
算法四:支持向量机
说到支持向量机,必须要提到july大神的《支持向量机通俗导论》,个人感觉再怎么写也不可能写得比他更好的了。这也正如青莲居士见到崔颢的黄鹤楼后也只能叹“此处有景道不得”。不过我还是打算写写SVM的基本想法与libSVM中R的接口。
一、SVM的想法
回到我们最开始讨论的KNN算法,它占用的内存十分的大,而且需要的运算量也非常大。那么我们有没有可能找到几个最有代表性的点(即保留较少的点)达到一个可比的效果呢?
要回答这个问题,我们首先必须思考如何确定点的代表性?我想关于代表性至少满足这样一个条件:无论非代表性点存在多少,存在与否都不会影响我们的决策结果。显然如果仍旧使用KNN算法的话,是不会存在训练集的点不是代表点的情况。那么我们应该选择一个怎样的“距离”满足仅依靠代表点就能得到全体点一致的结果?
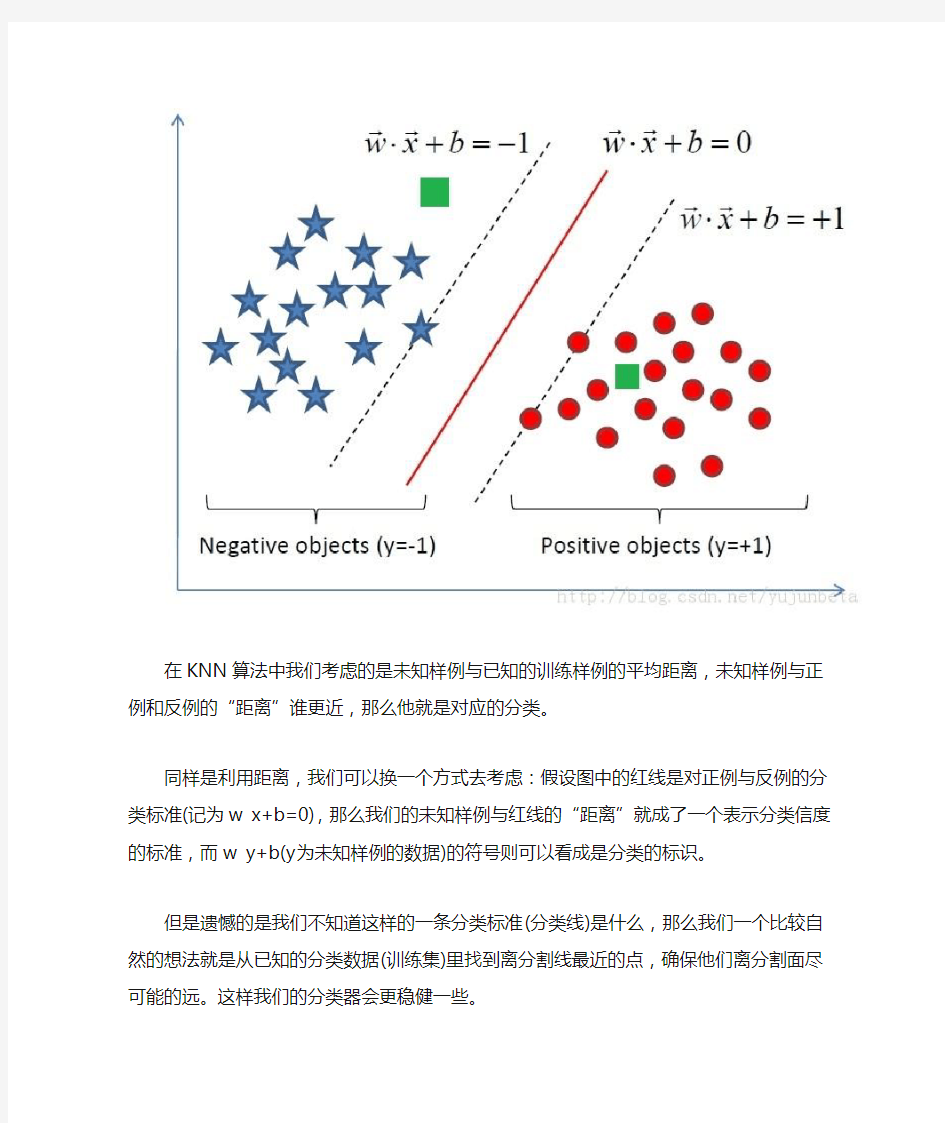
我们先看下面一个例子:假设我们的训练集分为正例与反例两类,分别用红色的圆圈与蓝色的五角星表示,现在出现了两个未知的案例,也就是图中绿色的方块,我们如何去分类这两个例子呢?
在KNN算法中我们考虑的是未知样例与已知的训练样例的平均距离,未知样例与正例和反例的“距离”谁更近,那么他就是对应的分类。
同样是利用距离,我们可以换一个方式去考虑:假设图中的红线是对正例与反例的分类标准(记为w x+b=0),那么我们的未知样例与红线的“距离”就成了一个表示分类信度的标准,而w y+b(y为未知样例的数据)的符号则可以看成是分类的标识。
但是遗憾的是我们不知道这样的一条分类标准(分类线)是什么,那么我们一个比较自然的想法就是从已知的分类数据(训练集)里找到离分割线最近的点,确保他们离分割面尽可能的远。这样我们的分类器会更稳健一些。
从上面的例子来看,虚线穿过的样例便是离分割线最近的点,这样的点可能是不唯一的,因为分割线并不确定,下图中黑线穿过的训练样例也满足这个要求:
所以“他们离分割面尽可能的远”这个要求就十分重要了,他告诉我们一个稳健的超平面是红线而不是看上去也能分离数据的黄线。
这样就解决了我们一开始提出的如何减少储存量的问题,我们只要存储虚线划过的点即可(因为在w x+b=-1左侧,w x+b=1右侧的点无论有多少都不会影响决策)。像图中虚线划过的,距离分割直线(比较专业的术语是超平面)最近的点,我们称之为支持向量。这也就是为什么我们这种分类方法叫做支持向量机的原因。
至此,我们支持向量机的分类问题转化为了如何寻找最大间隔的优化问题。
二、SVM的一些细节
支持向量机的实现涉及许多有趣的细节:如何最大化间隔,存在“噪声”的数据集怎么办,对于线性不可分的数据集怎么办等。
我这里不打算讨论具体的算法,因为这些东西完全可以参阅july大神的《支持向量机通俗导论》,我们这里只是介绍遇到问题时的想法,以便分析数据时合理调用R中的函数。
几乎所有的机器学习问题基本都可以写成这样的数学表达式:
给定条件:n个独立同分布观测样本(x1 , y1 ), (x2 , y2 ),……,(xn , yn )
目标:求一个最优函数f (x,w* )
最理想的要求:最小化期望风险R(w)
不同的是我们如何选择f,R。对于支持向量机来说,f(x,w*)=w x+b,最小化风险就是最大化距离|w x|/||w||,即arg max{min(label (w x+b))/||w||} (也就是对最不confidence 的数据具有了最大的 confidence)
这里的推导涉及了对偶问题,拉格朗日乘子法与一堆的求导,我们略去不谈,将结果叙述如下:
我们以鸢尾花数据来说说如何利用svm做分类,由于svm是一个2分类的办法,所以我们将鸢尾花数据也分为两类,“setosa”与“versicolor”(将后两类均看做一类),那么数据按照特征:花瓣长度与宽度做分类,有分类:
从上图可以看出我们通过最优化原始问题或者对偶问题就可以得到w,b,利用sign(w.x+b)就可以判断分类了。
我们这里取3, 10,56, 68,107, 120号数据作为测试集,其余的作为训练集,我们可以看到:
训练集 setosa virginica
setosa 48 0
virginica 0 96
测试集 setosa virginica
setosa 2 0
virginica 0 4
也就是完全完成了分类任务。
我们来看看鸢尾花后两类的分类versicolor和virginica的分类,我们将数据的散点图描绘如下:(我们把第一类“setosa“看做”versicolor“)
不难发现这时无论怎么画一条线都无法将数据分开了,那么这么办呢?我们一个自然的办法就是允许分类有一部分的错误,但是错误不能无限的大。我们使用一个松弛项来分类数据。最优化问题转变为:
当我们确定好松弛项C后,就可以得到分类:
我们还是先来看看分类的效果:(C=10)训练集 versicolor virginica versicolor 93 2
virginica 3 46
测试集 versicolor virginica versicolor 4 2
virginica 0 0
虽然分类中有一些错误,但是大部分还是分开了的,也就是说还是不错的,至少完成了分类这个任务。
我们再来看看一个更麻烦的例子:
假设数据是这样的:
这时再用直线作为划分依据就十分的蹩脚了,我们这时需要引入核的方法来解决这个问题。
在上图中,我们一眼就能看出用一个S型去做分类就可以把数据成功分类了(当然是在允许一点点错误的情况下),但是计算机能识别的只有分类器的分类结果是-1还是1,这时,我们需要将数据做出某种形式的转换,使得原来不可用直线
