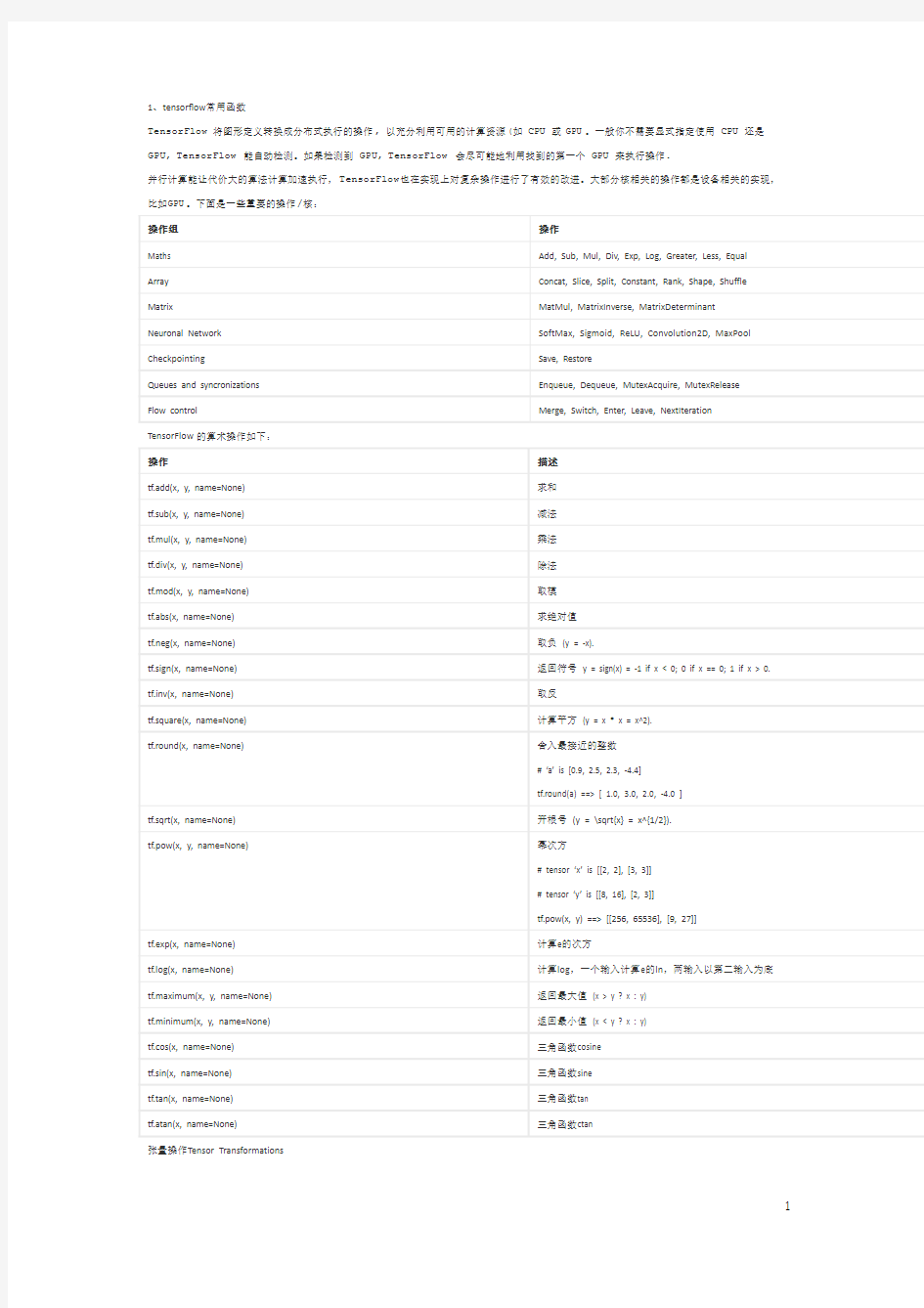

1、tensorflow常用函数
TensorFlow将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU。一般你不需要显式指定使用 CPU 还是 GPU, TensorFlow能自动检测。如果检测到 GPU, TensorFlow会尽可能地利用找到的第一个 GPU 来执行操作.
并行计算能让代价大的算法计算加速执行,TensorFlow也在实现上对复杂操作进行了有效的改进。大部分核相关的操作都是设备相关的实现,比如GPU。下面是一些重要的操作/核:
TensorFlow的算术操作如下:
张量操作Tensor Transformations
数据类型转换Casting
形状操作Shapes and Shaping
切片与合并(Slicing and Joining)
合并索引indices所指示params中的切片
矩阵相关运算
复数操作
归约计算(Reduction)
分割(Segmentation)
序列比较与索引提取(Sequence Comparison and Indexing)
神经网络(Neural Network)
激活函数(Activation Functions)
卷积函数(Convolution)
池化函数(Pooling)
数据标准化(Normalization)
损失函数(Losses)
分类函数(Classification)
符号嵌入(Embeddings)
循环神经网络(Recurrent Neural Networks)
求值网络(Evaluation)
监督候选采样网络(Candidate Sampling)
对于有巨大量的多分类与多标签模型,如果使用全连接softmax将会占用大量的时间与空间资源,所以采用候选采样方法仅使用一小部分类别与标签作为监督以加速训练。
保存与恢复变量
高中数学必修一求函数解析式解题 方法大全及配套练习 一、 定义法: 根据函数的定义求解析式用定义法。 【例1】设23)1(2 +-=+x x x f ,求)(x f . 2]1)1[(3]1)1[(23)1(22+-+--+=+-=+x x x x x f =6)1(5)1(2 ++-+x x 65)(2+-=∴x x x f 【例2】设2 1 )]([++= x x x f f ,求)(x f . 解:设x x x x x x f f ++=+++=++=11111 11 21)]([ x x f += ∴11)( 【例3】设3 3 22 1)1(,1)1(x x x x g x x x x f +=++ =+,求)]([x g f . 解:2)(2)1 (1)1(2222-=∴-+=+=+ x x f x x x x x x f 又x x x g x x x x x x x x g 3)()1(3)1(1)1(3333-=∴+-+=+=+ 故2962)3()]([2 4 6 2 3 -+-=--=x x x x x x g f 【例4】设)(sin ,17cos )(cos x f x x f 求=. 解:)2 ( 17cos )]2 [cos()(sin x x f x f -=-=π π x x x 17sin )172 cos()1728cos(=-=-+ =π π π.
