现代操作系统答案
- 格式:doc
- 大小:54.00 KB
- 文档页数:5
![现代操作系统教程(慕课版)习题 7-答案[3页]](https://uimg.taocdn.com/9b55ea0d59fb770bf78a6529647d27284b733715.webp)
习题71. 选择题(1)基于固定网络的分布式计算相比,移动计算的主要特点不包含以下的(C )。
A. 频繁断接性B. 网络协议多样性C. 网络通信对称性D. 有限能源支持(2)Android系统的版本命名具有一定的规律,Donut版本后的Android系统版本是(A )。
A.Eclair B.Froyo C.Jelly Bean D.Honeycomb(3)以下选项中,(C )不是典型的移动终端操作系统。
A.Symbian B.Palm OS C.macOS D.iOS(4)Android系统的( A )主要负责对驱动程序进行的封装,以屏蔽底层细节。
A.硬件抽象层B.Android 运行时C.Linux内核D.应用程序框架2. 填空题(1)Android系统的核心应用程序和开发人员开发的其他应用程序,大都基于(Java)语言开发。
(2)Android的系统类库通过(应用程序框架)将相关功能模块提供给开发者所使用,包括图形引擎、小型关系数据库、网络通信安全协议等。
(3)Android利用(Linux)内核服务实现电源管理、各种硬件设备驱动以及进程和内存管理、网络协议栈、无线通信等核心功能。
(4)iOS采用了一种称为(Metal)的架构,可以充分发挥iPhone 和iPad的图形处理和显示性能。
3. 简答题(1)请描述在物流系统中移动计算发挥的作用。
答:在物流的几个重要环节,如运输、储存保管、配送等,移动计算有着广阔的应用前景。
在运输方面,利用移动计算设备与GPS/GIS系统相连,使得整个运输车队的运行受到中央调度系统的控制。
中央控制系统可以对车辆的位置、状况等进行实施监控。
利用这些信息可以对运输车辆进行优化配置和调遣,极大地提高运输工作的效率,同时能够加强成本控制。
另外,通过将车辆载货情况及到达目的地的时间预先通知下游单位配送中心或仓库等,有利于下游单位合理地配置资源、安排作业,从而极大地提高运营效率,节约物流成本。


现代操作系统习题及答案现代操作系统习题及答案随着科技的不断进步和发展,现代操作系统成为了计算机领域的重要组成部分。
操作系统作为计算机硬件和软件之间的桥梁,起着管理和协调资源的重要作用。
为了更好地理解和掌握现代操作系统的相关知识,下面将给出一些习题及其答案,希望能够对读者有所帮助。
1. 什么是操作系统?它的主要功能是什么?答:操作系统是一种软件,它管理和控制计算机硬件资源,并为用户和应用程序提供接口。
其主要功能包括进程管理、内存管理、文件系统管理和设备管理等。
2. 请简要描述进程和线程的区别。
答:进程是程序的执行实例,拥有独立的内存空间和系统资源。
线程是进程中的一个执行单元,共享进程的资源,但拥有独立的执行路径。
进程之间相互独立,而线程之间可以共享数据和资源。
3. 什么是死锁?如何避免死锁的发生?答:死锁是指两个或多个进程互相等待对方释放资源,导致所有进程无法继续执行的情况。
为避免死锁的发生,可以采取以下几种方法:避免使用互斥锁、避免使用占有并等待、避免使用循环等待、引入资源预先分配策略等。
4. 请简要描述虚拟内存的概念及其作用。
答:虚拟内存是一种计算机系统使用的内存管理技术,它将物理内存和磁盘空间结合起来,为每个进程提供了一个虚拟地址空间。
虚拟内存的作用包括扩大可用内存空间、提供更高的内存访问效率、实现进程间的内存隔离等。
5. 什么是文件系统?请简要描述文件系统的组织结构。
答:文件系统是操作系统中用于管理和存储文件的一种机制。
文件系统的组织结构包括文件、目录和文件描述符等。
文件是存储在磁盘上的数据集合,目录是用于组织和管理文件的一种结构,文件描述符是操作系统中对文件进行操作的抽象。
6. 请简要描述操作系统的进程调度算法。
答:操作系统的进程调度算法决定了进程在系统中的执行顺序。
常见的进程调度算法包括先来先服务(FCFS)、最短作业优先(SJF)、轮转调度(RR)和优先级调度等。
不同的调度算法有不同的优缺点,可以根据系统需求选择合适的算法。

现代操作系统第二章进程与线程习题1. 图2-2中给出了三个进程状态,在理论上,三个状态可以有六种转换,每个状态两个。
但是,图中只给出了四种转换。
有没有可能发生其他两种转换中的一个或两个?A:从阻塞到运行的转换是可以想象的。
假设某个进程在I/O上阻塞,而且I/O 结束,如果此时CPU空闲,该进程就可以从阻塞态直接转到运行态。
而另外一种转换(从阻塞态到就绪态)是不可能的。
一个就绪进程是不可能做任何会产生阻塞的I/O或者别的什么事情。
只有运行的进程才能被阻塞。
2.假设要设计一种先进的计算机体系结构,它使用硬件而不是中断来完成进程切换。
CPU需要哪些信息?请描述用硬件完成进程切换的工作过程。
A:应该有一个寄存器包含当前进程表项的指针。
当I/O结束时,CPU将把当前的机器状态存入到当前进程表项中。
然后,将转到中断设备的中断向量,读取另一个过程表项的指针(服务例程),然后,就可以启动这个进程了。
3.当代计算机中,为什么中断处理程序至少有一部分是用汇编语言编写的?A:通常,高级语言不允许访问CPU硬件,而这种访问是必需的。
例如,中断处理程序可能需要禁用和启用某个特定设备的中断服务,或者处理进程堆栈区的数据。
另外,中断服务例程需要尽快地执行。
(补充)主要是出于效率方面的考量。
中断处理程序需要在尽量短的时间内完成所需的必要处理,尽量减少对线程/程序流造成的影响,因此大部分情况下用汇编直接编写,跳过了通用编译过程中冗余的适配部分。
4.中断或系统调用把控制转给操作系统时,为什么通常会用到与被中断进程的栈分离的内核栈?A:内核使用单独的堆栈有若干的原因。
其中两个原因如下:首先,不希望操作系统崩溃,由于某些用户程序不允许足够的堆栈空间。
第二,如果内核将数据保留在用户空间,然后从系统调用返回,那么恶意的用户可能使用这些数据找出某些关于其它进程的信息。
5.一个计算机系统的内存有足够的空间容纳5个程序。
这些程序有一半的时间处于等待I/O的空闲状态。

MODERNOPERATINGSYSTEMSTHIRD EDITION PROBLEM SOLUTIONSANDREW S.TANENBAUMVrije UniversiteitAmsterdam,The NetherlandsPRENTICE HALLUPPER SADDLE RIVER,NJ07458Copyright Pearson Education,Inc.2008SOLUTIONS TO CHAPTER1PROBLEMS1.Multiprogramming is the rapid switching of the CPU between multiple proc-esses in memory.It is commonly used to keep the CPU busy while one or more processes are doing I/O.2.Input spooling is the technique of reading in jobs,for example,from cards,onto the disk,so that when the currently executing processes arefinished, there will be work waiting for the CPU.Output spooling consists offirst copying printablefiles to disk before printing them,rather than printing di-rectly as the output is generated.Input spooling on a personal computer is not very likely,but output spooling is.3.The prime reason for multiprogramming is to give the CPU something to dowhile waiting for I/O to complete.If there is no DMA,the CPU is fully occu-pied doing I/O,so there is nothing to be gained(at least in terms of CPU utili-zation)by multiprogramming.No matter how much I/O a program does,the CPU will be100%busy.This of course assumes the major delay is the wait while data are copied.A CPU could do other work if the I/O were slow for other reasons(arriving on a serial line,for instance).4.It is still alive.For example,Intel makes Pentium I,II,and III,and4CPUswith a variety of different properties including speed and power consumption.All of these machines are architecturally compatible.They differ only in price and performance,which is the essence of the family idea.5.A25×80character monochrome text screen requires a2000-byte buffer.The1024×768pixel24-bit color bitmap requires2,359,296bytes.In1980these two options would have cost$10and$11,520,respectively.For current prices,check on how much RAM currently costs,probably less than$1/MB.6.Consider fairness and real time.Fairness requires that each process be allo-cated its resources in a fair way,with no process getting more than its fair share.On the other hand,real time requires that resources be allocated based on the times when different processes must complete their execution.A real-time process may get a disproportionate share of the resources.7.Choices(a),(c),and(d)should be restricted to kernel mode.8.It may take20,25or30msec to complete the execution of these programsdepending on how the operating system schedules them.If P0and P1are scheduled on the same CPU and P2is scheduled on the other CPU,it will take20mses.If P0and P2are scheduled on the same CPU and P1is scheduled on the other CPU,it will take25msec.If P1and P2are scheduled on the same CPU and P0is scheduled on the other CPU,it will take30msec.If all three are on the same CPU,it will take35msec.2PROBLEM SOLUTIONS FOR CHAPTER19.Every nanosecond one instruction emerges from the pipeline.This means themachine is executing1billion instructions per second.It does not matter at all how many stages the pipeline has.A10-stage pipeline with1nsec per stage would also execute1billion instructions per second.All that matters is how often afinished instruction pops out the end of the pipeline.10.Average access time=0.95×2nsec(word is cache)+0.05×0.99×10nsec(word is in RAM,but not in cache)+0.05×0.01×10,000,000nsec(word on disk only)=5002.395nsec=5.002395μsec11.The manuscript contains80×50×700=2.8million characters.This is,ofcourse,impossible tofit into the registers of any currently available CPU and is too big for a1-MB cache,but if such hardware were available,the manuscript could be scanned in2.8msec from the registers or5.8msec from the cache.There are approximately27001024-byte blocks of data,so scan-ning from the disk would require about27seconds,and from tape2minutes7 seconds.Of course,these times are just to read the data.Processing and rewriting the data would increase the time.12.Maybe.If the caller gets control back and immediately overwrites the data,when the writefinally occurs,the wrong data will be written.However,if the driverfirst copies the data to a private buffer before returning,then the caller can be allowed to continue immediately.Another