A note on the statistical power in extended twin designs
- 格式:pdf
- 大小:102.00 KB
- 文档页数:12

9. Nonparametric Statistics9.1 Sign Test 符号检验1The simplest of all nonparametric methods is the sign test, which is usually used to test the significance of the difference between two means in a paired experiment.最简单的非参数检验是符号检验检验两个总体均值差的显著程度It is particularly suitable when the various pairs are observed under different conditions, a case in which the assumption of normality may not hold. However, because of its simplicity, the sign test is often used even though the populations are normally distributed. As is implied by its name in this test only the sign of the differencebetween the paired variates is used.若两个总体的均值相等,那么符号‘+’、‘-’的概率一样。
D = sign of (X 1-X 2 )If p denotes the probability of a difference D being positive andq the probability of its being negative, we have as hypothesis p=1/2. appropriate test statistic is X , X~B (n, p), X --- N(‘+”)we will reject 0Hin favor of1Honly if the proportion of plussigns is sufficiently less than 1/2, that is , when the value x of our random variable is small. Hence, if the computed P -value12()P P X x when p =≤=is less than or equal to the significance level α, we reject 0Hinfavor of1H .we reject0Hin favor1Hwhen the proportion of plus signs issignificantly less than or significantly greater than 1/2. This, of course, is equivalent to x being sufficiently small or sufficiently large, respectively. Therefore, if /2x n < and the computed P-value 122()P P X x when p =≤=is less than or equal to α, or if /2x n > and the computed P-value 122()P P X x when p =≥= is less than or equal to α, we reject 0Hin favor1H .Car Radial tires Belted tires D1 4.2 4.1 + 2 4.7 4.9 -3 6.6 6.2 +4 7.0 6.9 +5 6.7 6.8 -6 4.5 4.4 +7 5.7 5.78 6.0 5.8 +9 7.4 6.9 +10 4.9 4.911 6.1 6.0 +12 5.2 4.9 +13 5.7 5.3 +14 6.9 6.5 +15 6.8 7.1 -16 4.9 4.8 +符号检验的利弊n 必须比较大因为对于n =5的样本,会出现永远不拒绝“总体均值相等“的假设。


Unit 111111III. Fill in the blank in each sentence with a word orphrase taken from the box, using its appropriate form.1.The local council has decreed that the hospitals that are not able to reach the service standards should close.2. When Hamlet murmured "To be, or not to be", he was faced with an agonizing dilemma.3. The young mother smiled approvingly at her son who asked to play outdoors.4. The Prime Minister is now firmly ensconced in Downing Street with a large majority.5. We need a manager with plenty of flair to run the business in China.6. It is noticed that quick-minded people suffer no vulnerability to criticism.7. It was a relief to be outside in the fresh air again after staying weeks-long underground.8. The government's avowed commitment to reduce tax has been largely appreciated.Unit3331.She thought she was too homely to get a date.2. I could hear the note of appeal in her voice as she asked me to talk things over again.3. In this decade of politics, many more women have become magistrates.4. I hope that we can settle this issue amicably.5. This is a far from solemn book -- it is a rich mix of pleasures and information, and is full of surprises.6. We rushed out of the shop in hot pursuit, but the thief had vanished into thin air.7. He twisted and turned, trying to free himself from the rope.8. I tried to excuse myself for missing her party but made the attempts very clumsily.U 5551.A useful definition of an air pollutant is a compound added directly or indirectly by humans to the atmosphere in such quantities as to affecthumans, animals, vegetation, or materials adversely.2.The most distant luminous objects seen by telescopes are probably ten thousand million light years away.3."Want some wine?" she asked. He smiled and took a swig from the bottle. He thanked her and retreated again into his silence.4.The self-educated son of a Delaware farmer, Evans became obsessed by the possibilities of mechanized production and steam power.5.Stone carvers engraved their motifs of skulls and crossbones and other religious icons of death, into the gray slabs that we still see standing today in old burial grounds.6.The employment department has undergone several metamorphoses over the past few years.7.Respect is never given freely; every shred of it has to be earned and you earn it by how well you treat others.8.The professor argued that these books had a pernicious effect on young and susceptible minds.Uu 6666666661. Her manner is friendly and relaxed and much less formidable than she appears at her after-game press conference.2. Nothing has ever equaled the magnitude and speed with which the human species is altering the physical and chemical world and demolishing the environment.3.When heated, the mixture becomes soft and malleable and can be formed by various techniques into a vast array of shapes and sizes.4. Where I part company with him, however, is over the link he forges between science and liberalism.5.Percy was lying prostrate, his arms outstretched and his eyes closed.6. Given data which are free from bias, there are further snares to avoid in statistical work.7.In pragmatics, the study of speech, one is able to see how specific acts are related to a temporal and spatial context.8. His dad might have been able to say something solacing, had he not been fighting back his own flood of anguish.Unit 7777771.When his prospective employers learned that he smoked, they said they wouldn't hire him.2.In him the polarities of life are resolved and balanced, male and female,strength and compassion, severity and mercy.3.Inarticulate and rather shy, he had always dreaded speaking in public.4.Allegations of brutality and theft have been leveled at the army.5.Our government cannot keep doling out money to those who are fastidious about the jobs offered to them.6.He was deeply grieved by the sufferings of the common people.7.Many studies have shown that "restrained eaters" will eventually binge and relapse.8.He reaffirmed his commitment to the country's economic reform programme.Unit 8888888881.This figure is five times the original estimate.2.They have no way to dispose of the hazardous waste they produce.3.Britain is intensifying its efforts to secure the release of three British hostages.4.Translation must always be a process of approximation and compromise.5.There's a sizzling summer of soccer ahead -- we're kicking it off with a series of cracking quizzes.6.Turning that vision into a reality is not easy.7.I don't envisage I will take an executive role, but rather become a consultant on merchandise and marketing.8.Surely it is economic nonsense to deplete the world of natural resources.Unit 101. Hallucination is common in patients who suffered damages to the brain.2. There are two main problems which afflict people's hearing.3. Having begun my life in a children's home, I have the greatest empathy with the little ones.4. Some people need to confront a traumatic past, others find it better to leave it alone.5.A new survey found that 50% of women had experienced some form of sexual harassment in their working lives.6.He's large and languid, meeting each inquiry with an impassive countenance.7.From the very first days of the reforms, the parliament kept on an incessant drumbeat of protest.8.I deeply resented those sort of rumors being circulated at a time of deeply personal grief.Unit 12. The new economic plan seeks to achieve a more equitable distribution of wealth.2.A number of enlightened landowners have recently set an example by making land available at less than normal market value.3. The consensus amongst the world's scientists is that the world is likely to warm up over the next few decades.4. It is useless trying to convince her that she doesn't need to lose any weight.5. A great number of industries have to sack managers to reduce their huge administrative costs.6. Sadly, the main beneficiaries of pension equality so far have been men, not women.7. He professed a violent distaste for everything related to commerce, production, and money.8. To make a sound diplomat is to first believe that bureaucratic delays are inevitable. Unit131.The Minister was alleged to have made disparaging remarks about the rest of theCabinet.2. The CEO was censured for his indecisiveness during the period of economic crisis.3. The actual damage to the brain cells is secondary to the damage caused to the bloodsupply.4.The Earth is thought to be around 4,600 million years old, an almost inconceivabletime-span.5. Harvard is one of the best equipped and most prestigious schools in the country.6. It was a Puritan who tried effectively to renounce the ancient customs of his country.7. Lloyd's results were carefully scrutinized as a guide to what to expect from the otherbanks.8. We often get complimentary remarks regarding the cleanliness of our patio.Unit15II. 1.conform 2. adapt 3. adapt 4. conform1. neglecting2. neglect3. ignoring4. ignore1.zest2. interest3. zest4. interests1. strain2. strain3. stress4. stressIII.1.Excessive conformity is usually caused by fear of disapproval.2.It did not require a great deal of perception to realize that the interview was over when the interviewers had absent-minded.3. A new machine may save animals from the agony of drug tests.4.He has published a great number of poems, but most anonymously.5.He has made a long-term investment, so he might expect to incur light losses in the first few years.6.When a book gets translated, all those linguistics subtleties get lost.7.It is your prerogative to stop seeing that particular therapist and find another one. 8.The proposal is a thinly disguised effort to revive the price controls of the 1990s.Translate the following sentences into Chinese (20%).BlackmailThe Duchess of Croydon – three centuries and a half of inbred arrogance behind her – did not yield easily. Springing to her feet, her face wrathful, gray-green eyes blazing, she faced the grossness of the house detective squarely.克罗伊敦公爵夫人——依仗着三个半世纪祖传下来的狂傲天性——并没有轻易就范。

SCI论文摘要中常用的表达方法要写好摘要,需要建立一个适合自己需要的句型库(选择的词汇来源于SCI高被引用论文)引言部分(1)回顾研究背景,常用词汇有review, summarize, present, outline, describe等(2)说明写作目的,常用词汇有purpose, attempt, aim等,另外还可以用动词不定式充当目的壮语老表达(3)介绍论文的重点内容或研究范围,常用词汇有study, present, include, focus, emphasize, emphasis, attention等方法部分(1)介绍研究或试验过程,常用词汇有test study, investigate, examine,experiment, discuss, consider, analyze, analysis等(2)说明研究或试验方法,常用词汇有measure, estimate, calculate等(3)介绍应用、用途,常用词汇有use, apply, application等结果部分(1)展示研究结果,常用词汇有show, result, present等(2)介绍结论,常用词汇有summary, introduce,conclude等讨论部分(1)陈述论文的论点和作者的观点,常用词汇有suggest, repot, present, expect, describe 等(2)说明论证,常用词汇有support, provide, indicate, identify, find, demonstrate, confirm, clarify等(3)推荐和建议,常用词汇有suggest,suggestion, recommend, recommendation, propose,necessity,necessary,expect等。
摘要引言部分案例词汇review•Author(s): ROBINSON, TE; BERRIDGE, KC•Title:THE NEURAL BASIS OF DRUG CRA VING - AN INCENTIVE-SENSITIZATION THEORY OF ADDICTION•Source: BRAIN RESEARCH REVIEWS, 18 (3): 247-291 SEP-DEC 1993 《脑研究评论》荷兰SCI被引用1774We review evidence for this view of addiction and discuss its implications for understanding the psychology and neurobiology of addiction.回顾研究背景SCI高被引摘要引言部分案例词汇summarizeAuthor(s): Barnett, RM; Carone, CD; 被引用1571Title: Particles and field .1. Review of particle physicsSource: PHYSICAL REVIEW D, 54 (1): 1-+ Part 1 JUL 1 1996:《物理学评论,D辑》美国引言部分回顾研究背景常用词汇summarizeAbstract: This biennial review summarizes much of Particle Physics. Using data from previous editions, plus 1900 new measurements from 700 papers, we list, evaluate, and average measuredproperties of gauge bosons, leptons, quarks, mesons, and baryons. We also summarize searches for hypothetical particles such as Higgs bosons, heavy neutrinos, and supersymmetric particles. All the particle properties and search limits are listed in Summary Tables. We also give numerous tables, figures, formulae, and reviews of topics such as the Standard Model, particle detectors, probability, and statistics. A booklet is available containing the Summary Tables and abbreviated versions of some of the other sections of this full Review.SCI摘要引言部分案例attentionSCI摘要方法部分案例considerSCI高被引摘要引言部分案例词汇outline•Author(s): TIERNEY, L SCI引用728次•Title:MARKOV-CHAINS FOR EXPLORING POSTERIOR DISTRIBUTIONS 引言部分回顾研究背景,常用词汇outline•Source: ANNALS OF STATISTICS, 22 (4): 1701-1728 DEC 1994•《统计学纪事》美国•Abstract: Several Markov chain methods are available for sampling from a posterior distribution. Two important examples are the Gibbs sampler and the Metropolis algorithm.In addition, several strategies are available for constructing hybrid algorithms. This paper outlines some of the basic methods and strategies and discusses some related theoretical and practical issues. On the theoretical side, results from the theory of general state space Markov chains can be used to obtain convergence rates, laws of large numbers and central limit theorems for estimates obtained from Markov chain methods. These theoretical results can be used to guide the construction of more efficient algorithms. For the practical use of Markov chain methods, standard simulation methodology provides several Variance reduction techniques and also gives guidance on the choice of sample size and allocation.SCI高被引摘要引言部分案例回顾研究背景presentAuthor(s): L YNCH, M; MILLIGAN, BG SC I被引用661Title: ANAL YSIS OF POPULATION GENETIC-STRUCTURE WITH RAPD MARKERS Source: MOLECULAR ECOLOGY, 3 (2): 91-99 APR 1994《分子生态学》英国Abstract: Recent advances in the application of the polymerase chain reaction make it possible to score individuals at a large number of loci. The RAPD (random amplified polymorphic DNA) method is one such technique that has attracted widespread interest.The analysis of population structure with RAPD data is hampered by the lack of complete genotypic information resulting from dominance, since this enhances the sampling variance associated with single loci as well as induces bias in parameter estimation. We present estimators for several population-genetic parameters (gene and genotype frequencies, within- and between-population heterozygosities, degree of inbreeding and population subdivision, and degree of individual relatedness) along with expressions for their sampling variances. Although completely unbiased estimators do not appear to be possible with RAPDs, several steps are suggested that will insure that the bias in parameter estimates is negligible. To achieve the same degree of statistical power, on the order of 2 to 10 times more individuals need to be sampled per locus when dominant markers are relied upon, as compared to codominant (RFLP, isozyme) markers. Moreover, to avoid bias in parameter estimation, the marker alleles for most of these loci should be in relatively low frequency. Due to the need for pruning loci with low-frequency null alleles, more loci also need to be sampled with RAPDs than with more conventional markers, and sole problems of bias cannot be completely eliminated.SCI高被引摘要引言部分案例词汇describe•Author(s): CLONINGER, CR; SVRAKIC, DM; PRZYBECK, TR•Title: A PSYCHOBIOLOGICAL MODEL OF TEMPERAMENT AND CHARACTER•Source: ARCHIVES OF GENERAL PSYCHIATRY, 50 (12): 975-990 DEC 1993《普通精神病学纪要》美国•引言部分回顾研究背景,常用词汇describe 被引用926•Abstract: In this study, we describe a psychobiological model of the structure and development of personality that accounts for dimensions of both temperament and character. Previous research has confirmed four dimensions of temperament: novelty seeking, harm avoidance, reward dependence, and persistence, which are independently heritable, manifest early in life, and involve preconceptual biases in perceptual memory and habit formation. For the first time, we describe three dimensions of character that mature in adulthood and influence personal and social effectiveness by insight learning about self-concepts.Self-concepts vary according to the extent to which a person identifies the self as (1) an autonomous individual, (2) an integral part of humanity, and (3) an integral part of the universe as a whole. Each aspect of self-concept corresponds to one of three character dimensions called self-directedness, cooperativeness, and self-transcendence, respectively. We also describe the conceptual background and development of a self-report measure of these dimensions, the Temperament and Character Inventory. Data on 300 individuals from the general population support the reliability and structure of these seven personality dimensions. We discuss the implications for studies of information processing, inheritance, development, diagnosis, and treatment.摘要引言部分案例•(2)说明写作目的,常用词汇有purpose, attempt, aimSCI高被引摘要引言部分案例attempt说明写作目的•Author(s): Donoho, DL; Johnstone, IM•Title: Adapting to unknown smoothness via wavelet shrinkage•Source: JOURNAL OF THE AMERICAN STATISTICAL ASSOCIATION, 90 (432): 1200-1224 DEC 1995 《美国统计学会志》被引用429次•Abstract: We attempt to recover a function of unknown smoothness from noisy sampled data. We introduce a procedure, SureShrink, that suppresses noise by thresholding the empirical wavelet coefficients. The thresholding is adaptive: A threshold level is assigned to each dyadic resolution level by the principle of minimizing the Stein unbiased estimate of risk (Sure) for threshold estimates. The computational effort of the overall procedure is order N.log(N) as a function of the sample size N. SureShrink is smoothness adaptive: If the unknown function contains jumps, then the reconstruction (essentially) does also; if the unknown function has a smooth piece, then the reconstruction is (essentially) as smooth as the mother wavelet will allow. The procedure is in a sense optimally smoothness adaptive: It is near minimax simultaneously over a whole interval of the Besov scale; the size of this interval depends on the choice of mother wavelet. We know from a previous paper by the authors that traditional smoothing methods-kernels, splines, and orthogonal series estimates-even with optimal choices of the smoothing parameter, would be unable to perform in a near-minimax way over many spaces in the Besov scale.Examples of SureShrink are given. The advantages of the method are particularly evident when the underlying function has jump discontinuities on a smooth backgroundSCI高被引摘要引言部分案例To investigate说明写作目的•Author(s): OLTV AI, ZN; MILLIMAN, CL; KORSMEYER, SJ•Title: BCL-2 HETERODIMERIZES IN-VIVO WITH A CONSERVED HOMOLOG, BAX, THAT ACCELERATES PROGRAMMED CELL-DEATH•Source: CELL, 74 (4): 609-619 AUG 27 1993 被引用3233•Abstract: Bcl-2 protein is able to repress a number of apoptotic death programs. To investigate the mechanism of Bcl-2's effect, we examined whether Bcl-2 interacted with other proteins. We identified an associated 21 kd protein partner, Bax, that has extensive amino acid homology with Bcl-2, focused within highly conserved domains I and II. Bax is encoded by six exons and demonstrates a complex pattern of alternative RNA splicing that predicts a 21 kd membrane (alpha) and two forms of cytosolic protein (beta and gamma). Bax homodimerizes and forms heterodimers with Bcl-2 in vivo. Overexpressed Bax accelerates apoptotic death induced by cytokine deprivation in an IL-3-dependent cell line. Overexpressed Bax also counters the death repressor activity of Bcl-2. These data suggest a model in which the ratio of Bcl-2 to Bax determines survival or death following an apoptotic stimulus.SCI高被引摘要引言部分案例purposes说明写作目的•Author(s): ROGERS, FJ; IGLESIAS, CA•Title: RADIATIVE ATOMIC ROSSELAND MEAN OPACITY TABLES•Source: ASTROPHYSICAL JOURNAL SUPPLEMENT SERIES, 79 (2): 507-568 APR 1992 《天体物理学杂志增刊》美国SCI被引用512•Abstract: For more than two decades the astrophysics community has depended on opacity tables produced at Los Alamos. In the present work we offer new radiative Rosseland mean opacity tables calculated with the OPAL code developed independently at LLNL. We give extensive results for the recent Anders-Grevesse mixture which allow accurate interpolation in temperature, density, hydrogen mass fraction, as well as metal mass fraction. The tables are organized differently from previous work. Instead of rows and columns of constant temperature and density, we use temperature and follow tracks of constant R, where R = density/(temperature)3. The range of R and temperature are such as to cover typical stellar conditions from the interior through the envelope and the hotter atmospheres. Cool atmospheres are not considered since photoabsorption by molecules is neglected. Only radiative processes are taken into account so that electron conduction is not included. For comparison purposes we present some opacity tables for the Ross-Aller and Cox-Tabor metal abundances. Although in many regions the OPAL opacities are similar to previous work, large differences are reported.For example, factors of 2-3 opacity enhancements are found in stellar envelop conditions.SCI高被引摘要引言部分案例aim说明写作目的•Author(s):EDV ARDSSON, B; ANDERSEN, J; GUSTAFSSON, B; LAMBERT, DL;NISSEN, PE; TOMKIN, J•Title:THE CHEMICAL EVOLUTION OF THE GALACTIC DISK .1. ANALYSISAND RESULTS•Source: ASTRONOMY AND ASTROPHYSICS, 275 (1): 101-152 AUG 1993 《天文学与天体物理学》被引用934•Abstract:With the aim to provide observational constraints on the evolution of the galactic disk, we have derived abundances of 0, Na, Mg, Al, Si, Ca, Ti, Fe, Ni, Y, Zr, Ba and Nd, as well as individual photometric ages, for 189 nearby field F and G disk dwarfs.The galactic orbital properties of all stars have been derived from accurate kinematic data, enabling estimates to be made of the distances from the galactic center of the stars‘ birthplaces. 