
《Hadoop大数据技术与应用》
实验报告
Hive-常用操作
一、实验目的
掌握Hive的使用
二、实验环境
Hadoop2.7.3
Hive2.3.3
源数据:dept.csv,emp.csv
三、实验内容与实验过程及分析(写出详细的实验步骤,并分析实验结果)
实验内容:
1.启动Hadoop,用jps查看进程
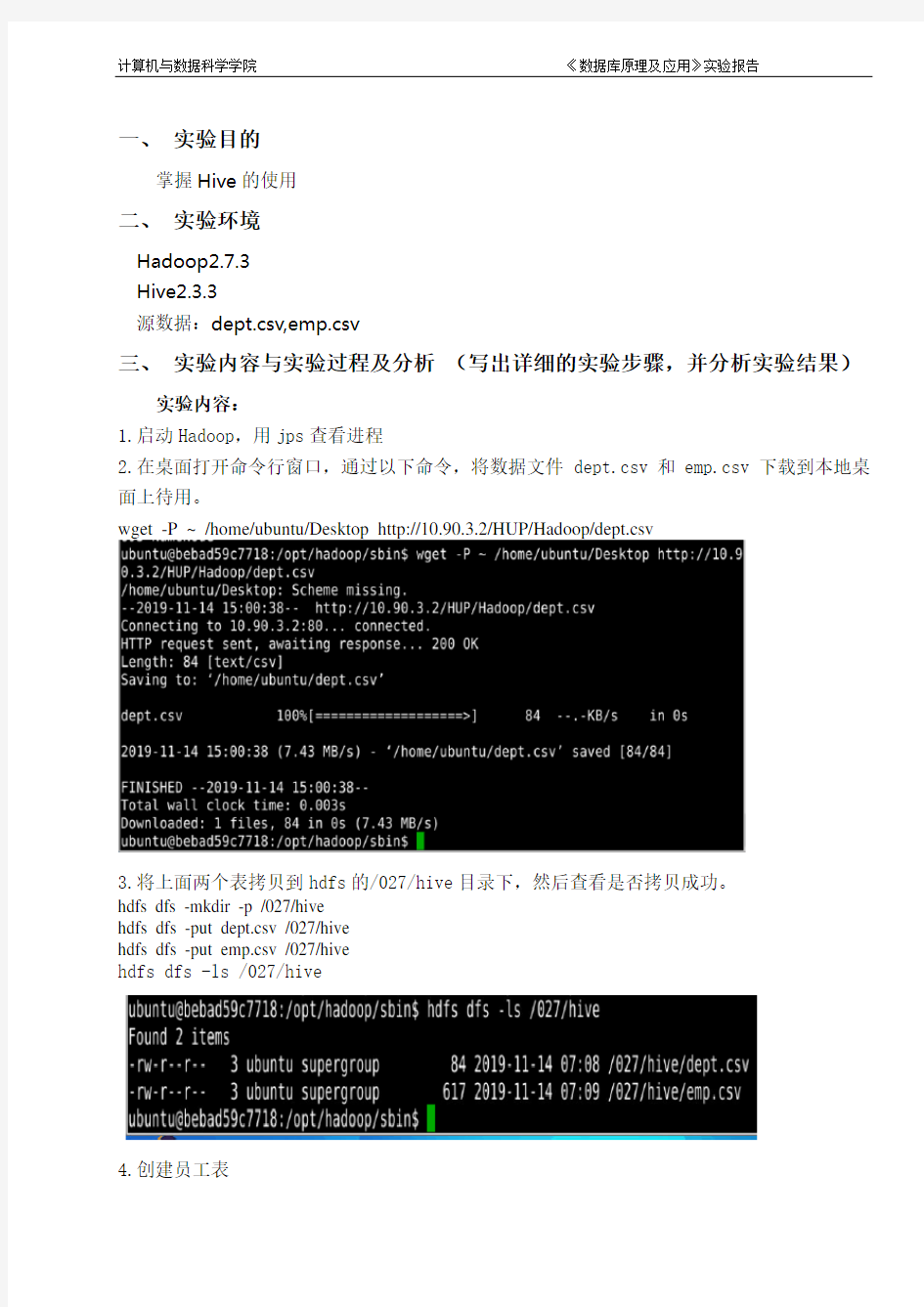
2.在桌面打开命令行窗口,通过以下命令,将数据文件dept.csv和emp.csv下载到本地桌面上待用。
wget -P ~ /home/ubuntu/Desktop http://10.90.3.2/HUP/Hadoop/dept.csv
3.将上面两个表拷贝到hdfs的/027/hive目录下,然后查看是否拷贝成功。
hdfs dfs -mkdir -p /027/hive
hdfs dfs -put dept.csv /027/hive
hdfs dfs -put emp.csv /027/hive
hdfs dfs -ls /027/hive
4.创建员工表
create table emp001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm
int,deptno int) row format delimited fields terminated by ',';
5.创建部门表
create table dept001(deptno int,dname string,loc string) row format delimited fields terminated by ',';
6.导入数据
load data inpath '/001/hive/emp.csv' into table emp001;
load data inpath '/001/hive/dept.csv' into table dept001;
7.根据员工的部门号创建分区,表名为emp_part027
create table emp_part001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int)partitioned by (deptno int)row format delimited fields terminated by ',';
往分区表中插入数据:指明导入的数据的分区
insert into table emp_part001 partition(deptno=10) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=10;
insert into table emp_part001 partition(deptno=20) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=20;
insert into table emp_part001 partition(deptno=30) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=30;
8.创建一个桶表,表名为emp_bucket027
create table emp_bucket001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int)clustered by (job) into 4 buckets row format delimited fields terminated by ',';
通过子查询插入数据
insert into emp_bucket027 select * from emp001;
9.查询所有的员工信息
10.查询员工信息:员工号姓名薪水
select empno,ename,sal from emp001;
11.做报表,根据职位给员工涨工资,把涨前、涨后的薪水显现出来select empno,ename,job,sal,
case job when 'PRESIDENT' then sal+1000
when 'MANAGER' then sal+800
else sal+400
end
from emp001;
四、实验总结(每项不少于20字)
存在问题:传dept.csv文件时出错,出现错误后一直找不到问题所在,各种操作也是很生疏。
解决方法:反复尝试,经过多次尝试熟练各种操作。回忆老师讲的内容,反复调试。
收获:掌握Hive的使用,对本节基础知识有了更深的认识。
五、教师批语
Hadoop测试题 一.填空题,1分(41空),2分(42空)共125分 1.(每空1分) datanode 负责HDFS数据存储。 2.(每空1分)HDFS中的block默认保存 3 份。 3.(每空1分)ResourceManager 程序通常与NameNode 在一个节点启动。 4.(每空1分)hadoop运行的模式有:单机模式、伪分布模式、完全分布式。 5.(每空1分)Hadoop集群搭建中常用的4个配置文件为:core-site.xml 、hdfs-site.xml 、mapred-site.xml 、yarn-site.xml 。 6.(每空2分)HDFS将要存储的大文件进行分割,分割后存放在既定的存储块 中,并通过预先设定的优化处理,模式对存储的数据进行预处理,从而解决了大文件储存与计算的需求。 7.