Loadrunner关联与参数化解释
- 格式:doc
- 大小:39.50 KB
- 文档页数:4

LoadRunner2010-10-29 10:24事务TRANSACTION所谓事务(TRANSACTION),就是在脚本定义中定义的某段操作(ACTION),更确切的说,就是一段脚本语句.定义事务时,首先在脚本中找到事务的开始和结束位置,然后分别插入一个事务起始标记,这样,当脚本运行的时候,LOADRUNER会自动在事务的起始点计时,脚本在运行到事务结束点时计时结束,系统会自动记录这段操作的运行时间等性能数据;在脚本运行完毕后,系统会在结果信息中单独反映每个事务运行结果.LR_START_TRANSACTION(“事务名称”)LR_END_TRANSACTION(“事务名称“)集合点RENDEZVOUS多用户同时加载并发,并发过程仅仅体现在开始执行的那一刹那,随着服务器对请求的响应时间的不一致或系统环境条件的限制,在运行过程中能集合到一点的可能性微乎其微,所以将一定数量的用户同时加载并不是真正意义上的并发.系统压力最大的情况是:所有用户都集中到系统瓶颈的某个点上进行操作,从脚本的角度来讲,这个点就是执行脚本的某一条或一段语句,为了真实模拟这个最坏的情况,查看系统在最坏情况下的反映,LOADRUNNER 提供了集合点的功能,帮助测试人员实现真正意义上的并发.LR_RENDEZVOUS(“集合点名称”)参数化PARAMETERS让所有用户都使用相同的数据来运行,对系统造成的压力与实际情况会有所不同.而对于那些禁止一个用户多次登陆的系统,也就严重到无法测试的地步了.为了解决这个问题,让系统更加真实的模拟多用户使用的实际环境,LOADRUNNER提供了对脚本进行参数化输入的功能.所谓的脚本参数化,就是针对脚本中的某些常量,定义一个或多个包含数据源的参数来取代,让场景中不同的虚拟用户在执行相同的脚本时,分别使用参数数据源中的不同数据代替这些常量,从而达到模拟多用户真实使用系统的目的.注:参数化输入只能用于函数中的参数,不能用参数代替非函数中的常量参数.检查点CHECKPOINTLOADRUNNER检查点的功能主要用来验证某个界面上是否存在指定的TEXT或IMAGE等对象,在使用LOADRUNNER测试WEB应用时,可以检查压力较大时WEB服务器能否返回正常的页面。

Load Runner 使用说明一、组件:(一) VuGen:用于捕获最终用户业务流程和创建怎动化性能测试脚本。
1. 录制脚本:(1) 集合点Rendezvous(2) 验证点Check Point:文本验证点Text Check、图片验证点Image Check(3) 事务Transaction:事务开始Start Transaction、事务结束End Transaction(4) 注释与消息Comment & Message:/***/2. 增强并编辑Vuser脚本(1) 参数化:在Select next now中的参数:Sequential顺序、Random随机、Unique唯一在Update value on 参数:Each iteration每次迭代、Each occurrence每次出现、Once 一次(2) 从数据库中导入数据3. 配置动行时设置Runtime settings(运行时设置)(1) Number of Iterations:迭代次数(2) 在Preferences中的Enable image and text check在脚本中添加验证点时必须选中。
4. 在独立模式下运行Vuser脚本5. 集成Vuser脚本(二) Controller:用于组织、驱动、管理和监控负载测试。
1. 创建方案(1) 创建手动方案(2) 创建百分比模式方案(3) 创建面向目标的方案2. 计划方案(1) 开始时间(2) 方案运行设置:加压Ramp Up、持续时间Duration、减压Ramp Dowm3. 运行方案4. 监视方案(1) RuntimeGraphs(运行时图)A. Running Vusers运行时图:Running正在运行的Vuser总数、Ready完成脚本初始化部分、即可以运行的Vuser数、Finished结束运行的Vuser数,包括通过的和失败的、Error执行时发生的错误VuserB. Transaction Graphs事务监视图:Trans Response Time事务响应时间、Trans/Sec(Passed)每秒事务数(通过)、Trans/Sec(Failed/Stopped)每秒事务数(失败、停止)、Total Trans/Sec(Passed)每秒事务总数(通过)。

loadrunner 参数化路径LoadRunner 参数化是一种常用的性能测试技术,可以有效地模拟真实世界的负载情况,实现测试数据的灵活性和可重复性。
在LoadRunner中,参数化路径是指在测试过程中将路径作为参数进行动态调整,以模拟不同用户访问不同路径的情况。
为了更好地理解LoadRunner参数化路径的使用,我们首先需要了解LoadRunner的基本原理。
LoadRunner是一款用于模拟和分析应用程序性能的测试工具,通过模拟用户的行为和生成负载来评估系统的性能。
在性能测试中,经常需要模拟大量用户同时访问不同路径的情况,以验证系统的承载能力和响应时间。
在LoadRunner中,参数化路径可以通过多种方式实现,常用的有使用数据文件、使用函数和使用正则表达式等。
下面将分别介绍这几种参数化路径的方法。
使用数据文件进行参数化路径是最常见的方法之一。
通过将路径保存在一个数据文件中,LoadRunner可以在每次执行测试时,自动从数据文件中读取不同的路径,并进行相应的访问。
这种方法适用于需要模拟大量用户访问不同路径的情况,可以有效地减少测试脚本的维护工作。
使用函数进行参数化路径是另一种常见的方法。
LoadRunner提供了一系列内置函数,可以在测试脚本中使用这些函数生成不同的路径。
例如,可以使用lr_paramarr_random函数从一个路径数组中随机选择一个路径进行访问,或者使用lr_paramarr_idx函数按照一定的顺序选择路径进行访问。
这种方法适用于需要按照一定的规则生成路径的情况,可以灵活地控制路径的生成方式。
使用正则表达式进行参数化路径是一种更为灵活的方法。
LoadRunner提供了lr_eval_string函数,可以在测试脚本中使用正则表达式从一个字符串中提取出符合某种规则的路径。
