空间统计分析实验报告
一、空间点格局的识别
1、平均最邻近分析
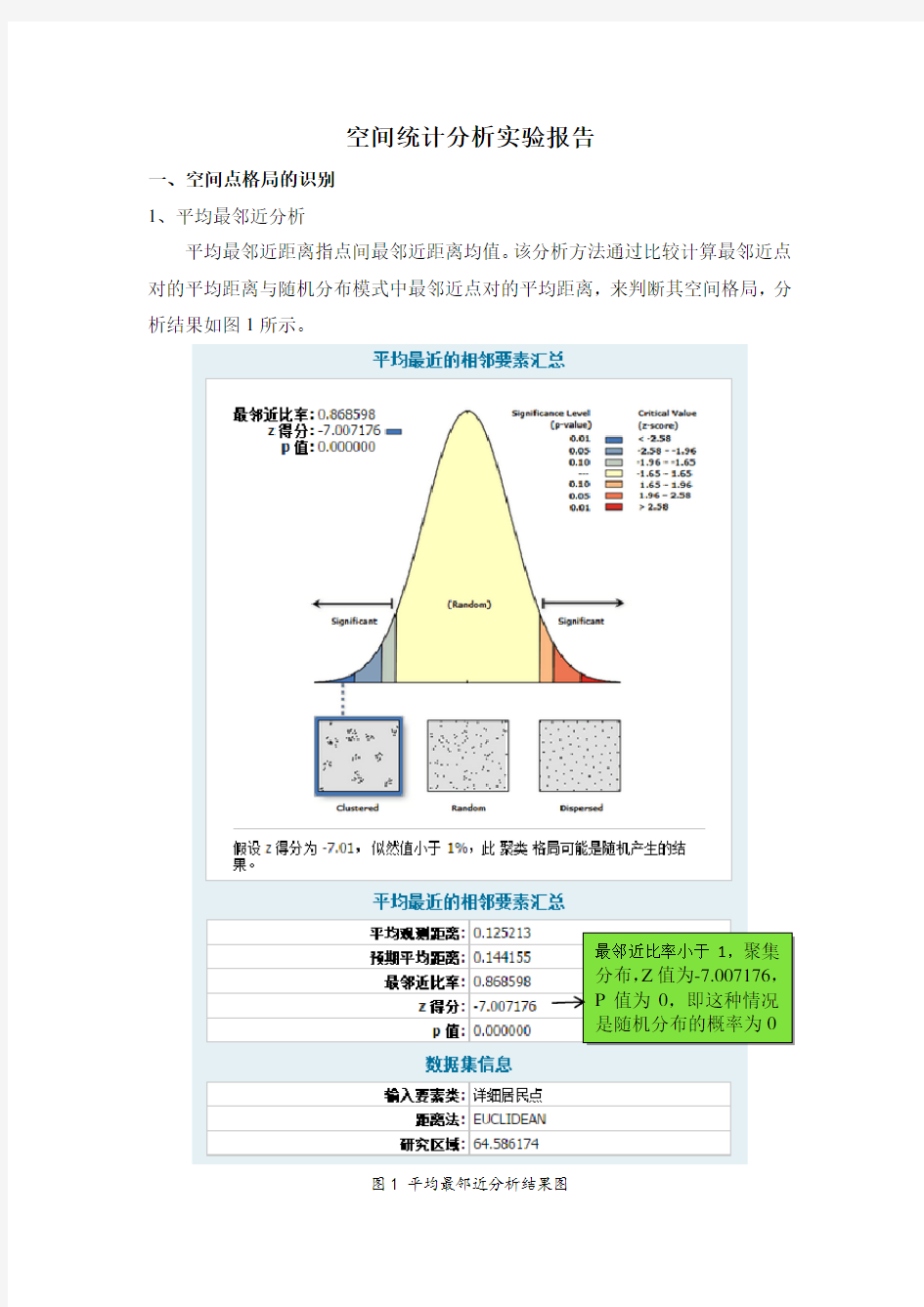
平均最邻近距离指点间最邻近距离均值。该分析方法通过比较计算最邻近点对的平均距离与随机分布模式中最邻近点对的平均距离,来判断其空间格局,分析结果如图1所示。
图1 平均最邻近分析结果图最邻近比率小于1,聚集分布,Z值为-7.007176,P值为0,即这种情况是随机分布的概率为0
计算结果共有5个参数,平均观测距离,预期平均距离,最邻近比率,Z 得分,P值。
P值就是概率值,它表示观测到的空间模式是由某随机过程创建而成的概率,P 值越小,也就是观测到的空间模式是随机空间模式的可能性越小,也就是我们越可以拒绝开始的零假设。最邻近比率值表示要素是否有聚集分布的趋势,对于趋势如何,要根据Z值和P值来判断。
本实验中的最邻近比率小于1 ,聚集分布,Z值为-7.007176,P值为0,即这种情况是随机分布的概率为0,该结果说明省详细居民点的分布是聚集分布的,不存在随机分布。
2、多距离空间聚类分析
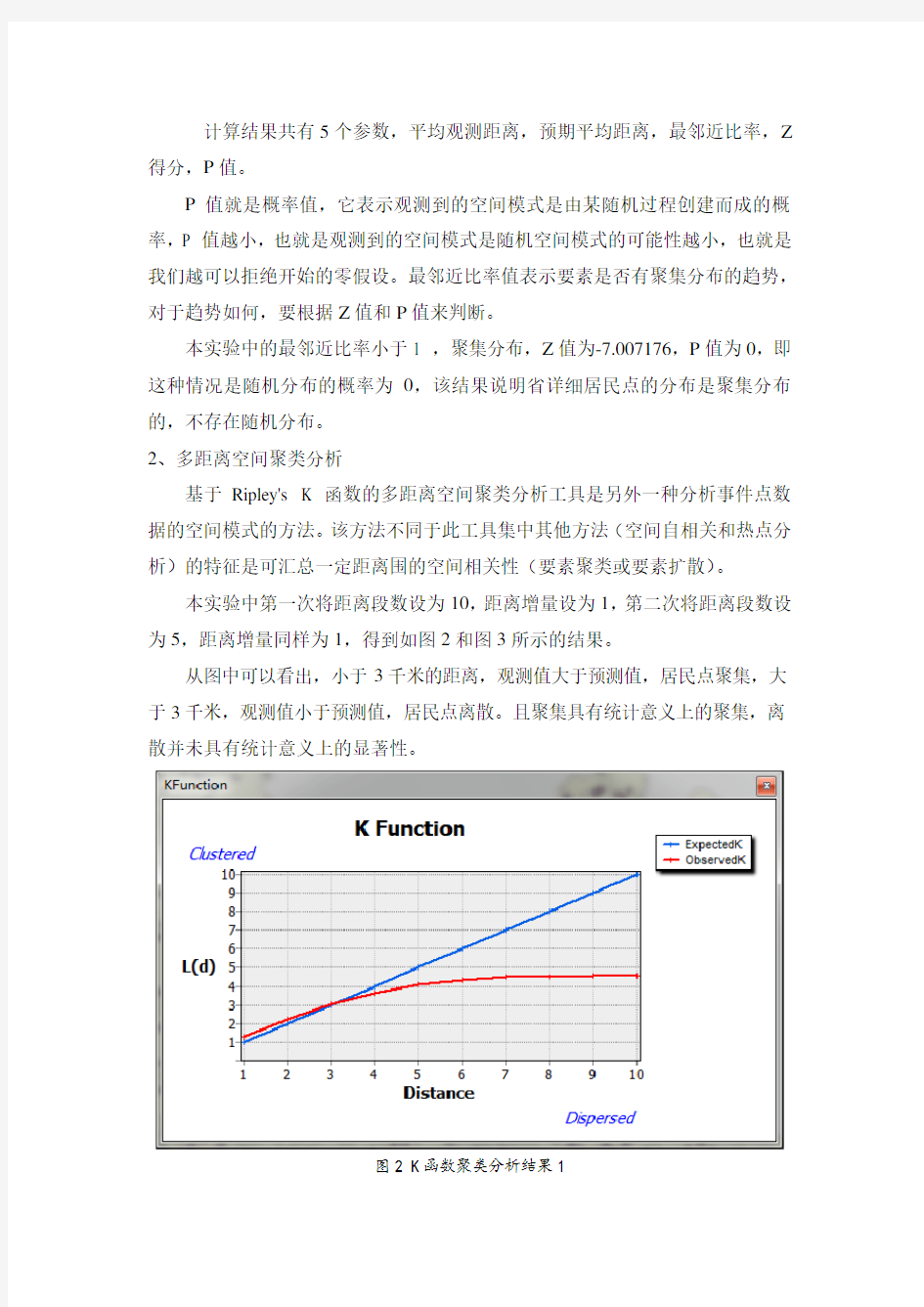
基于Ripley's K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。该方法不同于此工具集中其他方法(空间自相关和热点分析)的特征是可汇总一定距离围的空间相关性(要素聚类或要素扩散)。
本实验中第一次将距离段数设为10,距离增量设为1,第二次将距离段数设为5,距离增量同样为1,得到如图2和图3所示的结果。
从图中可以看出,小于3千米的距离,观测值大于预测值,居民点聚集,大于3千米,观测值小于预测值,居民点离散。且聚集具有统计意义上的聚集,离散并未具有统计意义上的显著性。
图2 K函数聚类分析结果1
小于3千米,居民点聚集,且聚集具有统
计意义上的聚集,大于3千米,居民点离
散,离散并未具有统计意义上的显著性
图3 K函数聚类分析结果2
3、密度制图
前面的最邻近分析和K函数聚类分析只能得到从数值上的出空间分布的状态,但并不能直观看到分布集聚或分散的位置、形状和大小。密度制图根据输入点要素的数值及其分布来计算整个区域的密度分布状况,并产生一个连续的栅格图形,利用密度制图可以通过密度显示点的聚集情况。
图4 核密度制图结果
在核密度分析中,落入搜索区的点具有不同的权重,靠近网格搜索中心的点会被赋予较大的权重,随着与其网格中心距离的加大,权重降低。图4中的值为详细居民点之间的距离的密度,从图中可以看出居民点密集的地方核密度分析的值越大,居民点越密集,如上图中用红色椭圆圈出来的区域,该地区位于滇东南,居民点比较密集,可能与该地区的地形、气候等因素有关。
二、中心位置测度分析
本实验中的测度分析包括省居民点的中心要素、平均中心和中位数中心,结果如图5所示。中心要素表示居民点中处在最中心的居民点,平均中心计算的是所有居民点质心的平均中心,中位数中心计算的是可使所有居民点的欧式距离达到最小的点。
平均中心和中位数中心的计算以GDP为权重,所以计算出来的平均中心和中位数中心为省的经济中心,而中位数中心在计算的时候受异常值的影响较小,所以计算经济中心时一般以中位数中心为准,如图5中以GDP为权重计算出的中位数中心位于市,与市是省的经济中心相一致。
图5 中心位置测度分析结果中心要素平均中心中位数中心
三、离散度的测度分析
图6 离散度测度分析结果
离散度测度分析的结果如图6所示,本实验中的离散度分析采用的是标准距离和标准差椭圆。标准距离创建的是一个包含以平均中心点为中心的圆面,半径为标准距离值,表示要素集中分布的围;标准差椭圆创建的椭圆的中心同样为平均中心,有两个不同的标准距离,表示要素集中分布的趋势。本实验中的离散度分析以GDP为权重来进行分析,结果如图6所示。图中的数据显示省居民点主要集中分布在中部和东部地区,是一个以安宁市为中心,半径为198千米的圆,说明省经济较发达的区域集中在以安宁市为中心的,半径为198千米的圆,集中分布的趋势为东北西南走向。
四、空间自相关和事物属性的空间分布格局
某类事物的出现(例如犯罪、某类用地、某居住空间等)是否造成了周边同类或异类事物或现象的出现,即空间是否自相关;找到某类事物或现象异常聚集的空间位置(例如低收入阶层聚集),以利于分析聚集的原因。
空间自相关是指分布于不同空间位置的地理事物,热门的某一属性存在同价相关性,通常距离越近的两值之间的相关性越大,具体可分为空间正相关和负相关,常用Moran指数来表示。
本实验通过分析来判断是否存在高收入和高收入聚集,低收入和低收入聚
集,或者高低收入相邻分布。一般情况下,适度的集聚可以更有效地满足不同阶层人的需求,但过度的高高收入和低低收入聚集会加剧居住空间分异,阶层对立,也容易引发各类环境问题及社会矛盾,同时集聚也关乎社会资源的分配。
