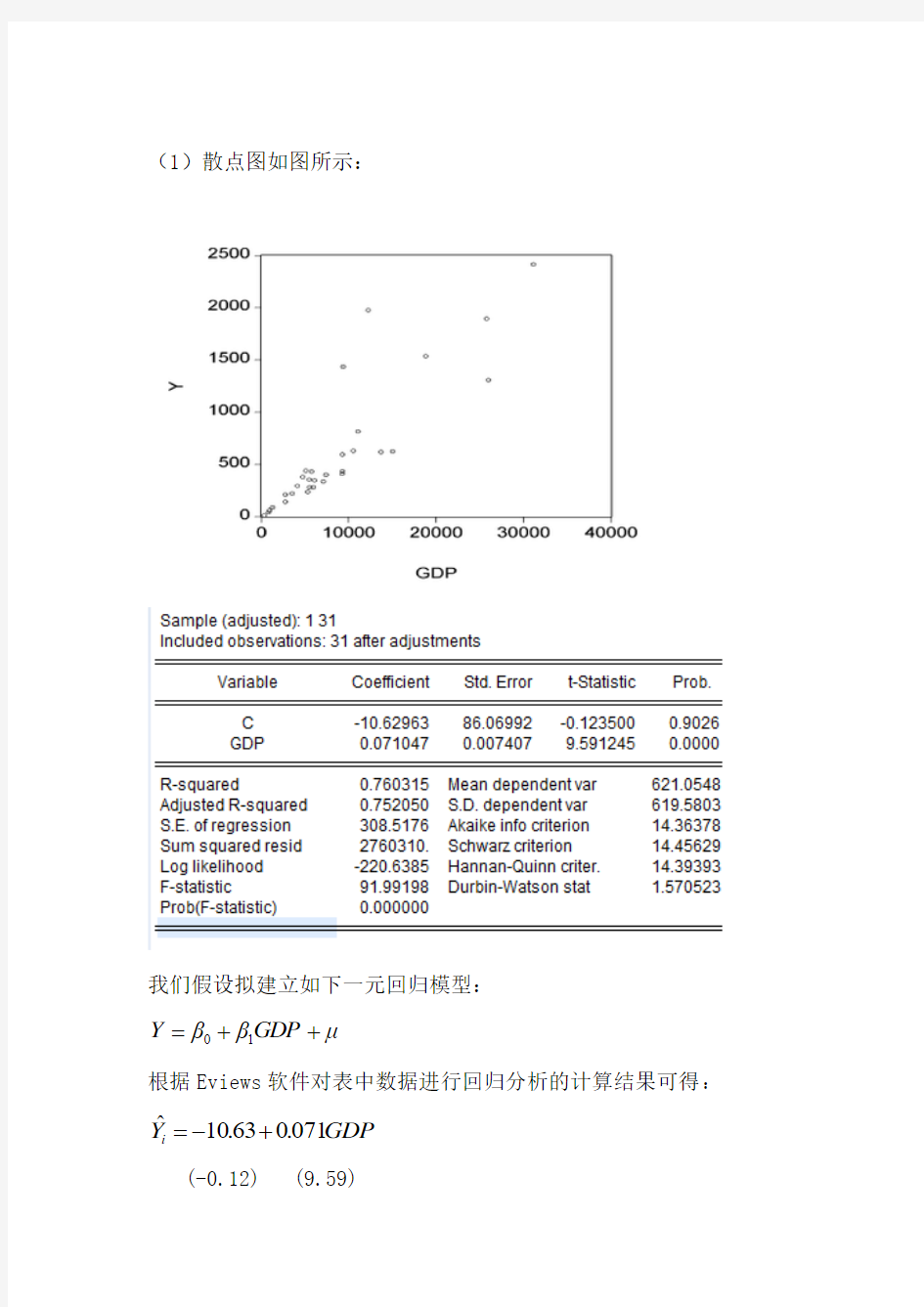

(1)散点图如图所示:
我们假设拟建立如下一元回归模型:
μGDP ββY ++=10
根据Eviews 软件对表中数据进行回归分析的计算结果可得: GDP ..Y i
07106310?+-= (-0.12) (9.59)
7603.02=R 99.91=F
因此斜率的经济意义:国内生产总值GDP 每增加1亿元,国内税收增加0.071亿元。
(2)从回归估计的结果看,模型拟合较好。可决系数7603.02=R ,表明国内税收变化的76.03%可由国内生产总值GDP 的变化来解释。从斜率项的t 检验值看,大于10%显著性水平下自由度为292=-n 的临界值699.1)29(05.0=t ,且该斜率值满足1071.00<<,符合经济理论中税收乘数在0与1之间的说法,表明2007年,国内生产总值GDP 每增加1亿元,国内税收增加0.071亿元。
(3)有上述回归方程可得中国国内税收的预测值:
87.5928500071.063.10?0
=?+-=Y (元) 下面给出国内生产总值90%置信度的预测区间
126.8891=E )(GDP
64.57823127)Var(=GDP
在90%的置信度下,某地区)E(0Y 的预测区间为:
)
,())()((5.11253.606.53287.5922
-3164.578231272-318891.126-850031112760310699.187.5922=±=?++??±
龙源期刊网 https://www.doczj.com/doc/7e1442773.html, 基于ARIMA模型下的时间序列分析与预测 作者:万艳苹 来源:《金融经济·学术版》2008年第09期 摘要:大多数的时间序列存在着惯性,或者说具有迟缓性。通过对这种惯性的分析,可以由时间序列的当前值对其未来值进行估计。本文以1949年到2004年江苏省社会消费品零售总额数据为研究对象,将这些数据平稳化并做分析,发现ARIMA(1,1,2)模型能比较好的对江苏省社会消费品零售总额进行市时间序列分析和预测,。 关键词:ARIMA;江苏省消费品零售总额;时间序列分析 一、引言 江苏省是一个经济大省,经济一直保持平稳较快增长,城乡居民收入都位于全国前茅,消费品需求旺盛,人们生活水平比较高。其中社会消费品零售总额是反映人民生活水平提高的一个很好的指标。所以对社会消费品零售总额做分析就比较重要。但是影响社会消费品零售总额的因素有很多,包括收入、住房、医疗、教育以及人们的预期等很多因素,而且这些因素之间又保持着错综复杂的联系。因此运用数理经济模型来分析和预测较为困难。所以本文采用ARIMA模型对江苏省的社会消费品零售总额进行分析,得出其规律性,并预测其未来值。 二、ARIMA模型的说明和构建 ARIMA模型又称为博克斯-詹金斯模型。ARIMA模型是由三个过程组成:自回归过程(AR(p));单整(I(d));移动平均过程(MA(q))。AR(p)即自回归过程,是指一个过程的当前值是过去值的线性函数。如:如果当前观测值仅与上期(滞后一期)的观测值有显著的线性函数关系,则我们就说这是一阶自回归过程,记作AR(1)。推广之,如果当前值与滞后p期的观测值都有线性关系则称p阶自回归过程,记作AR(p)。MA(q),即移动平均过程,是指模型值可以表示为过去残差项(即过去的模型拟合值与过去观测值的差)的线性函数。如:MA(1)过程,说明时间序列受到滞后一期残差项的影响。推广之,MA(q)是指时间序列受到滞后q期残差项的
计算分析题(共3小题,每题15分,共计45分) 1、下表给出了一含有3个实解释变量的模型的回归结果: 方差来源 平方和(SS ) 自由度(d.f.) 来自回归65965 — 来自残差— — 总离差(TSS) 66056 43 (1)求样本容量n 、RSS 、ESS 的自由度、RSS 的自由度 (2)求可决系数)37.0(-和调整的可决系数2 R (3)在5%的显著性水平下检验1X 、2X 和3X 总体上对Y 的影响的显著性 (已知0.05(3,40) 2.84F =) (4)根据以上信息能否确定1X 、2X 和3X 各自对Y 的贡献?为什么? 1、 (1)样本容量n=43+1=44 (1分) RSS=TSS-ESS=66056-65965=91 (1分) ESS 的自由度为: 3 (1分) RSS 的自由度为: d.f.=44-3-1=40 (1分) (2)R 2=ESS/TSS=65965/66056=0.9986 (1分) 2R =1-(1- R 2)(n-1)/(n-k-1)=1-0.0014?43/40=0.9985 (2分) (3)H 0:1230βββ=== (1分) F=/65965/39665.2/(1)91/40 ESS k RSS n k ==-- (2分) F >0.05(3,40) 2.84F = 拒绝原假设 (2分) 所以,1X 、2X 和3X 总体上对Y 的影响显著 (1分) (4)不能。 (1分) 因为仅通过上述信息,可初步判断X 1,X 2,X 3联合起来 对Y 有线性影响,三者的变化解释了Y 变化的约99.9%。但由于 无法知道回归X 1,X 2,X 3前参数的具体估计值,因此还无法 判断它们各自对Y 的影响有多大。 2、以某地区22年的年度数据估计了如下工业就业模型 i i i i i X X X Y μββββ++++=3322110ln ln ln 回归方程如下: i i i i X X X Y 321ln 62.0ln 25.0ln 51.089.3?+-+-= (-0.56)(2.3) (-1.7) (5.8) 2 0.996R = 147.3=DW 式中,Y 为总就业量;X 1为总收入;X 2为平均月工资率;X 3为地方政府的
