IDA反汇编学习心得
- 格式:doc
- 大小:333.00 KB
- 文档页数:15

2024年汇编语言实习心得今年暑假,我有幸在一家知名科技公司完成了一份汇编语言的实习。
通过实习的这一个月,我不仅对汇编语言有了更深入的了解,还学到了很多关于工作中需要的技能和方法。
以下是我对这次实习的心得体会。
首先,汇编语言是一门非常底层的编程语言,它直接操作计算机的硬件资源。
通过实习,我深刻体会到了汇编语言的强大能力和灵活性。
在完成实习期间的项目任务时,我需要使用汇编语言来完成一些底层任务,比如对主存进行读写,控制输入输出设备,以及处理中断等等。
这些任务在高级编程语言中可能会非常复杂,但是在汇编语言中则能够通过简单的指令来完成。
这给我留下了深刻印象,让我认识到了汇编语言的独特之处。
其次,汇编语言的学习对于理解计算机体系结构非常重要。
在实习中,我必须要了解计算机的各个部件是如何协同工作的,以便能够编写出高效且可靠的汇编代码。
我学会了如何读懂和分析汇编指令,理解寄存器和内存的含义,以及如何优化代码性能。
这些知识让我对计算机体系结构有了更深入的理解,也使我在未来的编程工作中能够更好地利用计算机的资源。
除了对于汇编语言的学习,这次实习还给我提供了一个很好的机会来锻炼我的解决问题的能力和团队合作能力。
在实习期间,我遇到了很多技术难题,有时候无法通过查阅文档和搜索解决方案来解决问题,这时候我就必须要靠自己的思考和分析来找到解决的办法。
这个过程让我学会了如何从不同的角度思考问题,快速找到问题的本质,并且采取合适的措施来解决。
同时,我也要非常感谢我的团队成员,在我遇到问题时给予了很大的帮助和支持。
我们共同讨论问题,分享经验,并且通过合作来解决难题,这让我深刻体会到了团队合作的重要性。
在实习过程中,我还学到了一些关于编程和软件开发的一般性原则和方法。
比如,我学会了如何进行代码调试和优化,如何编写清晰和可维护的代码,以及如何利用版本控制工具来管理代码。
这些方法和原则在本次实习中对我非常有帮助,而且我相信这些技能在我今后的职业生涯中也会派上用场。
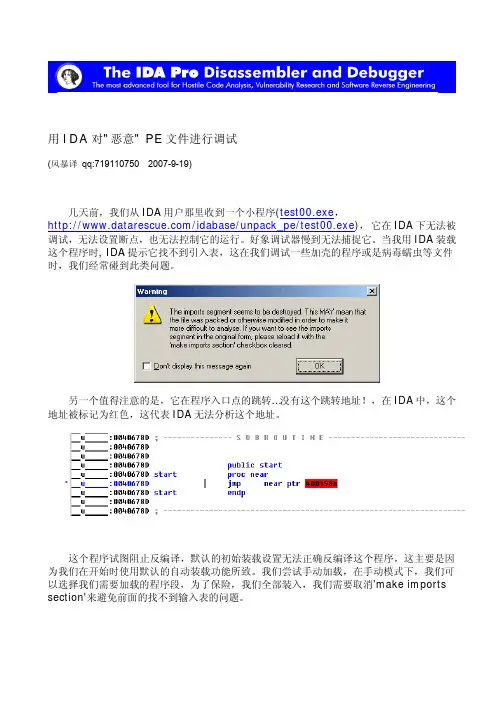
用IDA对"恶意" PE文件进行调试(风暴译 qq:719110750 2007-9-19)几天前,我们从IDA用户那里收到一个小程序(test00.exe,/idabase/unpack_pe/test00.exe),它在IDA下无法被调试,无法设置断点,也无法控制它的运行。
好象调试器慢到无法捕捉它。
当我用IDA装载这个程序时, IDA提示它找不到引入表,这在我们调试一些加壳的程序或是病毒蠕虫等文件时,我们经常碰到此类问题。
另一个值得注意的是,它在程序入口点的跳转…没有这个跳转地址!,在IDA中,这个地址被标记为红色,这代表IDA无法分析这个地址。
这个程序试图阻止反编译,默认的初始装载设置无法正确反编译这个程序,这主要是因为我们在开始时使用默认的自动装载功能所致。
我们尝试手动加载,在手动模式下,我们可以选择我们需要加载的程序段,为了保险,我们全部装入,我们需要取消'make imports section'来避免前面的找不到输入表的问题。
当我们一一确认了各个程序段的提示后,我们得到如下结果:我们发现入口点的跳转已经没有了红色标记,已经可以正常分析这个程序了。
第一条指令是个跳转,它跳转到了我们的程序头:loc_400158。
呵呵,通常文件头不支持任何代码,但这个程序违反常规跳到了这里,程序头是只读的,这就是为什么我们们无法设置断点的原因。
不管它,我们看它是如何工作的,它装载了一个指针到ESI和EBX:HEADER:00400158 mov esi, offset off_40601C HEADER:0040015D mov ebx, esi (Ctrl-O 将16进制数据转换为偏移标签)之后我们它调用了这个指针指向的子程序:HEADER:00400169 call dword ptr [ebx] 这是个隐式调用,这是个常规做法,我们跟随它来到这个指针所在:__u_____:0040601C off_40601C dd offset __ImageBase+130h 如果我们点击ImageBase,会发现这里是个双字数组,IDA将这里翻译为一个数组,在这里是错误的,我们现取消数组定义(快捷键U),退回指针处(快捷键ESC),重新跟随指针进入0x400130,这里应该有一个函数(这是由于在0x400169处,隐式调用了这里),通过快捷键P我们在这个地址创建一个子函数。

汇编逆向工程实验报告1. 实验目的本实验的目的是通过汇编逆向工程的方式,研究和分析已编译的二进制程序,揭示其内部逻辑和实现原理。
2. 实验环境- 操作系统:Windows 10- 反汇编工具:IDA Pro3. 实验步骤步骤一:选择目标程序本实验中选择了一个经典的二进制程序作为目标。
该程序是一款简单的加密工具,其加密算法相对简单,适合作为初学者进行汇编逆向工程的实践。
步骤二:静态分析使用IDA Pro工具对目标程序进行静态分析。
通过IDA Pro的功能,我们能够将二进制代码反汇编成汇编代码,并通过图形化界面清晰地查看和分析程序的各个模块和函数。
步骤三:动态调试在静态分析的基础上,我们可以利用IDA Pro的调试功能对目标程序进行动态调试。
通过动态调试,我们可以逐步执行程序,观察内存中的变化和处理流程,进一步深入了解程序的逻辑和实现细节。