1、全局自相关统计
存在空间自相关
聚集分布
图7 全局自相关统计报表
对于Global Moran's I统计量,零假设声明,所分析的属性在研究区域的要素之间是随机分布的;换句话说,用于促进观察值模式的空间过程是随机的。本实验中的z值为2.671575,大于0,表示省经济状况存在着空间自相关,存在
着聚集分布的趋势,即经济发达的地区周围的区域还是经济发达,经济落后区域周的区域还是经济落后,但是光靠Moran指数还无从判断是高高聚集还是低低聚集,可进一步采用高低聚类分析来判断是高高收入聚集还是低低收入聚集。
2、高、低聚类(Getis-Ord General G)
由于Moran's I指数不能判断空间数据是否显示高聚集还是低聚集,该分析也是用z值来检验空间自相关的统计显著性,但不同的是,z值得分为正值是意味着高高集聚,为负值意味着低低集聚。
高值聚集
图7 高、低聚类报表
最后得到的结果z值为4.519258,大于0,说明省的经济情况分布不均衡,存在着高高聚集的状态,正常情况下应该高低值都有,过于不均衡的聚集会导
致社会矛盾的出现,本实验中出现这个现象的原因可能是因为数据的问题,但
也不能排除这种高值聚集现象的出现。应该看高值出现的区域具体是在哪里,根据该地区的情况来分析高值出现的原因。
五、空间模式分析—局部空间自相关
1、聚类和异常值分析
聚类和异常值分析, 用于发现局域空间是否存在空间自相关,他计算每一个空间单元与邻近单元就某一属性的相关程度。HH为高高聚集,HL为高低聚集,LL为低低聚集。
从下图中可以看出,在和出现了几个高高聚集的点,其他的点均为无效的点,说明在省存在着一定的居民收入分布不均的情况,高收入主要集中在市、安宁市和市。地区不用说是省的政治经济文化中心,其产业的发展是全省较好的,所以出现了高值;市距较近,交通发达,其烟草行业带动了该地区的经济发展,使得该地区的居民收入增加。
图8 聚类和异常值分析结果图
2、热点分析
热点分析是可以较准确地探测出局域空间自相关的有效方法,它能较准确地探测出聚集区域,而聚类和异常值分析(Anselin Local Moran I)对聚集围的识别偏差较大,能大致他侧出聚集区域的中心,但探测出的围小于实际围。
在上述聚类和异常值分析的实验中,实验结果表明市市区和安宁市以及市存在着高高聚集的,但是热点分析做出来的实验结果表明高高聚集这个状态的围更广,存在于市大大部分地区、市的少数地区以及市的武定县,而不是只有之前的三个地方。
p值小,z得分越大,高值聚集;z得分越小,低值聚集。在下图中,热点分析值表示的市z得分下图表明,在省不存在者低低聚集的情况,这和实际有一定的区别,肯可能与实验的数据有关。除了在和地区存在着高高聚集外,在市也存在着高高聚集,但是其聚集的显著情况低于和地区。
图9 热点分析结果图
2.1.试叙述多元联合分布和边际分布之间的关系。 解:多元联合分布讨论多个随机变量联合到一起的概率分布状况,12(,,)p X X X X '=L 的联合分布密 度函数是一个p 维的函数,而边际分布讨论是12(,,)p X X X X '=L 的子向量的概率分布,其概率密度 函数的维数小于p 。 2.2设二维随机向量1 2()X X '服从二元正态分布,写出其联合分布。 解:设1 2()X X '的均值向量为()1 2μμ'=μ,协方差矩阵为21 122212σσσσ?? ? ?? ,则其联合分布密度函数为 1/2 12 2 2112112222122121()exp ()()2f σσσσσσσσ--???????? '=---?? ? ??? ?????? x x μx μ。 2.3已知随机向量12()X X '的联合密度函数为 12121222 2[()()()()2()()] (,)()()d c x a b a x c x a x c f x x b a d c --+-----= -- 其中1a x b ≤≤,2c x d ≤≤。求 (1)随机变量1X 和2X 的边缘密度函数、均值和方差; (2)随机变量1X 和2X 的协方差和相关系数; (3)判断 1X 和2X 是否相互独立。 (1)解:随机变量 1X 和2X 的边缘密度函数、均值和方差; 11212122 2[()()()()2()()] ()()()d x c d c x a b a x c x a x c f x dx b a d c --+-----=--? 1221222222 2()()2[()()2()()]()()()() d d c c d c x a x b a x c x a x c dx b a d c b a d c -------=+----? 121 222202()()2[()2()]()()()() d d c c d c x a x b a t x a t dt b a d c b a d c ------= +----? 221212222 2()()[()2()] 1()()()()d c d c d c x a x b a t x a t b a d c b a d c b a ------=+= ----- 所以 由于1X 服从均匀分布,则均值为2b a +,方差为 ()2 12 b a -。
