JBPM数据库表说明1 流程配置类数据库表:
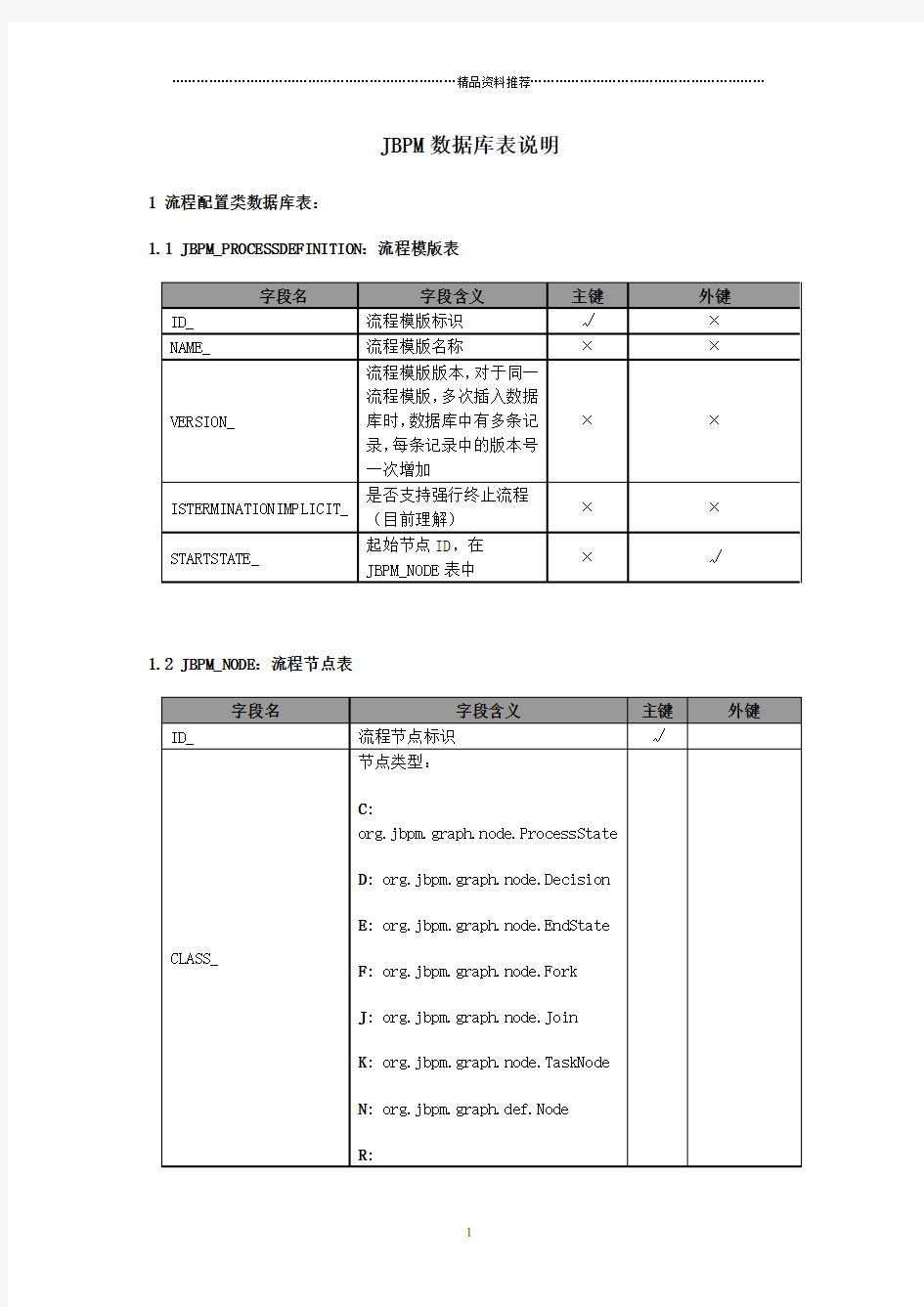
1.1 JBPM_PROCESSDEFINITION:流程模版表
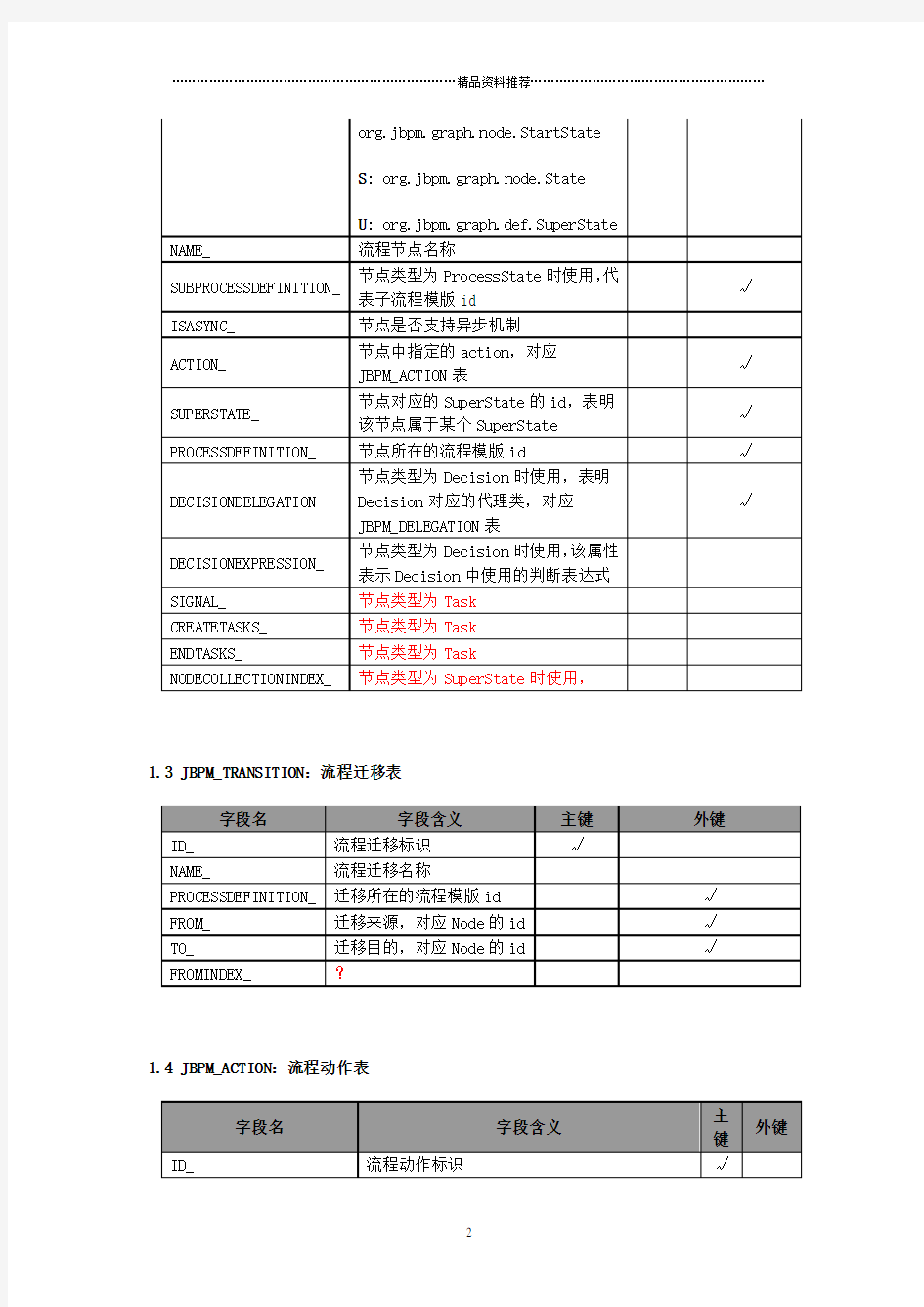
1.2 JBPM_NODE:流程节点表
1.3 JBPM_TRANSITION:流程迁移表
1.4 JBPM_ACTION:流程动作表
1.5 JBPM_EVENT:流程事件表
1.6 JBPM_DELEGATION:流程代理类表(用于实例化jbpm中的action类)
1.7 JBPM_TASK:流程任务表
1.8 JBPM_TASKCONTROLLER:流程任务控制器
系统分析师辅导:工作流管理系统体系结构设计 摘要:工作流管理系统将最终成为覆盖于各类台式机与网络操作系统之上的业务操作系统,但工作流技术目前还不够完善。作者在深入研究了工作流管理联盟提供的工作流管理系统模型和各大主流工作流管理系统的基础上设计了一套功能全面的工作流管理系统体系结构。本文主要从该体系结构的三个层次深入介绍了该系统结构。 关键词:工作流管理系统、业务操作系统、软件体系结构、业务建模 1、引言 在一个组织内部存在着两种信息:一种是数据信息,另一种是业务信息。在组织之间也同样存在着两种信息:一种是数据信息,另一种是业务往来信息。如果这两种信息用计算机系统来管理,前一种属于组织内部的信息系统,后一种属于B2B电子商务系统。目前对数据信息的计算机管理系统(即:数据库管理系统)经过多年的发展已经成熟。对业务过程的计算机管理系统由于比较复杂,可变因素较多,难度大,因此发展还不成熟。工作流技术作为现代组织实现过程管理与过程控制的一项关键技术,为组织的业务处理过程提供了一个从模型建立、管理到运行、分析的完整框架。同时,工作流管理系统(Workflow Management System ,WFMS)通过一套集成化、可互操作的软件工具为这个框架提供了全过程的支持。Thomas Koulopoulos曾预言:工作流管理系统将最终成为覆盖于各类台式机与网络操作系统(如:Windows,Unix,Windows NT)之上的业务操作系统BOS(Business Operating System),它将带来操作系统的一次革命。但是目前工作流技术无论从理论上还是从实践都还不够完善,要实现Thomas Koulopoulos的预言可能还需有一段路要走。本文主要介绍了由作者独立设计一套工作流管理系统体系结构,以供工作流技术爱好者参考。 2、工作流管理系统的基本概念 顾名思义,工作流就是工作任务在多个人或单位之间的流转。在计算机网络环境下,这种流转实际上表现为信息或数据在多个人之间的传送。工作流管理联盟( Workflow Management Coalition ,WfMC)对工作流的定义是:“业务过程的部分或全部在计算机应用环境下的自动化”。她所要解决的主要问题是,“使在多个参与者之间按照某种预定义规则传递的文档、信息或任务的过程自动进行,从而实现某个预期的业务目标,或者是促使此目标的实现”。 工作流管理系统就是通过管理一序列的工作活动以及相关人员、资源、信息技术资料来提供业务处理程序上的自动控制。工作流管理系统通过计算机软件来定义、管理和执行工作流程。在工作流管理系统中计算机运用程序的执行顺序是由工作流逻辑的计算机描述来驱动的。她的主要目标是对业务过程中各步骤(或称活动、环节)发生的先后次序,以及同各个步骤相关的人力、资源、信息资料的调用等进行管理,从而实现业务过程的自动化。当然这种管理可能会在不同的信息及通信环境下实现,所涉及的范围可以小至一个只有几人的工作组,也可以大到政府、企业组织各个机构之间。工作流管理系统将人员、组织结构、设备资源、信息源(如数据库、文件系统、电子邮件、计算机辅助设计工具等)整和成一个整体。这样,工作流管理系统就成为了一个理想的用来收容业务逻辑的业务知识仓库,并给予业务逻辑一个易操作易控制的界面。 工作流管理系统的最大优点就是实现具体应用逻辑和过程逻辑的分离,实现在不修改具体功能的情况下,通过修改业务流程模板来改变系统的功能,完成对组织生产经营过程的部
数据库设计说明书 (模板) 编号: 日期:年月日 编制: XXXX
文档控制
目录 1概述 (1) 2数据库设计 (1) 2.1外部设计 (1) 2.1.1标识符 (1) 2.1.2使用程序 (1) 2.2支持软件 (1) 2.2.1数据库命名规则 (2) 2.2.2数据库对象命名规则 (2) 2.2.3字段命名规则 (3) 2.2.4SQL语句规则 (3) 2.3数据库的逻辑结构设计 (3) 2.3.1关系数据库的逻辑设计过程 (3) 2.3.2E-R模型转换为关系模型 (3) 2.4数据库的物理设计 (3) 2.4.2视图设计 (1) 2.4.3存储过程设计 (1) 2.4.4触发器设计 (1) 2.5安全性设计 (2) 2.5.1防止用户直接操作数据库的方法 (2) 2.5.2用户账号密码的加密方法 (2) 2.5.3角色与权限 (2) 2.6优化 (2) 2.7数据库管理与维护说明 (3)
1概述 描述该数据库设计说明书适用的项目需求。 2数据库设计 2.1外部设计 2.1.1标识符 提示: 详细说明用于唯一地标识该数据库的名称或标识符以及附加的描述性信息。 说明: 本节不能裁剪。 样例: 本数据库名称为db_ymt。ymt是应用名称“银码头”的拼音简写。 2.1.2使用程序 提示: 列出将要使用或访问此数据库的所有应用程序,对于这些应用程序的每一个,给出它的名称和版本号。 说明: 本节不能裁剪。 样例: 银码头系统 Version1.0 使用本数据库。 2.2支持软件 提示: 简单介绍同此数据库直接有关的支持软件,如数据库管理系统、存储定位程序和用于装入、生成、修改、更新数据库的程序等。说明这些软件的名称、版本号和主要功能特性,如所用数据模型的类型、允许的数据容量等。列出这些支持软件的技术文件的标题、编号及来源。 说明: 本节不能裁剪。 样例: Powerdesigner V10.0 用于设计和生成数据库结构。
