1 SOME DESIGN CONSIDERATIONS FOR A CONCEPTUAL LEGAL INFORMATION RETRIEVAL SYSTEM
- 格式:pdf
- 大小:63.73 KB
- 文档页数:13
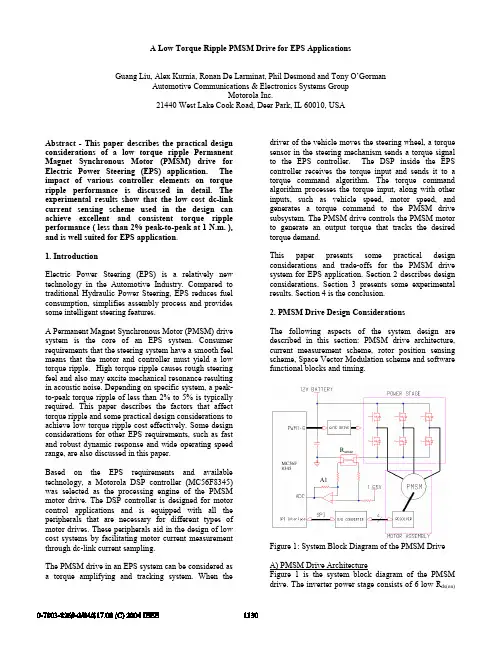
A Low Torque Ripple PMSM Drive for EPS ApplicationsGuang Liu, Alex Kurnia, Ronan De Larminat, Phil Desmond and Tony O’Gorman Automotive Communications & Electronics Systems GroupMotorola Inc.21440 West Lake Cook Road, Deer Park, IL 60010, USAAbstract - This paper describes the practical design considerations of a low torque ripple Permanent Magnet Synchronous Motor (PMSM) drive for Electric Power Steering (EPS) application. The impact of various controller elements on torque ripple performance is discussed in detail. The experimental results show that the low cost dc-link current sensing scheme used in the design can achieve excellent and consistent torque ripple performance ( less than 2% peak-to-peak at 1 N.m. ), and is well suited for EPS application.1. IntroductionElectric Power Steering (EPS) is a relatively new technology in the Automotive Industry. Compared to traditional Hydraulic Power Steering, EPS reduces fuel consumption, simplifies assembly process and provides some intelligent steering features.A Permanent Magnet Synchronous Motor (PMSM) drive system is the core of an EPS system. Consumer requirements that the steering system have a smooth feel means that the motor and controller must yield a low torque ripple. High torque ripple causes rough steering feel and also may excite mechanical resonance resulting in acoustic noise. Depending on specific system, a peak-to-peak torque ripple of less than 2% to 5% is typically required. This paper describes the factors that affect torque ripple and some practical design considerations to achieve low torque ripple cost effectively. Some design considerations for other EPS requirements, such as fast and robust dynamic response and wide operating speed range, are also discussed in this paper.Based on the EPS requirements and available technology, a Motorola DSP controller (MC56F8345) was selected as the processing engine of the PMSM motor drive. The DSP controller is designed for motor control applications and is equipped with all the peripherals that are necessary for different types of motor drives. These peripherals aid in the design of low cost systems by facilitating motor current measurement through dc-link current sampling.The PMSM drive in an EPS system can be considered as a torque amplifying and tracking system. When the driver of the vehicle moves the steering wheel, a torque sensor in the steering mechanism sends a torque signal to the EPS controller. The DSP inside the EPS controller receives the torque input and sends it to a torque command algorithm. The torque command algorithm processes the torque input, along with other inputs, such as vehicle speed, motor speed, and generates a torque command to the PMSM drive subsystem. The PMSM drive controls the PMSM motor to generate an output torque that tracks the desired torque demand.This paper presents some practical design considerations and trade-offs for the PMSM drive system for EPS application. Section 2 describes design considerations. Section 3 presents some experimental results. Section 4 is the conclusion.2. PMSM Drive Design ConsiderationsThe following aspects of the system design are described in this section: PMSM drive architecture, current measurement scheme, rotor position sensing scheme, Space Vector Modulation scheme and software functional blocks and timing.Figure 1: System Block Diagram of the PMSM DriveA) PMSM Drive ArchitectureFigure 1 is the system block diagram of the PMSM drive. The inverter power stage consists of 6 low R ds(on) MC56F8345A1R sense0-7803-8269-2/04/$17.00 (C) 2004 IEEE1130power MOSFETs. The power stage is driven by a gate drive which level-shifts the 6 PWM signals from the DSP. A low inductance sense resistor with Kelvin connections is used to measure dc link current.An op-amp A1 is connected as a differential amplifier across the resistor Kelvin connections. The bandwidth of the amplifier at the necessary gain should be about 1MHz to avoid distortion of the dc link current signal. The reference voltage for the ADC is 3.3V and the input of the op-amp is biased to 1.65V. Consequently, at zero dc link current, the output of the differential amplifier should be near 1.65V.B) Current Measurement SchemeCurrent measurement accuracy has a major impact on torque ripple performance. Closed loop Hall-effect current sensors can provide accurate motor phase current measurements [1] but the sensor cost is too high for EPS application. A lower cost method is to measure the motor phase current through 3 resistors at the bottom of each leg of the 3-phase inverter, requiring 3 sets of sense resistor, amplifier and filter. More importantly, it is difficult to maintain the same current measurement gain for the three phases as a result of variations among sense resistors and op-amp parameter variations. This accuracy variation can result in torque ripple.In the PMSM drive described in this paper, the motor current is measured through sampling of the dc link current with a single sense resistor and op-amp. Consequently, the problem of uneven measurement gain for different phases is eliminated. Furthermore, this method is the lowest cost of all the methods reported in the literature. The dc link current sensing method was first reported by T.C. Green [2] in 1989. Since then, numerous publications have documented progress on the dc link current sense method [3, 4]. Although the theory of dc link current sensing is well understood, the implementation plays a major role in the accuracy and robustness of the present solution. With the advent of modern DSP controllers, this need for robustness and accuracy can be achieved cost effectively in an electrically noisy automotive environment.Figure 2(a) shows the PSPICE simulation of the dc link current waveform and motor phase current waveforms. From the waveforms in Figure 2(a), it can be seen that if the dc link current waveform is sampled at the right instant, phase A and C current can be obtained from dc link current. Figure 2(b) shows the oscilloscope plot of the dc link current signal at differential op-amp output (V_i_dc_link), motor phase A current (i_a) and phase A voltage (v_a). It is seen that there are spikes on the dc link current signal but with the precise timing function of the DSP, we can sample the dc link current signal when the undesired transient has decayed to zero.Figure 2 (a) Simulated dc link and phase currents: I_a, I_b and I_c are the simulatied phase currents, I_dc_link is the simulated dc link current.Figure 2 (b): Measured dc link current signal (ch1, 13.3A/div), Phase A current (ch4, 20A/div.) and Phase A voltage (ch3, 2.5V/div.)During the product development process, Matlab/Simulink has been used to study the impact of dc link current sampling error on the torque ripple signature. The simulation helps to identify the effect of specific current measurement errors on torque ripple harmonic components, including specific errors of the dc-link current sense mechanism. Figure 3 shows the Simulink model of the dc-link current sensing subsystem.In Figure 3, the current sense outputs are selected by the sector number generated by Space Vector Modulation (SVM) software function. In each of the 6 sectors, two of the three phase currents are simulated accurately in addition to a sector dependent error. The third phase current is derived by using the relation that the sum of the three phase currents equals zero. A quantizationv_aI_aI_bI_dc_link,represents –I_a at this pointI_ci_aV_i_dc_link, Represents– i_a at this point.Represents i_c at this point.block is used to simulate the limited resolution of the A/D converter.Figure 4(a) shows the simulation result of a 0.15A measurement error on all sectors. The motor peak current is about 10A. As can be seen, the torque has a distinctive character of 3 pulses per electrical period, or 3-per-period torque ripple. Figure 4(b) is the measured torque ripple before the measurement error was corrected. The measured torque ripple signature matches that of the simulation. Modification to the currentsensing channel was made to reduce the measurement error. Figure4(c) is the measured torque ripple after the measurement error is corrected. One can see the 3-per-period torque ripple is completely eliminated.T o r q u e (N .m .)Time (Sec.)Current sense error = 0.15 (A)M o t o r c u r r e n t (A )Time (Sec.)Figure 4(a): Simulation result with 0.15A dc link sampling error. Top trace: torque (N.m.); Bottom trace: i a (A)Figure 4(b): Measured torque ripple before sampling error is corrected. Channel M2 is torque ripple (0.02 N.m./div), average torque is about 0.45 N.m. Ch4 is i a at 5A/div.Figure 4(c): Measured torque ripple after the sampling error is corrected. Channel M2 is torque ripple (0.02 N.m./div), average torque is about 0.45 N.m. Ch4 is i a at 5A/div.C) Position Sensing SchemeThere are many motor position sensors available in the market. Some of them are very accurate but expensive while others are lower cost but less accurate. For a cost effective PSMS drive, the position sensor should have sufficient accuracy to satisfy torque ripple requirements and must not be overly expensive. Matlab/Simulink can be used to simulate the impact of position measurement error on torque ripple performance. The position sensor error can be approximated as a periodical function of the motor mechanical angle as shown in the following equation:)cos(m A es K θθ⋅= … Eq. (1)Where, θes is the motor electrical angle with the measurement error, K A is the amplitude of the measurement error, and θm is the true mechanical angle.VaVbVc(3) (1) (5) (4)(6) (2)The actual measurement error depends on the specific sensor type used in the system. The reason to choose periodical error in the simulation is that it represents the worst case error pattern in terms of torque ripple.The quantization error due to limited resolution is simulated with a quantization block in Simulink.During simulation, the amplitude of the error K A is varied in 0.5 degree steps in the simulation model. The torque ripple for each error amplitude is recorded. The simulations are conducted for low motor speed and high motor speed (in deep flux weakening region). The results are shown in Figure 5(a) and 5(b).Figure 5 (a): Simulated torque ripple at 1 Hz, 4.1 N.m. average.Figure 5 (b): Simulated torque ripple at 160Hz, 1.0 N.m. average.Figure 5 (a) shows the position measurement error contribution to motor torque ripple at low speed. The torque ripple with a position error of 4 degrees is only 0.015 N.m., with an average output torque of 4 N.m., or 0.38% of the average motor torque. It is clear that at low speed, the position measurement error has very little impact on torque ripple. However, if we look at Figure 5 (b), the position error contribution to torque ripple at high speed, the torque ripple is 1.1 N.m. when the position error is 4 degrees. The average motor torque in this case is 1.0 N.m. The peak to peak torque ripple is therefore 110% of the average torque. Depending on thesystem moment of inertia, this torque ripple may or may not be acceptable. In our PMSM drive design, we included interfaces for both high accuracy sensors, such as resolvers [7] and low accuracy sensors [8] so that different system requirement can be covered. It should be noted that the position errors given in the horizontal axes of Figure 5 (a) and (b) can be due to manydifferent factors, such as resolution of the sensor, tolerance of the sensor and effective error due to transport delay.D) Space Vector Modulation (SVM) SchemeMany SVM schemes have been reported in the literature [9]. Although Minimum Loss SVM and Bus Clamping SVM are good for reducing loss, it is difficult to use these methods for measuring motor current through dc link current when the output voltage vector is very small. In an EPS motor controller, it is very important to maintain current control near zero torque command. As a result, a center aligned (or double edge) SVM scheme is used. With this method, the inverter outputs a maximum line to line voltage equal to the dc bus voltage. Figure 6 is the display of the DSP internal variables for PWM command and motor position angle. The display is obtained with PC Master, a software development tool provided by Motorola.Figure 6: DSP variables plot by PC Master - Top trace - phase A PWM command; Bottom trace – motor position angle. Motor rotates in forward direction.E) Software Functional Blocks and TimingFigure 7 is the Simulink block diagram for the PMSM control system. The DSP software is implemented with the same functional blocks as shown in Figure 7. The motor control system has two loops: one is the D and Q axes current control loop updated every 300us, and the other is the flux control loop updated every 1.2ms. Because of the current loops, non-linearity of the inverter stage is compensated and has little effect on torque ripple. The current loops also compensate the parameter drift of the motor and inverter. The complete motor control algorithm takes about 15 MIPS with majority of the code written in “C” language, which isone quarter of the total DSP processing power available. The remainder of the DSP MIPS is reserved for other EPS controller functions, such as torque command algorithm, CAN communication, system diagnosis and computational integrity checks. The program memory used is about 45 kilobytes, including motor control, diagnosis, computational integrity check functions, faultmanagement and system operating state machine.Figure 7: Simulink Diagram Represents Software Functional BlocksThe flux control loop generates the D and Q axes current reference based on torque command and motor speed. When the motor speed is below the base speed, D axis current reference is set to zero. When the speed is above base speed, a current advance angle is obtained from a look up table. Based on the advance angle, a negative D axis current reference will be generated for flux weakening operation.3. Experimental ResultsThe DSP based PMSM drive system has been built andexperimental results are presented in this section.Figure 8: Torque ripple at 2.39 N.m. average is 0.034 N.m., or 1.4% (channel M2 at 0.02 N.m./div.), channel 4 is motor current at 20A/div. Figure 8 through 10 show the torque ripple measurement at various average torque levels. Thetorque ripple at above 1 N.m. average is about 1.5% peak-to-peak, which is well within the EPS application requirement (usually 2% to 5%). This torque ripple performance is insensitive to the mismatch of the inverter MOSFET switching characteristics, therefore can be maintained at high volume production.Figure 9: Torque ripple at 1.05 N.m. average is 0.015 N.m., or 1.5% (channel M2 at 0.02 N.m./div.), channel 4 is motor current at 10A/div.Figure 10: Torque ripple at 0.12 N.m. average is 0.012 N.m. (channel M2 at 0.02 N.m./div.), channel 4 is motor current at 2A/div.Figure 11: Motor current when steering wheel is suddenly stopped. Current is limited to 100A (ch3,50A/div.)Figure 12: D axis current step response (1.8ms rise time), no overshoot (50A/div.)Figure 11 shows the motor current and torque sensor signals. With the 300us current loop, the motor current is controlled with a pre-set limit. In transient condition, such as sudden stop of the motor (end of rack travel), the motor current is still under control. Fast current control is important in preventing unwanted shutdown due to transient over current. Figure 12 shows the Q-axis current step response. The rise time is about 1.8ms and there is no overshoot.Figure 13 (a): Measured motor torque-speed curve above base speed.Figure 13 (b): Measured motor power vs. frequency. Figure 13 (a) shows the motor torque and speed measurement. The motor base speed is about 90 Hz. It can be seen that the motor speed operates above 90Hz with reduced torque. From Figure 13 (b) it can be seen that at flux weakening region, the motor output power is close to constant.4. ConclusionA low torque ripple PMSM drive system for EPS application has been presented in this paper. With the modern DSP controller and careful design of motor current and position sensing schemes, excellent torque ripple performance can be achieved without using expensive current sensors. Current measurement accuracy has the highest impact on torque ripple performance. The single sense resistor sampling method used in this design is accurate enough to obtain low torque ripple for volume production. Some other design considerations, such as SVM scheme selection, control software functional blocks, loop timing and MIPS requirement, etc are also presented. Fast and robust dynamic response and flux weakening operation are demonstrated. The experimental results prove that the PMSM drive presented in this paper is very suitable for EPS controllers.References[1] LEM Group, “Current Transducer LT 100-S/SP30”, website .[2] T.C. Green and B.W. Williams, “Derivation ofmotor line-current waveforms from the dc-link currentof an inverter”, IEE Proceedings, volume 136, Pt. B, No. 4, pp. 196-204, July 1989.[3] Frede Blaabjerg, John K. Pederson, Ulrik Jaeger, Paul Thoegersen, “Single Current Sensor Technique in the DC-Link of Three-Phase PWM-VS Inverters: A Review and Ultimate Solution”,Industry Applications Conference, 1996. Thirty-First IAS Annual Meeting, IAS '96., Conference Record of the 1996 IEEE , Volume: 2 , pp. 1192 -1202, 6-10 Oct. 1996.[4] Woo-Cheol Lee, Dong-Seok Hyun and Taeck-Kie Lee, “A Novel Control Method for Three-Phase PWM Rectifiers Using a Single Current Sensor”, IEEE TRANSACTIONS ON POWER ELECTRONICS, VOL. 15, NO. 5, pp. 861- 870, SEPTEMBER 2000. [5]Ion Boldea and S. A. Nasar, “Electric Drives”, CRC Press LLC, ISBN 0-8493-2521-8, 1999.[6] Mathworks, Inc.“Simulink – Dynamic System Simulation for MATLAB”, Release 12, November 2000.[7] NMB Minebea GmbH, “Variable Reluctance Resolver”, http://www.nmb-/minebea/Data/Pages/rotarycomponents/reso lver.html[8] Allegro MicroSystems, Inc. , “Ring Magnet Speed Sensing for Electronic Power Steering”,/techpub2/ring_magnet/ [9] Andrzej M. Trzynadlowski and Stanislow Legowski, “Minimum-Loss Vector PWM Strategy for Three-phase Inverters”. Transaction on Power Electronics, VOL. 9, NO. 1, pp. 26-34, January 1994.。