结构式摘要•Our extensive high resolution, high S/N, spectroscopic observations of carefully selected northern and southern stars provide accurate equivalent widths of up to 86 unblended absorption lines per star between 5000 and 9000 angstrom. The abundance analysis was made with greatly improved theoretical LTE model atmospheres. Through the inclusion of a great number of iron-peak element absorption lines the model fluxes reproduce the observed UV and visual fluxes with good accuracy. A new theoretical calibration of T(eff) as a function of Stromgren b - y for solar-type dwarfs has been established. The new models and T(eff) scale are shown to yield good agreement between photometric and spectroscopic measurements of effective temperatures and surface gravities, but the photometrically derived very high overall metallicities for the most metal rich stars are not supported by the spectroscopic analysis of weak spectral lines.•Author(s): PAYNE, MC; TETER, MP; ALLAN, DC; ARIAS, TA; JOANNOPOULOS, JD•Title:ITERA TIVE MINIMIZATION TECHNIQUES FOR ABINITIO TOTAL-ENERGY CALCULATIONS - MOLECULAR-DYNAMICS AND CONJUGA TE GRADIENTS•Source: REVIEWS OF MODERN PHYSICS, 64 (4): 1045-1097 OCT 1992 《现代物理学评论》美国American Physical Society SCI被引用2654 •Abstract: This article describes recent technical developments that have made the total-energy pseudopotential the most powerful ab initio quantum-mechanical modeling method presently available. In addition to presenting technical details of the pseudopotential method, the article aims to heighten awareness of the capabilities of the method in order to stimulate its application to as wide a range of problems in as many scientific disciplines as possible.SCI高被引摘要引言部分案例includes介绍论文的重点内容或研究范围•Author(s):MARCHESINI, G; WEBBER, BR; ABBIENDI, G; KNOWLES, IG;SEYMOUR, MH; STANCO, L•Title: HERWIG 5.1 - A MONTE-CARLO EVENT GENERA TOR FOR SIMULATING HADRON EMISSION REACTIONS WITH INTERFERING GLUONS SCI被引用955次•Source: COMPUTER PHYSICS COMMUNICATIONS, 67 (3): 465-508 JAN 1992:《计算机物理学通讯》荷兰Elsevier•Abstract: HERWIG is a general-purpose particle-physics event generator, which includes the simulation of hard lepton-lepton, lepton-hadron and hadron-hadron scattering and soft hadron-hadron collisions in one package. It uses the parton-shower approach for initial-state and final-state QCD radiation, including colour coherence effects and azimuthal correlations both within and between jets. This article includes a brief review of the physics underlying HERWIG, followed by a description of the program itself. This includes details of the input and control parameters used by the program, and the output data provided by it. Sample output from a typical simulation is given and annotated.SCI高被引摘要引言部分案例presents介绍论文的重点内容或研究范围•Author(s): IDSO, KE; IDSO, SB•Title: PLANT-RESPONSES TO ATMOSPHERIC CO2 ENRICHMENT IN THE FACE OF ENVIRONMENTAL CONSTRAINTS - A REVIEW OF THE PAST 10 YEARS RESEARCH•Source: AGRICULTURAL AND FOREST METEOROLOGY, 69 (3-4): 153-203 JUL 1994 《农业和林业气象学》荷兰Elsevier 被引用225•Abstract:This paper presents a detailed analysis of several hundred plant carbon exchange rate (CER) and dry weight (DW) responses to atmospheric CO2 enrichment determined over the past 10 years. It demonstrates that the percentage increase in plant growth produced by raising the air's CO2 content is generally not reduced by less than optimal levels of light, water or soil nutrients, nor by high temperatures, salinity or gaseous air pollution. More often than not, in fact, the data show the relative growth-enhancing effects of atmospheric CO2 enrichment to be greatest when resource limitations and environmental stresses are most severe.SCI高被引摘要引言部分案例介绍论文的重点内容或研究范围emphasizing •Author(s): BESAG, J; GREEN, P; HIGDON, D; MENGERSEN, K•Title: BAYESIAN COMPUTATION AND STOCHASTIC-SYSTEMS•Source: STATISTICAL SCIENCE, 10 (1): 3-41 FEB 1995《统计科学》美国•SCI被引用296次•Abstract: Markov chain Monte Carlo (MCMC) methods have been used extensively in statistical physics over the last 40 years, in spatial statistics for the past 20 and in Bayesian image analysis over the last decade. In the last five years, MCMC has been introduced into significance testing, general Bayesian inference and maximum likelihood estimation. This paper presents basic methodology of MCMC, emphasizing the Bayesian paradigm, conditional probability and the intimate relationship with Markov random fields in spatial statistics.Hastings algorithms are discussed, including Gibbs, Metropolis and some other variations. Pairwise difference priors are described and are used subsequently in three Bayesian applications, in each of which there is a pronounced spatial or temporal aspect to the modeling. The examples involve logistic regression in the presence of unobserved covariates and ordinal factors; the analysis of agricultural field experiments, with adjustment for fertility gradients; and processing oflow-resolution medical images obtained by a gamma camera. Additional methodological issues arise in each of these applications and in the Appendices. The paper lays particular emphasis on the calculation of posterior probabilities and concurs with others in its view that MCMC facilitates a fundamental breakthrough in applied Bayesian modeling.SCI高被引摘要引言部分案例介绍论文的重点内容或研究范围focuses •Author(s): HUNT, KJ; SBARBARO, D; ZBIKOWSKI, R; GAWTHROP, PJ•Title: NEURAL NETWORKS FOR CONTROL-SYSTEMS - A SURVEY•Source: AUTOMA TICA, 28 (6): 1083-1112 NOV 1992《自动学》荷兰Elsevier•SCI被引用427次•Abstract:This paper focuses on the promise of artificial neural networks in the realm of modelling, identification and control of nonlinear systems. The basic ideas and techniques of artificial neural networks are presented in language and notation familiar to control engineers. Applications of a variety of neural network architectures in control are surveyed. We explore the links between the fields of control science and neural networks in a unified presentation and identify key areas for future research.SCI高被引摘要引言部分案例介绍论文的重点内容或研究范围focus•Author(s): Stuiver, M; Reimer, PJ; Bard, E; Beck, JW;•Title: INTCAL98 radiocarbon age calibration, 24,000-0 cal BP•Source: RADIOCARBON, 40 (3): 1041-1083 1998《放射性碳》美国SCI被引用2131次•Abstract: The focus of this paper is the conversion of radiocarbon ages to calibrated (cal) ages for the interval 24,000-0 cal BP (Before Present, 0 cal BP = AD 1950), based upon a sample set of dendrochronologically dated tree rings, uranium-thorium dated corals, and varve-counted marine sediment. The C-14 age-cal age information, produced by many laboratories, is converted to Delta(14)C profiles and calibration curves, for the atmosphere as well as the oceans. We discuss offsets in measured C-14 ages and the errors therein, regional C-14 age differences, tree-coral C-14 age comparisons and the time dependence of marine reservoir ages, and evaluate decadal vs. single-year C-14 results. Changes in oceanic deepwater circulation, especially for the 16,000-11,000 cal sp interval, are reflected in the Delta(14)C values of INTCAL98.SCI高被引摘要引言部分案例介绍论文的重点内容或研究范围emphasis •Author(s): LEBRETON, JD; BURNHAM, KP; CLOBERT, J; ANDERSON, DR•Title: MODELING SURVIV AL AND TESTING BIOLOGICAL HYPOTHESES USING MARKED ANIMALS - A UNIFIED APPROACH WITH CASE-STUDIES •Source: ECOLOGICAL MONOGRAPHS, 62 (1): 67-118 MAR 1992•《生态学论丛》美国•Abstract: The understanding of the dynamics of animal populations and of related ecological and evolutionary issues frequently depends on a direct analysis of life history parameters. For instance, examination of trade-offs between reproduction and survival usually rely on individually marked animals, for which the exact time of death is most often unknown, because marked individuals cannot be followed closely through time.Thus, the quantitative analysis of survival studies and experiments must be based oncapture-recapture (or resighting) models which consider, besides the parameters of primary interest, recapture or resighting rates that are nuisance parameters. 结构式摘要•T his paper synthesizes, using a common framework, these recent developments together with new ones, with an emphasis on flexibility in modeling, model selection, and the analysis of multiple data sets. The effects on survival and capture rates of time, age, and categorical variables characterizing the individuals (e.g., sex) can be considered, as well as interactions between such effects. This "analysis of variance" philosophy emphasizes the structure of the survival and capture process rather than the technical characteristics of any particular model. The flexible array of models encompassed in this synthesis uses a common notation. As a result of the great level of flexibility and relevance achieved, the focus is changed from fitting a particular model to model building and model selection.SCI摘要方法部分案例•方法部分•(1)介绍研究或试验过程,常用词汇有test,study, investigate, examine,experiment, discuss, consider, analyze, analysis等•(2)说明研究或试验方法,常用词汇有measure, estimate, calculate等•(3)介绍应用、用途,常用词汇有use, apply, application等SCI高被引摘要方法部分案例discusses介绍研究或试验过程•Author(s): LIANG, KY; ZEGER, SL; QAQISH, B•Title: MULTIV ARIATE REGRESSION-ANAL YSES FOR CATEGORICAL-DATA •Source:JOURNAL OF THE ROY AL STA TISTICAL SOCIETY SERIES B-METHODOLOGICAL, 54 (1): 3-40 1992《皇家统计学会志,B辑:统计方法论》•SCI被引用298•Abstract: It is common to observe a vector of discrete and/or continuous responses in scientific problems where the objective is to characterize the dependence of each response on explanatory variables and to account for the association between the outcomes. The response vector can comprise repeated observations on one variable, as in longitudinal studies or genetic studies of families, or can include observations for different variables.This paper discusses a class of models for the marginal expectations of each response and for pairwise associations. The marginal models are contrasted with log-linear models.Two generalized estimating equation approaches are compared for parameter estimation.The first focuses on the regression parameters; the second simultaneously estimates the regression and association parameters. The robustness and efficiency of each is discussed.The methods are illustrated with analyses of two data sets from public health research SCI高被引摘要方法部分案例介绍研究或试验过程examines•Author(s): Huo, QS; Margolese, DI; Stucky, GD•Title: Surfactant control of phases in the synthesis of mesoporous silica-based materials •Source: CHEMISTRY OF MATERIALS, 8 (5): 1147-1160 MAY 1996•SCI被引用643次《材料的化学性质》美国•Abstract: The low-temperature formation of liquid-crystal-like arrays made up of molecular complexes formed between molecular inorganic species and amphiphilic organic molecules is a convenient approach for the synthesis of mesostructure materials.This paper examines how the molecular shapes of covalent organosilanes, quaternary ammonium surfactants, and mixed surfactants in various reaction conditions can be used to synthesize silica-based mesophase configurations, MCM-41 (2d hexagonal, p6m), MCM-48 (cubic Ia3d), MCM-50 (lamellar), SBA-1 (cubic Pm3n), SBA-2 (3d hexagonal P6(3)/mmc), and SBA-3(hexagonal p6m from acidic synthesis media). The structural function of surfactants in mesophase formation can to a first approximation be related to that of classical surfactants in water or other solvents with parallel roles for organic additives. The effective surfactant ion pair packing parameter, g = V/alpha(0)l, remains a useful molecular structure-directing index to characterize the geometry of the mesophase products, and phase transitions may be viewed as a variation of g in the liquid-crystal-Like solid phase. Solvent and cosolvent structure direction can be effectively used by varying polarity, hydrophobic/hydrophilic properties and functionalizing the surfactant molecule, for example with hydroxy group or variable charge. Surfactants and synthesis conditions can be chosen and controlled to obtain predicted silica-based mesophase products. A room-temperature synthesis of the bicontinuous cubic phase, MCM-48, is presented. A low-temperature (100 degrees C) and low-pH (7-10) treatment approach that can be used to give MCM-41 with high-quality, large pores (up to 60 Angstrom), and pore volumes as large as 1.6 cm(3)/g is described.Estimates 介绍研究或试验过程SCI高被引摘要方法部分案例•Author(s): KESSLER, RC; MCGONAGLE, KA; ZHAO, SY; NELSON, CB; HUGHES, M; ESHLEMAN, S; WITTCHEN, HU; KENDLER, KS•Title:LIFETIME AND 12-MONTH PREV ALENCE OF DSM-III-R PSYCHIATRIC-DISORDERS IN THE UNITED-STA TES - RESULTS FROM THE NATIONAL-COMORBIDITY-SURVEY•Source: ARCHIVES OF GENERAL PSYCHIATRY, 51 (1): 8-19 JAN 1994•《普通精神病学纪要》美国SCI被引用4350次•Abstract: Background: This study presents estimates of lifetime and 12-month prevalence of 14 DSM-III-R psychiatric disorders from the National Comorbidity Survey, the first survey to administer a structured psychiatric interview to a national probability sample in the United States.Methods: The DSM-III-R psychiatric disorders among persons aged 15 to 54 years in the noninstitutionalized civilian population of the United States were assessed with data collected by lay interviewers using a revised version of the Composite International Diagnostic Interview. Results: Nearly 50% of respondents reported at least one lifetime disorder, and close to 30% reported at least one 12-month disorder. The most common disorders were major depressive episode, alcohol dependence, social phobia, and simple phobia. More than half of all lifetime disorders occurred in the 14% of the population who had a history of three or more comorbid disorders. These highly comorbid people also included the vast majority of people with severe disorders.Less than 40% of those with a lifetime disorder had ever received professional treatment,and less than 20% of those with a recent disorder had been in treatment during the past 12 months. Consistent with previous risk factor research, it was found that women had elevated rates of affective disorders and anxiety disorders, that men had elevated rates of substance use disorders and antisocial personality disorder, and that most disorders declined with age and with higher socioeconomic status. Conclusions: The prevalence of psychiatric disorders is greater than previously thought to be the case. Furthermore, this morbidity is more highly concentrated than previously recognized in roughly one sixth of the population who have a history of three or more comorbid disorders. This suggests that the causes and consequences of high comorbidity should be the focus of research attention. The majority of people with psychiatric disorders fail to obtain professional treatment. Even among people with a lifetime history of three or more comorbid disorders, the proportion who ever obtain specialty sector mental health treatment is less than 50%.These results argue for the importance of more outreach and more research on barriers to professional help-seekingSCI高被引摘要方法部分案例说明研究或试验方法measure•Author(s): Schlegel, DJ; Finkbeiner, DP; Davis, M•Title:Maps of dust infrared emission for use in estimation of reddening and cosmic microwave background radiation foregrounds•Source: ASTROPHYSICAL JOURNAL, 500 (2): 525-553 Part 1 JUN 20 1998 SCI 被引用2972 次《天体物理学杂志》美国•The primary use of these maps is likely to be as a new estimator of Galactic extinction. To calibrate our maps, we assume a standard reddening law and use the colors of elliptical galaxies to measure the reddening per unit flux density of 100 mu m emission. We find consistent calibration using the B-R color distribution of a sample of the 106 brightest cluster ellipticals, as well as a sample of 384 ellipticals with B-V and Mg line strength measurements. For the latter sample, we use the correlation of intrinsic B-V versus Mg, index to tighten the power of the test greatly. We demonstrate that the new maps are twice as accurate as the older Burstein-Heiles reddening estimates in regions of low and moderate reddening. The maps are expected to be significantly more accurate in regions of high reddening. These dust maps will also be useful for estimating millimeter emission that contaminates cosmic microwave background radiation experiments and for estimating soft X-ray absorption. We describe how to access our maps readily for general use.SCI高被引摘要结果部分案例application介绍应用、用途•Author(s): MALLAT, S; ZHONG, S•Title: CHARACTERIZATION OF SIGNALS FROM MULTISCALE EDGES•Source: IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, 14 (7): 710-732 JUL 1992•SCI被引用508次《IEEE模式分析与机器智能汇刊》美国•Abstract: A multiscale Canny edge detection is equivalent to finding the local maxima ofa wavelet transform. We study the properties of multiscale edges through the wavelet。

The Power of Data in ArgumentationIn the world of argumentation, data holds immense power. It is the cold, hard evidence that can either make or break an argument. Without data, an argument often lackscredibility and persuasiveness. This essay explores the significance of data in argumentation, discussing how itcan strengthen an argument and make it more convincing.First and foremost, data provides a solid foundationfor an argument. When backed by reliable data, an argument becomes more credible and difficult to refute. For example, in a debate about the effectiveness of a new policy, presenting statistical data on its impact on the economy, society, or the environment can significantly strengthenone's position. Data not only adds weight to an argumentbut also helps to establish its legitimacy.Moreover, data can be used to refute opposing arguments. By presenting counter-data, one can effectively challenge the validity of an opponent's claims. For instance, in a discussion about the safety of a particular product, citing statistics on the number of accidents caused by its use can effectively undermine the opponent's argument that it issafe. Data, when used effectively, can turn the tide of an argument in one's favor.Additionally, data can help to clarify complex issues and make them easier to understand. By breaking down complex problems into manageable chunks of data, one can make them more accessible to a wider audience. This, in turn, increases the chances of说服他人接受自己的观点. For instance, in an essay arguing for the need for environmental conservation, presenting data on the rate of deforestation, climate change, and the impact of these issues on human health can help readers understand the urgency of the problem and the need for action.However, it is important to note that not all data is created equal. The credibility of an argument can be compromised if the data presented is incomplete, outdated, or biased. Therefore, it is crucial to ensure that the data used in an argument is reliable, accurate, and representative of the larger population. This involves conducting thorough research, cross-checking sources, and analyzing data critically.In conclusion, data is an essential tool in argumentation. It adds credibility, helps to refute opposing arguments, clarifies complex issues, and makes arguments more convincing. However, to ensure the effectiveness of data in argumentation, it is important to ensure its reliability, accuracy, and representativeness. By doing so, one can turn raw data into powerful ammunition in the battle of ideas.**数据论证的力量**在论证的世界里,数据具有巨大的力量。

