创建并管理SQL Server Analysis Services分区
- 格式:doc
- 大小:47.00 KB
- 文档页数:8

sql server创建数据库的操作步骤以SQL Server创建数据库的操作步骤为标题,本文将介绍如何使用SQL Server Management Studio (SSMS)来创建数据库。
按照以下步骤,您可以轻松创建一个全新的数据库。
1. 打开SQL Server Management Studio:首先,打开SQL Server Management Studio,您可以在开始菜单中找到它。
一旦打开,您将看到一个连接到数据库服务器的对话框。
2. 连接到数据库服务器:在对话框的服务器名称字段中输入要连接的数据库服务器的名称。
如果您正在本地运行SQL Server,则可以使用默认的本地服务器名称(通常是localhost)。
您还可以使用IP 地址来指定服务器。
如果要使用Windows身份验证进行连接,则选择“Windows身份验证”,如果要使用SQL Server身份验证进行连接,则选择“SQL Server身份验证”,并输入用户名和密码。
点击“连接”按钮。
3. 创建新查询:在成功连接到数据库服务器后,您将看到SQL Server Management Studio的主界面。
选择“文件”菜单,然后选择“新建”和“查询”。
4. 创建新数据库:在新查询窗口中,输入以下SQL语句来创建一个新的数据库:CREATE DATABASE [数据库名称]```将“数据库名称”替换为您想要的数据库名称。
注意,在SQL Server中,方括号([])用于引用对象名称。
点击“执行”按钮或按下F5键来执行该语句。
5. 验证数据库创建:在执行完创建数据库的SQL语句后,您可以在“对象资源管理器”窗口中看到新创建的数据库。
展开“数据库”节点,您应该能够在列表中找到您刚创建的数据库。
6. 设置数据库属性(可选):如果您需要对数据库进行更多的设置和配置,可以右键单击数据库名称,然后选择“属性”。
在属性窗口中,您可以更改数据库的名称、所有者、文件路径等。

大多数服务及其属性可通过使用SQL Server 配置管理器进行配置。
以下是在C 盘安装Windows 的情况下最新的四个版本的路径。
安装的服务SQL Server根据您决定安装的组件,SQL Server 安装程序将安装以下服务:•SQL Server Database Services - 用于SQL Server 关系数据库引擎的服务。
可执行文件为<MSSQLPATH>\MSSQL\Binn\sqlservr.exe。
•SQL Server 代理 - 执行作业、监视SQL Server、激发警报以及允许自动执行某些管理任务。
SQL Server 代理服务在SQL Server Express 的实例上存在,但处于禁用状态。
可执行文件为<MSSQLPATH>\MSSQL\Binn\sqlagent.exe。
•Analysis Services - 为商业智能应用程序提供联机分析处理(OLAP) 和数据挖掘功能。
可执行文件为<MSSQLPATH>\OLAP\Bin\msmdsrv.exe。
•Reporting Services - 管理、执行、创建、计划和传递报表。
可执行文件为<MSSQLPATH>\ReportingServices\ReportServer\Bin\ReportingServicesService.exe。
•Integration Services - 为Integration Services 包的存储和执行提供管理支持。
可执行文件的路径是<MSSQLPATH>\130\DTS\Binn\MsDtsSrvr.exe •SQL Server Browser - 向客户端计算机提供SQL Server 连接信息的名称解析服务。
可执行文件的路径为c:\Program Files (x86)\Microsoft SQLServer\90\Shared\sqlbrowser.exe•全文搜索 - 对结构化和半结构化数据的内容和属性快速创建全文索引,从而为SQL Server 提供文档筛选和断字功能。

SQL Server 2005 表分区操作详解SQL Server数据库表分区操作过程由三个步骤组成:1. 创建分区函数2. 创建分区架构3. 对表进行分区下面将对每个步骤进行详细介绍。
步骤一:创建一个分区函数此分区函数用于定义你希望SQL Server如何对数据进行分区的参数值([u]how[/u])。
这个操作并不涉及任何表格,只是单纯的定义了一项技术来分割数据。
我们可以通过指定每个分区的边界条件来定义分区。
例如,假定我们有一份Customer s表,其中包含了关于所有客户的信息,以一一对应的客户编号(从1到1,000,000)来区分。
我们将通过以下的分区函数把这个表分为四个大小相同的分区:这些边界值定义了四个分区。
第一个分区包括所有值小于250,000的数据,第二个分区包括值在250,000到49,999之间的数据。
第三个分区包括值在500,000到7499,999之间的数据。
所有值大于或等于750,000的数据被归入第四个分区。
请注意,这里调用的"RANGE RIGHT"语句表明每个分区边界值是右界。
类似的,如果使用"RANGE LEFT"语句,则上述第一个分区应该包括所有值小于或等于250,000的数据,第二个分区的数据值在250,001到500,000之间,以此类推。
步骤二:创建一个分区架构一旦给出描述如何分割数据的分区函数,接着就要创建一个分区架构,用来定义分区位置([u]where[/u])。
创建过程非常直截了当,只要将分区连接到指定的文件组就行了。
例如,如果有四个文件组,组名从"fg1"到"fg4",那么以下的分区架构就能达到想要的效果:注意,这里将一个分区函数连接到了该分区架构,但并没有将分区架构连接到任何数据表。
这就是可复用性起作用的地方了。
无论有多少数据库表,我们都可以使用该分区架构(或仅仅是分区函数)。