全新第四版工业与民用配电设计手册英文版Title: New Fourth Edition Industrial and Commercial Distribution Design ManualIntroduction:Welcome to the latest edition of the Industrial and Commercial Distribution Design Manual. This comprehensive guide provides essential information for designing electrical distribution systems for both industrial and commercial applications.Chapter 1: Fundamentals of Electrical DistributionThis chapter covers the basic principles of electrical distribution, including voltage levels, load types, and equipment selection. It serves as a foundation for the rest of the manual.Chapter 2: Design Considerations for Industrial ApplicationsLearn about the unique challenges and requirements of designing electrical distribution systems for industrial facilities. Topics include power factor correction, harmonics mitigation, and motor starting.Chapter 3: Design Considerations for Commercial ApplicationsExplore the specific considerations for designing electrical distribution systems in commercial buildings, such as lighting design, backup power systems, and energy efficiency measures.Chapter 4: Equipment Selection and SizingThis chapter provides guidance on selecting and sizing various components of an electrical distribution system, including transformers, switchgear, and protective devices.Chapter 5: Power Quality and ReliabilityLearn how to ensure power quality and reliability in electrical distribution systems through proper design practices, maintenance strategies, and troubleshooting techniques.Chapter 6: Safety and ComplianceUnderstand the importance of safety and compliance in electrical distribution design. This chapter covers relevant regulations, codes, and best practices to ensure a safe and reliable electrical system.Chapter 7: Case Studies and Practical ExamplesExplore real-world examples and case studies to apply the principles and concepts discussed throughout the manual. These examples provide valuable insights into the design process and implementation of electrical distribution systems.Conclusion:The fourth edition of the Industrial and Commercial Distribution Design Manual is a valuable resource for engineers, designers, and professionals involved in the design and implementation of electrical distribution systems. Whether you are working on an industrial facility or a commercial building, this manual will provide you with the knowledge and tools necessary to create efficient, reliable, and safe electrical distribution systems.。

ABB Corporate Research & ABB Industrie AG IGCT Series Connection for Medium Voltage ApplicationsA 24MVA Inverter using IGCT Series Connectionfor Medium Voltage ApplicationsA. Nagel, S. Bernet ABB Corporate Research D-68520 LadenburgGermany P. K. Steimer, O. Apeldoorn ABB Industrie AGCH-5300 TurgiSwitzerlandAbstract −This paper describes a 24MVA inverter utilizing the series connection of 3 IGCTs per switch position in a three level neutral point clamped inverter topology. The electrical and mechanical design, especially focused on a phase leg, as well as experimental results are shown.I. I NTRODUCTIONThe development of new high power semiconductors such as 3.3kV, 4.5kV and 6.5kV Insulated Gate Bipolar Transistors (IGBTs) and 4.5kV to 6kV Integrated Gate Commutated Thyristors (IGCTs), improved converter designs and the broad introduction of three-level topologies have led to a drastic increase of the market share of PWM controlled Voltage Source Converters. Meanwhile these converters, ranging from 0.5MVA to 10MVA, are becoming price competitive against conventional thyristor converters since reduced line har-monics, a better power factor, substantially smaller filters, elimination of transformers and the use of optimized electric machines enable a cost reduction of the system in many applications within industry, distribution and transmission [1],[2].A clear market trend for these applications is the increase of the rated converter voltage. However, today the maximum achievable converter output voltage of a three-level neutral point clamped voltage source inverter (3L NPC VSI) is limited to about 4.16kV using 5.5kV IGCTs respectively 4.9kV using 6.5kV IGBTs. To increase the output voltage the series connection of semiconductors is a simple solution [3],[4],[5].II. B ASIC D ESIGN C ONSIDERATIONSFor a new high power three phase inverter with an output voltage in the range of 10kV the three-level neutral point clamped (3L-NPC) topology has been chosen, because it offers significant advantages like•small number of additional components to increase the number of levels from 2 to 3 (only 2 additional NPCdiodes per phase leg)•two simple clamp circuits serving the whole 3 phase inverter•low output voltage harmonics / reduced filter efforts due to the three level characteristics•easy mechanical design (which is crucial in inverters with more than 3 levels)•well established direct torque control can be used •simple direct series connection of three IGCTs per switch position to increase the output voltageFig 1. Schematic of an 24MVA inverter with 9kV output voltageThe schematic of the chosen inverter topology is given in Fig. 1.The inverter is based on the IGCT technology, which enables• low conduction losses• well defined high switching speed• direct series connection using a small snubber• low costs due to the optimum semiconductor utilization • presspack housing (high reliability, very good thermalcycling behavior, short circuit in failure mode enables n +1 redundancy using an additional IGCT)To guarantee the symmetric voltage balancing of the series connected IGCTs parallel balancing resistors (R p in Fig. 1) as well as a small RC-snubbers (R snub , C snub in Fig. 1) are used.This simple and low loss balancing circuitry ensures the balancing even under critical operating conditions like GCT device variations, delay time between gate signals, different chip temperatures and tolerances of the snubber components [5].III. T EST S ETUPTo show the feasibility of this approach a full scale phase leg has been build up using a 3L-NPC topology with 3 devices (IGCT, diodes) in series per switch position, which are balanced by RC-snubbers. An inductor has been used as load,because it enables to test the converter with full output current while keeping the input power consumption low (Fig. 2). Thetechnical data of a three-phase inverter using three of these phase legs is summarized in TABLE 1.TABLE 1Basic technical data of a three phase inverter with an IGCT seriesconnection Parameter Value / Type total dc input voltage V DC = 14.4 kV rms output current I out = 1.5 kA nominal peak output current I out, peak = 2.1 kA output power P out = 24 MVA carrier frequency f s = 700 HzIGCT5SHY35L4503 (4.5kV 91mm)Diode (4.5kV 68mm)D65S45 (4.5kV 68mm)IV. EXPERIMENTAL RESULTSFig. 3 shows the inverter output voltage and output current at nominal dc input voltage and rated output current. Due to the rather small load inductor a small modulation index is needed to limit the current. Therefore, the NPC diodes and the inner IGCTs are the most stressed components, which are limiting the output power. However, this type of operation is a perfect simulation of a drive operating with full torque at low speed or zero speed, which is most demanding for the inverter regarding current stress and thermal loading.A more detailed view of the switching transient is given in Fig. 4, which is a zoom of Fig.3 (time window ranging from 16ms to 16.1ms, turn-on current 1.5kA, turn-off current 1.7kA). The typical waveforms with the overvoltage peak caused by the clamp can be clearly seen as well as perfect voltage balancing between the series connected devices.400VFig 2. Schematic of the test setup with one phase leg-10-5051005101520-2-112Time / msFig. 3. Output voltage and current waveforms at V DC = 14.2 kV, I out, rms = 1.5kA, f s = 700 Hz, f out = 50 Hz.-10-8-6-4-20020406080100Time / µsV o l t a g e / k VFig. 4. Zoom from Fig. 4. Voltage waveforms V1, V2,V3, V4 measured at the outer IGCTs towards ground (see Fig. 2).To analyze the voltage balancing under worst case operating conditions, an emergency shutdown at maximum current has been analyzed. Fig. 5 shows the device voltages during a turn-off transient at V DC = 14.2 kV and I off = 3.5 kA using poorly selected IGCTs. It can be clearly seen, that the slower switching component GCT1 takes over less voltage than the two other components. The voltage unbalance of -500V is no problem and even a faster switching device with a voltage unbalance of +500V will not harm any components.EfficiencyDue to the test setup it is rather easy to measure the overall inverter efficiency very precise, because the power consumption of the test setup is equal to the sum of the inverter losses and the output power, where the output power is only a small part caused by the ohmic losses in the reactive load.0100020003000400020406080t / µsU G C T / VFig. 5. Semiconductor voltage waveforms of series connected IGCTs (turn-off @ V DC = 14.2 kV, I off = 3.5 kA).TABLE 2EfficiencyParameter Measurement 1Measurement 2total dc input voltage V DC = 13.19 kV V DC = 13.22 kV rms output current I out = 1080 A I out = 1505 kA input powerP input = 55 kW P input = 79 kW output power (inductor losses)P out = 3.3 kW P out = 6.5 kW absolute inverter losses P loss = 51.7 kW P loss = 72.5 kW apparent output power S out = 5691 kVA S out = 7948 kVA relative inverter losses p loss = 0.908%p loss = 0.912%inverter efficiencyη = 99.092%η = 99.088%The measurements have proven an inverter efficiency of more than 99%, which is a pretty good value. However, the efficiency values which will be obtained under normal operating conditions – that is modulation index near one at full output current, which is common for motor as well as line side applications – will be even higher, because the losses are better balanced between the devices and especially the NPC diodes will no longer limit the output current.V. SUMMARYThis paper describes the design of a 24 MVA inverter utilizing the series connection of IGCTs. Experimental results of a phase leg are given showing the full power operation with good voltage balancing of series connected devices even under worst case operating conditions and a high efficiency. It has been proven, that the series connection of IGCTs is a simple and reliable solution for high power medium voltage applications.V o l t a g e / k VC u r r e n t / k AA CKNOWLEDGMENTThe authors would like to thank Gerold Knapp and Pascal Mauron, both of ABB Industrie AG, Turgi, for building up the inverter and doing the measurements.R EFERENCES[1]P. K. Steimer, J. K. Steinke, H. Grüning, “A reliable, interface-friendly medium voltage drive based the robust IGCT and DTC technologies,” IEEE IAS Annual Meeting 1999, Phoenix, Arizona, October 1999.[2]P. K. Steimer, H. Grüning, J. Werninger, “The IGCT - the keytechnology for low cost, high reliable high power converters with series connected turn-off devices,” EPE 1997, Trondheim, September 1997.[3]R. Sommer, A. Mertens, M. Griggs, H. J. Conraths, M. Bruckmann,T. Greif, “New medium voltage drive system using three-level neutral point clamped inverter with high voltage IGBT,” IEEE IAS Annual Meeting 1999, Phoenix, Arizona, October 1999.[4]J. P. Lyons, V. Vlatkovic, P. M. Espelage, F. H. Boettner, E. Larsen,“Innovation IGCT main drives,” IEEE IAS Annual Meeting 1999, Phoenix, Arizona, October 1999.[5] A. Nagel, S. Bernet, T. Brückner, P. K. Steimer, O. Apeldoorn,“Characterization of IGCTs for series connected operation,” IEEE IAS Annual Meeting 2000, Rome, October 2000.。

CommunicativeApproachAn Introduction of Communicative Approach1. The Communicative Approach is an approach to foreign or second LT which emphasizesthat the goal of language teaching is communication competence. The Communication Approach is also called Communication Language Teaching.2. The Communication Approach has been developed particularly by British appliedlinguists as a reaction away from grammar-based approaches such as the Audio-lingual Method.3. Teaching materials used with a Communication Approach often teach the languageneeded to express and understand different kinds of functions, such as requesting, describing, expressing likes and dislikes.4. The Communication Approach follow a Notional Syllabus or some othercommunicatively organized syllabus and emphasizes the processes of communication, such as using language appropriately in different kinds of tasks,e. g, to solve puzzles, to get information, and using language for socialinteraction with other people.Background of the Communication Approach1. Towards the end of the 1960s there went on a growing dissatisfaction among FLteachers and applied linguists with the dominating LT method of the time.①First, the criticism was that this kind of teaching produced structurallycompetent students who were oftencommunicatively incompetent.②Another reason for this dissatisfaction was undoubtedly for internationalcommunication, professionalcooperation and travel.③Meanwhile, some theoretical linguists had become conscious of the fact thatin linguistic researchmeaning and context were neglected.By the late 1960s, people began to consider semantics to be basic to any theoretical model of language. Meaning was seen to depend to a large degree on the sociocultural contexts in which speech acts occurred. Sociocultural aspects of language in use had been particularly stressed by the functionalists, who considered the purposes language serves in normal interaction to be basic to the determination of syntactic functions.2. All this was reflected in some proposals to reconstruct the language syllabusso that learning communicative conventions would become as important as learning grammatical conventions.3. D.A. Wilkins was the main figure in setting out the fundamental considerationsfor a “functional-notional “approach to syllabus design based on communicative criteria.4. The distinguishing characteristics of the Notional-Functional Syllabus (NFS)were its attention to function as the organizing elements of English language curriculum, and its contrast with a structural syllabus in which sequenced grammatical structures served as the organizers. Reacting to methods that attended too strongly to grammatical forms, the NFS sought to focus on the pragmatic purposes to which we put language.5. Wilkin’s book Notional Syllabuses had a significant impact on the developmentof Communicative Language Teaching. Courses for different languages were then developed based on his semantic / communicative analysis. The NFS did not necessarily develop communicative competence in learners. First of all, it is not a method. It was a syllabus. However, by attending to the functional purposes of language, and by providing contextual (notional) settings for the realization of those purposes, it provides a link between a dynasty of methods that was now perishing and a new era of language teaching------Communicative Language Teaching.6. The Communicative Approach is essentially a manifestation of the 1970sm, in thesense that this was the decade when the most explicit debate took place, especially in the U.K. The subsequent period has been characterized by explorations of other, related possibilities for the design of materials and methods. More importantly, teachers in many parts of the world are finding that they need to come to terms with changes in their role, as communicative principles in language teaching become central goals of their educational systems. These educational perspectives evolved alongside, and to some extent were derived from, significant developments in linguistics, sociolinguistics and psychology.7. What are the two categories of meaning of language proposed by Wilkins? What isthe distinction between the two terms?The two categories of meaning proposed by Wilkins are “notions” and “functions”. “Notions” are domains inwhich we use language to express thought and feeling. They are both general and specific. General notionsare abstract concepts such as existence, space, time, quantity and quality. Within the general notion of spaceand time, for example, are the concepts of location, motion, dimension, speed and length of time, andfrequency. Specific notions correspond more closely to what we have become accustomed to calling“contexts” or “situations”. Personal identification, for example, is a specific notion under which name,address, phone numbers, and other personal information is subsumed. “Functions”refer to the purposes forwhich utterances or units of language are used. In language learning, language functions are often describedas categories of behavior; e.g. requests, apologies, complaints, offers, and compliments.8. According to Wilkins, language has two categories of meaning :structural meaningand functional meaning.9. Wilkins analyzed the communicative meaning that a language learner needs tounderstand and express, and he insists that the structural component cannot be ignored.Theories of language underlying the Communicative Approach1. The Communicative Approach in language teaching starts from a theory of languageas communication. When we communicate, we use the language to accomplish some functions, such as arguing, persuading, or promising. Moreover, we carry out these functions within a social context.2. The Communicative Approach has a theory of language rooted in the functionalschool. Functional linguistics is concerned with language as an instrument of social interaction rather than a system that is viewed in isolation. In addition to talking about language function and language form, there are other dimensions of communication to be considered if we are to be offered a more complete picture.They are, at least, topics (e.g. health, transport ); context and setting ( both physical and social ); and roles of people involved .3. According to Halliday, a British linguist, social context of language use canbe analyzed in terms of three factors:①he field of discourse: what is happening, including what is being talked about;②he tenor of discourse: the participants who are taking part in this exchange of meaning, who they are and what kind of relationship they have to each other;③he mode of discourse: what part the language is playing in this particular situation, for example, in what way the language is organized to convey the meaning, and what channel is used---written or spoken or a combination of the two.4. This analysis leads to a new branch, discourse analysis, the study of how sentencesin spoken and written language form larger meaningful units such as paragraphs, conversations, and interviews. Therefore, discourse analysis becomes an indispensable part of Communicative Language Teaching.5. Closely related to Communicative Language Teaching (CLT) is pragmatics, the studyof the use of language in communication. Pragmatics is particularly interested in the relationships between sentences and the contexts and situations in which they are used.6. How do you understand the relationship between the grammatical forms of a languageand their communicative functions?The relationship between the grammatical forms of a language and their communicative functions is not a one-to-one correspondence. Whereas the sentence structure is stable and straightforward, its communicative function is variable and depends on specific situational and social factors. The fact is that a single linguistic form can express a number of functions, so also can a single communicative function be expressed by a number of linguistic forms. In a communicative perspective, this relationship is explored more carefully, and as a result our views on the properties of language have seen expanded and enriched.7. In talking about CLT, on cannot avoid talking about “ communicative competence”,a term coined by Hymes (1972) in order to contrast a communicative view oflanguage with Chomsky’s (1965) theory of competence.8. How do your teaching materials handle the relationship between grammar andcommunicative function? For instance, is a “function” taught together with several grammatical forms, or just one? Alternatively, is a “function” just used as an example where the main focus is on teaching grammar?Do this point according to what your teaching materials are used. You may refer to the key to No. 2 point above, and analyze the factors using a communicative perspective.9. Chomsky claimed that every normal human being was born with a language acquisitiondevice (LAD). The LAD is a sort of mechanism or device which contains the capacity to acquire one’s first language. The LAD includes basic knowledge about the nature and structure of human language. For Chomsky, the focus of linguistic theory was to characterize the abstract abilities speakers possess that enable them to produce grammatically correct sentences in a language.10. In Hymes’s view, “ communicative competence” (proposed by Hymes) refers tothe ability not only to apply the grammatical rules of a language in order to form grammatically correct sentences but also to know when and where to use these sentences and to whom. Hymes’s emphasis on the importance of context in determining appropriate patterns of behavior, both linguistic and extralinguistic, appealed to teachers who found an overemphasis on accurate use of language structures to be confining and unrealistic.11. Another linguistic theory of communication favored in CLT is Halliday’sfunctional account of language use. Halliday (1975) described seven basic functions that language performs for children learning their first language:①Language can be used to get things;②to control the behavior of others;③to create interaction with others;④to express personal feelings;⑤to learn and to discover;⑥to create a world of the imagination;⑦to communicate information.12. Another source of a communicative view of language can be found in Henry Widdowson,(1978) who presented a view of the relationship between linguistic system and their communicative values in text and discourse.13. Henry Widdowson focused on the communicative acts underlying the ability to uselanguage for different purposes. His distinction between appropriacy and accuracy, communicative competence and grammatical competence, use and usage threw much light on CLT.14. According to Canale and Swain (1980), communicative competence entails fourdimensions: grammatical competence; sociolinguistic competence; discourse competence and strategic competence.