《 期中练习题 1、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则是指( ) A .使 ∑=-n t t t Y Y 1)?(达到最小值 B.使∑=-n t t t Y Y 1达到最小值 C. 使 ∑=-n t t t Y Y 1 2 )(达到最小值 D.使∑=-n t t t Y Y 1 2)?(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为 ?ln 2.00.75ln i i Y X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( ) A. B. % C. 2 D. % 3、设k 为回归模型中的参数个数,n 为样本容量。则对总体回归模型进行显著性检验的F 统计量与可决系数2 R 之间的关系为( ) ~ A.)1/()1()/(R 2 2---=k R k n F B. )/(1)-(k )R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. ) 1()1/(2 2R k R F --= 6、二元线性回归分析中 TSS=RSS+ESS 。则 RSS 的自由度为( ) 9、已知五个解释变量线形回归模型估计的残差平方和为 8002=∑t e ,样本容量为46,则随机误 差项μ的方差估计量2 ?σ 为( ) D. 20 1、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2 i )V ar(u i σ= C. 0)u E(u j i ≠ ) D.随机解释变量X 与随机误差i u 不相关 E. i u ~),0(2 i N σ 2、对于二元样本回归模型i i i i e X X Y +++=2211???ββα,下列各式成立的有( ) A.0 =∑i e B. 0 1=∑i i X e C. 0 2=∑i i X e D. =∑i i Y e E. 21=∑i i X X 4、能够检验多重共线性的方法有( )
《计量经济学》期末考试试卷(A )(课程代码:070403014) 1.计量经济模型的计量经济检验通常包括随机误差项的序列相关检验、异方差性检验、解释变量的多重共线性检验。 2. 普通最小二乘法得到的参数估计量具有线性,无偏性,有效性统计性质。 3.对计量经济学模型作统计检验包括_拟合优度检验、方程的显著性检验、变量的显著性检验。 4.在计量经济建模时,对非线性模型的处理方法之一是线性化,模型β α+= X X Y 线性 化的变量变换形式为Y *=1/Y X *=1/X ,变换后的模型形式为Y *=α+βX *。 5.联立方程计量模型在完成估计后,还需要进行检验,包括单方程检验和方程系统检验。 1.计量经济模型分为单方程模型和(C )。 A.随机方程模型 B.行为方程模型 C.联立方程模型 D.非随机方程模型 2.经济计量分析的工作程序(B ) A.设定模型,检验模型,估计模型,改进模型 B.设定模型,估计参数,检验模型,应用模型 C.估计模型,应用模型,检验模型,改进模型 D.搜集资料,设定模型,估计参数,应用模型 3.对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值的(B )。
A.i C (消费)i I 8.0500+=(收入) B.di Q (商品需求)i I 8.010+=(收入)i P 9.0+(价格) C.si Q (商品供给)i P 75.020+=(价格) D.i Y (产出量)6.065.0i K =(资本)4 .0i L (劳动) 4.回归分析中定义的(B ) A.解释变量和被解释变量都是随机变量 B.解释变量为非随机变量,被解释变量为随机变量 C.解释变量和被解释变量都为非随机变量 D.解释变量为随机变量,被解释变量为非随机变量 5.最常用的统计检验准则包括拟合优度检验、变量的显著性检验和(A )。 A.方程的显著性检验 B.多重共线性检验 C.异方差性检验 D.预测检验 6.总体平方和TSS 、残差平方和RSS 与回归平方和ESS 三者的关系是(B )。 A.RSS=TSS+ESS B.TSS=RSS+ESS C.ESS=RSS-TSS D.ESS=TSS+RSS 7.下面哪一个必定是错误的(C )。 A. i i X Y 2.030?+= 8.0=XY r B. i i X Y 5.175? +-= 91.0=XY r
计量经济学(第四版)习题参考答案 潘省初
