
第一章导论
1.1参数:用来描述总体特征的概括性数字度量,用来描述总体特征。
统计量:用来描述样本特征的概括性数字度量。
1.3 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。这一研究的总体是什么?样本是什么?样本量是多少?
详细答案:总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
1.4一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。(1)这一研究的总体是什么?(2)研究者所关心的参数是什么?(3)研究者所使用的主要是描述统计方法还是推断统计方法?
详细答案:(1)总体是“所有的网上购物者”。(2)网上购物消费者的平均花费(3)推断统计方法。(推断统计是研究如何用样本
..数据来推断总体特征的统计方法。)
第二章数据的搜集
1、按照统计数据的收集方法,可以将其分为观测数据和实验数据。
2、收集数据的基本方法是自填式、面访式和电话式。
第三章数据的图表展示
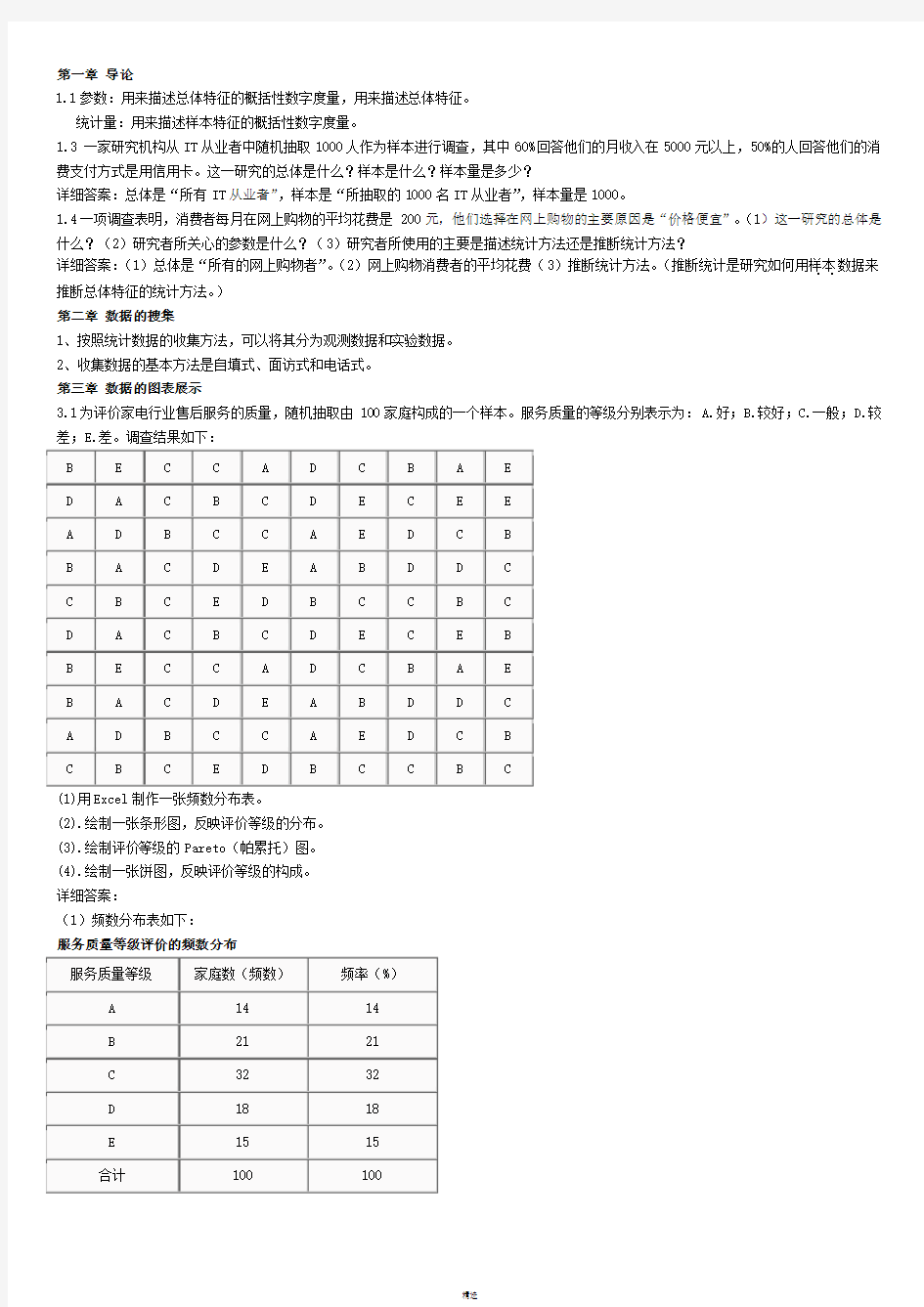
3.1为评价家电行业售后服务的质量,随机抽取由100家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C.一般;D.较差;E.差。调查结果如下:
(1)用Excel制作一张频数分布表。
(2).绘制一张条形图,反映评价等级的分布。
(3).绘制评价等级的Pareto(帕累托)图。
(4).绘制一张饼图,反映评价等级的构成。
详细答案:
(1)频数分布表如下:
服务质量等级评价的频数分布
(2)条形图如下:
(3)帕累托图如下:(4)饼图如下:
3.3某百货公司连续40天的商品销售额如下(单位:万元):
41 25
29 47 38 34 30 38 43 40
46 36 45 37 37 36 45 43 33 44
35 28 46 34 30 37 44 26 38 44
42 36 37 37 49 39 42 32 36 35
根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
详细答案:
1)确定组数:数据中最大值为49,最小值为25,知数据全距为49-25=24,确定将数据分为5组;2)确定组距:组距=(最大值-最小值)/组数=(49-25)/5=4.8,取组距为5;
3)频数分布表:
某百货公司日商品销售额频数分布表
按销售额分组(万元)频数(天)频率(%)
25~30 30~35 35~40 40~45 45~50 4
6
15
9
6
10.0
15.0
37.5
22.5
15.0
合计40 100.0 4)直方图:
3.4利用下面的数据构建箱线图和茎叶图。
57 29 29 36 31
23 47 23 28 28
35 51 39 18 46
18 26 50 29 33
21 46 41 52 28
21 43 19 42 20
详细答案:(1)箱线图:(首先找出一组数据的5个特征值,即最大值、最小值、中位数Me和两个四分位数(下四分位数QL和上四分位数QU),然后连接两个四分位数画出箱子,再将两个极值点与箱子相连接)
(2)茎叶图:
某公司电脑销售额分布的茎叶图
3.10下面是A、B两个班学生的数学考试成绩数据:
A班:
44 57 59 60 61 61 62 63 63 65
66 66 67 69 70 70 71 72 73 73
73 74 74 74 75 75 75 75 75 76
76 77 77 77 78 78 79 80 80 82
85 85 86 86 90 92 92 92 93 96
B班:
35 39 40 44 44 48 51 52 52 54
55 56 56 57 57 57 58 59 60 61
61 62 63 64 66 68 68 70 70 71
71 73 74 74 79 81 82 83 83 84
85 90 91 91 94 95 96 100 100 100
(1)将两个班的考试成绩用一个公共的茎制成茎叶图;
(2) 比较两个班的考试成绩的离散程度。
(3) 如果让你选择一个班,你会选择哪—个?试说明理由。 (4) 比较两个班考试成绩分布的特点。
详细答案:(1)
Stem-and-Leaf Plot
Frequency
Leaf (A 班)
Stem Leaf (B 班)
Frequency
0 3 59 2 1 4 4 0448 4 2 97
5 122456677789 12 11 97665332110
6 011234688 9 23 98877766555554443332100
7 00113449 8 7 6655200 8 123345 6 6 632220
9 011456 6 0
10
000
3
Stem width: 10 Each leaf: 1 case(s)
A 、
B 两个班学生的数学考试成绩分布的茎叶图
(2)A 班的考试成绩的离散系数x S v s
标准差)
(=
==1.97/7.2=0.2736
B 班的考试成绩的离散系数x
S v s
标准差)
(=
=0.74/6.93=0.1068
(3)选择第二种。因为第二种方式平均等待时间为 6.96,比第一种方式平均等待时间短,而且第二种排队方式的标准差离散系数V 2=0.1068,小于第一种排队方式的标准差离散系数V 1=0.2736,说明第二种方式的等待时间离散程度也小于第一种。 (4)比较可知:A 班考试成绩的分布比较集中,且平均分数较高;B 班考试成绩的分布比A 班分散,且平均成绩较A 班低。
3.12
第四章 数据的概括性度量
1几何平均数:n
n
i i
x G ∏==1
(∏连乘符号)
是连乘符号);异众比率:∑-
=i
m
r f f V 1(∑i f 是变量值的总频数,m f 是众数的频数);四分位差:Q d = Q U
–Q L ;平均差:n
x x M n
i i d
∑=-=1
;标准分数:s
x x i
i z -=
1.1一家汽车零售店的 10 名销售人员 5 月份销售的汽车数量(单位:辆)排序后如下: 2 4 7 10 10 10 12 12 14 15
(1)计算汽车销售量的众数、中位数和平均数。 (2)根据定义公式计算四分位数。 (3)计算销售量的标准差。 (4)说明汽车销售量分布的特征。 详细答案:
将汽车销售数量按升序排序: 2 4 7 10 10 10 12 12 14 15
(1)汽车销售数量出现频数最多的是10,所以众数M o =10(辆)
中位数位置= (10+1)/2=5.5,所以中位数为Me=(10+10)/2=10(辆)
平均数1
n
i
i X
X n
==
∑=(2+4+7+10+10+10+12+12+14+15)/10=9.6(辆)
(2)下四分位数Q L 的位置=n/4=10/4=2.5 即Q L 在第2个数和第3个数之间0.5的位置上 因此,Q L =4+(7-4)*0.5=5.5(辆)
上四分位数Q U 的位置=3n/4=3*10/4=7.75 即Q U 在第7个数和第8个数之间0.75的位置上 因此,Q U =12+(12-12)*0.75=12.75(辆) (3)
标准差:
1
)
(1
2
--=
∑=n x x s n
i i
=√[(2-9.6)2+(4-9.6)2+(7-9.6)2+(10-9.6)2+(10-9.6)2+(10-9.6)2+(12-9.6)2
+(12-9.6)
2
+(14-9.6)2
+(15-9.6)2
]/9=2.042(辆)
(4)(可画出数据分布直方图。)数据集中在Q L 和Q U 之间,分布较为集中,数据稍有左偏分布,轻微扁平分布。(①集中趋势②离散程度③偏态(左偏、右偏、对称)④峰态(扁平、尖峰、峰态适中))
4.8经验法则表明:当一组数据对称分布时, 约有68%的数据在平均数± 1个标准差的范围之内; 约有95%的数据在平均数± 2个标准差的范围之内; 约有99%的数据在平均数± 3个标准差的范围之内。 4.9标准分数:s
x x z i i -=
,选择高的。
第11章 一元线性回归
r=0时,说明Y 的取值与X 无关,即二者不存在线性相关关系。都不能说X 与Y 不相关或不存在任何关系。r 的绝对值大于0.8时为高度相关;在0.5到0.8之间为中度相关;0.3与0.5之间为低度相关;小于0.3视为不相关。 11.1从某一行业中随机抽取12家企业,所得产量与生产费用的数据如下: 企业编号 产量(台) 生产费用(万
元)
企业编号 产量(台) 生产费用(万
元) 1 40 130 7 84 165 2 42 150 8 100 170 3
50
155
9
116
167
4
55 140 10 125 180 5 65 150 11 130 175 6
78
154
12
140
185
(1)绘制产量与生产费用的散点图,判断二者之间的关系形态。
