
高级应用统计作业汇总
操作一:
某年级中随机抽取35名学生,现随机分成两组,A组有20名学生,B组有15学生具体资料见“学生基本资料”:
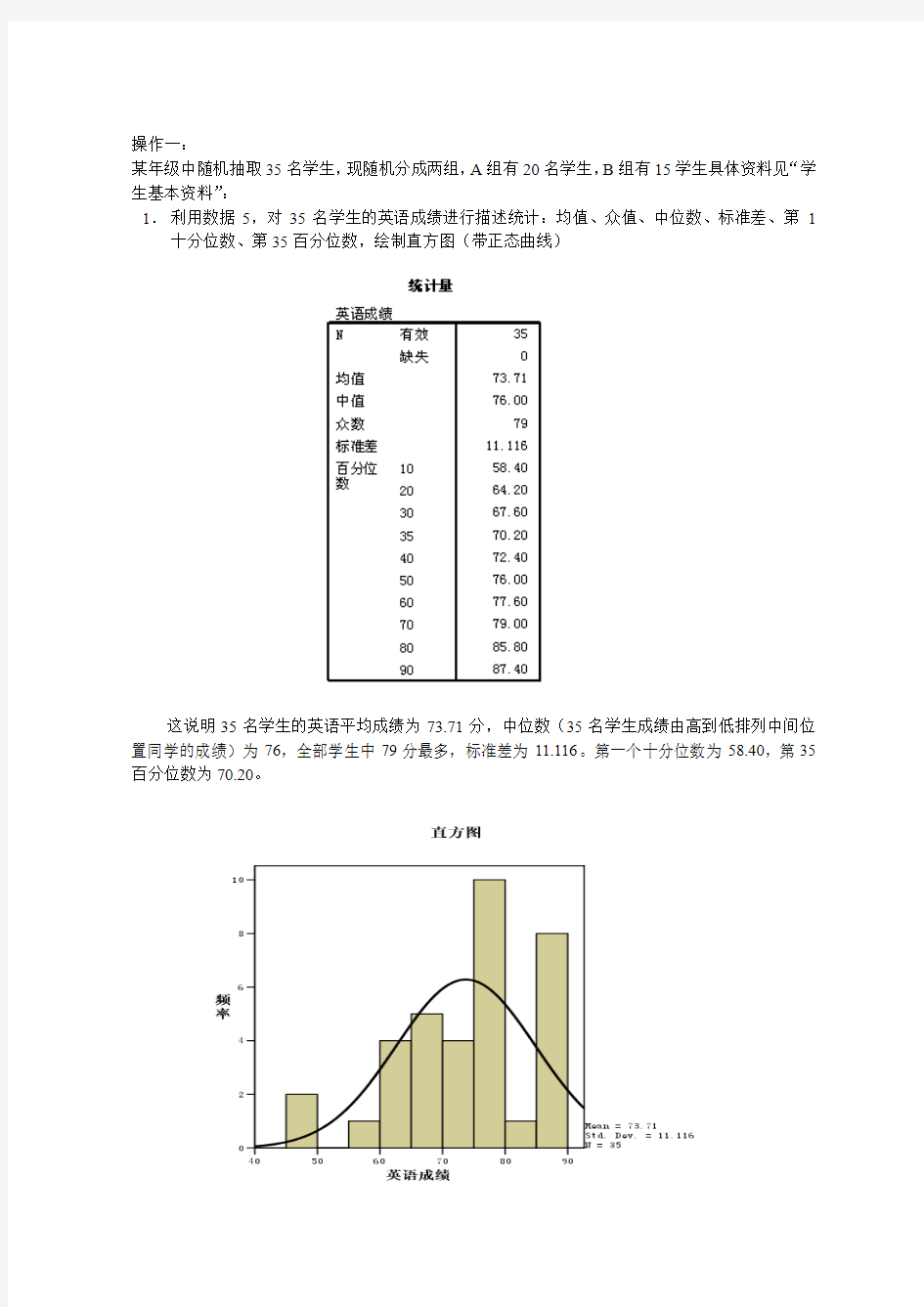
1.利用数据5,对35名学生的英语成绩进行描述统计:均值、众值、中位数、标准差、第1十分位数、第35百分位数,绘制直方图(带正态曲线)
这说明35名学生的英语平均成绩为73.71分,中位数(35名学生成绩由高到低排列中间位置同学的成绩)为76,全部学生中79分最多,标准差为11.116。第一个十分位数为58.40,第35百分位数为70.20。
2.利用数据5,对35名学生按性别分组,对英语成绩进行描述统计,绘制箱式图、茎叶图
由上表可知男、女同学英语成绩的平均分分别是74.80、72.90。男生中,中位数为78.00,最低分为49,最高分为88.女生中,中位数为74,最低分为45,最高分为89。下面是男女同学英语成绩的茎叶图和箱式图。
3. 对性别和专业进行交叉分组的频数分析
通过性别和专业的交叉分组可以看出,男生中,有4个会计专业的,7个工商管理专业的,4个经济学专业的。女生中,有8个会计专业的,4个工商管理专业的,8个经济学的。总计有12个会计专业的,11个工商管理专业的,12个经济学的。
4. 该35名学生的英语平均分与80分是否有显著差异(显著性水平0.05,假定成绩正态分布:
此问题为单样本t 检验,设原假设为80:0=μH ,由于α=0.05>p =0.002,所以应该拒绝
原假设,即35名学生的英语平均分与80分存在显著差异。
5. 男生和女生的英语平均分有无显著差异(显著性水平0.05,利用参数检验:
该问题为独立样本t 检验模型,由F 统计量和其概率值来完成。
设原假设为0210=-=μμH 。首先,由于F 统计量观测值为0.409,其概率p =0.527>0.05=α,所以男女生英语平均分的方差屋显著性差异。其次,由于方差无显著性差异,所以对其均值检验中只需要看假设方差相等那一行的t 值就行。由于t=0.624>0.05=α,所以应该接受原假设,即男女生英语平均分无显著性差异。
6. 不同专业的英语水平有无显著差异(显著性水平0.05,利用参数检验:单因素方差分析
此题进行单因素方差分析,由F 统计量和其概率值来完成。原始假设为0H =不同专业的英语水平均值无显著性差异。由于F 统计量观测值为1.946,而概率p =0.159>α=0.05,所以接受原始假设,认为不同专业间英语水平无显著性差异。 下面为与常规线性方程单变量的比较:
由上表可以看出其概率p 值依然为0.159,所以与单因素方差分析结果一致。
操作三:非参数检验
1. 马在8个圆形跑道的起点标杆位置上获胜的记录如下,试检验起点标杆位置对赛马结果是否
有影响?(皮尔逊ka 方检验) 起点位置号 1 2 3 4 5 6 7 8 总数 获胜频数
29
19
18
25
17
10
15
11
144
此题首先需要对其数据进行加权,然后分析。下面为左图对其进行加权后的数据,右图为分析结果。
H=起点标杆对赛马结果没有影响。由右图的分析结果可以知道,卡该问题的原始假设为
方检验的概率p=0.022<α=0.05,所以拒绝原始假设,认为起点标杆位置对赛马结果是有影响的。2.操作一中35名学生的,英语成绩的不及格率是否明显低于0.01(显著性水平0.05,)(二项分布检验)
该问题首先需要根据35名学生的成绩,利用SPSS软件找出其不及格的个案,讲所有结果用0、1表示为二值分布,然后进行二项分布检验。
H=英语成绩的不及格率不明显低于0.01。根据上面的检验结果可以看出不原始假设为:
及格的观测概率为0.09,其二项分布检验的概率p=0.254>α=0.05,所以不应拒绝原假设,认为不及格率不明显低于0.01。
3.对操作一中的35名学生的具体成绩,检验其是否服从正态分布(单样本K-S检验)
H=35名学生的成绩服从正态分布。其检验的概率p=0.905>α=0.05,该问题的原假设为
所以不能拒绝原假设,即认为35名学生的成绩分布与正态分布无显著性差异。
4.操作一(5)中,若假定现在35名的排列顺序就是学生抽取的顺序,试分析抽取学生的性别是否是随机的(游程检验)。
H=抽取学生的性别是随机的。其检验的概率p=0.634>α=0.05,所以接受原假原假设为
设,即抽取学生的性别是随机的。
5.对操作一的(8),利用非参数检验,试问男女生的平均成绩有无显著差异?(Mann-Whitey U 检验)
H:男女生平均成绩无显根据题意知此题为两独立样本的Mann-Whitey U检验。原假设为
著差异。其概率p=0.458>α=0.05,所以应该接受原假设,即男女生平均成绩无显著性差异。6.对操作一的(8),利用非参数检验,分别男女生成绩的分布是否一样?(可用两种方法)