二、 待定系数法:(主要用于二次函数) 已知函数解析式的类型,可设其解析式的形式,根据已知条件建立关于待定系数的方程, 从而求出函数解析式。 它适用于已知所求函数类型(如一次函数,二次函数,正、反例函数等)及函数的某些特征求其解析式的题目。其方法:已知所求函数类型,可预先设出所求函数的解析式,再根据题意列出方程组求出系数。 【例1】 设)(x f 是一次函数,且34)]([+=x x f f ,求)(x f 【解析】设b ax x f +=)( )0(≠a ,则 b ab x a b b ax a b x af x f f ++=++=+=2)()()]([ ∴???=+=342b ab a ∴????? ?=-===32 1 2b a b a 或 32)(12)(+-=+=∴x x f x x f 或 【例2】已知二次函数f (x )满足f (0)=0,f (x+1)= f (x )+2x+8,求f (x )的解析式. 解:设二次函数f (x )= ax 2+bx+c ,则 f (0)= c= 0 ① f (x+1)= a 2 )1(+x +b (x+1)= ax 2+(2a+b )x+a+b ② 由f (x+1)= f (x )+2x+8 与①、② 得 ?? ?=++=+8 2 2b a b b a 解得 ?? ?==. 7, 1b a 故f (x )= x 2+7x. 【例3】已知1392)2(2 +-=-x x x f ,求)(x f . 解:显然,)(x f 是一个一元二次函数。设)0()(2 ≠++=a c bx ax x f 则c x b x a x f +-+-=-)2()2()2(2 )24()4(2c b a x a b ax +-+-+= 又1392)2(2 +-=-x x x f 比较系数得:?????=+--=-=1324942c b a a b a 解得:?? ???=-==312c b a 32)(2 +-=∴x x x f
在HR同事电脑中,经常看到海量的Excel表格,员工基本信息、提成计算、考勤统计、合同管理....看来再完备的HR系统也取代不了Excel表格的作用。 一、员工信息表公式 1、计算性别(F列) =IF(MOD(MID(E3,17,1),2),"男","女") 2、出生年月(G列) =TEXT(MID(E3,7,8),"0-00-00") 3、年龄公式(H列)
=DATEDIF(G3,TODAY(),"y") 4、退休日期?(I列) =TEXT(EDATE(G3,12*(5*(F3="男")+55)),"yyyy/mm/dd aaaa") 5、籍贯(M列) =VLOOKUP(LEFT(E3,6)*1,地址库!E:F,2,) 注:附带示例中有地址库代码表 6、社会工龄(T列)
=DATEDIF(S3,NOW(),"y") 7、公司工龄(W列) =DATEDIF(V3,NOW(),"y")&"年"&DATEDIF(V3,NOW(),"ym")&"月"&DATEDIF(V3,NOW(),"md")&"天" 8、合同续签日期(Y列) =DATE(YEAR(V3)+LEFTB(X3,2),MONTH(V3),DAY(V3))-1 9、合同到期日期(Z列) =TEXT(EDATE(V3,LEFTB(X3,2)*12)-TODAY(),"[ 10、工龄工资(AA列) =MIN(700,DATEDIF($V3,NOW(),"y")*50) 11、生肖(AB列) =MID("猴鸡狗猪鼠牛虎兔龙蛇马羊 ",MOD(MID(E3,7,4),12)+1,1) 二、员工考勤表公式
函数解析式的求解方法 1.配凑法 例1.已知f (x + x 1)=2x +21x ,求()f x 的解析式 例2.已知3311()f x x x x +=+ ,求()f x 例3.已知f(x+1)=x-3, 求()f x 2.换元法(整体思想) 已知形如[()]y f x ?=的函数求解()f x 的解析式:令()x t ?=,反解()x t φ=,代入[()]y f x ?=,即可求解出。 例4.已知x x x f 2)1(+=+,求)1(+x f 例5.22)1(2++=+x x x f 求)3()(),3(+x f x f f 及 3.构造方程组法 若式子中,同时含有()f x 与()f x -,或者同时含有()f x 与1()f x ,那么将式子中的x 用x -替换,或是x 用1x 替换,得到另一个方程,通过求解方程组求解()f x
例6.设,)1(2)()(x x f x f x f =-满足求)(x f 例7.设)(x f 满足关系式x x f x f 3)1(2)(=+求函数的解析式 4.特殊值法 当题中所给变量较多,且含有“任意”等条件时,往往可以对具有“任意性”的变量进行赋值,使问题具体化、简单化,从而求得解析式。 例8.已知:1)0(=f ,对于任意实数x 、y ,等式)12()()(+--=-y x y x f y x f 恒成立, 求)(x f 例9.已知函数)(x f 对于一切实数 x,y 都有x y x y f y x f )12()()(++=-+成立,且0)1(=f 1.求)0(f 的值 2.求)(x f 的解析式 5.待定系数法(知道函数类型) 例10已知函数f(x)是一次函数,且满足关系式3f(x+1)-2f(x-1)=2x+17,求f(x)的解析式。 例11 已知f(x)是二次函数,且442)1()1(2 +-=-++x x x f x f ,求)(x f