例如,可以使用正则表达式从一个HTML页面中提取出所有的链接,并将这些链接作为路径进行访问。
这种方法适用于需要从复杂的页面中提取路径的情况,可以实现更加精细的参数化路径。

LoadRunner关联函数的脚本实例--如何操作关联参数这几天一直在学习LoadRunner的VuGen编程,今天想对关联函数web_reg_save_param做详细的试验和研究:问题提出:如何对关联的数据进行字符串操作。
下面使用了LoadRunner自带的订票例子为例,进行了这方面的试验。
假设我要关联的数据是由几个字符串组成的。
如何使这些字符串组成一个参数,供我后面的函数使用?解决方法:使用多个关联函数,对关联参数进行字符串操作,最后把生成的字符串保存成一个参数,供下面调用该参数的函数使用。
脚本如下:Action(){int number1,number2;char session11[1000];char string[1000];int length;char *stringtemp;//char session22[20];web_reg_save_param("session1","LB=name=userSessionvalue=","RB=.","Ord=ALL",LAST);web_reg_save_param("session2","LB=.","RB=<tableborder=0><tr><td> </td>","Ord=ALL",LAST);web_url("WebTours","URL=http://127.0.0.1:6080/WebTours/","Resource=0","RecContentType=text/html","Referer=","Snapshot=t1.inf","Mode=HTML",LAST);strcpy(string,"");strcpy(string,lr_eval_string("{session1_1}"));//strcpy(session1,"");sprintf(session11,"{session2_1}");strcat(string,".");length= strlen(lr_eval_string(session11));length=length-2;number1=atoi(lr_eval_string("{session1_count}"));number2=atoi(lr_eval_string("{session2_count}"));lr_output_message("%d,%d",number1,number2);//lr_output_message("%d",length);stringtemp=lr_eval_string(session11);strncat(string,stringtemp,length);//srcat(string,session11);lr_save_string(lr_eval_string(string),"session");lr_output_message("%s",lr_eval_string("{session1_1}"));lr_output_message("%s",lr_eval_string("{session2_1}"));web_submit_data("login.pl","Action=http://127.0.0.1:6080/WebTours/login.pl","Method=POST","RecContentType=text/html", "Referer =http://127.0.0.1:6080/WebTours/nav.pl?in=home","Snapshot=t2.inf","Mode=HTML",ITEMDATA,"Name=userSession", "Value={session}", ENDITEM,"Name=username", "Value=jojo", ENDITEM,"Name=password", "Value=bean", ENDITEM,"Name=JSFormSubmit", "Value=on", ENDITEM,"Name=login.x", "Value=50", ENDITEM,"Name=login.y", "Value=10", ENDITEM,LAST);lr_output_message("%s",lr_eval_string("{session}"));return 0;}有两个关联的参数,session1和session2,最后生成session,被web_submit_data 函数调用。
LoadRunner在使用参数化的时候,通常都是需要准备大数据量的,也因此LoadRunner 提供两种参数化取值方式,一种是手动编辑,另一种就是通过连接数据库取值。
一般在大型业务并发压力测试时,数据量肯定也都是非常大的,所以手动去编辑当然就不切实际了,还好有连接数据库的功能,所以就方便了很多。
不过提供连接数据库的功能到不是为了方便去取数据,而更重要的应该是借用数据库的造数据功能,通过简单的sql语句,便可以完成大量可复用的数据,这就是数据库的强大之处。
在脚本中设置参数化之后,进入参数化属性就可以发现一个标签按钮Data Wizard,这里就是连接数据库的接口。
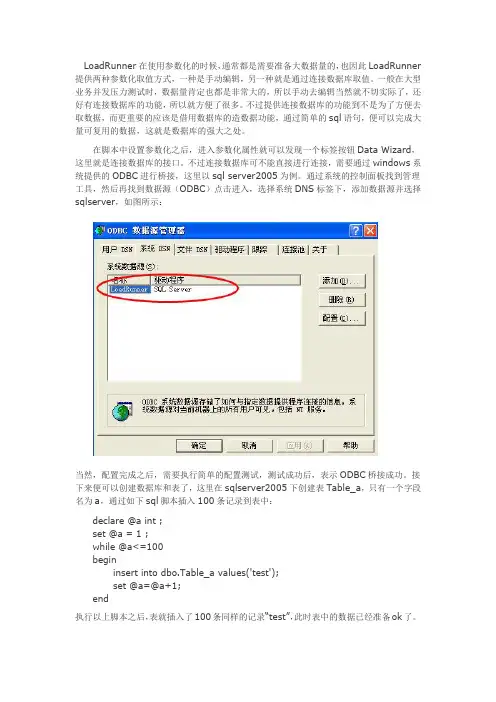
不过连接数据库可不能直接进行连接,需要通过windows系统提供的ODBC进行桥接,这里以sql server2005为例。
通过系统的控制面板找到管理工具,然后再找到数据源(ODBC)点击进入,选择系统DNS标签下,添加数据源并选择sqlserver,如图所示:当然,配置完成之后,需要执行简单的配置测试,测试成功后,表示ODBC桥接成功。
接下来便可以创建数据库和表了,这里在sqlserver2005下创建表Table_a,只有一个字段名为a,通过如下sql脚本插入100条记录到表中:declare @a int ;set @a = 1 ;while @a<=100begininsert into dbo.Table_a values('test');set @a=@a+1;end执行以上脚本之后,表就插入了100条同样的记录“test”,此时表中的数据已经准备ok了。