剖分的变得可分,易分。也就是需要找到一个从一个特征空间到另一个特征空间的映射。我们常用的映射有:
线性核:u'*v
多项式核:(gamma*u'*v+ coef0)^degree
高斯核:exp(-gamma*|u-v|^2)
Sigmoid核:tanh(gamma*u'*v + coef0)
我们这里使用各种常见的核来看看分类效果:
从图中我们可以看到正态核的效果是最好的,用数据说话,我们来看看分类错误率与折10交叉验证的结果(报告平均分类正确率):
我们可以看到,无论从存储数据量的多少(支持向量个数)还是分类精确度来看,高斯核都是最优的。所以一般情况,特别是在大样本情况下,优先使用高斯核,至少可以得到一个不太坏的结果(在完全线性可分下,线性函数的支持向量个数还是少一些的)。
三、libSVM的R接口
有许多介绍SVM的书都有类似的表述“由于理解支持向量机需要掌握一些理论知识,而这对读者来说有一定的难度,建议直接下载LIBSVM使用。”
确实,如果不是为了训练一下编程能力,我们没有必要自己用前面提到的做法自己实现一个效率不太高的SVM。R的函数包e1071提供了libSVM的接口,使用
e1071的函数SVM()可以得到libSVM相同的结果,write.svm()更是可以把R训练得到的结果写为标准的libSVM格式供其他环境下的libSVM使用。
在介绍R中函数的用法时,我们先简要介绍一下SVM的类型,以便我们更好地理解各个参数的设置。
对于线性不可分时,加入松弛项,折衷考虑最小错分样本和最大分类间隔。增加了算法的容错性,允许训练集不完全分类,以防出现过拟合。加入的办法有以下3类,写成最优化问题形式总结如上图:
上图中e为所有元素都为1的列向量,Qij=yiyjK(xi; xj), K(xi; xj) =phi(xi) phi (xj), phi(.)为核函数,K(. ;.)表示对应元素核函数的内积。
现在我们来看看svm()函数的用法。
## S3 method for class 'formula'
svm(formula, data = NULL, ..., subset,na.action =na.omit, scale = TRUE)
## Default S3 method:
svm(x, y = NULL, scale = TRUE, type = NULL,kernel =
"radial", degree = 3, gamma = if(is.vector(x)) 1 else 1 / ncol(x),
coef0 = 0, cost = 1, nu = 0.5,
class.weights = NULL, cachesize = 40,tolerance = 0.001, epsilon =
0.1,shrinking = TRUE, cross = 0, probability =FALSE, fitted = TRUE, seed = 1L,..., subset, na.action = na.omit)
主要参数说明:
Formula:分类模型形式,在第二个表达式中使用的的x,y可以理解为y~x。
Data:数据集
Subset:可以指定数据集的一部分作为训练集
Na.action:缺失值处理,默认为删除数据条目
Scale:将数据标准化,中心化,使其均值为0,方差为1.默认自动执行。
Type:SVM的形式,使用可参见上面的SVMformulation,type的选项有:
C-classification,nu-classification,one-classification (for novelty detection),eps-regression,nu-regression。后面两者为利用SVM做回归时用到的,这里暂不介绍。默认为C分类器,使用nu分类器会使决策边界更光滑一些,单一分类适用于所有的训练数据提取自同一个类里,然后SVM建立了一个分界线以分割该类在特征空间中所占区域和其它类在特征空间中所占区域。
Kernel:在非线性可分时,我们引入核函数来做非线性可分,R提供的核介绍如下:
线性核:u'*v
多项式核:(gamma*u'*v + coef0)^degree
高斯核:exp(-gamma*|u-v|^2)
Sigmoid核:tanh(gamma*u'*v + coef0)
默认为高斯核(RBF),libSVM的作者对于核的选择有如下建议:Ingeneral we suggest you to try the RBF kernel first. A recent result by Keerthiand Lin shows that if RBF is used with model selection, then there is no need to consider the linear kernel. The kernel matrix using sigmoid may not be positive definite and in general it's accuracy is not better than RBF. (see thepaper by Lin and Lin. Polynomial kernels are ok but if a high degree is used,numerical difficulties tend to happen (thinking about dth power of (<1) goes to 0 and (>1) goes to infinity).