个常用的E x c e l函数公 式 Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】
15个常用的Excel函数公式,拿来即用 1、查找重复内容 =IF(COUNTIF(A:A,A2)>1,"重复","") 2、重复内容首次出现时不提示 =IF(COUNTIF(A$2:A2,A2)>1,"重复","") 3、重复内容首次出现时提示重复 =IF(COUNTIF(A2:A99,A2)>1,"重复","") 4、根据出生年月计算年龄
=DATEDIF(A2,TODAY(),"y") 5、根据身份证号码提取出生年月 =--TEXT(MID(A2,7,8),"0-00-00") 6、根据身份证号码提取性别 =IF(MOD(MID(A2,15,3),2),"男","女") 7、几个常用的汇总公式 A列求和:=SUM(A:A) A列最小值:=MIN(A:A) A列最大值:=MAX (A:A) A列平均值:=AVERAGE(A:A)
A列数值个数:=COUNT(A:A) 8、成绩排名 =(A2,A$2:A$7) 9、中国式排名(相同成绩不占用名次) =SUMPRODUCT((B$2:B$7>B2)/COUNTIF(B$2:B$7,B$2:B$7))+1 10、90分以上的人数 =COUNTIF(B1:B7,">90")
11、各分数段的人数 同时选中E2:E5,输入以下公式,按Shift+Ctrl+Enter =FREQUENCY(B2:B7,{70;80;90}) 12、按条件统计平均值 =AVERAGEIF(B2:B7,"男",C2:C7) 13、多条件统计平均值 =AVERAGEIFS(D2:D7,C2:C7,"男",B2:B7,"销售")
电子表格常用函数公式 1.去掉最高最低分函数公式: =SUM(所求单元格…注:可选中拖动?)—MAX(所选单元格…注:可选中拖动?)—MIN(所求单元格…注:可选中拖动?) (说明:“SUM”是求和函数,“MAX”表示最大值,“MIN”表示最小值。)2.去掉多个最高分和多个最低分函数公式: =SUM(所求单元格)—large(所求单元格,1)—large(所求单元格,2) —large(所求单元格,3)—small(所求单元格,1) —small(所求单元格,2) —small(所求单元格,3) (说明:数字123分别表示第一大第二大第三大和第一小第二小第三小,依次类推) 3.计数函数公式: count 4.求及格人数函数公式:(”>=60”用英文输入法) =countif(所求单元格,”>=60”) 5.求不及格人数函数公式:(”<60”用英文输入法) =countif(所求单元格,”<60”) 6.求分数段函数公式:(“所求单元格”后的内容用英文输入法) 90以上:=countif(所求单元格,”>=90”) 80——89:=countif(所求单元格,”>=80”)—countif(所求单元格,”<=90”) 70——79:=countif(所求单元格,”>=70”)—countif(所求单元
格,”<=80”) 60——69:=countif(所求单元格,”>=60”)—countif(所求单元格,”<=70”) 50——59:=countif(所求单元格,”>=50”)—countif(所求单元格,”<=60”) 49分以下: =countif(所求单元格,”<=49”) 7.判断函数公式: =if(B2,>=60,”及格”,”不及格”) (说明:“B2”是要判断的目标值,即单元格) 8.数据采集函数公式: =vlookup(A2,成绩统计表,2,FALSE) (说明:“成绩统计表”选中原表拖动,“2”表示采集的列数) 公式是单个或多个函数的结合运用。 AND “与”运算,返回逻辑值,仅当有参数的结果均为逻辑“真(TRUE)”时返回逻辑“真(TRUE)”,反之返回逻辑“假(FALSE)”。条件判断 AVERAGE 求出所有参数的算术平均值。数据计算 COLUMN 显示所引用单元格的列标号值。显示位置 CONCATENATE 将多个字符文本或单元格中的数据连接在一起,显示在一个单元格中。字符合并 COUNTIF 统计某个单元格区域中符合指定条件的单元格数目。条件统计 DATE 给出指定数值的日期。显示日期
实验算法BP神经网络实验 【实验名称】 BP神经网络实验 【实验要求】 掌握BP神经网络模型应用过程,根据模型要求进行数据预处理,建模,评价与应用; 【背景描述】 神经网络:是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。其基本组成单元是感知器神经元。 【知识准备】 了解BP神经网络模型的使用场景,数据标准。掌握Python/TensorFlow数据处理一般方法。了解keras神经网络模型搭建,训练以及应用方法 【实验设备】 Windows或Linux操作系统的计算机。部署TensorFlow,Python。本实验提供centos6.8环境。 【实验说明】 采用UCI机器学习库中的wine数据集作为算法数据,把数据集随机划分为训练集和测试集,分别对模型进行训练和测试。 【实验环境】 Pyrhon3.X,实验在命令行python中进行,或者把代码写在py脚本,由于本次为实验,以学习模型为主,所以在命令行中逐步执行代码,以便更加清晰地了解整个建模流程。 【实验步骤】 第一步:启动python: 1