第五章:Analysis Services 配置–帐户设置使用SQL Server 安装向导的“Analysis Services 配置”页可以向要求对Analysis Services 进行不受限访问的用户或服务授予管理权限。
如果您正在安装PowerPivot for SharePoint,请考虑将管理权限授予负责在SharePoint 2010 场中部署SQL Server PowerPivot for SharePoint 的SharePoint 场管理员或服务管理员。
注意:设置SQL Server 的注意事项从SQL Server 2005 开始,为了帮助确保SQL Server 比早期版本更为安全,进行了一些重大的更改。
这些更改秉承了“设计安全、默认安全、部署安全”的策略,目的在于防止服务器实例及其数据库免遭安全攻击。
SQL Server 2008 通过对服务器和数据库组件引入更多更改,继续实施这一安全强化过程。
通过制定一个“最小权限”策略,SQL Server 2008 中引入的更改可进一步减少服务器及其数据库的外围应用和攻击区域,并使Windows 管理和SQL Server 管理进一步分离。
这意味着内部帐户受到保护,并分成操作系统功能和SQL Server 功能。
这些措施包括:∙新的SQL Server 2008 安装不再将本地Windows 组BUILTIN\Administrators 添加到Analysis Services sysadmin 固定服务器角色。
∙具有将一个或多个Windows 主体设置到SQL Server 内的sysadmin 服务器角色中的功能。
此选项在SQL Server 安装程序全新安装SQL Server 2008 期间可用。
∙已删除外围应用配置器(SAC) 工具,取而代之的是SQL Server 配置管理器工具中的基于策略的管理功能和一些相关更改。

sql server analysis services 使用SQL Server Analysis Services (SSAS) 是 Microsoft SQL Server数据平台中的一个组件,用于创建、部署和管理负责数据分析和报表生成的多维数据模型。
它支持在线分析处理 (OLAP)、数据挖掘和业务智能应用开发。
使用SQL Server Analysis Services,可以通过创建维度和度量,构建多维数据模型,将数据组织为多个维度和层次结构,以支持复杂的数据分析和报表需求。
SSAS 提供了 MDX(多维表达式)查询语言,用于查询多维数据模型,并提供了多种可视化工具和客户端应用程序,如SQL Server Management Studio、Power BI 等,用于分析和可视化数据。
使用 SQL Server Analysis Services,可以实现以下功能:1. 多维数据建模:通过定义维度、层次结构和度量,创建多维数据模型,可以支持复杂的数据分析需求。
2. OLAP 数据立方体:使用 SSAS 创建 OLAP 数据立方体,以便快速聚合和分析大量数据。
3. 数据挖掘:利用 SSAS 的数据挖掘功能,可以发现隐藏在数据中的模式和趋势,用于预测和决策支持。
4. 报表和可视化:通过使用 SSAS 的可视化工具和客户端应用程序,如 SQL Server Reporting Services、Power BI,可以轻松创建报表和仪表板,用于数据可视化和分析。
5. 安全性和权限管理:SSAS 提供了灵活的安全模型,可以定义角色和权限,以控制用户对多维数据模型的访问和操作权限。
总之,SQL Server Analysis Services 是一个强大的数据分析和报表生成工具,可以帮助组织和企业利用现有数据进行深入的分析,并提供有意义的洞察和决策支持。

sqlserver reporting services 用法SQL Server Reporting Services(SSRS)是微软的一款企业级报表生成和分发工具。
它允许用户设计、管理和生成各种类型的报表,包括表格、图表和多媒体报告。
SSRS被广泛应用于各种行业和组织,帮助用户快速、准确地获取关键业务数据并进行分析。
本文将详细介绍SSRS的用法,包括设计报表、数据源配置、报表部署和分发等方面。
第一步:报表设计SSRS提供了一个强大的报表设计环境,用户可以在该环境中创建和编辑报表。
在设计报表之前,需要先确定报表的目的和内容,并收集所需的数据。
以下是一些设计报表的基本步骤:1. 创建新的报表项目:在SSRS中,可以创建一个新的报表项目,并指定报表的名称和位置。
2. 添加数据源:在报表设计之前,需要配置报表使用的数据源。
可以选择从SQL Server数据库、Excel文件、Oracle数据库或其他数据源中获取数据。
配置数据源时,需要提供相应的连接信息和认证方式。
3. 创建数据集:数据集是报表所需数据的来源。
可以使用查询语言(如SQL)来定义数据集所需的数据。
在创建数据集时,需要指定数据源和查询语句。
4. 设计报表布局:在报表设计界面,可以添加表格、图表、文本框和其他控件来展示数据。
可以通过拖拽和调整控件的位置和大小来设计报表的布局。
5. 设置数据绑定:将数据源和数据集与报表中的控件进行绑定,以便在报表中显示相应的数据。
可以使用表达式和函数来处理数据和计算统计信息。
6. 格式化报表:可以调整报表的样式、颜色和字体等属性,使其符合用户需求和企业品牌。
第二步:数据源配置在设计报表时,需要配置报表使用的数据源。
以下是一些配置数据源的基本步骤:1. 添加数据源:在报表项目中,选择“数据”选项,并添加一个数据源。
可以选择数据库、共享数据源或其他类型的数据源。
2. 配置连接信息:为报表指定连接到数据源的信息,包括服务器名称、数据库名称和认证方式等。

SQL Server Analysis Services 教程欢迎使用Analysis Services 教程。
数据仓库开发人员使用Business Intelligence Development Studio 开发和部署Analysis Services 项目,并使用SQL Server Management Studio 管理从这些项目实例化的Analysis Services 数据库。