回到LoadRunnerVuser中,创建一个简单的参数化脚本如下:Action(){lr_eval_string("{testParam}");return 0;}右键参数进行参数属性对话框,点击Data Wizard进入连接数据库配置,选择“Spectify SQL statement manu”制定sql连接,然后选择下一步,再点击Create进入数据源选择方式,选择LoadRunner命名的数据源,如下图所示:在下面的SQL空白处,输入对应的sql语句,完成合适的数据导入,完成后,数据被导入到参数化列表中,如下图所示:做性能测试,最重要的准备工作就是数据,特别是对数据库的灵活运用,将会大大提高性能测试的效率。

LoadRunner如何建立关联关于loadrunner关联一、什么时候需要关联1.关联的含义关联(correlation):在脚本回放过程中,客户端发出请求,通过关联函数所定义的左右边界值(也就是关联规则),在服务器所响应的内容中查找,得到相应的值,已变量的形式替换录制时的静态值,从而向服务器发出正确的请求,这种动态获得服务器响应内容的方法被称作关联。
其实关联也属一同特定的参数化,只是与通常的参数化有些相同一般的参数化的参数来源于一个文件、一个定义的table、通过sql写的一个结果集等,但关联所获得的参数是服务器响应请求所返回的一个符合条件的、动态的值2.什么时候需要做关联必须想要弄清楚这个问题,我们首先必须晓得客户端与服务器端的命令与积极响应的过程过程表明:客户端发出获得登录页面的请求服务器端获得该命令后,回到登入页面,同时动态分解成一个sessionid当用户输入用户名密码,请求登录时,该sessionid同时被发送到服务器端如果该sessionid在当前可以话中有效率,那么回到登入顺利的页面,如果不恰当则登入失利在第一次演唱过程中loadrunner把这个值记录了下来,写道了脚本中,但再次录像时,客户端收到同样的命令,而服务器端再一次动态的分解成了sessionid,此时客户端收到的命令就是错误的,为了赢得这个动态的sessionid我们这里使用了关联。
所以我们得出结论:当客户端的某个请求是随着服务器端的相应而动态变化的时候,我们就需要用到关联当然我们在录制脚本时应该对测试的项目进行适当的了解,知道哪些请求需要用到服务器响应的动态值,如果我们不明确那些值需要做关联的话,我们也可以将脚本录制两遍,通过对比脚本的方法来查找需要关联的部分,但并不是说两次录制的所有不同点都需要关联,这个要具体情况具体分析二、自动关联loadrunner参数化自动关联涵盖两种机制:一种是loadrunner通过对比录制和回放时服务器响应的不同,而提示用户是否进行关联,用户可自己创建关联规则,这个功能可以方便的使我们获得需要关联的部分,但同时也存在一定的问题,如:自动关联所检测到的关联点不一定真的需要进行关联,这要我们更具实际情况进行判断;有些需要关联的动态数据自动关联无法找到,这是就需要做手动关联另一种就是loadrunner自带的自动关联规则,在演唱脚本时,可以根据这些规则自动建立关联自动关联的步骤如下:1.打开自动关联选项刚才提到的两种关联机制,如果用户想使用loadrunner自带的关联规则创建关联,那么需要在【recordingoptions】>【internetprotocol】>【correlation】中启用关联规则,选中“enablecorrelationduringrecording”,当录制这些应用系统的脚本时,vugen会在脚本中自动建立关联。

详细分析LoadRunner参数化在进⾏⽹页的性能测试时,对⽹页的登录界⾯进⾏压⼒测试情况下就会使⽤到多⽤户进⾏登录,就需要对登录名和密码进⾏参数化,那么loadrunner 怎么参数化设置呢?下⾯我们来详细分析⼀下。
⼀、我们这⾥通过loadurnner录制⼀个软件⾃带的航空⽹站登陆。
下⾯是截取的登录代码⼆、下⾯通过loadrunner对⽤户名和密码进⾏参数化设置。
1、双击jojo,右击选择Replace with a Parameter,弹出窗⼝Select or Create Parameter,在 Parameter name处输⼊变量名name,点击OK,密码重复名字的操作。
2、把⽤户名jojo改成变量name,密码bean改成变量psw三、下⾯对参数进⾏编辑添加。
第⼀种⽅法是直接在界⾯上添加编辑。
1、点击P图标或者按键盘ctrl +L 进⼊参数化设置界⾯,2、点击name进⾏编辑变量参数,点击Edit with Notepad,弹出记事本框,输⼊好⽤户名后,保存后,参数就设置完成了。
密码也是重复名字的操作。
3、也可以在界⾯上直接编辑,添加⾏、列或者删除⾏、列4、参数都添加后之后,我们要注意每个参数对应的名称5、也可以把所有的参数编辑在⼀个⽂件⾥⾯,⼀列对应⼀个参数。
6、当参数放在在⼀个⽂件⾥⾯时,设置处就要⼀⼀对应。
四、第2种⽅法对参数进⾏编辑添加,就是直接导⼊已编辑好了的数据。
1、在⽂件处选择已经编辑好的数据⽂件位置,点击打开后,⽂件111.dat的数据就⾃动导⼊进来了。
五、设置好参数后,就可以设置数据取值⽅式与更新⽅法。
1、Select next row: 选择下⼀⾏⽅法Sequential默认顺序的,按照参数化的数据顺序,从上往下⼀个⼀个的来取。
Random随机取,参数化中的数据,每次随机的从中抽取数据。
Unique唯⼀,唯⼀的向下取值,只能被⽤⼀次。
Same line as xxx,和xxx列取同⼀⾏的值,(⾏相同)步调⼀致例如:数据a b c d e f g ...,现有3个⽤户(甲⼄丙)取值;循环2次。

LoadRunner 参数化的功能详解参数化的定义:使用指定的数据源中的值来替换脚本录制生成的语句中的参数。
对Vuser脚本进行参数化的好处:1、减小脚本的大小2、提供了使用不同的脚本的值执行脚本的能力参数化涉及两个任务:1、用参数替换Vuser脚本的常量值2、为参数设置属性和数据源“Select next ro w”定义的是如何选择下一行数据。
该处有三个选项"Sequential","Random","Unique",Sequential:顺序地向Vuser分配数据。
Random:当测试开始运行时,“随机”方法为每个Vuser分配一个数据表中的随机值。
Unique:为每一个Vuser的参数分配一个唯一的顺序值。