实验五栅格数据的空间分析 一、实验目的 理解空间插值的原理,掌握几种常用的空间差值分析方法。 二、实验内容 根据某月的降水量,分别采用IDW、Spline、Kriging方法进行空间插值,生成中国陆地范围内的降水表面,并比较各种方法所得结果之间的差异,制作降水分布图。 三、实验原理与方法 实验原理:空间插值是利用已知点的数据来估算其他临近未知点的数据的过程,通常用于将离散点数据转换生成连续的栅格表面。常用的空间插值方法有反距离权重插值法(IDW)、 样条插值法(Spline)和克里格插值方法(Kriging)。 实验方法:分别采用IDW、Spline、Kriging方法对全国各气象站点1980年某月的降水量进行空间插值生成连续的降水表面数据,分析其差异,并制作降水分布图。 四、实验步骤 ⑴打开arcmap,加载降水数据,行政区划数据,城市数据,河流数据,并进行符号化, 对行政区划数据中的多边形取消颜色填充 ⑵点击空间分析工具spatial analyst→options,在general标签中将工作空间设置为实验数据所在的文件夹
⑶点击spatial analyst→interpolate to raster→inverse distance weighted,在input points 下拉框中输入rain1980,z字段选择rain,像元大小设置为10000 点击空间分析工具spatial analyst→options,在extent标签中将分析范围设置与行政区划一致,点击spatial analyst→interpolate to raster→inverse distance weighted,在input points下拉框中输入rain1980,z字段选择rain,像元大小设置为10000 点击空间分析工具spatial analyst→options在general标签中选province作为分析掩膜,点击spatial analyst→interpolate to raster→inverse distance weighted,在input points下拉框中输入rain1980,z字段选择rain,像元大小设置为10000
统计学数学实验报告 单因素方差分析 姓名 专业 学号
单因素方差分析 摘要统计学是关于数据的科学,它所提供的是一套有关数据收集、处理、分析、解释数据并从数据中得出结论的方法,统计研究的是来自各个领域的数据。单因素方差分析也是统计学分析的一种。单因素方差分析研究的是一个分类型自变量对一个数值型因变量的影响。关键字单因素、方差、数据统计 方差分析(analysis of variance,ANOVA)就是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。当方差分析中之涉及一个分类型自变量时称为单因素方差分析(one-way analysis of variance). 单因素方差分析研究的是一个分类型自变量对一个数值型因变量的影响。例如要检验汽车市场销售汽车时汽车颜色对销售数据的影响,这里只涉及汽车颜色一个因素,因而属于单因素方差分析。 为了更好的理解单因素方差分析,下面举个例子来具体说明单因素方差所要解决的问题。从3个总体中各抽取容量不同的样本数据,结果如下表1所示。检验3个总体的均值之间是否有显著差异(α=0.01)P29210.1 样本1 样本2 样本3 158 153 169 148 142 158 161 156 180 154 149 169 如果要进行单因素方差分析时,就需要得到一些相关的数据结构,从而对那些数据结构进行分析,如下表2所示: 分析步骤 1.提出假设 与通常的统计推断问题一样,方差分析的任务也是先根据实际情况提出原假设H0与备择假设H1,然后寻找适当的检验统计量进行假设检验。本节将借用上面的实例来讨论单因素试验的方差分析问题。
统 计 分 析 综 合 实 验 报 告 专业:班级: 姓名:学号: 规定题目
一.问题提出及分析目的 (一)问题提出 夏春同学打算毕业后去上海创办一家属于自己的投资咨询服务公司,以便利用在学校里学到的经济学知识,去为广大的货币市场从业人员提供必要的投资指导。为了能顺利地实现自己的创业计划,他着手编辑了一份投资信息简报、分发给一些投资商,希望这些人能提供各方面的建议,进而了解投资商们感兴趣的东西。(二)分析目的 (1)、对货币市场的交易规模和收益情况进行描述分析。 (2)在95%的置信水平下,对整个货币市场的投资规模、每周收益率和每月收益率进行区间估计,并作出解释。 (3)对周收益率和月收益率进行比较。 (4)资产规模大小对收益率影响是否显著? 二.数据收集及录入