命令行中键入python。 第二步:导入用到的包,并读取数据: (1).导入所需第三方包 import pandas as pd import numpy as np from keras.models import Sequential from https://www.doczj.com/doc/7313556308.html,yers import Dense import keras (2).导入数据源,数据源地址:/opt/algorithm/BPNet/wine.txt df_wine = pd.read_csv("/opt/algorithm/BPNet/wine.txt", header=None).sample(frac=1) (3).查看数据 df_wine.head() 1
函数解析式的表示形式及五种确定方式 函数的解析式是函数的最常用的一种表示方法,本文重点研究函数的解析式的表达形式与解析式的求法。 一、解析式的表达形式 解析式的表达形式有一般式、分段式、复合式等。 1、一般式是大部分函数的表达形式,例 一次函数:b kx y += )0(≠k 二次函数:c bx ax y ++=2 )0(≠a 反比例函数:x k y = )0(≠k 正比例函数:kx y = )0(≠k 2、分段式 若函数在定义域的不同子集上对应法则不同,可用n 个式子来表示函数,这种形式的函数叫做分段函数。 例1、设函数(]() ???+∞∈∞-∈=-,1,log 1,,2)(81x x x x f x ,则满足41)(=x f 的x 的值为 。 解:当(]1,∞-∈x 时,由4 12= -x 得,2=x ,与1≤x 矛盾; 当()+∞∈,1x 时,由4 1log 81=x 得,3=x 。 ∴ 3=x 3、复合式 若y 是u 的函数,u 又是x 的函数,即),(),(),(b a x x g u u f y ∈==,那么y 关于x 的函数[]()b a x x g f y ,,)(∈=叫做f 和g 的复合函数。 例2、已知3)(,12)(2 +=+=x x g x x f ,则[]=)(x g f ,[]=)(x f g 。 解:[]721)3(21)(2)(2 2+=++=+=x x x g x g f [][]4443)12(3)()(222 ++=++=+=x x x x f x f g 二、解析式的求法 根据已知条件求函数的解析式,常用待定系数法、换元法、配凑法、赋值(式)法、方程法等。 1待定系数法 若已知函数为某种基本函数,可设出解析式的表达形式的一般式,再利用已知条件求出系数。
电子表格常用函数公式 1、自动排序函数: =RANK(第1数坐标,$第1数纵坐标$横坐标:$最后数纵坐标$横坐标,升降序号1降0升) 例如:=RANK(X3,$X$3:$X$155,0) 说明:从X3 到X 155自动排序 2、多位数中间取部分连续数值: =MID(该多位数所在位置坐标,所取多位数的第一个数字的排列位数,所取数值的总个数) 例如:612730************在B4坐标位置,取中间出生年月日,共8位数 =MID(B4,7,8) =19820711 说明:B4指该数据的位置坐标,7指从第7位开始取值,8指一共取8个数字 3、若在所取的数值中间添加其他字样, 例如:612730************在B4坐标位置,取中间出生年、月、日,要求****年**月**日格式 =MID(B4,7,4)&〝年〞&MID(B4,11,2) &〝月〞& MID(B4,13,2) &〝月〞&
=1982年07月11日 说明:B4指该数据的位置坐标,7、11指开始取值的第一位数排序号,4、2指所取数值个数,引号必须是英文引号。 4、批量打印奖状。 第一步建立奖状模板:首先利用Word制作一个奖状模板并保存为“奖状.doc”,将其中班级、姓名、获奖类别先空出,确保打印输出后的格式与奖状纸相符(如图1所示)。 第二步用Excel建立获奖数据库:在Excel表格中输入获奖人以及获几等奖等相关信息并保存为“奖状数据.xls”,格式如图2所示。 第三步关联数据库与奖状:打开“奖状.doc”,依次选择视图→工具栏→邮件合并,在新出现的工具栏中选择“打开数据源”,并选择“奖状数据.xls”,打开后选择相应的工作簿,默认为sheet1,并按确定。将鼠标定位到需要插入班级的地方,单击“插入域”,在弹出的对话框中选择“班级”,并按“插入”。同样的方法完成姓名、项目、等第的插入。 第四步预览并打印:选择“查看合并数据”,然后用前后箭头就可以浏览合并数据后的效果,选择“合并到新文档”可以生成一个包含所有奖状的Word文档,这时就可以批量打印了。
资源Github,kaggle Python工具库:Numpy,Pandas,Matplotlib,Scikit-Learn,tensorflow Numpy支持大量维度数组与矩阵运算,也针对数组提供大量的数学函数库 Numpy : 1.aaa = Numpy.genfromtxt(“文件路径”,delimiter = “,”,dtype = str)delimiter以指定字符分割,dtype 指定类型该函数能读取文件所以内容 aaa.dtype 返回aaa的类型 2.aaa = numpy.array([5,6,7,8]) 创建一个一维数组里面的东西都是同一个类型的 bbb = numpy.array([[1,2,3,4,5],[6,7,8,9,0],[11,22,33,44,55]]) 创建一个二维数组aaa.shape 返回数组的维度print(bbb[:,2]) 输出第二列 3.bbb = aaa.astype(int) 类型转换 4.aaa.min() 返回最小值 5.常见函数 aaa = numpy.arange(20) bbb = aaa.reshape(4,5)
