Scalable Wavelet Coding for SyntheticNatural Hybrid Images
- 格式:pdf
- 大小:927.20 KB
- 文档页数:11

Single-Pixel Imaging via Compressive SamplingMarco F.Duarte,Mark A.Davenport,Dharmpal Takhar,Jason skaTing Sun,Kevin F.Kelly,Richard G.BaraniukRice UniversityHumans are visual animals,and imaging sensors that extend our reach–cameras–have improved dramatically in recent times thanks to the introduction of CCD and CMOS digital technology.Consumer digital cameras in the mega-pixel range are now ubiquitous thanks to the happy coincidence that the semiconductor material of choice for large-scale electronics integration (silicon)also happens to readily convert photons at visual wavelengths into electrons.On the contrary,imaging at wavelengths where silicon is blind is considerably more complicated,bulky, and expensive.Thus,for comparable resolution,a$500digital camera for the visible becomes a $50,000camera for the infrared.In this paper,we present a new approach to building simpler,smaller,and cheaper digital cameras that can operate efficiently across a much broader spectral range than conventional silicon-based cameras.Our approach fuses a new camera architecture based on a digital mi-cromirror device(DMD–see Sidebar:Spatial Light Modulators)with the new mathematical theory and algorithms of compressive sampling(CS–see Sidebar:Compressive Sampling in a Nutshell).CS combines sampling and compression into a single nonadaptive linear measurement process [1–4].Rather than measuring pixel samples of the scene under view,we measure inner products between the scene and a set of test functions.Interestingly,random test functions play a key role, making each measurement a random sum of pixel values taken across the entire image.When the scene under view is compressible by an algorithm like JPEG or JPEG2000,the CS theory enables us to stably reconstruct an image of the scene from fewer measurements than the number of reconstructed pixels.In this manner we achieve sub-Nyquist image acquisition.Our“single-pixel”CS camera architecture is basically an optical computer(comprising a DMD,two lenses,a single photon detector,and an analog-to-digital(A/D)converter)that computes random linear measurements of the scene under view.The image is then recovered orFig.1.Aerial view of the single-pixel compressive sampling(CS)camera in the lab[5].processed from the measurements by a digital computer.The camera design reduces the required size,complexity,and cost of the photon detector array down to a single unit,which enables the use of exotic detectors that would be impossible in a conventional digital camera.The random CS measurements also enable a tradeoff between space and time during image acquisition.Finally, since the camera compresses as it images,it has the capability to efficiently and scalably handle high-dimensional data sets from applications like video and hyperspectral imaging.This article is organized as follows.After describing the hardware,theory,and algorithms of the single-pixel camera in detail,we analyze its theoretical and practical performance and compare it to more conventional cameras based on pixel arrays and raster scanning.We also explain how the camera is information scalable in that its random measurements can be used to directly perform simple image processing tasks,such as target classification,withoutfirst reconstructing the underlying imagery.We conclude with a review of related camera architectures and a discussion of ongoing and future work.I.The Single-Pixel CameraArchitectureThe single-pixel camera is an optical computer that sequentially measures the inner products y[m]= x,φm between an N-pixel sampled version x of the incident light-field from the scene under view and a set of two-dimensional(2D)test functions{φm}[5].As shown in Fig.1,thelight-field is focused by biconvex Lens1not onto a CCD or CMOS sampling array but rather onto a DMD consisting of an array of N tiny mirrors(see Sidebar:Spatial Light Modulators).Each mirror corresponds to a particular pixel in x andφm and can be independently oriented either towards Lens2(corresponding to a1at that pixel inφm)or away from Lens2(corre-sponding to a0at that pixel inφm).The reflected light is then collected by biconvex Lens2and focused onto a single photon detector(the single pixel)that integrates the product x[n]φm[n]to compute the measurement y[m]= x,φm as its output voltage.This voltage is then digitized by an A/D converter.Values ofφm between0and1can be obtained by dithering the mirrors back and forth during the photodiode integration time.To obtainφm with both positive and negative values(±1,for example),we estimate and subtract the mean light intensity from each measurement,which is easily measured by setting all mirrors to the full-on1position.To compute CS randomized measurements y=Φx as in(1),we set the mirror orientations φm randomly using a pseudo-random number generator,measure y[m],and then repeat the process M times to obtain the measurement vector y.Recall from Sidebar:Compressive Sampling in a Nutshell that we can set M=O(K log(N/K))which is≪N when the scene being imaged is compressible by a compression algorithm like JPEG or JPEG2000.Since the DMD array is programmable,we can also employ test functionsφm drawn randomly from a fast transform such as a Walsh,Hadamard,or Noiselet transform[6,7].The single-pixel design reduces the required size,complexity,and cost of the photon detector array down to a single unit,which enables the use of exotic detectors that would be impossible in a conventional digital camera.Example detectors include a photomultiplier tube or an avalanche photodiode for low-light(photon-limited)imaging(more on this below),a sandwich of several photodiodes sensitive to different light wavelengths for multimodal sensing,a spectrometer for hyperspectral imaging,and so on.In addition to sensingflexibility,the practical advantages of the single-pixel design include the facts that the quantum efficiency of a photodiode is higher than that of the pixel sensors in a typical CCD or CMOS array and that thefill factor of a DMD can reach90%whereas that of a CCD/CMOS array is only about50%.An important advantage to highlight is the fact that each CS measurement receives about N/2times more photons than an average pixel sensor,which significantly reduces image distortion from dark noise and read-out noise.Theoretical advantages(a)(b)(c)Fig.2.Single-pixel photo album.(a)256×256conventional image of a black-and-white R.(b)Single-pixel camera reconstructed image from M=1300random measurements(50×sub-Nyquist).(c)256×256 pixel color reconstruction of a printout of the Mandrill test image imaged in a low-light setting using a single photomultiplier tube sensor,RGB colorfilters,and M=6500random measurements.that the design inherits from the CS theory include its universality,robustness,and progressivity.The single-pixel design falls into the class of multiplex cameras[8].The baseline standard for multiplexing is classical raster scanning,where the test functions{φm}are a sequence of delta functionsδ[n−m]that turn on each mirror in turn.As we will see below,there are substantial advantages to operating in a CS rather than raster scan mode,including fewer total measurements (M for CS rather than N for raster scan)and significantly reduced dark noise.Image acquisition examplesFigure2(a)and(b)illustrates a target object(a black-and-white printout of an“R”)x and reconstructed image x taken by the single-pixel camera prototype in Fig.1using N=256×256 and M=N/50[5].Fig.2(c)illustrates an N=256×256color single-pixel photograph of a printout of the Mandrill test image taken under low-light conditions using RGB colorfilters and a photomultiplier tube with M=N/10.In both cases,the images were reconstructed using Total Variation minimization,which is closely related to wavelet coefficientℓ1minimization[2].Structured illumination configurationIn a reciprocal configuration to that in Fig.1,we can illuminate the scene using a projector displaying a sequence of random patterns{φm}and collect the reflected light using a single lens and photodetector.Such a“structured illumination”setup has advantages in applications where we can control the light source.In particular,there are intriguing possible combinations of single-pixel imaging with techniques such as3D imaging and dual photography[9].Shutterless video imagingWe can also acquire video sequences using the single-pixel camera.Recall that a traditional video camera opens a shutter periodically to capture a sequence of images(called video frames) that are then compressed by an algorithm like MPEG that jointly exploits their spatio-temporal redundancy.In contrast,the single-pixel video camera needs no shutter;we merely continuously sequence through randomized test functionsφm and then reconstruct a video sequence using an optimization that exploits the video’s spatio-temporal redundancy[10].If we view a video sequence as a3D space/time cube,then the test functionsφm lie concentrated along a periodic sequence of2D image slices through the cube.A na¨ıve way to reconstruct the video sequence would group the corresponding measurements y[m]into groups where the video is quasi-stationary and then perform a2D frame-by-frame reconstruction on each group.This exploits the compressibility of the3D video cube in the space but not time direction.A more powerful alternative exploits the fact that even though eachφm is testing a different 2D image slice,the image slices are often related temporally through smooth object motions in the video.Exploiting this3D compressibility in both the space and time directions and inspired by modern3D video coding techniques[11],we can,for example,attempt to reconstruct the sparsest video space/time cube in the3D wavelet domain.These two approaches are compared in the simulation study illustrated in Fig.3.We employed simplistic3D tensor product Daubechies-4wavelets in all cases.As we see from thefigure,3D reconstruction from2D random measurements performs almost as well as3D reconstruction from 3D random measurements,which are not directly implementable with the single-pixel camera.II.Single-Pixel Camera TradeoffsThe single-pixel camera is aflexible architecture to implement a range of different multiplex-ing methodologies,just one of them being CS.In this section,we analyze the performance of CS and two other candidate multiplexing methodologies and compare them to the performance of a brute-force array of N pixel sensors.Integral to our analysis is the consideration of Poisson photon counting noise at the detector,which is image-dependent.We conduct two separate analyses to assess the“bang for the buck”of CS.Thefirst is a theoretical analysis that provides general guidance.The second is an experimental study that indicates how the systems typically perform(a)frame32(b)2D meas(c)2D meas(d)3D meas+2D recon+3D recon+3D reconFig.3.Frame32from a reconstructed video sequence using(top row)M=20,000and(bottom row) M=50,000measurements(simulation from[10]).(a)Original frame of an N=64×64×64video of a disk simultaneously dilating and translating.(b)Frame-by-frame2D measurements+frame-by-frame 2D reconstruction;MSE=3.63and0.82,respectively.(c)Frame-by-frame2D measurements+joint3D reconstruction;MSE=0.99and0.24,respectively.(d)Joint3D measurements+joint3D reconstruction; MSE=0.76and0.18,respectively.in practice.Scanning methodologiesThe four imaging methodologies we consider are:•Pixel array(PA):a separate sensor for each of the N pixels receives light throughout the total capture time T.This is actually not a multiplexing system,but we use it as the gold standard for comparison.•Raster scan(RS):a single sensor takes N light measurements sequentially from each of the N pixels over the capture time.This corresponds to test functions{φm}that are delta functions and thusΦ=I.The measurements y thus directly provide the acquired image x.•Basis scan(BS):a single sensor takes N light measurements sequentially from different combinations of the N pixels as determined by test functions{φm}that are not delta functions but from some more general basis[12].In our analysis,we assume a Walsh basis modified to take the values0/1rather than±1;thusΦ=W,where W is the0/1Walsh matrix.The acquired image is obtained from the measurements y by x=Φ−1y=W−1y.