possibility is to allow the caller to continue and give it a signal when the buffer may be reused,but this is tricky and error prone.13.A trap instruction switches the execution mode of a CPU from the user modeto the kernel mode.This instruction allows a user program to invoke func-tions in the operating system kernel.14.A trap is caused by the program and is synchronous with it.If the program isrun again and again,the trap will always occur at exactly the same position in the instruction stream.An interrupt is caused by an external event and its timing is not reproducible.15.The process table is needed to store the state of a process that is currentlysuspended,either ready or blocked.It is not needed in a single process sys-tem because the single process is never suspended.16.Mounting afile system makes anyfiles already in the mount point directoryinaccessible,so mount points are normally empty.However,a system admin-istrator might want to copy some of the most importantfiles normally located in the mounted directory to the mount point so they could be found in their normal path in an emergency when the mounted device was being repaired.PROBLEM SOLUTIONS FOR CHAPTER13 17.A system call allows a user process to access and execute operating systemfunctions inside the er programs use system calls to invoke operat-ing system services.18.Fork can fail if there are no free slots left in the process table(and possibly ifthere is no memory or swap space left).Exec can fail if thefile name given does not exist or is not a valid executablefile.Unlink can fail if thefile to be unlinked does not exist or the calling process does not have the authority to unlink it.19.If the call fails,for example because fd is incorrect,it can return−1.It canalso fail because the disk is full and it is not possible to write the number of bytes requested.On a correct termination,it always returns nbytes.20.It contains the bytes:1,5,9,2.21.Time to retrieve thefile=1*50ms(Time to move the arm over track#50)+5ms(Time for thefirst sector to rotate under the head)+10/100*1000ms(Read10MB)=155ms22.Block specialfiles consist of numbered blocks,each of which can be read orwritten independently of all the other ones.It is possible to seek to any block and start reading or writing.This is not possible with character specialfiles.23.System calls do not really have names,other than in a documentation sense.When the library procedure read traps to the kernel,it puts the number of the system call in a register or on the stack.This number is used to index into a table.There is really no name used anywhere.On the other hand,the name of the library procedure is very important,since that is what appears in the program.24.Yes it can,especially if the kernel is a message-passing system.25.As far as program logic is concerned it does not matter whether a call to a li-brary procedure results in a system call.But if performance is an issue,if a task can be accomplished without a system call the program will run faster.Every system call involves overhead time in switching from the user context to the kernel context.Furthermore,on a multiuser system the operating sys-tem may schedule another process to run when a system call completes, further slowing the progress in real time of a calling process.26.Several UNIX calls have no counterpart in the Win32API:Link:a Win32program cannot refer to afile by an alternative name or see it in more than one directory.Also,attempting to create a link is a convenient way to test for and create a lock on afile.4PROBLEM SOLUTIONS FOR CHAPTER1Mount and umount:a Windows program cannot make assumptions about standard path names because on systems with multiple disk drives the drive name part of the path may be different.Chmod:Windows uses access control listsKill:Windows programmers cannot kill a misbehaving program that is not cooperating.27.Every system architecture has its own set of instructions that it can execute.Thus a Pentium cannot execute SPARC programs and a SPARC cannot exe-cute Pentium programs.Also,different architectures differ in bus architecture used(such as VME,ISA,PCI,MCA,SBus,...)as well as the word size of the CPU(usually32or64bit).Because of these differences in hardware,it is not feasible to build an operating system that is completely portable.A highly portable operating system will consist of two high-level layers---a machine-dependent layer and a machine independent layer.The machine-dependent layer addresses the specifics of the hardware,and must be implemented sepa-rately for every architecture.This layer provides a uniform interface on which the machine-independent layer is built.The machine-independent layer has to be implemented only once.To be highly portable,the size of the machine-dependent layer must be kept as small as possible.28.Separation of policy and mechanism allows OS designers to implement asmall number of basic primitives in the kernel.These primitives are sim-plified,because they are not dependent of any specific policy.They can then be used to implement more complex mechanisms and policies at the user level.29.The conversions are straightforward:(a)A micro year is10−6×365×24×3600=31.536sec.(b)1000meters or1km.(c)There are240bytes,which is1,099,511,627,776bytes.(d)It is6×1024kg.SOLUTIONS TO CHAPTER2PROBLEMS1.The transition from blocked to running is conceivable.Suppose that a processis blocked on I/O and the I/Ofinishes.If the CPU is otherwise idle,the proc-ess could go directly from blocked to running.The other missing transition, from ready to blocked,is impossible.A ready process cannot do I/O or any-thing else that might block it.Only a running process can block.PROBLEM SOLUTIONS FOR CHAPTER25 2.You could have a register containing a pointer to the current process tableentry.When I/O completed,the CPU would store the current machine state in the current process table entry.Then it would go to the interrupt vector for the interrupting device and fetch a pointer to another process table entry(the ser-vice procedure).This process would then be started up.3.Generally,high-level languages do not allow the kind of access to CPU hard-ware that is required.For instance,an interrupt handler may be required to enable and disable the interrupt servicing a particular device,or to manipulate data within a process’stack area.Also,interrupt service routines must exe-cute as rapidly as possible.4.There are several reasons for using a separate stack for the kernel.Two ofthem are as follows.First,you do not want the operating system to crash be-cause a poorly written user program does not allow for enough stack space.Second,if the kernel leaves stack data in a user program’s memory space upon return from a system call,a malicious user might be able to use this data tofind out