交叉表,行列转换,交叉查询经典,分组小计合计报表,SQL,
- 格式:doc
- 大小:244.00 KB
- 文档页数:27

PostgreSQL实现交叉表(⾏列转换)的5种⽅法⽰例交叉表交叉表(Cross Tabulations)是⼀种常⽤的分类汇总表格。
使⽤交叉表查询,显⽰源于表中某个字段的汇总值,并将它们分组,其中⼀组列在数据表的左侧,另⼀组列在数据表的上部。
⾏和列的交叉处可以对数据进⾏多种汇总计算,如:求和、平均值、记数、最⼤值、最⼩值等。
使⽤交叉表查询数据⾮常直观明了,被⼴泛应⽤。
交叉表查询也是数据库的⼀个特点。
例如: select 表1.组名, (select 表1.成员姓名 from 表2 b where 表1.成员1id=表2.成员id) as 成员1id, (select 表1.成员姓名 from 表2 b where 表1.成员2id=表2.成员id) as 成员2id, (select 表1.成员姓名 from 表2 b where 表1.成员3id=表2.成员id) as 成员3id from 表1,表2 --这种就是交叉表查询交叉报表是报表当中常见的类型,属于基本的报表,是⾏、列⽅向都有分组的报表。
这⾥牵涉到另外⼀个概念即分组报表。
这是所有报表当中最普通,最常见的报表类型,也是所有报表⼯具都⽀持的⼀种报表格式。
从⼀般概念上来讲,分组报表就是只有纵向的分组。
传统的分组报表制作⽅式是把报表划分为条带状,⽤户根据⼀个数据绑定向导指定分组,汇总字段,⽣成标准的分组报表。
这⾥我来演⽰下在POSTGRESQL⾥⾯如何实现交叉表的展⽰,下⾯话不多说了,来⼀起看看详细的介绍吧原始表数据如下:t_girl=# select * from score;name | subject | score-------+---------+-------Lucy | English | 100Lucy | Physics | 90Lucy | Math | 85Lily | English | 95Lily | Physics | 81Lily | Math | 84David | English | 100David | Physics | 86David | Math | 89Simon | English | 90Simon | Physics | 76Simon | Math | 79(12 rows)Time: 2.066 ms想要实现以下的结果:name | English | Physics | Math------+---------+---------+------Simon | 90 | 76 | 79Lucy | 100 | 90 | 85Lily | 95 | 81 | 84David | 100 | 86 | 89⼤致有以下⼏种⽅法:1、⽤标准SQL展现出来t_girl=# select name,t_girl-# sum(case when subject = 'English' then score else 0 end) as "English",t_girl-# sum(case when subject = 'Physics' then score else 0 end) as "Physics",t_girl-# sum(case when subject = 'Math' then score else 0 end) as "Math"t_girl-# from scoret_girl-# group by name order by name desc;name | English | Physics | Math-------+---------+---------+------Simon | 90 | 76 | 79Lucy | 100 | 90 | 85Lily | 95 | 81 | 84David | 100 | 86 | 89(4 rows)Time: 1.123 ms2、⽤PostgreSQL 提供的第三⽅扩展 tablefunc 带来的函数实现以下函数crosstab ⾥⾯的SQL必须有三个字段,name, 分类以及分类值来作为起始参数,必须以name,分类值作为输出参数。


查询的类型在Access中,查洵分为5类,分别是选择査询、交叉表直询、参数査询、操作査询和SQL查询。
5类查询的应用目标不同,对数据源的操作方式和操作结果也不同。
1.选择查询选择査询是最常用的査询类型。
顾名思义,它是根据指定的条件,从一个或多个数据源中获取数据并显示结果。
也可对记录进行分组,并且对分组的记录进行总计、计数、平均以及其它类型的计算。
例如,查找1992年参加工作的男教师,统计各类职称的教师人数等。
2.交叉表查询交叉表査询能够汇总数据字段的内容,汇总计算的结果显示在行与列交叉的单元格中。
交叉表査询可以计算平均值、总计、最大值、最小值等。
例如,统计每个系男女教师的人数。
此时,可以将“系名”作为交叉表的行标题,“性别”作为交叉表的列标题,统计的人数显示在交叉表行与列交叉的单元袼中。
交叉表查询是对基表或查询中的数据进行计算和重构,可以简化数据分析。
3.参数査询参数查询是一种根据用户输入的条件或参数来检索记录的査询。
例如,可以设计一个参数查询,提示输入两个成绩值,然后Access检索在这两个值之间的所有记录。
输人不同的值,得到不同的结果。
因此,参数查询可以提高查询的灵活性。
执行参数查询时,屏幕会显示一个设计好的对话框,以提示输入信息。
将参数査询作为窗体和报表的基础也是非常方便的。
例如,以参数査询为基础创建某课程学生成绩统计报表。
在打印报表时,Access将显示对话框询问要显示的课程,在输入课程名称后,Access便可打印出相应课程的报表。
4.操作查询操作査询与选择査询相似,都需要指定査找记录的条件,但选择查询是检索符合特定条件的一组记录,而操作査询是在一次查询操作中对检索的记录进行编辑等操作。
操作查询有4种,分别是生成表、删除、更新和追加。
生成表查询是利用一个或多个表中的全部或部分数据建立新表,例如,将选课成绩在90分以上的记录找出后放在一个新表中。
删除査询可以从一个或多个表中删除记录,例如,将“计算机实用软件”课程不及格的学生从“学生”表中删除。

数据分层汇总交叉报表SQL语句实现方法在管理系统中,管理人员往往需要对业务数据进行不同需求的分层汇总,并产生各种形式交叉报表。
为了实现此类报表,程序员需要构造层次结构非常复杂的SQL语句,甚至使用前台编程工具或其它报表工具来完成。
以下通过二个实例,介绍此类报表的实现方法。
一、WITH as 语句使用WITH AS 语句可以为一个子查询语句块定义一个名称,使用这个子查询名称可以在查询语句的很多地方引用这个子查询。
