
重庆西南大学 2012 至 2013 学年度第 2 期 生物统计学 试题(A ) 试题使用对象: 2011 级 专业(本科) 命题人: 考试用时 120 分钟 答题方式采用: 闭卷 说明:1、答题请使用黑色或蓝色的钢笔、圆珠笔在答题纸上书写工整. 2、考生应在答题纸上答题,在此卷上答题作废. 一:判断题;(每小题1分,共10分 ) 1、正确无效假设的错误为统计假设测验的第一类错误。( ) 2、标准差为5,B 群体的标准差为12,B 群体的变异一定大于A 群体。( ) 3、一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( ) 4、30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1 (已知84.321,05.0=χ)。 ( ) 5、固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于推断处理的总体。( ) 6、率百分数资料进行方差分析前,应该对资料数据作反正弦转换。( ) 7、比较前,应该先作F 测验。 ( ) 8、验中,测验统计假设H 00:μμ≥ ,对H A :μμ<0 时,显著水平为5%,则测验的αu 值为1.96( ) 9、行回归系数假设测验后,若接受H o :β=0,则表明X 、Y 两变数无相关关系。 ( ) 10、株高的平均数和标准差为30150±=±s y (厘米),果穗长的平均数和标准差为s y ±1030±=(厘米),可认为该玉米的株高性状比果穗性状变异大。 ( ) 二:选择题;(每小题2分,共10分 ) 1分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( )。 A 、[-9.32,11.32] B 、[-4.16,6.16]
※<第一章习题> 1、什么是总体、个体、样本、样本含量、随机样本?统计分析的两个特点是什么? 2、什么是随机误差与系统误差?如何控制、降低随机误差、避免系统误差? 5 ※<第二章习题> 1、为什么要对资料进行整理?对于计量资料,整理的基本步骤怎样? 2、测得某肉品的化学成分的百分比(%)如下,请绘制成圆图。 水分蛋白质脂肪无机盐其他 62.0 15.3 17.2 1.8 3.7 5 ※<第三章习题> 随机测量了某品种120尾2龄鱼的体长,经整理得到如下数分布表。试利用加权法计算某平均数、标准差与变异系数。 组别组中值(x)次数(f) 80~ 84 2 88- 92 10 96- 100 29 104- 108 20 112- 116 20 120- 124 15 128- 132 13 136- 140 3 5※<第四章习题> 现有6条小鱼,其中4条是雌的,2条是雄的,从中抽取两次,每次取1只,在返回抽样情况下求: (1)取到的两条都是雌性的概率;
(2)取到的两只性别相同的概率; (3)取到的两只至少有1只是雌性的概率。 5※<第五章习题> 1 问此法是否有效?(提示:t0.05(9)=2.262,t0.05(9)=3.252 ) 2、随机抽测了10只兔的直肠温度,其数据为:38.7、39.0、38.9、39.6、39.1、39.8、38.5、39.7、39.2、38.4(℃),已知该品种兔直肠温度的总体平均数μ =39.5(℃), 5※<第六章习题> 3头公牛交配6头母牛(各随机交配两头),其女儿第一产305d产奶量饲料如下,试作方差分析,并估计方差组分。 公牛所配母牛的女儿产奶量(kg) 公牛序号S 母牛序号D 女儿产奶量C 母牛女儿头 数 公牛女儿头 数 1 1 5700 5700 2 4 2 6900 7200 2 2 3 5500 4900 2 4 4 5500 7400 2 3 5 4600 4000 2 4 6 5300 5200 2 5※<第七章习题>
《生物统计学》复习题 一、填空题(每空1分,共10分) 1 ?变量之间的相关关系主要有两大类: (因果关系),(平行关系) 2 ?在统计学中,常见平均数主要有( 算术平均数)、(几何平均数)、(调和平均数) S 、:'(X 迁 3 ?样本标准差的计算公式( 1 n 1 ) 4 ?小概率事件原理是指( 某事件发生的概率很小,人为的认为不会发生 ) 5. 在标准正态分布中, P (- K u w 1) = (0。6826 ) (已知随机变量1的临界值为0. 1587) 6. 在分析变量之间的关系时, 一个变量X 确定,Y 是随着X 变化而变化,两变量呈因果关系, 则X 称为(自 变量),Y 称为(依变量) 二、单项选择题(每小题 1分,共20分) 1、 ________________________________ 下列数值属于参数的是: A 、总体平均数 B 、自变量 C 依变量 D 、样本平均数 2、 下面一组数据中属于计量资料的是 _____________ A 、产品合格数 B 、抽样的样品数 C 病人的治愈数 D 、产品的合格率 3、 在一组数据中,如果一个变数 10的离均差是2,那么该组数据的平均数是 _________ 4、 变异系数是衡量样本资料 _________ 程度的一个统计量。 ___________ A 、变异 B 、同一 C 集中 D 、分布 5、 方差分析适合于, ____________ 数据资料的均数假设检验。 A 、两组以上 B 、两组 C 一组 D 、任何 8、平均数是反映数据资料 _________ 性的代表值。 A 、变异性 B 、集中性 C 差异性 D 、独立性 9、在假设检验中,是以 ___________ 为前提。 A 肯定假设 B 、备择假设 C 原假设 10、抽取样本的基本首要原则是 A 12 B 、10 D 、2 6、 在t 检验时,如果t = t o 、01,此差异是: A 、显著水平 B 、极显著水平 7、 生物统计中t 检验常用来检验 __________ A 、两均数差异比较 B 、两个数差异比较 C 无显著差异 D 、没法判断 C 两总体差异比较 D 、多组数据差异比 较 D 、有效假设
