第六章:描述性统计分析--
Descriptive Statistics菜单详解
描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。
§6.1 Frequencies过程
频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。
和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并
不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。
6.1.1 界面说明
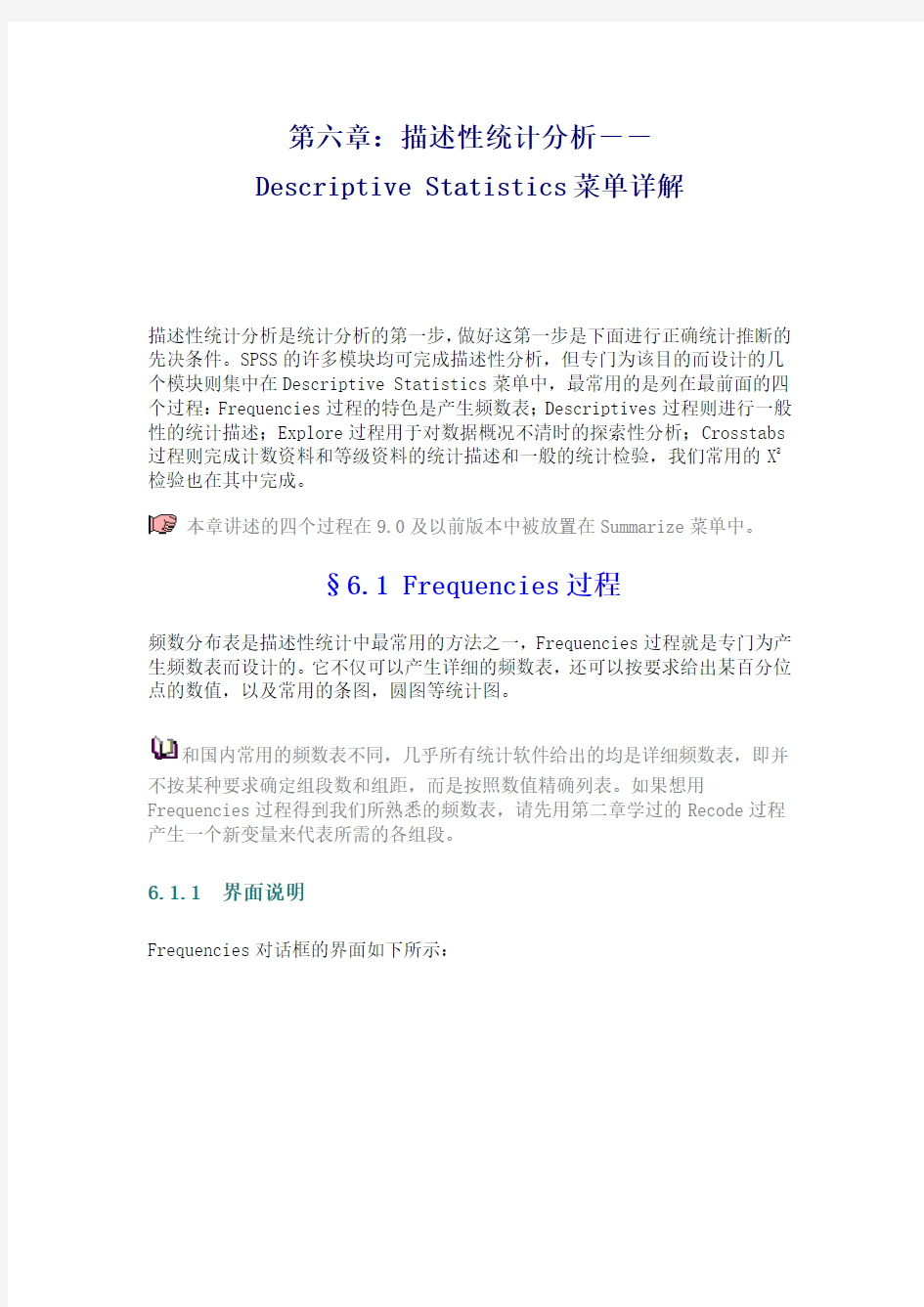
Frequencies对话框的界面如下所示:
该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】
确定是否在结果中输出频数表。
【Statistics钮】
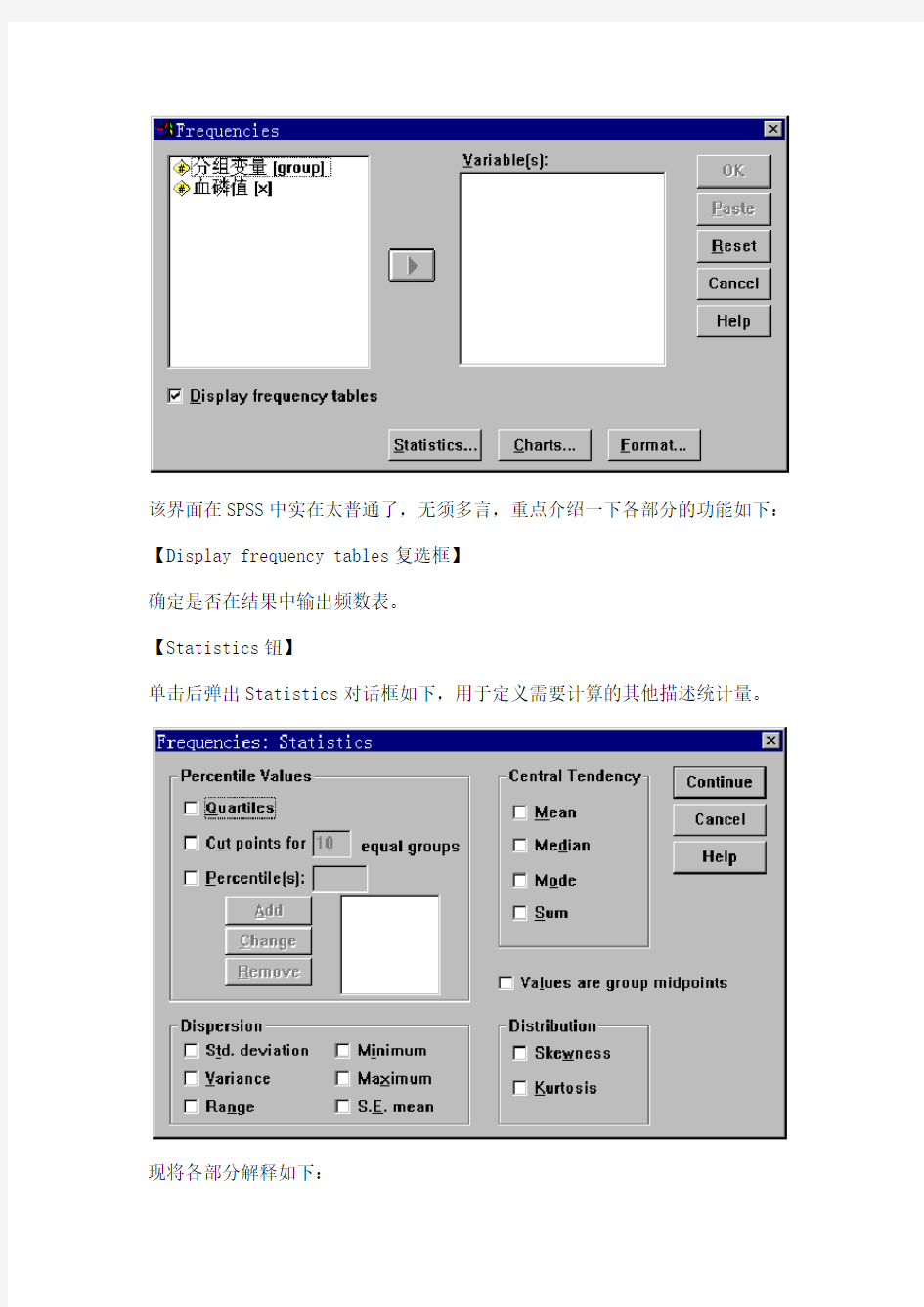
单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。
现将各部分解释如下:
o Percentile Values复选框组定义需要输出的百分位数,可计算四分位数(Quartiles)、每隔指定百分位输出当前百分位数(Cut points
for equal groups)、或直接指定某个百分位数(Percentiles),如直接指定输出P2.5和P97.5。
o Central tendency复选框组用于定义描述集中趋势的一组指标:均数(Mean)、中位数(Median)、众数(Mode)、总和(Sum)。
o Dispersion复选框组用于定义描述离散趋势的一组指标:标准差(Std.deviation)、方差(Variance)、全距 (Range)、最小值(Minimum)、最大值(Maximum)、标准误(S.E.mean)。
o Distribution复选框组用于定义描述分布特征的两个指标:偏度系数(Skewness)和峰度系数(Kurtosis)。
o Values are group midpoints复选框当你输出的数据是分组频数数据,并且具体数值是组中值时,选中该复选框以通知SPSS,免得它犯错误。
众数(Mode)指所有数值中出现频率最高的一个值,在国内用的非常少。【Charts钮】
弹出Charts对话框,用于设定所做的统计图。
o Chart type单选钮组定义统计图类型,有四种选择:无、条图(Bar chart)、圆图(Pie chart)、直方图Histogram),其中直方图还可以选择是否加上正态曲线(With normal curve)。
o Chart Values单选钮组定义是按照频数还是按百分比做图(即影响纵坐标刻度)。
【Format钮】
弹出Format对话框,用于定义输出频数表的格式,不过用处不大,一般不管。
o Order by单选钮组定义频数表的排列次序,有四个选项:Ascending values为根据数值大小按升序从小到大作频数分布;Descending values 为根据数值大小按降序从大到小作频数分布;Ascending counts为根据
频数多少按升序从少到多作频数分布;Descending counts为根据频数多少按降序从多到少作频数分布。
o Multiple Variables单选钮组如果选择了两个以上变量做频数表,则Compare variables可以将他们的结果在同一个频数表过程输出结果中显示,便于互相比较,Organize output by variables则将结果在不同的
频数表过程输出结果中显示。
o Suppress Tables more than...复选框当频数表的分组数大于下面设定数值时禁止它在结果中输出,这样可以避免产生巨型表格。
6.1.2 分析实例
例6.1 某地101例健康男子血清总胆固醇值测定结果如下,请绘制频数表、直方图,计算均数、标准差、变异系数CV、中位数M、p2.5和p97.5(卫统第三版p233 1.1题)。