Oracle 数据库像对待内联视图或临时表一样对待被引用的子查询名称,从而起到一定的优化作用。
with子句是9i新增语法。
你可以在任何一个顶层的SELECT 语句以及几乎所有类型的子查询语句前,使用子查询定义子句。
被定义的子查询名称可以在主查询语句以及所有的子查询语句中引用,但未定义前不能引用。
with子句中不能嵌套定义<也就是with子句中不能有with子句>,但子查询中出现的“子查询定义”语句可以引用已定义的子查询名称。
<可以引用前面已经定义的with子句> 。
复杂的查询会产生很大的sql,with as语法显示一个个中间结果,显得有条理些,可读性与易维护性大为提高。
前面的中间结果可以被语句中的select或后面的中间结果表引用,类似于一个范围仅限于本语句的临时表,在需要多次查询某中间结果时可以提升效率。
语法结构:with t1 as (...),t2 as (..)二、字典准备为了实现数据分层汇总交叉报表,需要建立行的层次结构表与列的交叉汇总对照表。
1、交叉汇总对照表:一般分为,代码字段与代码汇总二个字段。
如:SELECT fee_code,fee_stat_cate FROM FIN_COM_FEECODESTAT WHERE REPORT_CODE = 'ZY11'FEE_CIDE为数据表中的费用代码,FEE_STAT_CA TE为费用汇总归类代码。

分组表、交叉表和明细表是三种不同类型的表格,它们在数据分析和呈现中发挥着不同的作用。
以下是关于这三种表格的详细描述和相应的500-800字回答:分组表:分组表是将数据按照一定的分类标准进行分组,并对每个组的统计数据进行展示。
它可以帮助我们了解数据的整体分布情况,以及各个组之间的差异和关联。
制作分组表的关键是选择合适的分组标准和进行合理的数据整理。
在制作过程中,需要将数据按照指定的分类标准进行分组,并统计每个组中的数据数量或百分比,以便直观地展示数据的分布情况。
交叉表:交叉表是一种用于展示两个或多个分类变量之间的交叉关系的数据表格。
它通过将数据按照不同的分类变量进行分组,并统计每个组中不同类别的数据数量或百分比,来揭示数据之间的关联性和差异。
交叉表的优点在于它可以直观地展示多个变量之间的交互关系,帮助我们更好地理解数据。
在制作交叉表时,需要选择合适的分类变量,并按照一定的表格结构进行布局,以便清晰地展示数据之间的关联性。
明细表:明细表是用于展示单个记录详细信息的数据表格。
它通常用于对数据进行深入分析,如追踪单个记录的详细信息、记录之间的关联关系等。
制作明细表的关键是选择合适的字段和记录进行展示,并确保表格结构的清晰和易读。
明细表可以帮助我们深入了解数据的细节,从而更好地分析数据。
应用:分组表、交叉表和明细表在数据分析中具有广泛的应用。
它们可以用于市场调查、销售数据分析、财务报告等领域。
通过使用这些表格,我们可以更好地理解数据的分布、关联和细节,为决策制定提供有力的支持。
总结:分组表、交叉表和明细表是三种重要的数据表格类型,它们在数据分析和呈现中发挥着不同的作用。
制作这些表格需要选择合适的分类标准和进行合理的数据整理,以确保表格结构的清晰和易读。
通过使用这些表格,我们可以更好地理解数据的分布、关联和细节,为决策制定提供有力的支持。
随着数据分析技术的不断发展和应用领域的不断扩大,这些表格将在未来的数据分析中发挥更加重要的作用。

sql 的行列转换在 SQL 中进行行列转换是一种常见的数据操作,它可以将数据从行的形式转换为列的形式,或者从列的形式转换为行的形式。
下面是两种常见的行列转换方法:1. 使用 `PIVOT` 语句进行行列转换:`PIVOT` 是 SQL 中专门用于进行行列转换的语句。
它允许你将一个表中的行数据按照特定的列值进行分组,并将其他列的值转换为新的列。
下面是一个简单的示例,假设有一个名为 `sales` 的表,包含以下列:`product_id`、`category` 和 `quantity`。
```sqlSELECT category, SUM(quantity) AS total_quantityFROM salesGROUP BY category;```上述示例使用 `GROUP BY` 子句按照 `category` 列进行分组,并使用 `SUM` 函数计算每个分组的 `quantity` 列的总和。
2. 使用 `UNION ALL` 和子查询进行行列转换:有时候,你可能无法直接使用 `PIVOT` 语句进行行列转换,或者你需要更复杂的转换逻辑。
在这种情况下,可以使用 `UNION ALL` 和子查询来实现。
下面是一个示例,将一个包含员工信息的表转换为按部门和职位分类的交叉表。
```sqlSELECT department, job_title, COUNT(*) AS countFROM employeesGROUP BY department, job_title;SELECT department, 'All Jobs' AS job_title, COUNT(*) AS countFROM employeesGROUP BY department;```上述示例使用了两个子查询,一个按照 `department` 和 `job_title` 进行分组,另一个按照 `department` 进行分组,并将所有职位都归为一个名为 `All Jobs` 的虚拟职位。
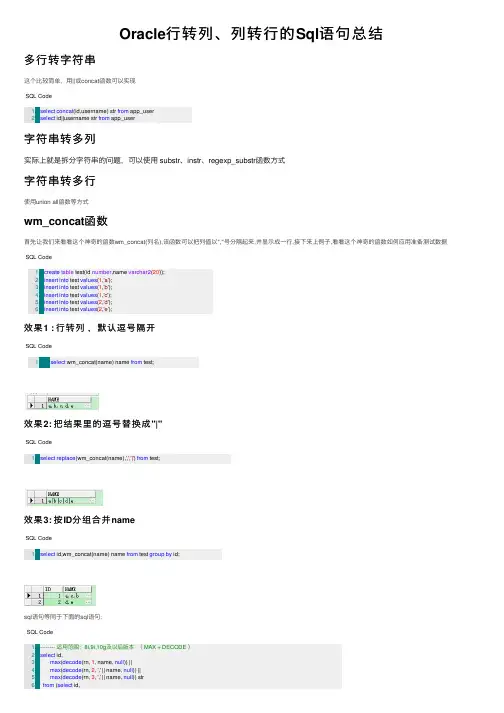
Oracle⾏转列、列转⾏的Sql语句总结多⾏转字符串这个⽐较简单,⽤||或concat函数可以实现SQL Code1 2select concat(id,username) str from app_user select id||username str from app_user字符串转多列实际上就是拆分字符串的问题,可以使⽤ substr、instr、regexp_substr函数⽅式字符串转多⾏使⽤union all函数等⽅式wm_concat函数⾸先让我们来看看这个神奇的函数wm_concat(列名),该函数可以把列值以","号分隔起来,并显⽰成⼀⾏,接下来上例⼦,看看这个神奇的函数如何应⽤准备测试数据 SQL Code1 2 3 4 5 6create table test(id number,name varchar2(20)); insert into test values(1,'a');insert into test values(1,'b');insert into test values(1,'c');insert into test values(2,'d');insert into test values(2,'e');效果1 : ⾏转列,默认逗号隔开SQL Code1select wm_concat(name) name from test;效果2: 把结果⾥的逗号替换成"|"SQL Code1select replace(wm_concat(name),',','|') from test;效果3: 按ID分组合并nameSQL Code1select id,wm_concat(name) name from test group by id;sql语句等同于下⾯的sql语句:SQL Code1 2 3 4 5 6-------- 适⽤范围:8i,9i,10g及以后版本( MAX + DECODE )select id,max(decode(rn, 1, name, null)) ||max(decode(rn, 2, ',' || name, null)) ||max(decode(rn, 3, ',' || name, null)) strfrom (select id,789101112131415161718192021222324252627282930313233343536 name,row_number () over(partition by id order by name) as rnfrom test) tgroup by idorder by 1;-------- 适⽤范围:8i,9i,10g 及以后版本 ( ROW_NUMBER + LEAD )select id, strfrom (select id,row_number () over(partition by id order by name) as rn,name || lead (',' || name, 1) over(partition by id order by name) ||lead (',' || name, 2) over(partition by id order by name) ||lead (',' || name, 3) over(partition by id order by name) as str from test)where rn = 1order by 1;-------- 适⽤范围:10g 及以后版本 ( MODEL )select id, substr (str, 2) strfrom test model return updated rows partition by (id) dimension by (row_number ()over(partition by id order by name) as rn) measures(cast (name as varchar2(20)) as str)rules upsert iterate (3) until(presentv(str [ iteration_number + 2 ], 1, 0) = 0)(str [ 0 ] = str [ 0 ] || ',' || str [ iteration_number + 1 ])order by 1;-------- 适⽤范围:8i,9i,10g 及以后版本 ( MAX + DECODE )select t.id id, max (substr (sys_connect_by_path(, ','), 2)) strfrom (select id, name, row_number () over(partition by id order by name) rnfrom test) tstart with rn = 1connect by rn = prior rn + 1and id = prior idgroup by t.id;懒⼈扩展⽤法:案例: 我要写⼀个视图,类似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多个字段,要是靠⼿⼯写太⿇烦了,有没有什么简便的⽅法? 当然有了,看我如果应⽤wm_concat 来让这个需求变简单,假设我的APP_USER 表中有(id,username,password,age )4个字段。

ExcelVBAADOSQL入门教程017:交叉表查询1.诸君好,我们今天聊SQL查询语句中的交叉表查询。
先说下什么是交叉表。
赌五根黄金,交叉表这个名字你可能陌生,但样子却肯定不陌生,赢了算我的,输了算老祝的……简而言之,交叉表就是一种分类汇总的二维表,由行和列两个变量汇总数据,例如下图所示的表格即是一份交叉表,成绩由姓名(行)和学科(列)共同分组定义:在SQL IN EXCEL中,实现交叉表查询的语句是TRANSFORM,其语法如下:TRANSFORM aggfunctionSELECT statementPIVOT pivotfield [IN (value1[, value2[, ...]])]语法看不懂哦?看不懂才正常呀,一眼就看懂那就扫地僧了不是?2.我们在第一章的时候讲过,对于没有VBA编程基础的EXCELer而言,SQL常和透视表搭配使用——透视表相信大家是不陌生的;它有四块区域构成,分别是筛选、行、列和值。
好端端的,怎么又扯到透视表去了呢?手拿开,男男授受不亲,没事乱摸我额头作甚,哥没烧糊涂。
我们之前说TRANSFROM语法如下TRANSFORM aggfunction SELECT statement PIVOT pivotfield [IN (value1[, value2[, ...]])]以透视表来比较,TRANSFORM 后的aggfunction,对应的是透视表的值区域,SELECT的statement对应的是透视表的行字段(透视表的行字段肯定是去重归类的),而PIVOT则是对应透视表的列字段。
因此TRANSFROM的语法汉化后如下:TRANSFROM 聚合值字段SELECT 行字段 FROM 数据源 GROUP BY 分组行字段PIVOT 分组列字段……说好的SELECT指定行字段,怎么又多出来FROM 和 GROUP BY 子句了呢?这是因为SELECT是指SELECT语句,而不是SELECT子句呀。

sql多表查询语句大全讲解
1. 在SQL语言中,多表查询是非常常见的操作之一。
2. 多表查询可以将不同表之间的数据进行联合,取出需要的数据。
3. 进行多表查询时,需要注意多表之间的关联字段,以保证查询结果
准确无误。
4. 常见的多表查询类型包括联合查询、交叉查询、子查询等。
5. 联合查询是指多个表之间按照一定规则联合,得到一张更完整的表格。
6. 联合查询常常使用union关键字,可以使用union all以保留重复项。
7. 交叉查询是指将两个表中的所有数据进行组合,形成一张新的表格。