①rammatical competence refers to what Chomsky calls “linguisticcompetence.”②Sociolinguistics competence refers to an understanding of the social contextin which communication takes place, including role relationships, the sharedinformation of the participants, and the communicative purpose for theinteraction.③Discourse competence refers to the interpretation of individual messageelements in terms of their interconnectedness and of how meaning isrepresented in relationship to the entire discourse or text.④Strategic competence refers to the coping strategies that communicatorsemploy to start, end, keep, repair and redirect communication.15. A communicative view of language has the following four characteristics byRichards and Rodgers:①Language is a system for the expression of meaning;②The primary function of language is for interaction and communication is oneof the CommunicativeApproach characteristics;③According to the Communicative Approach, the structure of language reflectsits functional andcommunicative uses;④The primary units of language are not merely its grammatical and structuralfeatures, but categories offunctional and communicative meaning as exemplified in discourse.。

Design Considerations for a Novel Single-Stage AC-DC PWM Full-Bridge ConverterAbstract— A new ac-dc single-stage PWM full-bridge converter is proposed in this paper. Theconverter uses an auxiliary transformer winding to keep the voltage across the primary-side dc bus below 450V over a universal line and wide load range. In this paper, the fundamental operating principles of the proposed converter are discussed, and a mathematical analysis of the converter is then performed. The analysis is used to derive graphs of steady-state characteristic curves that can be used to form the basis of a design procedure. The procedure can be used to select the values of key converter components, and is demonstrated with an example showing the design of a 48 Vdc, 500W power supply. Experimental results obtained on a laboratory prototype are presented to confirm the concepts presented in this paper.I. INTRODUCTIONAc-dc full-bridge single-stage converters can generally be classified as being either current-fed or voltage-fed converters [1]-[11]. Voltage-fed converters have a large energy-storage capacitor at the input of the full-bridge converter, across the primary-side dc bus. This capacitor keeps voltage overshoots and ringing from appearing across the dc bus, and filters out a large 120 Hz ac component so that it does not appear at the output. The primary-side dc bus voltage in these converters, however, can become excessive. It can exceed 500-600Vdc when the converter is operating with a high input line voltage. This voltage is dependent on input line and output load conditions, and the component values of the converter, especially the input inductor Lin and the output inductor Lo.It is possible to reduce this voltage through the selection of appropriate component values although overall converter performance suffers as a result. A new single-phase, single-stage, voltage-fed, ac-dc full-bridge converter that can operate with a lower dc bus voltage than other voltage-fed converters was, however, proposed in [12]. The lower dc bus voltage allows the selection of the converter components to be done under less stringent conditions. A greater emphasis on converter performance can therefore be placed when selecting converter components.In [12], however, the steady-state characteristics of the converter were not examined, and only a few, very general design guidelines were given. In this paper, the fundamental operating principles of the proposed converter are discussed, and a steady-state analysis of the converter is performed. The analysis is then used to derive graphs of steady-state characteristic curves. These graphs show the effect of certain key components on the operation of the converter, and are used as the basis of a design procedure. The procedure can be used to select appropriate values for the key components and is demonstrated with an example in the paper. Results obtained from an experimental prototype that confirm the feasibility of the converter are also presented in the paper.II. CONVERTER OPERATIONThe proposed converter is shown in Fig. 1. It can be seen in Fig. 1 that the inputinductor, Lin, is connected to one of the converter's bottom switches, S2, through a diode and the transformer auxiliary winding Naux. Switch S2 performs the same current–shaping function as the switch in a standard ac-dc PWM boost converter operating with power factor correction (PFC). The input current rises and energy is stored in Lin when the switch is on, and falls as inductor energy is transferred to Cb when the switch is off. When S2 is on, so too is S3, and a voltage is induced inauxiliary winding Naux with a polarity that reduces the net voltage across Lin. Since there is reduction in voltage across Lin, there is also a reduction in the energy stored in this inductor when S2 is on, and therefore a reduction in the inductor energy transferred to Cb when S2 is off. It is the reduction in the energy stored in Cb that causes the dc bus voltage to be reduced.The converter passes through eight distinct operation intervals during a steady-state switching period that were identified and explained in detail in [12]. In this section, only two fundamental operation stages are discussed: the power transfer stage and the freewheeling stage. The equivalent circuit diagrams are shown in Fig. 2 and the typical waveforms when the input inductor current is continuous and greater than the transformer primary current are shown in Fig.3.A. Power transfer stage (t0<t<t1 and t2<t<t3)The transition from a freewheeling stage to a power transfer stage only occurs whenever a transition is made from a top switch to a bottom switch – from S1 to S2 or from S3 to S4. During this stage, energy is delivered from capacitor Cb to the load through the transformer whenever a diagonally opposed pair of switches is on (S1 and S4 or S2 and S3).1) Interval 1[t0<t< t1]:At t=t0, switches S2 and S3 are on. The induced voltage across auxiliary winding Naux, NxVb, (Nx=Naux/N1) opposes the rectified input voltage Vin,rec, so that the positive voltage, Vin,rec-NxVb, is placed across Lin, and causes the input current Iin to rise only when Vin,rec>NxVb.2) Interval 3[t4<t<t5]:At t=t4, switches S1 and S4 are on. A voltage equal to NxVb is induced across the auxiliary winding Naux. This voltage increases the net negative voltage across Lin to Vin,rec+(Nx-1)Vb and forces the inductor current to decrease less quickly.B. Freewheeling stage (t2<t<t3 and t6<t<t7)During these two intervals, the two top switches S1 and S3 are both on, the converter enters a freewheeling stage of operation and there is no energy transfer to the load. The voltage across the transformer primary is zero and so is the induced voltage across Naux. The transformer primary current circulates through switches S1 and S3. The negative voltage, Vin,rec-Vb, across inductor Lin forces the current to fall down linearly.It should be noted that the proposed converter operates with constant duty cycle over the entire line period and with asymmetrical gating signals. If the bottom switch of a converter leg is on for a time of DTsw/2 (where D is the converter duty cycle and Tsw is the duration of the switching cycle), then the top switch of the same leg will be on for a time of (1-DTsw/2).III. STEADY STATE ANALYSIS AND CHARACTERISTICS OF THE PROPOSEDCONVERTERIt is important to determine the effect that individual converter parameters have on theoperation of the converter before a procedure can be established for its design. This can be done by performing a steady-state analysis of the converter's operation under various line and load conditions with various sets of converter parameter values. The results can then be used to derive graphs of characteristic curves that show the effect of a change in a single parameter values has on the operation of the converter. With these graphs, a systematic design procedure that will enable the selection of appropriate component values can then be derived.It is not, however, possible to derive closed form equations that can be used to analyze the converter’s characteristics so that the graphs can be derived. Since the converter is a single-stage converter, its dc bus voltage cannot be fixed as it can for a standard two-stage ac-dc converter with PFC, which has an independent ac-dc converter that can fix the dc bus voltage. This voltage varies with input line and load conditions. Moreover, if the converter is to be designed to operate with a universal input line voltage over a wide load range, it is possible for it to operate with several possible combinations of input current and output current modes over the line and load ranges. The input current may be either in discontinuous conduction mode (DCM), continuous conduction mode (CCM) (although it is rare) or semi-continuous conduction mode (SCM), which is a combination of DCM and CCM, and the output current may be either in DCM or CCM. It is the lack of a fixed dc bus voltage and the possibility of various combinations of input and output modes of operation over a wide line and load range that complicates the analysis of the converter.In [11], a general method for the analysis of single-stage voltage-fed converters was presented. This method used the fact that an energy-equilibrium must exist in the energy-storage capacitor, Cb, under steady-state conditions to determine the dc bus voltage for a particular set of operating points and conditions. According to this equilibrium, the energy pumped into the capacitor from the input inductor must be equal to the energy discharged from the capacitor to the load during a half line cycle, so that the net dc current flowing in and out of Cb must be zero. Once Vb is determined, then the process of calculating other converter voltages and currents is simplified. The reader is referred to [11] for the full details of the analysis method. The analysis method presented in [11] can be used to determine the dc bus voltage, Vb, the duty ratio, D, and the harmonic content of the input current for any particular operating point. An operating point can be considered to be any combination of input voltage Vin, output voltage Vo, switching frequency fsw, duty ratio D, input inductor Lin, output inductor Lo, transformer turns ratio N =N1/N2, auxiliary winding turns ratio Nx = Naux/N1, and output power Po. If the analysis is performed on a wide range of operating points, then the steady-state characteristics of the converter can be determined, and the effect that each of the above-mentioned parameter has on the operation of the converter can be studied.。

ENT-AN1158Application Note VSC858x Revision A to Revision B MigrationNovember 2015Contents1Revision History (1)1.1Revision 1.0 (1)2VSC858x Revision A to Revision B Migration (2)2.1Part Number Changes (2)2.2Product Changes (2)2.3Hardware Board Impact (2)2.4Software Impact (3)1Revision HistoryThe revision history describes the changes that were implemented in the document. The changes arelisted by revision, starting with the most current publication.1.1Revision 1.0Revision 1.0 was the first publication of this document.2VSC858x Revision A to Revision B MigrationThis document serves as the migration guide for the VSC8582 and VSC8584 devices from revision A torevision B silicon.2.1Part Number ChangesThe following table lists the revision A part numbers affected by this migration and their equivalentrevision B part numbers.The revision A column is empty for device variants that are new to revision B silicon.Table 1 • Part NumbersRev A Part Number Rev B Part NumberVSC8582XKS-10VSC8582XKS-11VSC8582XKS-13VSC8582XKS-14VSC8584XKS-10VSC8584XKS-11VSC8584XKS-13VSC8584XKS-14VSC8575XKS-11VSC8575XKS-14VSC8562XKS-11VSC8562XKS-14VSC8564XKS-11VSC8564XKS-142.2Product ChangesRevision B is an updated version of revision A with the following significant changes:VSC8582XKS-11, VSC8582XKS-14, VSC8584XKS-11, and VSC8584XKS-14 devices use the highresolution timing circuitry in the 1588 engine. This enables the 1588 ± 4 ns accuracy capability (whenusing the recommended software API 4.66, or later). Using previous software API versions thatworked with revision A silicon will result in the default 1588 accuracy capability (± 8 ns).The new revision B parts VSC8575XKS-11 and VSC8575XKS-14 feature 1588 ± 4 ns accuracycapability (for 1000Base-T/1000Base-X).VSC8582XKS-11, VSC8582XKS-14, VSC8584XKS-11, and VSC8584XKS-14 devices enable support forthe GCM-AES-XPN-128/256 cipher suite in accordance with the IEEE 802.1AEbw-2013 amendmentto the IEEE 802.1AE-2006 MACsec specification. This is in addition to the already supported 802.1AEbn-2011 amendment.The new revision B parts VSC8562XKS-11, VSC8562XKS-14, VSC8564XKS-11, and VSC8564XKS-14feature XPN.Note: Design considerations for revision A are now obsolete. Download the latest revision B datasheetsfor the updated design considerations.2.3Hardware Board ImpactCurrent consumption values have changed from revision A to revision B. These changes involve thebehavior of the internal datapath processor due to the new capabilities associated with revision B, buthave no effect on I/Os. For more information about the current consumption changes associated withrevision B devices, see the Current Consumption table in the Electricals section of a revision B datasheet.1588 SPI bus daisy-chain functionality is available in revision B devices.2.4Software ImpactRevision B devices for which there was an equivalent revision A device (such as VSC8584XKS-11/VSC8584XKS-10), will continue to work with previous versions of the software API to deliver existingrevision A features and functionality.Download the latest version of the software API (API 4.66 or later) to enable the latest features availablein revision B devices.Microsemi HeadquartersOne Enterprise, Aliso Viejo,CA 92656 USAWithin the USA: +1 (800) 713-4113Outside the USA: +1 (949) 380-6100Sales: +1 (949) 380-6136Fax: +1 (949) 215-4996Email:***************************© 2015 Microsemi. All rights reserved. Microsemi and the Microsemi logo are trademarks of Microsemi Corporation. All other trademarks and service marks are the property of their respective owners.Microsemi makes no warranty, representation, or guarantee regarding the information contained herein or the suitability of its products and services for any particular purpose, nor does Microsemi assume any liability whatsoever arising out of the application or use of any product or circuit. The products sold hereunder and any other products sold by Microsemi have been subject to limited testing and should not be used in conjunction with mission-critical equipment or applications. Any performance specifications are believed to be reliable but are not verified, and Buyer must conduct and complete all performance and other testing of the products, alone and together with, or installed in, any end-products. Buyer shall not rely on any data and performance specifications or parameters provided by Microsemi. It is the Buyer's responsibility to independently determine suitability of any products and to test and verify the same. The information provided by Microsemi hereunder is provided "as is, where is" and with all faults, and the entire risk associated with such information is entirely with the Buyer. Microsemi does not grant, explicitly or implicitly, to any party any patent rights, licenses, or any other IP rights, whether with regard to such information itself or anything described by such information. Information provided in this document is proprietary to Microsemi, and Microsemi reserves the right to make any changes to the information in this document or to any products and services at any time without notice.Microsemi, a wholly owned subsidiary of Microchip Technology Inc. (Nasdaq: MCHP), offers a comprehensive portfolio of semiconductor and system solutions for aerospace & defense, communications, data center and industrial markets. Products include high-performance and radiation-hardened analog mixed-signal integrated circuits, FPGAs, SoCs and ASICs; power management products; timing and synchronization devices and precise time solutions, setting the world's standard for time; voice processing devices; RF solutions; discrete components; enterprise storage and communication solutions; security technologies and scalable anti-tamper products; Ethernet solutions; Power-over-Ethernet ICs and midspans; as well as custom design capabilities and services. Microsemi is headquartered in Aliso Viejo, California, and has approximately 4,800 employees globally. Learn more at www. .VPPD-04110。

超姚激光脉冲。
,透I劐介质相互作用3.2对透明介质中形成的结构改变形态的观察在本节中,我们分别使用脉冲宽度为ps和fs量级,波长为800nm,重复频率lkHz的激光脉冲,在熔融石英中形成了单发脉冲导致的损伤位点阵列。
并对单个损伤位点,使用光学显微镜和图像传感器对其形态进行了观测。
同时参考了C胁sB.Schaffer与它的研究小组采用不同能量和不同聚焦条件下110ts的单脉冲激光照射石英玻璃产生的损伤形态。
3.2.1皮秒与飞秒激光脉冲在玻璃中形成的损伤图3一l:激光脉冲聚焦入射到透明介质内部示意如图3一l所示:将石英玻璃样品固定在一个计算机控制的三维移动平台上,分别使用数值孔径为0.45、0.65j}110.85的显微物镜,将不同单脉冲能量的2.1pS,800nm的激光脉冲聚焦到熔融石英体内同一深度处,用相位对比光学显微镜观察其损伤情况。
得出在不同聚焦条件下,2.1ps的激光脉冲对熔融石英玻璃的能量损伤阈值,观测了不同能量的激光脉冲所形成的损伤形态。
观测结构如图3—2和图3--3。
之所以要求将激光脉冲聚焦到透明介质表面下一定深度处.是因为考虑了光束在通过一定厚度的透明物质后,会形成像差的原故。
经测量,0.45-NA、0.65.NA和0.85.NA的物镜聚焦2.1ps的激光脉冲到熔融石英介质内距表面301.tm处的能量损伤闽值分别为300nJ、150rd和60nJ。
在对能量损伤阈值进行测量的实验中,发现不论用那种数值孔径的物镜进行聚焦,其最小的结构改变都是处于聚焦点附近的,近似球形的结构。
当入射激光脉冲能量高于能量损伤闽值数倍时,用不同数值孔径的显微物镜对激光脉冲进行聚焦,对所得到的损伤位点的形态进行了比较。
