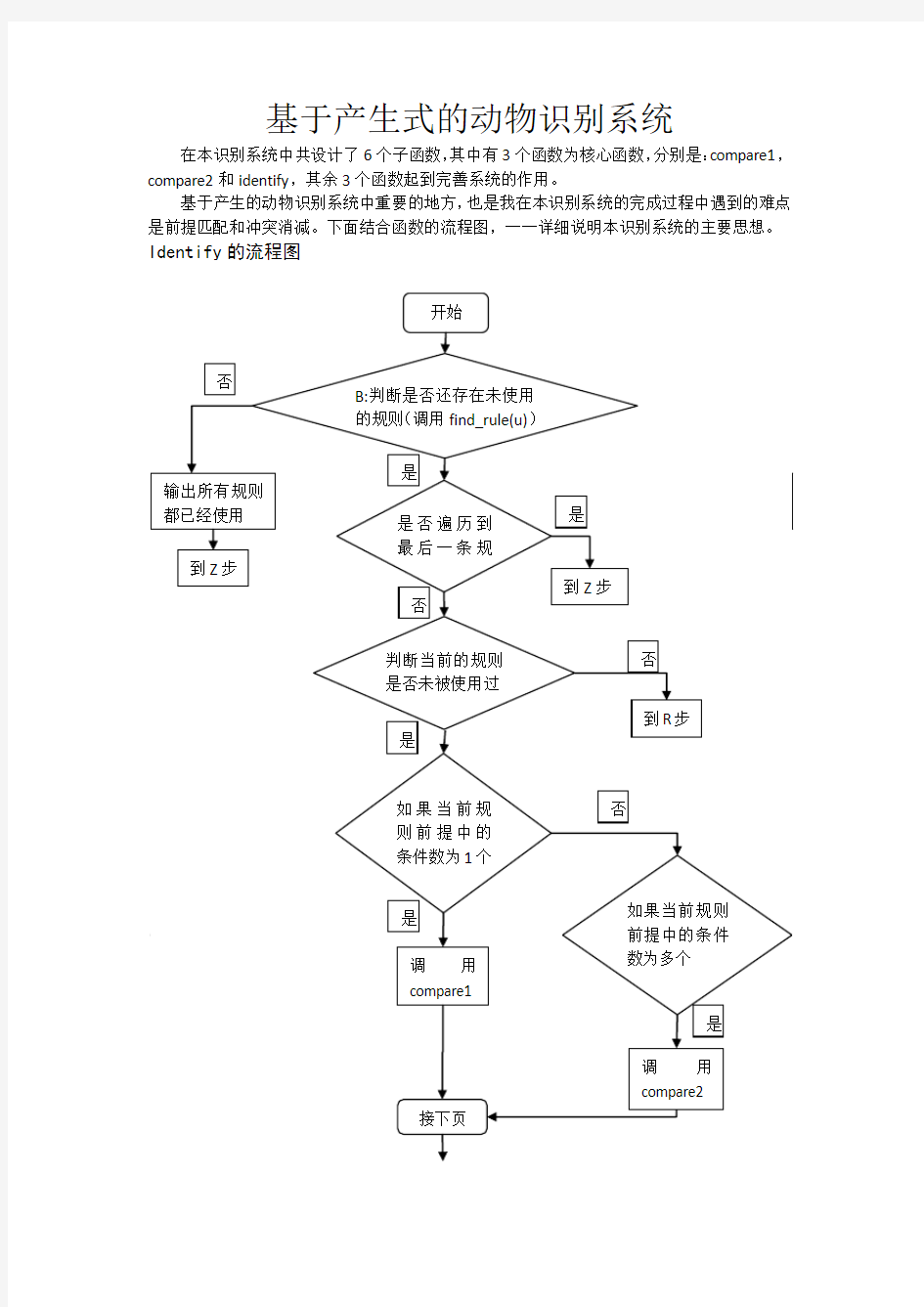

基于产生式的动物识别系统在本识别系统中共设计了6个子函数,其中有3个函数为核心函数,分别是:compare1,compare2和identify,其余3个函数起到完善系统的作用。
基于产生的动物识别系统中重要的地方,也是我在本识别系统的完成过程中遇到的难点是前提匹配和冲突消减。下面结合函数的流程图,一一详细说明本识别系统的主要思想。Identify的流程图
Identify函数的设计是为了实现根据规则的前提条件数的不同选择不同的函数来判断事实和前提条件是否匹配。其结束的出口有两个:一是当所有的规则都使用过,规则库中没有可以使用的规则时,判断结束;二是虽然规则库中还有未使用的规则,但是已经和事实不匹配,即无法使用该规则,则退出,这里我使用了检查事实库是否更新来判断是否还有与事实库匹配的规则。以上是idetify函数的重点,也是难点。
Compare2函数是用来判断当规则的前提条件有多个时,这多个条件是否和事实库中的所有事实匹配,由此得出该规则是否可用。提取规则库前提条件的第一条,用事实库中的所有事实与它匹配,若两者相同,则将设定的记录前提条件满足的变量加1,然后,在用同样的方法来查看事实库中是否有第二条前提条件,直到所有的前提条件都查看完毕截止。根据前提条件满足的变量是否等于该规则的前提条件数来判断该规则是否可用。
Compare1是相对比较简单的函数,它用来判断前提条件中条件数为一个的规则,用事实库中的事实逐个与前提条件中的条件对比,若匹配,则规则可用,若不匹配,则不可用。
Compare1和compare2均返回最终的判断结果,即:若判断出来当前规则可用,则将规则的标记改为已使用,返回到idetify 函数中后根据compare1和compare2的返回值来输出规则的使用情况,并且由此继续判断规则库中是否还有规则可用。
测试样例
人工智能实验报告大 全
人工智能课内实验报告 (8次) 学院:自动化学院 班级:智能1501 姓名:刘少鹏(34) 学号: 06153034 目录 课内实验1:猴子摘香蕉问题的VC编程实现 (1) 课内实验2:编程实现简单动物识别系统的知识表示 (5)
课内实验3:盲目搜索求解8数码问题 (18) 课内实验4:回溯算法求解四皇后问题 (33) 课内实验5:编程实现一字棋游戏 (37) 课内实验6:字句集消解实验 (46) 课内实验7:简单动物识别系统的产生式推理 (66) 课内实验8:编程实现D-S证据推理算法 (78)
人工智能课内实验报告实验1:猴子摘香蕉问题的VC编程实现 学院:自动化学院 班级:智能1501 姓名:刘少鹏(33) 学号: 06153034 日期: 2017-3-8 10:15-12:00
实验1:猴子摘香蕉问题的VC编程实现 一、实验目的 (1)熟悉谓词逻辑表示法; (2)掌握人工智能谓词逻辑中的经典例子——猴子摘香蕉问题的编程实现。 二、编程环境 VC语言 三、问题描述 房子里有一只猴子(即机器人),位于a处。在c处上方的天花板上有一串香蕉,猴子想吃,但摘不到。房间的b处还有一个箱子,如果猴子站到箱子上,就可以摸着天花板。如图1所示,对于上述问题,可以通过谓词逻辑表示法来描述知识。要求通过VC语言编程实现猴子摘香蕉问题的求解过程。 图1 猴子摘香蕉问题
四、源代码 #include
游戏人工智能实验报告记录四
————————————————————————————————作者:————————————————————————————————日期:
实验四有限状态机实验 实验报告 一、实验目的 通过蚂蚁世界实验掌握游戏中追有限状态机算法 二、实验仪器 Windows7系统 Microsoft Visual Studio2015 三、实验原理及过程 1)制作菜单 设置参数:点击会弹出对话框,设置一些参数,红、黑蚂蚁的家会在地图上标记出来 运行:设置好参数后点击运行,毒药、食物、水会在地图上随机显示 下一步:2只红蚂蚁和2只黑蚂蚁会随机出现在地图上,窗口右方还会出现红、黑蚂蚁当前数量的统计 不断按下一步,有限状态机就会不断运行,使蚁群产生变化 2)添加加速键
资源视图中下方 选择ID和键值
3)新建头文件def.h 在AntView.cpp中加入#include"def.h" 与本实验有关的数据大都是在这里定义的 int flag=0; #define kForage 1 #define kGoHome 2 #define kThirsty 3 #define kDead 4 #define kMaxEntities 200 class ai_Entity{ public: int type; int state; int row; int col; ai_Entity(); ~ai_Entity() {} void New (int theType,int theState,int theRow,int theCol); void Forage(); void GoHome(); void Thirsty(); void Dead();