•Compressive sampling(CS):a single sensor takes M≤N light measurements sequentially from different combinations of the N pixels as determined by random0/1test functions {φm}.Typically,we set M=O(K log(N/K))which is≪N when the image is com-pressible.In our analysis,we assume that the M rows of the matrixΦconsist of randomlydrawn rows from a0/1Walsh matrix that are then randomly permuted(we ignore thefirst row consisting of all1’s).The acquired image is obtained from the measurements y via a sparse reconstruction algorithm such as BPIC(see Sidebar:Compressive Sampling in a Nutshell).Theoretical analysisIn this section,we conduct a theoretical performance analysis of the above four scanning methodologies in terms of the required dynamic range of the photodetector,the required bit depth of the A/D converter,and the amount of Poisson photon counting noise.Our results are pessimistic in general;we show in the next section that the average performance in practice can be considerably better.Our results are summarized in Table I.An alternative analysis of CS imaging for piecewise smooth images in Gaussian noise has been reported in[13].Dynamic range:Wefirst consider the photodetector dynamic range required to match the performance of the baseline PA.If each detector in the PA has a linear dynamic range of0to D, then it is easy to see that single-pixel RS detector need only have that same dynamic range.In contrast,each Walsh basis test function contains N/21’s,and so directs N/2times more light to the detector.Thus,BS and CS each require a larger linear dynamic range of0to ND/2.On the positive side,since BS and CS collect considerably more light per measurement than the PA and RS,they benefit from reduced detector nonidealities like dark currents.Quantization error:We now consider the number of A/D bits required within the required dynamic range to match the performance of the baseline PA in terms of worst-case quantization distortion.Define the mean-squared error(MSE)between the true image x and its acquired version x as MSE=1ND2−B−1[14].Due to its larger dynamic range,BS requires B+ log2N bits per measurement to reach the same MSE distortion level.Since the distortion of CS reconstruction is up to C N times larger than the distortion in the measurement vector(see Sidebar: Compressive Sensing in a Nutshell),we require up to an additional log2C N bits per measurement. One empirical study has found roughly that C N lies between8and10for a range of different random measurement configurations[15].Thus,BS and CS require a higher-resolution A/D converter than PA and RS to acquire an image with the same worst-case quantization distortion.TABLE IComparison of the four camera scanning methodologies.Raster Scan Compressive Sampling N ND ND NDNB N(B+log2N)P N P(3N−2)P<3C2NM P3C2N, the MSE of CS is lower than that of RS.We emphasize that in the CS case,we have only a fairly loose upper bound and that there exist alternative CS reconstruction algorithms with better performance guarantees,such as the Dantzig Selector[3].Summary:From Table I,we see that the advantages of a single-pixel camera over a PA come at the cost of more stringent demands on the sensor dynamic range and A/D quantization and larger MSE due to photon counting effects.Additionally,the linear dependence of the MSE on the number of image pixels N for BS and RS is a potential deal-breaker for high-resolution imaging.The promising aspect of CS is the logarithmic dependence of its MSE on N through the relationship M=O(K log(N/K)).Experimental resultsSince CS acquisition/reconstruction methods often perform much better in practice than the above theoretical bounds suggest,in this section we conduct a simple experiment using real data from the CS imaging testbed depicted in Fig.1.Thanks to the programmability of the testbed, we acquired RS,BS,and CS measurements from the same hardware.Wefixed the number of A/D converter bits across all methodologies.Figure4shows the pixel-wise MSE for the capture of a N=128×128pixel“R”test image as a function of the total capture time T.Here the MSE combines both quantization and photon counting effects.For CS we took M=N/10total measurements per capture and used a Daubechies-4wavelet basis for the sparse reconstruction.We make two observations.First,the performance gain of BS over RS contradicts the aboveFig.4.Average MSE for Raster Scan(RS),Basis Scan(BS),and Compressive Sampling(CS)single-pixel images as a function of the total image capture time T(real data).worst-case theoretical calculations.We speculate that the contribution of the sensor’s dark current, which is not accounted for in our analysis,severely degrades RS’s performance.Second,the performance gain of CS over both RS and BS is clear:images can either be acquired in much less time for the same MSE or with much lower MSE in the same amount of time.rmation Scalability and the Smashed FilterWhile the CS literature has focused almost exclusively on problems in signal and image reconstruction or approximation,reconstruction is frequently not the ultimate goal.For instance, in many image processing and computer vision applications,data is acquired only for the purpose of making a detection,classification,or recognition decision.Fortunately,the CS framework is information scalable to a much wider range of statistical inference tasks[17–19].Tasks such as detection do not require reconstruction,but only require estimates of the relevant sufficient statistics for the problem at hand.Moreover,in many cases it is possible to directly extract these statistics from a small number of random measurements without ever reconstructing the image.The matchedfilter is a key tool in detection and classification problems that involve searching for a target template in a scene.A complicating factor is that often the target is transformed in some parametric way—for example the time or Doppler shift of a radar return signal;the translation and rotation of a face in a face recognition task;or the roll,pitch,yaw,and scale of a vehicle viewed from an aircraft.The matchedfilter detector operates by forming comparisons between the given test data and all possible transformations of the template tofind the match that optimizes some performance metric.The matchedfilter classifier operates in the same waybut chooses the best match from a number of different potential transformed templates.The na¨ıve approach to matchedfiltering with CS wouldfirst reconstruct the images under consideration and then apply a standard matchedfiltering technique.In contrast,the smashed filter(for dimensionally reduced matchedfilter)performs all of its operations directly on the random measurements[18].The two key elements of the smashedfilter are the generalized likelihood ratio test and the concept of an image appearance manifold[20].If the parametric transformation affecting the template image is well-behaved,then the set of transformed templates forms a low-dimensional manifold in the high-dimensional pixel space R N with the dimension K equal to the number of independent parameters.1Thus,the matchedfilter classifier can be interpreted as classifying a test image according to the closest template manifold in R N.The smashedfilter exploits a recent result that the structure of a smooth K-dimensional manifold in R N is preserved with high probability under a random projection to the lower dimensional space R M as long as M=O(K log N)[21].This is reminiscent of the number of measurements required for successful CS but with K now the manifold dimension.Thus,to classify an N-pixel test image,we can alternatively compare M random measurements of the test image to the M-dimensional projections(using the sameΦ)of the candidate image template manifolds.The upshot is that all necessary computations can be made directly in R M rather than in R N.As in the conventional matchedfilter,a byproduct of the closest manifold search is an estimate of the template parameters that best match the test image.Previous work in the computer science community(the other“CS”)has also employed the Johnson-Lindenstrauss lemma[22] to reduce the data dimensionality prior to computing features for classification;however,they have not considered the intrinsic manifold structure manifested in many image processing and computer vision settings.Figure5demonstrates the effectiveness of smashedfiltering for the task of classifying an N= 128×128pixel test image under an unknown translation in the vertical and horizontal directions (hence K=2).The three classes correspond to different translations of a bus,truck,or tank.The test data was generated randomly from one of the three classes.The random measurements were 1For the purposes of the discussion here,a K-dimensional manifold can be interpreted as a K-dimensional hypersurface in R N.Fig.5.Smashedfilter image classification performance plotted as a function of the number of random measurements M from a simulated single-pixel CS camera and the total acquisition time T.produced using a simulated single-pixel CS camera that takes into account the Poisson photon counting noise associated with a total measurement interval of length T.We average over10,000 iterations of each experiment.We see that increasing the number of measurements improves performance atfirst;however,performance then degrades due to the reduced time available to obtain each measurement.Correspondingly,increasing the total capture time improves the performance of the algorithm.IV.Other Multiplexing Camera ArchitecturesTwo notable existing DMD-driven imaging applications involve confocal microscopy(which relates closely to the raster scan strategy studied above)[23,24]and micro-optoelectromechanical (MOEM)systems[12,25,26].In a MOEM system,a DMD is positioned between the scene and the sensing array to perform column-wise multiplexing by allowing only the light from the desired pixels to pass through.In[12,25]the authors propose sets of N Hadamard patterns,which enables simple demultiplexing,and randomized Hadamard patterns,which yield a uniform signal-to-noise ratio among the measurements.Other compressive cameras developed to date include[27,28],which employ optical elements to perform transform coding of multispectral images.These designs obtain sampled outputs that correspond to coded information of interest,such as the wavelength of a given light signal or the transform coefficients in a basis of interest.The elegant hardware designed for these purposes uses optical projections,group testing,and signal inference.Recent work in[29]has compared several single and multiple pixel imaging strategies of varying complexities;their simulationresults for Poisson counting noise agree closely with those above.Finally,in[30]the authors use CS principles and a randomizing lens to boost both the resolution and robustness of a conventional digital camera.V.ConclusionsFor certain applications,CS promises to substantially increase the performance and capabil-ities of data acquisition,processing,and fusion systems while lowering the cost and complexity of deployment.A useful practical feature of the CS approach is that it off-loads processing from data acquisition(which can be complicated and expensive)into data reconstruction or processing (which can be performed on a digital computer,perhaps not even co-located with the sensor).We have presented an overview of the theory and practice of a simple yetflexible single-pixel architecture for CS based on a DMD spatial light modulator.While there are promising potential applications where current digital cameras have difficulty imaging,there are clear tradeoffs and challenges in the single-pixel design.Our current and planned work involves better understanding and addressing these tradeoffs and challenges.Other potential avenues for research include extending the single-pixel concept to wavelengths where the DMD fails as a modulator,such as THz and X-rays.Sidebar:Compressive Sampling in a NutshellCompressive Sampling(CS)is based on the recent understanding that a small collection of nonadaptive linear measurements of a compressible signal or image contain enough information for reconstruction and processing[1–3].For a tutorial treatment see[4]or the paper by Romberg in this issue.The traditional approach to digital data acquisition samples an analog signal uniformly at or above the Nyquist rate.In a digital camera,the samples are obtained by a2D array of N pixel sensors on a CCD or CMOS imaging chip.We represent these samples using the vector x with elements x[n],n=1,2,...,N.Since N is often very large,e.g.in the millions for today’s consumer digital cameras,the raw image data x is often compressed in the following multi-step transform coding process.Thefirst step in transform coding represents the image in terms of the coefficients{αi}of an orthonormal basis expansion x= N i=1αiψi where{ψi}N i=1are the N×1basis vectors.Forming the coefficient vectorαand the N×N basis matrixΨ:=[ψ1|ψ2|...