(2)计算产量与生产费用之间的线性相关系数,并说明二者之间的关系。 (3)对相关系数的显著性进行检验(
),并说明二者之间的关系强度。
(4)利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。 (5)计算判定系数和估计标准误差,并解释其意义。 (6)检验回归系数的显著性()。
(7)检验线性关系的显著性。
求生产费用为145元时,产量95%的置信区间和预测区间。
详细答案: (1)散点图如下:
产量与生产费用之间是正线性相关关系。
(2)相关系数,所以r=0.9243。产量与生产费用之间是中度正线性相关关系。(注:判定系数等于相关系数的平方,即R 2
=r 2
) (3)检验统计量
①提出假设:H0:ρ=0;H1:ρ≠0; ②计算检验的统计量:=1.2314。
根据显著性水平α=0.05,查t 分布表得t α/2(n-2)=0.069。
由于|t|=1.2314>t α/2(6-2)=0.069,拒绝H0,产量与生产费用之间存在着显著的线性相关关系。若 (4)() ???? ???--=-=∑∑x x y x n y x n x y i i i 22 110???βββ, x y 1 0???ββ+=,所以估计的回归方程为 y 1 0???ββ+= -0.3295 + 1.027895 x 回归系数 1?β的意义:表示生产费用每增加1万元,产量平均增加1.027895台。 (5)判定系数 ()() ()() ∑∑∑∑====--- =--== n i i n i i n i i n i i y y y y y y y y SST SSR R 12 12 1 2 12 2??1?,SST= SSR+SSE 。所以R 2 =85.43%,表明在产量的变差中,有85.43%是由于生产 费用的变动引起的。(注:判定系数等于相关系数的平方,即R 2 =r 2 ) 估计标准误差 ()MSE n SSE n y y s n i i i e =-= --= ∑=22 ?1 2 ,所以S e =0.5。意义:表示用生产费用预测产量的平均估计误差为0.5台。 (6)①提出假设:H0:β1=0,H1:β1≠0 ;②计算检验的统计量: 1 ? 1?ββs t = (其中 () ∑-= 2 ?1 x x s s i e β);③作出决策:若|t|>t α/2,拒绝 H0,表明产量与生产费用之间有显著的线性关系;若|t|>t α/2,不拒绝H0,没有证据表明产量和生产费用之间有显著的线性关系。 (7)①提出假设:H0:β1=0,两个变量之间线性关系不显著;②计算检验统计量F: ) 2,1(~21-=-= n F MSE MSR n SSE SSR F ,所以求得F=11.235;③根据显 著性水平α、分子自由度df 1=1和分母自由度df 2=n-2查F 分布表,找到临界值F αα④作出决策:若F>F α,拒绝H0,表明产量和生产费用之间的线性关系是显著的;若F (8)置信区间: ()() ∑=--+-±n i i e x x x x n s n t y 1 2 2001 )2(?α,预测区间: ()() ∑=--++-±n i i e x x x x n S n t y 1 2 20201 1)2(?α(其中 0?y = -0.3295 + 1.027895 ×145)。求出置信区间:[147.49,148.67];预测区间:[150.46,155.73]。 11.9 某汽车生产商欲了解广告费用(x )对销售量(y )的影响,收集了过去12年的有关数据。通过计算得到下面的有关结果: 方差分析表 参数估计表 (1)完成上面的方差分析表。 (2)汽车销售量的变差中有多少是由于广告费用的变动引起的? (3)销售量与广告费用之间的相关系数是多少? 详细答案: (1)方差分析表 (2)判定系数() ()()()∑ ∑∑ ∑====--- =--== n i i n i i n i i n i i y y y y y y y y SST SSR R 12 12 1 212 2??1?。所以R 2 =1422708.6/1462866.67=97.25%,表明在汽车销售量的变差中,有97.25%是由于广告费用的变动引起 的。 (3)r=√R 2 =√0.9725=98.62%。 第十二章 多元线性回归 12.2 根据下面Excel 输出的回归结果,说明模型中涉及多少个自变量?多少个观察值?写出回归方程,并根据F 、S e 、R 2 及调整的2 a R 的 值对模型进行讨论。 Adjusted R Square 0.630463 标准误差109.429596 观测值15(n) 方差分析 df SS MS F Significance F 回归 3 (k)321946.8018 107315.6006 8.961759 0.002724 残差11(n-k-1)131723.1982 11974.84 总计14(n-1)453670 Coefficients 标准误差t Stat P-value Intercept 657.0534 167.459539 3.923655 0.002378 X Variable 1 5.710311 1.791836 3.186849 0.008655 X Variable 2 -0.416917 0.322193 -1.293998 0.222174 X Variable 3 -3.471481 1.442935 -2.405847 0.034870 详细答案: (1)模型中涉及3个自变量,15个观察值。 (2)估计的回归方程为:y? =657.0534+5.710311X1-0.416917X2-3.471481X3。 (3)拟合优度:从判定系数R2=0.709650和调整的判定系数 2 a R=0.630463 ,表明在因变量的变差中,有63.05%是由于三个自变量的变动 引起的。 (4)估计标准误差S e=109.429596,表示用自变量预测因变量的平均估计误差为109.429596,预测误差比较大。 (5)线性关系的显著性检验:Significance F=0.002724<α=0.05,表明因变量Y与3个自变量之间的线性关系显著。 (5)回归系数的检验:β1的t检验的P=0.008655 12.4一家电气销售公司的管理人员认为,每月的销售额是广告费用的函数,并想通过广告费用对月销售额作出估计。下面是近8个月的销售额与广告费用数据。 月销售收入y(万元)电视广告费用(万元)报纸广告费用(万元) 96 5.0 1.5 90 2.0 2.0 95 4.0 1.5 92 2.5 2.5 95 3.0 3.3 94 3.5 2.3 94 2.5 4.2 94 3.0 2.5 (1)用电视广告费用和报纸广告费用作自变量,月销售额作因变量,建立估计的回归方程。 (2)对上述估计方程中电视广告费用的回归系数进行解释。 (3)在销售收入的总变差中,被估计的回归方程所解释的比例是多少。 (4)检验线性关系是否显著(a=0.05)。 (5)检验回归系数是否显著(a=0.05)。 详细答案: (1) 22110????x x y βββ++=。需要用Excel 计算,得出 y ?=83.23+2.29x 1+1.3x 2。 (2)电视广告费用的回归系数表示:在报纸广告费用不变的情况下,电视广告费用每增加1万元,月销售额平均增加2.29万元。 (3)多重判定系数R 2 =SSR/SST ,R E T )?()?()(222 SS SS SS y y y y y y i t i i +=-+-=-∑∑∑,所以R 2 =0.919;调整的 11 ) 1(122 -----=k n n R R a , 2 a R =0.88665。表明在销售收入的总变差中,被估计的多元回归方程所解释的比例为88.665%。 (4)①提出假设:H0:β1=β2=0,H1:β1和β2至少有一个不等于0;②计算检验统计量F:,所以求得F=19.704;③作出决策:根据显著性水平α、分子自由度df 1=2和分母自由度df 2=n-k-1=5查F 分布表,找到临界值F α;若F>F α,拒绝H0,表明销售收入与电视广告费用和报纸广告费用之间的线性关系是显著的;若F (5)①提出假设:对于任意参数βi (i=1,2),H0:βi =0,H1:βi ≠0 ;②计算检验的统计量: j S t i i ββ ? ?= (其中 ??????-= ∑∑22?)(1i i e x n x S S j β, 1--= k n SSE S e ),得出t 1=2.29/0.304=7.53,t 2=1.3/0.32=4.05;③作出决策:根据给定显著性水平a=0.05和自由度=n-k-1=5查表得 t 0.025(5)=2.57。|t 1|>t α/2,拒绝H0,表明y 与x 1之间有显著的线性关系;|t 2|>t α/2,拒绝H0,表明y 与x 2之间也有显著的线性关系。 第十三章 时间序列分析和预测 13.1下表是1981年—1999年国家财政用于农业的支出额数据 (1)绘制时间序列图描述其形态。 (2)计算年平均增长率。 (3)根据年平均增长率预测2000年的支出额。 详细答案: (1)时间序列图如下: 从时间序列图可以看出,国家财政用于农业的支出额大体上呈指数上升趋势。 (2)年平均增长率10 -=n n Y Y G ,所以G =。 (3)2000年的支出额预测值为。 第十三章 时间序列分析和预测 1.时间序列类型:平稳序列、有趋势的序列、有季节性的序列、有季节性和趋势的序列、有周期性的序列、随机性序列。 1、 增长率:环比增长率与定基增长率。环比增长率:G i =Y i /Y i-1-1,表现逐渐变化的程度;定基增长率:G i =Y i /Y 0-1,表现总增长变化程 度。均方误差:增长1%的绝对值表示增长率每增长1个百分点而增加的绝对数量。n F Y MSE n i i i ∑=-= = 1 2 ) (误差个数 误差平方和 13.1下表是 1981 年—1999 年国家财政用于农业的支出额数据 年份 支出额(亿元) 年份 支出额(亿元) 1981 110.21 1991 347.57 1982 120.49 1992 376.02 1983 132.87 1993 440.45 1984 141.29 1994 532.98 1985 153.62 1995 574.93 1986 184.2 1996 700.43 1987 195.72 1997 766.39 1988 214.07 1998 1154.76 1989 265.94 1999 1085.76 1990 307.84 (1)绘制时间序列图描述其形态。 (2)计算年平均增长率。 (3)根据年平均增长率预测2000年的支出额。 详细答案: (1)时间序列图如下: 从时间序列图可以看出,国家财政用于农业的支出额大体上呈指数上升趋势。 (2)年平均增长率为:10 -=n n Y Y G = n √(1085.76/110.21)-1=113.55%-1=13.55% (3)2000年的支出额预测值为:^ Y =1085.76*(1+13.55%)=1232.88 13.2下表是 1981 年—2000 年我国油彩油菜籽单位面积产量数据(单位: kg / hm2 ) 年份 单位面积产量 年份 单位面积产量 1981 1451 1991 1215 1982 1372 1992 1281 1983 1168 1993 1309 1984 1232 1994 1296 1985 1245 1995 1416 1986 1200 1996 1367 1987 1260 1997 1479 1988 1020 1998 1272 1989 1095 1999 1469 1990 1260 2000 1519 (1)绘制时间序列图描述其形态。 (2)用 5 期移动平均法预测 2001 年 的单位面积产量。 (3)采用指数平滑法,分别用平滑系数 a=0.3 和 a=0.5 预测2001年的单位面积产量,并说明用哪一个平滑系数预测更合适? (4)建立一个趋势方程预测各月的营业额,计算出估计标准误差。 详细答案: (1 )时间序列图如下: (2 )2001年的预测值为:=t Y (1367+1479+1272+1469+1519)/5=1421.2 (3 ) 年份 单位面积产量 指数平滑预测 误差平方 指数平滑预测 误差平方 a=0.3 a=0.5 1981 1451 1982 1372 1451.0 6241.0 1451.0 6241.0 1983 1168 1427.3 67236.5 1411.5 59292.3 1984 1232 1349.5 13808.6 1289.8 3335.1 1985 1245 1314.3 4796.5 1260.9 252.0 1986 1200 1293.5 8738.5 1252.9 2802.4 1987 1260 1265.4 29.5 1226.5 1124.3 1988 1020 1263.8 59441.0 1243.2 49833.6 1989 1095 1190.7 9151.5 1131.6 1340.8 1990 1260 1162.0 9611.0 1113.3 21518.4 1991 1215 1191.4 558.1 1186.7 803.5 1992 1281 1198.5 6812.4 1200.8 6427.7 1993 1309 1223.2 7357.6 1240.9 4635.8 1994 1296 1249.0 2213.1 1275.0 442.8 1995 1416 1263.1 23387.7 1285.5 17035.9 1996 1367 1308.9 3369.9 1350.7 264.4 1997 1479 1326.4 23297.7 1358.9 14431.3 1998 1272 1372.2 10031.0 1418.9 21589.8 1999 1469 1342.1 16101.5 1345.5 15260.3 2000 1519 1380.2 19272.1 1407.2 12491.7 合计 — — 291455.2 — 239123.0 2001年a=0.3时的预测值为:200020002001)1(F Y F αα-+==0.3*1519+(1-0.3)*1380.2=1421.8 2001年a=0.5时的预测值为:200020002001 )1(F Y F αα-+==0.5*1519+(1-0.5)*1407.1=1263.1 比较误差平方可知,a=0.5 更合适。 (4)线性模型法:线性方程的形式为 bt a Y t +=?( t Y ?—时间序列的预测值;t —时间标号) 根据最小二乘法得到求解a 和b ()?????-=--=∑∑∑∑∑t b Y a t t n Y t tY n b 2 2。估计标准误差 m n Y Y s n i i i Y --=∑=1 2 ) ?((m 为未知常数的个数) 所以,求得趋势方程为 t Y t 59439.08985.16?-=,估计标准误差为 60.0=Y s 。 (延伸:①二次曲线: 2?ct bt a Y t ++=,根据最小二乘法求 a ,b ,c 的标准方程?? ?????++=++=++=∑∑∑∑∑∑∑∑∑∑∑4322322 t c t b t a Y t t c t b t a tY t c t b na Y 。②指数曲线方程为 t t ab Y =?,根据最小二乘法,得到求解lga 、lgb 的标准方程为?????+=+=∑∑∑∑∑2 lg lg lg lg lg lg t b t a Y t t b a n Y ,求出lga 和lgb 后,再根据n m n m =log 公 式,即得a 和b 。) 13.5以下为某啤酒生产企业2000-2005年个季度的销售量数据: 1)完整表格。 2)计算各季的季节指数。 A B C D E 1 年/季度 时间标号t 销售量Y 中心化移动平均值CMA 比值 (Y/CMA) 2 2000/1 1 25 - - 3 2 2 32 - - 4 3 3 37 (1) 1.2082 5 4 4 2 6 (2) 0.8125 6 2001/1 5 30 (3) 0.8989 7 2 6 3 8 34.500 1.1014 8 3 7 42 34.875 1.2043 9 4 8 30 34.875 0.8602 10 2002/1 9 29 36.000 0.8056 11 2 10 39 37.625 1.0365 12 3 11 50 38.375 1.3029 13 4 12 35 38.500 0.9091 14 2002/1 13 30 38.625 0.7767 15 2 14 39 39.000 1.0000 16 3 15 51 39.125 1.3035 17 4 16 37 39.375 0.9397 18 2003/1 17 29 40.250 0.7205 19 2 18 42 40.875 1.0275 20 3 19 55 41.250 1.3333 21 4 20 38 41.625 0.9129 22 2004/1 21 31 41.625 0.7447 23 2 22 43 41.875 1.0269 24 3 23 54 - - 25 4 24 41 - - 详细答案: 1、(1)30.625 [(25+32+37+26)/4+(32+37+26+30)/4]/2=30.625 (2)32.000 [(32+37+26+30)/4+(37+26+30+38)/4]/2=32 (3)33.375 [(37+26+30+38)/4+(26+30+38+42)/4]/2=33.375 2、各季节指数计算表 A B C D E 1 年份季度 2 1 2 3 4 3 2000 - - 1.2082 0.8125 4 2001 0.8989 1.1014 1.2043 0.8602 5 2002 0.805 6 1.0365 1.3029 0.9091 6 2003 0.776 7 1.0000 1.3035 0.9397 7 2004 0.7025 1.0275 1.3333 0.9129 8 2005 0.7447 1.0269 - - 9 合计 3.9464 5.1924 6.3522 4.4344 10 平均0.7893 1.0385 1.2704 0.8869 11 季节指数0.7922 1.0424 1.2752 0.8902 季节指数=每季的季节比率的平均值/总平均值 总平均值=(0.7893+1.0385+1.2704+0.8869)/4=0.99627 所以,季节指数分别为0.7893/0.99627=0.7922 1.0385/0.99627=1.0424 1.2704/0.99627=1.2752 0.8869/0.99627=0.8902 ● 例1:某企业计划规定劳动生产率比上年提高10%,实际提高15%。