
《Verilog HDL数字集成电路设计原理与应用》上机作业
班级:*******
学号:*******
:*******
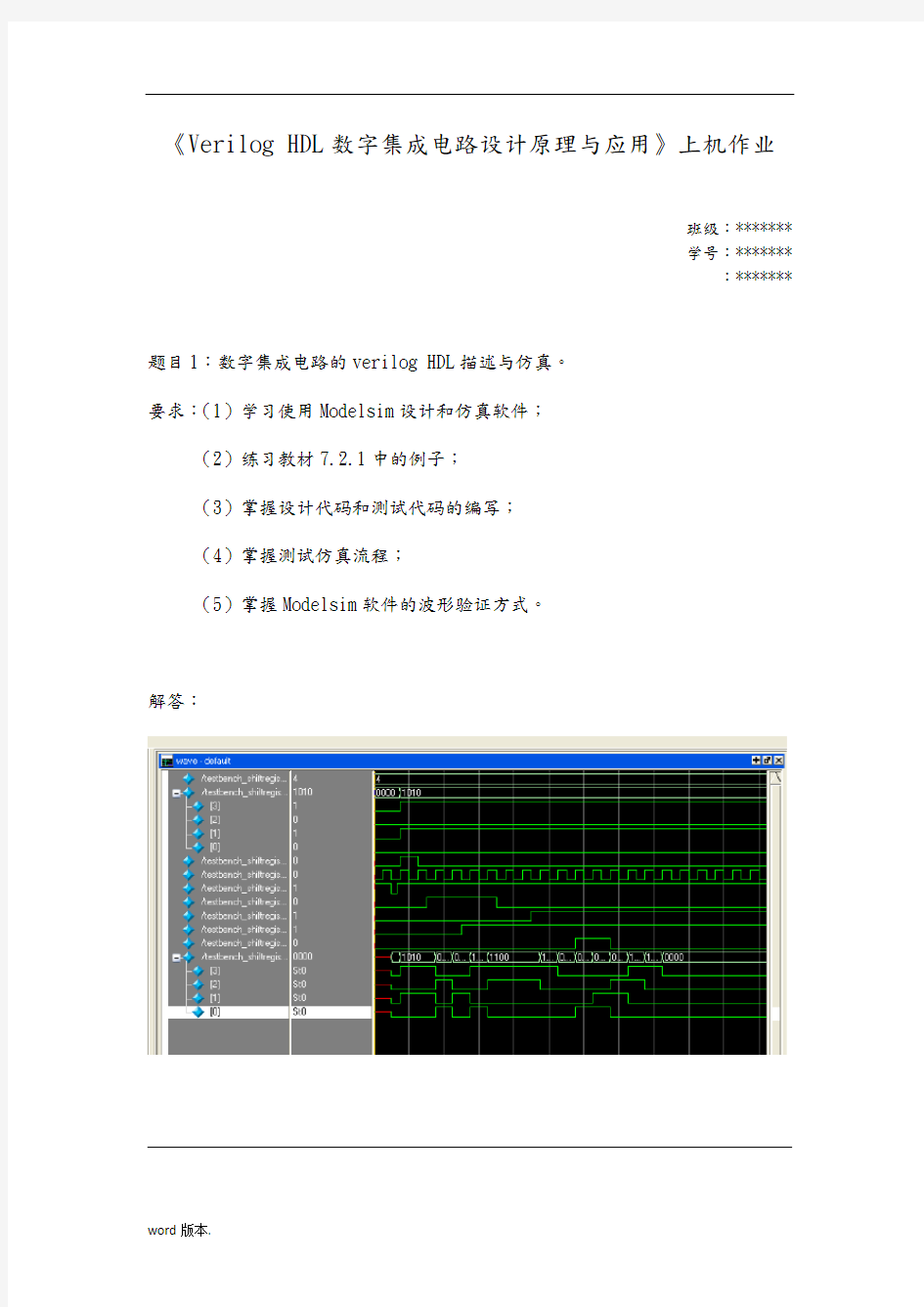
题目1:数字集成电路的verilog HDL描述与仿真。
要求:(1)学习使用Modelsim设计和仿真软件;
(2)练习教材7.2.1中的例子;
(3)掌握设计代码和测试代码的编写;
(4)掌握测试仿真流程;
(5)掌握Modelsim软件的波形验证方式。
解答:
题目2:简述begin-end语句块和fork-join语句块的区别,并写出下面信号对应的程序代码
A
B
解答:
(1)begin-end语句块和fork-join语句块的区别:
1、执行顺序:begin-end语句块按照语句顺序执行,fork-join语句块所有语句均在同一时刻执行;
2、语句前面延迟时间的意义:begin-end语句块为相对于前一条语句执行结束的时间,fork-join语句块为相对于并行语句块启动的时间;
3、起始时间:begin-end语句块为首句开始执行的时间,fork-join语句块为转入并行语句块的时间;
4、结束时间:begin-end语句块为最后一条语句执行结束的时间,fork-join 语句块为执行时间最长的那条语句执行结束的时间;
5、行为描述的意义:begin-end语句块为电路中的数据在时钟及控制信号的作用下,沿数据通道中各级寄存器之间的传送过程。fork-join语句块为电路上电后,各电路模块同时开始工作的过程。
(2)程序代码:
Begin-end语句:
module initial_tb1;reg A,B;
initial
begin
A=0;B=1;
#10 A=1;B=0;
#10 B=1;
#10 A=0;
#10 B=0;
#10 A=1;B=1;
end
endmodule
Frk-join语句:module wave_tb2; reg A,B;
parameter T=10; initial
fork
A=0;B=1;
#T A=1;B=0;
#(2*T) B=1;
#(3*T) A=0;
#(4*T) B=0;
#(5*T) A=1;B=1;
join
endmodule
题目3. 分别用阻塞和非阻塞赋值语句描述如下图所示移位寄存器的电路图。
解答:
(1)阻塞赋值语句
module block2(din,clk,out0,out1,out2,out3);
input din,clk;
output out0,out1,out2,out3;
reg out0,out1,out2,out3;
always(posedge clk)
begin
out0=din;
out1=out0;
out2=out1;
out3=out2;
end
endmodule
(2)非阻塞赋值语句
module non_block1 (din,clk,out0,out1,out2,out3);
input din,clk;
output out0,out1,out2,out3;
reg out0,out1,out2,out3;
always(posedge clk)
begin
out0<=din;
out1<=out0;
out2<=out1;
out3<=out2;
end
endmodule
题目4:设计16位同步计数器
要求:(1)分析16位同步计数器结构和电路特点;
(2)用硬件描述语言进行设计;
(3)编写测试仿真并进行仿真。
解答:
(1)电路特点:同步计数器的时间信号是同步的;每当到达最高计数后就会重新计数。(2)程序代码:
module comp_16 (count, clk, rst );
output [15:0] count;
input clk,rst;
reg [15:0] count;
always (posedge clk)
if (rst) count<=16'b00000;
else
if (count==16'b11111)
count<=16'b00000;
else
count<=count+1;
endmodule
(3)仿真代码:
module comp_16_tb;
wire [15:0] count;
reg clk,rst;
comp_16 U1 (count, clk, rst );
always #1 clk=~clk;
initial
begin
clk=0;rst=0; #1 rst=1; #10 rst=0; #10 rst=1; #10 rst=0;
#99999 $finish; end
endmodule
题目5. 试用Verilog HDL 门级描述方式描述如下图所示的电路。
解答:
module zy(D0,D1,D2,D3,S1,S2,T0,T1,T2,T3,Z); output Z;
input D0,D1,D2,D3,S1,S2;
wire T0,T1,T2,T3,wire1,wire2; not U1(wire1,S1), U2(wire2,S2);
and U3(T0,D0,wire2,wire1), U4(T1,D1,S1,wire1), U5(T2,D2,S1,wire2),
U6(T3,D3,S1,S2);
Z
or U7(Z,T0,T1,T2,T3,);
endmodule
题目6. 试用查找真值表的方式实现真值表中的加法器,写出Verilog HDL代码:
解答:
module homework6(SUM,COUT,A,B,CIN);
output SUM,COUT;
input A,B,CIN;
reg SUM,COUT;
always(A or B or CIN)