完成总结报告 项目名称:数独游戏设计与实现组员:王郑合 2014204081 栾杰 2014204080 文宽 2014204104 二〇二〇年三月二十四日
1 问题描述 1.1 问题说明 数独游戏起源于瑞士,由十八世纪的瑞士数学家欧拉发明,是一种数字拼图游戏,其游戏规则是: ①在9×9的大九宫格内,已给定若干数字,其他宫位留白,玩家需自己按照逻辑推敲出剩下的空格里是什么数字。 ②必须满足的条件:每一行与每一列都有1到9的数字,每个小九宫格里也有1到9的数字,并且一个数字在每行、每列及每个小九宫格里只能出现一次,既不能重复也不能少。 ③每个数独游戏都可根据给定的数字为线索,推算解答出来。 1.2 数独求解描述 由于数独游戏的推广与普及,在当今世界上有着大量的数独爱好者,本项目的目的就是按照数独的游戏规则,通过对数据结构的分析和人工智能算法的研究,利用计算机程序来实现对已知数独游戏的快速求解。 1.3 数独出题描述 数独游戏挑战者的水平各异,对数独题目的难度要求各不相同,所以本项目致力于设计一种算法,使其在尽可能短的时间内生成不同难度等级的数独题,以满足不同水平游戏者的需求。同时,该算法还要考虑到三个方面要求:可变化的难度、解的唯一性和算法复杂度最小化。
2 功能分析 2.1 数独求解 数独虽然号称是数学问题, 但在求解时几乎用不上数学运算方法,事实上它更像是一种思维方式。数独游戏开始后,要想在空格中填入正确的数字,先要根据数独游戏规则对1-9分别进行逻辑判断,然后选择正确的数字填入空格。另外,由于某个格子填入数据时,有可能还要对原来已填入的数据进行修正,所以可以考虑使用递推和回溯搜索来求解数独问题。 2.2 数独出题 出题时,要能保证算法生成的数独题具有可变化的难度和唯一解,该算法内部应该包含有对数独题的求解和评级功能。本项目使用了一种基于“挖洞”思想的数独题生成算法,将该算法的设计工作分为评级、求解和生成三部分工作。利用随机数出现的概率不同来确定不同的难度,通过避免重填一个被“挖去”的格子,或者回溯到一个曾经无法“挖去”的格子,来降低算法的复杂性。 2.3 题目保存 当用户需要退出却仍没有完成数独题目的解答时,可以选择是否保存当前的求解进度。如果需要,本系统会帮助用户将目前未完成的数独题目的解答进度保存起来,以便用户下次使用本系统时,可以继续解答上次未完成的题目。 2.4 题目读取 用户可以在程序开始运行后,选则读取一道之前保存起来的题目进行解答,被读取的题目将会显示到程序界面上。
计算机科学与技术学院 《人工智能》课程设计报告设计题目:动物识别系统 设计人员:学号: 学号: 学号: 学号: 学号: 学号: 指导教师: 2015年7月
目录 目录 (1) 摘要 (2) Abstract (2) 一、专家系统基本知识 (3) 1.1专家系统实际应用 (3) 1.2专家系统的开发 (3) 二、设计基本思路 (4) 2.1知识库 (4) ....................................................................................................... 错误!未定义书签。 2.1.2 知识库建立 (4) 2.1.3 知识库获取 (5) 2.2 数据库 (6) ....................................................................................................... 错误!未定义书签。 ....................................................................................................... 错误!未定义书签。 三、推理机构 (7) 3.1推理机介绍 (7) 3.1.1 推理机作用原理 (7) ....................................................................................................... 错误!未定义书签。 3.2 正向推理 (7) 3.2.1 正向推理基本思想 (7) 3.2.2 正向推理示意图 (8) 3.2.3 正向推理机所要具有功能 (8) 3.3反向推理 (8) ....................................................................................................... 错误!未定义书签。 3.3.2 反向推理示意图 (8) ....................................................................................................... 错误!未定义书签。 四、实例系统实现 (9)
