
多模态信息处理研究进展、现状及趋势
1. 任务定义、目标和研究意义
多模态(multimodality)的概念起源于计算机人机交互领域信息表示方式的研究,其中术语“模态”一词被定义为在特定物理媒介上信息的表示及交换方式。在研究中人们发现,用语言、视频、音频等媒体指称来描述信息表示方式过于宽泛、粒度太大,不足以区分实际采用的表示方式,为此引入了比媒体(或媒介)更细粒度的“模态”概念。而多媒体媒介可以分解为多个单模态,如视频作为一种多媒体媒介,可以分解为动态图像、动态语音、动态文本等多个单模态。为了模态概念定义的科学性和实用性,单模态的分类必须满足完整性、正交性、关联性和直观性的要求。在同一事物上多类单模态信息共生或共现的现象是十分普遍的。人与人交谈时有声语音与文字文本是共生的;互联网网页中图片与其对应的解说文字是共现的,凡此等等。共生或共现的多种单模态信息的统称即所谓的多模态信息。融合多种单模态的信息处理即所谓的多模态信息处理,其中涉及对多模态信息的获取、组织、分析、检索、理解、创建等。
多模态信息处理技术主要应用于对象识别、信息检索、人机对话等与智能系统及人工智能相关的领域。大量研究成果显示,基于多模态理念的信息处理算法和方法,往往会得到比传统方法更好的性能和效果。例如,语义计算相关领域基于指称语义的研究发现,采用语言表达式的视觉指称(即一组图片)来定义指称相似性度量,在某些语义推导任务中,效果好于基于纯文本的分布式语义表示;情感计算领域相关研究发现,不同模态的数据在情感表达中具有互补性,在愉悦度表达方面文本模态优于音频模态,而在激活度表达方面音频模态则优于文本模态。在基于内容的多媒体信息检索领域,针对基于内容的视音频检索中的语义鸿沟问题,利用与视音频数据共生或共现的文本信息,进行多模态的语义分析和相似性度量,是克服语义鸿沟问题的一种十分有效的方法。以媒体为单位的跨媒体信息处理任务,普遍存在语义鸿沟问题,所处理信息对象的语义,无论是基于外延语义(指称语义)还是内涵语义(关联语义)概念,在单一媒体信息范围内得不到完整或最终表达,而多模态信息处理方法为该问题的解决提供了新的思路和方法。
2. 研究内容和关键科学问题
多模态信息处理是在文本、图像、音频等现有单媒体信息处理的基础上发展起来的,现有单媒体数据的处理方法是多模态数据处理的基础。例如在特征提取层面,针对文本、图像、音频等单模态数据,往往直接利用成熟的文本、图像、音频特征提取方法来实现。多模态信息处理特有的研究内容主要关注于多模态信息的建模、获取、融合、语义度量、分析、检索等方面。
2.1 多模态信息建模
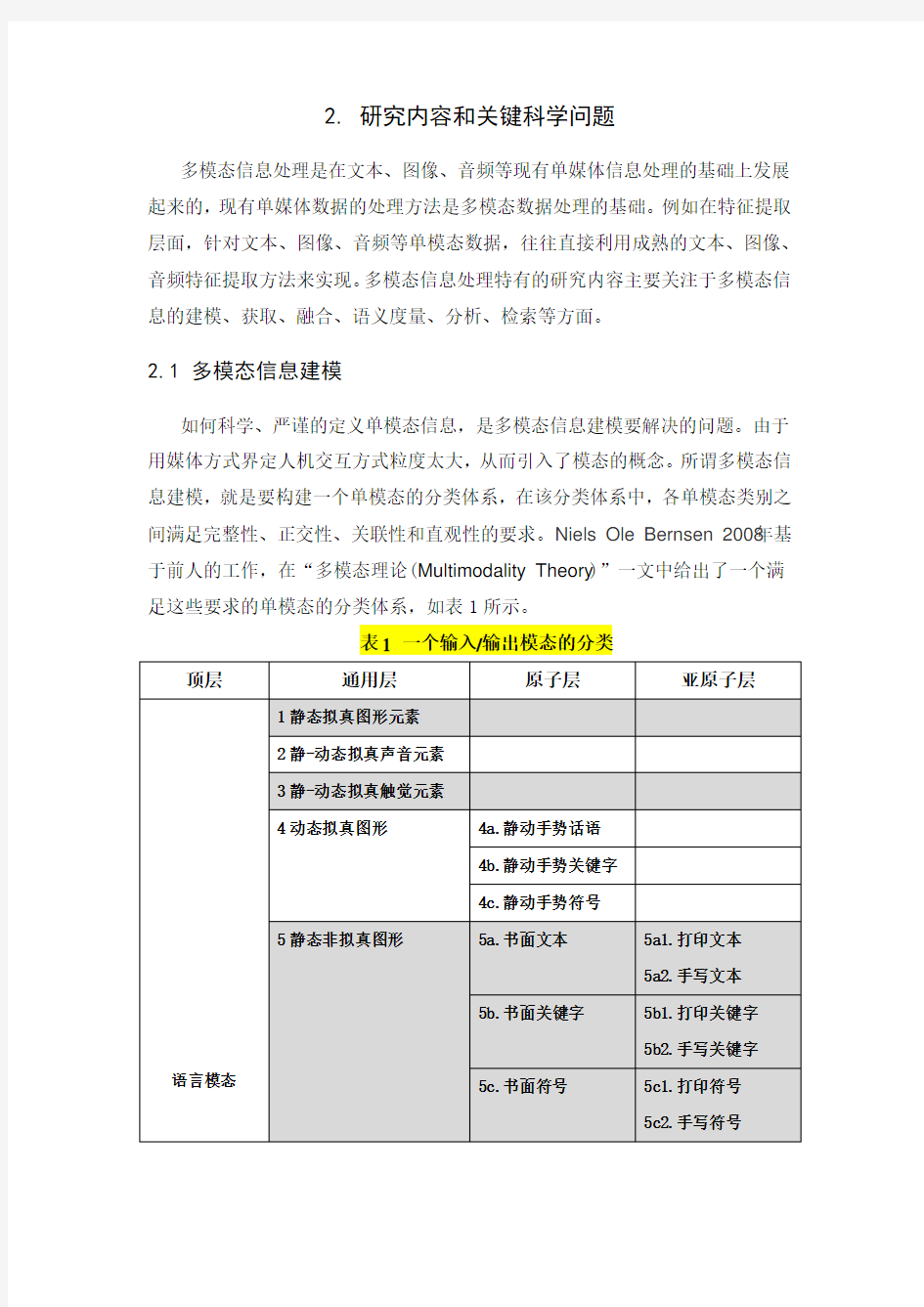
如何科学、严谨的定义单模态信息,是多模态信息建模要解决的问题。由于用媒体方式界定人机交互方式粒度太大,从而引入了模态的概念。所谓多模态信息建模,就是要构建一个单模态的分类体系,在该分类体系中,各单模态类别之间满足完整性、正交性、关联性和直观性的要求。Niels Ole Bernsen 2008年基于前人的工作,在“多模态理论(Multimodality Theory)”一文中给出了一个满足这些要求的单模态的分类体系,如表1所示。
表1 一个输入/输出模态的分类
随着人机交互设备的发展和丰富,新的传感器可以采集到更多新的、可与人交互的信息,如定位信息、重力加速度信息、脑电信息、热量消耗信息、步行运动信息等,表1 给出模态分类体系已不能完全覆盖新模态信息的种类,因此需要持续研究新的模态分类体系。
2.2 多模态信息获取
尽管人与人、人与机器之间交互信息的多模态现象是普遍存在的,但对于多模态信息处理而言,所处理的对象数据往往需要特殊处理才能获得。多模态信息的获取主要包括数据的采集、解析与数据集构建。
2.1.1多模态数据的采集
尽管可以对单模态数据类别进行比较形式化的定义,但实际研究中只要尽可能地遵守完整性、正交性、关联性和直观性的原则,新模态数据类别的引入是比较灵活,同时也是比较活跃的。比如除了图像、声音等信息外,针对社交媒体,可通过智能终端,采集到位置、重力加速度、睡眠、运动等人体信息;针对车联网,可通过车载传感器,采集到车速、位置、温度、发动机转速、雷达等汽车状态信息;针对监控网,可以采集红外、震动、烟雾浓度、生物指纹等与安防相关的信息。
多数情况下,多模态信息处理任务要求所有处理样本数据的各单模态数据是完整的。好在各单模态数据源经常是共生或共现的,满足完整性要求是可以做得到的。但也有例外的情况,例如歌曲多模态信息中,尽管音频与歌词是共生的,但歌词很难从音频中分离,因此,歌词文本数据还要通过其它单独途径采集。2.2.2多模态数据的解析
多模态数据的解析就是将原始混合状态的多模态数据,分解为单模态的数据。例如视频数据,需要分解为动态图像、音频语言、文本语言等三种单模态数据,其中文本语言部分,可能来自于视频字幕、图像内容中的文字和语音识别的结果等。
多模态数据的解析往往需要与数据采集相结合,例如歌曲MTV视频的解析,歌词文本很难从视频本身得到,可以通过采集系统来弥补。再例如,艺术、影视评论类文本数据的解析,其中涉及的图像、视频、音频数据的获取,更需要借助采集系统来完成。
2.2.3多模态训练数据集的构建
为了进行对多模态信息的机器学习处理,如分类、回归、聚类等,需要构建训练用样本数据集,特别是针对有监督学习,还需要进行数据标注。多模态训练数据集的构建有自己独特的方法。
以多模态人脸情感识别为例,需要选择一组参试人员,选择一组表达不同情感的诗词,准备一个相对封闭的环境,一个显示诗词的屏幕,一个面对受试人员脸部的摄像头,一个录音麦克风,一个采集视频、音频和交互数据的软件,交互数据通过受试人员拖动屏幕上采集软件的滚动条来产生。标注的情感数据可采用二维连续的VA情感模型来量化,由于标注的情感模型是二维的,因此每个诗词样本都需要标注两次。标注开始后,受试人朗诵屏幕上的诗词,并根据朗诵诗词的情感体验拖动滚动条。最终可以获得包含有声语言、文本语言和人脸视频的多模态情感标注数据及相应的训练数据集。
2.3 多模态语义分析
术语“语义分析”在不同领域有不同的含义,这里特指机器学习中的语义分
析。在机器学习中,语义分析是指构建一个文档集概念结构的任务,该概念结构逼近文档集所表达的概念。也即,运用机器学习的方法提取或挖掘文档的深层次概念。虽然语义分析一般不等同于文档的语义理解,但往往是语义理解的基础步骤。在语义分析相关研究中,所分析的文档集已从文本类数据,扩展到图像、视频、音频等其它媒体形式的数据集。以图像数据为例,所谓图像语义分析是指完整地将图像内容转换成可直观理解的类文本语言表达,即将图像内容“像素-区域-目标-场景”的层次关系,采用合适的词汇、合理的构词方式进行词汇编码和标注的过程。
语义分析过程中首先要面对的是如何克服语义本身在表达上的多义性和不
确定性问题,如同词不同义,同义不同词的问题。对于图像、音频这样的非文本类数据,更要解决在数据表达和语义解释之间建立合理的联系的问题,即语义鸿沟问题。大量研究表明,多模态语义分析方法对解决上述两类问题具有明显的优势。例如,在对足球比赛视频语义分析的基础上,辅以音频欢呼声事件的鉴别,能够更好地分析出进球事件的语义。
所谓多模态语义分析是指在同一个媒体对象的多个模态数据上,同时并行或协同进行语义分析,并最终通过融合得到分析结果的语义分析方法。
2.4 多模态情感识别
人机交互、多媒体信息处理等多个领域的研究和应用,对情感计算技术的发展起到了重要的推动作用。