第一章 绪论 试列出计量经济分析的主要步骤。 一般说来,计量经济分析按照以下步骤进行: (1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项? 为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。 什么是时间序列和横截面数据? 试举例说明二者的区别。 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。 横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。 估计量和估计值有何区别? 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。在一项应用中,依据估计量算出的一个具体的数值,称为估计值。如Y 就是一个估计量,1 n i i Y Y n == ∑。现有一样本,共4个数,100,104,96,130,则 根据这个样本的数据运用均值估计量得出的均值估计值为 5.1074 130 96104100=+++。 第二章 计量经济分析的统计学基础 略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间 N S S x = = 4 5= 用 =,N-1=15个自由度查表得005.0t =,故99%置信限为 x S t X 005.0± =174±×=174± 也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH 备择假设 120:1≠μH 检验统计量 () 10/2510/25 X X μσ-Z == == 查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH 备择假设 : 2500:1≠μH ()100/1200.83?480/16 X X t μσ-= === 查表得 131.2)116(025.0=-t 因为t = < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 () () n=30 R 2 = 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 13.假设某国的货币供给量Y 与国民收入X 的历史如系下表。 某国的货币供给量X 与国民收入Y 的历史数据 根据以上数据估计货币供给量Y 对国民收入X 的回归方程,利用Eivews 软件输出结果为: Dependent Variable: Y Variable Coefficient Std. Error t-Statistic Prob. X C R-squared Mean dependent var Adjusted R-squared . dependent var . of regression F-statistic Sum squared resid Prob(F-statistic) 问:(1)写出回归模型的方程形式,并说明回归系数的显著性() 。 (2)解释回归系数的含义。 (2)如果希望1997年国民收入达到15,那么应该把货币供给量定在什么水平 14.假定有如下的回归结果 t t X Y 4795.06911.2?-= 其中,Y 表示美国的咖啡消费量(每天每人消费的杯数),X 表示咖啡的零售价格(单位:美元/杯),t 表示时间。问: (1)这是一个时间序列回归还是横截面回归做出回归线。 (2)如何解释截距的意义它有经济含义吗如何解释斜率(3)能否救出真实的总体回归函数 (4)根据需求的价格弹性定义: Y X ?弹性=斜率,依据上述回归结果,你能救出对咖啡需求的价格弹性吗如果不能,计算此弹性还需要其他什么信息 15.下面数据是依据10组X 和Y 的观察值得到的: 1110=∑i Y ,1680 =∑i X ,204200=∑i i Y X ,315400 2=∑ i X ,133300 2 =∑i Y 假定满足所有经典线性回归模型的假设,求0β,1β的估计值; 16.根据某地1961—1999年共39年的总产出Y 、劳动投入L 和资本投入K 的年度数据,运用普通最小二乘法估计得出了下列回归方程: ,DW= 式下括号中的数字为相应估计量的标准误。 (1)解释回归系数的经济含义; (2)系数的符号符合你的预期吗为什么 17.某计量经济学家曾用1921~1941年与1945~1950年(1942~1944年战争期间略去)美国国内消费C和工资收入W、非工资-非农业收入
271 APPENDIX E SOLUTIONS TO PROBLEMS E.1 This follows directly from partitioned matrix multiplication in Appendix D. Write X = 12n ?? ? ? ? ? ???x x x , X ' = (1'x 2'x n 'x ), and y = 12n ?? ? ? ? ? ??? y y y Therefore, X 'X = 1 n t t t ='∑x x and X 'y = 1 n t t t ='∑x y . An equivalent expression for ?β is ?β = 1 11n t t t n --=??' ???∑x x 11n t t t n y -=??' ??? ∑x which, when we plug in y t = x t β + u t for each t and do some algebra, can be written as ?β= β + 1 11n t t t n --=??' ???