case({A,B,CIN})
3'b000:SUM<=0;
3'b000:COUT<=0;
3'b001:SUM<=1;
3'b001:COUT<=0;
3'b010:SUM<=1;
3'b010:COUT<=0;
3'b011:SUM<=0;
3'b011:COUT<=1;
3'b100:SUM<=1;
3'b100:COUT<=0;
3'b101:SUM<=0;
科目:微机原理与系统设计授课老师:李明、何学辉 学院:电子工程学院 专业:电子信息工程 学生姓名: 学号:
微机原理硬件设计综合作业 基于8086最小方式系统总线完成电路设计及编程: 1、扩展16K字节的ROM存储器,起始地址为:0x10000; Intel 2764的存储容量为8KB,因此用两片Intel 2764构成连续的RAM存储区域的总容量为2 8KB=16KB=04000H,鉴于起始地址为10000H,故最高地址为 10000H+04000H-1=13FFFH 电路如图
2、扩展16K 字节的RAM 存储器,起始地址为:0xF0000; Intel 6264的存储容量为8KB ,因此用两片Intel 6264构成连续的RAM 存储区域的总容量为2 8KB=16KB=04000H ,鉴于起始地址为F0000H ,故最高地址为 F0000H+04000H-1=F3FFFH 片内地址总线有13根,接地址总线的131~A A ,0A 和BHE 用于区分奇偶片,用74LS155作译码电路,如图所示 3、设计一片8259中断控制器,端口地址分别为:0x300,0x302; 鉴于端口地址分别是300H 和302H ,可将82590A 接到80861A ,其他作译码。电路如图:
4、设计一片8253定时控制器,端口地址分别为:0x320,0x322,x324,0x326; 根据端口地址可知,825301,A A 应该分别接到8086的12,A A ,其余参与译码。电路如图:
5、设计一片8255并行接口,端口地址分别为:0x221,0x223,x225,0x227; 由于端口地址为奇地址,8086数据总线应该接158~D D ,且BHE 参与译码。根据端口地址可得825501,A A 应该分别接到8086的12,A A ,其余参与译码。电路如图:
通信原理大作业 班级: 学号: 姓名:
2PSK信号的调制与解调 分析: 调制: 随机产生一段码元,设:码元个数为60,载波频率采用8KHz,每个周期8个采样点,信号波特率为1000,所以每个码元内有64数据,对这60*64个数据,得出2PSK信号。对原始信号和2PSK信号画图比较。 解调: 采用相干解调,通过混频器后可以得到带有载波的信号,通过滤波器后就可以得到基带信号。对原始信号和解调后的基带信号画图比较。 程序: clc close all clear all codn=60; % 仿真的码元个数 fc=8e+3; % 载波频率 fs=fc*8; %数据采样率 bode=1000; %信号波特率 code=round(rand(1,codn)); %产生随机信码 code_len=round(1/bode/(1/fs)); %得到一个码元周期的数据长度 for i=1:codn %产生双极性数字基带信号 x0((i-1)*code_len+1:code_len*i)=code(i); end x=2*x0-1; %x中有code_len(一个码元中的数据个数)*codn(码元个数) car=cos(2*pi*fc/fs*(0:length(x0)-1)); %产生载波 y=x.*car; %2PSK信号等于双极性数字基带信号乘以载波figure subplot(2,1,1) plot(x) axis([0 length(x0) -1.5 1.5]) grid on zoom on title('原始基带信号') subplot(2,1,2) plot(y)
人工智能大作业 学生:021151** 021151** 时间:2013年12月4号
一.启发式搜索解决八数码问题 1.实验目的 问题描述:现有一个3*3的棋盘,其中有0-8一共9个数字,0表示空格,其他的数字可以和0交换位置(只能上下左右移动)。给定一个初始状态和一个目标状态,找出从初始状态到目标状态的最短路径的问题就称为八数码问题。 例如:实验问题为
到目标状态: 从初始状态: 要求编程解决这个问题,给出解决这个问题的搜索树以及从初始节点到目标节点的最短路径。 2.实验设备及软件环境 利用计算机编程软件Visual C++ 6.0,用C语言编程解决该问题。 3.实验方法 (1).算法描述: ①.把初始节点S放到OPEN表中,计算() f S,并把其值与节点S联系 起来。 ②.如果OPEN表是个空表,则失败退出,无解。 ③.从OPEN表中选择一个f值最小的节点。结果有几个节点合格,当其 中有一个为目标节点时,则选择此目标节点,否则就选择其中任一节点作为节点i。 ④.把节点i从OPEN表中移出,并把它放入CLOSED的扩展节点表中。 ⑤.如果i是目标节点,则成功退出,求得一个解。 ⑥.扩展节点i,生成其全部后继节点。对于i的每一个后继节点j: a.计算() f j。 b.如果j既不在OPEN表中,也不在CLOSED表中,则用估价函数f
把它添加入OPEN表。从j加一指向其父辈节点i的指针,以便一旦 找到目标节点时记住一个解答路径。 c.如果j已在OPEN表或CLOSED表上,则比较刚刚对j计算过的f 值和前面计算过的该节点在表中的f值。如果新的f值较小,则 I.以此新值取代旧值。 II.从j指向i,而不是指向它的父辈节点。 III.如果节点j在CLOSED表中,则把它移回OPEN表。 ⑦转向②,即GO TO ②。 (2).流程图描述: (3).程序源代码: #include
