
DATA new;
DO i=1TO4;
DO trt=1TO3;
INPUT y@@;
OUTPUT;
END;
END;
DROP trt;
CARDS;
0.0780.1330.128
0.0840.1390.134
0.0730.1280.123
0.0650.1200.115
PROC ANOVA;
CLASS I;
MODEL y=I;
MEANS I/DUNCAN;
RUN;
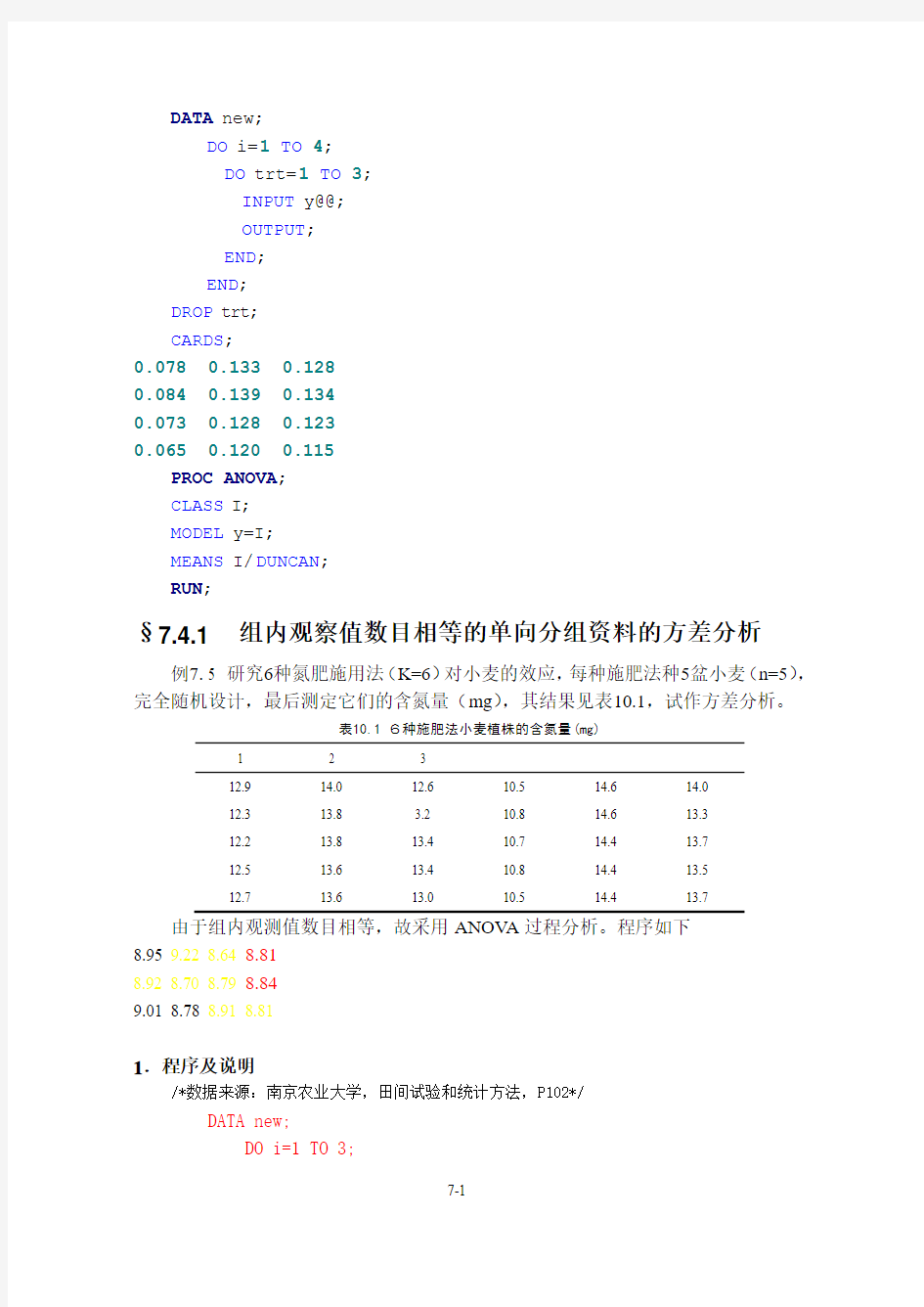
§7.4.1 组内观察值数目相等的单向分组资料的方差分析
例7.5 研究6种氮肥施用法(K=6)对小麦的效应,每种施肥法种5盆小麦(n=5),完全随机设计,最后测定它们的含氮量(mg),其结果见表10.1,试作方差分析。
表10.1 6种施肥法小麦植株的含氮量(mg)
1 2 3
12.9 14.0 12.6 10.5 14.6 14.0
12.3 13.8 3.2 10.8 14.6 13.3
12.2 13.8 13.4 10.7 14.4 13.7
12.5 13.6 13.4 10.8 14.4 13.5
12.7 13.6 13.0 10.5 14.4 13.7
由于组内观测值数目相等,故采用ANOV A过程分析。程序如下
8.95 9.22 8.64 8.81
8.92 8.70 8.79 8.84
9.01 8.78 8.91 8.81
1.程序及说明
/*数据来源:南京农业大学,田间试验和统计方法,P102*/
DATA new;
DO i=1 TO 3;
DO trt=1 TO 4;
INPUT y@@;
OUTPUT;
END;
END;
DROP i; /*删除临时变量I */
CARDS;
8.95
8.92
9.01
PROC ANOVA; /*调用ANOVA过程作方差分析*/
CLASS trt; /*规定以trt为分类变量 */
MODEL y=trt;
MEANS trt/DUNCAN; /*选用新复极差法作多重比较 */
RUN;
2.输出结果及说明
Analysis of Variance Procedure 方差分析过程
Class Level Information 处理水平信息
Class Levels Values
处理因素变量名水平数具体值
TRT 6 1 2 3 4 5 6
Number of observations in data set = 30 数据集中有30个观察值Dependent Variable: Y 依变量名为y
Sum of Mean
Source DF Squares Square F Value Pr > F
变异来源自由度平方和均方 F值概率值P
Model 5 44.46300000 8.89260000 164.17 0.0001
Error 24 1.30000000 0.05416667
Corrected Total 29 45.76300000
R-Square C.V. Root MSE Y Mean
所用模型的决定系数变异系数剩余标准差依变量均数
0.971593 1.786165 0.232737 13.0300000
Source DF Anova SS Mean Square F Value Pr > F
变异来源自由度平方和均方 F值概率值P
TRT 5 44.46300000 8.89260000 164.17 0.0001
Analysis of Variance Procedure
Duncan's Multiple Range Test for variable: Y 用DUNCAN法测验
NOTE: This test controls the type I experimentwise error rate
under the complete null hypothesis but not under
partial null hypotheses.
Alpha= 0.05 df= 24 MSE= 0.054167
α水平为0.05,自由度为24,MS误差为0.054167
Number of Means 2 3 4 5 6
Critical Range 0.3038 0.3191 0.3289 0.3358 0.3410 两两比较时的界值,两平均数之差大于该界值时则两组有统计学差异
Means with the same letter are not significantly different.
标有相同字母的两平均数间无差异
