导入dmp文件到本地后,存储过程里中文显示问号乱
- 格式:doc
- 大小:29.00 KB
- 文档页数:6

中文乱码解决方案一、引言随着全球化进程的加速,跨国交流和跨文化交流变得越来越频繁。
作为全球最大的人口国家之一,中国在国际交流中发挥着重要的作用。
然而,在跨文化交流的过程中,我们常常会遇到一个共同的问题,即中文乱码。
中文乱码是指在计算机系统中,由于编码方式不兼容或设置错误,导致中文字符无法正确显示的现象。
本文将介绍一些常见的中文乱码问题以及解决方案。
二、常见中文乱码问题及原因1. 网页中出现乱码在浏览网页时,我们经常会遇到中文乱码的问题,这主要是由于网页编码方式不兼容或设置错误所引起的。
常见的编码方式包括UTF-8、GBK、GB2312等,如果网页编码方式与浏览器设置的编码方式不一致,就会导致中文字符无法正确显示。
2. 文本文件打开后乱码当我们使用文本编辑器打开一个文本文件时,如果文件的编码方式与编辑器的默认编码方式不一致,就会导致文件内容显示为乱码。
常见的文本文件编码方式有UTF-8、GBK、GB2312等。
3. 数据库中存储的中文乱码在数据库中存储中文信息时,如果数据库的编码方式设置不正确,就会导致存储的中文字符显示为乱码。
常见的数据库编码方式有UTF-8、GBK、GB2312等。
三、中文乱码解决方案1. 网页中文乱码解决方案(1)设置浏览器编码方式:在浏览器的设置选项中,找到编码方式(通常在“字符编码”、“编码”或“语言”选项下),将其设置为与网页编码方式一致的选项,如将编码方式设置为UTF-8。
(2)手动指定网页编码:如果网页上没有明确设置编码方式的选项,可以尝试在浏览器地址栏中手动添加编码方式,如在URL后面添加“?charset=utf-8”。
2. 文本文件乱码解决方案(1)使用支持多种编码方式的文本编辑器:选择一个支持多种编码方式的文本编辑器,如Notepad++、Sublime Text等。
在打开文本文件时,可以手动选择文件的编码方式来正确显示内容。
(2)重新保存文件:将文本文件另存为选项,选择正确的编码方式,再重新打开文件即可解决乱码问题。

oracle中文乱码解决方法1. Oracle数据库设置数据库参数NLS_LANG为使Oracle数据库中存储与显示中文时无乱码问题,可以更改Oracle数据库的数据库参数NLS_LANG,更改该参数为中文字符集,如:simplified Chinese_China.ZHS16GBK,此参数设置会对数据库中的所有字符数据有效。
2. Oracle数据库中多个字符集混用的解决方案一般系统及数据库常用的字符集可能存在多样性,例如全角字符、英文字母、空格等,而Oracle数据库支持了多个字符集,用户可以在数据库中多个字符集混合使用。
例如,用UTF8字符集对中文、英文、全角字符编码;用UTF16字符集对Unicode字符编码;用GBK/GB2312字符集对中文字符编码。
3. 注意SQL语句及字符集的指定为了防止运行SQL语句时出现乱码,应当在SQL语句中指定运行的字符集,如:ALTER SESSION SET NLS_LANGUAGE=AMERICAN_AMERICA.AL32UTF84. 客户端应用指定编码格式对于客户端应用,如sqlplus、PL/SQL开发工具,需要在连接之前指定客户端编码格式以确保传输与显示时无乱码问题,这种解决方案比较常用,在客户端应用中设置NLS_LANG参数,让客户端的中文字符使用Unicode,例如: NLS_LANG = SIMPLIFIED CHINESE_CHINA.UTF8 即可成功连接Oracle数据库解决乱码问题。
5. 数据导入导出中文处理从其他数据库导入Oracle数据库时,应从源数据库中查找出字段编码,在导入时将字段编码转换成Oracle数据库中的字符编码,可以增加数据库中文字符的正常显示。
从Oracle数据库导出数据至其他数据库,应将 Oracle 数据库中的字符编码转换成目标数据库的编码方式,以保证导出数据无乱码状况。
6. 中文乱码的原因分析中文乱码的常见原因之一是程序的编码格式未正确设置,将GBK/GB2312等字符集与UTF-8 等Unicode字符集混用,也会出现中文乱码的情况。