在这种情况下必须确保表中的数据对所有的Vuser和它们的迭代来说是充足的。
如果拥有20个Vuser并且要进行5次迭代,则测试者的表格中必须至少包含100个数值。
“Update value on”定义的是什么时候更新数据值,备选项有每次迭代,每次出现和一次。
表LoadR unner参数更新方法和数据分配如果LoadRunner的函数中某个参数不能直接使用LoadRunner参数,那么可以通过lr_eval_string进行转换取到参数的值。
参数表中sel ect next row和upda te value on的设置LR的参数的取值,和select next row和update value on的设置都有密不可分的关系。
下表给出了select next row和update value on不同的设置,对于LR的参数取值的结果将不同,给出了详细的描述。
Loadrunner中参数的设置转载自51CMM做负载或者压力测试时,很多人选择使用了Loadrunner测试工具。
该工具的基本流程是先将用户的实际操作录制成脚本,然后产生数千个虚拟用户运行脚本(虚拟用户可以分布在局域网中不同的PC机上),最后生成相关的报告以及分析图。


loadRunner基本概念说明1、事务(Transaction)是这样一个点,我们为了衡量某个action的性能,需要在action的开始和结束位置插入这样一个范围,这就定义了一个 transaction,LoadRunner 运行到该事务的开始点时,LoadRunner 就会开始计时,直到运行到该事务的结束点,计时结束。
这个事务的运行时间在结果中会有反映。
所以 LR 的事务添加操作就是把测试所需要关注的操作定义成事务告诉 LR,这个是我想要重点检测性能的操作。
LR就会在运行过程中记录事务内操作的响应事件等性能数据。
并在Analysis中以报告的形式给出统计结果。
lr_start_transaction(”SubmitBookData”);/*中间代码部分*/lr_end_transaction(”SubmitBookData”, LR_AUTO);2、集合点(Rendezvous)集合点:是一个并发访问的点,在测试计划中,可能会要求系统能够承受1000人同时提交数据,在LoadRunner中可以通过在提交数据操作前面加入集合点,这样当虚拟用户运行到提交数据的集合点时,LoadRunner 就会检查同时有多少用户运行到集合点,如果不到1000人,LoadRunner就会命令已经到集合点的用户在此等待,当在集合点等待的用户达到1000 人时,LoadRunner 命令1000 人同时去提交数据,并发访问的目的。
注意:集合点经常和事务结合起来使用,常放在事务的前面,集合点只能插入到Action 部分,vuser_init和vuser_end 中不能插入集合点。
集合点函数如下,参数不能加空格:lr_rendezvous(”SumitQueryData”); 加入集合点之后,在后面运行过程中可以看到VU的状态,会等待集合。
3、IP Spoofer(IP 欺骗)LoadRunner允许运行的虚拟用户使用不同的IP 访问同一网站,这种技术称为“IP 欺骗”。

loadrunner关联参数的问题loadrunner关联分为两种一种是自动关联,一种是手动关联其实网上也有很多的实例供大家参考,自动关联可以从Recording Options设置Correlation可以把你要关联的规则设置好,当录制之前选择就你设置的这个规则,然后录制就行了第二种是手动关联,当你录制玩脚本的时候,没有设置关联,那么你需要手动就行关联手动关联的函数:Web_reg_save_parm参数的详细内容下表列出可用的属性。
注意,属性值字符串(例如Search=all)不区分大小写。
NotFound找不到边界并且生成了空字符串时的处理方法。
默认值“ERROR”表示找不到边界时LoadRunner应发出错误消息。
如果设置为“EMPTY”,则不会发出错误消息,并且脚本的执行将继续进行。
注意,如果为脚本启用了“出现错误时仍继续”,则即使将NOTFOUND 设置为“ERROR”,在找不到边界时脚本将仍然会继续执行,但会将错误消息写入扩展日志文件中LB参数或动态数据的左边界。
此参数必须为非空的、以null 结尾的字符串。
边界参数区分大小写;要忽略大小写,请在边界之后添加“/IC”。
如果在边界之后指定“/BIN”,则指定为二进制数据RB参数或动态数据的右边界。
此参数必须为非空的、以null 结尾的字符串。
边界参数区分大小写;要忽略大小写,请在边界之后添加“/IC”。
如果在边界之后指定“/BIN”,则指定为二进制数据.LB/RB赋值的是你要抓取文本的左/右边的内容,例如你要从"abcdefghijk"中抓取"de"保存在变量中,那么LB="abc"和RB="fghijk"就可以抓到你要的东西了RelFrameID与请求的URL 相关的HTML 页的层次结构级别。
LoadRunner参数化关联我们⽤ HTTP 协议做脚本,要注意的是,不同协议的函数是不⼀样的,假如换 websocket 协议,关联函数就要⽤其他的参数化原理1、什么叫参数化 把脚本内⼀个写死的值,去⼀个数组内取值,进⾏替换2、为什么要参数化 烂⼤街的回答:模拟真实场景,模拟真实情况 真实原因:应⽤程序/数据库对数据有唯⼀性要求(应⽤程序内就是单点登录;数据库内就是该字段为 Unique ,唯⼀)避免查询缓存对结果造成失真(重复查询同⼀条数据,如果该数据的表内开启了查询缓存,则会命中。