如图3—2所示,使用0.85一NA物镜时,损伤为很短的园柱型结构:使用0.65~NA物镜。
损伤为圆锥型;使用0.45-NA物镜时,有些脉冲在介质中沿入射光方向形成了两个分离的损伤点。
第三章激光脉冲与透叫介质结构改变abC翻3-2:不同数值孔径,不同能量的皮秒激光脉冲在熔融石英中形成的损伤位点的侧面图像。

设计图书馆英语作文Designing a Library for the 21st Century.Libraries have been a fixture of human civilization for centuries, serving as repositories of knowledge and centers of learning. However, in the 21st century, the role and design of libraries are evolving to meet the changing needs of society and technology. In this article, we will explore the design considerations for a modern library that is not only functional but also inviting and adaptive to thedigital age.1. Flexibility and Adaptability.The first consideration in designing a 21st-century library is its ability to adapt to change. Given the rapid pace of technological advancement and evolving reading habits, a library must be designed with flexibility in mind. This means that the building should be easily modified to accommodate new technologies, services, or layouts as theybecome necessary. Modular design elements and open floor plans can facilitate this adaptability, allowing for easy reconfiguration without major construction.2. Integration of Technology.Modern libraries must integrate technology seamlessly into their design. This includes providing high-speed internet access, wireless connectivity, and a range of digital devices such as computers, tablets, and e-readers. The library should also offer spaces dedicated to technology-enhanced learning, such as makerspaces with 3D printers, robotics kits, and other innovative tools. These spaces should be designed to encourage collaboration and creativity, with easy access to power outlets and Wi-Fi.3. Accessibility and Inclusion.Accessibility is crucial in ensuring that libraries are inclusive and welcoming to all. The design should accommodate individuals with disabilities, including those with visual or hearing impairments, physical limitations,and learning disabilities. Features such as ramps, elevators, and hearing loops for assistive listeningdevices are essential. Libraries should also strive to create an inclusive environment by providing diverse collections that reflect the communities they serve, aswell as programming that caters to a wide range ofinterests and ages.4. Comfort and Aesthetics.Libraries should be designed for comfort and aesthetics, creating inviting spaces that encourage visitors to linger and enjoy their stay. Natural light, soft seating, andquiet spaces for reading and studying are crucial elements. Libraries can also incorporate art, plants, and otherdesign elements to create a visually appealing and calming environment. The design should reflect the values andidentity of the library, whether it's a focus on sustainability, local history, or contemporary culture.5. Community Engagement.Libraries are not just about books; they are about community. The design of a modern library should facilitate community engagement and collaboration. This can beachieved through the creation of multipurpose event spaces that can be used for meetings, workshops, and public events. Libraries can also partner with local organizations and businesses to offer programming that serves the needs ofthe community, such as job training, literacy programs, and cultural events.6. Sustainability.Sustainability is an increasingly important consideration in building design, and libraries are no exception. The design should incorporate features that reduce energy usage, water consumption, and waste production. This can include the use of energy-efficient lighting and heating systems, water-saving appliances, and recyclable materials. Libraries can also promote sustainability through programming that educates visitors about environmental issues and encourages them to adopt sustainable practices in their daily lives.In conclusion, designing a library for the 21st century requires a comprehensive approach that considersflexibility, technology integration, accessibility, comfort, community engagement, and sustainability. By prioritizing these elements, we can create libraries that are not just repositories of knowledge but also vibrant centers of learning and community engagement that serve the needs of individuals and communities alike.。

BOARD DESIGN GUIDELINES FOR PCI EXPRESS™ INTERCONNECTIntel CorporationThe industry is on the threshold of a parallel-to-serial interconnect transition. This paper provides guidelines for that transition. From a board design viewpoint, the interconnect guidelines are different from prior experience and, generally, easier to implement.IntroductionThe input/output technology for connecting digital ASICs is unable to keep pace with Moore’s law, which predicts the doubling of silicon device performance every 18 months. The parallel bus I/O technology based on threshold voltage crossings, such PCI or PCI-X, popular in Intel Architecture platforms of the past decade, is now faced with several severe physical limitations. This bus technology is based on a multi drop, time-shared concept, where several devices share the bus and only two devices can communicate at a given instant. Some of the limitations with this technology are the power and ground noise, stubs due to multiple devices on the bus, trace skews, loss due to skin effect and dielectric loss, which in turn increases the settling time and large power consumption by the bus drivers. These limitations introduce various design challenges for high-speed and performance-intensive applications to use parallel, shared bus technology in a cost-effective manner. Point-to-point interconnect technology based on serial differential links is now being widely recognized as a suitable alternative for high-speed data transfer applications. This technology is based on zero-crossings of differential signals and differential signaling, which has the potential to be highly scaleable in performance with silicon devices of the next decade. Many of the limitations inherent in a parallel multidrop bus architectures are not present in point-to-point technology. This paper discusses design trade-offs required to implement the PCI Express interconnect—a point-to-point differential interconnect technology based Printed Circuit Board (PCB) trace layout. PCI Express BackgroundPCI Express is a dual simplex point-to-point serial differential low-voltage interconnect. The bit rate is 2.5 Gbit/sec/lane/direction at introduction. The signal is 8b/10b encoded with an embedded clock. Each lane consists of two pairs of differential signals. A link between the ports of 2 devices is a collection of lanes (x1, x2, x4, x8, x12, x16, x32 width). For example, a x16 link has 16 lanes which will provide an aggregate bandwidth of 10 Gbytes/sec. The PCI Express interconnect is cost-optimized for a 4-layer FR4 board design. The requirement is to support 20 inches between components using standard (no premium) FR4 and high volume/low cost connectors. Higher quality interconnects will support even longer distances. The Point-to-point, serial PCI Express interconnect offers layout advantages over traditional multi-drop parallel/stubbed interconnect. Trace routing occupies less space for simple point-to-point connections. The embedded clock simplifies routing rules by removing the length matching requirements between signal pairs. All sideband signals are eliminated to reduce pins and routing constraints in the base technology. The increased bit rate for PCI Express requires some design considerations for board designers that are discussed below. Interconnect losses, jitter, crosstalk, and mode conversions are the key parameters to meet instead of clock-to-data timing skews. Detailed simulation and validation are necessary to guarantee a successful design. We will now highlight some of the key points for motherboard and add-in card designers when implementing PCI Express interconnect on a PCB.Topology and Interconnect(Tx) located on one device connected through a differential pair (D+ and D- signals) connected to the receiver (Rx) on a second device. One of thedevices may be located on an add-in card in which one or more connectors may be present on the topology.Each lane is AC coupled between its corresponding transmitter and receiver. The AC coupling capacitor is located on the board where the transmitter of the device resides. Each end of the link is terminated on-die into nominal 100 Ω differential DC impedance. Board termination is not required.The D+ and D- signals from the transmitter must be attached to the D+ and D- signals at the receiver.Polarity Inversion is required to be supported by each receiver on a link to invert the received signal if necessary. This will alleviate layout that resulted in “bowtie” scenarios (D+ and D- crisscross). Lane Reversal (Re-ordering) support is optional between two devices. Lane Reversal allows for the re-ordering of lanes that connect transmitting and receiving devices. For example, in a x8 link, lane 0 of the transmitting device may be connected to lane 7 of the receiving device, and vice versa.Lane Width Negotiation will allow a device with a given size port to connect to a device with a different size port. For example, a 4-port devicecan connect to a 2-port device with only two of the lanes active.It is important to note that Polarity Inversion and Lane Reversal do not imply direction reversal. The Tx pair from a device must still connect to the Rx pair on the other device.Physical Layout Design ConsiderationsOne of the key points to note for PCI Express board design is to obey a set of rules that minimize losses, jitter, crosstalk, and mode conversion for differential traces on FR4. Another consideration is to rely on simulation analysis instead of generic layout guidelines to ensure the design will meet the interconnect budget specification.Loss for interconnect is the differential voltage signal swing attenuation from transmitter to receiver on the trace. The trace is subject to resistive, dielectric and skin effect losses. Loss increases as trace length and/or signal frequency increases. Loss also increases as trace width decreases. Vias and connectors also exhibit losses which are a part of the interconnect budget. Total loss allowed on the interconnect is 13.2 dB.Jitter includes both data dependent and random jitter contributions on the interconnect. Total jitter allowed is 0.3 Unit Interval (1 Unit Interval = 400 ps).Crosstalk is the coupling of energy from one signal trace to the other that results in a change in signal voltage and phase. Far-End Crosstalk (FEXT) appears at the receiver while Near-End Crosstalk (NEXT) appears at the transmitter. Crosstalk within the differential pair is not a concern. Cross talk can be minimized between differential pairs by keeping a large pair-to-pair spacing compared to spacing within a pair. Stripline traces show far less FEXT than microstrip traces.Mode Conversions are due to imperfections on the interconnect which transform differential mode voltage to common mode voltage and vice versa.Differential trace impedance target of 100Ω with a tolerance of 15% or better is desired. Tight coupling within the differential pair and increased spacing to other differential pairs helps to minimize crosstalk and EMI. If possible, Tx and Rx differential pairs should route alternately on the same layer (Tx pair next to a Rx pair rather than another Tx pair) to help minimize FEXT.Add-in CardPCI-SIG Developers ConferencePCB stackup for a 4-layer system board uses microstrip trace routing. However, microstrip traces inherently display greater skin-effect loss and impedance variation than stripline traces. Thicker dielectrics and wider traces demonstrate less loss.Trace lengths are determined from simulation analysis in order to meet the interconnect budget. Trace Shorter lengths may be used to tradeoff with more vias, tighter spacing, etc. on the interconnect. Inherent physical properties of the PCB trace can introduce as much as 1 to 5 ps of jitter and 0.35 to 0.50 dB of loss per inch per differential pair. For the add-in card form factor currently specified, trace length from the edge-finger pad to the device is limited to 3 inches. The exact trace lengths allowed for a given topology will be determined by analyzing the design tradeoffs for the interconnect.Trace Length matching between pairs is not required due to the embedded clock architecture and generous pair-to-pair skew allowance. However, it is desirable to keep the length differences small to minimize latency.Trace Segment Length matching within pair is required to ensure trace lengths are equal on a segment-by-segment basis. Length should be matched to less than a 5 mil delta overall. Each net within a differential pair should be length matched whenever possible on a segment-by-segment basis at the point of discontinuity. Examples of segments might include breakout areas, routes between two vias, routes between an AC coupling capacitor and a connector pin, etc.The points of discontinuity would be the via, the capacitor pad, or the connector pin.Trace Symmetry is required between two traces of the same differential pair.Vias are expected to contribute 0.5 to 1.0 dB per via to the loss budget. Limit the number to two vias on each trace for the differential pair on motherboard if possible. Vias on the add-in card should be limited to one near the breakout section and one at the edge finger. Vias should have minimum pad size (25 mils or less) and a small finished hole size (14 mils or less). Vias should not have pads on unused internal layers. Vias on the differential pair should not only match in number but in relative location on the differential pair to maintain trace symmetry. Bends on traces should be kept to a minimum. If bends are used, they should be at a 45-degree angle or smaller. Attempt should be made to match the number of left and right bends as closely as possible to minimize skew due to length differences between each signal of the differential pair.AC coupling capacitors of 75 nF to 500 nF should be placed at the same location (as close as possible) and should not be staggered fromPCI-SIG Developers Conferenceone trace to the other within the pair. While size 603 capacitors are acceptable, size 402 capacitors are strongly encouraged. C-packs are not allowed for AC coupling capacitors. The exact same package size of capacitor should be used for each signal in a differential pair. Pad sizes for each of the capacitors should be minimized. The “breakout” into and out of the capacitors should be symmetrical for both signal traces in a differential pair.Connector pins of a differential pair are offset from each other. This delta of mismatch between the pins should be directly accounted for by the PCB trace on the motherboard. Both traces of a differential pair should both route into a connector pin field from the same layer.Ground Plane Referencing is required along the entire route of the differential pair. The signal pair should avoid discontinuities in the reference plane such as splits and voids. Traces routed near the edge of the reference plane should maintain at least a 40 mil air gap to the edge. Any layer transition must maintain a ground reference plane from one layer to another by stitching vias connecting the two ground planes together. Ground stitching vias should be placed close to signal vias. A minimum of 1 to 3 stitching vias per differential pair is recommended.Breakout Areas near a device package that resulted in “neckdowns”and decreased spacing should be limited to no more than 500 mils in lengths. The necking down should be done symmetrically on both nets of the differential pair. Breakout sections require special attention to minimize crosstalk.Edge fingers of the specified add-in card are designed to mate with the connector pins to produce the target impedance of 100 Ω. The reference planes under the edge finger pads are removed to meet the impedance.Test points and probing structures may impact the loss and jitter budgets. If possible, test points and probe structures should not introduce stubs on the differential pairs.SummaryPCI Express will serve as the general-purpose I/O interconnect for a wide variety of computing and communications platforms. Its advanced features and scalable performance will enable it to become a unifying I/O solution across a broad range of platforms—desktop, mobile, server, workstations, communications and embedded devices. A PCI Express link is implemented using multiple, point-to-point connections called lanes and multiple lanes can be used to create an I/O interconnect whose bandwidth scales linearly and provides ample headroom for performance-intensive applications for the next decade. PCI Express silicon building blocks and platform ingredients are being designed now for initial interoperability validation and testing beginning in late 2003.The Point-to-point serial differential links, as adopted by the PCI Express, is now being widely recognized as a suitable alternative for high-speed data transfer applications. This technology is highly scaleable in performance with silicon devices of the next decade. Many of the limitations inherent in a parallel, multidrop bus architectures are avoided by the PCI Express technology. This paper has addressed design considerations for PCB engineers for successful implementation of the PCI Express serial interconnect. PCI Express opens up new system level opportunities to allow for creative form factors not possible with current parallel bus designs. Board designers will need to rely on simulation analysis and careful design tradeoffs to ensure a successful implementation.。