Duncan Grouping Mean N TRT
测验结果各组均数例数组别
A 14.4800 5 5
B 13.7600 5 2
B 13.6400 5 6
C 13.1200 5 3
D 12.5200 5 1
E 10.6600 5 4
在输出结果中,找CLASS语句指出的变量的Pr > F(概率)值。此例中,P≤0.0001,可得出各种施肥法间有极显著差异。说明6种施氮法的植株含氮量是显著不同的。
用DUNCAN新复极差法测验结果表明,除第2种施肥法和第6种施肥法之间的差异不显著外,其余各种方法间的差异均达到Alpha= 0.05水平,其中第5种施肥法的效果最好,其次是第2和第6种施肥法较好。
第7章方差分析
摘要:多组资料均数比较一般采用方差分析的方法,SAS中方差分析的功能非常全面,能实现方差分析功能的过程有ANOV A过程和GLM过程。
对于两个平均数的假设测验,一般采用t测验来完成,对于多个平均数的假设测验,若采用t测验两两进行,不仅非常麻烦,而且容易犯第一类错误。
方差或称均方,即标准差的平方,它是一个表示变异程度的量。在一项试验或调查中往往存在着许多种影响生物性状变异的因素,这些因素有较重要的,也有较次要的。方差分析就是将总变异分裂为各个因素的相应变异,作出其数量估计,从而发现各个因素在变异中所占的重要程度;而且除了可控制因素所引起的变异后,其剩余变异又可提供试验误差的准确而无偏的估计,作为统计假设测验的依据。
当试验结果受到多个因素的影响,而且也受到每个因素的各水平的影响时,为从数量上反映各因素以及各因素诸水平对试验结果的影响,可使用方差分析的方法。
SAS系统用于进行方差分析的过程主要有ANOV A过程和GLM过程,对于均衡数据的分析一般采用ANOV A过程,对于非均衡数据的分析一般采用GLM过程。
方差分析和协方差分析在SAS系统中由SAS/STAT模块来完成,其中我们常用的有ANOV A过程和GLM过程。前者运算速度较快,但功能较为有限;后者运算速度较慢,但功能强大,我们做协方差分析时就要用到GLM过程。本章将首先介绍方差分析所用数据集的建立技巧,然后重点介绍这两个程序步。
§7.1 方差分析概述
一、方差分析的应用场合、基本思想和前提条件
1.应用场合
当影响因素是定性变量(一般称为分组变量或原因变量),观测结果是定量变量(一般称为结果变量或反应变量),常用的数据处理方法是对均数或均值向量进行假设检验。
若只有一个原因变量,而且其水平数k≤2,一元时常用U检验、t检验、秩和检验,多元时用多元检验(T2检验或wilks’^检验);若原因变量的水平数k≥3或原因变量的个数≥2,一元时常用下检验,也叫一元方差分析(简写成ANOV A)或非参数检验,多元时用多元方差分析(简写成MANOV A,其中最常用的是Wilks’^检验)。2.基本思想
方差分析的基本思想可概述为:把全部数据关于总均数的离均差平方和分解成几个部分,每一部分表示某一影响因素或诸影响因素之间的交互作用所产生的效应,将各部分均方(即方差)与误差均方相比较,依据下分布作出统计推断,从而确认或否认某些因素或交互作用的重要性。
由于试验设计的类型多种多样,不同的设计类型往往需用不同的方差分析模型去处理,因此,用来作为度量影响因素作用大小的尺子——误差的均方,也就不是一成不变的了。这就出现了误差固定的设计类型及其定量资料的统计分析方法和误差变动的设计类型及其定量资料的统计分析方法。
3.前提条件
无论是进行ANOV A还是MANOV A,严格他说,都要求资料满足正态性和方差齐性的。要求,但方差齐性有时较难满足,此时可采用有关的非参数检验或对数据作某种变换后使之满足前提条件。此处仅给出一元情形时,如何用SAS程序实现对资料的正态性和方差齐性检验。
例7.1 为了研究轻度和重度再障贫血患者血清中可溶性CD,抗原水平(U/ml)与正常人有无显著性差别,以反映患者免疫状态紊乱而导致造血功能障碍的程度。从三种人群中分别随机地抽取了10人,测得CD8抗原水平如下,试对下列三组资料作正态性和方差齐性检验。
正常组:234,318,402,382,621,408,243,141,42,98。
轻度组:509,518,555,758,845,712,585,448,753,896。
重度组:851,562,918,631,653,843,659,849,762,901。
【分析与解答】
①关于正态性检验:H。:三组资料分别取自正态分布的总体;H1:三组资料并非取自正态分布的总体;α=0.05。