生物统计学考试题及答案
重庆西南大学 2012 至 2013 学年度第 2 期 生物统计学 试题(A ) 试题使用对象: 2011 级 专 业(本科) 命题人: 考试用时 120 分钟 答题方式采用: 一:判断题;(每小题1分,共10分 ) 1、正确无效假设的错误为统计假设测验的第一类错误。( ) 2、标准差为5,B 群体的标准差为12,B 群体的变异一定大于A 群体。( ) 3、一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( ) 4、30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1(已 知84.321,05.0=χ)。 ( ) 5、固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于推断处理的总体。( ) 6、率百分数资料进行方差分析前,应该对资料数据作反正弦转换。( ) 7、比较前,应该先作F 测验。 ( ) 8、验中,测验统计假设H 00:μμ≥ ,对H A :μμ<0 时,显著水平为5%,则测验的αu 值为1.96( ) 9、行回归系数假设测验后,若接受H o :β=0,则表明X 、Y 两变数无相关关系。( ) 10、株高的平均数和标准差为30150±=±s y (厘米),果穗长的平均数和标准差为s y ±1030±=(厘米),可认为该玉米的株高性状比果穗性状变异大。 ( ) 二:选择题;(每小题2分,共10分 ) 1分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( )。
A 、[-9.32,11.32] B 、[-4.16,6.16] C 、[-1.58,3.58] D 、都不是 2、态分布不具有下列哪种特征( )。 A 、左右对称 B 、单峰分布 C 、中间高、两头低 D 、概率处处相等 3、一个单因素6个水平、3次重复的完全随机设计进行方差分析,若按最小显著差数法进行多重比较,比较所用的标准误及计算最小显著差数时查表的自由度分别为( )。 A 、 2MSe/6 , 3 B 、 MSe/6 , 3 C 、 2MSe/3 , 12 D 、 MSe/3 , 12 4、已知),N(~x 2σμ,则x 在区间]96.1,[σμ+-∞的概率为( )。 A 、0.025 B 、0.975 C 、0.95 D 、0.05 5、 方差分析时,进行数据转换的目的是( )。 A. 误差方差同质 B. 处理效应与环境效应线性可加 C. 误差方差具有正态性 D. A 、B 、C 都对 三、简答题;(每小题6分,共30分 ) 1、方差分析有哪些步骤? 2、统计假设是?统计假设分类及含义? 3、卡方检验主要用于哪些方面? 4、显著性检验的基本步骤? 5、平均数有哪些?各用于什么情况? 四、计算题;(共4题、50分) 1、进行大豆等位酶Aph 的电泳分析,193份野生大豆、223份栽培大豆等位基因型的次数列于下表。试分析大豆Aph 等位酶的等位基因型频率是否因物种而不同。( 99 .52 05.0,2=χ, 81 .7205.0,3=χ)(10分) 野生大豆和栽培大豆Aph 等位酶的等位基因型次数分布 物 种 等位基因型 1 2 3 野生大豆 29 68 96
计算题 1、某小麦品种的常年平均亩产量为μ=210公斤, 现从外地引种一新品种, 在6 个试验点试种, 得平均亩产是X=224公斤,其标准差为S=4.63公斤, 试问该新品种的产量是否与原来的品种有显著差异?(α=0.05) 2.有一水稻品种的比较试验, 参试品种有4个, 对照品种一个(CK), 随机区组设计, 设置三次重复, 小区面积0.03亩, 试验结果如下: 进行方差分析 3.有一杂交水稻品种, 田间随机抽样调查10株主穗的穗粒数, 得以下数据: 株号 1 2 3 4 5 6 7 8 9 10 穗粒数110 112 128 131 125 104 117 121 115 126 试描述这组数据的主要特征特性. 4、有一水稻品种和栽插密度的两因子试验, 参试品种4个(a=4), 栽插密度3个(b=3), 设 5、有一晚稻品种的联合区域试验, 参试品种6个, 对照品种一个(CK), 共7个品种随机区组试验, 设置三次重复, 小区面积0.04亩, 试验结果如下: 各品种的小区平均产量(公斤)为: XA=19.4 XB=20.8 XC=12.5 XD=15.8 XE=20.4 XF=16.8 X(CK)=17.6 该试验的目的是对参试品种与指定的对照品种(CK)进行比较, 请继续进行多重比较, 采用LSDα法测验(α=0.05) 6、田间随机调查10株紧凑型玉米品种"掖单13号"的株高(CM)和果穗籽粒重(克),得以下数据: 株序号 1 2 3 4 5 6 7 8 9 10 株高191 192 189 185 201 193 198 211 210 215 穗重169 167 156 141 144 150 154 156 138 157 试问该两个性状中哪一个的变异程度大? 7、有一杂交玉米的品比试验, 参试品种6个, 对照品种一个, 共7个品种, 随机区组设
