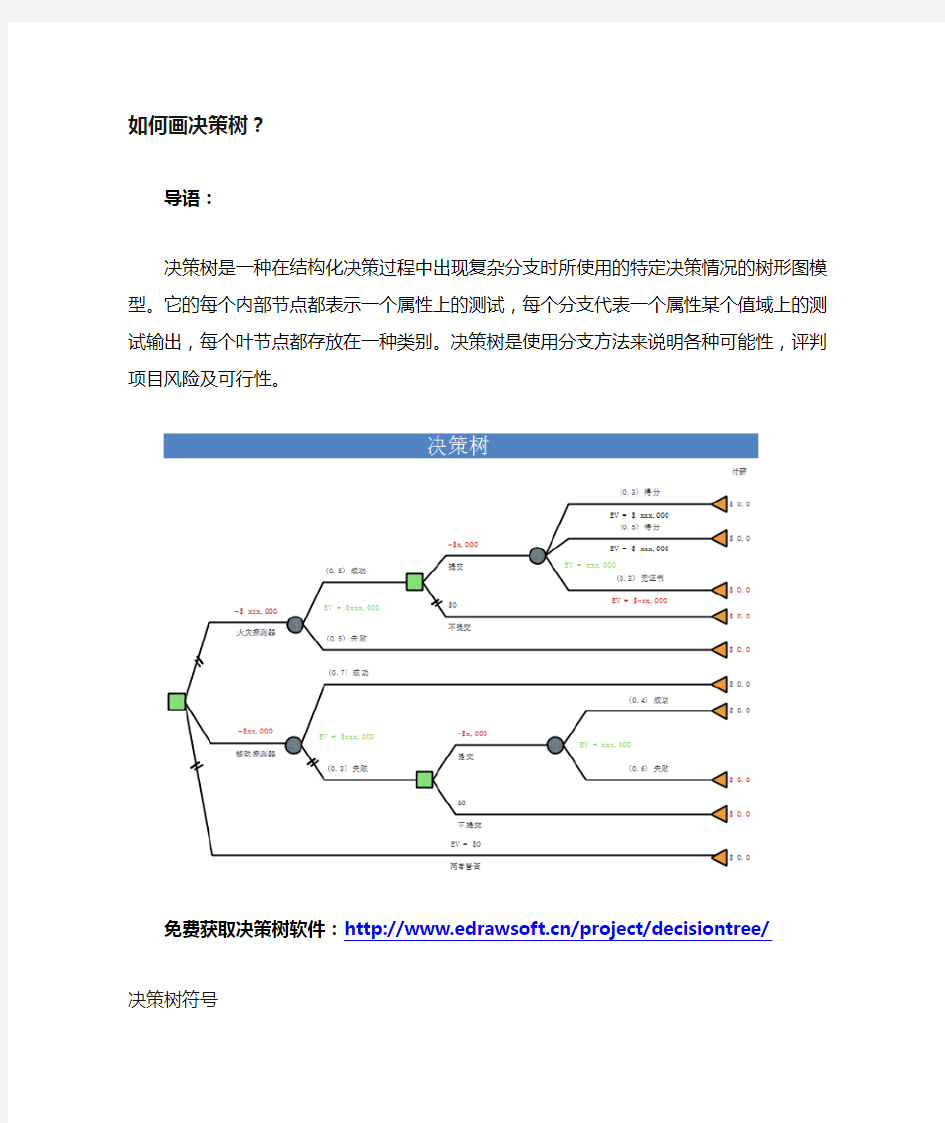

如何画决策树?
导语:
决策树是一种在结构化决策过程中出现复杂分支时所使用的特定决策情况的树形图模型。它的每个内部节点都表示一个属性上的测试,每个分支代表一个属性某个值域上的测试输出,每个叶节点都存放在一种类别。决策树是使用分支方法来说明各种可能性,评判项目风险及可行性。
免费获取决策树软件:https://www.doczj.com/doc/807417824.html,/project/decisiontree/
决策树符号
决策树通常包括决策节点,事件节点,结束等符号,如下图所示。图中所有的符号都是可以编辑的,用户可以根据自己的不同需求来改变符号的颜色,大小以及尺寸。
决策树的优点与缺点
优点:1.可读性好,具有描述性,易于人工理解与分析。
2. 效率高,一次创建可以反复使用。
3. 通过信息增益轻松处理不相关的属性,
缺点:1. 信息不是特别准确。
2. 决策容易受到法律问题和人为观点的影响。
亿图助你快速绘制决策树
第一步:新建空白页面
运行亿图软件,找到项目管理,通过双击模板页面下的决策树来打开一个空白页面。如果时间有限制的话,用户可以直接在例子页面选择合适的例子进行编辑以节省时间。
第二步:拖放符号
从右边符号库中拖放合适的决策树符号在空白页面上,并根据自己的需要调节符号的大小或颜色。
第三步:添加文本
用户有2种添加文本的方式。第一种是直接双击符号然后输入文本;第二种是ctrl+2打开一个文本框然后输入文本。
第四步:选择主题
导航到页面布局,从内置的主题中选择一个合适的主题让决策树显得更加专业和吸引人。
第五步:保存或导出决策树
回到文件页面,用户可以点击保存将决策树保存为默认的.eddx格式或者为了方便分享点击导出&发送将决策树导出为常见的文件格式。
获取更多决策树软件使用技巧:https://www.doczj.com/doc/807417824.html,/software/project/
盈亏平衡分析 某建筑工地需抽除积水保证施工顺利进行,现有A 、B 两个方案可供选择。 A 方案:新建一条动力线,需购置一台2.5W 电动机并线运转,其投资为1400元,第四年 末残值为200元,电动机每小时运行成本为0.84元,每年预计的维护费用120元, 因设备完全自动化无需专人看管。 B 方案:购置一台3.86KW 的(5马力)柴油机,其购置费用为550元,使用寿命为4年, 设备无残值。运行每小时燃料费为0.42元,平均每小时维护费为0.15元,每小 时的人工成本为0.8元。 若寿命都为4年,基准折现率为10%,试比较A 、B 方案的优劣。 解:两方案的总费用都与年开机小时数t 有关,故两方案的年成本均可表示t 的函数。 )4%,10,/(200)4%,10,/(1400F A P A C A -=t t 84.056.51884.0120+=++ t P A C B )8.015.042.0()4%,10,/(550+++= t 37.151.175+= 令C A =C B ,即518.56+0.84t=173.51+1.37t 可解出:t =651(h),所以在t =651h 这一点上, C A =C B =1065.4(元) A 、 B 两方案的年成本函数如图13所示。从图中可见,当年开机小时数低于651h ,选B 方案有利;当年开机小时数高于651h 则选A 方案有利。 图13 A 、B 方案成本函数曲线
决策树问题 55.某建筑公司拟建一预制构件厂,一个方案是建大厂,需投资300万元,建成后如销路 好每年可获利100万元,如销路差,每年要亏损20万元,该方案的使用期均为10年; 另一个方案是建小厂,需投资170万元,建成后如销路好,每年可获利40万元,如销路差每年可获利30万元;若建小厂,则考虑在销路好的情况下三年以后再扩建,扩建投资130万元,可使用七年,每年盈利85万元。假设前3年销路好的概率是0.7,销路差的概率是0.3,后7年的销路情况完全取决于前3年;试用决策树法选择方案。 决策树图示 考虑资金的时间价值,各点益损期望值计算如下: 点①:净收益=[100×(P/A,10%,10)×0.7+(-20)×(P/A,10%,10)×0.3]-300=93.35(万元) 点③:净收益=85×(P/A,10%,7)×1.0-130=283.84(万元) 点④:净收益=40×(P/A,10%,7)×1.0=194.74(万元) 可知决策点Ⅱ的决策结果为扩建,决策点Ⅱ的期望值为283.84+194.74=478.58(万元)点②:净收益=(283.84+194.74)×0.7+40×(P/A,10%,3)×0.7+30×(P/A,10%,10)×0.3-170=345.62(万元) 由上可知,最合理的方案是先建小厂,如果销路好,再进行扩建。在本例中,有两个决策点Ⅰ和Ⅱ,在多级决策中,期望值计算先从最小的分枝决策开始,逐级决定取舍到决策能选定为止。 56.某投资者预投资兴建一工厂,建设方案有两种:①大规模投资300万元;②小规模投 资160万元。两个方案的生产期均为10年,其每年的损益值及销售状态的规律见表15。 试用决策树法选择最优方案。 表15 各年损益值及销售状态