步骤四:破解算法在动态调试的过程中,我们可以针对目标程序的加密算法进行破解。
通过观察和分析算法的运行过程,我们可以推断出其中的关键步骤和参数,从而推导出解密算法。
步骤五:优化算法除了破解算法,我们还可以根据分析结果进行算法的优化。
通过对目标程序的逻辑进行深入研究,我们可以发现其中的潜在问题和瓶颈,并进行相应的优化和改进,提升程序的性能和安全性。
4. 实验结果经过以上步骤的分析和研究,我们成功破解了目标程序的加密算法,并推导出相应的解密算法。
通过IDA Pro的功能,我们还发现了目标程序中的一处逻辑错误,并进行了相应的优化和改进。
5. 实验感想通过本次实验,我深刻认识到汇编逆向工程的重要性和实践价值。
通过逆向分析,我们可以深入了解程序的实现原理,发现其中的问题和潜在安全隐患,并提供相应的优化和改进方案。
逆向工程不仅对软件开发和调试有着重要意义,对程序的安全性分析和加固也有着重要作用。
同时,这次实验也让我加深了对汇编语言的理解和掌握。
通过对目标程序的逆向分析,我不仅熟悉了汇编语言的常用指令和语法,还能够将其应用于实际的程序分析和优化中。

ida反汇编使用方法IDA反汇编使用方法IDA(Interactive DisAssembler)是一款强大的反汇编工具,广泛应用于逆向工程领域。
使用IDA可以将汇编代码还原为高级语言代码,方便分析和理解软件的运行机制。
本文将介绍IDA反汇编的使用方法,帮助读者快速上手。
一、安装和启动IDA我们需要下载和安装IDA软件。
在官方网站上选择适合自己操作系统的版本进行下载,并按照安装向导进行安装。
安装完成后,双击打开IDA软件。
根据操作系统的不同,可能会出现一些设置向导。
一般情况下,我们可以选择默认设置,然后点击“Finish”完成设置。
二、加载可执行文件在IDA的主界面中,点击“File”菜单,然后选择“Open”选项。
在弹出的对话框中,选择要反汇编的可执行文件,然后点击“OK”按钮。
IDA会自动识别可执行文件的类型,并加载到主界面中。
在加载过程中,IDA会分析可执行文件的结构,并生成反汇编代码。
三、查看反汇编代码在IDA的主界面中,我们可以看到左侧是反汇编代码的列表视图,右侧是对应的汇编代码。
我们可以通过双击列表视图中的函数或者地址,来查看对应的汇编代码。
在汇编代码窗口中,可以看到每行代码的地址、机器码和汇编指令。
四、分析反汇编代码在IDA的主界面中,我们可以通过一些功能来分析反汇编代码,以便更好地理解软件的运行机制。
1. 函数跳转:在汇编代码窗口中,可以看到一些跳转指令,如call、jmp等。
我们可以通过双击这些指令,来跳转到相应的函数或地址处。
2. 函数命名:在IDA中,可以给函数进行命名,以方便后续分析。
选中要命名的函数,点击右键,然后选择“Rename”选项进行命名。
3. 数据类型识别:IDA可以自动识别汇编代码中的数据类型,并在反汇编代码中进行标注。
我们可以通过双击数据标注,来查看详细的数据类型信息。
4. 交叉引用分析:在IDA中,可以通过交叉引用分析,查看函数或变量的调用关系。
选中要分析的函数或变量,点击右键,然后选择“Xrefs to”或“Xrefs from”选项进行分析。

ida 反汇编花指令
IDA反汇编器是一种用于将机器码转换成原始汇编代码的工具。
花指令是一种特殊的汇编指令,旨在增加程序的复杂性,使逆向工程师更加困惑。
花指令的目的是混淆代码,增加反汇编的难度,使分析者更难理解程序的逻辑。
IDA反汇编器可以识别并解析大多数常见的花指令,但对于一些更复杂的花指令可能需要手动进行分析和解释。
在使用IDA反汇编器时,可以使用以下方法来处理花指令:
1. 了解常见的花指令模式:花指令通常采用特殊的编码方式,例如使用无效指令、变长指令、冗余指令或无关代码来混淆程序。
通过了解这些模式,可以更容易地识别和处理花指令。
2. 分析程序的逻辑:花指令旨在混淆程序的逻辑和流程。
通过仔细分析程序的逻辑,可以更好地理解它的功能,揭示出隐藏在花指令下面的真实代码。
3. 标记和注释:在IDA中,可以使用标记和注释来标记花指
令和真实代码的区分。
这样可以帮助您更好地理解程序的结构和逻辑。
4. 手动分析:对于一些更复杂的花指令,可能需要手动进行分析和解释。
这包括查看反汇编代码、查找相关引用等。
虽然花指令可以增加逆向工程的难度,但使用适当的工具和技术,结合耐心和专注的分析,可以成功地处理和解决花指令。

使用IDA调试和反汇编受保护的PE文件
1、PE文件的受保护
PE文件是受到可执行文件保护的。
如果需要从PE文件中提取原始代码或其他重要信息,则必须进行反汇编,这也是保护PE文件所必需的。
保护PE文件的主要目的是防止把PE文件中的代码暴露给外部的攻击者。
除了最基本的反汇编之外,一些加壳程序和虚拟机可以防止PE文件的被反汇编。
调试受保护的PE文件就是要对PE文件进行调试,这是非常重要的,因为它可以帮助我们找到程序中隐藏的漏洞或把现有解决方案改进。
调试受保护的PE文件的最佳方法是使用IDA调试器,它同时提供了反汇编和汇编的功能,还可以查看PE文件中的每个断点,确定其变量值或参数等等。
另外,IDA调试器还支持在反汇编的代码中添加断点和观察点,并提供复杂的goto、step 进、step out等功能。
反汇编受保护的PE文件可以帮助我们更好地了解软件的实现,并找到隐藏在其中的bug或漏洞。
