
词法分析程序实验报告
一、实验目的
1. 理解词法分析器的基本功能
2. 理解词法规则的描述方法
3. 理解状态转换图及其实现
4. 能够编写简单的词法分析器
二、实验要求
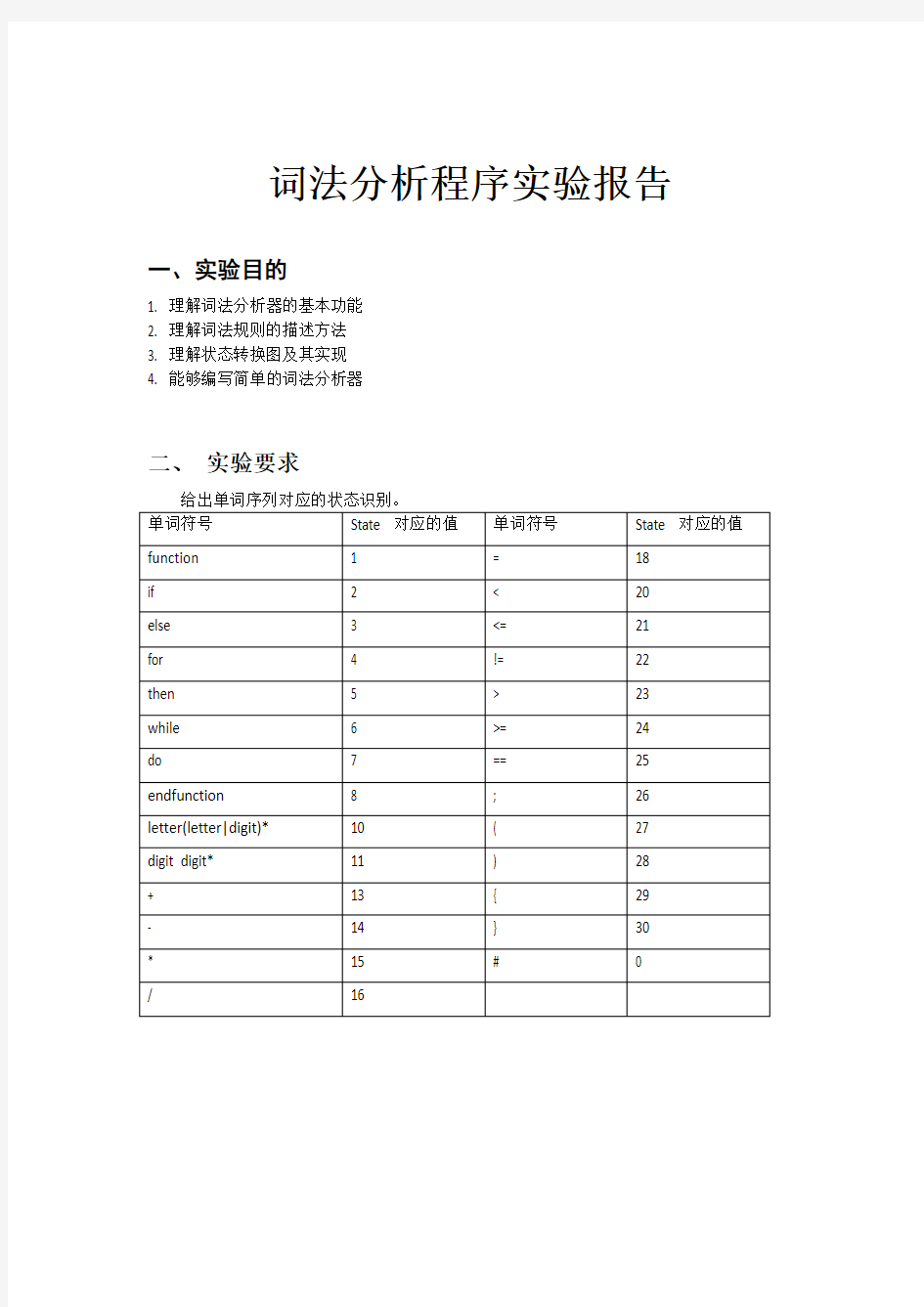
给出单词序列对应的状态识别。
单词符号State 对应的值单词符号State 对应的值function 1 = 18
if 2 < 20
else 3 <= 21
for 4 != 22
then 5 > 23
while 6 >= 24
do 7 == 25 endfunction 8 ; 26
letter(letter|digit)* 10 ( 27
digit digit* 11 ) 28
+ 13 { 29
- 14 } 30
* 15 # 0
/ 16
2、主程序流程图
N
程序开始
初始化
输入源程序
调用scanner()函数,识别单词序列
输出单词序列
Y
结束
输入串结束?