∑x x 11n t t t n u -=??' ??? ∑x . As shown in Section E.4, this expression is the basis for the asymptotic analysis of OLS using matrices. E.2 (i) Following the hint, we have SSR(b ) = (y – Xb )'(y – Xb ) = [?u + X (?β – b )]'[ ?u + X (?β – b )] = ?u '?u + ?u 'X (?β – b ) + (?β – b )'X '?u + (?β – b )'X 'X (?β – b ). But by the first order conditions for OLS, X '?u = 0, and so (X '?u )' = ?u 'X = 0. But then SSR(b ) = ?u '?u + (?β – b )'X 'X (?β – b ), which is what we wanted to show. (ii) If X has a rank k then X 'X is positive definite, which implies that (?β – b ) 'X 'X (?β – b ) > 0 for all b ≠ ?β . The term ?u '?u does not depend on b , and so SSR(b ) – SSR(?β) = (?β– b ) 'X 'X (?β – b ) > 0 for b ≠?β. E.3 (i) We use the placeholder feature of the OLS formulas. By definition, β = (Z 'Z )-1Z 'y = [(XA )' (XA )]-1(XA )'y = [A '(X 'X )A ]-1A 'X 'y = A -1(X 'X )-1(A ')-1A 'X 'y = A -1(X 'X )-1X 'y = A -1?β . (ii) By definition of the fitted values, ?t y = ?t x β and t y = t z β. Plugging z t and β into the second equation gives t y = (x t A )(A -1?β ) = ?t x β = ?t y . (iii) The estimated variance matrix from the regression of y and Z is 2σ(Z 'Z )-1 where 2σ is the error variance estimate from this regression. From part (ii), the fitted values from the two
期中练习题 1、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则是指( ) A .使∑=-n t t t Y Y 1 )?(达到最小值 B.使∑=-n t t t Y Y 1 达到最小值 C. 使 ∑=-n t t t Y Y 1 2 )(达到最小值 D.使∑=-n t t t Y Y 1 2)?(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为 ?ln 2.00.75ln i i Y X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( ) A. 0.75 B. 0.75% C. 2 D. 7.5% 3、设k 为回归模型中的参数个数,n 为样本容量。则对总体回归模型进行显著性检验的F 统计量与可决系数2 R 之间的关系为( ) A.)1/()1()/(R 2 2---=k R k n F B. )/(1)-(k ) R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. ) 1()1/(22R k R F --= 6、二元线性回归分析中 TSS=RSS+ESS 。则 RSS 的自由度为( ) A.1 B.n-2 C.2 D.n-3 9、已知五个解释变量线形回归模型估计的残差平方和为 8002=∑t e ,样本容量为46,则随机 误差项μ的方差估计量2 ?σ 为( ) A.33.33 B.40 C.38.09 D. 20 1、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2 i )V ar(u i σ= C. 0)u E(u j i ≠ D.随机解释变量X 与随机误差i u 不相关 E. i u ~),0(2 i N σ 2、对于二元样本回归模型i i i i e X X Y +++=2211???ββα,下列各式成立的有( ) A.0 =∑i e B. 0 1=∑i i X e C. 0 2=∑i i X e D. =∑i i Y e E. 21=∑i i X X 4、能够检验多重共线性的方法有( ) A.简单相关系数矩阵法 B. t 检验与F 检验综合判断法 C. DW 检验法 D.ARCH 检验法 E.辅助回归法