本教程通过在所有示例中使用虚构公司Adventure Works Cycles,说明如何使用BI Development Studio 开发和部署Analysis Services 项目。
学习内容在本教程中,您将了解以下内容:•如何在BI Development Studio 的Analysis Services 项目中定义数据源、数据源视图、维度、属性、属性关系、层次结构和多维数据集。
•如何通过将Analysis Services 项目部署到Analysis Services 实例来查看多维数据集和维度数据,以及如何在随后处理已部署的对象以使用基础数据源中的数据来填充对象。
•如何在Analysis Services 项目中修改度量值、维度、层次结构、属性和度量值组,以及如何将增量更改部署到开发服务器上的已部署多维数据集。
•如何定义多维数据集内的计算、关键绩效指标(KPI)、操作、透视、翻译和安全角色。
要求若要完成本教程,需要使用下列组件、示例和工具:•SQL Server 数据库引擎•Analysis Services•Business Intelligence Development Studio•AdventureWorks2008R2DW2008 示例数据库有关如何安装这些组件、示例和工具的信息,请参阅安装SQL Server 2008 R2和安装SQL Server 示例和示例数据库的注意事项。
此外,必须满足下列前提条件才能成功完成本教程:•您必须是Analysis Services 计算机上本地管理员组的成员或Analysis Services 实例中的服务器角色的成员。

sql server分区函数SQL Server分区函数是SQL Server数据库中的一种功能,用于将表或索引中的数据分别存储在不同的分区中。
通过使用分区函数,可以将数据均匀地分布在多个分区中,提高查询性能、数据加载速度以及数据维护的效率。
下面将详细介绍SQL Server分区函数的使用方法和相关注意事项。
一、什么是分区函数在SQL Server数据库中,分区函数是用于定义分区方案的一种方法。
分区方案是将表或索引按照某种规则分割成多个分区的过程。
而分区函数则是用来确定数据应该被分配到哪个分区中的规则。
二、分区函数的创建在SQL Server中,可以通过CREATE PARTITION FUNCTION语句来创建分区函数。
创建分区函数时需要指定函数的名称、参数类型和返回值类型。
例如,可以创建一个按照日期进行分区的分区函数,如下所示:CREATE PARTITION FUNCTION PartitionByDate(DATE)AS RANGE RIGHT FOR VALUES ('2019-01-01', '2020-01-01', '2021-01-01')上述语句创建了一个名为PartitionByDate的分区函数,参数类型为DATE,返回值类型为INT。
分区函数的参数类型决定了分区函数所依据的列的数据类型。
三、分区函数的使用在创建分区函数后,可以通过ALTER TABLE或CREATE INDEX语句来应用分区函数。
例如,可以将一个表按照日期进行分区,如下所示:ALTER TABLE TableNamePARTITION BY RANGE (ColumnToPartition)(PARTITION Partition1 VALUES LESS THAN (DateValue1),PARTITION Partition2 VALUES LESS THAN (DateValue2),...)上述语句将名为TableName的表按照ColumnToPartition列的值进行分区,并指定了每个分区的范围。

SQL SERVER 2005利用分区对大数据表处理操作手册超大型数据库的大小常常达到数百GB,有时甚至要用TB来计算。
而单表的数据量往往会达到上亿的记录,并且记录数会随着时间而增长。
这不但影响着数据库的运行效率,也增大数据库的维护难度。
除了表的数据量外,对表不同的访问模式也可能会影响性能和可用性。
这些问题都可以通过对大表进行合理分区得到很大的改善。
当表和索引变得非常大时,分区可以将数据分为更小、更容易管理的部分来提高系统的运行效率。
如果系统有多个CPU或是多个磁盘子系统,可以通过并行操作获得更好的性能。
所以对大表进行分区是处理海量数据的一种十分高效的方法。
本文通过一个具体实例,介绍如何创建和修改分区表,以及如何查看分区表。
SQL Server 2005是微软在推出SQL Server 2000后时隔五年推出的一个数据库平台,它的数据库引擎为关系型数据和结构化数据提供了更安全可靠的存储功能,使用户可以构建和管理用于业务的高可用和高性能的数据应用程序。
此外SQL Server 2005结合了分析、报表、集成和通知功能。
这使企业可以构建和部署经济有效的BI解决方案,帮助团队通过记分卡、Dashboard、Web Services 和移动设备将数据应用推向业务的各个领域。
无论是开发人员、数据库管理员、信息工作者还是决策者,SQL Server 2005都可以提供出创新的解决方案,并可从数据中获得更多的益处。
它所带来的新特性,如T-SQL的增强、数据分区、服务代理和与.NetFramework的集成等,在易管理性、可用性、可伸缩性和安全性等方面都有很大的增强。
表分区的具体实现方法:表分区分为水平分区和垂直分区。
水平分区将表分为多个表。
每个表包含的列数相同,但是行更少。
例如,可以将一个包含十亿行的表水平分区成12个表,每个小表表示特定年份内一个月的数据。
任何需要特定月份数据的查询只需引用相应月份的表。
而垂直分区则是将原始表分成多个只包含较少列的表。
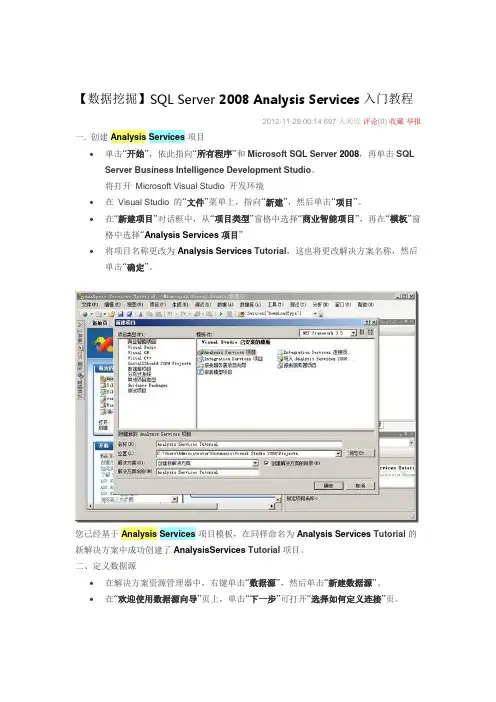
【数据挖掘】SQL Server 2008Analysis Services入门教程2012-11-29 00:14 697人阅读评论(0) 收藏举报一. 创建Analysis Services项目∙单击“开始”,依此指向“所有程序”和Microsoft SQL Server 2008,再单击SQL Server Business Intelligence Development Studio。
