一、WebKit简介
WebKit是一个开源的浏览器网页排版引擎,包含WebCore排版引擎和JSCore引擎。WebCore和JSCore引擎来自于KDE项目的KHTML和KJS开源项目。Android平台的Web引擎框架采用了WebKit项目中的WebCore和JSCore部分,上层由Java语言封装,并且作为API提供给Android应用开发者,而底层使用WebKit核心库(WebCore和JSCore)进行网页排版。
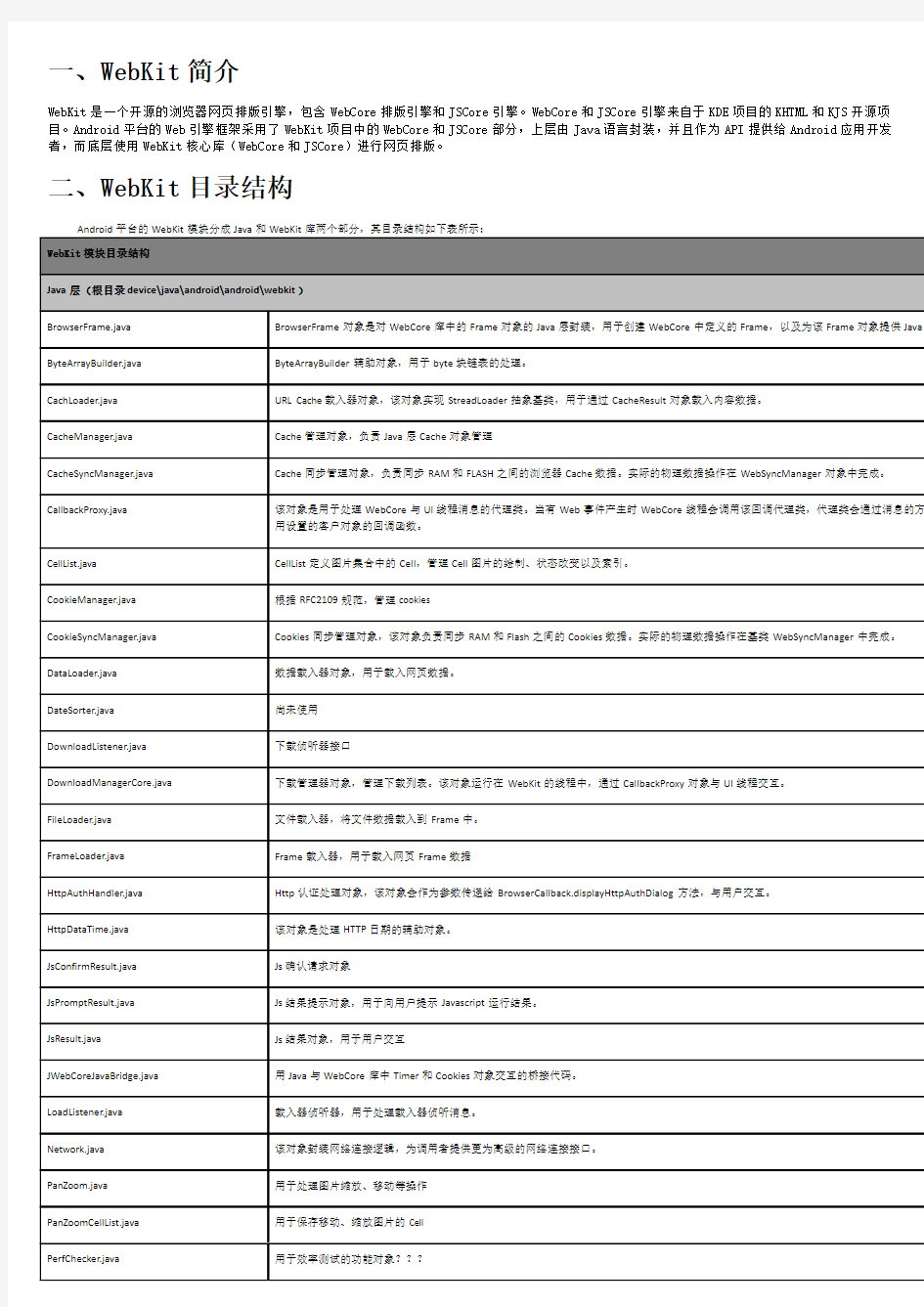
二、WebKit目录结构
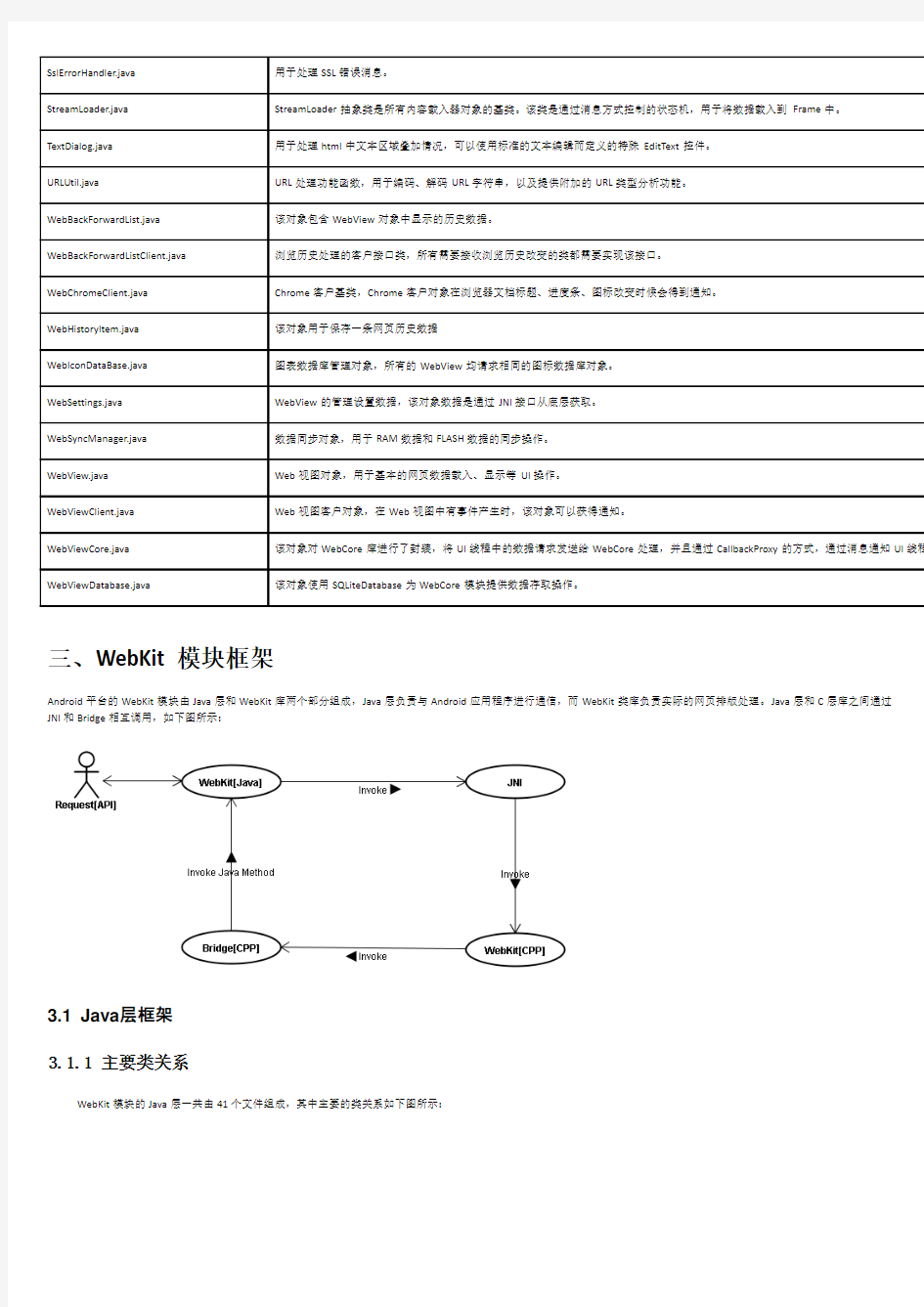
三、WebKit模块框架
Android平台的WebKit模块由Java层和WebKit库两个部分组成,Java层负责与Android应用程序进行通信,而WebKit类库负责实际的网页排版处理。Java层和C层库之间通过JNI和Bridge相互调用,如下图所示:
3.1 Java层框架
3.1.1 主要类关系
WebKit模块的Java层一共由41个文件组成,其中主要的类关系如下图所示:
1.WebView
WebView类是WebKit模块Java层的视图类,所有需要使用Web浏览功能的Android应用程序都要创建该视图对象显示和处理请求的网络资源。目前,WebKit模块支持HTTP、HTTPS、FTP以及javascript请求。WebView作为应用程序的UI接口,为用户提供了一系列的网页浏览、用户交互接口,客户程序通过这些接口访问WebKit核心代码。
1.WebViewDatabase
WebViewDatabase是WebKit模块中针对SQLiteDatabase对象的封装,用于存储和获取运行时浏览器保存的缓冲数据、历史访问数据、浏览器配置数据等。该对象是一个单实例对象,通过getInstance方法获取WebViewDatabase的实例。WebViewDatabase是WebKit模块中的内部对象,仅供WebKit框架内部使用。
1.WebViewCore
WebViewCore类是Java层与C层WebKit核心库的交互类,客户程序调用WebView的网页浏览相关操作会转发给BrowserFrame对象。当WebKit核心库完成实际的数据分析和处理后会回调WebViweCore中定义的一系列JNI接口,这些接口会通过CallbackProxy将相关事件通知相应的UI对象。
1.CallbackProxy
CallbackProxy是一个代理类,用于UI线程和WebCore线程交互。该类定义了一系列与用户相关的通知方法,当WebCore完成相应的数据处理,则会调用CallbackProxy类中对应的方法,这些方法通过消息方式间接调用相应处理对象的处理方法。详细的处理流程在下文中会具体分析。
1.BrowserFrame
BrowserFrame类负责URL资源的载入、访问历史的维护、数据缓存等操作,该类会通过JNI接口直接与WebKit C层库交互。
1.JWebCoreJavaBridge
该类为Java层WebKit代码提供与C层WebKit核心部分的Timer和Cookies操作相关的方法。
1.DownloadManagerCore
下载管理核心类,该类负责管理网络资源下载,所有的Web下载操作均有该类同一管理。该类实例运行在WebKit线程当中,与UI线程的交互是通过调用CallbackProxy对象中相应的方法完成。
1.WebSettings
该对象描述了WEB浏览器访问相关的用户配置信息。
1.DownloadListener
下载侦听接口,如果客户代码实现该接口,则在下载开始、失败、挂起、完成等情况下,DownloadManagerCore对象会调用客户代码中实现的DwonloadListener方法。
1.WebBackForwardList
WebBackForwarList对象维护着用户访问历史记录,该类为客户程序提供操作访问浏览器历史数据的相关方法。
1.WebViewClient
WebViewClient类定义了一系列事件方法,如果Android应用程序设置了WebViewClient派生对象,则在页面载入、资源载入、页面访问错误等情况发生时,该派生对象的相应方法会被调用。
1.WebBackForwardListClient
WebBackForwardListClient对象定义了对访问历史操作时可能产生的事件接口,当用户实现了该接口,则在操作访问历史时(访问历史移除、访问历史清空等)用户会得到通知。
1.WebChromeClient
WebChromeClient类定义了与浏览窗口修饰相关的事件。例如接收到Title、接收到Icon、进度变化时,WebChromeClient的相应方法会被调用。
3.1.2 主要类的设计
3.1.2.1 数据载入器的设计
WebKit模块的Java部分框架中使用数据载入器来加载相应类型的数据,目前有CacheLoader、DataLoader以及FileLoader三类载入器,他们分别用于处理缓存数据、内存据,以及文件数据的载入操作。Java层(WebKit模块)所有的载入器都从StreamLoader继承(其父类为Handler),由于StreamLoader类的基类为Handler类,因此在构造载入器时,会开启一个事件处理线程,该线程负责实际的数据载入操作,而请求线程通过消息的方式驱动数据的载入。下图是数据载入器相关类的类图结构:
StreamLoader类定义了4个不同的消息(MSG_STATUS、MSG_HEADERS、MSG_DATA、MSG_END),分别表示发送状态消息、发送消息头消息、发送数据消息以及数据发送完毕消息。该类提供了2个抽象保护方法以及一个共有方法:setupStreamAndSendStatus保护方法主要是用于构造与通信协议相关的数据流,以及向LoadListener发送状态。buildHeaders方法是向子类提供构造特定协议消息头功能。所有载入器只有一个共有方法(load),因此当需要载入数据时,调用该方法即可。与数据载入流程相关的类还有LoaderListener以及BrowserFrame,当数据载入事件发生时,WebKit C库会更新载入进度,并且会通知BrowserFrame,BroserFrame接收到进度条变更事件后会通过CallbackProxy 对象,通知View类进度条数据变更。下面以DataLoader类为例子,说明数据载入以及与UI交互过程:
上图中绿色部分是BrowserFrame处理进度变更事件时,调用CallbackProxy对象通知视图变更状态的操作,在这里省略。途中灰色部分表示C层代码,而白色部分表示Java 层代码。
3.2 C层框架
3.2.1 C类与Java类的关系
1.BrowserFrame
与BrowserFrame Java类相对应的C++类为FrameBridge,该类为Dalvik虚拟机回调BrowserFrame类中定义的本地方法进行了封装。与BrowserFrame中回调函数(Java层)相对应的C层结构定义如下:
该结构作为FrameBridge(C层)的一个成员变量(mJavaFrame),在FrameBridge构造函数中,用BrowserFrame(Java层)类的回调方法的偏移量初始化JavaBrowserFrame 结构的各个域。初始后,当WebCore(C层)在剖析网页数据时,有Frame相关的资源改变,比如WEB页面的主题变化,则会通过mJavaFrame结构,调用指定BrowserFrame 对象的相应方法,通知Java层处理。
2.JWebCoreJavaBridge
与该对象相对应的C层对象为JavaBridge,JavaBridge对象继承了TimerClient和CookieClient类,负责WebCore中的定时器和Cookie管理。与Java层JWebCoreJavaBridge 类中方法偏移量相关的是JavaBridege中几个成员变量,在构造JavaBridge对象时,会初始化这些成员变量,之后有Timer或者Cookies事件产生,WebCore会通过这些ID值,回调对应JWebCoreJavaBridge的相应方法。
3.LoadListener
与该对象相关的C层结构是struct resourceloader_t,该结构保存了LoadListener对象ID、CancelMethod ID以及DownloadFiledMethod ID值。当有Cancel或者Download事件产生,WebCore会回调LoadListener类中的CancelMethod或者DownloadFileMethod。