顺带说一句,在kernlab包中,可以自定义核函数。
Degree:多项式核的次数,默认为3
Gamma:除去线性核外,其他的核的参数,默认为1/数据维数
Coef0,:多项式核与sigmoid核的参数,默认为0
Cost:C分类的惩罚项C的取值
Nu:nu分类,单一分类中nu的取值
Cross:做K折交叉验证,计算分类正确性。
由于svm的编程确实过于复杂,还涉及到不少最优化的内容,所以在第二部分我的分类都是使用svm函数完成的(偷一下懒),现将部分R代码展示如下:
dataSim的函数:
simData=function(radius,width,distance,sample_size)
{
aa1=runif(sample_size/2)
aa2=runif(sample_size/2)
rad=(radius-width/2)+width*aa1
theta=pi*aa2
x=rad*cos(theta)
y=rad*sin(theta)
label=1*rep(1,length(x))
x1=rad*cos(-theta)+rad
y1=rad*sin(-theta)-distance
label1=-1*rep(1,length(x1))
n_row=length(x)+length(x1)
data=matrix(rep(0,3*n_row),nrow=n_row,ncol=3)
data[,1]=c(x,x1)
data[,2]=c(y,y1)
data[,3]=c(label,label1)
data
}
dataSim=simData(radius=10,width=6,distance=-6,sample_size=3000) colnames(dataSim)<-c("x","y","label")
dataSim<-as.data.frame(dataSim)
Sigmoid核的分类预测:
m1 <- svm(label ~x+y, data
=dataSim,cross=10,type="C-classification",kernel="sigmoid")
m1
summary(m1)
pred1<-fitted(m1)
table(pred1,dataSim[,3])
核函数那一小节作图的各种东西:
linear.svm.fit <- svm(label ~ x + y, data = dataSim, kernel ='linear') with(dataSim, mean(label == ifelse(predict(linear.svm.fit) > 0,1, -1)))
polynomial.svm.fit <- svm(label ~ x + y, data = dataSim, kernel
='polynomial')
with(dataSim, mean(label == ifelse(predict(polynomial.svm.fit) >0, 1, -1)))
radial.svm.fit <- svm(label ~ x + y, data = dataSim, kernel ='radial') with(dataSim, mean(label == ifelse(predict(radial.svm.fit) > 0,1, -1)))
sigmoid.svm.fit <- svm(label ~ x + y, data = dataSim, kernel ='sigmoid') with(dataSim, mean(label == ifelse(predict(sigmoid.svm.fit) > 0,1, -1)))
df <- cbind(dataSim,
data.frame(LinearSVM = ifelse(predict(linear.svm.fit) > 0, 1, -1), PolynomialSVM = ifelse(predict(polynomial.svm.fit) > 0, 1, -1), RadialSVM = ifelse(predict(radial.svm.fit) > 0, 1, -1),
SigmoidSVM = ifelse(predict(sigmoid.svm.fit) > 0, 1, -1)))
library("reshape")
predictions <- melt(df, id.vars = c('x', 'y'))
library('ggplot2')
ggplot(predictions, aes(x = x, y = y, color = factor(value))) +
geom_point() +
facet_grid(variable ~ .)
最后,我们回到最开始的那个手写数字的案例,我们试着利用支持向量机重做这个案例。(这个案例的描述与数据参见《R语言与机器学习学习笔记(分类算法)(1)》)
运行代码:
setwd("D:/R/data/digits/trainingDigits")
names<-list.files("D:/R/data/digits/trainingDigits")
data<-paste("train",1:1934,sep="")
for(i in 1:length(names))
assign(data[i],as.vector(as.matrix(read.fwf(names[i],widths=rep(1,32) ))))
label<-rep(0:9,c(189,198,195,199,186,187,195,201,180,204))
data1<-get(data[1])
for(i in 2:length(names))
data1<-rbind(data1,get(data[i]))
m <- svm(data1,label,cross=10,type="C-classification")
m
summary(m)
pred<-fitted(m)
table(pred,label)
setwd("D:/R/data/digits/testDigits")
names<-list.files("D:/R/data/digits/testDigits")
data<-paste("train",1:1934,sep="")
for(i in 1:length(names))
assign(data[i],as.vector(as.matrix(read.fwf(names[i],widths=rep(1,32) ))))
data2<-get(data[1])
for(i in 2:length(names))
data2<-rbind(data2,get(data[i]))
pred<-predict(m,data2)
labeltest<-rep(0:9,c(87,97,92,85,114,108,87,96,91,89))
table(pred,labeltest)
模型摘要:
Call:
svm.default(x = data1, y = label, type ="C-classification", cross =10)
Parameters:
SVM-Type: C-classification
SVM-Kernel: radial
cost: 1
gamma: 0.0009765625
Number of Support Vectors: 1139 ( 78 130 101 124 109 122 87 93 135 160 )
Number of Classes: 10
Levels: 0 1 2 3 4 5 6 7 8 9
10-fold cross-validation on training data:
Total Accuracy: 96.7425
Single Accuracies:
97.40933 98.96373 91.7525899.48187 94.84536 94.30052 97.40933 96.90722
98.96373 97.42268
当然,我们还可以通过m$SV查看支持向量的情况,m$index查看支持向量的标签,m$rho查看分类时的截距b。
训练集分类结果:
支持向量机算法 [摘要] 本文介绍统计学习理论中最年轻的分支——支持向量机的算法,主要有:以SVM-light为代表的块算法、分解算法和在线训练法,比较了各自的优缺点,并介绍了其它几种算法及多类分类算法。 [关键词] 块算法分解算法在线训练法 Colin Campbell对SVM的训练算法作了一个综述,主要介绍了以SVM为代表的分解算法、Platt的SMO和Kerrthi的近邻算法,但没有详细介绍各算法的特点,并且没有包括算法的最新进展。以下对各种算法的特点进行详细介绍,并介绍几种新的SVM算法,如张学工的CSVM,Scholkopf的v-SVM分类器,J. A. K. Suykens 提出的最小二乘法支持向量机LSSVM,Mint-H suan Yang提出的训练支持向量机的几何方法,SOR以及多类时的SVM算法。 块算法最早是由Boser等人提出来的,它的出发点是:删除矩阵中对应于Lagrange乘数为零的行和列不会对最终结果产生影响。对于给定的训练样本集,如果其中的支持向量是已知的,寻优算法就可以排除非支持向量,只需对支持向量计算权值(即Lagrange乘数)即可。但是,在训练过程结束以前支持向量是未知的,因此,块算法的目标就是通过某种迭代逐步排除非支持向时。具体的做法是,在算法的每一步中块算法解决一个包含下列样本的二次规划子问题:即上一步中剩下的具有非零Lagrange乘数的样本,以及M个不满足Kohn-Tucker条件的最差的样本;如果在某一步中,不满足Kohn-Tucker条件的样本数不足M 个,则这些样本全部加入到新的二次规划问题中。每个二次规划子问题都采用上一个二次规划子问题的结果作为初始值。在最后一步时,所有非零Lagrange乘数都被找到,因此,最后一步解决了初始的大型二次规划问题。块算法将矩阵的规模从训练样本数的平方减少到具有非零Lagrange乘数的样本数的平方,大减少了训练过程对存储的要求,对于一般的问题这种算法可以满足对训练速度的要求。对于训练样本数很大或支持向量数很大的问题,块算法仍然无法将矩阵放入内存中。 Osuna针对SVM训练速度慢及时间空间复杂度大的问题,提出了分解算法,并将之应用于人脸检测中,主要思想是将训练样本分为工作集B的非工作集N,B中的样本数为q个,q远小于总样本个数,每次只针对工作集B中的q个样本训练,而固定N中的训练样本,算法的要点有三:1)应用有约束条件下二次规划极值点存大的最优条件KTT条件,推出本问题的约束条件,这也是终止条件。2)工作集中训练样本的选择算法,应能保证分解算法能快速收敛,且计算费用最少。3)分解算法收敛的理论证明,Osuna等证明了一个定理:如果存在不满足Kohn-Tucker条件的样本,那么在把它加入到上一个子问题的集合中后,重新优化这个子问题,则可行点(Feasible Point)依然满足约束条件,且性能严格地改进。因此,如果每一步至少加入一个不满足Kohn-Tucker条件的样本,一系列铁二次子问题可保证最后单调收敛。Chang,C.-C.证明Osuna的证明不严密,并详尽地分析了分解算法的收敛过程及速度,该算法的关键在于选择一种最优的工
实验报告 实验名称:机器学习:线性支持向量机算法实现 学员:张麻子学号: *********** 培养类型:硕士年级: 专业:所属学院:计算机学院 指导教员: ****** 职称:副教授 实验室:实验日期:
一、实验目的和要求 实验目的:验证SVM(支持向量机)机器学习算法学习情况 要求:自主完成。 二、实验内容和原理 支持向量机(Support V ector Machine, SVM)的基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大。SVM是用来解决二分类问题的有监督学习算法。通过引入了核方法之后SVM也可以用来解决非线性问题。 但本次实验只针对线性二分类问题。 SVM算法分割原则:最小间距最大化,即找距离分割超平面最近的有效点距离超平面距离和最大。 对于线性问题: 假设存在超平面可最优分割样本集为两类,则样本集到超平面距离为: 需压求取: 由于该问题为对偶问题,可变换为: 可用拉格朗日乘数法求解。 但由于本实验中的数据集不可以完美的分为两类,即存在躁点。可引入正则化参数C,用来调节模型的复杂度和训练误差。
作出对应的拉格朗日乘式: 对应的KKT条件为: 故得出需求解的对偶问题: 本次实验使用python 编译器,编写程序,数据集共有270个案例,挑选其中70%作为训练数据,剩下30%作为测试数据。进行了两个实验,一个是取C值为1,直接进行SVM训练;另外一个是利用交叉验证方法,求取在前面情况下的最优C值。 三、实验器材 实验环境:windows7操作系统+python 编译器。 四、实验数据(关键源码附后) 实验数据:来自UCI 机器学习数据库,以Heart Disease 数据集为例。 五、操作方法与实验步骤 1、选取C=1,训练比例7:3,利用python 库sklearn 下的SVM() 函数进
题目:支持向量机的算法学习 姓名: 学号: 专业: 指导教师:、 日期:2012年6 月20日
支持向量机的算法学习 1. 理论背景 基于数据的机器学习是现代智能技术中的重要方面,研究从观测数据 (样本) 出发寻找规律,利用这些规律对未来数据或无法观测的数据进行预测。迄今为止,关于机器学习还没有一种被共同接受的理论框架,关于其实现方法大致可以分为三种: 第一种是经典的(参数)统计估计方法。包括模式识别、神经网络等在内,现有机器学习方法共同的重要理论基础之一是统计学。参数方法正是基于传统统计学的,在这种方法中,参数的相关形式是已知的,训练样本用来估计参数的值。这种方法有很大的局限性,首先,它需要已知样本分布形式,这需要花费很大代价,还有,传统统计学研究的是样本数目趋于无穷大时的渐近理论,现有学习方法也多是基于此假设。但在实际问题中,样本数往往是有限的,因此一些理论上很优秀的学习方法实际中表现却可能不尽人意。 第二种方法是经验非线性方法,如人工神经网络(ANN。这种方法利用已知样本建立非线性模型,克服了传统参数估计方法的困难。但是,这种方法缺乏一种统一的数学理论。 与传统统计学相比,统计学习理论( Statistical Learning Theory 或SLT) 是一种专门研究小样本情况下机器学习规律的理论。该理论针对小样本统计问题建立了一套新的理论体系,在这种体系下的统计推理规则不仅考虑了对渐近性能的要求,而且追求在现有有限信息的条件下得到最优结果。V. Vapnik 等人从六、七十年代开始致力于此方面研究[1] ,到九十年代中期,随着其理论的不断发展和成熟,也由于神经网络等学习方法在理论上缺乏实质性进展,统计学习理论开始受到越来越广泛的重视。 统计学习理论的一个核心概念就是VC维(VC Dimension)概念,它是描述函数集或学习机器的复杂性或者说是学习能力(Capacity of the machine) 的一个重要指标,在此概念基础上发展出了一系列关于统计学习的一致性(Consistency) 、收敛速度、推广性能(GeneralizationPerformance) 等的重要结论。 支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy) 和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以
支持向量机 支持向量机模型选择研究 摘要:统计学习理论为系统地研究有限样本情况下的机器学习问题提供了一套 比较完整的理论体系。支持向量机 (suPportvectorMachine,SVM)是在该理论体系下产生的一种新的机器学习方法,它能较好地解决小样本、非线性、维数灾难和局部极小等问题,具有很强的泛化能力。支持向量机目前已经广泛地应用于模式识别、回归估计、概率密度估计等各个领域。不仅如此,支持向量机的出现推动了基于核的学习方法(Kernel-based Learning Methods) 的迅速发展,该方法使得研究人员能够高效地分析非线性关系,而这种高效率原先只有线性算法才能得到。目前,以支持向量机为主要代表的核方法是机器学习领域研究的焦点课题之一。 众所周知,支持向量机的性能主要取决于两个因素:(1)核函数的选择;(2)惩罚 系数(正则化参数)C的选择。对于具体的问题,如何确定SVM中的核函数与惩罚系 数就是所谓的模型选择问题。模型选择,尤其是核函数的选择是支持向量机研究的中心内容之一。本文针对模型选择问题,特别是核函数的选择问题进行了较为深入的研究。其中主要的内容如下: 1.系统地归纳总结了统计学习理论、核函数特征空间和支持向量机的有关理论与算法。 2.研究了SVM参数的基本语义,指出数据集中的不同特征和不同样本对分类结 果的影响可以分别由核参数和惩罚系数来刻画,从而样木重要性和特征重要性的考察可以归结到SVM的模型选择问题来研究。在