班级:金融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAW sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出一个模型,容许u的方差在男女之间有所不同。这个方差不应该取决于其他因素。 在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u方差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。所以,当方差在male=1时,即为男性时,结果为δ0+δ1;当为女性时,结果为δ0。 将sleep对totwork,educ,age,age2,yngkid和male进行回归,回归结果如下: (ⅱ)利用SLEEP75.RAW的数据估计异方差模型中的参数。u的估计方差对于男人和女人而言哪个更高? 由截图可知:u2=189359.2?28849.63male+r
20546.36 (27296.36) 由于male 的系数为负,所以u 的估计方差对女性而言更大。 (ⅲ)u 的方差是否对男女而言有显著不同? 因为male 的 t 统计量为?1.06,所以统计不显著,故u 的方差是否对男女而言并没有显著不同。 C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利用HPRICE 1.RAW 中的数据得到方程(8.17)的异方差—稳健的标准误。讨论其与通常的标准误之间是否存在任何重要差异。 ● 先进行一般回归,结果如下: ● 再进行稳健回归,结果如下: 由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms 29.48 0.00064 0.013 (9.01) 37.13 0.00122 0.018 [8.48] n = 88, R 2=0.672 比较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较大。而sqrft 的稳健标准误也比通常的大,但相差不大,bdrms 的稳健标准误比通常的要小些。 (ⅱ)对方程(8.18)重复第(ⅰ)步操作。 n =706,R 2=0.0016
四、简答题(每小题5分) 1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。2.计量经济模型有哪些应用? 3.简述建立与应用计量经济模型的主要步骤。 4.对计量经济模型的检验应从几个方面入手? 5.计量经济学应用的数据是怎样进行分类的? 6.在计量经济模型中,为什么会存在随机误差项? 7.古典线性回归模型的基本假定是什么? 8.总体回归模型与样本回归模型的区别与联系。 9.试述回归分析与相关分析的联系和区别。 10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量有哪些统计性质? 11.简述BLUE 的含义。 12.对于多元线性回归模型,为什么在进行了总体显著性F 检验之后,还要对每个回归系数进行是否为0的t 检验? 13.给定二元回归模型: 01122t t t t y b b x b x u =+++,请叙述模型的古典假定。 14.在多元线性回归分析中,为什么用修正的决定系数衡量估计模型对样本观测值的拟合优度? 15.修正的决定系数2R 及其作用。 16.常见的非线性回归模型有几种情况? 17.观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 ①t t t u x b b y ++=310 ②t t t u x b b y ++=log 10 ③ t t t u x b b y ++=log log 10 ④t t t u x b b y +=)/(10 18. 观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 ①t t t u x b b y ++=log 10 ②t t t u x b b b y ++=)(210 ③ t t t u x b b y +=)/(10 ④t b t t u x b y +-+=)1(110 19.什么是异方差性?试举例说明经济现象中的异方差性。
计量经济学(第3版)例题和习题数据表表2.1.1 某社区家庭每月收入与消费支出统计表
表2.3.1 参数估计的计算表
表2.6.1 中国各地区城镇居民家庭人均全年可支配收入与人均全年消费性支出(元) 资料来源:《中国统计年鉴》(2007)。
表2.6.3 中国居民总量消费支出与收入资料 单位:亿元年份GDP CONS CPI TAX GDPC X Y 19783605.6 1759.1 46.21519.28 7802.5 6678.83806.7 19794092.6 2011.5 47.07537.828694.2 7551.64273.2 19804592.9 2331.2 50.62571.70 9073.7 7944.24605.5 19815008.8 2627.9 51.90629.899651.8 8438.05063.9 19825590.0 2902.9 52.95700.02 10557.3 9235.25482.4 19836216.2 3231.1 54.00775.5911510.8 10074.65983.2 19847362.7 3742.0 55.47947.35 13272.8 