生物统计学考试 一.判断题(每题2分,共10分) √1. 分组时,组距和组数成反比。 ×2. 粮食总产量属于离散型数据。 ×3. 样本标准差的数学期望是总体标准差。 ×4. F分布的概率密度曲线是对称曲线。 √5. 在配对数据资料用t检验比较时,若对数n=13,则查t表的自由度为12。 二. 选择题(每题3分,共15分) 6.x~N(1,9),x1,x2,…,x9是X的样本,则有() x N(0,1)B.11 - x ~N(0,1)C.91 - x ~N(0,1)D.以上答案均不正确 7. 假定我国和美国的居民年龄的方差相同。现在各自用重复抽样方法抽取本国人口的1%计 算平均年龄,则平均年龄的标准误() A.两者相等 B.前者比后者大 D.不能确定大小 8. 设容量为16人的简单随机样本,平均完成工作需时13分钟。已知总体标准差为3分钟。 若想对完成工作所需时间总体构造一个90%置信区间,则() u值 B.应用t分布表查出t值 C.应用卡方分布表查出卡方值 D.应用F分布表查出F值 9. 1-α是() A.置信限 B.置信区间 C.置信距 10. 如检验k (k=3)个样本方差s i2 (i=1,2,3)是否来源于方差相等的总体,这种检验在统计上称为 ( )。 B. t检验 C. F检验 D. u检验 三. 填空题(每题3分,共15分) 11. 12. 13. 已知F分布的上侧临界值F0.05(1,60)=4.00,则左尾概率为0.05,自由度为(60,1) 的F 14. 15.已知随机变量x服从N (8,4),P(x < 4.71)(填数字) 四.综合分析题(共60分)
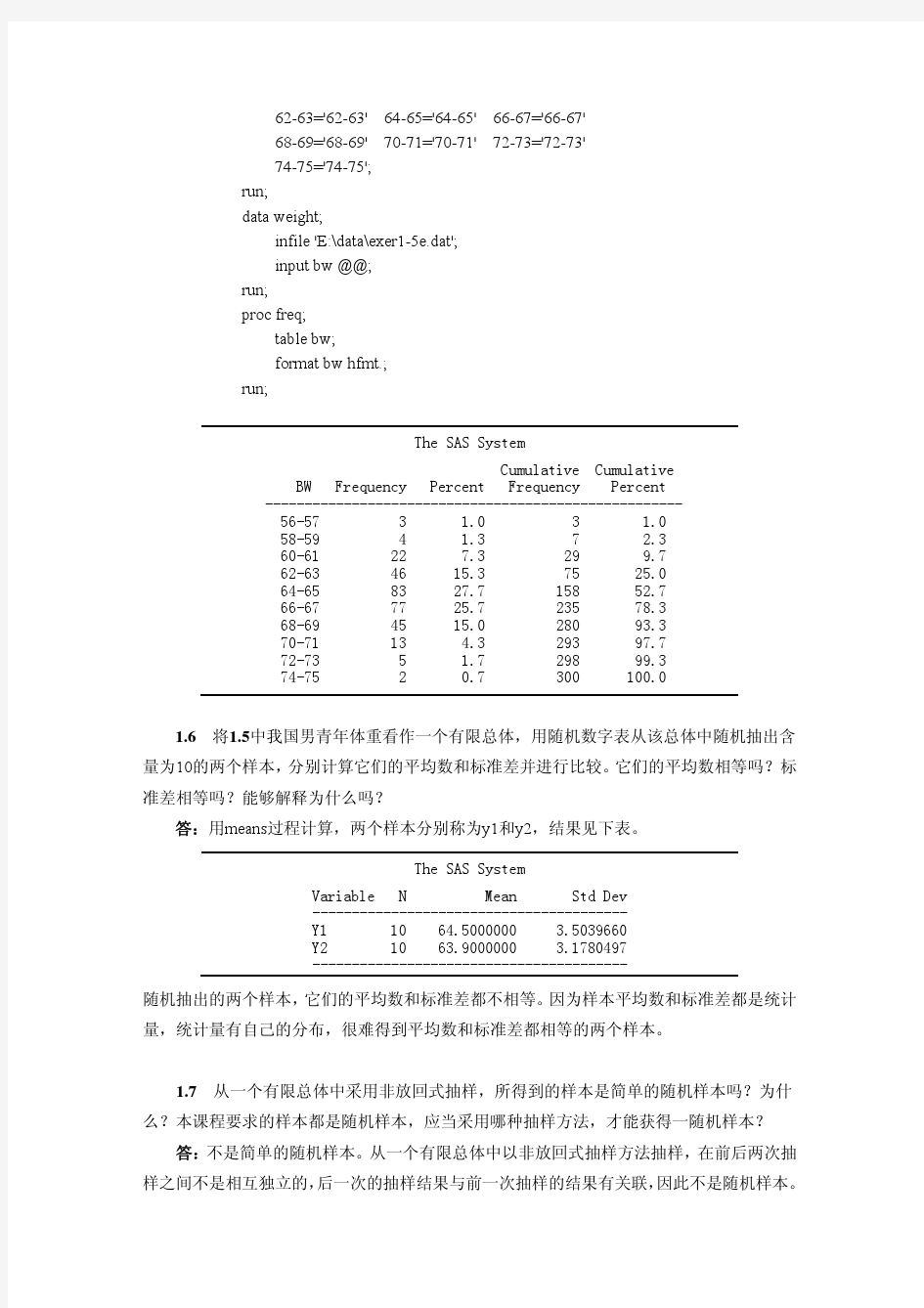
第一章统计数据的收集与整理1.1 算术平均数是怎样计算的?为什么要计算平均数? 答:算数平均数由下式计算:n y y n i i ∑ = =1 ,含义为将全部观测值相加再被观测值的个数 除,所得之商称为算术平均数。计算算数平均数的目的,是用平均数表示样本数据的集中点,或是说是样本数据的代表。 1.2 既然方差和标准差都是衡量数据变异程度的,有了方差为什么还要计算标准差? 答:标准差的单位与数据的原始单位一致,能更直观地反映数据地离散程度。 1.3 标准差是描述数据变异程度的量,变异系数也是描述数据变异程度的量,两者之间有什么不同? 答:变异系数可以说是用平均数标准化了的标准差。在比较两个平均数不同的样本时所得结果更可靠。 1.4 完整地描述一组数据需要哪几个特征数? 答:平均数、标准差、偏斜度和峭度。 1.5 下表是我国青年男子体重(kg)。由于测量精度的要求,从表面上看像是离散型数据,不要忘记,体重是通过度量得到的,属于连续型数据。根据表中所给出的数据编制频数分布表。 66 69 64 65 64 66 68 65 62 64 69 61 61 68 66 57 66 69 66 65 70 64 58 67 66 66 67 66 66 62 66 66 64 62 62 65 64 65 66 72 60 66 65 61 61 66 67 62 65 65 61 64 62 64 65 62 65 68 68 65 67 68 62 63 70 65 64 65 62 66 62 63 68 65 68 57 67 66 68 63 64 66 68 64 63 60 64 69 65 66 67 67 67 65 67 67 66 68 64 67 59 66 65 63 56 66 63 63 66 67 63 70 67 70 62 64 72 69 67 67 66 68 64 65 71 61 63 61 64 64 67 69 70 66 64 65 64 63 70 64 62 69 70 68 65 63 65 66 64 68 69 65 63 67 63 70 65 68 67 69 66 65 67 66 74 64 69 65 64 65 65 68 67 65 65 66 67 72 65 67 62 67 71 69 65 65 75 62 69 68 68 65 63 66 66 65 62 61 68 65 64 67 66 64 60 61 68 67 63 59 65 60 64 63 69 62 71 69 60 63 59 67 61 68 69 66 64 69 65 68 67 64 64 66 69 73 68 60 60 63 38 62 67 65 65 69 65 67 65 72 66 67 64 61 64 66 63 63 66 66 66 63 65 63 67 68 66 62 63 61 66 61 63 68 65 66 69 64 66 70 69 70 63 64 65 64 67 67 65 66 62 61 65 65 60 63 65 62 66 64 答:首先建立一个外部数据文件,名称和路径为:E:\data\exer1-5e.dat。所用的SAS程序和计算结果如下: proc format; value hfmt 56-57='56-57' 58-59='58-59' 60-61='60-61' 62-63='62-63' 64-65='64-65' 66-67='66-67'