反汇编PE文件是一个复杂的过程,因为受保护的PE文件通常会使用一些反调试技术,比如虚拟机和加壳程序。
为了解决这个问题,就需要一个强大的反汇编工具,帮助我们破坏反调试技术的护罩,从而使反汇编过程更加容易。

ida反汇编出来的函数不带参数摘要:1.函数不带参数的情况2.IDA 反汇编工具介绍3.如何解决不带参数的问题4.总结正文:在编程领域中,我们常常会遇到一些函数不带参数的情况。
这对于使用IDA 反汇编工具进行静态分析时可能会造成一定的困扰。
本文将详细介绍这一问题以及解决方法。
首先,我们需要了解IDA 反汇编工具。
IDA(Interactive Disassembler)是一款功能强大的反汇编工具,广泛应用于软件安全领域。
通过将二进制程序转换为汇编语言,IDA 可以帮助我们更好地理解程序的执行流程,从而进行静态分析。
当IDA 反汇编出来的函数不带参数时,我们应该如何解决这个问题呢?一种方法是在IDA 中手动修改函数的参数。
具体操作如下:1.打开IDA,载入需要分析的二进制文件。
2.找到不带参数的函数,在IDA 的Disassembly 窗口中双击该函数,将其打开。
3.在Function Attributes 窗口中,可以看到该函数的参数信息。
在这里,我们可以手动添加或修改函数的参数。
4.完成参数修改后,点击IDA 工具栏上的“Recompile”按钮,对修改后的函数进行重新编译。
5.编译完成后,IDA 会自动更新反汇编代码,此时我们可以看到带参数的函数已经被正确反汇编出来。
当然,在实际应用中,我们也可以通过其他方法来解决不带参数的问题,例如在编译时添加调试信息等。
但无论哪种方法,都需要我们对程序的执行过程有一定的了解。
总之,当IDA 反汇编出来的函数不带参数时,我们可以通过手动修改函数参数或在编译时添加调试信息等方法来解决这个问题。

IDA反汇编学习心得IDA(Interactive DisAssembler)是一款非常强大的反汇编工具,被广泛应用于逆向工程、漏洞研究、恶意代码分析等领域。
在学习IDA反汇编的过程中,我深刻体会到了它的实用性和复杂性,并获得了一些经验和心得。
首先,学习IDA反汇编需要有一定的汇编语言基础。
因为IDA反汇编的目的是将目标代码转化为汇编代码,所以理解汇编语言的基本语法和指令格式非常重要。
学习者需要了解常见的指令集,如x86、ARM等,并能够分辨不同指令在反汇编结果中的表现形式。
其次,了解计算机底层原理对于IDA反汇编的学习也十分重要。
IDA反汇编实际上是将二进制机器码转化为汇编指令,而这些指令是根据计算机底层硬件的工作方式来定义的。
因此,了解计算机的工作原理、内存管理、寄存器、堆栈等概念,可以帮助理解反汇编结果,并推测代码的功能和逻辑。
进一步,熟悉IDA的界面和功能是学习反汇编的必要条件。
IDA拥有复杂而强大的功能,包括函数和变量识别、交叉引用分析、字符串和常量定义、图形化反汇编和调试等。
学习者需要熟悉IDA的各种功能和快捷键,以便更高效地进行反汇编工作。
接下来,学习者应该掌握IDA中的反汇编技巧和技术。
反汇编是一门艺术,需要灵活运用各种技术来理解目标代码的含义。
例如,学习者可以通过查找字符串和常量,来推断函数的功能;可以通过交叉引用分析,来理解函数和变量之间的关系;可以通过图形化反汇编,来可视化代码的控制流程等。
掌握这些技术可以提高反汇编的效果和准确性。
最后,学习IDA反汇编需要具备耐心和毅力。
反汇编对于复杂的代码可能需要耗费大量精力和时间来理解。
有时候,反汇编结果可能不够直观,需要多方面的推理和尝试来理解代码的含义。
在学习过程中,要保持积极向上的态度,勇于挑战和解决难题。
总的来说,IDA反汇编是一项非常有挑战性的技能,但也是非常有意义和实用的。
通过学习IDA反汇编,我们可以理解和分析目标代码的逻辑和功能,进一步发现隐藏的安全漏洞或优化代码的执行效率。

2024年汇编语言实习心得分支程序设计(____课时)一、实验目的1、学习使用汇编语言、连接程序对汇编语言源程序进行汇编、链接装配操作。
2、学习使用调试程序debug对可执行文件.e____e进行调试运行。
3、训练分支程序的编制,逐步熟悉二元选择、多元选择等程序描述方法,加深对程序控制类指令的结构和功能的理解。
4、掌握调试分支程序的基本方法,以了解程序的静态结构和动态执行情况的差异性。
二、实验设备1、硬件:IBMPC及兼容机2、软件:操作系统Msdos/Windows98/Windows____/Windows____P编辑软件:edit、记事本汇编语言程序包:masm5.0以上(包括masm、link)三、实验内容题目A:设平面上有一点p直角坐标(____,y),试编制完成下列操作的程序如点p在第i象限,则K单元←i(1,2,3,4) 如点p在坐标轴上,则K单元←0题目B:编制程序求A、B、C三个有符号数的中间数。
(A、B、C 为字节单元)四、实验步骤1、编辑源程序,建立一个以后缀为.ASM的文件.2、汇编源程序,检查程序有否错误,有错时回到编辑状态,修改程序中错误行。
无错时继续第3步。
3、连接目标程序,产生可执行程序。
4、DEBUG调试可执行程序,记录程序运行结果。
5、在操作系统状态下,运行程序,并记录程序运行结果。
五、实验总结1、实验中遇到哪些问题?分析主要问题的出错原因及解决方法。
2、本次实验有何收获和体会。