r语言的p.adjust函数-回复"P.adjust function in R: A Comprehensive Guide"Introduction:R is a statistical programming language widely used by researchers and data scientists for data analysis and visualization. One of the key functions in R is the p.adjust function, which is used for adjusting p-values in multiple hypothesis testing scenarios. This article aims to provide a step-by-step guide on how to use the p.adjust function in R, explaining its significance and various adjustment methods available.What is p.adjust function?The p.adjust function in R helps correct for multiple hypothesis testing by adjusting the p-values obtained from statistical tests. In a typical scenario, when several hypothesis tests are conducted simultaneously, the probability of obtaining a false positive result increases. Therefore, adjusting the p-values is essential to control the overall false discovery rate (FDR) or family-wise error rate (FWER). The p.adjust function automates this adjustment process, saving time and effort for the user.Step 1: Understanding p-valuesBefore diving into the p.adjust function, it is essential to understand the concept of p-values. A p-value represents the probability of obtaining the observed data (or more extreme) if the null hypothesis is true. The lower the p-value, the stronger the evidence against the null hypothesis. In multiple testing scenarios, p-values need to be adjusted to account for the inflation of false positives.Step 2: Basic usage of p.adjust functionThe basic syntax of the p.adjust function in R is as follows:p.adjust(p, method = "BY")Here, 'p' denotes the vector of p-values obtained from multiple hypothesis tests, and 'method' specifies the adjustment method to be applied. The default adjustment method in R is the Benjamini-Hochberg (BH) method, known as the "BY" method, which controls the false discovery rate. Other available methods include "holm", "hochberg", "hommel", "bonferroni", "BH", "BY", "fdr", and "none".Step 3: Adjustment methods and their implicationsAs mentioned earlier, different adjustment methods are available in R's p.adjust function. These methods have varying control properties and are suited for different scenarios. A brief overview of some commonly used methods is as follows:- Holm method: This method is a step-down procedure that provides strong control over the family-wise error rate (FWER). It is suitable when dependent tests or strong control over FWER are required.- Hochberg method: Similar to the Holm method, the Hochberg method also offers strong control over FWER. However, it is slightly more powerful and often preferred when dealing with independent tests.- Bonferroni method: The Bonferroni method is a conservative approach that controls the FWER by dividing the significance level by the number of tests. This method is useful when precision is crucial, but it may become overly conservative for a large number of comparisons.- Benjamini-Hochberg (BH) method: The BH method controls thefalse discovery rate (FDR), which is usually less stringent than the FWER. It is widely used for exploratory analysis and can be used when the FDR control is desirable.Step 4: Examples and practical considerationsTo better understand the application of the p.adjust function, let's consider an example. Suppose we have conducted 20 independent hypothesis tests and obtained a vector of raw p-values. We can use the p.adjust function to adjust these p-values using the desired method. For instance, to use the BH method, we can write:adjusted_p <- p.adjust(raw_p, method = "BH")Once adjusted, the vector 'adjusted_p' will contain the adjusted p-values corresponding to each hypothesis test. These adjusted p-values can be used for further analysis or comparison while controlling for the desired error rate.It is important to note that appropriate adjustment method selection depends on the nature of the data and research goals. Considering the trade-off between statistical power and controlover errors is crucial. Additionally, it is recommended to explore sensitivity analyses and adjust methods accordingly.Conclusion:The p.adjust function in R is a powerful tool for adjusting p-values in multiple hypothesis testing scenarios. By controlling for the overall false discovery rate or family-wise error rate, it ensures more robust and reliable statistical inferences. This comprehensive guide discussed the significance of the p.adjust function, its usage, available adjustment methods, and practical considerations. By following these steps, R users can effectively utilize the p.adjust function for their data analysis needs.。
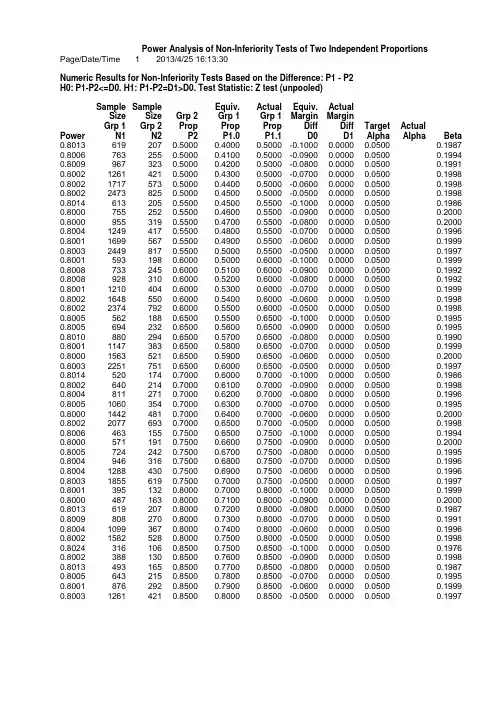
Numeric Re sults for Non-Inferiority Te sts Ba sed on the Difference: P1 - P2H0: P1-P2<=D0. H1: P1-P2=D1>D0. Te st Statistic: Z te st (unpooled)Sample Sample Equiv. Actual Equiv. ActualSize Size Grp 2 Grp 1 Grp 1 Margin MarginGrp 1 Grp 2 Prop Prop Prop Diff Diff Target ActualPower N1 N2 P2 P1.0 P1.1 D0 D1 Alpha Alpha Beta 0.8013 619 207 0.5000 0.4000 0.5000 -0.1000 0.0000 0.0500 0.1987 0.8006 763 255 0.5000 0.4100 0.5000 -0.0900 0.0000 0.0500 0.1994 0.8009 967 323 0.5000 0.4200 0.5000 -0.0800 0.0000 0.0500 0.1991 0.8002 1261 421 0.5000 0.4300 0.5000 -0.0700 0.0000 0.0500 0.1998 0.8002 1717 573 0.5000 0.4400 0.5000 -0.0600 0.0000 0.0500 0.1998 0.8002 2473 825 0.5000 0.4500 0.5000 -0.0500 0.0000 0.0500 0.1998 0.8014 613 205 0.5500 0.4500 0.5500 -0.1000 0.0000 0.0500 0.1986 0.8000 755 252 0.5500 0.4600 0.5500 -0.0900 0.0000 0.0500 0.2000 0.8000 955 319 0.5500 0.4700 0.5500 -0.0800 0.0000 0.0500 0.2000 0.8004 1249 417 0.5500 0.4800 0.5500 -0.0700 0.0000 0.0500 0.1996 0.8001 1699 567 0.5500 0.4900 0.5500 -0.0600 0.0000 0.0500 0.1999 0.8003 2449 817 0.5500 0.5000 0.5500 -0.0500 0.0000 0.0500 0.1997 0.8001 593 198 0.6000 0.5000 0.6000 -0.1000 0.0000 0.0500 0.1999 0.8008 733 245 0.6000 0.5100 0.6000 -0.0900 0.0000 0.0500 0.1992 0.8008 928 310 0.6000 0.5200 0.6000 -0.0800 0.0000 0.0500 0.1992 0.8001 1210 404 0.6000 0.5300 0.6000 -0.0700 0.0000 0.0500 0.1999 0.8002 1648 550 0.6000 0.5400 0.6000 -0.0600 0.0000 0.0500 0.1998 0.8002 2374 792 0.6000 0.5500 0.6000 -0.0500 0.0000 0.0500 0.1998 0.8005 562 188 0.6500 0.5500 0.6500 -0.1000 0.0000 0.0500 0.1995 0.8005 694 232 0.6500 0.5600 0.6500 -0.0900 0.0000 0.0500 0.1995 0.8010 880 294 0.6500 0.5700 0.6500 -0.0800 0.0000 0.0500 0.1990 0.8001 1147 383 0.6500 0.5800 0.6500 -0.0700 0.0000 0.0500 0.1999 0.8000 1563 521 0.6500 0.5900 0.6500 -0.0600 0.0000 0.0500 0.2000 0.8003 2251 751 0.6500 0.6000 0.6500 -0.0500 0.0000 0.0500 0.1997 0.8014 520 174 0.7000 0.6000 0.7000 -0.1000 0.0000 0.0500 0.1986 0.8002 640 214 0.7000 0.6100 0.7000 -0.0900 0.0000 0.0500 0.1998 0.8004 811 271 0.7000 0.6200 0.7000 -0.0800 0.0000 0.0500 0.1996 0.8005 1060 354 0.7000 0.6300 0.7000 -0.0700 0.0000 0.0500 0.1995 0.8000 1442 481 0.7000 0.6400 0.7000 -0.0600 0.0000 0.0500 0.2000 0.8002 2077 693 0.7000 0.6500 0.7000 -0.0500 0.0000 0.0500 0.1998 0.8006 463 155 0.7500 0.6500 0.7500 -0.1000 0.0000 0.0500 0.1994 0.8000 571 191 0.7500 0.6600 0.7500 -0.0900 0.0000 0.0500 0.2000 0.8005 724 242 0.7500 0.6700 0.7500 -0.0800 0.0000 0.0500 0.1995 0.8004 946 316 0.7500 0.6800 0.7500 -0.0700 0.0000 0.0500 0.1996 0.8004 1288 430 0.7500 0.6900 0.7500 -0.0600 0.0000 0.0500 0.1996 0.8003 1855 619 0.7500 0.7000 0.7500 -0.0500 0.0000 0.0500 0.1997 0.8001 395 132 0.8000 0.7000 0.8000 -0.1000 0.0000 0.0500 0.1999 0.8000 487 163 0.8000 0.7100 0.8000 -0.0900 0.0000 0.0500 0.2000 0.8013 619 207 0.8000 0.7200 0.8000 -0.0800 0.0000 0.0500 0.1987 0.8009 808 270 0.8000 0.7300 0.8000 -0.0700 0.0000 0.0500 0.1991 0.8004 1099 367 0.8000 0.7400 0.8000 -0.0600 0.0000 0.0500 0.1996 0.8002 1582 528 0.8000 0.7500 0.8000 -0.0500 0.0000 0.0500 0.1998 0.8024 316 106 0.8500 0.7500 0.8500 -0.1000 0.0000 0.0500 0.1976 0.8002 388 130 0.8500 0.7600 0.8500 -0.0900 0.0000 0.0500 0.1998 0.8013 493 165 0.8500 0.7700 0.8500 -0.0800 0.0000 0.0500 0.1987 0.8005 643 215 0.8500 0.7800 0.8500 -0.0700 0.0000 0.0500 0.1995 0.8001 876 292 0.8500 0.7900 0.8500 -0.0600 0.0000 0.0500 0.1999 0.8003 1261 421 0.8500 0.8000 0.8500 -0.0500 0.0000 0.0500 0.1997Numeric Re sults for Non-Inferiority Te sts Ba sed on the Difference: P1 - P2H0: P1-P2<=D0. H1: P1-P2=D1>D0. Te st Statistic: Z te st (unpooled)Sample Sample Equiv. Actual Equiv. ActualSize Size Grp 2 Grp 1 Grp 1 Margin MarginGrp 1 Grp 2 Prop Prop Prop Diff Diff Target ActualPower N1 N2 P2 P1.0 P1.1 D0 D1 Alpha Alpha Beta 0.8030 223 75 0.9000 0.8000 0.9000 -0.1000 0.0000 0.0500 0.1970 0.8009 274 92 0.9000 0.8100 0.9000 -0.0900 0.0000 0.0500 0.1991 0.8002 348 116 0.9000 0.8200 0.9000 -0.0800 0.0000 0.0500 0.1998 0.8010 454 152 0.9000 0.8300 0.9000 -0.0700 0.0000 0.0500 0.1990 0.8013 619 207 0.9000 0.8400 0.9000 -0.0600 0.0000 0.0500 0.1987 0.8001 889 297 0.9000 0.8500 0.9000 -0.0500 0.0000 0.0500 0.1999 0.8013 80 27 0.9500 0.8500 0.9500 -0.1000 0.0000 0.0500 0.0348 0.1987 0.8035 145 49 0.9500 0.8600 0.9500 -0.0900 0.0000 0.0500 0.1965 0.8037 184 62 0.9500 0.8700 0.9500 -0.0800 0.0000 0.0500 0.1963 0.8000 239 80 0.9500 0.8800 0.9500 -0.0700 0.0000 0.0500 0.2000 0.8002 325 109 0.9500 0.8900 0.9500 -0.0600 0.0000 0.0500 0.1998 0.8005 469 157 0.9500 0.9000 0.9500 -0.0500 0.0000 0.0500 0.1995 Note: exact results based on the binomial were only calculated when both N1 and N2 were less than 100. ReferencesChow, S.C.; Shao, J.; Wang, H. 2003. Sample Size Calculations in Clinical Research. Marcel Dekker. New York. Farrington, C. P. and Manning, G. 1990. 'Test Statistics and Sample Size Formulae for Comparative Binomial Trials with Null Hypothesis of Non-Zero Risk Difference or Non-Unity Relative Risk.' Statistics in Medicine, Vol. 9, pages 1447-1454.Fleiss, J. L., Levin, B., Paik, M.C. 2003. Statistical Methods for Rates and Proportions. Third Edition. JohnWiley & Sons. New York.Gart, John J. and Nam, Jun-mo. 1988. 'Approximate Interval Estimation of the Ratio in Binomial Parameters: A Review and Corrections for Skewness.' Biometrics, Volume 44, Issue 2, 323-338.Gart, John J. and Nam, Jun-mo. 1990. 'Approximate Interval Estimation of the Difference in Binomial Parameters: Correction for Skewness and Extension to Multiple Tables.' Biometrics, Volume 46, Issue 3,637-643.Lachin, John M. 2000. Biostatistical Methods. John Wiley & Sons. New York.Machin, D., Campbell, M., Fayers, P., and Pinol, A. 1997. Sample Size Tables for Clinical Studies, 2nd Edition. Blackwell Science. Malden, Mass.Miettinen, O.S. and Nurminen, M. 1985. 'Comparative analysis of two rates.' Statistics in Medicine 4: 213-226. Report Definitions'Power' is the probability of rejecting a false null hypothesis. It should be close to one.'N1 and N2' are the sizes of the samples drawn from the corresponding groups.'P2' is the response rate for group two which is the standard, reference, baseline, or control group.'P1.0' is the smallest treatment-group response rate that still yields a non-inferiority conclusion.'P1.1' is the treatment-group response rate at which the power is calculated.'D0' is the non-inferiority margin. It is the difference P1-P2 assuming H0.'D1' is the actual difference, P1-P2, at which the power is calculated.'Target Alpha' is the probability of rejecting a true null hypothesis that was desired.'Actual Alpha' is the value of alpha that is actually achieved.'Beta' is the probability of accepting a false H0. Beta = 1 - Power.'Grp 1' refers to Group 1 which is the treatment or experimental group.'Grp 2' refers to Group 2 which is the reference, standard, or control group.'Equiv.' refers to a small amount that is not of practical importance.'Actual' refers to the true value at which the power is computed.Summary StatementsSample sizes of 619 in group one and 207 in group two achieve 80% power to detect anon-inferiority margin difference between the group proportions of -0.1000. The reference group proportion is 0.5000. The treatment group proportion is assumed to be 0.4000 under the null hypothesis of inferiority. The power was computed for the case when the actual treatment group proportion is 0.5000. The test statistic used is the one-sided Z test (unpooled). The significance level of the test was targeted at 0.0500. The significance level actually achievedby this design is NA.Chart Section。

2021届高考英语精创预测卷浙江卷(三)一、MistyCopelandspendsmostdayspracticingandperfectingthegracefulmovementsofhe rart.Shetakesclassesalmosteverydayandtakescareofherbodysoshedoesn’tinjureitwhe nshegoestoworkatAmericanBalletTheatre,oneofthemostfamousballetcompaniesinthewor ld.“Itreatmybodywithther espectthatanymusicianwouldtheirinstrument.Iacceptall thatitisanddomybesttomakeitthebestitcanbe,”saysMisty.Mistydidn’talwaysfeelsoconfidentinherself.Thechallengesshehasfacedoveralm ost20yearsofdancinghavemadeherstrong.Shewasashychildandavoidedthespotlight.Buts helovedmusicandmovement.Whenshewas13,shejoinedthedrillteam.Oneday,hercoachsugge stedthatsheattendafreeballetclassattheBoys&Girlsclub.Fortwoweeks,Mistysatontheg ymplatformswatchingtheclass,afraidtojoinin.Finally,shegaveitatry.Atfirst,Mistyfeltoutofplaceint heclass.Shedidn’tknowanythingaboutballet,an dshewasolderthanmostofthestudents.EventhoughMistyfeltdiscouraged,shedidn’tquit .Shetalkedwithotherswhohadstruggledwithsimilarproblems.Withthesupportofthesefri ends,thingsslowlyimproved.Overthenextfiveyears,balletwa sMisty’slife.Shepracticed,performed,competed ,attendedsummerballetprograms,andgotloadsofawards.Today,Mistysays,“I’velearnedtoembracemyappearance,skincolor,andfigure.”Shewantstohelpotherdancers,especiallyballerinasofcolor,acceptthemselves,too.She wroteapicturebook,Firebird,inwhichhercharacterencouragesayoungAfricanAmericanba llerina.Inanoteattheendofthebook,Mistytellsreaderstofollowtheirdreams:“Nomatte rwhatthatdreamis,”shewrites,“youhavethepowertomakeitcometruewithhardworkandde dication.”1.WhenMistyCopelandbegantolearnballet,she_____________.A.feltasenseofbelongingimmediatelyB.joinedthedrillteamandpracticedactivelyC.encounteredmanychallengesbutstucktoherdreamD.encouragedotherswithsimilarproblemsandimprovedtogether2.WhichwordscanbestdescribeMistyCopeland?A.Determinedandindifferent.B.Persistentanddevoted.C.Diligentandpessimistic.D.Talentedandtraditional.3.Whatdoesthestoryintendtotellus?A.Manyhandsmakelightwork.B.Onegoodturndeservesanother.C.Diligenceisthemotherofsuccess.D.Afallinapit,againinyourwit.二、Digitaltechnologyhasmadelifeeasierformostpeople.Withasmartphoneinhand,peoplecan shoponline,watchTVshowsandarrangeataxi.ZhuYiwei,17,fromAnhuiprovince,wantedhisg randfathertohaveaccesstothisconvenience,soheboughthimanewphoneasagift.Buthisgra ndfatherstilluse sthephonejustforcallingandmessaging.“Hesaidotherfunctionsmakeh imconfused,”saidZhu.Thisisacommonproblemfacedbytheelderlyinthedigitalage.AlthoughChinaalreadyhasmor ethan900millionInternetusers,amongthem,thoseaged60andabovemakeupjust6.7percent, accordingtotheStatisticalReportonInternetDevelopment. EventhoughtheelderlyhaveaccesstotheInternet,theymainlydoitforcommunicationandin formationacquisition,accordingtoasurveybytheChineseAcademyofSocialSciences.Othe rservicesarestillstrangetothem.That’swhyelderlypeoplearesometimescalled“digit alrefugees”.Forexample,sincetheCOVID-19pandemic,peopleareoftenaskedtoshowagree nhealthcodeontheirphonetogetintopublicplaces.Butmostelderlypeopledon’tusesmart phones.Eveniftheyhaveone,manydon’tknowhowtooperateit,People’sDailynoted.“Wehavemadealifelongcontributiontosociety,butnowwefeelabandonedbyit,”a75-year -oldBeijingresidentsurnamedBaitoldtheGlobalTimes.Fortheelderly,onewayofmasterin gdigitaltechnologyistolearnfromyoungerfamilymembers.However,notalloftheseyounge rpeoplehavethepatienceortimetoteachtheelderly.Inaddition,agingresultsinmanyphys icalproblems,suchasweakeyesightandbadmemory.Thismakesithardertousesmartphones. ThegovernmentandotherorganizationsinChinaaretryingtohelp.SeeYoung,aBeijing-base dNGO,aimstohelpChina’selderlyusemobileservices.St udentvolunteershavebeenprovidingfreecomputerandsmartphonetrainingforelderlypeopleinover200communitiesacrosst hecountry.ZhaoJingchuan,17,fromXi’anGaoxinNo1HighSchool,andhisteammembersalsotriedtohelp .Thisyear,theirdraftproposalwasbroughttothetwosessions.Theysuggestedmorewaystoh elpintroducethetechnologytotheoldergeneration,includingsendingmanuals(手册),offeringtechnicalsupport,andcybersecurityeducation.1.WhyisZhuYiwei’sexamplementionedinthefirstparagraph?A.Topraisehimforcaringforhisgrandfather.B.Toshowhowtheelderlyusesmartphones.C.Totellhowdifferentgenerationsgetalong.D.Topresentthedifficultiestheelderlyface.2.Elderlypeopl earesometimescalled“digitalrefugees”because________.A.theyhavefewerchancestousetheInternetB.theyhavetroubleusingdigitaltechnologyC.theyareunwillingtousenewtechnologyD.theydon’thavesuitabledigitalproducts3.Whatdothelasttwoparagraphsmainlytalkabout?A.Theexpectationsoftheelderlyinthedigitalage.B.Theadvantagesofdigitaltechnologyfortheelderly.C.Theeffortsmadetohelptheelderlyusetechnology.D.Thehelpyoungpeopleprovidedfortheelderly.三、Inatimewhenadangerousnumberofpeopleareoverweight,manypeopleseemtohaveforgottent hemostimportantwaytokeephealthyandslim—exercise.Andasanewstudycarriedoutonmice inthelabhasshown,exercisedoneearlyinlifecanrewardyouinyouradultyears. AteamofresearchersattheUniversityofCaliforniastudiedtheeffectsofearlyexerciseon adultphysicalactivity,bodymassandeating.Theyfoundthatearly-ageexerciseofmicehas positiveeffectsonadultlevelsofvoluntaryexerciseinadditiontoreducingbodymass. "Theseresultsmayhaveaneffectontheimportanceofregularphysicaleducationinelementa ryandmiddleschools,"saidTheodoreGarland,aprofessorofbiology,wholedtheresearchproject."Ifkidsexerciseregularlyduringtheirschoolyears,thentheymaybemorelikelytoe xerciseasadults,whichcouldhavefar-reachingpositiveeffectsonhumanhealthandwell-b eing."Althoughthepositiveeffectsofearly-lifeexerciselastedforonlyoneweek,itisimportan ttonotethatoneweekinthelifeofamouseisthesameasaboutninemonthsforhumans."Ourresu ltssuggestthatanypositiveeffectofearly-lifeexerciseonadultexercisewillneedtobek eptupiftheyaretobelong-lasting."Histeamofresearchersfound,too,thatallmicethathadaccesstoearlyexercisewerelighte rinweightthannon-exercisedmice.Garlandexplained,ingeneral,thatexercisewillstimulateappetitesoonerorlater.Howev er,itispossiblethatcertaintypesofexercise,doneforcertainperiodsoftimeoratcertai nlightlevels,mightnotstimulateappetitemuch,ifatall,atleastforsomeindividuals. "Ifwecouldunderstandwhatsortsofexercisethesemightbe,thenwemightbeabletotailorex erciserecommendationsinawaythatwouldbringthebenefitsofexercisewithoutincreasing appetite,leadingtoabetterchanceofweightloss,"hesaid.1.Whatdoesthefirstparagraphmainlytalkabout?A.Thepositiveeffectsofmice.B.Thepossiblerisksofdoingexercise.C.Thepositiveeffectsofearly-lifeexercise.D.Newwaystofightagainstbeingoverweight.2.Howlongdothepositiveeffectsofearly-lifeexerciselastforamouse?A.Oneday.B.Oneweek.C.Onemonth.D.Ninemonths.3.Whatdoestheunderlinedword"stimulate"inParagraph6mean?A.Decline.B.Improve.C.Vary.D.Harm.4.Whatcanhelpuschooseproperexercisewithoutchangingourappetite?A.Early-lifeexercise.B.Kidsbeingencouragedtodoexerciseasearlyaspossible.C.Betterunderstandingtheeffectsofdifferenttypesofexercise.D.Havingregularphysicaleducationinelementaryandmiddleschools.四、根据短文内容,从短文后的选项中选出能填入空白处的最佳选项。