西安电子科技大学微机原理试题 姓名学号总分 一.填空题(每空1分,共30分) 1)15的8位二进制补码为,-15的8位二进制补码为。 2)某8位二进制补码为80H,其十进制表示为。 3)字符B的ASCII码为,字符0的ASCII码为。 4)8086CPU总线按功能可分为数据总线,总线和总线。 5)8086CPU数据总线包含条数据线,最多可寻址的存储器容量为。 6)CPU内部用于计算的部分为,用于保存下一条要执行的指令地址的 为。 A) 程序状态字B) 程序计数器C) ALU D) 工作寄存器 7)经常用作循环次数的寄存器是,用于I/O端口寻址的寄存器是。 A) AX B) BX C) CX D) DX 8)指令MOV CX, 1000的结果是CH= 。 9)将0D787H和4321H相加后,标志位CF= ,SF= ,ZF= , OF= ,AF= ,PF= 。 10)寄存器SI中能够表示的最大有符号数为,最小有符号数为。 11)设(DS)=4000H,(BX)=0100H,(DI)=0002H,(4002)=0A0AH,(40100)=1234H,(40102) =5678H,求以下指令分别执行后AX寄存器的值。 MOV AX , [2] (AX)= 。 MOV AX , [BX] (AX)= 。 MOV AX , [BX][DI] (AX)= 。 MOV AX , 1[BX] (AX)= 。 12)用一条指令将AX寄存器低四位清零,其余位不变:。 13)用一条指令将AX寄存器高四位取反,其余位不变:。 14)用一条指令将AX高8位与低8位交换:。 15)用一条指令将AL中的大写字母变成相应的小写:。 二.判断题(每题1分,共10分) 以下语句是语法正确的打√,语法错误打×,其中TABLE和TAB为两个字节类型的变量。 1)MOV DS , 1000H 2)MOV DS , TABLE 3)MOV [1200H] , [1300H] 4)ADD AX , BX , CX 5)XCHG AL , CL 6)CALL AL 7)MUL AX , BX 8)JU L1 9)SHR CL , CL
第一章 1、3 什么就是人工智能?它的研究目标就是什么? 人工智能(Artificial Intelligence),英文缩写为AI。它就是研究、开发用于模拟、延伸与扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 研究目标:人工智能就是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理与专家系统等。 1、7 人工智能有哪几个主要学派?各自的特点就是什么? 主要学派:符号主义,联结主义与行为主义。 1.符号主义:认为人类智能的基本单元就是符号,认识过程就就是符号表示下的符号计算, 从而思维就就是符号计算; 2.联结主义:认为人类智能的基本单元就是神经元,认识过程就是由神经元构成的网络的信 息传递,这种传递就是并行分布进行的。 3.行为主义:认为,人工智能起源于控制论,提出智能取决于感知与行动,取决于对外界复 杂环境的适应,它不需要只就是,不需要表示,不需要推理。 1、8 人工智能有哪些主要研究与应用领域?其中有哪些就是新的研究热点? 1、研究领域:问题求解,逻辑推理与定理证明,自然语言理解,自动程序设计,专家系统,机器 学习,神经网络,机器人学,数据挖掘与知识发现,人工生命,系统与语言工具。 2、研究热点:专家系统,机器学习,神经网络,分布式人工智能与Agent,数据挖掘与知识发 现。 第二章 2、8 用谓词逻辑知识表示方法表示如下知识: (1)有人喜欢梅花,有人喜欢菊花,有人既喜欢梅花又喜欢菊花。 三步走:定义谓词,定义个体域,谓词表示 定义谓词 P(x):x就是人
西安电子科技大学 考试时间 120 分钟 试题(A) 班级学号姓名任课教师 一、选择(请将答案填写到下面表格中)(每题2分,共2×10=20分) 1、多路信号复用方式中不含以下哪一种?() A. 频分复用 B. 时分复用 C. 码分复用 D. 相分复用 2、以下属于全双工通信的是:() A. 广播 B. 对讲机 C. 电话 D.无线寻呼 3、根据香农公式可知为了使信道容量趋于无穷大,不可以采取下列措施:( ) A、噪声功率为零 B、噪声功率谱密度始终为零 C、信号发射功率为无穷大 D、系统带宽为无穷大 4、设某随参信道的最大多径时延差等于2ms,为了防止出现频率选择性衰落,该信道的相关带宽为:() A、500Hz B、>500Hz C、<500Hz D、2KHz 5、即使在“0”、“1”不等概率出现情况下,以下哪种码仍然不包含直流成分:( ) 第1页共6页
第2页 共6页 A 、AMI 码 B 、双极性归零码 C 、单极性归零码 D 、差分码 6、二进制数字基带传输系统的误码率计算公式为:( ) A 、()()0/11/0P P P e += B 、()()()()1/010/10P P P P P e += C 、()()10P P P e += D 、()()()()0/111/00P P P P P e += 7、功率利用率最低调制方式是:( ) A 、2ASK B 、2FSK C 、2PSK D 、2DPSK 8、对二进制频带传输系统而言,下列说法错误的是:( ) A 、FSK 、PSK 、DPSK 的抗衰落性能均优于ASK ; B 、ASK 、PSK 、DPSK 的最佳判决门限比FSK 容易设置; C 、接收机的输入信噪比增加,解调的误码率一定下降; D 、ASK 、PSK 、DPSK 的频带利用率均高于FSK 。 