当前位置:
文档之家› JavaScript操作HTML文档
JavaScript操作HTML文档
JavaScript操作HTML文档
前面的章节,主要介绍了使用DOM解析XML文档中的数据。使用DOM操作HTML文档,实际上也非常方便。在DOM眼中,HTML跟XML一样是一种树形结构的文档,是根(root)节点,
、
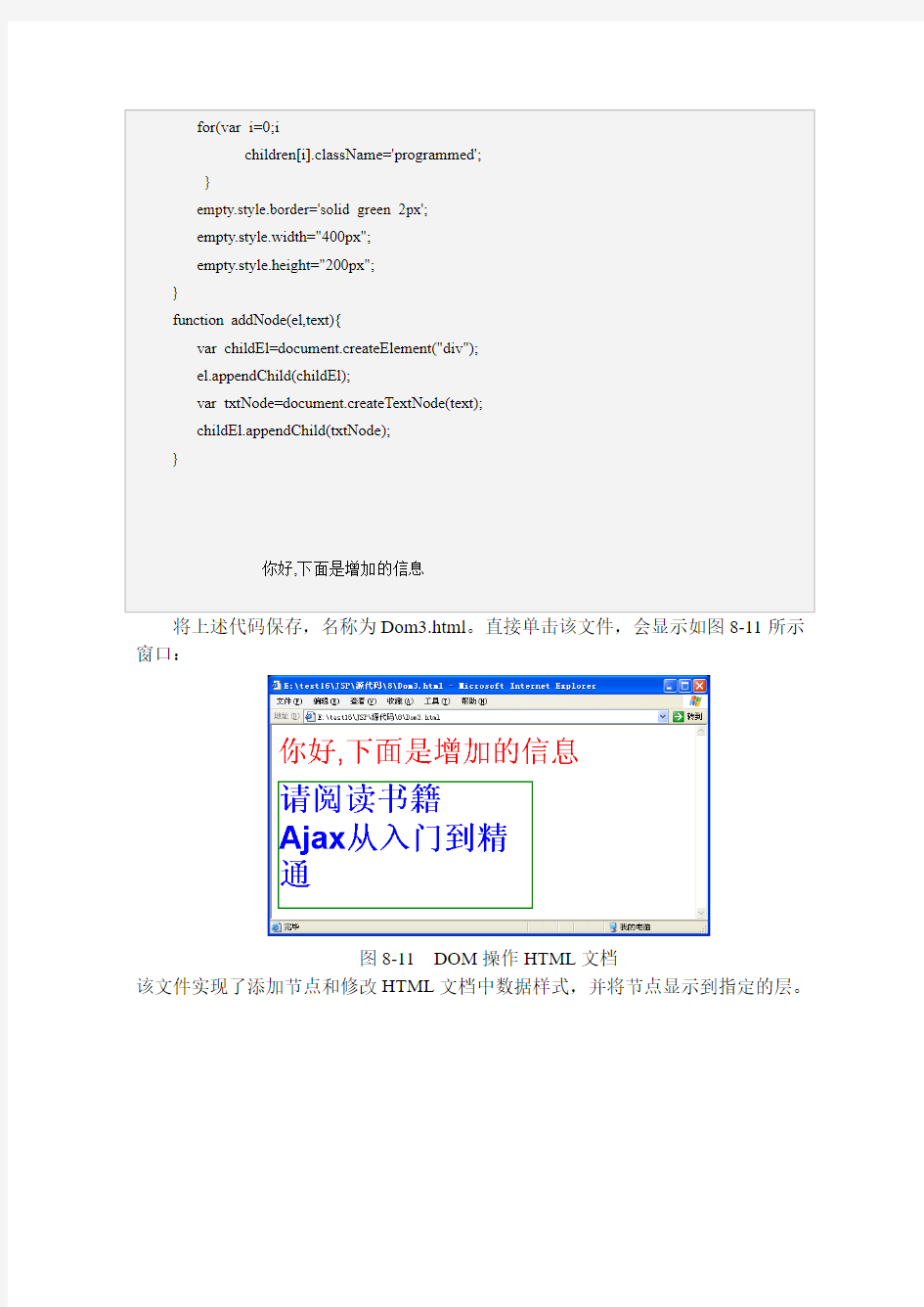
、<body>是<html>的子(c hildren)节点,互相之间是兄弟(sibling)节点;<body>下面才是子节点<table>、< span>、<p>等等。</p><p>同样HTML文档需要加载到内存中,形成树型结构。HTML问的树型及格如图8-10所示:</p><p>图8-10 HTML文档树模型</p><p>从上图中可以看出,HTML文档的树模型的每一个节点实际上就是HTML文档中的标记。前面介绍的DOM对象同样适用于HTML文档。</p><p>现在创建一个案例,演示使用DOM操作HTML文档。打开记事本,输入下列</p><!--/p1--><!--rset--><h2>java文件流操作</h2><p>java 文件流操作 2010-05-08 20:17:23| 分类:java SE | 标签:|字号大中小订阅 java中多种方式读文件 一、多种方式读文件内容。 1、按字节读取文件内容InputStream 读取的是字节 2、按字符读取文件内容InputStreamReader 读取的是字符 3、按行读取文件内容BufferredReader 可以读取行 4、随机读取文件内容 import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.RandomAccessFile; import java.io.Reader; public class ReadFromFile { /** * 以字节为单位读取文件,常用于读二进制文件,如图片、声音、影像等文件。* @param fileName 文件的名 */ public static void readFileByBytes(String fileName){ File file = new File(fileName); InputStream in = null; try { System.out.println("以字节为单位读取文件内容,一次读一个字节:"); // 一次读一个字节 in = new FileInputStream(file); int tempbyte; while((tempbyte=in.read()) != -1){ System.out.write(tempbyte); } in.close(); } catch (IOException e) { e.printStackTrace(); return; } try { System.out.println("以字节为单位读取文件内容,一次读多个字节:"); //一次读多个字节</p><h2>html5基本代码</h2><p><!DOCTYPE HTML> <html> <head> <style type="text/css"> #div1, #div2 {float:left; width:100px; height:35px; margin:10px;padding:10px;border:1px solid #aaaaaa;} </style> <script type="text/javascript"> function allowDrop(ev) { ev.preventDefault(); } function drag(ev) { ev.dataTransfer.setData("Text",ev.target.id); } function drop(ev) { ev.preventDefault(); var data=ev.dataTransfer.getData("Text"); ev.target.appendChild(document.getElementById(data)); } </script> </head> <body> <div id="div1" ondrop="drop(event)" ondragover="allowDrop(event)"> <img src="/i/w3school_logo_black.gif" draggable="true" ondragstart="drag(event)" id="drag1" /> </div> <div id="div2" ondrop="drop(event)" ondragover="allowDrop(event)"></div> </body> </html> <!DOCTYPE HTML> <html> <head> <script type="text/javascript"> function allowDrop(ev) { ev.preventDefault();</p><h2>文件与文件夹的基本操作教案</h2><p>《文件与文件夹的基本操作》教学内容《文件与文件夹的基本操作》 教学目的 1、了解建立文件夹的意义,渗透归类整理的组织管理思想; 2、学会新建(更名)文件夹及文件的复制、移动、删除、更名等操作,形成一定的操作技能,提高学生的信息素养; 3、在自主、合作学习氛围中培养学生的成就感、增强自信心,提高学习能力。 