那么响应时间会⽐市价值偏⼩)3、可不可以不⽤参数化 查询缓存的开关是⽤query_cache_size = 20M和query_cache_type = ON 打开查询缓存,程序校验就得修改代码了,数据库唯⼀要求,把 Unique 的限制给拿掉就ok如何参数化(参数化会变紫)1、选中需要参数化的内容,右键,选择"Replace with a Parameter",2、为参数命名,并且制定参数取值的⽂件格式 Parameter name,就是我么那要设定的参数名,这个是不能重复的 Parameter type 是参数取值的⽅式,这个 file 是从 .bat ⽂件中取值,这个⽂件会⾃动⽣成在项⽬路径下结果:例如:web_submit_data("提交","Action=http://192.168.66.129/bbs/member.php?mod=register&inajax=1","Method=POST","TargetFrame=","Referer=http://192.168.66.129/bbs/member.php?mod=register",ITEMDATA,"Name=regsubmit", "Value=yes", ENDITEM,"Name=formhash", "Value={formhash}", ENDITEM,"Name=referer", "Value=http://192.168.66.129/bbs/forum.php", ENDITEM,"Name=activationauth", "Value=", ENDITEM,"Name={Name}", "Value=hua00{username}", ENDITEM,"Name={pass}", "Value=123456", ENDITEM,"Name={conpass}", "Value=123456", ENDITEM,"Name={mail}", "Value=hua00{username}@", ENDITEM,LAST);另⼀种情况,我们要把另⼀个数值也运⽤之前同⼀个参数咋办?另外,我们的参数化还有种⽅式:可以先建好,然后再脚本内⽤,这种情况适⽤于只给了脚本,但是没有给参数化⽂件的情况打开变量列表,填写变量值参数化变量和值是怎样对应的根据脚本中的参数名({username})去找参数列表中的的参数username,再去找参数列表中的username对应的bat⽂件注意,我们 loadrunner 的参数化默认是以 {} 为边界的,我们也可以修改这个参数化的边界类型:在 Tools-->General Options-->Parameterization的Paramrter Braces 内可以设置,我们可以看到默认是 {}参数化策略 最常⽤的取值⽅式:唯⼀(Unique+XX)我们写⼀个脚本来执⾏不同的参数化策略:Action(){int i; //申明变量for (i = 0;i<2;i++) { //循环char *a = "{p1}"; //获取参数值传给 achar *b = "{p2}"; //获取参数值传给 bchar *c = "{p1}"; //获取参数值传给 clr_output_message("%s,\t%s,\t%s",lr_eval_string(a),lr_eval_string(b),lr_eval_string(c)); //分贝演⽰ 9 种不同的参数化策略组合结果}return0;}如下Loadrunner参数化取值策略由[select next row]、[update value on]两部分组成。
LoadRunner知识点一、两种录制基于html:1、A script describing user actions:模拟用户行为录制2、A script contaning explict URLs only:录制所有links(链接)、images(图片)和URL(web_url)。
基于URL模式1、Create concurrent groups for resources their source HTML page:将捕获所有HTML页面的资源,并将其保存在并发组中2、Use web_custom_request only:如果录制的是非浏览器的应用程序,可以设置VuGen自定义HTTP请求选择的根据:1)基于浏览器的应用程序推荐使用HTML-based script。
2)不是基于浏览器的应用程序推荐使用URL-based script。
3)如果基于浏览器的应用程序中包含了JavaScript,并且该脚本向服务器发送了请求,比如DataGrid的分页按钮等,推荐使用URL-based script。
4)基于浏览器的应用程序中使用了HTTPS安全协议,建议使用URL-based script。
如果使用HTML-based script模式录制后不能成功回放,可以考虑改用URL-based script模式来录制。
因为这种情况多是由上面所列举的原因所引起的。
二、参数化为什么参数化:1)借助参数化可以减小脚本的数量,如果不进行参数化为了达到目标可能需要拷贝并修改很多个脚本。
2)使业务更接近真实的客户业务,每个虚拟用户使用不同参数值来模拟,这样可以更好地接近客户的实际情况。
具体就是每次提交的数据不同,所以要参数化达到提交的数据变化参数化的方式:1、数据文件怎样多个参数对应起来:所有的参数放在一个文件里,分别放在各列里,每行的参数值对应起来2、数据库三、关联技术1、为什么关联:如果录制脚本过程中,服务器会返回一个动态的、变化的值给客户端时,该动态的值做为下次提交数据返回给服务器,那么就必须对脚本进行关联,比如:usersessionID2、关联原理:找到动态生成值的左边界和右边界,获取到左边界和右边界中间的动态值赋给变量,再把变量值作为参数赋给请求的数据3、关联函数:web_reg_save_param("WCSParam2","LB/IC=name=userSession value=","RB/IC=>","Ord=1","Search=Body","RelFrameId=1",LAST);四、检查点1、为什么需要检查:检查点的根本目的是验证测试过程中的步骤是否被正确的执行2、检查点函数:web_reg_find("Text=zjh","SaveCount=num",“search=body”,LAST);判断事务是否成功函数(代替原来的事务结束函数):if(atoi(lr_eval_string("{count}"))>0){lr_end_transaction("login", LR_PASS);}else{lr_end_transaction("login", LR_FAIL);}3、检查点的参数化:当提交数据进行参数化的情况下参数化检查点,要选择和提交数据同一个参数文件五、集合点1、为什么增加集合点:保证所有的Vuser在同一时刻进行操作,这样就达不到并发测试的目的,所以用到集合点技术2、集合点函数:lr_rendezvous("login")3、集合点要放在事务前面六、负载均衡1、为什么添加负载均衡:为了尽可能减少或者避免测试机成为测试过程中的瓶颈,在测试过程中,需要使用所有的测试机产生Vuser,对被测试系统进行施压七、IP欺骗1、为什么要设置IP欺骗:在场景运行时,每台负载发生器计算机上的Vuser都使用其计算机的固定IP地址。