②关于方差齐性检验:H。:三组资料所取自的总体的方差相等;H1:三组资料所取自的总体的方差不相等或不全相等;α=0.05。
【SAS程序】
DATA aa;
DO g=1 TO 3;
INPUT X@@;
OUTPUT;
END;
CARDS;
234 509 851 318 518 562 402 555 918
382 758 631 621 845 653 408 712 843
243 585 659 141 448 849 42 753 762
98 896 901
PROC SORT DATA=aa;
BY g;
PROC PRINT;
RUN;
二、方差分析数据集的建立技巧
1.方差分析的数据集格式
统计分析所用的数据格式和我们在分析整理资料时所用的格式是不同的。一般来说,数据集中应至少有一个结果变量,用于记录不同处理因素水平下观察值的大小;至少有一个处理因素变量,用于记录处理因素的类型及其水平数。以单因素方差分析为例,就应有一个结果变量和一个处理因素变量;而两因素的方差分析应有一个结果变量和两个处理因素变量。
例A 某职业病防治院对31名石棉矿工中的石棉肺患者、可疑患者及非患者进行了用力肺活量测定,请给出数据集的结构。
解:数据集中应有两个变量,x和group。x记录肺活量的大小;group取值为1、2或3,分别代表石棉肺患者、可疑患者及非患者。
例B 某厂医务室测定了10名氟作业工人工前、工中及工后4小时的尿氟浓度,请给出数据集的结构。
解:数据集中应有三个变量,x、group和worker。x记录尿氟浓度;group取值为1、2或3,分别代表工前、工中及工后;worker取值为1到10,分别代表10名工人。
2.方差分析数据集的建立方法
可见方差分析的数据集其变量取值有一定的规律,因此可以利用循环语句和判断语句来简化输入。
例7.2 请建立例B的数据集。
解:此例中数据较有规律,各组的例数均相等,这可正是循环语句大显身手的时候。
data NEW;
do group=1 to 3;
do worker=1 to 10;
input X @@;
output;
end;
end;
cards;
90.53 88.43 47.37 ...... 105.27 58.95
proc print;
run;
§7.2 ANOVA(Analysis of Variance)过程
如果实验的每种组合安排相同数目的实验单位,则这种实验设计称为平衡设计。由于数据是平衡的,则平方和的计算可以简化。这样的方差分析可用ANOV A过程,不必用占机时更多的GLM过程。ANOV A过程可进行单向分组资料的方差分析、随机区组试验及拉丁方试验的统计分析等。
一、过程格式
PROC ANOV A 选择项;
CLASS 变量表;必需,指定要分析的处理因素
MODEL 依变量表=效应表/选择项; 必需,给出分析用的方差分析模型
MEANS 效应表/选择项; 指定要两两比较的因素及比较方法
FREQ 变量名;
TEST H=效果名称E=效果名称; 指定多元方差分析的选项
MANOV A H=效果名称E=效果名称M=变量的转换式
PREFIX=新变量的名称代号MNAMES=新变量名表/选择项;
REPEATED 重复变量的名称组名变量转换/选择项;
BY 变量表;
二、语句说明
程序中CLASS语句和MODEL语句是必需的,而且CLASS语句必须出现在MODEL语句之前。如果选用TEST和MANOV A语句,则必须放在MODEL语句之后。MEANS、TEST和MANOV A语句可以重复使用,其他语句只能使用一次。1.PROC ANOV A语句选择项
DATA=数据集指定用来分析的数据集名,若缺省,则使用最新建立的数据集。
MANOV A要求PROC ANOV A语句将含一个或一个以上依变量缺失值的观察值剔除。当使用交互式进行方差分析时,最好指定此选择项。
OUTSTAT=数据集输出结果中包括离差平方和(SS)、F值以及各试验效果的显著程度。
2.CLASS语句
声明方差分析中因素的分类水平处理变量,也称为分类变量,指明数据集中的自变量,可以是数值型,也可以是字符型。若为字符变量,其长度不超过16个字母。3.MODEL语句
指明依变量(因子变量)效应。效应是分类变量的各种组合,效应可以是主效应、交互效应、嵌套效应和混合效应。MODEL语句的选择项有两个:
NOUNI抑制单变量方差分析结果的输出;
INTERCEPT或INT要求SAS将线性模型内的截距(也称为数据的总平均数)当作一个参数,同时对该参数作是否为零的测验。
4.MEANS语句
计算并输出所列的效应对应的依变量均数。其主要选择项可分三类:
①多重比较选择项若指明了该选择项,则将进行主效应平均数间的测验,即多重比较。常用的多重比较方法选择项如DUNCAN(Duncan新复极差法)、T或LSD(配对t测验或Fisher氏最小显著差数法)、SNK(Q测验)、TUKEY(Tukey固定极差测验)、DUNNETT和DUNNETU(Dunnett氏最小显著差数两尾和单尾测验法)、BON、CABRIEL、REGWF、REGWQ、SCHEFFE、SIDAK、SMM(GT2)、W ALLER等。
②统计显著水平以ALPHA=P设定,如ALPHA=0.01设定显著水平为0.01,缺省值为0.05。
③E=效应名称规定F测验的分母,若缺省则试验设计的误差的均方将自动成为分母。
5.FREQ语句
指定频次变量。其用法与第5章用法相同。
6.TEST语句
一般情况下,SAS默认采用误差的均方(MS Residual)作为F测验的分母。但也可自定F测验的分子和分母以进行不同的F测验,该语句中H=分子,E=分母。如:“TEST H=A B E=A*B;”表示F=A/(A*B),F=B/(A*B)。
7.MANOV A语句
当MODEL中有一个以上依变量时,要求进行多变量的方差分析。8.REPEATED语句
指定在一个或多个独立变量上对分析单位进行重复测量设计的分析。在某些情况下采用此语句可以精简程序代码。
9.BY语句
要求按其指定变量分别进行方差分析。
三、使用说明:
设有三个因素A、B及C,一个观测变量Y。
(1)如果只考虑主效应,则需下列语句:
PROC ANOV A:
CLASS A B C;
MODEL Y=A B C;
(2)如果具有交叉因素,则需下列语句:
PROC ANOV A;
CLASS A B C;
MODEL A B C A*B A*C B*C A*B*C;
(3)如果A和B是主效应,C嵌套于A和B中(对A和B的每一组合,观测到C的水平是不同的),则需下列语句:
PROC ANOV A;
CLASS A B C;
MODEL Y=A B C(A B)
其中C(AB)表示C嵌套于A和B中。再如C(A)表示C嵌套于A中。
(4)如果既有嵌套又有交叉效应,则在MODEL语句中可同时使用*和()。例如:
PROC ANOV A;
CLASS A B C;
MOOEL Y=A B(A)C(A)B*C(A);
四、输出说明
(1)CLASS LEVEL INFORMA TION分类水平信息。其中包括:
CLASS CLASS语句中列出的效应名。
LEVELS 因素效应的水平数。
V ALUES 因素效应中各水平的值或标记。
(2)SOURCE变异来源。
(3)SUM OF SOUARES(SS)平方和。
(4)MEAN SQUARE(MS)均方。
(5)F V ALUE F值。其中MODEL(模型)的下值为MODEL(模型)的均方除以ERROR(误差)的均方。用于检验模型中所有效应均为零的假设,以便说明模型的重要程度。
(6)Pr>F显著水平。
(7)MODEL模型。它的平方和等于各因素效应的平方和之和,其均方等于它的平方和除以自由度。
(8)ERROR误差。
(9)CORRECTED TOTAL校正总变异。
(10)R-SQUANE R2,其值为模型的平方和除以校正总平方和。一般来说,R2值越大,模型拟合数据越好。
(11)C.V变异系数。样本的变异系数为该样本的标准差除以均值,表示单位量的变异。
(12)ROOT MSE 误差均方根,是观测变量的标准差的估计值。
(13)T TEST FOR V ARIABLE 各处理平均数的多重比较T检验,凡有一个相同标记字母的即为差异不显著,凡具有不同标记字母的即为差异显著。
§7.3 GLM(General Linear Model)过程
GLM是General Linear Model(一般线性模型)的缩写,用于非均衡数据方差分析。在SAS/STAT中,GLM过程的分析功能最多,回归分析、方差分析、偏相关分析、协方差分析、多元方差分析等比较复杂的分析过程均可采用GLM过程。这里只介绍GLM过程在方差分析中的应用。
前面介绍的ANOV A过程只能用于均衡设计资料的方差分析,当不均衡时,只能用采用GLM过程进行分析。
一、过程格式
PROC GLM选择项;
CLASS 变量表;
MODEL 依变量=效应表/选择项;
MEANS 效应表/选择项;
FREQ 变量名;
TEST H=效果名称E=效果名称;
MANOVA H=效果名称E=效果名称M=变量的转换式
PREFIX=新变量的名称代号
MNAMES=新变量名表/选择项;