(每空2分)一个HDFS集群包括两大部分,即namenode 与datanode 。一般来说,一 个集群中会有一个namenode 和多个datanode 共同工作。 8.(每空2分) namenode 是集群的主服务器,主要是用于对HDFS中所有的文件及内容 数据进行维护,并不断读取记录集群中datanode 主机情况与工作状态,并通过读取与写入镜像日志文件的方式进行存储。 9.(每空2分) datanode 在HDFS集群中担任任务具体执行角色,是集群的工作节点。文 件被分成若干个相同大小的数据块,分别存储在若干个datanode 上,datanode 会定期向集群内namenode 发送自己的运行状态与存储内容,并根据namnode 发送的指令进行工作。 10.(每空2分) namenode 负责接受客户端发送过来的信息,然后将文件存储位置信息发 送给client ,由client 直接与datanode 进行联系,从而进行部分文件的运算与操作。 11.(每空1分) block 是HDFS的基本存储单元,默认大小是128M 。 12.(每空1分)HDFS还可以对已经存储的Block进行多副本备份,将每个Block至少复制到 3 个相互独立的硬件上,这样可以快速恢复损坏的数据。 13.(每空2分)当客户端的读取操作发生错误的时候,客户端会向namenode 报告错误,并 请求namenode 排除错误的datanode 后,重新根据距离排序,从而获得一个新的的读取路径。如果所有的datanode 都报告读取失败,那么整个任务就读取失败。14.(每空2分)对于写出操作过程中出现的问题,FSDataOutputStream 并不会立即关闭。 客户端向Namenode报告错误信息,并直接向提供备份的datanode 中写入数据。备份datanode 被升级为首选datanode ,并在其余2个datanode 中备份复制数据。 NameNode对错误的DataNode进行标记以便后续对其进行处理。 15.(每空1分)格式化HDFS系统的命令为:hdfs namenode –format 。 16.(每空1分)启动hdfs的shell脚本为:start-dfs.sh 。 17.(每空1分)启动yarn的shell脚本为:start-yarn.sh 。 18.(每空1分)停止hdfs的shell脚本为:stop-dfs.sh 。 19.(每空1分)hadoop创建多级目录(如:/a/b/c)的命令为:hadoop fs –mkdir –p /a/b/c 。 20.(每空1分)hadoop显示根目录命令为:hadoop fs –lsr 。 21.(每空1分)hadoop包含的四大模块分别是:Hadoop common 、HDFS 、
常用的系统状态查询命令 # lsdev –C –s scsi 列出各个SCSI设备的所有相关信息:如逻辑单元号,硬件地址及设备文件名等。 # ps -ef 列出正在运行的所有进程的各种信息:如进程号及进程名等。 ps aux查看进程信息 # netstat -rn 列出网卡状态及路由信息等。 # netstat -in 列出网卡状态及网络配置信息。 # df -k 列出已加载的逻辑卷及其大小信息。 #top 查看系统应用信息,如CPU、内存使用率。按u,输入用户名则可监视用户;按k然后输入特定进程PID可关闭此进程,输入信号代码15关闭进程,输入信号代码9强行关闭。 # mount 列出已加载的逻辑卷及其加载位置。 # ntsysv 选择启动服务 # uname -a 列出系统ID 号,系统名称,OS版本等信息。 # hostname 列出系统网络名称。 # lsvg –l rootvg,lsvg –p rootvg 显示逻辑卷组信息,如包含哪些物理盘及逻辑卷等。 # lslv –l datalv,lslv –p datalv 显示逻辑卷各种信息,如包含哪些盘,是否有镜像等。 八网络故障定位方法 网络不通的诊断过程: ifconfig 查看网卡是否启动 (up) netstat –i 查看网卡状态 Ierrs/Ipkts 和 Oerrs/Opkts是否>1% ping自己网卡地址 (ip 地址) ping其它机器地址,如不通,在其机器上用diag检测网卡是否有问题。 在同一网中, subnetmask 应一致。 网络配置的基本方法: (1) 如需修改网络地址、主机名等,一定要用 chdev 命令 # chdev –l inet0 –a hostname=myhost # chdev -l en0 -a netaddr='9.3.240.58' -a netmask=255.255.255.0’ (2) 查看网卡状态:# lsdev –Cc if
HADOOP表操作 1、hadoop简单说明 hadoop 数据库中的数据是以文件方式存存储。一个数据表即是一个数据文件。hadoop目前仅在LINUX 的环境下面运行。使用hadoop数据库的语法即hive语法。(可百度hive语法学习) 通过s_crt连接到主机。 使用SCRT连接到主机,输入hive命令,进行hadoop数据库操作。 2、使用hive 进行HADOOP数据库操作
3、hadoop数据库几个基本命令 show datebases; 查看数据库内容; 注意:hadoop用的hive语法用“;”结束,代表一个命令输入完成。 usezb_dim; show tables;