数据挖掘方法综述 [摘要]数据挖掘(DM,DataMining)又被称为数据库知识发现(KDD,Knowledge Discovery in Databases),它的主要挖掘方法有分类、聚类、关联规则挖掘和序列模式挖掘等。 [关键词]数据挖掘分类聚类关联规则序列模式 1、数据挖掘的基本概念 数据挖掘从技术上说是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在的有用的信息和知识的过程。这个定义包括好几层含义: 数据源必须是真实的、大量的、含噪声的、发现的是用户感兴趣的知识, 发现的知识要可接受、可理解、可运用, 并不要求发现放之四海皆准的知识, 仅支持特定的发现问题, 数据挖掘技术能从中自动分析数据进行归纳性推理从中发掘出潜在的数据模式或进行预测, 建立新的业务模型帮助决策者调整策略做出正确的决策。数据挖掘是是运用统计学、人工智能、机器学习、数据库技术等方法发现数据的模型和结构、发现有价值的关系或知识的一门交叉学科。数据挖掘的主要方法有分类、聚类和关联规则挖掘等 2、分类 分类(Classification)又称监督学习(Supervised Learning)。监
督学习的定义是:给出一个数据集D,监督学习的目标是产生一个联系属性值集合A和类标(一个类属性值称为一个类标)集合C的分类/预测函数,这个函数可以用于预测新的属性集合(数据实例)的类标。这个函数就被称为分类模型(Classification Model),或者是分类器(Classifier)。分类的主要算法有:决策树算法、规则推理、朴素贝叶斯分类、支持向量机等算法。 决策树算法的核心是Divide-and-Conquer的策略,即采用自顶向下的递归方式构造决策树。在每一步中,决策树评估所有的属性然后选择一个属性把数据分为m个不相交的子集,其中m是被选中的属性的不同值的数目。一棵决策树可以被转化成一个规则集,规则集用来分类。 规则推理算法则直接产生规则集合,规则推理算法的核心是Separate-and-Conquer的策略,它评估所有的属性-值对(条件),然后选择一个。因此,在一步中,Divide-and-Conquer策略产生m条规则,而Separate-and-Conquer策略只产生1条规则,效率比决策树要高得多,但就基本的思想而言,两者是相同的。 朴素贝叶斯分类的基本思想是:分类的任务可以被看作是给定一个测试样例d后估计它的后验概率,即Pr(C=c j︱d),然后我们考察哪个类c j对应概率最大,便将那个类别赋予样例d。构造朴素贝叶斯分类器所需要的概率值可以经过一次扫描数据得到,所以算法相对训练样本的数量是线性的,效率很高,就分类的准确性而言,尽管算法做出了很强的条件独立假设,但经过实际检验证明,分类的效果还是
注意答卷要求: 1.统一代号:P 为利润,C 为成本,Q 为收入,EP 为期望利润 2.画决策树时一定按照标准的决策树图形画,不要自创图形 3.决策点和状态点做好数字编号 4.决策树上要标出损益值 某企业似开发新产品,现在有两个可行性方案需要决策。 I 开发新产品A ,需要追加投资180万元,经营期限为5年。此间,产品销路好可获利170万元;销路一般可获利90万元;销路差可获利-6万元。三种情况的概率分别为30%,50%,20%。 II.开发新产品B ,需要追加投资60万元,经营期限为4年。此间,产品销路好可获利100万元;销路一般可获利50万元;销路差可获利20万元。三种情况的概率分别为60%,30%,10%。 (1)画出决策树 销路好 0.3 170 90 -6 100 50 20
(2)计算各点的期望值,并做出最优决策 求出各方案的期望值: 方案A=170×0.3×5+90×0.5×5+(-6)×0.2×5=770(万元) 方案B=100×0.6×4+50×0.3×4+20×0.1×4=308(万元) 求出各方案的净收益值: 方案A=770-180=590(万元) 方案B=308-60=248(万元) 因为590大于248大于0 所以方案A最优。 某企业为提高其产品在市场上的竞争力,现拟定三种改革方案:(1)公司组织技术人员逐渐改进技术,使用期是10年;(2)购买先进技术,这样前期投入相对较大,使用期是10年;(3)前四年先组织技术人员逐渐改进,四年后再决定是否需要购买先进技术,四年后买入技术相对第一年便宜一些,收益与前四年一样。预计该种产品前四年畅销的概率为0.7,滞销的概率为0.3。如果前四年畅销,后六年畅销的概率为0.9;若前四年滞销,后六年滞销的概率为0.1。相关的收益数据如表所示。 (1)画出决策树 (2)计算各点的期望值,并做出最优决策 投资收益 表单位:万元 解(1)画出决策树,R为总决策,R1为二级决策。
目录 1 决策树算法 (2) 1.1 具体应用场景和意义 (2) 1.2 现状分析 (3) 2 C4.5算法对ID3算法的改进 (4) 3 C4.5算法描述 (7) 3.1 C4.5算法原理 (7) 3.2 算法框架 (8) 3.3 C4.5算法伪代码 (9) 4 实例分析 (9) 5 C4.5算法的优势与不足 (12) 5.1 C4.5算法的优势 (12) 5.2 C4.5算法的不足: (12) 参考文献 (12)