RANDOM 效应表/选择项;
CONTRAST “对比说明” 各组效应系数/选择项;
REPEATED 重复变量的名称组名变量转换/选择项;
BY 变量表;
ID 变量表;
二、语句说明
CLASS语句和MODEL语句是必需的,且CLASS语必须出现在MODEL语句之前。
1.PROC GLM语句选择项
DATA=数据集指定用来分析的数据集名,若缺省,则使用最新建立的数据集。
ORDER=FREQ|DATA|INTERNAL|FORMATTED指定某一变量下各类别的输出次序。FREQ按递减计数次序排列;DATA按首先出现在输入数据集中的顺序放置;INTERNAL按值的内部表示排列;FORMATTED按外部的格式排列。缺省值为ORDER=INTERNAL。
MANOV A要求PROC ANOV A语句将含一个或一个以上依变量缺失值的观察值剔除。当使用交互式进行方差分析时,最好指定此选择项。
OUTSTAT=数据集输出结果中含离差平方和(SS)、F值以及各试验效果的显著程度。
NOPRINT要求PROC GLM抑制分析结果在报表上的输出。
2.RANDOM语句
用于指定模型中的随机效应。在MODEL语句后可多次应用RANDOM语句,若缺省则GLM过程将MODEL语句中的所有的效应为固定效应。其选择项有两个:Q 要求输出固定效应的二次式函数值。
TEST 要求对RANDOM语句中所指定的各项随机效应执行适当的F测验,并且F 测验的分母完全根据各效应的期望均方而定。需要注意的是:若某两个主效应被RANDOM指定为随机效应,其交互项并没有被相应指定为随机效应,需要特别指定。3.CONTRAST语句
用于对比测验。比较式的名字必须放在引号内,其长度最多为20个字符,命名方式可随意,但在其中不能出现“;”。各组效应系数前必须注明所要比较的效应,这些效应必须是MODEL语句中出现过的,这些系数的总和必须为0,而且只能是整数或小数,各系数间以空格隔开。该语句的选择项有:
E规定输出线性函数的向量;
E=效应名称指定以E的效应为CONTRAST中F测验的分母,系统默认值是误差的均方(MS Error);
ETYPE=1|2|3|4 用于指定计算E=效应名称中效应的离差均方的类型。4.PROC GLM过程中其他语句
CLASS语句、MODEL语句、MEANS语句等参见PROC ANOV A过程。
三、ANOVA过程和GLM过程中常用的数学模型
在使用ANOVA和GLM过程进行方差分析时,关键在于定义线性数学模型。同一试验资料选用不同的数学模型,结果将不同。因而需要依据试验设计选定正确的线性数学模型。
①模型定义语句的一般格式是:依变量=线性模型效应。线性模型效应主要有三类:
主效应直接写出效应变量,如:a。
交互效应以一个或多个以“*”号连接的变量表表示,如:a*b*c。
嵌套效应假定自变量b嵌套在主效应a中,则写作:b(a)。
②常用的模型定义语句有:
MODEL y=a; 单因素模型。
MODEL y= a b; 两因素主效模型。
MODEL y=a b a*b; 两因素主效带互作的模型。
MODEL y=a b(a); 嵌套(NESTED)模型,用于系统分组资料。
③在模型定义中,可以用“|”和“@n”简化模型效应的表达。“|”等价于将模型效应从左到右展开,“@n”表示互作效应和嵌套效应作用的最高元次。
常用模型简化表示法及其等价形式为:
a|b 等价于a b a*b
a|b|c 等价于a b a*b c a*c b*c a*b*c
a|b|c@2 等价于a b a*b c a*c b*c
a|c(b) 等价于a c(b) a*c(b)
a(b)|c(b) 等价于a(b) c(b) a*c(b)
a|b(a)|c 等价于a b(a) c a*c b(a)*c
a|b(a)|c@2 等价于a b(a) c a*c
a(b)|b(d e) 等价于a(b) b(d e)
四、使用说明
(1)对平衡资料的方差分析可用ANOVA过程,也可用GLM过程。但前者效率更高。对于非平衡资料的方差分析只能用GLM过程。
(2
例7.3 程序示例如下:
data new;
input n$ p$ y@@;
cards;
n1 p1 10 n1 p1 18 n2 p1 16 n2 p1 16
n1 p2 9 n1 p2 . n2 p2 24 n2 p2 28
proc glm;
class n p;
model y=n p n*p;
run;
上述程序中的数据也可用下面的方法读入:
例7.4
data new;
do p=1 to 2;