4.77 3.37 6.14 3.95 3.56 4.23 4.31 4.71
5.69 4.12 4.56 4.37 5.39
6.30 5.21
7.22 5.54 3.93 5.21 4.12 5.18 5.77 4.79 5.12 5.20 5.10 4.70 4.74 3.50 4.69 4.38 4.89 6.25 5.32 4.50 4.63 3.61 4.44 4.43 4.25 4.03 5.85 4.09 3.35 4.08 4.79 5.30 4.97 3.18 3.97 5.16 5.10 5.86 4.79 5.34 4.24 4.32 4.77 6.36 6.38 4.88 5.55 3.04 4.55 3.35 4.87 4.17 5.85 5.16 5.09 4.52 4.38 4.31 4.58 5.72 6.55 4.76 4.61 4.17 4.03 4.47 3.40 3.91 2.70 4.60 4.09 5.96 5.48 4.40 4.55 5.38 3.89 4.60 4.47 3.64 4.34 5.18 6.14 3.24 4.90 3.05
解:为节省篇幅,这里只给出精确频数表的做法,假设数据已经输好,变量名为X,具体解法如下:
1.Analyze==>Descriptive Statistics==>Frequencies
2.Variables框:选入X
3.单击Statistics钮:
4.选中Mean、Std.deviation、Median复选框
5.单击Percentiles:输入2.5:单击Add:输入97.5:单击Add:
6.单击Continue钮
7.单击Charts钮:
8.选中Bar charts
9.单击Continue钮
10.单击OK
得出结果后手工计算出CV。
上面做出的直方图分组太多,需要进一步编辑。
6.1.3 结果解释
上题除直方图外的的输出结果如下:
Frequencies
最上方为表格名称,左上方为分析变量名,可见样本量N为101例,缺失值0例,均数Mean=4.69,中位数Median=4.61,标准差STD=0.8616,P2.5=3.04,P97.5=6.45。
系统对变量x作频数分布表(此处只列出了开头部分),Vaild右侧为原始值,Frequency为频数,Percent为各组频数占总例数的百分比(包括缺失记录在内),Valid percent为各组频数占总例数的有效百分比,Cum Percent为各组频数占总例数的累积百分比。
§6.2 Descriptives过程
Descriptives过程是连续资料统计描述应用最多的一个过程,他可对变量进行描述性统计分析,计算并列出一系列相应的统计指标。这和其他过程相比并无不同。但该过程还有个特殊功能就是可将原始数据转换成标准正态评分值并以变量的形式存入数据库供以后分析。
6.2.1 界面说明
【Save standardized values as variables复选框】
确定是否将原始数据的标准正态评分存为新变量。
【Options钮】
弹出Options对话框,大部分内容均在前面Frequences过程的Statistics对话框中见过,只有最下方的Display Order单选钮组是新的,可以选择为变量列表顺序、字母顺序、均数升序或均数降序。
6.2.2 结果解释
下面是一个典型的Descriptives过程结果统计表:
一望可知,这里的大部分内容都在上一节见过,因此就不再多解释了。
讲了两个过程,也许大家已经发现了:结果中的统计专业单词多数在对话框中就已经出现,因此我们以后会详细解释对话框的内容,结果中相同的单词不再重复解释。
§6.3 Explore过程
Explore过程可对变量进行更为深入详尽的描述性统计分析,主要用于对资料的性质、分布特点等完全不清楚时,故又称之为探索性分析。它在一般描述性统计指标的基础上,增加有关数据其他特征的文字与图形描述,如枝叶图、箱图等,显得更加详细、全面,有助于用户制定继续分析的方案。
6.3.1 界面说明
【Display单选钮组】
用于选择输出结果中是否包含统计描述、统计图或两者均包括。