目前人机交互的主要方式仍是书面语言,书面语言交流与人类面对面交流的最大差别是,所谓副语言(Para-language)的缺失。副语言包括语气声、哭笑声、面部表情、肢体语言等。实现副语言的人机交流是实现和谐自然人机对话的基础。鉴于副语言更多地侧重情感语义表达的属性,引入情感识别技术来实现对副语言的理解是顺理成章的。为了处理语音和副语言这样的多模态数据,将情感识别技术扩展到处理多模态数据,既是所谓的多模态情感识别技术。
在多媒体检索研究领域,传统的基于文本知识的索引方法已显现出它的局限性,而基于情感的索引吸引了多媒体研究的学者们。在多媒体应用领域,用户也期望内容推荐和分发系统,能够更好地适应他们的体验和情感。多媒体情感分析
与识别的研究目标是,在多媒体内容的推荐和检索中使用情感因素。例如,当把“我想听一首欢快的歌”、“我想看一部恐怖片”等检索条件输入给计算机系统时,计算机系统能够给出满足要求的响应。其中关键的前提是,多媒体内容的情感属性,不是人工标注的,而是计算机自己通过计算获得的。歌曲、电影数据的多模态属性,同样要求情感识别技术是多模态的。
2.5 多模态信息检索
随着经典的文本检索文本、图像检索图像的单模态信息检索技术的成熟与大规模应用,各单模态之间相互检索,诸如用图像检索文本、文本检索音频这样的跨媒体检索系统,也成为信息检索领域的研究热点。与单模态信息检索方式相比,跨媒体信息检索不仅能够更好地表达用户的检索意图,改善用户的检索体验,提高检索召回率和准确率,而且对媒体数据语义的理解也具有重要作用。跨媒体信息检索首先要解决的是所谓语义鸿沟问题,由于各单模态内容的异构性导致语义的不可度量,使得传统多媒体检索方法不能直接适用于跨媒体检索。有多种方法被用来解决这一问题。一种方法是对多媒体数据不同模态的语义关系进行统一建模,以实现跨媒体检索。这种方法的缺点是受限于语义概念的建模规模;另一种方法是利用共生或共现的多模态信息作为语义桥梁,来实现跨媒体检索。广义上讲,上述两种检索方法,都可以被称为多模态信息检索,狭义上讲,后者为典型的多模态信息检索,前者可称为跨模态信息检索。
一个典型的多模态信息检索系统是欧盟基金项目I-SEARCH (Axenopoulos,2010,见图1),该项目的目标是提供一个统一的多模态内容索引、搜索和检索框架,该框架能够处理指定的多媒体和多模态内容类型,如文本、图像、图形、视频、3D对象和音频,现实对上述任何类型信息内容的检索和查询。I-SEARCH 将多种媒体类型封装到一个称为“内容对象(CO)”的媒体容器中,并共享相同的语义,同时,不同的媒体类型可拥有各自的的元数据,如文本、分类、位置或时间等信息。多模态信息的索引、检索和查询,都基于内容对象来完成。
图1 I-SEARCH多模态检索系统框架
2.6 多模态人机对话
多模态人机对话系统与基于文本语言的传统人机对话系统类似,由信息获取、信息处理和信息输出三部分组成,不同之处在于,多模态人机对话系统的信息获取模块通过麦克风、摄像机等输入设备,采集语音、面部表情、肢体动作等多模态信息作为输入;信息处理模块对输入信息进行多模态融合的语义分析,并基于多模态知识库产生协同对话内容,该内容除语言内容外,还包括反映情感的面部表情内容;信息输出部分将两部分内容同步输出到输出设备上,目前主要是输出到有模拟对话人脸部图像的屏幕上,长远目标是输出到仿真机器人上,实现整合了语音、手势和面部表情的、类似人类的自然互动与对话。已有许多多模态人机对话系统框架被提出,如较早的MIND系统(Chai, J. 2002,见图2),国内的中科院自动化所的系统(陶建华等, 2011,见图3)。
图2 MIND多模态人机对话系统框架
图3 多模态人机对话系统框架
多模态人机对话系统的核心研究内容是两个方面,即多模态会话内容的理解和多模态会话内容的生成。在会话内容理解方面,除了会话人情感识别外,对会话内容所涉及图像的理解,也成为研究的热点。如对基于图像的字幕生成(看图说话, image caption generation,见图3)的研究,以及更进一步的基于图像的问答系统的研究。这些研究的目标是实现机器对会话场景及会话视觉内容的理解。
图4 基于图像的字幕生成
3. 技术方法和研究现状
为实现多模态信息处理的目标,大量的文本和多媒体信息处理的技术和方法被多模态信息处理系统集成和采纳。下面仅就多模态信息处理中比较重要的关键技术和方法作一介绍。
3.1 多模态融合方法
多模态信息由于底层数据的异构性,比如图像是24位的RGB颜色值矩阵、音频是16位的声压值串、中文文本是16位或24位的汉字编码串。如何让这些异构的数据完成同一个识别或检索任务,是多模态信息处理首先要解决的问题。解决这个问题的方法被称为多模态融合(Multimodal fusion)。所谓多模态融合是指:整合各种输入模态的信息,并将它们合并在一个完成同一目标的系统中的处理方法。以多模态人脸情感识别为例,输入的多模态信息为人脸图像和语音,一个最直观的融合方案是,分别对人脸图像和语音各构造一个情感识别系统,然后对两个系统的输出进行加权平均,得到最终的识别结果。
Pradeep K. Atrey等人2010年在“多媒体分析的多模态融合综述”一文,对多模态融合方法作了较系统的总结和分析。关于实现多模态融合的方法,一般是在两个层次上进行融和,即特征层融合(或称早期融合)和决策层融合(或称后
期融合)。第三种融合策略是所谓混合融合方法,该方法是将特征层融合与决策层融合结合起来一起使用。图5是Pradeep K. Atrey等人对各种融合方法给出的图示。
图5 多模态融合方法示意图
其中,(a)是分析单元,(b)是特征层融合单元,(c)是决策层融合单元,(d)特征层多模态分析,(e)决策层多模态分析,(f)混合多模态分析。
特征层融合方法先对各模态信息分别进行特征提取,再对特征数据进行综合分析和处理,形成规模更大的多模态联合特征矩阵或向量。对于采用机器学习作为决策层分析的系统,特征层融合的主要作用是使学习器有结构统一的输入样本
数据。由于大多数机器学习方法对输入样本有格式要求,如等长的向量,此时特征融合是必须执行的处理步骤。最常见的融合方法是将不同模态的特征向量进行拼接。
决策层融合策略是,首先让每个模态单独完成各自的分析或属性判别,然后通过融合来它们的分析或属性判别结果,来形成最后的分析或判别结果。主要的融合技术有表决法、加权线性表达式、集成学习、协同学习、多层学习等。
为了结合特征层融合和决策层融合各自的优势,一些研究人员提出一种将特征层融合与决策层融合的组合策略,即所谓的混合融合。混合融合的方案有多种选择,图5(f)是其中的一种,这种方案可以实现部分模态采用特征层融合,部分模态采用决策层融合的融合策略。
3.2 多模态深度学习
采用深度学习方法研究多模态信息处理问题是近年来的热门方向。学者们充分利用了深度学习的特点,针对多模态信息处理任务,提出了一系列新的方法和算法。
深度学习是一个非常好的多模态融和工具。多模态深度学习模型的一种实现方案是,为每一个参与融和的单模态训练一个深度波尔兹曼机(DBM),然后在这些DBM之上增加一个额外的隐藏层给出融和后的联合表示(图6)。上述融和过程,如果是无监督的,则可视为特征学习过程,输出的即为特征层融和的结果特征;如果是有监督的,输出的即为决策层融和的最终分类结果。(更多关于深度学习的内容,请参见报告的《语言表示与深度学习》一章。)
图6 多模态深度学习模型
基于图像的字幕生成问题也可以用深度学习方法来解决,即采用所谓交叉模