环境准备 1、安装JDK 所有 JAVA 开发第一个需要安装的,没什么好说的。记得把系统变量 JAVA_HOME 设上。 2、安装Ant Ant 是使用 jBPM 必须的一个工具。 jBPM 中的很多操作都要用到 Ant 。 安装方法: ( 1 )先下载:https://www.doczj.com/doc/67435818.html,/dist/ant/binaries/,选一个如: apache-ant-1.6.5-bin.zip 。 ( 2 )解压到 D:\ant (当然其他目录也可以)。 ( 3 )设置如下系统变量: ANT_HOME=d:\ant 。 ( 4 )把 %ANT_HOME%\bin 加入到系统变量 PATH 中。 3、安装Eclipse Eclipse 不是开发 jBPM 必须的工具,但它是对 jBPM 开发很有帮助的工具,特别是 jBPM 提供了一个 Eclipse 插件用来辅助开发 jBPM 。关于 Eclipse 的安装不赘述了,本文用的版本是: Eclipse3.2 安装jBPM jBPM 的下载地址:https://www.doczj.com/doc/67435818.html,/products/jbpm/downloads ●JBoss jBPM 是jBPM 的软件包 ●JBoss jBPM Starters Kit 是一个综合包,它包括了jBPM 软件包、开发插件、一个配置好了的基于JBoss 的jBPM 示例、一些数据库配置文件示例。 ●JBoss jBPM Process Designer Plugin 是辅助开发jBPM 的Eclipse 插件。 ●JBoss jBPM BPEL Extension jBPM 关于BPEL 的扩展包 本指南选择下载:JBoss jBPM Starters Kit 。下载后解压到D:\jbpm-starters-kit-3.1 ,目录下含有五个子目录: ●jbpm jBPM 的软件包 ●jbpm-bpel 只含有一个网页
第五讲数据库表和数据库关系的实现 5.1数据类型 定义数据表的字段、声明程序中的变量时,都需要为他们设置一个数据类型。目的是指定该字段或变量所存放的数据类型,以及需要多少空间。 5.1.1整型:可以用来存放整数数据的字段或变量。有bigint、int、smallint、 两种类型,这两种类型完全相同,一般建议使用numeric。 使用numeric或decimal时,必须指明精确度(即全部有效位数)与小数点位数,例如:numeric(5,2)表示精度为5,总共位数为5位,其中3位整数及2位小数。若不指定,则默认值为numeric(18,0)。精确度可指定的范围为1~38, 取其“近似值”。例如:23456646677799变成 2.3E+13,此类数据类型有float 和real两种。注意:使用float和real类型,若数值的位数超过其有效位数的限
其中varchar及text的实际存储长度会依数据量而调整。如:varchar(10)表示最多可存储10字节,但若只填入5个字符,那么只会占用5字节。char与varchar 最多只能存储8000个字符,若数据超过此长度,请改用text类型。 在使用char及varchar时必须指定字符长度,例如char(50)、varchar(50); 的数据与字符串类型相当类似,Unicode字符串的一个字符是用2个字节存储,而一般字符串是一个字符用1个字节存储。此类数据类型有nchar、nvarchar、ntext。 在使用nchar及nvarchar时必须指定字符长度,例如nchar(50)、nvarchar 据多用16进制表示,而且要加上0x字头)。此类数据类型有binary、varbinary 与image,其特性分别相当于字符串类型的char、varchar、text。image类型还可以用来存放word文件、excel电子表格、以及位图、GIF和JPEG文件。 使用binary及varbinary时须指定字符长度,例如binary(50)、varbinary(30);若未指定,默认值为1。Image类型则不必指定长度。
3.简述如下概念,并说明它们之间的联系与区别:。 (1)域,笛卡尔积,关系,元组,属性 答:域:域是一组具有相同数据类型的值的集合。 笛卡尔积:给定一组域D1,D2,…,Dn,这些域中可以有相同的。这组域的笛卡尔积为:D1×D2×…×Dn={(d1,d2,…,dn)|di?Di,i=1,2,…,n }其中每一个元素(d1,d2,…,dn)叫作一个n元组(n-tuple)或简称元组(Tuple)。元素中的每一个值di叫作一个分量(Component)。 关系:在域D1,D2,…,Dn上笛卡尔积D1×D2×…×Dn的子集称为关系,表示为 R(D1,D2,…,Dn) 元组:关系中的每个元素是关系中的元组。 属性:关系也是一个二维表,表的每行对应一个元组,表的每列对应一个域。由于域可以相同,为了加以区分,必须对每列起一个名字,称为属性(Attribute)。 (2)超码,主码,候选码,外码 答:超码:对于关系r的一个或多个属性的集合A,如果属性集A可以唯一地标识关系r中的一个元组,则称属性集A为关系r的一个超码 (superkey) 。 候选码:若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码(Candidate key)。 主码:若一个关系有多个候选码,则选定其中一个为主码(Primary key)。 