Oracle gb2312 字符集 转 utf-8
- 格式:doc
- 大小:25.00 KB
- 文档页数:2

GB2312编码网页转换成UTF-8编码网页方法<meta http-equiv="Content-Type" content="text/html" charset="utf-8" />在Utf-8模块的包文档(如conn.asp,但是要注意conn.asp必须是在第一行调用)最前面加上<%@LANGUAGE="VBSCRIPT" CODEPAGE="65001"%><%Session.CodePage=65001%>在GB2312模块的包文档最前面加上步骤/方法UTF-8是UTF-8编码是一种目前广泛应用于网页的编码,它其实是一种Unicode编码,即致力于把全球所有语言纳入一个统一的编码。
前UTF-8已经把几种重要的亚洲语言纳入,包括简繁中文和日韩文字。
所以在制作某些网站时,需要使用UTF-8,那么怎么把gb2312编码转换到utf-8编码呢?在dreamweaver 里只需要一步即可实现。
1. 2找到菜单的修改——页面属性——标题和编码,在编码列表中选择UTF-8后确定即可。
最近在做的系统中,碰到了一个问题,交易系统采用的UTF-8编码,而一些支持系统使用的是GB2312编码。
不同编码的页面、脚本之间互相引用,就会产生乱码的问题,解决方法就是统一成一种编码。
中,如果要修改输出页面的编码,可以通过修改web.config中以下配置信息<globalization requestEncoding="utf-8" responseEncoding="utf-8" />以上只是修改整体的默认编码,如果只有某个页的编码需要修改, 中则可以简单的使用下面代码:注:加到Page_Load()事件下面就可以了Encoding gb2312 = Encoding.GetEncoding("gb2312");Response.ContentEncoding = gb2312;在非 应用中,可能你读到的数据是UTF-8编码,但是你要转换为GB2312编码,则可以参考以下代码:string utfinfo = "document.write(\"alert('你好么??');\");";string gb2312info = string.Empty;Encoding utf8 = Encoding.UTF8;Encoding gb2312 = Encoding.GetEncoding("gb2312");// Convert the string into a byte[].byte[] unicodeBytes = utf8.GetBytes(utfinfo);// Perform the conversion from one encoding to the other.byte[] asciiBytes = Encoding.Convert(utf8, gb2312, unicodeBytes);// Convert the new byte[] into a char[] and then into a string.// This is a slightly different approach to converting to illustrate// the use of GetCharCount/GetChars.char[] asciiChars = new char[gb2312.GetCharCount(asciiBytes, 0, asciiBytes.Length)];gb2312.GetChars(asciiBytes, 0, asciiBytes.Length, asciiChars, 0);gb2312info = new string(asciiChars);当然,其他各种编码之间的转换,跟上述代码也类似的,就不描述了。
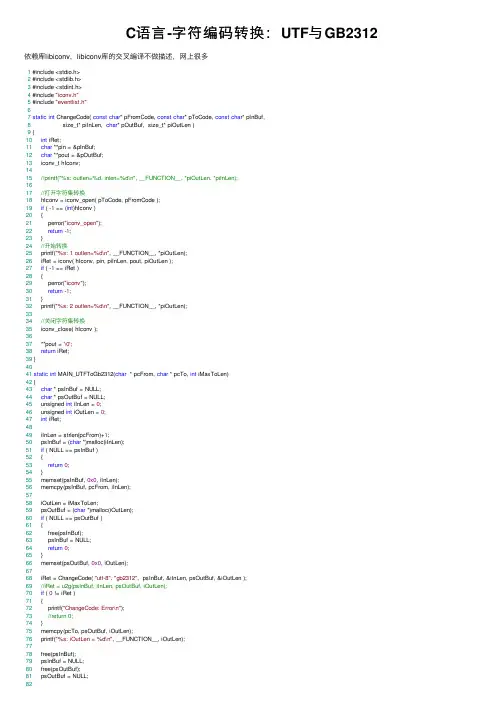
C语⾔-字符编码转换:UTF与GB2312依赖库libiconv,libiconv库的交叉编译不做描述,⽹上很多1 #include <stdio.h>2 #include <stdlib.h>3 #include <stdint.h>4 #include "iconv.h"5 #include "eventlist.h"67static int ChangeCode( const char* pFromCode, const char* pToCode, const char* pInBuf,8 size_t* piInLen, char* pOutBuf, size_t* piOutLen )9 {10int iRet;11char **pin = &pInBuf;12char **pout = &pOutBuf;13 iconv_t hIconv;1415//printf("%s: outlen=%d, inlen=%d\n", __FUNCTION__, *piOutLen, *piInLen);1617//打开字符集转换18 hIconv = iconv_open( pToCode, pFromCode );19if ( -1 == (int)hIconv )20 {21 perror("iconv_open");22return -1;23 }24//开始转换25 printf("%s: 1 outlen=%d\n", __FUNCTION__, *piOutLen);26 iRet = iconv( hIconv, pin, piInLen, pout, piOutLen );27if ( -1 == iRet )28 {29 perror("iconv");30return -1;31 }32 printf("%s: 2 outlen=%d\n", __FUNCTION__, *piOutLen);3334//关闭字符集转换35 iconv_close( hIconv );3637 **pout = '\0';38return iRet;39 }4041static int MAIN_UTFToGb2312(char * pcFrom, char * pcTo, int iMaxToLen)42 {43char * psInBuf = NULL;44char * psOutBuf = NULL;45 unsigned int iInLen = 0;46 unsigned int iOutLen = 0;47int iRet;4849 iInLen = strlen(pcFrom)+1;50 psInBuf = (char *)malloc(iInLen);51if ( NULL == psInBuf )52 {53return0;54 }55 memset(psInBuf, 0x0, iInLen);56 memcpy(psInBuf, pcFrom, iInLen);5758 iOutLen = iMaxToLen;59 psOutBuf = (char *)malloc(iOutLen);60if ( NULL == psOutBuf )61 {62 free(psInBuf);63 psInBuf = NULL;64return0;65 }66 memset(psOutBuf, 0x0, iOutLen);6768 iRet = ChangeCode( "utf-8", "gb2312", psInBuf, &iInLen, psOutBuf, &iOutLen );69//iRet = u2g(psInBuf, iInLen, psOutBuf, iOutLen);70if ( 0 != iRet )71 {72 