June 2017Corresponding Author:Johanna A. JoyceDate:Jun 13, 2017Life Sciences Reporting SummaryNature Research wishes to improve the reproducibility of the work we publish. This form is published with all life science papers and is intended to promote consistency and transparency in reporting. All life sciences submissions use this form; while some list items might not apply to an individual manuscript, all fields must be completed for clarity.For further information on the points included in this form, see Reporting Life Sciences Research . For further information on Nature Research policies, including our data availability policy , see Authors & Referees and the Editorial Policy Checklist.` Experimental design 1. Sample sizeDescribe how sample size was determined.Sample sizes were chosen based on power of 0.9 to detect a difference of>1.5 standard deviations between LF vs. HF means with 95% confidence.However, in most cases, previous data was sufficient to inform sample sizefor subsequent experiments. 2. Data exclusionsDescribe any data exclusions.Exclusion criteria were not needed. 3. ReplicationDescribe whether the experimental findings were reliably reproduced.All data included in the study are reproducible: all flow cytometryexperiments were repeated 3 or more times with similar results; all animaltrials were repeated with at least n=4 in at least 2 independent cohortswith similar results; all in vitro assays were repeated in at least 3independent experiments with similar results.4. RandomizationDescribe how samples/organisms/participants were allocated into experimental groups.For most experiments, a method for randomization was not needed since experimental groups were pre-determined by diet/weight. In cases whererandomization was required (e.g. Figure 7), average weight was used toensure balanced representation between experimental groups.5. BlindingDescribe whether the investigators were blinded to group allocation during data collection and/or analysis.For all experiments, automated quantitative methods were used. We chose to analyze data in this manner to avoid investigator bias.Note: all studies involving animals and/or human research participants must disclose whether blinding and randomization were used.6. Statistical parametersFor all figures and tables that use statistical methods, confirm that the following items are present in relevant figure legends (or the Methods section if additional space is needed).n/aConfirmedThe exact sample size (n) for each experimental group/condition, given as a discrete number and unit of measurement (animals, litters, cultures, etc.)A description of how samples were collected, noting whether measurements were taken from distinct samples or whether the same samplewas measured repeatedly.A statement indicating how many times each experiment was replicatedThe statistical test(s) used and whether they are one- or two-sided (note: only common tests should be described solely by name; morecomplex techniques should be described in the Methods section)A description of any assumptions or corrections, such as an adjustment for multiple comparisonsThe test results (e.g. pvalues) given as exact values whenever possible and with confidence intervals notedA summary of the descriptive statistics, including central tendency (e.g. median, mean) and variation (e.g. standard deviation, interquartile range)Clearly defined error barsSee the web collection on statistics for biologists for further resources and guidance.`SoftwarePolicy information about availability of computer code7. SoftwareDescribe the software used to analyze the data in this study. GraphPad Prism Pro5 was used for all data analysis.For all studies, we encourage code deposition in a community repository (e.g. GitHub). Authors must make computer code available to editors and reviewers upon request. The Nature Methods guidance for providing algorithms and software for publication may be useful for any submission.`Materials and reagentsPolicy information about availability of materials8. Materials availabilityIndicate whether there are restrictions on availability of uniquematerials or if these materials are only available for distribution by afor-profit company.All materials used in this study are available from commercial sources.9. AntibodiesDescribe the antibodies used and how they were validated for use inthe system under study (i.e. assay and species).Detailed information on antibody vendors, catalog and clone numbers anddilutions used can be found in Supplementary Table 3. All antibodies usedin this study were titrated for each lot, and an optimal dilution wasselected (see also Supplementary Table 4 for each type of assay). Mouseantibodies included: CD45 A700 and APC, Rat anti-mouse; Gr1 FITC andPerCP-Cy5.5, Rat anti-mouse; CD11b PE-Cy7 and PE, Rat anti-mouse/human; Ly6G PE, Rat anti-mouse; Ly6C BV421 and APC-Cy7, Rat anti-mouse; CD3 PE-Cy7, Rat anti-mouse; CD4 BV605, Rat anti-mouse; CD8AFITC, Rat anti-mouse; NK1.1 PerCP-Cy5.5, Rat anti-mouse; CD107a APC,Rat anti-mouse; SiglecF APC, Rat anti-mouseIL5ra A488, Rat anti-mouse. Human antibodies included: CD45 BV605, Ratanti-mouse/human; CD11B BUV395, Mouse anti-human; CD14 FITC,Mouse anti-human; CD16 A700, Mouse anti-human; CD66B PE-Cy7,Mouse anti-human; IL5RA PE, Mouse anti-human.June 201710. Eukaryotic cell linesa. State the source of each eukaryotic cell line used.Breast tumor cell lines were isolated from the MMTV-PyMT mouse model,backcrossed into the BL6 background for >10 generations. These cell lineswere subsequently selected for their capacity to grow in the mammary fatpad (7x105 cells injected/mouse) of WT BL6 animals within a reasonabletime period (<2 months). Three cell lines were selected for subsequentexperiments, including 99LN, 86R2, and 91R2. All breast tumor cell lines inculture were maintained in DMEM supplemented with 10% FBS, and werevalidated to be mycoplasma-free. For assays involving immune cell culture,primary cells were isolated from peripheral sources (i.e. blood or bonemarrow) by FACS and used immediately for functional assays, for exampleNK cell co-culture or T cell CFSE.b. Describe the method of cell line authentication used.Cell line authentication was not needed - all cell lines from this study weregenerated in-house for immediate downstream application.c. Report whether the cell lines were tested for mycoplasmacontamination.All cell lines were confirmed to be mycoplasma negative.d. If any of the cell lines used in the paper are listed in the databaseof commonly misidentified cell lines maintained by ICLAC,provide a scientific rationale for their use.No cell lines used in this study were found in the database of commonly misidentified cell lines that is maintained by ICLAC and NCBI Biosample.June 2017`Animals and human research participantsPolicy information about studies involving animals; when reporting animal research, follow the ARRIVE guidelines 11. Description of research animalsProvide details on animals and/or animal-derived materials used in the study.Diet-induced obesity (DIO) model: To model obesity with diet, 5w-oldfemale BL6 mice (Jackson Laboratory) were enrolled on either high fat (HF;60% kcal, Research Diets D12492) or low fat (LF; 10% kcal, Research DietsD12450) irradiated rodent diet for 15w. After 15w, animals were either sacrificed for flow cytometry, or injected with tumor cells. For the diet-switch model (HF-LF), 5w-old female BL6 mice were fed for 15w with HFdiet, and then switched to LF diet for 7w prior to sacrifice.Ob/ob model: To control for the effects of adipose tissue content in mice,4w-old female B6.Cg-Lep-ob (ob/ob; Jackson Laboratory) mice werepurchased and maintained on normal rodent diet. These mice gain weightdue to a homozygous mutation in the leptin (Lep) gene that causesexcessive eating and rapid weight gain. Weight was monitored over time beginning at 5w-old, and mice were euthanized when they reached >40g.This time period was significantly shorter (6w) than that of the DIO model(15w). After 6w, animals were sacrificed for flow cytometry analysis ofmyeloid cell populations in the lung, or injected with tumor cells for 48h metastasis assays.Balb/c obesity-resistant model: To control for the effects of nutrientcontent in diet, 5w-old WT female Balb/c mice (Jackson Laboratory) were enrolled on either HF or LF diet (Research Diets, see ‘DIO model’) for 15w.Balb/c animals do not gain weight in response to HF feeding. After 15w,animals were sacrificed for flow cytometry analysis of myeloid cellpopulations in the lung.Immune compromised mouse models: Two immune compromised mouse models were used in this study, athymic nude (lack T cells) and NOD-scidIL2r-gamma null (NSG; lack mature T, B and NK cells). In both cases, 5w-old female mice (Jackson Laboratory) were used. Mice were treated for 5dwith recombinant antibodies, and then sacrificed for flow cytometryanalysis of myeloid populations in blood and lung.Preparation of mouse samples for flow cytometry or FACS: Mice were anesthetized with avertin, blood was collected by submandibular bleeding,and cardiac perfusion with PBS was performed. All tissues weremechanically dissociated and filtered through a 40 um mesh to generate asingle cell suspension, and red blood cells were lysed (Pharm Lyse; BD Biosciences).Preparation of mouse serum: To collect serum from mice, blood wascollected by submandibular bleeding into eppendorf tubes and allowed toclot at room temperature for ~20 minutes. Samples were centrifuged at2000 x g, 4°C, 10 min. Supernatant was transferred to a polypropylenetube either individually or pooled. For pooled serum, three individualmouse samples were combined and stored at -80°C for downstream applications.June 2017Policy information about studies involving human research participants 12. Description of human research participantsDescribe the covariate-relevant population characteristics of the human research participants.Human blood samples: Blood collection from human donors was approvedby the Institutional Review Board of Rockefeller University, fully compliantwith all relevant ethical regulations regarding research involving human participants, and obtained with informed consent. Fresh whole-bloodsamples were obtained from healthy female donors (including 5 leandonors (BMI=18-25), and 2 obese donors with BMI equal to or more than35; donors were all postmenopausal) at Rockefeller University.Human serum samples: Human serum samples were obtained fromconsenting healthy female donors, and banked as individual or pooled.Serum samples were pooled from 9 lean (BMI=18-25) or 10 obese(BMI>35) postmenopausal women (median age=56 years old; age range45-66) and stored at -80°C for downstream application. For collection of matched human weight loss serum samples, the clinical trial wasconducted at Rockefeller University under identifierNCT01699906. Sample collection was approved by the Institutional ReviewBoard of Rockefeller University (New York, NY). Mean BMI before weightloss= 38.8 +/-3.4 sd; mean BMI after weight loss= 35.1 +/-3.0 sd; meanage= 60.6 years +/- 3.6 sd.June 2017June 2017Corresponding Author:Johanna A. Joyce Date:Jun 13, 2017Flow Cytometry Reporting Summary Form fields will expand as needed. Please do not leave fields blank.` Data presentationFor all flow cytometry data, confirm that:1. The axis labels state the marker and fluorochrome used (e.g. CD4-FITC).2. The axis scales are clearly visible. Include numbers along axes only for bottom left plot of group (a 'group' is an analysis of identical markers).3. All plots are contour plots with outliers or pseudocolor plots.4. A numerical value for number of cells or percentage (with statistics) is provided.` Methodological details5. Describe the sample preparation.For flow cytometry of mouse samples, mice were anesthetizedwith avertin, blood was collected by submandibular bleeding, andcardiac perfusion with PBS was performed. All tissues weremechanically dissociated and filtered through a 40 um mesh togenerate a single cell suspension and red blood cells were lysed(Pharm Lyse; BD Biosciences). Cells were counted, incubated withFc block (1h; BD Biosciences; 1:100/10^6 cells), incubated withfixable live/dead stain (30 min; Invitrogen), and then incubatedwith conjugated antibodies (1h). Alternatively, DAPI was used fordead cell exclusion instead of fixable live/dead stain. Mouseneutrophils were defined as CD45+CD11b+Gr1+/hi or CD45+CD11b+Ly6CloLy6G+. CD45+CD11b+Gr1lo cells were determined to beCD45+CD11b+Ly6Chi monocytes, and were therefore excludedfrom all neutrophil gating. OneComp eBeads (eBioscience) or ArC™Amine Reactive Compensation Beads (Invitrogen) were used for compensation.6. Identify the instrument used for data collection. A BD LSRFortessa was used for flow cytometry, and a BD FACSAria III was used for FACS.7. Describe the software used to collect and analyze the flow cytometry data.FlowJo was used for all flow cytometry and FACS data analysis, and for generating representative flow plots.8. Describe the abundance of the relevant cell populations within post-sort fractions.In all cases, post-sort purity was confirmed to be greater than>90% for downstream applications, including qRT-PCR and cytospin.9. Describe the gating strategy used.Mouse gating strategy: In all cases, dead cells and debris wereexcluded from analyses using FSC x SSC, a live/dead stain and/orDAPI. CD45+ was used as a marker for total leukocytes, CD11b+was used as a marker for myeloid cells. Neutrophils were furtherdefined as CD45+CD11b+Gr1+/hi or CD45+CD11b+Ly6CloLy6G+.CD45+CD11b+Gr1lo cells were determined to be CD45+CD11b+Ly6Chi monocytes, and were therefore excluded from allneutrophil gating. Eosinophils were defined as CD45+CD11b+myeloid cells with high side scatter, and Siglec-f+. In some cases,further gating on IL5ra+ or Ki67+ populations was performed foreosinophils, monocytes, and neutrophils as defined here. For CFSEassays, bulk T cells were gated as CD45+CD3+ and then furthergating according to positive CD4 or CD8 status for helper andcytotoxic T cells, respectively. For NK cell cytotoxicity assays, NKcells were defined as CD45+ with low side scatter, NK1.1+. Gatingon CD107a+ populations was used to further define NK cells withcytotoxic function.Human gating strategy: In all cases, dead cells and debris wereexcluded from analyses using FSC x SSC and DAPI. CD45+ was usedas a marker for total leukocytes, CD11b+ was used as a marker formyeloid cells. Gating strategy using cell surface markers were asfollows: Peripheral blood neutrophils (CD45+CD11b+CD66b+CD16+CD14lo), eosinophils (CD45+CD11b+CD66b+CD16-CD14lo), non-classical monocytes (CD45+CD11b+CD66b-CD16+CD14lo),intermediate monocytes (CD45+CD11b+CD66b-CD16+CD14hi),and classical monocytes (CD45+CD11b+CD66b-CD16-CD14+).Gating on IL5R+ cells was also included in analysis for eachpopulation. Eosinophils were used as a positive gating control forIL5R positivity as this is a canonical marker/signaling pathway forthis cell type.Tick this box to confirm that a figure exemplifying the gating strategy is provided in the Supplementary Information.June 2017。

2021届高三英语中学生标准学术能力根底性测试〔9月〕试题本试卷共150分,考试时间100分钟。
第一局部阅读理解〔共两节,总分值60分〕第一节〔共 15小题;每题3分,总分值45分〕阅读以下短文,从每题所给的A、B、C 和 D 四个选项中,选出最正确选项,并在答题卡上将该项涂黑。
AKeeping everyone happy is one of the greatest challenges for any globe-travelling family. Yet with its contrasting blend of gorgeous public green spaces and children-friendly cultural experiences, Abu Dhabi is a win-win for parents and kids alike.Qasr Al Hosn and Cultural FoundationYoung minds find plenty to be inspired at Qasr Al Hosn and the Cultural Foundation: neighboring landmarks that preserve the rich cultural heritage of Abu Dhabi. Since the 1790s, Qasr Al Hosn has served as palace and seat of power. Today, surrounded by modern towers, it is a reminder of the city’s incredible growth. The Cultural Foundation was known as a place to foster cultural exchange, a mission that continues today with an inspiring program of exhibitions and performances.Umm Al Emarat ParkThere’s no shortage of green spaces in downtown Abu Dhabi, but few are as beautiful as Umm Al Emarat: a vast extent of lawns, date palms, and winding walkways. Since 2021, the park features an indoor Botanic Garden and dedicated Children’s Garden, as well as a nearly 100-foot high Shade House with two viewing platforms overlooking the greenery. On Saturdays, the park is home to The Ripe Market filled with fresh organic and local produce. Events such as outdoor cinema and concerts keep families entertained all year round.Reem Central ParkArt and architecture exist side by side in Reem Central Park, a huge public space in the heart of the city where families and friends come to relax. Contemporary art installations〔装置〕and dancing fountains are dotted around the park. It’s a multicultural scene, where locals and visitors from all over the world relax on neat lawns and playgrounds, catch air at the skate park, and gather at restaurants and food trucks serving delicious snacks.1.Which place has the political function?A.Qasr Al Hosn. B.Reem Central Park.C.Cultural Foundation. D.Umm Al Emarat Park.2.What is the special part of Umm Al Emarat Park?A.It has dancing fountains.B.It serves delicious snacks.C.It has an indoor Botanic Garden.D.It is a reminder of the city’s incredible growth.3.What do these places have in common?A.They have a long history. B.They are modern architectures.C.They are the center of shopping. D.They can bring cultural experiences.BThe late, great Kobe Bryant may have been most famous for his basketball skills, but people in any field can draw inspiration from his constant commitment to self-improvement.As the world reacts to Kobe Bryant’s tragic passing on January 26, 2021, his massive influence extends far beyond the sports world. He wasn’t just a record-setting basketball player, devoted father, and Oscar- winning producer. His work spirit, unwavering motivation, and constant commitment to self-improvement made him stand out among his contemporaries.Case in point: his art of calling successful businesspeople —often ones he’d never even met before —and picking their brains about how they became successful. He was willing to put the legwork into growing his success, even if it meant admitting that he always had lots more to learn.In a 2021 interview with Bloomberg, Bryant described his process and name-dropped some of the people to whom he’d reached out. “I want to know more about how they build their businesses and how they run their companies and how they see the world,〞he said. At the time, he was building his company, Kobe Inc.“Some of the questions t hat I’ll ask will seem really, really simple and stupid, quite honestly, for them,〞he admitted. “But if I don’t know, I don’t know. You have to ask.〞 Humbling, maybe, but necessary.Who were some of these successful people that the already-very-successful Kobe Bryant so looked up to? To name a few: Oprah Winfrey, Mark Parker and president and CEO of Nike. Three years ago, Lowercase Capital founder Chris Sacca described his own interactions with Bryant. Sacca said he told Bryant to “do his homework〞 on investing —and, sure enough, Bryant went above and beyond. “For the next few months my phone never stops buzzing in the middle of the night,〞 Sacca said on The Bill Simmons Podcast. “It’s Kobe,reading this article, checking out this tweet, following this guy, diving into this TED Talk.〞 Clearly, this was someone unafraid to give his all.Though it might make his passing even more heartbreaking, Bryant’s constant desire to do more and be better is inspiring for sure. While the rest of us may not be able to just dial up Oprah or high-profile CEOs,we can certainly follow his example in other ways. We can surround ourselves with other motivated people that we can learn from, and not be afraid to ask potentially embarrassing questions if we know they’ll help us.4.What made Kobe Bryant superior to other people of similar age?A.His skills in playing basketball. B.His responsibility for his family. C.His determination and perseverance. D.His massive influence on other players. 5.What does the underlined word “p icking their brains〞 in the third paragraph refer to?A.Hitting their heads. B.Consulting them.C.Scolding them. D.Following them.6.What can we infer from Sacca’s words?A.Kobe’s success is owed to his own industry and insistence.B.It is annoying that Kobe often called him at night.C.Kobe may lack some talent in investing.D.Kobe couldn’t have succeeded without his investment.7.What message can we get from Kobe’s example?A.More haste, less speed. B.Don’t cry over spilt milk.C.Strike while the iron is hot. D.Nothing is impossible to a willing heart.CTeenagers worldwide do not get enough exercise, compromising their current and future health, the World Heath Organization said.A study conducted by the UN health agency found 81 percent of adolescents aged between l1 and 17fail to get at least one hour of moderate to intense daily physical activity such as walking, riding a bike or playing sports. The report on global trends for adolescent physical activity is based on survey data collected on 1.6 million students from 146 countries and territories between 2001 and 2021. The findings are troubling because physical activity is associated with better heart and respiratory functioning, mental health and cognitive activity, which have serious impact on student learning. Exercise, along with healthy eating, is also viewed by experts as key to controlling a global obesity problem.The report did not mention why adolescents are so inactive, but a WHO co-author of the study suggested digital technology means more young people spend time on electronic devices. The study also found gender differences worldwide, with 85 percent of girls and 78 percent of boys surveyed failing to hit the daily exercise target. Male youths in rich Western countries and female youths in South Asia get the most exercise.While in China, the qualified rate of Chinese students’ physical test in 2021 was 91.91 percent, and the excellent and good rate was 30.57 percent. From 2021 to 2021, the overall health status of students in the country showed an upward trend. However, excluding the statistical error factors, a change of only 1 to 2 percentage points does not indicate that the physical health of Chinese students has improved significantly, said Liu Bo, director of the Division of Sports Science and Physical Education in Tsinghua University.The current rate of obesity among students is still high, according to a report released by the Chinese Ministry of Education. Therefore, we should activate families, schools and society to guide students to develop healthy habits since childhood, do more exercise and prevent diseases such as myopia and obesity.8.Which of the following is true according to the study?A.Teenagers in south Asia get the most exercise.B.81 percent of adolescents fail to get proper exercise.C.More boys can achieve the daily exercise goal than girls.D.The key to controlling obesity problem is doing a lot of exercise.9.Why don’t adolescents often exercise?A.They put more time on study.B.They don’t think it a nec essity.C.They think exercise is a waste of time.D.Their time is given to electronic devices.10.What can we know from the last but one paragraph?A.10 percent of Chinese students failed in the physical test.B.Less than one third of Chinese students can reach the good rate.C.Chinese students’ health can improve significantly in the future.D.Health level of Chinese students increased a lot from 2021 to 2021.11.What should we do to help students become healthy?A.Prevent diseases. B.Take more exercise.C.Develop healthy habits. D.All of the above.DWorld Health Organization (WHO) declared an official name for the new coronavirus disease:COVID-19, which stands for Corona Virus Disease 19. Public health experts agree with the choice not to name the disease after a geographic region in China. “If the new name had included a reference to Wuhan it would put a tremendous insult to the people of Wuhan who are the victims of the disease,〞 Wendy Parmet, a law professor at Northeastern University and public health expert, tells Time.