numpy.arange(20) 生成0到19 aaa.reshape(4,5) 把数组转换成矩阵aaa.reshape(4,-1)自动计算列用-1 aaa.ravel()把矩阵转化成数组 bbb.ndim 返回bbb的维度 bbb.size 返回里面有多少元素 aaa = numpy.zeros((5,5)) 初始化一个全为0 的矩阵需要传进一个元组的格式默认是float aaa = numpy.ones((3,3,3),dtype = numpy.int) 需要指定dtype 为numpy.int aaa = np 随机函数aaa = numpy.random.random((3,3)) 生成三行三列 linspace 等差数列创建函数linspace(起始值,终止值,数量) 矩阵乘法: aaa = numpy.array([[1,2],[3,4]]) bbb = numpy.array([[5,6],[7,8]]) print(aaa*bbb) *是对应位置相乘 print(aaa.dot(bbb)) .dot是矩阵乘法行乘以列 print(numpy.dot(aaa,bbb)) 同上 6.矩阵常见操作
1 / 4 张喜林制 [选取日期] 高三数学第二轮专题讲座复习:求解函数解析式的几种常用方法 高考要求 求解函数解析式是高考重点考查内容之一,需引起重视 本节主要帮助考生在深刻理解函数定义的基础上,掌握求函数解析式的几种方法,并形成能力,并培养考生的创新能力和解决实际问题的能力 重难点归纳 求解函数解析式的几种常用方法主要有 1 待定系数法,如果已知函数解析式的构造时,用待定系数法; 2 换元法或配凑法,已知复合函数f [g (x )]的表达式可用换元法,当表达式较简单时也可用配凑法; 3 消参法,若已知抽象的函数表达式,则用解方程组消参的方法求解f (x ); 另外,在解题过程中经常用到分类讨论、等价转化等数学思想方法 典型题例示范讲解 例1 (1)已知函数f (x )满足f (log a x )=)1(1 2x x a a -- (其中a >0,a ≠1,x >0),求f (x )的表达式 (2)已知二次函数f (x )=ax 2+bx +c 满足|f (1)|=|f (-1)|=|f (0)|=1,求f (x ) 命题意图 本题主要考查函数概念中的三要素 定义域、值域和对应法则,以及计算能力和综合运用知识的能力 知识依托 利用函数基础知识,特别是对“f ”的理解,用好等价转化,注意定义域 错解分析 本题对思维能力要求较高,对定义域的考查、等价转化易出错 技巧与方法 (1)用换元法;(2)用待定系数法 解 (1)令t=log a x (a >1,t >0;01,x >0;0 电子表格常用函数公式及用法 1、求和公式: =SUM(A2:A50) ——对A2到A50这一区域进行求和; 2、平均数公式: =AVERAGE(A2:A56) ——对A2到A56这一区域求平均数; 3、最高分: =MAX(A2:A56) ——求A2到A56区域(55名学生)的最高分;4、最低分: =MIN(A2:A56) ——求A2到A56区域(55名学生)的最低分; 5、等级: =IF(A2>=90,"优",IF(A2>=80,"良",IF(A2>=60,"及格","不及格"))) 6、男女人数统计: =COUNTIF(D1:D15,"男") ——统计男生人数 =COUNTIF(D1:D15,"女") ——统计女生人数 7、分数段人数统计: 方法一: 求A2到A56区域100分人数:=COUNTIF(A2:A56,"100") 求A2到A56区域60分以下的人数;=COUNTIF(A2:A56,"<60") 求A2到A56区域大于等于90分的人数;=COUNTIF(A2:A56,">=90") 求A2到A56区域大于等于80分而小于90分的人数; =COUNTIF(A1:A29,">=80")-COUNTIF(A1:A29," =90") 求A2到A56区域大于等于60分而小于80分的人数; =COUNTIF(A1:A29,">=80")-COUNTIF(A1:A29," =90") 方法二: (1)=COUNTIF(A2:A56,"100") ——求A2到A56区域100分的人数;假设把结果存放于A57单元格; (2)=COUNTIF(A2:A56,">=95")-A57 ——求A2到A56区域大于等于95而小于100分的人数;假设把结果存放于A58单元格;(3)=COUNTIF(A2:A56,">=90")-SUM(A57:A58) ——求A2到A56区域大于等于90而小于95分的人数;假设把结果存放于A59单元格; (4)=COUNTIF(A2:A56,">=85")-SUM(A57:A59) ——求A2到A56区域大于等于85而小于90分的人数; …… 8、求A2到A56区域优秀率:=(COUNTIF(A2:A56,">=90"))/55*100 9、求A2到A56区域及格率:=(COUNTIF(A2:A56,">=60"))/55*100 10、排名公式: =RANK(A2,A$2:A$56) ——对55名学生的成绩进行排名; 11、标准差:=STDEV(A2:A56) ——求A2到A56区域(55人)的成绩波动情况(数值越小,说明该班学生间的成绩差异较小,反之,说明该班存在两极分化); 12、条件求和:=SUMIF(B2:B56,"男",K2:K56) ——假设B列存放学生的性别,K列存放学生的分数,则此函数返回的结果表示求该班 1.