【Dependent List框】
用于选入需要分析的变量。
【Factor List框】
如果想让所分析的变量按某种因素取值分组分析,则在这里选入分组变量。【Label cases by框】
选择一个变量,他的取值将作为每条记录的标签。最典型的情况是使用记录ID 号的变量。
【Statistics钮】
弹出Statistics对话框,用于选择所需要的描述统计量。有如下选项:o Descriptives复选框:输出均数、中位数、众数、5%修正均数、标准误、
方差、标准差、最小值、最大值、全距、四分位全距、峰度系数、峰度系数的标准误、偏度系数、偏度系数的标准误及指定的均数可信区间。
o M-estimators复选框:作中心趋势的粗略最大似然确定,输出四个不同权重的最大似然确定数。
o Outliers复选框:输出五个最大值与五个最小值。
o Percentiles复选框:输出第5%、10%、25%、50%、75%、90%、95%位数。【Plot钮】
弹出Plot对话框,用于选择所需要的统计图。有如下选项:
o Boxplots单选框组:确定箱式图的绘制方式,可以是按组别分组绘制(Factor levels together),也可以不分组一起绘制(Depentends
together),或者不绘制(None)。
o Descriptive复选框组:可以选择绘制茎叶图(Stem-and-leaf)和直方图(Histogram)。
o Normality plots with test复选框:绘制正态分布图并进行变量是否符合正态分布的检验。
o Spread vs. Level with Levene Test单选框组:当选择了分组变量时,绘制spread-versus-level图(我还没有找到他的中文名字该叫什么),设置绘图时变量的转换方式,并进行组间方差齐性检验。
【Options钮】
用于选择对缺失值的处理方式,可以是不分析有任一缺失值的记录、不分析计算某统计量时有缺失值的记录,或报告缺失值。
6.3.2 结果解释
以例6.1的数据为例,按默认方式下的选择,Explore过程的输出如下:Explore
首先是例行的处理记录缺失值情况报告,可见101例均为有效值。
上表详细列出了常用的描述统计量,如果有标准误也会列出(如偏度和峰度系数)。
X
X Stem-and-Leaf Plot
Frequency Stem & Leaf
1.00 2 . 7
8.00 3 . 00123334
9.00 3 . 556689999
24.00 4 . 000001111222333333344444
25.00 4 . 5555556666677777777788899
17.00 5 . 01111111222333334
9.00 5 . 556778889
6.00 6 . 112333
1.00 6 . 5
1.00 Extremes (>=7.2)
Stem width: 1.0000
Each leaf: 1 case(s)
以上是茎叶图,整数位为茎,小数位为叶。这样可以非常直观的看出数据的分布范围及形态,在国外非常流行。
以上是箱式图,中间的黑粗线为均数,红框为四分位间距的范围,上下两个细线为最大、最小值。
§6.4 Crosstabs过程
Crosstabs过程用于对计数资料和有序分类资料进行统计描述和简单的统计推断。在分析时可以产生二维至n维列联表,并计算相应的百分数指标。统计推断
)。如果安装了相应模块,则包括了我们常用的X2检验、Kappa值,分层X2(X2
M-H
还可计算n维列联表的确切概率(Fisher's Exact Test)值。
Crosstabs过程不能产生一维频数表(单变量频数表),该功能由Frequencies 过程实现。
6.4.1 界面说明
【Rows框】
用于选择行*列表中的行变量。
【Columns框】
用于选择行*列表中的列变量。
【Layer框】
Layer指的是层,对话框中的许多设置都可以分层设定,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next钮设为不同层。Layer 在这里用的比较少,在多元回归中我们将进行详细的解释。