1INTRODUCTIONT raditional musical instrument amplifier productscapable of providing high output are large and not easy for a person to transport frequently.There are also small,portable amplifiers available on the market,but they are limited in their sound level capability and cannot be used for group playing or loud music styles.Amateur and prof essional musicians requireequipment that will sound excellent while playing at all levels and w hich is very reliable.It is the goal of the amplifier described here to provide good sound and suff icient output f or almost all playing situations and musical styles ,w hile remaining very compact and easy to carry.2DESIGN GOALSM odern music can sometimes place large demands on amplification systems :w ith high sound pressurelevels and long periods of continuous maximum output.Soundlevel and frequency spectrum studiesw eremade of musicians playing amplif ied guitar under many different conditions.It w as determined f rom thisresearch that an amplifier w hich can produce an continuous output of at least 120dB SPL @1M is required to meet the needs of players under most conditions.Even under these very loud conditions,additional short-term power peaks should be available,“y ”Reaching this output level w ith a relatively small loudspeaker driver requires high electrical pow er and good loudspeaker eff iciency.Listening tests indicatedthat a bass cutoff below about 200Hz w as appropriate to the sound of an electric guitar.A 165mm driverw as chosen as the best compromise betw een ef ficiency and size.T o keep the enclosure small,aggressivefiltering of deep bass frequencies is performed,andgood control of signal dynamic range is maintained.The system block diagram is show n in Figure 1.T his block diagram is generally similar to other musical instrument amplif iers ,but additional f iltering andequalization are provided at several points in the signal flow .T his filtering is carefully adapted to the loud-speaker and enclosure,and is adapted to the outputsignal level.3ENCLOSURET he system enclosure is a critical part of the soundq y y f T 文章编号:1002-8684(2008)S 1-0067-06Design Consider ations for a New Class of Compact andEfficient Musical Instrument AmplifiersKenneth Kantor(ZT Amplifiers,Inc.,2329Fourth S tre et Berkeley,CA 94710,USA)【Abstr act 】This paper describes the design considerations f or a high output ,music al instr ument amplif ier in asmall,portable enclosure.The unique goal of this design is to achieve exc ellent sound quality,with a continuous sound pressure level greater than 120dB S PL,from package dimensions of only 178mm ×203mm ×102mm.Inaddition ,the system must be highly reliable .The technical development of the preamp circuit ,signal processor ,pow er amplif ier and loudspeaker dr iver are described below .Figure 1Block D iagramSpeakerPower Amp Post-Filter Rev erbT o neDynamicsFix ed EQ Pre-Filter Preamp InputT e c h n ic a l Es s e n cE技术精粹6to give the music a d namic audible characteristic.ualit in an musical instrument ampli ier.o handle7the high pow er dissipation and to achieve the most internal volume,a metal enclosure w as chosen.Theenclosure w as developed to meet several key require-ments:(1)High strength-to-w eight ratio.(2)Impact and w ear resistance.(3)Minimum external dimensions.(4)Maximum internal volume.(5)Good heat dissipation.(6)Enough mass to avoid vibration w hen played loudly.T he assembly uses a heavy aluminum structure to support the internal electrical and acoustical compo-nents.A ttached to this inner structure is an outer skin of thin steel to provide the proper cosmetic appear-ance and durability.Great care w as taken to minimize resonance in the enclosure.The tw o layers of metalare attached together using a silicon adhesive,w hichprovides strength and vibration damping.The feel ofthe enclosure is very solid to the touch.T he rear panel of the enclosure is bare aluminum and is the main point of heat dissipation in the system.However,the entire metal structure contributes to the heatsink ef fect and provides excellent heat dissipation f rom a small package,w hile avoiding any hotspots.The loudspeaker driver is of a relatively small diameter,therefore a sealed box design w as selectedto maximiz e the low frequency output.T his avoids the cancellation of long wavelengths from the rear of the driver and controls driver excursion below the Fc resonance point.Since there are f ew er anti -phase ref lections,a sealed box also has the benefit ofy f 4INPUT STAGEIt is generally understood that a electric guitars sound the best w hen presented with a load impedance of at least 1M !.T he input stage configuration isshow n in Figure 3.T he circuit topology is selected to provide the proper loading and low noise ,w hile alsoreducing the sensitivity of the input stage to possibleRF interference.Many amplifier designers assume that the maximum output of the electric guitar is only a few hundred mV.T his is true under most conditions.How ever,w henplayed very hard,some types of guitar pickups canput out instantaneous peak voltages of over 6V pp into a load of 1M !.(1)U p to 6Vpp.(2)0.5V average level.(3)High input impedance;1M !.(4)Immune to RF interference.(5)A C-coupled.(6)L ow noise.(7)Protected against accidental overload.5SIGNAL PROCESSINGO nce the guitar signal is handled by the preamplifier circuit,it operates at a more consistent level andlow er impedance.At this point,signal processingfunctions may be applied to achieve the desired sound quality.Important features of the signal processinginclude:(1)G ain.(2)Controlled non-linear distortion.(3)Frequency response equalization.(4)Reverberation.(5)U ser T one Controls.(6)f T f q y f f Figure 2MechanicalAssembly(a )Frontage(b )SideF igure 3Input Stage100p10k10"0.0047"2M2MInputT e c h n ic a lE s s e n c e技术精粹6maintaining a more consistent response when placed close to the wall or stacked with man other ampli iers.Power protection o the loudspeaker driver.heoverall re uenc responseo the ampli ier8circuit is show n in Figure 4.T his is the nominalelectrical response of the circuit,and does not include cabinet or loudspeaker influences.Notice the boostedcharacteristic of the upper f requencies,and the sharp f iltering above and below the operating band.T heexact shape of the curve is determined by ear and by comparison to standard designs.T he filtering aboveabout 8kHz and below about 200Hz is designed toprovide good sound,and to maximize the usablepow er output.6AUDIO AMPLIFIER D uring typical use,the pow er output stage of amusical instrument amplifier is often operated above the “clipping ”point.T his is normal and expected ,and helps to generate the harmonic overtones that are part of the musical sound.How the amplifier circuitreacts to the voltage overload condition is an important part of its sound quality.A t first,a Class D sw itching amplif ier w as considered,to try and maximize theeff iciency of the system.How ever ,it w as diff icult to obtain the kind of overload response that is desirable.With an AB design it w as much easier to achieve the required output overload characteristics.In practice a Class AB output stage operated at nearly the same efficiency as a Class D,because of the very lowcrest f actor and high level of the signal.Thus,not much pow er is w asted during high volume use ,themost important condition.T he A/B design used is also very stable as the power supply varies,w ith excellent rejection ratio.T f f y ,“”T y x z voltage available across the load.The output stagecan easily deliver more than 40V p across a nominal 8O hm loudspeaker.This is more than sufficient tomeet the sound pressure level targets required.7POWER SUPP LYThe pow er supply arrangement is show n in Figure 5.Thisarrangement provides+/-24V to the pow eramplifiers with a virtual ground,thus eliminating the requirement for coupling capacitors.+/-12V rails arecreated to operate the general audio circuitry.Inaddition,there is a small, 3.3V sub-regulator to supplythe digital circuitry used.No regulation is used on the +/-24V rails,sincethe natural behavior of a linear supply is very w ell-suited to musical instrument use.T he sag behaviorintroduced by the supply supports high short -termpeaks,w hile limiting the output dissipation of theamplifier under continuous signal conditions.8LOUDSPEAKER DRIVERProper selection of the loudspeaker driver is one of the critical elements in achieving the necessary sound and reliability from a musical instrument amplifier.This is especially true when the loudspeaker must be small,and w ill be pushed to near its operating limits.A driver diameter of 165mm w as determined to be the minimum siz e for operation at the high SPL levels needed.Many engineering aspects of this driver areoptimized to give the highest possible output level.For example,compared to typical high f idelity loud-speakers,this driver is not required to have very low distortion or good bass output.Thus,it may be con-structed w ith a small Xmax,relatively high Fs,andff y O f f F igure 5Pow er S upply Configur ation+3.3V-12V-24V +12V+24V48V DCINFigure 4Electrical FrequencyResponse20k10k 5k 2k 1k 5002001005020-40-35-30-25-20-15-10-50510152025303540f /Hzd B r Te c h n ic a l Es s e n cE技术精粹6he ampli ier output is a ull balanced bridge design.his topolog ma imi es the instantaneous peakthe highest possible e icienc .ther eatures o theloudspeaker driver include9very high pow er handling,and the ability to w orkw ell in a small,sealed enclosure.T he overall near -f ield response of the amplifier system,including both the electronics and the acoustical elements ,is show nin Figure 6.Tw o slightly different response curves are plotted.The red curve indicates the response w ith the tone control set to a“minimum ,”w hile the bluecurve is the opposite setting.T his response may becompared to the electrical curve show n previously in Figure 4in order to understand the transf er function of the loudspeaker driver.9SUM MARYT he engineering design of a small guitar amplifier M y f z f pressure level and compact size.T he system is capable of very loud output and excellent sound quality in z y T f y Figure 6A coustical Frequency Response and Tone ControlRange20k10k 5k 2k 1k 5002001005020-40-35-30-25-20-15-10-50510152025303540f /Hzd B r 新型紧凑高效乐器放大器的设计思路Kenneth Kantor(ZT Amplifiers,Inc.,2329Fourth S tre et Berkeley,CA 94710,USA)【摘要】介绍了封装在体积小、便携式音箱内大功率输出乐器放大器的设计理念。

游客服务中心设计英语作文Title: Designing a Tourist Service Center。
Introduction:In today's globalized world, tourism has become an integral part of many economies, contributing significantly to revenue generation and cultural exchange. With the increasing number of tourists visiting different destinations, the need for efficient tourist service centers is paramount. In this essay, we will explore the essential components and design considerations for atourist service center.Location:The first and foremost consideration in designing a tourist service center is its location. It should be strategically situated in a prominent area easily accessible to tourists. Preferably, it should be locatednear major tourist attractions, transportation hubs, and commercial areas. This ensures maximum visibility and convenience for tourists seeking assistance.Facilities:A well-equipped tourist service center should offer a range of facilities to cater to the diverse needs of travelers. These facilities may include:1. Information Desk: Staffed with knowledgeable personnel fluent in multiple languages to assist tourists with inquiries about local attractions, transportation, accommodations, and other essential services.2. Maps and Brochures: Provide comprehensive maps, brochures, and guidebooks showcasing local attractions, historical sites, dining options, and shopping areas. Digital kiosks can also be installed for interactive navigation.3. Ticketing and Reservation Services: Offer ticketingservices for attractions, events, and transportation, including bus and train tickets, museum passes, and guided tours. Additionally, facilitate hotel reservations and bookings for activities.4. Multi-lingual Support: Employ multilingual staff and provide translation services to accommodate tourists from different linguistic backgrounds. This ensures effective communication and enhances the overall tourist experience.5. Amenities: Include amenities such as restrooms, seating areas, and charging stations for electronic devices to ensure the comfort and convenience of tourists during their visit.Technology Integration:Incorporating technology into the design of a tourist service center can greatly enhance its functionality and efficiency. Some technological features to consider include:1. Interactive Displays: Install touchscreen displaysor digital kiosks featuring interactive maps, virtual tours, and multimedia presentations to provide engaging and informative content to visitors.2. Mobile Applications: Develop a dedicated mobile application that allows tourists to access information, make reservations, and receive real-time updates on events and attractions. Integration with GPS technology can offer personalized recommendations based on the user's location.3. Online Booking Platform: Create an online booking platform where tourists can make reservations for accommodations, tours, and activities in advance, streamlining the planning process and reducing waiting times.4. Digital Signage: Utilize digital signage throughout the center to display dynamic content such as upcoming events, weather forecasts, and promotional offers, keeping tourists informed and engaged.Accessibility and Inclusivity:It is essential to design the tourist service center with accessibility and inclusivity in mind to accommodate individuals with disabilities and special needs. This may involve implementing features such as wheelchair ramps, braille signage, and audio guides to ensure that all visitors can fully participate and enjoy their experience.Conclusion:In conclusion, designing a tourist service center requires careful consideration of various factors,including location, facilities, technology integration, and accessibility. By prioritizing the needs of tourists and embracing innovative solutions, we can create welcoming and efficient centers that enhance the overall tourism experience and contribute to the success of destinations.。
设计一个帮的机器人英语作文Designing a Helpful Robot.Robotics, an interdisciplinary branch of engineering and technology, has come a long way since its inception. With the advancement of technology, robots are no longer confined to industrial applications; they are now finding their way into our daily lives, assisting us in various tasks. In this article, we will explore the design considerations for a helpful robot that can enhance our lives.1. Understanding the User's Needs.The first step in designing a helpful robot is to understand the needs of the user. This involves identifying the tasks that the robot will be required to perform and the environments in which it will operate. For example, a robot designed for use in a household will need to have the ability to perform household chores such as sweeping,mopping, and cooking. On the other hand, a robot designed for use in a hospital may need to assist patients withdaily activities, transport them from one place to another, or even monitor their health status.2. Robot Hardware.The hardware of a helpful robot is crucial to its functionality. The robot should have the necessary sensors and actuators to perform the tasks it is designed for. For instance, a household robot may require sensors to detect obstacles, detect dirty areas on the floor, and identify different types of objects. Actuators, such as motors and servos, will enable the robot to move and interact with its environment.Moreover, the robot should have a user-friendly interface, such as a touchscreen display or voice recognition system, to enable easy communication and interaction with the user. This interface should beintuitive and allow the user to input instructions and receive feedback from the robot.3. Software and Artificial Intelligence.The software and artificial intelligence (AI) of a helpful robot are responsible for its decision-making and autonomous behavior. The robot should be able to process input from its sensors, understand the user's instructions, and make intelligent decisions about how to proceed. For example, a household robot may need to analyze the dirty areas on the floor and determine the most effective cleaning path.AI algorithms, such as machine learning and deep learning, can be used to train the robot to recognize objects, understand spoken commands, and learn from its experiences. This allows the robot to become more efficient and effective over time.4. Safety and Security.When designing a helpful robot, it is crucial to consider safety and security. The robot should be designedto operate safely in its environment, avoiding collisions and potential hazards. This may involve the use of sensorsto detect obstacles and avoid collisions or the implementation of safety features, such as emergency stop buttons.Additionally, the robot should have robust security features to protect sensitive information and prevent unauthorized access. This may include encryption techniques, secure communication protocols, and access control mechanisms.5. User Experience.The user experience is another crucial aspect of designing a helpful robot. The robot should be easy to use and integrate into the user's daily life. It should have a natural and intuitive way of interacting with the user, enabling seamless collaboration and improved efficiency.Moreover, the robot should be designed to be adaptable and customizable to different user preferences and needs.This may involve allowing the user to program custom tasks, adjust settings, or even personalize the robot's appearance.6. Sustainability.In today's world, sustainability is an important consideration in product design. When designing a helpful robot, it is essential to consider its environmental impact and the resources used in its manufacturing. The robot should be designed to be energy-efficient, durable, andeasy to recycle or dispose of at the end of its lifespan.In conclusion, designing a helpful robot requirescareful consideration of various factors, including user needs, hardware, software and AI, safety and security, user experience, and sustainability. By taking these factorsinto account, we can create robots that can enhance our lives, making tasks easier, safer, and more enjoyable. As technology continues to evolve, we can expect to see more innovative and helpful robots in our future.。