8. 交叉查询使用cross join关键字,需要谨慎使用,以避免数据爆炸
的情况。
9. 子查询是指将一个查询语句作为另一个查询语句的一部分,使得查
询能够更加精确。
10. 子查询可以放在where子句、from子句、select子句等位置。
11. 想要进行多表查询,首先需要明确各个表之间的联系,以便正确地编写联合条件。
12. 联合条件可以使用where子句或join关键字,不同的方式会对查询效率产生不同的影响。
13. 多表查询中,使用别名可以更加方便地进行表格的引用,同时也可
以让代码更易于阅读。
14. 在多表查询中,应该尽量避免使用select *,以免查询结果异常或效率低下。
15. 最后,进行多表查询时,需要关注SQL语句的性能,以保证查询效率和响应速度。

sql交叉查询语句交叉查询是一种常用的SQL查询技术,用于在多个表之间进行关联查询。
它可以通过将多个表的数据按照某些条件进行匹配,从而得到符合条件的结果集。
下面将列举10个符合要求的SQL交叉查询语句,并对其进行解释和说明。
1. 查询订单和客户信息```SELECT orders.order_id, customers.customer_nameFROM ordersJOIN customers ON orders.customer_id = customers.customer_id;```这个查询语句通过订单表和客户表之间的关联,将订单ID和客户名称进行匹配,从而得到订单和客户的对应关系。
2. 查询员工和部门信息```SELECT employees.employee_name, departments.department_nameFROM employeesJOIN departments ON employees.department_id = departments.department_id;```这个查询语句通过员工表和部门表之间的关联,将员工姓名和部门名称进行匹配,从而得到员工和部门的对应关系。
3. 查询商品和供应商信息```SELECT products.product_name, suppliers.supplier_name FROM productsJOIN suppliers ON products.supplier_id = suppliers.supplier_id;```这个查询语句通过商品表和供应商表之间的关联,将商品名称和供应商名称进行匹配,从而得到商品和供应商的对应关系。
4. 查询学生和课程信息```SELECT students.student_name, courses.course_name FROM studentsJOIN courses ON students.course_id = courses.course_id;```这个查询语句通过学生表和课程表之间的关联,将学生姓名和课程名称进行匹配,从而得到学生和课程的对应关系。
![sql交叉表剖析[详解]](https://uimg.taocdn.com/845446e44793daef5ef7ba0d4a7302768f996f44.webp)
sql 交叉表分析--逐步去理解--示例数据(用少量数据说明)create table tb(rqty int,item_no varchar(10),wh_no int)insert tb select 3,'1F40001A',801union all select 2,'1Z40031A',801union all select 1,'1Z40031A',400go--第一步,wh_no 固定的情况,生成交叉的列select item_no,[801]=case wh_no when 801 then rqty else 0 end,[400]=case wh_no when 400 then rqty else 0 endfrom tb/*--结果item_no 801 400---------- ----------- -----------1F40001A 3 01Z40031A 0 2 --和下面这条的item_no相同,现在被放在了两行上1Z40031A 0 1(所影响的行数为 3 行)--*/--第二步,按上面的写法,还要处理 item_no 相同的行合并在一齐,因此再用sum合并select item_no,[801]=sum(case wh_no when 801 then rqty else 0 end),[400]=sum(case wh_no when 400 then rqty else 0 end)from tbgroup by item_no/*--结果item_no 801 400---------- ----------- -----------1F40001A 3 01Z40031A 2 1 --这样合并了相同的 item_no ,得到了正确的结果(所影响的行数为 2 行)--*/--第三步,如果 wh_no 列的值不是预知的,那我们就只能通过查询表中的数据来获得 wh_no/*--并按第二步的方式生成重语句观察第二步的语句可以知道,[801]=sum(case wh_no when 801 then rqty else 0 end),[400]=sum(case wh_no when 400 then rqty else 0 end)中的 801,400 是根据表中的 wh_no 值生成的,语句的条数也是根据distinct wh_no 的条数决定的所以我们先按上面的格式很容易写出生成处理语句的select--*/select ',['+rtrim(wh_no)+']=sum(case wh_no when'+rtrim(wh_no)+' then rqty else 0 end)'from(select distinct wh_no from tb)a/*--结果,[400]=sum(case wh_no when 400 then rqty else 0 end),[801]=sum(case wh_no when 801 then rqty else 0 end)--*/--第四步,上面生成的语句正好是我们需要的,但我们还要想办法把它放到一个变量中,所以做如下处理declare @s varchar(8000) --定义一个保存结果的变量set @s='' --初始化变量(不初始化的变量值是null,无法进行后面的处理)select @s=@s+ --按顺序相加上面生成的结果(这个处理过程可以理解为一个游标逐条处理)',['+rtrim(wh_no)+']=sum(case wh_no when '+rtrim(wh_no)+' then rqty else 0 end)'from(select