“People tend to think of the disease as belonging to, as being a characteristic of some group of people associated with the place name, which can be really offensive,〞Parmet says. “To be thought of as a hole of disease is not going to be productive. It encourages the next city not to come forward, not to report a disease if your city is labeled as the disease.〞Experts note that there is a “long history〞 of diseases being named in ways that include particular groups of people or places or animals. Around the 1500s in France, Syphilis was called the Italian disease and in Italy it was called the French disease. The 1918 influenza pandemic was widely called the Spanish Flu in the U.S. even though it did not originate in Spain. In 2021, the WHO stopped using the term “swine flu〞 and replaced it with Influenza A (H1N1), following a drop in the pork market. Ebola was named after a river near where the outbreak first originated.Arnold Monto, a professor of epidemiology〔流行病学〕at the University of Michigan’s School of Public Health, says it’s important to be sensitive to different cultures when naming a disease. “If you have a name which is regional and it spreads globally, it’s confusing,〞 Monto says.For the disease, it’s ideal to have a name that’s easy to pronounce like COVID-19. Parmet says: it’s short,easy to say and two syllables. “You want something that’s easy and that people are going to keep using otherwise they’re going to substitute it with more problematic slang,〞 she says.12.Why did WHO name coronavirus disease COVID-19?A.To save the victims of the disease.B.To make it easy to remember its name.C.To avoid putting a bad name on Wuhan people.D.To be more productive than other organizations.13.What can we know about COVID-19?A.It originated in Spain.B.It was named after a river.C.It is an official name for a new disease.D.It is a disease found many years ago in Wuhan.14.What does the third paragraph mainly talk about?A.The long history of many diseases.B.Bad effects diseases bring to people.C.Some infectious diseases spreading in the world.D.Examples of naming diseases after people or regions.15.What can be the best title of the passage?A.A fast-spreading disease — COVID-19B.COVID-19 —the disease’s name mattersC.How to prevent a terrible disease — COVID-19D.The history of a disease — COVID-19第二节〔共5小题;每题3分,总分值15分〕根据短文内容,从短文后的选项中选出能填入空白处的最正确选项。

power of testTest power is the ability of a test to detect differences in the variables it measures. It is important in scientific research, where researchers often need to determine whether two or more treatments, or groups of individuals, differ in their responses.Test power is an important concept in the field of educational and psychological testing and assessment. A higher test power indicates that a test is more likely to detect any true differences that may exist between two or more groups.Test power is related to the size of the group being studied and the amount of variability that is expected in the population being measured. In addition, test power is a function of the number of items on the test and the standard error of measurement. All of these factors can be used to calculate the power of a given test, using a statistical formula known as the power equation.The most common use of test power is to determine the likelihood of correctly rejecting the null hypothesis, which states that there are no differences between two or more groups. By rejecting the null hypothesis, the researcher can then state that there is a significant difference between the two groups. If a test has a low power, it is more difficult to correctly reject the null hypothesis. In contrast, if a test has a high power, then it is easier to reject the null hypothesis, as the chances of correctly rejecting it are much higher.Test power is a vital tool for researchers and educators to utilize in seeking to establish the validity of results obtained from assessments or testing procedures. It provides useful information that can help researchers to determine the strength of their evidence. Furthermore, test power can provide useful results in designing future tests by allowing researchers to determine what types of tests should be used and how many items should be included on a test in order to maximize power.。
2023-2024学年上海市华东师范大学第一附属中学高一下期期终考试英语试卷1.A.Doctor and patient. B.Waitress and customer.C.Wife and husband. D.Secretary and boss.2.A.His signature. B.His room number.C.His receipt. D.His check.3.A.Move her bag at the desk. B.Tell a story with humor.C.Undergo an operation. D.Have a quarrel with the man.4.A.Mr. James is the new advisor. B.The new advisor is a woman.C.Every undergraduate has an advisor. D.The advisor is not there.5.A.She had difficulty getting tickets. B.She’s already been to the exhibition.C.She wanted to get tickets for everybody. D.She’ll try to get tickets after work.6.A.The meeting was announced today. B.She’ll make the call late r.C.There won’t be a meeting tomorrow.D.She has confirmed everything.7.A.He eats too much when playing chess.B.He won’t join the chess club.C.Chess is his favorite game.D.He doesn’t enjoy chess as much as he used to.8.A.The number of the train. B.When the next train will depart.C.Where to find some equipment. D.Where to board the train.9.A.She wouldn’t use her ticket.B.She didn’t want her ticket.C.She had forgotten about her ticket. D.She didn’t want to go to the game.10.A.The restaurant wasn’t very crowded.B.The meal was very expensive.C.The magazine wasn’t very interesting.D.The food wasn’t very good.Questions 11 through 13 are based on the following passage. 11.A.It varies from person to person.B.It is decided by the most healthy lifestyle.C.It needs some tests and comparison to the standard.D.It is based more on individual needs than personal goals.12.A.Strength. B.Endurance. C.Flexibility. D.Health.13.A.The variety of fitness in the future.B.The importance of three basic factors concerning fitness.C.The new concept of fitness and its essential factors.D.Training effects of some sports on people.Questions 14 through 16 are based on the following passage. 14.A.Recognizing one’s abilities.B.Analyzing one’s strengths and weaknesses.C.Matching one’s abilities to job vacancies.D.Presenting one’s abilities to future employers.15.A.Finding out what they can do about the employer.B.Avoiding asking unsure questions.C.Arriving as early as they can.D.Answering questions in a polite way.16.A.Graduates from famous universities. B.Determined, skilled and able people.C.Capable and modest people. D.People with much work experience. Questions 17 through 20 are based on the following conversation.17.A.Sharing pictures online with his followers.B.Picking out the pictures to be shared online.C.Having pictures taken by his followers online.D.Helping others to take some pictures online.18.A.His friends and relatives. B.His friends and followers.C.His social media friends and followers. D.All people online.19.A.Opposed. B.Favorable. C.Indifferent. D.Doubtful.20.A.There are a lot of virus and various crimes online.B.It’s full of too many false and unqualified products.C.It’s changeable and hard to be controlled by people.D.There are all kinds of cheats online actually.21. Soon after an earthquake __________ 7.4 struck northern Japan, experts on emergency rescue were called in to give those victims first aid.A.measured B.measuring C.measures D.to measure 22. It was not until five years had passed ________ the whole truth about the murder ________.A.when; emerged B.before; was emergedC.while; was merged D.that; emerged23. I once ________ in the countryside for ten years, and that’s why I know much about vegetables and crops.A.had worked B.have worked C.was working D.worked24. The floor, ________ regularly swept every morning, presented a littered surface.A.if B.though C.since D.because25. ______ the students think it their duty to study hard has laid the foundation for the school’s high reputation.A.That all B.What C.All that D.What all26. Promising news came nearly a month __________ the patient had the chip implanted (植入)__________ he could control a computer mouse with his brain.A.that… when B.that… what C.since… where D.after… that27. Students should involve themselves in community activities __________ they can gain experience for growth.A.where B.when C.that D.what28. Although the plan ________ to improve the living standards of the local people, it was not implemented for several reasons.A.had been intended B.had intended C.had beenintendingD.was intending29. The explosion heard shortly before noon on Friday in Stockholm is thought ________ by the gas leak, according to witnesses.A.to be caused B.to have been causedC.of as being caused D.of to be caused30. I passed a bakery on my way back home, ________ I could always see a variety of cookies, pies and bread appealing to my taste.A.through its window B.through window of whichC.through the window D.through whose window31. __________ huge amounts of human-created text, ChatGPT looks for statistical regularities in this data and learns what words and phrases are associated with others.A.Fed B.Being fed C.Feeding D.Having fed32. __________ to what you study can lessen stress, so it’s suggested that you choose a major or career path you love and enjoy.A.Drawn B.Being drawn C.To be drawn D.Having drawn 33. The daily routine of morning exercise and meditation helps to __________ negative thoughts with positive energy, significantly alleviating feelings of depression and promoting overall mental well-being.A.displace B.supply C.replace D.balance34. “Blossoms Shanghai”, a television drama __________ a decade-long journey of A Bao’s personal growth, __________ a strong sense of empathy and nostalgia in its viewers, who reflect on the nature of love, loss, and the enduring power of human connection.A.featured, evoking B.being featured, evokedC.featuring, evokes D.having featured, evokes35. Students are __________ to use chatbots like ChatGPT responsibly to facilitate learning and promote academic growth in a supportive and ethical manner instead of copying answers directly.A.supposed B.warned C.disciplined D.booked36. In the depths of their mutual understanding, they shared a bond so strong that it __________ respect and affectionately nurtured their love for each other.A.directed B.motivated C.commanded D.deserved37. It’s easy to lay ________ for impulsive (冲动的) behaviors on teenagers whose brain is underdeveloped rather than the shortage of guidance.A.blame B.discrimination C.complaint D.criticism38. On receiving a submission, an experienced editor needs to efficiently decide what part to adopt and how much to ________ for a better version awaiting for publication.A.adapt B.surf C.update D.quote39. Though a breakthrough in treatment, this baldness cure has to pass clinical before it becomes commercially available.A.therapies B.cases C.trials D.chances40. The heartfelt laughter of the children in the playground, which seemed to __________ the mood of the entire neighborhood, brought a wave of joy and lightheartedness that lasted long after the sun had set.A.affect B.infect C.conquer D.arouseFeeling depressed or lonely can age us faster than smoking, researchers sayFeeling unhappy, depressed or lonely could speed up the ageing processes more than smoking or even certain diseases, researchers have suggested. While everyone has an age based on their date of birth - “chronological age”, they also have 41 is known as a “biological age”, based on the ageing of the body’s functions, influenced by genetics, lifestyle and other factors. Studies have previously suggested the higher the biological age, the higher the risk of various diseases, and the risk of death. Now researchers say they have created a digital model of ageing, 42 (reveal) the importance of psychological health. “Your body and s oul are connected, 43 is our main message,” said Fedor Galkin, a co-author of the study and lead scientist at the Hong Kong startup Deep Longevity.“We demonstrate that psychological factors, such as feeling unhappy or being lonely, add up to 1.65 years to one’s biological age,” they write. While Galkin said the figure is an estimate, not least as the model assumes that different feelings like hopelessness or fearfulness are independent of each other, the study highlights that 44 fast we age is significantly associated with our psychological state.“Taking care of your psychological health is the greatest contributor that you can have to 45 (slow) down your pace of ageing,” he said. The team also report that people who smoke 46 (predict) to be 15 months older than their non-smoking peers while living in urban areas reduces biological age 47 five months. Similarly, 48 (marry) takes about seven months off one’s biological age.But, he said, it is unlikely isolation and loneliness are truly worse risk factors for health than smoking, while the study only looked at the data that 49 (collect) at one point in time. “The researchers did not follow up participants to show that those with psychological distress actually aged more rapidly,” he said. “It will be important in the future 50 (test)whether these predictions can be fulfilled by repeating testing over a number of years.”Directions: Fill in each blank with a proper word chosen from the box. Each word can be used only once. Note that there is one word more than you need.A. avoidedB. processedC. suitedD. equalE. steerF. interfereG. understandably H. concentration I. thirst J. cabin K. unsettleEating on a plane used to be common practice. But in the age of COVID-19, many passengers are 51 less inclined to remove their masks to take a mid-flight bite ― or to even have a snack at the airport.As a result, it’s more common to eat at home before e mbarking on a flight. Those with longer travel journeys may even eat a large meal to carry them through the day. Still, not all preflight eats are created 52 .Tracy Lockwood Beckerman, a registered dietitian based in New York City, said it’s worthconsid ering your overall health as you prep for travel, including what you eat and drink. “It’s important to eat foods that will keep your immune system strong, keep you hydrated and are easily digested before flying,” Beckerman said.So, which foods are best 53 on a day when you’re traveling by plane?“It’s super common for dehydration to set in when flying, thanks to the lack of humidity and dry air in the 54 ,” Beckerman said. “That’s why it’s not the smartest to have a meal high in sodium (钠) the day bef ore or morning of your flight.” Beckerman also advised going easy on the salt shaker, opting for snacks without added salt to avoid dehydration-related headaches.Alcohol consumption tends to cause dehydration and has a different effect on the body than if you were to have a drink at ground level due to the low pressure in the cabin and the low oxygen 55 in blood. Therefore you are more likely to get drunk faster and urinate frequently.A cup of coffee can leave you dehydrated in an already dry environment and coffee also has a mild diuretic effect, which can lead to more frequent trips to the bathroom.Beyond the dehydrating effects, caffeine can also keep you awake during a flight, which is often an opportunity to catch up on sleep. The need for more frequent bathroom visits can also 56 with your ability to doze during your travels.If you have a sensitive stomach, you might want to 57 clear of foods that can mess with your digestion. That includes highly 58 snacks like candy and fast food, which often contain ingredients that could 59 your digestive system.A balanced meal that satisfies your 60 with water and hydrating fruits contains moderate amounts of complex carbohydrates and lean protein, and is low in added sugars and sodium is ideal.AI can transform education for the betterAs students return to classrooms for the new year, it is striking to reflect on how little education has changed in recent decades. The sector remains a digital laggard (落后者). American schools and universities spend 2% and 5% of their budgets, _________, on technology, compared with 8% for the average American company.When the pandemic forced schools and universities to shut down, the moment for a digital_________ seemed close when the market value of online tutoring providers like Chegg and Byju’s both increased. However, once covid was brought under control, classes continued much as before. If the pandemic couldn’t overcome the education sector’s _________ to d igital interruption, can artificial intelligence? ChatGPT-like generative AI, which can converse cleverly on varieties of subjects, certainly _________. So much so that educationalists began to _________ that students would use it to cheat on essays and homework. Increasingly, however, it is generating excitement as a means to provide _________ tutoring to various students and speed up boring tasks such as marking.Learners, for their part, are _________ the technology. Two-fifths of undergraduates reported using an AI chatbot to help them with their studies. Indeed, the technology’s popularity has raised awkward questions for companies like Chegg, which was losing customers _________ ChatGPT. Yet there are good reasons to believe that education specialists like Chegg who employ AI will eventually _________ generalists such as OpenAI, the maker of ChatGPT.For one, AI chatbots often talk nonsense, an unhelpful trait in an educational context. “Students want content from __________ providers,” argues Kate Edw ards, chief pedagogist at Pearson, a textbook publisher. The company has not allowed ChatGPT and other AIs to __________ its material, but has instead used the content to train its own models, which it is embedding into its set of learning apps.