information about other processes.5.If each job has50%I/O wait,then it will take20minutes to complete in theabsence of competition.If run sequentially,the second one willfinish40 minutes after thefirst one starts.With two jobs,the approximate CPU utiliza-tion is1−0.52.Thus each one gets0.375CPU minute per minute of real time.To accumulate10minutes of CPU time,a job must run for10/0.375 minutes,or about26.67minutes.Thus running sequentially the jobsfinish after40minutes,but running in parallel theyfinish after26.67minutes.6.It would be difficult,if not impossible,to keep thefile system consistent.Sup-pose that a client process sends a request to server process1to update afile.This process updates the cache entry in its memory.Shortly thereafter,anoth-er client process sends a request to server2to read thatfile.Unfortunately,if thefile is also cached there,server2,in its innocence,will return obsolete data.If thefirst process writes thefile through to the disk after caching it, and server2checks the disk on every read to see if its cached copy is up-to-date,the system can be made to work,but it is precisely all these disk ac-cesses that the caching system is trying to avoid.7.No.If a single-threaded process is blocked on the keyboard,it cannot fork.8.A worker thread will block when it has to read a Web page from the disk.Ifuser-level threads are being used,this action will block the entire process, destroying the value of multithreading.Thus it is essential that kernel threads are used to permit some threads to block without affecting the others.9.Yes.If the server is entirely CPU bound,there is no need to have multiplethreads.It just adds unnecessary complexity.As an example,consider a tele-phone directory assistance number(like555-1212)for an area with1million6PROBLEM SOLUTIONS FOR CHAPTER2people.If each(name,telephone number)record is,say,64characters,the entire database takes64megabytes,and can easily be kept in the server’s memory to provide fast lookup.10.When a thread is stopped,it has values in the registers.They must be saved,just as when the process is stopped the registers must be saved.Multipro-gramming threads is no different than multiprogramming processes,so each thread needs its own register save area.11.Threads in a process cooperate.They are not hostile to one another.If yield-ing is needed for the good of the application,then a thread will yield.After all,it is usually the same programmer who writes the code for all of them. er-level threads cannot be preempted by the clock unless the whole proc-ess’quantum has been used up.Kernel-level threads can be preempted indivi-dually.In the latter case,if a thread runs too long,the clock will interrupt the current process and thus the current thread.The kernel is free to pick a dif-ferent thread from the same process to run next if it so desires.13.In the single-threaded case,the cache hits take15msec and cache misses take90msec.The weighted average is2/3×15+1/3×90.Thus the mean re-quest takes40msec and the server can do25per second.For a multithreaded server,all the waiting for the disk is overlapped,so every request takes15 msec,and the server can handle662/3requests per second.14.The biggest advantage is the efficiency.No traps to the kernel are needed toswitch threads.The biggest disadvantage is that if one thread blocks,the en-tire process blocks.15.Yes,it can be done.After each call to pthread create,the main programcould do a pthread join to wait until the thread just created has exited before creating the next thread.16.The pointers are really necessary because the size of the global variable isunknown.It could be anything from a character to an array offloating-point numbers.If the value were stored,one would have to give the size to create global,which is all right,but what type should the second parameter of set global be,and what type should the value of read global be?17.It could happen that the runtime system is precisely at the point of blocking orunblocking a thread,and is busy manipulating the scheduling queues.This would be a very inopportune moment for the clock interrupt handler to begin inspecting those queues to see if it was time to do thread switching,since they might be in an inconsistent state.One solution is to set aflag when the run-time system is entered.The clock handler would see this and set its ownflag, then return.When the runtime systemfinished,it would check the clockflag, see that a clock interrupt occurred,and now run the clock handler.PROBLEM SOLUTIONS FOR CHAPTER27 18.Yes it is possible,but inefficient.A thread wanting to do a system callfirstsets an alarm timer,then does the call.If the call blocks,the timer returns control to the threads package.Of course,most of the time the call will not block,and the timer has to be cleared.Thus each system call that might block has to be executed as three system calls.If timers go off prematurely,all kinds of problems can develop.This is not an attractive way to build a threads package.19.The priority inversion problem occurs when a low-priority process is in itscritical region and suddenly a high-priority process becomes ready and is scheduled.If it uses busy waiting,it will run forever.With user-level threads,it cannot happen that a low-priority thread is suddenly preempted to allow a high-priority thread run.There is no preemption.With kernel-level threads this problem can arise.20.With round-robin scheduling it works.Sooner or later L will run,and eventu-ally it will leave its critical region.The point is,with priority scheduling,L never gets to run at all;with round robin,it gets a normal time slice periodi-cally,so it has the chance to leave its critical region.21.Each thread calls procedures on its own,so it must have its own stack for thelocal variables,return addresses,and so on.This is equally true for user-level threads as for kernel-level threads.22.Yes.The simulated computer could be multiprogrammed.For example,while process A is running,it reads out some shared variable.Then a simula-ted clock tick happens and process B runs.It also reads out the same vari-able.Then it adds1to the variable.When process A runs,if it also adds one to the variable,we have a race condition.23.Yes,it still works,but it still is busy waiting,of course.24.It certainly works with preemptive scheduling.In fact,it was designed forthat case.When scheduling is nonpreemptive,it might fail.Consider the case in which turn is initially0but process1runsfirst.It will just loop forever and never release the CPU.25.To do a semaphore operation,the operating systemfirst disables interrupts.Then it reads the value of the semaphore.If it is doing a down and the sema-phore is equal to zero,it puts the calling process on a list of blocked processes associated with the