《人工智能》课外实践报告 项目名称:剪枝法五子棋 所在班级: 2013级软件工程一班 小组成员:李晓宁、白明辉、刘小晶、袁成飞、程小兰、李喜林 指导教师:薛笑荣 起止时间: 2016-5-10——2016-6-18
项目基本信息 一、系统分析 1.1背景
1.1.1 设计背景 智力小游戏作为人们日常休闲娱乐的工具已经深入人们的生活,五子棋更成为了智力游戏的经典,它是基于AI的αβ剪枝法和极小极大值算法实现的人工智能游戏,让人们能和计算机进行对弈。能使人们在与电脑进行对弈的过程中学习五子棋,陶冶情操。并且推进人们对AI的关注和兴趣。 1.1.2可行性分析 通过研究,本游戏的可行性有以下三方面作保障 (1)技术可行性 本游戏采用Windows xp等等系统作为操作平台,使用人工智能进行算法设计,利用剪枝法进行编写,大大减少了内存容量,而且不用使用数据库,便可操作,方便可行,因此在技术上是可行的。 (2)经济可行性 开发软件:SublimText (3)操作可行性 该游戏运行所需配置低、用户操作界面友好,具有较强的操作可行性。 1.2数据需求 五子棋需要设计如下的数据字段和数据表: 1.2.1 估值函数:
估值函数通常是为了评价棋型的状态,根据实现定义的一个棋局估值表,对双方的棋局形态进行计算,根据得到的估值来判断应该采用的走法。棋局估值表是根据当前的棋局形势,定义一个分值来反映其优势程度,来对整个棋局形势进行评价。本程序采用的估值如下: 状态眠二假活三眠三活二冲四假活三活三活四连五 分值 2 4 5 8 12 15 40 90 200 一般来说,我们采用的是15×15的棋盘,棋盘的每一条线称为一路,包括行、列和斜线,4个方向,其中行列有30路,两条对角线共有58路,整个棋盘的路数为88路。考虑到五子棋必须要五子相连才可以获胜,这样对于斜线,可以减少8路,即有效的棋盘路数为72路。对于每一路来说,第i路的估分为E(i)=Ec(i)-Ep(i),其中Ec(i)为计算机的i路估分,Ep(i)为玩家的i路估分。棋局整个形势的估值情况通过对各路估分的累加进行判断,即估值函数: 72 F(n)= Σ E(i) i=1 1.2.2 极小极大值算法: 极大极小搜索算法就是在博弈树在寻找最优解的一个过程,这主要是一个对各个子结点进行比较取舍的过程,定义一个估值函数F(n)来分别计算各个终结点的分值,通过双方的分值来对棋局形势进行分析判断。以甲乙两人下棋为例,甲为max,乙为min。当甲走棋时,自然在博弈树中寻找最大点的走法,轮到乙时,则寻找最小点的走法,如此反复,这就是一个极大极小搜索过程,以此来寻找对机器的最佳走法。
实验四有限状态机实验 实验报告 一、实验目的 通过蚂蚁世界实验掌握游戏中追有限状态机算法 二、实验仪器 Windows7系统 Microsoft Visual Studio2015 三、实验原理及过程 1)制作菜单 设置参数:点击会弹出对话框,设置一些参数,红、黑蚂蚁的家会在地图上标记出来 运行:设置好参数后点击运行,毒药、食物、水会在地图上随机显示 下一步:2只红蚂蚁和2只黑蚂蚁会随机出现在地图上,窗口右方还会出现红、黑蚂蚁当前数量的统计 不断按下一步,有限状态机就会不断运行,使蚁群产生变化 2)添加加速键 资源视图中 下方
选择ID和键值 3)新建头文件def.h 在AntView.cpp中加入#include"def.h" 与本实验有关的数据大都是在这里定义的 int flag=0; #define kForage 1 #define kGoHome 2 #define kThirsty 3 #define kDead 4 #define kMaxEntities 200 class ai_Entity{ public: int type; int state; int row; int col; ai_Entity(); ~ai_Entity() {} void New (int theType,int theState,int theRow,int theCol); void Forage(); void GoHome(); void Thirsty(); void Dead(); }; ai_Entity entityList[kMaxEntities]; #define kRedAnt 1 #define kBlackAnt 2