试计算劳动生产率计划完成百分数。 ● ● 例2:某企业计划规定某产品单位成本降低5%,实际降低7%,试计算成本计划完成指标。 ● 答案: 答案: 答案: 起重量(吨)X 台数f 起重总量(吨)xf 40 1 40 25 2 50 10 3 30 5 4 20 合计 10 140 起重量(吨) 起重机台数构成(%) (吨) 40 10 4 25 20 5 10 30 3 5 40 2 合计 100 14 技术级别 月工资(元) 工资总额(元) 1 146 730 2 152 2280 3 160 1880 4 170 1700 5 185 370 合计 —— 7960 答案: 答案: 某地区国内生产总值的资料 单位:亿元 答案: 某企业2014年第三季度职工人数:6月30日435人,7月31日452人,8月31日462人,9月30日576人,要求计算第三季度平均职工人数. 答案如右图 计划完成程度(%) 组中值(%) 企业数 实际完成数(万元) 计划任务数(万元) 90—100 95 5 95 100 100—110 105 8 840 800 110—120 115 2 115 100 合计 — 15 1050 1000 日产量 (公斤) 工人数(人)f 组中值 (公斤)x xf 20—30 10 25 250 30—40 70 35 2450 40—50 90 45 4050 50—60 30 55 1650 合计 200 — 8400 2009年 2010年 2011年 2012年 2013年 2014年 18530.7 21617.8. 26635.4 34515.1 45005.8 57733 : 典型计算题一 1、某地区销售某种商品的价格和销售量资料如下: 根据资料计算三种规格商品的平均销售价格。 解: 36== ∑∑ f f x x (元) 点评: 第一,此题给出销售单价和销售量资料,即给出了计算平均指标的分母资料,所以需采用算术平均数计算平均价格。第二,所给资料是组距数列,因此需计算出组中值。采用加权算术平均数计算平均价格。第三,此题所给的是比重权数,因此需采用以比重形式 表示的加权算术平均数公式计算。 2、某企业1992年产值计划是1991年的105%,1992年实际产值是1991的的116%,问1992年产值计划完成程度是多少? 解: %110% 105% 116=== 计划相对数实际相对数计划完成程度。即1992年计划完成程度为 110%,超额完成计划10%。 点评:此题中的计划任务和实际完成都是“含基数”百分数,所以可以直接代入基本公式计算。 3、某企业1992年单位成本计划是1991年的95%,实际单位成本是1991年的90%,问1992年单位成本计划完成程度是多少? 解: 计划完成程度 %74.94% 95% 90==计划相对数实际相对数。即92年单位成本计划完成程度是 94.74%,超额完成计划5.26%。 点评:本题是“含基数”的相对数,直接套用公式计算计划完成程度。 4、某企业1992年产值计划比91年增长5%,实际增长16%,问1992年产值计划完成程度是多少? 解: 计划完成程度%110% 51% 161=++= 点评:这是“不含基数”的相对数计算计划完成程度,应先将“不含基数”的相对数还原成“含基数”的相对数,才能进行计算。 5、某企业1992年单位成本计划比1991年降低5%,实际降低10%,问1992年单位成 如何绘制频数表? 求组距 确定各组段的两个端点 归组计数 频数分布表与分布图作用 1.揭示变量分布形态 2.揭示变量分布趋势 3.便于发现特大的或特小的极端值 4.便于进一步计算统计指标和分析 5.作为一种数据陈述的形式 算数应用条件: 对称分布,尤其正态分布 几何应用条件: 1.对数对称分布、等比资料 2.变量值中不能有0;不能同时有正值和负值;若全是负值,计算时可先把负号去掉,得出结果后再加上负号。 中位数条件: 所有分布、尤其偏态分布: 1.变量值中出现个别特小或特大的数值 2.资料的分布呈明显偏态 3.含有不确定数值 4.资料的分布不清 极差应用条件:所有分布、尤其偏态分布 不足: 不能全面的反映所有值的偏离程度 不稳定、小样本小于大样本、样本小于总体 四分位数间距应用条件 所有分布、尤其偏态分布: 1.变量值中出现个别特小或特大的数值 2.资料的分布呈明显偏态 3.含有不确定数值 4.资料的分布不清 方差应用条件: 对称分布,尤其正态分布 变异系数应用 1.量纲不一致 散点图作用 观察两组数据的总体趋势和明显偏离趋势的观察点 判断两组数据的关联形式、方向和密切程度 相关分类 线性相关 秩相关 分类变量相关 线性相关意义 r>0表示正相关,r=1表示完全正相关;r<0表示负相关,r=-1表示完全负相关。 |r|→0表示相关性越弱,|r|→1表示相关性越强。 r=0表示没有线性相关,不代表没有相关。 如何判断线性相关 画散点图 计算线性相关系数 假设检验 如何进行秩相关 编秩次 计算秩相关系数 假设检验 回归分析:利用样本信息,找到变量间数量依存关系。 线性回归分析:利用样本信息,找到变量间线性数量依存关系。 决定系数:反映回归贡献的相对程度,即Y的变异被X解释的比例。 如何进行分类变量的相关分析 交叉表的制作,计算各种概率 计算列联系数 假设检验 相关分析的条件 线性相关系数:二元正态分布的定量变量 秩相关系数:非二元正态分布的定量变量、有序分类变量 列联系数:无序分类变量 轶闻数据:由坊间流传或各种媒体报道的一些个案数据,由于其特殊性往往给公众留下突出和深刻的印象。 特点:缺乏代表性,常诱导人们进行简单的推论,得到一些具有倾向性的结论。 可得数据:为了某些特定目的已收集或积累的数据。如:各类监测数据、统计年鉴等。 一、统计学概论 分理论统计和应用统计 应用统计分为描述统计学和推断统计学。 描述统计为一组数据的中(位置均值、中位数)、散(极差、方差、标准差)、形|(偏度)描述。 推断统计分为参数估计和假设检验。技能 1、经验——数据收集加工——画成图形——数理(规律)(数据不等于数字) PPT 原则用图不用表、用表不用栏、用栏不用字实际问题 5M1E ——组成过程——产品(结果)——属性(包括几何(形位方尺)、物理、生化、人文)——集合统计问题 ——(构成)总体——样本——数据——类型分计数型(离散性)和计量型(连续性),即概率分布为计量型分布和技术型分布)——规律分描述和推断。 1、总体与样本中间有一种学问抽样验收抽样、统计抽样样本量 2、样本和数据中间有一门测量技术MSA 3、分布规律 总体参数平均值() 标准差() 总位数() 比例(p ) 样本统计量的特点随机变化,不要轻易用样本下结论。拉丁字母在数学上用于总体参数阿拉伯字母表示样本统计量希腊字母表示计算 总体参数统计分参数统计和非参数统计。推断统计分 估计总体总体某参数未知,用对应的样本统计量去猜测。检验假设总体某参数已知,用对应的样本统计量去验证。 二统计数据收集与整理1、数据不等于数字 2、数据的两种类型 描述性分类——响应变量(因变量)和预报因子(独立变量)如性别叫因子,男女叫水平。 四种尺度定类、定序、定距、定比 3.数据管理的7个层次无假不乱浅深系4.软件每一列表示一个变量,每一行表示一个样本鱼骨图只适用于一个为什么, 变量程序图IPO 适用于多个为什么。 I (变量)P O 水质烧开水色香味器皿材质火燃料风压强 目的要抓住关键的变量。 2、统计数据的表现形式绝对数——时期数和时点数相对数——比例部分比总体比率部分比部分 统计的数据来源直接来源和间接来源。 1、数据收集分被动收集(利用历史和现场)和主动收集(DOE 试验设计)现场收集数据是被动收集,分临时数据和常态数据。试验是临时数据。 数据好的特征。。。。 数据不好的7个陷阱缺少假混窄异病 统计学知识点 第一章绪论 1、今天,“统计”一词有三种含义: ⒈统计工作:搜集、整理和分析统计数据的活动。 ⒉统计数据:统计工作的成果。 ⒊统计学:指导统计工作的理论。如数理统计学,社会统计学,经 济统计学,应用统计学等。 统计三个含义的关系十分密切:统计工作与统计数据是过程与成果的关系;统计工作与统计学是实践与理论的关系。 