3、有何改进意见及建议。
2024年汇编语言实习心得(2)一、实习概述2024年暑期,我有幸在一家知名科技公司进行了为期两个月的汇编语言实习。
在这段时间里,我深入了解了汇编语言的基本知识和应用领域,并且通过实践项目锻炼了我的编程能力。
以下是我在实习期间的心得体会。
二、基础知识学习在实习开始之前,我首先对汇编语言进行了系统的学习。
我阅读了相关教材和在线资源,了解了汇编语言的基本概念、指令集、寻址方式等重要知识点。

汇编心得体会汇编语言是一种机器级别的编程语言,是计算机硬件与指令系统紧密相关的语言。
学习汇编语言对于加深对计算机底层原理的理解以及优化代码的效率非常重要。
在学习汇编语言的过程中,我收获了许多体会和心得,下面是我个人的一些总结。
首先,汇编语言让我深入理解了计算机底层原理。
通过学习汇编语言,我了解了计算机是如何执行指令的,如何进行内存和寄存器的读写操作,以及如何利用不同的指令进行各种运算和逻辑控制。
这些知识帮助我更好地理解计算机的工作原理,对于理解其他高级编程语言的底层运行机制也非常有帮助。
其次,汇编语言让我对程序的优化有了更深入的认识。
在学习汇编语言的过程中,我发现通过编写高效的汇编代码可以大大提高程序的执行效率。
在编写汇编代码时,我需要深入思考每一条指令的作用,并结合计算机底层原理选择最合适的指令来完成任务。
通过对程序进行细致的优化,我可以减少不必要的运算,减小内存占用,提高程序的响应速度和整体性能。
此外,学习汇编语言还使我更加注重代码的可读性和可维护性。
由于汇编语言的语法相对底层,代码更接近机器指令,因此编写清晰、可读性强的代码变得尤为重要。
在编写汇编代码时,我需要注重使用有意义的变量和标签来命名代码块,以便于理解和维护。
同时,我也学会了注释和文档化代码的重要性,这有助于他人理解和继续开发我编写的代码。
此外,汇编语言的学习也让我更加注重代码的健壮性和安全性。
汇编语言并没有诸如自动内存管理和异常处理等高级语言中常见的安全机制,因此我需要自己手动进行错误处理和异常处理,以确保程序的稳定性和安全性。
同时,我还学会了使用一些常见的安全编程技术,如缓冲区溢出的检测和防止代码注入等,以提高程序的安全性和抵御一些常见的安全攻击。
最后,学习汇编语言也给我提供了一个更深入了解计算机体系结构和指令集的机会。
通过学习不同的汇编语言和指令集,我了解了不同计算机架构的特点和差异,从而更好地理解不同计算机平台的工作原理和性能特点。

汇编语言实习中的学习方法及个人经验心得。
一、以实际操作为主汇编语言的实习必须通过实际操作来掌握。
因此,在学习汇编语言的过程中,要尽量多的实践,将理论知识转化为实际代码。
通过实际操作,我们不仅能够更加深入地了解知识点,还能够加强记忆,提高理解能力,从而更好地掌握汇编语言。
在实际操作中,可以选择一些经典的汇编语言案例进行实习,例如模拟简单的操作系统,编写简单的计算器等,通过这些练习可以深入了解汇编语言的基本结构和原理,掌握各种寄存器的使用方法,了解机器语言和汇编语言的关系等。
二、注重基础知识汇编语言是一种基础知识,因此在学习汇编语言的过程中,要注重理解基础知识。
首先要掌握汇编语言的基本语法结构,例如指令的格式、数据类型、寄存器、内存地址等。
要了解机器语言和汇编语言的关系,了解机器指令的含义和功能。
只有掌握了这些基础知识,才能更好地理解和掌握汇编语言。
三、多次重复练习汇编语言的实习需要反复重复,进行多次练习,以便掌握知识点。
尤其是对于一些难以理解和掌握的知识点,多次重复练习是必须的。
通过多次练习,我们可以加强记忆,提高对知识点的理解能力。
四、及时解决遇到的问题在学习汇编语言的过程中,遇到问题时要及时寻找解决办法,这样可以及时消除困惑,加强对汇编语言的掌握力。
在遇到问题时,可以参考一些汇编语言的教材,或向老师或同学寻求帮助,还可以通过互联网查找相关资料,获取更多的知识和方法。
五、多与他人交流在学习汇编语言的过程中,与他人交流是非常重要的。
通过与同学或老师交流,可以互相帮助和学习。
另外,还可以通过参加一些汇编语言的交流活动,了解汇编语言的最新发展动态,增加对汇编语言的认知,提高学习兴趣。
六、总结经验和教训在学习汇编语言的过程中,要及时总结经验和教训。
多次练习后,要及时反思自己的掌握程度和学习效果,找出自己不足之处,针对性地改进,不断提高学习的效率和质量。
同时,还要及时总结学习的经验,加强对汇编语言的理解力和掌握能力。
IDA反汇编深度总结(转载)1,[eax]的歧义(其中eax指向SourceString):到底是*SourceString还是SourceString所处的结构的第⼀个偏移的结构。
这个应该根据语境来,⽐如[eax]赋给的值的结构和第⼀偏移结构匹配,就是后⾯⼀种可能;反之就是第⼀种可能。
2,IDA翻译的代码不⼀定是完全正确的,⽐如⼊⼝函数它会翻译为DriverEntry(int,PUNICODE_STRING SourceString)。
所以翻译的时候还是要坚持原则,能肯定的就不⼀定⾮要完全照抄IDA的结果。
3,PUNICODE_STRING和UNICODE_STRING的选择:如果出现DiskperfRegistryPath.Length或DiskperfRegistry.Buffer则必定是UNICODE_STRING.⾸先我们知道指针哪有长度和缓存呢。
我们可以根据这样去记忆。