do n=1 to 2;
input y@@;
output;
end;
end;
cards;
10 18 16 16
9 . 24 28
proc glm;
class n p;
model y=n p n*p;
run;
§7.4 单向分组资料的方差分析
观察值仅按一个方向分组,同组各供试单位受相同处理,不同组受不同处理,也称完全随机设计实验。
§7.4.1 组内观察值数目相等的单向分组资料的方差分析
例7.5 研究6种氮肥施用法(K=6)对小麦的效应,每种施肥法种5盆小麦(n=5),完全随机设计,最后测定它们的含氮量(mg),其结果见表10.1,试作方差分析。
表10.1 6种施肥法小麦植株的含氮量(mg)
1 2 3 4 5 6
12.9 14.0 12.6 10.5 14.6 14.0
12.3 13.8 3.2 10.8 14.6 13.3
12.2 13.8 13.4 10.7 14.4 13.7
12.5 13.6 13.4 10.8 14.4 13.5
12.7 13.6 13.0 10.5 14.4 13.7
由于组内观测值数目相等,故采用ANOV A过程分析。程序如下:
1.程序及说明
/*数据来源:南京农业大学,田间试验和统计方法,P102*/
DATA new;
DO i=1 TO 5;
DO trt=1 TO 6;
INPUT y@@;
OUTPUT;
END;
END;
DROP i; /*删除临时变量I */
CARDS;
12.9 14.0 12.6 10.5 14.6 14.0
12.3 13.8 13.2 10.8 14.6 13.3
12.2 13.8 13.4 10.7 14.4 13.7
12.5 13.6 13.4 10.8 14.4 13.5
12.7 13.6 13.0 10.5 14.4 13.7
PROC ANOVA; /*调用ANOVA过程作方差分析*/
CLASS trt; /*规定以trt为分类变量 */
MODEL y=trt;
MEANS trt/DUNCAN; /*选用新复极差法作多重比较 */
RUN;
2.输出结果及说明
Analysis of Variance Procedure 方差分析过程
Class Level Information 处理水平信息
Class Levels Values
处理因素变量名水平数具体值
TRT 6 1 2 3 4 5 6
Number of observations in data set = 30 数据集中有30个观察值Dependent Variable: Y 依变量名为y
Sum of Mean
Source DF Squares Square F Value Pr > F
变异来源自由度平方和均方 F值概率值P
Model 5 44.46300000 8.89260000 164.17 0.0001
Error 24 1.30000000 0.05416667
Corrected Total 29 45.76300000
R-Square C.V. Root MSE Y Mean
所用模型的决定系数变异系数剩余标准差依变量均数
0.971593 1.786165 0.232737 13.0300000
Source DF Anova SS Mean Square F Value Pr > F
变异来源自由度平方和均方 F值概率值P
TRT 5 44.46300000 8.89260000 164.17 0.0001
Analysis of Variance Procedure
Duncan's Multiple Range Test for variable: Y 用DUNCAN法测验
NOTE: This test controls the type I experimentwise error rate
under the complete null hypothesis but not under
partial null hypotheses.
Alpha= 0.05 df= 24 MSE= 0.054167
α水平为0.05,自由度为24,MS误差为0.054167
Number of Means 2 3 4 5 6
Critical Range 0.3038 0.3191 0.3289 0.3358 0.3410 两两比较时的界值,两平均数之差大于该界值时则两组有统计学差异
Means with the same letter are not significantly different.