态特征学习。由于字幕与图像之间存在内在的多模态关联关系,因此,运用上述多模态深度学习模型,可以学习到融和的特征(也称为共享特征表示,Shared Representation),那么理论上该模型应该支持训练一个模态,而测试另外一个模态,且仍能获得好的分类效果。
3.3 多模态语义表示
所谓语义表示是指在计算机系统中对语义的形式化描述或表达。因此,多模态语义表示是指,人机交互过程中不同模态之间交互语义信息的形式化描述。对语音、文本和视觉信息进行处理、理解和生成的多模态系统,必然会涉及到多模态信息输入输出过程中的语义表示问题。由于多模态信息的异构性,在多模态系统中,一种模态的输入信息需要先映射到一种语义表示,当在另外一种模态进行输出时,再将这种语义表示映射到指定模态进行输出。
多模态语义表示的发展是基于应用驱动的,许多多模态应用或实验系统,都提出了自己的语义表示方案,其中采用比较多的是基于框架语义学(Frame)和XML语言的表示方案。在特定的多模态应用系统中,语义表示问题可理解为,基于框架语义学对应用系统语义表示空间的XML编码。
上述多模态语义表示方法事实上是对语义的显式表示,在基于机器学习,特别是基于深度学习的多模态系统中,语义表示常常以模型的形式存在,这种语义表示可理解为隐式的多模态语义表示。
4.技术展望与发展趋势
多模态信息处理研究的发展,受到来自移动智能终端、可穿戴设备、物联网、自然语言处理、人机对话、仿真机器人、信息检索、模式识别、情感识别、深度学习、大数据、认知科学等工作的促进和推动。随着移动智能终端、可穿戴设备、物联网的普及,人机交互的信息从传统的文字、声音、影像,发展到位置、重力加速度、睡眠、运动等人体信息,共生、共现的单模态信息种类大大增加;由于人的感知和认知机理的多模态本质,自然语言处理、人机对话、仿真机器人、信息检索、模式识别、情感识别等研究领域,越来越多地采用多模态信息处理的方法和思路,取得了许多具有实际应用价值的成果,从而大大提升了多模态信息处
理的能力;深度学习、大数据的兴起,即为多模态信息处理提供了新的技术手段,也为多模态信息处理提供了更丰富的数据来源。
模态分析技术的发展现状综述 摘要:本文首先系统的介绍了模态分析的定义,并以模态分析技术的理论为基础,查阅了大量的文献和资料后,介绍了三种模态分析技术在各领域的应用,以及国内外对于结构模态分析技术研究的发展现状,分析并总结三种模态分析技术的特点与发展前景。 关键词:模态分析技术发展现状 Modality Analysis Technology Development Present Situation Summary Abstract:This article first systematic introduction the definition of modality analysis,and based on modal analysis theory,after has consulted the massive literature and the material.Introduced application about three kind of modality analysis technology in various domains. At home and abroad, the structural modal analysis technology research and development status quo.Analyzes and summarizes three kind of modality analysis technology characteristic and the prospects for development. Key words:Modality analysis Technology Development status 0 引言 模态分析是研究结构动力特性一种近代方法,是系统辨别方法在工程振动领域中的应用。模态是机械结构的固有振动特性,每一个模态具有特定的固有频率、阻尼比和模态振型。这些模态参数可以由计算或试验分析取得,这样一个计算或试验分析过程称为模态分析。模态分析的过程如果是由有限元计算的方法完成的,则称为计算模态分析;如果是通过试验将采集的系统输入与输出信号经过参数识别来获得模态参数的,称为试验模态分析。通常,模态分析都是指试验模态分析。振动模态是弹性结构的固有的、整体的特性。如果通过模态分析方法搞清楚了结构物在某一易受影响的频率范围内各阶主要模态的特性,就可能预言结构在此频段内在外部或内部各种振源作用下实际振动响应。因此,模态分析是结构动态设计及设备故障诊断的重要方法。 1 数值模态分析的发展现状 数值模态分析主要采用有限元法,它是将弹性结构离散化为有限数量的具体质量、弹性特性单元后,在计算机上作数学运算的理论计算方法。它的优点是可以在结构设计之初,根据有限元分析结果,便预知产品的动态性能,可以在产品试制出来之前预估振动、噪声的强度和其他动态问题,并可改变结构形状以消除或抑制这些问题。只要能够正确显示出包含边界条件在内的机械振动模型,就可以通过计算机改变机械尺寸的形状细节。有限元法的不足是计算繁杂,耗资费时。这种方法,除要求计算者有熟练的技巧与经验外,有些参数(如阻尼、结合面特征等)目前尚无法定值,并且利用有限元法计算得到的结果,只能是一个近似值。 正因如此,大多数数学模拟的结构,在试制阶段常应做全尺寸样机的动态试验,以验证计算的可靠程度并补充理论计算的不足,特别对一些重要的或涉及人身安全的结构,就更是如此。 70 年代以来,由于数字计算机的广泛应用、数字信号处理技术以及系统辨识方法的发展 , 使结构模态试验技术和模态参数辨识方法有了较大进展,所获得的数据将促进产品性能的改进、更新[1] 。在硬件上,国外许多厂家研制成功各种类型的以FFT和
569小动物多模态分子医学影像系统院系:工学院 小动物多模态分子医学影像系统 国家重大科学仪器设备开发专项项目《小动物多模态分子影像重大科研仪器及关键技术研究项目》ZL201220380368.1人,硕士生1人;博士后3人。三年内利用该仪器作为主要科研手段发表学术论文(三大检索) 12 篇,其中代表论文:论文题目期刊名年 卷(期)起止页码Gold Nanoshelled Nanomicelles for Potential MRI Imaging, Light-Triggered Drug Release, and Photothermal Therapy.Adv Funct Mater 201323(7)815-822Laser Oblique Scanning Optical Microscopy (LOSOM) for Optics Express 201220(13)14100-14108RGD-conjugated gold nanorods induce radiosensitization in melanoma cancer cells by downregulating alpha(v)beta(3) International Journal of Nanomedicine 20127915-924Position mapping and a uniformity correction method for small-animal SPECT based on connected regional recognition.Nuclear Instruments and Methods in Physics Research Section A 20137041-6