上面为应用Mann-Whitney Test 检验结果。其检验的概率p=0.458>α=0.05,所以接受原假设,即认为男女生成绩的分布是一样的。
上面为应用两独立样本的游程检验的结果。其最小可能性的概率p=0.177>α=0.05,所以接受原假设,即男女生成绩分布无显著性差异;其最大可能性的p=0.970>α=0.05,所以接受原假设,即男女生成绩分布也无显著性差异。所以,该检验的结果是男女生成绩分布无显著性差异。
7.有一种新的游泳训练方法,人们怀疑它可能会提高一部分人的游泳成绩,但也会降低另一部分人的游泳成绩。先从一个少年游泳队中随机抽20人,在随机分成两组,一组用老方法,一一组用新方法,训练一段时间后,测的成绩如下,试回答怀疑是否有根据。(Moses极端反应检验,注意数据录入方式)
老方法66 86 80 78 77 63 62 87 75 84
新方法95 85 56 46 91 79 94 45 41 54 该问题应该采用两独立样本的录入方法,具体如下:
分析结果显示如下:
H:新方法与老方法的训练效果无显著性差异。根据上面的结果显示可以看出:原假设为
跨度和截头跨度分别为12和10。未剔除极端值的检验概率p=0.003<α=0.05;而剔除极端值的概率p=0.035<α=0.05,所以不管是否剔除极端值都有检验概率小于显著性水平,因此应该拒绝原假设,即认为新方法和老方法的训练效果有差异。
8.操作一中35名学生,不同性别的不及格率是否有显著差别?(四格表卡方检验)该问题首先需要对数据进行交叉分组处理,处理结果如下:
分析结果如下图:
该问题的原假设为
H:男女生的不及格率存在显著差异。根据上面的结果可以看出,双侧检验的概率p=0.565>α=0.05,单侧检验的概率p=0.390>α=0.05,所以无论单侧还是双侧其概率值都大于显著性水平α,所以应该接受原假设,即认为男女生的不及格率有显著差异。
9.检验幼儿园生活是否对儿童的社会知识有影响,随机指定每对孪生儿童中的一个在幼儿园生活,另一个在幼儿园之外生活。一学期期未,进行社会知识的考查,成绩如下(可用两种方法)
配对 1 2 3 4 5 6 7 8
幼儿园非幼儿园82
63
69
42
73
74
43
37
58
51
56
43
76
80
85
82
利用符号检验和Wilcoxon符号秩检验。原假设为
H:幼儿园生活对儿童的知识有影响。
符号检验的结果如下:
符号检验的结果分析:检验的概率p值=0.289>α=0.05,所以应该接受原假设,即:幼儿园生活对儿童的知识有影响。
Wilcoxon符号秩检验结果如下:
≤=0.05,所以不应该接受原假设,Wilcoxon符号秩检验的结果分析:检验的概率p=0.05α
即:幼儿园生活对儿童的知识没有影响。
7.分析三种不同运动方法在30分钟内消耗的热量是否相等。(可用三种方法)
游泳306 285 319 300 320
打球311 364 338 315 398
骑车289 188 221 302 201
H:三种不同运动方法消耗的热量相等。该问题应该采用多独立样本进行分析:其原假设都为
(1)Kruskal-Wallis 检验:
由上面两个表可知三种方法的平均秩分别为:8.2,12.2,3.6,K-W统计量为9.26。检验的概率p=0.01<α=0.05,于是应该拒绝原假设,即认为三种不同运动在30分钟内消耗的热量不相等。
(2)中位数检验:
上面的结果表面三种方法的共同中位数为306。中位数检验的概率p=0.006<α=0.05,因此应该拒绝原假设,即认为三种不同运动在30分钟内消耗的热量不相等。
(3)Jonckheere-Terpstra 检验
J-T 检验的概率p=0.154>α=0.05,所以不应该接受原假设,即:三种不同运动在30分钟内消耗的热量相等。
8.为了试验某种减肥药的性能,测量10个人在服用该药物前以及服用该药物一个月后、两个月后、3 个月后的体重。请问在这4个时期,10个人的体重有无发生显著的变化。
H:10个人的体重无显著性变化。本问题该问题为多配对样本的非参数检验。其原假设为
可以用三种方法进行检验,在此采用Friedman 方法进行检验,检验结果如下:
上面左表表明在使用前、使用后一月、两月和三月的秩的平均值分别为3.65,3.15,1.85,和1.35。右表表明其卡方观测值为24.929,其检验的概率p=0.000<α=0.05,所以应该接受原假设,即认为在使用药物时期体重无明显变化。
9.消费者协会调查顾客对3种品牌的电视机的满意程度,共10名顾客参与了调查。数据表如下所示,请问顾客对这三个品牌的电视机的满意度有无显著性差异?