9、为了防止ΔM 编码过程的过载现象出现,不可以采取以下哪种措施:( ) A 、减小量化台阶 B 、增大量化台阶 C 、增大采样速率 D 、减小采样周期 10、按照A 律13折线编码实现PCM 编码时,第7段落的段落码为:( ) A 、011 B 、110 C 、101 D 、 111 二、填空(每空2分,共2×10=20分) 1、 频谱从零频附近开始的信号是 基带信号 。 2、16进制码元速率若为1300B ,则信息速率为 5200b/s 。 3、信道中的干扰和噪声可以简化为乘性干扰和加性噪声,若乘性干扰随时 间快速变化,则对应的信道称为 随参信道 。 4、在地面微波无线中继传输系统中,若A 站和B 站相距50公里,不考虑大 气折射率的影响,则收发天线的架设高度需要大于 50米 。
1.(该题目硕士统招生做)请用框架法和语义网络法表示下列事件。(10分) 2015年2月20日上午11点40分,广东省深圳市光明新区柳溪工业园附近发生山体滑坡,经初步核查,此次滑坡事故共造成22栋厂房被掩埋,涉及公司15家,截至目前已安全撤离900人,仍有22人失联。 答:框架表示法(5分):(给分要点:确定框架名和框架槽,根据报道给出的相关数据填充,主要内容正确即可给分,不必与参考答案完全一致) <山体滑坡> 时间:2015年2月20日上午11点40分 地点:广东省深圳市光明新区柳溪工业园附近 掩埋厂房:22栋 涉及公司数目:15家 安全撤离人数:900人 失联人数:22人 语义网络表示法(5分):(给分要点:确定语义网络的节点及其连接关系,根据报道内容进行填充,主要内容正确即可给分,不必与参考答案完全一致) 1. (该题目全日制专业学位硕士做)请用一种合适的知识表示方法来表示下面知识。(10分) How Old Are YOU是微软推出的一款测年龄应用,该应用架设在微软服务平台Azure上,该平台具有机器学习的开发接口,第三方开发者可以利用相关的接口和技术,分析人脸照片。
(给分要点:采用合适的知识表示方法,正确即可给分,不必与参考答案完全一致) 答:
微机系统实验报告 班级:031214 学号:03121370 姓名:孔玲玲 地点:E-II-312 时间:第二批
实验一汇编语言编程实验 一、实验目的 (1)掌握汇编语言的编程方法 (2)掌握DOS功能调用的使用方法 (3)掌握汇编语言程序的调试运行过程 二、实验设备 PC机一台。 三、实验内容 (1)将指定数据区的字符串数据以ASCII码形式显示在屏幕上,并通过DOS功能 调用完成必要提示信息的显示。 (2) 在屏幕上显示自己的学号姓名信息。 (3)循环从键盘读入字符并回显在屏幕上,然后显示出对应字符的ASCII码,直到 输入“Q”或“q”时结束。 (4)自主设计输入显示信息,完成编程与调试,演示实验结果。 考核方式:完成实验内容(1)(2)(3)通过, 完成实验内容(4)优秀。 实验中使用的DOS功能调用:INT 21H 表3-1-1 显示实验中可使用DOS功能调用 AH 值功能调用参数结果 1 键盘输入并回显AL=输出字符 2 显示单个字符(带Ctrl+Break检查) DL=输出字符光标在字符后面 6 显示单个字符(无Ctrl+Break检查) DL=输出字符光标在字符后面 8 从键盘上读一个字符AL=字符的ASCII码 9 显示字符串DS:DX=串地址,‘$’为结束字符光标跟在串后面 4CH 返回DOS系统AL=返回码
四、实验步骤 (1)运行QTHPCI软件,根据实验内容编写程序,参考程序流程如图3-1-1所示。 (2)使用“项目”菜单中的“编译”或“编译连接”命令对实验程序进行编译、连接。 (3)“调试”菜单中的“进行调试”命令进入Debug调试,观察调试过程中数据传输指令执行后各寄存器及数据区的内容。按F9连续运行。 (4)更改数据区的数据,考察程序的正确性。 五、实验程序 DATA SEGMENT BUFFER DB '03121370konglingling:',0AH,0DH,'$' BUFFER2 DB 'aAbBcC','$' BUFFER3 DB 0AH,0DH,'$' DATA ENDS CODE SEGMENT ASSUME CS:CODE,DS:DA TA START: MOV AX,DA TA MOV DS,AX mov ah,09h mov DX,OFFSET BUFFER int 21h
西电人工智能大作业
八数码难题 一.实验目的 八数码难题:在3×3的方格棋盘上,摆放着1到8这八个数码,有1个方格是空的,其初始状态如图1所示,要求对空格执行空格左移、空格右移、空格上移和空格下移这四个操作使得棋盘从初始状态到目标状态。例如: (a) 初始状态 (b) 目标状态 图1 八数码问题示意图 请任选一种盲目搜索算法(深度优先搜索或宽度优先搜索)或任选一种启发式搜索方法(A 算法或 A* 算法)编程求解八数码问题(初始状态任选),并对实验结果进行分析,得出合理的结论。 本实验选择宽度优先搜索:选择一个起点,以接近起始点的程度依次扩展节点,逐层搜索,再对下一层节点搜索之前,必先搜索完本层节点。 二.实验设备及软件环境 Microsoft Visual C++,(简称Visual C++、MSVC、VC++或VC)微软公司的C++开发工具,具有集成开发环境,可提供编辑C语言,C++以及C++/CLI 等编程语言。 三.实验方法 算法描述: (1)将起始点放到OPEN表; (2)若OPEN空,无解,失败;否则继续; (3)把第一个点从OPEN移出,放到CLOSE表; (4)拓展节点,若无后继结点,转(2); (5)把n的所有后继结点放到OPEN末端,提供从后继结点回到n的指针; (6)若n任意后继结点是目标节点,成功,输出;否则转(2)。