4、在hadoop数据库上面建表; a1: 了解hadoop的数据类型 int 整型; bigint 整型,与int 的区别是长度在于int; int,bigint 相当于oralce的number型,但是不带小数点。 doubble 相当于oracle的numbe型,可带小数点; string 相当于oralce的varchar2(),但是不用带长度; a2: 建表,由于hadoop的数据是以文件有形式存放,所以需要指定分隔符。 create table zb_dim.dim_bi_test_yu3(id bigint,test1 string,test2 string)
row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符 a2.1 查看建表结构: describe A2.2 往表里面插入数据。 由于hadoop的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用SFTP将数据文件导入表中。
SQL常用命令使用方法: (1) 数据记录筛选: sql="select * from 数据表where 字段名=字段值order by 字段名" sql="select * from 数据表where 字段名like ‘%字段值%‘order by 字段名" sql="select top 10 * from 数据表where 字段名order by 字段名" sql="select * from 数据表where 字段名in (‘值1‘,‘值2‘,‘值3‘)" sql="select * from 数据表where 字段名between 值1 and 值2" (2) 更新数据记录: sql="update 数据表set 字段名=字段值where 条件表达式" sql="update 数据表set 字段1=值1,字段2=值2 ……字段n=值n where 条件表达式" (3) 删除数据记录: sql="delete from 数据表where 条件表达式" sql="delete from 数据表" (将数据表所有记录删除) (4) 添加数据记录: sql="insert into 数据表(字段1,字段2,字段3 …)valuess (值1,值2,值3 …)" sql="insert into 目标数据表select * from 源数据表" (把源数据表的记录添加到目标数据表) (5) 数据记录统计函数: AVG(字段名) 得出一个表格栏平均值 COUNT(*|字段名) 对数据行数的统计或对某一栏有值的数据行数统计 MAX(字段名) 取得一个表格栏最大的值 MIN(字段名) 取得一个表格栏最小的值 SUM(字段名) 把数据栏的值相加 引用以上函数的方法: sql="select sum(字段名) as 别名from 数据表where 条件表达式" set rs=conn.excute(sql) 用rs("别名") 获取统的计值,其它函数运用同上。 (5) 数据表的建立和删除: CREATE TABLE 数据表名称(字段1 类型1(长度),字段2 类型2(长度) ……) 例:CREATE TABLE tab01(name varchar(50),datetime default now()) DROP TABLE 数据表名称(永久性删除一个数据表) 4. 记录集对象的方法: rs.movenext 将记录指针从当前的位置向下移一行 rs.moveprevious 将记录指针从当前的位置向上移一行 rs.movefirst 将记录指针移到数据表第一行 rs.movelast 将记录指针移到数据表最后一行 rs.absoluteposition=N 将记录指针移到数据表第N行 rs.absolutepage=N 将记录指针移到第N页的第一行 rs.pagesize=N 设置每页为N条记录 rs.pagecount 根据pagesize 的设置返回总页数 rs.recordcount 返回记录总数 rs.bof 返回记录指针是否超出数据表首端,true表示是,false为否 rs.eof 返回记录指针是否超出数据表末端,true表示是,false为否 rs.delete 删除当前记录,但记录指针不会向下移动 rs.addnew 添加记录到数据表末端 rs.update 更新数据表记录 判断所填数据是数字型 if not isNumeric(request("字段名称")) then response.write "不是数字" else response.write "数字" end if -------------------------------------------------------------------------------- simpleli 于2002-03-23 15:08:45 加贴在ASP论坛上