|ψN]by stacking the vectors{ψi}as columns,we can concisely write the samples as x=Ψα.The aim is to find a basis where the coefficient vectorαis sparse(where only K≪N coefficients arenonzero)or r-compressible(where the coefficient magnitudes decay under a power law withscaling exponent−r).For example,natural images tend to be compressible in the discrete cosinetransform(DCT)and wavelet bases on which the JPEG and JPEG-2000compression standardsare based.The second step in transform coding encodes only the values and locations of the Ksignificant coefficients and discards the rest.This sample-then-compress framework suffers from three inherent inefficiencies:First,wemust start with a potentially large number of samples N even if the ultimate desired K is small.Second,the encoder must compute all of the N transform coefficients{αi},even though it will discard all but K of them.Third,the encoder faces the overhead of encoding the locations of the large coefficients.As an alternative,CS bypasses the sampling process and directly acquires a condensedrepresentation using M<N linear measurements between x and a collection of test functions{φm}M m=1as in y[m]= x,φm .Stacking the measurements y[m]into the M×1vector y and the test functionsφT m as rows into an M×N matrixΦwe can writey=Φx=ΦΨα.(1)The measurement process is non-adaptive in thatΦdoes not depend in any way on the signal x.The transformation from x to y is a dimensionality reduction and so loses information in general.In particular,since M<N,given y there are infinitely many x′such thatΦx′=y. The magic of CS is thatΦcan be designed such that sparse/compressible x can be recovered exactly/approximately from the measurements y.While the design ofΦis beyond the scope of this review,an intriguing choice that works with high probability is a random matrix.For example,we can draw the elements ofΦas independent and identically distributed(i.i.d.)±1random variables from a uniform Bernoulli distribution[22]. Then,the measurements y are merely M different randomly signed linear combinations of the elements of x.Other possible choices include i.i.d.,zero-mean,1/N-variance Gaussian entries (white noise)[1–3,22],randomly permuted vectors from standard orthonormal bases,or random。

一种高效的小波Contourlet变换阈值去噪算法万智萍【摘要】针对现有图像去噪算法去噪效率与信号保真度不高的现象,通过研究小波变换与Contourlet变换,将其有机的结合在一起从而实现优势互补,并提出一种高效的阈值去噪算法,通过建立最大值列表,引入适当的阈值将其系数进行分类,并使用优化后的软阈值去噪算法与边缘优化算法对其分类处理,实验表明,该算法能够有效的对含噪图像进行去噪的同时保留其边缘信息,具有高效性、保真度高的图像去噪特性,在图像去噪领域有较好的发展前景.【期刊名称】《激光与红外》【年(卷),期】2013(043)007【总页数】6页(P831-836)【关键词】Contourlet变换;小波变换;小波Contourlet变换;阈值去噪【作者】万智萍【作者单位】中山大学新华学院,广东广州,510520【正文语种】中文【中图分类】TP3911 引言随着图像处理技术的不断发展,使得图像处理技术得以广泛地研究与应用;人类获取信息是通过人的视觉、听觉以及触觉等感官来获取的,其中绝大部分信息是来源于人的视觉,而在现实的生活之中,图像的采集容易受到外界的干扰形成含噪图像,并且在含噪图像进行图像分割与参数估计的过程中,都会引起让生成的图像产生误差,其平均误差率为0.5%,使得图像的去噪处理成为了当前图像处理领域的研究热点;1992年Donoho和 Johnstone提出了小波阈值萎缩方法,该算法凭借其自身的去噪优越性很快引起了人们的关注[1-4],随后人们纷纷对其展开了研究,但其“过扼杀”小波系数的倾向与不能最优表示图像中的线和面奇异性,使得小波变换在图像去噪中具有一定的局限性现象,为了弥补该算法的缺陷,各种高维多分辨率相继被提出,有复小波邻域隐马尔科夫模型[5]、Bandelet[6]、Contourlet[7-8]降噪方法等;其中 Contourlet变换是于2002年由M.N.Do和 Vetterli M.提出了一种“真正”的二维图像稀疏表达方法[9],该变换方式能够很好地体现图像的各向异性特征,能够很好地捕获图像的边缘信息,因此,如果能够选用合理的阈值其去噪能力将获得比小波算法更好的去噪效果。

前言:最近由于工作的关系,接触到了很多篇以前都没有听说过的经典文章,在感叹这些文章伟大的同时,也顿感自己视野的狭小。
想在网上找找计算机视觉界的经典文章汇总,一直没有找到。
失望之余,我决定自己总结一篇,希望对 CV领域的童鞋们有所帮助。
由于自
己的视野比较狭窄,肯定也有很多疏漏,权当抛砖引玉了
1990年之前
1990年
1991年
1992年
1993年
1994年
1995年
1996年
1997年
1998年
1998年是图像处理和计算机视觉经典文章井喷的一年。
大概从这一年开始,开始有了新的趋势。
由于竞争的加剧,一些好的算法都先发在会议上了,先占个坑,等过一两年之后再扩展到会议上。
1999年
2000年
世纪之交,各种综述都出来了
2001年
2002年
2003年
2004年
2005年
2006年
2007年
2008年
2009年
2010年
2011年
2012年。

基于贝叶斯估计自适应软硬折衷阈值 Curvelet 图像去噪技术杨国梁;雷松泽【摘要】针对传统阈值图像去噪方法存在的不足,提出了基于贝叶斯估计和Curvelet变换的软硬折衷阈值图像去噪方法,自适应地对不同的Curvelet子带进行阈值化处理.实验结果表明,该方法对图像中的边缘曲线特征有更好的复原.去噪后图像的峰值信噪比值(PSNR)更高,视觉效果更好.%According to the defects of soft thresholding and hard thresholding image denoising methods,the image denoising method of soft and hard adaptive thresholding is proposed based on Curvelet transform and Bayesian estimation image denoising. Experiment results show that the new method has the advantages in denoised images with higher quality recovery of edges. It is capable for achieving the higher peak signal-to-noise ratio (PSNR) and giving better visual quality.【期刊名称】《西安工程大学学报》【年(卷),期】2011(025)006【总页数】6页(P857-861,866)【关键词】脊波变换;Curvelet变换;贝叶斯估计;图像去噪【作者】杨国梁;雷松泽【作者单位】西安工业大学计算机学院,陕西西安710032;西安工业大学计算机学院,陕西西安710032【正文语种】中文【中图分类】TN9110 引言多分辨分析小波变换[1-4]在时频域具有良好的多分辨率的特性,能够同时进行时频域的局部分析,并且能够对信号的局部奇异特征进行提取和滤波.然而小波变换由一维小波张成的,仅具有有限的方向,因此主要适用于具有各向同性奇异性的对象,对于各向异性的奇异性,如图像的边界以及线状特征等,小波并不是一个很好的表示工具.在小波理论基础上,文献[5-7]提出了一种特别适合于表示各向异性的脊波变换,是为解决二维或更高维奇异性而产生的一种新的分析工具,脊波变换能稀疏表示具有直线特征的图像,可以应用到二维图像处理的许多领域.脊波本质上是通过小波基函数添加一个表征方向的参数得到的,它具有小波的优点,同时还具有很强的方向选择和辨识能力,能够有效地表示信号中具有方向性的奇异性.为了进一步表示多维信号中更为普遍的曲线型奇异性,Donoho等人提出了曲波(Curvelet)变换理论[8-10],用多个尺度的局部直线来近似表示曲线.曲波变换可以很好地逼近图像中的奇异曲线.本文在曲波变换的基础上,利用贝叶斯估计自适应阈值结合软硬折衷阈值的去噪方法,对含噪图像进行去噪处理.实验表明,提出的方法能很好地恢复图像,特别是在噪声严重的情况下与小波去噪相比优越性显著.1 Curvelet变换1.1 Ridgelet变换若函数ψ满足容许条件,则称ψ为容许激励函数,并称为以ψ 为容许条件的Ridgelet函数[11].令u=(cosθ,sinθ),x=(x1,x2),则 Ridgelet函数为由此可知,Ridgelet函数在直线x1 cosθ+x2 sinθ=c方向上是常数,而与该直线垂直方向上是小波函数.图1显示了一个Ridgelet函数.1.2 Ridgelet离散化Ridgelet变换的快速实现可以在Fourier域中实现,在空(时)域中f的Radon变换可以通过f的二维FFT在径向上做逆的一维FFT得到,对于这个结果再进行一次非正交的一维小波变换即可得到Ridgelet的快速离散化实现.图2描述了离散Ridgelet变换的过程.图1 一个Ridgelet函数ψa,b,θ(x1,x2)的示例图2 离散Ridgelet变换过程通过Radon变换,一幅n×n的图像的像素点变为n×2n的阵列,再对n×2n阵列进行一维小波变换就得到了2n×2n阵列Ridgelet变换的结果.1.3 Curvelet变换Curvelet变换是一个多尺度、多方向的图像表示框架,是对含有曲线边缘的目标的一种有效的非自适应的表示方法,它能够同时获得对图像平滑区域和边缘区域的稀疏描述.它从Ridgelet发展而来,本质上可以看成多尺度分析下的Ridgelet实现.因此Curvelet变换时各向异性的,从而相对于小波分析提供了更为丰富的方向信息.Curvelets变换的主要步骤[9]如下:(1)子带分解:f→(p0(f),Δ1(f),Δ2(f),…);(2)平滑分割:Δs(f)→(wQΔs(f),Q∈Qs,其中wQ表示在二进制子块Q=[k1/2s,(k1+1)/2s]×[k2/2s,(k2+1)/2s]上的平滑窗函数集,wQ可以对各自带分块进行平滑;(3)正规化:gQ=2-s(TQ)-1(wQΔs(f)),Q ∈ Qs,其中,(TQ f)(x1,x2)=f(2s x1-k1,2s x2-k2)对每个子块进行归一化处理,还原为单位尺度;(4)Ridgelet分析:αμ =〈gQ,ρλ〉,μ =(Q,λ),其中,pλ是构成L2(R2)空间上正交基的函数.Curvelet具有以下性质:(4)对于含有边界光滑的二维信号有稀疏表示,逼近误差能够到达ο(M-2).(5)各向异性.Curvelet变换的实现过程如图3所示.进行Curvelet变换的基本步骤:(1)对图像进行子带分解.(2)对不同尺度的子带图像采用不同大小的分块.图3 子带的空间平滑分块过程(3)对每个子块进行Ridgelet分析.每个子块的频率带宽W、长度L近似满足关系W=L2.这种频率划分方式使得Curvelet变换具有强烈的各向异性,而且这种各向异性随尺度的不断缩小呈指数增长.(4)在进行子带分解的时候,通过带通滤波器组将目标函数f分解成从低频到高频的系列子带,以减少不同尺度下的计算冗余.如图4所示,Curvelet变换的核心部分是子带分解和Ridgelet变换.图4中p0(f)为多尺度分析后图像的低频部分,Δi(f)为高频部分.2 图像去噪实现2.1 阈值计算在贝叶斯估计理论框架下,假设图像的Curvelet系数服从高斯分布(均值为0,方差为),即图4 图像Curvelet变化前后的各子带变化过程框架对于给定的参数σX,需要找到一个使贝叶斯风险r(T)=E(^X-X)2=Ex Ey|x(^X-X)2最小(^X为X的贝叶斯估计)的阈值T.用T*=argmin rT(T)表示优化阈值.其中σ2为加入的高斯噪声方差,σx为不带噪声信号的标准方差.T是对T*=argmin rT(T)的近似,最大偏差不超过1%.2.2 参数估计对式(4)中的参数进行估计.噪声方差的估计公式为由于=+σ2,又因为可由式(6)估计噪声方差σ2用一个具有鲁棒性的中值估计器[13]估计.2.3 软硬阈值折衷法定义当a分别取0和1时,式(8)即成为硬阈值和软阈值估计方法.对于一般的0<a<1来讲,该方法估计数据Wδ的大小介于软硬阈值方法之间,叫做软硬折衷法.在阈值估计器中加入a因子:a取值为0,则等价于硬阈值方法;a取值为1,则等价于软阈值方法在0与1之间适当调整a的大小,可以获得更好的去噪效果.在此实验中,暂取a=0.5.2.4 Curvelet图像去噪的主要算法步骤和实验结果(1)对含噪声图像进行多尺度分解,得到各级子带细节(高频部分);(2)对各高频子带进行二维Curvelet分解;(3)根据式(5)估计噪声方差;(4)根据式(6)计算图像每个子带的方差;(5)根据式(7)为图像的每个子带计算相应的阈值;(6)用得到的阈值对各层的高频系数进行软硬折衷阈值化去噪;(7)对各高频子带做二维Curvelet逆变换并重构原始图像.针对该方法进行实验并且比较相关实验结果:本文主要采用峰值信噪比(PSNR)来衡量灰度图像的去噪性能.实验使用的峰值信噪比公式为其中 f'为处理后的图像的灰度,f为原始图像的灰度,N为图像像素的个数.算法实验选取了256×256,施加不同级别高斯噪声(σ =10,20,30)的图像.对离散小波变换和Curvelet变换的分解和重构是四层.实验结果如图5(σ =20)所示.(1)从人眼识别角度看,本文提出的方法效果比较明显,Curvelet变换在均匀区域的去噪结果比离散小波变换的结果要平滑,在各种噪声水平下其去噪效果都比其他相关方法要好;(2)从量化数据上看,本文方法计算得到的峰值信噪比参数值比其他去噪算法要高,见表1.表1 不同方法的去噪结果比较(PSNR)σ 噪声图像 DWT全局阈值去噪Curvlet全局阈值去噪Curvlet全局软硬折衷去噪本文方法去噪10 28.129 3 28.990 930.492 31.065 8 32.805 6 2 22.155 7 26.395 7 28.101 28.332 6 29.439 6 3 18.638 4 23.304 8 24.550 3 25.377 5 26.691 5(3)对Curvelet变换具有平移不变性和良好的方向选择性等优点以及自适应软硬折衷阈值处理的特点所决定.3 结束语本文基于Curvelet变换提出了一种根据贝叶斯估计计算阈值并以软硬折衷的方式对图像噪声去除的方法,该方法去除噪声较彻底,边界、纹理等特征保留较好.通过本文的方法进行的实验结果表明,提出的方法在去除噪声的同时,能更好地保留图像的细节.去噪后的图像峰值信噪比值高,视觉效果较好.参考文献:图5 Barbara图像及其去噪结果[5] STARCK JL,CANDESE J,DONOHOD.The curvelet transform for image denosing[J].IEEE Transaction on Image Processing,2002,11(6):131-141.[6] CANDESEmmanuel J,DONOHODavid L.Continuous curvelet transform:Resolution of thewavefront set[EB/OL].(2003-05-06)[2004-08-15].http://www-stat.stanford.edu/~donoho/Reports/2003/ContCurveletTransform-I.pdf.[7] DONOHOD L.Ridgelet functions and orthonormal ridgelets [J].Journal of Approximation Theory,2001;111(2):143-179.[8] CANDESEmmanuel J,DONOHODavid L.Curvelets a surprisingly effective nonadaptive representation for objectswith edges[EB/OL].(1999-12-16)[2004-09-20].http://www.acm.caltech.edu/~emmanuel/papers/Curvelet-SMStyle.pdf.[9] CANDESE J,DONOHO D L.Continuous Curvelet transform:reso-lution of the wavefront set[EB/OL].(2003-05-06)[2004-08-15].http://www.acm.caltech.edu/~emmanuel/publication.html.[10] CANDESE J,DONOHO D L.Fast discrete curvelet transform [R].California:California Institute of Technology,2005.[11] CANDESE J.Ridgelet:theory and application[D].Stanford:Department of Statistic,Stanford University,1998.[12] CHEN Y,HAN C.Adaptivewavelet thresholding for Image denoising[J].Electronics Letters,2005,41(10):586-587.[13] DONOHOD L,JONHNSTONE IM.Ideal spatial adaptation via wavelet shrinkage[J].Biometrika,1994,81(3):425-455.【相关文献】[1] MALLAT S.A wavelet tour of signal processing[M].2nd ed.Beijing:China Academic Press,1999:67-216.[2] MALLAT S.A theory formultiresolution signal decomposition:the wavelet representation[J].IEEE Trans PAMI,1989,11(7):674-693.[3]SARKAR TK,SUC.A tutorialonwavelets from an electricalengineering perspective,Part2:the continuous case[J].IEEEAntennas &Propa-gation Magazine,1988,40(6):36-48.[4]焦李成,谭山.图像的多尺度几何分析:回顾和展望[J].电子学报,2003,31(12A):1 975-1 981.。
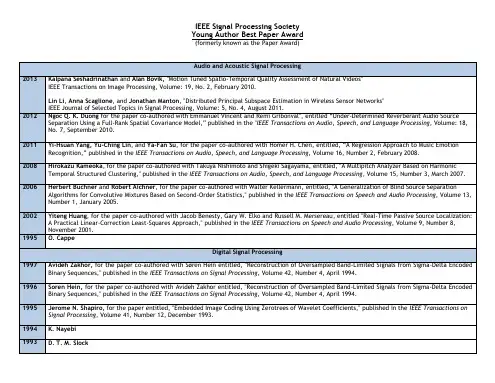


Image Coding Based on Wavelet Feature VectorShinfeng D.Lin,Shih-Chieh Shie,Kuo-Yuan LeeDepartment of Computer Science and Information Engineering,National Dong Hwa University, Hualien,Taiwan,Republic of ChinaReceived20December2003;accepted01June2005ABSTRACT:In this article,an efficient image coding scheme that takes advantages of feature vector in wavelet domain is proposed. First,a multi-stage discrete wavelet transform is applied on the image.Then,the wavelet feature vectors are extracted from the wavelet-decomposed subimages by collecting the corresponding wavelet coefficients.Andfinally,the image is coded into bit-stream by applying vector quantization(VQ)on the extracted wavelet feature vectors.In the encoder,the wavelet feature vectors are encoded with a codebook where the dimension of codeword is less than that of wavelet feature vector.By this way,the coding system can greatly improve its efficiency.However,to fully reconstruct the image,the received indexes in the decoder are decoded with a codebook where the dimension of codeword is the same as that of wavelet feature vector.Therefore,the quality of reconstructed images can be pre-served well.The proposed scheme achieves good compression effi-ciency by the following three methods.(1)Using the correlation among wavelet coefficients.(2)Placing different emphasis on wavelet coefficients at different decomposing levels.