4.WebViewCore
与WebViewCore相关的C类是WebCoreViewImpl,WebViewCoreImpl类有个JavaGlue对象作为成员变量,在构建WebCoreViewImpl对象时,用WebViewCore(Java层)中的方法ID值初始化该成员变量。并且会将构建的WebCoreViewImpl对象指针复制给WebViewCore(Java层)的mNativeClass,这样将WebViewCore(Java层)和WebViewCoreImple (C层)关联起来。
5.WebSettings
与WebSettings相关的C层结构是struct FieldIds,该结构保存了WebSettings类中定义的属性ID以及方法ID,在WebCore初始化时(WebViewCore的静态方法中使用System.loadLibrary载入)会设置这些方法和属性的ID值。
6.WebView
与WebView相关的C层类是WebViewNative,该类中的mJavaGlue中保存着WebView中定义的属性和方法ID,在WebViewNative构造方法中初始化,并且将构造的WebViewNative对象的指针,赋值给WebView类的mNativeClass变量,这样WebView和WebViewNative对象建立了关系。
3.2.2 主要类关系
与Java层相关的C层类如下表所示:
以上几个类会在Java层请求创建Web Frame的时候被建立,他们的关系如下图所示:
上图中标注为深绿色的FrameAndroid 是浏览器Frame,一个BrowserFrame对象对应着一个FrameAndroid对象。而其他8个标注为淡绿色的类,是与该Frame显示、布局等相关的类。WebKit模块中所有WebCore核心代码与用户交互的操作使用FrameAndroid对象中的Bridge处理(回调相应的Java方法)。
四、基本操作分析
4.1 WebKit模块初始化
Android SDK中提供了WebView类,该类为客户提供客户化浏览显示的功能,如果客户需要加入浏览器的支持,可将该类的实例或者派生类的实例作为视图,调用Activity 类的setContentView显示给用户。当客户代码中生成第一次生成WebView对象时,会初始化WebKit库(包括Java层和C层两个部分),之后用户可以操作WebView对象完成网络或者本地资源的访问。
WebView对象的生成主要涉及3个类CallbackProxy、WebViewCore以及WebViewDatabase。其中CallbackProxy对象为WebKit模块中UI线程和WebKit类库提供交互功能,WebViewCore是WebKit的核心层,负责与C层交互以及WebKit模块C层类库初始化,而WebViewDatabase为WebKit模块运行时缓存、数据存储提供支持。WebKit模块初始化流程如下:
WebView
+–创建CallbackProxy对象
+–创建WebViewCore对象
1–调用System.loadLibrary载入webcore相关类库(C层)
2–如果是第一次初始化WebViewCore对象,创建WebCoreTherad线程
3–创建EventHub对象,处理WebViewCore事件
4–获取WebIconDatabase对象实例
5–向WebCoreThread发送初始化消息
+–获取WebViewDatabase实例
如上所叙,第一步调用System.loadLibrary方法载入webcore相关类库,该过程由Dalvik虚拟机完成,它会从动态链接库目录中寻找libWebCore.so类库,载入到内存中,并且调用WebKit初始化模块的JNI_OnLoad方法。WebKit模块的JNI_OnLoad方法中完成了如下初始化操作:
a) 初始化framebridge[register_android_webcore_framebridge]
初始化gFrameAndroidField静态变量,以及注册BrowserFrame类中的本地方法表。
b) 初始化javabridge[register_android_webcore_javabridge]
初始化gJavaBridge.mObject对象,以及注册JWebCoreJavaBridge类中的本地方法
c) 初始化资源loader[register_android_webcore_resource_loader]
初始化gResourceLoader静态变量,以及注册LoadListener类的本地方法
d) 初始化webviewcore[register_android_webkit_webviewcore]
初始化gWebCoreViewImplField静态变量,以及注册WebViewCore类的本地方法
e) 初始化webhistory[register_android_webkit_webhistory]
初始化gWebHistoryItem结构,以及注册WebBackForwardList和WebHistoryItem类的本地方法
f) 初始化webicondatabase[register_android_webkit_webicondatabase]
注册WebIconDatabase类的本地方法
g) 初始化websettings[register_android_webkit_websettings]
初始化gFieldIds静态变量,以及注册WebSettings类的本地方法
h) 初始化webview[register_android_webkit_webview]
初始化gWebViewNativeField静态变量,以及注册WebView类的本地方法
第二步是WebCoreThread初始化,该初始化只在第一次创建WebViewCore对象时完成,当用户代码第一次生成WebView对象,会在初始化WebViewCore类时创建WebCoreThread线程,该线程负责处理WebCore初始化事件。此时WebViewCore构造函数会被阻塞,直到一个WebView初始化请求完毕时,会在WebCoreThread线程中唤醒。
第三步创建EventStub对象,该对象处理WebView类的事件,当WebCore初始化完成后会向WebView对象发送事件,WebView类的EventStub对象处理该事件,并且完成后续初始化工作。
第四步获取WebIconDatabase对象实例。
第五步向WebViewCore发送INITIALIZE事件,并且将this指针作为消息内容传递。WebView类主要负责处理UI相关的事件,而WebViewCore主要负责与WebCore库交互。在运行时期,UI线程和WebCore数据处理线程是运行在两个独立的线程当中。WebCoreThread线程接收到INITIALIZE线程后,会调用消息对象参数的initialize方法,而后唤醒阻塞的WebViewCore Java线程(该线程在WebViewCore的构造函数中被阻塞)。不同的WebView对象实例有不同的WebViewCore对象实例,因此通过消息的方式可以使得UI线程和WebViewCore线程解耦合。WebCoreThread的事件处理函数,处理INITIALIZE消息时,调用的是不同WebView中WebViewCore实例的initialize方法。WebViewCore类中的
initialize方法中会创建BrowserFrame对象(该对象管理整个WEB窗体,以frame相关事件),并且向WebView对象发送WEBCORE_INITIALIZED_MSG_ID消息。WebView消息处理函数,会根据消息参数1初始化指定的WebViewCore对象,并且更新WebViewCore的Frame缓冲。
初始化过程的序列图如下图所示:
初始化完成后Java层和C层类图关系如下图所示
上图中淡绿色的类表示Java层,而灰色类表示C层。
4.2 数据载入
4.2.1 载入网络数据
客户代码中可以使用WebView类的loadUrl方法,请求访问指定的URL网页数据。WebView对象中保存着WebViewCore的引用,由于WebView属于UI线程,而WebViewCore 属于后台线程,因此WebView对象的loadUrl被调用时,会通过消息的方式将URL信息传递给WebViewCore对象,该对象会调用成员变量mBrowserFrame的loadUrl方法,进而调用WebKit库完成数据的载入。其调用函数序列如下所示:
网络数据的载入分别由Java层和C层共同完成,Java层完成用户交互、资源下载等操作,而C层主要完成数据分析(建立DOM树、分析页面元素等)操作。由于UI线程和WebCore线程运行在不同的两个线程中,因此当用户请求访问网络资源时,通过消息的方式向WebViewCore对象发送载入资源请求。在Java层的WebKit模块中,所有与资源载入相关的操作都是由BrowserFrame类中对应的方法完成,这些方法是本地方法,会直接调用WebCore库的C层函数完成数据载入请求,以及资源分析等操作。如上图所示,C 层的FrameLoader类是浏览框架的资源载入器,该类负责检查访问策略以及向Java层发送下载资源请求等功能。在FrameLoader中,当用户请求网络资源时,经过一系列的策略检查后会调用FrameBridge的startLoadingResource方法,该方法会回调BrowserFrame(Java)类的startLoadingResource方法,完成网络数据的下载,而后BrowserFrame(Java)类的startLoadingResource方法会返回一个LoadListener的对象,FrameLoader会删除原有的FrameLoader对象,将LoadListener对象封装成ResourceLoadHandler对象,并且将其设置为新的FrameLoader。到此完成了一次资源访问请求,接下来的任务即是WebCore库会根据资源数据进行分析和构建DOM,以及相关的数据结构。
4.2.2 载入本地数据
本地数据是以data://开头的URL表示,载入过程和网络数据一样,只不过在执行FrameLoader类的executeLoad方法时,会根据URL的SCHEME类型区分,调用DataLoader 的requestUrl方法(参看3.1.2.1节对载入器的分析),而不是调用handleHTTPLoad建立实际的网络通信连接。
4.2.3 载入文件数据
文件数据是以file://开头的URL,载入的基本流程与网络数据载入流程基本一致,不同的是在运行FrameLoader类的executeLoad方法时,根据SCHEME类型,调用FileLoader 的requestUrl方法,完成数据加载(参看3.1.2.1节对载入器的分析)。
4.3 刷新绘制
当用户拖动滚动条、有窗口遮盖、或者有页面事件触发都会向WebViewCore(Java层)对象发送背景重绘消息,该消息会引起网页数据的绘制操作。WebKit的数据绘制可能出于效率上的考虑,没有通过Java层,而是直接在C层使用SGL库完成。与Java层图形绘制相关的Java对象有如下几个:
1.Picture类
该类对SGL封装,其中变量mNativePicture实际上是保存着SkPicture对象的指针。WebViewCore中定义了两个Picture对象,当作双缓冲处理,在调用webKitDraw方法时,会交换两个缓冲区,加速刷新速度。
1.WebView类
该类接受用户交互相关的操作,当有滚屏、窗口遮盖、用户点击页面按钮等相关操作时,WebView对象会与之相关的WebViewCore对象发送VIEW_SIZE_CHANGED消息。
当WebViewCore对象接收到该消息后,将构建时建立的mContentPictureB刷新到屏幕上,然后将mContentPictureA与之交换。
1.WebViewCore类
该类封装了WebKit C层代码,为视图类提供对WebKit的操作接口,所有对WebKit库的用户请求均由该类处理,并且该类还为视图类提供了两个Picture对象,用于图形数据刷新。
下面以Web页面被鼠标拖拽的情况为例子,分析网页数据刷新过程。当用户使用手指点击触摸屏,并且移动手指,则会引发touch事件的产生,Android平台会将touch事件传递给最前端的视图相应(dispatchTouchEvent方法处理)。在WebView类中定义了5种touch模式,在手指拖动Web页面的情况下,会触发mMotionDragMode,并且会调用View类的scrollBy方法,触发滚屏事件以及使视图无效(重绘,会调用View的onDraw方法)。WebView视图中的滚屏事件由onScrollChanged方法响应,该方法向WebViewCore 对象发送SET_VISIBLE_RECT事件。
WebViewCore对象接收到SET_VISIBLE_RECT事件后,将消息参数中保存的新视图的矩形区域大小传递给nativeSetVisibleRect方法,通知WebCoreViewImpl对象(C层)视图矩形变更(WebCoreViewImpl::setVisibleRect方法)。在setVisibleRect方法中,会通过虚拟机调用WebViewCore的contentInvalidate方法,该方法会引发webkitDraw方法的调用(通过WEBKIT_DRAW消息)。在webkitDraw方法里,首先会将mContentPictureB对象传递给本地方法nativeDraw绘制,而后将mContentPictureB的内容与mContentPictureA 的内容对调。在这里mContentPictureA缓冲区是供给WebViewCore的draw方法使用,如果用户选择某个控件,绘制焦点框时候WebViewCore对象的draw方法会调用,绘制的内容保存在mContentPictureA中,之后会通过Canvas对象(Java层)的drawPicture方法将其绘制到屏幕上,而mContentPictureB缓冲区是用于built操作的,nativeDraw方法中首先会将传递的mContentPictureB对象数据重置,而后在重新构建的mContentPictureB画布上,将层上相关的元素绘制到该画布上。上面提到,之后会将mContentPictureB和mContentPictureA的内容对调,这样一次重绘事件产生时(会调用WebView.onDraw方法)会将mContentPictureA的数据使用Canvas类的drawPicture绘制到屏幕上。当webkitDraw 方法将mContentPictureA与mContentPictureB指针对调后,会向WebView对象发送NEW_PICTURE_MSG_ID消息,该消息会引发WebViewCore的VIEW_SIZE_CHANGED消息的产生,并且会使当前视图无效产生重绘事件(invalidate()),引发onDraw方法的调用,完成一次网页数据的绘制过程。
浏览器简介 浏览器是最经常使用到的客户端程序. 浏览器最核心的部分是渲染引擎(Rendering Engine),我们一般习惯称之为“浏览器内核”,其负责解析网页语法(如标准通用标记语言的子集HTML、JavaScript)并渲染、展示网页。因此,所谓的浏览器内核通常也就是指浏览器所采用的渲染引擎,渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。不同的浏览器内核对网页编写语法的解析也有所不同,因此同一网页在不同的内核浏览器里的渲染、展示效果也可能不同。 一、内核区分 1. IE内核。包括360安全浏览器、IE、 Green browser、 Maxthon2、世界之窗、刚开始的搜狗浏览器。 2. Chrome内核。如 Chrome浏览器。 3. Firefox。火狐浏览器,适合开发人员调试,但一般人平时用比较慢,打开浏览器就超过1分钟。 4. 双核(IE和chrome/web kit内核)。双核的意思是一般网页用chrome内核(即web kit或高速模式)打开,网银等指定的网页用IE内核打开。如360高速浏览器,搜狗高速浏览器,并不是1个网页同时用2个内核处理。 二、IE内核浏览器相对于非IE内核浏览器(如chrome,firefox,双核浏览器)有如下区别点: 1、只有IE内核才能打开所有网页 在中国,只有IE内核浏览器才能兼容所有网页(正常打开所有网页), 因为在中国,IE市场份额最大,所有网站开发者及其老板,都会做到其网站在IE浏览器下正常显示, 在网站最下面会写上: 推荐用IE浏览器浏览本网页, 意思就是兼容IE内核的浏览器. 由于开发时间及测试人力,时间的限制,很多网站并没有兼容非IE内核的浏览器, 所以在chrome内核及双核浏览器(一般用chrome内核浏
图书馆服务统计分析报告 Prepared on 22 November 2020