1.打开SPSS 应用程序,在“变量视图”编辑框中录入以下数据: 2.在“数据视图”编辑框中依据收集的数据录入以下数据:(因版面需要在此呈现前5行数据,后面27行按前5行方式录入) 三.数据分析 (一)描述性分析 1.在SPSS 中依次选取“分析”—“描述统计”—“描述”,将资产规模和过去一周、一月的平均收益率全部选取转至右侧方框: 2.在描述性对话框中点击右侧“选项”,进入选项属性设置对话框,选中“均值”、“标准差”、“最大值”、“最小值”、“峰度”、“偏度”、“变量列表”选项:
(二)区间估计 1.在SPSS中依次选取“分析”—“描述统计”—“探索过程”,将资产规模和过去一周、一月的平均收益率全部选取转至右侧方框: 2. .在“探索”对话框中点击右侧“统计量”,进入统计量设置对话框,设置均值置信区间为95%: (三)周月收益率分析 1.在SPSS中依次选取“分析”——“比较均值”——“配对样本T检验”,将过去一周、一月的平均收益率选取转至右侧方框: 2. .在“配对样本T检验”对话框中点击右侧“选项”,进入选项属性设置对话框,设置置信区间为95%:
综合测试题 一、选择题: 1.为筹备班级的初中毕业联欢会,班长对全班学生爱吃哪几种水果作了民意调查,决定最终买什么水果,下面的调查数据中最值得关注的是(). A.中位数 B.平均数 C.众数 D.加权平均数 2.为了了解某中学某班的睡眠情况,随机抽取该班10名学生,在一段时间里,每人平均每天的睡眠时间统计如下(单位:小时):6,8,8,7,7,9,10,7,6,9,由此估计该班多数学生每天的睡眠时间为() A.7小时 B.7.5小时 C.7.7小时 D.8小时 3.小明准备参加校运会的跳远比赛,下面是他近期六次跳远的成绩(单位:米):3.6,3.8, 4.2,4.0,3.8,4.0,那么这组数据的() A、众数是3.9米 B、中位数是3.8米 C、极差是0.6米 D、平均数是4.0米 4.小伟五次数学考试成绩分别为:86分、78分、80分、85分、92分,老师想了解小伟数学学习变化情况,则老师最关注小伟数学成绩的() A、平均数 B、众数 C、中位数 D、方差 5.已知一组数据为:4、5、5、5、6,其中平均数、中位数和众数的大小关系是()A、平均数>中位数>众数 B、中位数<众数<平均数 C、众数=中位数=平均数 D、平均数<中位数<众数 6.如果一组数据6,x,2,4的平均数是3,那么x是(). A. 0 B.3 C.4 D. 2 7.某班一次英语测验的成绩如下:得100分的3人,得95分的6人,得90分的5人,得80分的2人,得70分的18人,得60分的6人,则该班这次英语测验成绩的众数是(). A.70分 B. 18人 C. 80分 D.10人 8.某校四个科技兴趣小组在“科技活动周”上交的作品数分别如下:10、10、x、8,已知这组数据的众数与平均数相等,则这组数据的中位数是() A.8 B. 12 C.9 D. 10 9.甲、乙两人在同样的条件下练习射击,每人打5发子弹,命中环数如下: 甲:6,8,9,9,8 乙: 10,7,7,7,9 则两人射击成绩谁更稳定(). A.甲 B.乙 C.一样稳定 D.无法确定 10.若数据的平均数为m,2,5,7,1,4,n则的平均数为4,则m、n的平均数为()A、7.5 B、5.5 C、2.5 D、4.5
实验一 一、实验目的及要求 对应分析是你也降维的思想以达到减化数据结构的目的,凤的研究广泛用于定义属性变量构成的列联表利用对应分析方法分析问卷中教育程度与网上购物支付方式之间的相互关系。 二、实验环境 SPSS 19.0 window 7系统 三、实验内容及实验步骤(实践内容、设计思想与实现步骤) 实验题目: 通过分析问卷数据,绘制如下的教育程度与网上购物支付方式的交叉表,运用对应分析方法研究教育程度与网上购物所选择的支付方式之间的相关性,及揭示不同人群网上购物的特征等问题。 设计思想:原假设:H1:χ2>χα2[(n?1)(p?1)] 实现步骤: 1.在变量视窗中录入3个变量,用edu表示【教育程度】,用fangshi表示【在网上购物时采用什么样的支付方式】,用pinshu表示【频数】;如图所示:
2.先对数据进行预处理。执行【数据】→【加权个案】命令,弹出【加权个案】对话框。选中【加权个案】按钮,把【频数】放入【频率变量】框中,点击【确定】按钮完成。 3.打开主窗口,选择菜单栏中的【分析】→【降维】→【对应分析】命令,弹出【对应分析】对话框。 4.将【教育程度】导入【行】,将【在网上购物时采用什么样的支付方式】导入【列】。 5. 单击【定义范围(D)】,打开【对应分析:定义行范围】对话框; 定义行变量分类全距最小值为1,最大值为4,单击【更新】;点击【继续】,返回【对应分析】对话框;同方法打开【对应分析:定义列范围】对话框; 定义列变量全距最小值为1,最大值为5,单击【更新】; 6. 单击【统计量】打开【对应分析:统计量】对话框;选择【行轮廓表】,【列轮廓表】;单击【继续】,返回【对应分析】对话框, 7.选择【绘制】→【对应分析:图】对话框,选择【散点图】中的【行点】、【列点】选择【线图】中的【已转换的行类别】、【已转换的列类别】,单击【继续】,返回【对应分析】对话框。 8.单击【确定】按钮,完成设置并执行列联表分析。 四、调试过程及实验结果(详细记录实验在调试过程中出现的问题及解决方法。记录实验的结果) SPSS实验结果及分析: 上表显示了在32155名被调查者中,大多数消费者在网上购物时选择第三方支付和网上银行支付,在网上购物的消费人群以大学本科生相对最多。
实验一熟悉SPSS 一、实验目的 通过本次实验,了解SPSS的基本特征、结构、运行模式、主要窗口等,了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法,对SPSS有一个浅层次的综合认识。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.操作SPSS的基本方法(打开、保存、编辑数据文件) 2.问卷编码 3.录入数据 五、实验学时 2学时(可根据实际情况调整学时) 六、实验方法与步骤 1.开机 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS 3.认识SPSS数据编辑窗、结果输出窗、帮助窗口、图表编辑窗、语 句编辑窗 4.对一份给出的问卷进行编码和变量定义 5.按要求录入数据 6.联系基本的数据修改编辑方法 7.保存数据文件 8.关闭SPSS,关机。 七、实验注意事项
1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。 3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员 同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换, 应报指导教师或实验室管理人员同意。 5.上机时间,禁止使用计算机从事与课程无关的工作。 八、上机作业 (1)、定义变量:试录入以下数据文件,并按要求进行变量定义。 1)变量名同表格名,以“()”内的内容作为变量标签。对性别(Sex)设值标签“男=0;女=1”。 2)正确设定变量类型。其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。
3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
《空间数据结构基础》上机实验报告(2010级) 姓名 班级 学号 环境与测绘学院 1.顺序表的定义与应用(课本P85习题) 【实验目的】 熟练掌握顺序表的定义与应用,通过上机实践加深对顺序表概念的理解。 【实验内容】
设有两个整数类型的顺序表A(有m个元素)和B(有n个元素),其元素均从小到大排列。试编写一个函数,将这两个顺序表合并成一个顺序表C,要求C的元素也从小到大排列。【主要代码】 #include
精心整理 综合练习(二) 一.判断题: 1.所谓序时平均数就是将同一总体的不同时期的平均数按时间顺序排列起来。× 2.发展水平就是时间数列中的每一项指标的数值,又称发展量。(√) 3.定基发展速度等于相应各个环比发展速度的连乘积,定基增长速度也等于相 应各个环比增长速度的连乘积。(×) 4.季节变动指的就是现象受自然因素的影响而发生的一种有规律的变动。(×) 5. 6. 7. 8. 9. 10. 二. 1. C. 2. A. 3. 4. 5. 6. (D 7. C.各期发展水平. D.平均增长速度. 8.平均发展速度是(C) A.定基发展速度的算术平均数. B.环比发展速度的算术平均数. C.环比发展速度连乘积的几何平均数. D.增长速度加上100%. 9.说明现象在较长时期内发展的总速度的指标是(C) A.环比发展速度. B.平均发展速度 C.定基发展速度. D.定基增长速度. 10.若要观察现象在某一段时期内变动的基本趋势,需要测定现象的(C). A.季节变动. B.循环变动. C.长期趋势. D.不规则变动. 三.多项选择题: 1.下列哪些现象侧重于用几何平均法计算平均发展速度( BDE ).