(3)Preserving the most important information of the image by coding the lowest-pass sub-image individually.In our experiments,simulation results show that the proposed scheme outperforms the recent VQ-based image cod-ing schemes and wavelet-based image coding techniques,respec-tively.Moreover,the proposed scheme is also suitable for very low bit rate image coding.V C2005Wiley Periodicals,Inc.Int J Imaging Syst Technol,15,123–130,2005;Published online in Wiley InterScience ().DOI10.1002/ima.20045Key words:image coding;discrete wavelet transformation;wavelet feature vector;vector quantizationI.INTRODUCTIONImage compression has become essential for both storage and net-work transmission in multimedia applications in recent years.Vec-tor quantization(VQ)has shown to be a prominent coding techni-que for decades(Linde et al.,1980;Gray,1984).One unique fea-ture of VQ is that high-compression ratios are possible with relatively small block sizes.The other attractiveness of VQ as source coding scheme derives from its optimality and simplicity of hardware implementation of the decoder.Wavelet transform is a mathematical function that converts the raw image data on spatial domain to wavelet coefficients on fre-quency domain(Graps,1995).In the beginning,the wavelet trans-form was developed for using in thefields of seismic geology, mathematics,electrical engineering,and quantum physics.However in recent years,wavelets are further used in image processing.The famous example is that the JPEG2000standard uses wavelet trans-formation in the image compression.There are two categories on wavelet-based image compression methods:scalar quantization and VQ.Scalar quantization technique allocates the bits among the subimages optimally to achieve high compression ratio.However,VQ uses the characteristics of correla-tion among subimages to obtain better compression efficiency than scalar quantization.In1988,Westerink proposed a coding scheme that applies VQ on wavelet frequency domain(Westerink et al., 1988).This method uses subband coding and full search VQ for the decomposed vectors.Though it can use the correlation among subi-mages and achieve good compression ratio,the computational com-plexity increases exponentially with vector dimension.Therefore, Gersho proposed a nonlinear interpolative vector quantization (NIVQ)method to improve the coding efficiency of traditional VQ (Gersho,1990).To decrease the computational complexity,Gersho makes use of the dimension-reduced feature vector to perform VQ. However,directly reducing the dimension of feature vector could introduce serious data loss in VQ system.It is observed that defin-ing the feature vector is an important and hard task in NIVQ sys-tem.To define the feature vector,wavelet transform is a superior method because of the presence of its obvious correlations and sim-ilarity among the decomposed wavelet coefficients at different lev-els.Therefore,Wang et al.(1996)proposed a wavelet-based image compression scheme that makes use of NIVQ to further improve the compression efficiency.In this article,we propose a simple image coding scheme that makes use of the wavelet feature vectors of image.In our scheme,a multistage discrete wavelet transform isfirst applied on the input image.VQ is then performed on wavelet feature vectors extracted from the decomposed wavelet coefficients.To obtain better com-pression efficiency,we make uses of the following three methods.(1)Using the correlation among wavelet coefficients.(2)Placing different emphasis on wavelet coefficients at different levels.(3) Preserving the most important information of the image.In the encoder,the feature vectors are encoded with a dimension-reduced codebook.By this way,the coding system can greatly improve itsCorrespondence to:Shinfeng D.Lin;e-mail:david@.tw '2005Wiley Periodicals,Inc.efficiency.In the decoder,the dimension of codeword is the same as that of the feature vectors.Therefore,the quality of reconstructed images can be preserved well.The rest of this article is organized as follows.In the following section,the main features of traditional VQ system and discrete wavelet decomposition are reviewed.Section III describes the details of the proposed image coding scheme.Simulation results of the proposed scheme and discussions are made in Section IV. Finally,conclusions are drawn in Section V.II.PRELIMINARIESA.Vector Quantization.A VQ coding system can be simply defined as a mapping from a k-dimensional Euclidean space R k to a finite subset of space R k.Thefinite subset C¼{y i:y i[R k and i¼0,1,...,N yÀ1}is called a codebook,where N y is the size of thiscodebook.Each y i¼(y i,0,y i,1,...,y i,kÀ1)in codebook C is called a codeword or a codevector.These codewords are generally gener-ated,based on an iterative clustering algorithm such as the LBG algorithm(Linde et al.,1980),from the training set.The compres-sion efficiency is significantly dependent on these codewords. Therefore,the design of a codebook plays an important role in the VQ coding system.An ordinary VQ system has two parts:the encoder and the decoder,each of which is equipped with the same codebook.In the encoder,the closest codeword y i to the input block x can be found by searching the codebook,and the index i will be sent to the decoder.Consequently,in the decoder,the codeword y i can be found via the received index i,and the block x will be replaced by codeword y i.In this case,a quantization error is unavoidable.Therefore,VQ belongs to lossy compression scheme. The distortion between the input block x and its quantized block y can be obtained by the squared Euclidean distance measure crite-rion given as Eq.(1).Moreover,the overall distortion between the original image and the reconstructed image can be obtained by sum-ming all the distortion caused by quantizating image blocks.dðx;yÞ¼k xÀy k2¼XkÀ1P¼0ðx PÀy PÞ2ð1ÞB.Discrete Wavelet Transform.Discrete wavelet transform is identical to hierarchical subband system,where the subbands are logarithmically spaced in frequency and represent octave-band decomposition.During the transformation,an image isfirst decom-posed into four subbands,LL1,LH1,HL1,and HH1,by cascading critically subsampled horizontal and verticalfilter banks(Calder-bank et al.,1998).The subbands labeled LH1,HL1,and HH1repre-sent thefinest scale wavelet coefficients,respectively.To obtain the next coarser scale of wavelet coefficients,the subband LL1is fur-ther decomposed and critically subsampled.This process continues until somefinal scale is reached.On the basis of the above wavelet decomposing process,the correlation among decomposed subi-mages can be represented by a quad-tree structure.This is a distinc-tive characteristic of wavelet transformation,and it has been widely applied on image processing.DWT is an effective tool for image analysis.The similarity and correlation among subimages can easily be decomposed from the input image by DWT.The detailed steps of N-stage wavelet decom-position are described as follows.Step1.Apply wavelet transform to the input image.Four subi-mages can be generated after thefirst level decomposition.The low pass subimage is LL1,and the other high pass subimages in hori-zontal,vertical,and diagonal directions are HL1,LH1,and HH1, respectively.Step2.Recursively apply wavelet transform to the lowest pass subimage NÀ1times.Therefore,3Nþ1subimages can be generated after N th level decomposition.The lowest pass subimage is LL N,the other subimages are HL N,LH N,HH N,HL NÀ1,LH NÀ1, HH NÀ1,...,HL1,LH1,and HH1,respectively.To illustrate,the3-stage wavelet decomposition for image and its corresponding quad-tree structure are given in Figure1.In this case,the LL3subimage is the lowest frequency part of the image and is the most important one among the subimages.Note that these subimages are strongly correlated,so there exists a quad-tree struc-ture that maps each subimage in a level to four subimages in the corresponding next level.More precisely,a parent–child relation-ship can be defined among wavelet coefficients at different scales corresponding to the same location.With the exception of the high-est frequency subbands,every wavelet coefficient at a given scale can be related to a set of coefficients at the nextfiner scale of simi-lar orientation.The coefficient at the coarse scale is called the parent,and all coefficients corresponding to the same spatial loca-tion at the nextfiner scale of similar orientation are called children. With the exception of the lowest frequency subband,parents have four children.Figure1(a)shows the wavelet pyramid subband decomposition and the parent–child dependencies.A wavelet quad-tree descending from a coefficient in the subband HH3is given in Figure1(b).III.THE PROPOSED IMAGE CODING SCHEME Traditional VQ is a powerful technique in image compression. However,it only makes use of the statistical redundancy among neighboring pixels within an image block,but ignores the correla-tion among neighboring image blocks.To improve the efficiency of VQ-based image coding technique,we have to extract and take advantages of the correlation within an image.DWT is a successful tool for image analysis.It is quite easy to obtain the correlations among wavelet-decomposed subimages.Therefore,we apply DWT to extract some useful information from image in the proposed scheme.A.Generation of Wavelet Feature Vectors.In the proposed scheme,an N-stage wavelet transformation isfirst applied on the input image,resulting in3Nþ1decomposed subimages.To use the correlation among these subimages,we have to introduce an appro-priate format of wavelet feature vectors.These feature vectors can be generated from the decomposed subimages,and the extraction process is described as follows.Step1.Extract elements for a specific wavelet feature vector from level N subimages.In level N subimages LL N,HL N,LH N,and HH N,the elements extracted from the corresponding positions are respectively treated as s0,s1,s2,and s3in the feature vector.Step2.Extract elements for a specific wavelet feature vector from level NÀ1subimages.In level NÀ1subimages HL NÀ1, LH NÀ1,and HH NÀ1,the elements extracted from the corresponding positions are treated as s4$s7,s8$s11,and s12$s15,respectively. The elements s4$s7,s8$s11,and s12$s15correspond to s1,s2, and s3,respectively.Step3.Recursively extract elements for a specific wavelet fea-ture vector from level NÀI subimages(I¼2,3,...,NÀ1).In level NÀI subimages,HL NÀI,LH NÀI,and HH NÀI,the elements extracted from the corresponding positions are treated as s4I$s(2*4IÀ1), s(2*4I)$s(3*4IÀ1),and s(3*4I)$s(4*4IÀ1),respectively.124Vol.15,123–130(2005)For N-stage wavelet-transformed image,a feature vector is com-posed of4N wavelet coefficients.This means the dimension of wavelet feature vector is4N.To illustrate,Figure2gives an exam-ple of extracting feature vector from3-stage wavelet-transformed image.It also shows the positions of coefficient elements where the first wavelet feature vector is extracted from the image.As shown in Figure2,a64-D vector(s0$s63)is formed from the10subi-mages,exploiting the correlation of coefficients among different levels.B.Codebooks Training for Wavelet Feature Vectors.To efficiently encode the wavelet feature vectors of image,thewell-Figure1.(a)The3-stage wavelet decomposition.(b)The quad-tree structure of wavelet coefficients.Vol.15,123–130(2005)125known VQ technique is applied in the proposed scheme.The coding efficiency of VQ depends much on the quality of VQ codebook.Therefore,a feasible codebook training method that cooperates well with the proposed scheme is introduced in this subsection.The detailed steps of codebook training procedure are given as follows.Step 1.Extract the 4N -D feature vectors,(s 0,s 1,s 2,...,s 4N À1),from the N -stage wavelet-decomposed training images.Step 2.Train the (4N À1)-D feature vectors,(s 1,s 2,...,s 4N À1),by a modified LBG algorithm.Since the importance of element within the codeword varies,the weighted Euclidean distance meas-ure criterion is applied here.In this case,more weight w p is assigned to element on higher level of subimage.The distance measure criterion is given as Eq.