三、 识别单词的状态转换图
Scanner()函数流程图
变量初始化
忽略空格和换行
num 读取常数
state=11
Token[]读入关键字、标识符
关键字?
判断关键字 state
state=10
判断运算符和分界符 state
其余符号 state=-1
Return
N
Y
{
)
(
;
其他
其他
=
=
=
其他
!
=
其他
<
/
* - + 非数字
数字
数字
开始
空格或换行
字母
0 1
返回’10’或
关键字
2
3
4 返回’11’
5
6
7 8
返回’13’ 返回’14’ 返回’15’ 返回’16’ 9
10
11
12
13 14 15
16
17
18
19 20 >
=
22
23
24
25
返回’20’
返回’21’
返回’-1’
返回’22’ 返回’23’ 返回’24’
返回’18’
返回’25’ 返回’26’ 返回’27’ 返回’28’ 返回’29’
} #
2. 分析直接转向法和表驱动法的优缺点
状态转换图的实现通常有两种方法:状态转换表和直接转向法(1) :状态转换表法又称数据中心,是把状态转换图看作一种数据结构,由控制程序控制字符在其上运行,从而完成词法分析。优点是程序短,但是占存储空间多,
(2)直接转向法又称程序中心法,是把状态转换图看成一个流程图,从状态转换图的初态开始,对它的每一个状态节点都编写一段相应的程序。
源程序如下
#include
#include
char ch;//扫描哪一个字符
char stoken[100];//扫描到的单词序列
char token[10];//存储已扫描到的单词
int p,m,n;
int state;//词法分析时进入哪一个状态
int row;//用于标注哪一行不能识别
long int num;
char
*key[8]={"function","if","else","for","then","while","do","endfunction"};//定义好的能识别的关键字
void scanner()
{
for(n=0;n<10;n++) //变量初始化
token[n]=NULL;
m=0;
ch=stoken[p];
p++;
while(ch == ' '||ch == '\n')//跳过空格或是换行符
{
ch=stoken[p];
p++;
}
if(ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z')
{
m = 0;
while(ch >= 'a' && ch <= 'z' || ch >= '0' && ch <= '9' || ch >= 'A' && ch <= 'Z')
{
token[m++] = ch;
ch = stoken[p++];//扫描下一个
}
ch = stoken[--p];
state = 10;
for(n = 0; n < 8; n++)
if(strcmp(token, key[n])== 0)
{
state = n + 1;
break;
}
}
else
if(ch >= '0' && ch <= '9')//是数字
{
num = 0;
while(ch >= '0' && ch <= '9')//可能是多位数字
{
num = num * 10 + ch - '0';
ch =stoken[p++];
}
ch = stoken[--p];
state = 11;
}
else
switch(ch)
{
case '<':
m = 0;
token[m++] = ch;
ch = stoken[p++];
if(ch == '=')
{
state = 21;
token[m++] = ch;
}
else
{
state = 20;
ch = stoken[--p];
}
break;
case '>':
m = 0;
token[m++] = ch;
ch = stoken[p++];
if(ch == '=')
{
state = 24;
token[m++] = ch;
}
else
{
state = 23;
ch = stoken[--p];
}
break;
case'=':
m=0;
token[m++]=ch;
ch = stoken[p++];
if(ch=='=')
{
state = 25;
token[m++]=ch;
}
else
{
state=18;
ch = stoken[--p];
}
break;
case'!':
m=0;
token[m++]=ch;
ch = stoken[p++];
if(ch == '=')
{
state=22;
token[m++]=ch;
}
else
{
state = -1;
}
break;
case'+':
state=13;
token[0]=ch;
break;
case'-':
state=14;
token[0]=ch;
break;
case'*':
state=15;
token[0]=ch;
break;
case'/':
state=16;
token[0]=ch;
break;
case';':
state=26;
token[0]=ch;
break;
case'(':
state=27;
token[0]=ch;
break;
case')':
state=28;
token[0]=ch;
break;
case'{':
state=29;
token[0]=ch;
break;
case'}':
state=30;
token[0]=ch;
break;
case '#':
state = 0;
token[0] = ch;
break;