office基本操作讲解课件 学好office的决窍: 1.上课认真听,关键步骤记好笔记 2.打好操作基础,汉字录入每分钟达60个字以上 3.重视操作,课堂笔记和练习要练习3—5遍,练一遍是不够的 4.树立速度和质量观念,每次的练习要在规定的时间内高质量完成操作任务 5.有创新精神,注意运用所学知识来进行创作 6.要有一定的审美观 第一讲 一、键盘的使用 1、键盘的组成:(功能区、主键盘区、游标控制区、小键盘区) 2、F1:帮助 3、F2:重命名 4、F3:搜索 5、F4:打开IE中的地址列表 6、Alt+F4:关闭窗口 7、F5:刷新 8、Tab:跳格键(在录入文字时可使光标快速的跳到一行) 9、Caps lock:大小写锁定键 10、Shift:上档键(控制双字符的上半部分) 11、Ctrl/alt:组合键(加鼠标复制) 12、Backspace:退格键(删除文字左边的部分) 13、Enter:确定键 14、Inster:改写键 15、Delete:删除键(删除文字右边的位置) 16、num lock:数字锁定键 17、prtscsysrq:抓屏键 18、SHIFT+DELETE 永久删除所选项,而不将它放到“回收站”中 19、Shift+2 中圆点Shift+6 省略号 二、指法练习 三、软件盘的使用 四、输入法的切换(添加\删除) 五、文档的组成(文件名+分隔符+扩展名) 六、鼠标(控制面板-鼠标) 七、文件及文件夹 1)文件类型: 常用文件类型: 音频文件:MP3 视频文件:AVI RMVB SWF FLV 图像文件:BMP JPG .docx .xlsx .pptx .txt 2)隐藏文件扩展名:打开我的电脑--左上方组织---文件夹和搜索选项---查看----隐藏已知文件类型的扩展名前面的勾去掉。 3)文件及文件夹的新建、移动、复制 新建:右击/新建 移动:在同一个磁盘中:选中后直接拖动 不同文件夹中:用ctrl+x剪贴,再用ctrl+v粘贴 复制:在同一个文件夹中:按ctrl+拖动或用ctrl+c复制后粘贴
UNIX系统常用命令 UNIX系统常用命令格式: command [flags] [argument1] [argument2] ... 其中flags以-开始,多个flags可用一个-连起来,如ls -l -a 与ls -la相同。 根据命令的不同,参数分为可选的或必须的;所有的命令从标准输入接受输入,输出结果显示在标准输出,而错误信息则显示在标准错误输出设备。可使用重定向功能对这些设备进行重定向。 命令在正常执行结果后返回一个0值,如果命令出错可未完全完成,则返回一个 非零值(在shell中可用变量$?查看). 在shell script中可用此返回值作为控制逻辑的一部分。 注:不同的UNIX版本的flags可能有所不同。 1、与用户相关的命令 1.1 login (在LINUX Redhat下此命令功能与Solaris/BSD不同,执行login会退出当前任务). login: Password: 相关文件: 在下面的这些文件中设定shell运行时必要的路径,终端类型,其他变量或特殊程序. $HOME/.profile (Bourne shell, sh, bash) $HOME/.cshrc (csh, tcsh) $HOME/.tcshrc (tcsh) /etc/passwd文件中列出每个用户的shell /etc/csh.cshrc /etc/csh.login /etc/profile (Bourne shell, bash) /etc/login (Bourne shell, bash) csh: /etc/csh.cshrc和$HOME/.cshrc每次执行都会读取, 而/etc/csh.login和$HOME/.login只有注册shell才执行 修改相应文件后使用 source .cshrc使能相关修改,如果修改了path则 还需使用rehash刷新可执行文件hash表。 tcsh: $HOME/.tcshrc, 没有些文件读取.cshrc sh: /etc/profile和$HOME/.profile注册shell bash: /etc/profile和$HOME/.bash_profile注册shell读取 .bashrc交互式非注册shell才读取。
文件和目录 cd /home 进入'/ home' 目录' cd .. 返回上一级目录 cd ../.. 返回上两级目录 cd 进入个人的主目录 cd ~user1 进入个人的主目录 cd - 返回上次所在的目录 pwd 显示工作路径 ls 查看目录中的文件 ls -F 查看目录中的文件 ls -l 显示文件和目录的详细资料 ls -a 显示隐藏文件 ls *[0-9]* 显示包含数字的文件名和目录名 tree 显示文件和目录由根目录开始的树形结构(1) lstree 显示文件和目录由根目录开始的树形结构(2) mkdir dir1 创建一个叫做'dir1' 的目录' mkdir dir1 dir2 同时创建两个目录 mkdir -p /tmp/dir1/dir2 创建一个目录树 rm -f file1 删除一个叫做'file1' 的文件' rmdir dir1 删除一个叫做'dir1' 的目录' rm -rf dir1 删除一个叫做'dir1' 的目录并同时删除其内容rm -rf dir1 dir2 同时删除两个目录及它们的内容
mv dir1 new_dir 重命名/移动一个目录 cp file1 file2 复制一个文件 cp dir/* . 复制一个目录下的所有文件到当前工作目录 cp -a /tmp/dir1 . 复制一个目录到当前工作目录 cp -a dir1 dir2 复制一个目录 ln -s file1 lnk1 创建一个指向文件或目录的软链接 ln file1 lnk1 创建一个指向文件或目录的物理链接 touch -t 0712250000 file1 修改一个文件或目录的时间戳- (YYMMDDhhmm) file file1 outputs the mime type of the file as text iconv -l 列出已知的编码 iconv -f fromEncoding -t toEncoding inputFile > outputFile creates a new from the given input file by assuming it is encoded in fromEncoding and converting it to toEncoding. find . -maxdepth 1 -name *.jpg -print -exec convert "{}" -resize 80x60 "thumbs/{}" \; batch resize files in the current directory and send them to a thumbnails directory (requires convert from Imagemagick) 文件搜索