(2),and x and y represent two wavelet feature vectors.d ðx ;y Þ¼k x Ày k 2¼XN À1P ¼1ðw P Þðx P Ày P Þ2ð2ÞStep 3.Generate another dimension-reduced codebook.This codebook can be simply obtained by taking the first M elements,(s 1,s 2,...,sM ),from the (4N À1)-D codebook generated in step 2.Therefore,the dimension of codeword in this codebook is M .Step 4.Collect the first element (s 0)of 4N -D feature vectors.The resulting collection is identical with the lowest-pass subimage LL N .Train a codebook based on the traditional LBG algorithm for coding this subimage.Three different codebooks are generated based on the abovetraining steps.One codebook is for coding the lowest-pass sub-image LL N and this codebook is equipped with the encoder and decoder,respectively.The other two codebooks are for wavelet fea-ture vectors.These two codebooks are distinct because the dimen-sions of codeword in these codebooks are different.The dimension-reduced codebook is equipped with the encoder,while the other codebook is provided for the decoder.Therefore,the codebooks in encoder and decoder are different in the proposed scheme.How-ever,the sizes of the two codebooks must be the same because we have to preserve the one-to-one mapping property of VQ.C.Image Coding Based on Wavelet Feature Vector.In the proposed scheme,the input image is first decomposed into 3N þ1sub-images by applying the N -stage wavelet transform on the image.Then,the wavelet feature vectors with dimension 4N (s 0,s 1,...,s 4N À1)are generated,based on the steps described in Section III(A).Because the importance of the first element (s 0)in the feature vector is much higher than the other elements,it is coded individually for obtaining better image quality.Therefore,the resulting wavelet fea-ture vectors are with dimension 4N À1(s 1,s 2,...,s 4N À1).To encode the (4N À1)-D wavelet feature vectors,the interpolative VQ coding technique is applied in our scheme.This technique efficiently makes use of the correlation among the wavelet subimages.The detailed steps of interpolative VQ scheme are described asfollows.Figure 2.An example of wavelet feature vector extraction.126Vol.15,123–130(2005)Step1.Extract thefirst M elements(s1$sM)from the wavelet feature vector(s1,s2,...,s4NÀ1).Thefirst element(s0)in each wavelet feature vector is collected for VQ,separately.Step2.Quantize the M-D vectors based on the M-D codebook in the encoder.It is performed based on the weighted Euclidean dis-tance measure criterion.The indexes of M-D codewords are trans-mitted to the decoder.Step3.Decode the received indexes with the(4NÀ1)-D code-book.On the basis of the high correlation among subimages in dif-ferent levels,the decoder uses the indexes received to reconstruct the wavelet coefficients by searching the corresponding codeword from the(4NÀ1)-D codebook.Note that thefirst element s0extracted from the4N-D vector(s0, s1,s2,...,s4NÀ1)is collected to form a small subimage.This lowest pass subimage looks like a size-reduced original image.To code this subimage,a traditional VQ scheme is adopted.Since the lowest-pass subimage contains the most important information of the original image,the distortion introduced by VQ should be as small as possible. Therefore,to code the lowest-pass subimage in the proposed scheme, the block size should be as small as possible while the codebook size should be as large as possible.Another main advantage of the pro-posed image coding scheme is that the computational complexity can be greatly reduced in encoder and the quality of reconstructed image can be maintained on a satisfactory level in decoder.The block dia-grams of the proposed image coding scheme are given in Figure3.In summary,an input image isfirst processed with N-stage wavelet transformation,and the(4NÀ1)-D feature vectors are then extracted from the subimages.A(4NÀ1)-D codebook is trained from these (4NÀ1)-D feature vectors,and,concurrently,another codebook with dimension-reduced codeword is obtained from the(4NÀ1)-D code-book.VQ is performed using dimension-reduced codebook in the encoder and the indexes are transmitted to the decoder.Note that the lowest pass subimage is also vector quantized and the indexes are transmitted to the decoder as well.The decoder takes the indexes received and reconstructs the image with a(4NÀ1)-D codebook(for high-pass subimages)and a traditional codebook(for the lowest pass subimage).Finally,the inverse wavelet transform is performed to obtain the reconstructed image in spatial domain.IV.SIMULATION RESULTSIn computer simulations,the proposed image coding scheme has been applied to standard test images.These images are mono-chrome images with256gray levels and with resolution of512Â512pixels.To evaluate the reconstructed image quality,thepeak Figure3.The block diagrams of the proposed scheme.(a)Encoder.(b)Decoder.Vol.15,123–130(2005)127signal-to-noise ratio(PSNR)criterion is applied in our experiments. The PSNR value is obtained by the following equation.PSNR¼10log102552MSEdBð3ÞNote that the mean-squared error(MSE)for an mÂn image is defined as Eq.(4).MSE¼1mÂnX mi¼1X nj¼1ðx ijÀy ijÞ2ð4ÞIn Eq.(4),x ij and y ij denote the original and the reconstructed pixel intensities,respectively.Another evaluative criterion for measuring the performance of image coding scheme is compression ratio.In this article,we apply the bit rate criterion to evaluate the compres-sion efficiency of image coding techniques.Note that bit rate is in the unit of bit per pixel.A.Simulation Results of Recent VQ-Based Coding Tech-niques.Some efficient VQ-based coding techniques such as side-match VQ(SMVQ)(Kim,1992),two-pass side-matchfinite-state VQ(TPSMVQ)(Chang and Kuo,1999),and the recently proposed side-matchfinite-state VQ with adaptive block classification (SMVQ-ABC)(Lin and Shie,2000)have been introduced in earlier literatures.SMVQ is a VQ scheme that exploits the correlations between neighboring blocks to reduce bit rate.It tries to make the transition of pixel intensities across boundaries of image blocks as smooth as possible.SMVQ acts well in the elimination of blocking artifacts caused by ordinary VQ.However,better approximation of the input block may not be found in state codebook because of low correlations in some situations.Under these circumstances,the quality of encoded image will be reduced by ordinary SMVQ. Therefore,TPSMVQ has been proposed to solve this problem.TPSMVQ encodes an image with two passes.In thefirst pass,each image block is encoded with small state codebook.Therefore,the approximate image is obtained byfirst pass.In the second pass, only the blocks obtained by thefirst pass whose variance values are greater than a predefined threshold are encoded again.Another image coding scheme that makes use of edge information of image blocks as well as the average values of blocks has been proposed by Lin and Shie(2000).This scheme incorporates classified VQ with SMVQ to improve the usability of state codebook in SMVQ.The classification method adaptively predicts the characteristic of cur-rent image block based on the properties of its neighboring blocks.To compare the proposed scheme with the mentioned VQ-based coding techniques,the experimental results of SMVQ,TPSMVQ (Chang and Kuo,1999),and SMVQ-ABC are given in Table I.In this experiment,test images are‘‘Lena,’’‘‘Lenna,’’‘‘Barbara,’’‘‘Boat,’’‘‘Toys,’’‘‘Peppers,’’‘‘Airplane,’’and‘‘Zelda.’’The training set for codebook generation consists of thefirstfive images,however,‘‘Air-plane,’’‘‘Peppers,’’and‘‘Zelda’’are outside the training set.Images inside the training set are partitioned into blocks with4Â4pixels, and these blocks are classified into different classes,based on their characteristics,to generate the associated class codebooks.The size of each class codebook and master codebook is256.In addition,the size of state codebook is4,32,or64,depending on the characteristic of current encoding block.The quality of reconstructed images,in PSNR,via SMVQ-ABC technique at0.230bits per pixel are given, together with the qualities of images coded by SMVQ,and TPSMVQ at nearly0.250bits per pixel.Furthermore,the respective encoding times,in the unit of second,for images encoded by SMVQ and SMVQ-ABC are given as well.B.Simulation Results of the Proposed Scheme.In thefirst experiment,we used the same test images and the same training set for codebooks as that of the one used by Chang and Kuo(1999)and Lin and Shie(2000)to compare the proposed scheme with the recently proposed SMVQ-based coding schemes introduced in Sec-Table I.Coding performance of SMVQ,TPSMVQ(Chang and W.J.Kuo,1999),and SMVQ-ABC(Lin and Shie,2000).Inside or Outside Image512Â512SMVQ TPSMVQ SMVQ-ABCPSNR Bit Rate Time PSNR Bit Rate PSNR Bit Rate TimeInside Lena28.4650.25419.230.7290.25031.4430.22930.6 Lenna27.1450.25419.328.7980.26228.9050.23130.9Barbara23.8420.25419.224.7050.26525.8010.23133.4Boat26.9370.25419.228.4550.25229.3900.23032.7Toys27.4260.25419.329.9480.25232.0050.23032.8 Outside Airplane27.5600.25419.329.3040.25029.7930.23031.3 Peppers28.8760.25419.230.5360.25930.7930.23030.7Zelda31.5480.25419.332.8080.24632.7660.23032.3 Table II.Coding performance of the proposed scheme based on3-stage wavelet transform without entropy coding.Inside or Outside Image512Â512Scheme(A)Scheme(B)Scheme(C)PSNR Bit Rate Time PSNR Bit Rate Time PSNR Bit Rate TimeInside Lena31.2330.21117.831.9210.21520.932.2560.21927.1 Lenna30.0810.21117.831.1630.21520.931.4740.21927.1Barbara27.2350.21117.827.5470.21520.927.8140.21927.1Boat28.7430.21117.829.1110.21520.929.3280.21927.1Toys30.2320.21117.830.9210.21520.930.9600.21927.1 Outside Airplane28.6250.21117.829.0040.21520.929.1570.21927.1 Peppers29.5110.21117.830.0890.21520.930.5150.21927.1Zelda31.3210.21117.831.9920.21520.932.5980.21927.1 128Vol.15,123–130(2005)tion A.We apply3-stage wavelet transformation on the test images, that is N¼3.The training set for generating codebooks of wavelet feature vector is obtained by collecting the63-D feature vectors of wavelet coefficients.The high-pass subimages at different levels are weighted when calculating Euclidean distance in the process of code-book training.In this experiment,the weights are8,6,and1,corre-sponding to the levels3,2,and1,respectively.The dimension of codewords in the encoder codebook is15,that is M¼15.In the cod-ing process,thefirst15elements of the63-D wavelet feature vector are read and the nearest codeword in the15-D codebook is found. After that,the corresponding index is transmitted to the decoder.The decoder decodes the received index with the63-D codebook in the decoding process.Since the lowest-pass subimages are with the most importance,they are separated to form another training set and encoded with traditional VQ.The block size for these lowest-pass subimages is2Â2.Table II shows the coding performance of the proposed scheme without entropy coding.The codebook size for wavelet feature vector is2048.And the codebook sizes for the lowest-pass subimage are1024,2048,and4096,respectively,corresponding to simulation results A,B,and C.Table II demonstrates that the pro-posed scheme outperforms the mentioned SMVQ-based image coding schemes,even at lower bit rate.It also shows that apparent improve-ment of image quality can be obtained with the proposed scheme by spending more but very little bit rate.To further reduce the bit rate of proposed scheme,the indexes of the lowest-pass subimages and the wavelet feature vectors are compressed by entropy coding.The coding performance of the proposed scheme after entropy coding is given in Table III.To analyze the complexity of proposed scheme,we compare the encoding times for images among SMVQ,SMVQ-ABC,and the proposed scheme.As shown in Table I,the average encoding times for images by SMVQ and SMVQ-ABC are19.25and31.83sec-onds,respectively.The encoding times for images before and after entropy coding of the proposed scheme,with various sizes of code-book for the lowest-pass subimage,are listed in Tables II and III, respectively.Although the size of master or class codebook for SMVQ and SMVQ-ABC is256,relatively small as compared with the size of codebook for wavelet feature vectors in the proposed scheme,both SMVQ and SMVQ-ABC have to spend extra compu-tation time on building a sorted state codebook or analyzing the characteristic for each input block.On the contrary,the proposed scheme simply has tofind out the best matched codewords in the wavelet feature vector codebook and lowest-pass subimage code-book,respectively,for each input block.Moreover,the dimension of codewords in lowest-pass subimage codebook is4.Therefore, the computational complexity of the proposed scheme generally falls between SMVQ and SMVQ-ABC in this experiment.In the second experiment,we further apply4-stage wavelet transformation on the test images,‘‘Lena,’’‘‘Lenna,’’‘‘Tiffany,’’and‘‘Zelda.’’In this experiment,the dimension of wavelet feature vector is255and that of the dimension-reduced feature vector in encoder is63.The high-pass subimages at different levels are weighted when calculating Euclidean distance in the processes of codebook training and VQ encoding.Note that the weights here are 4,3,2,and2corresponding to wavelet-decomposing levels4,3,2, and1,respectively.The second experimental results are given in Table IV.To show the coding performance of the proposed scheme at very low bit rate,the size of codebook for wavelet feature vector and the lowest-pass subimage varies with the bit rate.The simula-tion results demonstrate that the proposed image coding scheme is also suitable for very low bit rate image coding.In the third experiment,we compare the proposed scheme with the earlier wavelet-based image coding scheme(WTC-NIVQ) (Wang et al.,1996),which takes advantages of nonlinear interpola-tive VQ.For comparison,the performance analysis of Wang et al. (1996)and the experimental results of our scheme are given in Table V.As in the earlier studies(Wang et al.,1996),the test image ‘‘Lena,’’with256gray levels and with resolution256Â256pixels, is coded by the proposed scheme using the codebooks generated from16test images(including‘‘Lena’’and each with resolution 256Â256pixels).In this experiment,we apply3-stage wavelet transformation on test images.The size of codebook for wavelet feature vector is1024,and the size of codebook for the lowest-pass subimage is4096.This table shows that the proposed schemeTable III.Coding performance of the proposed scheme based on3-stage wavelet transform with entropy coding.Inside or Outside Image512Â512Scheme(A)Scheme(B)Scheme(C)PSNR Bit Rate Time PSNR Bit Rate Time PSNR Bit Rate TimeInside Lena31.2330.19618.131.9210.19721.132.2560.19927.3 Lenna30.0810.20318.031.1630.20521.131.4740.20627.3Barbara27.2350.20518.027.5470.20721.227.8140.20827.3Boat28.7430.19918.029.1110.20121.229.3280.20327.4Toys30.2320.18718.030.9210.18921.130.9600.19027.3 Outside Airplane28.6250.19118.129.0040.19221.129.1570.19427.4 Peppers29.5110.18218.130.0890.18521.230.5150.18727.3Zelda31.3210.19418.031.9920.19521.132.5980.19727.3 Table IV.Very low bit rate coding performance of the proposed scheme based on4-stage wavelet transform.The bit rate(BR)in simulations D to I varies from0.056to0.066bits per pixel.Image 512Â512Scheme(D)(BR¼0.056)Scheme(E)(BR¼0.058)Scheme(F)(BR¼0.060)Scheme(G)(BR¼0.062)Scheme(H)(BR¼0.064)Scheme(I)(BR¼0.066)Lena27.32627.45327.59627.73427.91828.073 Lenna27.03127.55027.22727.79727.49628.070 Tiffany28.40829.06928.52329.22428.73329.486 Zelda28.49328.99528.79929.34628.87629.448Vol.15,123–130(2005)129。