2、第一部统计学著作是英国人威廉·配第(1623—1687)的《政治算 术》(1690)一书。 3、统计学是一门搜集、整理、显示和分析统计数据的科学,其目的 是探索数据内在的数量规律性。 4、统计工作全过程一般可以划分为四个环节: 统计设计、统计调查、统计整理、统计分析 5.统计的基本方法 大量观察法、综合分析法(整理、分析)、归纳推断法(分析) 6、统计学与其他学科的关系 (一)统计学与数学的关系 区别:首先,数学研究抽象的数,统计学则研究具体事物的数量; 其次,数学使用纯粹的演绎方法,而统计学则使用演绎与归纳相结合的逻辑方法。 (二)统计学与其他学科的关系 凡涉及处理实质性数据的学科都要以统计方法为工具。可以说,统计学是其他学科的工具。 第二章调查与整理 1、目前,数据的计量尺度由粗略(低级)到精确(高级)分为四个层次,即列名尺度、顺序尺度、定距尺度和定比尺度。 1.列名尺度:按照事物的某种属性对其进行平行的分类。例如,人按性别分为男、女,……。该尺度的数据不能比较大小、优 劣。 2.顺序尺度:对事物之间等级差或顺序差别的一种测度。例如,考试成绩可分为优、良、中、……。该尺度的数据能比较优劣,不能进行数学运算。 3.定距尺度:对事物之间等级差或顺序差别较精确地定量测度。 如考试成绩的95 分、86 分、……;天气温度的50C、00C、-50C、……。该尺度的“0”表示一个水平。该尺度的数据能 进行加、减运算。 4.定比尺度:用来表明数值中存在绝对零点状况下数量特征的描述尺度。例如,企业利润、产品数量等。该尺度的“0”表示“没有”或“不存在”。该尺度的数据能进行加、减、乘、除运算。 2、数据的类型 1.定性数据。也称品质数据,由列名尺度或顺序尺度计量形成,说明事物品质特征,通常用文字描述。 统计学复习笔记 第七章 一、 思考题 1. 解释估计量和估计值 在参数估计中,用来估计总体参数的统计量称为估计量。估计量也是随机变量。如样本均值,样本比例、样本方差等。 根据一个具体的样本计算出来的估计量的数值称为估计值。 2. 简述评价估计量好坏的标准 (1)无偏性:是指估计量抽样分布的期望值等于被估计的总体参数。 (2)有效性:是指估计量的方差尽可能小。对同一总体参数的两个无偏估计量,有更小方差的估计量更有效。 (3)一致性:是指随着样本量的增大,点估计量的值越来越接近被估总体的参数。 3. 怎样理解置信区间 在区间估计中,由样本统计量所构造的总体参数的估计区间称为置信区间。置信区间的论述是由区间和置信度两部分组成。有些新闻媒体报道一些调查结果只给出百分比和误差(即置信区间),并不说明置信度,也不给出被调查的人数,这是不负责的表现。因为降低置信度可以使置信区间变窄(显得“精确”),有误导读者之嫌。在公布调查结果时给出被调查人数是负责任的表现。这样则可以由此推算出置信度(由后面给出的公式),反之亦然。 4. 解释95%的置信区间的含义是什么 置信区间95%仅仅描述用来构造该区间上下界的统计量(是随机的)覆盖总体参数的概率。也就是说,无穷次重复抽样所得到的所有区间中有95%(的区间)包含参数。 不要认为由某一样本数据得到总体参数的某一个95%置信区间,就以为该区间以0.95的概率覆盖总体参数。 5. 简述样本量与置信水平、总体方差、估计误差的关系。 1. 估计总体均值时样本量n 为 2. 样本量n 与置信水平1-α、总体方差、估计误差E 之间的关系为 其中: 2222α2222)(E z n σα=n z E σα2= 2009---2010学年第2学期 统计学原理 课程考核试卷(B ) 一、填空题(每空1分,共15分) 1、观测数据、实验数据 2、自填式、面访式和电话式 3、1153.3、1020 4、2 a b +、2 ()12b a - 5、-56、0、1 7、F 8、有效性、一致性 1、按照统计数据的收集方法,可以将其分为 和 。 2、收集数据的基本方法是 、 和 。 3、在某城市中随机抽取9个家庭,调查得到每个家庭的人均月收入数据:1080,750,780,1080,850,960,2000,1250,1630(单位:元),则人均月收入的平均数是 , 中位数是 。 4(a,b)内取值,且X 服从均匀分布,其概率密度函数为0()1f x b a ??=??-? 则X ,方差为 。 5、设随机变量X 、Y 的数学期望分别为E(X)=2,E(Y)=3,求E(2X-3Y)= 。 6、概率是___ 到_____ 之间的一个数,用来描述一个事件发生的经常性。 7、对回归方程线性关系的检验,通常采用的是 检验。 8、在参数估计时,评价估计量的主要有三个指标是无偏性、 和 。 五、计算题(第1题7分、第2题8分,第3题8分,第4题12分,第5题15分,总共50分) 1、设X~N (9,4),试描述10X 的抽样分布。(7分) 1、解:2 ~(9,2)X N ,根据数学期望的性质10X 也服从正态分布, 由于 E (10X )=10E (X )=90 D (10X )=100D (X )=100×4=400 所以 10~(90,400X N 2、某城市想要估计下岗职工中女性所占的比例,采取重复抽样方法随机抽取了100名下岗职工,其中65人为女性。试以95%的置信水平估计该城市下岗职工中女性所占比例的置信区间。(2 1.96z α=)(8分) 2、解:已知100n =,2 1.96z α=,6565%100 p == 根据公式得: 第二章 六、计算题. 1.下面是某公司工人月收入水平分组情况和各组工人数情况: 月收入(元)工人数(人) 400-500 20 500-600 30 600-700 50 700-800 10 800-900 10 指出这是什么组距数列,并计算各组的组中值和频率分布状况。 答:闭口等距组距数列,属于连续变量数列,组限重叠。各组组中值及频率分布如下: 2.抽样调查某省20户城镇居民平均每人全年可支配收入(单位:百元)如下: 88 77 66 85 74 92 67 84 77 94 58 60 74 64 75 66 78 55 70 66 ⑴根据上述资料进行分组整理并编制频数分布数列 ⑵编制向上和向下累计频数、频率数列 答:⑴⑵ 某省20户城镇居民平均每人全年可支配收入分布表 第三章 六、计算题. ⒈某企业生产情况如下: 要求:⑴填满表内空格. ⑵对比全厂两年总产值计划完成程度的好坏。 解:⑴某企业生产情况如下:单位:(万元) ⑵该企业2005年的计划完成程度相对数为110.90%,而2006年只有102.22%,所以2005年完成任务程度比2006好。 ⒉某工厂2006年计划工业总产值为1080万吨,实际完成计划的110%,2006年计划总产值比2005年增长8%,试计算2006年实际总产值为2005年的百分比? 解:118.8% 3.某种工业产品单位成本,本期计划比上期下降5%,实际下降了9%,问该种产品成本 计划执行结果? 解:95.79% 4.我国“十五”计划中规定,到“十五”计划的最后一年,钢产量规定为7200万吨,假设“八五”期最后两年钢产量情况如下:(万吨) 根据上表资料计算: ⑴钢产量“十五”计划完成程度; ⑵钢产量“十五”计划提前完成的时间是多少? 解:⑴102.08%;⑵提前三个月 5.某城市2005年末和2006年末人口数和商业网点的有关资料如下: 计算:⑴平均每个商业网点服务人数; ⑵平均每个商业职工服务人数; ⑶指出是什么相对指标。 解: 某城市商业情况 ⑶上述两个指标是强度相对指标。 6.某市电子工业公司所属三个企业的有关资料如下: 医师资格考试蓝宝书-预防医学 令狐文艳 医学统计学方法 第一节基本概念和基本步骤(非常重要) 一、统计工作的基本步骤 设计(最关键、决定成败)、搜集资料、整理资料、分析资料。 总体:根据研究目的决定的同质研究对象的全体,确切地说,是性质相同的所有观察单位某一变量值的集合。总体的指标为参数。 实际工作中,经常是从总体中随机抽取一定数量的个体,作为样本,用样本信息来推断总体特征。样本的指标为统计量。 由于总体中存在个体变异,抽样研究中所抽取的样本,只包含总体中一部分个体,这种由抽样引起的差异称为抽样误差。抽样误差愈小,用样本推断总体的精确度愈高;反之,其精确度愈低。 某事件发生的可能性大小称为概率,用P表示,在0~1之间,0和1为肯定不发生和肯定发生,介于之间为偶然事件,<0.05或0.01为小概率事件。 二、变量的分类 变量:观察单位的特征,分数值变量和分类变量。 第二节数值变量数据的统计描述(重要考点) 一、描述计量资料的集中趋势的指标有 1.均数均数是算术均数的简称,适用于正态或近似正态分布。 2.几何均数适用于等比资料,尤其是对数正态分布的计量资料。对数正态分布即原始数据呈偏态分布,经对数变换后(用原始数据的对数值lgX代替X)服从正态分布,观察值不能为0,同时有正和负。 3.中位数一组按大小顺序排列的观察值中位次居中的数值。可用于描述任何分布,特别是偏态分布资料的集中位置,以及分布不明或分布末端无确定数据资料的中心位置。不能求均数和几何均数,但可求中位数。