distinct wh_no from tb)aselect 得到的变量值=@s/*--结果得到的变量值----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------,[400]=sum(case wh_no when 400 then rqty else 0end),[801]=sum(case wh_no when 801 then rqty else 0 end)(所影响的行数为 1 行)--*/--第五步,通过上面的处理,已经把动态处理的sql脚本部分放到一个变量@s中了--按下来只需要加上固定的部分就是一个完整的处理过程了set @s='select item_no' --加上第二步处理语句中的头+@s --@s代替了第二步中的列处理部分+'from tbgroup by item_no' --加上第二步处理中的尾select 最终生成的动态sql语句=@s/*--结果select item_no,[400]=sum(case wh_no when 400 then rqty else 0 end),[801]=sum(case wh_no when 801 then rqty else 0 end)fromtbgroup by item_no--*/--第六步,通过上面的处理,已经得到了和第二步分析中一样的sql 语句(格式稍有区别)--剩下的就是用exec执行这个动态语句就OK了exec(@s)/*--结果(与第二步的结果一致,除了列序)item_no 400 801---------- ----------- -----------1F40001A 0 31Z40031A 1 2--*/go--删除测试drop table tb。
SQL实现交叉表的⽅法交叉⼀般来讲是分组统计的⼀种,形式更复杂,显⽰更清淅,但数据库本⾝并没有提供实现交叉表的功能,⾃⼰创建交叉表不仅要对过程、游标、临时表、动态SQL等⾮常熟悉,⽽且思路也要清淅,本例以PUBS.DBO.SALES表的数据做样本:CREATE PROCEDURE UP_TEST(@T1 VARCHAR(30),@T2 VARCHAR(30),@T3 VARCHAR(30),@T4 VARCHAR(30)) AS--T1 表名,T2,T3是交叉表的两上分类字段,T4是汇总字段--T2是⾏字段,T3列字段BEGINDECLARE @SQL VARCHAR(7999),@FIELD VARCHAR(30)SELECT @SQL='SELECT DISTINCT '+@T3+' FROM '+@T1CREATE TABLE #FIELD(FIELD VARCHAR(30))--将列字段提取到临时表#FIELD中INSERT INTO #FIELD EXEC(@SQL)SELECT @SQL='CREATE TABLE CROSS_TEST('+@T2+' VARCHAR(30),'DECLARE CUR_FIELD CURSOR LOCAL FOR SELECT * FROM #FIELDOPEN CUR_FIELDFETCH CUR_FIELD INTO @FIELDWHILE @@FETCH_STATUS=0 BEGINSELECT @FIELD='['+@FIELD+']'SELECT @SQL=@SQL+@FIELD+' DECIMAL(8,2) DEFAULT 0,'FETCH CUR_FIELD INTO @FIELDENDSELECT @SQL=LEFT(@SQL,LEN(@SQL)-1)+')'--创建临时交叉表CROSS_TESTEXEC(@SQL)SELECT @SQL='INSERT INTO CROSS_TEST('+@T2+') SELECT DISTINCT '+@T2+' FROM '+@T1--将⾏数据存⼊交叉表#CROSS_TESTEXEC(@SQL)--创建分组数据表TEMPSELECT @SQL='CREATE TABLE TEMP('+@T2+' VARCHAR(30),'+@T3+' VARCHAR(30),'+@T4+' DECIMAL(8,2))'EXEC(@SQL)--将交叉汇总数据放⼊交叉表SELECT @SQL='SELECT '+@T2+','+@T3+', SUM(QTY) QTY FROM '+@T1 +' GROUP BY '+@T2+','+@T3INSERT INTO TEMP EXEC(@SQL)--将汇总数据写⼊交叉表DECLARE CUR_SUM CURSOR LOCAL FOR SELECT * FROM TEMPDECLARE @F1 VARCHAR(30),@F2 VARCHAR(30),@QTY DECIMAL(8,2),@Q1 VARCHAR(30)OPEN CUR_SUMFETCH CUR_SUM INTO @F1,@F2,@QTYWHILE @@FETCH_STATUS=0 BEGINSELECT @F2='['+@F2+']',@Q1=CAST(@QTY AS VARCHAR(30))SELECT @SQL='UPDATE CROSS_TEST SET '+@F2+'='+@Q1+' WHERE '+@T2+'='''+@F1+''''EXEC(@SQL)FETCH CUR_SUM INTO @F1,@F2,@QTYENDCLOSE CUR_SUMSELECT * FROM CROSS_TESTDROP TABLE TEMPDROP TABLE CROSS_TESTDROP TABLE #FIELDEND说明:字段加中括号为了处理字段中含有特殊字符,值得注意得是要实现交叉表的表必须有两个分类,本例只⽀持分类字段的数据类型是字符型的,最⼤的问题就是⾼亮显⽰这⾏的WHERE条件啦,字符类型字段查询时条件必须加单引号,如果是数值类型就可以直接写,所以数值类型的分类字段更容易实现⼀些,更可以融合在⼀个过程中。
大数据1+x理论题库单选题1.在转换操作中,可以实现从一个字符串中截取特定长度的子串的操作为() [单选题] *A. TermExtractB. Substring(正确答案)C. TriD. Concatenate1.下列关于数据转换器说法正确的是() [单选题] *A. ArraySplit是文本型转换器(正确答案)B. Left是集合型转换器C. Datelnc是集合型转换器D. Formatdate转换器使用时可以不区分日期形式1函数关系是一种确定性关系;2相关关系是一种非确定性关系;3回归分析是对具有函数关系的两个变量进行统计分析的一种方法;4回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法.() [单选题] *A.1,2B.1,2,3C.1,2,4(正确答案)D.1,2,3,41.数据库中常用的数据类型包括:文本型、数字型、日期时间型、货币型等。