第29卷第6期2002年11月浙 江 大 学 学 报(理学版)Journal of Zhej iang University (Science Edition )Vo l.29No.6Nov.2002一种基于预测分类的小波图像编码顾寅红,杨长生,宋广华(浙江大学计算机系统工程研究所,浙江杭州310027)收稿日期:2001-09-21.作者简介:顾寅红(1974—),男,硕士,主要从事计算机图形学和图像处理研究.摘 要:对于小波图像编码,如何有效地组织小波域系数是提高图像压缩效果的关键.本文在研究小波域系数统计特性的基础上,提出一种用于图像压缩的预测分类模式.与基于零树结构的编码不同的是它充分利用了小波域中“重要”系数的各种相关性,并通过结合提出的种子膨胀算法实现系数的分类输出.实验结果表明该方法所取得的压缩效果要优于基于零树结构的图像编码,同时又具有较强的鲁棒性.关 键 词:图像压缩;小波变换;预测;分类中图分类号:T N 919.81 文献标识码:A 文章编号:1008-9497(2002)06-663-06GU Y in-ho ng ,Y A N G Chang-sheng ,SON G Guang -hua (I nstitute of Comp uter Sy stem Engineering ,Zhej iang University ,H angz hou 310027,China )Wavelet coding based on predicted classif ication .Jo ur nal o f Z hejiang U niver sity (Science Editio n),2002,29(6):663~668Abstract :O rg anizing the w av elet coefficient s effectiv ely is pivo tal to the per for mance o f im age co dingbased o n w avelet t ransfor m.With study ing o f the st atistical pr opert ies o f w avelet co efficients,a pr e-dict ed classificatio n mo del for image co ding is presented .Contr ar y t o the Zer otr ee based metho d ,thismodel takes the advantag e of dependencies betw een sig nificant coefficients in t he w avelet do main.Byusing this model com bined w it h the pr oposed seed-dila tio n alg o rit hm ,our ex per iment sho w s that the r e-sults of image co ding have better reco nstr uctio n quality and high r obustness .Key words :imag e coding ;wav elet tra nsfo rm ;pr edictio n ;classificat ion小波变换[1]是将图像空间域上的像素点映射成小波域上具有一定结构的系数,由于它具有很好的时域和频域局部性,使得它成为图像处理中的一个重要工具.目前,对于基于小波变换的图像编码研究主要包括3个方面:(1)构造性能优良的小波,使得它具有更好的变换特性;(2)设计小波变换的快速算法[2],降低小波变换的运算复杂度;(3)如何对变换后的小波系数进行有效编码.其中第3方面的研究是编码算法设计的目标,只有充分考虑小波域系数的分布统计特性才能获得好的图像编码效果.EZW [3]中提出的零树结构利用了不同频带中零父子系数的相关性,它通过揭示零区域来间接地表示剩余的非零系数.由于零区域分布的任意性,采用严格的零树结构会使得那些不符合该结构的零系数的表示付出较高的代价.同时由于它对“重要”数据表示的间接性,可能在某种程度上降低重建图像的质量.与之相反,本文提出的算法则是通过直接揭示“重要”系数来实现图像编码.本文在安排上,首先定义了小波域系数之间的三种相关性,分析了系数的分布特性,提出了基于“重要”系数的预测分类模型,接着描述了用于分类输出的种子膨胀算法,最后实现了基于预测分类的图像编码方法,并对该算法的实验结果作出分析与评价.1 预测分类设计1.1 小波域系数的分布特性利用金字塔算法[1]对图像进行树形分解.它的过程为:一幅图像进行一次小波变换后,得到第1级的4个频带L L1,H L1,L H1和H H1;接着对各级的L L频带进行进一步分解,得到更粗一级的4个频带;最后根据所需的分解级数要求得到一组树形结构化小波系数,如图1所示.图1 3级小波分解F ig.1 T hr ee-level wav elet ana lysis图2 系数之间的3种相关性Fig.2 T hr ee dependencies betw eenw av elet co efficients定义1 在相邻级同一方向上,把两个频带对应位置系数之间的相关性称为父子相关性,并规定粗一级频带中的系数为父系数,细一级频带中所对应的4个系数称为子系数.如图2“■”所示.定义2 兄弟频带中对应位置系数之间的相关性称为兄弟相关性,并称这些系数互为兄弟系数,如图2“◆”所示.定义3 在同一个频带内,把一个系数与其相邻系数之间的相关性称为邻居相关性.如图2“●”所示.定义4 设定一个系数阈值S,若系数的绝对值大于S,则称该系数为“重要”(significant)数据,反之则为“无用”(insignificant)数据.基于零树结构的图像编码充分利用了零值系数之间的父子相关性,因为在小波域系数中,大量的零值系数的分布呈现零树结构,即父系数为零值,则其对应的子系数往往也是零值.同样,对于“重要数据”(在图像中体现为边界轮廓信息),它的分布也具有一定的相关性,主要表现为:(1)如果当前系数为“重要”数据,则其邻居系数往往也是“重要”数据,即它们之间具有邻居相关性;(2)如果父系数为“重要”数据,则子系数很大可能也是“重要”数据,即它们之间具有父子相关性或存在类似于零树的“重要”树;(3)如果当前系数为“重要”数据,其兄弟频带中对应的系数一般也表现为“重要”性.其中邻居相关性与父子相关性较强,而兄弟相关性相对较弱.1.2 预测分类不同于利用零值系数相关性的零树结构编码方式,本文所提出的预测分类思想则是针对“重要”系数,利用上述“重要”系数的3种相关性进行预测分类.如果当前系数所在位置被预测为重要, 664浙江大学学报(理学版)第29卷 则该系数被标识为“预测重要”,其它所剩余的系数皆被标识为“预测无用”.基于上述3种相关性的强弱,分别提出相应的预测模式.(1)对于邻居系数,其“+”方向的相关性强于“×”方向.规定在“+”方向上预测半径为2,“×”方向上预测半径为1.如图3所示,“重要”系数(黑色方框)周围被标识成“预测重要”的邻居系数位置(灰色方框).(2)对于“重要”父系数的子系数位置,皆标识成“预测重要”.同时考虑到邻居相关性较强,将与子系数相毗邻的各系数位置也标识成“预测重要”(它的前提是这些毗邻系数属于当前子系数所处频带).如图4所示,“重要”父系数(黑色方框),被标识的“预测重要”的位置(灰色方框).(3)对于“兄弟”系数的重要性预测,规定以HH 频带中的系数为基准.如图4所示,“重要”系数(黑色方框)相应的被标识为“预测重要”的兄弟系数位置(灰色菱形框).图3 邻居系数预测Fig .3 Pr edictio n o n neighbor coefficients 图4 子系数与兄弟系数预测F ig .4 Pr ediction o n child a nd sibling coefficient s上述预测模式应用于各个子带后,将剩余的未被标识为“预测重要”的系数位置皆标识成“预测无用”.从而根据系数的“重要”或“无用”性及其“预测重要”或“预测无用”的标识将系数划分成4组:(1)标识为“预测重要”,并且实际是“重要”的系数;(2)标识为“预测重要”,但是实际是“无用”的系数;(3)标识为“预测无用”,但是实际是“重要”的系数;(4)标识为“预测无用”,并且实际是“无用”的系数.通过上述的预测分类,把具有不同特性的系数分别归入到相应的分组中.这样使得:一方面,对于最后的自适应算术编码输出,可以根据不同分组的系数特性采用不同的频率分布表;另一方面,分组4中“预测无用”且“无用”的非零系数,它们在很大程度上表现为噪声,因此统一将这些非零系数设置为0,在一定程度上可实现频域内降噪.实验表明,上述三种预测模式组合产生的分组所获得的图像压缩性能最佳.2 种子膨胀算法种子膨胀算法用于预测分类后不同系数分组的输出,它的基本步骤如下:1.按光栅扫描次序对各子带系数进行扫描,跳过当前已经被发送的系数.2.若当前系数为“无用”系数,则直接发送此系数.3.若当前系数为“重要”系数,发送一个特殊的“指示符号”给解码端以告知此事件的发生,同时:(a )发送当前“重要”系数至解码端.(b)以此系数为中心,按从上到下、从左到右次序逐个发送3×3方阵中系数(跳过已被发送的665 第6期顾寅红,等:一种基于预测分类的小波图像编码系数).(c)若方阵中又包含新的“重要”系数,则递归重复步骤(a),(b),否则回到步骤1继续扫描剩余的系数.4.当整个子带系数皆被扫描时算法结束.下面是该算法的举例说明,图5为一组系数分布.假设所有非零系数为“重要”系数.图6中各子图给出了种子膨胀的递归过程,其中灰色矩形框代表已发送系数,灰色圆圈代表当前被发送的系数,空心圆圈代表下一颗种子系数.整个系数的发送顺序为“0000000/指示符合/-9000/160/20/8000/00/-50000/-70000”.图5 系数分布Fig .5 Coefficient distribution 图6 种子膨胀过程F ig .6 Seed -dilation pro cess此算法有效地俘获了“重要”系数簇,并且对于每一系数簇的位置只需一个符号来指示,它反映了当前系数从“无用”区域到“重要”区域的过渡.它的突出优点在于,只要知道了一个簇起始系数的位置,其他的系数位置就不言而喻,从而避免了各个系数位置信息的高代价表示.3 算法实现变换编码主要包括4个基本阶段:反关联变换,量化,系数编码,熵编码输出.下面是基于预测分类和种子膨胀算法的图像编码步骤:1.采用双正交10/18[4]小波对图像进行5级小波变换.2.基于作为DC 分量的L L 5包含了图像的大部分能量,它的系数采用DPCM 无损编码方式.3.均匀量化小波域系数(Deadzone=0.75qstep).4.根据设定的系数阈值S 进行预测分类,并根据预测分类的结果实现频域降噪[5].5.编码“前处理”(a)记录各非零系数的‘±’符号,并取系数绝对值,使得算术编码的频率分布表长度缩小一半.(b )按一定顺序,以位流(bit stream )方式输出记录的非零系数符号.6.逐个扫描每一个子带(a )计算分组(1),(2)分别对应的算术编码符号转换表,初始化各自的频率分布表[6].第一遍扫描当前子带中系数.若当前系数为“预测重要”且未被访问过: 若当前系数为“重要”系数,则利用种子膨胀算法俘获“预测重要”且“重要”的系数簇.666浙江大学学报(理学版)第29卷 若当前系数为“无用”系数,则直接进行算术编码.∥“预测重要”但“无用”的系数.(b)计算分组(3),(4)分别对应的算术编码符号转换表,初始化各自的频率分布表[6].第二遍扫描当前子带中系数.若当前系数为“预测无用”且未被访问过:若当前系数为“重要”系数,则利用种子膨胀算法俘获“预测无用”且“重要”的系数簇.若当前系数为“无用”系数,则直接进行算术编码.∥已降噪,仅有一个符号‘0’.4 实验结果表1列出了本算法在不同比特率下与两种典型的基于零树结构图像编码算法的性能比较.选择EZW [2]是因为该算法最先提出零树结构并取得成功,而选择SPITHT [7]则是因为它被公认为基于零树结构的具有最佳压缩性能的算法.其中EZW 采用9-tap QM F,6级变换;SPITHT 采用18/10小波,5级变换.表1中空格表示原文献未列出该数据,压缩率的单位是每像素占用比特数(bpp),压缩结果用峰值性噪比(PSNR)表示,它的计算公式为PSNR=10log 102552M SE ,其中,M SE =1N ∑N i =1(x i -x i )2.表1 不同BPP 下的PSN R 比较T able 1 PSN R under different BPP压缩率(bpp)L ena Go ldhill Bar ba ra 0.250.50 1.000.250.50 1.000.250.50 1.00EZW33.1736.2839.55---26.7730.5335.14SP IHT34.1237.2240.4130.5633.1336.5527.7931.72-本文算法34.3637.3840.4930.6533.2536.6728.1531.8736.775 结 论本文提出的基于预测分类的种子膨胀图像编码,与传统的基于零树结构的编码算法相比,具有以下几个特点:(1)在PSNR 性能指标上,该算法要优于基于零树结构的图像编码,而且对三幅实验图像的效果均好,具有较强的通用性.(2)算法的出发点与基于零树结构相反,它通过编码揭示“重要”系数簇直接地反映图像,而后者则是通过探索零系数区域间接地反映图像结构.因此与后者相比,本算法的重建图像质量具有一定程度的提高.(3)针对小波域中“重要”系数的分布特点,提出了一种面向“重要”系数的预测模型.进一步挖掘了系数之间相关性,其具体表现为父子、邻居和兄弟相关性.(4)压缩编码与频域降噪的内在结合.在不专门引入降噪模型前提下,实现图像的降噪,一方面,避免了降噪过程所带来的运算复杂度;另一方面,使得重建图像的视觉质量有一定程度的提高.图7、图8给出了0.25bbp 下的Lena 和Goldhill 的重建图像.(5)自适应算术编码时,按不同的系数分组的特征采用不同频率分布表,同时频率分布表按不667 第6期顾寅红,等:一种基于预测分类的小波图像编码同子带不断地进行重置,提高了编码传送的鲁棒性(Robustness ).综上所述,本文所提出的算法在PSNR 性能指标、视觉质量及其鲁棒性方面均优于基于零树结构的图像编码.另外,当前算法仅采用了简单的均匀量化,如果对当前量化器进行改进,图像的编码效果将会有进一步的提高.图7 重建的Lena 图像(0.25bpp )F ig.7 L ena im age r econstructio n at 0.25bpp 图8 重建的Go ldhill 图像(0.25bpp )F ig.8 Go ldhill im age r econstructio n at 0.25bpp 参考文献:[1] DA U BECHIES I.Ten Lectures on Wavelets [M ].Philadelphia,P A :Society fo r Industr ial and A ppliedM athemat ics ,1992.[2] A DA M S D ,K OSSEN T I NI F.R ever sible integ er-to-integ er w avelet tr ansfo rms for imag e co mpression:per -fo rmance evaluatio n and analysis [J].IEEE Trans Image Proc ,2000,9(6):1010-1024.[3] SHAP IRO J .Embedded imag e coding using zer o trees o f wa velet coefficients [J ].IEEE Trans Signal Proc ,1993,41(12):3445-3462.[4] VI LL A SEN OR J,T SA I M J,CHEN Feng.Imag e co mpr ession using stack-run imag e co ding [J].IEEETrans Image Proc ,1996,6(5):519-521.[5] GR A CE S ,Y U Bin ,V ET T ER L I M .Adaptiv e w av elet thr esho lding for imag e denoising and co mpr ession[J ].IEEE Trans Image Proc ,2000,9(9):1532-1546.[6] WIT T EN I H,N EA L R M ,CLEA RY J G.Ar ithmet ic co ding fo r data co mpressio n [J].C ommunications ofthe ACM ,1987,30(6):520-540.[7] SA ID A ,PEA RL M A N W .A new ,fast ,and efficient image co dec based on set par titioning in hier ar chicaltr ees [J ].IEEE Trans Circuits and System f or Video Tech ,1996,6(3):243-250.(责任编辑 涂 红)668浙江大学学报(理学版)第29卷 。

《几种非对称结构二维材料中的电-声子相互作用》篇一一、引言在当代材料科学中,非对称结构二维材料因其独特的物理和化学性质,在电子器件、传感器和能量转换等领域展现出巨大的应用潜力。
其中,电-声子相互作用是决定这些材料性能的关键因素之一。
本文将探讨几种具有非对称结构的二维材料中的电-声子相互作用,分析其相互作用机制及其对材料性能的影响。
二、非对称结构二维材料的概述非对称结构二维材料通常指在原子层面具有非对称性的材料,如过渡金属硫化物、氮化硼等。
这些材料因其独特的电子结构和晶格结构,在电子传输、热传导和光学性质等方面表现出独特的性能。
本文将重点分析几种典型的非对称结构二维材料中的电-声子相互作用。
三、几种典型的非对称结构二维材料1. 过渡金属硫化物:如MoS2、WSe2等,具有较弱的层间相互作用和较强的层内相互作用,使其在电-声子相互作用方面表现出独特的性质。
2. 氮化硼:具有类似于石墨烯的蜂窝状结构,但其电子结构和声子模式与石墨烯有所不同,因此电-声子相互作用也有所差异。
3. 其他新型二维材料:如黑磷等,因其独特的电子结构和物理性质,在电-声子相互作用方面也具有独特的表现。
四、电-声子相互作用机制电-声子相互作用是指电子与声子之间的相互作用,这种相互作用对材料的热学、光学和电学性质产生重要影响。
在非对称结构二维材料中,电-声子相互作用主要通过以下几种机制实现:1. 电子散射机制:电子与声子之间的散射作用,导致电子的动量和能量发生变化。
2. 极化子机制:电子与晶格振动引起的极化子相互作用,影响材料的介电性质和光学性质。
3. 电子热输运机制:电子与声子的热输运过程,对材料的热导率和热稳定性产生影响。
五、电-声子相互作用对材料性能的影响电-声子相互作用对非对称结构二维材料的性能产生重要影响,主要表现在以下几个方面:1. 改变电子传输性能:电-声子相互作用可能影响电子的传输速度和传输效率,从而改变材料的导电性能。
《几种非对称结构二维材料中的电-声子相互作用》篇一一、引言近年来,二维材料因其独特的物理和化学性质,在电子器件、光电器件、传感器等领域得到了广泛的应用。
其中,非对称结构二维材料因其具有特殊的电子能带结构和声子模式,使得其电-声子相互作用具有独特的性质。
本文将探讨几种典型的非对称结构二维材料中的电-声子相互作用,并对其在电子器件中的应用进行探讨。
二、非对称结构二维材料的电-声子相互作用1. 过渡金属硫化物过渡金属硫化物(TMDs)是一种典型的非对称结构二维材料,其具有独特的电子能带结构和声子模式。
在TMDs中,电子和声子之间的相互作用主要发生在导带和价带之间的跃迁过程中。
由于TMDs的电子态和声子模式的不对称性,使得电子在跃迁过程中能够与特定的声子模式发生耦合,从而产生独特的电-声子相互作用。
这种电-声子相互作用对于电子输运具有重要影响,如可调节的半导体性能和负泊松效应等。
在TMDs基的电子器件中,这种电-声子相互作用可用于设计高效的电子输运和热管理策略。
2. 拓扑绝缘体拓扑绝缘体是一种具有非平凡能带结构的二维材料,其表面具有特殊的电子态和声子模式。
在拓扑绝缘体中,由于电子态的特殊性质,使得其与声子的相互作用也具有独特的性质。
在拓扑绝缘体中,由于表面态的存在,使得电子和声子之间的相互作用更加复杂。
这种相互作用不仅与材料的电子能带结构和声子模式有关,还与表面态的分布和能量有关。
因此,在拓扑绝缘体基的电子器件中,电-声子相互作用可用于实现特殊的电子输运和热管理策略。
3. 石墨烯及其衍生物石墨烯及其衍生物是一种具有蜂窝状结构的二维材料,其具有独特的电子能带结构和声子模式。
在石墨烯及其衍生物中,由于结构的非对称性,使得其电子和声子之间的相互作用也具有特殊的性质。
在石墨烯及其衍生物中,电子和声子的相互作用受到结构的特殊调制。
由于蜂窝状结构的非对称性,使得电子在跃迁过程中能够与特定的声子模式发生耦合。
这种电-声子相互作用对于石墨烯基的电子器件具有重要的应用价值,如高性能的晶体管、传感器等。
Scalable Wavelet Coding for Synthetic/Natural Hybrid Images Iraj Sodagar,Hung-Ju Lee,Paul Hatrack,and Ya-Qin Zhang,Fellow,IEEEAbstract—This paper describes the texture representation scheme adopted for MPEG-4synthetic/natural hybrid coding (SNHC)of texture maps and images.The scheme is based on the concept of multiscale zerotree wavelet entropy(MZTE) coding technique,which provides many levels of scalability layers in terms of either spatial resolutions or picture quality. MZTE,with three different modes(single-Q,multi-Q,and bilevel),provides much improved compression efficiency and fine-gradual scalabilities,which are ideal for hybrid coding of texture maps and natural images.The MZTE scheme is adopted as the baseline technique for the visual texture coding profile in both the MPEG-4video group and SNHC group.The test results are presented in comparison with those coded by the baseline JPEG scheme for different types of input images.MZTE was also rated as one of the topfive schemes in terms of compression efficiency in the JPEG2000November1997evaluation,among 27submitted proposals.Index Terms—Compression,image and video coding,JPEG-2000,MPEG-4,texture coding,wavelet.I.I NTRODUCTIONS CALABLE picture coding has received considerable at-tention lately in academia and industry in terms of both coding algorithms and standards activities.In many appli-cations,enhanced features such as content-based scalability, content-based access,and manipulations are required in ad-dition to increased compression efficiency,as exemplified by the effort undertaken in the emerging MPEG-4international standard[1]–[3].In contrast to the MPEG-1and MPEG-2 standards,MPEG-4includes increasedflexibility and user in-teraction at many different levels for both natural and synthetic image/video contents.This paper describes the scalable texture coding scheme using zerotree wavelet techniques.Zerotree wavelet coding provides very high compression efficiency as well as spatial and quality scalability features compared with discrete cosine transform(DCT)-based approaches[16],[17]. With the advantages of its scalability and high compression, the zerotree wavelet coding technique was adopted in the MPEG-4standard as the visual texture coding tool[3],which allows the hybrid coding of natural images and video(e.g.,Manuscript received October1,1997;revised November1,1998.This paper was recommended by Guest Editors H.H.Chen,T.Ebrahimi,G.Rajan, C.Horne,P.K.Doenges,and L.Chiariglione.I.Sodagar,H.