其次,这明显就是UNICODE_STRING的结构,可以查到。
4,局部变量和全局变量:关于⼀个新的变量,我们到底怎么去判断是前者还是后者呢。
如果在函数中显视出现,则判定它为全局变量。
如果是局部变量,则会根据偏移量制造出来。
5.关于头⽂件,我们可以在全部翻译完成读C代码的时候查看函数的DDK。
看他们都定义在哪些头⽂件⾥⾯。
6,函数后⾯的eax。
我们都知道,函数执⾏之后返回值放在eax寄存器⾥⾯。
有时候不要脑⼦死掉了,看到eax就去找前⾯显视放进去的数据。
不要犯这种低级的错误。
7,offset:它也是地址的标志,不要只记住lea⽽忘了这个offset。
8,在if语句⾥⾯,如果IDA直译是if(a=0)那么我们应该翻译成if(a!=0)。
9,循环语句:我们都知道循环语句的初始化是在⼤⽅框的上⾯那⼀⾏代码。
我们如果不太确定这⾏代码是不是初始化,可以先把他直译出来,不放到循环体⾥⾯。
等到翻译出了判断式的条件语句,再回过头看下这⾏代码是不是该循环体的初始化语句。
ida 反编译函数参数IDA是一款常用的逆向工程工具,可以对二进制文件进行反编译和分析。
在使用IDA进行函数参数反编译时,我们可以通过以下几个方面来理解和分析函数参数的含义和作用。
一、函数参数的命名在反编译的过程中,IDA会自动给函数参数命名,这些命名通常是基于参数在函数中的使用情况来命名的。
通过观察函数参数的命名,我们可以初步了解参数的用途和含义。
例如,如果一个函数参数被命名为“count”,那么可以初步判断该参数表示的是某个计数器的值。
二、函数参数的类型除了函数参数的命名外,IDA还会根据参数在函数调用过程中的使用情况来推断其类型。
通过观察参数的使用方式,我们可以初步判断参数的数据类型,如整型、字符型、指针等。
这有助于我们理解参数的作用和功能。
三、函数参数的传递方式函数参数的传递方式通常有两种:值传递和引用传递。
值传递是指将参数的值复制一份作为实参传递给函数,函数内部对参数的修改不会影响到实参。
而引用传递是指将参数的地址传递给函数,函数内部对参数的修改会影响到实参。
通过观察函数参数的使用情况,我们可以初步判断参数的传递方式,从而理解函数参数的使用规则和限制。
四、函数参数的默认值有些函数在定义时会给参数设置默认值,这样在函数调用时如果没有显式地传入参数,就会使用默认值。
通过观察函数参数的定义和使用情况,我们可以确定参数是否有默认值,并了解默认值的具体取值。
这有助于我们在调用该函数时正确地传入参数,避免出现错误的结果。
五、函数参数的个数和顺序通过观察函数参数的个数和顺序,我们可以初步判断函数的功能和用途。
参数的个数和顺序通常与函数的逻辑关系密切相关。
例如,如果一个函数有两个参数,其中一个参数表示输入,另一个参数表示输出,那么可以初步判断该函数是一个输入输出函数。
总结:通过IDA进行函数参数反编译,我们可以通过观察参数的命名、类型、传递方式、默认值、个数和顺序等方面来理解和分析函数参数的含义和作用。
ida反编译笔记一、ida反编译是什么玩意儿。
ida反编译呀,简单来说,就是一个超厉害的工具,能帮我们把那些编译好的程序代码还原回比较接近源代码的样子。
就好比你有一个做好的蛋糕,ida反编译就像是能把这个蛋糕一点点拆开,看看里面都放了啥原料,这些原料又是怎么搭配的。
它在逆向工程里可是扮演着超级重要的角色哦,很多时候我们想要了解一个程序的内部原理,或者找一找里面有没有什么漏洞啥的,ida反编译就派上大用场啦。
二、ida反编译的基本操作。
1. 打开ida。
当我们要开始反编译之旅的时候,第一步当然是打开ida啦。
找到ida的图标,双击它,然后就会弹出一个界面。
这个界面看着可能有点复杂,不过别担心,咱慢慢熟悉就好啦。
2. 载入目标文件。
打开ida之后呢,我们要把想要反编译的文件给它装进去。
可以通过菜单里的“File”选项,然后选择“Open”,找到你要分析的那个文件,点一下“Open”,ida 就会开始读取这个文件啦。
这个过程可能会有点慢哦,特别是文件比较大的时候,就像你要打开一个超级大的压缩包,得等它解压一会儿呢。
3. 选择分析模式。
ida会根据文件的类型和特点,给我们提供几种分析模式让我们选。
一般来说,有自动模式和手动模式。
自动模式呢,ida会自己去尝试分析这个文件,按照它觉得最合适的方式来处理。
手动模式就需要我们自己多费点心思啦,要告诉ida一些关于这个文件的信息,比如它是用什么编程语言写的,有没有什么特殊的结构之类的。
大多数情况下,自动模式就够用啦,除非你对这个文件特别了解,知道一些ida可能不知道的小秘密,那才需要手动模式哦。
三、ida反编译的界面介绍。
1. 函数窗口。
在ida的界面里,有一个函数窗口,这里面会列出这个程序里所有的函数。
每个函数就像是一个小模块,负责完成一个特定的任务。
你可以通过点击这些函数,查看它们的具体代码和实现逻辑。
比如说,有一个函数是用来计算两个数相加的,你点进去就能看到它是怎么一步一步把这两个数加起来的,是不是很神奇呀?2. 反汇编窗口。
使用IDA调试和反受保护的PE文件IDA (Interactive Disassembler) 是一款强大的反汇编和调试工具,用于分析和理解计算机程序。
在本文中,我们将探讨如何使用IDA进行调试和反受保护的可执行文件。
首先,什么是反受保护的PE文件?通常情况下,开发人员会在编写软件时添加各种防护机制来防止他人对其进行逆向工程。