下列对应用途错误的是()。
[单选题] *A. DATETIME的用途是时间值或持续时间(正确答案)B.SMALLINT的用途是大整数值C.VARCHAR的用途是变长字符串D.TINYTEXT的用途是短文本字符串1.关系数据库所谓的关系是指()。
[单选题] *A.各记录中的数据彼此有一定关联B.数据模型符合满足一定条件的二维表格式(正确答案)C.某两个数据库之间有一定的关系D.表中两个字段有一定的关系1.关系型数据库中的“关系”是指存储数据的表,这个表类似于以下哪种样式?()[单选题] *A.B.(正确答案)C.D.2.以下不属于关系型数据库的是()。
[单选题] *A. DB2B. HBase(正确答案)C. MySQLD. Oracle2.以下不属于关系型数据库的是()。
[单选题] *A.DB2B. HBase(正确答案)C.MySQLA.Oracle2.关联规则是()的工作流 [单选题] *A.数据库B.算法(正确答案)C.转换D.落地2.清洗数据应使用() [单选题] *A.ES落地B.流转换C.抽样D.转换(正确答案)3.注释是属于()工作流节点 [单选题] *A.数据库B.算法C.转换D.其他(正确答案)3.有一个关系,课程目录(课程号,授课教师,所述专业),规定授课教师不能取空值,这一规则属于()。
SQL交叉表之前做货品横向展⽰时,有看到评论说⽤到交叉表。
公司最近需要给订单表做⼀个数据汇总的功能,同事给到⼀个参考SQLselect * from (select COUNT(1) as 已锁定 from tbl_order where orderLock = 1) as A,(select COUNT(1) as 未锁定 from tbl_order where orderLock = 0) as B,(select COUNT(1) as 未发货 from tbl_order where PushStatus=1 and statusid=14) as C,(select COUNT(1) as 待发货 from tbl_order where PushStatus=1 and statusid=14 and isshipments=1) as D, (select COUNT(1) as 已发货 from tbl_order where statusid=4) as E,(select COUNT(1) as 未分配 from tbl_order where statusid = 14 and PushStatus<>3 and pushstatus=0) as F, (select COUNT(1) as 已分配 from tbl_order where PushStatus=1) as G,(select COUNT(1) as 已推送 from tbl_order where PushStatus=2) as H看完改为下⾯SQLSELECTCOUNT(CASE WHEN orderLock=1 THEN 1 ELSE NULL END) AS '已锁定',COUNT(CASE WHEN orderLock=0 THEN 1 ELSE NULL END) AS '未锁定',COUNT(CASE WHEN PushStatus=1 and statusid=14 THEN 1 ELSE NULL END) AS '未发货',COUNT(CASE WHEN PushStatus=1 and statusid=14 and isshipments=1 THEN 1 ELSE NULL END) AS '待发货', COUNT(CASE WHEN statusid=4 THEN 1 ELSE NULL END) AS '已发货',COUNT(CASE WHEN statusid = 14 and PushStatus<>3 and pushstatus=0 THEN 1 ELSE NULL END) AS '未分配', COUNT(CASE WHEN PushStatus=1 THEN 1 ELSE NULL END) AS '已分配',COUNT(CASE WHEN PushStatus=2 THEN 1 ELSE NULL END) AS '已推送'FROM tbl_order与上⾯参考SQL相⽐只⽤到了⼀次查询表,并且如果有where条件更利于扩展。
交叉报表什么是交叉报表?交叉报表是一种基本的报表样式,是一种行、列方向都有分组的报表。
以下表为例,产品销售数据分析表,行按产品品类分组,列按时间分组,便于查看某个特定时段、某个特定产品的销售情况,也便于按时间和产品项来分别计算合计。
同时,对于销售量大于2000的数据,还做了高亮显示。
在制作交叉报表的过程中,需要明确的是,报表的行和列表头数据,均是从数据集中动态获取,因此,要求制作报表的工具要能方便的实现,并可设置数据的分组、排序、过滤、小计、合计等操作,满足用户对报表进行智能数据分析等需求。
如何实现交叉报表?以下以葡萄城报表为工具,介绍如何实现交叉报表。
葡萄城报表的矩表控件,是实现交叉报表的利器。
在矩阵控件中,组的行数和列数由每个行分组和列分组中的唯一值的个数确定,同时,用户可以按行组和列组中的多个字段或表达式对数据进行分组。
在运行时,当组合报表数据和数据区域时,随着为列组添加列和为行组添加行,矩阵将在页面上水平和垂直增长。
在矩阵控件中,也可以包括最初隐藏详细信息数据的明细切换,然后用户便可单击该切换以根据需要显示更多或更少的详细信息,以此实现数据向下钻取功能。
以下将演示上面这张“产品销售数据分析表“的制作过程,列分组按照产品类别和产品名称进行分组,行分组按照年和月进行分组,并对销量大于2000的数据进行高亮显示。
第一步,创建报表文件第二步,打开报表资源管理器,并创建报表数据源第三步,添加数据集第四步,设计报表界面从Visual Studio 工具箱中,将葡萄城布局报表分类下的Matrix 控件添加到报表设计界面,然后从属性窗口的命令区域选择属性对话框命令,以打开矩阵控件Matrix 的属性设置对话框,然后按照以下表格设置矩阵控件Matrix 的属性:完成以上设置后,回到报表设计界面,选中数据单元格TextBox4 ,在属性窗口的命令区域中点击属性对话框命令,并按照以下表格设置数据单元格的属性:需要注意的是,我们将外观-背景色-颜色属性通过表达式的方式来完成对数据的高亮显示,如果销售量大于2000单元格背景色设置为高亮,小于等于2000设置为白色。