51Testing 软件测试论坛 » [LoadRunner] » 关于LoadRunner 参数的详细解释(自己看的)[转贴] 关于LoadRunner 参数的详细解释(自己看的)1# 大 中 小 发表于 2010-6-18 10:05 只看该作者关于LoadRunner 参数的详细解释(自己看的)通过创建表方式和数据向导方式都可以成功创建数据文件,操作员可以随意选择自己习惯的方式。
总之,能坚守数据文件放数据的原则,就不会出问题了。
当回到“参数属性页面”中后,发现数据已经准备好了,而且原来灰色的区域目前也可以选择了。
“选择下一行”共有下面几个选项:Sequential :按照顺序一行行的读取。
每一个虚拟用户都会按照相同的顺序读取。
Random :任意选择。
但是在每一次迭代中,将不发生变化。
Unique :唯一的数。
当使用该选项时,需要保证准备的数据文件中有足够的数据。
比如要做20个虚拟用户,每个用户要进行5次迭代,第一个用户在5次迭代中分别使用数据文件中的数据1~数据5,第二个用户在5次迭代中分别使用数据文件中的数据6~数据10,类推以后20个用户将使用到100个数据。
那么必须保证准备的数据文件中有100个以上的数据,否则运行时会出错。
Same line as 某个参数:和前面定义的参数取同行的记录。
通常用在有关联性的数据上面。
比如当我做登录密码的参数化时,由于它和UserID 是有关联的,所以会用到这种选择方式。
“更新值的时间”共有下面几个选项:Each iteration :每次迭代更新一个新的值。
Each occurrence :每次出现时该参数时更新一个新的值。
Once不管迭代多少次该参数的值一直保持不变。
*****注意*****1、参数类型:在创建参数的时候,我选择了参数类型为File。
参数类型共有9种,现在来简单介绍一下所有的参数类型以及意义。
1.1、DateTime:在需要输入日期/时间的地方,可以用DateTime 类型来替代。
LR参数取值的几种配置介绍
“Select next row ”有以下几种选择:
⏹ Sequential:按照顺序一行行的读取。
每一个虚拟用户都会按照相同的顺序读取
⏹ Random:在每次循环里随机的读取一个,但是在循环中一直保持不变
⏹ Unique :唯一的数。
注:使用该类型必须注意数据表有足够多的数。
比如Controller 中设定20 个虚拟用户进行5 次循环,那么编号为1 的虚拟用户取前5个数,编号为2 的虚拟用户取6-10 的数,依次类推,这样数据表中至少要有100个数据,否则Controller 运行过程中会返回一个错误。
⏹ Same Line As 某个参数(比如Name):和前面定义的参数Name 取同行的记录。
通常用在有关联性的数据上面。
我们这里取值Sequential 即可。
Advance row each iteration 选中即可,表示每一次循环都往前走一行。
手工输入数据比较简单,这里就不再单独介绍了。
LR参数取值配置举例:
假设有2个虚拟用户,每个用户执行3次循环,共有10条数据,如下:100001,100002,100003,100004,100005,100006,100007,100008,1000109,100110。
LoadRunner的参数化好久不⽤loadrunner,以前的东西⼜都还给百度了,今天⼼⾎来潮,把参数化搞了⼀下1 Action()2 {34 web_url("WebTours",5"URL=http://127.0.0.1:1080/WebTours/",6"Resource=0",7"RecContentType=text/html",8"Referer=",9"Snapshot=t1.inf",10"Mode=HTML",11 EXTRARES,12"Url=../favicon.ico", "Referer=", ENDITEM,13"Url=/upload/201507/8afc2fe48db9060fe1bdda2089e1d950.png", ENDITEM,14"Url=/upload/201507/3b491068507d8f85ea7b35d756da7215.png", ENDITEM,15"Url=https:///favicon.ico", "Referer=", ENDITEM,16 LAST);1718 web_link("sign up now",19"Text=sign up now",20"Snapshot=t2.inf",21 LAST);2223 web_reg_find("Text=Thank you, <b>t1",24 LAST);2526 web_submit_form("login.pl",27"Snapshot=t3.inf",28 ITEMDATA,29"Name=username", "Value=t1", ENDITEM,30"Name=password", "Value=123456", ENDITEM,31"Name=passwordConfirm", "Value=123456", ENDITEM,32"Name=firstName", "Value=", ENDITEM,33"Name=lastName", "Value=", ENDITEM,34"Name=address1", "Value=", ENDITEM,35"Name=address2", "Value=", ENDITEM,36"Name=register.x", "Value=57", ENDITEM,37"Name=register.y", "Value=1", ENDITEM,38 LAST);3940return0;41 }参数化常⽤的⽅式⽆⾮两种:1,右键---【Replace with a new parameter】。
Loadrunner参数化策略测试小组齐国杰使用工具:Loadrunner 8.1试用版引子近日没有具体的项目做,就总去泡论坛,发现有的网友会问一些参数化的问题,回答他们的问题时,突然发现自己也是一知半解,因此写了三个实验脚本,目的是彻底搞清楚参数化的做法以及参数化策略的疑问。