A.基本建设投资额. B.商品销售量. C.垦荒造林数量. D.居民消费支出状况. E.产品产量. 2.下列哪些属于序时平均数( ABDE ) A.一季度平均每月的职工人数. B.某产品产量某年各月的平均增长量. C.某企业职工第四季度人均产值. D.某商场职工某年月平均人均销售额. E.某地区近几年出口商品贸易额增长速度. 3.增长1%的绝对值( AD ) A.等于前期水平除以100. B.等于逐期增长量除以环比增长速度. C.等于逐期增长量除以环比发展速度. D.表示增加1%所增加的绝对量. E.表示增加1%所增加的相对量. 4.定基增长速度等于( BDE ). A. 5. 6. 7. . 8. A. D. 9. A. D. 10. A. D. 样调查资料。③综合指数的分子与分母之差具有一定的经济内容,即说明由于指数化因素变动带来的价值总量指标的增减量,而平均指数的分子与分母之差却不具有价值总量指标增减的经济内容。特别是采用固定权数的平均指数,只有相对数的意义。因此,纵然平均指数有许多优点,也不能完全取代综合指数的应用。 2.平均发展速度的几何平均法和方程式法的计算原理有何不同?各适用于哪些现象? 几何平均法(水平法)和代数平均法(累计法或方程式法) 几何平均法侧重于考察最末一年发展水平,按这种方法所确定的平均发展速度,推算最末一年发展水平,等于最末一年的实际水平;几何平均法的实质是要求从最初水平出发,按所求的平均发展速度发展,计算出的末期水平应等于实际末期水平。适用预测目标发展过程一贯上升或下降,且逐期
一、实验类型 验证型实验。分析1991-2013年中国1年期实际储蓄存款利率的变化特点,运用名义利率、通货膨胀率和物价指数的数据用两种方法来计算并分析哪种方法更科学。 二、实验目的 1、掌握实际利率的两种计算方法,并分析1991-2013年中国1年期实际储蓄存款利率的变化特点。 2、比较两种实际利率测算方法的差异性及科学性。 三、实验背景 利率是国家调控经济的重要杠杆之一,特定的宏观经济目标和微观经济目标可以通过利率调整实现。利率调整是在一定的经济运行环境下进行的,它的调整对经济增长、居民消费、居民储蓄、市场投资等都会产生直接或是简洁的影响。 实际利率(Effective Interest Rate/Real interest rate) 是指剔除通货膨胀率后储户或投资者得到利息回报的真实利率。研究实际利率对经济发展有很大的作用,本实验就1991年至2013年中国1年期实际储蓄利率的变化特点进行探讨,并比较分析实际利率的计算方法。 四、实验环境 本实验属于自主实验,由学员课后自主完成,主要使用Excel软件。 数据来源:通过国家统计局网站、中国人民银行网站获取数据。 五、实验原理 1、实际利率=名义利率-通货膨胀率。 2、实际利率=(名义利率-通货膨胀率)/(1+通货膨胀率)。 六、实验步骤 1、采集实验基础数据。通过网上登录国家统计局网站查看中国统计年鉴,以及登录中国人民银行网站获取相应数据。数据样本区间为1991-2013年。 2、利用Excel软件分别按照两种方法计算实际利率。 3、做出实际储蓄存款利率的变化以及两种不同算法下实际利率变化的折线图。 4、分析图表,考察实际存款利率变化特点并比较两种计算方法的科学性。 七、实验结果分析 (一)实验结果 经过整理和测算的结果如图所示
空间分析原理 及应用 上机实验
练习1:利用缺省参数创建一个表面 1.1 启动ArcMap并激活地统计分析模块 单击窗口任务栏的Start按扭,光标指向Programs,再指向ArcGIS,然后单击ArcMap。在ArcMap中,单击Tools,在单击Extensions,选中Geostatistical Analyst复选框,单击Close按扭。 1.2 添加Geostatistical Analyst工具条到ArcMap中。 单击View菜单,光标指向Toolbars,然后单击Geostatistical Analyst。 1.3 在ArcMap中添加数据层 一旦数据加入后,就能利用ArcMap来显示数据,而且如果需要,还可以改变没一层的属性设置(如符号等等) 1.单击Standard工具条上的Add Data按扭。 找到安装练习数据的文件夹(缺省安装路径是C:\ArcGIS\ArcTutor\Geostatistics),按住Ctrl键,然后点击并高亮显示Ca_ozone_pts和ca_outline数据集。 3.单击Add按扭。 4.单击目录表中的ca_outline图层的图例,打开Symbol Selector对话框。 5.单击Fill Color下拉箭头,然后单击No Color。 6.在Symbol Selector对话框中单击OK按钮。 点击Standard工具条上的Save按扭。新建一个本地工作目录(如C:\geostatistical),定位到本地工作目录。
1.4 利用缺省值创建表面 单击Geostatistical Analyst,然后单击Geostatistical Wizard。 2.点击Input Data下拉箭头,单击并选中ca_ozone_pts。 3.单击Attribute下拉框箭头,单击并选中属性OZONE。 4.在Methord对话框中单击Kriging. 单击Next按扭。缺省情况下,在Geostatistical Method Selection对话框中,Ordinary Kriging和Prediction Map被选中. 6.在Geostatistical Method Selection对话框中单击next按扭。 7.点击next按扭。
综合实验课程设计 一、实验目的 综合运用统计学知识和SPSS软件整理分析问卷调查信息,独立完成调查报告,初步具备实际中的应用能力。 二、实验内容 选择一个与学生学习生活的相关问题,制订统计调查方案、设计相应的调查问卷,然后进行问卷调查,根据需要,利用SPSS软件对问卷调查获得的数据信息进行整理、分析,最后写出4000字以上的统计调查报告。 三、实验步骤 EXCEL软件整理分析问卷调查信息,根据需要参照实验一到实验五,调查方案设计参见附件1,调查问卷设计参见附件2,问卷调查报告参见附件3。 四、实验要求 EXCEL软件实验要求根据情况分别参照实验一到实验六,调查方案设计参见附件1,调查问卷设计参见附件2,问卷调查报告参见附件3。 要求每组6--8个同学,选取一个组长,选择以下十个题目中的一个作为统计调查对象,要完成:统计问卷设计-----发放----回收----数据收集和整理----用统计学方法分析统计数据---到最后统计分析报告的撰写,完整的统计活动过程,最后每组上交一份统计分析报告,包括四部分:调查方案设计、调查问卷、数据收集和分析和最后报告结果。组长在最后的统计报告中要注明小组里每个成员主要完成了什么任务,作为最后给分数的凭证。统计报告在第十八周的周五之前必须上交。 五、调查项目(同一个班不允许有相同的调查题目) 项目1 我校大学生生活费支出状况调查 项目2 我校大学毕业生择业志向调查 项目3 我校大学生选择专业情况调查 项目4 我校大学生恋爱观念调查 项目5 我校大学生服装生活费支出情况调查 项目6 我校大学生手机普及情况调查