C4.5算法综述 摘要 最早的决策树算法是由Hunt等人于1966年提出的CLS。当前最有影响的决策树算法是Quinlan于1986年提出的ID3和1993年提出的C4.5。ID3只能处理离散型描述属性,它选择信息增益最大的属性划分训练样本,其目的是进行分枝时系统的熵最小,从而提高算法的运算速度和精确度。ID3算法的主要缺陷是,用信息增益作为选择分枝属性的标准时,偏向于取值较多的属性,而在某些情况下,这类属性可能不会提供太多有价值的信息。C4.5是ID3算法的改进算法,不仅可以处理离散型描述属性,还能处理连续性描述属性。C4.5采用了信息增益比作为选择分枝属性的标准,弥补了ID3算法的不足。 C4.5算法在ID3算法的基础上进行了改进,对于预测变量的缺值处理、剪枝技术、派生规则等方面作了较大的改进,既适合于分类问题,又适合于回归问题,是目前应用最为广泛的归纳推理算法之一,在数据挖掘中收到研究者的广泛关注。 1 决策树算法 1.1具体应用场景和意义 决策树(Decision Tree)是用于分类和预测的主要技术,它着眼于从一组无规则的事例推理出决策树表示形式的分类规则,采用自顶向下的递归方式,在决策树的内部节点进行属性值的比较,并根据不同属性判断从该节点向下分支,在决策树的叶节点得到结论。因此,从根节点到叶节点就对应着一条合理规则,整棵树就对应着一组表达式规则。基于决策树算法的一个最大的优点是它在学习过程中不需要使用者了解很多背景知识,只要训练事例能够用属性即结论的方式表达出来,就能使用该算法进行学习。 决策树算法在很多方面都有应用,如决策树算法在医学、制造和生产、金融分析、天文学、遥感影像分类和分子生物学、机器学习和知识发现等领域得到了广泛应用。 决策树技术是一种对海量数据集进行分类的非常有效的方法。通过构造决策树模型,提取有价值的分类规则,帮助决策者做出准确的预测已经应用在很多领
17秋学期(1709)《经管学》在线作业一 一、单选题(共30道试卷,共60分。)1.(C)是进行组织设计的基本出发点。 A. 人员配备 B. 组织文化 C. 组织目标 D. 组织结构满分:2分2.领导的特质理论告诉我们. A A. 领导是天生的 B. 领导的行为决定了领导才能 C. 下属的服从是领导之所以为领导的关键 D. 领导行为是可以模仿的满分:2分3.决策方法中的“硬技术”是指(A)。 A. 计量决策方法 B. 专家意见法 C. 定性决策法 D. 决策树法满分:2分4.(B )是指企业经管系统随着企业内外部环境的变化,而不断更新自己的经营理念、经营方针和经营目标,为达此目的,必须相应的改变有关的经管方法和手段,使其与企业的经营目标相适应。 A. 激励原理 B. 动态原理 C. 创新原理 D. 可持续发展原理满分:2分5.被称为“科学经管之父”的经管学家是(A)。 A. 泰勒 B. 法约尔 C. 德鲁克 D. 西蒙满分:2分6.现在很多大公司都实行所谓的“门户开放”政策(比如IBM),即鼓励各级员工通过多种途径直接向公司高层领导反映意见、提出建议,公司总裁也会设立专门的信箱,以接收这些意见或者抱怨。这里的沟通渠道可以看成是一种(B)。 A. 下行沟通 B. 上行沟通 C. 对角沟通 D. 横向沟通满分:2分7.非程序化决策往往是有关企业重大战略问题的决策,主要由(B)承担。 A. 一线工人 B. 上层经管人员 C. 中层经管人员 D. 低层经管人员满分:2分8.下面关于内部招聘的说法不正确的是(B)。 A. 内部员工的竞争结果必然有胜有败,可能影响组织的内部团结。 B. 内部招聘人员筛选难度大,成本高。 C. 可能在组织中滋生“小集团”,削弱组织效能。 D. 组织内的“近亲繁殖”现象,可能不利于个体创新。满分:2分9.(D)是指依靠企业各级行政组织的法定权力,通过命令、指示、规定、制度、规范以及具有约束性的计划等行政手段来经管企业的方法。 A. 教育方法 B. 经济方法 C. 法制方法 D. 行政方法满分:2分10.目标经管的提出者是(C)。 A. 泰罗 B. 法约尔 C. 德鲁克 D. 巴纳德满分:2分11.解决复杂问题应采用的沟通方式是(D)。 A. 链式 B. 轮式 C. 环式 D. 全通道式满分:2分12.(D)就是对一系列典型的事物进行观察分析,找出各种因素之间的因果关系,从中找出事物发展变化的一般规律,这种从典型到一般的研究方法也称为实证研究。 A. 演绎法 B. 调查法 C. 实验法 D. 归纳法满分:2分13.泰罗经管理论的代表着作是(B)。
注意答卷要求: 欧阳光明(2021.03.07) 1.统一代号:P为利润,C为成本,Q为收入,EP为期望利润2.画决策树时一定按照标准的决策树图形画,不要自创图形3.决策点和状态点做好数字编号 4.决策树上要标出损益值 某企业似开发新产品,现在有两个可行性方案需要决策。 I开发新产品A,需要追加投资180万元,经营期限为5年。此间,产品销路好可获利170万元;销路一般可获利90万元;销路差可获利-6万元。三种情况的概率分别为30%,50%,20%。 II.开发新产品B,需要追加投资60万元,经营期限为4年。此间,产品销路好可获利100万元;销路一般可获利50万元;销路差可获利20万元。三种情况的概率分别为60%,30%,10%。 (1)画出决策树
(2)计算各点的期望值,并做出最优决策 求出各方案的期望值: 方案A=170×0.3×5+90×0.5×5+(-6)×0.2×5=770(万元) 方案B=100×0.6×4+50×0.3×4+20×0.1×4=308(万元) 求出各方案的净收益值: 方案A=770-180=590(万元) 方案B=308-60=248(万元) 因为590大于248大于0 所以方案A 最优。 某企业为提高其产品在市场上的竞争力,现拟定三种改革方案:(1)公司组织技术人员逐渐改进技术,使用期是10年;(2)购 销路好 0.3 170 90 -6 100 50 20