Hadoop 练习题姓名:分数: 单项选择题 1.下面哪个程序负责HDFS数据存储。 a)NameNode b)Jobtracker c)Datanode √ d)secondaryNameNode e)tasktracker 2.HDfS中的block默认保存几份? a)3份√ b)2份 c)1份 d)不确定 3.下列哪个程序通常与NameNode在一个节点启动? a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker√ 4.Hadoop作者 a)Martin Fowler b)Kent Beck c)Doug cutting√ 5.HDFS默认Block Size a)32MB b)64MB√ c)128MB 6.下列哪项通常是集群的最主要的性能瓶颈 a)CPU b)网络 c)磁盘√ d)内存
7.关于SecondaryNameNode哪项是正确的? a)它是NameNode的热备 b)它对内存没有要求 c)它的目的是帮助NameNode合并编辑日志,减少NameNode启动时间√ d)SecondaryNameNode应与NameNode部署到一个节点 8.一个gzip文件大小75MB,客户端设置Block大小为64MB,请我其占用几个Block? a) 1 b)2√ c) 3 d) 4 9.HDFS有一个gzip文件大小75MB,客户端设置Block大小为64MB。当运行mapreduce 任务读取该文件时input split大小为? a)64MB b)75MB√ c)一个map读取64MB,另外一个map读取11MB 10.HDFS有一个LZO(with index)文件大小75MB,客户端设置Block大小为64MB。当运 行mapreduce任务读取该文件时input split大小为? a)64MB b)75MB c)一个map读取64MB,另外一个map读取11MB√ 多选题: 11.下列哪项可以作为集群的管理工具 a)Puppet√ b)Pdsh√ c)Cloudera Manager√ d)Rsync + ssh + scp√ 12.配置机架感知的下面哪项正确 a)如果一个机架出问题,不会影响数据读写√ b)写入数据的时候会写到不同机架的DataNode中√ c)MapReduce会根据机架获取离自己比较近的网络数据√ 13.Client端上传文件的时候下列哪项正确 a)数据经过NameNode传递给DataNode b)Client端将文件以Block为单位,管道方式依次传到DataNode√ c)Client只上传数据到一台DataNode,然后由NameNode负责Block复制工作 d)当某个DataNode失败,客户端会继续传给其它DataNode √
Windows操作: 1、一些快捷键:ctrl+c复制ctrl+x剪切ctrl+v粘贴ctrl+z恢复ctrl+s保存ctrl+a全选Ctrl + Shift各种输入法循环切换Ctrl+空格中西文切换Delete删除print screen复制整个屏幕内容Alt+Tab切换当前窗口 2、要掌握操作 (1)选定文件或文件夹 (2)打开文件或文件夹 (3)创建文件和文件夹(重点/难点) (4)复制/移动文件或文件夹 (5)删除文件或文件夹 (6)创建文件的快捷方式 (7)更改文件或文件夹的名称 (8)查看及设置文件和文件夹的属性 (9)查找文件和文件夹(*与?) 3、创建新文件 [1].右键选择“新建”-〉“文本文档” [2].确认创建的文件是否有扩展名txt [3].显示扩展名 将“隐藏已知文件类型的 扩展名”选项的勾去掉
[4]. 将文件名与扩展名一起去掉,改成指定的名字与扩展名
Office 操作 在office 中当选定表格、图片、文本框、艺术字等等时会出现浮动选项卡,相应的一些设置在浮动选项卡中设置。 Word 操作: 1、 文本输入:中文和英文输入法互相切换(CTRL+SPACE ) 不同输入法之间的切换(CTRL+SHIFT ) 段落结束标记(回车符); 一些标点的输入:顿号:\(中文标点)、书名号:<>(中文标点)、省略号:^ (中文标点)、圆点:@(中文标点) 软键盘的使用。 2、 文档排版常用操作: ①字符格式:字体、字号、字型、颜色、字符间距、字体效果(空心、阴影等)、着重号、下划线 开始-〉字体 ②段落格式:对齐方式、段落缩进、首行缩进、段落间距、行距、项目符号和编号 开始-〉段落 注意:√这里的对齐方式包括段落文字、页眉页脚的对齐方式,但是单元格的对齐方式不在此处。 √编号设置不成功时,点击“定义新编号格式”中 重新选择指定的编号即可。 ① 边框和底纹:要区分段落和文字边框以及段落和文字底纹,没有指明的话可以看样张 页面布局-〉页面背景-〉页面边框 边框的设置注意是方框还是阴影或是其他,样式颜色宽度选择正确,注意文字边框和段落边框的不同。 注意范围的选择(文字和段落)