项目7 我校大学生上网情况调查 项目8 我校大学生逃课情况调查 项目9 我校大学生电脑使用情况调查 项目10 我校图书馆或体育馆利用情况调查 附件1 调查方案设计 一、调查方案的内容 1、确定调查目的。明确调查目的便于确定向谁调查、调查什么、用什么样的方式进行调查等等。 2、确定调查对象。确定调查对象,要明确总体的界限,调查的范围(统计总体),每一被调查的单位就是总体单位。 3、确定调查项目。调查项目是所要调查的具体内容,即总体单位所承担的基本标志,就是向被调查者调查什么,需要被调查者回答什么问题。 (1)确定调查项目时应注意的4个问题: ①现实调查目的所急需要的项目,可有可无和备而不用的项目一律不要列入。 ②调查项目应是能够取得实际资料的项目。 ③调查项目要注意彼此衔接,避免重复和相互矛盾。 ④列出调查项目的表格形式。可采用一览表形式,亦可采用单一表形式,这应依调查目的、任务而定。一览表是在一张表上登记若干个调查单位的资料,每个单位都同时填写解答调查项目所提出的问题,但只适合在调查项目不多时使用。单一表是在一张表上只登记一个调查单位,可以比较详细地列出各种标志,内容比较详尽,并便于整理汇总,但费时较多。 (2)问卷调查表的设计应遵守的一定原则是: ①问卷形式应服从调查目的,并适合于调查对象的特点。 ②问卷中备选的项目必须具有互斥性。 ③问卷中应防止渗入调查者的主观意图。 4、确定调查时间、调查期限、调查地点 调查时间:指调查资料所属的时间(时期或时点)。明确规定调查的时期或时点,是保证调查资料准确性的重要备件。如果所要调查的资料是某一时期的总量,就要规定报告期的起止日期;如果调查资料是某一时点上的水平,就要规定统一的标准时点。 调查期限:指进行调查工作的时间,包括搜集资料和报送资料的整个工作所需的时间。
实验报告 课程名称统计学学号 11学生姓名辅导教师 系别经济与管理系实验室名称实验时间 1.实验名称 统计指数分析 2.实验目的 掌握各项指数的计算及因素分析法的运用。 在 Excel 中完成各项指数及有关数值的计算,主要用到的是公式和公式复制 3.实验内容 甲乙丙三种商品基期和报告期各项数据如下: 价格(元) P销量 q 商品计量单位 基期 p0报告期 p1基期 q0报告期 q1 甲个302810001200 乙双202120001600 丙公斤232515001500 合计 1)计算三种商品的个体销售量指数和个体价格指数。 2)三种商品的销售额总指数。 3)三种商品的销售量总指数和价格总指数。 4)分析销售量变动和价格变动对销售额影响的绝对额。(这一问分析要手写完成) 4.实验原理 在 Excel 中实现综合指数及其相关数值的计算,主要用到的是公式和公式的复制功 能 5.实验过程及步骤 (1)在工作表中输入已知数据的名称和数值(包括商品名称,计量单位,基期价格,报告 期价格,基期销售量和报告期销售量) (2)计算综合指标的各个综合总量在单元格G4中输入公式“ =C4*E4”,在H4中输入“=D4*F4”, 在 I4 中输入“ =C4*F4”, 在 J4 中输入“ =D4*E4”, 公式复制 在 A7 中输入合计,在单元格中输入“=SuM(G4:G6),再将单元格 G7的公式向右复制到 J7 (3)分别计算各个综合指标及其分子分母之差额 在单元格 A10 中输入“销售额总额指数” ,在单元格 F10 中输入公式“ =H7/G7*100” , 在单元格 H10 中输入公式” =H7-G7”
Abbo无私奉献,只收1个金币,BS收5个金币的… 何老师考简单点啊……
第九章 典型相关分析 9.1 什么是典型相关分析?简述其基本思想。 答: 典型相关分析是研究两组变量之间相关关系的一种多元统计方法。用于揭示两组变量之间的内在联系。典型相关分析的目的是识别并量化两组变量之间的联系。将两组变量相关关系的分析转化为一组变量的线性组合与另一组变量线性组合之间的相关关系。 基本思想: (1)在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。即: 若设(1) (1)(1) (1)12(,,,)p X X X =X 、(2) (2)(2)(2) 12(,,,)q X X X =X 是两组相互关联的随机变量, 分别在两组变量中选取若干有代表性的综合变量Ui 、Vi ,使是原变量的线性组合。 在(1)(1)(1)(2)()()1D D ''==a X b X 的条件下,使得(1)(1)(1)(2)(,)ρ''a X b X 达到最大。(2)选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对。 (3)如此继续下去,直到两组变量之间的相关性被提取完毕为此。 9.2 什么是典型变量?它具有哪些性质? 答:在典型相关分析中,在一定条件下选取系列线性组合以反映两组变量之间的线性关系,这被选出的线性组合配对被称为典型变量。具体来说, ()(1) ()(1)()(1)()(1) 11 22i i i i i P P U a X a X a X ' =+++a X ()(2) ()(2)()(2) ()(2) 11 22i i i i i q q V b X b X b X ' =+++b X 在(1)(1)(1)(2)()()1D D ''==a X b X 的条件下,使得(1)(1)(1)(2)(,)ρ''a X b X 达到最大,则称 (1)(1)'a X 、(1)(2) 'b X 是(1)X 、(2)X 的第一对典型相关变量。 典型变量性质: 典型相关量化了两组变量之间的联系,反映了两组变量的相关程度。 1. ()1,()1 (1,2,,)k k D U D V k r === (,)0, (,)0 ()i j i j C ov U U C ov V V i j ==≠ 2. 0 (,1,2,,)(,)0()0()i i j i j i r C ov U V i j j r λ≠==?? =≠??>? 9.3 试分析一组变量的典型变量与其主成分的联系与区别。 答:一组变量的典型变量和其主成分都是经过线性变换计算矩阵特征值与特征向量得出的。主成分分析只涉及一组变量的相互依赖关系而典型相关则扩展到两组变量之间的相互依赖关系之中,度量了这两组变量之间联系的强度。 ()(1)()(1)()(1)()(1) 1122i i i i i P P U a X a X a X '=+++a X ()(2)()(2)()(2)()(2) 1122i i i i i q q V b X b X b X '=+++b X (1)(1)(1)(1)1 2 (,,,)p X X X = X 、(2)(2)(2)(2)1 2 (,,,)q X X X = X