default:
state=-1;
break;
}
}
main()
{
p=0;
row=1;
printf("请输入要分析的单词:\n");
while(ch!='#')
{
scanf("%c",&ch);
stoken[p++]=ch;
}
printf("词法分析如下:\n");
p=0;
do
{
scanner();
switch(state)
{
case 11:
printf("\n(%d, %d)",num,state);
break;
case -1:
printf("\n不能识别 %d",row);
break;
default:
printf("\n(%s, %d)",token,state);
break;
}
}
while(state!=0);
}
实验一词法分析 一、实验目的 通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。 编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的内部编码及单词符号自身值。(遇到错误时可显示“Error”,然后跳过错误部分继续显示) 二、实验要求 使用一符一种的分法 关键字、运算符和分界符可以每一个均为一种 标识符和常数仍然一类一种 三、实验内容 功能描述: 1、待分析的简单语言的词法 (1)关键字: begin if then while do end (2)运算符和界符: := + –* / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义: ID=letter(letter| digit)* NUM=digit digit * (4)空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM,运算符、界符和关键字,词法分析阶段通常被忽略。 2、各种单词符号对应的种别码 图 1
程序结构描述: 图 2 四、实验结果 输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图3所示:
图3 输入private x:=9;if x>0 then x:=2*x+1/3; end#后经词法分析输出如下序列:(private 10)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图4所示: 图4 显然,private是关键字,却被识别成了标示符,这是因为图1中没有定义private关键字的种别码,所以把private当成了标示符。 输入private x:=9;if x>0 then x:=2*x+1/3; @ end#后经词法分析输出如下序列:(private 10)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5所示
数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】
2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验
结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据:
编译技术 班级网络0802 学号3080610052姓名叶晨舟 指导老师朱玉全2011年 7 月 4 日
一、目的 编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。 二、任务及要求 基本要求: 1.词法分析器产生下述小语言的单词序列 这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表: 单词符号种别编码助记符内码值 DIM IF DO STOP END 标识符 常数(整)= + * ** , ( )1 2 3 4 5 6 7 8 9 10 11 12 13 14 $DIM $IF $DO $STOP $END $ID $INT $ASSIGN $PLUS $STAR $POWER $COMMA $LPAR $RPAR - - - - - - 内部字符串 标准二进形式 - - - - - - 对于这个小语言,有几点重要的限制: 首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的: IF(5)=x 其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。 再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为
实验一误差分析 实验1.1(病态问题) 实验目的:算法有“优”与“劣”之分,问题也有“好”与“坏”之别。对数值方法的研究而言,所谓坏问题就是问题本身对扰动敏感者,反之属于好问题。通过本实验可获得一个初步体会。 数值分析的大部分研究课题中,如线性代数方程组、矩阵特征值问题、非线性方程及方程组等都存在病态的问题。病态问题要通过研究和构造特殊的算法来解决,当然一般要付出一些代价(如耗用更多的机器时间、占用更多的存储空间等)。 问题提出:考虑一个高次的代数多项式 显然该多项式的全部根为1,2,…,20共计20个,且每个根都是单重的。现考虑该多项式的一个扰动 其中ε(1.1)和(1.221,,,a a 的输出b ”和“poly ε。 (1(2 (3)写成展 关于α solve 来提高解的精确度,这需要用到将多项式转换为符号多项式的函数poly2sym,函数的具体使用方法可参考Matlab 的帮助。 实验过程: 程序: a=poly(1:20); rr=roots(a); forn=2:21 n form=1:9 ess=10^(-6-m);