__________, as Chegg’s Mr Rosensweig argues, teaching is not merely about giving students an answer, but about presenting it in a way that helps them learn. Understanding pedagogy (教学法) thus gives education specialists an __________. Pearson has designed its AI tools to __________ students by breaking complex topics down, testing their understanding and providing quick feedback, says Ms Edwards. Byju’s is incorporating “forgetting curves” for students into the design of its AI tutoring tools, refreshing their memories at personalized __________.Bringing AI to education will not be easy, but once answers on how to make use of this technology become clearer, such a development will certainly deserve top marks.61.A.respectively B.appropriately C.totally D.ultimately62.A.divide B.reverse C.boom D.withdrawal 63.A.tendency B.resistance C.attention D.anxiety64.B.break the ice C.take the initiative D.do some good A.serve thepurpose65.A.maintain B.panic C.doubt D.wonder66.A.personalized B.individualistic C.characteristic D.attentive 67.A.attempting B.declining C.opposing D.embracing 68.A.for B.under C.to D.in69.A.detect B.transform C.overtake D.enhance 70.A.comprehensive B.advanced C.distinguished D.trusted71.A.give away B.take in C.bring about D.hold up72.A.By contrast B.Despite this C.What’s more D.As a result 73.A.applause B.edge C.hesitation D.improvement 74.A.convince B.engage C.capture D.challenge 75.A.intervals B.cost C.mercy D.bestThe train was at a standstill, some twenty minutes outside Kolkata, when an unexpected stroke of luck presented Piya with an opportunity to go for a seat beside a window for some fresh air. She had been sitting in the stuffiest part of the train compartment, on the edge of a bench: now, moving to the open window, she saw that the train had stopped at a station called Champahati.Looking over her shoulder, Piya spotted a tea-seller on the platform. Reaching through the bars of the window, she called him with a wave. She had never cared for the kind of chai, Indian tea, sold in Seattle, her hometown in the USA, but somehow, in the ten days she had spent in India she had developed an unexpected taste for milky, overboiled tea served in earthenware cups. There were no spices in it for one thing, and this was more to her taste than the chai at home.She paid for her tea and was trying to get in the cup through the bars when the man in the seat opposite her own suddenly turned over a page, jolting her hand. She turned her wrist quickly enough to make sure that most of the tea spilled out of the window, but she could not prevent some from spilling over his papers.“Oh, I’m so sorry!” Piya was very embarrassed: of everyone in the compartment, this was the last person she would have chosen to injure with her tea. She had noticed him while waiting on the platform in Kolkata and she had been struck by the self-satisfied tilt of his head and the way in which he stared at everyone around him, taking them in, sizing them up, sorting them all into their places.“Here,” said Piya, producing a handful of tissues. “Let me help you clean up.”“There’s nothing to be done,” he said testily (暴躁地). “These pages are ruined anyway.”For a moment she considered pointing out that it was he who had knocked her hand. But all she could bring herself to say was, “I’m very sorry. I hope you’ll excuse me.”“Do I really have a choice?” he said. “Does anyone have a choice when they’re dealing with Americans these days?”Piya had no wish to get into an argument so she let this pass. Instead, she opened her eyes wide and, in an attempt to restore peace, came out with, “But how did you guess?”“About what?”“About my being American? You’re very observant.”This seemed to do the trick. His shoulders relaxed as he leane d back in his seat. “I didn’t guess,” he said. “I knew.”76. In the first paragraph, Piya was relieved when she got a window seat because it meantthat_________.A.there was more room for her luggageB.she no longer had to suffer from a lack of airC.there was less chance that she would miss her stopD.she didn’t have to stand for the rest of the train journey77. Piya found that the tea or chai she had drunk in India ________.A.was disappointingly weak in taste B.reminded her of her home in SeattleC.would have tasted better if served fresh D.was preferable to the chai she had hadbefore78. When Piya first saw the man she thought that ________.A.he was someone who was observant of surroundingsB.he seemed to think he was better than other peopleC.he had tried to keep his distance from his fellow passengersD.he had been looking for someone he knew on the station platform79. Piya asked “But how did you guess?” in order to _________.A.find out what the man really thought about AmericansB.try to calm the situation down by starting a conversationC.ensure the man realized that she had apologizedD.make sure the man knew he was being rudeOur library offers different types of studying places and provides a good studying environment.ZonesThe library is divided into different zones. The upper floor is a quiet zone with over a thousand places for silent reading, and places where you can sit and work with your own computer. The reading places consist mostly of tables and chairs. The ground floor is the zone where you can talk. Here you can find sofas and armchairs for group work.ComputersYou can use your own computer to connect to the wi-fi specially prepared for notebook computers; you can also use library computers, which contain the most commonly used applications, such as Microsoft Office. They are situated (位于) in the area known as the Experimental Field on the ground floor.Group-study placesIf you want to discuss freely without disturbing others, you can book a study room or sit at a table on the ground floor. Some study rooms are for 2-3 people and others can hold up to 6-8 people. All rooms are marked on the library maps.There are 40 group-study rooms that must be booked via the website. To book, you need an active University account and a valid University card. You can use a room three hours per day, nine hours at most per week.Storage of Study MaterialThe library has lockers for students to store course literature. When you have got at least 40 credits (学分), you may rent a locker and pay 400 SEK for a year’s rental period.Rules to be FollowedMobile phone conversations are not permitted anywhere in the library. Keep your phone on silent as if you were in a lecture and exit the library if you need to receive calls.Please note that food and fruit are forbidden in the library, but you are allowed to have drinks and sweets with you.80. What can students do on the upper floor of the library?A.Chat at the table. B.Have group discussion.C.Relax themselves. D.Read attentively.81. What is required if you want to reserve a group-study room?A.The application form. B.The marked library map.C.An active school account. D.The topic of the discussion.82. How can a student rent a locker?A.By booking in advance. B.By attending enough courses.C.By paying the rental fee. D.By earning the required credits.States will be able to force more people to pay sales tax when they make online purchases under a Supreme Court decision Thursday that will leave shoppers with lighter wallets but is a big financial win for states.The Supreme Court’s opinion Thursday overruled a pair of decades-old decisions that states said cost them billions of dollars in lost revenue annually. The decisions made it more difficult for states to collect sales tax on certain online purchases.The cases the court overturned said that if a business was shipping a customer’s purchase to a state where the business didn’t have a physical presence such as a warehouse or office, the business didn’t have to collect sales tax for the state. Customers were generally responsible for paying the sales tax to the state themselves if they weren’t charged it, but most didn’t realize they owed it and few paid. Justice Anthony Kennedy wrote that the previous decisions were flawed. “Eac h year the physical presence rule becomes further removed from economic reality and results in significant revenue losses to the States,” he wrote in an opinion joined by four other justices. Kennedy wrote that the rule “limited States’ ability to seek lon g-term prosperity and has prevented market participants from competing on an even playing field.”The ruling is a victory for big chains with a presence in many states, since they usually collect sales tax on online purchases already. Now, rivals will be c harging sales tax where they hadn’t before. Big chains have been collecting sales tax nationwide because they typically have physical stores in whatever state a purchase is being shipped to. , with its network of warehouses, alsocollects sales tax in every state that charges it, though third-party sellers who use the site don’t have to.Until now, many sellers that have a physical presence in only a single state or a few states have been able to avoid charging sales taxes when they ship to addresses outside those states. Sellers that use eBay and Etsy, which provide platforms for smaller sellers, also haven’t been collecting sales tax nationwide. Under the ruling Thursday, states can pass laws requiring out-of-state sellers to collect the state’s sales tax from customers and send it to the state.Retail trade groups praised the ruling, saying it levels the playing field for local and online businesses. The losers, said retail analyst Neil Saunders, are online-only retailers, especially smaller ones. Those retailers may face headaches complying with various state sales tax laws. The Small Business & Entrepreneurship Council advocacy group said in a statement, “Small businesses and internet entrepreneurs are not well served at all by this decision.”83. The Supreme Court decision Thursday will ______.A.better businesses’ relations with statesB.put most online businesses in a dilemmaC.make more online shoppers pay sales taxD.force some states to cut sales tax84. It can be learned from paragraphs 2 and 3 that the overruled decisions ______.A.have led to the dominance of e-commerceB.have cost consumers a lot over the yearsC.were widely criticized by online purchasersD.were considered unfavorable by states85. According to Justice Anthony Kennedy, the physical presence rule has ______.A.hindered economic development B.brought prosperity to the countryC.harmed fair market competition D.boosted growth in states revenue86. In dealing with the Supreme Court decision Thursday, the author ______.A.gives a factual account of it and discusses its consequencesB.describes the long and complicated process of its makingC.presents its main points with conflicting views on themD.cites some cases related to it and analyzes their implicationsTwilight of the BrandsIt's a truism of business-book thinking that a company's brand is its "most important asset," more valuable than technology or patents or manufacturing prowess.But brands have never been more fragile.The reason is simple: consumers are supremely well informed and far more likely to investigate the real value of products than to rely on logos.Absolute Value, a new book by Itamar Simonson and Emanuel Rosen shows that, historically, the rise of brands was a response to an information-poor environment. 87 If a car was made by G.M, or a ketchup by Heinz, you assumed that it was pretty good.It was hard to figure out if a new product from an unfamiliar company was reliable or not, so brand loyalty was a way of reducing risk.Today, consumers can read much research about whatever they want to buy.This started back with Consumer Reports, which did objective studies of products. 88 It has given ordinary consumers easy access to expert reviews, user reviews, and detailed product data, in an array of categories.A recent study found that eighty per cent of consumers look at online reviews before making major purchases, and a host of studies have logged the strong influence those reviews have on the decisions people make. 89 An undesirable product can become a laughingstock(笑柄) in a matter of hours.In the old days, you might buy a Sony television set because you'd owned one before, or because you trusted the brand.Today, such considerations matter much less than reviews on Amazon and Engadget and CNET. As Simonson said, "each product how has to prove itself on its own."It's been argued that in a world where consumers are overwhelmed with information, the information will actually make brands more valuable.Indeed, the role a brand plays in people's lives has become all the more important, But information overload is largely a myth. 90 And this has made customer loyalty pretty much a thing of the past.Only twenty-five per cent of American respondents in a recent study said that brand loyalty affected how they shopped.91. 你越多练习武术,你就越能理解为什么它是一个值得传承的国之瑰宝。
幸运数字是否真的和幸运有关英语作文全文共3篇示例,供读者参考篇1Is lucky number really related to luck?IntroductionMany people believe in the concept of lucky numbers. They may associate certain numbers with good fortune, success, or positive outcomes. However, the question remains: do lucky numbers truly have any influence on one's luck? In this essay, we will explore the concept of lucky numbers and whether they are truly related to luck.Origins of lucky numbersThe belief in lucky numbers has been around for centuries, with different cultures having their own interpretations of which numbers bring good luck. For example, in Chinese culture, the number 8 is considered extremely lucky because it sounds similar to the word for prosperity. In Western culture, the number 7 is often seen as lucky, due to its frequent appearance in religious texts and folklore.However, the idea of lucky numbers is largely based on superstition and personal beliefs. There is no scientific evidence to support the notion that certain numbers can actually influence one's luck or destiny.The psychology of lucky numbersPsychologically, the belief in lucky numbers can provide a sense of comfort and control in an uncertain world. By attaching significance to certain numbers, individuals may feel that they have some influence over their fate. This can be psychologically empowering, even if there is no rational basis for the belief in lucky numbers.Furthermore, the concept of lucky numbers can also serve as a form of self-fulfilling prophecy. If someone strongly believes that a certain number will bring them good luck, they may subconsciously act in ways that attract positive outcomes, thus reinforcing their belief in the lucky number.The role of probabilityFrom a statistical perspective, the idea of lucky numbers becomes even more implausible. Random events such as lottery draws, casino games, or sports outcomes are governed by probability and chance, rather than any mystical influence ofnumbers. In these situations, the notion of lucky numbers is purely coincidental and has no impact on the actual outcome.In fact, studies have shown that people who rely on lucky numbers or superstitions in gambling are more likely to engage in risky behavior and make poor decisions. This can lead to financial losses and reinforce the idea that lucky numbers are nothing more than a misleading belief.ConclusionIn conclusion, while the concept of lucky numbers may hold personal significance for some individuals, there is no concrete evidence to suggest that they have any real impact on luck or success. Believing in lucky numbers can provide psychological comfort and a sense of control, but ultimately, luck is determined by a combination of factors beyond our control. Instead of relying on superstitions, it is more productive to focus on practical actions and decision-making to achieve our goals and aspirations. Luck may play a role in life, but it is not dictated by a specific number.篇2Lucky numbers are numbers that are believed to bring good luck, fortune, or happiness to those who possess or use them.These numbers vary from culture to culture and can hold great significance in people's lives. However, the question remains: Are lucky numbers really associated with luck, or is it just a superstition?To begin with, the concept of lucky numbers is deeply rooted in various cultures and traditions around the world. In Chinese culture, the number 8 is considered extremely lucky because it sounds like the word for prosperity in Chinese. Similarly, the number 7 is often considered lucky in Western cultures due to its associations with perfection, spirituality, and good fortune.Many people believe that using lucky numbers can bring them luck in various aspects of their lives, such as relationships, finances, health, and personal growth. For example, someone might choose to play the lottery using their lucky numbers in the hopes of winning a jackpot. Others might incorporate their lucky numbers into important decisions, such as choosing a wedding date or a phone number.On the other hand, skeptics argue that lucky numbers are nothing more than a product of superstition and have no real impact on people's lives. They believe that attributing success or failure to certain numbers is irrational and illogical. From ascientific perspective, there is no concrete evidence to support the idea that numbers can influence a person's luck or fate.In reality, the concept of lucky numbers may be more about mindset and perception than actual luck. Believing in lucky numbers can give people a sense of control and confidence in uncertain situations. It can also serve as a source of motivation and positivity, which may ultimately improve a person's outlook and resilience in the face of challenges.In conclusion, whether or not lucky numbers are truly associated with luck is a subjective matter. For some, lucky numbers hold great significance and can bring a sense of joy and optimism. For others, they are simply a fun and harmless superstition. Ultimately, the idea of luck is deeply personal and can vary from person to person. Whether you believe in lucky numbers or not, it's important to remember that true luck often comes from hard work, perseverance, and a positive attitude.篇3Are Lucky Numbers Really Related to Luck?In many cultures around the world, there is the belief that certain numbers are considered lucky. These lucky numbers are often thought to bring good fortune, success, and prosperity tothose who have them. However, the question remains: Are lucky numbers really related to luck, or is it simply a superstition?One of the most well-known lucky numbers is the number seven. In Western culture, seven is often associated with luck and good fortune. This belief dates back to ancient times when the number seven was considered sacred in many religions and belief systems. Seven is also a common number in nature, with seven colors in the rainbow and seven days in a week. As a result, many people believe that having the number seven in their lives will bring them luck.Similarly, in Chinese culture, the number eight is considered extremely lucky. This is because the word for the number eight, "ba" in Mandarin, sounds similar to the word for prosperity or wealth. As a result, many Chinese people believe that having the number eight in their lives will bring them financial success and abundance.On the other hand, there are also cultures where certain numbers are considered unlucky. For example, the number thirteen is often considered unlucky in Western culture. This superstition is so strong that many buildings skip the thirteenth floor, and many people avoid getting married or starting new ventures on the thirteenth day of the month.But are these beliefs in lucky numbers based on any scientific evidence, or are they just cultural superstitions? While there is no concrete scientific proof that certain numbers can bring luck, some researchers argue that the placebo effect may play a role in people's perceptions of lucky numbers.The placebo effect is a well-documented phenomenon where a person's belief in something can actually cause a physical or psychological change. In the case of lucky numbers, if someone believes that a particular number is lucky, they may be more confident, optimistic, and open to opportunities when that number is present in their lives. As a result, they may be more likely to take risks, make bold decisions, and ultimately create their own luck.In addition, some psychologists argue that the belief in lucky numbers can also serve as a form of self-fulfilling prophecy. If someone believes that a certain number will bring them luck, they may subconsciously start to notice and focus on positive events or opportunities associated with that number. This increased awareness and positivity can then lead to a cycle of good fortune, reinforcing the person's belief in their lucky number.However, it is important to note that the concept of lucky numbers is ultimately a cultural construct and may vary from person to person. While some people may strongly believe in the power of lucky numbers, others may dismiss them as mere superstition. Ultimately, whether lucky numbers are truly related to luck is a subjective question that depends on individual beliefs and perspectives.So, are lucky numbers really related to luck? The answer may depend on who you ask. But one thing is clear: whether you believe in lucky numbers or not, having a positive mindset, being open to opportunities, and taking action are key ingredients to creating your own luck in life. After all, luck may just be a matter of perspective.。