将打开Microsoft Visual Studio 开发环境∙在Visual Studio 的“文件”菜单上,指向“新建”,然后单击“项目”。
∙在“新建项目”对话框中,从“项目类型”窗格中选择“商业智能项目”,再在“模板”窗格中选择“Analysis Services项目”∙将项目名称更改为Analysis Services Tutorial,这也将更改解决方案名称,然后单击“确定”。
您已经基于Analysis Services项目模板,在同样命名为Analysis Services Tutorial的新解决方案中成功创建了AnalysisServices Tutorial项目。
二、定义数据源∙在解决方案资源管理器中,右键单击“数据源”,然后单击“新建数据源”。
∙在“欢迎使用数据源向导”页上,单击“下一步”可打开“选择如何定义连接”页。
∙∙在“选择如何定义连接”页上,可以基于新连接、现有连接或以前定义的数据源对象来定义数据源。
在本教程中,将基于新连接定义数据源。
确保已选中“基于现有连接或新连接创建数据源”,再单击“新建”。
∙在“连接管理器”对话框中,为数据源定义连接属性。
在“提供程序”列表中,确保已选中“本机OLE DB\SQL Server Native Client 10.0”。
Analysis Services还支持“提供程序”列表中显示的其他访问接口。
∙在“服务器名称”文本框中,键入localhost。

SqlServer数据库分区分表实例分享(有详细代码和解释)数据库单表数据量太⼤可能会导致数据库的查询速度⼤⼤下降(感觉都是千万级以上的数据表了),可以采取分区分表将⼤表分为⼩表解决(当然这只是其中⼀种⽅法),⽐如数据按⽉、按年分表,最后可以使⽤视图将⼩表重新并为总的虚拟表,其实并不影响上层程序的使⽤(程序也许都不知道分表了)。
主要步骤:1、新建⽂件组,将数据表⽂件保存路径指向相应⽂件组(应将⽂件组和⽂件放⼊不同的磁盘中,甚⾄不同服务器形成分布式数据库,因为数据的读取瓶颈很⼤程度在于磁盘的的读写速度,多个磁盘存放⼀个表可以负载均衡)2、设置分区函数(声明分区的标准)3、设置分区⽅案(即哪些区域使⽤哪个分区函数,形成完整的分区⽅案)4、给新表或现有表设置分区⽅案5、建⽴视图详细步骤(看需求可选):⼀、数据库状态备份和恢复USE master-- 备份BACKUP DATABASE AdventureWorksTO DISK = 'AdventureWorks.bak'WITH FORMAT---- 恢复RESTORE DATABASE AdventureWorksFROM DISK = 'AdventureWorks.bak'WITH REPLACEGO⼆、⽂件组和⽂件操作添加⽂件组USE [master]GOALTER DATABASE ZHH ADD FILEGROUP [⽂件组名称]Go添加⽂件并把其指向指定⽂件组USE master;GOALTER DATABASE 数据库名ADD FILE(NAME=N'⽂件名',FILENAME='存放路径', //如:E:\201109.NDF(精确到⽂件名)⽂件组存放与不同磁盘可以提⾼IO读写效率(多个磁头并发)SIZE=3MB,MAXSIZE=100MB,FILEGROWTH=5MB)TO FILEGROUP [⽂件组名]Go修改⽂件(可选)USE master;GOALTER DATABASE 数据库名MODIFY FILE(NAME = ⽂件名,SIZE = 20MB); //可以修改所有属性,列举即可GO删除⽂件(可选)ALTER DATABASE 数据库名 REMOVE FILE [⽂件组名]三、分区函数和分区⽅案分区函数⽤于规范如何分区的标准,如已哪列进⾏为标准分区、分区的⽅式(按时间、ID等)、分区的具体界限(⼀般来说,界限指标数要⽐分区数少1,⼀⼑则有两段)USE 数据库名GOCREATE PARTITION FUNCTION 分区函数名 (指标列的数据类型) //如:datetime、intAS RANGE RIGHT //右边界切分,默认为LEFTFOR VALUES (划分界限) //如时间划分('2003/01/01', '2004/01/01'),两个时间界限可划分出三个分区GO分区⽅案⽤于将已经建⽴好的分区函数组织成完整的⽅案,为每个分区分配存储位置Use 数据库名gocreate partition scheme 分区⽅案名as partition 分区函数to(⽂件组1,⽂件组2,⽂件组3,...) //注意分区数要与实际分区⼀致go在原有的基础上添加分区(可选)use 数据库名goalter partition scheme ps_OrderDate next used [FG4] //修改分区⽅案ps_OrderDate,定义新新分区使⽤FG4⽂件组alter partition function pf_OrderDate() split range('2005/01/01') //修改分区函数pf_OrderDate,在末尾添加界限'2005/01/01'go为现有表设置分区⽅案(可选)//为AutoBench表的InsertTime列创建新聚集索引,并绑定Scheme_DateTime分区⽅案CREATE CLUSTERED INDEX IX_CreateDate ON AutoBench (InsertTime)ON Scheme_DateTime (InsertTime)注:如原来主键有聚众索引要将其改为⾮聚集索引,才可添加新聚众索引//删除原主键上的聚集索引PK_ProductALTER TABLE Product DROP CONSTRAINT PK_Product//重新创建主键⾮聚集索引PK_ProductALTER TABLE Product ADD CONSTRAINT PK_Product PRIMARY KEY NONCLUSTERED (ProductID ASC)上⾯语句也可直接在索引属性中将聚集改为⾮聚集为新建表设置分区⽅案(可选)//创建表格Order,并设置Scheme_DateTime分区⽅案,指标列为OrderDateCREATE TABLE [Order](OrderID INT IDENTITY(1,1) NOT NULL,UserID INT NOT NULL,TotalAmount DECIMAL(18,2) NULL,OrderDate DATETIME NOT NULL) ON Scheme_DateTime (OrderDate)查询分区数据四、其他操作查询分区数据$partition函数--为任何指定的分区函数返回分区号,⼀组分区列值将映射到该分区号中语法: [ database_name. ] $PARTITION.partition_function_name(expression)参数: database_name 包含分区函数的数据库的名称。