第22卷 第2期2004年6月 广西师范大学学报(自然科学版)JOU RNAL O F GUAN GX INORM AL UN I V ERS ITY V o l .22 N o.2June 2004收稿日期:2004203218 基金项目:广西教育厅科研基金资助项目 作者简介:王修信(1963—),男,广西桂林人,广西师范大学副教授,硕士. 多模态医学图像的融合研究 王修信1,张大力2 (11广西师范大学物理与信息工程学院,广西桂林541004;21清华大学自动化系,北京100084) 摘 要:图像融合作为一种有效的信息融合的技术,已广泛用于医学图像、军事、遥感、机器视觉等领域.基于 小波变换的图像融合是一种新的多尺度分解像素级融合方法,利用小波变换分别对CT ,M R I 医学图像进行 分解处理,按照融合规则构造融合图像对应的各小波系数,再根据融合图像的各小波系数重构融合图像,重构 后的融合图像完好地显示源图像各自的信息.实验图像使用互信息量化判据来评价融合效果,结果表明小波 变换比传统的像素级加权平均融合算法效果更好. 关键词:医学图像;融合;小波变换 中图分类号:T P 391141 文献标识码:A 文章编号:100126600(2004)022******* 医学影像学为临床提供了超声图像、X 射线、 电子计算机体层扫描(CT )、磁共振成像(M R I )、数字减影成像(D SA )、正电子发射体层扫描(PET )、单光子发射断层成像(SPECT )等多种模态影像信息[1~3].不同的医学影像可以提供人体相关脏器和组织的不同信息,如CT 和M R I 提供解剖结构信息,而PET 和 SPECT 提供功能信息 .在实际临床应用中,单一模态图像往往不能提供医生所需要的足够信息,通常需要将不同模态图像融合在一起,得到更丰富的信息以便了解病变组织或器官的综合信息,从而做出准确的诊断或制订出合适的治疗方案.例如,CT 利用各种组织器官对X 射线吸收系数的不同和计算机断层技术对人体进行成像,它对于骨、软组织和血管的组合成像效果很好,而对软组织则近乎无能为力.M R I 利用水质子信息成像,对软组织和血管的显像灵敏度比CT 高得多,但对骨组织则几乎不显像.由此可见不同成像技术对人体同一解剖结构所得到的形态和功能信息是互为差异、互为补充的,因此对不同影像信息进行适当的集成便成为临床医生诊断和治疗疾病的迫切需要. 小波变换具有多分辨率分析特点,可聚焦到分析对象的任意细节,特别适合图像信号非平稳信源的处理[4].基于小波变换的图像融合是一种新的多尺度分解像素级融合方法,已有的应用研究主要是热图像和可视图像的融合[5,6].本文利用小波变换分别对CT ,M R I 医学图像进行分解处理,按照融合规则构造融合图像对应的各小波系数,再根据融合图像的各小波系数重构融合图像,重构后的融合图像完好地显示源图像各自的信息.实验图像使用互信息量化判据来评价融合效果,结果表明小波变换比传统的像素级加权平均融合算法效果更好. 1 基于小波变换的图像融合原理 小波变换是用一族小波函数系去逼近一信号,而小波函数系是通过一个基本小波函数在不同尺度下经伸缩和平移构成[7]. 7a ,b (x )=1?a ? 7x -b a , a ,b ∈R ,a ≠0其中a 为伸缩因子,b 为平移因子. 对于二维情况,设V 2j (j ∈Z )是空间L 2(R 2)的一个可分离多分辨率分析,对每一个j (j ∈Z )来说,尺度
模态分析意义模态分析是研究结构动力特性一种近代方法,是系统辨别方法在工程振动领域中的应用。模态是机械结构的固有振动特性,每一个模态具有特定的固有频率、阻尼比和模态振型。这些模态参数可以由计算或试验分析取得,这样一个计算或试验分析过程称为模态分析。这个分析过程如果是由有限元计算的方法取得的,则称为计算模态分析;如果通过试验将采集的系统输入与输出信号经过参数识别获得模态参数,称为试验模态分析。通常,模态分析都是指试验模态分析。振动模态是弹性结构的固有的、整体的特性。如果通过模态分析方法搞清楚了结构物在某一易受影响的频率范围内各阶主要模态的特性,就可能预言结构在此频段内在外部或内部各种振源作用下实际振动响应。因此,模态分析是结构动态设计及设备的故障诊断的重要方法。机器、建筑物、航天航空飞行器、船舶、汽车等的实际振动千姿百态、瞬息变化。模态分析提供了研究各种实际结构振动的一条有效途径。首先,将结构物在静止状态下进行人为激振,通过测量激振力与胯动响应并进行双通道快速傅里叶变换(FFT)分析,得到任意两点之间的机械导纳函数(传递函数)。用模态分析理论通过对试验导纳函数的曲线拟合,识别出结构物的模态参数,从而建立起结构物的模态模型。根据模态叠加原理,在已知各种载荷时间历程的情况下,就可以预言结构物的实际振动的响应历程或响应谱。近十多年来,由于计算机技术、
FFT 分析仪、高速数据采集系统以及振动传感器、激励器等技术的发展,试验模态分析得到了很快的发展,受到了机械、电力、建筑、水利、航空、航天等许多产业部门的高度重视。已有多种档次、各种原理的模态分析硬件与软件问世。在各种各样的模态分析方法中,大致均可分为四个基本过程:(1)动态数据的采集及频响函数或脉冲响应函数分析1)激励方法。试验模态分析是人为地对结构物施加一定动态激励,采集各点的振动响应信号及激振力信号,根据力及响应信号,用各种参数识别方法获取模态参数。激励方法不同,相应识别方法也不同。目前主要由单输入单输出(SISO)、单输入多输出(SIMO)多输入多输出(MIMO)三种方法。以输入力的信号特征还可分为正弦慢扫描、正弦快扫描、稳态随机(包括白噪声、宽带噪声或伪随机)、瞬态激励(包括随机脉冲激励)等。2)数据采集。SISO 方法要求同时高速采集输入与输出两个点的信号,用不断移动激励点位置或响应点位置的办法取得振形数据。SIMO 及MIMO 的方法则要求大量通道数据的高速并行采集,因此要求大量的振动测量传感器或激振器,试验成本较高。3)时域或频域信号处理。例如谱分析、传递函数估计、脉冲响应测量以及滤波、相关分析等。(2)建立结构数学模型根据已知条件,建立一种描述结构状态及特性的模型,作为计算及识别参数依据。目前一般假定系统为线性的。由于采用的识别方法不同,也分为频域建模和时
^ | You have to believe, there is a way. The ancients said:" the kingdom of heaven is trying to enter". Only when the reluctant step by step to go to it 's time, must be managed to get one step down, only have struggled to achieve it. -- Guo Ge Tech 医学图像处理技术 摘要:随着医学成像和计算机辅助技术的发展,从二维医学图像到三维可视化技术成为研究的热点,本文介绍了医学图像处理技术的发展动态,对图像分割、纹理分析、图像配准和图像融合技术的现状及其发展进行了综述。在比较各种技术在相关领域中应用的基础上,提出了医学图像处理技术发展所面临的相关问题及其发展方向。关键词:医学图像处理;图像分割;图像配准;图像融合;纹理分析 1.引言 近20 多年来,医学影像已成为医学技术中发展最快的领域之一,其结果使临床医生对 人体部病变部位的观察更直接、更清晰,确诊率也更高。