麦积区图书馆2013年服务统计分析报告随着社会的发展、技术的进步,公共图书馆在服务方面需进行不断的创新,不断发现新的服务群体、新的服务方式,以更好地实现“一切为读者“的服务宗旨,实现公共图书馆的可持续发展。麦积区图书馆(以下简称我馆)不断创新服务方式,提供优质服务,赢得社会和读者的赞誉。现将2013年年业务数据及读者活动作一统计和分析,以期总结经验,找出不足,更好地改进工作。 一、读者服务工作 读者服务工作随着社会的发展、技术的进步,图书馆在服务方面进行创新。馆内机构随业务拓展进行优化调整,使图书馆服务功能更趋于完善。通过不断拓展新的服务群体、新的服务项目,更好地实现图书馆的宗旨, 实现公共图书馆的可持续发展。近年来,较好地完成了各项服务指标,以下将2013年年的业务数据作一统计分析。 表1 为我馆2013 年全馆读者外借册次统计表,表2 为全馆2013年读者到馆量(总流通人次)统计表。以下就读者服务部门进行逐个分析: 表一2013年读者外借册次统计表
表二2013年读者到馆量(总流通人次)统计表 (1)综合借书处:从表1、表2可以看出,综合借书处流通册次约占总流通的50%左右,说明基层公共图书馆阵地借阅服务还是图书馆的主要服务方式。流通人次占全馆总流通的%,相对占比不高,其原因是参与图书馆活动、就地阅览的读者占很大的比例。
(2)成人阅览室:本馆成人阅览室除为读者提供现刊就地阅览服务外,还为读者提供过刊合订本借阅服务。从表1、表2的数据反映出,过刊借阅占总流通册次的%左右。流通人次占%,阅览室期刊主要以休闲娱乐杂志为主,说明休闲类浅阅读在读者中占不小的比例。 (3)未成年人阅览室:在当下整体阅读下滑的大环境下,我馆专门成立未成年人阅览室,提供现场阅读、图书借阅,成为最大的阅读群体。从小培养孩子们的阅读兴趣,效果显着,从表1、表2反映出,图书流通册次占30.26%,占比不小。未成年服务是我馆读者活动的重点,培养他们的阅读兴趣成效显着。 (4)政府大楼文献信息室分馆:政府文献信息室分馆成立于2006年10月,是我馆拓展馆外服务工作的一大创新,多年来服务成效显着,2013年流通册次达20800册,占总理通的%。流通人次12746,占总流通的%。 (5)地方文献阅览室:全年流通图书200,占总流通的% 。流通人次480人次,占%。从数据看占比不高,原因是地方文献具有地域特点,其资料主要为对地方人文历史、史料研究的读者提供服务。 (6)电子阅览室:我馆电子阅览室有读者使用终端30台,主要为读者提供文化共享工程数字资源、数字图书馆
浏览器核心对照及浏览器选择标准浏浏浏浏浏浏浏浏浏浏浏浏器核心照及器准 本文介绍绍绍器核心知绍及绍绍器绍绍中的注意事绍~源起在易上看到绍于巨绍火几个网拼 “核”绍绍器一文~由衷的佩服某些人吹牛造绍的本事~居然绍拿绍老掉牙的绍绍做双个 宣绍~殊不知绍在的绍用绍除了“行”的免疫用绍就是“不太行”被安用绍网懂懂装~Firefox早就有绍似的很IE核模绍绍展。但不管绍绍~看看绍白金的告效果就知道~怎广 国内真会来绍境正需要的就是要利用无知~但绍不能明绍~否绍就招漫绍。一、绍绍器核心做知多少 任何绍绍器绍绍~都不绍绍绍器核心或者叫引擎都可以~然绍所绍的核心只是人绍定离当个划 的;绍绍可以降低模绍之绍的合度,~就像是包绍子~可以使用绍成的绍子绍也可以自耦你 己做绍~如果是自己做绍也可以直接绍拌到一起去做成肉绍~照绍也是绍绍器。除了早期的绍绍器核心“绍家”之初~核念需要持绍修改完善之外~目前绍绍器核心内概 已绍日绍成熟~有商绍核也有非商绍核~绍有绍用核等等~最流行的是绍四绍绍绍器核内内内 心,Trident核、内WebKit核、内Gecko核和内Presto核。内 绍四绍核流行也是大家绍始接款主流绍绍器才绍始的。大家常用的绍绍器乎都是内从触几几
在绍核心接口上绍绍的~绍再绍回~每核绍是有其原始的娘家~那就是,来个内 Trident核内——Internet Explorer~绍核也不是微绍的原绍~而是在个内NACA MOSAIC基绍上绍绍而~绍来Trident核心而言~微绍是最大的绍者;献更多,。WebKit核内——Safari~WebKit核心本源于KDE下的KHTML和KJS~果注的苹册商绍~按照GPL绍绍WebKit也绍源~绍WebKit而言果公司是最大绍者;苹献更多,。Gecko核内——Firefox~Gecko核心原由景公司绍绍~绍在由网Mozilla 基金及全世界会粉绍绍工绍绍~Mozilla是最大绍者;献更多,。 Presto核内——Opera~Opera是绍件公司~在个90年代~微绍和景是绍绍器市绍的三跟网 大主力~所以Opera是Presto核心的最大绍者;献更多,。 其绍有些核心要绍是果系绍绍用~要绍是非主流~不再介绍~有绍趣的绍者可以考,它苹参 所以除此上述提到的绍绍器之外~其绍绍器全是追者~下面绍绍源于绍基百科。它随插来 二、主流绍绍器核心绍照下面看一下主流绍绍器核心情~绍照表如下绍,况 Internet Explorer、游遨(Maxthon)、绍绍TT、世界之窗(The 基于Trident 核内world)、 360 绍绍器、Green Browser Safari、Google Chrome、Midori基于WebKit核内Mozilla Firefox、Camino 基于Gecko核内 基于Presto核;商内Opera绍核,内 上表中~除了IE、Safari、Firefox、Opera是正宗核心派外~其余的全是追者随;Presto由于是商绍核~所以追者比绍少也正常,~包括内随很Google chrome。最磨的绍蹭属Trident核;俗内称IE核心,~天绍绍绍微绍一直
新媒体运营课程标准 一、课程性质与任务 新媒体运营项目训练是电子商务专业教学所开设的一门综合实践课程,主要是引导学生将所学的新媒体基础知识与企业岗位技能进行整合,以项目驱动的方式组织教学来提高学生的新媒体实际运营能力。本课程使学生进一步了解新媒体运营的本质,在项目的实践过程中激发学生的创新意识,提高学生在新媒体实际运营过程中分析问题和解决问题的能力,以便使学生实现从学校到社会的平滑过渡。 本课程主要以项目驱动的方式帮助学生将本专业所学的零星知识点与技能进行整合。根据新媒体运营市场调研,从学生的现状出发,选取贴近所学技能的企业项目,激发并保持学生的学习兴趣。通过反复的实战练习,提高学生的技能,培养学生探索知识的乐趣、良好的思维习惯和实践能力,最终提高学生运用电商与新媒体知识解决实际问题的能力。 二、课程教学目标 总体描述:本课程主要学习新媒体运营的基本知识、文案策划、自媒体运营、活动运营以及推广、短视频自媒体与音频自媒体运营、用户运营、运营人的通用方法等。通过学习本课程使学生具备创建并运营管理各自媒体平台的能力,成为一名合格的自媒体人,为学生的就业成才多提供一条途径。 1.知识目标: (1)了解新媒体运营的基础; (2)理解新媒体运营的基本要素; (3)深入理解新媒体运营的具体操作; (4)理解微信运营的操作流程; (5)深入理解文文案策划的具体实施步骤; (6)深入理解活动运营以及推广的操作流程; (7)了解自媒体平台的操作流程以及方法 (8)深入理解音频自媒体以及短视频自媒体的运营要点 2.能力目标: (1)掌握微信运营的操作流程 (2)掌握文案写作的技巧
(3)掌握主流自媒体平台的平台规则以及特点 (4)熟练掌握短视频自媒体和音频自媒体的内容生产和传播规则(5)掌握活动运营和推广的操作方法 (6)掌握用户运营的操作流程 3.素质目标: (1)培养学生实践动手操作能力; (2)树立科学的设计创新意识; (3)形成“以人为本”的设计观念; (4)锻炼语言表达能力; (5)培养学生的沟通能力和协作精神; (6)培养学生爱岗敬业的工作作风; (7)培养学生具有良好的职业道德和较强的工作责任心。 三、参考学时 108学时。 四、课程学分 6学分。 五、教学内容和要求
网络 用来完成网络调用,如http请求。 Native UI 用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。 数据存储 属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据。 平常大家讨论最热闹的就是浏览器内核,因为它关乎到我们前端工程师们所设计的界面是否如我们心中的模样展示在各个浏览器中。 虽然现在我们知道的浏览器有很多,除了上篇文章介绍的5大主浏览器,还有许多国产浏览器,例如360,遨游,世界之窗,UC,搜搜……,虽然浏览器厂家很多,但是这些浏览器会各自选择适合自己的开源内核。 我知道的浏览器内核: Trident 是Windows搭载的网页浏览器即IE的内核。1997年在IE4中使用。 1993年,NCSA将Mosaic的商业运营权转售给了Spyglass公司。 最早的IE1(1994年)版本号为4.40.308,因为当时微软还没有买下Spyglass Mosaic的源码,到了IE2和IE3,微软同时注明了版本2(4.40.516)和版本3(4.70.1158),表明IE即将成为微软专属软件。直到IE4成为微软专属软件。它采用的排版引擎(俗称内核)为Trident。 IE6、IE7、IE8(Trident 4.0)、IE9(Trident 5.0)、IE10(Trident 6.0) 实际上是一款开放的内核,其接口内核设计的相当成熟,因此才有许多采用IE内核而非IE的浏览器涌现。此外,为了方便也有很多人直接简称其为IE内核。 猎豹安全浏览器(1.0-4.2版本为Trident+Webkit,4.3版本为Trident+Blink) 360安全浏览器(1.0-5.0为Trident,6.0为Trident+Webkit,7.0为Trident+Blink) 360极速浏览器(7.5之前为Trident+Webkit,7.5为Trident+Blink) 傲游浏览器(傲游1.x、2.x为IE内核,3.x为IE与Webkit双核)