英文翻译原文:(一)BORING AND BORING MACHINESAs carried out on a lathe, boring produces circular internal profiles in hollow work-pieces or on a hole made by drilling or another process, Boring is done with cutting tools that are similar to those used in turning. Because the boring bar has to reach the full length of the bore, tool deflection and, therefore, maintainance of dimensional accuracy can be a significant problem.The boring bar must be sufficiently stiff—that is, made of a material with high elastic modulus, such as tungsten carbide –to minimize deflection and avoid vibration and chatter. Boring bars have been designed with capabilities for damping vibration.Although boring operations on relatively small work-pieces. Can be carried out on a lathe, boring mills are used for large work-pieces. These machines are either vertical or horizontal, and are capable of performing operations such as turning, facing, grooving, and chamfering. A vertical boring machine is similar to a lathe but has a vertical axis of work-piece rotation.The cutting tool (usually a single point made of M-2 and M-3 high-speed steel and C-7 and C-8 carbide) is mounted on the tool head, which is capable of vertical movement (for boring and turning) and radial movement (for facing), guided by the cross-rail. The head can be swiveled to produce conical (tapered) surfaces.In horizontal boring machine, the work-piece is mounted on a table that can move horizontally in both the axial and radial directions. The cutting tool is mounted on a spindle that rotates in the headstock, which is capable of both vertical and longitudinal movements. Drills, reamer, taps, and milling cutters can also be mounted on the machine spindle.Boring machine are available with a variety of features. Although work-piece diameters are generally 1 m-4 m(3ft-12ft),work-piece as large as 20 m(60ft) can be machined in some vertical boring machines. Machine capacities range up to 150 kw (200hp).these machines are also available with computer numerical controls, which allow all movements to be programmed. With such controls, little operaror involvement is required and consistency and productivity are improved. Cutting speeds and feeds for boring are similar to those for turning.(For capabilities of boring operations)Jig borers are vertical boring machines with high –precision bearings. Although they are available in various sizes and used in tool rooms for making jigs and fixtures,they are now being replaced by more versatile numerical control machines.Design considerations for boring. Guidelines for efficient and economical boring operations are similar to those for turning. Additionally, the following factors should be considered:a.Whenever possible, through holes rather than blind holes should bespecified.(The term blind hole refers to a hole that does not go thoughthe thickness of the work-piece )b.The greater the length –to –bore-diameter ratio, the more difficult it is tohold dimensions because of the deflections of the boring bar due tocutting forces.c.Interrupted internal surfaces should be avoided.(2)Fundamentals of Machine Tools In many cases products form the primary forming processes must undergo further refinements in size and surface finish to meet their design specifications. To meet such precise tolerances the removal of small amounts of material is needed. Usually machine tools are used for such operation.In the United States material removal is a big business-in excess of $ per year, including material, labor, overhead, and machine-tool shipments, is spent. Since 60 percent of the mechanical and industrial engineering and technology graduates have something connection with the machining industry either through sale, design, or operation of machine shops, or working in related industry, it is wise for an engineering student to devote some time in his curriculum to studying material removal and machine tools.A machine tool provides the means for cutting tools to shape a workpiece to required dimensions; the machine supports the tool and the workpiece in a controlled relationship through the functioning of its basic members, which are as follow:(a) Bed, Structure or Frame. This is the main member which provides a basis for, and a connection between, the spindles and slides; the distortion and vibration under load must be kept to a minimum.(b) Slides and Sideways. The translation of a machine element (e.g. the slide) is normally achieved by straight-line motion under the constraint of accurate guiding surfaces (the slideway).(c) Spindles and Bearings. Angular displacements take place about an axis of rotation; the position of this axis must be constant within extremely fine limits in machine tools, and is ensured by the provision of precision spindles and bearings.(d) Power Unit. The electric motor is the universally adopted power unit for machine tools. By suitably positioning individual motors, belt and gear transmissions are reduced to a minimum.(e) Transmission Linkage. Linkage is the general term used to denote the mechanical, hydraulic, pneumatic or electric mechanisms which connect angular andlinear displacements in defined relationship.There are two broad divisions of machining operations:(a) Roughing, for which the metal removal rate, and consequently the cutting force, is high ,but the required dimensional accuracy relatively low .(b) Finishing, for which the metal removal rate, and consequently the cutting force, is low, but the required dimensional accuracy and surface finish relatively high . It follows that static loads and dynamic loads, such as result form an unbalanced grindingwheel, are more significant in finishing operations than in roughing operations, The degree of precision achieved in any machining process will usually be influenced by the magnitude of the deflections, which occur as a result of the force acting.Machine tool frames are generally made in cast iron, although some may be steel casting or mild-steel fabrications. Cast iron is chosen because of its cheapness, rigidity, compressive strength and capacity for damping the vibrations set-up in machine operations, To avoid massive sections in castings, carefully designed systems of ribbing are used to offer the maximum resistance to bending and torsional stresses. Two basic types of ribbing are box and diagonal. The box formation is convenient to produce, apertures in walls permitting the positioning and extraction of cores. Diagonal ribbing provides greater torsional stiffness and yet permits swarf to fall between the sections; it is frequently used for lathe beds.The slides and slideways of a machine tool locate and guide members which move relative to each other, usually changing the position of the tool relative to workpiece .The movement generally takes the form of translation in a straight line, but is sometimes angular rotation, e.g. tilting the wheel-head of a universal thread-grinding machine to an angle corresponding which the helix angle of the workpiece thread. The basic geometric elements of slides are flat, vee, dovetail and cylinder. These elements may be used separately or combined in various ways according to the applications . Features of slideways are as follows :(a) Accuracy of Movement. Where a slide is to be displaced in a straight line, this line must lie in two mutually perpendicular planes and there must be no slide rotation. The general tolerance for straightness of machine tool slideways is 0~0.02mm per 1000mm; on horizontal surfaces this tolerance may be disposed so thata convex surface results, thus countering the effect of "sag" of the slideway.(b) Means of Adjustment. To facilitate assembly, maintain accuracy and eliminate "play" between sliding members after wear has taken place, a strip is sometimes inserted in slides. This is called a gibstrip. Usually, the gib is retained by socket-head screws passing through elongated slots;and is adjusted by grub-screws secured by lock nuts.(c) Lubrication. Slideways may be lubricated by either of the following systems:1)Intermittently through grease or oil nipples, a method suitable wheremovements are infrequent and speed low.2) Continuously e.g. by pumping through a metering valve and pipe-work to the point of application; the film of oil introduced between surfaces by these means must be extremely thin to avoid the slide “floating”.If sliding surfaces were optically flatoil would be squeezed out,resulting in the surfaces sticking. Hence in practice slide Sill"faces are either grourld using the edge of a cup wheel,or scraped. Both processes produee minulte surface depressions,which retain‘‘pocket” of oil,and complete separation of the parts may not occur at all points.(d) Protection.To maintain slideways in good order, the following conditions must be met:1) Ingress of foreign matter,e.g.swarf,must be prevented. Where this is no possible,it is desirable to have a form of slideway,which does not retain swarf,e.g. the inverted vee.2) Lubricating oil must be retained.The adhesive property of oil for use on vertical or inclined slide surface is important; oils are available which have been specially developed for this purpose. The adhesiveness of oil also preverts it being washed away by cutting fluids.3) Accidental damage must be prevented by protective guards.译文:(一)镗削加工和镗床像车床加工零件一样,镗床能在中空的工件或由钻削加工或其它工艺所加工的孔上进行内轮廓圆的加工。
商业名片英语作文范文英文回答:Business Card Writing: A Comprehensive Guide.Introduction:A business card is an indispensable tool for professionals, entrepreneurs, and job seekers alike. It serves as a tangible representation of your brand and a quick reference for potential clients, customers, and employers to contact you. Crafting an effective business card requires attention to detail, strategic design, and clear communication. This comprehensive guide will walk you through the essential steps involved in writing a business card that will make a lasting impression.1. Essential Elements:The following elements are essential for any businesscard:Name: Your full name, as it appears on your resume and professional social media profiles.Title: Your current professional title or designation.Company Name: The name of the company or organization you represent.Contact Information: Your phone number, email address, and website (if applicable).Call-to-Action: A brief statement or slogan that encourages the recipient to take action (e.g., "Contact us today for a free consultation").2. Design Considerations:The design of your business card should be professional, memorable, and consistent with your brand. Consider the following factors:Font and Typography: Choose clear, easy-to-read fonts and avoid excessive use of italics or bolding.Colors: Select colors that are visually appealing and reflect your industry or brand identity. Avoid using too many colors or contrasting shades.Layout: The layout should be well-organized and visually balanced. Use white space effectively to create a sense of openness and readability.Logo: If your company has a logo, incorporate it prominently on your card.3. Content Optimization:In addition to the essential elements, your business card should convey key information about your professional expertise and value proposition. Consider including:Tagline or Slogan: A brief statement that summarizesyour unique skills or services.Testimonials: Positive reviews or endorsements from satisfied clients or colleagues.QR Code: A QR code that links to your online portfolio, social media profile, or company website.Social Media Icons: Include icons linking to youractive social media accounts.4. Proofreading and Printing:Once you have created your business card design, carefully proofread it for any errors in grammar, spelling, or contact information. Ensure that the colors, fonts, and layout appear as intended. Choose a reputable printer that specializes in high-quality business card printing.5. Distribution and Usage:When handing out your business card, be strategic aboutwho you give it to and when. Offer it during business meetings, networking events, and social functions. Be sure to follow up with the recipient within 24-48 hours to reiterate the purpose of your encounter and express your interest in further communication.Conclusion:Crafting an effective business card is an essential part of professional branding and networking. By following these comprehensive guidelines, you can create a business card that will make a lasting impression, convey your value proposition, and drive engagement with potential clients, customers, and employers.-----------------------------------------------------------------------------------------------------------。
“The Construction Structure of Iron Towers”Iron towers, also known as steel towers, are prominent structures characterized by their robust construction and diverse applications across various industries. The construction of iron towers involves several key structural elements and considerations:1.Foundation: The foundation of an iron tower is crucial for providing stability and support.Depending on the tower’s height and load-bearing requirements, foundations may vary from simple concrete slabs to deep concrete piles.2.Tower Components: The main components of an iron tower include the tower body itself,which is typically constructed from steel sections such as angles, channels, or plates welded together. These sections are designed to withstand vertical and lateral forces effectively. ttice Structure: Many iron towers feature a lattice structure composed of interconnectedsteel bars or plates. This lattice design offers high strength-to-weight ratio, minimizing material usage while providing structural integrity. It also allows for easy transportation and assembly.4.Guyed Towers: In some cases, iron towers are supported by guy wires extending from thetop of the tower to the ground. This guyed design increases stability and allows for taller structures without significantly increasing material weight.5.Design Considerations: Engineers meticulously calculate loads such as wind, ice, andoperational stresses when designing iron towers. Advanced computer simulations and structural analysis ensure the tower can withstand these loads over its lifespan.6.Construction Methods: Iron towers are typically assembled on-site using prefabricatedsections. Bolted connections are common for ease of assembly and disassembly, facilitating maintenance and potential relocation.7.Coating and Maintenance: To protect against corrosion and ensure longevity, iron towers areoften coated with specialized paints or galvanized finishes. Regular inspection and maintenance of coatings are essential to prevent structural degradation.8.Applications: Iron towers serve diverse purposes including telecommunications (for antennasand signal transmission), power transmission (supporting electrical conductors), observation (as lookout towers), and even as architectural landmarks.In summary, the construction of iron towers involves intricate planning, precise engineering, and adherence to safety standards. Their versatility, durability, and strength make them indispensable in modern infrastructure and industrial applications worldwide.。
AN706: EZSP-UART Host Interfacing GuideThis application note describes how to connect a Host processorto a Network Co-Processor (NCP) using the UART-based Em-berZNet Serial Protocol (EZSP). It assumes that you already have a basic understanding of the EZSP-UART Gateway proto-col, as well as the signals needed by the UART interface. If not, refer to UG101: UART Gateway Protocol Reference Guide be-fore continuing.Zigbee EmberZNet SDK 7.0 introduced a new component-based architecture, along with a Project Configurator and other tools to replace AppBuilder and plugin configura-tion. In general, the new software components are comparable to the plugins. When applicable, instructions for both version 7.0 and higher and 6.10.x and lower are provi-ded. For more information, see AN1301: Transitioning from Zigbee EmberZNet SDK 6.x to SDK 7.x.KEY POINTS•EZSP-UART protocol overview•Physical interfaces•Command line options for Hostapplications•Hardware design considerations •Powering up, power cycling, and rebooting •BootloadingRev. 1.3Protocol Overview 1. Protocol OverviewSilicon Labs designed EZSP as a protocol to allow communications between components running pieces of the EmberZNet PRO wire-less mesh stack, namely a Host processor and an NCP. The Host processor runs the application layer and executes on the POSIX platform such as Mac OS, Linux, or a Windows PC running Cygwin or the new Windows 10 BASH shell. You can also run this on an embedded platform like the Raspberry Pi. This lets you develop and test your application on an easy-to-use platform before porting your solution to a different Host processor with few changes. The NCP runs the EmberZNet PRO stack and physical layer (PHY). It is deployed and executed on a Silicon Labs wireless mesh chip processor such as the Wireless Gecko EFR32™.2. EZSP-UART Physical InterfacesThe following figure represents the EZSP-UART physical interfaces.Figure 2.1. EZSP-UART Physical Interfaces2.1 Serial Data: Tx and RxThe EZSP protocol sends data in both directions, utilizing a standard Universal Asynchronous Receiver-Transmitter (UART). Both the Tx and Rx pins are utilized on the NPC and Host. When connecting the NCP and Host, the connections should be from NCP Tx to Host Rx and NCP Rx to Host Tx. This interface is required for NCP-to-Host communications.2.2 Flow Control: RTS and CTSEZSP requires flow control for operation. This can be in the form of either XON/XOFF software flow control or RTS/CTS hardware flow control. RTS/CTS hardware flow control is part of the standard UART interface. When connecting the NCP and Host, the connections should be from NCP CTS to Host RTS and NCP RTS to Host CTS. With this interface, RTS enables transmission from the Host to the NCP and CTS enables NCP transmissions to the Host.If needed, the Host can restrain the NCP from sending to it by deasserting the NCP’s CTS input. The NCP will stop sending immediate-ly, except to finish sending a byte already in progress. The NCP will do the same to the Host when it requires the Host to stop sending data.While hardware or software flow control can be utilized, EZSP-UART will have better performance and speed using hardware flow con-trol. Hardware flow control allows operation up to 115,200 bps (other baud rates may be selected by a configuration value programmed into flash during manufacturing).Rev. 1.3 | 32.3 Reset Control: nRESETnRESET is a hardware input that can reset the NCP. For normal operation, the nRESET line should be held high. While pulling the line low, the NCP will hold in a reset state. Upon returning the line high, on the rising edge of the signal, the part will restart operation. Silicon Labs NCP chips include an internal pull-up resistor on this input so adding one is not necessary.The Host must be able to reset the NCP to run the EZSP protocol. This can normally be accomplished utilizing software reset frames sent via EZSP from the Host to the NCP. However, in cases where the NCP fails to respond to EZSP frames, this hardware backup can be utilized.While this interface is optional for NCP-to-Host communications, Silicon Labs recommends including nRESET in all Host-NCP hard-ware designs as a backup for situations where continued NCP operation is impossible or where unforeseen NCP operation blocks the Host.For secure designs (utilizing secure EZSP) or security products, these connections should be considered mandatory.2.4 Recover / Bootload: BootloadThe Bootload line allows the Host to force an NCP into bootloader mode during a reset or power cycle. For normal operation, the Boot-load line should be held high. During a reset (while the nRESET line is held low) or a power cycle, the Bootload line should be pulled low. Upon release of the nRESET line or powering up the NCP, the low input on the Bootload pin will signal the bootload software (Gecko or legacy) to override normal NCP operation, allowing the Host to update the firmware of the NCP. Because the Bootload pin can be configured on any input, a pull-up resistor should be placed on this input or set internally.Bootloading is normally accomplished utilizing software bootload frames sent via EZSP from the Host to the NCP. However, in cases where the NCP fails to respond to EZSP frames, this hardware backup, in conjunction with nRESET, can be utilized.While this interface is optional for NCP-to-Host communications Silicon Labs recommends including the Bootload pin in all Host-NCP hardware designs as a backup for situations where unforeseen operation or corruption block the NCP from responding to any software commands from the Host.For secure designs (utilizing secure EZSP) or security products, these connections should be considered mandatory.2.5 Pin ConnectionsThe following table lists the pin connections.Table 2.1. Pin Connections | Building a more connected world.Rev. 1.3 | 43. Command Line Options for Host ApplicationsTo test your Host-NCP interface Silicon Labs recommends that you build a Host application using Simplicity Studio. (If necessary, refer to QSG106: Getting Started with EmberZNet PRO for SDK 6.x and Lower or QSG180: Zigbee EmberZNet Quick-Start Guide for SDK 7.0 and Higher for additional help.) <Z3GatewayHost> is the generic name for a Host application.To build your application in EmberZNet Zigbee SDK 7.0 and higher, follow these steps:unch Simplicity Studio.2.Change your perspective to the Simplicity IDE perspective.3.Create a new Z3Gateway Host project:a.Select File > New > Silicon Labs Project Wizard.b.Configure the following:i.Target Boards: Custom Board.ii.Target Device: Linux (32 bit or 64 bit).iii.SDK: Gecko SDK Suite 4.0.2.iv.IDE/Toolchain: Makefile IDE.c.Click Next.d.Select Z3Gateway and click Next.e.Enter a name for your project and click Finish.4.Simplicity Studio will now display your Z3 Gateway slcp project file. The default settings are enough to test your EZSP settings.This will create the files for your project. The project is a POSIX-compliant Make project.5.You can transfer your project to your platform and build it using a standard make command.6.Once your project is built, you can run it and use the command line options to test your interface. As long as your application prop-erly interfaces the NCP and properly executes, you can be assured that your connections are working properly. You should see a message similar to this one:./Z3GatewayHost -p /dev/bmodem0004402507811Reset info: 11 (SOFTWARE)ezsp ver 0x08 stack type 0x02 stack ver. [7.0.2 GA build 406]Ezsp Config: set address table size to 0x0002:Success: setTo build your application in EmberZNet Zigbee SDK 6.10.x and lower, follow these steps:unch Simplicity Studio.2.Change your perspective to the Simplicity IDE perspective.3.Create a new AppBuilder Host project:a.Select File > New > Project.b.Select Silicon Labs AppBuilder Project and click Next.c.Select Silicon Labs Zigbee and click Next.d.Select EmberZNet <version> Host and click Next.e.Select the Z3 Gateway application and click Next.f.Enter a name for your project and click Next.g.On the Project setup page, leave the board section blank. For the part, make sure None is selected. The toolchain should alsoreflect no toolchain as well (or None).h.Click Finish.4.Simplicity Studio will now be displaying your Z3 Gateway ISC project file. The default settings are enough to test your EZSP set-tings. Select Generate. This will create the files for your project. The project is a POSIX-compliant Make project. You can transfer your project to your platform and build it using a standard make command.5.Once your project is built, you can run it and use the command line options to test your interface. As long as your application prop-erly interfaces the NCP and properly executes, you can be assured that your connections are working properly. You should see a message similar to this one:./Z3GatewayHost -p /dev/bmodem0004402507811Reset info: 11 (SOFTWARE)ezsp ver 0x08 stack type 0x02 stack ver. [7.0.2 GA build 406]Ezsp Config: set address table size to 0x0002:Success: setThe following table summarizes the <Z3GatewayHost> command line options.Table 3.1. <Z3GatewayHost> Command Line Options | Building a more connected world.Rev. 1.3 | 6Design Considerations for Host and NCP Communications 4. Design Considerations for Host and NCP CommunicationsSilicon Labs recommends these best practices for Host and NCP communications:•Use a well-tuned crystal (38.4 MHz) for any wireless mesh application.