流程图:
代码: #include
4.37 (上机题)编写程序实现,将缓冲区BUFFER中的100个字按递增排序,并按下列格式顺 序显示: 数据1 <原序号> 数据2 <原序号> …… 算法流程图: 调试问题、心得体会: 通过这道题,熟悉了流程图画法,掌握了产生随机数,“冒泡法”排序,子函数编写调用等的基本过程,尤其对于中断调用,并利用ASCII码回显和对课本字节型数据“冒泡法”排序改进为字形排序的过程,是我受益匪浅。并且亲身实践了源程序的汇编、调试也连接。 问题:将字节型冒泡法直接应用于该题,导致出错,该题存储的是字型数据!
原因在于只是排列的AL中的数值,并不是产生的随机数! 同时对于字型与字节型在运算类指令中的应用还是有误,以及其他的一些小错误,应加以改善! 运行结果: 程序代码: STACK SEGMENT STACK 'STACK' DW 100H DUP(?) TOP LABEL WORD STACK ENDS DATA SEGMENT BUFFER LABEL WORD
X=17 REPT 100 X=(X+80)mod 43 DW X ENDM BUF DW 100 DUP(?) DATA ENDS CODE SEGMENT ASSUME CS:CODE,DS:DATA,ES:DATA,SS:STACK START: MOV AX,DATA MOV DS,AX MOV ES,AX MOV AX,STACK MOV SS,AX LEA SP,TOP MOV CX,100 LEA SI,BUFFER LEA DI,BUF L1: MOV AX,[SI] INC SI INC SI MOV [DI],AX INC DI INC DI LOOP L1 MOV CX,100 DEC CX LEA SI,BUFFER PUSH CX ADD CX,CX ADD SI,CX POP CX L2: PUSH CX PUSH SI L3: MOV AX,[SI] CMP AX,[SI-2] JAE NOXCHG XCHG AX,[SI-2] MOV [SI],AX NOXCHG:
Adaptive Evolutionary Artificial Neural Networks for Pattern Classification 自适应进化人工神经网络模式分类 Abstract—This paper presents a new evolutionary approach called the hybrid evolutionary artificial neural network (HEANN) for simultaneously evolving an artificial neural networks (ANNs) topology and weights. Evolutionary algorithms (EAs) with strong global search capabilities are likely to provide the most promising region. However, they are less efficient in fine-tuning the search space locally. HEANN emphasizes the balancing of the global search and local search for the evolutionary process by adapting the mutation probability and the step size of the weight perturbation. This is distinguishable from most previous studies that incorporate EA to search for network topology and gradient learning for weight updating. Four benchmark functions were used to test the evolutionary framework of HEANN. In addition, HEANN was tested on seven classification benchmark problems from the UCI machine learning repository. Experimental results show the superior performance of HEANN in fine-tuning the network complexity within a small number of generations while preserving the generalization capability compared with other algorithms. 摘要——这片文章提出了一种新的进化方法称为混合进化人工神经网络(HEANN),同时提出进化人工神经网络(ANNs)拓扑结构和权重。进化算法(EAs)具有较强的全局搜索能力且很可能指向最有前途的领域。然而,在搜索空间局部微调时,他们效率较低。HEANN强调全局搜索的平衡和局部搜索的进化过程,通过调整变异概率和步长扰动的权值。这是区别于大多数以前的研究,那些研究整合EA来搜索网络拓扑和梯度学习来进行权值更新。四个基准函数被用来测试的HEANN进化框架。