semaphore.If it is doing an up,it must check to see if any processes are blocked on the semaphore.If one or more processes are block-ed,one of them is removed from the list of blocked processes and made run-nable.When all these operations have been completed,interrupts can be enabled again.8PROBLEM SOLUTIONS FOR CHAPTER226.Associated with each counting semaphore are two binary semaphores,M,used for mutual exclusion,and B,used for blocking.Also associated with each counting semaphore is a counter that holds the number of up s minus the number of down s,and a list of processes blocked on that semaphore.To im-plement down,a processfirst gains exclusive access to the semaphores, counter,and list by doing a down on M.It then decrements the counter.If it is zero or more,it just does an up on M and exits.If M is negative,the proc-ess is put on the list of blocked processes.Then an up is done on M and a down is done on B to block the process.To implement up,first M is down ed to get mutual exclusion,and then the counter is incremented.If it is more than zero,no one was blocked,so all that needs to be done is to up M.If, however,the counter is now negative or zero,some process must be removed from the list.Finally,an up is done on B and M in that order.27.If the program operates in phases and neither process may enter the nextphase until both arefinished with the current phase,it makes perfect sense to use a barrier.28.With kernel threads,a thread can block on a semaphore and the kernel canrun some other thread in the same process.Consequently,there is no problem using semaphores.With user-level threads,when one thread blocks on a semaphore,the kernel thinks the entire process is blocked and does not run it ever again.Consequently,the process fails.29.It is very expensive to implement.Each time any variable that appears in apredicate on which some process is waiting changes,the run-time system must re-evaluate the predicate to see if the process can be unblocked.With the Hoare and Brinch Hansen monitors,processes can only be awakened on a signal primitive.30.The employees communicate by passing messages:orders,food,and bags inthis case.In UNIX terms,the four processes are connected by pipes.31.It does not lead to race conditions(nothing is ever lost),but it is effectivelybusy waiting.32.It will take nT sec.33.In simple cases it may be possible to determine whether I/O will be limitingby looking at source code.For instance a program that reads all its inputfiles into buffers at the start will probably not be I/O bound,but a problem that reads and writes incrementally to a number of differentfiles(such as a compi-ler)is likely to be I/O bound.If the operating system provides a facility such as the UNIX ps command that can tell you the amount of CPU time used by a program,you can compare this with the total time to complete execution of the program.This is,of course,most meaningful on a system where you are the only user.34.For multiple processes in a pipeline,the common parent could pass to the op-erating system information about the flow of data.With this information the OS could,for instance,determine which process could supply output to a process blocking on a call for input.35.The CPU efficiency is the useful CPU time divided by the total CPU time.When Q ≥T ,the basic cycle is for the process to run for T and undergo a process switch for S .Thus (a)and (b)have an efficiency of T /(S +T ).When the quantum is shorter than T ,each run of T will require T /Q process switches,wasting a time ST /Q .The efficiency here is thenT +ST /QT which reduces to Q /(Q +S ),which is the answer to (c).For (d),we just sub-stitute Q for S and find that the efficiency is 50%.Finally,for (e),as Q →0the efficiency goes to 0.36.Shortest job first is the way to minimize average response time.0<X ≤3:X ,3,5,6,9.3<X ≤5:3,X ,5,6,9.5<X ≤6:3,5,X ,6,9.6<X ≤9:3,5,6,X ,9.X >9:3,5,6,9,X.37.For round robin,during the first 10minutes each job gets 1/5of the CPU.Atthe end of 10minutes,C finishes.During the next 8minutes,each job gets 1/4of the CPU,after which time D finishes.Then each of the three remaining jobs gets 1/3of the CPU for 6minutes,until B finishes,and so on.The fin-ishing times for the five jobs are 10,18,24,28,and 30,for an average of 22minutes.For priority scheduling,B is run first.After 6minutes it is finished.The other jobs finish at 14,24,26,and 30,for an average of 18.8minutes.If the jobs run in the order A through E ,they finish at 10,16,18,22,and 30,for an average of 19.2minutes.Finally,shortest job first yields finishing times of 2,6,12,20,and 30,for an average of 14minutes.38.The first time it gets 1quantum.On succeeding runs it gets 2,4,8,and 15,soit must be swapped in 5times.39.A check could be made to see if the program was expecting input and didanything with it.A program that was not expecting input and did not process it would not get any special priority boost.40.The sequence of predictions is 40,30,35,and now 25.41.The fraction of the CPU used is35/50+20/100+10/200+x/250.To beschedulable,this must be less than1.Thus x must be less than12.5msec. 42.Two-level scheduling is needed when memory is too small to hold all theready processes.Some set of them is put into memory,and a choice is made from that set.From time to time,the set of in-core processes is adjusted.This algorithm is easy to implement and reasonably efficient,certainly a lot better than,say,round robin without regard to whether a process was in memory or not.43.Each voice call runs200times/second and uses up1msec per burst,so eachvoice call needs200msec per second or400msec for the two of them.The video runs25times a second and uses up20msec each time,for a total of 500msec per second.Together they consume900msec per second,so there is time left over and the system is schedulable.44.The kernel could schedule processes by any means it wishes,but within eachprocess it runs threads strictly in priority order.By letting the user process set the priority of its own threads,the user controls the policy but the kernel handles the mechanism.45.The change would mean that after a philosopher stopped eating,neither of hisneighbors could be chosen next.In fact,they would never be chosen.Sup-pose that philosopher2finished eating.He would run test for philosophers1 and3,and neither would be started,even though both were hungry and both forks were available.Similarly,if philosopher4finished eating,philosopher3 would not be started.Nothing would start him.46.If a philosopher blocks,neighbors can later see that she is hungry by checkinghis state,in test,so he can be awakened when the forks are available.47.Variation1:readers have priority.No writer may start when a reader is ac-tive.When a new reader appears,it may start immediately unless a writer is currently active.When a writerfinishes,if readers are waiting,they are all started,regardless of the presence of waiting writers.Variation2:Writers have priority.No reader may start when a writer is waiting.When the last ac-tive processfinishes,a writer is started,if there is one;otherwise,all the readers(if any)are started.Variation3:symmetric version.When a reader is active,new readers may start immediately.When a writerfinishes,a new writer has priority,if one is waiting.In other words,once we have started reading,we keep reading until there are no readers left.Similarly,once we have started writing,all pending writers are allowed to run.48.A possible shell script might beif[!