简述激活函数的作用 使用激活函数的目的是为了向网络中加入非线性因素;加强网络的表示能力,解决线性模型无法解决的问题 2.那为什么要使用非线性激活函数? 为什么加入非线性因素能够加强网络的表示能力?——神经网络的万能近似定理 ?神经网络的万能近似定理认为主要神经网络具有至少一个非线性隐藏层,那么只要给予网络足够数量的隐藏单元,它就可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的函数。 ?如果不使用非线性激活函数,那么每一层输出都是上层输入的线性组合;此时无论网络有多少层,其整体也将是线性的,这会导致失去万能近似的性质 ?但仅部分层是纯线性是可以接受的,这有助于减少网络中的参数。3.如何解决训练样本少的问题? 1.利用预训练模型进行迁移微调(fine-tuning),预训练模型通常在特征上拥有很好的语义表达。此时,只需将模型在小数据集上进行微调就能取得不错的效果。CV 有 ImageNet,NLP 有 BERT 等。 2.数据集进行下采样操作,使得符合数据同分布。 3.数据集增强、正则或者半监督学习等方式来解决小样本数据集的训练问题。 4.如何提升模型的稳定性? 1.正则化(L2, L1, dropout):模型方差大,很可能来自于过拟合。正则化能有效的降低模型的复杂度,增加对更多分布的适应性。 2.前停止训练:提前停止是指模型在验证集上取得不错的性能时停止训练。这种方式本质和正则化是一个道理,能减少方差的同时增加的偏差。目的为了平衡训练集和未知数据之间在模型的表现差异。 3.扩充训练集:正则化通过控制模型复杂度,来增加更多样本的适应性。 4.特征选择:过高的特征维度会使模型过拟合,减少特征维度和正则一样可能会处理好方差问题,但是同时会增大偏差。 5.你有哪些改善模型的思路? 1.数据角度 增强数据集。无论是有监督还是无监督学习,数据永远是最重要的驱动力。更多的类型数据对良好的模型能带来更好的稳定性和对未知数据的可预见性。对模型来说,“看到过的总比没看到的更具有判别的信心”。 2.模型角度 Excel常用函数公式大全 1、查找重复内容公式:=IF(COUNTIF(A:A,A2)>1,"重复","")。 2、用出生年月来计算年龄公式:=TRUNC((DAYS360(H6,"2009/8/30",FALSE))/360,0)。 3、从输入的18位身份证号的出生年月计算公式: =CONCATENATE(MID(E2,7,4),"/",MID(E2,11,2),"/",MID(E2,13,2))。 4、从输入的身份证号码内让系统自动提取性别,可以输入以下公式: =IF(LEN(C2)=15,IF(MOD(MID(C2,15,1),2)=1,"男","女"),IF(MOD(MID(C2,17,1),2)=1,"男","女"))公式内的“C2”代表的是输入身份证号码的单元格。 1、求和:=SUM(K2:K56) ——对K2到K56这一区域进行求和; 2、平均数:=AVERAGE(K2:K56) ——对K2 K56这一区域求平均数; 3、排名:=RANK(K2,K$2:K$56) ——对55名学生的成绩进行排名; 4、等级:=IF(K2>=85,"优",IF(K2>=74,"良",IF(K2>=60,"及格","不及格"))) 5、学期总评:=K2*0.3+M2*0.3+N2*0.4 ——假设K列、M列和N列分别存放着学生的“平时总评”、“期中”、“期末”三项成绩; 6、最高分:=MAX(K2:K56) ——求K2到K56区域(55名学生)的最高分; 7、最低分:=MIN(K2:K56) ——求K2到K56区域(55名学生)的最低分; 8、分数段人数统计: (1)=COUNTIF(K2:K56,"100") ——求K2到K56区域100分的人数;假设把结果存放于K57单元格; (2)=COUNTIF(K2:K56,">=95")-K57 ——求K2到K56区域95~99.5分的人数;假设把结果存放于K58单元格; (3)=COUNTIF(K2:K56,">=90")-SUM(K57:K58) ——求K2到K56区域90~94.5分的人数;假设把结果存放于K59单元格; (4)=COUNTIF(K2:K56,">=85")-SUM(K57:K59) ——求K2到K56区域85~89.5分的人数;假设把结果存放于K60单元格; 电子表格常用函数公式-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII 电子表格常用函数公式 1.去掉最高最低分函数公式: =SUM(所求单元格‘注:可选中拖动’)—MAX(所选单元格‘注:可选中拖动’)—MIN(所求单元格‘注:可选中拖动’) (说明:“SUM”是求和函数,“MAX”表示最大值,“MIN”表示最小值。) 2.去掉多个最高分和多个最低分函数公式: =SUM(所求单元格)—large(所求单元格,1)—large(所求单元格,2) —large(所求单元格,3)—small(所求单元格,1) —small(所求单元格,2) —small(所求单元格,3) (说明:数字123分别表示第一大第二大第三大和第一小第二小第三小,依次类推) 3.计数函数公式: count 4.求及格人数函数公式:(”>=60”用英文输入法) =countif(所求单元格,”>=60”) 5.求不及格人数函数公式:(”<60”用英文输入法) =countif(所求单元格,”<60”) 6.