百分位数是个界值,将全部观察值分为两部分,有X%比小,剩下的比大,可用于计算正常值范围。 二、描述计量资料的离散趋势的指标 1.全距和四分位数间距。 2.方差和标准差最为常用,适于正态分布,既考虑了离均差(观察值和总体均数之差),又考虑了观察值个数,方差使原来的单位变成了平方,所以开方为标准差。均为数值越 小,观察值的变异度越小。 3.变异系数多组间单位不同或均数相差较大的情况。变 基础统计学笔记统计学基础笔记整理 一、统计学概论: 分理论统计和应用统计: 应用统计分为描述统计学和推断统计学。 描述统计为一组数据的中(位置:均值、中位数)、散(极差、方差、标准差)、形|(偏度)描述。 推断统计分为参数估计和假设检验。技能: 1、经验——数据收集加工——画成图形——数理(规律) (数据不等于数字) PPT 原则:用图不用表、用表不用栏、用栏不用字实际问题: 5M1E ——组成过程——产品(结果)——属性(包括:几何(形位方尺)、物理、生化、人文)——集合统计问题: ——(构成)总体——样本——数据——类型:分计数型(离散性)和计量型(连续性),即概率分布为计量型分布和技术型分布)——规律分描述和推断。 1、总体与样本中间有一种学问:抽样:验收抽样、统计抽样样本量 2、样本和数据中间有一门测量技术:MSA 3、分布规律 总体参数:平均值() 标准差() 总位数() 比例(p ) 样本统计量的特点:随机变化,不要轻易用样本下结论。拉丁字母在数学上用于总体参数阿拉伯字母表示样本统计量希腊字母表 示计算 总体参数统计分参数统计和非参数统计。推断统计分 估计:总体总体某参数,用对应的样本统计量去猜测。检验:假设总体某参数已知,用对应的样本统计量去验证。 二:统计数据收集与: 1、数据不等于数字 2、数据的两种类型: 描述性分类——响应变量(因变量)和预报因子(独立变量)如性别叫因子,男女叫水平。 四种尺度:定类、定序、定距、定比 3.数据管理的7个层次:无假不乱浅深系 4.软件每一列表示一个变量,每一行表示一个样本鱼骨图只适用于一个为什么, 变量程序图IPO 适用于多个为什么。 I (变量) P O 水质烧开水色香味器皿材质火燃料风压强 目的要抓住关键的变量。 2、统计数据的表现形式:绝对数——时期数和时点数相对数——比例:部分比总体比率:部分比部分 统计的数据:直接和间接。 统计总体:统计总体是根据一定目的确定的所要研究事物的全体,它是客观存在,并在某一相同性质基础上结合起来的由许多个别事物组成的整体,简称总体。 样本:是指在全及总体中按随机原则抽取的那部分单位所构成的集合体。 算术平均数:算术平均数是统计中最基本、最常用的一种平均数,它的基本计算形式是用总体的单位总数去除总体的标志总量。 调和平均数:是根据变量值的倒数计算的,是变量值倒数的算术平均数的倒数,也叫倒数平均数。 简单分组:是指对所研究的总体按一个标志进行分组。 复合分组:复合分组是指对所研究的总体按两个或两个以上的标志进行的多层次分组。 结构相对指标:结构相对指标是表明总体内部的各个组成部分在总体中所占比重的相对指标,也叫比重指标。 强度相对指标:是指两个性质不同,但有一定联系的总量指标数值之比。 类型抽样:又称分类抽样或分层抽样,它是先将总体按某个主要标志进行分组(或分类),再按随机原则从各组(类)中抽取样本单位的一种抽样方式。 机械抽样:它是将总体各单位按某一标志顺序排列,然后按固定顺序和相等距离或间隔抽取样本单位的抽样组织方式。 综合指数:凡是一个总量指标可以分解为两个或两个以上的因素指标时,为观察某个因素指标的变动情况,将其他因素指标固定下来计算出的指数称为综合指数。 平均指数:平均指数法是以个体指数为基础来计算总指数,根据选用的权数不同,平均指数法可以进一步分为加权算术平均法,加权调和平均法,固定权数加权平均法。 相关关系:是指现象之间客观存在的,在数量变化上受随机因素的影响,非确定性的相互依存关系。 回归分析:现象之间的相关关系,虽然不是严格的函数关系,但现象之间的一般关系值,可以通过函数关系的近似表达式来反映,这种表达式根据相关现象的实际对应资料,运用数学的方法来建立,这类数学方法称为回归分析。 统计调查:就是根据统计研究的目的、要求和任务,运用各种科学的调查方法,有计划、有组织的搜集有关现象的各个单位的资料,对客观事实进行登记,取得真实可靠的调查资料的活动过程。 统计指数:广义指数泛指社会经济现象数量变动的比较指标,及用来表明同类现象在不同空间、不同时间,实际与计划对比变动情况的相对数。狭义指数仅指反应不能直接想家的复杂社会经济现象在数量上综合变动情况的相对数。 简单随机抽样:简单随机抽样也叫纯随机抽样,它对总体单位不做任何分类排队,而是直接从总体中随机抽取一部分单位来组成样本的抽样组织方式。 季节分析的含义:是指某些现象由于自然因素和社会条件的影响在一年之内比较有规律的变动。 总量指标:是指反映一定时间、地点和条件下某种现象总体规模或水平的统计指标。 相对指标:是指说明现象之间数量对比关系的指标,用两个或两个以上有联系的指标数值对比来求得,其结果表现为相对数,故也将相对指标称为相对数。 平均指标:是同类社会经济现象总体内,各单位某一数量标志在一定时间、地点和条件下,数量差异抽象化的代表性水平指标,其数值表现为平均数。 1计算运用总量指标的原则。 (1)在计算实物指标时,应注意现象的同类性 (2)统计总量指标时要有明确的统计含义和合理的统计方法 总体:根据研究目的所确定的同质的观察单位的全体。具体到特征指标。 样本:从总体中随机抽取有代表性的一部分。抽样:从总体中抽取样本的过程(动 样本容量:指一个样本的必要抽样单位数目 同质:同一总体内,性质相同或相似。变异:同质观察单位之间的差异。 异质:不同总体间的差异。 定性变量:按某种属性,清点每一类的个数。分类变量:变量的取值无具体意义。 有序变量或等级变量:变量的取值表示各类别之间的等级(大小)关系; 定量变量:说明数量大小,记录指标值本身,一般有度量衡单位。 离散型变量:变量的取值只能为整数;连续型:变量取值可为实数轴上任何数值 参数:描述总体特征的统计指标; 统计量:描述样本特征的统计指标。 统计工作的步骤:①设计②收集③整理④统计分析 统计描述:统计表;统计图;统计指标。 统计推断:参数估计(点估计,区间估计)、假设检验。 1、描述定量资料的统计表与统计图(统计表同下) 直方图:①在频率表的基础上,绘制频率直方图。 ②图的标题位于图的下端居中;文字等要求同频率分布表。 ③纵轴为频率(%),横轴为组段值。要在横纵轴的端点处或轴的中 部写标目和单位。 ④矩形直条的起点无须从原点开始。 ⑤横纵轴长度适中,横七直五。 2、描述定量资料集中趋势的统计指标有哪些?各自的定义、计算及适用条件; a) 算术均数。样本均数记为 ,总体均数记为 。 直接法: 间接法(加权法)——针对频率表: 适用于正态资料。 b) 几何均数 直接法: 间接法(加权法)——针对频率表: 适用于呈倍数关系的资料。即成指数关系的数据资料。 c) 中位数。将原始观察值排序后(从小到大或从大到小均可),位次居中的 那个数。 直接法 间接法(百分位数percentile 法): 普适。偏峰分布资料有极值,或分布末端缺失。 X μn X n X X X X n i i n ∑==+++=1 21Λ∑∑∑=====K i i K i i i K i i i f f X n f X X 1 1 010n n X X X G Λ21=]log [log 1n X G ∑-=]*log [log ]*log [log 11n f X f f X G ∑∑∑ --==?????+=++.),(21.,*12*2*21为偶数为奇数n X X n X M n n n )%(L x f x n f i L P -?+= 应用统计分析复习笔记 BY 东海 2009年12月1日星期二 第一章 导论 1、统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。内容:收集数据(取得数据);处理数据(整理与图表展示);分析数据(利用统计方法分析数据);数据解释(结果的说明);得到结论(从数据分析中得出客观结论)。 2、统计研究的循环过程:实际问题—收集数据—处理数据—分析数据—数据解释—实际问题。 4、描述统计:研究数据收集、整理和描述的统计学分支。内容:收集数据;整理数据;展示数据;描述性分析。目的:描述数据特征;找出数据的基本规律。 5、推断统计:研究如何利用样本数据来推断总体特征的统计学分支。内容:参数估计;假设检验。目的:对总体特征做出推断。 6、描述统计与推断统计的关系: 7、统计数据的类型 (1)按计量层次:分类数据、顺序数据、数值型数据(2)按收集方法:观测数据和实验数据(3)按时间状况:截面数据和时间序列数据 8、总体:所研究的全部个体(数据) 的集合,其中的每一个个体也称为元素。分为有限总体和无限总体。 样本:从总体中抽取的一部分元素的集合。构成样本的元素的数目称为样本容量或样本量。 9、参数:描述总体特征的概括性数字度量,是研究者想要了解的总体的某种特征值。