用来表示网络上的robot可以访问的权限。
该表(RobotTbl)主要有以下字段。
hostinfo Web站点主机的信息path 不允许robot访问的目录---- 5.建立我们需要屏蔽的那些网页(比如一些内容不健康的或者没有必要去搜索的站点)的一张表(ForbiddenWWW Tbl),主要的字段就是网页的URL。
---- 6.另外我们需要建立一个我们所要得到的文件类型的表(FileTypeTbl),比如,对于一个简单的Web搜索引擎,我们可能只需要得到后缀为.html,htm,.shtml和txt的类型文件。
其他的我们只是简单的忽略它们。
主要的字段就是文件的类型和说明。
---- 其中关于停止词的表的内容是我们要实现要根据各种语言的统计结果,把那些意义不大的单词放进去。
关于文档单词、URL和Robot的表的内容都是在获取Web网页的时候动态增加记录的。
---- 2.2 具体网页获取算法描述---- 具体的网页的获取步骤是这样的:---- 我们可以设定我们的搜索程序最大可以开的线程的数目,然后这些线程可以同时在网上进行搜索,它们根据数据库中已有的关于网页的信息,找出那些需要更新的网页(如何判断哪些网页需要更新是一个值得研究的过程,现在有很多启发式和智能的算法,基本上是基于统计规律进行建模。