本文由我司收集整编,推荐下载,如有疑问,请与我司联系oracle数据库中文乱码的原因与解决2008/10/23 54423 资料: 很久以来,字符集一直是困扰着众多Oracle爱好者的问题,在此我们就这个问题做一些分析和探讨。
首先,我们要明确什么是字符集?字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包括关系,如us7ascii就是zhs16gbk的子集,从us7ascii到zhs16gbk不会有数据解释上的问题,不会有数据丢失,Oracle对这种问题也要求从子集到超集的导出受支持,反之不行。
在所有的字符集中utf8应该是最大,因为它基于unicode,双字节保存字符(也因此在存储空间上占用更多)。
其次,一旦数据库创建后,数据库的字符集是不能改变的。
因此,在设计和安装之初考虑使用哪一种字符集是十分重要的。
数据库字符集应该是操作系统本地字符集的一个超集。
存取数据库的客户使用的字符集将决定选择哪一个超集,即数据库字符集应该是所有客户字符集的超集。
在实际应用中,和字符集问题关系最大的恐怕就是exp/imp了。
在做exp/imp时,如果Client 和Server的nls_lang设置是一样的,一般就没有问题的。
但是,要在两个不同字符集的系统之间导数据就经常会有这样或那样的问题,如,导出时数据库的显示正常,是中文,当导入到其他系统时,就成了乱码,这也是一类常见问题。
现在,介绍一些与字符集有关的NLS_LANG参数,NLS_LANG格式:NLS_LANG = language_territory.charset 有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。
其中:language 指定服务器消息的语言。
territory 指定服务器的日期和数字格式。
charset 指定字符集例如:AMERICAN_7SCII AMERICAN _ AMERICA. ZHS16GBK 还有一些子集可以更明确定义NLS_LANG参数:DICT.BASE 数据字典基本表版本DBTIMEZONE 数据库时区NLS_LANGUAGE 语言NLS_TERRITORY 地域NLS_CURRENCY 本地货币字符NLS_ISO_CURRENCY ISO货币字符NLS_NUMERIC_CHARACTERS 小数字符和组分隔开NLS_CHARACTERSET 字符集NLS_CALENDAR 日历系统NLS_DATE_FORMAT 缺省的日期格式NLS_DATE_LANGUAGE 缺省的日期语。


中文乱码的解决方法在进行中文文本处理过程中,可能会遇到乱码的情况,这主要是由于使用了不兼容的编码格式或者在数据传输过程中出现了错误。
下面是一些解决中文乱码问题的方法:1.使用正确的编码方式2.修改文件编码如果已经打开了一个包含乱码的文本文件,可以通过修改文件编码方式来解决问题。
例如,在记事本软件中,可以尝试选择“另存为”功能,并将编码方式改为UTF-8,然后重新保存文件,这样就可以解决乱码问题。
3.检查网页编码当浏览网页时遇到乱码问题,可以在浏览器的“查看”或“选项”菜单中找到“编码”选项,并将其设置为正确的编码方式(例如UTF-8),刷新网页后,乱码问题通常会得到解决。
5.使用转码工具如果已经得知文件的原始编码方式但无法通过其他方式解决乱码问题,可以尝试使用一些转码工具来将文件以正确的编码方式转换。
例如,iconv是一款常用的转码工具,可以在命令行界面下使用。
6.检查数据传输过程在进行数据传输时,特别是在网络传输中,可能会出现数据传输错误导致中文乱码。
可以检查数据传输过程中的设置和参数,确保传输过程中不会造成乱码问题。
7.检查数据库和应用程序设置在进行数据库操作和应用程序开发时,也可能会出现中文乱码问题。
可以检查数据库和应用程序的设置,确保正确地处理和显示中文字符。
8.清除特殊字符和格式有时候,中文乱码问题可能是由于文本中存在特殊字符或格式导致的。
可以尝试清除文本中的特殊字符和格式,然后重新保存或传输文件,看是否能够解决乱码问题。
总结起来,解决中文乱码问题的关键是了解文件的编码方式,并确保在处理过程中使用相同的编码方式。
此外,要注意数据传输过程中的设置和参数,以及数据库和应用程序的设置,确保正确地处理和显示中文字符。
最后,如果以上方法仍然无法解决乱码问题,可以尝试使用专业的转码工具来转换文件的编码方式。