外码:设F是基本关系R的一个或一组属性,但不是关系R的码,如果F与基本关系S 的主码Ks相对应,则称F是基本关系R的外码(Foreign key),简称外码。 基本关系R称为参照关系(Referencing relation),基本关系S称为被参照关系(Referenced relation)或目标关系(Target relation)。关系R和S可以是相同的关系。 (3)关系模式,关系,关系数据库 答:关系模式:关系的描述称为关系模式(Relation Schema)。它可以形式化地表示为:R(U,D,dom,F) 其中R为关系名,U为组成该关系的属性名集合,D为属性组U中属性所来自的域,dom 为属性向域的映象集合,F为属性间数据的依赖关系集合。 关系:在域D1,D2,…,Dn上笛卡尔积D1×D2×…×Dn的子集称为关系,表示为 R(D1,D2,…,Dn) 关系是关系模式在某一时刻的状态或内容。关系模式是静态的、稳定的,而关系是动态的、随时间不断变化的,因为关系操作在不断地更新着数据库中的数据。 关系数据库:关系数据库也有型和值之分。关系数据库的型也称为关系数据库模式,是对关系数据库的描述,它包括若干域的定义以及在这些域上定义的若干关系模式。关系数据库的值是这些关系模式在某一时刻对应的关系的集合,通常就称为关系数据库。 2.3.为什么需要空值null? 答:引入空值,可以方便于数据库的维护和建立,数字或者字符有时并不能解决想要解决的问题,毕竟它们是真实的存在,有了空值,那么有些操作,比如查询,插入,删除都可以更加方便,比如公司的部门,新增的部门,信息是不存在的,是之后数据库人员进行添加之后才有的,所以让它为空,比给它0更加贴近实际。空值是所有可能的域的一个取值,表明值未知或不存在。 2.3.关系模型的完整性规则有哪些? 答:关系模型的完整性规则是对关系的某种约束条件。关系模型中可以有三类完整性约束:实体完整性、参照完整性和用户定义的完整性。 其中实体完整性和参照完整性是关系模型必须满足的完整性约束条件,被称作是关系的
activity工作流表结构分析 activity工作流表结构分析 版权声明:本文为博主原创文章,未经博主允许不得转载。 1、结构设计 1.1、逻辑结构设计 Activiti使用到的表都是ACT_开头的。 ACT_RE_*: ’RE’表示repository(存储),RepositoryService接口所操作的表。带此前缀的表包含的是静态信息,如,流程定义,流程的资源(图片,规则等)。 ACT_RU_*: ‘RU’表示runtime,运行时表-RuntimeService。这是运行时的表存储着流程变量,用户任务,变量,职责(job)等运行时的数据。Activiti只存储实例执行期间的运行时数据,当流程实例结束时,将删除这些记录。这就保证了这些运行时的表小且快。 ACT_ID_*: ’ID’表示identity (组织机构),IdentityService接口所操作的表。用户记录,流程中使用到的用户和组。这些表包含标识的信息,如用户,用户组,等等。 ACT_HI_*: ’HI’表示history,历史数据表,HistoryService。就是这些表包含着流程执行的历史相关数据,如结束的流程实例,变量,任务,等等ACT_GE_*: 全局通用数据及设置(general),各种情况都使用的数据。 1.2、所有表的含义
序号表名说明 1 act_ge_bytearray二进制数据表 2 act_g e_property 属性数据表存储整个流程引擎级别的数据,初始化表结构时,会默认插入三条记录, 3 act_hi_actinst历史节点表 4 act_hi_attachment历史附件表 5 act_hi_comment历史意见表 6 act_hi_identitylink历史流程人员表 7 act_hi_detail历史详情表,提供历史变量的查询 8 act_hi_procinst历史流程实例表 9 act_hi_taskinst历史任务实例表 10act_hi_varinst历史变量表 11act_id_group用户组信息表 12act_id_info用户扩展信息表 13act_id_membership用户与用户组对应信息表 14act_id_user用户信息表 15. act_re_deployment部署信息表 16. act_re_model流程设计模型部署表 17act_re_procdef流程定义数据表 18act_ru_event_subscr throwEvent、catchEvent时间监听信息表 19act_ru_execution运行时流程执行实例表 20act_ru_identitylink运行时流程人员表,主要存储任务节点与参与者的相关信息 21act_ru_job运行时定时任务数据表 22act_ru_task运行时任务节点表 23act_ru_variable运行时流程变量数据表 2、表以及索引信息 2.1 二进制数据表(act_ge_bytearray) 2.1.1 简要描述 保存流程定义图片和xml、Serializable(序列化)的变量,即保存所有二进制数据,特别注意类路径部署时候,不要把svn等隐藏文件或者其他与流程无关的文件也一起部署到该表中,会造成一些错误(可能导致流程定义无法删除)。 2.1.2 表结构说明