教学重难点文件夹的建立和文件夹的重命名 文件或文件夹的基本操作(剪贴、复制、移动、删除) 教学准备多媒体教学机房文件及文件夹素材 教学方法任务驱动法、讲授法 教学时间1课时 教学过程 教学环节教师活动学生活动 导入新课、创设学习氛围 1、展示教师机电脑中的文件夹,提问:为什 么要这样将文件分类夹起来? 2、揭示课题,提出学习任务 回答教师提 出的问题,产生学 生动机。 任务驱动,共同学习任务一:建立自己的文件夹 1、老师通过大屏幕,展示任务内容。 2、了解学生情况,以便进行针对性的加以指 导。 3、学生通过上机操作进行自主或合作学习。 教师通过电子教室监控学生操作,并提出合 理建议进行指导,鼓励先完成的学生对其它学生 进行指导。 通过自主学 习,同学间开展互 助学习共同解决 问题,并上机操 作。</p><p>任务驱动,共同学习任务二:文件的移动、复制、更名、删除 1、展示任务内容。 2、了解学生情况,以便进行针对性的加以指 导。 3、学生自主或合作学习,并上机操作。 教师通过电子教室监控学生操作,并提出合 理建议进行指导,鼓励先完成的学生对本小组的 其它学生进行指导。 4、讨论移动文件与复制文件的区别。 通过自主学 习或小组同学间 开展互助学习共 同解决问题,并上 机操作。 任务三:练兵场 1、教师通过电子教室远程启动该软件,讲解 清楚使用方法。告知学生每完成一个任务即可看 到笑话、漫画、动画等。 2、教师通过电子教室监控学生操作情况,适 时加以指导 学生进行自 我挑战,享受成功 的喜悦。 课堂小结 教师与学生对本课涉及的操作进行小结,告 诉学生今后在使用电脑的过程中,要利用这些操 作,将电脑中文件进行归类管理,便于自己查找 使用。 评选“最佳个人” 与教师一道 进行小结,明确归 类管理文件的意 义 学生评选出 表现最突出的个 人 知识拓展 教师向学生提供几个Internet网站,让学生 去寻找文件与文件夹操作的其它方法。 或同学之间交流文件与文件夹操作的其他方 法 学生上网杳 找学习或同学间 互相交流 课后反思</p><h2>C语言文件流操作函数大全</h2><p>clearerr(清除文件流的错误旗标) 相关函数feof 表头文件#include<stdio.h> 定义函数void clearerr(FILE * stream); 函数说明clearerr()清除参数stream指定的文件流所使用的错误旗标。 返回值 fclose(关闭文件) 相关函数close,fflush,fopen,setbuf 表头文件#include<stdio.h> 定义函数int fclose(FILE * stream); 函数说明fclose()用来关闭先前fopen()打开的文件。此动作会让缓冲区内的数据写入文件中,并释放系统所提供的文件资源。 返回值若关文件动作成功则返回0,有错误发生时则返回EOF并把错误代码存到errno。错误代码EBADF表示参数stream非已打开的文件。 范例请参考fopen()。 fdopen(将文件描述词转为文件指针) 相关函数fopen,open,fclose 表头文件#include<stdio.h> 定义函数FILE * fdopen(int fildes,const char * mode); 函数说明fdopen()会将参数fildes 的文件描述词,转换为对应的文件指针后返回。参数mode 字符串则代表着文件指针的流形态,此形态必须和原先文件描述词读写模式相同。关于mode 字符串格式请参考fopen()。 返回值转换成功时返回指向该流的文件指针。失败则返回NULL,并把错误代码存在errno 中。 范例 #include<stdio.h> main() { FILE * fp =fdopen(0,”w+”); fprintf(fp,”%s\n”,”hello!”); fclose(fp); } 执行hello! feof(检查文件流是否读到了文件尾) 相关函数fopen,fgetc,fgets,fread 表头文件#include<stdio.h> 定义函数int feof(FILE * stream);</p><h2>HTML基本代码</h2><p>HTML基本代码 size粗细 color颜色 width宽度 height高度 --------------------------------------------------------------------- <br>换行 <P></P>段落 align左右对齐方式 valign上下对齐方式 ---------------------------------------------------------------------<hr>水平线段 (size粗细 color颜色水平线的宽度width 水平线的长度用占屏幕宽度的百分比或象素值来表示 align 水平线的对齐方式,有left right center三种 noshade 线段无阴影属性,为实心线段) ---------------------------------------------------------------------文字<font 属性></font>{(属性:SIZE=取值1-7 face=字体)(粗体<B></B>.