买先进技术,这样前期投入相对较大,使用期是10年;(3)前四年先组织技术人员逐渐改进,四年后再决定是否需要购买先进技术,四年后买入技术相对第一年便宜一些,收益与前四年一样。预计该种产品前四年畅销的概率为0.7,滞销的概率为0.3。如果前四年畅销,后六年畅销的概率为0.9;若前四年滞销,后六年滞销的概率为0.1。相关的收益数据如表所示。 (1)画出决策树 (2)计算各点的期望值,并做出最优决策 投资收益表单位:万元 解(1)画出决策树,R为总决策,R1为二级决策。
科技论坛 决策树学习研究综述 叶萌 (黑龙江电力职工大学,黑龙江哈尔滨150030) 1概述 决策树是构建人工智能系统的主要方法之一,随着数据挖掘技术在商业智能等方面的应用,决策树技术将在未来发挥越来越强大的作用[1]。自从Quinlan 在1979年提出构造决策树ID3算法以来,决策树的实现已经有很多算法,常见的有:CLS (concept learning system )学习算法,ID4、ID5R 、C4.5算法,以及CART 、C5.0、FuzzyC4.5、0C1、QUEST 和CAL5等[2]。 现在,许多学者在规则学习与决策树学习的结合方面,做了大量的研究工作。Brako 等的ASSISTANT ,将AQ15中的近似匹配方法引入决策树中。Clark 等的CN2,将ID3算法和AQ 算法编织在一起,用户可选择其中任何一种算法使用。Utgoff 等的ID5R 算法,不要求一次性提供所有的训练实例,训练实例可以逐次提供,生成的决策树逐次精化,以支持增量式学习。洪家荣教授结合实际应用问题对ID3算法作了一些改进,提出了两个ID3和AQ 结合的改进算法,IDAQ 和AQID ,此外,还陆续出现了处理大规模数据集的决策树算法,如SLIQ ,SPRINT 等等[3]。 2决策树算法研究2.1构造决策树算法 决策树学习是从无次序、无规则的样本数据集中推理出决策树表示形式、逼近离散值目标函数的分类规则方法。它采用自顶向下的递归方式,在决策树的内部结点进行属性值的比较并根据不同的属性值判断从该结点向下的分支,在决策树的叶结点得到结论,因此从根结点到叶结点的一条路径就对应着一条规则,整棵决策树就对应着一组表达式规则。我们可将决策树看成是定义布尔函数的一种方法。其输入是一组属性描述的对象,输出为yes/no 决策。决策树代表一个假设,可以写成逻辑公式。决策树的表达能力限于命题逻辑,该对象的任一个属性的任一次测试均是一个命题。在命题逻辑范围内,决策树的表达能力是完全的。一棵决策树可以代表一个决定训练例集分类的决策过程,树的每个结点对应于一个属性名或一个特定的测试,该测试在此结点根据测试的可能结果对训练例集进行划分。划分出的每个部分都对应于相应训练例集子空间的一个分类子问题,该分类子问题可以由一棵决策树来解决。因此,一 棵决策树可以看作是一个对目标分类的划分和获取策略[4] 。 2.2处理大规模数据集的决策树算法 ID3或者C4.5算法都是在建树时将训练集一次性装载入内存的。但当面对大型的有着上百万条纪录的数据库时,就无法实际应用这些算 法。针对这一问题, 前人提出了不少改进方法,如数据采样法、连续属性离散化法或将数据分为若干小块分别建树然后综合成一个最终的树,但这些改进都以降低了树的准确性为代价。直到M etha,Agrawal 和Ris-sane 在1996年提出了SLIQ 方法,以及在此基础上进行改进得到的SPRINT [6]方法。 3决策树学习的常见问题3.1过度拟合 在利用决策树归纳学习时,需要事先给定一个假设空间,且必须在这个假设空间中选择一个,使之与训练实例集相匹配。我们知道任何一个学习算法不可能在没有任何偏置的情况下学习。如果事先知道所要学习的函数属于整个假设空间中的一个很小的子集,那么即使训练实例不完整,也有可能从已有的训练实例集中学习到有用的假设,使它对未来的实例进行正确的分类。当然,我们往往无法事先知道所要学习的函数属于整个假设空间中的哪个很小的子集,即使是知道,我们还是希望有一个大的训练实例集。因为训练实例集越大,关于分类的信息就越多。这时,即使随机地从与训练实例集相匹配的假设集中选择一个,它也能对未知实例的分类进行预测。相反,如果训练实例集与整个假设空间相比 过小,即使在有偏置的情况下,仍有过多的假设与训练实例集相匹配,这 时作出假设的泛化能力将很差。当有过多的假设与训练实例集相匹配,便称为过度拟合(overfit )。 3.2树剪枝 对决策树进行修剪可以控制决策树的复杂程度,避免决策树过于复 杂和庞大。此外, 还可以解决过度拟合的问题。修剪决策树有多种算法,通常分为这样五类。最为常用的是通过预 剪枝(pre-pruning )和后剪枝(post-pruning )完成,或逐步调整树的大小;其次是扩展测试集方法,首先按特征构成是数据驱动还是假设驱动的差别,将建立的特征组合或分割,然后在此基础上引进多变量测试集。第三类方法包括选择不同的测试集评价函数,通过改善连续特征的描述或修改搜索算法本身实现;第四类方法使用数据库约束,即通过削减数据库或实例描述特征集来简化决策树;第五类方法是将决策树转化成另一种数据结构。这些方法通常可以在同另一种算法相互结合中,增强各自的功能。 4决策树在工程中的应用 决策树在工程中的诸多领域获得了非常广泛的应用,主要有以下几个方面: 4.1决策树技术应用于机器人导航 E.Swere 和D .J.M ulvaney 将决策树技术应用于移动机器人导航并取得了一定的成功。 4.2决策树技术应用于地铁中的事故处理 法国的Brezillon 等人成功地将决策树技术应用于地铁交通调度智能系统。