–f numbers];then echo0>numbers;ficount=0while(test$count!=200)docount=‘expr$count+1‘n=‘tail–1numbers‘expr$n+1>>numbersdoneRun the script twice simultaneously,by starting it once in the background (using&)and again in the foreground.Then examine thefile numbers.It will probably start out looking like an orderly list of numbers,but at some point it will lose its orderliness,due to the race condition created by running two cop-ies of the script.The race can be avoided by having each copy of the script test for and set a lock on thefile before entering the critical area,and unlock-ing it upon leaving the critical area.This can be done like this:if ln numbers numbers.lockthenn=‘tail–1numbers‘expr$n+1>>numbersrm numbers.lockfiThis version will just skip a turn when thefile is inaccessible,variant solu-tions could put the process to sleep,do busy waiting,or count only loops in which the operation is successful.SOLUTIONS TO CHAPTER3PROBLEMS1.It is an accident.The base register is16,384because the program happened tobe loaded at address16,384.It could have been loaded anywhere.The limit register is16,384because the program contains16,384bytes.It could have been any length.That the load address happens to exactly match the program length is pure coincidence.2.Almost the entire memory has to be copied,which requires each word to beread and then rewritten at a different location.Reading4bytes takes10nsec, so reading1byte takes2.5nsec and writing it takes another2.5nsec,for a total of5nsec per byte compacted.This is a rate of200,000,000bytes/sec.To copy128MB(227bytes,which is about1.34×108bytes),the computer needs227/200,000,000sec,which is about671msec.This number is slightly pessimistic because if the initial hole at the bottom of memory is k bytes, those k bytes do not need to be copied.However,if there are many holes andmany data segments,the holes will be small,so k will be small and the error in the calculation will also be small.3.The bitmap needs1bit per allocation unit.With227/n allocation units,this is224/n bytes.The linked list has227/216or211nodes,each of8bytes,for a total of214bytes.For small n,the linked list is better.For large n,the bitmap is better.The crossover point can be calculated by equating these two formu-las and solving for n.The result is1KB.For n smaller than1KB,a linked list is better.For n larger than1KB,a bitmap is better.Of course,the assumption of segments and holes alternating every64KB is very unrealistic.Also,we need n<=64KB if the segments and holes are64KB.4.Firstfit takes20KB,10KB,18KB.Bestfit takes12KB,10KB,and9KB.Worstfit takes20KB,18KB,and15KB.Nextfit takes20KB,18KB,and9 KB.5.For a4-KB page size the(page,offset)pairs are(4,3616),(8,0),and(14,2656).For an8-KB page size they are(2,3616),(4,0),and(7,2656).6.They built an MMU and inserted it between the8086and the bus.Thus all8086physical addresses went into the MMU as virtual addresses.The MMU then mapped them onto physical addresses,which went to the bus.7.(a)M has to be at least4,096to ensure a TLB miss for every access to an ele-ment of X.Since N only affects how many times X is accessed,any value of N will do.(b)M should still be atleast4,096to ensure a TLB miss for every access to anelement of X.But now N should be greater than64K to thrash the TLB, that is,X should exceed256KB.8.The total virtual address space for all the processes combined is nv,so thismuch storage is needed for pages.However,an amount r can be in RAM,so the amount of disk storage required is only nv−r.This amount is far more than is ever needed in practice because rarely will there be n processes ac-tually running and even more rarely will all of them need the maximum al-lowed virtual memory.9.The page table contains232/213entries,which is524,288.Loading the pagetable takes52msec.If a process gets100msec,this consists of52msec for loading the page table and48msec for running.Thus52%of the time is spent loading page tables.10.(a)We need one entry for each page,or224=16×1024×1024entries,sincethere are36=48−12bits in the page numberfield.。

1.这些系统直接把程序载入内存,并且从word0(魔数)开始执行。
为了避免将header作为代码执行,魔数是一条branch指令,其目标地址正好在header之上。
按这种方法,就可能把二进制文件直接读取到新的进程地址空间,并且从0开始运行。
5.rename 调用不会改变文件的创建时间和最后的修改时间,但是创建一个新的文件,其创建时间和最后的修改时间都会改为当前的系统时间。
另外,如果磁盘满,复制可能会失败。
10.由于这些被浪费的空间在分配单元(文件)之间,而不是在它们内部,因此,这是外部碎片。
这类似于交换系统或者纯分段系统中出现的外部碎片。
11.传输前的延迟是9ms,传输速率是2^23Bytes/s,文件大小是2^13Bytes,故从内存读取或写回磁盘的时间都是9+2^13/2^23=9.977ms,总共复制一个文件需要9.977*2=19.954ms。
为了压缩8G磁盘,也就是2^20个文件,每个需要19.954ms,总共就需要20,923 秒。
因此,在每个文件删除后都压缩磁盘不是一个好办法。
12.因为在系统删除的所有文件都会以碎片的形式存在磁盘中,当碎片到达一定量磁盘就不能再装文件了,必须进行外部清理,所以紧缩磁盘会释放更多的存储空间,但在每个文件删除后都压缩磁盘不是一个好办法。
15.由于1024KB = 2^20B, 所以可以容纳的磁盘地址个数是2^20/4 = 2^18个磁盘地址,间接块可以保存2^18个磁盘地址。
与 10 个直接的磁盘地址一道,最大文件有 262154 块。
由于每块为 1 MB,最大的文件是262154 MB。
19.每个磁盘地址需要D位,且有F个空闲块,故需要空闲表为DF位,采用位图法则需要B位,当DF<B时,空闲表采用的空间少于位图,当D=16时,得F/B<1/D=6.25%,即空闲空间的百分比少于6.25%.20.a)1111 1111 1111 0000b)1000 0001 1111 0000c)1111 1111 1111 1100d)1111 1110 0000 110027.平均时间T = 1*h + 40*(1-h)=-39h+40ms28.1500rpm(每分钟1500转),60s/1500=0.004s=4ms,即每转需要4ms,平均旋转延迟为2ms;读取一个k个字节的块所需要的时间T是平均寻道时间,平均旋转延迟和传送时间之和。

1.一般用户更喜欢使用的系统是()。
A.手工操作B.单道批处理C.多道批处理D.多用户分时系统2. 与计算机硬件关系最密切的软件是()。
A.编译程序B.数据库管理系统C.游戏程序D.OS3. 现代OS具有并发性和共享性,是()的引入导致的。
A.单道程序B. 磁盘C. 对象D.多道程序4. 早期的OS主要追求的是()。
A.系统的效率B.用户的方便性C.可移植D.可扩充性5.()不是多道程序系统A.单用户单任务B.多道批处理系统C.单用户多任务D.多用户分时系统6.()是多道操作系统不可缺少的硬件支持。
A.打印机B.中断机构C.软盘D.鼠标7. 特权指令可以在()执行。
A.目态B.浏览器中C.任意的时间D.进程调度中8. 没有了()计算机系统就启动不起来。
A.编译器B.DBMSC.OSD.浏览器9. 通道能够完成()之间的数据传输。
A.CPU与外设B.内存与外设C.CPU与主存D.外设与外设10. 操作系统的主要功能有()。
A.进程管理、存储器管理、设备管理、处理机管理B.虚拟存储管理、处理机管理、进程调度、文件系统C.处理机管理、存储器管理、设备管理、文件系统D.进程管理、中断管理、设备管理、文件系统11. 单处理机计算机系统中,()是并行操作的。
A.处理机的操作与通道的操作是并行的B.程序与程序C.主程序与子程序D.用户程序与操作系统程序12. 处理机的所有指令可以在()执行。
A.目态B.浏览器中C.任意的时间D.系统态13.()功能不是操作系统直接完成的功能。
A.管理计算机硬盘B.对程序进行编译C.实现虚拟存储器D.删除文件14. 要求在规定的时间内对外界的请求必须给予及时响应的OS是()。
A.多用户分时系统B.实时系统C.批处理系统时间D.网络操作系统15. 操作系统是对()进行管理的软件。
A.硬件B.软件C.计算机资源D.应用程序16.()对多用户分时系统最重要。
A.实时性B.交互性C.共享性D.运行效率17.()对多道批处理系统最重要。

现代操作系统中文答案篇一:操作系统习题答案整理】(固定分区)支持多道程序设计、管理最简单,但存储碎片多;(段式)使内存碎片尽可能少,而且使内存利用率最高。
2 为使虚存系统有效地发挥其预期的作用,所运行的程序应具有的特性是该程序应具有较好的局部性(locality)。
3 提高内存利用率主要是通过内存分配功能实现的,内存分配的基本任务是为每道程序(分配内存)。