11Sql Server 生成数据透视表(交叉表)数据透视表是分析数据的一种方法,在Excel中就包含了强大的数据透视功能。
数据透视是什么样的呢?给个例子可能更容易理解。
假设有一张数据表:销售人员书籍销量----------------------------------------小王Excel教材 10小李Excel教材15小王Word教材8小李Excel教材7小王Excel教材 9小李Excel教材2小王Word教材3小李Excel教材5一种数据透视的方法是统计每个销售人员对每种书籍的销量 ,结果如下----------------------------------------------------------------Excel教材Word教材总计---------------------------------------------- -----------------小王29029小李191130各位看明白了吗?这是最简单的一种数据透视了,如果有必要也可以有多级分组。
好了,那在Sql Server中如何视现数据透视的功能呢?我是Sql Server的初学者,看了网上的一些例子,结合自己的理解写了下面这些Sql语句.生成基础数据的代码Create table s([name] nvarchar(50),book nvarchar(50),saledNumber int)insert into s ([name],book,saledNumber) values('小王','Excel教材',10);insert into s ([name],book,saledNumber)values('小李','Excel教材',15);insert into s ([name],book,saledNumber)values('小王','Word教材',8);insert into s ([name],book,saledNumber)values('小李','Excel教材',7);insert into s ([name],book,saledNumber)values('小王','Excel教材',9);insert into s ([name],book,saledNumber)values('小李','Excel教材',2);insert into s ([name],book,saledNumber)values('小王','Word教材',3);insert into s ([name],book,saledNumber)values('小李','Excel教材',5);生成数据透视表use testdeclare@sql nvarchar(4000)set@sql='SELECT [name], 'select@sql=@sql+'sum(case book when '+quotename(book,'''')+' then saledNumber else 0 end) as '+quotename(book)+','from s group by book select@sql=left(@sql,len(@sql)-1)select@sql=@sql+', sum(saledNumber) as [sum] from s group by [name]' --select @sqlexec(@sql)上面的查询语句首先是拼接了一条"Sql语句",它的最终结果为:SELECT [name],sum(case book when 'Excel教材' then saledNumber else 0 end) as [Excel教材],sum(case book when 'Word教材' then saledNumber else 0 end) as [Word教材], sum(saledNumber) as [sum]from sgroup by [name]当然,如果表中的数据不同,那么这生成的Sql语句也是不同的。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~/Render/archive/2006/12/19/596485.html分组小计合计报表的SQLTable1结构如下:OrgName,StaffName, PayArea,Pay要生成如下形式报表:Org1,A1,100,4Org1,A2,100,4Org1,A3,100,4Org1小计,XX,XX,XXOrg2,B1,100,4....合计, XX ,XXSQL:select OrgName DD,STAFFNAME,PayArea, Pay,OrgName as EE from Table1 as t1unionselect OrgName || '小计' DD,'',sum(PayArea),sum(Pay),OrgName || '_' EE from Table1 as t2 group by DEPT_IDunionSelect '合计' as DD,'',sum(PayArea),sum(Pay),'ZZZZZZZZ' as EE from Table1order by EE其中的OrgName||'_' 是为了取得一个比下一个不同的OraName大一些的值,以便让小计这条数据排在适当的位置,如Org1小计要排在Org1和Org2之间,所以要选一个在数据库中字符排序号小的字符,这里以"_"表示。
'ZZZZZZZZ'则是为了把合计记录排在最后,所以要选一串在数据库中字符排序最大的字符构成的串,这里只是用'Z'来表示。
用ee 排序,但合计中'ZZZZZZZZ' EE ,如果OrgName是汉字的话,那么排序后,合计将会变为第一行的,英文字母总是显示在汉字前面,这样就达不到合计显示在最后一行的目的了,如果将合计中'ZZZZZZZZ' EE 变为'做做做做做做做做' EE 这样就能使合计排在最后一行,因为'做'字是字典中最后一个字~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~交叉表、行列转换和交叉查询经典Access 静态叉表行列转换统计语句SELECT a.客户号,sum(iif(a.期初五级=1,a.期初余额,null)) as "期初正常",sum(iif(a.期初五级=2,a.期初余额,null)) as "期初关注",sum(iif(a.期初五级=3,a.期初余额,null)) as "期初次级",sum(iif(a.期初五级=4,a.期初余额,null)) as "期初可疑",sum(iif(a.期初五级=5,a.期初余额,null)) as "期初损失",sum(a.期初余额) as 期初总计,sum(iif(a.期未五级=1,a.期未余额,null)) as "期未正常",sum(iif(a.期未五级=2,a.期未余额,null)) as "期未关注",sum(iif(a.期未五级=3,a.期未余额,null)) as "期未次级",sum(iif(a.期未五级=4,a.期未余额,null)) as "期未可疑",sum(iif(a.期未五级=5,a.期未余额,null)) as "期未损失",sum(a.期未余额) as 期未总计,FROM [work-1] as aGROUP BY a.客户号;/content/10/0609/23/314324_32230468.shtml一、什么是交叉表“交叉表”对象是一个网格,用来根据指定的条件返回值。