他们根据决策树的基本思想开发出上下文图表来帮助驾驶员针对事故做出正确的处理。 4.3决策树技术应用于图像识别 决策树技术应用于包括图像在内的科学数据分析。如利用决策树对上百万个天体进行分类,利用决策树对卫星图像进行分析以估计落叶林和针叶林的基部面积值。 4.4决策树应用于制造业 决策树技术已经成功应用于焊接质量的检测以及大规模集成电路 的设计,它不仅可以规划印刷电路板的布线, 波音公司甚至将它用于波音飞机生产过程的故障诊断以及质量控制。 5决策树技术面临的问题和挑战发展至今,决策树技术面临的问题和挑战表现在以下几个方面:5.1决策树方法的效率亟待提高 数据挖掘面临的数据往往是海量的,对实时性要求较高的决策场所,数据挖掘方法的主动性和快速性显得日益重要。应用实时性技术、主动数据库技术和分布并行算法设计技术等现代计算机先进技术,是数据挖掘方法实用化的有效途径。 5.2适应多数据类型、容噪的决策树挖掘方法随着计算机网络和信息的社会化,数据挖掘的对象已不是关系数据库模型,而是分布、异构的多类型数据库,数据的非结构化程度、噪声等现象越来越突出,这也是决策树技术面临的困难问题。 6结论 决策树技术早已被证明是利用计算机模仿人类决策的有效方法,已经得到广泛的应用,并且已经有了许多成熟的系统。但是,解决一个复杂的数据挖掘问题的任何算法都要面临以下问题:从错误的数据中学习、从分布的数据中学习、从有偏的数据中学习、学习有弹性的概念、学习那些抽象程度不同的概念、整合定性与定量的发现等,因此,还有很多未开 发的课题等待研究。若将决策树技术与其他新兴 摘要:决策树分类学习算法是使用广泛、实用性很强的归纳推理方法之一,在机器学习、数据挖掘等人工智能领域有相当重要的理 论意义与实用价值。在详细阐述决策树技术的几种典型算法以及它的一些常见问题后, 介绍了它在工程上的实际应用,最后提出了它的研究方向以及它所面临的问题和挑战。 关键词:决策树;决策树算法;ID3;C4.5;SLIQ ;SPRINT (下转156页)22··
摘要 随着信息科技的高速发展,人们对于积累的海量数据量的处理工作也日益增重,需发明之母,数据挖掘技术就是为了顺应这种需求而发展起来的一种数据处理技术。 数据挖掘技术又称数据库中的知识发现,是从一个大规模的数据库的数据中有效地、隐含的、以前未知的、有潜在使用价值的信息的过程。决策树算法是数据挖掘中重要的分类方法,基于决策树的各种算法在执行速度、可扩展性、输出结果的可理解性、分类预测的准确性等方面各有千秋,在各个领域广泛应用且已经有了许多成熟的系统,如语音识别、模式识别和专家系统等。本文着重研究和比较了几种典型的决策树算法,并对决策树算法的应用进行举例。 关键词:数据挖掘;决策树;比较
Abstract With the rapid development of Information Technology, people are f acing much more work load in dealing with the accumulated mass data. Data mining technology is also called the knowledge discovery in database, data from a large database of effectively, implicit, previou sly unknown and potentially use value of information process. Algorithm of decision tree in data mining is an important method of classification based on decision tree algorithms, in execution speed, scalability, output result comprehensibility, classification accuracy, each has its own merits., extensive application in various fields and have many mature system, such as speech recognition, pattern recognition and expert system and so on. This paper studies and compares several kinds of typical decision tree algorithm, and the algorithm of decision tree application examples. Keywords: Data mining; decision tree;Compare