这些保护措施旨在防止非法用户通过分析程序来窃取知识产权或者发现其中的漏洞。
因此,反受保护的PE文件是指已经去除了这些保护机制的可执行文件。
现在我们将重点解释如何使用IDA来调试反受保护的PE文件。
首先,你需要打开IDA并选择要调试的可执行文件。
这可以通过不同的方式完成,例如通过在IDA界面中选择“File”-> “Open” 或者使用命令行参数启动IDA来加载文件。
一旦你成功加载了可执行文件,你将进入IDA的主界面。
此时,你可以看到程序的汇编代码。
但是,由于该文件是反受保护的,IDA可能无法正确解析文件的所有解释,例如函数名、变量名等。
因此,我们需要手动分析并添加这些信息。
首先,你需要特定的保护机制。
这些可以是常见的保护,例如ASLR(地址空间布局随机化)、DEP(数据执行保护)、代码签名等。
通过在IDA中进行,你可以找到这些字符串、函数调用或其他特征。
一旦你找到了它们,你可以从程序流程跟踪开始分析。
通过单步执行或设置断点,你可以控制程序的执行流。
这使你能够观察到程序在运行时的行为。
在IDA界面中,你可以选择“Debugger”选项来启动调试会话。
在调试过程中,你可以在IDA中看到寄存器和内存的内容,以及在程序运行时的变化。
如果程序中存在加密或打包的代码,你可能需要通过动态调试的方式进行的额外的分析。
IDA提供了一些有用的工具和插件来帮助你进行此类分析,例如OllyDump或WinAppDbg。
一旦你分析并理解了程序的流程和内部工作方式,你可以使用IDA的其他功能来进一步深入分析。
IDA反汇编使用方法1. 什么是IDA?IDA(Interactive DisAssembler)是一款功能强大的交互式反汇编工具,被广泛用于逆向工程、漏洞分析、恶意代码分析等领域。
它能够将机器码转换为可读的汇编代码,并提供了丰富的功能和插件来辅助分析。
2. IDA的安装与基本配置•下载IDA:可以从Hex-Rays官网()购买正版,也可以在一些第三方网站找到破解版。
下载后,按照安装向导进行安装。
•打开IDA:双击打开IDA图形界面,选择要分析的二进制文件。
•选择处理器类型:IDA会自动检测文件的处理器类型,如果检测错误,可以手动选择正确的处理器类型。
•设置符号:在Options菜单中选择”General…“,勾选”Auto load local symbols”和”Auto load PDB symbols”以加载符号信息。
•设置反编译选项:在Options菜单中选择”General…“,在”Decompiler”选项卡中可以设置反编译选项,如输出语言、变量名显示等。
3. IDA的界面介绍IDA的界面包含多个窗口,每个窗口用于显示不同的信息,以下是主要的窗口及其功能:•Disassembly窗口:显示反汇编代码,以汇编指令的形式展示。
可以通过双击指令跳转到相关代码。
•Hex View窗口:以16进制形式显示二进制文件内容,可以查看文件的原始字节。
•Graph View窗口:以图形化方式展示函数调用关系,便于理解程序的结构。
•Names窗口:显示函数、变量、常量等的命名信息。
•Imports/Exports窗口:显示导入和导出函数的信息。
•Strings窗口:显示二进制文件中的字符串。
•Structures窗口:显示定义的结构体信息。
•Segments窗口:显示二进制文件的段信息。
4. IDA的基本操作4.1 导航操作•使用鼠标:在Disassembly窗口中,可以使用鼠标左键选中指令,右键弹出菜单进行跳转、分析等操作。
IDA.【转】利⽤IDAPro反汇编程序是⼀款强⼤的反汇编软件,特有的IDA视图和交叉引⽤,可以⽅便理解程序逻辑和快速定位代码⽚断,以⽅便修改。
IDA视图⽰例程序下⾯会通过修改⽰例程序的输出字符串,来讲解如何使⽤IDA Pro。
#includemain(){int n;scanf ("%d",&n);if (n > 0)printf("a > 0"); //后⾯会⽤IDA Pro把'a'改成'n'elseprintf("n < 0");}编译后的程序下载:运⾏IDA Pro运⾏IDA Pro,并使⽤PE⽂件的⽅式打开⽰例的test.exe⽂件。
IDA Pro会新建⼀个⼯程,并开始反汇编程序。
反汇编完成后,在[IDA-View]窗⼝中,可以看到程序逻辑的树形图,如下:树形图把条件分⽀清晰地显⽰出来了,绿⾊线连着的表⽰条件为true时执⾏的逻辑,⽽红⾊线表⽰条件为false时执⾏的逻辑。
右下⾓有IDA 视图的缩略图,在上⾯点击可以快速定位到视图的指定位置。
IDA的⼯具栏有⼏个按钮对定位代码很重要,如下图所⽰:从左到右分别是: Open exports window:打开导出窗⼝ Open import window:打开导⼊窗⼝ *Open names window:函数和参数的命名列表*Open functions window:程序调⽤的所有函数窗⼝ *Open strings window: 打开字符串显⽰窗⼝,会列出程序中的所有字符串,该窗⼝有助于你通过程序的运⾏输出逆向找出对应的代码⽚断。
定位代码⽚断假设我们现在接到个任务,需修正程序,把输出“a > 0”修正为“n > 0”。