ve=zeros(1,21); ve(n)=ess; r=roots(a+ve); -6-m s=max(abs(r-rr)) end end 利用符号函数:(思考题一)a=poly(1:20); y=poly2sym(a); rr=solve(y) n
很容易的得出对一个多次的代数多项式的其中某一项进行很小的扰动,对其多项式的根会有一定的扰动的,所以对于这类病态问题可以借助于MATLAB来进行问题的分析。 学号:06450210 姓名:万轩 实验二插值法
实验一词法分析实验报告
实验一词法分析 一、实验目的 通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。 编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的内部编码及单词符号自身值。(遇到错误时可显示“Error”,然后跳过错误部分继续显示) 二、实验要求 使用一符一种的分法 关键字、运算符和分界符可以每一个均为一种标识符和常数仍然一类一种 三、实验内容 功能描述: 1、待分析的简单语言的词法 (1)关键字:
begin if then while do end (2)运算符和界符: := + –* / < <= <> > > = = ; ( ) # (3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义: ID=letter(letter| digit)* NUM=digit digit * (4)空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM,运算符、界符和关键字,词法分析阶段通常被忽略。 2、各种单词符号对应的种别码 图 1
程序结构描述: 是 否 是 调用scanner() 字母 数 其他 运算符、 符号 界符等符号 否 是 图 2 四、实验结果 输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如 变量忽略 是否输入返 拼数 syn=11返 对不同报拼字是否关syn 为对syn=10
SPSS相关分析实验报告 篇一:spss对数据进行相关性分析实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。 (1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.0000.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为 0.0000.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.0000.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.86650.921,说明它们之间的显著性关系稍有减弱。通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。 三、实验总结 1、熟悉了用spss软件对数据进行相关性分析,熟悉其操作过程。 2、通过spss软件输出的数据结果并能够分析其相互之间的关系,并且解决实际问题。 3、充分理解了相关性分析的应用原理。
. 编译原理实验专业:13级网络工程
语法分析器1 一、实现方法描述 所给文法为G【E】; E->TE’ E’->+TE’|空 T->FT’ T’->*FT’|空 F->i|(E) 递归子程序法: 首先计算出五个非终结符的first集合follow集,然后根据五个产生式定义了五个函数。定义字符数组vocabulary来存储输入的句子,字符指针ch指向vocabulary。从非终结符E函数出发,如果首字符属于E的first集,则依次进入T函数和E’函数,开始递归调用。在每个函数中,都要判断指针所指字符是否属于该非终结符的first集,属于则根据产生式进入下一个函数进行调用,若first集中有空字符,还要判断是否属于该非终结符的follow集。以分号作为结束符。 二、实现代码 头文件shiyan3.h #include
#include int a=0; cout<<"按1结束程序"< 数值分析实验报告 姓名:周茹 学号: 912113850115 专业:数学与应用数学 指导老师:李建良 线性方程组的数值实验 一、课题名字:求解双对角线性方程组 二、问题描述 考虑一种特殊的对角线元素不为零的双对角线性方程组(以n=7为例) ?????????? ?????? ? ???? ?d a d a d a d a d a d a d 766 55 44 3 32 211??????????????????????x x x x x x x 7654321=?????????? ? ???????????b b b b b b b 7654321 写出一般的n (奇数)阶方程组程序(不要用消元法,因为不用它可以十分方便的解出这个方程组) 。 三、摘要 本文提出解三对角矩阵的一种十分简便的方法——追赶法,该算法适用于任意三对角方程组的求解。 四、引言 对于一般给定的d Ax =,我们可以用高斯消去法求解。但是高斯消去法过程复杂繁琐。对于特殊的三对角矩阵,如果A 是不可约的弱对角占优矩阵,可以将A 分解为UL ,再运用追赶法求解。 五、计算公式(数学模型) 对于形如????? ?? ????? ??? ?