11565.06745.7 19859076.7 4687.4 60.652040.79 14966.8 11601.77729.2 198610508.5 5302.1 64.572090.37 16273.7 13036.58210.9 198712277.4 6126.1 69.302140.36 17716.3 14627.78840.0 198815388.6 7868.1 82.302390.47 18698.7 15794.09560.5 198917311.3 8812.6 97.002727.40 17847.4 15035.59085.5 199019347.8 9450.9 100.002821.86 19347.8 16525.99450.9 199122577.4 10730.6 103.422990.17 21830.9 18939.610375.8 199227565.2 13000.1 110.033296.91 25053.0 22056.511815.3 199336938.1 16412.1 126.204255.30 29269.1 25897.313004.7 199450217.4 21844.2 156.655126.88 32056.2 28783.413944.2 199563216.9 28369.7 183.416038.04 34467.5 31175.415467.9 199674163.6 33955.9 198.666909.82 37331.9 33853.717092.5 199781658.5 36921.5 204.218234.04 39988.5 35956.218080.6 199886531.6 39229.3 202.599262.80 42713.1 38140.919364.1 199991125.0 41920.4 199.7210682.58 45625.8 40277.020989.3 200098749.0 45854.6 200.5512581.51 49238.0 42964.622863.9 2001108972.4 49213.2 201.9415301.38 53962.5 46385.424370.1 2002120350.3 52571.3 200.3217636.45 60078.0 51274.026243.2 2003136398.8 56834.4 202.7320017.31 67282.2 57408.128035.0 2004160280.4 63833.5 210.6324165.68 76096.3 64623.130306.2 2005188692.1 71217.5 214.4228778.54 88002.1 74580.433214.4 2006221170.5 80120.5 217.6534809.72 101616.3 85623.136811.2资料来源:根据《中国统计年鉴》(2001,2007)整理。
财大计量经济学期末考试标准试题 计量经济学试题一 (1) 计量经济学试题一答案 (4) 计量经济学试题二 (9) 计量经济学试题二答案 (11) 计量经济学试题三 (15) 计量经济学试题三答案 (18) 计量经济学试题四 (22) 计量经济学试题四答案 (25) 计量经济学试题一 课程号:课序号:开课系:数量经济系 一、判断题(20分) 1.线性回归模型中,解释变量是原因,被解释变量是结果。() 2.多元回归模型统计显着是指模型中每个变量都是统计显着的。() 3.在存在异方差情况下,常用的OLS法总是高估了估计量的标准差。() 4.总体回归线是当解释变量取给定值时因变量的条件均值的轨迹。()5.线性回归是指解释变量和被解释变量之间呈现线性关系。() R的大小不受到回归模型中所包含的解释变量个数的影响。()6.判定系数2 7.多重共线性是一种随机误差现象。()
8.当存在自相关时,OLS估计量是有偏的并且也是无效的。() 9.在异方差的情况下,OLS估计量误差放大的原因是从属回归的2R变大。()10.任何两个计量经济模型的2R都是可以比较的。() 二.简答题(10) 1.计量经济模型分析经济问题的基本步骤。(4分) 2.举例说明如何引进加法模式和乘法模式建立虚拟变量模型。(6分) 三.下面是我国1990-2003年GDP对M1之间回归的结果。(5分) 1.求出空白处的数值,填在括号内。(2分) 2.系数是否显着,给出理由。(3分) 四.试述异方差的后果及其补救措施。(10分) 五.多重共线性的后果及修正措施。(10分) 六.试述D-W检验的适用条件及其检验步骤?(10分) 七.(15分)下面是宏观经济模型 变量分别为货币供给M、投资I、价格指数P和产出Y。 1.指出模型中哪些是内是变量,哪些是外生变量。(5分) 2.对模型进行识别。(4分) 3.指出恰好识别方程和过度识别方程的估计方法。(6分) 八、(20分)应用题 为了研究我国经济增长和国债之间的关系,建立回归模型。得到的结果如下:Dependent Variable: LOG(GDP) Method: Least Squares Date: 06/04/05 Time: 18:58 Sample: 1985 2003 Included observations: 19 Variable Coefficient Std. Error t-Statistic Prob.