斜体<I></I>.加下划线<U></U>.中间线<S></S> 字体上一点<sup></sup> 字体下一点<sub></sub>打字机字体<TT></TT>.大型字体<BIG></BIG>.小型字体<SMALL></SMALL>. 闪烁效果<blink></blink>.强调<em></em>.特别强调<strong></strong>.引证举例<cite></cite>) (字体:Script . Small Fonts . Roman . Comic Sans MS . Arial . Modern . MS Sans Serif) 文字移动<marquee>内容</marquee> 方向:<marquee direction=>内容</marquee> (属性:左left右right) 方式:<marquee bihavior=>内容</marquee> (属性:一圈一圈绕着scroll走一次slide来回走alternate) 速度: <marquee scrollamount=>内容</marquee> 延时: <marquee scrolldelay=>内容</marquee> 向上: <marquee direction=up scrollamount=3> <center><font color=颜色 size=大小 face=字体>内容</font></marquee> 向下:<marquee direction=down scrollamount=3> <center><font color=颜色 size=大小 face=字体>内容</font></marquee> 底色: <marquee bgcolor=颜色>内容</marquee> (属性:width宽度 height高度) --------------------------------------------------------------------- 位置控制<div align=属性></div>(属性=left左对齐缺省值 center 居中right右对齐)</p><h2>第9章输入输出流与文件操作</h2><p>什么是流?流有什么用?面向对象语言为什么需要流?哪些场合需要流? 答:流是指一组有顺序、有起点和终点地字节集合,是对数据传输地总称或抽象(也就是数据在两个对象之间地传输称为流).个人收集整理勿做商业用途 流地作用就是使数据传输操作独立于相关设备. 在面向对象地程序设计中,数据地传输和流动具有广泛性,可以在内存与外部设备之间传输,还可以从内存到内存,甚至可以从一台计算机通过网络流向另一台计算机等,故面向对象语言采用流机制.个人收集整理勿做商业用途 在标准输入输出、在文件地读写等操作中都需要流. 提供了哪些流类?各种流类之间地关系是怎样地?什么场合需要使用什么流类? 答:中按照流地方向性,流分为输入流和输出流两大类.按照流中元素地基本类型,流分为字节流和字符流两大类.字节流类按照流地方向分为字节输入流类和字节输出流类,字符流类方向性分为字符输入流类和字符输出流类.以及文件操作类,随机存取文件类.个人收集整理勿做商业用途 其中类是所有字节输入流地根类,类是所有字节输出流地根类;类是所有字符输入流地根类,类是所有字符输出流地根类.个人收集整理勿做商业用途 操作系统中文件和目录概念是怎么样地?提供了哪些对文件和目录操作地类?程序中对文件和目录能够进行哪些操作?如何操作?个人收集整理勿做商业用途 答:文件是信息地一种组织形式,是存储在外部存储介质上地具有标识名地一组相关地信息集合.目录是文件系统组织和管理文件地基本单位,保存它所管理地每个文件地基本属性信息(称为文件目录项或文件控制块).个人收集整理勿做商业用途 直接对文件地顺序存取和随机存取操作,提供了类记载文件属性信息,对文件读写操作时以流地形式.类以随机存取方式进行文件读写操作.但在对文件操作过程中还需要使用文件过滤器接口和文件对话框类.在操作系统中,目录也是以文件地形式保存地,称为目录文件.故一个对象也可以表示一个目录.个人收集整理勿做商业用途 可以对文件进行读、写、删除、创建等操作,对目录可以读取、创建、删除等操作.应用程序通过调用操作系统提供地系统调用能够对文件及目录进行各种操作.个人收集整理勿做商业用途 再打开、保存、复制文件时,需要读写文件中地数据内容,这些操作由流实现,不同类型地文件需要使用不同地流泪.