2019人工智能产业投资分析报告 前言: 人工智能(AI)将接棒移动互联网,成为下一轮科技创新红利的主要驱动力。透过丰富的数据采集(互联网和IoT)、更快的数据传输(5G)、更强大的数据运算处理(AI),科技企业和传统企业将在更广泛的领域深度融合。 AI将广泛助力传统行业转型,渗透互联网竞争下半场,催生无人驾驶、城市大脑、工业互联网、农业大脑、智慧医疗、Fintech、机器人等广义AI 应用,酝酿万亿级市场和投资机会。
▌AI主导下一轮科技创新红利AI孕育万亿级别市场 人工智能(AI)指利用技术学习人、模拟人,乃至超越人类智能的综合学科。人工智能技术可以显著提升人类效率,在图像识别、语音识别等领域快速完成识别和复杂运算。 此外,面对开放性问题,人工智能技术亦可通过穷举计算找到人类预料之外的规律和关联。自1956年“人工智能”概念首次被提出,AI技术“三起两落”。 本轮人工智能腾飞受益于持续提升的AI算力对神经网络算法的优化。 AI产业链分为:基础层、技术层、应用层。 基础层主要包括:AI芯片、IoT传感器等,技术层主要包括:图像识别、语音识别、自然语言处理NLP、知识图谱等,应用层的场景包括:无人驾驶、智慧安防、智慧城市(城市大脑)、金融科技(Fintech)、智慧医疗、智慧物流等领域。 AI市场规模快速成长。 中国是全球第二大AI力量,人工智能企业超过1000家。
2018年中国AI市场规模约330亿元人民币,全球AI市场规模约2700亿美元。我们预计,中国人工智能市场规模有望成长至万亿量级,成为下一轮科技创新红利的主导力量。 Statista预计2019、2020年,全球人工智能市场规模将分别增长59%、61%,成长至6800亿美元量级。 我们判断,中国人工智能市场有望在2030年达到万亿量级,传统行业和技术的结合是主要的应用领域,2G(对政府)和2B(对企业)将成为主要的营收来源。
人工智能导论实验报告 学院:计算机科学与技术学院 专业:计算机科学与技术 2016.12.20
目录 人工智能导论实验报告 (1) 一、简介(对该实验背景,方法以及目的的理解) (3) 1. 实验背景 (3) 2. 实验方法 (3) 3. 实验目的 (3) 二、方法(对每个问题的分析及解决问题的方法) (4) Q1: Depth First Search (4) Q2: Breadth First Search (4) Q3: Uniform Cost Search (5) Q4: A* Search (6) Q5: Corners Problem: Representation (6) Q6: Corners Problem: Heuristic (6) Q7: Eating All The Dots: Heuristic (7) Q8: Suboptimal Search (7) 三、实验结果(解决每个问题的结果) (7) Q1: Depth First Search (7) Q2: Breadth First Search (9) Q3: Uniform Cost Search (10) Q4: A* Search (12) Q5: Corners Problem: Representation (13) Q6: Corners Problem: Heuristic (14) Q7: Eating All The Dots: Heuristic (14) Q8: Suboptimal Search (15) 自动评分 (15) 四、总结及讨论(对该实验的总结以及任何该实验的启发) (15)
人工智能课内实验报告 (8次) 学院:自动化学院 班级:智能1501 姓名:刘少鹏(34) 学号: 06153034
目录 课内实验1:猴子摘香蕉问题的VC编程实现 (1) 课内实验2:编程实现简单动物识别系统的知识表示 (5) 课内实验3:盲目搜索求解8数码问题 (18) 课内实验4:回溯算法求解四皇后问题 (33) 课内实验5:编程实现一字棋游戏 (37) 课内实验6:字句集消解实验 (46) 课内实验7:简单动物识别系统的产生式推理 (66) 课内实验8:编程实现D-S证据推理算法 (78)
人工智能课内实验报告实验1:猴子摘香蕉问题的VC编程实现 学院:自动化学院 班级:智能1501 姓名:刘少鹏(33) 学号: 06153034 日期: 2017-3-8 10:15-12:00
实验1:猴子摘香蕉问题的VC编程实现 一、实验目的 (1)熟悉谓词逻辑表示法; (2)掌握人工智能谓词逻辑中的经典例子——猴子摘香蕉问题的编程实现。 二、编程环境 VC语言 三、问题描述 房子里有一只猴子(即机器人),位于a处。在c处上方的天花板上有一串香蕉,猴子想吃,但摘不到。房间的b处还有一个箱子,如果猴子站到箱子上,就可以摸着天花板。如图1所示,对于上述问题,可以通过谓词逻辑表示法来描述知识。要求通过VC语言编程实现猴子摘香蕉问题的求解过程。 图1 猴子摘香蕉问题 四、源代码 #include
研究生课程考试成绩单 任课教师签名: 日期:
浅谈基于人工神经网络的日负荷预测 学号:138071 姓名:万玉建 摘要 本文是作者在学习《人工智能》课程以后,结合作者本人工作的需要,根据《人工智能》课程中人工神经网络知识和在网上搜索到的相关资料,提出关于电力系统日负荷预测,运用基于人工神经网络的算法的组网结构和实现步骤的一些简单的构思和设想。 1引言 本人一直从事电力系统监控软件研发和管理工作,电力系统监控软件监控的对象就是电力负荷情况,而电力负荷预测则是系统的高级应用,它是根据历史的负荷数据,预测未来的负荷情况。由于电力负荷资源不可储存性,即发电机发出多少电,实时就要用多少负荷量,因此,就要求事先需要知道未来的用电负荷。正确地预测电力负荷,既是为了保证人们生活充足的电力的需要,也是电力工业自身健康发展的需要。 日负荷预测是指对未来1日的负荷进行预测,一般每15分钟一个负荷点,1日共96个数据。实际工作中,当天上午负荷预测人员根据昨天和更前的历史负荷数据预测明天的负荷数据,然后按一定格式生成文件上传到相关负荷管理部门。之前公司负荷预测软件中提供了线性回归法、曲线拟合法、平均值外推法、最小二乘法等负荷预测算法,但是这些算法都只是根据历史负荷数据进行一些数学的运算,没有考虑天气、节假日等情况,这些因素是负荷变化的重要的因素,而这些算法无法将这些因素量化并参加计算。 本学期学习了《人工智能》课程,其中有关于人工神经网络知识,这让本人想起来早在几年前在设计负荷预测软件时,曾经看到有人使用基于人工神经网络,把天气、节假日等因素加进来的进行预测的算法,当时也想增设这样的算法,但因为对算法不是很理解和其他种种原因一直没有实现。而今,恰好在课本学了人工神经网络,就考虑设计一种基于人工神经网络的负荷预测算法。本文描述这种算法的构思和设想。 2影响负荷预测因素的分析 由于电力系统负荷是一个很复杂的非线性系统,有许多直接或间接的因素都会对电力系统的日负荷产生直接的影响。但是在实际的负荷预测中,又不能考虑太多的影响因素。这一方面是收集这些资料困难,另一方面因素太多会造成建模困难,并且会带来大量的计算。因此,在考虑神经网络输入量的问题上,应抓住其中几个最具特征的影响因素。根据对历史负荷的分析,一般可把负荷分为两类:周期性负荷和变动性负荷。周期性负荷,或者说标准负荷,反映的是负荷自身变化的基本规律,呈较强的周期性,尤其受到时间周期的影响。针对短期负荷,时间周期因素包括:周周期、日周期等。它们对于日负荷的曲线模式有着极为重要的影响。 在气象条件中,起主要作用的是温度因素和天气状况。因此为了在负荷预测中考虑这两方面的影响,本文对每天的气温的输入变量可以进行分段处理,将天气状况中最重要的气温因素进行量化处理并作为神经网络的一个输入量。这样就更加能够体现出实际负荷的变化情况。
计算机科学与技术1341901301 敏 实验一:知识表示方法 一、实验目的 状态空间表示法是人工智能领域最基本的知识表示方法之一,也是进一步学习状态空间搜索策略的基础,本实验通过牧师与野人渡河的问题,强化学生对知识表示的了解和应用,为人工智能后续环节的课程奠定基础。 二、问题描述 有n个牧师和n个野人准备渡河,但只有一条能容纳c个人的小船,为了防止野人侵犯牧师,要求无论在何处,牧师的人数不得少于野人的人数(除非牧师人数为0),且假定野人与牧师都会划船,试设计一个算法,确定他们能否渡过河去,若能,则给出小船来回次数最少的最佳方案。 三、基本要求 输入:牧师人数(即野人人数):n;小船一次最多载人量:c。 输出:若问题无解,则显示Failed,否则,显示Successed输出一组最佳方案。用三元组(X1, X2, X3)表示渡河过程中的状态。并用箭头连接相邻状态以表示迁移过程:初始状态->中间状态->目标状态。 例:当输入n=2,c=2时,输出:221->110->211->010->021->000 其中:X1表示起始岸上的牧师人数;X2表示起始岸上的野人人数;X3表示小船现在位置(1表示起始岸,0表示目的岸)。 要求:写出算法的设计思想和源程序,并以图形用户界面实现人机交互,进行输入和输出结果,如: Please input n: 2 Please input c: 2 Successed or Failed?: Successed Optimal Procedure: 221->110->211->010->021->000 四、算法描述 (1)算法基本思想的文字描述;
实验报告 1.对CLIPS和其运行及推理机制进行介绍 CLIPS是一个基于前向推理语言,用标准C语言编写。它具有高移植性、高扩展性、 强大的知识表达能力和编程方式以及低成本等特点。 CLIPS由两部分组成:知识库、推理机。它的基本语法是: (defmodule< module-n ame >[< comme nt >]) CLIPS的基本结构: (1).知识库由事实库(初始事实+初始对象实例)和规则库组成。 事实库: 表示已知的数据或信息,用deftemplat,deffact定义初始事实表FACTLIS,由关系名、后跟 零个或多个槽以及它们的相关值组成,其格式如下: 模板: (deftemplate