该问题采用多配对样本进行检验,本题采用Friedman 方法进行检验,其原假设为0H :顾客对这三个品牌的电视机的满意度无显著性差异。下面为检验结果:
上面的结果表明,检验的概率值p=0.115> =0.05,所以应该拒绝原假设,即认为顾客对这三种品牌的电视机的满意度有显著性差异。
10. 某公司聘请了5名心理学家为其进行中层干部招聘考试中的面试,面试分数记录如下。
请问各考官评分的一致性如何?
本题为对配对样本模型,采用Kendall 协同系数检验。其原假设为0H :各考官评分的一致性无差异。检验结果如下:
专家1 专家2 专家3 专家4 专家5 干部1 2 3 4 5 6 7 8 9 10 79 89 67 56 78 56 89 90 56 66 80 88 77 66 56 56 78 67 67 56 77 78 78 56 45 34 45 67 78 89 88 88 55 46 78 65 78 66 55 46 77 88 77 66 55 44 89 76 56 45
结果表明,检验的概率值p=0.004<α=0.05,所以不能拒绝原假设,即认为各考官的评分一致性无显著性差异。
操作四:回归分析及扩展
研究某市各经济开发区经济发展与招商投资的关系,因变量Y 为各开发区的销售收入(百万元),选取两个自变量:X1到1998年底各开发区累计招商数目,X2为招商企业注册资本(百万元)。 要求:
1计算各变量间的简单相关系数,偏相关系数 (1)、简单相关系数
上表说明1X 与2X 之间的简单相关系数为0.439,说明两者之间存在着正的弱相关关系,其相关系数检验的概率值p=0.101>α=0.05,应该接受原假设,即认为21X X 与之间是零相关的。
(2)、偏相关系数
本题的偏相关分析可以采用分别控制21..X X Y ,在此仅以控制Y 为例进行分析。
上面的结果表明,在没有控制变量的情况下,12X X 与之间存在正的弱相关性,但是其相关系数检验的概率值p 为0.101,大于显著性水平0.05,所以认为两者之间存在零相关关系。Y X 与2之间的简单相关系数为0.746,两者存在正的强相关关系,其相关系数检验的概率值p 为0.001小于显著性水平0.05,所以认为两者之间确实存在着正的强相关关系。Y X 与1之间的简单相关系数为0.807,说明两者之间存在正的强相关关系,其相关系数检验的概率值近似为0,小于显著性水平,说明两者之间确实存在正的强相关关系。
下面的结果为在Y 作为控制变量的情况下,12X X 与之间的偏相关系数为-0.416,存在着负的弱相关关系,偏相关系数检验值的概率p=0.139>α=0.05,所以两者之间存在着零相关关系。
2建立 Y 对X1和X2的二元线性回归,写出回归方程,回归方程的显著性检验的分析(F 、t 检验)。
上表为回归方程的显著性检验,其检验的概率值p 近似为0,小于显著性水平(α=0.05),因此被解释变量与解释变量间的线性关系显著,建立线性模式是恰当的。
此表为向后筛选的结果,结果显示在回归方程中应该包括21X X 和两个变量,对1X 而言,其回归系数的显著性检验的概率值p=0.001<α=0.05,因此1X 与Y 之间的线性关系是显著的,保留在模型中是合理的。对2X 而言,其回归系数的显著性检验的概率值p=0.003<α=0.05,因此2X 与Y 之间的线性关系也是显著地,保留在模型中时合理的。 回归方程可以表示为21468.0036.2039.327X X Y ++-= 3.探测样本是否存在异常值。
观察上图可以看出,存在着异常值。 4.异方差的检验:(1)绘制残差和各自变量的散点图,判断是否可以存在异方差
上图为Y X 与1的散点图
上图为Y X 与2的散点图
上图为残差与Y 的散点图 通过上面三个散点图可以判断出存在异方差。
(2)利用等级相关系数,判断是否存在异方差,并确定主要是哪个自变量导致的异方差(哪
个的等级相关系数大则可能就是哪个变量引起的)。
上表为标准化残差与标准化预测值的Spearman 等级相关分析的结果。结果表明,1X 的残差与预测值的等级相关系数为0.068,且检验显著;2X 的残差与预测值的等级相关系数为0.064,检验同样显著;1X 与2X 残差的等级相关系数为0.979,且检验不显著,所以认为存在异方差,由于1X 的相关系数大于2X 的相关系数的绝对值,所以异方差主要由1X 引起的。
(3)利用weight estimate 估计幂指数m ,得到的最优值后,进行加权最小二乘法回归估计
上表为进行weight estimate 估计的结果,WGT1表示以Y 作为权重变量,WG2表示以1X 作为权重变量,WG3表示以2X 作为权重变量。
上表为进行最小加权二乘法的F 检验,其检验的概率值p =0.002>α=0.05,所以认为被解释变量与解释变量全体的现行关系显著,可以进行建立模型。
上表为最小加权二乘法的最后结果,1X 的T 检验观测值为2.736,概率值p =0.0181<α=0.05,2X 的T 检验观测值为2.187,概率值p =0.0493<α=0.05,所以它们的检验结果表明回归方程是有效的,回归方程为:214188.0123.2698.267X X Y ++-=
(4)计算加权最小乘法估计的残差并保存,绘制残差同各自变量的散点图,计算等级相关系数,分析是否还存在异方差。
上图为加权最小二乘法估计的残差
上面两图分别为变量12X X 、的散点图
上表为Spearman 相关性检验结果,结果表明 不存在异方差。
4.为研究民航客运量的变化趋势及其成因,以民航客运量为因变量,以国民收入、消费额、铁路客运量、民航航线里程、来华旅游入境人数为影响因素。 (1)拟合多元线性回归方程 采用向后筛选策略进行拟合。
数据分析方法及软件应用 (作业) 题目:4、8、13、16题 指导教师: 学院:交通运输学院 姓名: 学号:
4、在某化工生产中为了提高收率,选了三种不同浓度,四种不同温度做试验。在同一浓度与温度组合下各做两次试验,其收率数据如下面计算表所列。试在α=0.05显著性水平下分析 (1)给出SPSS数据集的格式(列举前3个样本即可); (2)分析浓度对收率有无显著影响; (3)分析浓度、温度以及它们间的交互作用对收率有无显著影响。 解答:(1)分别定义分组变量浓度、温度、收率,在变量视图与数据视图中输入表格数据,具体如下图。 (2)思路:本问是研究一个控制变量即浓度的不同水平是否对观测变量收率产生了显著影响,因而应用单因素方差分析。假设:浓度对收率无显著影响。 步骤:【分析-比较均值-单因素】,将收率选入到因变量列表中,将浓度选入到因子框中,确定。 输出: 變異數分析 收率 平方和df 平均值平方 F 顯著性 群組之間39.083 2 19.542 5.074 .016 在群組內80.875 21 3.851 總計119.958 23 显著性水平α为0.05,由于概率p值小于显著性水平α,则应拒绝原假设,认为浓度对收率有显著影响。