盈亏平衡分析 某建筑工地需抽除积水保证施工顺利进行,现有A 、B 两个方案可供选择。 A 方案:新建一条动力线,需购置一台2.5W 电动机并线运转,其投资为1400元,第四年 末残值为200元,电动机每小时运行成本为0.84元,每年预计的维护费用120元,因设备完全自动化无需专人看管。 B 方案:购置一台3.86KW 的(5马力)柴油机,其购置费用为550元,使用寿命为4年, 设备无残值。运行每小时燃料费为0.42元,平均每小时维护费为0.15元,每小时的人工成本为0.8元。 若寿命都为4年,基准折现率为10%,试比较A 、B 方案的优劣。 解:两方案的总费用都与年开机小时数t 有关,故两方案的年成本均可表示t 的函数。 )4%,10,/(200)4%,10,/(1400F A P A C A -=t t 84.056.51884.0120+=++ t P A C B )8.015.042.0()4%,10,/(550+++= t 37.151.175+= 令C A =C B ,即518.56+0.84t=173.51+1.37t 可解出:t =651(h),所以在t =651h 这一点上, C A =C B =1065.4(元) A 、 B 两方案的年成本函数如图13所示。从图中可见,当年开机小时数低于651h ,选B 方案有利;当年开机小时数高于651h 则选A 方案有利。 图13 A 、B 方案成本函数曲 线
决策树问题 55.某建筑公司拟建一预制构件厂,一个方案是建大厂,需投资300万元,建成后如销路 好每年可获利100万元,如销路差,每年要亏损20万元,该方案的使用期均为10年; 另一个方案是建小厂,需投资170万元,建成后如销路好,每年可获利40万元,如销路差每年可获利30万元;若建小厂,则考虑在销路好的情况下三年以后再扩建,扩建投资130万元,可使用七年,每年盈利85万元。假设前3年销路好的概率是0.7,销路差的概率是0.3,后7年的销路情况完全取决于前3年;试用决策树法选择方案。 决策树图示 考虑资金的时间价值,各点益损期望值计算如下: 点①:净收益=[100×(P/A,10%,10)×0.7+(-20)×(P/A,10%,10)×0.3]-300=93.35(万元) 点③:净收益=85×(P/A,10%,7)×1.0-130=283.84(万元) 点④:净收益=40×(P/A,10%,7)×1.0=194.74(万元) 可知决策点Ⅱ的决策结果为扩建,决策点Ⅱ的期望值为283.84+194.74=478.58(万元)点②:净收益=(283.84+194.74)×0.7+40×(P/A,10%,3)×0.7+30×(P/A,10%,10)×0.3-170=345.62(万元) 由上可知,最合理的方案是先建小厂,如果销路好,再进行扩建。在本例中,有两个决策点Ⅰ和Ⅱ,在多级决策中,期望值计算先从最小的分枝决策开始,逐级决定取舍到决策能选定为止。 56.某投资者预投资兴建一工厂,建设方案有两种:①大规模投资300万元;②小规模投 资160万元。两个方案的生产期均为10年,其每年的损益值及销售状态的规律见表15。 试用决策树法选择最优方案。 表15 各年损益值及销售状态
1、已知产品出库管理的过程是:仓库管理员将提货人员的零售出库单上的数据登记到零售出库流水账上,并每天将零售出库流水账上当天按产品名称、规格分别累计的数据记入库存账台。请根据出库管理的过程画出它的业务流图。 产品出库管理业务流图 2、设产品出库量的计算方法是:当库存量大于等于提货量时,以提货量作为出库量;当库存量小于提货量而大于等于提货量的10%时,以实际库存量作为出库量;当库存量小于提货量的10%时,出库量为0(即提货不成功)。请表示出库量计算的决策树。 3、有一工资处理系统,每月根据职工应发的工资计算个人收入所得税,交税额算法如下: 若职工月收入=<800元,不交税; 若800职工<职工月收入=<1300元,则交超过800元工资额的5%;
若超过1300元,则交800到1300元的5%和超过1300元部分 的10%。 试画出计算所得税的决策树和决策表。 1、解:(1)决策树 设X为职工工资,Y为职工应缴税额。 X<=800 ——Y=0 某工资处理系统800
《数据挖掘》 数据挖掘分类算法综述 专业:计算机科学与技术专业学号:S2******* 姓名:张靖 指导教师:陈俊杰 时间:2011年08月21日
数据挖掘分类算法综述 数据挖掘出现于20世纪80年代后期,是数据库研究中最有应用价值的新领域之一。它最早是以从数据中发现知识(KDD,Knowledge Discovery in Database)研究起步,所谓的数据挖掘(Data Mining,简称为DM),就从大量的、不完全的、有噪声的、模糊的、随机的、实际应用的数据中提取隐含在其中的、人们不知道的但又有用的信息和知识的过程。 分类是一种重要的数据挖掘技术。分类的目的是根据数据集的特点构造一个分类函数或分类模型(也常常称作分类器)。该模型能把未知类别的样本映射到给定类别中的一种技术。 1. 分类的基本步骤 数据分类过程主要包含两个步骤: 第一步,建立一个描述已知数据集类别或概念的模型。如图1所示,该模型是通过对数据库中各数据行内容的分析而获得的。每一数据行都可认为是属于一个确定的数据类别,其类别值是由一个属性描述(被称为类别属性)。分类学习方法所使用的数据集称为训练样本集合,因此分类学习又可以称为有指导学习(learning by example)。它是在已知训练样本类别情况下,通过学习建立相应模型,而无指导学习则是在训练样本的类别与类别个数均未知的情况下进行的。 通常分类学习所获得的模型可以表示为分类规则形式、决策树形式或数学公式形式。例如,给定一个顾客信用信息数据库,通过学习所获得的分类规则可用于识别顾客是否是具有良好的信用等级或一般的信用等级。分类规则也可用于对今后未知所属类别的数据进行识别判断,同时也可以帮助用户更好的了解数据库中的内容。 图1 数据分类过程中的学习建模 第二步,利用所获得的模型进行分类操作。首先对模型分类准确率进行估计,例如使用保持(holdout)方法。如果一个学习所获模型的准确率经测试被认为是可以接受的,那么就可以使用这一模型对未来数据行或对象(其类别未知)进行分类。例如,在图2中利用学习获得的分类规则(模型)。对已知测试数据进行模型