-J.Lee,and P.Hatrack are with the Multimedia Technology Laboratory,Sarnoff Corp.,Princeton,NJ08512USA.Y.-Q.Zhang was with the Multimedia Technology Laboratory,Sarnoff Corp.,Princeton,NJ08512USA.He is now with Microsoft Research,Beijing 100080China(e-mail:yzhang@).Publisher Item Identifier S1051-8215(99)02338-1.Fig.1.N layers of spatial scalability.acquired with cameras)together with synthetic scenes(e.g., generated by computers).The organization of this paper is as follows.We begin with a general overview of the scalable image coding and its features. Then,we describe the embedded zerotree wavelet(EZW)that providesfine scalability and zerotree entropy coding(ZTE) that provides spatial scalability with much higher compression efficiency than EZW.Finally,the most general case,known as the multiscale zerotree wavelet entropy(MZTE)coding,is presented to provide an arbitrary number of spatial and quality scalability as well as good compression efficiency.The MPEG-4still-picture visual texture coding consists of three modes: single-Quant,multiple-Quant,and bilevel Quant.This paper mainly describes thefirst two modes,developed by Sarnoff Corp.The bilevel mode is presented in detail in[18],and the extension of MZTE to include arbitrary shape wavelet coding, another important feature of MPEG-4,is covered in[10].II.S CALABLE T EXTURE C ODING U SING W A VELETSIn scalable compression,the bitstream can be progressively decoded to provide different versions of the image in terms of spatial resolutions(spatial scalability),quality levels[signal-to-noise ratio(SNR)scalability],or combinations of spatial and quality scalabilities.Figs.1and2show two examples of such scalabilities.In Fig.1,the bitstreamhas layers of spatial scalability.In this case,the bitstream consistsofFig.2.M layers of quality scalability.by progressively decoding the additional segments,the viewer can increase the spatial resolution of the image.Fig.2shows an example in which the bitstreamincludesdifferentsegments.Decoding the first segment provides an early view of the reconstructed image.Further decoding of the next segments results in increase of the quality of the reconstructed imageatspatial layers,and each spatial layerincludes,then all wavelet coefficients of the sameorientation at the same spatial location at finer wavelet scales are also likely to be insignificant with respect tothat.A coefficient issignificant if its amplitude is greaterthan,with allits children in the zerotree data structure alsobelowbutwith at least one child notbelowFig.3.N 2M layers of spatial/qualityscalabilities.Fig.4.The parent–child relationship of wavelet coefficients.4)The alphabet of symbols for classifying the tree nodes is changed to one that performs significantly better for very low bit-rate encoding of video.Although ZTE does not produce a fully embedded bitstream like EZW,it gains flexibility and other advantages over EZW coding,including substantial improvement in compression efficiency,simplicity,and spatial quality.In ZTE coding,the coefficients of each wavelet tree are reorganized to form a wavelet block,as shown in Fig.5.Each wavelet block comprises those coefficients at all scales and orientations that correspond to the image at the spatial location of that block.The concept of the wavelet block provides an association between wavelet coefficients and what they represent spatially in the image.The ZTE entropy encoding is performed by assigning the zerotree symbol of a coefficient,then encoding the coefficient value with its symbol in one of the two different scanning orders described later.A symbol is assigned to each node in a wavelet tree describing the wavelet coefficient corresponding to that node.Quantization of the wavelet transform coefficients can be done prior to theconstruction of the wavelet tree or as a separate task,or it can be incorporated into the wavelet tree construction.In the second case,as a wavelet tree is traversed for coding,the wavelet coefficients can be quantized in an adaptive fashion,according to spatial location and/or frequency content.The extreme quantization required to achieve a very low bit rate produces many zero coefficients.Zerotrees exist at any tree node where the coefficient is zero and all the node’s chil-dren are zerotrees.The wavelet trees are efficiently represented by scanning each tree depth-first from the root in the low-low band through the children and assigning one of four symbols to each node encountered:ZTR,valued ZTR (VZTR),value (V AL),or IZ.A zerotree root denotes a coefficient that is the root of a zerotree.Zerotrees do not need to be scanned further because it is known that all coefficients in such a tree have an amplitude of zero.A valued zerotree root is a node where the coefficient has nonzero amplitude and all four children are zerotree roots.The scan of this tree can stop at this symbol.A value symbol identifies a coefficient with amplitude nonzero and also with some nonzero st,an isolated symbol identifies a coefficient with an amplitude of zero but with some nonzero descendant.The symbols and quantized coefficients are then losslessly encoded using an adaptive arithmetic coder.The arithmetic encoder adaptively tracks the statistics of the zerotree symbols.In ZTE coding,the quantized wavelet coefficients are scanned either in the tree-depth or the band-by-band fashion.In the tree-depth scanning order,all coefficients of each tree are encoded before starting encoding of the next tree.In the band-by-band scanning order,all coefficients are encoded from the lowest to the highest frequency subbands.The wavelet coefficients of dc band are encoded independently from the other bands.First,the quantization step size is encoded,then the magnitude of the minimum value of the differential quantization indexes “band offset”and the maximum value of the differential quantization indexes “band max value”are encoded into the bitstream.The parameter band offset is a negative or a zero integer,and the parameter band max is a positive integer,so only the magnitudes of these parameters are written into the bitstream.The differential quantizationFig.5.Building wavelet blocks after taking two-dimensionalDWT.Fig.6.Differential pulse code modulation encoding of dc band coefficients.indexes are encoded using the arithmetic encoder in a raster-scan order,starting from the upper left index and ending with the lowest right one.The model is updated with encoding of each bit of the predicted quantization index to adopt the probability model to the statistics of the dc band.The band offset is subtracted from all the values,and a forward predictive scheme is applied.As shown in Fig.6,each of thecurrentcoefficientsis predicted from three other quantized coefficients in its neighborhood,i.e.,and If any of nodes A,B,or C are not in the image,its value isset to zero for the purpose of the forward prediction.For wavelet coefficients in all other subbands (i.e.,ac subbands),Fig.7shows the scanning order for a16,24represent one tree.First,coefficients in this tree are encoded starting from index 4and ending at index 24.Then,thecoefficients in the second tree are encoded starting from index 25and ending at 45.The third tree is encoded starting from index 46and ending at index 66,and so on.Fig.8shows that the wavelet coefficients are scanned in the subband-by-subband fashion,from the lowest to the highest frequency subbands for a16Fig.7.The tree-depth scanning order in ZTE encoding.advantages of incorporating quantization into ZTE are the following.1)The status of the encoding process and bit usage areavailable to the quantizer for adaptation purposes.2)By quantizing coefficients as the wavelet trees are tra-versed,information such as spatial location and fre-quency band is available to the quantizer for it to adapt accordingly and thus provide content-based coding. C.Multiscale Zerotree Wavelet Entropy(MZTE)CodingThe MZTE coding technique is based on ZTE coding [13],[14],but it utilizes a new framework to improve and extend the ZTE method to achieve a fully scalable yet very efficient coding technique.In this scheme,the low-low band is separately encoded.To achieve a wide range of scalability levels efficiently as needed by the application,the other bands are encoded using the multiscale zerotree entropy coding scheme.This multiscale scheme provides a veryflexible approach to support the right tradeoff between layers and types of scalability,complexity,and coding efficiency for any multimedia application.Fig.9shows the concept of this technique.The wavelet coefficients of thefirst spatial(and/or quality) layerfirst are quantized with the quantizer Q0.These quantized coefficients are scanned using the zerotree concept,and then the significant maps and quantized coefficients are entropy coded.The output of the entropy coder at this level,BS0,is thefirst portion of the bitstream.The quantized wavelet coef-ficients of thefirst layer are also reconstructed and subtracted from the original wavelet coefficients.These residual wavelet coefficients are fed into the second stage of the coder,in which the wavelet coefficients are quantized with Q1,zerotree scanned,and entropy coded.The output of this stage,BS1, is the second portion of the output bitstream.The quantized coefficients of the second stage are also reconstructed and sub-tracted from the original coefficients.As shown in Fig.9, stages of the schemeprovide layers of scalability.Each level represents one layer of SNR quality,spatial scalability, or a combination of both.In MZTE,the wavelet coefficients are quantized by a uniform and midstep quantizer with a dead zone equal to the quantization step size as closely as possible at each scalability layer.Each quality layer and/or spatial layer has a quantization(values.The quantization of coefficients is performed in three steps:1) construction of initial quantization value sequence from input parameters,2)revision of the quantization sequence,and3) quantization of the coefficients.Fig.8.The band-by-band scanning in ZTEencoding.Fig.9.MZTE encoding structure.Let be thenumber of quality layers associated with spatial layer as the sum of all the quality layers fromthat spatial layer and all higher spatiallayersvalue corresponding to spatiallayer .The quantization sequence(orvalues from all the quality layers fromthe.To make this successive refinementefficient,thesequenceth value of the quantizationsequenceis an integer number greater than one,each quantizedcoefficient oflayer)as each quantization stepsize equal partitions in layer ().IfTABLE IR EVISIONOF THEQ UANTIZATION SEQUENCEvalues that cannot be evenly dividedintothlayer,so we simplyrevisedall coefficients that first appear in spatial layerandall coefficients that appear in spatiallayer,we usethevaluesare positive integers,and they represent the range of values that a quantization level spans at that scalability layer.For the initial quantization we simply divide the value bythe.This partitioningalways leaves a discrepancy of zero between the partition sizes if thepreviousvalue (e.g.,previous andcurrentvalue is not evenly divisible by thecurrentvaluesin .Case II:If the previous quality level quantized to a nonzero value,then (since the sign is already known at the inverse quantizer)the residual has to be one ofthevalues (associated with each quality layer),the initial quantization value,and the residuals.At the first scalability layer,the zerotree symbols and the corresponding values are encoded for the wavelet coefficients of that scalability layer.The zerotree symbols are generated in the same way as in the ZTE method.For the next scalability layers,the zerotree map is updated along with the corresponding value refinements.In each scalability layer,a new zerotree symbol is encoded for a coefficient only if it was encoded as ZTR,VZTR,or IZ in the previous scalability layer.If the coefficient was decoded as V AL in the previous layer,a V AL symbol is also assigned to it at the current layer,and only its refinement value is encoded from bitstream.In MZTE,the wavelet coefficients are scanned in either the tree-depth scanning for each scalability layer or in the subband-by-subband fashion,from the lowest to