数据显示在压缩行和列中。
这种格式易于比较数据并辨别其趋势。
它由三个元素组成:行列摘要字段“交叉表”中的行沿水平方向延伸(从一侧到另一侧)。
在上面的示例中,“手套”(Gloves) 是一行。
“交叉表”中的列沿垂直方向延伸(上下)。
在上面的示例中,“美国”(USA) 是一列。
汇总字段位于行和列的交叉处。
每个交叉处的值代表对既满足行条件又满足列条件的记录的汇总(求和、计数等)。
在上面的示例中,“手套”和“美国”交叉处的值是四,这是在美国销售的手套的数量。
“交叉表”还可以包括若干总计:每行的结尾是该行的总计。
在上面的例子中,该总计代表一个产品在所有国家/地区的销售量。
“手套”行结尾处的值是8,这就是手套在所有国家/地区销售的总数。
注意:总计列可以出现在每一行的开头。
每列的底部是该列的总计。
在上面的例子中,该总计代表所有产品在一个国家/地区的销售量。
“美国”一列底部的值是四,这是所有产品(手套、腰带和鞋子)在美国销售的总数。
注意:总计列可以出现在每一行的顶部。
“总计”(Total) 列(产品总计)和“总计”(Total) 行(国家/地区总计)的交叉处是总计。
在上面的例子中,“总计”列和“总计”行交叉处的值是12,这是所有产品在所有国家/地区销售的总数。
二、行列转换和交叉查询:1: 列转为行:eg1:假设有张学生成绩表(CJ)如下name subject result张三语文80张三数学90张三物理85李四语文85李四数学92李四物理82相关sql语句:Create table CJ(name char(10),subject char(10),result int);insert into CJ(name,subject,result) values('张三','语文',99);insert into CJ(name,subject,result) values('张三','数学',86);insert into CJ(name,subject,result) values('张三','英语',75);insert into CJ(name,subject,result) values('李四','语文',78);insert into CJ(name,subject,result) values('李四','数学',85);insert into CJ(name,subject,result) values('李四','英语',78)select * from CJ想变成如下的交叉表姓名语文数学物理张三99 90 85李四85 92 82我们首先来看一下如何建立静态的交叉表,也就是说列数固定的交叉表,这种情况其实只要一句简单的Select查询就可以搞定:select name,sum(case when a.subject='语文' then result else null end) as "语文",sum(case when a.subject='数学' then result else null end) as "数学",sum(case when a.subject='英语' then result else null end) as "英语"from CJ agroup by name;当要增加“总计”列:"合计总分"时,如下表所示:姓名合计总分语文数学物理张三260 99 90 85李四241 85 92 82只需增加sum(a.result) as "合计总分",sql如下:select name,sum(a.result) as "合计总分",sum(case when a.subject='语文' then result else null end) as "语文",sum(case when a.subject='数学' then result else null end) as "数学",sum(case when a.subject='英语' then result else null end) as "英语"from CJ agroup by name;其中利用了CASE语句判断,如果是相应的列,则取需要统计的cj数值,否则取NULL,然后再合计。
其中有两个常见问题说明一下:a、用NULL而不用0是有道理的,假如用0,虽然求和函数SUM可以取到正确的数,但类似COUNT函数(取记录个数),结果就不对了,因为Null不算一条记录,而0要算,同理空字串("")也是这样,总之在这里应该用NULL,这样任何函数都没问题。
b、假如在视图的设计界面保存以上的查询,则会报错“没有输出列”,从而无法保存,其实只要在查询前面加上一段:Create View ViewName AS ...,ViewName是你准备给查询起的名称,...就是我们的查询,然后运行一下,就可以生成视图了,对于其他一些设计器不支持的语法,也可以这样保存。
以上查询作用也很大,对于很多情况,比如产品销售表中按照季度统计、按照月份统计等列头内容固定的情况,这样就行了,但往往大多数情况下列头内容是不固定的,象City,用户随时可能删除、添加一些城市,这种情况就是我们所说的动态交叉表,在SQLServer中我们可以用存储过程来解决。
下面我们补充一些知识:相关子查询相关子查询和普通子查询区别在于:相关子查询引用了外部查询的列。
这种引用外部查询的能力意味着相关子查询不能自己独立运行,其中对于外部查询引用会使会使其无法正常执行。
因此相关子查询的执行顺序如下:1.首先执行一遍外部查询2.对于外部查询的每一行分别执行一遍子查询,而且每次执行子查询时候都会引用外部的当前行的值。
使用子查询的结果来确定外部查询的结果集。
举个例子;SELECT t1.typeFROM titles t1GROUP BY t1.typeHA VING MAX(t1.advance) >=ALL(SELECT 2 * A VG(t2.advance)FROM titles t2WHERE t1.type = t2.type)这个结果返回最高预付款超过给定组中平均预付款两倍的书籍类型。