对样本加权SVM模型(例如模糊SVM)分析的基础上,运用了特征加权SVM模型,即FWSVM,本质上就是SVM与特征加权的结合。 3,在系统归纳总结SVM模型选择。尤其是核函数参数选择的常用方法(例如交叉验证技术、最小化LOO误差及其上界、优化核评估标准)。关键词:机器学习;模式分类;支持向量机;模型选择;核函数;核函数评估 支持向量机基础 引言 机器学习的科学基础之一是统计学。传统统计学所研究的是渐近理论,即当样本数目趋于无穷大时的极限特性。基于传统统计学的机器学习,也称为统计模式识别,由Duda等人提出。Duda的贡献主要是以经典统计理论为工具刻画了模式识别与机器学习的各类任务,同时暗示了对所建模型的评价方法。然而,在实际应用中,学习样本的数目往往是有限的,特别当问题处于高维空问时尤其如此。统计学习理论研究的是有限样本情况下的机器学习问题,它基于PAC(Probably Approximately Correct)框架给出关于学习算法泛化性能的界,从而可以得出误差精度和样木数目之间的关系。这样,样木集合成为泛化指标的随机变量,由此建立了结构风险理论。 Minsky和PaPert在20世纪60年代明确指出线性学习机计算能力有限。总体上,现实世界复杂的应用需要比线性函数更富有表达能力的假设空间"多层感知器可以作为这个问题的一个解,由此导向了 多层神经网络的反向传播算法。核函数表示方式提供了另一条解决途径,即将数据映射到高维空间来增强线性学习机的计算能力。核函数的引入最终使得在适当的特征空间中使用人们熟知的线性算法高效地检测非线性关系成为一可能。SVM是建立在统计学习理论(包括核函数的表示理论)基础上的第一个学习算法,目前主要应用于求解监督学习问题,即分类和回归问题。SVM以泛化能力为目标,其目的不是
SVM 1.判断题 (1) 在SVM训练好后,我们可以抛弃非支持向量的样本点,仍然可以对新样本进行分类。(T) (2) SVM对噪声(如来自其他分布的噪声样本)鲁棒。(F) 2.简答题 现有一个点能被正确分类且远离决策边界。如果将该点加入到训练集,为什么SVM的决策边界不受其影响,而已经学好的logistic回归会受影响? 答:因为SVM采用的是hinge loss,当样本点被正确分类且远离决策边界时,SVM给该样本的权重为0,所以加入该样本决策边界不受影响。而logistic回归采用的是log损失,还是会给该样本一个小小的权重。 3.产生式模型和判别式模型。(30分,每小题10分) 图2:训练集、最大间隔线性分类器和支持向量(粗体) (1)图中采用留一交叉验证得到的最大间隔分类器的预测误差的估计是多少(用样本数表示即可)? 从图中可以看出,去除任意点都不影响SVM的分界面。而保留所有样本时,所有的样本点都能被正确分类,因此LOOCV的误差估计为0。 (2)说法“最小结构风险保证会找到最低决策误差的模型”是否正确,并说明理由。(F) 最小结构风险(SRM)只能保证在所有考虑的模型中找到期望风险上界最小的模型。 (3)若采用等协方差的高斯模型分别表示上述两个类别样本的分布,则分类器的VC维是多少?为什么? 等协方差的高斯模型的决策边界为线性,因为其VC维维D+1。题中D=2.
4、SVM 分类。(第1~5题各4分,第6题5分,共25分) 下图为采用不同核函数或不同的松弛因子得到的SVM 决策边界。但粗心的实验者忘记记录每个图形对应的模型和参数了。请你帮忙给下面每个模型标出正确的图形。 (1)、211min , s.t.2N i i C ξ=??+ ? ?? ∑w ()00, 1, 1,....,, T i i i y w i N ξξ≥+≥-=w x 其中0.1C =。 线性分类面,C 较小, 正则较大,||w||较小,Margin 较大, 支持向量较多(c ) (2)、211min , s.t.2N i i C ξ=??+ ? ?? ∑w ()00, 1, 1,....,, T i i i y w i N ξξ≥+≥-=w x 其中1C =。 线性分类面,C 较大, 正则较小,||w||较大,Margin 较小 支持向量的数目少(b ) (3)、()111 1max ,2N N N i i j i j i j i i j y y k ααα===?? - ??? ∑∑∑x x 1 s.t. 0, 1,....,, 0N i i i i C i N y αα=≤<==∑ 其中()()2 ,T T k '''=+x x x x x x 。 二次多项式核函数,决策边界为二次曲线 (d)
实验2分类预测模型——支持向量机SVM 一、 实验目的 1. 了解和掌握支持向量机的基本原理。 2. 熟悉一些基本的建模仿真软件(比如SPSS 、Matlab 等)的操作和使用。 3. 通过仿真实验,进一步理解和掌握支持向量机的运行机制,以及其运用的场景,特别是在分类和预测中的应用。 二、 实验环境 PC 机一台,SPSS 、Matlab 等软件平台。 三、 理论分析 1. SVM 的基本思想 支持向量机(Support Vector Machine, SVM ),是Vapnik 等人根据统计学习理论中结构风险最小化原则提出的。SVM 能够尽量提高学习机的推广能力,即使由有限数据集得到的判别函数,其对独立的测试集仍能够得到较小的误差。此外,支持向量机是一个凸二次优化问题,能够保证找到的极值解就是全局最优解。这希尔特点使支持向量机成为一种优秀的基于机器学习的算法。 SVM 是从线性可分情况下的最优分类面发展而来的,其基本思想可用图1所示的二维情况说明。 图1最优分类面示意图 图1中,空心点和实心点代表两类数据样本,H 为分类线,H1、H2分别为过各类中离分类线最近的数据样本且平行于分类线的直线,他们之间的距离叫做分类间隔(margin )。所谓最优分类线,就是要求分类线不但能将两类正确分开,使训练错误率为0,而且还要使分类间隔最大。前者保证分类风险最小;后者(即:分类间隔最大)使推广性的界中的置信范围最小,从而时真实风险最小。推广到高维空间,最优分类线就成为了最优分类面。 2. 核函数 ω
支持向量机的成功源于两项关键技术:利用SVM 原则设计具有最大间隔的最优分类面;在高维特征空间中设计前述的最有分类面,利用核函数的技巧得到输入空间中的非线性学习算法。其中,第二项技术就是核函数方法,就是当前一个非常活跃的研究领域。核函数方法就是用非线性变换 Φ 将n 维矢量空间中的随机矢量x 映射到高维特征空间,在高维特征空间中设计线性学习算法,若其中各坐标分量间相互作用仅限于内积,则不需要非线性变换 Φ 的具体形式,只要用满足Mercer 条件的核函数替换线性算法中的内积,就能得到原输入空间中对应的非线性算法。 常用的满足Mercer 条件的核函数有多项式函数、径向基函数和Sigmoid 函数等,选用不同的核函数可构造不同的支持向量机。在实践中,核的选择并未导致结果准确率的很大差别。 3. SVM 的两个重要应用:分类与回归 分类和回归是实际应用中比较重要的两类方法。SVM 分类的思想来源于统计学习理论,其基本思想是构造一个超平面作为分类判别平面,使两类数据样本之间的间隔最大。SVM 分类问题可细分为线性可分、近似线性可分及非线性可分三种情况。SVM 训练和分类过程如图2所示。 图2 SVM 训练和分类过程 SVM 回归问题与分类问题有些相似,给定的数据样本集合为 x i ,y i ,…, x n ,y n 。其中,x i x i ∈R,i =1,2,3…n 。与分类问题不同,这里的 y i 可取任意实数。回归问题就是给定一个新的输入样本x ,根据给定的数据样本推断他所对应的输出y 是多少。如图3-1所示,“×”表示给定数据集中的样本点,回归所要寻找的函数 f x 所对应的曲线。同分类器算法的思路一样,回归算法需要定义一个损失函数,该函数可以忽略真实值某个上下范围内的误差,这种类型的函数也就是 ε 不敏感损失函数。变量ξ度量了训练点上误差的代价,在 ε 不敏感区内误差为0。损失函数的解以函数最小化为特征,使用 ε 不敏感损失函数就有这个优势,以确保全局最小解的存在和可靠泛化界的优化。图3-2显示了具有ε 不敏感带的回归函数。 o x y 图3-1 回归问题几何示意图 o x y 图3-2 回归函数的不敏感地