关于数据库表的说明 T_CD表存放所有要调用:物料名称、物料代码、库存地名称、指令执行情况、普通或者连续供料、班次、班组。 T_EMPLOYEE表存放的是:班组、班次、用户名称等用户信息。T_ERROR表存放的是:程序执行中所出现的记录,都存放到这张表中。 T_FACTORY_TO_FACTORY_ORDER表存放的是:厂际间的指令都存放到这张表中。 T_FACTORY_TO_FACTORY_PLAN表存放的是:从3级下发的厂际计划都存放到这张表中。 T_FACTORY_TO_FACTORY_RSLT表存放的是:厂际间所有产生的实绩记录都在这张表中。 T_FLOW表存放的是:所有流程的使用情况。 T_FLOW_CHILD表存放的是:每一条流程包括的皮带设备名称,流程选择时,出现的该流程所包含的设备。 T_FLOW_ENABLE表存放的是:每条流程的相干性。 T_FLOW_L2L1_RELATION表存放的是:每条流程是普通供料,还是连续供料情况,在TR中绑定的一级程序点。 T_FLOW_STACK_RELATION表存放的是:流程选择时,堆取料机所对应的料堆情况。 T_GET_FLOW_ENABLED表存放的是:每条留成当前的可用状
态。 T_IN_ORDER表存放的是:所有入库指令都存放在该表中,只要存储的指令都存放到该表中。 T_IN_PLAN表存放的是:三级系统给二级系统下发的入库作业计划,都存放到该表中。 T_IN_RSLT表存放的是:执行完的入库指令,所生成的入库作业实绩记录都存放在该表中。 T_JOB_DEL_LOG表存放的是:绑定TNS要执行的数据定期删除工作项目。 T_L1_CONTROL表存放的是:TNS绑定的流程设备是否通过TNS 下发给一级了,可以到该表中查询,并且能更改状态。T_L2L1_HY_DISK_FLUX表存放的是:混匀14台圆盘给料机的当前瞬时流量。 T_L2L1_HY_DZC表存放的是:混匀电子称累计重量、启动状态、清零指令。 T_L2L1_JL_PDC表存放的是:24台皮带秤的清零、当前重量、当前状态。 T_L2L1_SET_HYGJ表存放的是:二级给一级下发圆盘给料机的瞬时流量值。 T_L2L1_SFY_AVR表存放的是:水分仪的实时值。 T_L2L1_STORE_BLAST表存放的是:料仓料位计的当前实际数值。
Jbpm工作流与ssh框架集成 目录 简述 使用jbpm-starters-kit-3.1.4生成数据库表及安装eclipse图形化配置插件部署jbpm的jar包和moudle的jar包 部署hbm文件到项目 设置大字段string-max 配置configration、template 过滤器的设置与建立 编写发布流程定义xml的人机页面及程序 写在最后
简述 Jbpm工作流框架与现有ssh框架的集成工作其实很简单,但国内外的资料太小,所以会在集成时走入太多误区,本文是在struts1.2,spring2.5,hibernat e3.2上集成成功的详细步骤。其中解决了,jbpm的访问数据库session与原有h ibernate的session不同的问题,string-max大字段问题。完成了流程部署web 及后台程序。利用spring-modules-0.8当中的spring31做为集成的桥梁(其实它已经做好了集成,但文档和实例实在是太简单)。 使用jbpm-starters-kit-3.1.4生成数据库表及安装eclipse图形化配置插件 1下载jbpm-starters-kit-3.1.4到其网站,包含所有需要的工具及jar包。 2数据库的安装以oracle为例,其它数据库可按此例修改。 2.1创建所需用户及表空间,如果有了用户和表空间就不需要了。 2.2 找到jbpm-starters-kit- 3.1.4文件夹,在其下的jbpm文件夹的下级文件夹lib中加入oracle的驱动包ojdbc1 4.jar. 2.3 在jbpm\src\resources文件夹下建立oracle文件夹, 将\jbpm\src\resou rces\hsqldb里的create.db.hibernate.properties和identity.db.xml文件copy到刚刚建立的oracle文件夹当中. 2.4 修改create.db.hibernate.properties文件,修改目标数据库的连接属性如下: # these properties are used by the build script to create # a hypersonic database in the build/db directory that contains # the jbpm tables and a process deployed in there hibernate.dialect=org.hibernate.dialect.OracleDialect hibernate.connection.driver_class=oracle.jdbc.driver.OracleDriver hibernate.connection.url=jdbc:oracle:thin:@10.62.1.12:1521:oracle https://www.doczj.com/doc/67435818.html,ername=dpf hibernate.connection.password=dpf hibernate.show_sql=true hibernate.cache.provider_class=org.hibernate.cache.HashtableCacheProvider 2.5 修改jbpm\src\config.files\hibernate.cfg.xml文件,同样是配置数据库的连接属性如下:
Database术语表 Access method :访问方法 Alias:别名 Alternate keys:备用键,ER/关系模型Anomalies:异常 Application design:应用程序设计 Application server:应用服务器 Attribute:属性,关系模型 Attribute:属性,ER模型 Attribute inheritance:属性继承 Base table:基本表 Binary relationship:二元关系 Bottom-up approach:自底向上方法 Business rules:业务规则 Candidate key:候选键,ER/关系模型Cardinality:基数 Centralized approach:集中化方法,用于数据库设计Chasm trap:深坑陷阱 Client:客户端 Clustering field:群集字段 Clustering index:群集索引 Column:列,参见属性(attribute) Complex relationship:复杂关系 Composite attribute:复合属性 Composite key:复合键 Concurrency control:并发控制 Constraint:约束 Data conversion and loading:数据转换和加载Data dictionary:数据字典 Data independence:数据独立性 Data model:数据模型 Data redundancy:数据冗余 Data security:数据安全 Database:数据库 Database design:数据库设计 Database integrity:数据库完整性 Database Management System:数据管理系统Database planning:数据库规划 Database server数据库服务器 DBMS engine:DBMS引擎 DBMS selection:DBMS选择 Degree of a relationship:关系的度Denormalization:反规范化
表名表说明 T_Condition 报表条件 T_ConditionDetail 报表条件详细值 T_DatacenterUser 基层用户信息 T_FadeBespeak 调查退订表 T_fieldItem 调查项目表输入项信息 T_fieldItemDetail 调查项目表输入项信息详细 T_InceptForm 调查总表 T_InputReport 输入报表信息 T_InputReportConfirm 输入报表确认 T_InputReportCrm 可录入基层单位 T_InputReportItem 输入项信息 T_InputReportItemClose 输入项锁定 T_InputReportItemtype 输入项信息种类 T_OutReport 输出报表信息 T_OutReportCondition 输出报表条件项 T_OutReportItem 输出报表项定义 T_OutReportItemCondition 输出报表项中的条件信息 T_OutReportItemCoordinate T_OutReportItemRow 输出报表项中的行展开循环信息 T_OutReportItemRowGroup 输出报表项中第一列指定的客户信息T_OutReportItemTable 输出报表项中的表名信息 T_OutReportShare 输出报表共享信息 T_OutReportStatitem 明细报表报表统计项 T_ReportStatitemTable 明细报表数据库表信息 T_ResearchTable 调查表 T_ Statitem 统计项维护 T_SurveyItem 调查项目表 SMS_Message 短信信息表 HrmRoleMembers 人力资源角色成员表 HrmRoles 人力资源角色表 Prj_Cpt 项目资产表 Prj_ProjectInfo 项目基本信息表 Prj_ProjectStatus 项目状态表 Prj_ProjectType 项目类型表 Prj_T_ShareInfo 项目类型共享信息表 Prj_Task_NeedDoc 项目任务所需文档表 Prj_Task_NeedWf 项目任务所需流程表 Prj_Task_ReferDoc 项目任务参考文档表 Prj_TaskProcess 项目任务信息表 Prj_Template 项目模板信息表 Prj_TemplateTask 项目任务模板信息表 Prj_TaskTemplet_NeedDoc 项目任务模板所需文档表 Prj_TempletTask_NeedWf 项目任务模板所需流程表
网约车平台数据库接入情况表说明表(2) 测试接口数据问题明细说明: 1上报记录数量不足,要求车辆、驾驶员报送记录数量超过200,实际完成订单数量500以上,驾驶员和车辆定位信息6000以上。并且车辆保险信息、车辆里程统计信息、驾驶员培训信息、驾驶员信誉等记录数量应与车辆、驾驶员数量相符。 2. 接口中非必选字段,也就是数据表中必选选项为“否”,目前统一要求尽可能填全,规范有些细节还不是很完善,数据表中必选选项为“否”也需要上报。 A.4.1 BusinessScope 经营范围按照网络预约出租汽车经营许可证内容填写 注册资本的格式小写加汉字,单位万元,例如“3000万元”。 A.4.3 State 状态 0:有效1:失效 A.4.6 合乘车的运价比网约车的运价低。 时间的填报需严格按照总体技术要求的格式填报 OtherPeakTimeOn 其他营运高峰时间起需填报 OtherPeakTimeOff 其他营运高峰时间止需填报 FareType运价类型编码,尽可能用英文或数字 faretypenote运价类型要填写中文说明,例如“XXX运价”。 运价生效失效日期要填报符合正常业务逻辑 A.4.7 无数据 A.4.10 无数据 A.4.11 数据量不足200,目前只有198条 A.4.12 数据量不足200,目前只有198条 AppVersion 使用APP版本号应填报 A.4.13 数据量不足200,目前只有198条 A.4.14 重新推送 PassengerGender 乘客性别 1:男 2:女 FTP 文件不符合规范。 A.5.1 FareType 运价类型编码运价填报应与订单类型对应,非合乘订单应 填报非合乘的运价编码 A.6.3 FareType 运价类型编码运价填报应与订单类型对应,非合乘订单应 填报非合乘的运价编码 A.6.5 FareType 运价类型编码运价填报应与订单类型对应,非合乘订单应 填报非合乘的运价编码 A7.1 A7.2 接口,可以查询到驾驶员车辆定位信息 注意车辆和驾驶员定位信息报送要求 1 定位辅助信息,包括速度、方向等也应尽量采集报送。 2 BizStatus营运状态,技术要求中要求填报 1:载客,2:接单,3:空驶,4:停运,其中1、2状态,有订单号码,3、4状态,订单号码 0 ,不同营运状态的记录都应有报送