statistical 例句1. The statistical analysis of the data revealed significant differences between the two groups.2. According to the statistical report, the average income in the country has increased by 10%.3. Statistical methods were used to analyze the relationship between variables in the study.4. The statistical software allows for easy manipulation and visualization of complex data sets.5. The statistical significance of the results was confirmed through hypothesis testing.6. The study relied on a large sample size to ensure statistical power.7. Statistical outliers were identified and removed from the data set.8. The statistical distribution of the data was found to be skewed to the right.9. The statistical model accurately predicted the outcome of the experiment.10. The statistical analysis uncovered a correlation between two previously unrelated variables.11. Statistical techniques were used to control for confounding variables in the study.12. The statistical software provided descriptive statistics for the data set.13. The statistical inference drawn from the sample was applied to the population at large.14. The statistical evidence supported the conclusionthat there is a relationship between the two variables.15. Statistical programming languages allow for the automation of data analysis processes.16. The statistical method used was deemed appropriate for the research question.17. The statistical consultant provided expertise on the best methods for analyzing the data.18. Statistical tests were conducted to determine the significance of the findings.19. The statistical analysis revealed a clear trend in the data over time.20. The statistical model accurately represented the underlying patterns in the data.21. Statistical measures such as mean, median, and mode were used to summarize the data.22. The statistical significance of the results was confirmed through a p-value of less than 0.05.23. The statistical software provided graphical representations of the data for better understanding.24. The statistical approach to the problem proved to be effective in identifying patterns in the data.25. Statistical quality control methods were used to monitor production processes in the factory.26. The statistical distribution of the data set was found to be normal.27. Statistical techniques such as regression analysis were employed to understand the relationships between variables.28. The statistical findings were presented in a clear and accessible manner for easy interpretation.29. The statistical trends in the data were analyzed to inform future decision-making.30. Statistical tools such as ANOVA were used to compare means between multiple groups.31. The statistical analysis confirmed the hypothesisthat there was a significant difference between the two conditions.32. The statistical approach allowed for theidentification of patterns in the data that were previously overlooked.33. Statistical process control was implemented to monitor and improve the quality of the manufacturing process.34. The statistical analysis revealed no significant difference between the two groups, contrary to the initial hypothesis.35. The statistical software allowed for thevisualization of the data through various types of charts and graphs.36. The statistical modeling of the data allowed for the prediction of future trends.37. Statistical techniques such as chi-square tests were used to analyze categorical data.38. The statistical evidence supported the conclusionthat the intervention had a significant impact on the outcome.39. A statistical analysis plan was developed to outline the methods for analyzing the data.40. The statistical approach to the problem allowed for a deeper understanding of the underlying factors at play.41. Statistical significance was determined using a confidence interval of 95%.42. The statistical findings were cross-validated with an independent data set to ensure their reliability.43. The statistical analysis provided valuable insights into the behavior of the variables in the study.44. Statistical techniques such as cluster analysis were used to group similar data points together.45. The statistical software provided a wide range of tools for exploratory data analysis.46. The statistical model accurately predicted the outcome of the experiment with a high degree of confidence.47. Statistical outliers were identified and further investigated to understand their impact on the results.48. The statistical report highlighted key findings and their implications for future research.49. The statistical inference drawn from the sample was extrapolated to the larger population.50. The statistical software allowed for the calculation of basic descriptive statistics for the data set.51. Statistical tests of significance were conducted to determine the reliability of the results.。
医学SCI论文Title: The Efficacy of Yoga as an Adjunctive Treatment for Depression: A Systematic Review and Meta-analysis of Randomized Controlled TrialsAbstract:Objective: This systematic review and meta-analysis aimed to evaluate the efficacy of yoga as an adjunctive treatment for depression based on randomized controlled trials (RCTs).Methods: A comprehensive search was conducted in PubMed, Embase, PsycINFO, and Cochrane Library databases from inception to [date]. RCTs investigating the effectiveness of yoga as an adjunctive treatment for depression in adults were included. The primary outcome measure was the change in depressive symptoms from baseline to post-intervention. Secondary outcomes included anxiety symptoms, quality of life, and adverse events. Meta-analysis was performed using a random-effects model.Results: A total of [number] RCTs with [number] participants were included in the meta-analysis. The results showed that yoga, as an adjunctive treatment for depression, was associated with a significant reduction in depressive symptoms compared to control groups (standardized mean difference [SMD] = -[value], 95% confidence interval [CI]: -[lower limit] to -[upper limit], p < 0.001). Furthermore, yoga showed a significant reduction in anxiety symptoms (SMD = -[value], 95% CI: -[lower limit] to -[upper limit], p < 0.001) and improvement in quality of life (SMD = [value], 95% CI: [lower limit] to [upper limit], p = 0.001). Nosignificant adverse events were reported in any of the included studies.Conclusion: This systematic review and meta-analysis indicate that yoga, when used as an adjunctive treatment for depression, is effective in reducing depressive and anxiety symptoms and improving quality of life. Future research should focus on long-term effects and different populations to further establish the role of yoga in depression management.Keywords: yoga, depression, systematic review, meta-analysis, adjunctive treatmentIntroduction:Depression is a common mental health disorder characterized by persistent feelings of sadness, hopelessness, and loss of interest or pleasure in daily activities. It has significant negative consequences on individuals' overall well-being, functioning, and quality of life. Current treatment options for depression mainly include pharmacotherapy and psychotherapy. However, the efficacy of antidepressant medications has limitations, and many individuals experience side effects or do not respond adequately to these treatments. Hence, there is a growing interest in complementary and alternative treatments, such as yoga, as adjunctive therapies for depression.Yoga is a mind-body practice that originated in ancient India and combines physical postures, breathing exercises, meditation, and relaxation techniques. It has gained popularity worldwide and hasbeen increasingly recognized for its potential mental health benefits. Several studies have suggested that yoga can improve mood, reduce stress, and promote overall well-being. However, the efficacy of yoga as an adjunctive treatment for depression is still a topic of debate and requires further investigation.Methods:A systematic review and meta-analysis were conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. The study protocol was registered in PROSPERO database [registration number]. The primary objective was to assess the efficacy of yoga as an adjunctive treatment for depression based on RCTs. The secondary objectives were to evaluate the effects of yoga on anxiety symptoms, quality of life, and adverse events.The search strategy included the following databases: PubMed, Embase, PsycINFO, and Cochrane Library. The search strategy consisted of a combination of keywords related to yoga, depression, and RCTs. The search was limited to articles published in English. Two independent reviewers screened the titles and abstracts of the identified articles for relevance and eligibility. Full-text articles were retrieved for potentially eligible studies. Any disagreements were resolved through consensus or consultation with a third reviewer. Data regarding study characteristics, participants, intervention details, outcomes, and adverse events were extracted using a predefined extraction form.Results:A total of [number] RCTs with [number] participants met the inclusion criteria and were included in the systematic review and meta-analysis. The characteristics of included studies are summarized in Table 1. The overall quality of included studies was assessed using the Cochrane Risk of Bias tool.The meta-analysis results showed that yoga, as an adjunctive treatment for depression, was associated with a significant reduction in depressive symptoms compared to control groups (SMD = -[value], 95% CI: -[lower limit] to -[upper limit], p <0.001). Subgroup analysis by [variables] showed consistent results (Table 2). Furthermore, yoga showed a significant reduction in anxiety symptoms (SMD = -[value], 95% CI: -[lower limit] to -[upper limit], p < 0.001) and improvement in quality of life (SMD = [value], 95% CI: [lower limit] to [upper limit], p = 0.001). No significant adverse events were reported in any of the included studies.Discussion:The findings of this systematic review and meta-analysis suggest that yoga, as an adjunctive treatment for depression, can help reduce depressive symptoms, anxiety symptoms, and improve quality of life. The results are in line with previous studies that have reported the positive effects of yoga on mental health. The mechanisms underlying these effects could be attributed to the combination of physical activity, mindfulness, and relaxation techniques involved in yoga practice.Despite the promising results, several limitations should be considered. First, the included studies had variations in terms of yoga interventions, control groups, and outcome measures, which may impact the generalizability of the findings. Second, most studies had relatively small sample sizes, limiting the statistical power and generalizability of the results. Lastly, the included studies primarily focused on adults, and the efficacy of yoga for depression in other populations such as adolescents or older adults remains unclear.Conclusion:This systematic review and meta-analysis provide evidence supporting the use of yoga as an adjunctive treatment for depression. Yoga appears to be effective in reducing depressive and anxiety symptoms and improving quality of life. Future research should aim to overcome the limitations of the existing studies and focus on long-term effects, different populations, and comparisons with other treatment modalities to further establish the role of yoga in depression management.。
济南新航道学校IELTS READING雅思阅读高分必备习题集注:本习题集仅供济南新航道内部学员使用,严禁翻印,传阅。
Contents1.Amateur naturalist 业余自然学家(P3)municating Styles and Conflict 交流的方式与冲突(P6)3.Health in the Wild 野生动物自愈.(p10)4.The Rainmaker 人工造雨(P13)5.Shoemaker-Levy 9 Collision with Jupiter 舒梅克彗星撞木星(P16)6. A second look at twin studies 双胞胎研究(P19)7.Transit of Venus 金星凌日(P22)8.Placebo Effect—The Power of Nothing安慰剂效应(P25)9.The origins of Laughter 笑的起源(P29)10.Rainwater Harvesting 雨水收集(P32)11.Serendipity:The Accidental Scientists科学偶然性(P36)12.T erminated! Dinosaur Era! 恐龙时代的终结(P40) ADDICTION 电视上瘾(P43)14.E I nino and Seabirds 厄尔尼诺和水鸟(P46)15.T he extinct grass in Britain 英国灭绝的某种草(P50)16.E ducation philosophy教育的哲学(P53)17.T he secret of Yawn打哈欠的秘密(P57)18.c onsecutive and simultaneous translation交替传译和同声传译(P60)19.N umeracy: can animals tell numbers?动物会数数么?(P63)20.G oing nowhere fast(P66)21.T he seedhunters种子收集者(P69)22.T he conquest of Malaria in Italy意大利征服疟疾(P72)READING PASSAGE 1You should spend about 20minutes on Questions 27-40 which are based on Reading Passage 3 below.文章背景:业余自然学家主要讲述的是有一些人,平时喜欢观察自然界的植物生长,养蜂过程,气候变化,等等与大自然相关的变化并且做记录得到一些数据,这种数据叫做“amateur data”. 本文主要介绍业余自然学家以及一些专业自然学家探讨业余自然学家的数据是否能用,以及应该如何使用这些自然学家的数据,其可信度有多少等问题。
QTL’s) and sources due to background genetic vari-ance (Fulker, Cherny, & Cardon, 1995; Fulker, Cherny,Sham, et al.,1999; Nance and Neale, 1989; Boomsma and Dolan, 1998). A necessary first step in mapping complex traits to QTL’s is to establish the amount of genetic variation that underlies the phenotypic varia-tion of the trait. If phenotypic variation in a trait is found to be caused in part by genetic sources, linkage and/or association studies can be conducted in order to characterize the effects of specific genetic loci on the phenotypic variation. If phenotypic variation is not found to be heritable, the search for effects of specific genetic loci will not be initiated. However, in some cases it may be concluded that phenotypic variance in INTRODUCTIONRecent advances in molecular genetics have made it possible to partition genetic variance into sources due to particular genetic loci (quantitative trait loci’s;A Note on the Statistical Power in Extended Twin DesignsDaniëlle Posthuma 1,2and Dorret I. Boomsma 1Received 7 Oct. 1999—Final 20 Feb. 2000The power to detect sources of genetic and environmental variance varies with sample size,study design, effect size and the statistical significance level chosen. We explored whether the power of the classical twin study may be increased by adding non-twin siblings to the classical twin design. Sample sizes to detect genetic and shared environmental variation were compared for kinships with only twins, kinships consisting of twins and one additional sibling, and kin-ships with twins and two additional siblings. The effect of adding siblings to the classical twin design was considered for univariate and bivariate analyses.For the univariate case, adding one non-twin sibling resulted in a decrease in sample size needed to detect additive genetic influences in the presence of environmental influences. How-ever, adding two additional siblings did not decrease the number of subjects as compared to the classical twin design. The sample size required to detect common environmental factors was also greatly decreased by adding one non-twin sibling. Adding two non-twin siblings resulted in a small additional decrease. In models including additive genetic, dominant genetic, and unique environmental effects, adding one sibling to a twin family decreased the required sample size to detect dominant genetic influences. Adding two siblings to a twin family resulted in only a slight additional decrease in sample size.In the bivariate case a similar pattern of results was found, in addition to the observation that the overall required sample size, as expected, was lower than in the univariate case. The decrease in sample size from bivariate testing was more pronounced in a design with one or two additional siblings, as compared to a design with twins only. It is concluded that a well con-sidered choice of family design, i.e. including families with twins and one or two additional sib-lings increases the statistical power to detect sources of variance due to additive and non-additive genetic influences, and common environment.KEY WORDS:Sample size; heritability; methodology; sibship size; twin study.Behavior Genetics, Vol. 30, No. 2, 20001470001-8244/00/0300-0147$18.00/0 ©2000 Plenum Publishing Corporation1Department of Biological Psychology, Vrije Universiteit Amster-dam, Netherlands.2Correspondence and requests for reprints should be sent to: D.Posthuma, Vrije Universiteit, Department of Biological Psychol-ogy, De Boelelaan 1111, 1081 HV, Amsterdam, The Netherlands.Telephone: +31 20 444 8814, telefax: +31 20 444 8832, email:danielle@psy.vu.nlWe gratefully acknowledge the financial support of the USF (grant number 96/22) and the HFSP (grant number rg0154/1998-B). We wish to thank Eco de Geus, Leo Beem and Conor Dolan for their comments on draft versions of this paper.a trait can not be ascribed to genes because the statis-tical power to detect sources of genetic variation is in-sufficient (Svikis, Velz & Pickens, 1994; Pickens,Svikis, McGue, Lykken, et al.,1991). This will pre-clude further searching for effects of QTL’s on that par-ticular trait, even though such QTL’s may be present.The statistical power of quantitative genetic stud-ies is influenced by the size of the effect (e.g. heri-tability), the sample size, the probability level (α)chosen, and the homogeneity of the sample (Neale and Cardon, 1992; Cohen, 1992; Tanaka, 1987). Increasing the sample size is the most common way to increase the statistical power of a study, but is often limited by re-sources of time and money. Another means to increase statistical power is the use of multivariate testing. In the context of structural equation modeling the statistical power to detect genetic effects rises as a (non-linear)function of multivariate testing under the condition that the measures are correlated (Schmitz, Cherny, and Fulker, 1998). In the context of partitioned twin analy-ses it has been shown that choosing a different (e.g.other than 1 to 1) MZ to DZ ratio influences statistical power such that an MZ to DZ ratio of 1 to 4 is optimal for partitioned twin analyses (Nance & Neale, 1989).In the present paper we focus on increasing the sta-tistical power of the classical twin study by adding non-twin siblings to MZ and DZ twin pairs. Since non-twin siblings share on average half of their segregating genes,just like DZ twins, adding non-twin siblings to the clas-sical twin design may provide an efficient way to in-crease the power to detect sources of genetic and shared environmental variance. Adding two more siblings to a twin kinship provides five additional observed covari-ances, whereas adding a whole new family consisting of two siblings provides only one additional observed co-variance. In the present paper we examine the effects of adding non-twin siblings to twin families on the esti-mated sample size needed to detect additive genetic (A)variance (V a ), dominant genetic (D) variance (V d ), and common environmental (C) variance (V c ), with a power of 80% in the context of structural equation modeling.METHODWe calculated covariance matrices for three ex-perimental designs, which differed in family constitu-tion. Design 1 included only MZ twins and DZ twins.Design 2 included families with MZ and DZ twins and one additional sibling. Design 3 included families with MZ and DZ twins and two additional siblings. For all three designs we calculated the sample size needed to 148Posthuma and Boomsmadetect an effect of interest with a power of 80%. The MZ twins to DZ twins ratio was 1 to 1 for all three de-signs (thus, the ratio MZ to ‘non MZ sibpairs’, is not 1 to 1 for all designs). It should be noted that we re-port sample size in subjects and not in twin pairs. The same number of subjects refers to different numbers of twin pairs and a different number of families for all three designs. We will use the terms ‘highest power’and ‘fewest subjects needed’ to refer to an optimal de-sign to detect sources of phenotypic variance.All analyses were carried out using the statistical software package Mx (Neale, 1997). Estimation of pa-rameters was obtained by normal theory maximum like-lihood. Goodness of fit testing was based on the likelihood ratio tests. First univariate models were con-sidered. In order to obtain the sample size needed to detect varying levels of additive genetic variance with a fixed power level of (1 −β) =.80, covariance matri-ces were calculated with sources of additive genetic variance (V a ) accounting for 10% to 90% of the phe-notypic variance in the presence of sources of common environmental variance (V c ) accounting for 00%, 10%,and 20% of the variance. Remaining variance was at-tributed to unique environmental (E) sources of vari-ance (V e ). To detect sources of V c covariance matrices were calculated with V c accounting for 10% to 90% of the phenotypic variance in the context of sources of V a accounting for 00%, 10%, and 20% of the phenotypic variance. In addition, covariance matrices were calcu-lated with sources