我有一个的dmp文件,是从字符集ZHS16GBK的oracle10g的数据库中导出的,现在要导入的oracle10g,字符集是WE8ISO8859P1的数据库中,直接导入后数据中的中文乱码,查了一些资料做了以下测试,1,将客户端(客户端是windows2003)的字符集改为WE8ISO8859P1,从客户端导入,(修改注册表项NLS_LANG)2,从服务器端导入(服务器系统是rethat5,系统变量NLS_LANG=american_america.WE8ISO8859P1)。
注:服务器端NLS_LANG设成其他的字符集就登录不了数据库,用select userenv('language') from dual查看字符集是:SIMPLIFIED CHINESE_CHINA.WE8ISO8859P13,修改dmp文件第2,3字节为001f,然后导入,注:原来是0354,通过select nls_charset_name(to_number('0354','xxxx')) from dual查看是ZHS16GBK字符集,通过select to_char(nls_charset_id('WE8ISO8859P1'), 'xxxx') from dual查的WE8ISO8859P1字符集id是001f4,修改服务器字符集,提示信息:new character set must be a superset of old character set,我理解是WE8ISO8859P1是ZHS16GBK的超集,字符集只能从子集改成超集,不能从超集改成子集,以上几种方法导入后中文还是乱码,请哪位高手指点指点,另问一下客户端字符集是ZHS16GBK时imp提示信息中文显示正常,改为WE8ISO8859P1时提示信息中文乱码,我服务器的字符集是WE8ISO8859P1,怎样既让客户端字符集与服务器端保持一致,又可以使那些工具的中文显示正常你在导入的时候要保证3者之间的字符集一致客户端在windows平台下,就是注册表里面相应OracleHome的NLS_LANG。

中文转码乱码规律-概述说明以及解释1.引言1.1 概述概述部分:中文乱码是指在文本处理过程中因编码格式不统一导致中文字符显示不正确的现象。
在数字化时代,人们越来越频繁地在互联网上进行文字交流,而中文乱码问题也随之变得更加普遍。
中文乱码的产生源于多方面原因,例如使用不同的编码格式、系统之间的不兼容性、网页编码错误等。
为了有效解决中文乱码问题,我们需要深入了解其产生原因和解决方法,以便更好地处理和显示中文文本。
本文将探讨中文乱码的原因、现象及解决方法,希望能帮助读者更好地理解和处理中文乱码问题。
1.2文章结构文章结构部分的内容:本文共分为引言、正文和结论三部分。
在引言部分,将介绍本文的概述、文章结构和目的;在正文部分,将详细讨论中文乱码产生原因、中文乱码现象和中文乱码解决方法;最后在结论部分,对本文进行总结、归纳并展望未来研究方向。
整个文章结构清晰,逻辑严谨,旨在全面而系统地讨论中文转码乱码规律相关问题。
1.3 目的本文旨在探讨中文转码乱码现象的规律和机制,通过对中文乱码产生原因、现象以及解决方法的分析,希望能够帮助读者更好地理解和解决在日常使用电脑、网络等场景中遇到的中文乱码问题。
同时,也旨在引起更多人对中文乱码问题的关注,促进相关技术的改进和提升,提升中文信息传输的效率和准确性。
通过深入研究和讨论,希望能够为解决中文乱码问题提供一些新的思路和方法。
2.正文2.1 中文乱码产生原因中文乱码产生的主要原因可以归纳为以下几点:1.字符编码不一致:在传输过程中,如果发送端和接收端使用的字符编码不一致,就会导致中文乱码。
例如,发送端使用UTF-8编码发送数据,而接收端使用GBK编码接收数据,就会出现乱码现象。
2.文本信息传输过程中被篡改:在信息传输过程中,可能会经过多个中间节点,如果有中间节点对文本信息进行了篡改,可能会导致中文乱码。
3.文件格式不匹配:如果在打开文件时使用的解码器与文件本身的编码格式不匹配,也会导致中文乱码。

数据库出现乱码的原因和解决办法数据库出现乱码的原因和解决办法“在SQL*Plus中insert进的都是中文的,为什么一存入服务器后,再select出的就是”“有的时候,服务器数据先导出,重装服务器,再导入数据,结果,发生数据查询成”……这些问题,一般,是因为字符集设置不对照成的。