此外,HEANN测试了七个分类基准问题的UCI机器学习库。实验结果表明在少数几代算法中,HEANN在微调网络复杂性的性能是优越的。同时,他还保留了相对于其他算法的泛化性能。 I. INTRODUCTION Artificial neural networks (ANNs) have emerged as a powerful tool for pattern classification [1], [2]. The optimization of ANN topology and connection weights training are often treated separately. Such a divide-and-conquer approach gives rise to an imprecise evaluation of the selected topology of ANNs. In fact, these two tasks are interdependent and should be addressed simultaneously to achieve optimum results. 人工神经网络(ANNs)已经成为一种强大的工具被用于模式分类[1],[2]。ANN 拓扑优化和连接权重训练经常被单独处理。这样一个分治算法产生一个不精确的评价选择的神经网络拓扑结构。事实上,这两个任务都是相互依存的且应当同时解决以达到最佳结果。
汇编语言上机题 姓名:学号:成绩: 实验一、上机过程及DEBUG应用 编写程序,建立数据段DATA,将你的姓名(汉语拼音)及学号存入DATA数据段的BUFFER1区域,然后利用程序将BUFFER1区域中的字符串(姓名及学号)依次传送到从BUFFER2开始的内存区域中去。 上机过程与要求 1.建立原程序: 源程序文件名为,源程序清单如下: data segment buffer1 db 'hepan04105038' buffer2 db 13 dup() data ends code segment ASSUME CS:CODE,DS:DATA START: mov ax,data mov ds,ax mov es,ax lea si,buffer1 lea di,buffer2 mov cx,0d cld rep movsb mov ah,4ch int 21h code ends end start 2.汇编后生成的obj文件名为buffer .OBJ 3.连接后生成的目标文件名为buffer .EXE 4.DEBUG调试:在DEBUG下,利用U、D、G、R等命令对EXE文件进行调试后,相关信息如下: (1)表1-1 反汇编清单中所反映的相关信息 *注:最后一条指令是对应于代码段中最后一条指令 (2)在未执行程序之前,用D命令显示内存区域BUFFER1及BUFFER2中的内容, 其相关信息如表1-2所示。 表1-2 未执行程序之前的数据区内容
(3)执行程序以后用D命令显示内存区域的相关信息,如表1-3。 表1-3 执行程序之后的数据区内容 (4)用R命令检查寄存器的内容如表1-4所示。 回答问题 a)宏汇编命令MASM的作用是什么 答:产生OBJ文件。 b)连接命令LINK的作用是什么连接后生成什么文件 答:产生EXE文件,生成EXE文件。 c)DEBUG下U命令的作用是什么 答:反汇编被调试命令。 d)DEBUG下D命令的作用是什么 答:显示内存单元的内容。 e) 在DEBUG下如何执行.EXE文件,写出执行命令的常用格式。 答:DEBUG 。 实验二、寻址方式练习 掌握8086/8088的寻址方式是学习汇编语言的基础,因此,我们以数据传送指令为例编写了下面的程序,通过该程序对主要的几种寻址方式进行练习。 DATA1 SEGMENT M1 DB 0A0H,0A1H,0A2H,0A3H,0A4H,0A5H M2 DB 0A6H,0A7H,0A8H,0A9H,0AAH,0ABH,0ACH,0ADH,0AEH,0AFH DATA1 ENDS DATA2 SEGMENT N1 DB 0B0H,0B1H,0B2H,0B3H, 0B4H,0B5H N2 DB 0B6H,0B7H, 0B8H,0B9H,0BAH,0BBH, 0BCH,0BDH,0BEH,0BFH DATA2 ENDS STACK SEGMENT PARA STACK ‘STACK’ DB 0C0H,0C1H,0C2H,0C3H, 0C4H,0C5H DB 0C6H,0C7H, 0C8H,0C9H,0CAH,0CBH, 0CCH,0CDH,0CEH,0CFH
通信原理大作业 1、说明 在通信原理课程中,介绍了通信系统的基本理论,主要包括信道、基带传输、调制 / 解调方法等。为了进一步提高和改善学生对课程基本内容的掌握,进行课程作业方法的改革的试点,设立计算机仿真大作业。成绩将计入平时成绩。 2、要求 参加的同学3~5人一组,选择1?2个题目,协作和共同完成计算机编程和仿真,写出计算机仿真报告。推荐的计算机仿真环境为MATLAB也可以 选择其它环境。 3、大作业选题 (1) 信道噪声特性仿真产生信道高斯白噪声,设计信道带通滤波器对高斯白噪 声进行滤波, 得到窄带高斯噪声。对信道带通滤波器的输入输出的噪声的时域、频域特性进行统计和分析,画出其时域和频域的图形。 (2) 基带传输特性仿真利用理想低通滤波器作为信道,产生基带信号,仿真验证奈氏第一准则的给出的关系。改变低通滤波器的特性,再次进行仿真,验证存在码间干扰时的基带系统输出,画出眼图进行观察。加入信道噪声后再观 察眼图。 (3) 2ASK言号传输仿真 按照2ASK产生模型和解调模型分别产生2ASK言号和高斯白噪声,经过信道传