流程参数化要做一些准备,主要是参数化数据的准备,例如TXT 文本、EXCEL表格以及数据库中的表都可以作为参数的数据集载体,而且LR都是支持的。
具体的参数化流程如下:1、录制脚本2、准备参数的数据集(也可以不准备,让LR自己生成固定格式参数)3、把对应的变量参数化4、选择对应的参数化策略具体的操作请查询LR帮助手册例子下面我来介绍几个例子,例子统一使用try_params.txt做参数数据集,txt内容如下:aaa bbba1 b1a2 b2……a30 b30脚本一:Action(){char *a = "{aaa}"; //获得参数赋值给achar *b = "{bbb}";//获得参数赋值给blr_log_message("%s,%s,%s,",lr_eval_string(a),lr_eval_string (b),ctime(&t));//打印结果return 0;}运行时设置:设置action的迭代次数为30(runtime-setting的Run Logic里)回放结果:备注:“…,…”省略符号,如果前后都相同则省略相同部分,如果前后不同则省略不同部分。
脚本二:Action(){int i; //循环种子for (i=0;i<30;i++) //循环30次{char *a = "{aaa}"; //获得参数赋值给achar *b = "{bbb}";//获得参数赋值给blr_log_message("%s,%s\n",lr_eval_string (a),lr_eval_string (b));}//打印结果return 0;}运行时设置:设置action的迭代次数为1(runtime-setting 的Run Logic里)回放结果:备注:“…,…”省略符号,如果前后都相同则省略相同部分,如果前后不同则省略不同部分。
一、什么时候需要关联1.关联的含义关联(correlation):在脚本回放过程中,客户端发出请求,通过关联函数所定义的左右边界值(也就是关联规则),在服务器所响应的内容中查找,得到相应的值,已变量的形式替换录制时的静态值,从而向服务器发出正确的请求,这种动态获得服务器响应内容的方法被称作关联。
其实关联也属于一同特殊的参数化,只是与一般的参数化有些不同。
一般的参数化的参数来源于一个文件、一个定义的table、通过sql写的一个结果集等,但关联所获得的参数是服务器响应请求所返回的一个符合条件的、动态的值。
2.什么时候需要做关联要想弄清这个问题,我们首先要知道客户端与服务器端的请求与响应的过程。
过程说明:客户端发出获得登录页面的请求服务器端得到该请求后,返回登录页面,同时动态生成一个Session Id,当用户输入用户名密码,请求登录时,该Session Id同时被发送到服务器端如果该Session Id在当前会话中有效,那么返回登录成功的页面,如果不正确则登录失败。
在第一次录制过程中loadrunner把这个值记录了下来,写到了脚本中,但再次回放时,客户端发出同样的请求,而服务器端再一次动态的生成了Session Id,此时客户端发出的请求就是错误的,为了获得这个动态的Session Id我们这里用到了关联。
所以我们得出结论:当客户端的某个请求是随着服务器端的相应而动态变化的时候,我们就需要用到关联。
当然我们在录制脚本时应该对测试的项目进行适当的了解,知道哪些请求需要用到服务器响应的动态值,如果我们不明确那些值需要做关联的话,我们也可以将脚本录制两遍,通过对比脚本的方法来查找需要关联的部分,但并不是说两次录制的所有不同点都需要关联,这个要具体情况具体分析二、自动关联loadrunner参数化自动关联包含两种机制:一种是loadrunner通过对比录制和回放时服务器响应的不同,而提示用户是否进行关联,用户可自己创建关联规则,这个功能可以方便的使我们获得需要关联的部分,但同时也存在一定的问题,如:自动关联所检测到的关联点不一定真的需要进行关联,这要我们更具实际情况进行判断;有些需要关联的动态数据自动关联无法找到,这是就需要做手动关联另一种是loadrunner自带的自动关联规则,在录制脚本时,会根据这些规则自动创建关联自动关联的步骤如下:1.开启自动关联选项刚才提到的两种关联机制,如果用户想使用loadrunner自带的关联规则创建关联,那么需要在【Recording Options】>【Internet Protocol】>【Correlation】中启用关联规则,选中“Enable correlation during recording”,当录制这些应用系统的脚本时,VuGen会在脚本中自动建立关联。
也可以在【Recording Options】>【Internet Protocol】>【Correlation】中添加关联规则,达到自动关联的目的。
如果需要在回放脚本时,loadrunner自动检测需要关联的部分,那么需要在【Tools】>【general options】>【Correlation】中选中“save correlation information during replay”和“show scan for correlations popup after replay of vuser”,当回放玩脚本后,会弹出Scan action for correlation窗口,进行关联点的搜索2.录制脚本录制脚本的过程在这里就不多说了3.回放脚本如果录制的脚本存在需要做关联的部分,那么在回放脚本时会出现错误4.系统自动弹出检测关联对话框,或手动启动关联检测对话框如果选择了【Tools】>【general options】>【Correlation】中的“save correlation information during replay”和“show scan for correlations popup after replay of vuser”,那么在回放脚本后会自动弹出“Scan action for correlation”窗口,点击“yes”进行自动查找,如果没有选择上述设置,那么也可以按CTRL+F8启动关联自动搜索5.查看系统检测出的关联点进行关联设置,如果在录制和回放中存在差异,loadrunner会在“Correlation Results”中列出需要做关联的内容,用鼠标点击一条需要做关联的内容,点击“Create Rule”,系统会显示获得当前数据的规则,点击“yes”,完成规则的创建,同时查看脚本中增加了一个web_reg_save_param函数,也可以点击【Correlate】按钮创建关联,一笔一笔做,或是按下【Correlate All】让VuGen一次就对所有的数据建立关联。