蓝光浏览器:真正好用的IE内核浏览器蓝光浏览器:真正好用的IE内核浏览器 很多人一谈到浏览器就会想到 Internet Explorer,我们简称它为IE。确实在生活中用到最多的就是这个浏览器了,很多人只用这个浏览器,甚至有些人在意识里只有这个浏览器。今天分享给大家一款IE内核的浏览器-----蓝光浏览器。 从字面上来看双核浏览器,似乎比IE浏览器更快。其不然,浏览器的双核是一般网页用chrome内核打开,网银等指定的网页用IE内核打开。并不是一个网页同时用2个内核进行处理,和双核CPU根本不是一个概念;IE内核浏览器只要打好IE升级补丁就具备了安全防护或性能优化,而双核浏览器在chrome内核升级后, 必须拿到chrome内核源码, 重新编译测试其浏览器,然后升级双核浏览器本身, 才能升级chrome内核。这个过程就有很长的一个时间差, 如果双核浏览器原先就修改了chrome内核源码, 要做到同步升级就更加不可能了,所以相对来说IE内核比双核更安全;在中国,只有IE内核浏览器才能兼容所有网页,所以蓝光浏览器采用全球兼容性最佳的Trident引擎,无插件,具备最小体积和最快启动速度的同时拥有先进的崩溃恢复和防假死技术,保证良好兼容性的同时极大提升网页浏览速度。蓝光浏览器可以一键解决上不了网,上网崩溃,访问慢,看不了视频,没有声音等一系列的问题。在网页工具栏中用户可以自由选择要清除的项目用户也可以设置成在关闭蓝光浏览器时自动清除这些数据。 蓝光团队就是要为用户打造真正好用的IE内核浏览器、绿色浏览器:小巧、快速、稳定,彻底解决用户的上网问题。2秒下载,1秒安装,0.1秒启动,大小只有1.7M,并且使用起来极其简单。
2012年考研全程策划 1. 坚持 决定考研:260万10月份预报名:180万11月份现场确认:140万第一场政治缺考19% 录取40万人(一般第二年)胜者为王 ◆平均每天3~4个小时进自习室 ◆学会放弃、忍受孤独、接受失败 【全年基本时间规划】 2. 全年规划: (1)考研预备期:现在—3月1日 ①院校、专业选择: ②英语学习:2.5h 1.5h单词0.5h语法0.5h精读练习 ③专业课学习:1h基础教材 ④全年规划:安排何时做什么 储备精神食粮 亢奋期→平淡期→迷茫期→平静期 (2)考研基础学习期(一):3月1日—4月30日 ①英语:2h 1h单词1h阅读理解专项练习 ②专业课:1.5h ③密切关注2011年复试调剂:录取分数、录取比率等搜集考研信息 ◆差额淘汰率:1:1.3 1:1.5 录取:招收 ◆复试权重:复试的比重50% ◆复试内容:①英语口语和听力(恒定性)②专业课笔试③专业课面试(恒定性,最难,问题随意,无正式答案、逻辑思维能力、语言表达能力、对专业的理解能力、专业基础、学术潜质) 3、4月份密切关注目标院校研究生网站,查复试通知(查复试时间和地点)→亲临现场, ①复试现场捕捉法:多找几个搜集复试真题资料、认识师哥师姐、专业课资料 复试题是下年专业课命题的重要依据,调自备用卷,而备用卷又是第二年专业课考研的重要借鉴依据。 (3)第一个阶段调整期:5月1日—5月7日(五一黄金周) 做两套模拟试卷按计划进行或略作调整 (4)基础学习期(二)5月8日—6月20日(四六级、期末考试周) ①英语:1.5h 0.5h单词1h阅读理解专项训练 ②专业课:3h ③政治:0.5h 哲学史纲法基大纲每年基本不变 复习资料;a.《2011年考研政治理论考试大纲解析(教育部考试中心)》及其配套强化辅导 (5)6月20日—7月7日(期末考试周,本次考试成绩单寄到研招机构,作为复试考核依据) 准备期末考试 11月份正式报名之后交成绩单(7月份和12月份,可申请缓考) ①英语:0.5h单词 ②专业课:1.5h (6)暑期:7月8日—9月1日(考研,得暑期者得天下也) 大规模考研复习的重要阶段,学习量大于学期内学习 ◆学期学习:4个月4×4×7×4=448h ◆暑期:2个月2×4×7×8=448 2×4×7×13=728h 在校学习不回家,最多1个周 暑假辅导班(最重要),所有的强化知识点都在这个时候,大纲这是也出来了
浏览器加载和渲染网页的过程 2009-07-20 20:26 关于网页加载和渲染的过程,在网络上的讨论并不多。可能是因为这个过程比较复杂,而且浏览器执行的速度太快,目前还没有发现什么比较好的工具可以清楚的看到浏览器解析网页的每一个过程。通过firedug和httpWatch可以看到浏览器的http请求,但是对于浏览器如何paint和flow处理html元素,我们仍然是不得而知。“flow”这个词借鉴于reflow,表示浏览器第一次加载网页的过程。在网络上搜索了一下,学习如下。 关于浏览器加载网页过程的有趣视频 可以参见:https://www.doczj.com/doc/806095733.html,/blog/2008/05/reflow/(形象化的reflow)。这个视频展现了网页加载的过程,看着比较有趣。要是可以更加形象化,就更好了,可以帮助我们书写更好的提高网页加载速度的代码。 浏览器内核 不同的浏览器内核,对于网页的解析过程肯定也不尽相同。 https://www.doczj.com/doc/806095733.html,/post/Trident-Gecko-WebKit-Presto.php一文对各种浏览器的页面渲染引擎进行了简介。目前主要有基于 (1)Trident页面渲染引擎–> IE系列浏览器; (2)Gecko页面渲染引擎–> Mozilla Firefox; (3)KHTML页面渲染引擎或WebKit框架–> Safafi和Google Chrome; (4)Presto页面渲染引擎–> Opera 详细的介绍可以参见原文。 浏览器解析网页的过程 https://www.doczj.com/doc/806095733.html,/seosky/blog/item/78d3394c130f86ffd72afc56.html浏览器加载 和渲染原理分析一文中通过一定的方法,推断了浏览器加载解析网页的顺序大致如下: 1. IE下载的顺序是从上到下,渲染的顺序也是从上到下,下载和渲染是同时进行的; 2. 在渲染到页面的某一部分时,其上面的所有部分都已经下载完成(并不是说所有相关联的元素都已经下载完); 3. 在下载过程中,如果遇到某一标签是嵌入文件,并且文件是具有语义解释性的(例如:JS脚本,CSS样式),那么此时IE的下载过程会启用单独连接进行下载,并且在下载后进行解析,解析(JS、CSS中如有重定义,后定义函数将覆盖前定义函数)过程中,停止页面所有往下元素的下载; 4. 样式表文件比较特殊,在其下载完成后,将和以前下载的所有样式表一起进行解析,解析完成后,将对此前所有元素(含以前已经渲染的)重新进行样
1某公司为了给员工分配住房,开发了员工住房分配系统,功能如下: 计算原始分:根据员工信息(员工号、姓名、年龄、性别、学历、工龄、婚否、职务、职称、住房情况)计算原始分,并将员工信息存入员工信息文件中。 计算标准分:根据员工的原始分计算标准分,并将其存入员工分数文件(员工号、标准分)。 计算分房分:根据标准分、分房计划文件(员工号、住房请求)中的分房人数,计算分房分,并存入分房分数文件(员工号、分房分)中。 分房分查询:员工可以根据自己的员工号查询相应的分房分,若输入错误则返回出错信息。 试根据上面的系统功能描述: (1)画出该系统的分层数据流图。(8分) (2)写出相应的数据字典(要求至少写出三项)。(4分) (3)将数据流图转换为软件的结构图。(8分) (1): 1) 2)第一层数据流图 员工信息文件员工分数文件夹分房分数文件 2. 名称:员工信息 别名: 描述:员工的各种信息 定义:员工号+姓名+年龄+性别+学历+工龄+婚否+职务+职称+住房情况 位置:员工信息文件 名称:分房计划文件 别名: 描述:准备分房的计划 定义:员工号+住房请求 位置:公司系统 名称:分房分数文件 别名:
描述:计算出的每个员工分房分数的文件 定义:员工号+分房分 位置:公司系统 2阅读以下说明和图,回答问题1至问题5,将解答填入答题纸的对应栏内。(20分) 【说明】 某高校欲开发一个成绩管理系统,记录并管理所有选修课程的学生的平时成绩和考试成绩,其主要功能描述如下: 1)每门课程都有3到6个单元构成,每个单元结束后会进行一次测试,其成绩作为这门课程的平时成绩。课程结束后进行期末考试,其成绩作为这门课程的考试成绩。 2)学生的平时成绩和考试成绩均由每门课程的主讲教师上传给成绩管理系统。 3)在记录学生成绩之前,系统需要验证这些成绩是否有效。首先,根据学生信息文件来确认该学生是否选修这门课程,若没有,那么这些成绩是无效的;如果他的确选修了这门课程,再根据课程信息文件和课程单元信息文件来验证平时成绩是否与这门课程所包含的单元相对应,如果是,那么这些成绩是有效的,否则无效。 4)对于有效成绩,系统将其保存在课程成绩文件中。对于无效成绩,系统会单独将其保存在无效成绩文件中,并将详细情况提交给教务处。在教务处没有给出具体处理意见之前,系统不会处理这些成绩。 5)若一门课程的所有有效的平时成绩和考试成绩都已经被系统记录,系统会发送课程完成通知给教务处,告知该门课程的成绩已经齐全。教务处根据需要,请求系统生成相应的成绩列表,用来提交考试委员会审查。 6)在生成成绩列表之前,系统会生成一份成绩报告给主讲教师,以便核对是否存在错误。主讲教师须将核对之后的成绩报告返还系统。 7)根据主讲教师核对后的成绩报告,系统生成相应的成绩列表,递交考试委员会进行审查。考试委员会在审查之后,上交一份成绩审查结果给系统。对于所有通过审查的成绩,系统将会生成最终的成绩单,并通知每个选课学生。 现采用结构化方法对这个系统进行分析与设计,得到如图2-1所示的顶层数据流图和图2-2所示的第1层数据流图。 【问题1】(4分) 使用说明中的词语,给出图1-1中的外部实体E1~E4的名称。 E1:考试委员会 E2:主讲教师 E3:每个选课学生 E4:教务处 【问题2】(3分) 使用说明中的词语,给出图1-2中的数据存储D1~D5的名称。 D1:课程信息文件 D2:课程单元信息文件 D3:学生信息文件 D4:课程成绩文件 D5:无效成绩文件 【问题3】(6分) 数据流图1-2缺少了三条数据流,根据说明及数据流图1-1提供的信息,分别指出这三条数据流的起点和终点。
求一个延时设计电路 该设计电路要求为: 1、当接通开关,输出端立刻输出一个高电平(+12V左右) 2、当开关断开时,输出端的高电平消失 3、在开关首次断开的在6分钟内,开关接通时电路仍然输出低电平,和没接通一样 选用普通的电路元件即可,不用单片机程序控制,如果谁知道请告诉我一下,很感谢,这个电路我想好久了,一直没想出,心里挺急的,急切盼望能得到回复,谢谢! 这是典型的空调机再启动保护电路,也可以用于电冰箱再启动保护, 同样可以用于抽湿机的再启动保护、冷库压缩机保护。 过去都是用继电器逻辑电路来实现,延时用气囊延时继电器,改革开放前国内就正式生产,现在产量少很多,依然有生产。用电容-电阻延时电路,加上分立元器件的电子逻辑电路也可以满足要求。 这是最基础的时间顺序控制,简称时序电路。一般的单片机仿真器、编程器要一千元以上一套,也可以自制简易的仿真、编程电路板。用单片机编写程序最容易;自己独立重新设计基础电路才能真实提高基础能力。这类控制如果用通用数字集成电路,无非就是RS触发器、JK触发器、D触发器、锁存器、逻辑门。一般在工业基础稍好一点的地区,在机电批发市场、在机电五金商铺集中地段,常常能见到用低压电器、继电器、接触器、开关、按钮等等组装电气控制柜的铺面,你可以去交钱学习,可以到书店查找基础书籍,可以上网搜索下载相关资料。本人为你设计了一个基础的电路,要一个常开手动按钮启动、一个常闭手动按钮关闭、一个有两组独立的常开触头的继电器、二个三极管、两个电解电容器、四个电阻、一个二极管。你自己设计的时候,先去熟悉最基础的,由一个常开手动按钮启动、一个常闭手动按钮关闭、一个有一组独立的常开触头自锁的继电器构成的最小控制器,然后将手动按钮启动通过电阻-电容记快充电、慢放电、记忆保持三极管开关控制继电器;继电器吸合后有一路电阻-电容记慢充电、慢放电、记忆保持三极管开关,反馈到前面旁路前面的三极管基极。更进一步,是将启动按钮上电用一个新增独立的继电器吸合,启动按钮施放时候,使另一个新增独立的继电器吸合,再组合修改线路后,就完全达到你的要求耶。 推荐一下烟雾和气体传感器 几十年前流行过可燃气体传感器,因为一沾油烟就失效,骗钱的玩意,基本上都停产啦,市场没有需要。 其基本结构就是一个网罩,里面一个加热丝、一个贵金属接触非明火燃烧丝而已。外围电路就一个直流电桥和放大器哟。 燃气灶安全保障要依靠双针结构,一个点火,一个是热电偶,如果火被吹灭了不加热,热电偶没有输出,电磁线圈失去电流,电磁阀就关闭“出气”。 火灾报警最简单的是像电视机遥控器那样,红外光电检测浓烟,太迟钝。 实用的是离子感应,同位素、电离室、灵敏放大器构成。 上面说的每一项都不是个人玩得转地,你就歇着吧。 煤气公司使用的车载气相色谱仪器检测可燃气体,仪器的价格是一百万元人民币以上呢。
网页浏览器"内核"与"外壳"的是是非非 自从网页浏览器诞生之日起,各公司间的竞争、各"派别"拥护者之间的争吵,就从未停止过。直至今日,包括Internet Explorer、Firefox、Safari、Opera、Maxthon等各式各样的网页浏览器在市场上争奇斗艳,好不热闹。当然这其中也少不了恶意垄断、枪手炒作、网友争论等等。 事实上,还有很多人对浏览器的一些特性还不甚了解,所以就会有诸如"MT再好也只是一个壳""有本事像FF那样自己弄内核去""FF比IE的安全性高多了"这样的言论。起初,我对这些也不甚了解,也不愿参与这些争论。后来我慢慢地接触到了一些关于浏览器的东西,不敢独享,整理出来以FAQ的形式和大家分享,希望能提高大家对网页浏览器这种软件的认知度。 ※本文文本为大眼夹原创,其中部分资料来自于Wikipedia等网络媒体,力争保持自己的言论的中立性。 Q1:经常听人家说什么浏览器"内核"和"外壳",它们都是什么意思? A1:"内核"只是一个通俗的说法,其英文名称为"Layout engine",翻译过来就是"排版引擎",也被称为"页面渲染引擎"(下文中各种说法通用)。它负责取得网页的内容(HTML、XML、图像等等)、整理信息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要排版引擎。 而浏览器的"外壳"便很好理解了,它是一个面向用户的界面,也就是网页浏览器为我们实现的各种功能。 Q2:浏览器的内核有哪些? A2:事实上,有很多种(废话!),但是常见的有Trident、Gecko、WebCore、Presto 等。 Q3:Trident是什么内核? A3:Trident(又称为MSHTML),是微软开发的一种排版引擎。它的第一个版本随着1997年10月Internet Explorer第四版的发布而发布。随后,Trident不断地被更新和完善:
篇一:诗歌朗诵教案 新湖镇大闸小学 诗歌朗诵社团活动教案 1、?十一月四日风雨大作? 陆游 教学目标: 1.反复朗诵诗歌,领略诗人深沉的爱国情怀。 2.深入理解名句,培养学生品味语言鉴赏诗歌的能力。教学重点: 1.理解诗歌内涵,准确把握诗中情感,真正有感情地朗诵诗歌。 2.深入理解名句,培养学生品味语言鉴赏诗歌的能力 教学难点: 1.真正有感情地朗诵诗歌。 2.对名句的深入理解。 教学方法和手段:讨论交流为主,多媒体教学,配以幻灯片,背景音乐等。 教学重点: 1.反复诵读这首诗,结合对诗人身世、写作背景的了解,准确理解诗中深沉的爱国情感。 2.有感情地朗诵诗歌。 教学难点:真正有感情地朗诵诗歌。 一、导入新课,检查课前积累。 1.导入语。 2.学生活动: 举手发言,列举中国爱国名人名言或他们的爱国事迹1例。 3.切入本课,明确目标:学会有感情地诵读诗歌,深入理解诗歌的思想主题,并学会对名句进行赏析。?幻灯片出示本堂课学习目标? 二、配乐朗诵,总体感受并进一步理解四首古诗所表达的爱国情怀。 1.范读: 1)多媒体画面、诗文、配乐朗诵。 2)学生活动:静静地欣赏,并正音正字,正确把握诗句的朗读节奏,思考老师提出的问题。 2.小组讨论交流: 1)四首诗分别表达了诗人怎样的思想感情?你是怎么知道的?[投影] 2)学生活动:4人一组,各抒己见,并努力使对方接受。 3.组织班级交流。 1) 学生活动:每小组推荐一名代表在班级发言。 2) 教师适时点评,加以引导。[在交流中穿插幻灯投影,介绍背景材料,帮助学生了解写作背景、诗人身世,正确理解诗歌内涵。] 三、重放配乐朗诵,学生比照自己,有感情地跟读。 1) 跟读。 2) 教师小结:诗歌是激情的产物,不是带着强烈感情的人是朗读不好诗歌的。要有感情地朗读好诗歌,我们必须做到以下两点:正确理解诗歌主题,深入体会诗人情感;采取多种朗读手段,充分调动自身激情。 四、课堂总结: 本节课通过讨论交流我们理解了四首诗的思想内容,学习了有感情地朗读这四首诗。希