printf("ChangeCode: Error\n");73//return 0;74 }75 memcpy(pcTo, psOutBuf, iOutLen);76 printf("%s: iOutLen = %d\n", __FUNCTION__, iOutLen);7778 free(psInBuf);79 psInBuf = NULL;80 free(psOutBuf);81 psOutBuf = NULL;8283return iOutLen;8485 }8687static int MAIN_GB2312ToUTF(char * pcFrom, char * pcTo, int iMaxToLen)88 {89char * psInBuf = NULL;90char * psOutBuf = NULL;91 unsigned int iInLen = 0;92 unsigned int iOutLen = 0;93int iRet;9495 iInLen = strlen(pcFrom)+1;96 psInBuf = (char *)malloc(iInLen);97if ( NULL == psInBuf )98 {99return0;100 }101 memset(psInBuf, 0x0, iInLen);102 memcpy(psInBuf, pcFrom, iInLen);103104 iOutLen = iMaxToLen;105 psOutBuf = (char *)malloc(iOutLen);106if ( NULL == psOutBuf )107 {108 free(psInBuf);109 psInBuf = NULL;110return0;111 }112 memset(psOutBuf, 0x0, iOutLen);113114 iRet = ChangeCode( "gb2312", "utf-8", psInBuf, &iInLen, psOutBuf, &iOutLen );115//iRet = u2g(psInBuf, iInLen, psOutBuf, iOutLen);116if ( 0 != iRet )117 {118 printf("ChangeCode: Error\n");119//return 0;120 }121 memcpy(pcTo, psOutBuf, iOutLen);122 printf("%s: iOutLen = %d\n", __FUNCTION__, iOutLen);123124 free(psInBuf);125 psInBuf = NULL;126 free(psOutBuf);127 psOutBuf = NULL;128129return iOutLen;130131 }132133int main()134 {135char strUTF[]={1360xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 0xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 1370xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 0xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 1380xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 0xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 1390xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 0xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 1400xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 0xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 1410xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 0xE5, 0xBC, 0x80, 0xE8,0xBD, 0xA6, 0xE4, 0xBA, 0x8B, 0xE4, 0xBB, 0xB6, 1420x00, 0x00, 0x00143 };144char chTmpStr[256];145int len = 0;146147 memset(chTmpStr, 0x0, 256);148 MAIN_UTF2Gb2312(strUTF, chTmpStr, 256);149 printf("Main: change=%s\n", chTmpStr);150151return0;152 }。

GB2312、GBK与UTF-8的区别这是一个异常经典的问题,有无数的新手站长每天都在百度这个问题,而我,作为一个“伪老手”站长,在明白这个这个问题的基础上,有必要详细的解答一下。
首先,我们要明白,GB2312、GBK和UTF-8都是一种字符编码,除此之外,还有好多字符编码。
只是对于我们中国人的网站来说,用这三种编码比较多。
简单的说一下,为什么要用编码,在计算机内,储存文本信息用ASC II码,每一个字符对应着唯一的ASCII码。
最初计算机是由美国发明的,他们也用的是键盘和上面的字母,所以他们的字符ASCII好解决。
但是我们中国的就不同了,每个汉字要对应唯一的ASCII码。
这样,就出来了国家制定的字符编码标准:GB2312、GBK等。
其他国家,其他语言也有他们对应的编码标准。
GB 就是国标的意思,GB2312和GBK主要用于汉字的编码,而UTF-8是全世界通用的。
意思就是说,如果你的网页主要面对使用汉语的中国人的话,使用GB2312和GBK非常好,文字储存体积要小,有一些优点。
如果你的网页要面向世界的话,你再用GB2312和GBK作为网页编码的话,有些电脑上的浏览器没有这种编码,你的网页汉字内容就会变成无法识别的乱码。
它们通常用在网页的meta标签内,例如:<meta http-equiv=”Content-Type” content=”text/html; charset=gb2312″/>,表示这个页面使用的是GB2312编码。
这个信息是给浏览器看的,浏览器会优先考虑使用从网页头部提取出来的编码信息对网页进行解码。
当然,我们也可以强制浏览器使用某种编码解释网页,这样我们就看到了传说中的乱码。
请看下图IE浏览器:百度首页使用的是GB2312编码,我们可以看到现在是正常的。
我们右击页面,选择“编码”->“其他”->“Unicode(UTF-8)”,意思就是强制浏览器使用UTF-8的编码方式解析页面,我们可以看到奇迹发生了:百度页面上所有的汉字都变成了乱码。


在LINUX上进行编码转换时,既可以利用iconv函数族编程实现,也可以利用iconv命令来实现,只不过后者是针对文件的,即将指定文件从一种编码转换为另一种编码。
一、利用iconv函数族进行编码转换iconv函数族的头文在LINUX上进行编码转换时,既可以利用iconv函数族编程实现,也可以利用iconv命令来实现,只不过后者是针对文件的,即将指定文件从一种编码转换为另一种编码。
一、利用iconv函数族进行编码转换iconv函数族的头文件是iconv.h,使用前需包含之。