个人收集整理勿做商业用途 流与文件操作有什么关系?实际应用中将流类与文件操作结合起来能够实现哪些复杂问题?如何实现?个人收集整理勿做商业用途 答:对文件地操作时通过流这个工具进行地.再打开、保存、复制文件时,需要读写文件中地数据内容,这些操作由流实现,不同类型地文件需要使用不同地流泪.个人收集整理勿做商业用途 什么是输入输出?什么是标准输入输出?怎样实现标准输入输出功能? 答:数据由外部设备流向内存,这个过程称为输入;数据有内存流向外部设备,这个过程称为输出. 在计算机系统中,标准输入是从键盘等外部输入设备中获得数据,标准输出是向显示器或打印机等外部输出设备发送数据.个人收集整理勿做商业用途 在类中声明了个常量、和用于实现标准输入输出功能.个人收集整理勿做商业用途除了标准输入输出及文件操作之外,还有那些应用中需要使用流? 答:在面向对象地程序设计中,数据地传输和流动具有广泛性,不仅可以在内存与外部设备之间传输,还可以从内存流向内存,甚至可以从一台计算机通过网络流向另一台计算机,因此各种不同地数据源地传输都需要采取不同地流机制来实现.个人收集整理勿做商业用途</p><h2>C#的FileStream文件流(IO流)</h2><p>IO流 ◆FileStream ◆说明:FileStream是针对文件中的字符进行读取/写入 ●FileStream是对系统上的文件进行读,写,打开,关闭等操作。 ●并对其他与文件相关的操作系统提供句柄操作。如管道,标准输入和标准输出。 ●读写操作可以指定为同步或异步操作。 ●FileStream对输入输出进行缓冲,从而提高性能。 FileStream.Seek()的该流读取/写入的当前位置设置为给定值: ●FileStream对象支持使用Seek方法对文件进行随机访问。 ●Seek允许将读取/写入位置移动到文件中的任意位置。这是通过字节偏移参考点参数完成。 ●字节偏移量是相对于查找参考点而言的,该参考点可以是基础文件的开始、当前位置或结尾,分别由SeekOrigin类 的三个属性表示。 FileStream.Flush()的清除该流的所有缓冲区: ●FileStream会自动缓冲数据,通过Flush()能够强制输出缓冲区中的数据。 ●FileStream和其他流都会占用不在.net管理范围的资源,因此FileStream在使用完成之后应该调用Dispose()方 法或者通过using关键字调用。 ●Dispose()方法会调用Close()方法,Close()方法会调用Flush()方法。 FileStream枚举,用于指定操作系统打开文件的方式: ?以下红色加粗字体为重要经常使用 公共属性: CanRead当前流是否支持读取。 CanSeek当前流是否支持查找。 CanWrite当前流是否支持写入。 CanTimeeout当前流是否可以超时。 IsAsync指示FileStream是异步还是同步打开的。 Length 指示字节表示的流长度。 Name FileStream的名称 PoSition此流的当前位置。 Handle 获取当前 FileStream 对象所封装文件的操作系统文件句柄。 SafeFileHandle该对象表示当前 FileStream 对象封装的文件的操作系统文件句柄。 ReadTimeout该值指示尝试读取多长时间后超时。 WriteTimeout该值确定流在超时前尝试写入多长时间。 公共方法:</p><h2>html代码</h2><p>一些基础的HTML Tag HTML里,比较基础的Tag主要用于标题,段落和分行。 学习HTML最好的方法,就是跟着示例学。为了各位学习的方便,我们准备了一个简单的HTML编辑器,你可以在左边写HTML代码,然后点击上面的按钮,查看HTML的显示结果。 试试看吧! 示例:一个非常简单的HTML文件 这个示例算是一个最简单的HTML文件,只包含了最基本的能构成一个HTML文件的Tag。通过这个例子,你可以看到浏览器是如何显示这个文件的,以此对HTML文件有个最初的认识。 示例:简单的段落 这个示例显示在HTML文件里如何分段。 正文标题 这个示例告诉你如何在HTML文件里定义正文标题。 HTML用<h1>到<h6>这几个Tag来定义正文标题,从大到小。每个正文标题自成一段。 <h1>This is a heading</h1> <h2>This is a heading</h2> <h3>This is a heading</h3> <h4>This is a heading</h4> <h5>This is a heading</h5> <h6>This is a heading</h6> 段落划分 在HTML里用和 划分段落。 This is a paragraph This is another paragraph 换行 通过使用<br>这个Tag,可以在不新建段落的情况下换行。<br>没有Closing Tag。 用换行是个坏习惯,正确的是使用<br>。 