⽰例程序⽐较简单,直接看IDA视图我们就能找到需修改的代码⽚断,但实际处理时,可能程序有⼏m⼤,通过⼀个个看IDA视图已没法有效找到相关的执⾏代码⽚断,这时怎么办?使⽤字符串窗⼝和IDA 强⼤的交叉引⽤!点击⼯具栏的[Open strings windows]按钮,可以看到如下的程序字符串:程序的字符串较少,可以很快地看到我们需要的字符串“a > 0”在数据段00403003位置。
用IDA反汇编动态库最近,一直在学习如何利用IDA来反汇编动态库,这里把我的学习心得写下来。
为简单起见,这里就自己所写的一个动态库里的一个简单函数进行一下反汇编,给出如何写出其C代码的详细过程,希望对新手有点帮助。
废话少说,先给出其动态连接库的C代码如下_declspec(dllexport) int add(char a, int b, int c[2]){int d = a + b + c[0] + c[1];return d;}至于为什么要设置这样的参数,待会在反汇编时进行说明。
下面给出其详细的反汇编过程,并补充相关的经验总结。
第一步、装载动态库文件” first .dll”,装载之后得到下面的截图:通过在Functions一栏中双击add函数,我们来到add()函数的地方(同上图),我们看到”text:10001010 add proc near ; CODE XREF: add(char,int,int * const) j”这样一栏显示了add函数的参数,虽然有点出入,但大体正确。
可能是因为add函数本身比较简单,所以IDA很容易就识别出了其参数,一般地,IDA是识别不出来的,网上有一个插件为”Flair.v5.20”据说可以部分地解决函数的参数识别问题,但这个软件我没有下载到,就不说这个了。
第二步、我们看到”.text:10001010”这些栏有很多标示,在下面的汇编语句中会用到。
我们看接下来的三行代码:.text:10001010 push ebp.text:10001011 mov ebp, esp.text:10001013 sub esp, 44h这三行代码模式基本上是固定的,(至少我遇到的都是这样)首先是保存ebp, 然后用ebp来保存esp的原始指向,再将esp的指向向上移动44h个字节,(当然这里44h不是固定的)为什么会有这样固定的代码呢?就代码“sub esp 44h”而言,在原esp的基础上向上移动44h 的字节空间,而esp ----- esp-44h这个44h的空间是为了存放一般变量的。
其他两行相信读者很容易理解其理由。
第三步、看下面三行代码..text:10001016 push ebx.text:10001017 push esi.text:10001018 push edi当我们在函数的开头看到这样的代码时,而后面又没有紧跟着”call + function”时,我们大可不用理解,因为这些push语句目的都是为了不破坏原始ebx,esi,edi的值而将他们保存起来,并且这里我们可以看到,是保存在esp-44h之上的。
也就是说,如果我们看到函数的开头出现将寄存器push进esp-x之上的空间(我们将”esp-x 至esp”的堆栈空间成为“一般变量栈空间”),这里就是指push进esp-44h之上的堆栈空间,我们不用去关心,在函数末尾肯定会有相应的代码将他们还原的。
(待会我们会看到)第四步、继续向下看,进入关键代码段。
在做进一步解释之前我先画一幅堆栈图。
如下:好了,有了上一幅图,说明起来会容易些。
看接下来的四条代码:.text:10001019 lea edi, [ebp+var_44].text:1000101C mov ecx, 11h.text:10001021 mov eax, 0CCCCCCCCh.text:10001026 rep stosd这四条代码和上面的三条代码一样,其模式一般是固定不变的。
其作用就是实现了“一般变量栈空间”的初始化。
这里将图中所示的“一般变量栈空间“初始化为0xCCCCCCCC.其具体的代码解释如下:lea edi, [ebp+var_44] : edi = ebp + vat_44mov ecx, 11h :ecx = 0x11hmov eax, 0CCCCCCCCh : eax = 0xCCCCCCCC;rep stosd : for(int i1=0; i1<ecx; i1++)edi[i1] = eax;这里因为ecx=0x11(44h/4),所以将整个“一般变量栈空间”全部初始化为eax=0xCCCCCCCC; 这下就清楚了为什么上面的四条代码一般模式是固定的,原因就是对将要用到的“一般变量栈空间”进行初始化。
第五步、进入核心代码段.text:10001028 movsx eax, [ebp+arg_0].text:1000102C add eax, [ebp+arg_4].text:1000102F mov ecx, [ebp+arg_8].text:10001032 add eax, [ecx].text:10001034 mov edx, [ebp+arg_8].text:10001037 add eax, [edx+4].text:1000103A mov [ebp+var_4], eax.text:1000103D mov eax, [ebp+var_4]从图上我们可以知道arg_0,arg_4,arg_8分别是0x8,0xc,0x10。
(要是从图上看不清,请参考文件”first.txt”)代码”movsx eax, [ebp+arg_0]”表示将[ebp+arg_0]的值进行有符号扩展后传给eax。