标有相同字母的两平均数间无差异
Duncan Grouping Mean N TRT
测验结果各组均数例数组别
A 14.4800 5 5
B 13.7600 5 2
B 13.6400 5 6
C 13.1200 5 3
D 12.5200 5 1
E 10.6600 5 4
在输出结果中,找CLASS语句指出的变量的Pr > F(概率)值。此例中,P≤0.0001,可得出各种施肥法间有极显著差异。说明6种施氮法的植株含氮量是显著不同的。
用DUNCAN新复极差法测验结果表明,除第2种施肥法和第6种施肥法之间的差异不显著外,其余各种方法间的差异均达到Alpha= 0.05水平,其中第5种施肥法的效果最好,其次是第2和第6种施肥法较好。
§7.4.2 组内观察值数目不等的单向分组资料的方差分析
例7.6 研究三块麦田的基本苗数,按面积比例抽取样点,得三块麦田各样点的苗数分别为:21,29,24,22,25,30,27,26;20,25,25,23,29,31,24,26,20,21;24,22,28,25,21, 26。
试作方差分析。
1.序及说明
/*数据来源:南京农业大学,田间试验和统计方法,P105*/
DATA new;
DO trt=1 TO 3; /* 变量trt代表不同麦田,其水平数是3 */
INPUT n; /* 变量n代表各组数据个数*/
DO i=1 TO n;
INPUT y@@;
OUTPUT;
END;
END;
DROP n i;
CARDS;
8
21 29 24 22 25 30 27 26
10
20 25 25 23 29 31 24 26 20 21
6
24 22 28 25 21 26
PROC GLM;
CLASS trt; /* 指明分类变量trt */
MODEL y=trt; /* 指明单因素的效果模型*/
RUN;
2.输出结果及说明
General Linear Models Procedure
Class Level Information
Class Levels Values
TRT 3 1 2 3
Number of observations in data set = 24
Dependent Variable: Y
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 2 6.76666667 3.38333333 0.32 0.7314
Error 21 223.73333333 10.65396825
Corrected Total 23 230.50000000
R-Square C.V. Root MSE Y Mean
0.029356 13.18805 3.264042 24.7500000
Source DF Type I SS Mean Square F Value Pr > F
TRT 2 6.76666667 3.38333333 0.32 0.7314 Source DF Type III SS Mean Square F Value Pr > F TRT 2 6.76666667 3.38333333 0.32 0.7314
麦田间:F=0.32,P=0.7314>0.05,故三块麦田的基本苗数是没有显著差异的。
F
§7.4.3 组内又分亚组的单向分组资料的方差分析
例7.7 在温室内以4种培养液培养某作物,每种3盆,每盆4株,一个月后测定其株高生长量(mm ),得结果见表10.2,试作方差分析。
1.程序及说明
/*数据来源:南京农业大学,田间试验和统计方法,P108*/
DATA new;
DO i=1 TO 4; /* i 为亚组内观察值数*/ DO trt="A","B","C","D"; /* trt 为组 */ DO pot=1 TO 3; /* pot 为亚组 */ INPUT y@@; OUTPUT; END;END;END; CARDS;
50 35 45 50 55 55 85 65 70 60 60 65 55 35 40 45 60 45 60 70 70 55 85 65 40 30 40 50 50 65 90 80 70 35 45 85 35 40 50 45 50 55 85 65 70 70 75 75 P ROC ANOVA;
CLASS trt pot i;
MODEL y=trt pot(trt) i(trt pot);/* 定义嵌套模型,用于系统分组资料 */
TEST H=trt E=pot(trt); /* 指明组效应采用亚组效应pot(trt)均方作误差项*/ TEST H=pot(trt) E=i(trt pot); /*亚组效应采用亚组内重复观察值间的均方作误差项*/ MEANS trt/DUNCAN E=pot(trt); /* 指定采用DUNCAN 法进行均值比较,α=0.05 */ MEANS trt/DUNCAN E=pot(trt) ALPHA=0.01; /* 采用DUNCAN 法进行均值比较,α=0.01 */ RUN;
2.输出结果及说明
Analysis of Variance Procedure
Class Level Information
Class Levels Values
TRT 4 A B C D
POT 3 1 2 3
I 4 1 2 3 4
Number of observations in data set = 48
Dependent Variable: Y
Source DF Sum of Squares Mean Square F Value Pr > F Model 47 11595.31250000 246.70877660 ··
Error 0 ··
Corrected Total 47 11595.31250000 /*采用合适的嵌套模型则不存在误差项*/
R-Square C.V. Root MSE Y Mean
1.000000 0 0 57.81250000
Source DF Anova SS Mean Square F Value Pr > F
TRT 3 7126.56250000 2375.52083333 ··
POT(TRT) 8 1262.50000000 157.81250000 ··
I(TRT*POT) 36 3206.25000000 89.06250000 ··
/* 因为没有误差项,这里不进行F值计算*/
/*下面分别输出组间和组内亚组间的方差计算*/
Tests of Hypotheses using the Anova MS for POT(TRT) as an error term
Source DF Anova SS Mean Square F Value Pr > F
TRT 3 7126.56250000 2375.52083333 15.05 0.0012
Tests of Hypotheses using the Anova MS for I(TRT*POT) as an error term
Source DF Anova SS Mean Square F Value Pr > F
POT(TRT) 8 1262.50000000 157.81250000 1.77 0.1154
Duncan's Multiple Range Test for variable: Y
NOTE: This test controls the type I comparisonwise error rate, not the experimentwise error rate
Alpha= 0.05 df= 8 MSE= 157.8125
Number of Means 2 3 4
Critical Range 11.83 12.32 12.60
Means with the same letter are not significantly different.
Duncan Grouping Mean N TRT
A 73.333 12 C
A 64.583 12 D
B 52.083 12 B
B 41.250 12 A
Alpha= 0.01 df= 8 MSE= 157.8125
Number of Means 2 3 4
Critical Range 17.21 17.91 18.34
Means with the same letter are not significantly different.