(3)思路:本问首先是研究两个控制变量浓度及温度的不同水平对观测变量收率的独立影响,然后分析两个这控制变量的交互作用能否对收率产生显著影响,因而应该采用多因素方差分析。假设,H01:浓度对收率无显著影响;H02:温度对收率无显著影响;H03:浓度与温度的交互作用对收率无显著影响。 步骤:【分析-一般线性模型-单变量】,把收率制定到因变量中,把浓度与温度制定到固定因子框中,确定。 输出: 主旨間效果檢定 因變數: 收率 來源第 III 類平方 和df 平均值平方 F 顯著性 修正的模型70.458a11 6.405 1.553 .230 截距2667.042 1 2667.042 646.556 .000 浓度39.083 2 19.542 4.737 .030 温度13.792 3 4.597 1.114 .382 浓度 * 温度17.583 6 2.931 .710 .648 錯誤49.500 12 4.125 總計2787.000 24 校正後總數119.958 23 a. R 平方 = .587(調整的 R 平方 = .209) 第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是均方;第五列是F检验统计量的观测值;第六列是检验统计量的概率p值。可以看到观测变量收率的总变差为119.958,由浓度不同引起的变差是39.083,由温度不同引起的变差为13.792,由浓度和温度的交互作用引起的变差为17.583,由随机因素引起的变差为49.500。浓度,温度和浓度*温度的概率p值分别为0.030,0.382和0.648。 浓度:显著性<0.05说明拒绝原假设(浓度对收率无显著影响),证明浓度对收率有显著影响;温度:显著性>0.05说明不拒绝原假设(温度对收率无显著影响),证明温度对收率无显著影响;浓度与温度: 显著性>0.05说明不拒绝原假设(浓度与温度的交互作用对收率无显著影响),证明温浓度与温度的交互作用对收率无显著影响。 8、以高校科研研究数据为例:以课题总数X5为被解释变量,解释变量为投入人年数X2、投入科研事业费X4、专著数X6、获奖数X8;建立多元线性回归模型,
一元线性回归实验指导 一、使用spss进行线性回归相关计算 题目: 为研究医药企业销售收入与广告支出的关系,随机抽取了20家医药企业,得到它们的销售收入和广告支出的数据如下表(数据在‘广告.sav’中) 1.绘制散点图描述收入与广告支出的关系 结果:(散点图粘贴在下面) 从散点图可直观看出销售收入和广告支出(存在/不存在)线性关系 2.计算两个变量的相关系数r及其检验 相关性结果表格:(粘贴在下面)
从结果中可看出,销售收入与广告支出的相关系数为(),双侧检验的P值(),r在0.01显著性水平下(),表明销售收入与广告支出之间(存在/不存在)线性关系。 3.一元线性回归分析 计算回归分析;并输出标准化残差的pp图和直方图 分析输出的结果: 模型汇总表格:(粘贴在下面) 这个表格给出相关系数R=()以及标准估计的误差() 方差分析(ANOVA)表格:(粘贴在下面) 这个表格给出回归模型的方差分析表,包括回归平方和SSR、回归均方MSR、残差平方和SSE、残差均方MSE、总平方和SST和总均方MST,F值129.762以及P值(),此处p 值(),说明回归的线性关系(显著/不显著) 系数表格:(粘贴在下面) 上面这个表格给出的是参数估计和检验的有关内容,包括回归方程的常数项、非标准化回归系数、常数项和回归系数检验的统计量t和显著性水平sig,以及回归系数的%95置信区间从此表可以得出销售收入与广告支出的估计方程为()。回归系数()表示广告支出每变动1万元,销售收入平均变动()万元。
4.残差的检验 从上面的输出结果中可得到标准化残差的标准pp图和直方图(粘贴在下面) 同时在数据表格中出现残差以及估计值和区间的上下界,其中 PRE_1为点估计值; RES_1为非标准化残差; ZRE_1为标准化残差; LMCI_1和UMCI_1表示平均值的置信区间(均值的预测区间); LICI_1和UICI_1表示个别值的预测区间的上界和下界; 下面绘制非标转化残差图:(粘贴在下面) 从残差图上可以看出,各个残差随机分布于0轴两侧,没有任何固定模式,这表明在销售收入与广告支出的一元线性回归中,线性假定以及等方差的假定成立。 下面检验残差正态性: 做出标准化残差(ZRE_1)的散点图,并在图上画出0,2,-2三条y轴参考线(粘贴在下面)
spss数据分析总结 2018-01-15 下面就是小编为您收集整理的spss数据分析总结的相关文章,希望可以帮到您,如果你觉得不错的话可以分享给更多小伙伴哦! 篇一:spss数据分析总结 实验一 SPSS基本操作 一、实验目的 1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置; 2.掌握SPSS的数据管理功能。二、实验内容及步骤 (一)数据的输入和保存 1. SPSS界面 当打开SPSS后,展现在我们面前的界面如下: 请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。这是一个典型的Windows软件界面,有菜单栏、工具栏。该界面和EXCEL极为相似,很多操作也与EXCEL类似,同学们可以自己试试。 2.定义变量 选择菜单Data==>Define Variable。系统弹出定义变量对话框如下: 对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。 假如有两组数据如下: GROUP 1: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 GROUP 2: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 先来建立分组变量GROUP。请将变量名改为GROUP,然后单击OK按钮。现在SPSS的数据管理窗口如下所示:
《SPSS统计基础》课程数据分析报告 (2016— 2017学年度第二学期) 题目:关于381名大学生学习适应情况的分析报告 班级:14小教2班 学号: 姓名: 2017年6月