目录 一 Codd的RDBMS12法则——RDBMS的起源 二关系型数据库设计阶段 三设计原则 四命名规则 数据库设计,一个软件项目成功的基石。很多从业人员都认为,数据库设计其实不那么重要。现实中的情景也相当雷同,开发人员的数量是数据库设计人员的数倍。多数人使用数据库中的一部分,所以也会把数据库设计想的如此简单。其实不然,数据库设计也是门学问。 从笔者的经历看来,笔者更赞成在项目早期由开发者进行数据库设计(后期调优需要DBA)。根据笔者的项目经验,一个精通OOP和ORM的开发者,设计的数据库往往更为合理,更能适应需求的变化,如果追其原因,笔者个人猜测是因为数据库的规范化,与OO的部分思想雷同(如内聚)。而DBA,设计的数据库的优势是能将DBMS的能力发挥到极致,能够使用SQL和DBMS实现很多程序实现的逻辑,与开发者相比,DBA优化过的数据库更为高效和稳定。如标题所示,本文旨在分享一名开发者的数据库设计经验,并不涉及复杂的SQL语句或DBMS使用,因此也不会局限到某种DBMS产品上。真切地希望这篇文章对开发者能有所帮助,也希望读者能帮助笔者查漏补缺。 一?Codd的RDBMS12法则——RDBMS的起源 Edgar Frank Codd(埃德加·弗兰克·科德)被誉为“关系数据库之父”,并因为在数据库管理系统的理论和实践方面的杰出贡献于1981年获图灵奖。在1985年,Codd 博士发布了12条规则,这些规则简明的定义出一个关系型数据库的理念,它们被作为所有关系数据库系统的设计指导性方针。 1.信息法则?关系数据库中的所有信息都用唯一的一种方式表示——表中的值。 2.保证访问法则?依靠表名、主键值和列名的组合,保证能访问每个数据项。 3.空值的系统化处理?支持空值(NULL),以系统化的方式处理空值,空值不依赖于数据类型。 4.基于关系模型的动态联机目录?数据库的描述应该是自描述的,在逻辑级别上和普通数据采用同样 的表示方式,即数据库必须含有描述该数据库结构的系统表或者数据库描述信息应该包含在用 户可以访问的表中。 5.统一的数据子语言法则?一个关系数据库系统可以支持几种语言和多种终端使用方式,但必须至少 有一种语言,它的语句能够一某种定义良好的语法表示为字符串,并能全面地支持以下所有规 则:数据定义、视图定义、数据操作、约束、授权以及事务。(这种语言就是SQL) 6.视图更新法则?所有理论上可以更新的视图也可以由系统更新。 7.高级的插入、更新和删除操作?把一个基础关系或派生关系作为单个操作对象处理的能力不仅适应 于数据的检索,还适用于数据的插入、修改个删除,即在插入、修改和删除操作中数据行被视 作集合。 8.数据的物理独立性?不管数据库的数据在存储表示或访问方式上怎么变化,应用程序和终端活动都 保持着逻辑上的不变性。 9.数据的逻辑独立性?当对表做了理论上不会损害信息的改变时,应用程序和终端活动都会保持逻辑 上的不变性。 10.数据完整性的独立性?专用于某个关系型数据库的完整性约束必须可以用关系数据库子语言定 义,而且可以存储在数据目录中,而非程序中。
很详细的系统架构图--专业推荐 2013.11.7
1.1.共享平台逻辑架构设计 如上图所示为本次共享资源平台逻辑架构图,上图整体展现说明包括以下几个方面: 1 应用系统建设 本次项目的一项重点就是实现原有应用系统的全面升级以及新的应用系统的开发,从而建立行业的全面的应用系统架构群。整体应用系统通过SOA面向服务管理架构模式实现应用组件的有效整合,完成应用系统的统一化管理与维护。 2 应用资源采集 整体应用系统资源统一分为两类,具体包括结构化资源和非机构化资源。本次项目就要实现对这两类资源的有效采集和管理。对于非结构化资源,我们将通过相应的资源采集工具完成数据的统一管理与维护。对于结构化资源,我们将通过全面的接口管理体系进行相应资源采集模板的搭建,采集后的数据经过有效的资源审核和分析处理后进入到数据交换平台进行有效管理。 3 数据分析与展现 采集完成的数据将通过有效的资源分析管理机制实现资源的有效管理与展现,具体包括了对资源的查询、分析、统计、汇总、报表、预测、决策等功能模块的搭建。 4 数据的应用 最终数据将通过内外网门户对外进行发布,相关人员包括局内各个部门人员、区各委办局、用人单位以及广大公众将可以通过不同的权限登录不同门户进行相关资源的查询,从而有效提升了我局整体应用服务质量。 综上,我们对本次项目整体逻辑架构进行了有效的构建,下面我们将从技术角度对相
关架构进行描述。 1.2.技术架构设计 如上图对本次项目整体技术架构进行了设计,从上图我们可以看出,本次项目整体建设内容应当包含了相关体系架构的搭建、应用功能完善可开发、应用资源全面共享与管理。下面我们将分别进行说明。 1.3.整体架构设计 上述两节,我们对共享平台整体逻辑架构以及项目搭建整体技术架构进行了分别的设计说明,通过上述设计,我们对整体项目的架构图进行了归纳如下:
1.工作流与JBPM 开发实例 前几天发了一篇文章,没几个人看也没人留言,看来我这功夫差的还是远啊,今天来一个实际点的吧。可能上回的废话太多。说说这个jbpm应该怎么来用。 首先当你想学一个框架的时候一定是你要有项目来用他了,OK,那么你项目当中的流程是什么你应该清楚吧,那么当你清楚了这些的时候我们就开始我们这个最简单的例子吧。 假如我们现在有这么一个例子,公司员工想报销点出差费,那么他要将他的申请提交给他的第一级领导——部门主管去审批,然后部门主管审批完了之后还要交给这个部门主管的上级公司老总进行审批。那么针对这个简单的流程,我们应该从哪里下手呢? 首先第一件事情就是写流程定义文件,那么这个文件我们用什么来写呢,他就是一个符合某个语法的xml文件,幸运的是jbpm给我们提供了一个集成的开发环境让我们来用。 首先去官网上下一个jbpm-jpdl-suite-3.2.GA包,解压后你会发现他里面有一个designer文件夹,那个里面就是我们写流程定义文件的开发环境,他是一个eclipse的插件,但是好像他给我们的那个eclipse版本有问题,建议大家从新下一个eclipse-SDK-3.2.1-win32.zip这个版本的eclipse,然后覆盖他给我们提供的那个。 准备工作做完了,那么我们就开始吧,首先我们打开解压目录下的designer 文件夹中的designer.bat文件,他弹出一个eclipse,然后我们就用这个东西来开发我们的流程定义文件了。 打开之后你就会看见一个他的小例子,不过我们不去用他,我们自己新建一个工程。右键-new-other-jBoss jbpm-process project。这个时候你会看见他弹出一个对话框,输入你的工程名字,然后点击next,这个时候你会发现他已经把jbpm加载进去了,记住要选中Generate simple ......。 工程建立完了,我们开始建立我们的流程定义文件。在工程里面你会发现src/main/jpdl这个source folder,然后你会看见他里面已经有了一个流程定义文件了,但是我们不去用他的,我们自己建立一个,右键src/main/jpdl,然后new-other-jBoss jbpm-process definition。这个时候他就会弹出一个对话框,起一个你要写的流程定义文件的名字输入进去,OK,可以了。这个时候你打开你建立的那个文件夹,里面就有processdefinition.xml文件,ok,打开他。 在右面的图里面你就可以看到一张什么都没有的白纸,我们看看这部分左面的那些东西,什么start啊,end啊,tasknode啊,fork啊,join啊。那我们来解释一下这是个什么东西呢,我们看看我们的需求,员工要写一个报销单,然
学科实验报告 班级2010级金融姓名陈光伟学科管理系统中计算机应用实验名称数据库的创建与表间关系的各种操作 实验工具Visual foxpro 6.0 实验目的1、掌握数据库结构的创建方式 2、表间的关联关系 实验步骤一、建立数据库。 1、在项目管理器中建立数据库。首先选择数据库,然后单击“新建”建立数据库,出现的界面提示用户输入数据库的名称,按要求输入后单击“保存”则完成数据库的建立,并打开i“数据库设计器”。 2、从“新建”对话框建立数据库。单击工具栏上的“新建”按钮或者选择菜单“文件——新建”打开“新建”对话框,首先在“文件类型”组框中选择“数据库”,然后单击“新建文件”建立数据库,后面的操作和步骤与1相同。 3、用命令交互建立数据库。命令是create database【databasename ▏?】 二、表间关系的各种操作。 1、创建索引文件。可以再创建数据表时建立其结构复合索引文件,但是也可以先建立好数据表,以后再创建或修改索引文件。 2、索引的操作。A、打开与关闭。要使用索引,必须先要打开索引。一旦数据表文件关闭所有相应的索引文件也就自动关闭了。B、确定主控索引。可以使用命令确定当前主控索引。命令格式1:set order to 【tag】<索引标识>【ascending| desceding】命令格式2:use<表文件名>order【tag】<索引标识>【ascending | esceding】C、删除索引标识。要删除结构复合索引文件中的索引标识,应当打开数据表文件,并打开其表设计器对话框。在“索引”页面中选定要删除的索引标识后,单击“删除”按钮删除。 3、创建关联。在创建数据表之间的关联时,把当前数据表叫做父表,而把要关联的表叫做子表。必须保证两个要建立关系的数据表中存在能够建立联系的同类字段;同时要求每个数据表事先分别以该字段建立了索引。A、建立表间的一对一的关系。在“数据库设计器”窗口中选择M表中的字段,并按住左键拖到关联表H中对应字段上,放开鼠标左键。这是可以看到在两个表之间的相关字段上产生了一条连线,表明两个表之间已经建立了“一对一”关系。B、建立表间一对多的关系。将M表的名称字段MC设定为主索引,或者候选索引;H表中的JG字段已经设置成普通索引。在“数据库设计器”窗口中将MC字段拖到关联表中对应字段JG上,放开鼠标左键。这时可以看到在两个表之间的相关字段上产生了一条显然与“一对一”关联不同形式的连线,表明两个表之间已经建立了“一对多”关系。 4、调整或删除关联。A、删除关联。在数据库设计器对话框窗口中,首先必须用鼠标左键单击关联线,该连线变粗了说明它已被选中。如果要删除可敲【del】。也可以单击鼠标右键在弹出对话框窗口中单击“删除关联”选项。B、编辑关联。在数据库设计器对话框窗口中,首先必须用鼠标左键单击关联线,该连线变粗了说明已被选中。在主菜单“数据库”选项的下拉菜单中的“编辑关系”选项,也可以单击鼠标右键在弹出对话框窗口中单击“编辑关系”选项。 5、设置数据表之间的参照完整性。在对数据库表建立关联关系后,就可以设置两个相关数据表之间操作的有效性原则。这些规则可以控制相关表中的记录的插入、删除或修改。