Hadoop 集群基本操作命令 列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help (注:一般手动安装hadoop大数据平台,只需要创建一个用户即可,所有的操作命令就可以在这个用户下执行;现在是使用ambari安装的dadoop大数据平台,安装过程中会自动创建hadoop生态系统组件的用户,那么就可以到相应的用户下操作了,当然也可以在root用户下执行。下面的图就是执行的结果,只是hadoop shell 支持的所有命令,详细命令解说在下面,因为太多,我没有粘贴。) 显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name (注:可能有些命令,不知道什么意思,那么可以通过上面的命令查看该命令的详细使用信息。例子: 这里我用的是hdfs用户。) 注:上面的两个命令就可以帮助查找所有的haodoop命令和该命令的详细使用资料。
创建一个名为 /daxiong 的目录 $ bin/hadoop dfs -mkdir /daxiong 查看名为 /daxiong/myfile.txt 的文件内容$ bin/hadoop dfs -cat /hadoop dfs -cat /user/haha/part-m-00000 上图看到的是我上传上去的一张表,我只截了一部分图。 注:hadoop fs <..> 命令等同于hadoop dfs <..> 命令(hdfs fs/dfs)显示Datanode列表 $ bin/hadoop dfsadmin -report
$ bin/hadoop dfsadmin -help 命令能列出所有当前支持的命令。比如: -report:报告HDFS的基本统计信息。 注:有些信息也可以在NameNode Web服务首页看到 运行HDFS文件系统检查工具(fsck tools) 用法:hadoop fsck [GENERIC_OPTIONS]
cad命令大全 L, *LINE 直线 ML, *MLINE 多线(创建多条平行线) PL, *PLINE 多段线 PE, *PEDIT 编辑多段线 SPL, *SPLINE 样条曲线 SPE, *SPLINEDIT 编辑样条曲线 XL, *XLINE 构造线(创建无限长的线) A, *ARC 圆弧 C, *CIRCLE 圆 DO, *DONUT 圆环 EL, *ELLIPSE 椭圆 PO, *POINT 点 DCE, *DIMCENTER 中心标记 POL, *POLYGON 正多边形 REC, *RECTANG 矩形 REG, *REGION 面域 H, *BHATCH 图案填充 BH, *BHATCH 图案填充 -H, *HATCH HE, *HATCHEDIT 图案填充...(修改一个图案或渐变填充)SO, *SOLID 二维填充(创建实体填充的三角形和四边形)*revcloud 修订云线 *ellipse 椭圆弧 DI, *DIST 距离 ME, *MEASURE 定距等分 DIV, *DIVIDE 定数等分
DT, *TEXT 单行文字 T, *MTEXT 多行文字 -T, *-MTEXT 多行文字(命令行输入) MT, *MTEXT 多行文字 ED, *DDEDIT 编辑文字、标注文字、属性定义和特征控制框ST, *STYLE 文字样式 B, *BLOCK 创建块... -B, *-BLOCK 创建块...(命令行输入) I, *INSERT 插入块 -I, *-INSERT 插入块(命令行输入) W, *WBLOCK “写块”对话框(将对象或块写入新图形文件)-W, *-WBLOCK 写块(命令行输入) -------------------------------------------------------------------------------- AR, *ARRAY 阵列 -AR, *-ARRAY 阵列(命令行输入) BR, *BREAK 打断 CHA, *CHAMFER 倒角 CO, *COPY 复制对象 CP, *COPY 复制对象 E, *ERASE 删除 EX, *EXTEND 延伸 F, *FILLET 圆角 M, *MOVE 移动 MI, *MIRROR 镜像 LEN, *LENGTHEN 拉长(修改对象的长度和圆弧的包含角)
3.6 误) 3.7Hadoop支持数据的随机读写。(错) (8) NameNode负责管理metadata,client端每次读写请求,它都会从磁盘中3.8 读取或则会写入metadata信息并反馈client端。(错误) (8) NameNode本地磁盘保存了Block的位置信息。(个人认为正确,欢迎提出其它意见) (9) 3.9 3.10 3.11DataNode通过长连接与NameNode保持通信。(有分歧) (9) Hadoop自身具有严格的权限管理和安全措施保障集群正常运行。(错误)9 3.12 3.13 3.14Slave节点要存储数据,所以它的磁盘越大越好。(错误) (9) hadoop dfsadmin–report命令用于检测HDFS损坏块。(错误) (9) Hadoop默认调度器策略为FIFO(正确) (9) 100道常见Hadoop面试题及答案解析 目录 1单选题 (5) 1.1 1.2 1.3 1.4 1.5 1.6 1.7下面哪个程序负责HDFS数据存储。 (5) HDfS中的block默认保存几份? (5) 下列哪个程序通常与NameNode在一个节点启动? (5) Hadoop作者 (6) HDFS默认Block Size (6) 下列哪项通常是集群的最主要瓶颈: (6) 关于SecondaryNameNode哪项是正确的? (6) 2 3多选题 (7) 2.1 2.2 2.3 2.4 2.5 下列哪项可以作为集群的管理? (7) 配置机架感知的下面哪项正确: (7) Client端上传文件的时候下列哪项正确? (7) 下列哪个是Hadoop运行的模式: (7) Cloudera提供哪几种安装CDH的方法? (7) 判断题 (8) 3.1 3.2 3.3 Ganglia不仅可以进行监控,也可以进行告警。(正确) (8) Block Size是不可以修改的。(错误) (8) Nagios不可以监控Hadoop集群,因为它不提供Hadoop支持。(错误) 8 3.4如果NameNode意外终止,SecondaryNameNode会接替它使集群继续工作。(错误) (8) 3.5Cloudera CDH是需要付费使用的。(错误) (8) Hadoop是Java开发的,所以MapReduce只支持Java语言编写。(错 8
SAP系统常用命令介绍 1、系统配置常用命令 所谓系统配置命令,通常包含系统操作配置、系统传输配置、系统自定义内容配置等相关命令。系统配置的范围很广,这里介绍的系统配置不包括模块配置内容,主要是系统层面的相关配置命令。常用的操作命令主要包含以下几种。 (1)系统传输配置命令:SE09/SE10、STMS (2)系统后台参数配置命令:SPRO (3)系统信息发布命令:SM02 (4)目标集团参数配置命令:SCC4 2、后台维护常用命令 在SAP系统中,普通用户常常因为权限不够导致很多事项无法处理,需要通过管理员在后台对相应的主数据及参数进行修改设置。这里主要介绍以下几个常用的后台维护命令。 (1)批处理命令:SCAT (2)定义后台作业命令:SM36 (3)查看后台作业命令:SM37 3、程序编辑常用命令 程序编辑属于SAP系统开发的一个重要组成部分,SAP系统本身带有ABAP语言编辑器,可以提供强大的自开发程序功能。这里介绍程序编辑通常使用的相关命令。一般来说,程序编辑常用到的命令有以下3各。 (1)程序编辑器命令:SE38 (2)韩式编辑器命令:SE37 (3)对象浏览器命令:SE80 4、表间维护常用命令: (1)SAP系统中的数据都是存储在不同的表空间中。对于这些表的查询、修改及数据整理,SAP提供有相应的操作命令。常用的表间维护命令主要包括以下几种。 (1)ABAP数据字典命令:SE11 (2)维护表视图命令:SM30 5、用户及权限控制常用命令 在SAP系统中对于用户及权限的控制是非常严格的,权限参数、权限、用户的管理,均有一套专有的体系。这里介绍用户及权限控制常用的命令,包括以下几种。 (1)权限创建及修改命令:PFCG (2)用户创建及配置命令:SU01 (3)用户批量处理命令:SU10
Hadoop命令大全 Hadoop配置: Hadoop配置文件core-site.xml应增加如下配置,否则可能重启后发生Hadoop 命名节点文件丢失问题:
1、列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help 2、显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name 3、用户可使用以下命令在指定路径下查看历史日志汇总 $ bin/hadoop job -history output-dir 这条命令会显示作业的细节信息,失败和终止的任务细节。 4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看 $ bin/hadoop job -history all output-dir 5、格式化一个新的分布式文件系统: $ bin/hadoop namenode -format 6、在分配的NameNode上,运行下面的命令启动HDFS: $ bin/start-dfs.sh bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。 7、在分配的JobTracker上,运行下面的命令启动Map/Reduce: $ bin/start-mapred.sh bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves 文件的内容,在所有列出的slave上启动TaskTracker守护进程。 8、在分配的NameNode上,执行下面的命令停止HDFS: $ bin/stop-dfs.sh bin/stop-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止DataNode守护进程。 9、在分配的JobTracker上,运行下面的命令停止Map/Reduce: $ bin/stop-mapred.sh bin/stop-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止TaskTracker守护进程。 10、启动所有 $ bin/start-all.sh 11、关闭所有 $ bin/stop-all.sh DFSShell 10、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 11、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 12、查看名为 /foodir/myfile.txt 的文件内容 $ bin/hadoop dfs -cat /foodir/myfile.txt