使每道程序能在不受干扰的环境下运行,主要是通过(内存保护)功能实现的。
4 适合多道程序运行的存储管理中,存储保护是为了防止各道作业相互干扰。
5 (分段存储管理)方法有利于程序的动态链接6 在请求分页系统的页表增加了若干项,其中状态位供(程序访问)7 关于请求分段存储管理的叙述中,正确的叙述(分段的尺寸受内存空间的限制,但作业总的尺寸不受内存空间的限制)。
8 虚拟存储器的特征是基于(局部性原理)。
9 实现虚拟存储器最关键的技术是(请求调页(段))。
10“抖动”现象的发生是由(置换算法选择不当)引起的。
11 在请求分页系统的页表增加了若干项,其中修改位供(换出页面)12 虚拟存储器是程序访问比内存更大的地址空间13 测得某个请求调页的计算机系统部分状态数据为:cpu 利用率20%,用于对换空间的硬盘的利用率97.7 %,其他设备的利用率5%。
由此断定系统出现异常。
此种情况下(减少运行的进程数)能提高cpu 的利用率。
14 在请求调页系统中,若逻辑地址中的页号超过页表控制寄存器中的页表长度,则会引起(越界中断)。
15 测得某个请求调页的计算机系统部分状态数据为:cpu 利用率20%,用于对换空间的硬盘的利用率97.7 %,其他设备的利用率5%。
由此断定系统出现异常。
此种情况下(加内存条,增加物理空间容量)能提高cpu 的利用率。
16 对外存对换区的管理应以(提高换入换出速度)为主要目标,对外存文件区的管理应以(提高存储空间的利用率)为主要目标。
17 在请求调页系统中,若所需的页不在内存中,则会引起(缺页中断)。
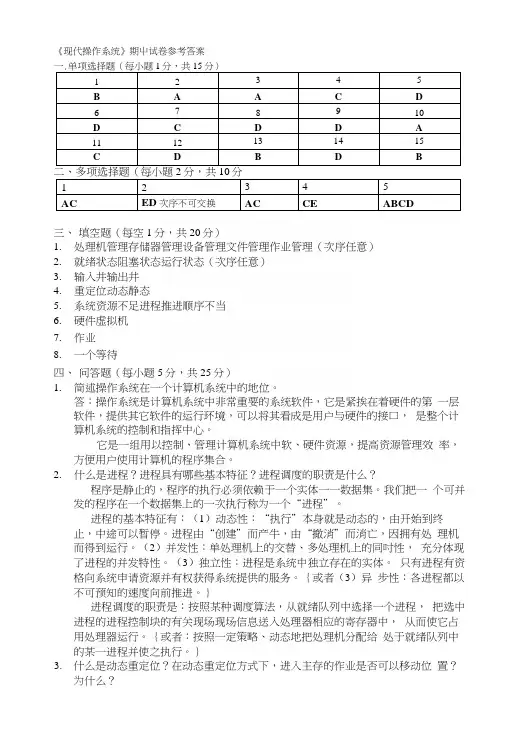
《现代操作系统》期屮试卷参考答案一.单项选择题(每小题1分,共15分)12345B A AC D678910D C D D A1112131415C D B D B二、多项选择题(每小题2分,共10分12345AC ED次序不可交换AC CE ABCD三、填空题(每空1分,共20分)1.处理机管理存储器管理设备管理文件管理作业管理(次序任意)2.就绪状态阻塞状态运行状态(次序任意)3.输入井输出井4.重定位动态静态5.系统资源不足进程推进顺序不当6.硬件虚拟机7.作业8.一个等待四、问答题(每小题5分,共25分)1.简述操作系统在一个计算机系统中的地位。
答:操作系统是计算机系统中非常重要的系统软件,它是紧挨在着硬件的第一层软件,提供其它软件的运行环境,可以将其看成是用户与硬件的接口,是整个计算机系统的控制和指挥中心。
它是一组用以控制、管理计算机系统中软、硬件资源,提高资源管理效率,方便用户使用计算机的程序集合。
2.什么是进程?进程具有哪些基本特征?进程调度的职责是什么?程序是静止的,程序的执行必须依赖于一个实体一一数据集。
我们把一个可并发的程序在一个数据集上的一次执行称为一个“进程”。
进程的基本特征有:(1)动态性:“执行”本身就是动态的,由开始到终止,中途可以暂停。
进程由“创建”而产牛,由“撤消”而消亡,因拥有处理机而得到运行。
(2)并发性:单处理机上的交替、多处理机上的同吋性,充分体现了进程的并发特性。
(3)独立性:进程是系统中独立存在的实体。
只有进程有资格向系统申请资源并有权获得系统提供的服务。
{或者(3)异步性:各进程都以不可预知的速度向前推进。
}进程调度的职责是:按照某种调度算法,从就绪队列中选择一个进程,把选中进程的进程控制块的有关现场现场信息送入处理器相应的寄存器中,从而使它占用处理器运行。
{或者:按照一定策略、动态地把处理机分配给处于就绪队列中的某一进程并使之执行。
}3.什么是动态重定位?在动态重定位方式下,进入主存的作业是否可以移动位置?为什么?答:动态重定位就是进程在装入主存吋没有做地址变换,而是到进程执行时再做虚地址到物理地址的变换。
![现代操作系统教程(慕课版)习题 6-答案[4页]](https://uimg.taocdn.com/93c4ba92fc0a79563c1ec5da50e2524de518d061.webp)
习题 61. 选择题(1)Openstack中提供身份认证的组件是(B )。
A. NovaB. KeystoneC. NeutronD. Glance(2)Openstack中的负责镜像资源管理的组件是( A )。
A.Glance B.Cinder C.Swift D.RabbitMQ(3)(A )是将系统虚拟化技术应用于服务器上,将一个服务器虚拟成若干个服务器使用。
A.服务器虚拟化B.存储虚拟化C.应用存储虚拟化D.网络虚拟化(4)Docker可以快速创建和删除( A ),实现快速迭代,大量节约开发成本。
A.容器B.虚拟机C.程序D.数据(5)( B )是嵌入在Linux操作系统内核中的一个虚拟化模块。
A.Xen B.KVM C.VMware D.Nova2. 填空题(1)(分布式计算)技术和网络通信技术的高速发展和广泛应用,通过网络将分散在各处的硬件、软件、信息资源连接成为一个整体,使得人们能够利用地理上分散于各处的资源,完成大规模、复杂的计算和数据处理任务。
(2)(私有云)是由某个机构投资、建设、拥有和管理且仅限本机构用户使用的云计算系统,提供对数据、安全性和服务质量的最有效控制,用户可以自由配置自己的服务。
(3)OpenStack中的组件与亚马逊的AWS系统中的组件有对应关系,例如Nova对应AWS 系统中的(EC2),Swift对应AWS系统中的(S3)。
(4)OpenStack中负责处理消息验证、消息转换和消息路由的模块是(RabbitMQ)。
(5)(Keystone)主要为OpenStack中的其他模块提供认证服务,提供统一的、完整的OpenStack服务目录以及令牌。
3. 简答题(1)计算服务Nova是OpenStack的重要构成组件。
请描述Nova负责完成的功能,以及所包含的主要组件及其发挥的作用。
答:Nova是OpenStack计算的弹性控制器,在OpenStack系统中,计算实例生命期所需的各种活动都将由Nova进行处理和支撑,这就意味着Nova以管理平台的身份登场,负责管理整个云的计算资源、网络、授权及测度。

第四章文件系统习题Q1:给出文件/etc/passwd的五种不同的路径名。
(提示:考虑目录项和”…。
”)A:/etc/passwd/./etc/passwd/././etc/passwd/./././etc/passwd/etc/ …/etc/passwd/etc/ …/etc/ - /etc/passwd/etc/ …/etc/ - /etc/ - /etc/passwd/etc/ …/etc/ •• /etc/ •• /etc/ …/etc/passwdQ2 :在Windows中,当用户双击资源管理器中列出的一个文件时,就会运行一个程序,并以这个文件作为参数。
操作系统要知道运行的是哪个程序,请给出两种不同的方法。
A:Windows使用文件扩展名。
每种文件扩展名对应一种文件类型和某些能处理这种类型的程序。
另一种方式时记住哪个程序创建了该文件,并运行那个程序。
Macintosh以这种方式工作。
Q3 :在早期的UNIX系统中,可执行文件(a.out )以一个非常特別的魔数开始,这个数不是随机选择的。
这些文件都有文件头,后面是正文段和数据段。
为什么要为可执行文件挑选一个非常特别的魔数,而其他类型文件的第一个字反而有一个或多或少是随机选择的魔数?A :这些系统直接把程序载入内存,并且从wordO (魔数)开始执行。
为了避免将header作为代码执行,魔数是一条branch指令,其目标地址正好在header之上。
按这种方法,就可能把二进制文件直接读取到新的进程地址空间,并且从0开始运行。
Q4:在UNIX中open系统调用绝对需要吗?如果没有会产生什么结果?A: open调用的目的是:把文件属性和磁盘地址表装入内存,便与后续调用的快速访问。
首先,如果没有open系统调用,每次读取文件都需要指定要打开的文件的名称。
系统将必须获取其i节点,虽然可以缓存它,但面临一个问题是何时将i节点写回磁盘。
可以在超时后写回磁盘,虽然这有点笨拙,但它可能起作用。
2.由题意得,读或写每个字节需要10/4 = 2.5ns,且128 MB = 2^27 字节,内存紧缩时,几乎整个内存都必须复制,也就是要求读出每一个内存字,然后重写到不同的位置。
因此,对于每个字节的压缩需要5ns。
故总共需要的时间为 2^27 * 5 ns = 671 ms 。
3.128 MB = 2^27 字节对于位图,用于存储管理需要2^27/8n字节,故总共需要 2^27 + 2^27/8n = 2^27*(1+1/8n)字节;对于链表,用于存储管理需要2^27 / 2^16(64kb)=2^11个节点,每个节点大小为需要(32+16+16)/8 = 8字节,故总共需要2^27 + 2^11*8 = 2^27 + 2^14 = 2^27 *(1 +1/(8*2^10) )字节;因此,当n < 2^10字节(即1KB)时,位图> 链表,则使用链表;当n > 1KB时,位图< 链表,则使用位图。
4.首次适配:20KB,10KB,18KB;最佳适配:12KB,10KB,9KB;最差适配:20KB,18KB,15KB;下次适配:20KB,18KB,9KB。
5.虚拟页号|偏移量虚拟地址4KB(页大小)12位偏移量8KB(页大小)13位偏移量20000 100|111000100000 10|0111000100000 32768 1000|000000000000 100|0000000000000 60000 1110|101001100000 111|01010011000007.a)M的最小值是4096,才能使内层循环的每次执行时都引起TLB失效,N的值只会影响到X的循环次数,与TLB失效无关。
b)M的值应该大于4096才能在内层循环每次执行时引起TLB失效,但现在N 的值要大于64K,所以X会超过256KB。
9.页大小为8KB,所以页內地址为13位,故页框有19位,可表示的物理空间有2^19个页框。
第一章1.设计现代OS的主要目标是什么?答:(1)有效性(2)方便性(3)可扩充性(4)开放性2.OS的作用可表现在哪几个方面?答:(1)OS作为用户与计算机硬件系统之间的接口(2)OS作为计算机系统资源的管理者(3)OS实现了对计算机资源的抽象3.为什么说OS实现了对计算机资源的抽象?答:OS首先在裸机上覆盖一层I/O设备管理软件,实现了对计算机硬件操作的第一层次抽象;在第一层软件上再覆盖文件管理软件,实现了对硬件资源操作的第二层次抽象。
OS 通过在计算机硬件上安装多层系统软件,增强了系统功能,隐藏了对硬件操作的细节,由它们共同实现了对计算机资源的抽象。
4.试说明推动多道批处理系统形成和发展的主要动力是什么?答:主要动力来源于四个方面的社会需求与技术发展:(1)不断提高计算机资源的利用率;(2)方便用户;(3)器件的不断更新换代;(4)计算机体系结构的不断发展。
5.何谓脱机I/O和联机I/O?答:脱机I/O 是指事先将装有用户程序和数据的纸带或卡片装入纸带输入机或卡片机,在外围机的控制下,把纸带或卡片上的数据或程序输入到磁带上。
该方式下的输入输出由外围机控制完成,是在脱离主机的情况下进行的。
而联机I/O方式是指程序和数据的输入输出都是在主机的直接控制下进行的。
6.试说明推动分时系统形成和发展的主要动力是什么?答:推动分时系统形成和发展的主要动力是更好地满足用户的需要。
主要表现在:CPU 的分时使用缩短了作业的平均周转时间;人机交互能力使用户能直接控制自己的作业;主机的共享使多用户能同时使用同一台计算机,独立地处理自己的作业。
7.实现分时系统的关键问题是什么?应如何解决?答:关键问题是当用户在自己的终端上键入命令时,系统应能及时接收并及时处理该命令,在用户能接受的时延内将结果返回给用户。
解决方法:针对及时接收问题,可以在系统中设置多路卡,使主机能同时接收用户从各个终端上输入的数据;为每个终端配置缓冲区,暂存用户键入的命令或数据。
现代操作系统第四版答案SANY标准化小组 #QS8QHH-HHGX8Q8-GNHHJ8-HHMHGN#第五章输入/输出习题1.芯片技术的进展已经使得将整个控制器包括所有总线访问逻辑放在一个便宜的芯片上成为可能。
这对于图1-5的模型具有什么影响?答:(题目有问题,应该是图1-6)在此图中,一个控制器有两个设备。
单个控制器可以有多个设备就无需每个设备都有一个控制器。
如果控制器变得几乎是自由的,那么只需把控制器做入设备本身就行了。
这种设计同样也可以并行多个传输,因而也获得较好的性能。
2.已知图5-1列出的速度,是否可能以全速从一台扫描仪扫描文档并且通过802.1lg网络对其进行传输请解释你的答案。
答:太简单了。
扫描仪最高速率为400KB/Sec,而总线程和磁盘都为16.7MB/sec,因此磁盘和总线都无法饱和。
3.图5-3b显示了即使在存在单独的总线用于内存和用于I/O设备的情况下使用内存映射I/O的一种方法,也就是说,首先尝试内存总线,如果失败则尝试I/O总线。
一名聪明的计算机科学专业的学生想出了一个改进办法:并行地尝试两个总线,以加快访问I/O设备的过程。
你认为这个想法如何?答:这不是一个好主意。
内存总线肯定比I/O总线快。
一般的内存请求总是内存总线先完成,而I/O总线仍然忙碌。
如果CPU要一直等待I/O总线完成,那就是将内存的性能降低为I/O总线的水平。
4.假设一个系统使用DMA将数据从磁盘控制器传送到内存。
进一步假设平均花费t2ns获得总线,并且花费t1ns在总线上传送一个字(t1>>t2)。
在CPU对DMA控制器进行编程之后,如果(a)采用一次一字模式,(b)采用突发模式,从磁盘控制器到内存传送1000个字需要多少时间?假设向磁盘控制器发送命令需要获取总线以传输一个字,并且应答传输也需要获取总线以传输一个字。
答:(a)1000×[(t1+t2)+(t1+t2)+(t1+t2)];第一个(t1+t2)是获取总线并将命令发送到磁盘控制器,第二个(t1+t2)是用于传输字,第三个(t1+t2)是为了确认。
《现代操作系统第四版》第三章答案第三章内存管理习题1.IBM360 有⼀个设计,为了对2KB ⼤⼩的块进⾏加锁,会对每个块分配⼀个4bit 的密钥,这个密钥存在PSW(程序状态字)中,每次内存引⽤时,CPU 都会进⾏密钥⽐较。
但该设计有诸多缺陷,除了描述中所⾔,请另外提出⾄少两条缺点。
A:密钥只有四位,故内存只能同时容纳最多⼗六个进程;需要⽤特殊硬件进⾏⽐较,同时保证操作迅速。
2. 在图3-3 中基址和界限寄存器含有相同的值16384 ,这是巧合,还是它们总是相等?如果这只是巧合,为什么在这个例⼦⾥它们是相等的?A:巧合。
基地址寄存器的值是进程在内存上加载的地址;界限寄存器指⽰存储区的长度。
3. 交换系统通过紧缩来消除空闲区。
假设有很多空闲区和数据段随机分布,并且读或写32 位长的字需要10ns 的时间,紧缩128MB ⼤概需要多长时间?为了简单起见,假设空闲区中含有字0,内存中最⾼地址处含有有效数据。
A:32bit=4Byte===> 每字节10/4=2.5ns 128MB=1282^20=2^27Byte 对每个字节既要读⼜要写,22.5*2^27=671ms4. 在⼀个交换系统中,按内存地址排列的空闲区⼤⼩是10MB ,4MB,20MB ,18MB,7MB,9MB,12MB,和15MB 。
对于连续的段请求:(a) 12MB(b) 10MB(c) 9MB 使⽤⾸次适配算法,将找出哪个空闲区?使⽤最佳适配、最差适配、下次适配算法呢?A:⾸次适配算法:20MB ,10MB ,18MB ;最佳适配算法:12MB ,10MB ,9MB;最差适配算法:20MB ;18MB ;15MB ;下次适配算法:20MB ;18MB ;9MB;5. 物理地址和虚拟地址有什么区别?A:实际内存使⽤物理地址。
这些是存储器芯⽚在总线上反应的数字。
虚拟地址是指⼀个进程的地址空间的逻辑地址。