生物统计学习题(1)
第一章绪论 一、填空 1 变量按其性质可以分为___变量和_____变量。 2 样本统计数是总体__估计量。 3 生物统计学是研究生命过程中以样本来推断__ __的一门学科。 4 生物统计学的基本内容包括_、----两大部分。 5 统计学的发展过程经历了_ _3个阶段。 6 生物学研究中,一般将样本容量_n大于等于30_称为大样本。 7 试验误差可以分为__ _两类。 二、判断 (-)1 对于有限总体不必用统计推断方法。 ( - )2 资料的精确性高,其准确性也一定高。 ( + ) 3 在试验设计中,随机误差只能减少,而不可能完全消除。 ( - )4 统计学上的试验误差,通常指随机误差。 第二章试验资料的整理与特征数的计算 一、填空 1 资料按生物的性状特征可分为_ _变量和__变量。 2 直方图适合于表示__ _资料的次数分布。 3 变量的分布具有两个明显基本特征,即_和__ _。
D 正态分布的算术平均数、中位数、几何平均数均相等 4 如果对各观测值加上一个常数a ,其标准差____。 A 扩大a 倍 B 扩大a 倍 C 扩大a 2倍 D 不变 5 比较大学生和幼儿园孩子身高变异度,应采用的指标是__ __。 A 标准差 B 方差 C 变异系数 D 平均数 第三章 概率与概率分布 一、填空 1 如果事件A 和事件B 为独立事件,则事件A 与事件B 同时发生地概率P (AB )=__ _。 2 二项分布的形状是由_____和___ __两个参数决定的。 3 正态分布曲线上,____ _确定曲线在x 轴上的中心位置,_确定曲线的展开程度。 4 样本平均数的标准误x σ等于___。 5 t 分布曲线和正态分布曲线相比,顶部偏_____,尾部偏___ ____。 二、判断 ( - ) 1 事件A 的发生与事件B 的发生毫无关系,则事件A 和事件B 为互斥事件。 ( - )2 二项分布函数x n x x n q p c -恰好是二项式()n q p +展开式的第x 项,故称二项分布。 ( - ) 3 样本标准差s 是总体标准差的无偏估计值. ( + ) 4 正态分布曲线形状与样本容量n 值无关。
第一章绪论 一、填空 1 变量按其性质可以分为___变量和_____变量。 2 样本统计数是总体__估计量。 3 生物统计学是研究生命过程中以样本来推断__ __的一门学科。 4 生物统计学的基本内容包括_、----两大部分。 5 统计学的发展过程经历了_ _3个阶段。 6 生物学研究中,一般将样本容量_n大于等于30_称为大样本。 7 试验误差可以分为__ _两类。 二、判断 (-)1 对于有限总体不必用统计推断方法。 (- )2 资料的精确性高,其准确性也一定高。 ( + ) 3 在试验设计中,随机误差只能减少,而不可能完全消除。(- )4 统计学上的试验误差,通常指随机误差。 第二章试验资料的整理与特征数的计算 一、填空 1 资料按生物的性状特征可分为_ _变量和__变量。 2 直方图适合于表示__ _资料的次数分布。
3 变量的分布具有两个明显基本特征,即_和__ _。 4 反映变量集中性的特征数是_____ __,反映变量离散性的特征数是__ _。 5 样本标准差的计算公式s=__√∑(x-x横杆)平方/(n-1)_____。 二、判断 ( - ) 1 计数资料也称连续性变量资料,计量资料也称非连续性变量资料。 ( - ) 2 条形图和多边形图均适合于表示计数资料的次数分布。(+)3 离均差平方和为最小。 (+ )4 资料中出现最多的那个观测值或最多一组的中点值,称为众数。 (- )5 变异系数是样本变量的绝对变异量。 四、单项选择 1 下面变量中属于非连续性变量的是_____。 A 身高 B 体重 C 血型 D 血压 2 对某鱼塘不同年龄鱼的尾数进行统计分析时,可做成__ _图来表示。 A 条形图 B 直方图 C 多边形图 D 折线图 3 关于平均数,下列说法正确的是__ __。 A 正态分布的算术均数与几何平均数相等 B 正态分布的算术平均数与中位数相等 C 正态分布的中位数与几何平均数相等
第一章 填空 1.变量按其性质可以分为(连续)变量和(非连续)变量。 2.样本统计数是总体(参数)的估计值。 3.生物统计学是研究生命过程中以样本来推断(总体)的一门学科。 4.生物统计学的基本内容包括(试验设计)和(统计分析)两大部分。 5.生物统计学的发展过程经历了(古典记录统计学)、(近代描述统计学)和(现代推断统计学)3个阶段。 6.生物学研究中,一般将样本容量(n ≥30)称为大样本。 7.试验误差可以分为(随机误差)和(系统误差)两类。 判断 1.对于有限总体不必用统计推断方法。(×) 2.资料的精确性高,其准确性也一定高。(×) 3.在试验设计中,随机误差只能减小,而不能完全消除。(∨) 4.统计学上的试验误差,通常指随机误差。(∨) 第二章 填空 1.资料按生物的性状特征可分为(数量性状资料)变量和(质量性状资料)变量。 2. 直方图适合于表示(连续变量)资料的次数分布。 3.变量的分布具有两个明显基本特征,即(集中性)和(离散性)。 4.反映变量集中性的特征数是(平均数),反映变量离散性的特征数是(变异数)。 5.样本标准差的计算公式s=( )。 判断题 1. 计数资料也称连续性变量资料,计量资料也称非连续性变量资料。(×) 2. 条形图和多边形图均适合于表示计数资料的次数分布。(×) 3. 离均差平方和为最小。(∨) 4. 