381名大学生学习适应性调查数据分析报告 姓名:学号:班级: 一、数据分析目的及内容 (一)数据分析的目的 通过对师范学院学生学习适应现状及其影响因素的调查研究,了解我院学生对自己所学专业在适应学习动机、适应教学模式、使用学习能力、适应学习态度、适应环境因素、适应总分六个维度的基本情况。本文拟在以往研究的基础上对大学生学习适应状况进行调查,并探讨影响大学生学习适应的因素,从而让大学生能更快更好地适应大学生活。 (二)数据分析的内容 1. 381名大学生在适应学习动机、适应教学模式、使用学习能力、适应学习态度、适应 环境因素五个维度的得分及适应总分. 2.对年级、专业、生源地变量的容量等数据分布指标的描述,了解数据分布的全貌。 3.对适应学习动机、适应教学模式、使用学习能力、适应学习态度、适应环境因素五个 维度的极大值、极小值、均值和标准差的统计。 4.学习适应各因子之间的相关分析。 5.学习适应五因子及适应总分的相关性分析。 二、数据库介绍 (一)数据来源: 1被试分布:总容量为381、年级(大一156人、大二136人、大三89人)、专业(小学教育140人、学前教育本科113人、学前教育专科128人)、生源地(城镇145人、农村236人)等方面的人数分布; 2、调查工具:《大学生学习适应量表》由冯廷勇等人编制,共29 个题目,量表采 用Likert5 点计分法,即完全不符合计 1 分,比较不符合计 2 分,不确定计 3 分,较符合计4 分,完全符合计 5 分。各维度和总量表分数越高,表明适应状况越好。总分低于58分,表明学习适应状态较差需要做较大调整;总分在59到87分之间,表明学习适应状态中等,需要做适当的调整;总分在88到116分之间,表明学习适应状态良好;总分在117到145分之间,表明学习适应状态良好。量表的效度为0.85,信度为0.87。该量表由五个维度构成: (1)学习动机(8题):1、6、7、8、9、13、17、23 (2)教学模式(7题):2、3、10、14、18、22、24 (3)学习能力(6题):4、11、15、21、25、26 (4)学习态度(4题):5、12、20、27 (5)环境因素(4题):16、19、28、29 (二)变量介绍: 1、本次问卷调查有三个变量; 2、变量名称为:专业,年级,生源地; 3、变量名称的取值为:专业:1=“小学教育”,2=“学前教育本科”,3=“学前教育专 科”;年级:1=“大一”,2=“大二”,3=“大三”,4=“大四”;生源地:1=“城镇”,2=“农村”。 三、数据统计与分析
当代大学生对全球气候变化 认知程度的研究 摘要:随着我国经济建设的飞速发展,人们向大自然排放的有害物质与日俱增,环境问题日益严重。环境污染问题不仅影响我国人民的生存环境和生存质量,也危害人民的身体健康,在环境污染中城市环境污染已经成为制约社会发展的重要问题。本研究采样方式为匿名方式随机投放网络问卷以及纸质问卷,采用SPSS statistics软件分析采样数据,得到频率表以及考虑性别的交叉表。本文考虑性别、城乡等差异,分别从基本的环保知识到主动投身环保事业等各方面加以分析,研究当代大学生对环境污染问题认知程度的差异。 关键字:性别;气候变化;差异;SPSS 一、研究背景 我国改革开放30多年的经济发展迅速,主要是以粗放式发展为主要模式。由此而带来的就是高增长、高能耗、高排放的三高企业,我国是发展中国家,在经济发展的过程中,政府对环境破坏的监管不力,睁一眼闭一眼,所以我国改革开放30年快速发展以牺牲能源、破坏环境为代价的,尤其我国的经济发展又极不平衡,主要是以城市主力军,这样城市的环境恶化就很严重。同样,农村人口环境保护意识淡薄,农村环境恶化也不可小觑,我国高速发展的近几十年来,环境的恶化程度逐年增加,应该引起政府环保部门的重视。 环境污染对人们的生活影响越来越严重,我们现在出门看到的最打眼的一景就是戴口罩的人越来越多,人们越来越感受到空气污染对
自己身心健康的威胁,据统计,世界儿童死亡80%是由于空气污染导致的,这个数字让人触目惊心。 环境污染很大因素是由于企业恣意排放污染物,但在日常生活中,民众的环保意识与环保行为对生活污染——尤其是随处可见的污染——有较大的影响。性别、年龄等不同,对气候变化认知程度也会存在差异。本文考虑到男女性别的差异、城乡区别,分别从基本的环保知识到主动投身环保事业等各方面加以分析,研究不同性别对环境污染问题认知程度的差异。 二、研究方法及样本描述 (一)研究方法 本研究采样方式为匿名方式随机投放网络问卷以及纸质问卷调查的方法,与2014年5月在西安交通大学进行问卷调查。调查面向西安交大本科生以及研究生,最终获得有效问卷431份。 (二)样本特征描述 431位被访者中,女性209位,占48.5%;男性222位,占51.5%。如图1所示,样本主要来自大一、大二以及大三群体,总共381位,占88.4%;大四毕业生以及研究生占11.6%。被访者所读专业性质也有较大差别,文科生178位,占41.3%;工科生人数122位,占28.3%;理科生108位,占比25.1%,如表1所示。
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。
吉林财经大学 《SPSS统计软件分析》作业(2010——2011学年第一学期) 学院信息学院 专业班级电子商务0806班 学生姓名王瑞霞 学号1403080616
1、对未分组资料频数分析 从中国统计局中获得从11月21日至30日国内50个城市主要食品平均价格变动情况,以该数据为例为例,进行频数分析。 首先输入数据: 选择Analyze中Descriptive Statistics——Frequencies,打开Frequencies对话框;将需处理的变量键入变量框中
单击Statistics…按钮统计量子对话框12指标,选中所需要计算的指标: 单击Charts …按钮,选择需绘制的统计图: 单击OK按钮开始运行,运行结果为:
从上图中可以看出数据中缺失值为0,花生油的平均价格104.84是最高的,而巴氏牛奶的平均价格1.81最低,全部食品平均价格的平均数为16.5327,标准差为22.4668,各种食品的平均价格差距较大。
条形图、饼形图以及直方图是用不同的图形表示方法来说明数据的指标,其实质是一样的,从图中可以看出平均价格在0—22元之间的食品是最多的,20—40元之间的食品数次之,接下来是40—60元之间的食品,不存在平均价格在60—100之间的食品。 2、以食品平均价格为依据对数据进行分组并对分组后的数据进行频数分析: Transform —Recode—Into same V ariables ,将要分组的变量放入Numeric 栏中,单击Old and new V alues分组:
分组结果如下图所示: 回到数据编辑窗,定义变量的V alue labels : 再对食品平均价格进行频数分析,分析结果如下截图所示
一、作业分析 案例背景:拟分析导致急救后颅脑损伤的主要影响因素,某省医院的外科 医生收集了2003-2005年间在该科室进行过急救治疗的脑外伤病例共201例。 研究目的:差异性比较 资料类型:本例根据是否出现迟发性脑损伤将数据分为两个独立样本。 本例的数据变量有性别、年龄、入院时血循环指标、入院时症状、入院时 意识程度、是否手术急救、其它治疗、是否出现迟发性脑损伤。在这些变量中 既有连续变量又有分类变量,所以在检验时需分成两种:定量检验与定性检验。 其中定量检验为:年龄、入院时血循环指标;定性检验为:性别、入院时 症状、入院时意识程度、是否手术急救、其它治疗。 二、数据描述 1 数量变量的描述 利用SPSS软件分析→描述统计→描述,将年龄、收缩压、舒张压、血小 板拖入,得到下表: 通过表格可以发现血小板的极差为372,标准差为63.568.极差和标准差都较大,通过求自然对数来减小标准差,所以我们改用血小板的自然对数为数据。得到下表:
2.分类变量的描述 利用SPSS软件分析→表→设定表,选中性别、脑挫伤、中线移位、脑肿胀、意识程度、手术、止血药、激素、脱水剂拖入框中,得到下表: 从表中可以大致看出,脑挫伤、手术、中线移位、意识程度、激素和脱水剂几个变量和是否发生脑损伤有关。但是,这些关联是否具有统计学意义还需要进行检验。 三、差异性比较 1数量变量的差异性比较
(1)年龄与迟发性脑损伤的关系 本案例为两独立样本,我们对其进行正态性检验。 利用SPSS软件分析→统计描述→探索,得到下表: 从表中,可得出年龄成正态性分布。 利用SPSS软件分析→比较均值→独立样本T检验,检验变量为年龄,分组变量为迟发性脑损伤,单击确定得到如下结果: 发生迟发性脑损伤与未发生迟发性脑损伤组中年龄均服从正态分布,两总体方差齐。 采用两独立样本的t检验:t=-1.038,df=199,P=0.300,可以得出,以 α=0.05为检验水准,年龄与是否发生迟发性脑损伤无明显差异。 (2)收缩压、舒张压与迟发性脑损伤的关系 与上述方式相同,对数据进行正态性检验,检验结果为:
s p s s的数据分析案例 Modified by JACK on the afternoon of December 26, 2020
关于某公司474名职工综合状况的统计分析报告一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin (起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分 析能够了解变量的取值状况,对把握数据的分布特征非常有用。 此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为%和%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
16 59 17 11 18 9 19 27 20 2 .4 .4 21 1 .2 .2 Tot al 474 上 表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的%,其次为15年,共有116人,占中人数的%。且接受过高于20年的教育的人数只有1人,比例很低。 2、 描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的
SPSS课后作业 第一章 1-1、spss的运行方式有几种?分别是什么? 答:SPSS的运行方式有三种,分别是批处理方式、完全窗口菜单运行方式、程序运行方式。1-2、SPSS中“DataView”所对应的表格与一般的电子处理软件有什么区别? 答:与一般电子表格处理软件相比,SPSS的“Data View”窗口还有以下一些特性:(1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征;(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括一个观测中的单个变量值;(4)数据文件是一张长方形的二维表。 第二章 2-1、在SPSS中可以使用那些方法输入数据? 答:SPSS中输入数据一般有以下三种方式:(1)通过手工录入数据;(2)可以将其他电子表格软件中的数据整列(行)的复制,然后粘贴到SPSS中;(3)通过读入其他格式文件数据的方式输入数据。 2-2、对于缺失值,如何利用SPSS进行科学替代? 答:选择“Transform”菜单的Replace Missing Values命令,弹出Replace Missing Values 对话框。先在变量名列中选择1个或多个存在缺失值的变量,使之添加到“New Variable(s)”框中,这时系统自动产生用于替代缺失值的新变量。最后选择合适的替代方式即可。 2-3、在计算数据的加权平均数时,如何对变量进行加权? 答:选择“Data”菜单中的Weight Cases命令,出现如图2-22所示的Weight Cases对话框。其中, Do not weight cases项表示不做加权,这可用于取消加权;Weight cases by 项表示选择1个变量做加权。 2-4、如何对变量进行自动赋值? 答:变量的自动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在一个新的变量中。具体操作的过程如下:选择“Transform”菜单中的Automatic Recode命令,在出现的对话框中,从左边的变量列表中选择需要自动赋值的变量,将它添加到Variable -> New Name框中,然后在下面New Name右边的文本框中输入新的变量名称,单击New Name 按钮,将新的变量名添加到上面的框中。从Recode Starting from框中有两个选项中选择一个,然后单击OK按钮,即可完成自动赋值运算。 3-1、一组数据的分布特征可以从哪几个方面进行测度? 答:一组数据的分布特征可以从平均数、中位数、众数、方差、百分位、频数、峰度、偏度等方面描述。 3-2、简述众数、中位数和均值的特点及应用场合。 答:均值是总体各单位某一数量标志的平均数。平均数可应用于任何场合,比如在简单时序预测中可用一定观察期内预测目标的时间序列的均值作为下一期的预测值。中位数是指将数据按大小顺序排列起来,形成一个数列,居于数列中间位置的那个数据。中位数的作用与算术平均数相近,也是作为所研究数据的代表值。在一个等差数列或一个正态分布数列中,中位数就等于算术平均数。在数列中出现了极端变量值的情况下,用中位数作为代表值要比用算术平均数更好,因为中位数不受极端变量值的影响。众数是指一组数据中出现次数最多的那个数据。它主要用于定类(品质标志)数据的集中趋势,当然也适用于作为定序(品质标志)数据以及定距和定比(数量标志)数据集中趋势的测度值。 3-3、