. 注意答卷要求: EP为期望利润P1.统一代号:为利润,C为成本,Q为收入,2.画决策树时一定按照标准的决策树图形画,不要自创图形 3.决策点和状态点做好数字编号.决策树上要标出损益值4 某企业似开发新产品,现在有两个可行性方案需要决策。年。此间,产品销路好5I开发新产品A,需要追加投资180万元,经营期限为万元。三种情况的90可获利170万元;销路一般可获利万元;销路差可获利-6 概率分别为30%,50%,20%。年。此间,产品销路好开发新产品B,需要追加投资万元,经营期限为460II.三种情况的万元。万元;销路差可获利2050可获利100万元;销路一般可获利,10%。,概率分别为60%30%(1)画出决策树0.3 销路好 170 0.5销路一90 2 0.1 销路差-6 A 开发产品1 0.6 销路好 100 B 开发产品0.3 销路一般 3 50 0.1
销路差 20 4 / 1 . (2)计算各点的期望值,并做出最优决策 求出各方案的期望值: 方案A=170×0.3×5+90×0.5×5+(-6)×0.2×5=770(万元) 方案B=100×0.6×4+50×0.3×4+20×0.1×4=308(万元) 求出各方案的净收益值: 方案A=770-180=590(万元) 方案B=308-60=248(万元) 因为590大于248大于0 所以方案A最优。 某企业为提高其产品在市场上的竞争力,现拟定三种改革方案:(1)公司组织技术人员逐渐改进技术,使用期是10年;(2)购买先进技术,这样前期投入相对较大,使用期是10年;(3)前四年先组织技术人员逐渐改进,四年后再决定是否需要购买先进技术,四年后买入技术相对第一年便宜一些,收益与前四年一样。预计该种产品前四年畅销的概率为0.7,滞销的概率为0.3。如果前四年畅销,后六年畅销的概率为0.9;若前四年滞销,后六年滞销的概率为0.1。相关的收益数据如表所示。 (1)画出决策树 (2)计算各点的期望值,并做出最优决策 投资收益 为总决策,)画出决策树,1(解 RR1为二级决策。 4 / 2
决策树算法综述 摘要:决策树是用于分类和预测的一种树结构。本文介绍了决策树算法的基本概念,包括决策树的基本原理、分类方法,发展过程及现状等。详细介绍了基于决策树理论的分类方法,包括ID3算法的基本思想,属性选择度量等。在分析传统的决策树算法的基础之上,引入了属性关注度,提出了一个基于属性选择度量改进的算法。 关键词:决策树;ID3;属性关注度 1.决策树的基本概念 1.1决策树的基本原理 决策树是用于分类和预测的一种树结构。决策树学习是以实例为基础的归纳学习 算法。它着眼于从一组无次序、无规则的实例中推理出决策树表示形式的分类规则。它采用自顶向下的递归方式,在决策树的内部节点进行属性值的比较并根据不同的属 性判断从该节点向下的分支,在决策树的叶节点得到结论。所以从根节点就对应着一 条合取规则,整棵树就对应着一组析取表达式规则。 一棵决策树是一棵有向无环树,它由若干个节点、分支、分裂谓词以及类别组成。节点 是一棵决策树的主体。其中,没有父亲节点的节点称为根节点,没有子节点的节点称为叶子节点,一个节点按照某个属性分裂时,这个属性称为分裂属性。决策树算法构造决策树来 发现数据中蕴涵的分类规则。如何构造精度高、规模小的决策树是决策树算法的核心 内容。决策树构造可以分两步进行。 第一步,决策树的生成。决策树采用自顶向下的递归方式:从根节点开始在每个 节点上按照给定标准选择测试属性,然后按照相应属性的所有可能取值向下建立分枝,划分训练样本,直到一个节点上的所有样本都被划分到同一个类,或者某一节点中的 样本数量低于给定值时为止。这一阶段最关键的操作是在树的节点上选择最佳测试属性,该属性可以将训练样本进行最好的划分。最佳测试属性的选择标准有信息增益、基尼指数、以及基于距离的划分等。 第二步,决策树的剪技。构造过程得到的并不是最简单、紧凑的决策树,因为许 多分枝反映的可能是训练数据中的噪声或孤立点。树剪枝过程试图检测和去掉这种分枝,以提高对未知数据集进行分类时的准确性。树剪枝方法主要有先剪枝和后剪枝。树剪枝方法的剪枝标准有最小描述长度(MDL)和最小期望错误率等。前者对决策树进 行二进位编码,最佳剪枝树就是编码所需二进位最少的树;后者计算某节点上的子树 被剪枝后出现的期望错误率,由此判断是否剪枝。决策树的构造过程如下图所示。
1、某运输公司收取运费的标准如下: ①本地客户每吨5元。 ②外地客户货物重量W在100吨以(含),每吨8元。 ③外地客户货物100吨以上时,距离L在500公里以(含)超过部分每吨增加7元,距离500公里以上时,超过部分每吨再增加10元。 试画出决策树、决策表,反映运费策略。 2、邮寄包裹收费标准如下: 若收件地点在1000公里以,普通件每公斤2元,挂号件每公斤3元;若收件地点在1000公里以外,普通件每公斤2.5元,挂号件每公斤3.5元,若重量大于30公斤,超重部分每公斤加收0.5元。绘制收费标准的决策树和决策表(重量用W表示)。 3、某工厂对一部分职工重新分配工作,其原则如下: 年龄不满20岁,文化程度为小学脱产学习,文化程度是中学的为电工。年龄满20岁但不足50岁,文化程度为小学或中学,男性为钳工,女性为车工;文化程度是大学的为技术员。年龄满50岁及50岁以上,文化程度是小学或中学的为材料员;文化程度是大学的为技术员。请画出处理职工分配政策(以文化程度为基准)的决策表、决策树。