资料中出现最多的那个观测值或最多一组的中点值,称为众数。(∨) 5. 变异系数是样本变量的绝对变异量。(×) 单项选择 1. 下列变量中属于非连续性变量的是( C ). A. 身高 B.体重 C.血型 D.血压 2. 对某鱼塘不同年龄鱼的尾数进行统计分析,可做成( A )图来表示. A. 条形 B.直方 C.多边形 D.折线 3. 关于平均数,下列说法正确的是( B ). A. 正态分布的算术平均数和几何平均数相等. B. 正态分布的算术平均数和中位数相等. C. 正态分布的中位数和几何平均数相等. D. 正态分布的算术平均数、中位数、几何平均数均相等。 4. 如果对各观测值加上一个常数a ,其标准差( D )。 A. 扩大√a 倍 B.扩大a 倍 C.扩大a 2倍 D.不变 5. 比较大学生和幼儿园孩子身高的变异度,应采用的指标是( C )。 A. 标准差 B.方差 C.变异系数 D.平均数 第三章 12 2--∑∑n n x x )(
生物统计学期末复习题 库及答案 https://www.doczj.com/doc/6a6288074.html,work Information Technology Company.2020YEAR
第一章 填空 1.变量按其性质可以分为(连续)变量和(非连续)变量。 2.样本统计数是总体(参数)的估计值。 3.生物统计学是研究生命过程中以样本来推断(总体)的一门学科。 4.生物统计学的基本内容包括(试验设计)和(统计分析)两大部分。 5.生物统计学的发展过程经历了(古典记录统计学)、(近代描述统计学)和(现代推断统计学)3个阶段。 6.生物学研究中,一般将样本容量(n ≥30)称为大样本。 7.试验误差可以分为(随机误差)和(系统误差)两类。 判断 1.对于有限总体不必用统计推断方法。(×) 2.资料的精确性高,其准确性也一定高。(×) 3.在试验设计中,随机误差只能减小,而不能完全消除。(∨) 4.统计学上的试验误差,通常指随机误差。(∨) 第二章 填空 1.资料按生物的性状特征可分为(数量性状资料)变量和(质量性状资料)变量。 2. 直方图适合于表示(连续变量)资料的次数分布。 3.变量的分布具有两个明显基本特征,即(集中性)和(离散性)。 4.反映变量集中性的特征数是(平均数),反映变量离散性的特征数是(变异数)。 5.样本标准差的计算公式s=( )。 122--∑∑n n x x )(
判断题 1. 计数资料也称连续性变量资料,计量资料也称非连续性变量资料。(×) 2. 条形图和多边形图均适合于表示计数资料的次数分布。(×) 3. 离均差平方和为最小。(∨) 4. 资料中出现最多的那个观测值或最多一组的中点值,称为众数。(∨) 5. 变异系数是样本变量的绝对变异量。(×) 单项选择 1.下列变量中属于非连续性变量的是( C ). A.身高 B.体重 C.血型 D.血压 2.对某鱼塘不同年龄鱼的尾数进行统计分析,可做成( A )图来表示. A.条形 B.直方 C.多边形 D.折线 3. 关于平均数,下列说法正确的是( B ). A.正态分布的算术平均数和几何平均数相等. B.正态分布的算术平均数和中位数相等. C.正态分布的中位数和几何平均数相等. D.正态分布的算术平均数、中位数、几何平均数均相等。 4. 如果对各观测值加上一个常数a,其标准差(D)。 A.扩大√a倍 B.扩大a倍 C.扩大a2倍 D.不变 5. 比较大学生和幼儿园孩子身高的变异度,应采用的指标是(C)。 A.标准差 B.方差 C.变异系数 D.平均数 第三章 填空
生物统计学课后习题解答-李春喜汇总
第一章概论 解释以下概念:总体、个体、样本、样本容量、变量、参数、统计数、效应、互作、随机误差、系统误差、准确性、精确性。 第二章试验资料的整理与特征数的计算习题 2.1 某地 100 例 30 ~ 40 岁健康男子血清总胆固醇(mol · L -1 ) 测定结果如下: 4.77 3.37 6.14 3.95 3.56 4.23 4.31 4.71 5.69 4.12 4.56 4.37 5.39 6.30 5.21 7.22 5.54 3.93 5.21 6.51 5.18 5.77 4.79 5.12 5.20 5.10 4.70 4.74 3.50 4.69 4.38 4.89 6.25 5.32 4.50 4.63 3.61 4.44 4.43 4.25 4.03 5.85 4.09 3.35 4.08 4.79 5.30 4.97 3.18 3.97 5.16 5.10 5.85 4.79 5.34 4.24 4.32 4.77 6.36 6.38 4.88 5.55 3.04 4.55 3.35 4.87 4.17 5.85 5.16 5.09 4.52 4.38 4.31 4.58 5.72 6.55 4.76 4.61 4.17 4.03 4.47 3.40 3.91 2.70 4.60 4.09 5.96 5.48 4.40 4.55 5.38 3.89 4.60 4.47 3.64 4.34 5.18 6.14 3.24 4.90 计算平均数、标准差和变异系数。 【答案】=4.7398, s=0.866, CV =18.27 % 2.2 试计算下列两个玉米品种 10 个果穗长度 (cm) 的标准差和变异系数,并解释所得结果。 24 号: 19 , 21 , 20 , 20 , 18 , 19 , 22 , 21 , 21 , 19 ; 金皇后: 16 , 21 , 24 , 15 , 26 , 18 , 20 , 19 , 22 , 19 。 【答案】 1 =20, s 1 =1.247, CV 1 =6.235% ; 2 =20, s 2 =3.400, CV 2 =17.0% 。 2.3 某海水养殖场进行贻贝单养和贻贝与海带混养的对比试验,收获时各随机抽取 50 绳测其毛重(kg) ,结果分别如下:
统计选择题 1,由于(1,研究对象本身的性质)造成我们所遇到的各种统计数据的不齐性。 2,研究某一品种小麦株高,因为该品种小麦是个极大的群体,其数量甚至于是个天文数字,该体属于(4,无限总体) 3,从总体中(2,随机抽出)一部分个体称为样本。 4,用随机抽样方法从总体中获得一个样本的过程称为(3,抽样) 5,身高,体重,年龄这一类数据属于(3,连续型数据;1,度量数据) 6,每10个中男性人数,每亩麦田中杂草株数,喷洒农药后每100只害虫中死虫数等,这一类数据属于(1,离散型数据;2,计数数据) 7,把频数按其组值的顺序排列起来,称为(3,频数分布) 8,以组值作为一个边,相应的频数为另一个边,做成的连续矩形图称为(2,直方图)9,绘制(4,多边形图)的方法是在坐标平面内点上各点(中值,频数),以线段连接各点,最高和最低非零频数点与相邻零频数点相连。 10,累积频数图是根据(3,累积频数表)直接绘出的。 11,样本数据总和除以样本含量,称为(算数平均数 12,已知样本平方和为360,样本含量为10,以下4种结果中(2,6.0)是正确的标准差。 13,概率的古典定义是(2,基本事件数与事件总数之比) 14,下面第(2,概率是事物所固有的特性) 15,对于事件A和B,P(A∪B)等于(2,P(AB)) 16,对于事件A和事件B,P(A|B)等于(P(AB)/P(B)) 17,对于任意事件A和B,P(AB)等于(P(B)P(B|A)) 18,下述(3随机试验中所输入的变量)项称为随机变量 19,关于连续型随机变量,有以下4种提法,其中(1,可取某一区间内的任何数值)20,总体平均数可以用以下4种符号中的一种表示,它是(2,μ) 21,样本标准差可以用以下4种符号中的一种表示,它是(1,s) 22,在养鱼场中,A鱼塘的面积占10%,A鱼塘中鱼的发病率为1%,问从养鱼场中任意捕捞一条鱼,它既是A鱼塘,又是生病的鱼的概率是(4,0.003) 23,以下4点是描述连续型随机变量特征的,其中(2,f(x)=lim △x→0P(x 第一章概论 一、什么是生物统计学?生物统计学主要内容和作用? 1、生物统计学是数理统计在生物学研究中的应用,它是应用数理统计的原理,运用统计方法来认识、分析、推断和解释生命过程中的各种现象和试验调查资料的科学。属于生物数学的范畴 2、主要内容 基本原则对比设计 试验设计方案制定随机区组设计 常用试验设计方法裂区设计 资料的搜集和整理拉丁方设计、正交设计 统计分析数据特征数的计算 统计推断、方差分析 协方差分析、回归和相关分析 3、生物统计学的基本作用: (1)提供整理和描述数据资料的科学方法,确定某些性状和特征的数量特征 (2)运用显著检验,判断试验结果的可靠性或可行性 (3)提供由样本推断总体的方法 (4)提供试验设计的一些重要原则 二、解释概念:总体、个体、样本、变量、参数、统计数、效应、试验误差 总体:具有相同性质或属性的个体所组成的集合称为总体,它是指研究对象的全体; 个体:组成总体的基本单元称为个体 样本:从总体中抽出若干个体所构成的集合称为样本 变量:变量,或变数,指相同性质的事物间表现差异性或差异特征的数据 参数:描述总体特征的数量称为参数,也称参量 统计数:描述样本特征的数量称为统计数,也称统计量 效应:通过施加试验处理,引起试验差异的作用称为效应 试验误差:误差也称为实验误差,是指观测值偏离真值的差异,可分为随机误差和系 统误差 三、准确性与精确性有何区别? 准确性,也叫准确度,指在调查或试验中某一试验指标或性状的观测值与其真值接近 的程度。精确性,也叫精确度,指调查或试验中同一试验指标或性状的重复观测值彼 此接近的程度。准确性反应测量值与真值符合程度的大小,而精确性则是反映多次测 定值的变异程度。(具体在课本第7页) 第二章样本统计量与次数分布 一、算数平均数与加权平均数形式上有何不同?为什么说它们的实质是一致的? 1. 算术平均数定义:总体或样本资料中所有观测数的总和除以观测数 的个数所得的商,简称平均数、均数或均值 直接计算法或减去(加上)常数法 加权平均数 2、实质是一样的,是因为它们都反映的一组数据的平均水平 二、为了评价两种药物对于小鼠体重的影响,随机从两组各抽出20只测定其体重(g),结果如下: 药物A处理组: 15, 15, 23, 24, 26, 25, 22, 19, 15, 17, 15, 20, 23, 21, 19, 22, 26, 21, 18, 23 药物B处理组: 31, 28, 26, 31, 28, 34, 32, 29, 32, 35, 28, 29, 33, 30, 34, 32, 36, 38, 40, 38 一、填空 变量按其性质可以分为连续变量和非连续变量。 样本统计数是总体参数的估计量。 生物统计学是研究生命过程中以样本来推断总体的一门学科。 生物统计学的基本内容包括试验设计、统计分析两大部分。 统计学的发展过程经历了古典记录统计学、近代描述统计学、现代推断统计学3 个阶段。 生物学研究中,一般将样本容量n >30称为大样本。 试验误差可以分为随机误差、系统误差两类。 资料按生物的性状特征可分为数量性状资料变量和质量性状资料变量。 