the highest frequency subbands (as shown in Fig.8).At the first scalability layer,the zerotree symbols and the corresponding values are encoded for the wavelet coefficients of that scalability layer.For the next scalability layers,the zerotree map is updated along with the corresponding value refinements.In each scalability layer,a new zerotree symbol is encoded for a coefficient only if it was decoded as ZTR or IZ in the previousFig.11.A synthetic image is compressed and decompressed by JPEG.scalability layer.If the coefficient was decoded as V AL in the previous layer,a V AL symbol is also assigned to it at the current layer,and only its refinement value is decoded from bitstream.Fig.10shows the relationship between the symbols of one layer and the next layer.If the node is not coded before(shown as“x”in thefigure),it can be encoded using any of four symbols.If it is ZTR in one layer,it can remain ZTR or be any of the other three symbols in the next layer.If it is detected as IZ,it can remain IZ or only become V AL.If it is VZTR,it can remain VZTR or become V st,once it is assigned V AL,it always stays V AL,and no symbol is transmitted in this care.D.Entropy Coding in EZW,ZTE,and MZTESymbols and quantized coefficient values generated by the zerotree stage are all encoded using an adaptive arithmetic coder,such as presented[15].The arithmetic coder is run over several data sets simultaneously.A separate model with an associated alphabet is used for each.The arithmetic coder uses adaptive models to track the statistics of each set of input data,then encodes each set close to its entropy.The symbols encoded differ based upon whether EZW,ZTE,or MZTE coding is used.For EZW,a four-symbol alphabet is used for the significance map,and a different two-symbol alphabet is used for the SAQ information.The arithmetic coder is restarted every time a new significance map is encoded or a new bit plane is encoded by SAQ.For ZTE,symbols describing node type(zerotree root,valued zerotree root,value,or isolated zero)are encoded.The list of nonzero quantized coefficients that correspond one-to-one with the valued zerotree root or value symbols are encoded using an alphabet that does not include zero.The remaining coefficients,which correspond one-to-one to the value symbols,are encoded using an alphabet that does include zero.For any node reached in a scan that is a leaf with no children,neither root symbol can apply.Therefore,Fig.12.A synthetic image is compressed and decompressed by MZTE.bits are saved by not encoding any symbol for this node and encoding the coefficient along with those corresponding to the value symbol using the alphabet that includes zero.In MZTE,one additional probability model,residual,is used for encoding the refinements of the coefficients that were encoded with the V AL or VZTR symbol in any previous scalability layers.If in the previous layer a V AL symbol was assigned to a node,the same symbol is kept for the current pass and no zerotree symbol is encoded.The residual model,same as the other probability models,is also initialized to the uniform probability distribution at the beginning of each scalability layer.The numbers of bins for the residual model is calculated based on the ratio of the quantization step sizes of the current and previous scalability.When a residual model is used,only the magnitude of the refinements are encoded,as these values are always zero or positive integers. Furthermore,to utilize the high correlation of zerotree symbol between scalability layers,a context modeling,based on the zerotree symbol of the coefficient in the previous scalability layer in MZTE,is used to better estimate the distribution of zerotree symbols.In MZTE,only INIT and LEAF INIT are used for thefirst scalability layer for the nonleaf subbands and leaf subbands,respectively.Subsequent scalability layers in the MZTE use the context associated with the symbols.The different zerotree symbol models and their possible values are summarized in Table II.If a spatial layer is added,then the contexts of all previous leaf subband coefficients are switched into the corresponding nonleaf contexts.The coefficients in the newly added subbands use the LEAF INIT context initially.III.T EST R ESULTSSarnoff’s MZTE algorithm has been tested and verified throughout the MPEG-4core experiment process,with many iterative refinements and support from other partners,such as Sharp,TI,Vector Vision,Rockville,Lehigh,Oki,and Sony.TABLE IIZ EROTREE S YMBOL M ODELSContext for Nonleaf subbands Possible valuesINIT ZTR(2),IZ(0),VZTR(3),V AL(1) ZTR ZTR(2),IZ(0),VZTR(3),V AL(1) ZTR DESCENDENT ZTR(2)IZ IZ(0),V AL(1)Context for Leaf subbands Possible valuesLEAF_INIT ZTR(0),VZTR(1)LEAF_ZTR ZTR(0),VZTR(1)LEAF_ZTR_DESCENDENT ZTR(0),VZTR(1)TABLE IIIPSNR V ALUESCompression scheme PSNR-Y PSNR-U PSNR-YDCT-based JPEG28.3634.7434.98Wavelet-based MZTE30.9841.6840.14This section presents a small subset of the representative results of MZTE in comparison with the JPEG compression, using a hybrid natural and synthetic image.The images in Figs.11and12are generated by JPEG and MZTE com-pression schemes,respectively,at the same compression ratio of45:1.The resultant images show that the MZTE scheme generates much better image quality with good preservation offine texture regions and absence of the blocking effect compared with JPEG.The PSNR values for both reconstructed images are tabulated in Table III.Fig.13demonstrates the spatial and quality scalabilities at different resolutions and bit rates using the MZTE compression scheme.The images in(a)are of size of128256at a bit rate of192and320 kbits,respectively,and thefinal resolution of512254IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY,VOL.9,NO.2,MARCH1999 [2]“MPEG-4requirements document v.5,”in Proc.Fribourg MPEG Meet-ing,Oct.1997,Doc.ISO/IEC JTC1/SC29/WG11W1886.[3]“Text of ISO/IEC FDIS14496-2,”in Proc.Atlantic City MPEG Meeting,Oct.1998,Doc.ISO/IEC JTC1/SC29/WG11MPEG97/W2502.[4]J.M.Shapiro,“Embedded image coding using zerotrees of waveletcoefficients,”IEEE Trans.Signal Processing,vol.41,pp.3445–3462,Dec.1993.[5]M.Vetterli and J.Kovacevic,Wavelets and Subband Coding.Engle-wood Cliffs,NJ:Prentice-Hall,1995.[6] A.Arkansi and R.A.Haddad,Multiresolution Signal Decomposition:Transforms,Subbands,Wavelets.New York:Academic,1996.[7] A.Said and W.Pearlman,“A new,fast,and efficient image codec basedon set partitioning in hierarchical trees,”IEEE Trans.Circuits Syst.VideoTechnol.,vol.6,pp.243–250,June1996.[8] D.Taubman and A.Zakhor,“Multirate3-D subband coding of video,”IEEE Trans.Image Process.,vol.3,pp.572–588,Sept.1994.[9]Z.Xiong,K.Ramchandran,and M.T.Orchard,“Joint optimization ofscalar and tree-structured quantization of wavelet image decomposition,”in Proc.27th Annu.Asilomar Conf.Signals,Systems,and Computers,Pacific Grove,CA,Nov.1993,pp.891–895.[10]S.Li and W.Li,“Shape-adaptive wavelet coding,”in Proc.SPIE VisualCommunications and Image Processing,Jan.1998.[11] A.Zandi et al.,“CREW:Compression with reversible embeddedwavelets,”in Proc.IEEE Data Compression Conf.,Snowbird,UT,Mar.1995.[12]S.Servetto,K.Ramchandran,and M.Orchard,“Wavelet based imagecoding via morphological prediction of significance,”in Proc.Int.Conf.Image Processing,Washington,DC,1995.[13]S.A.Martucci,I.Sodagar,T.Chiang,and Y.-Q.Zhang,“A zerotreewavelet video coder,”IEEE Trans.Circuits Syst.Video Technol.,vol.7,pp.109–118,Feb.1997.[14]Sarnoff Corp.,“Zero-Tree Wavelet Entropy(ZTE)Coding for MPEG4,”ISO/IEC/JTC/SC29/WG11/MPEG95/W512,Nov.1995[15]I.Witten,R.Neal,and J.Cleary,“Arithmetic coding for data compres-sion,”Commun.ACM,vol.30,pp.520–540,June1987.[16]Y.-Q.Zhang and S.Zafar,“Motion-compensated wavelet transform cod-ing for color compression,”IEEE Trans.Circuits Syst.Video Technol.,vol.2,Sept.1992.[17]Z.Xiong,K.Ramachandran,M.Orchard,and Y.-Q.Zhang,“A com-parison study of DCT and wavelet-based coding,”in Proc.ISCAS’97;see also IEEE Trans.Circuits Syst.Video Technol.,to be published.[18]J.Liang,“Highly scalable image coding for multimedia applications,”in Proc.ACM Multimedia,Seattle,WA,Oct.1997.[19]“Requirements and profiles of JPEG-2000,”in Sydney JPEG Meeting,Nov.1997,Doc.ISO/IEC JTC1/SC29/WG1N715.Iraj Sodagar received the B.S.degree from TehranUniversity,Tehran,Iran,in1987and the M.S.and Ph.D.degrees from the Georgia Institute ofTechnology(Georgia Tech.),Atlanta,in1993and1994,respectively,all in electrical engineering.He is Head of the Interactive Media Group at theMultimedia Technology Laboratory,Sarnoff Corp.,Princeton,NJ.He was a Research Assistant at theSchool of Electrical Engineering,Georgia Tech.,from1991to1994.At Georgia Tech.,his researchwas focused on multiratefilter banks and wavelets and their applications in image coding.In January1995,he joined Sarnoff Corp.,where he has developed low bit-rate image and video compression algorithms for multimedia applications.He has been representing Sarnoff at ANSI NCITS,ISO MPEG-4,and JPEG-2000standards bodies since1995. He was the Chair of the MPEG-4visual texture coding group and Cochair of the MPEG-4Version2core experiments and JPEG-2000scalability and progressive-to-lossless coding ad hoc groups.His current interests include low bit-rate image and video coding,multimedia content-based representation and indexing,interactive media authoring,MPEG-4,MPEG-7,andJPEG-2000.Hung-Ju Lee received the B.S.degree from TatungInstitute of Technology,Taipei,Taiwan,in1987and the M.S.and Ph.D.degrees from Texas A&MUniversity in1993and1996,respectively,all incomputer science.In1996,he joined Sarnoff Corp.,Princeton,NJ,as a Member of Technical Staff.He actively partic-ipates in ISO’s MPEG digital video standardizationprocess,with a particular focus on wavelet-basedvisual texture coding and scalable rate control.Hisresearch interests include image and video coding and network resource management for multimediaapplications.Paul Hatrack received the B.S.degree from GeorgeWashington University,Washington,DC,in1987and the M.S.degree from Rutgers—The State Uni-versity,New Brunswick,NJ,in1998,both in electri-cal engineering.He currently is pursuing the Ph.D.degree in electrical engineering at Rutgers.He currently is a Member of the Wireless Infor-mation Network Laboratory(Winlab)at Rutgers.Heis an Associate Member of Technical Staff in theInteractive Media Group,Sarnoff Corp.,Princeton,NJ,which he joined in summer1996.His previous research interests included multiuser detection and power control for CDMA systems and video and image coding.His current research interests include video and image coding,joint source-channel coding,and signal detection andestimation.Ya-Qin Zhang(S’87–M’90–SM’93–F’97)wasborn in Taiyuan,China,in1966.He received theB.S.and M.S.degrees in electrical engineeringfrom the University of Science and Technologyof China(USTC)in1983and1985,respectively,and the Ph.D.degree in electrical engineering fromGeorge Washington University,Washington DC,in1989.He joined Microsoft Research,Beijing,China,inJanuary1999.He was Director of the MultimediaTechnology Laboratory,Sarnoff Corp.,Princeton, NJ(formerly David Sarnoff Research Center and RCA Laboratories).His laboratory is actively engaged in R&D and commercialization of digital television,MPEG,multimedia,and Internet technologies.He is a Cofounder of ,a startup venture that develops image and video compression and communications technologies and products on the Internet.He was with GTE Laboratories,Inc.,Waltham,MA,and Contel Technology Center, V A,from1989to1994.He is the author or coauthor of more than150 refereed papers and30U.S.patents granted or pending in image/video compression and communications,multimedia,wireless networking,satellite communications,and medical imaging.Many of the technologies he and his team developed have become the basis for startup ventures,products, and international standards.He is a member of the editorial boards of seven professional journals and more than a dozen conference committees.He has been an active contributor to and participant in ISO/MPEG and ITU standardization efforts.Dr.Zhang is Editor-in-Chief of the IEEE T RANSACTIONS ON C IRCUITS AND S YSTEMS FOR V IDEO T ECHNOLOGY.He is Chairman of the Visual Signal Processing and Communications Committee of the IEEE Circuits and Systems Society.He has received many awards,including several industry technical achievement awards,the“1997Research Engineer of the Year”award by the Central Jersey Engineering Council,and“The1998Outstanding Young Electrical Engineer”award from Eta Kappa Nu.。