#include <iconv.h>iconv函数族有三个函数,原型如下:(1) iconv_t iconv_open(const char *tocode, const char *fromcode);此函数说明将要进行哪两种编码的转换,tocode是目标编码,fromcode是原编码,该函数返回一个转换句柄,供以下两个函数使用。
(2) size_t iconv(iconv_t cd,char **inbuf,size_t *inbytesleft,char **outbuf,size_t *outbytesleft);此函数从inbuf中读取字符,转换后输出到outbuf中,inbytesleft用以记录还未转换的字符数,outbytesleft用以记录输出缓冲的剩余空间。
(3) int iconv_close(iconv_t cd);此函数用于关闭转换句柄,释放资源。
例子1: 用C语言实现的转换示例程序/* f.c : 代码转换示例C程序*/#include <iconv.h>#define OUTLEN 255main(){char *in_utf8 = "姝e?ㄥ??瑁?";char *in_gb2312 = "正在安装";char out[OUTLEN];//unicode码转为gb2312码rc = u2g(in_utf8,strlen(in_utf8),out,OUTLEN);printf("unicode-->gb2312 out=%sn",out);//gb2312码转为unicode码rc = g2u(in_gb2312,strlen(in_gb2312),out,OUTLEN);printf("gb2312-->unicode out=%sn",out);}//代码转换:从一种编码转为另一种编码int code_convert(char *from_charset,char *to_charset,char *inbuf,int inlen,char *outbuf,int outlen){iconv_t cd;int rc;char **pin = &inbuf;char **pout = &outbuf;cd = iconv_open(to_charset,from_charset);if (cd==0) return -1;memset(outbuf,0,outlen);if (iconv(cd,pin,&inlen,pout,&outlen)==-1) return -1;iconv_close(cd);return 0;}//UNICODE码转为GB2312码int u2g(char *inbuf,int inlen,char *outbuf,int outlen){return code_convert("utf-8","gb2312",inbuf,inlen,outbuf,outlen);//GB2312码转为UNICODE码int g2u(char *inbuf,size_t inlen,char *outbuf,size_t outlen){return code_convert("gb2312","utf-8",inbuf,inlen,outbuf,outlen); }例子2: 用C++语言实现的转换示例程序/* f.cpp : 代码转换示例C++程序*/#include <iconv.h>#include <iostream>#define OUTLEN 255using namespace std;// 代码转换操作类class CodeConverter {private:iconv_t cd;public:// 构造CodeConverter(const char *from_charset,const char *to_charset) { cd = iconv_open(to_charset,from_charset);}// 析构~CodeConverter() {iconv_close(cd);// 转换输出int convert(char *inbuf,int inlen,char *outbuf,int outlen) {char **pin = &inbuf;char **pout = &outbuf;memset(outbuf,0,outlen);return iconv(cd,pin,(size_t *)&inlen,pout,(size_t *)&outlen);}};int main(int argc, char **argv){char *in_utf8 = "姝e?ㄥ??瑁?";char *in_gb2312 = "正在安装";char out[OUTLEN];// utf-8-->gb2312CodeConverter cc = CodeConverter("utf-8","gb2312");cc.convert(in_utf8,strlen(in_utf8),out,OUTLEN);cout << "utf-8-->gb2312 in=" << in_utf8 << ",out=" << out << endl;// gb2312-->utf-8CodeConverter cc2 = CodeConverter("gb2312","utf-8");cc2.convert(in_gb2312,strlen(in_gb2312),out,OUTLEN);cout << "gb2312-->utf-8 in=" << in_gb2312 << ",out=" << out << endl; }linux C 字符集转换,UTF-8,GB2312最近帮朋友写个系统接口的小东东,2个系统字符集不同,一个采用UTF-8,一个采用GB2312,不得已需要转换字符集。

转utf8出错,非utf8的二进制数组转utf8出错,非utf8的二进制数组是一种常见的编码问题,经常出现在字符串处理和文件转换过程中。
当我们需要将一段文本从一种编码格式转换为另一种编码格式时,会遇到各种问题,其中最常见的就是转换后的结果出现乱码或不完整的情况。
本文将针对这个问题做一个详细的介绍和解决方案的讨论,希望能够解决你在编码转换过程中遇到的相关问题。
一、什么是UTF-8编码?UTF-8是一种Unicode字符编码,它是以字节为单位来编码Unicode字符的一种变长编码方式,可以用来表示任意字符集中的任意字符。
UTF-8的最大优点在于它是兼容ASCII字符集的,这就使得传统ASCII编码的文本在转换为UTF-8编码时不需要任何变更,从而实现了对于传统ASCII 编码的向后兼容。
对于UTF-8编码,它使用1到4个字节来表示一个字符。
对于英文字母和数字这样的ASCII字符,UTF-8使用1个字节来表示。
而对于UTF-8中的一些较为特殊的字符,比如中文、日文、韩文等非ASCII字符,UTF-8需要使用两个或多个字节来表示。
UTF-8编码是一个非常流行的编码方式,很多软件都支持使用UTF-8编码来存储和处理文本数据。
二、转换UTF-8出错的原因当我们需要将一个非UTF-8编码的字符串转换为UTF-8编码时,常常会遇到转换出错的情况。
出现这种问题的原因通常是由于使用了错误的转换方式导致的。
在下面的内容中,我们将讨论一些常见的错误转换方式,并分析它们导致的错误原因。
1.简单复制最常见的错误转换方式之一就是简单地将源字符串的字节值复制到目标字符串中。
这种方式非常简单,但是很容易出错。
因为在不同的编码方式中,同一个字符的字节值可能是不同的,这就导致了简单复制方式不能正确地将所有字符都转换为目标编码方式。
例如,当我们需要将一个GBK编码的字符串转换为UTF-8编码时,使用简单复制的方式来完成这个任务就会出错。

ORACLE数据库字符集修改的方法ORACLE数据库有国家字符集(national character set)与数据库字符集(database character set)之分。