---b a c b a c b a c b n n n n n 111 2 2 2 11... ... ...的三对角矩阵UL A =,容易验证U 、L 具有如下形式: ??????? ????? ??? ?=u a u a u a u n n U ...... 3 3 22 1 , ?? ????? ? ?? ??????=1 (1) 1132 1l l l L 比较UL A =两边元素,可以得到 ? ?? ??-== = l a b u u c l b u i i i i i i 111 i=2, 3, ... ,n 考虑三对角线系数矩阵的线性方程组 f Ax = 这里()T n x x x x ... 2 1 = ,()T n f f f f ... 2 1 = 令y Lx =,则有 f Uy = 于是有 ()?????-== --u y a f y u f y i i i i i 1 1 11 1 * i=2, 3, ... ,n 再根据y Lx =可得到 编译原理实验报告 实验名称:分析调试语义分析程序 TEST抽象机模拟器完整程序 保证能用!!!!! 一、实验目的 通过分析调试TEST语言的语义分析和中间代码生成程序,加深对语法制导翻译思想的理解,掌握将语法分析所识别的语法范畴变换为中间代码的语义翻译方法。 二、实验设计 程序流程图 extern int TESTScan(FILE *fin,FILE *fout); FILE *fin,*fout; //用于指定输入输出文件的指针 int main() { char szFinName[300]; char szFoutName[300]; printf("请输入源程序文件名(包括路径):"); scanf("%s",szFinName); printf("请输入词法分析输出文件名(包括路径):"); scanf("%s",szFoutName); if( (fin = fopen(szFinName,"r")) == NULL) { printf("\n打开词法分析输入文件出错!\n"); return 0; } if( (fout = fopen(szFoutName,"w")) == NULL) { printf("\n创建词法分析输出文件出错!\n"); return 0; } int es = TESTScan(fin,fout); fclose(fin); fclose(fout); if(es > 0) printf("词法分析有错,编译停止!共有%d个错误!\n",es); else if(es == 0) { printf("词法分析成功!\n"); int es = 0; 企业实习相关分析报告范文 本次外出实习,部里安排我到xx会计师事务所实习,主要任务是协助各注册会计师到各街道进行查账,主要工作有编制工作底稿,查阅凭证,帐簿,报表发现问题,提出审计意见,进行现金盘点,资产清查,编制审计报告等。 本次外出实习,我感觉收获特别大。第一:收集了很多教学素材案例,在审计过程中,一旦我发现有对我以后教学有用的东西,我都会用笔记本记录下来。故此,这次外出企业实习,我做的笔记就有3本。我相信这些素材将会对我以,后教学提供很多帮助。本学期我讲授企业单项实训课程,在授课时就经常顺手拈来我外出审计中碰到的很多案例感觉教学效果很好。第二:了解目前企业会计现状以及他们在做帐过程中存在的各种问题及种种舞弊现象。第三:向注册会计师学习了很多知识,对于我在审计过程中碰到的各种问题,我都会虚心地向xx会计师事务所的老师询问,对于我提出的各种轰炸式提问,他们都很耐心地给予回答。第四:近距离接触,真正了解到对会计人员各方面素质及要求,为我以后在讲授课程时对于授课内容如何有所侧重更有帮助。本次发言,张部长主要让我谈一谈目前企业对会计人员要求,我们在教学中应注重培养学生哪些方面知识.我以为主要有以下几方面:一,会计电算化知识 本次外出企业查帐,我发现大部分企业已实现用电脑做帐,而且大部分企业公司都是采用金蝶财务软件做帐,少部分采用用友软件做帐。故此,我们应重点加强这方面知识讲授,让每位同学都能达到熟练运用这2个财务软件.既然是用电脑做帐,对打字速度有一定要求,一般要求学生每分钟要达到40-50个字左右。 二,税务知识 本次外出企业查帐,我发现很多公司因为规模较小,只设有一名会计人员,会计人员可以说是一名多面手、做帐、报税等均是他的工作。所以,我们以后应加强税务知识讲授,尤其是税务实务操作练习,教会每会学生如何申请报税、计税、缴税、尤其是几个主要税种,如个人所得税、企业所得税、营业税、房产税等更要重点讲授。 三,出纳方面知识 由于我们的学生学历较低,很多同学毕业后只能担任出纳,故此,对于出纳工作主要职责(如登记现金日记帐、银行存款日记帐、保管库存现金、有价证券、空白发票、支票印章)以及应具备技能(如点钞、计算器、辩别真假钞票)等应让学生熟练掌握。 四,财会法规知识 词法分析器实验报告 词法分析器设计 一、实验目的: 对C语言的一个子集设计并实现一个简单的词法分析器,掌握利用状 态转换图设计词法分析器的基本方法。利用该词法分析器完成对源程 序字符串的词法分析。输出形式是源程序的单词符号二元式的代码, 并保存到文件中。 二、实验内容: 1. 设计原理 词法分析的任务:从左至右逐个字符地对源程序进行扫描,产生一个个单词符号。 理论基础:有限自动机、正规文法、正规式 词法分析器(Lexical Analyzer) 又称扫描器(Scanner):执行词法分析的程序 2. 词法分析器的功能和输出形式 功能:输入源程序、输出单词符号 程序语言的单词符号一般分为以下五种:关键字、标识符、常数、运算符,界符 3. 