sqlserver中partition用法在SQL Server中,分区(Partition)是一种将表的数据分布在多个物理位置的技术,以便更有效地管理数据和访问速度。
通过分区,可以将表拆分为较小的逻辑部分,以便更方便地执行查询和管理操作。
以下是SQL Server中分区的一些常见用法:1、创建分区表:在创建分区表时,需要定义分区的数量和每个分区包含的列。
以下是一个创建分区表的示例:sqlCREATE TABLE PartitionedTable(Column1 INT,Column2 VARCHAR(50),...)WITH (DATA_COMPRESSION = PAGE)ON PartitionScheme (PartitionColumn) =(PARTITION_Scheme1 (01, 02, 03),PARTITION_Scheme2 (04, 05, 06),...);在上面的示例中,PartitionedTable 是要创建的分区表的名称,Column1 和Column2 是表中的列。
WITH (DATA_COMPRESSION = PAGE) 指定了使用页压缩来压缩数据。
ON PartitionScheme 指定了分区方案,其中PartitionColumn 是用于分区的列,而PARTITION_Scheme1 和PARTITION_Scheme2 是定义分区的方案和范围。
2、查询分区表:查询分区表时,可以使用分区键的值来确定要查询的分区。
以下是一个查询分区表的示例:sqlSELECT *FROM PartitionedTableWHERE PartitionColumn = '01'; --根据分区键的值筛选数据在上面的示例中,PartitionedTable 是已分区的表,PartitionColumn 是用于分区的列。
通过在WHERE 子句中使用适当的分区键值,可以仅查询特定的分区。
一、先决条件若要完成本教程,需要使用下列组件、示例和工具:•SQL Server 数据库引擎(SQL Server 2012自带)•Analysis Services(SQL Server 2012自带)•SQL Server Data Tools(SQL Server 2012自带)•HealthDW数据库(微软webcast提供,这里也提供一个下载)•Excel 2010二、设定场景Health 公司是一家保健公司,积累了员工信息,产品信息,产品的单价和产品的销售息产品信息产品的单价和产品的销售量。
该公司希望建立多维数据集了解不同部门员工的销售业绩。
部门员工的销售业绩。
例如,想要了解2008年网售部门销售八组石雷的销售业绩。
三、实现步骤1、新建并还原HealthDW数据库到本机实例中,略去。
2、打开SQL Server 2012自带的SSDT,新建一个Analysis Services Multidimensional and Data Mining Project,命名为SSASLearn01,然后建立数据源、数据源视图,这个略去。
3、新建cube,并引用前面刚新建的数据源视图。
4、新建三个维度,选择三个维度表,其他全部默认。
完成后界面如图:5、我们首先创建日期维度,产品维度和员工维度与些相似。
注意月维度必须包含年,因为独立的月毫无意义。
好了,此时,部署整个项目,第一次需要这样,后面只需要单独处理维度或cube即可完成部署。
部署完成后,我们可以浏览下日期维度的浏览效果:注意上图中的月1有多个,但代表的是不同年份。
这里有个小小的bug,就是月份排列按字符排列,不是按实际月份数字排列,修正一下即可此时对该维度,Process,并Reconnection,得到如下效果:排序妥了,我们希望的得到一个日期的层次结构钻取,再做如下修改即可。
对Cube,Process,并Reconnection,得到如下效果:注意,SQL Server 2012自带的SSDT已经废除了在该开发界面中对多维数据集的浏览,我们只能转到Excel界面完成6、我们继续完成产品维度和员工维度的设计。
visual studio analysis services 使用Visual Studio Analysis Services(简称SSAS)是微软提供的用于开发和管理多维数据模型的工具。
它是 SQL Server 数据平台的一部分,用于创建、部署和管理分析解决方案。
本文将介绍如何使用Visual Studio Analysis Services进行多维数据模型的开发。
Visual Studio Analysis Services提供了丰富的功能,方便开发人员创建和管理多维数据模型。
以下是使用Visual Studio Analysis Services的一些基本步骤:1. 安装Visual Studio Analysis ServicesVisual Studio Analysis Services是SQL Server Data Tools(SSDT)的一部分,可以通过下载和安装SQL Server Data Tools来安装Visual Studio Analysis Services。
2. 创建新的多维数据模型项目在Visual Studio中,选择“文件”菜单,然后选择“新建”>“项目”。
在“新建项目”对话框中,选择“分析服务多维项目”模板,指定项目的名称和位置,然后单击“确定”按钮。