第七章 课后练习答案 7.1 (1)已知:96.1%,951,25,40,52/05.0==-===z x n ασ。 样本均值的抽样标准差79.0405== = n x σ σ (2)边际误差55.140 5 96.12/=? ==n z E σ α 7.2 (1)已知:96.1%,951,120,49,152/05.0==-===z x n ασ。 样本均值的抽样标准差14.249 15== = n x σ σ (2)边际误差20.449 1596.12 /=? ==n z E σ α (3)由于总体标准差已知,所以总体均值μ的95%的置信区间为 20.412049 1596.11202 /±=? ±=±n z x σ α 即()2.124,8.115 7.3 已知:96.1%,951,104560,100,854142/05.0==-===z x n ασ。 由于总体标准差已知,所以总体均值μ的95%的置信区间为 144.16741104560100 8541496.11045602 /±=? ±=±n z x σ α 即)144.121301,856.87818( 7.4 (1)已知:645.1%,901,12,81,1002/1.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的90%的置信区间为: 974.181100 12645.1812 /±=? ±=±n s z x α 即)974.82,026.79(
(2)已知:96.1%,951,12,81,1002/05.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的95%的置信区间为: 352.281100 1296.1812 /±=? ±=±n s z x α 即)352.83,648.78( (3)已知:58.2%,991,12,81,1002/05.0==-===z s x n α。 由于100=n 为大样本,所以总体均值μ的99%的置信区间为: 096.381100 1258.2812 /±=? ±=±n s z x α 即)096.84,940.77( 7.5 (1)已知:96.1%,951,5.3,25,602/05.0==-===z x n ασ。 由于总体标准差已知,所以总体均值μ的95%的置信区间为: 89.02560 5.39 6.1252 /±=? ±=±n z x σ α 即)89.25,11.24( (2)已知:33.2%,981,89.23,6.119,752/02.0==-===z s x n α。 由于75=n 为大样本,所以总体均值μ的98%的置信区间为: 43.66.11975 89.2333.26.1192 /±=? ±=±n s z x α 即)03.126,17.113( (3)已知:645.1%,901,974.0,419.3,322/1.0==-===z s x n α。 由于32=n 为大样本,所以总体均值μ的90%的置信区间为: 283.0419.332 974.0645.1419.32 /±=? ±=±n s z x α 即)702.3,136.3(
加封面)经济学-经贸学院(大纲.
经济学专业 实验课程教学大纲 学验理济经管实教中心 1 2012年
1 目录 1.《计量经济学实验教学大》.........................................................纲 (1) 1 《计量经济学实验》教学大纲 一、课程代码:401sy07 二、课程名称: 1. 中文名:《计量经济学实验》 2. 英文名:Econometrics、Experment of Econometrics 三、课程管理院(系)及教研室: 经济贸易学院计量经济学教研室 四、大纲说明 1. 适用专业(层次):经济类专业本科学生 2. 学时与学分数:16学时,0.5学分 3. 必开实验项目数:8 4. 制订本教学大纲的依据
计量经济学的理论知识结构、Eviews5.0和Stata9.0的计量经济软件支持。 5. 先行、后续课程 《微积分》、《概率论与数理统计》、《计算机基础》、《西方经济学》、《计量经济学》等。 五、本课程的性质、教学目的与要求 (一)本课程性质 本实验课程是经济类本科专业的学科基础 1 实验课程。是一门在对社会经济现象作定性分析的基础上,探讨如何运用统计模型方法来定量描述具有随机性特征的经济变量关 系的应用经济分支,是结合计量经济学理论知识进行实验操作的实验课程。 本课程以建立计量经济模型的基本过程为 主线,结合样本数据收集,掌握计量经济模型的建立、估计、检验、应用,学会用计量经济模型对实际经济问题进行实证分析。该课程在学生知识结构中占有重要位置,是研究能力和实践能力的重要组成部分。 (二)本课程教学目的 通过本课程的学习,使学生了解经济数量分
第2章练习12 下表是中国2007年各地区税收Y和国内生产总值GDP的统计资料。 1.做出散点图,建立税收随国内生产总值GDP变化的一元线性回归方程,并解释斜率的经济意义。 2.对所建立的回归方程进行检验。 3.若2008年某地区国内生产总值为8500,求该地区税收收入的预测值及预测区间。(置信度为90%)
(1)散点图如图所示: 我们假设拟建立如下一元回归模型: μGDP ββY ++=10 根据Eviews 软件对表中数据进行回归分析的计算结果可得: GDP ..Y i 07106310?+-= (-0.12) (9.59) 7603.02=R 99.91=F 斜率的经济意义:国内生产总值GDP 每增加1亿元,国内税收增加0.071亿元。
(2)从回归估计的结果看,模型拟合较好。可决系数7603.02 =R ,表明国内税收变化的76.03%可由国内生产总值GDP 的变化来解释。从斜率项的t 检验值看,大于10%显著性水平下自由度为292=-n 的临界值699.1)29(05.0=t ,且该斜率值满足1071.00<<,符合经济理论中税收乘数在0与1之间的说法,表明2007年,国内生产总值GDP 每增加1亿元,国内税收增加0.071亿元。 (3)有上述回归方程可得中国国内税收的预测值: 87.5928500071.063.10?0 =?+-=Y (元) 下面给出国内生产总值90%置信度的预测区间 126.8891=E )(GDP 64.57823127)V ar(=GDP 在 90%的置信度下,某地区 ) E(0Y 的预测区间为: ) ,() )() ((5.11253.606.53287.5922 -3164.578231272-318891.126-850031112760310699.187.5922 =±=?++?? ±