支持向量机算法推导及其分类的算法实现 摘要:本文从线性分类问题开始逐步的叙述支持向量机思想的形成,并提供相应的推导过程。简述核函数的概念,以及kernel在SVM算法中的核心地位。介绍松弛变量引入的SVM算法原因,提出软间隔线性分类法。概括SVM分别在一对一和一对多分类问题中应用。基于SVM在一对多问题中的不足,提出SVM 的改进版本DAG SVM。 Abstract:This article begins with a linear classification problem, Gradually discuss formation of SVM, and their derivation. Description the concept of kernel function, and the core position in SVM algorithm. Describes the reasons for the introduction of slack variables, and propose soft-margin linear classification. Summary the application of SVM in one-to-one and one-to-many linear classification. Based on SVM shortage in one-to-many problems, an improved version which called DAG SVM was put forward. 关键字:SVM、线性分类、核函数、松弛变量、DAG SVM 1. SVM的简介 支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力。 对于SVM的基本特点,小样本,并不是样本的绝对数量少,而是与问题的复杂度比起来,SVM算法要求的样本数是相对比较少的。非线性,是指SVM擅长处理样本数据线性不可分的情况,主要通过松弛变量和核函数实现,是SVM 的精髓。高维模式识别是指样本维数很高,通过SVM建立的分类器却很简洁,只包含落在边界上的支持向量。
百度文库- 让每个人平等地提升自我 支持向量机实验模型的研究与设计 用户手册 1.简介 本模型是基于SVM(即支持向量机)的机器学习模型,能够将线性可分的和非线性可分的两种情况下的两类数据集进行分类,并对分类结果进行分析。用户可以选择装载已有的数据进行分类,也可以手动创建两类数据集进行分类。用户根据要分类的数据集,从两个训练算法中选择适当的训练算法,并且从三个核函数中选择适当的核函数对数据集进行分类。 2.系统要求 操作系统方面:Windows 98,Windows NT,Windows ME,Windows 2000, Windows XP及Windows 2003系统; 应用软件方面:必须安装MATLAB 或以上版本 3.使用说明 (1)首先运行或者文件,进入模型主界面,如下图: 用户在进入实验前必须先按“设置路径”按钮设置路径,然后就可以通过“进入支持向量机模型”按钮进入模型。
百度文库- 让每个人平等地提升自我(2)进入支持向量机机器学习模型后,界面如下图:用户可以通过各个按钮对模型进行操作 (3)装载或创建数据 a.通过“装载数据”按钮装载数据,用户选择数据所在的文件 b.通过“创建数据”按钮创建数据
百度文库- 让每个人平等地提升自我 可以创建线性可分数据集如下: 可以创建非线性可分数据集如下: C.装载数据或创建数据后的界面上显示数据点,如下图:
百度文库- 让每个人平等地提升自我 (4)通过“训练SVM”按钮对数据集进行分类 在此仅介绍了对线性可分数据集分类的情况,对其他的数据集,操作也跟如下类似。在数据集线性可分情况下,使用不同算法的分类结果: 选择SMO训练算法和Linear核函数的分类结果: (5)通过“重新设置”按钮,重新选择SMO训练算法和Polynomial核函数的分类结果
2007,43(5)ComputerEngineeringandApplications计算机工程与应用 1问题的提出 航空公司在客舱服务部逐步实行“费用包干”政策,即:综合各方面的因素,总公司每年给客舱服务部一定额度的经费,由客舱服务部提供客舱服务,而客舱服务产生的所有费用,由客舱服务部在“费用包干额度”中自行支配。新的政策既给客舱服务部的管理带来了机遇,同时也带来了很大的挑战。通过“费用包干”政策的实施,公司希望能够充分调用客舱服务部的积极性和主动性,进一步改进管理手段,促进新的现代化管理机制的形成。 为了进行合理的分配,必须首先搞清楚部门的各项成本、成本构成、成本之间的相互关系。本文首先对成本组成进行分析,然后用回归模型和支持向量机预测模型对未来的成本进行预测[1-3],并对预测结果的评价和选取情况进行了分析。 2问题的分析 由于客舱服务部的特殊性,“费用包干”政策的一项重要内容就集中在小时费的重新分配问题上,因为作为客舱乘务员的主要组成部分—— —“老合同”员工的基本工资、年龄工资以及一些补贴都有相应的政策对应,属于相对固定的部分,至少目前还不是调整的最好时机。乘务员的小时费收入则是根据各自的飞行小时来确定的变动收入,是当前可以灵活调整的部分。实际上,对于绝大多数员工来说,小时费是其主要的收入部分,因此,用于反映乘务人员劳动强度的小时费就必然地成为改革的重要部分。 现在知道飞行小时和客万公里可能和未来的成本支出有关系,在当前的数据库中有以往的飞行小时(月)数据以及客万公里数据,并且同时知道各月的支出成本,现在希望预测在知道未来计划飞行小时和市场部门希望达到的客万公里的情况下的成本支出。 根据我们对问题的了解,可以先建立这个部门的成本层次模型,搞清楚部门的各项成本、成本构成、成本之间的相互关系。这样,可以对部门成本支出建立一个层次模型:人力资源成本、单独预算成本、管理成本,这三个部分又可以分别继续分层 次细分,如图1所示。 基于支持向量机回归模型的海量数据预测 郭水霞1,王一夫1,陈安2 GUOShui-xia1,WANGYi-fu1,CHENAn2 1.湖南师范大学数学与计算机科学学院,长沙410081 2.中国科学院科技政策与管理科学研究所,北京100080 1.CollegeofMath.andComputer,HunanNormalUniversity,Changsha410081,China 2.InstituteofPolicyandManagement,ChineseAcademyofSciences,Beijing100080,China E-mail:guoshuixia@sina.com GUOShui-xia,WANGYi-fu,CHENAn.Predictiononhugedatabaseontheregressionmodelofsupportvectormachine.ComputerEngineeringandApplications,2007,43(5):12-14. Abstract:Asanimportantmethodandtechnique,predictionhasbeenwidelyappliedinmanyareas.Withtheincreasingamountofdata,predictionfromhugedatabasebecomesmoreandmoreimportant.Basedonthebasicprincipleofvectormachineandim-plementarithmetic,apredictionsysteminfrastructureonanaircompanyisproposedinthispaper.Lastly,therulesofevaluationandselectionofthepredictionmodelsarediscussed. Keywords:prediction;datamining;supportvectormachine;regressionmodel 摘要:预测是很多行业都需要的一项方法和技术,随着数据积累的越来越多,基于海量数据的预测越来越重要,在介绍支持向量机基本原理和实现算法的基础上,给出了航空服务成本预测模型,最后对预测结果的评价和选取情况进行了分析。 关键词:预测;数据挖掘;支持向量机;回归模型 文章编号:1002-8331(2007)05-0012-03文献标识码:A中图分类号:TP18 基金项目:国家自然科学基金(theNationalNaturalScienceFoundationofChinaunderGrantNo.10571051);湖南省教育厅资助科研课题(theResearchProjectofDepartmentofEducationofHunanProvince,ChinaunderGrantNo.06C523)。 作者简介:郭水霞(1975-),女,博士生,讲师,主要研究领域为统计分析;王一夫(1971-),男,博士生,副教授,主要研究领域为计算机应用技术,软件工程技术;陈安(1970-),男,副研究员,主要研究领域为数据挖掘与决策分析。 12