输后进行解调。对调制解调过程中的波形进行时域和频域观察,并且对解调结果进行误码率测量。2ASK信号的解调可以选用包络解调或者相干解调法。(4) 2FSK信号传输仿真 按照2FSK产生模型和解调模型分别产生2FSK信号和高斯白噪声,经过信道传输后进行解调。对调制解调过程中的波形进行时域和频域观察,并且对解调结果进行误码率测量。2FSK信号的解调可以选用包络解调或者相干解调法。(5) 2PSK信号传输仿真 按照2PSK产生模型和解调模型分别产生2PSK言号和高斯白噪声,经过信道传输后进行解调。对调制解调过程中的波形进行时域和频域观察,并且对解调结果进行误码率测量。2PSK信号的解调选用相干解调法。 ⑹2DPSK言号传输仿真 按照2DPSK产生模型和解调模型分别产生2DPSK言号和高斯白噪声,经过信道传输后进行解调。对调制解调过程中的波形进行时域和频域观察,并且对解调结果进行误码率测量。2DPSK信号的解调可以选用非相干解调或者相干解调法。 (7) 模拟信号的数字传输 产生模拟语音信号,进行PCM编码过程的计算机仿真。仿真发送端采样、 量化编码的过程、仿真接收端恢复语音信号的过程。按照有或者无信道噪 声两种情况分别进行仿真。
人工智能基础 大作业 —---八数码难题 学院:数学与计算机科学学院 班级:计科14—1 姓名:王佳乐 学号:12 2016、12、20 一、实验名称 八数码难题得启发式搜索 二、实验目得 八数码问题:在3×3得方格棋盘上,摆放着1到8这八个数码,有1个方格就是空得,其初始状态如图1所示,要求对空格执行空格左移、空格右移、空格上移与空格下移这四个操作使得棋盘从初始状态到目标状态. 要求:1、熟悉人工智能系统中得问题求解过程; 2、熟悉状态空间得启发式搜索算法得应用; 3、熟悉对八数码问题得建模、求解及编程语言得应用。 三、实验设备及软件环境 1.实验编程工具:VC++ 6、0 2.实验环境:Windows7 64位 四、实验方法:启发式搜索 1、算法描述 1.将S放入open表,计算估价函数f(s)
2.判断open表就是否为空,若为空则搜索失败,否则,将open表中得第 一个元素加入close表并对其进行扩展(每次扩展后加入open表中 得元素按照代价得大小从小到大排序,找到代价最小得节点进行扩展) 注:代价得计算公式f(n)=d(n)+w(n)、其中f(n)为总代价,d(n)为节点得度,w(n)用来计算节点中错放棋子得个数. 判断i就是否为目标节点,就是则成功,否则拓展i,计算后续节点f(j),利用f(j)对open表重新排序 2、算法流程图: 3、程序源代码: #include<stdio、h> # include<string、h> # include
微机上机作业三 容: 编写如下程序,并在机器上调试成功。程序采用菜单式选择,可以接收用户从键盘输入的五个命令(1-5),各命令功能分别为: (1)按下“1”键,完成字符串小写字母变成大写字母。 (2)按下“2”键,完成找最大值(二选一)。 (3)按下“3”键,完成排序(二选一)。 (4)按下“4”键,显示时间。 (5)按下“5”键,结束程序运行,返回系统提示符。 汇编程序: STACK SEGMENT STACK DB 256 DUP(?) TOP LABEL WORD STACK ENDS DATA SEGMENT TABLE DW G1, G2, G3, G4, G5 STRING0 DB' Form the school ID is 02111460 Li Cheng',0DH,0AH,'$' STRING1 DB '1. Change small letters into capital letters of string;', 0DH, 0AH, '$' STRING2 DB '2. Find the maximum of string;', 0DH, 0AH, '$' STRING3 DB '3. Sort for datas;', 0DH, 0AH, '$' STRING4 DB '4. Show Time;', 0DH, 0AH, '$' STRING5 DB '5. Exit.', 0DH, 0AH, '$' STRINGN DB 'Input the number you select (1-5) : $' IN_STR DB 'Input the string (including letters & numbers, less than 60 letters) :', 0DH, 0AH, '$' PRESTR DB 'Original string : $' NEWSTR DB 'New string : $' OUT_STR DB 'The string is $' MAXCHR DB 'The maximum is $' IN_NUM DB 'Input the numbers (0 - 255, no more than 20 numbers) : ', 0DH, 0AH, '$' OUT_NUM DB 'Sorted numbers : ', 0DH, 0AH, '$' IN_TIM DB 'Correct the time (HH:MM:SS) : $' HINTSTR DB 'Press ESC, go back to the menu; or press any key to play again!$' KEYBUF DB 61 DB ? DB 61 DUP (?) NUMBUF DB ? DB 20 DUP (?) DATA ENDS