【Display clustered bar charts复选框】
显示重叠条图。
【Suppress table复选框】
禁止在结果中输出行*列表。
【Exact钮】
针对2*2以上的行*列表设定计算确切概率的方法,可以是不计算(Asymptotic only)、蒙特卡罗模拟(Monte Carlo)或确切计算(Exact)。蒙特卡罗模拟默认进行10000次模拟,给出99%可信区间;确切计算默认计算时间限制在5分钟内。这些默认值均可更改。
如果你在安装SPSS时没有安装EXACT模块,则此处对话框中不会出现Exact 钮。
在3*3及以上的行*列表中,确切概率的精确计算是极为漫长的过程。我曾经用SAS 6.12在P133机上计算过一个12格表的确切概率,整整跑了两个小时后,SAS告诉我说机器内存不足:(。SPSS的计算速度比SAS要慢许多倍,因此一般只需要选用蒙特卡罗模拟算出概率值的99%可信区间就行了,精度完全可以满足需要,而速度极快(10000次模拟一般耗时在10秒左右)。
【Statistics钮】
弹出Statistics对话框,用于定义所需计算的统计量。
o Chi-square复选框:计算X2值。
o Correlations复选框:计算行、列两变量的Pearson相关系数和Spearman 等级相关系数。
o Norminal复选框组:选择是否输出反映分类资料相关性的指标,很少使用。
a.Contingency coefficient复选框:即列联系数,其值界于0~1之
间;
b.Phi and Cramer's V复选框:这两者也是基于X2值的,Phi在四格表
X2检验中界于-1~1之间,在R*C表X2检验中界于0~1之间;Cramer's
V 则界于0~1之间;
https://www.doczj.com/doc/799348599.html,mbda复选框:在自变量预测中用于反映比例缩减误差,其值为1
时表明自变量预测应变量好,为0时表明自变量预测应变量差;
d.Uncertainty coefficient复选框:不确定系数,以熵为标准的比例
缩减误差,其值接近1时表明后一变量的信息很大程度来自前一变
量,其值接近0时表明后一变量的信息与前一变量无关。
o Ordinal复选框组:选择是否输出反映有序分类资料相关性的指标,很少使用。
a.Gamma复选框:界于0~1之间,所有观察实际数集中于左上角和右
下角时,其值为1;
b.Somers'd复选框:为独立变量上不存在同分的偶对中,同序对子数
超过异序对子数的比例;
c.Kendall's tau-b复选框:界于-1~1之间;
d.Kendall's tau-c复选框:界于-1~1之间;
o Eta复选框:计算Eta值,其平方值可认为是应变量受不同因素影响所致方差的比例;
o Kappa复选框:计算Kappa值,即内部一致性系数;
o Risk复选框:计算比数比OR值;
o McNemanr复选框:进行McNemanr检验(一种非参检验);
o Cochran's and Mantel-Haenszel statistics复选框:计算X2M-H统计量
(分层X2,也有写为X2
CMH 的),可在下方输出H
假设的OR值,默认为1。
【Cells钮】
弹出Cells对话框,用于定义列联表单元格中需要计算的指标:
o Counts复选框组:是否输出实际观察数(Observed)和理论数(Expected);
o Percentages复选框组:是否输出行百分数(Row)、列百分数(Column)以及合计百分数(Total);
o Residuals复选框组:选择残差的显示方式,可以是实际数与理论数的差值(Unstandardized)、标化后的差值(Standardized,实际数与理论数的差值除理论数),或者由标准误确立的单元格残差(Adj.
Standardized);
【Format钮】
用于选择行变量是升序还是降序排列。
6.4.2 分析实例
例6.2 某医生用国产呋喃硝胺治疗十二指肠溃疡,以甲氰咪胍作对照组,问两种方法治疗效果有无差别(医统第二版P37 例3.10)?