3. 定义数据源和数据源视图在解决方案资源管理器中,右键单击“数据源”文件夹,选择“添加新项”。
在“添加新项”对话框中,选择“数据源”模板,指定数据源的名称和连接字符串,然后单击“添加”按钮。
在解决方案资源管理器中,右键单击“数据源”文件夹,选择“添加新项”。
在“添加新项”对话框中,选择“数据源视图”模板,指定视图的名称和选择相关的表和列即可。
4. 创建和定义维度在解决方案资源管理器中,右键单击“维度”文件夹,选择“添加新项”。
在“添加新项”对话框中,选择“维度”模板,指定维度的名称和表格名称,然后单击“添加”按钮。
sqlserver数据库分区分表sql server 数据库分区分表作为演⽰,本⽂使⽤的数据库 sql server 2017 管理⼯具 sql server management studio 18,,创建数据库mytest,添加Test表,Test表列为 id和name,具体可以⾃⾏创建sql server 数据库分区分表具体步骤如下1、选择数据库选择右键新建查询,内容如下--数据库分区分表--1、给数据库mytest添加⽂件分组ALTER DATABASE mytest add filegroup group1;ALTER DATABASE mytest add filegroup group2;ALTER DATABASE mytest add filegroup group3;--2、给数据库mytest的⽂件分组添加分区⽂件ALTER DATABASE mytest add file(name=N'group1',filename=N'E:\Databasepartitionsubtable\group1.ndf',size=5Mb,filegrowth=5mb) to filegroup group1;ALTER DATABASE mytest add file(name=N'group2',filename=N'E:\Databasepartitionsubtable\group2.ndf',size=5Mb,filegrowth=5mb) to filegroup group2;ALTER DATABASE mytest add file(name=N'group3',filename=N'E:\Databasepartitionsubtable\group3.ndf',size=5Mb,filegrowth=5mb) to filegroup group3;注意:在添加分区⽂件的时候这个分区⽂件的路径filename 必须是存在的,菲欧泽报错,可以先创建⼀个路径和⽂件夹即可,本⽂是: E:\Databasepartitionsubtable创建成功之后,可以查看,选择mytest数据库,右键属性⽂件组,如下所⽰2、数据库mytest中的数据表Test添加分区--例如:dbo.Test表做分区--选择dbo.Test表-》右键存储-》创建分区,更具创建分区向导处理即可,在选择分区列时,--我们选择ID,这样就可以设置分区了,--如id 为1-10000,存储到主⽂件组PRIMARY--如id 为10001-20000,存储到group1--如id 为20001-30000,存储到group2--如id 为30000以上,存储到group3向导如下图下⾯分区的范围,左边界和右边界意思就是,分界值存储在房钱分组还是下⼀个分组选择左边界--我们选择ID,这样就可以设置分区了,--如id 为1-10000,存储到主⽂件组PRIMARY--如id 为10001-20000,存储到group1--如id 为20001-30000,存储到group2--如id 为30000以上,存储到group3上述操作完成以后,我们的数据库分区分表就完成了,查看表的分区存储情况选择Test表右键属性-》存储可以看到分区和⽂件组选择myest数据库右键属性-》⽂件,可以看到分区⽂件、⽂件组注意:⼀盘数据库分区分表建议不要进⾏全表扫描,可以使⽤条件查询,这个性能更好,本⽂只是问了演⽰做了id来警醒分区分表存储的,其实如果Table中时间字段的话,并且有按照年分来使⽤的话,那么可以⼀句这个书简字段分进⾏分区分表存储,例如销售数据,2010-12-31,2011-12-31,2012-12-31,2013-12-31等等来进⾏分区分表。
SQLServer2008体系结构Microsoft SQL Server 2008系统有四部分组成:数据库引擎、Analysis Services、Reporting Services、Integration Services。
四个部分关系如下:1、数据库引擎数据库引擎是Microsoft SQL Server 2008的核⼼服务。
它是存储和处理关系格式数据或XML⽂档数据的服务,完成数据的存储、处理和安全管理。
例如创建数据库,创建表,创建视图,查询数据和访问数据库等操作,都是由数据库完成的。
通常,使⽤数据系统实际上就是使⽤数据库引擎。
2、Analysis ServicesAnalysis Services的主要作⽤是通过服务器和客户端技术组合提供联机分析处理和数据挖掘功能。
使⽤Analysis Services,⽤户可以设计、创建、管理包含其他数据源的多维结构,通过多维结构进⾏多⾓度分析,可以使管理⼈员对业务结构有更全⾯的理解。
3、Reporting ServicesReporting Services是⼀种基于服务器的解决⽅案。
⽤于⽣成多种数据源和多维数据源提取内容的企业报表,以及集中 管理安全性和订阅。
创建的报表可以通过基于Web的连接进⾏查看,也可以作为Microsoft Windows 应⽤程序的⼀部分进⾏查看。
4、Integration ServicesIntegration Services是⼀个数据集成平台。
负责完成有关数据的提取、转换和加载等操作。
对于Analysis Services来说,数据库引擎是⼀个重要的数据源,⽽如何将数据源中的数据经适当的处理加载到Analysis Services中以便进⾏各种分析处理。
这正是Integration Services所要解决的问题。