收稿日期:2003-06-13 作者简介:姬水旺(1977)),男,陕西府谷人,硕士,研究方向为机器学习、模式识别、数据挖掘。 支持向量机训练算法综述 姬水旺,姬旺田 (陕西移动通信有限责任公司,陕西西安710082) 摘 要:训练SVM 的本质是解决二次规划问题,在实际应用中,如果用于训练的样本数很大,标准的二次型优化技术就很难应用。针对这个问题,研究人员提出了各种解决方案,这些方案的核心思想是先将整个优化问题分解为多个同样性质的子问题,通过循环解决子问题来求得初始问题的解。由于这些方法都需要不断地循环迭代来解决每个子问题,所以需要的训练时间很长,这也是阻碍SVM 广泛应用的一个重要原因。文章系统回顾了SVM 训练的三种主流算法:块算法、分解算法和顺序最小优化算法,并且指出了未来发展方向。关键词:统计学习理论;支持向量机;训练算法 中图分类号:T P30116 文献标识码:A 文章编号:1005-3751(2004)01-0018-03 A Tutorial Survey of Support Vector Machine Training Algorithms JI Shu-i wang,JI Wang -tian (Shaanx i M obile Communicatio n Co.,Ltd,Xi .an 710082,China) Abstract:Trai n i ng SVM can be formulated into a quadratic programm i ng problem.For large learning tasks w ith many training exam ples,off-the-shelf opti m i zation techniques quickly become i ntractable i n their m emory and time requirem ents.T hus,many efficient tech -niques have been developed.These techniques divide the origi nal problem into several s maller sub-problems.By solving these s ub-prob -lems iteratively,the ori ginal larger problem is solved.All proposed methods suffer from the bottlen eck of long training ti me.This severely limited the w idespread application of SVM.T his paper systematically surveyed three mains tream SVM training algorithms:chunking,de -composition ,and sequenti al minimal optimization algorithms.It concludes with an illustrati on of future directions.Key words:statistical learning theory;support vector machine;trai ning algorithms 0 引 言 支持向量机(Support Vector M achine)是贝尔实验室研究人员V.Vapnik [1~3]等人在对统计学习理论三十多年的研究基础之上发展起来的一种全新的机器学习算法,也使统计学习理论第一次对实际应用产生重大影响。SVM 是基于统计学习理论的结构风险最小化原则的,它将最大分界面分类器思想和基于核的方法结合在一起,表现出了很好的泛化能力。由于SVM 方法有统计学习理论作为其坚实的数学基础,并且可以很好地克服维数灾难和过拟合等传统算法所不可规避的问题,所以受到了越来越多的研究人员的关注。近年来,关于SVM 方法的研究,包括算法本身的改进和算法的实际应用,都陆续提了出来。尽管SVM 算法的性能在许多实际问题的应用中得到了验证,但是该算法在计算上存在着一些问题,包括训练算法速度慢、算法复杂而难以实现以及检测阶段运算量大等等。 训练SVM 的本质是解决一个二次规划问题[4]: 在约束条件 0F A i F C,i =1,, ,l (1)E l i =1 A i y i =0 (2) 下,求 W(A )= E l i =1A i -1 2 E i,J A i A j y i y j {7(x i )#7(x j )} = E l i =1A i -1 2E i,J A i A j y i y j K (x i ,x j )(3)的最大值,其中K (x i ,x j )=7(x i )#7(x j )是满足Merce r 定理[4]条件的核函数。 如果令+=(A 1,A 2,,,A l )T ,D ij =y i y j K (x i ,x j )以上问题就可以写为:在约束条件 +T y =0(4)0F +F C (5) 下,求 W(+)=+T l -12 +T D +(6) 的最大值。 由于矩阵D 是非负定的,这个二次规划问题是一个凸函数的优化问题,因此Kohn -Tucker 条件[5]是最优点 第14卷 第1期2004年1月 微 机 发 展M icr ocomputer Dev elopment V ol.14 N o.1Jan.2004
支持向量机训练算法的实验比较 姬水旺,姬旺田 (陕西移动通信有限责任公司,陕西西安710082) 摘 要:S VM是基于统计学习理论的结构风险最小化原则的,它将最大分界面分类器思想和基于核的方法结合在一起,表现出了很好的泛化能力。并对目前的三种主流算法S VM light,Bsvm与SvmFu在人脸检测、M NIST和USPS手写数字识别等应用中进行了系统比较。 关键词:统计学习理论;支持向量机;训练算法 中图法分类号:TP30116 文献标识码:A 文章编号:100123695(2004)1120018203 Experimental C omparison of Support Vector Machine Training Alg orithms J I Shui2wang,J I Wang2tian (Shanxi Mobile Communication Co.,LTD,Xi’an Shanxi710082,China) Abstract:Support vector learning alg orithm is based on structural risk minimization principle.It combines tw o remarkable ideas:maxi2 mum margin classifiers and im plicit feature spaces defined by kernel function.Presents a com prehensive com paris on of three mainstream learning alg orithms:S VM light,Bsvm,and SvmFu using face detection,M NIST,and USPS hand2written digit recognition applications. K ey w ords:S tatistical Learning T heory;Support Vector Machine;T raining Alg orithms 1 引言 支持向量机(Support Vector Machine)是贝尔实验室研究人员V.Vapnik等人[30]在对统计学习理论三十多年的研究基础之上发展起来的一种全新的机器学习算法,也是统计学习理论第一次对实际应用产生重大影响。