很久以来,字符集一直是困扰着众多Oracle爱好者的问题,笔者从事Oracle数据库管理和应用已经几年了,经常接到客户的类似上面提到的有关数据库字符集的“告急”和“求救”,今天,就这个问题打算做一些分析和探讨。
首先,我们要明确什么是字符集?字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包括关系,如us7ascii就是zhs16gbk 的子集,从us7ascii到zhs16gbk不会有数据解释上的问题,不会有数据丢失,oracle对这种问题也要求从子集到超集的导出受支持,反之不行。
在所有的字符集中utf8应该是最大,因为它基于unicode,双字节保存字符(也因此在存储空间上占用更多)。
其次,一旦数据库创建后,数据库的字符集是不能改变的。
因此,在设计和安装之初考虑使用哪一种字符集是十分重要的。
数据库字符集应该是操作系统本地字符集的一个超集。
存取数据库的客户使用的字符集将决定选择哪一个超集,即数据库字符集应该是所有客户字符集的超集。
在实际的应用中,和字符集问题最相关的恐怕就是exp/imp了。
在做exp/imp是,如果client 和server的nls_lang设置是一样的,一般就没有问题。
但是,要在两个不同字符集的系统之间导数据就经常会有这样那样的问题,如,导出时数据库的显示正常,是中文,当导入到其他系统时,就成了乱码,这也是一类常见问题。
对于这个问题,有一个常用的转换方法,首先用一个二进制编辑器(如,UltraEdit)察看到出文件(DMP文件)的第二和第三字节,这两个字节的内容是服务器端的字符集,比如0001,那么在数据库中查找出它代表的字符集:然后,如果在导入数据时需要修改为ZHS16GBK,我们就需要知道如何修改这两个字节才能让他们和ZHS16GBK对应:因此,可以将这两个字节手工修改为0354(不足4位时前面补0),然后就可以正常导入数据了。

Oracle数据库工具中文显示乱码问题的解决Oracle客户端查询工具有时会有查处的结果为中文时不能正常显示,要么为乱码,要么为问号,plsql出现这种问题,以为是版本造成的,用了老的和最新的还是一样,换了另外的数据库工具也一样,但注意一点,数据其实是没有问题的,取出来显示是正常的中文,只是在工具里显示的是问号。
其实问题的原理很简单,就是字符集设置不正确造成的,但如此简单的原理在解决的过程中却会遇到很多麻烦,下面结合我遇到和解决的过程,给朋友们一点思路,说不定你们跟我的问题一样,通过这篇文章不用再折腾了,很快搞定,感觉飘飘……首先讲讲字符集的知识,Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。
ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。
它使数据库工具,错误消息,排序次序,日期,时间,货币,数字,和日历自动适应本地化语言和平台。
影响oracle数据库字符集最重要的参数是NLS_LANG参数。
它的格式如下:NLS_LANG = language_territory.charset它有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。
其中: Language 指定服务器消息的语言,territory 指定服务器的日期和数字格式,charset 指定字符集。
如:AMERICAN _ AMERICA. ZHS16GBK。
从NLS_LANG的组成我们可以看出,真正影响数据库字符集的其实是第三部分。
所以两个数据库之间的字符集只要第三部分一样就可以相互导入导出数据,前面影响的只是提示信息是中文还是英文。
如何查询Oracle的字符集,很多人都碰到过因为字符集不同而使数据导入失败的情况。
这涉及三方面的字符集,一是oracel server端的字符集,二是oracle client端的字符集;三是dmp文件的字符集。
在做数据导入的时候,需要这三个字符集都一致才能正确导入。

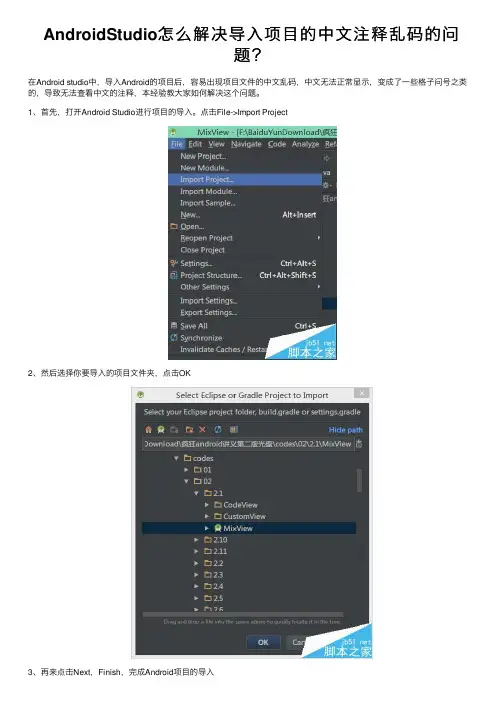
AndroidStudio怎么解决导⼊项⽬的中⽂注释乱码的问
题?