Duncan Grouping Mean N TRT
A 73.333 12 C
B A 64.583 12 D
B C 52.083 12 B
C 41.250 12 A
该试验不同培养液间有极显著的差异(P=0.0012<0.01),而同一培养液内各盆间的生长量无显著差异(P=0.1154>0.05)。故前者需要进行多重比较,而后者不需要进行多重比较。新复极差测验结果表明,4种培养液对生长的效应,除C与D、B与A 差异不显著外,其余对比均有显著或极显著差异。
§7.5 两向分组资料的方差分析
实验数据按两个因素交叉分组,称为两向分组资料(交叉分组)。
§7.5.1 组内只有单个观察值的两向分组资料的方差分析
例7.8 用生长素处理豌豆,共6处理。豌豆种子发芽后,分别在每一木箱中移植4株,每组6个木箱,每箱1个处理。试验共有4组24箱,试验时按组排于温室中,使同组各箱的环境条件一致。然后记录各箱见第一朵花时4株豌豆的总节数,其结见表7.8,试作方差分析。
表7.8 生长素处理豌豆的试验结果
组(B)
处理(A)
ⅠⅡⅢⅣ
对照(未处理)60 62 61 60
赤霉素65 65 68 65
动力精63 61 61 60
吲哚乙酸64 67 63 61
硫酸腺嘌呤62 65 62 64
马来酸61 62 62 65
1.程序及说明
/*数据来源:南京农业大学,田间试验和统计方法,P111*/
DATA new;
DO a=1 TO 6; /* a代表不同处理方法*/
DO b=1 TO 4; /* b代表区组因素内不同植株*/
INPUT x@@;
OUTPUT;
END;END;
CARDS;
60 62 61 60 65 65 68 65 63 61 61 60
64 67 63 61 62 65 62 64 61 62 62 65
PROC ANOV A;
CLASS a b;
MODEL x=a b; /* 指明二因素的效果模型*/
MEANS a/LSD; /* 由于本例中有对照,故用LSD法*/ RUN;/* 否则,常采用DUNCAN法*/
2.输出结果及说明
Analysis of Variance Procedure
Class Level Information
Class Levels Values
A 6 1 2 3 4 5 6
B 4 1 2 3 4
Number of observations in data set = 24
Dependent Variable: X
Source DF Sum of Squares Mean Square F Value Pr > F Model 8 71.33333333 8.91666667 3.09 0.0285 Error 15 43.29166667 2.88611111
Corrected Total 23 114.62500000
R-Square C.V. Root MSE X Mean
0.622319 2.701958 1.69885582 62.87500000
Source DF Anova SS Mean Square F Value Pr > F
A 5 65.87500000 13.17500000 4.56 0.0099
B 3 5.45833333 1.81944444 0.63 0.6066
T tests (LSD) for variable: X
NOTE: This test controls the type I comparisonwise error rate not the experimentwise error rate.
Alpha= 0.05 df= 15 MSE= 2.886111
Critical Value of T= 2.13
Least Significant Difference= 2.5605
Means with the same letter are not significantly different.
T Grouping Mean N A
A 65.750 4 2
B A 63.750 4 4
B A
C 63.250 4 5
B C 62.500 4 6
B C 61.250 4 3
C 60.750 4 1
总处理间:F=3.09,P=0.0285<0.05,故总体有显著差异。A因素:F=4.56,P=0.0099<0.05,故认为因素A(处理)间有显著差异。B因素:F=0.63,P=0.6066>0.05,故认为因素B(不同植株)间无显著差异。
例7.9 有一小麦品比试验,共有A、B、C、D、E、F、G、H8个品种,其中A是标准品种,采用随机区组设计,重复3次,小区计产面积200平方尺,其产量依次为:10.9,10.8,11.1,9.1,11.8,10.1,10.0,9.3;9.1,12.3,12.5,10.7,13.9,10.6,11.5,10.4;12.2,14.0,10. 5,10.1,16.8,11.8, 14.1,14.4。试作方差分析。
1.问题分析
本例采用完全随机区组设计,该方法是试验设计中最简单的一种,广泛用于盆栽试验,以及田间试验中材料变异不大的情况下。在这里,区组可被看作一个因素,小麦品种可被看成另外一个因素,因此可以采用组内只有单个观察值的两向分组资料的方差分析方法。
2.程序及说明
/*数据来源:南京农业大学,田间试验和统计方法,P146*/
DATA new;
DO blk=1 TO 3; /* blk代表不同区组*/
DO trt=1 TO 8; /* trt代表不同的小麦品种*/
INPUT y@@;
OUTPUT;
END;END;
CARDS;
10.9 10.8 11.1 9.1 11.8 10.1 10.0 9.3
9.1 12.3 12.5 10.7 13.9 10.6 11.5 10.4
12.2 14.0 10.5 10.1 16.8 11.8 14.1 14.4
PROC ANOV A;
CLASS trt blk;
MODEL y=trt blk; /* 指明二因素的效果模型*/
MEANS trt/DUNCAN; /* 对不同品种间进行新复极差测验*/
RUN;
3.输出结果及说明(略)
§7.5.2 组内有重复观察值的两向分组资料的方差分析
例7.10 施用A1、A2、A3三种肥料于B1、B2、B3三种土壤,以小麦为指示作物,每处理组合种3盆,得产量结果(g)见下表10.4,试作方差分析。
表7.10 作物产量表