直方图适合于表示连续变量资料的次数分布。 变量的分布具有两个明显基本特征,即集中性和离散性。 反映变量集中性的特征数是平均数,反映变量离散性的特征数是变异数。 林星s= 样本标准差的计算公式s= 如果事件A和事件B为独立事件,则事件A与事件B同时发生地概率P (AB) = P(A)*P(B)。 二项分布的形状是由n和p两个参数决定的。 正态分布曲线上,卩确定曲线在x轴上的中心位置,c确定曲线的展开程度。样本平均数的标准误等于c Wi。 t分布曲线和正态分布曲线相比,顶部偏低,尾部偏高。 统计推断主要包括假设检验和参数估计两个方面。 参数估计包括点估计和区间估计假设检验首先要对总体提出假设,一般应作两个假设,一个是无效假设,一个是备择假设。 对一个大样本的平均数来说,一般将接受区和否定区的两个临界值写作卩-U a^x_ 卩+U a c x 在频率的假设检验中,当np或nq v30时,需进行连续性矫正。 2检验主要有3种用途:一个样本方差的同质性检验、适应性检验和独立性检验。 2检验中,在自由度df = (1)时,需要进行连续性矫正,其矫正的2 = ( p85 )。 2分布是连续型资料的分布,其取值区间为[0.+ %)。 猪的毛色受一对等位基因控制,检验两个纯合亲本的F2代性状分离比是否符合 孟德尔第一遗传规律应采用适应性检验法。 独立性检验的形式有多种,常利用列联表进行检验。 根据对处理效应的不同假定,方差分析中的数学模型可以分为固定模型、随机模型和混合模型混合模型3类。 在进行两因素或多因素试验时,通常应该设置重复,以正确估计试验误差,研究因素间的交互作用。 在方差分析中,对缺失数据进行弥补时,应使补上来数据后,误差平方和最小。方差分析必须满足正态性、可加性、方差同质性3个基本假定。 如果样本资料不符合方差分析的基本假定,则需要对其进行数据转换,常用的数据转换方法有平方根转换、对数转换、正反弦转换等。 相关系数的取值范围是[-1,1]O 《生物统计学》教案授课教师:陈彦云宁夏大学生命科学学院 教学内容与组织安排: 第一章绪论 讲述本章教学目标、概述 本课时主要内容摘要:生物统计学是数理统计学的原理和方法在生命科学领域的具体应用,它是运用统计的原理和方法对生物有机体开展调查和试验,目的是以样本的特征来估计总体的特征,对所研究的总体进行合理的推论,得到对客观事物本质和规律性的认识。生物统计学主要内容包括试验设计和统计分析两大部分,其作用主要有四个方面:提供整理、描述数据资料的可行方法并确定其数量特征;判断试验结果的可靠性;提供由样本推断总体的方法;提供试验设计的原则。生物体计学的发展概况及六组统计学常用术语。 重点内容:生物统计学的概念、内容及作用,常用术语。 第一节、生物统计学的概念及其重要性 统计学(Statistics)是把数学的语言引入具体的科学领域,把具体科学领域中要待研究的问题抽象为数学问题的过程,它是收集、分析、列示和解释数据的一门艺术和科学,目的是求得可靠的结果。它有许多分支,如工业统计、农业统计、卫生统计等等。 生物统计学是数理统计在生物学研究中的应用,它是应用数理统计的原理和方法,分析、推断和解释生命过程中的各种现象和试验调查资料的科学。属于生物数学的范畴 第二节生物统计学的主要内容及作用 生物体计学主要内容包括试验设计和统计分析两大部分。 在试验设计中,主要介绍试验设计的有关概念、试验设计的基本原则,试验设计方案的制定,常用试验设计方法,其中主要有对比试验设计、随机区组设计、拉方设计,正交设计等;在统计分析中,主要包括数据资料的搜集与整理、数据特征数的计算、统计推断、方差分析、回归和相关分析等。 生物统计学的作用主要有四个方面: 1提供整理、描述数据资料的可行方法并确定其数量特征; 2判断试验结果的可靠性; 3提供油样本推断总体的方法; 4提供试验设计的一些重要原则。 第三节统计学的发展概况 由于人类的统计实践是随着计数活动而产生的,因此,统计发展史可以追溯到远古的原始社会,也就是说距今足有五千多年的漫长岁月。但是,能使人类的统计实践上升到理论上予以概括总结的程度,即开始成为一门系统的学科统计学,却是近代的事情,距今只有三百余年的短暂历史。统计学发展的概貌,大致可划分为古典记录统计 第一章统计数据的收集与整理算术平均数是怎样计算的为什么要计算平均数 答:算数平均数由下式计算:n y y n i i ∑ = =1 ,含义为将全部观测值相加再被观测值的个数 除,所得之商称为算术平均数。计算算数平均数的目的,是用平均数表示样本数据的集中点,或是说是样本数据的代表。 既然方差和标准差都是衡量数据变异程度的,有了方差为什么还要计算标准差答:标准差的单位与数据的原始单位一致,能更直观地反映数据地离散程度。 标准差是描述数据变异程度的量,变异系数也是描述数据变异程度的量,两者之间有什么不同 答:变异系数可以说是用平均数标准化了的标准差。在比较两个平均数不同的样本时所得结果更可靠。 完整地描述一组数据需要哪几个特征数 答:平均数、标准差、偏斜度和峭度。 下表是我国青年男子体重(kg)。由于测量精度的要求,从表面上看像是离散型数据,不要忘记,体重是通过度量得到的,属于连续型数据。根据表中所给出的数据编制频数分布表。 