在Android studio中,导⼊Android的项⽬后,容易出现项⽬⽂件的中⽂乱码,中⽂⽆法正常显⽰,变成了⼀些格⼦问号之类的,导致⽆法查看中⽂的注释,本经验教⼤家如何解决这个问题。
1、⾸先,打开Android Studio进⾏项⽬的导⼊。
点击File->Import Project
2、然后选择你要导⼊的项⽬⽂件夹,点击OK
3、再来点击Next,Finish,完成Android项⽬的导⼊
4、在Android studio左侧窗⼝栏,切换到Project视图,打开项⽬的src⽂件夹下的Java⽂件夹,再打开Java⽂件夹下的Java⽂件,然后就可以看到Java源⽂件的内容,发现⾥⾯的中⽂注释都是乱码
5、点击Android studio右下⾓的⽂件编码按钮,图中红⾊区域,然后选择UTF-8改选为GBK
6、此时会弹出窗⼝提⽰是否重载⽂件,选择“Reload”
7、重载之后即可看到中⽂注释能够正常显⽰了,此时点击左上⾓的保存按钮,就可以保存⽂件,那么下次打开就会默认为GBK编码,就不会出现乱码了
注意事项:此⽅法适⽤于打开GBK编码的⽂件,如果⽂件原本就是UTF-8的编码就不会出现乱码了。
第1篇随着互联网技术的飞速发展,各种应用程序和系统之间的数据交换变得越来越频繁。
在这个过程中,数据传输过程中的乱码问题成为了开发者和运维人员的一大难题。
乱码问题不仅影响了用户体验,还可能引发系统错误和安全隐患。
本文将全面解析传值乱码解决方案,帮助读者解决这一问题。
一、乱码问题的成因1. 编码不一致在数据传输过程中,如果发送方和接收方的编码不一致,就会导致乱码。
常见的编码有UTF-8、GBK、GB2312等。
2. 数据转换错误在数据传输过程中,如果对数据进行转换时未正确处理编码,也会导致乱码。
3. 字符集不支持有些字符集不支持某些特殊字符,导致在传输过程中出现乱码。
4. 网络传输错误网络传输过程中,由于信号干扰、丢包等原因,也可能导致数据传输错误,进而产生乱码。
二、传值乱码解决方案1. 确保编码一致性(1)统一编码格式在开发过程中,应确保所有项目使用相同的编码格式,如UTF-8。
这样,在数据传输过程中,发送方和接收方都能正确识别数据。
(2)明确编码要求在项目文档中明确编码要求,确保开发人员和运维人员了解并遵守编码规范。
2. 正确处理数据转换(1)使用正确的方法进行数据转换在数据转换过程中,应使用正确的编码转换方法,如使用String类的`getBytes(String charsetName)`和`new String(byte[] bytes, String charsetName)`方法。
(2)处理异常情况在数据转换过程中,应处理异常情况,避免因转换错误导致乱码。
3. 支持字符集(1)使用支持字符集在开发过程中,尽量使用支持更多字符集的编码格式,如UTF-8。
(2)处理特殊字符在处理特殊字符时,确保使用正确的编码格式,避免因字符集不支持导致乱码。
4. 网络传输优化(1)确保网络稳定在数据传输过程中,确保网络稳定,减少因网络问题导致的乱码。
(2)数据校验在数据传输过程中,进行数据校验,确保数据的完整性和准确性。
中文产生的乱码
中文产生的乱码是因为中文字符在传输过程中可能受到网络传输延迟、带宽不足、数据丢失等因素的影响,导致在接收端无法正确地解码为中文字符。
在传输过程中,中文字符通常需要使用 UTF-8 编码方式传输,UTF-8 是一种支持多种语言的字符编码方式,能够表示多种语言的字符,包括中文字符。
但是在传输过程中,如果 UTF-8 编码的中文字符遇到编码不够长度时,可能会使用前面的字节补位,这些补位字节在接收端可能被认为是其他字符,从而导致乱码的出现。
在网络传输中,中文字符还会受到网络延迟、数据丢失等因素的影响,使得传输过程中的数据变得不稳定,从而导致乱码的出现。
为了避免中文字符产生的乱码,可以采用以下措施:
1. 使用合适的字符编码方式:在传输过程中,应该使用合适的字符编码方式,例如 UTF-8 编码方式,以确保传输的数据能够正确地解码为中文字符。
2. 保证网络传输的稳定性:在网络传输过程中,应该保证网络传输的稳定性,避免数据丢失或延迟等问题,从而避免中文字符产生的乱码。
3. 使用正确的字符集:在编写应用程序时,应该使用正确的字符集,例如简体中文或繁体中文,以确保输出的中文字符能够正确地显示。
导入dmp文件到本地后,存储过程里中文显示问号乱我先将源库3个用户导出的dmp分别导入目标库的3个用户,imp语句--导入本地dmp,保证dmp的版本号较低imp jd_a1/jd_a1@orcl full=y ignore=y file=E:\jd_a1.dmp log=E:\jd_a1.log grants=n imp edmadmin/edmadmin@orcl full=y ignore=y file=E:\jd_a2.dmp log=E:\jd_a2.log grants=n imp jd_synuser/jd_synuser@orcl full=y ignore=y file=E:\jd_synuser.dmp log=E:\jd_synuser.log grants=n 之后再执行了一个由sqlplus导出的sql脚本(断定是sqlplus导出因为内有spool标示当然也可能是用plsql导出,脚本也内含spool 标示)因为DMP文件不大,干脆用UE打开看了下exp版本号,V09.02,随后上oracle官网下了个win64_11g(本地是64位win7系统),版本号11.2.1.0,其imp版本当然也是11.2.1.0。