但是这里的[ebp+arg_0]究竟是什么呢?我们假设[ebp+arg_0]=can1,如图,那么”movsx eax, [ebp+arg_0]”就表示”eax = (char)can1”。
因为我们有源代码,我们知道函数add()的参数为int add(char a, int b, int c[2]),这样我们有理由怀疑(char)can1就是char a,即add的第一个参数。
我们接着看下一条代码:”add eax, [ebp+arg_4]”,有了上面的猜想,我们不无理由认为[ebp+arg_4]就是can2,这样就实现了eax = can1+can2;再看代码”mov ecx, [ebp+arg_8]”和”add eax, [ecx]”,我们可以猜想得到[ebp+arg_8]其实是一个地址,因为后面有” add eax, [ecx]”这样的代码,表示为将ecx所指向的地址的值传给eax。
所以肯定这就是can3,即一个int型的地址参数。
”add eax, [ecx]”之后,eax = can1+can2+can3[0]。
接下来的两行代码”mov edx, [ebp+arg_8”和”add eax, [edx+4]”与上面的相似,实现了eax = can1+can2+can3[0]+can3[1]。
再看剩下的两行代码,”mov [ebp+var_4], eax”,” mov eax, [ebp+var_4]”,这两行代码是先将eax的值赋给[ebp+var_4],再将其值给eax。
第一行代码其实是将结果储存在[ebp+var_4],第二行代码是将返回值给eax。
(一般地,函数的返回值要是是int型的话,都会将返回值赋给exa,这也可以看成是一种固定的模式)。
到这里,函数基本上完成了,这里可以看出为什么将add函数的参数设置成char,int和int*了,目的就是为了认清楚原来的参数是放在堆栈中具体什么地方就目前可见,函数的第i个参数放在esp+4+i*4所指的堆栈中(i从1开始,esp是指最先的栈顶指针,后来传给了ebp)(一般第一个参数都是从[ebp+arg_0]开始,而arg_0一般为8,其他的参数依次放置)。
同时我们也看到了参数返回的值会存放在寄存器eax中。
这些到底是不是固定的,由于自己刚入门,不敢随便肯定。
第六步、接下来的代码基本上就是还原先前存储的寄存器,就不做详细解释了。
.text:10001040 pop edi.text:10001041 pop esi.text:10001042 pop ebx.text:10001043 mov esp, ebp.text:10001045 pop ebp.text:10001046 retn.text:10001046 add endp好了,到这里,我们对用IDA反汇编动态库文件有了一定的认识和经验积累。
但是这样反汇编成C语言似乎太慢了,对于这个简单的add()函数还好,遇到难一点的函数那就说不定了。
好在我们有”hexray”这个将汇编代码转成C语言代码的插件,下面我们就用试着用这个插件来写C代码。
加载first.dll文件后,同样在”Functions”一栏双击函数add,来到view的add函数区。
按F5键,得到如下的截图int __cdecl add(char a1, int a2, int a3){char v4; // [sp+Ch] [bp-44h]@1memset(&v4, -858993460, 0x44u);return *(_DWORD *)(a3 + 4) + *(_DWORD *)a3 + a2 + a1;}这里很明显Hexray在做转换时,第三个参数没有分清是地址还是值,没关系,在下面的代码中我们看到*(_DWORD *)(a3 + 4)这样的代码,其实就是a3[4/4] = a3[1],后面的*(_DWORD *)a3就是a3[0]了。
很多时候,都会出现上面的强制转换问题,比如遇到代码*(_DWORD *)(str + 4*i)那么一般地,str就是一个地址,代码本身就表示是str[i](要对这些常见的转换做出很快的反应以节省时间)。
这样,Hexray就直接帮我们转换得到了源代码。
当然,有时候Hexray的转换是不可信的,这时我们就要写程序进行检测了。
接续看上面的代码,char v4;和后面紧跟着的memset(&v4, -858993460, 0x44u)其实就是将“一般变量栈空间”初始化为-858993460=0xcccccccc,这两行代码一般是固定模式的,其作用都是将“一般变量栈空间”初始化,一般不用管,接下来的才是真正的代码区。
既然这里我们说到了Hexray的转换问题,这里我们不妨将所见到的几个常见转换问题规整出来,以便以后我们更快地根据DLL得到C源代码。
1、如果函数的参数中出现int*这样整型指针,Hexray一般会视为int型进行转换,(原因就是因为地址int*其实也是一个整形,只不过是表示一个地址而已)。
怎样看出这样的转换问题呢,很简单,一般出现这样的转换问题,在转换的C代码中都有像“*(_DWORD *)(par + 4*i)”这样的代码,(其中par是函数中的一个整型参数),这时一般地,我们能肯定转化除了问题,直接将“*(_DWORD *)(par + 4*i)”改成par[i]就可以了。