面向大数据的人工智能技术综述报告 【摘要】 本文通过分析人工智能技术当前的主流分类及所采用的核心技术,对其现状进行梳理,据此总结出目前所存在的问题及难点,并在上述研究和分析的基础上,探讨在大数据快速发展的背景下,人工智能技术的发展趋势和关键技术领域,就面向大数据的人工智能技术未来发展的相互关系和潜力进行一些初步探讨,提出可以利用大数据完善人工智能技术的建议。 【关键词】面向大数据;人工智能;发展趋势 引言 2016年正好是人工智能诞生60周年,它从科学成果逐渐转化为商业应用成果,并在人们的生活中逐渐起到越来越重要的作用。近年来,人工智能技术日益融入金融、科研等各个领域,随之而来的是大量的新型信息数据和资料的产生。当人工智能遇上大数据,究竟会引爆怎样一种改变世界的力量?是更大的数据让人工智能凸显出独立性,还是更强的算法成就了机器的自我学习? 对于进入机器学习的时代,应用需求已经超越了原来普通的编程和数据库所能提供的解决范畴,面对空前庞大的数据量,通过人工智能技术将可能提供智能化的处理服务解决方案。面对大量的数据,如何进行整合处理,将大数据用于实时分析并对未来预测,使当下获取到的数据信息能进行有利于现有行为的分析预测,转化为有利的资源,俨然成为新的思潮。 1.研究背景 1.1 大数据和人工智能的概念 什么是大数据?是技术领域发展趋势的一个概括,这一趋势打开了理解世界和制定决策的新办法之门。根据技术研究机构IDC的预计,大量新数据无时不刻不在涌现,它们以每年50%的速度在增长,或者说每两年就要翻一番多。并不仅仅是数据的洪流越来越大,而且全新的支流也会越来越多。比方说,现在全球就有无数的数字传感器依附在工业设备、汽车、电表和板条箱上。它们能够测定方位、运动、振动、温度、湿度、甚至大气中的化学变化,并可以通信。将这些通
《人工智能导论》作业(1-4章) 1.人工智能有哪几个主要的学派?各学派的基本理论框架和主要研究方向有何不同?2.用谓词逻辑方法表述下面问题积木世界的问题。 (定义谓词、描述状态、定义操作、给出操作序列) 3.请给出下列描述的语义网络表示: 1)11月5日,NBA常规赛火箭主场对阵小牛,火箭107-76大胜小牛。 2)张老师从9月至12月给自动化专业学生教授《自动控制原理》。李老师从10至12月 给计算机专业学生教授《操作系统原理》。 3)树和草都是植物;树和草都有根和叶;水草是草,生活在水中;果树是树,会结果; 苹果树是果树,结苹果。 4.请用相应谓词公式描述下列语句: 1)有的人喜欢足球、有的人喜欢篮球;有的人既喜欢足球又喜欢篮球。 2)喜欢编程的同学都喜欢计算机。 3)不是每个自控系的学生都喜欢编程。 4)有一个裁缝,他给所有不自己做衣服的人做衣服。 5)如果星期六不下雨,汤姆就会去爬山。 5.什么是谓词公式的解释?对于公式?x ?y (P(x)→Q(f(x),y)) D={1,2,3} 分别给出使公式为真和假的一种解释。 6.什么是合一?求出下面公式的最一般合一: P(f(y), y, x) P(x, f(a),z)。 7.把下面谓词公式化为子句集 ?x ?y (P(x,y)∨Q(x,y))→R(x,y)) ?x (P(x) →?y(P(y)∧R(x,y))
?x (P(x)∧?y(P(y) →R(x,y))) 8.证明下面各题中,G是否是F的逻辑结论? F1: ?x (P(x) →?y(Q(y)→L(x,y))) F2: ?x (P(x)∧?y(R(y) →L(x,y))) G: ?x (R(x) →~Q(x)) F1: ?z (~B(z)→?y(D(z,y)∧C(y))) F2: ?x (E(x)∧A(x)∧?y (D(x,y) →E(y))) F3: ?y(E(y) →~B(y)) G: ?z (E(z) ∧C(z)) 9.已知:John, Mike, Sam是高山俱乐部成员。 高山俱乐部成员都是滑雪运动员或登山运动员(也可以都是)。 登山运动员不喜欢雨。 滑雪运动员都喜欢雪。 凡是Mike喜欢的,John就不喜欢。 凡是Mike 不喜欢的,John就喜欢。 Mike喜欢雨和雪。 问:高山俱乐部是否有一个成员,他是登山运动员,但不是滑雪运动员?如果有,他是谁?10.为什么说归结式是其亲本子句的逻辑结论? 11.何为完备的归结策略?有哪些归结策略是完备的? 12.何谓搜索?有哪些常用的搜索方法?盲目搜索与启发式搜索的根本区别是什么?13.用状态空间法表示问题时,什么是问题的解?什么是最优解?在图搜索算法中,OPEN 表和CLOSED表的作用是什么?f(x)有何不同含义? 14.宽度优先搜索和深度优先搜索有何不同?在何种情况下,宽度优先搜索优于深度优先搜索,何种情况反之? 15.什么是启发式搜索,g(x)与h(x)各有什么作用?A*算法的限制条件是什么?