选择完全导入,通过看日志(不用担心,正式的导入肯定会提供给你完整准确的源库信息,包括exp版本、字符集、用户表空间等等),做了一些必要的创建,比如用户,然后导入完毕,对于本次无需关注的如显式授权错误则忽略(grant select on to 不重要的用户)。
导入完毕后,开始浏览导入的内容,比如表,表数据,在查看自定义过程和函数的时候,发现里面的中文都是问号乱码,难道是plsql 窗口的显示问题?通过create table aa as select '乱码' as 乱码from dual验证了下,无论时候工作区还是结果集,中文都显示正常。
那会不会是字符集的问题呢?先来认知下字符集##########字符集begin人类的文字是符号,是字符,字符产生的作用是存(记录)和读(懂),数字时代之后字符成了数字信息,但最终依然需要被人懂(因为人是主导),字符的载体不再是书本,而是数据设备如计算机,计算机中信息的存放本质是二进制,是一个挨着一个的0/1,这就意味着人<-->机间需要有一个转换的的规则,其实这个转换的规则就是字符集(计算机的字符<-->人的字符).字符集的产生是文字信息化的结果,字符集方案像其他许多事物一样经历了许多。
从安卓手机中将电话簿导入到Wm手机出现乱码的处理方
法.doc
1、个人收集整理勿做商业用处从安卓手机中将电话薄导入到Wm 手机出现乱码的处理方法1.用360手机助手或者其它方式导出安卓手机中的电话薄,在计算机中存为“.csv”格式,例如“360手机助手导出的联系人。
csv.2.双击“360导出的电话簿.csv文件或者用excel将此文件打开.3.点击“文件、另存为出现下面界面,选择“CSV 〔逗号分隔)”,将原来的文件名修改后如“360手机助手导出的联系人1保存到计算机中.4.打开计算机中的outlook,选择“联系人、导入导出”,在导入和导出向导界面中选择“从另一程序或文件导入”。
5.点“下一步”,出现下面
2、的界面6.选择“以逗号为分隔符(DOS)”选项,再点击“下一步”,出现选择文件界面7.通过“浏览”窗口,找到刚刚存入的“360手机助手导出的联系人1文件.点击“确定”、“下一步,出现导入窗口8.默认为“联系人,点击“下一步:,出现9.不要忙着点击“完成”,需要点击“映射自定义字段,出现下面的窗口10.将左边小窗口对应的字段与右边小窗口的字段进行相关,如左边的“中文称谓与右边的“姓名进行相关〔将左边的“中文称谓”拉到右边“姓名处放下)。
11.需要相关的字段处理完后,按“确定”,再点击“完成”.1
3、2.OK,安卓手机的电话簿就导入了outlook!
第1页。
深度揭秘乱码问题背后的原因及解决方式做Web开发的IT人,如果工作中没遇到过几次乱码的问题,估计都不好意思说自己是开发工程师。
:)而乱码问题也是各种各样,有保存到数据库中是乱码的,有在服务端接收到参数是乱码的,有在后台返回到客户端时候出现乱码的……这形形色色的乱码问题,如果处理起来不得要领,着实会让开发人员费不少工夫。
本文,将从乱码的产生原因,应用服务器内部对参数的处理各方面详解原理及解决方案。
1编码在开发中,只要有IO的地方,都会涉及到编码。
例如下面的代码:System.out.println( 'Hello 中国' );你猜这个会输出什么呢?这个其实是和你的文件编码有很大关系的,可能会输出Hello 中国也有可能会输出成下面这个样子Hello你可以改动IDE中的文件编码重复试几次。
那为什么会产生这个原因呢?我们来看这行代码执行过程中的调用栈:我们看到,简单的一句输出,也是有编码的。
看看CharsetEncoder,实现类真多啊再比如我们都无比熟悉的equals方法,先声明常量STR如下:之后,代码中有如下的逻辑你认为,这个时候会有输出吗?答案是看情况!当我把Constant类以UTF-8为编码保存后,把包含if逻辑的代码以GBK保存之后,equals执行时比较的两个参数就变成了下面的样子:所以这一定是不会为true的。
这也是乱码产生的原因,原因即解码时采用的encoding与编码时用的encoding不一致所造成的。
2应用服务器内的乱码在Web应用中,乱码的成因和上述分析是一致的。
我们向应用服务器发送一个这样的请求:http://localhost:8080/test/servlet?abc=你好服务器用request.getParameter('abc')来获取,这个时候有乱码问题吗?答案依然是It depends.这次的看情况是要看哪些情况呢?有以下这些。
文件出现乱码怎么解决?文件出现乱码怎么解决?使用电脑、移动硬盘、U盘等时间比较长的朋友可能会遇到过这样的情况:无缘无故的出现一些文件名是乱码的文件(文件名乱码文件),这些文件名乱码文件无法打开、移动、重命名、删除。
查看文件属性则系统显示:无文件类型,且一般占用磁盘空间较大。
这些文件名乱码文件的存在,严重影响了用户的使用。
下面将两个问题:一、文件名乱码文件是怎么产生的?;二、文件名乱码文件如何清理?一、文件名乱码文件是怎么产生的文件名乱码文件的产生有可能是多种因素导致的,主要包括以下几点:1. 病毒导致的文件名乱码文件这种乱码文件产生的原因比较复杂,一般是由于病毒自己制造或杀毒软件删除病毒不彻底导致磁盘逻辑错误。