6 66 9 6 4 6 5 6 4 6 6 6 8 6 5 6 2 6 4 6 9 6 1 6 1 6 8 6 657 6 6 6 9 6 6 6 5 7064586766666766666266666462626564656672 6 06 6 6 5 6 1 6 1 6 6 6 7 6 2 6 5 6 5 6 1 6 4 6 2 6 4 6 5 6 2 6 5 6 8 6 8 6 5 6768626370656465626662636865685767666863 6 46 6 6 8 6 4 6 3 6 6 4 6 9 6 5 6 6 6 7 6 7 6 7 6 5 6 7 6 7 6 6 6 8 6 4 6 7 5 96 6 6 5 6 3 5 6 6 6 6 3 6 3 6 6 6 7 6 370 6 770 6 2 6 472 6 9 6 7 6 7 6 66 8 6 4 6 5 7 1 6 1 6 3 6 1 6 4 6 4 6 7 6 970 6 6 6 4 6 5 6 4 6 370 6 4 6 26 970 6 8 6 5 6 3 6 5 6 6 6 4 6 8 6 9 6 5 6 3 6 7 6 370 6 5 6 8 6 7 6 9 6 66 5 6 7 6 674 6 4 6 9 6 5 6 4 6 5 6 5 6 8 6 7 6 5 6 5 6 6 6 772 6 5 6 7 6 2677 1 6 9 6 5 6 5 7 5 6 2 6 9 6 8 6 8 6 5 6 3 6 6 6 6 6 5 6 2 6 1 6 8 6 5 6 4676 6 6 4 6 6 1 6 8 6 7 6 3 5 9 6 5 6 6 4 6 3 6 9 6 2 7 1 6 9 6 6 3 5 9676 1 6 8 6 9 6 6 6 4 6 9 6 5 6 8 6 7 6 4 6 4 6 6 6 9 7 3 6 8 6 6 6 3 366666666726666666666 生物统计学复习题库新 编 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】 填空 1.变量按其性质可以分为(连续)变量和(非连续)变量。 2.样本统计数是总体(参数)的估计值。 3.生物统计学是研究生命过程中以样本来推断(总体)的一门学科。 4.生物统计学的基本内容包括(试验设计)和(统计分析)两大部分。 5.生物统计学的发展过程经历了(古典记录统计学)、(近代描述统计学)和(现代推断统计学)3个阶段。 6.生物学研究中,一般将样本容量(n ≥30)称为大样本。 7.试验误差可以分为(随机误差)和(系统误差)两类。 1.资料按生物的性状特征可分为(数量性状资料)变量和(质量性状资料)变量。 2. 直方图适合于表示(连续变量)资料的次数分布。 3.变量的分布具有两个明显基本特征,即(集中性)和(离散性)。 4.反映变量集中性的特征数是(平均数),反映变量离散性的特征数是(变异数)。 5.样本标准差的计算公式s=( )。 1.如果事件A 和事件B 为独立事件,则事件A 与事件B 同时发生的概率P (AB )= P (A )?P (B )。 2.二项分布的形状是由( n )和( p )两个参数决定的。 3.正态分布曲线上,( μ )确定曲线在x 轴上的中心位置,( σ )确定曲线的展开程度。 4.样本平均数的标准误 =( )。 5.t 分布曲线与正态分布曲线相比,顶部偏( 低 ),尾部偏( 高 )。 1.统计推断主要包括(假设检验)和(参数估计)两个方面。 2.参数估计包括(点)估计和(区间)估计。 3.假设检验首先要对总体提出假设,一般要作两个:(无效)假设和(备择)假设。 4.在频率的假设检验中,当np 或nq (<)30时,需进行连续性矫正。 1.根据对处理效应的不同假定,方差分析中的数学模型可以分为(固定模型)、(随机模型)和(混合模型)3类。 2.在进行两因素或多因素试验时,通常应设置(重复),以正确估计试验误差,研究因素间的交互作用。 3.在方差分析中,对缺失数据进行弥补2时,应使补上来数据后,(误差平方和)最小。 4.方差分析必须满足(正态性)、(可加性)和(方差同质性)3个基本假定。 5.如果样本资料不符合方差分析的基本假定,则需要对其进行数据转换,常用的数据转换方法有(平方根转换)、(对数转换)、(反正弦转换)等。 6.一个试验的总变异依据变异来源分为相应的变异,将总平方和分解为:(处理间平方和)与(处理内平方和)。 变量之间的关系分为(函数关系)和(相关关系),相关关系中表示因果关系的称为回归。 2、一元线性回归方程 中,a 的含义是(样本回归截距),b 的含义是(样本回归系数)。 可用个体间的(相似程度)和(差异程度)来表示亲疏程度。 1.对于有限总体不必用统计推断方法。(×) 2.资料的精确性高,其准确性也一定高。(×) 3.在试验设计中,随机误差只能减小,而不能完全消除。(∨) 4.统计学上的试验误差,通常指随机误差。(∨) 1. 计数资料也称连续性变量资料,计量资料也称非连续性变量资料。(×) 2. 条形图和多边形图均适合于表示计数资料的次数分布。(×) 3. 离均差平方和为最小。(∨) 4. 资料中出现最多的那个观测值或最多一组的中点值,称为众数。(∨) 5. 变异系数是样本变量的绝对变异量。(×) 1.事件A 的发生和事件B 的发生毫无关系,则事件A 和事件B 为互斥事件。(× ) 2.二项分布函数C n x p x q n-x 恰好是二项式(p+q )n 展开式的第x 项,故称二项分布。( × ) 1 2 2--∑∑n n x x )(n /σx σ?y a bx =+生物统计学
生物统计学试题及答案
生物统计学第一章
生物统计学(版)杜荣骞课后习题答案统计数据的收集与整理
生物统计学复习题库新编完整版
相关主题
文本预览