实验四空间数据处理 实验容: 掌握空间数据的处理(融合、拼接、剪切、交叉、合并)的基本方法和原理,领会其用途。掌握地图投影变换的基本原理和方法,熟悉ArcGIS中投影的应用及投影变换的方法和技术,并了解地图投影及其变换在实际中的应用。 实现方法: (一)空间数据处理 打开ArcMap,在菜单栏中选择“地理处理->环境”,打开环境变量对话框。在环境变量对话框中的常规设置选项中,设定“临时工作空间”为“D:\04实验四\04实验四\Exec4”,如图1所示。 图1 第1步裁剪实体 在ArcMap中,添加数据“县界.shp”、“clip.shp”(Clip中有四个实体),添加完后如图2所示。
图2 ●开始编辑,激活Clip图层,选中Clip图层中的一个实体,如图3所示。 图3 ●点击工具栏上按钮,打开ArcToolBox,选择“分析工具->提取->裁剪”, 如图4所示,弹出裁剪对话框,指定输入的实体为“县界”,剪切的实体为“Clip”(必须为多边形实体),并指定输出实体类路径及名称为“县界_Clip1”,如图5所示。裁剪完成后弹出如图6所示的对话框。
图4 图5
图6 ●依次选中Clip主题中其他三个实体,重复以上操作步骤,完成操作后得到四 个图层——“县界_Clip1”,“县界_Clip2”,“县界_Clip3”,“县界_Clip4”,如图7所示。完成操作后,保存编辑。 图7 第2步拼接图层 ●在ArcMap中新建一个地图文档,加载在上一步操作中得到的4个图层,如 图8所示。
图8 ●在工具箱中选择“数据管理工具->常规->追加”,设置输入实体和输出实体,拼 接效果如图9所示。 图9 ●右键点击图层“县界_Clip1”,在出现的右键菜单中执行“数据->导出数据”,弹 出导出数据对话框,将输出的图层命名为“YONK.shp”,如图10所示。
统计学实验报告 一、实验主题:大学生专业与实习工作的关系 二、实验背景: 二十一世纪的今天大学生已是一个普遍的社会群体,高校毕业人数日益增加,社会、企业所提供的职位日益紧张,大学生就业问题是当今社会关注的焦点。面对日益沉重的就业压力,越来越多的大学毕业生选择了企业需求的职业,而这种职业与自己在校所学专业根本“无关”或相去甚远,大学毕业生就业专业不对口的现象非常严重。专业对口是个广义的概念,就是说你所学的专业与你所作的工作相关,比如你专业是会计,工作后你到了一个企业做会计,或者到银行做柜员,这都是与经济相关的,这就是对口。如果你学机械设计,但工作后却做了统计员,业务员等于你所学专业无关的工作,这就叫专业不对口。专业不对口导致毕业生所学知识没有用武之地,所以这是一种人力资源的浪费。 三、实验目的: 大学生就业专业不对口是客观存在的问题,我们研究此问题有这几点目的:①了解当代大学生实习工作与专业是否对口的情况,当代大学生对工作与专业不对口现象的态度。②分析大学生就业结构和
专业对口问题,了解当今大学生专业对口情况,为以后大学生选择专业、选择工作岗位提供有效的信息和借鉴。③寻找导致专业不对口的原因,以减少社会普遍存在的人力资源的浪费。 四、实验要求:就相关问题收集一定数量的数据,用EXCEL进行如下 分析:1进行数据筛选、排序、分组;2、制作饼图并进行简要解释;3、制作频数分布图,直方图等并进行简要解释。 五、实验设备及材料:计算机,手机,EXCEL软件,WORD软件。 六、实验过程: (一)制作并发放调查问卷。 (二)收回并统计原始数据:收回了102名大学生填写的调查问卷,并对相关数据进行统计。 (三)筛选与实验相关问题: 1.您的性别( ): A. 男B.女
统计分析综合实验考题 一.样本数据特征分析: 要求收集国家统计局2011年与2000年全国人口普查相关数据,进行二者的比较,然后写出有说明解释的数据统计分析报告,文字通顺,对统计结果的说明分析重点突出,几条要求如下:1.报告必须包含所收集的原始数据表,至少包括总人口,流动人口,城乡、性别、年龄、民族构成,教育程度,家庭户人口八大指标; 2.报告中必须有针对某些指标的条形图,饼图,直方图以及累计频率条形图,(茎叶图可选作) 3.采用适当方式分别检验二次调查得到的人口年龄比例以及教育程度这两个指标是否有显著不同,写明检验过程及结论。二.一元线性回归分析: 回归模型:自由建立,如将某地人均食品消费支出与人均收入作为因变量与解释变量,或某地家用汽车消费量与人均收入作为因变量与解释变量等均可。 统计分析报告必须写明:实际问题的背景,所采用的模型与数据来源,至少有20个原始的样本数据,回归方差分析表以及回归系数及显著性检验表(5%),回归系数的95%置信区间,散点图,分析结论,应用价值等均不可缺少。 特别提醒:按时交打印稿并且附此试题!
统计分析综合实验答题 一、样本数据特征分析 2000年全国人口普查与2011年全国人口普查相关数据分析报告 2011年第六次全国人口普查数据显示,总人口数为1339724852,比2000年的第五次人口普查的1242612226人次,总人口数增加97112626人,增长7.82%,平均年增长率为0.78%。 (二)家庭户人口 2000年人口普查家庭户人口数共有1178271219人,有家庭户340491197,平均每个家庭3.46人。2011年增长到1244608395人,平均每个家庭户的人口为3.10人,比2000年减少0.36人。 (三)流动人口 2011年人口普查数据中,居住地与户口登记地所在的乡镇街道不一致且离开户口登记地半年以上的人口为261386075人,同2000年第五次全国人口普查相比,居住地与户口登记地所在的乡镇街道不一致且离开户口登记地半年以上的人口增加116995327人,增长81.03%。 (四)城乡构成 2000年农村居民人口数为783841243人,占63.08%;城镇居民则有458770983人,占36.92%。2011年人口普查显示居住在城镇的人口为665575306人,占49.68%;居住在乡村的人口为674149546人,占50.32%。通过下面的条形图可以清楚的看到2000年—2011年十年间,农村居民减少而城镇居民增加,通过进一步计算可以得知城镇人口比重上升12.76个百分点。
应用多元统计分析课后答案 第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞)
1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 (一)夹角余弦 (二)相关系数 在进行系统聚类时,不同类间距离计算方法有何区别选择距离公式应遵循哪些原则 答: 设d ij 表示样品X i 与X j 之间距离,用D ij 表示类G i 与G j 之间的距离。 (1). 最短距离法 ,min i k j r kr ij X G X G D d ∈∈= min{,}kp kq D D = (2)最长距离法 ,max i p j q pq ij X G X G D d ∈∈= 21 ()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑ cos p ik jk ij X X θ= ∑ ()() p ik i jk j ij X X X X r --= ∑ ij G X G X ij d D j j i i ∈∈= ,min