输出的单词符号的表示形式: 单词种别用整数编码,关键字一字一种,标识符统归为一种,常数一种,各种符号各一种。 4. 词法分析器的结构 单词符号 5. 状态转换图实现 三、程序设计 1.总体模块设计 /*用来存储目标文件名*/ string file_name; /*提取文本文件中的信息。*/ string GetText(); /*获得一个单词符号,从位置i开始查找。并且有一个引用参数j,用来返回这个单词最后一个字符在str的位置。*/ string GetWord(string str,int i,int& j); /*这个函数用来除去字符串中连续的空格和换行 int DeleteNull(string str,int i); /*判断i当前所指的字符是否为一个分界符,是的话返回真,反之假*/ bool IsBoundary(string str,int i); /*判断i当前所指的字符是否为一个运算符,是的话返回真,反之假*/ bool IsOperation(string str,int i); (此文档为word格式,下载后您可任意编辑修改!) 2012级6班###(学号)计算机数值方法 实验报告成绩册 姓名:宋元台 学号: 成绩: 数值计算方法与算法实验报告 学期: 2014 至 2015 第 1 学期 2014年 12月1日课程名称: 数值计算方法与算法专业:信息与计算科学班级 12级5班 实验编号: 1实验项目Neton插值多项式指导教师:孙峪怀 姓名:宋元台学号:实验成绩: 一、实验目的及要求 实验目的: 掌握Newton插值多项式的算法,理解Newton插值多项式构造过程中基函数的继承特点,掌握差商表的计算特点。 实验要求: 1. 给出Newton插值算法 2. 用C语言实现算法 二、实验内容 三、实验步骤(该部分不够填写.请填写附页) 1.算法分析: 下面用伪码描述Newton插值多项式的算法: Step1 输入插值节点数n,插值点序列{x(i),f(i)},i=1,2,……,n,要计算的插值点x. Step2 形成差商表 for i=0 to n for j=n to i f(j)=((f(j)-f(j-1)(x(j)-x(j-1-i)); Step3 置初始值temp=1,newton=f(0) Step4 for i=1 to n temp=(x-x(i-1))*temp*由temp(k)=(x-x(k-1))*temp(k-1)形成 (x-x(0).....(x-x(i-1)* Newton=newton+temp*f(i); Step5 输出f(x)的近似数值newton(x)=newton. 2.用C语言实现算法的程序代码 #include 数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00 标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验 实验一 误差分析 实验(病态问题) 实验目的:算法有“优”与“劣”之分,问题也有“好”与“坏”之别。对数值方法的研究而言,所谓坏问题就是问题本身对扰动敏感者,反之属于好问题。通过本实验可获得一个初步体会。 数值分析的大部分研究课题中,如线性代数方程组、矩阵特征值问题、非线性方程及方程组等都存在病态的问题。病态问题要通过研究和构造特殊的算法来解决,当然一般要付出一些代价(如耗用更多的机器时间、占用更多的存储空间等)。 问题提出:考虑一个高次的代数多项式 )1.1() ()20()2)(1()(20 1∏=-=---=k k x x x x x p 显然该多项式的全部根为1,2,…,20共计20个,且每个根都是单重的。现考虑该多项式的一个扰动 )2.1(0 )(19=+x x p ε 其中ε是一个非常小的数。这相当于是对()中19x 的系数作一个小的扰动。我们希望比较()和()根的差别,从而分析方程()的解对扰动的敏感性。 实验内容:为了实现方便,我们先介绍两个Matlab 函数:“roots ”和“poly ”。 roots(a)u = 其中若变量a 存储n+1维的向量,则该函数的输出u 为一个n 维的向量。设a 的元素依次为121,,,+n a a a ,则输出u 的各分量是多项式方程 01121=+++++-n n n n a x a x a x a 的全部根;而函数 poly(v)b = 的输出b 是一个n+1维变量,它是以n 维变量v 的各分量为根的多项式的系数。可见“roots ”和“poly ”是两个互逆的运算函数。 ;000000001.0=ess );21,1(zeros ve = ;)2(ess ve = ))20:1((ve poly roots + 上述简单的Matlab 程序便得到()的全部根,程序中的“ess ”即是()中的ε。 实验要求: (1)选择充分小的ess ,反复进行上述实验,记录结果的变化并分析它们。 如果扰动项的系数ε很小,我们自然感觉()和()的解应当相差很小。计算中你有什么出乎意料的发现表明有些解关于如此的扰动敏感性如何 (2)将方程()中的扰动项改成18x ε或其它形式,实验中又有怎样的现象 出现 (3)(选作部分)请从理论上分析产生这一问题的根源。注意我们可以将 方程()写成展开的形式, ) 3.1(0 ),(1920=+-= x x x p αα 同时将方程的解x 看成是系数α的函数,考察方程的某个解关于α的扰动是否敏感,与研究它关于α的导数的大小有何关系为什么你发现了什么现象,哪些根关于α的变化更敏感 思考题一:(上述实验的改进) 在上述实验中我们会发现用roots 函数求解多项式方程的精度不高,为此你可以考虑用符号函数solve 来提高解的精确度,这需要用到将多项式转换为符号多项式的函数poly2sym,函数的具体使用方法可参考Matlab 的帮助。 