•Use of RTS/CTS hardware flow control is highly recommended. It will aid in electrically-noisy environments.•UART-based NCP is not suitable for low-power designs due to the inability of the NCP to enter into any sleep modes. In designs where low power NCPs are required, Silicon Labs recommends using SPI-NCP instead. (For more information, refer to AN711: SPI Host Interfacing Guide for Zigbee.)•Silicon Labs recommends including the nRESET and Bootload pins in all Host-NCP hardware designs as a backup for situations where serial communication are lost between the Host and NCP. For secure designs (utilizing secure EZSP) or security products, these connections should be considered mandatory.Powering On, Power Cycling, and Rebooting 5. Powering On, Power Cycling, and RebootingWhen the Host powers on or reboots, it cannot guarantee that the NCP is ready to receive commands. Therefore, the Host should al-ways perform a reset of the NCP to place it into a known state. It is far simpler to reset the NCP and begin from a known state than to try to recover and resync with the previous (unknown) state of the NCP. This reset can be performed either via an ASH RST frame or toggling the nRESET line (if it is enabled). By guaranteeing that the NCP is freshly booted just like the Host, the Host can proceed with standard node and network initialization instead of consuming extra code space just trying to determine what state the NCP was left in. When the NCP resets, it will issue an RSTACK frame to alert the Host it has reset, which includes the reset type as defined by platform/ base/hal/micro/generic/em2xx-reset-defs.h. Once the RSTACK frame is received, the Host will know the NCP is in a known state to start operation.Bootloading 6. BootloadingThe NCP can enter bootload mode through either a software command or a hardware toggle.6.1 Software BootloadingWhen operating in EZSP mode, issuing the bootloader frame launchStandaloneBootloader will cause the NCP to enter into the boot-loader. This can be used at any time when the Host wants to restart the NCP in the bootloader.6.2 Hardware BootloadingAsserting the bootloader pin (low) while powering up or resetting the NCP will cause the chip to enter the bootloader instead of resum-ing normal NCP operation. In the Gecko Bootloader, a recovery pin can be defined in the board configuration to initiate bootloader mode. You define the recovery pin using the Gecko Bootloader's "GPIO Activation" component located in Platform > Utils, where the SL_BTL_BUTTON can be configured.An example of performing this reset would be as follows:1.Assert nRESET to hold the NCP in reset.2.While nRESET is asserted, assert BOOTLOAD, and then deassert nRESET to boot the NCP.3.The BOOTLOAD line can be deasserted once the reset line has been deasserted.For more information on using the Gecko Bootloader, see UG266: Silicon Labs Gecko Bootloader User's Guide for GSDK 3.2 and Low-er or UG489: Silicon Labs Gecko Bootloader User's Guide for GSDK 4.0 and Higher.6.3 Bootloader OperationThe target device’s bootloader sends output over its serial port after it receives a carriage return from the source device at the expected baud rate. This prevents the bootloader from prematurely sending commands that might be misinterpreted by other devices that are connected to the serial port. Note that serial bootloaders typically do not enforce any timeout when awaiting the initial serial handshake via carriage return, so the bootloader will wait indefinitely in this mode until guided by the source device or until the chip is reset.After the bootloader receives a carriage return from the target device, it displays a menu with the following ASCII-based output (where X.Y.A corresponds to the major, minor, and sub-minor fields of the bootloader version number, respectively).Gecko Bootloader vX.Y.A1. upload gbl2. Run3. ebl infoBL >Once this is received, the Host can be assured that the NCP is operating in bootloader mode.IoT Portfolio /products Quality /quality Support & Community /communitySilicon Laboratories Inc.400 West Cesar Chavez Austin, TX 78701USA DisclaimerSilicon Labs intends to provide customers with the latest, accurate, and in-depth documentation of all peripherals and modules available for system and software imple-menters using or intending to use the Silicon Labs products. Characterization data, available modules and peripherals, memory sizes and memory addresses refer to each specific device, and “Typical” parameters provided can and do vary in different applications. Application examples described herein are for illustrative purposes only. Silicon Labs reserves the right to make changes without further notice to the product information, specifications, and descriptions herein, and does not give warranties as to the accuracy or completeness of the included information. Without prior notification, Silicon Labs may update product firmware during the manufacturing process for security or reliability reasons. Such changes will not alter the specifications or the performance of the product. Silicon Labs shall have no liability for the consequences of use of the infor -mation supplied in this document. This document does not imply or expressly grant any license to design or fabricate any integrated circuits. The products are not designed or authorized to be used within any FDA Class III devices, applications for which FDA premarket approval is required or Life Support Systems without the specific written consent of Silicon Labs. A “Life Support System” is any product or system intended to support or sustain life and/or health, which, if it fails, can be reasonably expected to result in significant personal injury or death. Silicon Labs products are not designed or authorized for military applications. Silicon Labs products shall under no circumstances be used in weapons of mass destruction including (but not limited to) nuclear, biological or chemical weapons, or missiles capable of delivering such weapons. Silicon Labs disclaims all express and implied warranties and shall not be responsible or liable for any injuries or damages related to use of a Silicon Labs product in such unauthorized applications. Note: This content may contain offensive terminology that is now obsolete. Silicon Labs is replacing these terms with inclusive language wherever possible. For more information, visit /about-us/inclusive-lexicon-projectTrademark InformationSilicon Laboratories Inc.®, Silicon Laboratories ®, Silicon Labs ®, SiLabs ® and the Silicon Labs logo ®, Bluegiga ®, Bluegiga Logo ®, EFM ®, EFM32®, EFR, Ember ®, Energy Micro, Energy Micro logo and combinations thereof, “the world’s most energy friendly microcontrollers”, Redpine Signals ®, WiSeConnect , n-Link, ThreadArch ®, EZLink ®, EZRadio ®, EZRadioPRO ®, Gecko ®, Gecko OS, Gecko OS Studio, Precision32®, Simplicity Studio ®, Telegesis, the Telegesis Logo ®, USBXpress ® , Zentri, the Zentri logo and Zentri DMS, Z-Wave ®, and others are trademarks or registered trademarks of Silicon Labs. ARM, CORTEX, Cortex-M3 and THUMB are trademarks or registered trademarks of ARM Holdings. Keil is a registered trademark of ARM Limited. Wi-Fi is a registered trademark of the Wi-Fi Alliance. All other products or brand names mentioned herein are trademarks of their respective holders.。
PrefaceLegal knowledge based systemsJURIX 92Information Technology and LawThe Foundation for Legal Knowledge SystemsEditors:C.A.F.M. GrüttersJ.A.P.J. BreukerH.J. Van den HerikA.H.J. SchmidtC.N.J. De Vey MestdaghC.A.M. Wildemast and R.V. de Mulder, Some Designs Considerations for a Conceptual Legal Information Retrieval System, in: C.A.F.M. Grütters, J.A.P.J. Breuker, H.J. Van den Herik, A.H.J. Schmidt, C.N.J. De Vey Mestdagh (eds.),Legal knowledge based systems JURIX 92: Information Technology and Law , The Foundation for Legal Knowledge Systems, Lelystad: Koninklijke Vermande, pp. 81-92, 1994 ISBN 90 5458 031 3.More information about the JURIX foundation and its activities can be obtained by contacting the JURIX secretariat:Mr. C.N.J. de Vey MestdaghUniversity of Groningen, Faculty of LawOude Kijk in 't Jatstraat 26P.O. Box 7169700 AS GroningenTel: +31 50 3635790/5433Fax: +31 50 3635603Email: sesam@rechten.rug.nl1992 JURIX The Foundation for Legal Knowledge Systems http://jurix.bsk.utwente.nl/1SOME DESIGN CONSIDERATIONS FOR A CONCEPTUAL LEGALINFORMATION RETRIEVAL SYSTEMC.A.M. WILDEMAST and R.V. DE MULDERCentre for Computers and Law, Erasmus University, Rotterdam, The Netherlands SummaryConcept formation in law is not based on empirirical observation nor on explicit and unequivocal conventions. Therefore, concepts in law are not objective data, but rather interpretations determined by social circumstances. Consequently, attempts to design conceptual legal information retrieval systems in which predetermined legal concepts are fixed into the system will always be unsuccesful. In this article, a brief review of these attempts is given and an outline is presented of a "learning concept processor" which enables the user to define his own concepts and enter these into the system.1.IntroductionThere is now a large consensus of opinion that conceptual retrieval methods are preferable to word-based search procedures. In this article, attention will be paid to design considerations for conceptual legal information retrieval systems. These design considerations must take into account, not only general information retrieval theories, but also the specific demands placed upon such systems by lawyers.A brief examination is made of the present theories of retrieval, concentrating on three aspects: the interface, representation techniques and search methods. An outline will be given of the problems particularly associated with developing legal information retrieval systems. Various solutions have been advanced to deal with the specific problems in this area.The solutions are directed towards modifying the interface and the means of representing legal documents. Design considerations regarding the interface are aimed at allowing the user to describe his questions more satisfactorily which in term will make the search procedure more efficient. Proposals include a thesaurus, hypertext and the development of intelligent interfaces. This article will show that the main obstacle remains the limitation placed on the user of having to work within a preordained set of opinions. Various techniques for document representation have been proposed in recent literature. These approaches may be characterized as manual or automatic, employing either a reducing technique or an interpreting technique. It is argued here that manual techniques are expensive; reducing techniques may involve the loss of potential information while the danger of interpreting techniques is that the user may not be able to modify the concepts presented so that they correspond more closely to his own interpretation of legal notions.Finally, we will outline the "learning concept processor" which has been developed by the Centre for Computers and Law of the Erasmus University. This is a conceptual legal information retrieval system which incorporates a number of considerations detailed in this article.81Wildemast, C.A.M. and R.V. de Mulder2.The significance of "conceptual retrieval methods"Information of importance to lawyers is increasingly being stored in, and accessed by, computers [Franken et al., 1992]. What has been stored must also be capable of being located again. Search procedures are usually based on comparing words in the search question with words in the stored documents or representations of those documents. This comparison of words is usually referred to as "string matching". If a question pertains to more words, word combinations can be formulated with the help of logical (boolean) operations. A search can then be carried out on the basis of these word combinations. Recent research has [Blair & Maron, 1985] shown, however, that this search method remains unsatisfactory. Not all relevant documents are found and of those documents which are found, not all are relevant. These shortcomings are connected to the fact that, on the one hand, (a logical combination of) words is still not suitable to describe sufficiently the user's information question while, on the other hand, not enough is known of the relationship between the words used in the documents and the subjects which can be read in the texts.Extensive research has been, and still is being, carried out to find more effective search methods. Within the legal sphere, there is a fairly high level of consensus concerning a rejection of word-based searches, preference being given to search procedures based on the (legal) interpretation of the search question and of the documents required. Search methods in which this concept is applied are referred to by the term "conceptual retrieval methods".Although there is agreement that conceptual search methods will be more effective, there are differing views as to the way in which this can best be realized. Several proposals have been presented in the literature on the subject. A summary of these will be given below.3.The retrieval processThe search for relevant documents with the help of a computer can be presented schematically as shown below:questioncommandcommand interpretationsearchoperationrepresentation storepresentationofdocumentsFigure 1 82Some Design Considerations for a Conceptual Legal Information Retrieval System The user has a question. This question has to be converted by the user into a command for the system. The interpretation of the command within the system provides for the translation of the command into an actual search instruction for the system. This results in a comparison between words, numbers and other symbols in the search instruction and those in the representations of the original documents.When texts are stored in a databank, a list is usually (automatically) drawn up of all the words which appear in the texts (apart from extremely frequent words such as "the", "and" etc.). For each word a reference is made of the document(s) in which it appears. This list is often called an "inverted file". This is a means of representing the original texts.If the search instruction corresponds to one or more elements of the representation, the texts (documents) pertaining to it will be presented to the user. The search result can be printed out or used to reformulate the search question or command. The latter is sometimes referred to as "relevance feedback".The methods proposed in the literature for conceptual retrieval are aimed at three elements in the diagram:*The interface with the users*The representation of documents*The search operation.4. A summary of conceptual retrieval methodsThe following summary presents the approaches to the three elements specified above. First of all, the interface. Methods which try to realize conceptual retrieval by helping the user in the formulation of the question will be discussed. Under the title of representation, the next section discusses those methods based on the assumption that conceptual retrieval can be realized if the representations of the original texts are based on the legal importance or the legal meaning of a text. Decisions with respect to the design of the interface and the method of representation are related to each other. For example, if the interface provides the user with alternative search terms, these have to be part of the representation of the documents in order to be at all useful.In this article, relatively little attention will be paid to the third element of the retrieval process, the search procedure. Given the representation methods and the possibilities of the interface, all sorts of search methods could be applied. These could vary from simple (boolean) string matching via statistical techniques to neural networks. Furthermore, as far as design considerations are concerned this aspect is not crucial, as supplements and/or alterations to a search method will, in general, not alter the design of a retrieval method. It is also usually possible to incorporate a number of search procedures within a retrieval system without changing the design.4.1.The interfaceIt is the interface which makes communication between the user and the computer possible. It assists in the translation of the user's question into an actual search instruction for the computer. When the search instruction has been carried out, the interface is responsible for the reproduction of the results. On the basis of these results it is then possible to assess the relevance of the documents which have been found and to reformulate the question (or the actual command) if necessary. An interface can also assist the user in the formulation of the question [Vries et al., 1991].83Wildemast, C.A.M. and