解:由于此处给出的直接是频数表,因此在建立数据集时可以直接输入三个变量――行变量、列变量和指示每个格子中频数的变量,然后用Weight Cases对话框指定频数变量,最后调用Crosstabs过程进行X2检验。假设三个变量分别名为R、C和W,则数据集结构和命令如下:
R C W
1.00 1.00 54.00
1.00
2.00 44.00
2.00 1.00 8.00
2.00 2.00 20.00
1.Data==>Weight Cases
2.Weight Cases by单选框:选中
3.Freqency Variable:选入W
4.单击OK钮
5.Analyze==>Descriptive Statistics==>Crosstabs
6.Rows框:选入R
7.Columns框:C
8.Statistics钮:Chi-square复选框:选中:单击Continue钮
9.单击OK钮
6.4.3 结果解释
上题的结果如下:
Crosstabs
首先是处理记录缺失值情况报告,可见126例均为有效值。
上面为列出的四格表,实际使用时可以在其中加入变量值标签,使看起来更清楚。
上表给出了一堆检验结果,从左到右为:检验统计量值(Value)、自由度(df)、双侧近似概率(Asymp.Sig.2-sided)、双侧精确概率(Exact Sig.2-sided)、单侧精确概率(Exact Sig.1-sided);从上到下为:Pearson卡方(Pearson Chi-Square 即常用的卡方检验)、连续性校正的卡方值(Continuity Correction)、对数似然比方法计算的卡方(Likelihood Ratio)、Fisher's确切概率法(Fisher's Exact Test)、线性相关的卡方值(Linear by Linear Association)、有效记录数(N of Valid Cases)。另外,Continuity Correction和Pearson卡方值处分别标注有a和b,表格下方为相应的注解:a.只为2*2表计算。b.0%个格子的期望频数小于5,最小的期望频数为13.78。因此,这里无须校正,直接采用第一行的检验结果,即X2=6.133,P=0.013。
如何选用上面众多的统计结果令许多初学者头痛,实际上我们只需要在未校正卡方、校正卡方和确切概率法三种方法之间选择即可,其余的对我们而言用处不大,可以视而不见。
实验一数据的描述性统计分析 一、选择题 1、以下( B )语句对变量进行分组,在使用前需按分组变量进行排序? 以下( C )语句可对变量进行分类,在使用前不必按分类变量进行排序? 用( A )语句可以选择输入数据集的一个行子集来进行分析? (A)WHERE语句(B)BY语句(C)CLASS语句(D)FREQ语句2、排序过程步中必须用什么语句对变量进行排序?( A ) (A)BY语句(B)CLASS语句(C)WHERE语句 3、如果要对数据集中的数据进行正态性检验,需要使用哪个过程?( B )(A)MEANS (B)UNIV ARIATE (C)FREQ 4、用UNIV ARIATE过程进行数据分析,要求此过程输出茎叶图、正态概率图等,应在语句中加上什么选项?(plot ) 5、用UNIV ARIATE过程进行数据分析,在输出结果中哪个统计量是对样本均值 为零的T检验的概率值?( A ) (A)T: Mean (B)Prob>|S| (C)Sgn Rank (D)Prob>|T| 二、假设某校100名女生的血清总蛋白含量(g/L)服从均值为75,标准差为3的正态分布,试产生样本数据,并利用SAS软件解决下面问题: 1、计算样本均值、方差、标准差、极差、四分位极差、变异系数、偏度、峰度; 2、画出直方图(垂直条形图); 3、画出茎叶图、盒形图和正态概率图; 4、试进行正态性检验。 Data N; DO i=1to100; x=75+3*normal(12345); output; end; proc print; run; proc univariate data=N; var x; run; proc gchart data=N; block x; run; proc univariate data=N plot; var x;
第六章:描述性统计分析-- Descriptive Statistics菜单详解 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并 不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明 Frequencies对话框的界面如下所示:
该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】 确定是否在结果中输出频数表。 【Statistics钮】 单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。 现将各部分解释如下:
第五讲描述性统计分析评价方法——综合指标 实际上,从这一讲开始的教学内容都是介绍教育评价技术中的重要方法——教育统计分析方法,也即是分析资料的方法。其中包括描述性统计分析方法和推断性统计分析方法两大部分。 一、描述性统计分析评价方法的主要特点。对数据资料计算综合指标,然后根据综合指标值对教育客观事物给予评价。所谓综合指标指的是从数量方面综合说明事物特征的指标。常用的综合指标有绝对数、相对数、平均数和标准差。重点介绍后面两种。 二、综合指标的计算及解释 (一)绝对数(规模) (二)相对数(程度) (三)平均数(水平) 通常可用符号表示平均数 1.算术平均数(未经分类汇总的测量数据资料)计算方法见p62的(4.1)公式。 2.加权平均数(已经分类汇总的资料)
①组距数列平均数(对测量数据分组统计人数)例如P63表4-1的资料。计算方法如P63的(4.2)公式及83名教师平均年龄的计算。 * 为了减少计算的麻烦,在此介绍计算器统计功能的使用: A、操作步骤 计算器的统计功能的计算只能得到如下六个统计结果:n(数据个数)、(数据和)、(数据平方和)、(平均数)、(总体标准差)和S(样本标准差)。操作步骤如下:1)显示统计状态:2ndF STAT(或SD) 2)输入数据:每输入一个数据按DATA 3)取出统计结果:这时六个统计结果均处于待取状态,可根据需要取出其中的结果。 B、注意事项 1)若需继续进行第二组数据的统计运算时,需取消统计状态,再按上述步骤操作。按2ndF STAT即可取消统计的状态。 2)若不需要计算、、、、和S时(即进行 其他一般运算时),也应取消统计状态)。