第1题:基本统计分析1 分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。 1、基本思路: (1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。分组后进行频数分析并绘制带正态曲线的直方图。 (2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。 操作步骤: (1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。 存取款金额1 频率百分比有效百分比累积百分比 有效1.00 82 34.6 34.6 34.6 2.00 76 32.1 32.1 66.7 3.00 10 4.2 4.2 70.9 4.00 22 9.3 9.3 80.2 5.00 47 19.8 19.8 100.0 合计237 100.0 100.0 (2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。 统计量 存(取)款金额 20岁以下 N 有效 1 缺失 0 百分位数 25 50.00 50 50.00 75 50.00 20~35岁 N 有效 131 缺失 0 百分位数 25 500.00 50 1000.00 75 5000.00 35~50岁 N 有效 73 缺失 0 百分位数 25 500.00 50 1000.00 75 4500.00 50岁以上 N 有效 32 缺失 0 百分位数 25 525.00 50 1000.00 75 2000.00 结果及结果描述: 频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
S P S S调查报告期末作业 Document serial number【LGGKGB-LGG98YT-LGGT8CB-LGUT-
---------------------------------------------装--------------------------------- --------- 订 ---------------------------------------- -线----------------------------------- -- - --
上表表明,5中不同年级形式下共有80个样本,大一的均值最高,大二的均值次之,接着,大四的均值排第三,而大三的均值是最低的。由于在录入数据当中,选择调查问卷中选项A“是”,身边有请人带过课的同学,则录为1:;选择调查问卷中选项B“否”,身边没有请人带过课的同学,则录为2。所以,均值的结果表明,数值越大,则身边出现代课同学越少,数值越小,则表明身边出现的代课同学越多。因此,大三中的代课同学是最多的,大四次之,大二次之,大一最少。 上表表明,不同年级下代课情况的方差齐性检验值为,概率为,。如果显着性水平为,由于概率值大于显着性水平,不应拒绝零假设,认为不同年级下代课情况的总体方差无显着差异,满足方差分析的前提要求。 上表分别显示了两两不同年级下代课情况均值检验的结果。通过两两比较,最终可以得出,大一的均值>大二的均值>大三的均值,大四的均值大小情况不能确定,基本上得出的结论与实际情况相符。 五、建议 在以上对数据的分析过程当中,我们提到了逃课现象严重,收费代课行为愈发普遍的原因,这里稍微再做一下总结。原因如下: a.一些专业课程,教学内容循规蹈矩,考试题目照本宣科,无法引起学生兴趣; b.学校管理有较大漏洞,上课学生中“替身”大量潜伏而不知; c.学生自身自制力不够,容易受到外界的影响,不能静心学习; d.社会就业压力大,导致学生青睐于早点实习; 针对以上这些导致收费代课产生的原因,我想提出几点建议: (一)学校在专业设置、教师的互动性教学、知识的创新性和灵活体现、教学管理体系建设等诸多方面,都应反思,并采取一定的措施。高校则应该实行自主办学措施,在课程设置、专业方向设置上应当有自我特色。与其大张旗鼓地对“收费代课”现象进行大力批判,还不如放开手来,从根本上指导学生如何学会自主学习,如何利用有限的学习时间。倘若不加以反思,做出课程设置、教师互动性教学的改进,而是纯粹地一味加强考勤管理,必然会扼杀一部分学生的学习积极性,“人在心不在”的上课状态恐怕也难以培养出符合时代需求的大学生。 (二)学生应该分清楚学习和工作的不同意义,学习是一种能力的提高过程。大学生应当学会对自己的现在以及未来负责。大学四年,是相当宝贵的青春年华。我们年轻,我们活动,但是这些都不应该成为我们虚度时间,不学习的理由。调查结果中显示,大三的收费代课现象是最为严重的,这样的结果确实应该引起学生的重视了。我们都知道,大三是专业学习的主要一年,很多的专业课都在大三进行安排。可是大三的同学的不认真学习专业课,选择请人代课,这不是明显浪费了学习专业课的机会吗所以,这里,我想提醒本部的同学们,要合理地定位自己的身份与任务,不要在该学习的阶段去实习或娱乐。另外,也要明确自己上大学的初衷,不要因为大学生活的闲适,而慢慢丢失了自己的理想。 (三)政府要给大学生提供公平的就业环境,打击不规范的就业行为,消除掉大学生的就业焦虑。为大学生就业,提供更加全面完整的服务系统,让大学生在大学期间安心学
物流统计实验作业 <一>:试述聚类分析的基本思想以及SPSS操作的基本步骤? 系统聚类的基本思想是 聚类分析法又称集群分析法,它是研究样品或指标分类问题的一种多元统计方法。寻找一种能客观反应事物之间亲疏关系或合理评价事物性质相似程度的统计量,然后根据这种统计量和规定的分类准则把事物进行分类。 操作步骤: 1. 在SPSS窗口中选择Analyze→Classify→Hierachical Cluster,调出系统聚类分析主界面,并将变量移入Variables框中。在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。 2. 点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。这里我们选择系统默认值,点击Continue按钮,返回主界面。 3. 点击Plots,设置结果输出窗口给出的聚类分析统计图。选中Dendrogram复选框和Icicle栏中的None单选按钮,即只给出聚类树形图,而不给出冰柱图。单击Continue,返回主界面。 4. 点击Method,设置系统聚类的方法选项。Cluster Method下拉列表用于指定聚类的方法,包括组间连接法、组内连接法、最近距离法、最远距离法等;Measure栏用于选择对距离和相似性的测度方法;剩下的Transform Values和Transform Measures栏用于选择对原始数据进行标准化的方法。这里我们仍然均沿用系统默认选项。单击Continue,返回主界面。 5. 点击Save按钮,指定保存在数据文件中的用于表明聚类结果的新变量。None表示不保存任何新变量;Single solution表示生成一个分类变量,在其后的矩形框中输入要分成的类数;Range of solutions表示生成多个分类变量。这里我们选择Range of solutions,并在后面的两个矩形框中分别输入2和4,即生成三个新的分类变量,分别表明将样品分为2类、3类和4类时的聚类结果。点击Continue,返回主界面。 6. 点击OK按钮,运行系统聚类过程。 <二>:利用2001年全国31个省自治区各类小康和现代化指数的数据,利用K-均值聚类方法对地区进行聚类分析。并且对SPSS分析的结果进行分析。文件名为“小康指数.sav”。 31个省市自治区小康和现代化指数的K-Means聚类分析结果(一) 这张表展示了3类的初始类中心点的情况。由表可知第二类各指数均是最优的,第一类次之,第三类各指数最不理想。 31个省市自治区小康和现代化指数的K-Means聚类分析结果(二)