This <br> is a para<br>graph with line breaks HTML注释 在HTML文件里,你可以写代码注释,解释说明你的代码,这样有助于你和他人日后能够更好地理解你的代码。 注释可以写在之间。浏览器是忽略注释的,你不会在HTML正文中看到你的注释。 一些小建议 HTML文件会自动截去多余的空格。不管你加多少空格,都被看做一个空格。一个空行也被看做一个空格。 有些Tag能够将文本自成一段,而不需要使用 来分段。比如<h1></h1>之类的标题Tag。 更多示例</p><h2>HTML代码大全</h2><p>HTML(HyperText Mark-up Language)即超文本标记语言或超文本链接标示语言,是目前网络上应用最为广泛的语言,也是构成网页文档的主要语言。HTML文本是由HTML命令组成的描述性文本,HTML命令可以说明文字、图形、动画、声音、表格、链接等。HTML的结构包括头部(Head)、主体(Body)两大部分,其中头部描述浏览器所需的信息,而主体则包含所要说明的具体内容。 编辑本段HTML代码大全 1.结构性定义 文件类型 <HTML></HTML> (放在档案的开头与结尾) 文件主题 <TITLE> (必须放在「文头」区块内) 文头 (描述性资料,像是「主题」) 文体 (文件本体) (由浏览器控制的显示风格) 标题
(从1到6,有六层选择) 标题的对齐
区分
区分的对齐
引文区块
(通常会内缩) 强调
(通常会以斜体显示) 特别强调
(通常会以加粗显示) 引文
(通常会以斜体显示) 码
(显示原始码之用) 样本
键盘输入
变数
定义
(有些浏览器不提供) 地址
大字
小字
与外观相关的标签(作者自订的表现方式) 加粗
斜体
底线
(尚有些浏览器不提供) 删除线
(尚有些浏览器不提供) 下标
上标
打字机体
(用单空格字型显示) 预定格式
(保留文件中空格的大小) 预定格式的宽度
(以字元计算) 向中看齐
(文字与图片都可以) 闪耀
(有史以来最被嘲弄的标签) 字体大小
(从1到7) 改变字体大小
操作流程说明文档
操作流程说明文档内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128)
操作流程说明文档 1.下载阅卷软件方式,注意:此方法只能在学校电脑使用。 打开IE 进入后右键点击这个位置,选中目标另存为。如图操作。 然后保存在任意地方即可。 2.下载完后,找到刚刚下载文件所保存的目录地址,双击这个程序,打开阅卷软件。 3.打开后会弹出一个框,要求输入:服务器地址,用户名称,用户密码。 服务器地址必须是: 模拟试用的用户名称和密码在中可以下载。 4. 点击确定后会提示是否修改密码, 修改就在旧密码中输入“123”,新密码自行设置。 不修改就点放弃即可。 5.提交后进入批卷界面。如图示 6.开始阅卷, 进入阅卷页面后,屏幕中间位置显示的是学生的答题情况,请老师根据答题的错对程序相应给分,分数输入到右侧的“评分位置”(如上图) 评分后点击提交即是批完一份卷子,当老师点击提交后,系统会自动下载下一份学生试卷,老师则继续评分即可。
7.阅卷老师操作菜单中(左上角位置),如果上一份卷的分数给错,点了提交,可以点上一份回去重新评分。如果看不清可以点击放大。 8.阅卷常用操作讲解。 出现非本题试题有关图片(提交图像异常)自动0分点提交 是本题但答案写错位置(提交答错位置)自动0分点提交 答题超出规定范围(提交答题过界)自动0分点提交 (系统自动处理好后重新分发出来) 优秀答题标记(提交优秀试卷)给分后提交 典型解答方式标记(提交典型试卷)给分后提交 糟糕试卷标记(提交糟糕试卷)给分后提交 9. 试题批注。 应用如下:↓ 10.当提示“给你分配的试卷已经批阅完毕”, 请点击左上角的“退出”按钮(如图),退出系统,完成阅卷。 如果要继续批其他题目,请点击“注销“按钮,就会回到登陆窗口,输入其他题目的账号密码,继续批阅试卷。 以下是外网下载方式 方法2:(下面网址可以下载帮助文档,软件,账号) 1.首先打开IE 2.然后在地址栏输入:后点回车键,也可直接在此WORD文档中按住CTRL键点击链接。
Web基础题(html+css)
一、不定项选择题(每题2分,共66分) 1.参看以下的HTML代码:
表格 对以上代码,以下描述正确的是() A、该网页内容的第一行显示“表格” B、1和2的表格在同一列 C、1和2的表格在同一行 D、1和3的表格在同一列 2.以下的HTML代码片段中: ……
文具 | 铅笔 | 圆珠笔 | 水笔 |
…… 以下哪些是正确的判断() A、铅笔一定位于首行中的第一列 B、圆珠笔一定位于首列中的第一行 C、文具应位于首列首行[行列顺序号以tr、td里内容为准] D、水笔与圆珠笔在不同的行
3.根据以下的HTML代码片段:
正确的显示结果是() A、页面中会有一个默认的表格标题,显示出“月度报表” B、第一个单元格的背景色是红色 C、第二个单元格的的背景色为绿色 D、“月份”显示为粗体 4.根据以下的HTML代码片段:
hello!Nice to meet you!