计量经济学试题及答案(1) 程代码:00142 第一部分选择题 一、单项选择题(本大题共30小题,每小题1分,共30分)在每小题列出的四个选项中只有一个选项是符合题目要求的,请将正确选项前的字母填在题后的括号内。 1.对联立方程模型进行参数估计的方法可以分两类,即:( ) A.间接最小二乘法和系统估计法 B.单方程估计法和系统估计法 C.单方程估计法和二阶段最小二乘法 D.工具变量法和间接最小二乘法 2.当模型中第i个方程是不可识别的,则该模型是( ) A.可识别的 B.不可识别的 C.过度识别 D.恰好识别 3.结构式模型中的每一个方程都称为结构式方程,在结构方程中,解释变量可以是前定变量,也可以是( ) A.外生变量 B.滞后变量 C.内生变量 D.外生变量和内生变量 4.已知样本回归模型残差的一阶自相关系数接近于-1,则DW统计量近似等于( ) A.0 B.1 C.2 D.4 5.假设回归模型为其中Xi为随机变量,Xi与Ui相关则的普通最小二乘估计量( ) A.无偏且一致 B.无偏但不一致 C.有偏但一致 D.有偏且不一致 6.假定正确回归模型为,若遗漏了解释变量X2,且X1、X2线性相关则的普通最小二乘法估计量( ) A.无偏且一致 B.无偏但不一致 C.有偏但一致 D.有偏且不一致 7.对于误差变量模型,模型参数的普通最小二乘法估计量是( ) A.无偏且一致的 B.无偏但不一致 C.有偏但一致 D.有偏且不一致 8.戈德菲尔德-匡特检验法可用于检验( ) A.异方差性 B.多重共线性 C.序列相关 D.设定误差 9.对于误差变量模型,估计模型参数应采用( ) A.普通最小二乘法 B.加权最小二乘法 C.广义差分法 D.工具变量法 10.设无限分布滞后模型满足koyck变换的假定,则长期影响乘数为() A. B. C. D. 11.系统变参数模型分为( ) A.截距变动模型和斜率变动模型 B.季节变动模型和斜率变动模型 C.季节变动模型和截距变动模型 D.截距变动模型和截距、斜率同时变动模型 12.虚拟变量( ) A.主要来代表质的因素,但在有些情况下可以用来代表数量因素 B.只能代表质的因素 C.只能代表数量因素
DATA SET HANDBOOK Introductory Econometrics: A Modern Approach, 4e Jeffrey M. Wooldridge This document contains a listing of all data sets that are provided with the fourth edition of Introductory Econometrics: A Modern Approach. For each data set, I list its source (wherever possible), where it is used or mentioned in the text (if it is), and, in some cases, notes on how an instructor might use the data set to generate new homework exercises, exam problems, or term projects. In some cases, I suggest ways to improve the data sets. Special thanks to Edmund Wooldridge, who provided valuable assistance in updating the page numbers for the fourth edition. 401K.RAW Source:L.E. Papke (1995), “Participation in and Contributions to 401(k) Pension Plans: Evidence from Plan Data,”Journal of Human Resources 30, 311-325. Professor Papke kindly provided these data. She gathered them from the Internal Revenue Service’s Form 5500 tapes. Used in Text: pages 64, 80, 135-136, 173, 217, 685-686 Notes: This data set is used in a variety of ways in the text. One additional possibility is to investigate whether the coefficients from the regression of prate on mrate, log(totemp) differ by whether the plan is a sole plan. The Chow test (see Section 7.4), and the less restrictive version that allows different intercepts, can be used. 401KSUBS.RAW Source: A. Abadie (2003), “Semiparametric Instrumental Variable Estimation of Treatment Response Models,”Journal of Econometrics 113, 231-263. Professor Abadie kindly provided these data. He obtained them from the 1991 Survey of Income and Program Participation (SIPP). Used in Text: pages 165, 182, 222, 261, 279-280, 288, 298-299, 336, 542 Notes: This data set can also be used to illustrate the binary response models, probit and logit, in Chapter 17, where, say, pira (an indicator for having an individual retirement account) is the dependent variable, and e401k [the 401(k) eligibility indicator] is the key explanatory variable.