重要的是,Integration Services可以⾼效的处理各种各样的数据源,例如SQL Server、Oracle、Excel、XML、⽂本⽂档等。
sql server创建分区的步骤以SQL Server创建分区的步骤为标题,本文将详细介绍在SQL Server中创建分区的步骤和注意事项。
一、了解分区概念在开始创建分区之前,首先需要了解分区的概念。
分区是将数据库表或索引的数据划分为多个逻辑部分,以便更高效地管理和查询数据。
分区可以提高查询性能、简化数据维护和管理等方面的工作。
二、选择适合分区的表不是所有的表都适合进行分区,需要根据实际情况进行选择。
一般来说,具有以下特点的表适合进行分区:1. 数据量较大且频繁查询的表;2. 经常需要进行数据维护和管理的表;3. 需要按照某个特定的列进行频繁范围查询的表。
三、选择分区列分区列是用来确定如何将数据划分为不同分区的依据。
选择一个合适的分区列非常重要,它应该满足以下要求:1. 数据类型应该是整型、日期时间类型或字符类型;2. 数据分布均匀,避免某个分区过大或过小;3. 分区列应该是经常用于查询的列。
四、创建分区函数分区函数是用来定义如何将数据划分到不同分区的规则。
在创建分区函数时,需要指定分区的方式,可以按照范围、列表或哈希等方式进行分区。
1. 范围分区:按照一定的范围将数据划分到不同的分区,例如按照日期范围或数字范围等进行划分。
2. 列表分区:根据一个列的值列表将数据划分到不同的分区,例如按照地区或部门等进行划分。
3. 哈希分区:根据哈希算法将数据均匀地划分到不同分区,可以确保数据分布均匀。
五、创建分区方案分区方案是将分区函数与表或索引进行关联的对象。
在创建分区方案时,需要指定要分区的表或索引,以及使用的分区函数。
六、创建分区表在分区方案创建完成后,就可以创建分区表了。
创建分区表时,需要指定分区方案、分区列以及其他表的结构信息。
七、创建分区索引如果需要在分区表上创建索引,可以使用与创建普通索引相同的方法进行创建。
分区索引可以提高查询性能,并且可以根据分区的范围进行数据的快速定位。
八、分区表的维护和管理分区表的维护和管理与普通表有一些差异,需要注意以下几点:1. 分区表支持分区级别的维护操作,可以只对某个分区进行操作,而不影响其他分区。
创建并管理SQL Server Analysis Services分区分区是SQL Server Analysis Services度量值组的一部分,它保存度量值组的一些或全部数据。
当一个度量值组被首先创建之后,它包含了一个单一的分区,相当于事实表或视图中的所有数据。
额外的分区需要为有超过2000万行数据的度量值组而创建。
由于大多数企业数据库的事实表都有超过2000万行数据,所以你应该知道如何创建分区并注意良好分区的设计原则。
你可以Business Intelligence Development Studio (BIDS)定义分区。
在项目的分区标签页上,点击新建分区来打开分区向导。
另一种创建新分区的方法是使用XMLA脚本,这项工作是BIDS在后台完成的。
你可以在SQL Server Management Studio (SSMS)中编写已存在的分区脚本,只需右击一个分区,然后选择Script Partition创建脚本来打开新的查询窗口。
你需要修改一些属性,比如分区标签、名称以及用于填充分区的查询等。
下面就是一个简单的分区XMLA:< DatabaseID>Adventure Works DW 2008< CubeID>Adventure WorksFact Internet Sales 1Internet_Sales_2001Internet_Sales_2001Adventure Works DWSELECT[dbo].[FactInternetSales].[ProductKey],[dbo].[FactInternetSales].[OrderDateKey],[dbo].[FactInternetSales].[DueDateKey],[dbo].[FactInternetSales].[ShipDateKey],[dbo].[FactInternetSales].[CustomerKey],[dbo].[FactInternetSales].[PromotionKey],[dbo].[FactInternetSales].[CurrencyKey],[dbo].[FactInternetSales].[SalesTerritoryKey],[dbo].[FactInternetSales].[SalesOrderNumber],[dbo].[FactInternetSales].[SalesOrderLineNumber],[dbo].[FactInternetSales].[RevisionNumber],[dbo].[FactInternetSales].[OrderQuantity],[dbo].[FactInternetSales].[UnitPrice],[dbo].[FactInternetSales].[ExtendedAmount],[dbo].[FactInternetSales].[UnitPriceDiscountPct],[dbo].[FactInternetSales].[DiscountAmount],[dbo].[FactInternetSales].[ProductStandardCost],[dbo].[FactInternetSales].[TotalProductCost],[dbo].[FactInternetSales].[SalesAmount],[dbo].[FactInternetSales].[TaxAmt],[dbo].[FactInternetSales].[Freight],[dbo].[FactInternetSales].[CarrierTrackingNumber],[dbo].[FactInternetSales].[CustomerPONumber]FROM [dbo].[FactInternetSales]WHERE OrderDateKey <= '20011231'MolapRegular-PT1S-PT1S-PT1S-PT1SMolapOnlyServer1013Internet Sales 1注意:当要定义有效分区时,确定数据来源是最重要的一步。