注意:由于Correlation Studio会找出所有有变动的数据,但是并不是所有的数据都需要做关联,所以不建议您直接用【Correlate All】。
6.回放脚本检查关联的正确性,创建好关联后,回放脚本检查关联的正确性三、手动关联手动关联的过程大致如下:第一步:录制测试脚本,录制二遍第二步:使用WinDiff工具找出两次脚本的不同,判断是否需要进行关联第三步:确定插入关联的位置第四步:在VIEW TREE中使用web_reg_save_param函数手动建立关联第五步:将脚本中有用到关联的数据,用参数代替第六步:验证关联的正确性下面详细介绍:第一步:录制测试脚本,录制二遍这一步就不用多说了,相同的操作,录制两份,分别保存第二步:使用WinDiff工具协助找出需要关联的数据1. 在第二份脚本中,点选VuGen的【Tools】>【Compare with Vuser…】,并选择第一份脚本。
2. 接着WinDiff会开启,同时显示二份脚本,并显示有差异的地方。
WinDiff会以一整行黄色标示有差异的脚本,并且以红色的字体显示真正差异的文字。
(假如没看到红色字体,请点选【Options】>【View】>【Show Inline Differences】)。
查看二份脚本中差异的部份,每一个差异都可能是需要做关联的地方。
注意:lr_thik_time部分的差异可以忽略找到不同的部分后,复制,然后打开Recording Log或是Generation Log,按Ctrl+F,在查找窗口中粘贴差异部分的内容,点击查找找到后,查看该部分的信息,确认是客户端的请求信息还是服务器回应的信息如果出现在$$$$$$ Request Header For Transaction With Id 3 Ended $$$$$$这个部分,那证明是客户端发出的请求,这里是不需要做关联的一般做的关联都是出现在****** Response Header For Transaction With Id 7 ******和****** Response Body For Transaction With Id 7 ******中的部分。
在找到这个信息后,需要记录如下信息:a、记录这个不同数据之前的内容和之后的内容b、记录这个不同数据出现的位置,是Header还是Body第三步:确认插入关联的位置我们在日志中找到了两次脚本的不同点的位置,根据这个位置,我们再确定是在哪个请求之后产生的,也就是说要定位发生不同点的response是由哪个request产生的,找到了这个请求的函数位置,我们就知道要往哪里做关联了。
一般情况下关联函数写到发出请求的函数之前就可以了。
第四步:插入关联函数在插入关联函数前,我们先介绍关联函数web_reg_save_param一个web_reg_save_param函数的例子:web_reg_save_param ("sessionid","LB=Session_id:","RB=;","Search=Body",LAST);在这里我们只介绍几个常用参数的含义语法:int web_reg_save_param(const char *ParamName, <list of Attributes>, LAST);参数说明:ParamName: 存放得到的动态内容的参数名称list of Attributes: 其它属性,包括:Notfound, LB, RB, RelFrameID, Search, ORD, SaveOffset, Convert, SaveLen。
属性值不分大小写LB( Left Boundary ) : 返回信息的左边界字串。
该属性必须有,并且区分大小写。
RB( Right Boundary ): 返回信息的右边界字串。
该属性必须有,并且区分大小写。
Search : 返回信息的查找范围。
可以是Headers,Body,Noresource,All(缺省)。
该属性质可有可无。
那么如何插入该关联函数呢?1.将vugun切换到view tree 模式下2.在左边的列表中,找到在上一步发出请求的函数,点击“右键”选择“insert before”3.在弹出的“add step”对话框的“find function”中输入“web_reg_save_param”,点击“ok”在“parameter name”中输入,关联函数的名称,这里最好有含义,“sessionid”在“left boundary”中输入,刚才记录下的不同点字符串的左面的几个字符,定义左边界,Session_id:在“right boundary”中输入,刚才记录下的不同点字符串的右面的几个字符,定义右边界,; 在“search in ”中,选择“body”点击“ok”4.回到脚本编辑模式下,查看该函数插入是否正确在发出请求的函数前应该看到:web_reg_save_param ("sessionid","LB=Session_id:","RB=;","Search=Body",LAST);第五步:将脚本中有用到关联的数据,用参数代替如发出请求的参数如下,那么将原来服务器返回的动态值使用{ sessionid } 来替换:web_submit_form("login.php_2","Snapshot=t2.inf",ITEMDATA,"Name=login", "Value=wangjin", ENDITEM, "Name=password", "Value=wangjin", ENDITEM, "Name=Session_id","Value={ sessionid } ", ENDITEM, "Name=Submit", "Value=Login", ENDITEM, EXTRARES,"URL=/media/images/border_bg_l.gif", ENDITEM, "URL=/media/images/header_bg.gif", ENDITEM, "URL=/media/images/th.gif", ENDITEM,LAST);第六步:验证关联的正确性回放脚本,验证关联的正确性。