20 世纪70 年代初,X-CT 的发明 曾引发了医学影像领域的一场革命,与此同时,核磁共振成像象(MRI :Magnetic Resonance Imaging)、超声成像、数字射线照相术、发射型计算机成像和核素成像等也逐步发展。计算机和医学图像处理技术作为这些成像技术的发展基础,带动着现代医学诊断正产生着深刻的变革。各种新的医学成像方法的临床应用,使医学诊断和治疗技术取得了很大的进展,同时将各种成像技术得到的信息进行互补,也为临床诊断及生物医学研究提供了有力的科学依据。 在目前的影像医疗诊断中,主要是通过观察一组二维切片图象去发现病变体,往往需要借助医生的经验来判定。至于准确的确定病变体的空间位置、大小、几何形状及与周围生物组织的空间关系,仅通过观察二维切片图象是很难实现的。因此,利用计算机图象处理技术对二维切片图象进行分析和处理,实现对人体器官、软组织和病变体的分割提取、三维重建和三维显示,可以辅助医生对病变体及其它感兴趣的区域进行定性甚至定量的分析,可以大大提高医疗诊断的 准确性和可靠性。此外,它在医疗教学、手术规划、手术仿真及各种医学研究中也能起重要的辅助作用。 本文对医学图像处理技术中的图像分割、纹理分析、图像配准和图像融合技术的现状及其发展进行了综述。 2.医学图像三维可视化技术 2.1三维可视化概述 医学图像的三维可视化的方法很多,但基本步骤大体相同,如图.。从#$ /&’(或超声等成像系统获得二维断层图像,然后需要将图像格式(如0(#1&)转化成计算机方便处理的格式。通过二维滤波,减少图像的噪声影响,提高信噪比和消除图像的尾迹。采取图像插值方法,对医学关键部位进行各向同性处理,获得体数据。经过三维滤波后,不同组织器官需要进行分割和归类,对同一部位的不同图像进行配准和融合,以利于进一步对某感兴趣部位的操作。根据不同的三维可视化要求和系统平台的能力,选择不同的方法进行三维体绘制,实现三维重构。
模态参数识别方法的比较研究 发表时间:2017-09-07T14:07:39.937Z 来源:《防护工程》2017年第9期作者:安鹏强[导读] 本文将频域法、时域法和整体识别法识别模态参数的应用范围、存在的优缺点进行对比、分析和说明。 航天长征化学工程股份有限公司兰州分公司甘肃兰州 730050 摘要:本文将频域法、时域法和整体识别法识别模态参数的应用范围、存在的优缺点进行对比、分析和说明,对模态参数识别的研究方向具有指导意义。 关键词:模态参数识别;频域法;时域法;整体识别法 引言 多自由度线性振动系统的微分方程可以表达为[1]: [M]{x ?(t)}+[C]{x ?(t)}+[K]{x(t)}={f(t)} 通过将试验采集的系统输入与输出信号用于参数识别的方法中,进而对系统的模态质量、模态阻尼、模态刚度、模态固有频率及模态振型进行识别,这一过程称为结构的模态参数识别。本文将对模态参数识别的频域法、时域法及整体识别法三者的应用范围、存在的优缺点进行对比、分析和说明。 1频域法 模态参数识别的频域法是结合傅里叶变换理论[1]形成的,这种方法是从实测数据的频响函数曲线上对测试结构的模态参数进行估计。图解法[1]是最早的频域模态参数识别方法,随之,又陆续发展了导纳圆拟合法[2]、最小二乘迭代法[2]、有理式多项式法[2]等多种频域模态参数识别方法。 频域法的优点是直观、简便,噪声影响小,模态定阶问题易于解决。频域法识别模态参数的思路是首先借助实测频响函数曲线对模态参数进行粗略的估计,进而将初步观测的模态估计值作为一些频域识别法的最初输入值,通过反复的迭代获取最终的模态参数。频域识别方法对于实测频响函数的分布容易控制,其输人数据是主观人为的。频域中参数识别方法识别结果的精准度,取决于测试试验中获得的频响函数质量的好坏。判断实测频响函数的质量,就要看其曲线的光滑[2]和曲线的饱满程度[2],曲线越光滑越饱满的实测频响函数,用其进行参数识别时,识别精度越高。 2时域法 模态参数识别的时域法的研究与应用比频域法晚,时域法可以克服频域法的一些缺陷。时域模态参数识别的技术优点在于无需获得激励力即可进行参数的识别[3-7]。对于一些大型的工程结构如大坝、桥梁等,获取激励荷载不太容易,但容易测得他们在风、地脉动等环境激励下的响应数据,把这些响应数据用于时域中一些参数识别的方法上,即可对测试结构的模态参数进行识别。 时域法的优点不仅在于其无需激励设备、减少测试费用而且可以避免由信号截断而造成对识别精度的影响,并且可实现对大型工程结构的在线参数识别,真实地反映结构的动力特性。但是由于响应信号中含有大量的噪声,这会使得所识别的模态中含有虚假模态。目前,对于如何剔除噪声模态、优化识别过程中的一些参数问题、以及怎样更稳定、可靠地进行模态定阶等成为时域法研究中的重要课题。目前常用的判定模态真假的方法是稳定图方法[8],该方法的基本思想在于不同阶次的系统模型会对虚假模态的影响比较大,在稳定图中出现次数最多的模态可认为是系统的真实模态。 3整体识别法 结构模态参数识别的单输入单输出类型是针对单个响应点的数据进行相应的计算,从而得到该测点对应的模态频率、阻尼比和振型系数等动力参数,但是对于有多个测点的试验,若要用单输入单输出类型的识别方法对多自由度结构进行参数识别,则需要对各个测点单独计算来识别各个测点对应的模态参数,通过对各个测点分别计算处理,得到每一个测点数据所识别的模态参数,然后求取所有测点响应识别的算术平均值来作为整体结构最终的识别结果。理论上讲,用每个测点数据识别的结果应该是一样的,但实际测试实验中,因测试实验中测点布置位置的不同、测试中其他因素及识别方法上的不完善会使得各个测点的识别结果不同、识别精度不同及错误的识别结果等现象。因此,对于多测点的测试试验,用单输入单输出类型的识别方法进行参数识别不仅会因多次重复导致计算工作量复杂累赘而且识别结果的正确性及精度无法保证。 整体识别的方法避免了单输入单输出类型的一些不足之处。该方法通过将结构上的所有测点的实测数据同时进行识别计算,所识别得到的结果作为结构整体的模态参数,每阶模态的固有频率和阻尼比是唯一的,减小了随机误差,提高了识别进度,并且使得计算工作量大大减少。 4三种识别方法的比较分析 (1)频域内的模态参数识别方法方便、快捷,但在实际运用中人为的主观选择性对识别结果的影响较大; (2)基于环境激励的时域模态参数的识别方法具有测试试验的花费较少、测试相对安全,并且识别精度较高。因此,基于环境激励的时域模态参数的识别方法已成为科研工作者研究的热点问题。 (3)对于多测点的测试试验,用频域和时域的单输入单输出类型识别模态参数不仅会因多次重复导致计算工作量复杂累赘而且识别结果的正确性及精度无法保证。整体识别法将所有测点的数据同时进行处理计算,得到结构的整体识别结果。整体识别方法通过对所有测点数据同时进行识别计算,减小了随机误差,提高了识别进度,使得计算工作量大大减少。 (4)对比时域和频域识别方法对虚假模态的剔除,可以看出,频域中的剔除虚假模态主要依据模态频率在频幅曲线图上会出现峰值的原理,利用该峰值处的幅值角是否为0°或180°来剔除虚假模态;相对频域剔除虚假模态的方法来说,时域中的剔除虚假模态的方法有定量的精度判别指标。总体看来,时域识别方法无法判别是否已将系统的所有模态进行识别且对于阻尼比的确定还有待研究。参考文献 [1] 曹树谦,张德文,萧龙翔. 振动结构模态分析-理论、实验与应用[M]. 天津大学出版社,2001. [2] 王济,胡晓. Matlab在振动信号处理中的应用[M]. 水利水电出版社,2006.