因此,具有32 位字的机器可以⽣成⾼达4GB 的虚拟地址,⽽不管机器的内存是否多于或少于4GB。
现代操作系统课后答案【篇一:现代操作系统习题答案】>(汤小丹编电子工业出版社2008.4)第1章操作系统引论习题及答案1.11 os有哪几大特征?其最基本的特征是什么?答:并发、共享、虚拟和异步四个基本特征,其中最基本的特征是并发和共享。
1.15 处理机管理有哪些主要功能?其主要任务是什么?答案略,见p17。
1.22 (1)微内核操作系统具有哪些优点?它为何能有这些优点?(2)现代操作系统较之传统操作系统又增加了哪些功能和特征?第2章进程的描述与控制习题及答案略第3章进程的同步与通信习题及答案3.9 在生产者-消费者问题中,如果缺少了signal(full)或signal(empty),对执行结果将会有何影响?答:资源信号量full表示缓冲区中被占用存储单元的数目,其初值为0,资源信号量empty表示缓冲区中空存储单元的数目,其初值为n,signal(full)在生产者进程中,如果在生产者进程中缺少了signal(full),致使消费者进程一直阻塞等待而无法消费由生产者进程生产的数据;signal(empty)在消费者进程中,如果在消费者进程中缺少了signal(empty),致使生产者进程一直阻塞等待而无法将生产的数据放入缓冲区。
3.13 试利用记录型信号量写出一个不会出现死锁的哲学家进餐问题的算法。
答:参考答案一:至多只允许有四位哲学家同时去拿左边的筷子,最终能保证至少有一位哲学家能够进餐,并在用毕时能释放出他用过的两支筷子,从而使更多的哲学家能够进餐。
采用此方案的算法如下:var chopstick:array[0,…,4] of semaphore :=1;room:semphore:=4;repeatwait(room);wait(chopstick[i]);wait(chopstick[(i+1) mod 5]);…eat;…signal(chopstick[i]);signal(chopstick[(i+1) mod 5);signal(room);…think;until false;第4章处理机调度与死锁习题及答案4.1 高级调度与低级调度的主要任务是什么?为什么要引入中级调度?答:略,见p73。
第五章输入/输出习题1.芯片技术的进展已经使得将整个控制器包括所有总线访问逻辑放在一个便宜的芯片上成为可能。
这对于图1-5的模型具有什么影响?答:(题目有问题,应该是图1-6)在此图中,一个控制器有两个设备。
单个控制器可以有多个设备就无需每个设备都有一个控制器。
如果控制器变得几乎是自由的,那么只需把控制器做入设备本身就行了。
这种设计同样也可以并行多个传输,因而也获得较好的性能。
2.已知图5-1列出的速度,是否可能以全速从一台扫描仪扫描文档并且通过802.1lg网络对其进行传输请解释你的答案。
答:太简单了。
扫描仪最高速率为400KB/Sec,而总线程和磁盘都为16.7MB/sec,因此磁盘和总线都无法饱和。
3.图5-3b显示了即使在存在单独的总线用于内存和用于I/O设备的情况下使用内存映射I/O的一种方法,也就是说,首先尝试内存总线,如果失败则尝试I/O 总线。
一名聪明的计算机科学专业的学生想出了一个改进办法:并行地尝试两个总线,以加快访问I/O设备的过程。
你认为这个想法如何?答:这不是一个好主意。
内存总线肯定比I/O总线快。
一般的内存请求总是内存总线先完成,而I/O总线仍然忙碌。
如果CPU要一直等待I/O总线完成,那就是将内存的性能降低为I/O总线的水平。
4.假设一个系统使用DMA将数据从磁盘控制器传送到内存。
进一步假设平均花费t2ns获得总线,并且花费t1ns在总线上传送一个字(t1>>t2)。
在CPU对DMA控制器进行编程之后,如果(a)采用一次一字模式,(b)采用突发模式,从磁盘控制器到内存传送1000个字需要多少时间?假设向磁盘控制器发送命令需要获取总线以传输一个字,并且应答传输也需要获取总线以传输一个字。
答:(a)1000×[(t1+t2)+(t1+t2)+(t1+t2)];第一个(t1+t2)是获取总线并将命令发送到磁盘控制器,第二个(t1+t2)是用于传输字,第三个(t1+t2)是为了确认。
第一章:1. Multiprogramming is the rapid switching of the CPU between multiple processes in memory. It is commonly used to keep the CPU busy while one ormore processes are doing I/O.2. Input spooling is the technique of reading in jobs, for example, from cards,onto the disk, so that when the currently executing processes are finished,there will be work waiting for the CPU. Output spooling consists of firstcopying printable files to disk before printing them, rather than printing directlyas the output is generated. Input spooling on a personal computer is notvery likely, but output spooling is.3. The prime reason for multiprogramming is to give the CPU something to do while waiting for I/O to complete. If there is no DMA, the CPU is fully occupied doing I/O, so there is nothing to be gained (at least in terms of CPU utilization)by multiprogramming. No matter how much I/O a program does, theCPU will be 100% busy. This of course assumes the major delay is the waitwhile data are copied. A CPU could do other work if the I/O were slow forother reasons (arriving on a serial line, for instance).7. Choices (a), (c), and (d) should be restricted to kernel mode.9. Every nanosecond one instruction emerges from the pipeline. This means the machine is executing 1 billion instructions per second. It does not matter atall how many stages the pipeline has. A 10-stage pipeline with 1 nsec perstage would also execute 1 billion instructions per second. All that matters ishow often a finished instruction pops out the end of the pipeline.10. Average access time =0.95 × 2 nsec (word is cache)+ 0.05 × 0.99 × 10 nsec (word is in RAM, but not in cache)+ 0.05 × 0.01 × 10,000,000 nsec (word on disk only)= 5002.395 nsec= 5.002395 μsec13. A trap instruction switches the execution mode of a CPU from the user modeto the kernel mode. This instruction allows a user program to invoke functionsin the operating system kernel.14. A trap is caused by the program and is synchronous with it. If the program is run again and again, the trap will always occur at exactly the same position inthe instruction stream. An interrupt is caused by an external event and itstiming is not reproducible.15. The process table is needed to store the state of a process that is currently suspended, either ready or blocked. It is not needed in a single process system because the single process is never suspended.17. A system call allows a user process to access and execute operating system functions inside the kernel. User programs use system calls to invoke operating system services.(一)21. Time to retrieve the file =1 * 50 ms (Time to move the arm over track # 50)+ 5 ms (Time for the first sector to rotate under the head)+ 10/100 * 1000 ms (Read 10 MB)= 155 ms23. System calls do not really have names, other than in a documentation sense. When the library procedure read traps to the kernel, it puts the number of the system call in a register or on the stack. This number is used to index into a table. There is really no name used anywhere. On the other hand, the nameof the library procedure is very important, since that is what appears in the program.第二章:3. Generally, high-level languages do not allow the kind of access to CPU hardware that is required. For instance, an interrupt handler may be required toenable and disable the interrupt servicing a particular device, or to manipulate data within a process’ stack area. Also, interrupt service routines must executeas rapidly as possible.4. There are several reasons for using a separate stack for the kernel. Two ofthem are as follows. First, you do not want the operating system to crash becausea poorly written user program does not allow for enough stack space.Second, if the kernel leaves stack data in a user program’s memory spaceupon return from a system call, a malicious user might be able to use this datato find out information about other processes.12. User-level threads cannot be preempted by the clock unless the whole process’quantum has been used up. Kernel-level threads can be preempted individually.In the latter case, if a thread runs too long, the clock will interrupt thecurrent process and thus the current thread. The kernel is free to pick a different thread from the same process to run next if it so desires.14. The biggest advantage is the efficiency. No traps to the kernel are needed to switch threads. The biggest disadvantage is that if one thread blocks, the entire process blocks.17. It could happen that the runtime system is precisely at the point of blocking or unblocking a thread, and is busy manipulating the scheduling queues. Thiswould be a very inopportune moment for the clock interrupt handler to begin inspecting those queues to see if it was time to do thread switching, since they might be in an inconsistent state. One solution is to set a flag when the runtime system is entered. The clock handler would see this and set its own flag,then return. When the runtime system finished, it would check the clock