Activiti数据表结构 目录 1ACTIVITI数据库表结构 ----------------------------------------------------------------------------------------------- 2 1.1数据库表名说明 ------------------------------------------------------------------------------------------------ 2 1.2数据库表结构---------------------------------------------------------------------------------------------------- 3 1.2.1Activiti数据表清单: ---------------------------------------------------------------------------------------- 3 1.2.2表名:ACT_GE_BYTEARRAY (通用的流程定义和流程资源)-------------------------------- 3 1.2.3表名:ACT_GE_PROPERTY (系统相关属性) ----------------------------------------------------- 4 1.2.4表名:ACT_HI_ACTINST (历史节点表) ------------------------------------------------------------ 5 1.2.5表名:ACT_HI_ATTACHMENT (附件信息)-------------------------------------------------------- 6 1.2.6表名:ACT_HI_COMMENT (历史审批意见表)-------------------------------------------------- 6 1.2.7表名:ACT_HI_DETAIL (历史详细信息)----------------------------------------------------------- 7 1.2.8表名:ACT_HI_IDENTITYLINK (历史流程人员表) ---------------------------------------------- 8 1.2.9表名:ACT_HI_PROCINST(历史流程实例信息)核心表---------------------------------------- 8 1.2.10表名:ACT_HI_TASKINST(历史任务流程实例信息)核心表------------------------------ 9 1.2.11表名:ACT_HI_VARINST(历史变量信息) ------------------------------------------------------ 9 1.2.12表名:ACT_ID_GROUP(用户组表) ------------------------------------------------------------ 10 1.2.13表名:ACT_ID_INFO (用户扩展信息表) ---------------------------------------------------- 10 1.2.14表名:ACT_ID_MEMBERSHIP(用户用户组关联表) -------------------------------------- 11 1.2.15表名:ACT_ID_USER(用户信息表) ------------------------------------------------------------ 11 1.2.16表名:ACT_RE_DEPLOYMENT(部署信息表)------------------------------------------------ 12 1.2.17表名:ACT_RE_MODEL (流程设计模型部署表) ----------------------------------------------- 12 1.2.18表名:ACT_RE_PROCDEF (流程定义表) ---------------------------------------------------- 13 1.2.19表名:ACT_RU_EVENT_SUBSCR (运行时事件) ------------------------------------------------- 14 1.2.20表名:ACT_RU_EXECUTION (运行时流程执行实例) ----------------------------------- 15 1.2.21表名:ACT_RU_IDENTITYLINK(身份联系) --------------------------------------------------- 15 1.2.22表名:ACT_RU_JOB(运行中的任务)---------------------------------------------------------- 16 1.2.23表名:ACT_RU_TASK(运行时任务数据表) ------------------------------------------------------ 16 1.2.24表名:ACT_RU_VARIABLE(运行时流程变量数据表) ----------------------------------------- 17 2ACTIVITI中主要对象的关系 -------------------------------------------------------------------------------------- 18