求分数段函数公式:(“所求单元格”后的内容用英文输入法)90以上:=countif(所求单元格,”>=90”) 80——89:=countif(所求单元格,”>=80”)—countif(所求单元 格,”<=90”) 70——79:=countif(所求单元格,”>=70”)—countif(所求单元 格,”<=80”) 60——69:=countif(所求单元格,”>=60”)—countif(所求单元 格,”<=70”) 50——59:=countif(所求单元格,”>=50”)—countif(所求单元 格,”<=60”) 49分以下: =countif(所求单元格,”<=49”) 7.判断函数公式: =if(B2,>=60,”及格”,”不及格”) (说明:“B2”是要判断的目标值,即单元格) 8.数据采集函数公式: =vlookup(A2,成绩统计表,2,FALSE) (说明:“成绩统计表”选中原表拖动,“2”表示采集的列数) 公式是单个或多个函数的结合运用。 AND “与”运算,返回逻辑值,仅当有参数的结果均为逻辑“真(TRUE)”时返回逻辑“真(TRUE)”,反之返回逻辑“假(FALSE)”。条件判断 AVERAGE 求出所有参数的算术平均值。数据计算 COLUMN 显示所引用单元格的列标号值。显示位置 CONCATENATE 将多个字符文本或单元格中的数据连接在一起,显示在一个单元格中。字符合并 COUNTIF 统计某个单元格区域中符合指定条件的单元格数目。条件统计 求函数解析式的六种常用方法 一、换元法 已知复合函数f [g (x )]的解析式,求原函数f (x )的解析式.令g (x )= t ,求f (t )的解析式,再把t 换为x 即可. 例1 已知f (x x 1+)= x x x 1122++,求f (x )的解析式. 解: 设x x 1+= t ,则 x= 1 1-t (t ≠1), ∴f (t )= 1 11)11(1)11(22-+-+-t t t = 1+2)1(-t +(t -1)= t 2-t+1 故 f (x )=x 2-x+1 (x ≠1). 评注: 实施换元后,应注意新变量的取值范围,即为函数的定义域. 二、配凑法 例2 已知f (x +1)= x+2 x ,求f (x )的解析式. 解: f (x +1)= 2)(x +2 x +1-1=2)1(+x -1, ∴ f (x +1)= 2)1(+x -1 (x +1≥1),将x +1视为自变量x , 则有 f (x )= x 2-1 (x ≥1). 评注: 使用配凑法时,一定要注意函数的定义域的变化,否则容易出错. 三、待定系数法 例3 已知二次函数f (x )满足f (0)=0,f (x+1)= f (x )+2x+8,求f (x )的解析式. 解:设二次函数f (x )= ax 2+bx+c ,则 f (0)= c= 0 ① f (x+1)= a 2)1(+x +b (x+1)= ax 2+(2a+b )x+a+b ② 由f (x+1)= f (x )+2x+8 与①、② 得 ???=++=+822b a b b a 解得 ???==. 7,1b a 故f (x )= x 2+7x. 评注: 已知函数类型,常用待定系数法求函数解析式. 工作中最常用的excel函数公式大全 一、数字处理 1、取绝对值 =ABS(数字) 2、取整 =INT(数字) 3、四舍五入 =ROUND(数字,小数位数) 二、判断公式 1、把公式产生的错误值显示为空 公式:C2 =IFERROR(A2/B2,"") 说明:如果是错误值则显示为空,否则正常显示。 2、IF多条件判断返回值 公式:C2 =IF(AND(A2<500,B2="未到期"),"补款","") 说明:两个条件同时成立用AND,任一个成立用OR函数。 三、统计公式 1、统计两个表格重复的内容 公式:B2 =COUNTIF(Sheet15!A:A,A2) 说明:如果返回值大于0说明在另一个表中存在,0则不存在。 2、统计不重复的总人数 公式:C2 =SUMPRODUCT(1/COUNTIF(A2:A8,A2:A8)) 说明:用COUNTIF统计出每人的出现次数,用1除的方式把出现次数变成分母,然后相加。 四、求和公式 1、隔列求和 公式:H3 =SUMIF($A$2:$G$2,H$2,A3:G3) 或 =SUMPRODUCT((MOD(COLUMN(B3:G3),2)=0)*B3:G3)说明:如果标题行没有规则用第2个公式 2、单条件求和 公式:F2 =SUMIF(A:A,E2,C:C) 说明:SUMIF函数的基本用法 3、单条件模糊求和 公式:详见下图 说明:如果需要进行模糊求和,就需要掌握通配符的使用,其中星号是表示任意多个字符,如"*A*"就表示a前和后有任意多个字符,即包含A。 4、多条件模糊求和 公式:C11 =SUMIFS(C2:C7,A2:A7,A11&"*",B2:B7,B11) 说明:在sumifs中可以使用通配符* Excel常用电子表格公式大全 1、查找重复内容公式:=IF(COUNTIF(A:A,A2)>1,"重复","")。 2、用出生年月来计算年龄公式: =TRUNC((DAYS360(H6,"2009/8/30",FALSE))/360,0)。 3、从输入的18位身份证号的出生年月计算公式: =CONCATENATE(MID(E2,7,4),"/",MID(E2,11,2),"/",MID(E2 ,13,2))。 