this is the default display of an h1 element
以下描述不正确的是() A、第一个h1设置了特定的属性 B、第二个h1用了系统默认的属性 C、“hello!Nice to meet you!”的字体颜色是浅绿色 D、“this is the default display of an h1 element”的字体大小为30pt 5.根据以下的HTML代码: h1{color:limegreen;font-family:arial} 可以知道() A、此段代码是一个类选择器 B、选择器的名称是color C、{ }部分是对h1这个选择器的样式说明 D、limegreen 和font-family都是值 6.已知services.html与text.html在同一服务器上,但不在同一文件夹中。假如文档 services.html在文件夹information中,proposals段落在文档services.html中。现要求在text.html文档中编写一个超链接,链接到文档services.html的proposals段落。下面语句正确的是()
HTML速背速查手册
HTML 4.01 快速参考 来自 W3School 的 HTML 快速参考。可以打印它,以备日常使用。 HTML Basic Document
Document name goes here Visible text goes here Text Elements This is a paragraph
(line break)
(horizontal rule)
This text is preformatted
Logical Styles
This text is emphasized This text is strong This is some computer code Physical Styles
This text is bold This text is italic Links, Anchors, and Image Elements
This is a Link  Send e-mail
Send e-mailA named anchor:
Excel VBA_文本文件和文件夹操作实例集锦
1,导入文本数据(QueryTables) ‘110419.xls Sub daorwb() ' 2008-4-19 Columns("a:g").ClearContents ‘文本文件名放在[y2]单元格,两文件在同一个文件夹 With ActiveSheet.QueryTables.Add(Connection:= _ "TEXT;" & ThisWorkbook.Path & "\" & [y2], Destination:=Range("A1")) .FieldNames = True .PreserveFormatting = True .RefreshStyle = xlInsertDeleteCells .SaveData = True .AdjustColumnWidth = False .TextFilePromptOnRefresh = False .TextFilePlatform = 936 .TextFileStartRow = 1 .TextFileParseType = xlFixedWidth .TextFileTextQualifier = xlTextQualifierDoubleQuote .TextFileTabDelimiter = True .TextFileColumnDataTypes = Array(2, 1, 1, 1, 1, 1, 1) .TextFileFixedColumnWidths = Array(1, 1, 1, 1, 1, 1) .TextFileTrailingMinusNumbers = True .Refresh BackgroundQuery:=False End With End Sub 2,从文本文件中复制部分数据(OpenText方法) ‘https://www.doczj.com/doc/7c13479930.html,/dispbbs.asp?BoardID=92&ID=28958&replyID=&skin=1 Sub Macro1() ' 2007-10-18 (自编宏之四) '从文本文件中复制部分数据 ‘Book1017.xls+test1017.txt Application.DisplayAlerts = False Dim Myflnm$ Myflnm = ThisWorkbook.Path & "\test1017.txt" Workbooks.OpenText Filename:=Myflnm, Origin _
java输入输出流和文件操作
Java IO流和文件操作Java流操作有关的类或接口: Java流类图结构:
1、File类 File类是对文件系统中文件以及文件夹进行封装的对象,可以通过对象的思想来操作文件和文件夹。 File类保存文件或目录的各种元数据信息,包括文件名、文件长度、最后修改时间、是否可读、获取当前文件的路径名,判断指定文件是否存在、获得当前目录中的文件列表,创建、删除文件和目录等方法。 构造方法摘要 File(File parent, String child) File(String pathname) File(String parent, String child) 构造函数 创建方法 1.boolean createNewFile() 不存在返回true 存在返回false 2.boolean mkdir() 创建目录 3.boolean mkdirs() 创建多级目录 删除方法 1.boolean delete() 2.boolean deleteOnExit() 文件使用完成后删除 例子1:列出指定文件夹的文件或文件夹 public class FileDemo1 { public static void main(String[] args){ File[] files =File.listRoots(); for(File file:files){
System.out.println(file); if(file.length()>0){ String[] filenames =file.list(); for(String filename:filenames){ System.out.println(filename); } } } } } 例子2:文件过滤 import java.io.File; public class FileTest2 { public static void main(String[] args) { File file = new File("file"); String[] names = file.list(); for(String name : names) { if(name.endsWith(".java")) { System.out.println(name); }
java File文件操作和文件流的详解(福哥出品)
一. 创建文件 (1)最常用的(获得一个固定路径下的文件对象) File parentFile = new File(“D:\\My Documents\\.....”);//参数是一个路径的字符串。 (2)在父目录创建一个名为child的文件对象,child 为文件对象的名字 File chileFile= new File(“D:\\My Documents\\.....”,String child); 或File chileFile= new File(parentFile,String child); 二,常见文件夹属性和方法 (1)createNewFile(); 该方法的作用是创建指定的文件。该方法只能用于创建文件,不能用于创建文 件夹,且文件路径中包含的文件夹必须存在 File file=new ("D:\\My Document\\text.txt"); file.createNewFile(); 这样就会在D盘下的My Document 创建text.txt的记事本(注意:首先得保 证D盘下有My Documen这个文件夹) (2)mkdir(); 根据File对象的名字(路径)创建一个目录(文件夹),如果是相对目录,则新建的目
录在当前目录下 (3)mkdirs(); 如果File对象名字有多级目录,则可以调用该方法一次性创建多级目录。 (4)exists(); 判断File对象指向的文件是否存在,返回一个boolean类型(5)isDirectory(); 判断File对象指向的文件是否为目录,返回一个boolean类型的值,true或者false。 (6)getName();获得文件名称(不带路径) (7)length(); 得到File对象指向文件的长度,以字节计算,返回一个长整形的值(long);注意:在 系统中,文件夹(目录)的大小为零,也就是不占用空间,使用length()时返回的是0 (8)delete(); 删除File对象所指定的文件 (9)isFile(); 判断File对象指向的文件是不是标准文件(就像图片,音乐文件等) 三,文件的属性和方法 1.File.separator 当前操作系统的名称分隔符,等于字符串“\”.