S VM是基于统计学习理论的结构风险最小化原则的,它将最大分界面分类器思想和基于核的方法结合在一起,表现出了很好的泛化能力。由于S VM 方法有统计学习理论作为其坚实的数学基础,并且可以很好地克服维数灾难和过拟合等传统算法所不可规避的问题,所以受到了越来越多的研究人员的关注。近年来,关于S VM方法的研究,包括算法本身的改进和算法的实际应用,都陆续提了出来。但是,到目前为止,还没有看到有关支持向量算法总体评价和系统比较的工作,大多数研究人员只是用特定的训练和测试数据对自己的算法进行评价。由于支持向量机的参数与特定的问题以及特定的训练数据有很大的关系,要对它们进行统一的理论分析还非常困难,本文试从实验的角度对目前具有代表性的算法和训练数据进行比较,希望这些比较所得出的经验结论能对今后的研究和应用工作有指导意义。本文所用的比较算法主要有S VM light[14],Bsvm[12]和SvmFu[25],它们分别由美国C ornell University的Thorsten Joachims教授,National T aiwan U2 niversity的Chih2Jen Lin教授和美国麻省理工学院Ryan Rifkin博士编写的,在实验的过程中,笔者对算法进行了修改。由于这些算法有很大的相似之处,而且训练支持向量机是一个凸函数的优化过程,存在全局唯一的最优解,训练得到的模型不依赖于具体的算法实现,因此,本文在实验过程中不对具体的算法做不必要的区别。实验所采用的训练和测试数据也是目前非常有代表性的,它们大部分由国内外研究人员提供。 2 比较所用数据简介 本文所用的人脸检测数据是从美国麻省理工学院生物和计算学习中心[31](Center for Biological and C omputational Lear2 ning)得到的,这些数据是C BC L研究人员在波士顿和剑桥等地收集的,每个训练样本是一个由19×19=361个像素组成的图像,我们用一个361维的向量来代表每一个图像,每一个分量代表对应的像素值。用于训练的样本共有6977个,其中有2429个是人脸,其余4548个是非人脸;在测试样本集中共有24045个样本,包含472个人脸和23573个非人脸。这是一个两类分类问题。图1是训练样本中部分人脸的图像。 图1 人脸检测数据中部分人脸的图像 M NIST手写数字识别数据是由美国AT&T的Y ann LeCun 博士收集的[32],每个样本是0~9中的一个数字,用28×28= 784维的向量表示。在训练集中有60000个样本,测试集中有10000个样本。图2是训练样本中前100个样本的图像。 USPS手写识别数据是由美国麻省理工学院和贝尔实验室的研究人员共同从U.S.P ostal Service收集的[33],每个样本是0~9中的一个数字,用16×16=256维的向量中的各个分量表示所对应像素的灰度值。训练集中共有7291个样本,测试集中有2007个样本。图3是训练集中部分样本的图像。 ? 8 1 ?计算机应用研究2004年 收稿日期:2003206220;修返日期:2003211212
机器学习的定义 从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。 机器学习的范围 其实,机器学习跟模式识别,统计学习,数据挖掘,计算机视觉,语音识别,自然语言处理等领域有着很深的联系。 从范围上来说,机器学习跟模式识别,统计学习,数据挖掘是类似的,同时,机器学习与其他领域的处理技术的结合,形成了计算机视觉、语音识别、自然语言处理等交叉学科。因此,一般说数据挖掘时,可以等同于说机器学习。同时,我们平常所说的机器学习应用,应该是通用的,不仅仅模式识别 模式识别=机器学习。两者的主要区别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。在著名的《Pattern Recognition And Machine Learning》这本书中,Christopher M. Bishop在开头是这样说的“模式识别源自工业界,而机器学习来自于计算机学科。不过,它们中的活动可以被视为同一个领域的两个方面,同时在过去的10年间,它们都有了长足的发展”。 数据挖掘 数据挖掘=机器学习+数据库。这几年数据挖掘的概念实在是太耳熟能详。几乎等同于炒作。但凡说数据挖掘都会吹嘘数据挖掘如何如何,例如从数据中挖出金子,以及将废弃的数据转化为价值等等。但是,我尽管可能会挖出金子,但我也可能挖的是“石头”啊。这个说法的意思是,数据挖掘仅仅是一种思考方式,告诉我们应该尝试从数据中挖掘出知识,但不是每个数据都能挖掘出金子的,所以不要神话它。一个系统绝对不会因为上了一个数据挖掘模块就变得无所不能(这是IBM最喜欢吹嘘的),恰恰相反,一个拥有数据挖掘思维的人员才是关键,而且他还必须对数据有深刻的认识,这样才可能从数据中导出模式指引业务的改善。大部分数据挖掘中的算法是机器学习的算法在数据库中的优化。 统计学习 统计学习近似等于机器学习。统计学习是个与机器学习高度重叠的学科。因为机器学习中的大多数方法来自统计学,甚至可以认为,统计学的发展促进机器学习的繁荣昌盛。例如著名的支持向量机算法,就是源自统计学科。但是在某种程度上两者是有分别的,这个分别在于:统计学习者重点关注的是统计模型的发展与优化,偏数学,而机器学习者更关注的是能够解决问题,偏实践,因此机器学习研究者会重点研究学习算法在计算机上执行的效率与准确性的提升。 计算机视觉 计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。计算机视觉相关的应用非常的多,例如百度识图、手写字符识别、车牌识别等等应用。这个领域是应用前景非常火热的,同时也是研究的热门方向。随着机器学习的新领域深
Modeler 支持向量机模型评估银行客户信用 本文要介绍的预测分析模型是“支持向量机模型”,我们将为大家简要介绍支持向量机模型的理论,然后结合IBM SPSS Modeler 产品详细讲述如何利用支持向量机模型来解决客户的具体商业问题—银行如何评估客户信用 银行典型案例 商业银行个人信用评估就是根据个人信息和借贷记录等历史数据,判断个人信用,它是保证信贷安全的重要一环。但是商业银行用于信用评估的数据往往具有特性不稳定,历史样本容量较小,指标较多,呈明显的非正态分布。这些特点导致很难利用一般的统计技术进行有效的评估。支持向量机模型( 简称SVM) 能够很好的处理此类数据,进行有效的信用评估。本文介绍了SVM 的基本概念以及Modeler 中使用SVM 进行信用评估的基本步骤和方法,并对结果进行分析和应用 支持向量机模型简介 支持向量机(Support Vector Machine, 简称SVM) 是一项功能强大的分类和回归技术,可最大化模型的预测准确度。与其他常用模型不同,SVM 一个优势就是能很好的处理小样本,高维数,非正态的数据。 SVM 的工作原理是将原始数据通过变换映射到高维特征空间,这样即使数据不是线性可分,也可以对该数据点进行分类。之后,使用变换后的新数据的进行预测分类。例如,图 1 中的数据点落到了两个不同的类别中,可以用一条曲线分隔这两个类别。对数据使用某种数学函数变换后,可以用超平面定义这两个类别之间的边界。 图 1. 数据变换后线性可分示意图
用于变换的数学函数称为核函数。IBM SPSS Modeler 中的SVM 支持下列核函数类型: ?线性 ?多项式 ?径向基函数(RBF) ?Sigmoid 如果数据的线性分隔比较简单,则建议使用线性核函数。在其他情况下,应当使用其他核函数。在所有情况下,最好尝试使用不同的核函数,才能从中找出最佳模型,因为每一个函数均使用不同的算法和参数。 回页首 使用IBM SPSS Modeler 支持向量机模型评估客户信用 IBM SPSS Modeler 中的SVM 提供了可视化的操作方法,具有界面友好,操作方便的特点。此节,介绍如何使用IBM SPSS Modeler SVM 评估客户信用。操作步骤分为: ?创建基本流(Modeler Stream),建立模型;