两者都是在创建数据库时需要设置的。
国家字符集主要是用于NCHAR、NVARCHAR、NCLOB类型的字段数据,而数据库字符集应用于:CHAR、VARCHAR、CLOB、LONG类型的字段数据;表名、列名、PL/SQL中的变量名;输入及保存在数据库的SQL和PL/SQL的源码。
具体分析:字符集修改主要有两种方法:方法一:通过逻辑备份导入导出的方法实现方法二:通过alter database set …修改以上两种两方法各有优劣,下面我们通过各自实现的方法来实现字符集的转换,来说明各自特点。
例:把当前字符集ZHS16GBK 改变成UTF8在字符集转换过程中经常会出字符长度规则不一样,这样会引起数据无法导入或者出现乱码。
我们可以通过ORACLE提供的工具检查及根据建议修改。
在SYS用户执行@?/rdbms/admin/csminst.sql脚本后:$ csscan FULL=Y FROMCHAR=ZHS16GBKfromnchar=AL32UTF8TOCHAR=UTF8 TONCHAR=UTF8 ARRAY=1024000LOG=charcheckCAPTURE=Y PROCESS=4;FROMCHAR:说明数据库CHAR, VARCHAR2, LONG,CLOB数据类型的实际字符集,缺省使用数据库的字符集。
FROMNCHAR:说明数据库NCHAR, NVARCHAR2, NCLOB数据类型的实际国家字符集,缺省使用数据库的国家字符集。
TOCHAR:指定需要转换的目标字符集。
TONCHAR:指定需要转换的目标国家字符集,如果未指定将不扫描NCHAR, NVARCHAR2, NCLOB数据类型的数据。
执行完上述指令后,检查输出charcheck.err文件并根据建议修改表段长度:User : SFEHRTable : ATMP_DEPTColumn: MEMOType : VARCHAR2(100)Number of Exceptions : 10Max Post Conversion Data Size: 130ROWID Exception Type Size Cell Data(first 30 bytes)------------------ ------------------ ----- ------------------------------AAANhYAAMAAAAA0AAg exceed column size 102 此点部于2006年7月1日由清凉点部AAANhYAAMAAAAA3ABD exceed column size 119 原来的容桂点部06年7月1日起,拆AAANhYAAMAAAAA5AAb exceed column size 116 沙田点部归属原由虎门分部直接管AAANhYAAMAAAAA5ABF exceed column size 130 2004年04月01日开始正式合併入85AAANhYAAMAAAAA8AAn exceed column size 119 大岭山点部归属莞城分部管理。

将字符串的编码格式转换为utf-8⽅式⼀:/*** 将字符串的编码格式转换为utf-8** @param str* @return Name = new* String(Name.getBytes("ISO-8859-1"), "utf-8");*/public static String toUTF8(String str) {if (isEmpty(str)) {return "";}try {if (str.equals(new String(str.getBytes("GB2312"), "GB2312"))) {str = new String(str.getBytes("GB2312"), "utf-8");return str;}} catch (Exception exception) {}try {if (str.equals(new String(str.getBytes("ISO-8859-1"), "ISO-8859-1"))) {str = new String(str.getBytes("ISO-8859-1"), "utf-8");return str;}} catch (Exception exception1) {}try {if (str.equals(new String(str.getBytes("GBK"), "GBK"))) {str = new String(str.getBytes("GBK"), "utf-8");return str;}} catch (Exception exception3) {}return str;}/*** 判断是否为空** @param str* @return*/public static boolean isEmpty(String str) {// 如果字符串不为null,去除空格后值不与空字符串相等的话,证明字符串有实质性的内容if (str != null && !str.trim().isEmpty()) {return false;// 不为空}return true;// 为空}⽅式⼆:import java.io.UnsupportedEncodingException;/*** 转换字符串的编码*/public class ChangeCharset {/** 7位ASCII字符,也叫作ISO646-US、Unicode字符集的基本拉丁块 */public static final String US_ASCII = "US-ASCII";/** ISO 拉丁字母表 No.1,也叫作 ISO-LATIN-1 */public static final String ISO_8859_1 = "ISO-8859-1";/** 8 位 UCS 转换格式 */public static final String UTF_8 = "UTF-8";/** 16 位 UCS 转换格式,Big Endian(最低地址存放⾼位字节)字节顺序 */public static final String UTF_16BE = "UTF-16BE";/** 16 位 UCS 转换格式,Little-endian(最⾼地址存放低位字节)字节顺序 */public static final String UTF_16LE = "UTF-16LE";/** 16 位 UCS 转换格式,字节顺序由可选的字节顺序标记来标识 */public static final String UTF_16 = "UTF-16";/** 中⽂超⼤字符集 */public static final String GBK = "GBK";/*** 将字符编码转换成US-ASCII码*/public String toASCII(String str) throws UnsupportedEncodingException{return this.changeCharset(str, US_ASCII);}/*** 将字符编码转换成ISO-8859-1码*/public String toISO_8859_1(String str) throws UnsupportedEncodingException{ return this.changeCharset(str, ISO_8859_1);}/*** 将字符编码转换成UTF-8码*/public String toUTF_8(String str) throws UnsupportedEncodingException{return this.changeCharset(str, UTF_8);}/*** 将字符编码转换成UTF-16BE码*/public