医学图像处理综述 墨南-初夏2010-07-24 23:51:56 医学图像处理的对象是各种不同成像机理的医学影像。广泛使用的医学成像模式主要分为X射线成像(X—CT) ,核磁共振成像(MRI),核医学成像(NMI)和超声波成像(UI) 这四类。 (1)x射线成像:传统x射线成像基于人体不同器官和组织密度不同。对x射线的吸收衰减不同形成x射线影像。(例如人体中骨组织密度最大,在图像上呈白影,肺是软组织并且含有气体,密度最低,在照片上的图像通常是黑影。)常用于对人体骨骼和内脏器官的疾病或损伤进行诊断和定位。现代的x射线断层成像(x—cT) 发明于20世纪70年代,是传统影像技术中最为成熟的成像模式之一,其速度已经快到可以对心脏实现动态成像。其缺点是医生要在病人接收剂量和片厚之间进行折衷选择,空间分辨率和对比度的还需进一步提高。 (2)核磁共振成像(MIR) 发展于20世纪70年代,到80年代才进入市场,这种成像设备具有在任意方向上的多切片成像、多参数和多核素成像、可实现整个空问的真三维数据采集、结构和功能成像,无放射性等优点。目前MRI的功能成像(fMRI) 是MIR设备应用的前沿领域,广泛应用于大脑功能性疾病的诊断,并为肿瘤等占位性病变提供功能信息。MRI 受到世人的广泛重视,其技术尚在迅速发展
过程中。 (3)核医学成像(NMI ) ,目前以单光子计算机断层成像(SPECT) 和正电子断层成像(PET) 为主,其基本原理是向人体注射放射性核素示踪剂,使带有放射性核素的示踪原子进入人体内要成像的脏器或组织通过测量其在人体内的分布来成像。NMI不仅可以提供静态图像,而且可提供动态图像。 (4)超声波成像(Ultrasonic Imaging ) ,属于非电离辐射的成像模态,以二维平面成像的功能为主,加上血液流动的彩色杜普勒超声成像功能在内,在市场上已经广泛使用。超声成像的缺点是图像对比度差、信噪比不好、图像的重复性依赖于操作人员。但是,它的动态实时成像能力是别的成像模式不可代替的 在目前的影像医疗诊断中,主要是通过观察一组二维切片图象去发现病变体.这往往需要借助医生的经验来判定。至于准确地确定病变体的空间位置、大小、几何形状及与周围 生物组织的空间关系,仅通过观察二维切片图象是很难实现的。因此,利用计算机图像处理技术对二维切片图象进行分析和处理。实现对人体器官,软组织和病变体的分割提取,三维重建和三维显示,可以辅助医生对病变体及其它感兴趣的区域进行定性甚至定量的分
数字图像处理的应用 数字图像处理又称为计算机图像处理,它是指将图像信号转换成数字信号,并通过计算机对图像进行去除噪声、增强、复原、分割、提取特征等处理的方法和技术。 数字图像处理的产生和迅速发展主要受三个因素的影响:一是计算机的发展;二是数学的发展;三是广泛的农牧业、林业、环境、军事、工业和医学等方面的应用需求的增长。 进行数字图像处理所需要的设备包括摄像机、数字图像采集器(包括同步控制器、模数转换器及帧存储器)、图像处理计算机和图像显示终端。 图像是人类获取和交换信息的主要来源,因此,图像处理的应用领域必然涉及到人类生活和工作的方方面面。随着人类活动范围的不断扩大,图像处理的应用领域也将随之不断扩大。 接下来,就讨论一下数字图像处理在医学上的应用。 自发现X射线以来,在医学领域可以用图像的形式揭示更多有用的医学信息,医学的诊断方式也发生了巨大的变化。随着科学技术的不断发展,现代医学已越来越离不开医学图像的信息处理。 目前的医学图像包括CT图像、核磁共振图像、B超扫描图像、数字X 光机图像、X 射线透视图像、各种电子内窥镜图像、显微镜下病理切片图像等。由于人眼识别度等客观因素的影响,大部分的图像需要依靠计算机的帮助。随着数字图像处理技术的发展,对这些图像的分析以及处理,会变得更加快捷,分析的结果也会更加精准。
与其他领域的应用相比较,医学影像等卫生领域信息更具独特性,医学图像较普通图像纹理更多,分辨率更高,相关性更大,存储空间要更大,并且为严格确保临床应用的可靠性,其压缩、分割等图像预处理、图像分析及图像理解等要求更高。 首先,对于一个病例,要进行图像采集,由于采集到的图像因试验测量系统和测量者个人因素存在较多噪声,所以要先通过预处理对图像进行去噪处理和灰度变换处理等使其变得较为清晰。预处理完成后再利用中心路径提取算法对所获取的图像进行进一步处理。 接下来要做的就是图像处理。 先对图像二值化,二值形态学的运算对象是集合给出一个图像集合和一个结构元素集合利用结构元素对图像进行操作。然后做中心线的提取等。 使用计算机进行图像的采集预处理以及二值化和计算排除了人为测 量的不精确性和误差提高了测量结果的可靠性。 随着信息技术的飞速发展和计算机应用水平的不断提高,利用计算机断层成像、正电子放射层析成像、单光子辐射断层摄像、磁共振成像、超声成像及其它医学影像设备所获得的图像被广泛应用于医疗诊断、组织容积定量分析、病变组织定位、解剖结构学习、治疗规划、功能成像数据的局部体效应校正、计算机指导手术和术后监测等各个环节。 医学图像处理借助于计算机图形、图像技术,使医学图像的质量和显示方法得到了极大的改善。这不仅可以基于现有的医学影像设备来极
多模态图像融合算法综述 多模态图像融合能最大限度地提取各模态的图像信息,同时减少冗余信息。文章提出一种新的图像融合算法的分类体系,在分析新体系的基础上,阐述了各体系下的代表性算法,论述图像融合的研究背景及研究进展,最后提出了未来趋势的新目标。 标签:图像融合;像素级;特征级;决策级;图像融合算法 引言 不同模态传感器关于同一场景所采集到的图像数据经过相关技术处理相融合的过程称为多模态图像融合,本文站在新的角度,提出一种新的分类体系,同时阐述各体系下的代表性算法,论述图像融合领域的发展现状。 1 图像融合的体系 根据融合的对象,图像融合一般分为三个等级:像素级、特征级及决策级[1]。像素级的处理对象是像素,最简单直接,特征级建立在抽取输入源图像特征的基础上,决策级是对图像信息更高要求的抽象处理,本文在此基础上提出一种不同的的分类体系,即直接融合和间接融合。 1.1 直接图像融合算法 直接图像融合算法分基于像素点和基于特征向量的融合方法,基于像素点的融合主要针对初始图像数据而进行[2],是对各图像像素点信息的综合处理[3]。 1.2 间接图像融合算法类 间接图像融合算法是指对图像进行变换、分解重构或经神经网络处理后,通过逻辑推理来分析多幅图像的信息。 2 直接图像融合算法类 直接图像融合算法分基于像素点和基于特征向量的图像融合算法。 2.1 基于像素点的直接图像融合算法 设待融合图像X、Y,且X(i,j)、Y(i,j)为图像X、图像Y在位置(i,j)的灰度值,则融合后的图像Z(i,j)=x X(i,j)+y Y(i,j),x、y是加权系数且x+y=1。算法简单、融合速度快,但减弱了图像的对比度[4]。 2.2 基于特征向量的直接图像融合算法
第36卷 第7期2008年 7月 华 中 科 技 大 学 学 报(自然科学版) J.Huazhong Univ.of Sci.&Tech.(Natural Science Edition )Vol.36No.7 J ul. 2008 收稿日期:2007209203. 作者简介:毛宽民(19642),男,副教授,E 2mail :kmmao4645@https://www.doczj.com/doc/7a14403868.html,. 基金项目:国家重点基础研究发展计划资助项目(2005CB7244101);国家高技术研究发展计划资助项目 (2006AA04Z407). 基于响应信号的结构模态参数提取方法 毛宽民a ,b 李 斌a (华中科技大学a 机械科学与工程学院;b 数字制造与装备国家重点试验室,湖北武汉430074) 摘要:基于现有实验模态分析技术,提出了以一个响应信号作为参考信号,并且只利用响应信号提取结构模态参数的方法.以一个自由的钢梁为实验对象,通过与传统的用传递函数矩阵进行模态参数识别的实验模态分析法的识别结果比较,验证了所提出方法的有效性:固有频率识别精度和模态阻尼比的识别精度较高,误差分别不超过0.5%和18%;振型有一定的误差,但是总体趋势是一致的,能够反映结构的振动形态.该方法特别适合于用力锤或激振器无法激振的大型重型结构,如大型机床等设备,也适合于那些不宜用外力激振的设备,如高精密机床等. 