2. 不正确的操作导致文件名乱码文件产生在使用软件时,下载进度到99%时就停止下载,并自己修改文件名,由于BT下载不是顺序下载,这样有可能导致文件索引信息错误,导致乱码文件出现。
3. 删除文件不当导致文件名乱码文件产生有时候在Windows中执行的删除文件操作,只是将磁盘上文件分配表里的相关文件信息删掉了,并没有实际删除文件。
4. 存储设备使用不当导致文件名乱码文件产生闪存、移动硬盘等移动存储设备出现乱码文件,尤其是手机存储卡最容易出现这种问题。
这种情况多是由于不正确地使用移动存储设备造成的,比如直接拔离设备等。
但是有的时候质量不好的闪存或移动硬盘也会出现乱码文件,这是移动设备本身的质量问题。
比如当往存储卡中写入数据时出错,出现乱码文件,同时系统右下角出现“W indows延缓写入失败,Windows无法为x:/windows/windowsupdate.log文件保存所有数据”的提示,这多半是由于存储卡已经损坏了。
5. 硬盘故障导致文件名乱码文件产生硬盘磁道或扇区出现错误,导致文件名出现乱码,这样的文件无法正常删除。
6. 磁盘管理工具导致文件名乱码文件产生使用磁盘工具PQmagic转换过分区格式之后(如从NTFS到FAT32),出现文件名乱码现象。
我先将源库3个用户导出的dmp分别导入目标库的3个用户,imp语句
--导入本地dmp,保证dmp的版本号较低
imp jd_a1/jd_a1@orcl full=y ignore=y file=E:\jd_a1.dmp log=E:\jd_a1.log grants=n imp edmadmin/edmadmin@orcl full=y ignore=y file=E:\jd_a2.dmp log=E:\jd_a2.log grants=n
imp jd_synuser/jd_synuser@orcl full=y ignore=y file=E:\jd_synuser.dmp log=E:\jd_synuser.log grants=n
之后再执行了一个由sqlplus导出的sql脚本(断定是sqlplus导出因为内有spool标示当然也可能是用plsql导出,脚本也内含spool标示)
因为DMP文件不大,干脆用UE打开看了下exp版本号,V09.02,随后上oracle官网下了个win64_11g(本地是64位win7系统),版本号11.2.1.0,其imp版本当然也是11.2.1.0。
选择完全导入,通过看日志(不用担心,正式的导入肯定会提供给你完整准确的源库信息,包括exp版本、字符集、用户表空间等等),做了一些必要的创建,比如用户,
然后导入完毕,对于本次无需关注的如显式授权错误则忽略(grant select on to 不重要的用户)。
导入完毕后,开始浏览导入的内容,比如表,表数据,在查看自定义过程和函数的时候,发现里面的中文都是问号乱码,难道是plsql窗口的显示问题?
通过create table aa as select '乱码' as 乱码from dual验证了下,无论时候工作区还是结果集,中文都显示正常。
那会不会是字符集的问题呢?
先来认知下字符集
##########字符集begin
人类的文字是符号,是字符,字符产生的作用是存(记录)和读(懂),数字时代之后字符成了数字信息,但最终依然需要被人懂(因为人是主导),字符的载体不再是书本,而是数据设备如计算机,
计算机中信息的存放本质是二进制,是一个挨着一个的0/1,这就意味着人<-->机间需要有一个转换的的规则,其实这个转换的规则就是字符集(计算机的字符<-->人的字符).
字符集的产生是文字信息化的结果,字符集方案像其他许多事物一样经历了许多。
最有名的字符集当属ASCⅡ码,用8个位bit(小写b是位的意思),一个位有0和1两个状态,8个位就是2的8次方,有256种状态,这个8位后来直接被定义为一个“字节”(大写B是字节的意思),
对了美国人来说,英文的最小单元是26个字母,算上其他符号,也差不多够表示了,所以如果全世界都只说英语,今天的问题或许就不会遇上了。
但我们不是英语的国家,最终需要将数字设备中的信息转换为汉字才行(韩语日语是同样的需求),但是汉字和英文的构成差异大,汉字有上万个,常用的也要两三千,
所以汉字需要有0/1<-->汉字的特别字符集,这就是汉字自己的字符集:gb2312、gbk、gb18030等等,不过主要这不是国际字符集,是国家字符集,比如我的操作系统就是gbk 的字符集。
后来为了全球的统一,实现信息跨平台,出现了unicode,他用多字节可变长度来实现二进制和全世界所有语言的文字做唯一性对应,不过这通常意味着空间上的浪费。
unicode是国际字符集方案,其具体的字符集有utf-8和utf-16。
utf-16是两个字节一个对应,如果信息都是英文,第二个字节根本用不到,但却会占空间,这就是为何英文论坛不用-16的原因。
utf-8绝不是一个字节一个对应!而是说一个字符对应的字节数是可变的(叫utf-n比较合适),如果是英文就一个字节,汉字就三个字节或者四个字节(切记),每种文字在其中占几个字节是不一样的,
那读取utf-8的时候怎么知道每个字符的开始和结束呢?