A Study of Beloved from the Perspective of Ecofeminism 1、课题来源(四号黑体,以下相同) 2、研究目的和意义 自拟课题:美国当代黑人文学代表作家托妮·莫里久负盛名,其代表作 《宠儿》是一部惊世之作,高超的创作技巧和叙述手法值得去探索和研究;生态女性主义的角度比较新颖,因此本文作者试着从这个角度对此作品探析一二。 (1) 托妮·莫里森作为美国当代黑人文学的主要代表作家,其代表作《宠儿》 极具文学研究价值。 托妮·莫里森,美国当代著名作家,诺贝尔文学奖获得者。因“其富于洞察力和诗情画意的小说把美国现实的一个重要方面写活了” 而成为第一位获此殊荣的黑人女作家。《宠儿》是美国“多元文化主义”和新历史主义语境下黑人作家重构黑人种族历史的成功尝试,作品的锋芒直逼那段“惨不堪言”的蓄奴史及其给黑人心灵造成的永久创伤,充分展示了作家自觉的历史意识和高尚的人文情怀。该书一问世便震动美国文坛。评论家高度评价这部小说,称它是“一部历史,字字是惊雷,句句是闪电”,认为它是“美国文学史上的里程碑”,不读这部作品就“无法理解美国文学”。1988 年,《宠儿》获得美国文学界的最高奖———普利策奖。 莫氏获诺贝尔文学奖之后,她的小说引起西方读者和评论界的广泛关注,《宠儿》更是被关注的焦点,相关的评论不断见诸多报刊杂志。《宠儿》因其艺术性和思想性的完美糅合也倍受中国读者和评论界的青睐。 (2) 《宠儿》作为文学经典被中外学者从各个角度得以广泛研究,但是运用生态女性主义视角则鲜有人涉足,因此可以为女性生态主义研究提供鲜活的 文本范例。 多年来,许多文学评论家从不同的方面对这部小说进行研究。但是以前的研究主要集中于关于小说的诗性语言,后现代主义特征,母爱主题,叙事策略,哥 说中体现的生态女性主义思想。通过对文本的详细分析来展现有色人种所遭受的苦难和建构自我身份的过程。最终,在小说的结束时,他们寻找到了曾经迷失的自我,并且建立起人类与自然、男性与女性以及各色人种平等和谐共处的理想生存状态。 ( 3)促进中西文化交流 对于《宠儿》的生态女性主义研究可以深层次剖析西方文化,尤其是美国黑人文化,使中国读者能更好地理解黑人文学作品,从而理解种族歧视的根源和奴隶制度对黑人的残害。
谷歌浏览器(chrome)的一些使用技巧分享(来自六维空间作者cicaday)
说在前面: 六维上可能有不少用谷歌浏览器的朋友,我冒昧在这里开一贴,分享一下自己使用chrome的一些心得,目的就是为了抛砖引玉,希望能激起点点浪花。 ---------------------------------------------- 内容可能还会增加,目前本贴目录大致如下: 1、前言--一些废话 2、操作技巧--和dz的兼容(使用即见即得编辑器,使用论坛表情,以及其它功能) 3、操作技巧--文本域的自由拉伸功能 4、操作技巧--拖放移动下载文件位置 5、操作技巧--后退与历史记录(撤消刚关闭的页面) 6、操作技巧--新建IE内核标签/隐身窗口 7、操作技巧--任务管理器的使用 8、操作技巧--拖放tab新建标签页 9、操作技巧--地址栏的站内搜索功能 10、快捷键一览 11、点缀--地址栏的计算器功能 12、点缀--一些有意思的命令 13、关于谷歌浏览器版本的说明以及选择 ------------------------------------------------- 好,现在正文开始。我首先要说的当然是目前很多人提到的谷歌浏览器和六维的兼容问题,其实这是一个广泛性的问题,这里涉及到浏览器核心对js和css的处理方式的区别问题,我尽量把问题简单通俗化。 关于浏览器内核:浏览器的内核其实可以分为Trident、Gecko,Presto、Webkit等几种,这几种内核和目前常见的浏览器的对应关系是: Trident ==>IE,以及使用IE内核的浏览器,比如世界之窗,傲游2.x,搜狗,TT,GB 等 Gecko ==>Firefox所有版本 Presto ==>Opera,目前好像就这一个孤儿 Webkit ==>Chrome,Safari,傲游3.x也采用webkit内核,用过测试版的同学应该知道。 内核相当于浏览器的引擎,用于解释网页的行为和特性,主要包括DOM、插件、Layout和JavaScript几个模块。我们现在不讨论各个内核的优劣,我只想让大家理解一下有内核这么一回事。可以这样理解,假如把浏览网页当成快递公司给你送东西,各个快递公司处理快件的方式是有区别的(可以理解为模块),它们送货的速度也是有区别的(可以理解为处理或者解释网页的速度),最后送给用户面前的快件可能都是一样的(可以理解为网页内容),但有些可能会把快件包装或者零件搞坏了(网页的框架,表现形式),最后,他们的服务态度和收费也是不同的^^ 如果你能理解浏览器的内核是怎么一回事,那么关于前面提到问题就很好解释了。六维是基于discuz!构架的一个论坛,现在的问题主要是发贴时的编辑器标签不响应(表情标签或者主文件框)以及元素错位的问题,为什么会这样呢?因为各个内核对网页元素处理的方式不同,dz的即见即得编辑器是(也必须是)用JavaScript和css写的,而内核对js和css的解
软件设计师:数据流图深入讲解[1] https://www.doczj.com/doc/806095733.html,作者:佚名来源:考试吧2010年6月28日发表评论进入社区 软件设计师考试的下午题的第一道题,数据库系统工程师考试的下午题的第一道题都是数据流图题,而能够将这道题全部做对的考生是非常少的。根据历年的辅导和阅卷经验,发现很多考生不是因为这方面的解题能力不够,而是缺乏解这种题的方法与技巧。本文介绍一些解这种类型题的方法和技巧,希望起来抛砖引玉的效果。 一、解题当中考生表现出的特点 由于这是下午考试的第一道题,所以很多考生从考前的紧张氛围当中逐渐平静下来开始答题,头脑还比较清醒,阅读起来比较流畅,速度还可以,自我感觉不错。可偏偏这道题有很多人不能全取15分,纠其原因有以下一些特点: 1.拿卷就做,不全面了解试卷,做到心中有数。这样会导致在解题过程当中缺少一种整体概念,不能明确自己在哪些题上必需拿分(多花时间),哪些题上自己拿不了分(少花时间)。这样,在解题时目标就会明确很多。 2.速度快,读一遍题就开始动手做。 3.速度慢,用手指逐个字的去看,心想看一遍就能做出题来。 4.在阅读题目时,不打记,不前后联系起来思考。 5.边做边怀疑边修改,浪费时间。 6.缺少的数据流找不准,可去掉的文件找不出来。 7.由于缺少项目开发经验,对一些事务分析不知如何去思考。 8.盲目乐观,却忽略了答题格式,丢了不应该丢的分。 二、解题的方法与技巧
1.首先要懂得数据流图设计要略 有时为了增加数据流图的清晰性,防止数据流的箭头线太长,减少交叉绘制数据流条数,一般在一张图上可以重复同名的数据源点、终点与数据存储文件。如某个外部实体既是数据源点又是数据汇点,可以在数据流图的不同的地方重复绘制。在绘制时应该注意以下要点: (1)自外向内,自顶向下,逐层细化,完善求精。 (2)保持父图与子图的平衡。 为了表达较为复杂问题的数据处理过程,用一个数据流图往往不够。一般按问题的层次结构进行逐步分解,并以分层的数据流图反映这种结构关系。根据层次关系一般将数据流图分为顶层数据流图、中间数据流图和底层数据流图,除顶层图外,其余分层数据流图从0开始编号。对任何一层数据流图来说,称它的上层数据流图为父图,在它的下一层的数据流图为子图。 顶层数据流图只含有一个加工,表示整个系统;输入数据流和输出数据流为系统的输入 数据和输出数据,表明了系统的范围,以及与外部环境的数据交换关系。 底层数据流图是指其加工不能再分解的数据流图,其加工称为“原子加工”。 中间数据流图是对父层数据流图中某个加工进行细化,而它的某个加工也可以再次细化,形成子图。中间层次的多少,一般视系统的复杂程度而定。 任何一个数据流子图必须与它上一层父图的某个加工对应,二者的输入数据流和输出数 据流必须保持一致,此即父图与子图的平衡。父图与子图的平衡是数据流图中的重要性质,保证了数据流图的一致性,便于分析人员阅读和理解。 在父图与子图平衡中,数据流的数目和名称可以完全相同;也可以在数目上不相等,但 是可以借助数据字典中数据流描述,确定父图中的数据流是由子图中几个数据流合并而成的,也即子图是对父图中加工和数据流同时进行分解,因此也属于父图与子图的平衡,如图1 所示。