词法分析器实验报告 一、实验目的及要求 本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。 运行环境: 硬件:windows xp 软件:visual c++6.0 二、实验步骤 1.查询资料,了解词法分析器的工作过程与原理。 2.分析题目,整理出基本设计思路。 3.实践编码,将设计思想转换用c语言编码实现,编译运行。 4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。 三、实验内容 本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。标识符、常数是在分析过程中不断形成的。 对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。 输出形式例如:void $关键字 流程图、程序流程图: 程序: #include 数值分析实验报告模板 篇一:数值分析实验报告(一)(完整) 数值分析实验报告 1 2 3 4 5 篇二:数值分析实验报告 实验报告一 题目:非线性方程求解 摘要:非线性方程的解析解通常很难给出,因此线性方程的数值解法就尤为重要。本实验采用两种常见的求解方法二分法和Newton法及改进的Newton法。利用二分法求解给定非线性方程的根,在给定的范围内,假设f(x,y)在[a,b]上连续,f(a)xf(b) 直接影响迭代的次数甚至迭代的收敛与发散。即若x0 偏离所求根较远,Newton法可能发散的结论。并且本实验中还利用利用改进的Newton法求解同样的方程,且将结果与Newton法的结果比较分析。 前言:(目的和意义) 掌握二分法与Newton法的基本原理和应用。掌握二分法的原理,验证二分法,在选对有根区间的前提下,必是收 敛,但精度不够。熟悉Matlab语言编程,学习编程要点。体会Newton使用时的优点,和局部收敛性,而在初值选取不当时,会发散。 数学原理: 对于一个非线性方程的数值解法很多。在此介绍两种最常见的方法:二分法和Newton法。 对于二分法,其数学实质就是说对于给定的待求解的方程f(x),其在[a,b]上连续,f(a)f(b) Newton法通常预先要给出一个猜测初值x0,然后根据其迭代公式xk?1?xk?f(xk) f'(xk) 产生逼近解x*的迭代数列{xk},这就是Newton法的思想。当x0接近x*时收敛很快,但是当x0选择不好时,可能会发散,因此初值的选取很重要。另外,若将该迭代公式改进为 xk?1?xk?rf(xk) 'f(xk) 其中r为要求的方程的根的重数,这就是改进的Newton 法,当求解已知重数的方程的根时,在同种条件下其收敛速度要比Newton法快的多。 程序设计: 本实验采用Matlab的M文件编写。其中待求解的方程写成function的方式,如下 function y=f(x); 《词法分析》实验报告 目录 目录错误!未定义书签。 1 实验目的错误!未定义书签。 2 实验内容错误!未定义书签。 TINY计算机语言描述错误!未定义书签。 实验要求错误!未定义书签。 3 此法分析器的程序实现错误!未定义书签。状态转换图错误!未定义书签。 程序源码错误!未定义书签。 实验运行效果截图错误!未定义书签。 4 实验体会错误!未定义书签。 实验目的 1、学会针对DFA转换图实现相应的高级语言源程序。 2、深刻领会状态转换图的含义,逐步理解有限自动机。 3、掌握手工生成词法分析器的方法,了解词法分析器的内部工作原理。 实验内容 TINY计算机语言描述 TINY计算机语言的编译程序的词法分析部分实现。 从左到右扫描每行该语言源程序的符号,拼成单词,换成统一的内部表示(token)送给语法分析程序。 为了简化程序的编写,有具体的要求如下: 1、数仅仅是整数。 2、空白符仅仅是空格、回车符、制表符。 3、代码是自由格式。 4、注释应放在花括号之内,并且不允许嵌套 TINY语言的单词 要求实现编译器的以下功能 1、按规则拼单词,并转换成二元式形式 2、删除注释行 3、删除空白符(空格、回车符、制表符) 4、列表打印源程序,按照源程序的行打印,在每行的前面加上行号,并且打印出每行包含的记号的二元形式 5、发现并定位错误 词法分析进行具体的要求 1、记号的二元式形式中种类采用枚举方法定义;其中保留字和特殊字符是每个都一个种类,标示符自己是一类,数字是一类;单词的属性就是表示的字符串值。 2、词法分析的具体功能实现是一个函数GetToken(),每次调用都对剩余的字符串分析得到一个单词或记号识别其种类,收集该记号的符号串属性,当识别一个单词完毕,采用返回值的形式返回符号的种类,同时采用程序变量的形式提供当前识别出记号的属性值。这样配合语法分析程序的分析需要的记号及其属性,生成一个语法树。 实验课程专业统计软件应用 上课时间2012 学年 1 学期15 周(2012 年12 月18日—28 日) 学生姓名李艳学号2010211587 班级0331002 所在学院经济管 上课地点经管3 楼指导教师胡大权理学院 实验内容写作 第六章 一实验目的 1、理解方差分析的基本概念 2、学会常用的方差分析方法 二实验内容 实验原理:方差分析的基本原理是认为不同处理组的均值间的差别基本来源有两个:随机误差,如测 量误差造成的差异或个体间的差异,称为组内差异 根据老师的讲解和课本的习题完成思考与练习的5、6、7、8题。 第5题:为了寻求适应某地区的高产油菜品种,今选5个品种进行试验,每一种在4块条件完全相同的试验田上试种,其他施肥等田间管理措施完全一样。