R.V. de MulderFigure 24.1.1.ThesaurusAs it is often difficult for the user to find the right words for the description of the question, use can be made of a thesaurus. A thesaurus is a list of synonyms. The advantage of this is that the system is able to offer the user alternatives to the words being looked for. It has been pointed out [Bing, 1987, p.44] that while a thesaurus can be useful, it is not able to solve all retrieval problems. In particular, it is not able to solve the problem that the meaning of a term is dependent on its context. This means that the interface should also contain information on the context.4.1.2.Intelligent interfacesInterfaces which give information on the relationships between legal concepts in a particular field have been described in [Bing, 1987] and [Guidotti et al., 1990]. Bing based the hierarchical structures which he proposed on the applicable legal regulations. The texts of the legal regulations were converted by hand into IF-THEN lines. All the legal regulations which have been rewritten in this way together determine the hierarchical structure. This is shown to the users graphically by means of arrow diagrams. The whole field can be reviewed with the help of these diagrams. Words from the diagrams which are relevant to the question can then be selected. When a choice has been made, synonyms are also shown in order that a search can be made with these. It is for the user to decide. The system itself then generates a (boolean) question to the databank.In [Guidotti et al., 1990], a semantic network is proposed to reflect such a hierarchical conceptual structure. The concepts are connected to each other on the basis of selected (legal) semantic relationships. The user is shown a graphic representation of the network. The user can choose terms which refer to the concepts in order to describe his question. The selected terms are connected to others in the network (for example, because they are synonymous). These terms are also incorporated in the search question which the system automatically generates.84Some Design Considerations for a Conceptual Legal Information Retrieval System 4.1.3.HypertextHypertext is a way of linking pieces of information that are stored in separate locations. This makes it possible to connect related information stored in different documents [Wiley, 1989, p. 223]. Greenleaf states that legal materials are particularly suited to hypertext presentation because of the fact that legal texts are densely cross-related [Greenleaf et al., 1991, p. 216]. A possible use of hypertext in the field of text retrieval is a hypertext presentation of the retrieved documents [Greenleaf et al., 1991][Merkl et al., 1990]. The documents are not presented as separate, individual items, but as a network in which interconnections between the documents are visible through linking terms. This enables the user to browse through the documents following his own line of interest.4.1.4.Conclusion on interfacesOne of the characteristics of intelligent interfaces is that the user must work with the concepts which have been programmed into the interface. As Leith [1990] and others have convincingly argued, these concepts are not objective data but rather interpretations determined by social circumstances. De Mulder emphasises the fact that, unlike the physical sciences, the concepts used are not derived from empirical observation nor, as in mathematics, are they based on explicit and univocal conventions [Mulder, 1984] [Mulder et al., 1989]. Concepts therefore could change from user to user, from time to time and even within one search question.1 The interfaces described above, however, provide only one set of opinions. The user should be able to change the legal knowledge that is incorporated in the interface. This means that the interface should be flexible and be able to "learn" from, possibly a number of, users. Each individual user should be able to access the information through his own concepts.4.2.RepresentationThe representation methods which have been proposed fall into two categories: those which use (only) manual methods and those which use automatic methods. Each of these categories can be further subdivided between "mainly reducing" and "mainly interpreting" approaches. The reducing approach means that the original texts are not represented by all the words which appear in them and the order in which they appear, but only by those words or groups of words which reflect most adequately the (legal) contents of the text. The interpreting approach uses various methods which represent documents with the help of (legal) knowledge.representationreducinginterpretingindexingdocument profileclusteringmanual methodsautomatic methodsindexingknowledgerepresentationFigure 385Wildemast, C.A.M. and R.V. de Mulder4.2.1.Manual, reducingIntellectual indexingTo search directly in untreated texts is not expedient for practising lawyers given the present state of computer technology and that which can be expected in the near future. The data files from which lawyers must select their texts are simply too extensive. Documents must, therefore, still be adapted before search instructions can be carried out. Texts may be, for example, represented by lists of words. One of the methods for producing such lists of words is to let an "expert" allot words to a text. An advantage of this method is that a word can be allotted to a text regardless of whether that word actually appears in the text. This approach also often leads to a considerable reduction in the files which would be consulted by the search program. This reduction, however, may entail a loss of potential information. Possibly the most significant disadvantage of this kind of representation is that every text has to be worked through by hand which is labour intensive and, therefore, expensive.4.2.2.Manual, interpretingKnowledge representationThis approach is based on the assumption that conceptual retrieval can only be realized if the search is carried out on the basis of legal "knowledge". This means that legal "knowledge" has to be described in a way which can be represented by a computer. In order to do this, various knowledge representation techniques have been developed. It is beyond the scope of this article to examine these in any depth [Oskamp, 1990].The choice of representation technique does not answer the question, however, of what knowledge should be represented. Hafner has proposed that designs for computerized search mechanisms should reflect the way in which a (human) legal expert remembers and classifies judgements [Hafner, 1978][Hafner, 1987]. In order to do this, a model of the legal field required is necessary.Dick proposes a somewhat different approach [Dick, 1987][Dick, 1991]. She proposes that lawyers search for information in the form of arguments which will support a solution to a concrete legal problem. The original texts must, therefore, be represented in terms of the arguments which appear in them.Manual adaptation of the original texts is, in both cases, necessary in order to obtain the information required for the representation. A consequence of this is that the application is restricted to a relatively small legal field. Once again, these approaches are labour intensive and hence rather expensive.4.2.3.Automatic, reducingIndexingTexts can be represented by all the words which appear in them (except for semantically irrelevant words such as the indefinite article). The disadvantage of this is, however, that if a word search is carried out many irrelevant texts are presented because that word appears in many texts [Davis, 1986][Mulder & Oskamp, 1979]. This problem is even more blatant in the case of legal texts. Research has shown that in these texts fewer different words are used than in "ordinary" texts. One solution would be to represent texts by words which are capable of distinguishing (several) texts from the rest of the collection. Words which would be capable of being used as distinguishers are those which appear with a certain frequency in only a few texts.Davis has carried out research concerning obtaining these words automatically [Davis, 1986]. This tested the following hypothesis: words which have a poor distinguishing86Some Design Considerations for a Conceptual Legal Information Retrieval System capacity show a poisson distribution, words which have a good distinguishing capacity show a distribution other than poisson. Words from statute law and case law were examined to ascertain whether there was a poisson distribution. Those words which did not show a poisson distribution were compared to words allotted to the text by hand.As regards case law, too few words were found this way which meant it was pointless to carry out a comparison with words allotted by hand. Statute law, on the other hand, produced a satisfactory number of words which meant that the comparison could be carried out with the aim of determining which words were the same in both methods. It was discovered that only a small section of the words were common to both methods. Although the number of corresponding words was small, the researchers expect that those words will semantically represent the text the best. It will be necessary to test this assumption further. A weakness that is inherent in this method is that the interpretation of the terms which have or have not been incorporated in the extraction will vary from user to user and during time.4.2.4.Automatic, interpretingDocument profilesIn [Gelbart & Smith, 1990] and [Gelbart & Smith, 1991] it is proposed that documents should be represented by document profiles. A profile can be derived from each document. This profile consists of four parts: concepts, cases, legislation and facts. Each part is described by so-called profile key words. Concepts are described by statements of applicable law and resolutions to the issues when the law has been applied to the facts. Cases are described by citations of related issues, legislation by citations of applicable legislation and facts by description of the factual situation.These profile key words are automatically generated from the original text by means of a method which combines legal knowledge with linguistic methods. This makes it possible to recognize legal word combinations as well as words. Each profile key word has a weight ascribed to it. The key words are then ordered according to weight.The user's question is also described in the form of a profile. The user provides a profile sketch of the documents he requires by describing which concepts, cases, legislation and facts are considered to be important. Relevant documents are found on the basis of comparing the question profile with the documents' profiles. Documents with profiles which correspond most closely to the question profile are ordered according to the level of similarity and are presented to the user. It is also possible, however, to describe only one component, for example the facts. In this way cases are found in which there is a similarity in the factual situation.This method may be considered to be a compromise between an approach which advocates the desirability of a concept structure and one which advocates the desirability of variable interpretation depending on the user and the course of time. The concept structure used here (the fourfold distinction) is kept extremely general. It cannot in itself, however, be changed by the user.Document classificationThe underlying principle of this method is that documents which deal with "the same" matters should be grouped together. This is also referred to as the clustering of documents [Salton, 1989, p. 326-345]. The process of clustering is based on the similarity between documents. As concerns the legal application of this method, the following has been proposed.Merkl calculates the similarity between pairs of documents at four levels [Merkl et al., 1990]:87Wildemast, C.A.M. and R.V. de Mulder1co-occurrent terms,2co-occurrent law citations,3co-occurrent terms and law citations which appear together and4co-occurrent law citations which refer to a subject domain.Level 1 contributes the least and level 4 the most to the similarity. The idea behind this is that documents which deal with the same legal subject will be more similar than documents which deal with differing legal subjects. Levels 1, 2 and 3 are calculated on the basis of statistical information which is acquired in the indexing phase such as term frequencies, document frequencies and the weight of terms. Level 4 is determined according to information from knowledge files. A certain legal field is then divided into subject fields. The knowledge file is a hierarchical reproduction of legal subjects which can be distinguished in a particular legal domain plus the corresponding legal regulations.A document is considered to belong to a certain subject domain if the corresponding legislative article appears [Merkl et al., 1992].2After all the pairs of documents have been compared, a hierarchical structure of clusters is automatically generated. Documents concerned with the same legal subject appear in each cluster. Certain clusters are chosen from the hierarchy to serve as so-called super documents. A super document is represented by terms and law citations which appear in the documents belonging to the super document. A user's question is compared with the representations of the super documents. Documents belonging to the super document which corresponds most closely to the question are presented to the user. The advantage of this method is that it is possible to search more directly for a set of documents, in which set the documents have an equal information value.4.2.5.Conclusion on representationAll the reducing methods have the disadvantage of the potential loss of information. Their main advantage is the lower cost of computer storage and a decrease in the time that a search operation takes. On the basis of technical developments, which have made a marked decrease in the cost of processing and storage possible, the expectation is that these advantages will not compensate for the disadvantage. Reducing methods of representation, however, are useful in a full text system in order to achieve a quick response time when such is desired.Given the fast growth of the amount of documents that are available in the legal field, it seems that methods which are based on manual representation will increasingly become too expensive to be feasible. Furthermore, in addition to the problem in the legal field that there is no established empirical or conventional scientific basis for indexing, achieving an appropriate level of objectivity will be costly, if not impossible.Knowledge representation could be useful in certain specific domains, but has, apart from its apparent cost, the disadvantage of representing only the opinion of one expert, or group of experts, at a certain time. Different users may hold different opinions, and they may wish to change the knowledge brought into the representation. If they would be enabled to do so, this could easily lead to errors and inconsistencies given the complexity of a domain of minimal sophistication. Automatic interpretative methods would also have to be based on opinions of one expert or group of experts and would also be hard to modify by the user. The representation could possibly be partly based upon linguistic techniques. This in itself would not compensate for the empirically unfounded legal notions. It would seem that providing end-users with the option of making non-trivial changes to a vast and complex set of automatically or manually interpreted data cannot be expected in the next decade.88Some Design Considerations for a Conceptual Legal Information Retrieval System The conclusion is, that legal documents will have to be electronically stored in the foreseeable future by a full text representation, with additional automatically generated non-interpretative indexes.4.3.Search operationsBy search operation is understood the function which ensures that the concrete search instruction (whether or not already reworked in the interface) is carried out on the documents represented in the system. Even in more complicated techniques than the pure boolean search, the search operation will in principle consist of the comparison of words, numbers and/or other symbols or combinations of these in the search instruction with those in the representations. These terms will typically only be searched for in terms of occurrence, rather then, for example, their frequency in the documents. The result of the boolean search operation is the answering of a yes/no question for each document as to whether the document satisfies the search instruction. In other search operations, what is looked for is a measurement which indicates the extent to which the document satisfies the search instruction. This may possibly be expressed in the form of an estimation of probability. In the case of such techniques, it is usually possible to order the documents found according to their expected relevancy [Salton, 1989][Bookstein & Klein, 1990]. This allows the user to devote his attention firstly to those documents at the top of the list. If he finds a large number of these to be relevant he can then work his way through the list until he has exhausted those of use to him. Ordinary statistical methods are applied in such search techniques.A similar result is achieved by search techniques which make use of "neural networks". Neural networksConceptual retrieval with the help of neural networks was proposed in [Belew, 1987] and [Rose & Belew, 1989]. These networks make a certain level of associative searching possible. A simple example will illustrate how this is realized.Neural networks consist of nodes and links between the nodes. Imagine that there are two layers: term nodes and document nodes. Each term node is connected to the document node in which the term appears. The retrieval mechanism works as follows. If there is a search for a term, there is activity in the network. This activity can best be imagined as a current which flows from the term to all the documents in which the term appears. The documents are activated and pass on the activity to all the connected terms. The activity is then passed on to the documents again via the terms and so on. In the course of time, the spreading of the activity can be stopped. It now appears that certain documents and terms are more activated than others. Those documents which are the most activated are presumed to be relevant to the question.The terms which have been most activated can be presented to the user. These terms are probably ones which correspond to the term in the question. With the help of these terms, the question can be adapted for a new search operation.4.3.1.Conclusion on search operationsAn advantage of the neural network technique is that no legally fixed, and therefore limited, representation of the incorporated texts is chosen. The user can keep trying to improve his command description so that it corresponds as well as possible to his search requirements. The techniques of neural networks are still in the developing stage. It would seem that this field could contribute substantially to improving conceptual legal information retrieval. Ordinary statistical techniques, however, should not be ruled out prematurely.89。