4、某学校对教职工拟定奖励策略如下:(1)高级职称且教学评估优秀的奖励1000元,教学效果评估合格的奖励800元;(2)中级职称且教学评估优秀的奖励800元,教学效果评估合格的奖励500元;(3)初级职称且教学评估优秀的奖励500元。要求画出奖励策略的决策树。 5、某用电量计费系统记费如下:如果按固定价格方法记帐,对耗电量小于100度(不包含100度)的情况,按每月最低费用收费。超过100度时,就按A类计费办法收费。如果按可变价格方法记帐,则对100度以下(不包含100度)耗电量,按A类计费办法收费,超过100度时按B类计费办法收费。画出上述说明的决策树。 6、某金融部门的贷款发放最高限额问题描述如下: 对于固定资产超过500万元(含500万元)的企业:·如果无不良还款记录,低于3年期(含3年)的贷款最高限额为100万元; ·如果有不良还款记录,低于3年期(含3年)的贷款最高限额为50万元。 对于固定资产低于500万元的企业: ·如果无不良还款记录,低于3年期(含3年)的贷款最高限额为60万元;
分类算法综述 1 分类算法分类是数据挖掘中的一个重要课题。分类的目的是学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个。分类可用于提取描述重要数据类的模型或预测未来的数据趋势。分类可描述如下:输入数据,或称训练集(Training Set),是一条条的数据库记录(Record)组成的。每一条记录包含若干个属性(Attribute),组成一个特征向量。训练集的每条记录还有一个特定的类标签(Class Label)与之对应。该类标签是系统的输入,通常是以往的一些经验数据。一个具体样本的形式可为样本向量:(v1,v2,…, vn ;c)。在这里vi表示字段值,c表示类别。分类的目的是:分析输入数据,通过在训练集中的数据表现出来的特性,为每一个类找到一种准确的描述或者模型。这种描述常常用谓词表示。由此生成的类描述用来对未来的测试数据进行分类。尽管这些未来的测试数据的类标签是未知的,我们仍可以由此预测这些新
数据所属的类。注意是预测,而不能肯定,因为分类的准确率不能达到百分之百。我们也可以由此对数据中的每一个类有更好的理解。也就是说:我们获得了对这个类的知识。 2 典型分类算法介绍解决分类问题的方法很多,下面介绍一些经典的分类方法,分析 各自的优缺点。 2.1 决策树分类算法决策树(Decision Tree)是一种有向无环图(Directed Acyclic Graphics,DAG)。决策树方法是利用信息论中 的信息增益寻找数据库中具有最大信息量的属性字段,建立决策树的一个结点,在根据该属性字段的 不同取值建立树的分支,在每个子分支子集中重复 建立树的下层结点和分支的一个过程。构造决策树 的具体过程为:首先寻找初始分裂,整个训练集作 为产生决策树的集合,训练集每个记录必须是已经 分好类的,以决定哪个属性域(Field)作为目前最 好的分类指标。一般的做法是穷尽所有的属性域, 对每个属性域分裂的好坏做出量化,计算出最好的 一个分裂。量化的标准是计算每个分裂的多样性(Diversity)指标。其次,重复第一步,直至每个叶 节点内的记录都属于同一类且增长到一棵完整的树。
决策树是分类应用中采用最广泛的模型之一。与神经网络和贝叶斯方法相比,决策树无须花费大量的时间和进行上千次的迭代来训练模型,适用于大规模数据集,除了训练数据中的信息外不再需要其他额外信息,表现了很好的分类精确度。其核心问题是测试属性选择的策略,以及对决策树进行剪枝。连续属性离散化和对高维大规模数据降维,也是扩展决策树算法应用范围的关键技术。本文以决策树为研究对象,主要研究内容有:首先介绍了数据挖掘的历史、现状、理论和过程,然后详细介绍了三种决策树算法,包括其概念、形式模型和优略性,并通过实例对其进行了分析研究 目录 一、引言 (1) 二、数据挖掘 (2) (一)概念 (2) (二)数据挖掘的起源 (2) (三)数据挖掘的对象 (3) (四)数据挖掘的任务 (3) (五)数据挖掘的过程 (3) (六)数据挖掘的常用方法 (3) (七)数据挖掘的应用 (5) 三、决策树算法介绍 (5) (一)归纳学习 (5) (二)分类算法概述 (5) (三)决策树学习算法 (6) 1、决策树描述 (7) 2、决策树的类型 (8) 3、递归方式 (8) 4、决策树的构造算法 (8) 5、决策树的简化方法 (9) 6、决策树算法的讨论 (10) 四、ID3、C4.5和CART算法介绍 (10) (一)ID3学习算法 (11) 1、基本原理 (11) 2、ID3算法的形式化模型 (13) (二)C4.5算法 (14) (三)CART算法 (17) 1、CART算法理论 (17) 2、CART树的分支过程 (17) (四)算法比较 (19) 五、结论 (24) 参考文献...................................................................................... 错误!未定义书签。 致谢.............................................................................................. 错误!未定义书签。