1.请选用框架法和语义网络法表示下述报道的沙尘暴灾害事件。 (虚拟新华社3月16日电)昨日,沙尘暴袭击韩国汉城,气场与高速公路被迫关闭,造成的损失不详。此次沙尘暴起因中韩专家认为是由于中国内蒙古地区过分垦牧破坏植被所致。 (提示:分析概况用下划线标出的要点,经过概念化形成槽或节点) 2. 请用归结反演的方法求解下述问题。 已知:(1)John 是贼。 (2)Paul 喜欢酒(wine )。 (3)Paul 也喜欢奶酪(cheese )。 (4)如果Paul 喜欢某物,那么John 也喜欢某物。 (5)如果某人是贼,而且他喜欢某物,那么他就会偷窃该物。 请回答下面的问题:John 会偷窃什么? 3. MYCIN 是一个用于细菌感染性疾病诊断的专家系统,它的不确定性推理模型中采用可信度作为不确定性量度。请简述什么是不确定性推理及不确定性推理几个关键问题,并按照MYCIN 系统的推理方法计算结论B1和B2的可信度。 已知初始证据A1,A2,A3的可信度值均为1,推理规则如下: R1: IF A1 THEN B1 (0.8) R2: IF A2 THEN B1 (0.5) R3: IF A3∧B1 THEN B2 (0.8) 求CF(B1)和CF(B2)的值。 ()()()(),()0,()0121212 ()()()()(),()0,()012121212 ()()12,()()0121min{|()|,|()|}12CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H CF H ????????????????? +-?≥≥=++?<<+?<- 4.设A 、B 分别是论域U 、V 上的模糊集, U=V={1,2,3,4,5}, A=1/1+ 0.5/2, B=0.4/3+0.6/4+1/5 并设模糊知识及模糊证据分别为: IF x is A THEN y is B x is A ’ 其中,A ’的模糊集为:A ’=1/1+ 0.4/2+ 0.2/3 假设A 和A ’可以匹配,请利用模糊推理的方法求出该模糊知识和模糊证据能得出什么样的模糊结论。
西安电子科技大学 通信原理大作业蜂窝通信网 姓名: 班级: 学号:
蜂窝移动通信网 通信网是在多点之间传递信息的通信系统。通信网的基本组成部分是终端 设备、通信链路和交换设备,有些通信网中还包含转发设备。随着时代的发展,通信网也有着多种不同的应用和技术的进步。其中移动通信网在我们的生活中 起到无可取代的作用,蜂窝网是当前最主要的一种移动通信网,主要由基站、 移动台、移动交换中心组成,并与固定电话网相连。第一代蜂窝网采用模拟调 制体制,现已淘汰。第二段蜂窝网采用数字调制体制,以电话通信为主,目前 正在广泛使用中。我国采用的第二代蜂窝网体制主要是GSM。第三代蜂窝网正 在发展中,它应能满足数据传输和多媒体通信的需求,以及全球漫游。本文主 要介绍蜂窝移动通信网及其相关问题 1.蜂窝移动通信系统基本概述 蜂窝系统也叫“小区制”系统。是将所有要覆盖的地区划分为若干个小区,每个小区的半径可视用户的分布密度在1~10km左右。在每个小区设立一个基站 为本小区范围内的用户服务。并可通过小区分裂进一步提高系统容量。 这种系统由移动业务交换中心(MSC)、基站(BS)设备及移动台(MS)(用户设备)以及交换中心至基站的传输线组成。目前在我国运行的900MHz 第一代移动通信系统(TACS)模拟系统和第二代移动通信系统(GSM)数字系统 都属于这一类。 就是说移动台的移动交换中心与公共的电话交换网(就是我们平时所说的 电话网PSTN)之间相连,移动交换中心负责连接基站之间的通信,通话过程中,移动台(比如手机)与所属基站建立联系,由基站再与移动交换中心连接,最 后接入到公共电话网。 通过把地理区域分成一个个称为小区的部分,蜂窝系统就可以在这个区域 内提供无线覆盖。蜂窝无线系统指的是在地理上的服务区域内,移动用户和基 站的全体,而不是将一个用户连到一个基站的单个链路。 1
第一章 1.3 什么是人工智能?它的研究目标是什么? 人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 研究目标:人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。 1.7 人工智能有哪几个主要学派?各自的特点是什么? 主要学派:符号主义,联结主义和行为主义。 1.符号主义:认为人类智能的基本单元是符号,认识过程就是符号表示下的符号计算,从 而思维就是符号计算; 2.联结主义:认为人类智能的基本单元是神经元,认识过程是由神经元构成的网络的信息 传递,这种传递是并行分布进行的。 3.行为主义:认为,人工智能起源于控制论,提出智能取决于感知和行动,取决于对外界 复杂环境的适应,它不需要只是,不需要表示,不需要推理。 1.8 人工智能有哪些主要研究和应用领域?其中有哪些是新的研究热点? 1.研究领域:问题求解,逻辑推理与定理证明,自然语言理解,自动程序设计,专家系 统,机器学习,神经网络,机器人学,数据挖掘与知识发现,人工生命,系统与语言工具。 2.研究热点:专家系统,机器学习,神经网络,分布式人工智能与Agent,数据挖掘与 知识发现。 第二章 2.8 用谓词逻辑知识表示方法表示如下知识: (1)有人喜欢梅花,有人喜欢菊花,有人既喜欢梅花又喜欢菊花。 三步走:定义谓词,定义个体域,谓词表示 定义谓词 P(x):x是人 L(x,y):x喜欢y y的个体域:{梅花,菊花}。 将知识用谓词表示为: (?x)(P(x)→L(x, 梅花)∨L(x, 菊花)∨L(x, 梅花)∧L(x, 菊花)) (2) 不是每个计算机系的学生都喜欢在计算机上编程序。 定义谓词 S(x):x是计算机系学生