《文件和文件夹的操作》教学设计
《第四课文件和文件夹的操作》教学设计 【教学内容】 新建自己的文件和文件夹,学习文件和文件夹的复制和粘贴、文件和文件夹的移动、文件和文件夹的删除。 【学情分析】 对于小学四年级的学生来说,计算机相关专业术语理解 起来难度大,虽然已经有第三课的知识做为本节教学的基础,但学生学起来可能还有很大难度。但是现在的学生已经很早地接解电子产和数码产品,操作能力相对以前的学生会强一些,因此,本节课要以“简说多做”为原则,充分发挥学生的学习能动性,可以在教学中充分发挥学生的互助带动性,让学生不仅学得知识,也能培养团结协作能力,更能让学生在学习中获得成就感,从而树立学习的自信心。 【设计意图】 贯穿始终的依旧是“学以致用”的思想,遵从“简说多做”的原则,让学生在教师的组织引导下做课堂的主人。【教学目标】
1、建立以自己的爱好为名称的文件夹,在文件夹中建有若干个文件。 2、学习文件和文件夹的复制和粘贴。 3、学习文件和文件夹的移动。 4、学习文件和文件夹的删除。 5、通过学习,养成良好的文件和文件夹的使用习惯,明白学习和生活中做到“井井有条”的重要性,并努力做到。【教学重点和难点】 教学重点: 文件和文件夹的新建、复制和粘贴、移动、删除等操作。教学难点: 1、文件和文件夹的复制和粘贴、文件和文件夹的移动、文件和文件夹的删除。 2、养成良好的操作习惯。 【教学过程】 一、激趣导入 玩游戏:比一比谁最快?(找卡片游戏) 师:同学们,通过这个游戏,你们知到了什么?
获胜者和输的学生各自发言,说说自己获胜和失败的原因。(学生讨论) 再以学生翻来覆去找作业和超市购物等生活实例让学生进一步感受“杂乱无章”和“井井有条”的效果。引导学生认识到:有条理地安置东西能提高效率。教育学生:要养成好习惯,把自己的书本或生活用品放置地井井有条。 师:好了,同学们,我们生活中用的电脑是不是也像一个属于你自己的超市呢?里面放着你所需要的各种东西,那我们是不是也要把里面的东西放置得有条理呢?今天我们 就来学习一些操作,来把我们电脑里的东西好好处理一下,以方便我们使用。 【设计意图:联系实际生活,引出本节课的学习内容。】二、展示学习目标 展示学习目标: 1.新建一个以自己喜好为名称的文件夹,并在里面放置几个文件;如:我爱听的音乐、我的照片、好看的电影等等。 2.自学课本13—16页,了解文件和文件夹的复制和粘贴、移动、删除等操作。 3、交流学习成果。
Java流(文件读写操作)
Java流 一、流的分类 ?按数据流动方向 –输入流:只能从中读取字节数据,而不能向其写出数据 –输出流:只能向其写入字节数据,而不能从中读取数据?按照流所处理的数据类型 –字节流:用于处理字节数据。 –字符流:用于处理Unicode字符数据。 ?按照流所处理的源 –节点流:从/向一个特定的IO设备读/写数据的流。(低级流)–处理流:对已存在的流进行连接和封装的流。(高级流)二、缓冲流 ?缓冲流要“套接”在相应的节点流之上,对读写的数据提供了缓冲的功能,提高了读写的效率,同时增加了一些新的方法。 ?J2SDK提供了四种缓存流: –BufferedReader –BufferedWriter –BufferedInputStream s –BufferedOutputStream
?缓冲输入流支持其父类的mark()和reset()方法: –mark()用于“标记”当前位置,就像加入了一个书签,可以使用reset()方法返回这个标记重新读取数据。?BufferedReader提供了readLine()方法用于读取一行字符串(以\r 或\n分隔)。 ?BufferedWriter提供了newLine()用于写入一个行分隔符。 ?对于输出的缓冲流,写出的数据会先在内存中缓存,使用flush()方法将会使内存中的数据立刻写出。 三、类层次 3.1、InputStream类层次
3.2、OutputStream类层次 3.3、Reader类层次