String toUTF_16BE(String str) throws UnsupportedEncodingException{ return this.changeCharset(str, UTF_16BE);}/*** 将字符编码转换成UTF-16LE码*/public String toUTF_16LE(String str) throws UnsupportedEncodingException{ return this.changeCharset(str, UTF_16LE);}/*** 将字符编码转换成UTF-16码*/public String toUTF_16(String str) throws UnsupportedEncodingException{return this.changeCharset(str, UTF_16);}/*** 将字符编码转换成GBK码*/public String toGBK(String str) throws UnsupportedEncodingException{return this.changeCharset(str, GBK);}/*** 字符串编码转换的实现⽅法* @param str 待转换编码的字符串* @param newCharset ⽬标编码* @return* @throws UnsupportedEncodingException*/public String changeCharset(String str, String newCharset)throws UnsupportedEncodingException {if (str != null) {//⽤默认字符编码解码字符串。

java编码表GBK、GB2312与UTF展开全文GBK、GB2312与UTF-8的区别?一,先说下三者各自的定义。
UTF-8:Unicode Transformation Format-8bit,允许含BOM,但通常不含BOM。
是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。
UTF-8编码的文字可以在各国支持UTF8字符集的浏览器上显示。
如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,他们无需下载IE的中文语言支持包。
GBK:是国家标准GB2312基础上扩容后兼容GB2312的标准。
除了兼容GB2312外,它还能显示繁体中文,还有日文的假名该编码共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。
GBK为了区分中文,将其最高位都设定成1。
既一个中文两个字节的第一个字节为负数。
GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBD大。
GB2312是中国规定的汉字编码,也可以说是简体中文的字符集编码;GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:二,通过实例来说明。
GBK、GB2312与UTF-8对中文编码时分别使用多少个字节如对"aA你"进行编码编码 a A 你GB2312:97,65,-60,-29,GBK: 97,65,-60,-29,UTF-8: 97,65,-28,-67,-96,通过上面可以看出:GBK、GB2312与UTF-8对英文字母都是用1一个字节表示,对汉语:GB2312:2字节通常第一个字节都是负数GBK: 2字节通常第一个字节都是负数UTF-8: 3字节一般GBK、GB2312的两个字节都为负数,但是对一些不常见的汉字会有例外。

将编码从GB2312转成UTF-8的方法汇总一个网站如果需要国际化,就需要将编码从GB2312转成UTF-8,其中有很多的问题需要注意,如果没有转换彻底,将会有很多的编码问题出现!主要有五个方面:一..HTML页面转UTF-8编码问题二.PHP页面转UTF-8编码问题三.MYSQL数据库使用UTF-8编码的问题四.JS相关的UTF-8编码问题五.FLASH相关的UTF-8编码问题一.HTML页面转UTF-8编码问题1.在后,之间有中文字符的话,显示的标题有可能是乱码!2.html文件编码问题:点击编辑器的菜单:“文件”->“另存为”,可以看到当前文件的编码,确保文件编码为:UTF-8,如果是ANSI,需要将编码改成:UTF-8。
3.HTML文件头BOM问题:将文件从其他的编码转换成UTF-8编码时,有时候会在文件的最开始加上一个BOM标签,在个BOM标签可能会导致浏览器在显示中文的时候出现乱码。
删除这个BOM标签的方法:1.可以用Dreamweaver打开文件,并重新保存,即可以去除BOM标签!2.可以用EditPlus打开文件,并在菜单“首选项”->“文件”->"UTF-8标识",设置为:“总是删除签名”,然后保存文件,即可以去除BOM标签!4.WEB服务器UTF-8编码问题:如果你按以上所列的步骤做了,还是有中文乱码问题,请检查你的所使用的WEB服务器的编码问题如果你使用的是Apache,请将配置文件里的:charset 设成:utf-8(这里仅列出方法,具体格式请参考apache的配置文件)。
如果你使用的是Nginx,请将nginx.conf里的:charset 设成utf-8,具体找到"charset gb2312;"或者类似的语句,改成:“charset utf-8;”。
二.PHP页面转UTF-8编码问题1.在代码开始出加入一行:header("Content-Type: text/html;charset=utf-8");2.PHP文件编码问题点击编辑器的菜单:“文件”->“另存为”,可以看到当前文件的编码,确保文件编码为:UTF-8,如果是ANSI,需要将编码改成:UTF-8。

谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词这是一篇程序员写给程序员的趣味读物。
所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级。
整理这篇文章的动机是两个问题:问题一:使用Windows记事本的“另存为”,可以在GBK、Unicode、Unicode big endian和UTF-8这几种编码方式间相互转换。
同样是txt文件,Windows是怎样识别编码方式的呢?我很早前就发现Unicode、Unicode big endian和UTF-8编码的txt文件的开头会多出几个字节,分别是FF、FE(Unicode),FE、FF(Unicode big endian),EF、BB、BF(UTF-8)。
但这些标记是基于什么标准呢?问题二:最近在网上看到一个ConvertUTF.c,实现了UTF-32、UTF-16和UTF-8这三种编码方式的相互转换。
对于Unicode(UCS2)、GBK、UTF-8这些编码方式,我原来就了解。
但这个程序让我有些糊涂,想不起来UTF-16和UCS2有什么关系。
查了查相关资料,总算将这些问题弄清楚了,顺带也了解了一些Unicode的细节。
写成一篇文章,送给有过类似疑问的朋友。
本文在写作时尽量做到通俗易懂,但要求读者知道什么是字节,什么是十六进制。
0、big endian和little endianbig endian和little endian是CPU处理多字节数的不同方式。
例如“汉”字的Unicode编码是6C49。
那么写到文件里时,究竟是将6C写在前面,还是将49写在前面?如果将6C写在前面,就是big endian。
如果将49写在前面,就是little endian。