实训一利用Excel进行数据整理和描述性统计分析 一、实训目的 目的有三:(1)掌握Excel中基本的数据处理方法;(2)学会使用Excel进行统计分组;(3)学会使用Excel计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;理解描述性统计指标中的统计计算问题;已阅读本次实训指导书,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个描述性统计指标计算问题及相应数据(可用本实训所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤 (一)问题与数据 有顾客反映某家航空公司售票处售票的速度太慢。为此,航空公司收集了解100位顾客购票所花费时间的样本数据(单位:分钟),结果如下表。
航空公司认为,为一位顾客办理一次售票业务所需的时间在五分钟之内就是合理的。上面的数据是否支持航空公司的说法顾客提出的意见是否合理请你对上面的数据进行适当的分析,回答下列问题。 (1)对数据进行等距分组,整理成频数分布表,并绘制频数分布图(直方图、折线图、饼图)。 (2)根据分组后的数据,计算中位数、众数、算术平均数和标准差。 (3)分析顾客提出的意见是否合理为什么 (4)使用哪一个平均指标来分析上述问题比较合理 答:(1): 2:
从表中我们可以得到中位数为众数为1平均数为标准差为 (3):合理,虽然他的平均数是<5属于正常范围,但是依旧有将近20%的购票时间>5分钟属于超过正常范围,那就是速度太慢了。平均数不能代表一切。 所以顾客提出的理由是正确的,购票太慢的现象确实存在。 (4):平均数比较合理,它能较好的反映购票的大概时间。比较有代表性! 实训二用Excel数据分析功能进行统计整理 和计算描述性统计指标 一、实训目的 学会使用Excel数据分析功能进行统计整理和计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解统计整理和描述性统计指标中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个数字特征计算问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤
主讲人:刘莎莎 第三讲 描述性统计分析
一、 序列窗口下的描述性统计分析
知识点 1:如何以建立组对象的方式将数据导入到 Eviews 中去(第二种导入数 据的方式) 。 知识点 2:如何在序列窗口下实现简单描述性统计量和直方图,将直方图和正态 分布曲线叠加在一起,从而更直观地观察数据的分布特征。 (如何将 EViews 图形 复制粘贴到 word 中) 知识点 3:如何在序列窗口下实现描述性统计量的假设检验 知识点 4:如何实现将单序列按某一变量分类后再进行描述性统计分析(本案例 的分类变量是该天是星期几) 知识点 5:如何实现将单序列按某一变量分类后再进行假设检验 知识点 6:如何画上证综指日对数收益率的 QQ 图 知识点 7:如何估计数据的经验分布函数的参数 案例数据说明:2003 年 1 月 6 日-2009 年 6 月 26 日上证综指日对数收益率。
二、序列组窗口下的描述性统计分析
知识点 1:如何通过打开 excel 文件的方式将数据导入到 Eviews 中去。 (第三种 导入数据的方式) 。 知识点 2:如何实现多变量的描述性统计量 知识点 3:如何实现多变量描述性统计量的假设检验 案例数据说明:国家统计调查队分别在两个地区调查了 10 个家庭的收入 知识点 4:如何计算当前序列组的相关系数矩阵,协方差矩阵
主讲人:刘莎莎
案例数据说明:1983-2000 年我国粮食生产与相关投入的数据,变量包括粮食产 量(单位:万吨)、农业化肥施用量(单位:万千克)、粮食播种面积(单位: 公顷)
附注:描述性统计量的计算公式
标准差(Std.Dev.)的计算公式是:
s=
2 ( y ? y ) ∑ t t =1
T
T ?1
其中,
yt 是观测值, y 是样本平均数。
偏度(Skewness)的计算公式是:
1 T yt ? y 3 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。对
称分布的偏度是零,比如正态分布。
峰度(Kurtosis)的计算公式是:
1 T yt ? y 4 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。
正态分布的峰度值是 3。
§3.2多组和分类数据的描述性统计分析17 ?盒子图 盒子图能够直观简洁地展现数据分布的主要特征.我们在R 中使用boxplot()函数作盒子图.在盒子图中,上下四分位数分别确定中间箱体的顶部和底部,箱体中间的粗线是中位数所在的位置.由箱体向上下伸出的垂直部分为“触须”(whiskers),表示数据的散布范围,其为1.5倍四分位间距内距四分位点最远的数据点.超出此范围的点可看作为异常点(outlier). §3.2多组和分类数据的描述性统计分析 在对于多组数据的描述性统计量的计算和图形表示方面,前面所介绍的部分方法不能够有效地使用,例如许多函数都不能直接对数据框进行操作.这时我们需要一些其他的函数配合使用. 1.图形表示: ?散点图:前面介绍的plot,可直接对数据框操作.此时将绘出数据框中所对应的所有变量两两之间的散点图.所做图框中第一行的散点图是以第一个变量为纵坐标,分别以第二、三...个变量为横坐标的散点图.这里数据举例说明. library(DAAG);plot(hills) ?盒子图:前面介绍的boxplot,亦可直接对数据框操作,其在同一个作图区域内画出各组数的盒子图.但是注意,此时由于不同组数据的尺度可能差别很大,这样的盒子图很多时候表达出来不是很有意义.boxplot(faithful).因此这样做比较适合多组数据具有同样意义或近似尺度的情形.例如,我们想做某一数值变量在某个因子变量的不同水平下的盒子图.我们可采用类似如下的命令: boxplot(skullw ~age,data=possum),亦可加上参数horizontal=T,将该盒子图横向放置. boxplot(possum$skullw ~possum$sex,horizontal=T) ?条件散点图:当数据集中含有一个或多个因子变量时,我们可使用条件散点图函数coplot()作出因子变量不同水平下的多个散点图,当然该方法也适用于各种给定条件或限制情形下的作图.其调用格式为 coplot(formula,data)比如coplot(possum[[9]]~possum[[7]] possum[[4]]),或 coplot(skullw ~taill age,data=possum); coplot(skullw ~taill age+sex,data=possum)
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。
A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如 何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的自变量和因变量相关; 3、偏相关:在某一现象与多种现象相关的场合,当假定其他变量不变时,其中两个变量之间的相关关系称为偏相关。 六、方差分析