所关心的参数主要有总体均值(μ )、标准差(σ)、总体比例(π)等。总体参数通常用希腊字母表示。 10、统计量:用来描述样本特征的概括性数字度量,它是根据样本数据计算出来的一些量,是样本的函数。所关心的样本统计量有样本均值(x )、样本标准差(s)、样本比例(p)等。样本统计量通常用小写英文字母来表示。 变量:说明现象某种特征的概念,如商品销售额、受教育程度、产品的质量等级等。变量的具体表现称为变量值,即数据变量可以分为:(1)分类变量(说明事物类别的名称)、顺序变量(说明事物有序类别的名称)和数值型变量(说明事物数字特征的名称)。其中数值型变量又分离散变量(取有限个值)和连续变量(可以取无穷多个值)。(2)经验变量(所描述的是我们周围可以观察到的事物)和理论变量(由统计学家用数学方法所构造出来的一些变量,比如,z 统计量、t 统计量、χ2统计量、F 统计量等)。(3)随机变量和非随机变量。 11、随机现象的一个特点是:不确定性。随机现象也存在其固有的量的规律性,人们把这一规律性称为随机现象的统计规律性。 对随机现象的观察称为随机试验,并简称试验,用以研究随机现象的统计规律性。随机试验的特点:可重复性、可观察性和随机性。统计中的抽样过程其实就是一次随机试验。因而可以利用概率论的技巧来分析推断统计方法。而样本其实就是随机变量。 12、常见分布:二项分布、几何分布、指数分布、正态分布。 13、统计学中泛称统计量(或枢轴量)的分布为抽样分布。讨论抽样分布的途经有两种:1)精确地求出抽样分布,并称相应地统计推断为小样本统计推断;2) 让样本容量趋于无穷,并求出抽样分布的极限分布。以极限分布作为抽样分 统计方法 描述统计 推断统计 参数估计 假设检验 点估计 区间估计 复习提纲:(计算部分全用红色标注了!其他红色的是我的推断,可能出什么题型;有下划线的重点记忆!当然整理的知识点都是重点!都要背和理解!Fighting!) 第一章绪论 一.统计的含义 即统计工作、统计资料和统计学 统计工作:统计实践活动,搜集,整理,分析和提供关于社会现象数字资料工作总称 统计资料:统计实践活动过程中所取得的各项资料,包括原始资料和加工整理资料 统计学:关于认识客观现象总体数量特征和数量关系的科学 二.统计工作过程 就一次统计活动来讲,一个完整的认识过程一般可以分为统计调查、统计整理和统计分析三个阶段。 统计调查:第一阶段,是认识客观经济现象的起点,是统计整理和统计分析的基础。 统计整理:第二阶段,处于统计工作的中间环节,起着承前启后的作用。 统计分析:第三阶段,通过第三阶段,事物由感性认识上升到理性认识。 三.总体与总体单位(会辨析总体与总体单位即可) 总体,亦称统计总体,是指客观存在的、在同一性质基础上结合起来的许多个别单位的整体;构成总体的这些个别单位称为总体单位。 总体由总体单位构成,要认识总体必须从总体单位开始,总体是统计认识的对象。 例如:所有的工业企业就是一个总体,其中的每一个工业企业就是一个总体单位。 四.标志和指标 标志是用来说明总体单位特征的名称。 指标,亦称统计指标,是说明总体的综合数量特征的。一个完整的统计指标包括数量指标名称和指标数值两部分。(以上内容理解即可) 1.指标和标志的区别和联系(简答) 指标与标志的区别:(1)指标是说明总体特征的,而标志是说明总体单位特征的;(2)指标都能用数值表示,而标志中的品质标志不能用数值表示,是用属性表示的;(3)指标数值是经过一定的汇总取得的,而标志中的数量标志不一定经过汇总,可直接取得;(4)一个完整的统计指标,一定要讲时间、地点、范围,而标志一般不具备时间、地点等条件。 指标与标志的联系:(1)有许多统计指标的数值是从总体单位的数量标志值汇总而来的;(2)两者存在着一定的变换关系,即由于研究目的不同,原来的统计总体如果变成总体单位了,则相应的统计指标也就变成数量标志了。 2.标志与标志值(会区分) 标志分为品质标志和数量标志,数量标志用来说明总体单位量的特征,可以用数值表示,即为标志值(如:年龄、工资额、身高) 3.变异与变量(会什么是变异,什么是变量) 变异:品质标志在总体单位之间的不同具体表现。如:性别表现为男、女,民族表现为汉、满、蒙等。 变量:数量标志抽象化即为变量,而数量标志的不同具体表现则称为变量值(或标志值)。如:某职工的年龄是42岁,月工资2200元。 4.统计指标的划分 (1)统计指标按其所反映的总体内容的不同,可分为数量指标和质量指标。数量指标指说明总体规模和水平的各种总量指标。质量指标指反应现象总体的社会经济效益和工作质量的各种相对指标和平均指标。 (2)统计指标按其作用和表现形式的不同,有总量指标(绝对数)、相对指标(绝对数)、平均指标(平均数)三种。 第二章统计调查与整理 一.统计调查的含义 统计调查是统计工作过程的第一阶段。它是按照统计任务的要求,运用科学的调查方法,有组织的向社会实际搜索各项原始资料的过程。统计调查是整个统计认识活动的基础,决定着统计认识过程及其结果的成败。 二.统计调查方案设计的内容+调查对象、调查单位的含义 ⒈确定调查目的;(为什么调查) 根据实际需要和可能确定 例1:某企业计划规定劳动生产率比上年提高10%,实际提高15%。试计算劳动生产率计划完成百分数。 例2:某企业计划规定某产品单位成本降低5%,实际降低7%,试计算成本计划完成指标。 答案: 答案: 答案: 起重量(吨)X台数f起重总量(吨)xf 40140 25250 10330 5420 合计10140 起重量(吨)起重机台数构成(%)(吨) 40104 25205 10303 5402 合计10014 技术级别月工资(元)工资总额(元) 1146730 21522280 31601880 41701700 5185370 合计——7960 答案: 答案: 某地区国内生产总值的资料 单位:亿元 答案: 某企业2014年第三季度职工人数:6月30日435人,7月31日452人,8月31日462人,9月30日576人,要求计算第三季度平均职工人数. 答案如右图 计划完成程度(%) 组中值(%) 企业数 实际完成数(万元) 计划任务数(万元) 90—100 95 5 95 100 100—110 105 8 840 800 110—120 115 2 115 100 合计 — 15 1050 1000 日产量 (公斤) 工人数(人)f 组中值 (公斤)x xf 20—30 10 25 250 30—40 70 35 2450 40—50 90 45 4050 50—60 30 55 1650 合计 200 — 8400 2009年 2010年 2011年 2012年 2013年 2014年 . 57733 某工厂成品仓库中某产品在2009年库存量如下: 单位:台 答案 如右图: 某厂某年一月份的产品库存变动记录资料如下: 单位:台 答案 如右图: 某企业2014年计划产值和产值计划完成程度的资料如下表,试计算该企业年产值计划平均完成程度指标。 答案 如右图 我国1985—1990年社会劳动者(年底数)人数如下表,试计算“七五”时期第三产业人数在全部社会劳动者人数中的平均比重。 单位:万 年份 1985 1986 1987 1988 1989 1990 社会劳动者人数b 49873 51282 52783 54334 55329 56740 第三产业人数a 8350 8819 9407 9949 10147 10533 第三产业人数的比重(%)c 答案: 日期 库存量 38 42 24 11 60 0 日期 1日 4日 9日 15日 19日 26日 31日 库存量 38 42 39 23 2 16 0 季度 1 2 3 4 计划产值(万元)b 860 887 875 898 计划完成(%)c 130 135 138 125 卫生统计学知识点总结-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN 卫生统计学 统计工作基本步骤:统计设计(调查设计和实验设计)、资料分析{收集资料、整理资料、分析资料【统计描述和统计推断(参数估计和假设检验)】。 ★统计推断:是利用样本所提供的信息来推断总体特征,包括:参数估计和假设检验。a参数估计是指利用样本信息来估计总体参数,主要有点估计(把样本统计量直接作为总体参数估计值)和区间估计【按预先设定的可信度(1-α),来确定总体均数的所在范围】。b假设检验:是以小概率反证法的逻辑推理来判断总体参数间是否有质的区别。 变量资料可分为定性变量、定量变量。不同类型的变量可以进行转化,通常是由高级向低级转化。 资料按性质可分为计量资料、计数资料和等级资料。 定量资料的统计描述 1频率分布表和频率分布图是描述计量资料分布类型及分布特征的方法。离散型定量变量的频率分布图可用直条图表达。 2频率分布表(图)的用途:①描述资料的分布类型;②描述分布的集中趋势和离散趋势;③便于发现一些特大和特小的可疑值;④便于进一步的统计分析和处理;⑤当样本含量足够大时,以频率作为概率的估计值。 ★3集中趋势和离散趋势是定量资料中总体分布的两个重要指标。 (1)描述集中趋势的统计指标:平均数(算术均数、几何均数和中位数)、百分位数(是一种位置参数,用于确定医学参考值范围,P50就是中位数)、众数。算术均数:适用于对称分布资料,特别是正态分布资料或近似正态分布资料;几何均数:对数正态分布资料(频率图一般呈正偏峰分布)、等比数列;中位数:适用于各种分布的资料,特别是偏峰分布资料,也可用于分布末端无确定值得资料。 (2)描述离散趋势的指标:极差、四分位数间距、方差、标准差和变异系数。四分位数间距:适用于各种分布的资料,特别是偏峰分布资料,常把中位数和四分位数间距结合起来描述资料的集中趋势和离散趋势。方差和标准差:都适用于对称分布资料,特别对正态分布资料或近似正态分布资料,常把均数和标准差结合起来描述资料的集中趋势和离散趋势;变异系数:主要用于量纲不同时,或均数相差较大时变量间变异程度的比较。 标准差的应用:①表示变量分布的离散程度;②结合均数计算变异系数、描述对称分布资料;③结合样本含量计算标准误。 定性资料的统计描述 1定性资料的基础数据是绝对数。描述一组定性资料的数据特征,通常需要计算相对数。定性变量可以通过频率分布表描述其分布特征。 2 指标频率型指标强度型指标相对比型指标 概念近似反映某一时间出现概率单位时间内某现象的发生 率 两个有关联的指标A和B之比 计算 公式 A/B 有无 量纲 无有可有、可无 取值 范围 【0,1】可大于1无限制 本质大样本时作为概率近似值分子式分母的一部分频率强度,即概率强度的 似 值 表示相对于B的一个单位,A有多少 位 A和B可以是绝对数、相对数和平均 第三章统计整理 (一)填空题 1、统计整理是统计工作的第三阶段。在这一阶段,通过对原始资料进行科学的加工,可以得出反映事物总体特征的资料。 2、统计整理在统计分析中起着承前启后的作用,它既是统计调查的必然继续,又是统计分析的基础和前提条件。 3、统计分组实质上是在统计总体内部进行的一种定性分类。 4、对原始资料审核的重点是真实性。 5、区分现象质的差别是统计分组的根本作用。 6、标志是统计分组的依据,是划分组别的标准。 7、根据分组标志的特征不同,统计总体可以按品质分组,也可以按数量分组。 8、对所研究的总体按两个或两个以上的标志结合进行的分组,称为复合分组。 9、次数分布数列根据分组标志特征的不同,可以分为品质分布数列和数量分布数列两种。 10、变量数列是单项变量分组、组距式分组所形成的次数分布数列。 11、按品质标志分组的结果,形成品质分布数列。 12、组限是组距变量数列中表示各组数量界限的变量值,其中下限是指最小值的变量值,上限是指最大值的变量值。 13、组距变量数列的组距大小与组数的多少成反比。与全距的大小成正比。 14、组距变量数列的分布可以用次数分布曲线图表示。 15、划分连续变量的组限时,相邻组的组限必须重叠;划分离散型变量的组限时,相邻组的组限可以重叠,也可以不重叠。 16、统计资料的整理方法主要有统计分组和统计汇总两种。 17、钟形分布、U形分布和J形分布是次数分布的三种主要类型。 18、统计分组体系有品质标志分组和数量标志分组两种。 19、统计表按主词是否分组和分组的程度可分为简单表、简单分组表和复合分组表三种。 20、统计表从内容结构上看,是由主词和宾词两部分构成。 (二)单项选择题(在每小题备选答案中,选出一个正确答案) 1、统计分组的结果表现为( A ) A. 组内同质性,组间差异性 B. 组内差异性,组间同质性 C. 组内同质性,组间同质性 D. 组内差异性,组间差异性 2、统计分组的依据是( A ) A、标志 B、指标 C、标志值 D、变量值 3、下面属于按品质标志分组的有( C ) A. 企业按职工人数分组 B. 企业按工业总产值分组 C. 企业按经济类型分组 D. 企业按资金占用额分组 4、统计分组的关键在于( A ) A、正确选择分组标志 B、正确划分各组界限 C、正确确定组数和组限 D、正确选择分布数列种类 5、下面属于按数量标志分组的有( B ) A. 工人按政治面貌分组 B. 工人按年龄分组 C. 工人按工种分组 D. 工人按民族分组 卫生统计学 第一章绪论 1、卫生统计学的概念(P1) 卫生统计学是应用概率论和数理统计学的基本原理和方法,研究居民卫生状况以及卫生服务领域中数据的收集、整理和分析的一门科学,是卫生及其相关领域研究中不可缺少的分析问题。 2、卫生统计学的4个基本步骤(P3): 设计、收集资料、整理资料、分析资料 3、卫生统计学的几个基本概念(P4): ⑴同质:在统计学中,若某些观察对象具有相同的特征或属性,我们就称 之为同质,或具有同质性。 ⑵变异:同质个体的某项特征或属性的观察值或测量值之间的差 异。 ⑶总体:同质的所有观察单位某种特征或属性的观察值或测量值 的集合。 ⑷样本:从总体中随机抽取的具有代表性的部分观察单位的集 合。样本中 包含的观察单位个数成为样本含量。 ⑸参数:反映总体特征的指标,一般是未知的,常用希腊字母表 示,如总 体均数μ、总体率π等。 ⑹统计量:根据样本观察值计算出来的指标,常用拉丁字母表 示,如样本 均数x 、样本率等。 ⑺变量与资料:对每个观察单位进行观察或测量的某项特征或属 性称为变 量;变量值的集合成为资料。 ⑻定量资料:亦称计量资料,其变量值是定量的,表现为数值大 小,一般 有度、量、衡单位。 ⑼定性资料:亦称分类资料,其观察值是定性的,表现为互不相 容的类别 或属性,一般无度、量、衡单位。可细分为:①计数资料; ②等级资料 第二章调查研究设计 ★1、调查研究的特点(P7): ①不能人为施加干预措施;②不能随机分组; ③很难控制干扰因素;④一般不能下因果结论 2、常用抽样方法(名称、原理): ⑴单纯随机抽样:先将调查总体的全部观察单位统一编号,然后 采用随机数字表、统计软件或抽签方法之一随机抽取n(样本大小)个编号,由这n个编号所对应的n个观察单位构成研究样本。 ⑵系统抽样:又称机械抽样或等距抽样。事先将总体内全部观察 单位按某一顺序号等距分成n(样本大小)个部分,每一部分内含m个观察单位;然后从第一部分开始,从中随机抽出第i 号观察单位,依此用相等间隔m机械地在第2部分、第3部分直至第n部分内各抽出一个观察单位组成样本。 ⑶分层抽样:先按对观察指标影响较大的某项或某几项特征,将 总体分成若干层,该特征的测定值在层内变异较小,层间变异 1.统计主体:是统计所要研究对象的全体,是由客观存在的、具有某种共同性质的许多个别事物构成的整体 总体单位:构成总体的每一个个别事物 总体容量:总体中总体单位的数量 (定义及相关联系) 2.标志:总体各单位所共同具有的属性或特征 标志表现:总体单位个标志的具体体现 及其分类 (品质,数量; 可变性) 可变标志可以视为变量 (定义及其相关关系 3.指标:概念:统计活动按照一定的统计方法,对总体单位数、总体各单位的标志表现进行记录、核算、汇总、综合而形成的,用于反映统计总体某一综合数量特征的科学范畴 、特征:数量性,综合性,具体性 六要素:指标概念,指标数值,计算方法,计算单位,时间规定性,空间规定性 分类(质量(相对数)、数量(绝对数) 、时期、时点:) 4.指标、标志的区别联系:统计指标说明的是总体数量特征,而标志是说明总体单位特征的名称;指标都可以用数值表示,而标志有不能用数值表示的品质标志和能用数值表示的数量标志;统计指标是对总体单位数、总体单位标志表现经过一定处理后得到的 5.描述性统计:是研究如何取得反映客观现象的数据,并将收集的数据进行加工处理,通过表格、图形或数值形式显示,进而通过综合、概括与分析得出反映客观现象总体的数量特征、数量关系和数量规律 推断统计:是主要研究如何根据样本数据来推断总体的数量特征。主要包括参数估计的方法、假设检验的方法、方差分析的方法、相关与回归分析的方法等(了解) 第二章 1.数据的测量值 (将尽量尺度从低级到高级、由粗略到精确分为定类,定序,定距,定比) 2.统计调查方式 (报表:全面调查、全面报表、定期 普查:普查是为了某种特定目的而专门组织的一次性的全面调查 特点:一次性或周期性;需要规定统一的标准调查时间;数据比较准确;范围比较狭窄 、抽样:是对样本单位进行调查的一种专门组织的非全面调查。有随机抽样和非随机抽样两种 随机抽样:按随机原则从统计总体中抽取部分的单位进行实际调查,并根据样本信息对总体数量特征做出具有一定可靠程度的判断 重点调查:是了解基本情况的非全面调查 典型调查:是根据调查目的和要求,有意识地选择有代表性的单位,进行深入调查的方法)(基本概念,特点) 3.抽样调查:(调查对象:统计学整理笔记
统计学计算题整理
卫生统计学整理笔记
基础统计学笔记 统计学基础笔记整理
统计学期末以及考研复习知识点内容详细
统计学复习笔记
统计学期末考试试题整理
统计学计算题汇总
卫生统计学重点笔记之令狐文艳创作
基础统计学笔记统计学基础笔记整理
统计学期末复习重点
统计学整理
应用统计分析复习笔记
统计学知识点梳理
统计学整理笔记
卫生统计学知识点总结
统计学_第三章_统计整理
卫生统计学-重点整理资料东大
统计学期末复习重点
相关主题
文本预览