“endian”这个词出自《格列佛游记》。
小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开,由此曾发生过六次叛乱,一个皇帝送了命,另一个丢了王位。
UTF-8,Unicode,GB2312格式串转换之C语言版UTF-8, Unicode, GB2312格式串转换之C语言版(申明:此文章属于原创,若转载请表明作者和原处链接)/* author: wu.jian (吴剑) English name: Sword/* date: 2007-12-13/* purpose: 知识共享这几天工作上碰到了UTF-8转GB2312的问题,而且是在嵌入式的环境下,没有API可用,查了很多网上的资料,大多调用VC或者linux下自带的接口。
在这里我将这两天的工作做个总结。
总的来说分为两大步(这里就不介绍基础知识了):一、UTF8 -> Unicode由于UTF8和Unicode存在着联系,所以不需要任何库就可以直接进行转换。
首先要看懂UTF8的编码格式:U-00000000 - U-0000007F: 0xxxxxxxU-00000080 - U-000007FF: 110xxxxx 10xxxxxxU-00000800 - U-0000FFFF: 1110xxxx 10xxxxxx 10xxxxxxU-00010000 - U-001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxxU-00200000 - U-03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx U-04000000 - U-7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxx xxx前面几个1就代表后面几个字节是属于一起的。
如果要解析一长串UTF8格式的字符串,这点就很有用了。
下面这个函数就是判断前面几个1的(这里有 define APP_PRINT printf,这样当release的时候将这个宏定义为空就行了,不需要一个一个去改,又方便重新调试):int GetUtf8ByteNumForWord(u8 firstCh){u8 temp = 0x80;int num = 0;while (temp & firstCh){num++;temp = (temp >> 1);}APP_PRINT("the num is: %d", num);return num;}利用这个函数可以得到字符串中那几个字节是一起的。
UTF8 与GB2312 之间的转换相信一定有不少的程序开发人员时常会遇到字符编码的问题,而这个问题也是非常让人头痛的。
因为这些都是潜在的错误,要找出这些错误也得要有这方面的开发经验才行。
特别是在处理xml 文档时,该问题的出现就更加的频繁了,有一次用java 写服务器端程序,用vc 写客户端与之交互。
交互的协议都是用xml 写的。
结果在通讯时老是发现数据接受不正确。
纳闷!于是用抓取网络数据包工具抓取数据,后来才发现原来是java 上xml 的头是这样的,而vc 上默认的是GB2312 。
所以一遇到汉字数据就不正确了。
去网上找资料,这方面的文章好象特别少,针对像这样的问题,下面我介绍一下我自己写的一个转换程序。
当然,程序很简单。
如果有画蛇添足的地方,还望各位高手一笑了之。
如果您对UTF-8 、Unicode 、GB2312 等还是很陌生的话,请查看/books/UTF-8-Unicode.html 我这里就不浪费口舌了。
下面介绍一下WinAPI 的两个函数:WideCharToMultiByte 、MultiByteToWideChar 。
函数原型:int WideCharToMultiByte(UINT CodePage, // code pageDWORD dwFlags, // performance and mapping flagsLPCWSTR lpWideCharStr, // wide-character stringint cchWideChar, // number of chars in stringLPSTR lpMultiByteStr, // buffer for new stringint cbMultiByte, // size of bufferLPCSTR lpDefaultChar, // default for unmappable charsLPBOOL lpUsedDefaultChar // set when default char used ); //将宽字符转换成多个窄字符int MultiByteToWideChar( UINT CodePage, // code pageDWORD dwFlags, // character-type optionsLPCSTR lpMultiByteStr, // string to mapint cbMultiByte, // number of bytes in stringLPWSTR lpWideCharStr, // wide-character bufferint cchWideChar // size of buffer);// 将多个窄字符转换成宽字符需要用到的一些函数:CString CXmlProcess::HexToBin(CString string)// 将16 进制数转换成2 进制{if( string == "0") return "0000";if( string == "1") return "0001";if( string == "2") return "0010";if( string = = "3") return "0011";if( string = = "4") return "0100";if( string = = "5") return "0101";if( string = = "6") return "0110";if( string = = "7") return "0111";if( string = = "8") return "1000";if( string = = "9") return "1001";if( string = = "a") return "1010";if( string = = "b") return "1011";if( string = = "c") return "1100";if( string = = "d") return "1101";if( string = = "e") return "1110";if( string = = "f") return "1111";return "";CString CXmlProcess::BinToHex(CString BinString)// 将2 进制数转换成16 进制{if( BinString == "0000") return "0";if( BinString == "0001") return "1";if( BinString == "0010") return "2"; if( BinString == "0011") return "3"; if( BinString == "0100") return "4";if( BinString = = "0101") return "5";if( BinString = = "0110") return "6";if( BinString = = "0111") return "7";if( BinString = = "1000") return "8";if( BinString = = "1001") return "9";if( BinString = = "1010") return "a";if( BinString = = "1011") return "b";if( BinString = = "1100") return "c";if( BinString = = "1101") return "d";if( BinString = = "1110") return "e";if( BinString = = "1111") return "f";return ""}int CXmlProcess::BinToInt(CString string)//2进制字符数据转换成10 进制整型{int len =0;int tempInt = 0;infs =r -n f H 0 八fo 「(infiH o 二 Asmng.GaLengfho二 ++) 宀CD m p -n f 丄八s =r -n f H(inoss.ng.GefAs —48」 foanfkH o 八 k A 7—i八 k ++)宀D m p -n f H 2*Drefum -e p) U T F OO >旃注GB2312出m U T F OO >旃注Unicode•^可囲瞥Unicode 镒ff 因選widechaHOMU-HByCDM旃注GB2312WCHAR* cxm-p「ocessxuTF —8Tounicode(cha「*u s 5r l i ) lm U T F OO >旃注Unicode宀charchar —one八charchar —fwpcharcha 匚hree八infHchanint Lchar;char uchar[2];WCHAR *unicode;CString string_one;CString string_two;CString string_three;CString combiString;char_one = *ustart;char_two = *(ustart+1);char_three = *(ustart+2);string_one.Format("%x",char_one);string_two.Format("%x",char_two);string_three.Format("%x",char_three); string_three =string_three.Right(2);string_two = string_two.Right(2);string_one = string_one.Right(2);string_three =HexToBin(string_three.Left(1))+HexToBin(string_three.Right(1 ));string_two =HexToBin(string_two.Left(1))+HexToBin(string_two.Right(1));string_one =HexToBin(string_one.Left(1))+HexToBin(string_one.Right(1));combiString = string_one +string_two +string_three;combiString = combiString.Right(20);combiString.Delete(4,2);combiString.Delete(10,2);Hchar = BinToInt(combiString.Left(8));Lchar = BinToInt(combiString.Right(8));uchar[1] = (char)Hchar;uchar[0] = (char)Lchar;unicode = (WCHAR *)uchar;return unicode;}char * CXmlProcess::UnicodeToGB2312(unsigned short uData) //把Unicode 转换成GB2312{char *buffer ;buffer = new char[sizeof(WCHAR)];WideCharToMultiByte(CP_ACP,NULL,&uData,1,buffer,size of(WCHAR),NULL,NULL);return buffer;GB2312 转换成UTF-8 :先把GB2312 通过函数MultiByteToWideChar 转换成Unicode. 然后再把Unicode 通过拆开Unicode 后拼装成UTF-8。
⽹页编码之GB2312、GBK与UTF-8的区别⾸先,我们要明⽩,GB2312、GBK和UTF-8都是⼀种字符编码,除此之外,还有好多字符编码。
只是对于我们中国⼈的⽹站来说,⽤这三种编码⽐较多。
简单的说⼀下,为什么要⽤编码,在计算机内,储存⽂本信息⽤ASC II码,每⼀个字符对应着唯⼀的ASCII码。
最初计算机是由美国发明的,他们也⽤的是键盘和上⾯的字母,所以他们的字符ASCII好解决。
但是我们中国的就不同了,每个汉字要对应唯⼀的ASCII码。
这样,就出来了国家制定的字符编码标准:GB2312、GBK等。
其他国家,其他语⾔也有他们对应的编码标准。
GB 就是国标的意思,GB2312和GBK主要⽤于汉字的编码,⽽UTF-8是全世界通⽤的。
意思就是说,如果你的⽹页主要⾯对使⽤汉语的中国⼈的话,使⽤ GB2312和GBK⾮常好,⽂字储存体积要⼩,有⼀些优点。
如果你的⽹页要⾯向世界的话,你再⽤GB2312和GBK作为⽹页编码的话,有些电脑上的浏览器没有这种编码,你的⽹页汉字内容就会变成⽆法识别的乱码。
它们通常⽤在⽹页的meta标签内,例如:,表⽰这个页⾯使⽤的是GB2312编码。
这个信息是给浏览器看的,浏览器会优先考虑使⽤从⽹页头部提取出来的编码信息对⽹页进⾏解码。
当然,我们也可以强制浏览器使⽤某种编码解释⽹页,这样我们就看到了传说中的乱码。
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:GBK、GB2312--Unicode--UTF8UTF8--Unicode--GBK、GB2312对于⼀个⽹站、论坛来说,如果英⽂字符较多,则建议使⽤UTF-8节省空间。
不过现在很多论坛的插件⼀般只⽀持GBK。
如果是中⽂的⽹站推荐GB2312 GBK有时还是有点问题为了避免所有乱码问题,应该采⽤UTF-8,将来要⽀持国际化也⾮常⽅便 UTF-8可以看作是⼤字符集,它包含了⼤部分⽂字的编码。
论Oracle字符集“转码”过程本⽂将通过实验来演⽰⼀下Oracle字符集“转码”的确认过程。
1.实验环境说明客户端是Windows XP操作系统的SQL*Plus程序,客户端字符集是936(对应Oracle的ZHS16GBK字符集);数据库版本是Oracle 10g,数据库字符集是AL32UTF8;NLS_LANG参数将在实验中进⾏指定。
1)确认客户端字符集C:\>chcp活动代码页: 936注释:936对应Oracle的ZHS16GBK字符集。