flag,see that a clock interrupt occurred, and now run the clock handler.18. Yes it is possible, but inefficient. A thread wanting to do a system call first sets an alarm timer, then does the call. If the call blocks, the timer returnscontrol to the threads package. Of course, most of the time the call will not block, and the timer has to be cleared. Thus each system call that might block(二)has to be executed as three system calls. If timers go off prematurely, all kinds of problems can develop. This is not an attractive way to build athreads package.21. Each thread calls procedures on its own, so it must have its own stack for the local variables, return addresses, and so on. This is equally true for user-level threads as for kernel-level threads.28. With kernel threads, a thread can block on a semaphore and the kernel can run some other thread in the same process. Consequently, there is no problem using semaphores. With user-level threads, when one thread blocks on a semaphore, the kernel thinks the entire process is blocked and does not run it ever again. Consequently, the process fails.37. For round robin, during the first 10 minutes each job gets 1/5 of the CPU. At the end of 10 minutes, C finishes. During the next 8 minutes, each job gets 1/4 of the CPU, after which time D finishes. Then each of the three remainingjobs gets 1/3 of the CPU for 6 minutes, until B finishes, and so on. The finishing times for the five jobs are 10, 18, 24, 28, and 30, for an average of 22 minutes. For priority scheduling, B is run first. After 6 minutes it is finished. The other jobs finish at 14, 24, 26, and 30, for an average of 18.8 minutes. If the jobs run in the order A through E, they finish at 10, 16, 18, 22, and 30, for an average of 19.2 minutes. Finally, shortest job first yields finishing times of 2, 6, 12, 20, and 30, for an average of 14 minutes.第三章:2. Almost the entire memory has to be copied, which requires each word to be read and then rewritten at a different location. Reading 4 bytes takes 10 nsec,so reading 1 byte takes 2.5 nsec and writing it takes another 2.5 nsec, for atotal of 5 nsec per byte compacted. This is a rate of 200,000,000 bytes/sec.To copy 128 MB (227 bytes, which is about 1.34 × 108 bytes), the computer needs 227 /200,000,000 sec, which is about 671 msec. This number is slightly pessimistic because if the initial hole at the bottom of memory is k bytes,those k bytes do not need to be copied. However, if there are many holes and many data segments, the holes will be small, so k will be small and the errorin the calculation will also be small.3. The bitmap needs 1 bit per allocation unit. With 227 /n allocation units, this is 224 /n bytes. The linked list has 227 /216 or 211 nodes, each of 8 bytes, for atotal of 214 bytes. For small n, the linked list is better. For large n, the bitmapis better. The crossover point can be calculated by equating these two formulas and solving for n. The result is 1 KB. For n smaller than 1 KB, a linkedlist is better. For n larger than 1 KB, a bitmap is better. Of course, the assumption of segments and holes alternating every 64 KB is very unrealistic. Also, we need n <= 64 KB if the segments and holes are 64 KB.4. First fit takes 20 KB, 10 KB, 18 KB. Best fit takes 12 KB, 10 KB, and 9 KB. Worst fit takes 20 KB, 18 KB, and 15 KB. Next fit takes 20 KB, 18 KB, and 9 KB.(三)5. For a 4-KB page size the (page, offset) pairs are (4, 3616), (8, 0), and (14, 2656). For an 8-KB page size they are (2, 3616), (4, 0), and (7, 2656).28. NRU removes page 2. FIFO removes page 3. LRU removes page 1. Second chance removes page 2.第四章:11. It takes 9 msec to start the transfer. To read 213 bytes at a transfer rate of 223 bytes/sec requires 2−10 sec (977 msec), for a total of 9.977 msec. Writing itback takes another 9.977 msec. Thus copying a file takes 19.954 msec. To compact half of a 16-GB disk would involve copying 8 GB of storage, whichis 220 files. At 19.954 msec per file, this takes 20,923 sec, which is 5.8 hours. Clearly, compacting the disk after every file removal is not a great idea.19. The bitmap requires B bits. The free list requires DF bits. The free list requires fewer bits if DF < B. Alternatively, the free list is shorter ifF/B < 1/D, where F/B is the fraction of blocks free. For 16-bit disk addresses,the free list is shorter if 6% or less of the disk is free.20. The beginning of the bitmap looks like:(a) After writing file B: 1111 1111 1111 0000(b) After deleting file A: 1000 0001 1111 0000(c) After writing file C: 1111 1111 1111 1100(d) After deleting file B: 1111 1110 0000 110021. It is not a serious problem at all. Repair is straightforward; it just takes time. The recovery algorithm is to make a list of all the blocks in all the files andtake the complement as the new free list. In UNIX this can be done by scanningall the i-nodes. In the FAT file system, the problem cannot occur becausethere is no free list. But even if there were, all that would have to bedone to recover it is to scan the FA T looking for free entries.28. At 15,000 rpm, the disk takes 4 msec to go around once. The average access time (in msec) to read k bytes is then 8 + 2 + (k /262144) × 4. For blocks of 1 KB, 2 KB, and 4 KB, the access times are 10.015625 msec, 10.03125 msec,and 10.0625 msec, respectively (hardly any different). These give rates ofabout 102,240 KB/sec, 204,162 KB/sec, and 407,056 KB/sec, respectively.29. If all files were 1 KB, then each 2-KB block would contain one file and 1 KB of wasted space. Trying to put two files in a block is not allowed because theunit used to keep track of data is the block, not the semiblock. This leads to50% wasted space. In practice, every file system has large files as well asmany small ones, and these files use the disk much more efficiently. For example, a 32,769-byte file would use 17 disk blocks for storage, given a spaceefficiency of 32768/34816, which is about 94%.33. The following disk reads are needed:directory for /i-node for /usrdirectory for /usri-node for /usr/ast(四)directory for /usr/asti-node for /usr/ast/coursesdirectory for /usr/ast/coursesi-node for /usr/ast/courses/osdirectory for /usr/ast/courses/osi-node for /usr/ast/courses/os/handout.tIn total, 10 disk reads are required.第五章:11. (a) Device driver.(b) Device driver.(c) Device-independent software.(d) User-level software.24. (a) 10 + 12 + 2 + 18 + 38 + 34 + 32 = 146 cylinders = 876 msec.(b) 0 + 2 + 12 + 4 + 4 + 36 +2 = 60 cylinders = 360 msec.(c) 0 + 2 + 16 + 2 + 30 + 4 + 4 = 58 cylinders = 348 msec.25. In the worst case, a read/write request is not serviced for almost two full disk scans in the elevator algorithm, while it is at most one full disk scan in the modified algorithm.28. Two msec 60 times a second is 120 msec/sec, or 12% of the CPU。