统计分析往往是从了解数据的基本特征开始的。描述数据分布特征的统计量可分为两类:一类表示数量的中心位置,另一类表示数量的变异程度(或称离散程度)。两者相互补充,共同反映数据的全貌。 这些内容可以通过SPSS中的“Descriptive Statistics”菜单中的过程来完成。 1 频数分析 (Descriptive Statistics - Frequencies) 频数分布分析主要通过频数分布表、条形图和直方图,以及集中趋势和离散趋势的各 种统计量来描述数据的分布特征。 下面我们通过例子来学习单变量频数分析操作。 1) 输入分析数据 在数据编辑器窗口打开“data1-2.sav”数据文件。 2)调用分析过程 在主菜单栏单击“Analyze”,在出现的下拉菜单里移动鼠标至“Descriptive Statistics”项上,在出现的次菜单里单击“Frequencies”项,打开如图3-4所示的对话框。 图3-4 “Frequencies” 对话框 3)设置分析变量 从左则的源变量框里选择一个和多个变量进入“Variable(s):”框里。在这里我们选“三化 螟蚁螟[虫口数]”变量进入“Variable(s):”框。 4)输出频数分布表
Display frequency tables,选中显示。 5)设置输出的统计量 单击“Statistics”按钮,打开图3-5所示的对话框,该对话框用于选择统计量: 图3-5 “Statistics”对话框 ①选择百分位显示“Percentiles Values”栏: Quartiles:四分位数,显示25%、50%和75%的百分位数。 Cut points for 10 equal groups:将数据平分为输入的10个等份。 Percentile(s)::用户自定义百分位数,输入值0—100之间。选中此项后,可以利用“Add”、“Change”和 “Remove”按钮设置多个百分位数。 ②选择变异程度的统计量“Dispersion”:(离散趋势) Std.deviation标准差 Minimum 最小值 Variance 方差 Maximum 最大值 Range 极差 S.E.mean均值标准误 ③选择表示数据中心位置的统计量“Central Tendency”:(集中趋势) Mean 均值 Median 中位数 Mode 众数 Sum 算术和
第六章描述性统计分析-- Descriptive Statistics菜单详解 6.1 Frequencies过程 6.1.1 界面说明 6.1.2 分析实例 6.1.3 结果解释 6.2 Descriptives过程 6.2.1 界面说明 6.2.2 结果解释 6.3 Explore过程 6.3.1 界面说明 6.3.2 结果解释 6.4 Crosstabs过程 6.4.1 界面说明 6.4.2 分析实例 6.4.3 结果解释 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明
关于描述性统计分析 作者:记忆de&#…文章来源:csdn blog 点击数:156 更新时间:2007-2-12 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Anal ysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。 (1)数据的频数分析:在数据的预处理部分,我们曾经提到利用频数分析和交叉频数分析来检验异常值。此外,频数分析也可以发现一些统计规律。比如说,收入低的被调查者用户满意度比收入高的被调查者高,或者女性的用户满意度比男性低等。不过这些规律只是表面的特征,在后面的分析中还要经过检验。 (2)数据的集中趋势分析:数据的集中趋势分析是用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。各指标的具体意义如下: 平均值:是衡量数据的中心位置的重要指标,反映了一些数据必然性的特点,包括算术平均值、加权算术平均值、调和平均值和几何平均值。 中位数:是另外一种反映数据的中心位置的指标,其确定方法是将所有数据以由小到大的顺序排列,位于中央的数据值就是中位数。 众数:是指在数据中发生频率最高的数据值。 如果各个数据之间的差异程度较小,用平均值就有较好的代表性;而如果数据之
间的差异程度较大,特别是有个别的极端值的情况,用中位数或众数有较好的代表性。 (3)数据的离散程度分析:数据的离散程度分析主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。方差是标准差的平方,根据不同的数据类型有不同的计算方法。 (4)数据的分布:在统计分析中,通常要假设样本的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本是否符合正态分布。偏度衡量的是样本分布的偏斜方向和程度;而峰度衡量的是样本分布曲线的尖峰程度。一般情况下,如果样本的偏度接近于0,而峰度接近于3,就可以判断总体的分布接近于正态分布。 (5)绘制统计图:用图形的形式来表达数据,比用文字表达更清晰、更简明。在SPSS软件里,可以很容易的绘制各个变量的统计图形,包括条形图、饼图和折线图等。 示例SIM手机描述性统计分析 为简化起见,我们只分析SIM手机用户满意调查中的两个变量:“总体感知质量”和“总体满意度”变量。 (1)数据的频数分析 用SPSS软件的频数分析可以很容易地画出两个变量的频数图:
描述性统计分析 作者:清华大学中国企业研究中心阅读次数:24704次发布日期:2005-07-04 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。 (1)数据的频数分析:在数据的预处理部分,我们曾经提到利用频数分析和交叉频数分析来检验异常值。此外,频数分析也可以发现一些统计规律。比如说,收入低的被调查者用户满意度比收入高的被调查者高,或者女性的用户满意度比男性低等。不过这些规律只是表面的特征,在后面的分析中还要经过检验。 (2)数据的集中趋势分析:数据的集中趋势分析是用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。各指标的具体意义如下: 平均值:是衡量数据的中心位置的重要指标,反映了一些数据必然性的特点,包括算术平均值、加权算术平均值、调和平均值和几何平均值。 中位数:是另外一种反映数据的中心位置的指标,其确定方法是将所有数据以由小到大的顺序排列,位于中央的数据值就是中位数。 众数:是指在数据中发生频率最高的数据值。 如果各个数据之间的差异程度较小,用平均值就有较好的代表性;而如果数据之
间的差异程度较大,特别是有个别的极端值的情况,用中位数或众数有较好的代表性。