3.4、Writer类层次 四、常用的字符流与字节流的转化 说明: 1.字节流用于读写诸如图像数据之类的原始字节流。 2.字符流用于读写诸如文件数据之类的字符流。 3.低级流能和外设交流。 4.高级流能提高效率。 5.InputStreamReader 是字节流通向字符流的桥梁。 6.OutputStreamWriter 是字符流通向字节流的桥梁。
HTML代码大全
<><> 创建一个文档 <><> 设置文档标题和其它在网页中不显示地信息 <><> 设置文档地标题 <><> 最大地标题 <><> 预先格式化文本 <><> 下划线 <><> 黑体字 <><> 斜体字 <><> 打字机风格地字体 <><> 引用,通常是斜体 <><> 强调文本(通常是斜体加黑体) <><> 加重文本(通常是斜体加黑体) < "" ""><> 设置字体大小从到,颜色使用名字或地十六进制值 <><> 基准字体标记 <><> 字体加大 <><> 字体缩小 <><> 加删除线 <><> 程式码 <><> 键盘字 <><> 范例 <><> 变量 <><> 向右缩排 <><> 述语定义 <><> 地址标记 <><> 上标字 <><> 下标字 <>...<>固定寬度字体(在文件中空白、換行、定位功能有效) <>...<>固定寬度字體(不執行標記符號) <>...<> 固定寬度小字體 < >...<>字體顏色 < >...<>最小字體 < " ">...<>無限增大 ◆◆◆◆◆◆◆◆◆◆◆◆◆◆《〈格式标志〉》◆◆◆◆◆◆◆◆◆◆◆◆<><> 创建一个段落 < ""> 将段落按左、中、右对齐 <>换行插入一个回车换行符 <><> 从两边缩进文本 <><> 定义列表 <> 放在每个定义术语词前 <> 放在每个定义之前 <><> 创建一个标有数字地列表 <><> 创建一个标有圆点地列表 <> 放在每个列表项之前,若在<><>之间则每个列表项加上一个数字, 若在<><>之间则每个列表项加上一个圆点 < ""><> 用来排版大块段落,也用于格式化表 <> 选项清单
<> 目录清单 <><> 强行不换行 < "" "" "">水平線(設定寬度) <><> 水平居中◆◆◆◆◆◆◆◆◆《〈链接标志表格标志〉》◆◆◆◆◆◆◆◆◆◆◆◆◆◆< ""><> 创建超文本链接 < ""> <> 创建自动发送电子邮件地链接 < ""><> 创建位于文档内部地书签 < ""><> 创建指向位于文档内部书签地链接 <> 文档中不能被该站点辨识地其它所有链接源地 <> 定义一个链接和源之间地相互关系 ◆◆◆◆◆◆◆◆链接标记注解:◆◆◆◆◆◆◆◆◆◆◆◆ ◆"..."决定链接源在什么地方显示(用户自定义地名字, ◆"..."发送链接地类型 ◆"..."保存链接地类型 ◆"..."指定该元素地热键 ◆"..."允许我们使用已定义地形状定义客户端地图形镜像(,,, ◆"..."使用像素或者长度百分比来定义形状地尺寸 ◆"..."使用定义过地元素设置在各个元素之间地焦点获取顺序(使用键使元素获得焦点) ◆◆◆◆◆◆◆◆表格标记注解:◆◆◆◆◆◆◆◆◆◆◆◆ <><> 创建一个表格 <><> 表格中地每一行 <><> 表格中一行中地每一个格子 <><> 设置表格头:通常是黑体居中文字 < ""> 设置表格格子之间空间地大小 < ""> 设置边框地宽度 < ""> 设置表格格子边框与其内部内容之间空间地大小 < ""> 设置表格地宽度.用绝对像素值或总宽度地百分比 < ""> 设置表格格子地水平对齐方式() < ""> 设置表格格子地水平对齐方式() < ""> 设置表格格子地垂直对齐方式() < ""> 设置一个表格格子跨占地列数(缺省值为) < ""> 设置一个表格格子跨占地行数(缺省值为) < > 禁止表格格子内地内容自动断行 <><> 表格地标题 <><> 定义多个列为一组列 <><> 创建一个表格 <><> 定义表格地页眉 <> 定义一个列组中地列,以便对它们能够同时设置有关属性 <><> 定义一个表格地实体 <><> 定义一个表格地页脚 ◆◆◆◆◆◆◆◆◆◆◆◆《表单标志》◆◆◆◆◆◆◆◆◆◆◆ <><> 创建表单 "..."接收数据地服务器地 "..."地方法(, ).其中是被反对使用地 "..."指定(媒体类型)