关 键 词:模态识别;频率响应函数;振动;运行模态分析 中图分类号:T H113.1 文献标识码:A 文章编号:167124512(2008)0720077203 R esponse signals 2based structural modal parameter identif ication M ao Kuanmi n a ,b L i B i n a (a College of Mechanical Science and Engineering ;b The State Key Laboratory of Digital Manufacturing Equipment and Technology ,Huazhong University of Science and Technology ,Wuhan 430074,China ) Abstract :On t he basis of present research o n experimental modal analysis technology ,a new met hod is p ut forward ,which uses one response signal as a reference signal and only use response signals to identify st ruct ural modal parameters.This met hod is especially applicable for big and heavy st ruct ure which can not be excited by hammer or exciter ,like big machine tool equip ment ;and it is also right for t he equip ment s like high 2precision machine tool ,which can not be excited by external forces.This paper does experiment on a free steel beam and testify t he effectiveness of t his met hod by comparing it wit h t he t raditional experimental modal analysis met hod ,which uses a t ransform f unction mat rix to identify modal parameters.The frequency identification precision is very high ,t he error is less t han 0.5%;modal damping ratio n identification p recision is very high ,t he error is less t han 18%;t he model shape is generally t he same wit h a certain difference but is able to reflect t he vibration state.K ey w ords :modal identification ;frequency response f unctio n ;vibration ;operation modal analysis 结构的动态性能主要是由结构的模态参数决定的,结构模态参数提取方法,主要是实验模态分析技术,已经发展得相当丰富[1].这些技术的基本思路是通过实验,在知道结构的激励和响应的情况下,通过频率响应函数(频域法)[2]或脉冲响应函数(时域法)[3]提取结构的模态参数.利用结构的振动响应信号提取结构的模态参数,已经得到 了实验模态分析领域研究人员的普遍关注,提出了许多相应的方法,包括ODS (运行变形形状)和OMA (运行模态分析)[4~8].但这些新方法无一例 外的是在假设结构激励为稳态白噪声激励条件下.显然实际情况并非如此. 本文在现有实验模态分析技术的研究基础上,提出了以一个响应信号作为参考信号,并且只
土木工程结构模态参数识别-理论、实现与应用 中文摘要 土木工程结构模态参数识别-理论、实现与应用的课题研究来源于国家自然科学基金项目(批准号:50378021)。 土木工程结构是国家基础设施的重要组成部分,直接影响人民的生活和安全。对土木工程结构进行全面的检测、评估和健康监测,就需要充分了解土木工程结构的动力特征参数。模态参数是决定结构动力特征的主要参数,其识别方法一般可分为传统的模态参数识别方法和环境激励下的模态参数识别方法。环境激励振动试验,具有无需贵重的激励设备,不打断结构的正常使用,方便省时等显著的优点,更加适合土木工程结构的实际使用。环境振动试验不同于传统的基于输入和输出的模态参数识别,仅测得了结构振动响应的输出数据,而真正的输入是没有测量的,是仅基于输出数据的模态参数识别。成为目前工程结构系统识别十分活跃的研究课题,也是一种挑战。 本文主要研究了环境激励情况下,土木工程结构的模态参数识别问题。对频域的峰值法和时域的随机子空间识别的理论算法、计算机实现和实际应用进行了深入的研究。完成的主要工作和结论如下: 1.系统地讨论了环境激励情况下模态参数识别频域方法,重点研究了峰值法和频域 分解法,对峰值法改进的途径进行了研究,建议采用平均正则化功率谱,并借助传递函数幅角辅助进行峰值选取,使峰值的选取更加客观准确。频域分解法本质上是基于奇异值分解的峰值法,可以比较客观的选择特征频率和识别相近的模态,识别精度高,是目前较先进的频域识别方法。 2.详细讨论了时域随机子空间识别基本理论和算法,包括协方差驱动随机子空间识 别和数据驱动随机子空间识别。提出了基于稳定图的平均正则化稳定图算法,辅助进行模态参数的自动识别,适应大型土木工程结构分组测试的特点。平均正则化稳定图将不同阶数模型计算的结果综合考虑,提高识别效率和识别精度。分析比较表明,协方差驱动和数据驱动随机子空间方法都可以有效识别结构的模态参数,数据驱动随机子空间方法理论上会比协方差驱动随机子空间方法识别结果更稳定、更精确,但计算时间相对要长些。通过算例详细比较分析了这两种随机子空间识别中不同的加权方法对识别结果的影响。 3.基于VC平台开发了土木工程结构模态分析软件MACES,用计算机实现了模态 参数识别的频域峰值法,包括不同加权方法的时域随机子空间识别算法,可以方便、快捷和高效地完成大型土木工程结构模态参数识别的全过程。主要功能包括
各种模态分析方法总结与比较 一、模态分析 模态分析是计算或试验分析固有频率、阻尼比和模态振型这些模态参数的过程。 模态分析的理论经典定义:将线性定常系统振动微分方程组中的物理坐标变换为模态坐标,使方程组解耦,成为一组以模态坐标及模态参数描述的独立方程,以便求出系统的模态参数。坐标变换的变换矩阵为模态矩阵,其每列为模态振型。 模态分析是研究结构动力特性一种近代方法,是系统辨别方法在工程振动领域中的应用。模态是机械结构的固有振动特性,每一个模态具有特定的固有频率、阻尼比和模态振型。这些模态参数可以由计算或试验分析取得,这样一个计算或试验分析过程称为模态分析。这个分析过程如果是由有限元计算的方法取得的,则称为计算模记分析;如果通过试验将采集的系统输入与输出信号经过参数识别获得模态参数,称为试验模态分析。通常,模态分析都是指试验模态分析。振动模态是弹性结构的固有的、整体的特性。如果通过模态分析方法搞清楚了结构物在某一易受影响的频率围各阶主要模态的特性,就可能预言结构在此频段在外部或部各种振源作用下实际振动响应。因此,模态分析是结构动态设计及设备的故障诊断的重要方法。 模态分析最终目标是在识别出系统的模态参数,为结构系统的振动特性分析、振动故障诊断和预报以及结构动力特性的优化设计提供依据。 二、各模态分析方法的总结
(一)单自由度法 一般来说,一个系统的动态响应是它的若干阶模态振型的叠加。但是如果假定在给定的频带只有一个模态是重要的,那么该模态的参数可以单独确定。以这个假定为根据的模态参数识别方法叫做单自由度(SDOF)法n1。在给定的频带围,结构的动态特性的时域表达表示近似为: ()[]}{}{T R R t r Q e t h r ψψλ= 2-1 而频域表示则近似为: ()[]}}{ {()[]2ωλωψψωLR UR j Q j h r t r r r -+-= 2-2 单自由度系统是一种很快速的方法,几乎不需要什么计算时间和计算机存。 这种单自由度的假定只有当系统的各阶模态能够很好解耦时才是正确的。然而实际情况通常并不是这样的,所以就需要用包含若干模态的模型对测得的数据进行近似,同时识别这些参数的模态,就是所谓的多自由度(MDOF)法。 单自由度算法运算速度很快,几乎不需要什么计算和计算机存,因此在当前小型二通道或四通道傅立叶分析仪中,都把这种方法做成置选项。然而随着计算机的发展,存不断扩大,计算速度越来越快,在大多数实际应用中,单自由度方法已经让位给更加复杂的多自由度方法。 1、峰值检测 峰值检测是一种单自由度方法,它是频域中的模态模型为根据对系统极点进行局部估计(固有频率和阻尼)。峰值检测方法基于这样的事实:在固有频率附近,频响函数通过自己的极值,此时其实部为零(同相部分最
基于多模态融合的情感计算研究 移动终端和智能设备目前与人类生活、学习和工作息息相关,基于智能设备的情感计算技术已成为国内外学者的研究热点。随着人口老龄化趋势加剧,老年人的家庭护理需求日益增多,通过对老年人的情感状态、行为姿态进行研究可以更好的理解和关注老年人的身心健康。利用情感计算可以建立和谐的人机环境,但是目前情感计算仍存在一些急需解决的问题,在行为姿态识别中,虽然选择手机传感器的底层统计特征对人体行为进行识别可取得较好效果,但是这些底层特征忽略了行为的高层语义表达,对训练集中有限样本行为的识别率较差。而在情感识别中,人的情感在表达时由生理、心理、表情和音调等多个模态信息共同组成,使用单模态进行情感识别时,由于情感表示信息不足容易导致一些情绪的识别率较差等问题。针对以上两种分类识别所面临的问题提出两种识别方法,主要工作包括如下两方 面:(1)针对现有日常行为识别中跌倒样本采集困难,跌倒行为样本规模较少导致识别率较差的问题,提出一种基于低层特征与高层语义的人体行为识别方法。该方法引入语义属性特征以便在某些行为样本较少的情况下能够共享行为之间的低层特征信息,通过构建属性-行为矩阵,利用低层特征信息训练语义属性检测器,得到语义属性特征,对属性特征与低层特征分别进行预分类,融合两种特征的预分类结果得到最终判决的人体行为类别。实验结果表明,与过采样算法、欠采样算法和最小二乘支持向量机相比,本文所提方法获得了更好的分类结果。(2)一般多模态特征融合方法仅通过简单的拼接来组合特征,或将