(3)数据的离散程度分析:数据的离散程度分析主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。方差是标准差的平方,根据不同的数据类型有不同的计算方法。 (4)数据的分布:在统计分析中,通常要假设样本的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本是否符合正态分布。偏度衡量的是样本分布的偏斜方向和程度;而峰度衡量的是样本分布曲线的尖峰程度。一般情况下,如果样本的偏度接近于0,而峰度接近于3,就可以判断总体的分布接近于正态分布。 (5)绘制统计图:用图形的形式来表达数据,比用文字表达更清晰、更简明。在SPSS软件里,可以很容易的绘制各个变量的统计图形,包括条形图、饼图和折线图等。 示例SIM手机描述性统计分析 为简化起见,我们只分析SIM手机用户满意调查中的两个变量:“总体感知质量”和“总体满意度”变量。 (1)数据的频数分析 用SPSS软件的频数分析可以很容易地画出两个变量的频数图:
统计数据的描述性分析 一、实验目的 熟悉在matlab中实现数据的统计描述方法,掌握基本统计命令:样本均值、样本中位数、样本标准差、样本方差、概率密度函数pdf、概率分布函数df、随机数生成rnd。 二、实验内容 1 、频数表和直方图 数据输入,将你班的任意科目考试成绩输入 >> data=[91 78 90 88 76 81 77 74]; >> [N,X]=hist(data,5) N = 3 1 1 0 3 X = 75.7000 79.1000 82.5000 85.9000 89.3000 >> hist(data,5)
2、基本统计量 1) 样本均值 语法: m=mean(x) 若x 为向量,返回结果m是x 中元素的均值; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的均值。 2) 样本中位数 语法: m=median(x) 若x 为向量,返回结果m是x 中元素的中位数; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的中位数3) 样本标准差 语法:y=std(x) 若x 为向量,返回结果y 是x 中元素的标准差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的标准差
std(x)运用n-1 进行标准化处理,n是样本的个数。 4) 样本方差 语法:y=var(x); y=var(x,1) 若x 为向量,返回结果y 是x 中元素的方差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的方差 var(x)运用n-1 进行标准化处理(满足无偏估计的要求),n 是样本的个数。var(x,1)运用n 进行标准化处理,生成关于样本均值的二阶矩。 5) 样本的极差(最大之和最小值之差) 语法:z= range(x) 返回结果z是数组x 的极差。 6) 样本的偏度 语法:s=skewness(x) 说明:偏度反映分布的对称性,s>0 称为右偏态,此时数据位于均值右边的比左边的多;s<0,情况相反;s 接近0 则可认为分布是对称的。 7) 样本的峰度 语法:k= kurtosis(x) 说明:正态分布峰度是3,若k 比3 大得多,表示分布有沉重的尾巴,即样本中含有较多远离均值的数据,峰度可以作衡量偏离正态分布的尺度之一。 >> mean(data) ,
用Excel进行数据分析:描述性统计分析 郑来轶发表于2013-04-14 22:03 来源:本站原创 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形,常用的指标有均值、中位数、众数、方差、标准差等等。 接下来我们讲讲在Excel2007中完成描述性统计分析。 一、案例场景 某网站的专题活动积累了一定访问数据后,需要统计流量的的均值、区间,以及给出该专题访问量差异的量化标准,借此来作为分析每天访问量的价值、参差不齐、此起彼伏一个衡量的依据。要求得到均值、区间、众数、方差、标准差等统计数据。 二、操作步骤 1、打开数据表格,这个案例中用的数据无特殊要求,只是一列数值就可以了。 2、选择“工具”——“数据分析”——“描述统计”后,出现属性设置框
注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,可以参考上一篇文章《用Excel进行数据分析:数据分析工具在哪里?》。 3、依次选择 选项有2方面,输入和输出选项 输入区域:原始数据区域,选中多个行或列,选择相应的分组方式逐行/逐列;
如果数据有标志,勾选“标志位于第一行”;如果输入区域没有标志项,该复选框将被清除,Excel 将在输出表中生成适宜的数据标志; 输出区域可以选择本表、新工作表或是新工作簿; 汇总统计:包括有平均值、标准误差(相对于平均值)、中值、众数、标准偏差、方差、峰值、偏斜度、极差、最小值、最大值、总和、总个数、最大值、最小值和置信度等相关项目。第K大(小)值:输出表的某一行中包含每个数据区域中的第k 个最大(小)值。 平均数置信度:数值95% 可用来计算在显著性水平为5% 时的平均值置信度
在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形,常用的指标有均值、中位数、众数、方差、标准差等等。 接下来我们讲讲在Excel2007中完成描述性统计分析。一、案例场景 某网站的专题活动积累了一定访问数据后,需要统计流量的的均值、区间,以及给出该专题访问量差异的量化标准,借此来作为分析每天访问量的价值、参差不齐、此起彼伏一个衡量的依据。要求得到均值、区间、众数、方差、标准差等统计数据。 二、操作步骤 1、打开数据表格,这个案例中用的数据无特殊要求,只是一列数值就可以了。 2、选择“工具”——“数据分析”——“描述统计”后,出现属性设置框
注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,可以参考上一篇文章《用Excel进行数据分析:数据分析工具在哪里?》。 3、依次选择 选项有2方面,输入和输出选项 输入区域:原始数据区域,选中多个行或列,选择相应的分组方式逐行/逐列;
如果数据有标志,勾选“标志位于第一行”;如果输入区域没有标志项,该复选框将被清除,Excel 将在输出表中生成适宜的数据标志; 输出区域可以选择本表、新工作表或是新工作簿; 汇总统计:包括有平均值、标准误差(相对于平均值)、中值、众数、标准偏差、方差、峰值、偏斜度、极差、最小值、最大值、总和、总个数、最大值、最小值和置信度等相关项目。 第K大(小)值:输出表的某一行中包含每个数据区域中的第 k 个最大(小)值。 平均数置信度:数值 95% 可用来计算在显著性水平为 5% 时的平均值置信度。