基本MapReduce模式计数与求和基本MapReduce模式计数与求和 问题陈述: 有许多文档,每个文档都有一些字段组成。需要计算出每个字段在所有文档中的出现次数或者这些字段的其他什么统计值。例如,给定一个log文件,其中的每条记录都包含一个响应时间,需要计算出平均响应时间。 解决方案: 让我们先从简单的例子入手。在下面的代码片段里,Mapper每遇到指定词就把频次记1,Reducer一个个遍历这些词的集合然后把他们的频次加和。 1.class Mapper 2. method Map(docid id, doc d) 3. for all term t in doc d do 4. Emit(term t, count 1) 5. 6.class Reducer 7. method Reduce(term t, counts [c1, c2,...]) 8. sum = 0 9. for all count c in [c1, c2,...] do 10. sum = sum + c 11. Emit(term t, count sum) 复制代码 这种方法的缺点显而易见,Mapper提交了太多无意义的计数。它完全可以通过先对每个文档中的词进行计数从而减少传递给Reducer的数据量: [size=14.166666030883789px] 1. 1 class Mapper 2. 2 method Map(docid id, doc d) 3. 3 H = new AssociativeArray 4. 4 for all term t in doc d do 5. 5 H{t} = H{t} + 1
听的看的是时间轴,图像上的是字幕轴 一、初轴一aegisub的结构及其各部分作用:总面图 常常是点击这里来保存或者打开字幕 经常是通过这里来设置相应的字体样式 通过这里来修正延迟或者是提前的时间 通过这里来打开制作字幕的视频 可以直接打开样式处理器 直接打开平移时间框 这个是你目前可以选择使用的字体样式
以上,这个就是我们用来写字幕用的时间轴了 依次分别是开始时间结束时间持续时间 这些就是用来设置字体样式的部分了。前面四个:粗体斜体下划线删除线 字体名称,点击后如下,用来设置字体 主要颜色顾名思义就是字体的主要颜色点击开会出现这个边框选项
一般的大多数设置都用不到字幕的颜色是主要是取决于视频的场景和视频本身带有的原字幕所决定的 颜色我们主要通过这个,叫做取色笔的东东,会在后面讲怎么用 次要颜色点击开和主要颜色一样作用也基本一样所以不再讲解 边框颜色就是字体边框的颜色举个例子来说 字体本来的颜色是黑色一旦改了边框颜色之后就会变成其他的颜色 这里我们改成红色来看看 于是就变成这样了 阴影颜色同样举个例子
阴影颜色是黑色我们改成黄色来就变成了 提交当以上都搞定之后就可以按这个把字幕提交上去喽~ 这个勾选时间或帧 这个白白的框子就是用来输入字幕内容,使用样式,特效等等一切的地方 这个就是设置好了并提交上的字幕的样板 二怎样用aegisub写字幕 在打开视频前需要注意: 视频的名字和所在的路径不能有中文也就是视频名字和路径是纯字母和数字的才能打开 要打开视频点选打开视频选择你要写字幕的视频
用来设置播放视频的尺寸12.5%一直到200% 可以设置自己喜欢的尺寸 这个用来设置坐标不用基本没什么大用完全可以用下面这个来代替 就是这个蓝十字点击它会出现用它来设置字幕的位置 我放在了比较左上的位置字体位置的设置是非常自由的那里都可以 然后是这个点击它会出现
Windows操作系统常用命令及蓝屏代码 一域控管理工具 1 dcpromo------- 安装域控制器 2 dsa.msc-------打开AD用户和计算机 3 dssite.msc-------打开AD站点和服务 4 domain.msc-------打开AD域和信任关系 5 dnsmgmt.msc-------打开DNS服务器 6 services.msc------- 打开服务 7 MMC-------(管理控制台) 8 compmgmt.msc------- 计算机管理控制台 9 devmgmt.msc------- 设备管理器控制台 10 diskmgmt.msc------- 磁盘管理器控制台 11 eventvwr.msc------- 日志管理器控制台 12 fsmgmt.msc------- 共享文件夹控制台 13 gpedit.msc------- 组策略管理控制台 14 iis6.msc iis-------管理控制台 15 lusrmgr.msc------- 本地账户管理控制台 16 napclcfg.msc------- NAP管理控制台 17 printmanagement.msc------- 打印管理控制台 18 rsop.msc------- 组策略结果集控制台 19 wf.msc------- 防火墙管理控制台 20 lusrmgr.msc------- 本机用户和组 21 devmgmt.msc-------设备管理器 22 rsop.msc-------组策略结果集 23 secpol.msc-------本地安全策略 24 services.msc-------本地服务设置