表 6.20所示为每一品种下每一块田的亩产量,根 据这些数据分析不同品种油菜的平均产量在显著水平0.05下有无显著性差异。 第一步分析 由于考虑的是控制变量对另一个观测变量的影响,而且是5个品种,所以不宜采用独立样本T检验,应该采用单因素方差分析。 第二步数据的组织 从实验材料中直接导入数据 第三步方差相等的齐性检验 由于方差分析的前提是各水平下的总体服从方差相等的正态分布,而且各组的方差具有齐性,其中正 态分布的要求并不是非常严格,但是对于方差相等的要求还是比较严格的,因此必须对方差相等的前提进 行检验。 第四步多重比较分析 通过上面的步骤,只能判断不同的施肥等田间操作效果是否有显著性差异,如果要想进一步了解究竟那 个品种与其他的有显著性均值差别等细节问题,就需要单击上图中的两两比较按钮。 第五步运行结果及分析 多重比较结果表:从该表可以看出分别对几个不同的品种进行的两两比较。最后我们可以得出结论第4品种是最好的。其他的次之。 第6题:某公司希望检测四种类型类型轮胎A,B,C,D的寿命,如表 6.21所示。其中每种轮胎应用在随选择的6种汽车上,在显著性水平0.05下判断不同类型轮胎的寿命间是否存在显著性差异。 第一步分析 由于考虑的是一个控制变量对另一个控制变量的影响,而且是4种轮胎,所以不宜采用独立样本T 检验,应该采用单因素方差分析。 第二步数据的组织 从实验材料中直接导入数据。 第三步方差相等的齐性检验 由于方差分析的前提是各水平下的总体服从方差相等的正态分布,而且各组的方差具有齐性,其中正态分 布的要求并不是非常严格,但是对于方差相等的要求还是比较严格的,因此必须对方差相等的前提进行检 验。选择菜单“分析”—均值比较—单因素ANOVA。 编译原理语法分析器实验报告 班级: 学号: 姓名: 实验名称语法分析器 一、实验目的 1、根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。 2、本次实验的目的主要是加深对自上而下分析法的理解。 二、实验内容 [问题描述] 递归下降分析法: 0.定义部分:定义常量、变量、数据结构。 1.初始化:从文件将输入符号串输入到字符缓冲区中。 2.利用递归下降分析法分析,对每个非终结符编写函数,在主函数中调用文法开始符号的函数。 LL(1)分析法: 模块结构: 1、定义部分:定义常量、变量、数据结构。 2、初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体等); 3、运行程序:让程序分析一个text文件,判断输入的字符串是否符合文法定义的规则; 4、利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式 符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示简 单的错误提示。 [基本要求] 1. 对数据输入读取 2. 格式化输出分析结果 2.简单的程序实现词法分析 public static void main(String args[]) { LL l = new LL(); l.setP(); String input = ""; boolean flag = true; while (flag) { try { InputStreamReader isr = new InputStreamReader(System.in); BufferedReader br = new BufferedReader(isr); System.out.println(); System.out.print("请输入字符串(输入exit退出):"); input = br.readLine(); } catch (Exception e) { e.printStackTrace(); } if(input.equals("exit")){ flag = false; }else{ l.setInputString(input); l.setCount(1, 1, 0, 0); l.setFenxi(); System.out.println(); System.out.println("分析过程"); System.out.println("----------------------------------------------------------------------"); System.out.println(" 步骤| 分析栈 | 剩余输入串| 所用产生式"); System.out.println("----------------------------------------------------------------------"); boolean b = l.judge(); System.out.println("----------------------------------------------------------------------"); if(b){ System.out.println("您输入的字符串"+input+"是该文法的一个句子"); }else{ System.out.println("您输入的字符串"+input+"有词法错误!");数值分析实验报告
TEST语言 -语法分析,词法分析实验报告
(实习报告)企业实习相关分析报告范文
词法分析器实验报告
数值计算实验报告
数据分析实验报告
数值分析实验报告1
词法分析器实验报告
数值分析实验报告模板
词法分析的实验报告
spss实验报告最终版本
编译原理语法分析器实验报告
相关主题
文本预览