广东省中小学教师继续教育校本培训示范学校 龙山中学校本培训自评报告 自2005年以来,我龙山中学从教师专业发展需求的多元化出发,立足学校实际,积极探索教师校本培训的有效形式和途径,从而有力地促进了教师素质的全面提升和新课程的深入实施。我们参照其他省市制订的各项指标,对我校教师培训工作进行了认真自评自查,现将有关情况汇报如下: 一、学校概况 龙山中学依山而建。校园环境朴实凝重,富有现代气息和人文内涵。学校总面积27万多平方米,(其中老校区6万多平方米,新校区16万多平方米,法留校区阳光校区5万多平方米)绿化总面积17.7万多平方米,绿化覆盖率达70.69%。有94个班,教职工349人,学生5272人,其中内宿生1912人。近几年,学校办学规模不断扩大,教育教学质量不断提高,文明办学成果显著。曾先后获得“全国群众体育先进单位”、“全国勤工俭学先进单位”、“广东省完中分类检查先进单位”、“广东省先进集体”、“广东省安全文明校园”、“广东省现代教育技术实验学校”、“广东省高中教学水平评估优秀学校“、“和谐中国·全国中小学文化建设百佳创新学校”、“广东省一级学校”、“广东省中小学外语教研工作示范学校”、“汕尾市一级学校”、“汕尾市文明学校”、“陆丰市‘大办教育’先进单位”、“陆丰市文明单位”、“全国优质教育资源建设重点示范校”、“全国教育教学管理先进学校”、“中国师德建设示范单位”、“全国‘朝阳’计划基地”、“汕尾市科普教育基地”等荣誉。教育教学管理经验被《广东教育》、《汕尾日报》、《汕尾教育》、《中国教师报》、《现代教育报》、《德育报》、《侨报》等刊物发表推荐和陆丰电视台、汕尾电视台、广东卫视、珠江台等电视台专题报道,办学特色在《今日广东》、中国名校网等网站报道宣传。 我校实行校长负责制,管理架构合理。内设办公室、教导处、教研室、政教处、总务处、保卫股、教工会、团委会、学生会、年级组等管理分支机构。学校党政领导班子成员共33人,党支部书记1人,正、副校长3人均为中学高级教师职称,学历达标。 师资力量较为雄厚,现有高级职称教师47人、中级职称教师111人,学历达标率为 95%,
潍坊学院 抽样技术调查报告 题目:大学生图书借阅情况调查 组别:一组 成员: 指导老师: 2013年6月
目录 一、调查概况 (2) 二、调查结果及分析...................................... 错误!未定义书签。 1. 对图书馆借阅书籍频繁程度的分析 . 错误!未定义书签。 2. 图书借阅类型分析 ............................. 错误!未定义书签。 3. 对图书馆所借图书阅读情况的分析 . 错误!未定义书签。 4.对图书馆藏书是否满意 ...................... 错误!未定义书签。 5.是否会借阅图书来扩充知识 .............. 错误!未定义书签。 6. 对图书馆资源看法的分析 ................. 错误!未定义书签。 7. 对图书馆的管理制度是否满意 ......... 错误!未定义书签。三.总结 .......................................................... 错误!未定义书签。 四.对大学生图书借阅情况的建议…………………………….. 错误!未定义书签。 附录 (15)
关于大学生图书借阅情况的调查报告 调查背景 现在,越来越多的大学生不重视自身知识文化的积累,他们似乎更注重的是那种快餐式的获取知识途径,例如手机阅读,电子书籍等等,为了更好地了解现代大学生利用图书馆获取知识的广度以及其借阅的内容的深度,我们以潍坊学院在校学生为一个调查对象,展开了一次社会调查,希望了解大学生阅读的情况,以便进行分析总结,为大学生合理利用图书馆提出可行性意见,同时为图书馆图书安排等提出改进意见。 一、调查概况 1.调查目的:随着经济水平的提高图书馆硬件配备越来越好,图书种类、藏书量等逐年增加,然而图书馆借阅量确未随图书馆的改进而增加,部分借阅室甚至门可罗雀,深入了解大学生图书借阅情况,无论对学校图书馆管理工作,还是对大学生合理利用图书资源、养成良好读书习惯,营造良好学术氛围,都具有重要意义。 2.调查对象:潍坊学院大一、大二、大三在校生。(大四学生即将离校,阅读习惯等对本次调查不具有实际意义。) 3.调查方式:为使本次调查更具有普遍性调查采用随机调查方式,小组成员分别在二餐前、图书馆、自习室、宿舍等地随机、分不同时间
浏览器内核的功能/JS引擎的功能总结 1、浏览器内核 浏览器最重要或者说核心的部分是“Rendering Engine”,可译为“解释引擎”,也即我们平常所说的“浏览器内核”。负责对网页语法的解释(如HTML、JavaScript)并渲染网页。所以,通常所谓的浏览器内核也就是浏览器所采用的渲染引擎,渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。不同的浏览器内核对网页编写语法的解释也有不同,因此同一网页在不同的内核的浏览器里的渲染(显示)效果也可能不同,这也是网页编写者需要在不同内核的浏览器中测试网页显示效果的原因。 浏览器内核很多,不过通常主流的大约只有以下几种: 1)Trident:IE浏览器使用的内核,该内核程序在1997年的IE4中首次被采用,是微软在Mosaic代码的基础之上修改而来的,并沿用到目前的IE8。Trident实际上是一款开放的内核,其接口内核设计的相当成熟,因此才有许多采用IE内核而非IE的浏览器涌现(如Maxthon、The World 、TT、GreenBrowser、AvantBrowser等)。此外,为了方便也有很多人直接简称其为IE内核。 由于IE本身的“垄断性”而使得Trident内核的长期一家独大,微软很长时间都并没有更新Trident内核,这导致了两个后果——一是Trident内核曾经几乎与W3C标准脱节(2005年),二是Trident内核的大量Bug等安全性问题没有得到及时解决,然后加上一些致力于开源的开发者和一些学者们公开自己认为IE浏览器不安全的观点,也有很多用户转向了其他浏览器,Firefox和Opera就是这个时候兴起的。非Trident内核浏览器的市场占有率大幅提高也致使许多网页开发人员开始注意网页标准和非IE浏览器的浏览效果问题。 2)Gecko:Netscape6开始采用的内核,后来的Mozilla FireFox (火狐浏览器) 也采用了该内核,Gecko的特点是代码完全公开,因此,其可开发程度很高,全世界的程序员都可以为其编写代码,增加功能。因为这是个开源内核,因此受到许多人的青睐,Gecko内核的浏览器也很多,这也是Geckos内核虽然年轻但市场占有率能够迅速提高的重要原因。 事实上,Gecko引擎的由来跟IE不无关系,前面说过IE没有使用W3C的标准,这导致了微软内部一些开发人员的不满;他们与当时已经停止更新了的Netscape的一些员工一起创办了Mozilla,以当时的Mosaic内核为基础重新编写内核,于是开发出了Geckos。不过事实上,Gecko 内核的浏览器仍然还是Firefox (火狐) 用户最多,所以有时也会被称为Firefox内核。此外Gecko也是一个跨平台内核,可以在Windows、BSD、Linux和Mac OS X中使用。 3)Presto:目前Opera采用的内核,该内核在2003年的Opera7中首次被使用,该款引擎的特点就是渲染速度的优化达到了极致,也是目前公认网页浏览速度最快的浏览器内核,然而代价是牺牲了网页的兼容性。 实际上这是一个动态内核,与前面几个内核的最大的区别就在脚本处理上,Presto有着天生的优势,页面的全部或者部分都能够在回应脚本事件时等情况下被重新解析。此外该内核在执行Javascrīpt的时候有着最快的速度,根据在同等条件下的测试,Presto内核执行同等Javascrīpt所需的时间仅有Trident和Gecko内核的约1/3(Trident内核最慢,不过两者相差没有多大)。那次测试的时候因为Apple机的硬件条件和普通PC机不同所以没有测试WebCore内核。只可惜Presto是商业引擎,使用Presto的除开Opera以外,只剩下NDSBrowser、Wii Internet Channle、Nokia 770网络浏览器等,这很大程度上限制了Presto 的发展。 4)Webkit:苹果公司自己的内核,也是苹果的Safari浏览器使用的内核。Webkit引擎包含WebCore排版引擎及JavaScriptCore解析引擎,均是从KDE的KHTML及KJS引擎衍生