人工智能导论 实验报告 姓名:蔡鹏 学号:1130310726 实验一
一、实验内容 有如下序列,试把所有黑色格移到所有白色格的右边,黄色格代表空格,黑色格和白色格可以和距离不超过三的空格交换。 二、实验代码 #include
Enstack(root,&S); while(S.num!=0) { n=Destack(&S); if(n->f < min->f) { min=n; } for(i=0;i
人工智能课程项目报告 姓名: 班级:二班
一、实验背景 在新的时代背景下,人工智能这一重要的计算机学科分支,焕发出了他强大的生命力。不仅仅为了完成课程设计,作为计算机专业的学生, 了解他,学习他我认为都是很有必要的。 二、实验目的 识别手写字体0~9 三、实验原理 用K-最近邻算法对数据进行分类。逻辑回归算法(仅分类0和1)四、实验内容 使用knn算法: 1.创建一个1024列矩阵载入训练集每一行存一个训练集 2. 把测试集中的一个文件转化为一个1024列的矩阵。 3.使用knnClassify()进行测试 4.依据k的值,得出结果 使用逻辑回归: 1.创建一个1024列矩阵载入训练集每一行存一个训练集 2. 把测试集中的一个文件转化为一个1024列的矩阵。 3. 使用上式求参数。步长0.07,迭代10次 4.使用参数以及逻辑回归函数对测试数据处理,根据结果判断测试数 据类型。 五、实验结果与分析 5.1 实验环境与工具 Window7旗舰版+ python2.7.10 + numpy(库)+ notepad++(编辑)
Python这一语言的发展是非常迅速的,既然他支持在window下运行就不必去搞虚拟机。 5.2 实验数据集与参数设置 Knn算法: 训练数据1934个,测试数据有946个。
数据包括数字0-9的手写体。每个数字大约有200个样本。 每个样本保持在一个txt文件中。手写体图像本身的大小是32x32的二值图,转换到txt文件保存后,内容也是32x32个数字,0或者1,如下图所 示 建立一个kNN.py脚本文件,文件里面包含三个函数,一个用来生成将每个样本的txt文件转换为对应的一个向量:img2vector(filename):,一个用 来加载整个数据库loadDataSet():,最后就是实现测试。
2019年人工智能数据资源开发及服务行业分析报告 2019年4月
目录 一、行业主管部门、监管体制、主要法律法规政策 (5) 1、行业主管部门及监管体制 (5) 2、行业主要法律法规政策 (6) 3、行业主要法律法规政策的影响 (8) 二、行业发展情况和发展趋势 (9) 1、行业技术发展概况 (9) (1)深度学习算法突破人工智能算法瓶颈 (9) (2)大量、优质的训练数据是人工智能持续发展的基础性动力 (10) (3)运算力的提升大幅推动人工智能发展 (10) 2、行业模式与发展业态 (11) 3、行业现状与发展趋势 (12) 三、行业竞争格局 (14) 1、Appen (15) 2、慧听科技 (15) 3、标贝科技 (15) 4、海天瑞声 (16)
数据、算力和算法是当前人工智能发展的三个核心要素。近年来,国内在人工智能算法和算力领域涌现出了一大批新兴优质企业。国内人工智能数据领域的领先企业,通过供给海量优质的人工智能数据资源产品,为国内人工智能领域的高速发展提供了重要支持与助力。 图:人工智能技术架构示意 人工智能技术从架构上分为基础层、技术层和应用层。基础层主要为人工智能技术提供计算能力以及数据输入;技术层包括算法和其他人工智能技术,主要在基础层上开发算法模型,并通过数据训练和机器学习建模开发面向不同应用领域的技术,如智能语音、计算机视觉和自然语言处理等,在应用层将人工智能技术与应用场景结合起来,
实现商业化落地。 人工智能数据资源产品及服务隶属于人工智能产业链的基础层,是自主研发人工智能技术的企业与机构必需的基础生产要素,其数量多寡和质量高低将会直接影响到人工智能产业链内企业的研发周期、产品性能和可扩展性。例如,要搭建和实现一个较成熟的人工智能语音识别引擎,就必须导入海量经过精确结构化处理的语音数据进行深度学习和模型训练,数据量至少需要达到上万小时。 数据资源定制服务。根据客户对人工智能算法模型开发、训练、拓展及优化等过程所需数据资源的个性化需求,为客户量体裁衣地提供定制化数据资源的设计及开发服务,对客户提供的数据进行处理,最终形成符合客户需求的定制化数据资源。在该种业务类型下,企业为客户提供数据资源定制服务,客户享有最终形成的定制化数据资源的知识产权。 数据资源定制服务内容具体如下: 数据库产品。根据对人工智能算法模型应用领域、行业发展趋势、市场需求等的评估和研判,设计并开发多种数据库产品,开发完成后授权给客户使用。在该种业务类型下,企业开发数据库产品,并拥有数据库产品的知识产权。
《一人工智能方向实习一》 实习报告 专业:计算机科学与技术 班级:12419013 学号: 姓名: 江苏科技大学计算机学院 2016年3月