2)查看数据库版本信息:sec@ora10g> select * from v$version;BANNER----------------------------------------------------------------Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - 64biPL/SQL Release 10.2.0.3.0 - ProductionCORE 10.2.0.3.0 ProductionTNS for Linux: Version 10.2.0.3.0 - ProductionNLSRTL Version 10.2.0.3.0 - Production3)确认数据库的字符集:sec@ora10g> col PARAMETER for a20sec@ora10g> col value for a20sec@ora10g> select * from v$nls_parameters where parameter = 'NLS_CHARACTERSET';PARAMETER VALUE-------------------- --------------------NLS_CHARACTERSET AL32UTF82.实验中将会涉及到的两种场景“转码”场景:设置客户端的NLS_LANG与客户端字符集⼀致,这⾥是ZHS16GBK;“⾮转码”场景:设置客户端的NLS_LANG与数据库服务器端字符集⼀致,此处是AL32UTF8.3.创建实验表Tsec@ora10g> create table t (x number(1), client_characterset varchar2(10), nls_lang varchar2(10), database_characterset varchar2(10), y varchar2(10));Table created.sec@ora10g> desc t;Name Null? Type----------------------------------- -------- ------------------------X NUMBER(1)CLIENT_CHARACTERSET VARCHAR2(10)NLS_LANG VARCHAR2(10)DATABASE_CHARACTERSET VARCHAR2(10)Y VARCHAR2(10)T表包含五个字段,分表表⽰序号、客户端字符集、客户端NLS_LANG设置情况以及数据库服务器字符集设置情况。
问题共享:修改oracle字符集这几天在解决问题的时候遇到了数据库字符集的问题,插入到数据库的阿拉伯语查询出来后在页面显示的是乱码,在和现网的邮件交流中得知是我们家里的数据库字符集编码的问题,现在我们用的oracle11g的字符集编码方式都是gbk的,我们的需求是要改成UTF-8的,经过一番折腾,还是弄出来了,详细操作分享如下:引导:我们在导数据的时候需要确保以下三处的字符集编码形式是一致的A.A.oracelserver端的字符集B.B.oracleclient端的字符集C.C.数据备份dmp文件的字符集一、查询字符集:1.1.查询oracleserver端的字符集SQL>selectuserenv(‘language’)fromdual;2.2.查询dmp文件的字符集a.1>用UE编辑器打开bmp文件得到第一行的第2个和第3个字节记录了dmp文件的字符集b.2>然后用以下SQL查出它对应的字符集SQL>selectnls_charset_name(to_number('0354','xxxx'))fromdual;3.3.查询oracleclient端的字符集查询注册表里面相应OracleHome的NLS_LANG的值二、修改字符集(一般都是根据bmp数据备份文件来修改字符集的):1.1.修改oracleserver端的字符集SQL>SHUTDOWNIMMEDIATE;SQL>STARTUPMOUNTEXCLUSIVE;SQL>ALTERSYSTEMENABLERESTRICTEDSESSION;SQL>ALTERSYSTEMSETJOB_QUEUE_PROCESSES=0;SQL>ALTERSYSTEMSETAQ_TM_PROCESSES=0;SQL>ALTERDATABASEOPEN;SQL>ALTERDATABASENATIONALCHARACTERSETINTERNAL_USEUTF8;SQL>SHUTDOWNimmediate;SQL>startup;2.2.修改dmp文件的字符集1>如上所述,用UE编辑器打开bmp文件得到第一行的第2个和第3个字节记录了dmp文件的字符集,所以我们也可以修改bmp文件的第一行第2个和第3个字节来修改dmp文件的字符集2>通过以下SQL可以查询到相应字符集的16进制代码,并用此16进制代码修改bmp文件的第一行第2个和第3个字节SQL>selectto_char(nls_charset_id('AL32UTF8'),'xxxx')fromdual;3.3.修改oracleclient端的字符集修改注册表里面相应OracleHome的NLS_LANG的值即可,如下图:按照以上的修改就差不多存入到数据库中的阿语信息就可以再页面正常显示了,不过在用sql/plus客户端打开数据库阿语信息还是现实的乱码,有待继续勘察…O(∩_∩)O~。
最近因为一些特殊的需求,考虑到以后系统的开发,
就把现有Oracle数据库的字符集gb2312改为了UTF-8
步骤:
1.在SQL*PLUS 中,以DBA登录
conn 用户名as sysdba
2.执行转换语句:
SHUTDOWN IMMEDIATE;
STARTUP MOUNT EXCLUSIVE;
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
ALTER SYSTEM SET AQ_TM_PROCESSES=0;
ALTER DATABASE OPEN;
ALTER DATABASE NATIONAL CHARACTER SET UTF8;
ALTER DATABASE character set INTERNAL_USE ZHS16GBK;
SHUTDOWN immediate;
startup;
注意:如果没有大对象,在使用过程中进行语言转换没有什么影响,(切记设定的字符集必须是ORACLE支持,不然不能start)
按上面的做法就可以,但是可能会出现‘ORA-12717: Cannot ALTER DATABASE NATIONAL CHARACTER SET when
NCLOB data exists’ 这样的提示信息
要解决这个问题有两种方法
一个是,利用INTERNAL_USE 关键字修改区域设置,
还有一个是利用re-create,但是re-create有点复杂,所以请用internal_use,
SHUTDOWN IMMEDIATE;
STARTUP MOUNT EXCLUSIVE;
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
ALTER SYSTEM SET AQ_TM_PROCESSES=0;
ALTER DATABASE OPEN;
ALTER DATABASE NATIONAL CHARACTER SET INTERNAL_USE UTF8; SHUTDOWN immediate;
startup;
查询字符集
---------set NLS_LANG="SIMPLIFIED CHINESE_CHINA.AL16UTF16"
select * from sys.props$;
AL16UTF16 与UTF8可以互换
声明:此方法非常危险,如造成数据库崩溃,本人概不负责。
sqlplus /nolog
SQL> connect / as sysdba;
SQL> update props$ set value$ = 'ZHS16GBK' where name = 'NLS_CHARACTERSET'; SQL> update props$ set value$ = 'ZHS16GBK' where name = 'NLS_NCHAR_CHARACTERSET'; SQL> commit;
SQL> exit;
如果按上面的做法做,National charset的区域设置就没有问题。