每个字符都有开始和结束的标示,规则如下:
0xxxxxxx 如果是这样的一串,就表示把一个字节做为一个单元.就跟ASCII完全一样.
110xxxxx 10xxxxxx 如果是这样的格式,则把两个字节当一个单元
1110xxxx 10xxxxxx 10xxxxxx 如果是这种格式则是三个字节当一个单元.
-8的容错能力强,而且空间占用小,其编码的文件也就相对小,这就是他流行的原因。
那一个文件是什么编码,读取工具是怎么知道的呢?答案是猜和分析,所有有时候也会猜错。
##########字符集end
##########oracle的字符集begin
oracle是数据库,主要的作用就是存储数据,数据可能含有英文、中文或者特殊符号,那这数据在硬盘上的存取也必然涉及到字符集的设置。
安装Oracle的时候常有选项让设置字符集,比如你常看到al32utf8、zhs16gbk,并不是说
哪一个好,他的设置取决于很多因素。
要搞清楚oracle的字符系统,必须明白3个东西,
1、数据库字符集,一个数据库只能选择一个字符集,理论上建好库就不能改了,不过实际也能。
查询数据库字符集用sql:select userenv('language') from dual / select * from nls_database_parameter(oracle的系统视图)
(注:oracle的userenv是一个函数,用来查看当前用户的环境信息,类似的函数还有sys_context,如select sys_context('userenv','host') from dual查询当前用户的主机名)2、nls_lang环境变量,这个环境变量作用是告知服务器数据去时的编码和来后的编码,nls_lang的格式是language_territory.charset,language是国家,territory地区,charset 是字符集。
查询当前环境变量nls_lang的方法有:select * from nls_session_parameters(session级别)/ select * from nls_instance_parameters(库级别)/ 看nls_lang环境变量和注册表。
设置nls_lang的方法有三:1、添加一个系统变量nls_lang,值为SIMPLIFIED CHINESE_CHINA.AL32UTF8;2、在修改注册表中的nls_lang的值;3、在程序的session 级别设置,如在cmd中set nls_lang=SIMPLIFIED CHINESE_CHINA.ZHS16GBK(切记要写完整,不是ZHS16GBK,否则sqlplus会报错ORA-12705: Cannot access NLS data files or invalid environment specified)。
如果3种都设置了,优先级是session>其他
3、客户端操作系统字符集,只是影响字符在你看到时的“样子”。
4、平时用的三方工具,比如sqlplus、plsql dev,其本身没有字符集概念,也不会成为导致乱码的原因。
举一个例子:,我本地通过plsql dev连接远方数据库(centos系统),用insert into aa(name)values('中国')插入数据,你现在在plsql dev中看到的“中国”,字符集是什么,其实是
本地操作系统的字符集(样子),通过cmd中chcp得到本地操作系统代码页是936,对应的字符集是gbk,那这个“中国”的真实编码假设是1234,当你insert后,这个1234被交给plsql dev,plsql dev
则将其交给数据库,数据库收到指令后问plsql dev这个1234是什么编码格式,plsql dev 说参照nls_lang,数据库一看nls_lang是ZHS16GBK,而自己是AL32UTF8,不一样,那就转换,这个
功能数据库必须有的,假设最后按照编码5678存了下来,后来我又select name from aa,数据库问plsql dev要什么编码格式,plsql dev依然说nls_lang,然后数据库将5678再转换为1234给plsql dev
然后你就看到了结果集。
再来说下exp和imp中字符集的处理:
exp的时候,对字符集有影响的只有数据库字符集和nls_lang字符集设置,其他都不起作用,exp的时候,如果数据库字符集和nls_lang一致就直接导出无需转码,
如果不同,最终会转换为nls_lang的字符集,imp的时候,如果dmp的字符集(源nls-lang)和数据库是一致就直接导入,否则就以数据库为准做转换。
##########oracle的字符集end
##########我们继续分析存储过程中的中文乱码时候怎么回事
我的操作系统字符集是gbk,nls_lang是zhs16gbk,数据库是zhs16gbk,貌似没啥问题,还有就是为什么数据中的中文和中文字段没问题?偏偏过程中的中文是问号乱码,做不科学。
恍然大悟,过程和函数不是dmp导入的,是手工执行的sql脚本,一定这个过程出了问题。