4、从输入的身份证号码内让系统自动提取性别,可以输入以下公式: =IF(LEN(C2)=15,IF(MOD(MID(C2,15,1),2)=1,"男","女 "),IF(MOD(MID(C2,17,1),2)=1,"男","女"))公式内的“C2”代表 的是输入身份证号码的单元格。 1、求和:=SUM(K2:K56) ——对K2到K56这一区域进行求和; 2、平均数:=AVERAGE(K2:K56) ——对K2 K56这一区域求平均数; 3、排名:=RANK(K2,K$2:K$56) ——对55名学生的成绩进行排名; 4、等级:=IF(K2>=85,"优",IF(K2>=74,"良",IF(K2>=60,"及格","不及格"))) 5、学期总评:=K2*0.3+M2*0.3+N2*0.4 ——假设K列、M 列和N列分别存放着学生的“平时总评”、“期中”、“期末”三项成绩; 6、最高分:=MAX(K2:K56) ——求K2到K56区域(55名学生)的最高分; 7、最低分:=MIN(K2:K56) ——求K2到K56区域(55名学生)的最低分; 8、分数段人数统计: (1)=COUNTIF(K2:K56,"100") ——求K2到K56区域100分的人数;假设把结果存放于K57单元格; (2)=COUNTIF(K2:K56,">=95")-K57 ——求K2到K56区域95~99.5分的人数;假设把结果存放于K58单元格; 6 Tensorflow笔记:第七讲 卷积神经网络 本节目标:学会使用CNN实现对手写数字的识别。 7.1 √全连接NN:每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测的结果。 参数个数:∑(前层×后层+后层) 一张分辨率仅仅是28x28的黑白图像,就有近40万个待优化的参数。现实生活中高分辨率的彩色图像,像素点更多,且为红绿蓝三通道信息。 待优化的参数过多,容易导致模型过拟合。为避免这种现象,实际应用中一般不会将原始图片直接喂入全连接网络。 √在实际应用中,会先对原始图像进行特征提取,把提取到的特征喂给全连接网络,再让全连接网络计算出分类评估值。 例:先将此图进行多次特征提取,再把提取后的计算机可读特征喂给全连接网络。 √卷积Convolutional 卷积是一种有效提取图片特征的方法。一般用一个正方形卷积核,遍历图片上的每一个像素点。图片与卷积核重合区域内相对应的每一个像素值乘卷积核内相对应点的权重,然后求和,再加上偏置后,最后得到输出图片中的一个像素值。 例:上面是5x5x1的灰度图片,1表示单通道,5x5表示分辨率,共有5行5列个灰度值。若用一个3x3x1的卷积核对此5x5x1的灰度图片进行卷积,偏置项 b=1,则求卷积的计算是:(-1)x1+0x0+1x2+(-1)x5+0x4+1x2+(-1)x3+0x4+1x5+1=1(注意不要忘记加偏置1)。 输出图片边长=(输入图片边长–卷积核长+1)/步长,此图为:(5 – 3 + 1)/ 1 = 3,输出图片是3x3的分辨率,用了1个卷积核,输出深度是1,最后输出的是3x3x1的图片。 √全零填充Padding 有时会在输入图片周围进行全零填充,这样可以保证输出图片的尺寸和输入图片一致。 例:在前面5x5x1的图片周围进行全零填充,可使输出图片仍保持5x5x1的维度。这个全零填充的过程叫做padding。 输出数据体的尺寸=(W?F+2P)/S+1 W:输入数据体尺寸,F:卷积层中神经元感知域,S:步长,P:零填充的数量。 例:输入是7×7,滤波器是3×3,步长为1,填充为0,那么就能得到一个5×5的输出。如果步长为2,输出就是3×3。 如果输入量是32x32x3,核是5x5x3,不用全零填充,输出是(32-5+1)/1=28,如果要让输出量保持在32x32x3,可以对该层加一个大小为2的零填充。可以根据需求计算出需要填充几层零。32=(32-5+2P)/1 +1,计算出P=2,即需填充2 求解函数解析式 求解函数解析式是高考重点考查内容之一,需引起重视.本节主要帮助考生在深刻理解函数定义的基础上,掌握求函数解析式的几种方法,并形成能力,并培养考生的创新能力和解决实际问题的能力. ●难点磁场 (★★★★)已知f (2-cos x )=cos2x +cos x ,求f (x -1). [例1](1)已知函数f (x )满足f (log a x )=)1 (1 2x x a a -- (其中a >0,a ≠1,x >0),求f (x ) 的表达式. (2)已知二次函数f (x )=ax 2 +bx +c 满足|f (1)|=|f (-1)|=|f (0)|=1,求f (x )的表达式. 命题意图:本题主要考查函数概念中的三要素:定义域、值域和对应法则,以及计算能力和综合运用知识的能力.属★★★★题目. 知识依托:利用函数基础知识,特别是对“f ”的理解,用好等价转化,注意定义域. 错解分析:本题对思维能力要求较高,对定义域的考查、等价转化易出错. 技巧与方法:(1)用换元法;(2)用待定系数法. 解:(1)令t=log a x (a >1,t >0;01,x >0;0
电子表格常用函数公式及用法
题库深度学习面试题型介绍及解析--第7期
Excel常用函数公式大全(实用)
电子表格常用函数公式
高中数学-求函数解析式的六种常用方法
工作中最常用的excel函数公式大全71954
Excel常用电子表格公式大全
人工智能实践:Tensorflow笔记 北京大学 7 第七讲卷积网络基础 (7.3.1) 助教的Tenso
求解函数解析式
相关主题
文本预览