统计分析与SPSS的应用 摘要:为对统计分析与spss应用分析所学知识进行巩固和检验,特运用所学知识进行简单的统计分析应用,下文以某校学生学期成绩进行模拟分析。 一:原始数据:10级市场营销2班成绩 分析一:综测成绩四分位数 上表表明:综测成绩的最小值为68.61分,最大值为89.15分。其中25%的学生综测成绩为74.4100分,50%的学生综测成绩为80.3740分,75%的学生综测成绩为85.2200分。四分位数差从侧面证实了学生综测成绩呈一定左偏分布。
分析二:综测成绩直方图 上图表明:该班学生的综测成绩均分为80.07分,标准差为5.62。从图中可以看出,综测成绩呈左偏性分布,在85分左右的学生人数最多,70分左右的学生人数最少。 分析三:综测成绩的基本统计量分析 上表表明:综测成绩的极差为20.55分,意味着数据相对较分散。另外,综测成绩的最小值和最大值分别为68.61分和89.15分,平均分为80.0734分,标准差为5.61963。从偏度系数可以看出,系数小于0,偏度标准误差为0.421,因而该班综测成绩呈左偏分布,。从峰度系数可以看出,峰度值小于0,峰度标准误差为0.821,因而数据的分布比标准正态分布更加平缓,称
为平峰分布。 分析四:各科成绩的统计量分析比较 各科成绩统计量结果分析表 由上表可知:宏观经济学的全距最大,而生产与运作管理的全距最小,表明宏观经济学的成绩离散程度最高,而生产与运作管理的成绩离散程度最低;同时,对于标准差而言,也是宏观经济学的标准差最大而生产与运作管理的标准差最小。各科成绩平均分最高的为体育成绩,平均分最低的为英语成绩。各科成绩中只有人力资源管理的成绩是呈右偏分布,其他各科成绩均呈左偏分布。另外,各科成绩中,只有宏观经济学的成绩呈尖峰分布,其他各科呈平峰分布。
关于某地区361个人旅游情况统计分析报告 一、数据介绍: 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好 4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析,以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分地区359个人旅游基本 状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性情况的基本分布。 统计量 积极性性别 N 有效359 359 缺失0 0 首先,对该地区的男女性别分布进行频数分析,结果如下
性别 频率百分比有效百分 比 累积百分 比 有效女198 男161 合计359 表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为%和%,该公司职工男女数量差距不大,女性略多于男性。 其次对原有数据中的旅游的积极性进行频数分析,结果如下表: 积极性 频率百分比有效百分 比 累积百分 比 有效差171 一般79 比较 好 79 好24 非常 好 6 合计359 其次对原有数据中的积极性进行频数分析,结果如下表: 其次对原有数据中的是否进通道进行频数分析,结果如下表:
广东财经大学答题纸(格式二) 课程数据处理技术与SPSS 20 15 —20 16学年第1学期 成绩评阅人 评语: (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课” 现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面, 帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷, 回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。
高级应用统计作业汇总
操作一: 某年级中随机抽取35名学生,现随机分成两组,A组有20名学生,B组有15学生具体资料见“学生基本资料”: 1.利用数据5,对35名学生的英语成绩进行描述统计:均值、众值、中位数、标准差、第1十分位数、第35百分位数,绘制直方图(带正态曲线) 这说明35名学生的英语平均成绩为73.71分,中位数(35名学生成绩由高到低排列中间位置同学的成绩)为76,全部学生中79分最多,标准差为11.116。第一个十分位数为58.40,第35百分位数为70.20。
2.利用数据5,对35名学生按性别分组,对英语成绩进行描述统计,绘制箱式图、茎叶图 由上表可知男、女同学英语成绩的平均分分别是74.80、72.90。男生中,中位数为78.00,最低分为49,最高分为88.女生中,中位数为74,最低分为45,最高分为89。下面是男女同学英语成绩的茎叶图和箱式图。
3. 对性别和专业进行交叉分组的频数分析 通过性别和专业的交叉分组可以看出,男生中,有4个会计专业的,7个工商管理专业的,4个经济学专业的。女生中,有8个会计专业的,4个工商管理专业的,8个经济学的。总计有12个会计专业的,11个工商管理专业的,12个经济学的。 4. 该35名学生的英语平均分与80分是否有显著差异(显著性水平0.05,假定成绩正态分布: 此问题为单样本t 检验,设原假设为80:0=μH ,由于α=0.05>p =0.002,所以应该拒绝
原假设,即35名学生的英语平均分与80分存在显著差异。 5. 男生和女生的英语平均分有无显著差异(显著性水平0.05,利用参数检验: 该问题为独立样本t 检验模型,由F 统计量和其概率值来完成。 设原假设为0210=-=μμH 。首先,由于F 统计量观测值为0.409,其概率p =0.527>0.05=α,所以男女生英语平均分的方差屋显著性差异。其次,由于方差无显著性差异,所以对其均值检验中只需要看假设方差相等那一行的t 值就行。由于t=0.624>0.05=α,所以应该接受原假设,即男女生英语平均分无显著性差异。 6. 不同专业的英语水平有无显著差异(显著性水平0.05,利用参数检验:单因素方差分析 此题进行单因素方差分析,由F 统计量和其概率值来完成。原始假设为0H =不同专业的英语水平均值无显著性差异。由于F 统计量观测值为1.946,而概率p =0.159>α=0.05,所以接受原始假设,认为不同专业间英语水平无显著性差异。 下面为与常规线性方程单变量的比较: 由上表可以看出其概率p 值依然为0.159,所以与单因素方差分析结果一致。 操作三:非参数检验 1. 马在8个圆形跑道的起点标杆位置上获胜的记录如下,试检验起点标杆位置对赛马结果是否 有影响?(皮尔逊ka 方检验) 起点位置号 1 2 3 4 5 6 7 8 总数 获胜频数 29 19 18 25 17 10 15 11 144