实验一数据聚类分析 一、实验目的 编程实现数据聚类的算法。 二、实验内容 k-means聚类算法。 三、实验原理方法和手段 k-means算法接受参数k ;然后将事先输入的 n个数据对象划分为 k个聚类以便使得 所获得的聚类满足:同一聚类中的对象相似度较高 四、实验条件 Matlab2014b 五、实验步骤 (1)初始化k个聚类中心。 (2)计算数据集各数据到中心的距离,选取到中心距离最短的为该数据所属类别。 (3)计算(2)分类后,k个类别的中心(即求聚类平均距离) (4)继续执行(2)(3)直到k个聚类中心不再变化(或者数据集所属类别不再变化) 六、实验代码 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % mai n.m % k-mea ns algorithm % @author matcloud %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% clear; close all ; load fisheriris ; X = [meas(:,3) meas(:,4)]; figure; plot(X(:,1),X(:,2), 'ko' ,'MarkerSize' ,4); title( 'fisheriris dataset' , 'FontSize' ,18, 'Color' , 'red'); [idx,ctrs] = kmea ns(X,3); figure; subplot(1,2,1); plot(X(idx==1,1),X(idx==1,2), 'ro' , 'MarkerSize' ,4); hold on;
全球人工智能产业数据报告
报告摘要 1.截至2019年3月底全球活跃人工智能企业达5386家,其中美国、中国、英国、加拿大、印度位列全球前 五。中国人工智能企业集中在北上广和江浙地区,美国人工智能企业集中在加州、纽约等地。 2.全球AI领域独角兽企业有41家,其中中国17家,美国18家,日本3家,印度、德国和以色列各1家。 3.2018年Q2以来全球AI领域投资热度逐渐下降。2019Q1全球融资规模126亿美元,环比下降7.3%, 同比 持平;融资笔数达310笔,环比回升29.7%,同比下降44.1%。其中,中国AI领域融资金额30亿美元,同比下降55.8%,在全球融资总额中占比23.5%,比2018年同期下降了29个百分点。 4.统计近10年AI领域学术论文的发表情况,在论文发表总量上中国位列第一,其中高被引论文数量不及美 国,位列第二。 5.国内中国科学院、清华大学等科研单位在AI学术研究上位于前列。 6.谷歌和微软是全球范围内在AI顶级会议上发文最多的企业。
目录
?截至2019年3月底全球活跃人工智能企业注达5386家。 ?AI企业数量TOP5国家:美国(2169家)、中国大陆(1189家)、英国(404家)、加拿大(303家)和印度(169家)。
?AI企业数量Top5城市:北京(468)、旧金山(328)、伦敦(290)、上海(233)、纽约(207)。?AI企业数量排名前20的城市,中国4个,美国10个,加拿大3个,英国、印度和以色列各1个。 ?中国AI企业主要集中在北上广和江浙地区,美国AI企业主要集中在加州、纽约州和马瑟诸塞州。
****大学 人工智能基础课程实验报告 (2011-2012学年第一学期) 启发式搜索王浩算法 班级: *********** 学号: ********** 姓名: ****** 指导教师: ****** 成绩: 2012年 1 月 10 日
实验一 启发式搜索算法 1. 实验内容: 使用启发式搜索算法求解8数码问题。 ⑴ 编制程序实现求解8数码问题A *算法,采用估价函数 ()()()() w n f n d n p n ??=+???, 其中:()d n 是搜索树中结点n 的深度;()w n 为结点n 的数据库中错放的棋子个数;()p n 为结点n 的数据库中每个棋子与其目标位置之间的距离总和。 ⑵ 分析上述⑴中两种估价函数求解8数码问题的效率差别,给出一个是()p n 的上界的()h n 的定义,并测试使用该估价函数是否使算法失去可采纳性。 2. 实验目的 熟练掌握启发式搜索A *算法及其可采纳性。 3. 实验原理 使用启发式信息知道搜索过程,可以在较大的程度上提高搜索算法的时间效率和空间效率; 启发式搜索的效率在于启发式函数的优劣,在启发式函数构造不好的情况下,甚至在存在解的情形下也可能导致解丢失的现象或者找不到最优解,所以构造一个优秀的启发式函数是前提条件。 4.实验内容 1.问题描述 在一个3*3的九宫格 里有1至8 八个数以及一个空格随机摆放在格子中,如下图: 初始状态 目标状态 现需将图一转化为图二的目标状态,调整的规则为:每次只能将空格与其相邻的一个数字进行交换。实质是要求给出一个合法的移动步骤,实现从初始状态到目标状态的转变。 2.算法分析 (1)解存在性的讨论 对于任意的一个初始状态,是否有解可通过线性代数的有关理论证明。按数组存储后,算出初始状态的逆序数和目标状态的逆序数,若两者的奇偶性一致,则表明有解。 (2)估价函数的确定