of variation due to A, D (dominant genetic variance) and E. Only the situation in which dominance was ‘complete’ (V a to V d =2 to 1; see ap-pendix I) was considered. In the ADE-models the total genetic variance, i.e. V a and V d together accounted for 30% to 90% of the total phenotypic variance. For all situations, remaining variance was attributed to V e .Since non-twin siblings, like DZ twins, share on average half of their genes, expectations for non-twin sibling covariances were modeled similarly to expec-tations for DZ covariances.In the ACE-models the expected phenotypic vari-ance (σ2) of twins and siblings is V a +V c +V e , the ex-pected MZ covariance V a +V c , and the expected DZ and sibling covariance .5 V a +V c . In ADE-models, the expected phenotypic variance is V a +V d +V e , the ex-pected MZ covariance V a +V d , and the expected DZ and sibling covariance .5 V a +.25 V d .It is known that the use of a multivariate pheno-type, as opposed to a univariate phenotype, results in a gain of statistical power if the multivariate traits are correlated (Schmitz et al.1998). To find out how muchadding siblings and using a multivariate phenotype af-fects statistical power we also looked at several bi-variate designs. We calculated covariance matrices for two traits with a phenotypic correlation of .50. Both traits could be influenced by A, C, and E or by A, D,and E. Total influences of sources of A, C or D, and E were uniform for each trait. The phenotypic correlation between the two traits could be due to additive genetic correlation (rA), dominant genetic correlation (rD),common environmental correlation (rC), or to unique environmental correlation (rE), depending on the spe-cific situation that was considered. Figure 1 depicts the construction of covariance matrices for kinships con-sisting of twins and one additional sibling for a bi-variate ADE-model (Cholesky decomposition) in which rE is absent and all phenotypic correlation is due to rA and rD. All latent variables have unit variance.Power calculations were carried out by fitting the known model to the exact (population) covariance ma-trices as described in Neale and Cardon (1992). In mod-els which contain a parameter which is known to be zero,the zero parameter can either be fixed at zero or freed (estimated) while computing the power to detect one of the other non-zero parameters. For example, when treat-ing the ACE-model in which V c is zero as an AE-model,the power to detect sources of variation due to A is sig-nificantly higher than when the ACE-model is treated as an ACE-model, i.e. with V c estimated as a free param-eter. In the power calculations the zero-parameter wasPower and Sibship Size 149estimated as a free parameter because we are interested in computing the power to detect V a , in ACE-models,regardless of the value of V c (and vice versa). The same reasoning applies to the bivariate calculations.Constraining a certain set of parameters to zero and refitting the model provides the non-centrality parame-ter. From this non-centrality parameter the sample size required to reject the false model with a power of 80%and a significance level αof .05 can be calculated (Mar-tin et al.,1978; Hewitt and Heath, 1988) and is conve-niently supplied by Mx.RESULTS Univariate Models ACE-modelsWe fitted full univariate models with sources of variation due to additive genetic (A), common environ-mental (C) and unique environmental influences (E).Dropping either genetic or common environmental parameters and refitting the model provides the non-cen-trality parameter. With Mx (Neale, 1997) the cor-responding number of subjects required to detect the parameter that was dropped with a power of 80% and αof 5% was calculated for 1 degree of freedom. Results concerning the estimated sample size (in subjects)needed to detect V a in ACE-models for the three designsare depicted in Figure 2 (and appendix II). Figure 2a con-Fig. 1.Pathdiagram for the bivariate ADE-model, cholesky decomposition. Example for twins and one additional sibling, no unique environ-mental correlation (rE). The covariance between trait 1 and trait 2 is (a 11*a 21) +(d 11*d 21) and the correlation between trait 1 and trait 2 is (a 11*a 21) +(d 11*d 21)/√(σ21*σ22).cerns low values of V a (10% −20%), Figure 2b concerns intermediate values of V a (30%–50%), and Figure 2c concerns high values of V a (60%–90%) accounting for the total phenotypic variance. All values of V a are re-ported three times, i.e. in the context of values of V c of 0%, 10%, and 20%.As can be seen in Figure 2a, 2b, and 2c, for vari-ous values of V a and V c , design 2 (families consisting of MZ and DZ twins and one non-twin sibling) is the most optimal design to detect sources of variation due to A, i.e. with design 2 fewer subjects are required to achieve a power of 80% (see appendix II). The number of subjects needed to detect a fixed value of V a is on average 9.3% more in the classical twin design (design 1) compared with a design with twins and one additional sibling. This can result in 2849 fewer subjects that are needed with design 2 to detect an additive genetic in-fluence of 10% compared with the classical twin design.Including families with twins and two additional sibs, is less powerful than including families with twins and one additional sibling, and also less powerful than including families with twins only for the detection of V a ; adding two siblings at the cost of the total number of MZ twins is disadvantageous, but adding one sib-ling is ideal.Results for detecting common environmental in-fluences are given in Figures 3a, 3b, and 3c, for low,moderate, and high values of V c respectively (see also Appendix III).150Posthuma and BoomsmaUnder various values of V c and V a , the power to detect sources of variation due to C rises substantially when one sibling is added to the classical twin design;on average 50.4% fewer subjects are needed as com-pared to the classical twin design (design 1). Adding two siblings decreases sample size even more, but not as dramatically as the decrease from no additional sib-lings to one additional sibling.Many empirical studies suggest models in which sources of variation due to C are of less importance than sources of variation due to A (Plomin, DeFries, &McClearn, 1990). Therefore, we also calculated the sam-ple size required to detect small values of V c in the con-text of higher values of V a . Figure 4 depicts the number of subjects needed to detect values of V c of 10% and 20% in the context of values of V a of 20% , 30%, 40%or 50% (Appendix IV).As expected, sample size required to detect V c with a power of 80% decreases as a result of higher values of V c and higher values of V a . Comparing the sample size required to detect sources of variation due to A (Figure 2b) with the sample size required to detect sources of variation due to C, shows that in the realis-tic situation where V a > V c sources of variation due to C are very difficult to detect. Even if the sample size is large enough to detect sources of variation due to A, the small value of V c may still go undetected. If for exam-ple the true model is an ACE-model with V a =50%, V c =20%, and V e =30%, and the total sample size 328Fig. 2 a,b,c.Required sample size to detect sources of variance due to additive genetic effects in ACE models for three different family de-signs with a power of 80%. Design 1 =MZ and DZ twins only, Design 2 =MZ and DZ twins and one additional sibling, Design 3 =MZ and DZ twins and two additional siblings.(just enough for design 1 to detect V a of 50%, with power of 80%), V c will not be detected and the AE-model will be proposed as the most parsimonious model.This results in a biased estimate of V a (in this case V a is estimated to be 70%).Adding siblings to the classical twin design de-creases the sample size required to detect both V a and V c and has the largest effect on the sample size required to detect V c (i.e. 50.4% fewer subjects needed for V c ,9.3% fewer subjects needed for V a ). Therefore, the bias towards overestimating values of V a as a result of not detecting V c in situations where V a > V c , is less likelyPower and Sibship Size 151to be present in designs where siblings are added to the classical twin design.ADE-ModelsWe also fitted full univariate models with sources of variation due to additive genetic (A), dominance (D)and unique environmental influences (E). Since a DE-model is unrealistic we report the sample size required to detect sources of variation due to A and D (2 df test)and to detect sources of variation due to D (1 df test)with a power of 80%. Results for detecting V a and V d ,or V dare given in Figures 5a and 5b (and appendix V).Fig. 3 a,b,c.Required sample size to detect sources of variance due to common environmental influences in ACE models for three differentfamily designs with a power of 80%.Fig. 4.Required sample size to detect sources of variance due to common environmental influences in ACE models where V a > V c , for threedifferent family designs with a power of 80%.Under various values of V a and V d , with fixed ratio of V a to V d is 2 to 1, adding one sibling to a twin family decreases the sample size required to detect V d . Adding two siblings decreases sample size even more but less than the decrease due to adding one sibling. Absolute ef-fects are slightly higher with increasing values of V a and V d . Figure 5a also emphasizes the very large sample size that is required to detect dominant genetic influences.Even the largest possible value of V d under complete dominance with the most optimal design will go unde-tected if the sample is smaller than 1776 subjects.Sample sizes required to detect both V a and V d si-multaneously are considerably smaller as compared to sample sizes required to detect V d . In contrast, how-ever, adding siblings does not decrease sample size needed to detect V a and V d simultaneously. In fact, a design with one or two siblings requires somewhat more subjects to detect V a and V d with a power of 80%,as can be seen in Figure 5b. It should be noted how-ever that the number of subjects needed to detect V a and V d at the same time is considerably less than the number of subjects needed to detect V d only. This im-plies that if the sample size is large enough to detect V d it will also be sufficient to detect V a and V d .152Posthuma and BoomsmaIn conclusion, to optimize the power to detect V d ,a design with additional siblings, as compared to a de-sign with twins only, is preferred.Bivariate Models ACE-ModelsTo detect sources of variance due to additive ge-netic influence (A), we calculated both the sample size required to detect all sources of V a (df =3; paths a 11,a 21, and a 22in Figure 1) and the required sample size to detect the common genetic pathway (df =1; path a 21).We considered the test for the detection of the common pathway to be a test for the presence of a genetic cor-relation (rA). The following situations to detect sources of variance due to A were considered: a) The genetic correlation (rA) is ‘moderate’ and equal to the common environmental correlation (rC) and to the unique envi-ronmental correlation (rE). Variances due to A, C and E (uniform for both traits) are 40%, 10%, and 50% re-spectively of the phenotypic variance. b) rC is absent,rA is high (.80), and rE is small (.36), variances dueto A, C and E are 40%, 10%, and 50% respectively.Fig. 5 a,b.Required sample size to detect sources of variance due to dominant genetic influences (a) and total genetic (dominant & additiveinfluences)(b) influences in ADE models, for three different family designs with a power of 80%.c) Variances due to C are absent. rA is .60, rE is .27,variances due to A and E are 70% and 30% respec-tively. As mentioned before, all parameters were es-timated, as opposed to constraining these parameters,which were zero in the full model. It should also be noted that considering the tests for total V a , total V c , and total V d to be 3 df-tests is a conservative approach, as it could be argued these are actually 2 df-tests, or tests with df’s somewhere between 2 and 3. Testing, for ex-ample, whether either or both univariate genetic vari-ances equal zero, implies that the genetic covariance is zero. If variances due to additive genetic influences for both traits equal zero, a correlation between these sources of variance is not possible. In other words, if the sample size required to detect each of the univa-riate variances due to additive genetic influences is insufficient, a correlation due to additive genetic in-fluences can also not be detected. Therefore, consider-ing the test for the power to detect ‘total V a ’ (i.e. both univariate variances due to additive genetic influences and the correlation due to additive genetic influences in the bivariate case) a 3 df test will provide an overesti-mation of the sample size needed for a power of 80%.Results of situation a, b, and c for the three different kinships, are given in Table I.As can be seen in Table I the same pattern of re-sults is found in the bivariate case as in the univariate case; a design with one additional sibling is optimal for the detection of V a in ACE-models. In addition, sig-nificantly fewer subjects are needed in the bivariate case as compared to the univariate case. Depending on whether the phenotypic correlation is due to rA, rC, or rE, the sample size required to detect V a may decrease and is lowest in cases where there is no influence of common environmental sources (i.e. statistical power Power and Sibship Size 153is highest in these cases). However, when there are uni-variate common environmental influences but no com-mon environmental correlation, the sample size required to detect variance due to additive genetic influences in-creases. Comparing situations a, b, and c leads to the conclusion that the power to detect sources of variance and covariance due to A (df 3) is highest (and the re-quired sample size is smallest) when there is no uni-variate common environmental source of variation.However, if there are common environmental sources of variation, sources of variance due to A are easier to detect when there is also a correlation between these two univariate common environmental sources of vari-ation, and again a design with one additional sibling is optimal.To detect sources of common environmental sources of variation, we calculated both the power to detect all sources of variation due to C (df =3) and the power to detect the common pathway (df =1), which is a test to detect the environmental correlation (rC).We considered situations analogous to the situations in which power was calculated to detect sources of vari-ation due to A; a) The common environmental corre-lation is ‘moderate’ and equal to the genetic correlation and to the unique environmental correlation, i.e. rC =rA =rE =.50. Uniform univariate variances due to A,C and E are 10%, 40%, and 50% respectively. b) rA is absent. rC is high (.80), and rE is small (.36), variances due to A, C and E are 10%, 40%, and 50% respectively,c) Variances due to A and rA are absent. rC is .60, rE is .27, variances due to C and E are 70% and 30% re-spectively. Again, for all situations the phenotypic cor-relation was .50. Results are given in Table II.Although the results in the bivariate case resem-ble those in the univariate case (i.e. a design with twoTable I.Total samplesize (in number of subjects) needed to detect additive genetic influences in full bivariate ACE models under three dif-ferent sibship sizes with power (1 −β) =.80 and α=.05V a =40% rA =.50V a =40% rA =.80V a =70% r A =.60V c =10% rC =.50V c =10% rC =.00V c =00% r C =.00V e =50% rE =.50V e =50% rE =.36V c =30% r E =.27all V a (df =3)rA (df =1)all V a (df =3)rA (df =1)all V a (df =3)rA (df =1)design 16602392782884156270design 25641917678735147237design 36802260820876180284Note : MZ/DZ ratio =1/1; design 1 =twins only, design 2 =twins and one additional sibling, design 3 =twins and two additional siblings.‘All V a ’ refers to both univariate variances and the genetic correlation.In order to calculate the total number of families needed, all cells concerning design 1 need to be divided by 2, all cells concerning design 2need to be divided by 3, and all cells concerning design 3 need to be divided by 4.additional siblings is optimal for the detection of V c ),the difference between design 2 and design 3 (i.e.adding one or two siblings) in the bivariate case is more substantial. Whereas in the univariate case only a small additional effect was found, in the bivariate case 4 to 5 times less subjects are needed with two additional siblings as compared to one additional sibling.ADE-ModelsWe calculated covariance matrices for two traits that were influenced by A, D, and E in the context of complete dominance. Sources of variance due to A and D accounted for 40% and 20% respectively of the total phenotypic variance. We assumed that the ratio V a to V d remained equal over the two traits. This implies that rA =rD (see appendix I). Three situations were con-sidered: a) rA =rD =.80,; b) rA =rD =.50; c) rA =rD =.30. For all three situations the phenotypic correla-tion was fixed at .50 by attributing all remaining co-variance to rE. We report the total number of individual subjects needed to detect sources of total V a and V d due to A and D (df =6), rA & rD (df =2), total D (df =3),and rD (df =1) for a power of 80%. Results are given in Table III.Analogous to the univariate case a design with two additional siblings is optimal for the detection of V d and a design with twins only is optimal for the detec-tion of V a and V d simultaneously. Comparison with the univariate results shows that in a design with twins only, fewer subjects are needed to detect sources of variance due to D as a result from bivariate testing. This effect, however, is stronger when a design consisting of twins and two additional siblings is used, suggest-ing that in addition to the decrease in sample size as a result from bivariate testing, adding siblings will de-crease the sample size required to detect sources of variance due to D even further.154Posthuma and BoomsmaDesigns Where Only Sibs of mz Twins are Included In the previous analyses all families were of the same structure; consisting of MZ and DZ twins only,or with one or two additional siblings. For several rea-sons this may not always be realistic. For illustrative purposes, we included two other designs in which one (design 4) or two siblings (design 5) were added to MZ twin families, but not to DZ families. Analyses were run for a few ‘standard’ situations of the ACE-models and ADE-models for univariate testing only. Results for ACE and ADE models are given in Table IV.Comparison of the results of designs 4 and 5 and the results of designs 2 and 3 shows that in ACE-mod-els a design consisting of MZ twins and one additional sibling and DZ twins only (design 4) is optimal for the detection of V a , and performs even better than design 2.For the detection of V c in ACE-models design 3 and 5are both optimal.In the context of ADE-models, design 3 (MZ/DZ twins with two additional siblings), requires the smallest sample size and is more optimal than design 4 or 5 for the detection of sources of variation due to dominance.CONCLUSIONWe demonstrated that with a fixed power of 80%,a probablity level of 5% and under varying levels of heritability and common environmental influences,adding one sibling to the classical twin design signifi-cantly decreases the number of subjects that are needed to detect each of these sources of variation. Adding two siblings to a twin pair yields an additional decrease of sample size to detect sources of variation due to the common environment but is not optimal for the detec-tion of additive genetic influences. If the trait is influ-enced by additive and non-additive genetic factors,adding one sibling to the classical twin design decreases the sample size needed to detect sources of variationTable II.Total samplesize (in number of subjects) needed to detect common environmental influences in full bivariate ACE models underthree different sibship sizes with power (1 −β) =.80 and α=.05V a =10% r A =.50V a =10% rA =.00V a =0% rA =.00V c =40% r C =.50V c =40% r C =.80V c =70% r C =.60V e =50% r E =.50V e =50% rE =.36V e =30% rE =.27all V c (df =3)r C (df =1)all V c (df =3)r C (df =1)all V c (df =3)rC (df =1)design 14441498518560100156design 22137742492794896design 3487604426816108Note : see table 1 for definitions.。