从以往经验来看,你的分区必须包含5到2000万行实际数据。
此外,你还要避免分区文件超过500MB。
分区文件存储在Analysis Services目录下:data\database_name\cube_name\measure_group_name。
你还可以将一个分区同表、视图和SQL查询绑定。
如果一个关系型数据仓库有多个表单存储事实数据,并且表单大小不超过建议范围,那么你就应该将分区同表绑定。
如果你有一个单一的大事实表,那么你可以为每一个Analysis Services分区写一个SQL 查询来检索部分数据。
视图为分区绑定提供了一个不错的选择,特别是在做立方体测试时。
例如:如果事实表有数百万行数据,那么对它的处理就会十分耗时。
在测试解决方案时,你不必读取所有数据,而只需创建一个视图,只选择表中部分行就可以了。
然后,当你准备将方案应用到生产中时,修改你的分区定义,让它们同适合的表、查询和视图绑定。
你如何决定什么样的数据应该出现在分区当中?SQL Server Analysis Services使用分区来加速MDX查询。
每个分区都包含一个XML文件,它定义了某个分区内的成员维度标识范围。
当执行一个MDX查询时,Analysis Services引擎将根据每个分区中的XML 文件value来决定扫描那些分区文件。
XML文件是在处理分区时创建的,它存储在每个分区文件夹中。
不要试图编辑它,因为维度的关键参考值是内部值,SQL Server Analysis Services不可以进行检索。
如果MDX查询的数据请求遍布度量组的所有分区时,Analysis Services就不得不读取所有分区。
想要知道度量组中哪些分区被读取了,你可以记录一个SQL Profiler追踪。
如果查询数据请求只存在于单一分区中,你的查询只需扫描一个分区文件就可以了。
读取一个500MB的文件总比扫描总大小相同的200个文件要强。
如果你要读取200个分区,Analysis Services可以并行扫描器中的一部分。
要是有良好的分区设计,你就不必非要进行200次的缓慢查询了。
为达到最佳MDX查询性能,你应该调整分区设计以适应普通查询。
大多数SQL Server Analysis Services方案都以使用数据或周期维度的度量组分区开始,每个分区生成一个月或一天的数据。
如果你的查询通常集中在某个月内,这不失为一种好的方法。
但是如果查询检验所有月份的数据并具体到产品类别该怎么办?这样的话,按月分区并不是最佳方法。
如果你有十年内的有用数据,并按月分区(这种情况并不常见),那每个查询将检索120个分区。
这种情况下,如果按照产品类别维度来适当增长分区日期跨度,那么查询性能无疑会更好。
像其他SQL Server Analysis Services对象一样,分区拥有大量属性。
而被谈论最多的恐怕就是partition slice了。
这一属性定义了度量组中的部分数据,Analysis Services期望它们被分区曝光。
大多数Analysis Services资料建议不必为多维OLAP存储分区而设置partition slice属性。
然而在大多数情况下,Analysis Services可以通过检测info.xml 文件中的数据ID来判断每个分区中的成员维度,为安全起见你应该设置partition slice属性,无论分区采用哪种存储模式。
partition slice通过MDX定义。
下面是一个例子,2001分区的slice定义:[Date].[Calendar].[Calendar Year]. &[2001]按照产品分类进行数据分区,slice定义如下:([Date].[Calendar].[Calendar Year]. & [2001], [Product].[Product Catego ries].[Category]. & [1])你如果在某个维度中没有定义slice,SQL Server Analysis Services就默认为任何维度中的成员都能在分区中找到。
例如:在partition slice中指定一个月份和产品类别但没有指定商店。
按照商店检索销售数据的查询可能就会检索所有分区了。
你还可以为每个分区都自定义一个存储模式。
MOLAP存储模式对于数据检索是最佳的,但它会对你的相关数据进行拷贝。
如果不想拷贝,你可以使用关系型OLAP模式。
比如:最近的分区可以使用MOLAP模式而原来的分区可以使用ROLAP。
SQL Server Analysis Services对于分区数有一个上限2,147,483,647,但是cube 拥有这么多分区的情况并不常见。
所以不必担心分区上限问题。
但数据很陈旧并很少有人访问时,你可以把原来的分区合并为周分区或月分区。
你可以使用SSMS来合并分区,右键点击分区选择合并分区选项。
以下是一个合并分区的XMLA:<MergePartitionsxmlns="/analysisservices/2003/engine"><Sources><Source><DatabaseID>Adventure Works DW 2008</DatabaseID><CubeID>Adventure Works</CubeID><MeasureGroupID>Fact Internet Sales 1</MeasureGroupID><PartitionID>Internet_Sales_2002</PartitionID></Source></Sources><Target><DatabaseID>Adventure Works DW 2008</DatabaseID><CubeID>Adventure Works</CubeID><MeasureGroupID>Fact Internet Sales 1</MeasureGroupID><PartitionID>Internet_Sales_2001</PartitionID></Target></MergePartitions>注意你可以把集合设计从一个分区拷贝到另一个分区。