所有模态信息直接利用深度模型进行融合,这样会导致特征冗余和关键特征不足等问题,本文提出多模态深度信念网络对各模态特征分别进行融合,以解决所有模态直接融合后进行特征选择带来的实验成本过高的问题,并提高各情绪识别性能。通过多模深度信念网络优选生理信号和视频信号的初始特征,再利用双模深度信念网络将各模态统一结构化的特征进行融合,得到多模态高层表示特征,利用支持向量 机对该特征进行分类识别。在The BioVid Emo DB数据集上对高兴、难过、生气、恐惧和厌恶这五种情绪的平均识别率是80.89%,实验表明该方法在降低融合成本的同时,对多模态情绪识别性能也有较好的改善。
17.3 模态参数(频率、振型、阻尼比)作业指导书1 目的 测试桥梁的模态参数,了解桥梁的自振特性。 2 适用范围 适用于桥梁或结构构件的模态参数测试及分析。 3 试验准备 3.1 仪器、设备、材料 3.2 资料 ①、桥梁或结构构件拾振器测点布置图 ②、相关仪器、软件使用说明书 ③、原始记录表格(见附表1~2) ④、仪器、设备、材料清单表确认单(见附表3) 3.3 检查仪器、设备及软件是否正常运行(见附表4) 4 试验流程
4.1 测点布置: 试验前应对桥梁结构进行有限元分析,计算理论的振型图,根据振型图确定测点布置(测点布置的原则和数量要求见5.1)。由于试验用的拾振器可能有限,所以应在桥上选择合适的参考点(参考点的选择要求见5.2),分批搬动其他拾振器到所有测点。 4.2 拾振器安装: 拾振器安装前,应将测点位置清洁除尘。安装时,将拾振器通过橡皮泥牢固粘贴在测点位置,保证拾振器和构件能共同移动,同时传感器的主轴方向应与测点主振方向一致。 4.3 仪器连接: 仪器连接详见《DH5922N动态信号测试分析系统使用说明书》。 4.4 数据采集: 在数据采集之前,应对软件及拾振器各参数进行设置(参数设置要点见5.3)。仪器参数设置及采集软件的操作详见《DHDAS4.1.3基本分析软件说明书》。 为了消除随机因素影响,应对采集的长样本信号进行能量平均。对于悬索桥、斜拉桥等自振频率较低的桥型,为保证频率分辨率和提高信嘈比,采集时间不宜小于20分钟,一般采集时间取20~45分钟,对于小跨径桥梁,采集时间可酌情减小。 4.5 数据处理: 自振频率:可采用频谱分析法、波形分析法或模态分析法得到桥梁结构自振频率。 阻尼比:采用波形分析法、半功率带宽法或模态分析法得到。 振型参数:采用环境激振等方法进行模态参数识别。 数据后期处理及分析的软件操作详见《DHDAS4.1.3基本分析软件说明书》。 4.6模态参数的评定: 1结构的自振最低频率应大于有关标准限值,结构最大振幅应小于相应标准限值。
第36卷第3期 计算机仿真2019年3月文章编号:1006-9348 (2019)03-0248-04 多模态医学图像外边界点云数据实时配准仿真 李玮琳\曾琪峰\李颖1 (1.长春工业大学人文信息学院,吉林长春13_;2.长春光学精密机械与物理研究所光电技术研发中心,吉林长春13_) 摘要:为了提升医学图像识别质量,需要对医学图像外边界点云数据进行实时配准。针对当前多模态医学图像外边界点云 数据实时配准中,存在着配准精度较低、完成时间过长、误差较大等问题。提出基于特征点对齐度的图像外边界点云数据实 时配准方法。采用SIFT算法提取出医学图像待配准特征点,以小波边缘检测法获取待配准特征点中的医学图像外边界点 云数据,构建附近区域外边界点云数据特征,求出具有显著外边界点特征的特征点,结合Shape-context算子和显著外边界特 征点,构建特征描述向量,利用角度直方图提取以特征点为中心的图像外边界点特征子图,计算出所有外边界点特征子图的 对齐度来确定候选配准点对,引用线性加权法消除错误配准,以此完成正确配准。实验结果表明,所提方法在进行医学图像 外边界点云数据配准中,配准精度较高、所需完成时间较短误差较小。 关键词:多模态;医学图像;外边界点云数据;实时配准 中图分类号:TP391.41 文献标识码:B Multi-Modal Medical Image Boundary Point Cloud Data Real-Time Registration Simulation LI Wei-lin 丨,ZENG Qi -feng2,LI Ying1 (1. College of Humanities and Information, Changchun University of Technology, Changchun J i l i n 130000, China; 2. Optoelectronic Technology r&d Center, Changchun I n s t i t u t e of Optics, Fine Mechanics and Physics, Chinese Academy of Sciences, Changchun J i l i n 130000, China) A B S T R A C T:In t h i s article, a method of real-time regis t r a t i o n f o r cloud data of external boundary point i n medical image based on the alignment metric of feature points was presented.Firstly, SIFT algorithm was used t o extract the feature points t o be registered i n medical image.Secondly, wavelet edge detection method was used t o obtain the cloud data of external boundary points i n the feature points t o be registered.Thirdly, the cloud data features of exter-nal boundary points i n nearby region were established t o get the feature point with remarkable external boundary point https://www.doczj.com/doc/7a14403868.html,bined with Shape-context operator and s i g n i ficant external boundary feature point, the feature description vector was constructed.In addition, the angle histogram was used t o extract sub graph of external boundary point fea-ture centered on the feature point.Meanwhile, the alignment degree of a l l the external boundary point feature sub graphs was calculated t o determine the candidate matching point pairs.Finally, the linear weighting method was used t o eliminate the wrong registration, so as t o complete the correct registration.Simulation resu l t s show t h a t the pro-posed method has higher r e g i s t r a t i o n accuracy, l e s s completion time and l ess error during the r e g i s t r a t i o n of cloud data of external boundary point i n medical image. K E Y W O R D S-.Multimodal; Medical image; External boundary point cloud data; Real-time r e g i s t r a t i o n i引言 医学技术、计算机技术和生物工程技术的不断发展,医学影像为临床诊断提供了多种模态的医学图像[1]。医学图 像配准是对图像处理的基本,是对相同两幅医学图像进行最 基金项目:吉林省教育厅"十三五"科学技术项目(jjkh20171025k) 收稿日期=2018-05-23修回日期:2018-06-20佳匹配的过程[2_3]。但是在现阶段医学图像外边界点云数据 配准的过程中,存在着配准精度较低、完成时间过长、误差较 大等问题。在这种情况下,如何有效提取图像外边界点特征,得到高精度的外边界点云数据配准成为当今社会亟待解 决的问题―51。 目前,陆雪松、涂圣贤、张素[6]提出一种基于多维特征度 量的医学图像非刚性配准方法。该方法采用最小距离树建 立多维特征矩阵,利用多维特征矩阵对形变模型参数进行解 —248 —