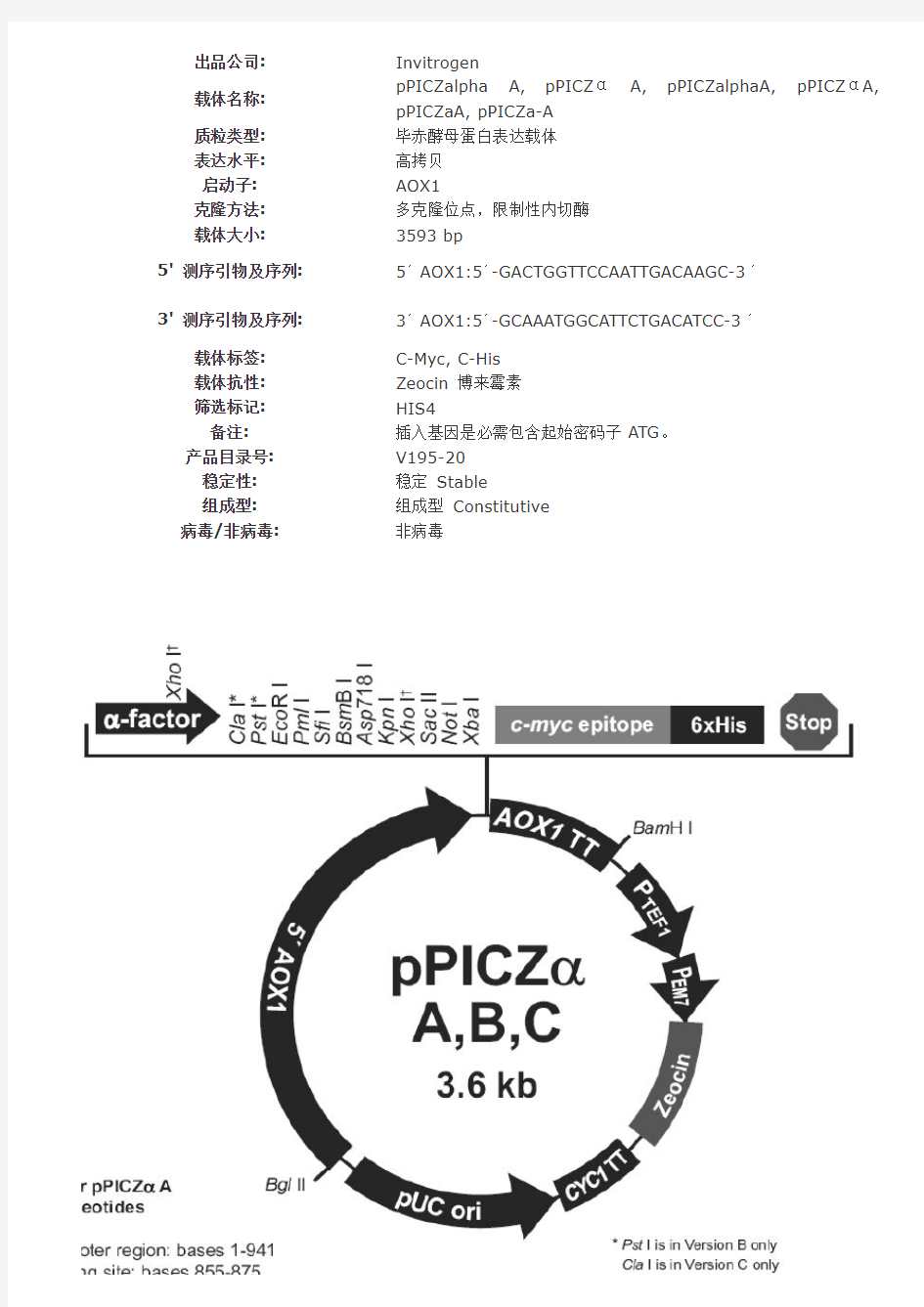

出品公司:Invitrogen
载体名称:pPICZalpha A,pPICZαA,pPICZalphaA,pPICZαA, pPICZaA,pPICZa-A
质粒类型:毕赤酵母蛋白表达载体
表达水平:高拷贝
启动子:AOX1
克隆方法:多克隆位点,限制性内切酶
载体大小:3593bp
5'测序引物及序列:5′AOX1:5′-GACTGGTTCCAATTGACAAGC-3′3'测序引物及序列:3′AOX1:5′-GCAAATGGCATTCTGACATCC-3′
载体标签:C-Myc,C-His
载体抗性:Zeocin博来霉素
筛选标记:HIS4
备注:插入基因是必需包含起始密码子ATG。
产品目录号:V195-20
稳定性:稳定Stable
组成型:组成型Constitutive
病毒/非病毒:非病毒
pPICZaa载体简介
pPICZαA,B和C是3.6kb的毕赤酵母蛋白分泌表达载体。表达的重组蛋白是融合蛋白,含有一个N-端多肽,编码酿酒酵母(Saccharomyces cerevisiae)α-因子分泌信号。载体能够在毕赤酵母中利用甲醇诱导的高水平的表达目的蛋白,并且可以用在任何毕赤酵母中,包括X33,GS115菌株,SMD1168H,KM71H。
pPICZαA,B和C系列载体包含以下元素:
?5'端含有AOX1启动子的严格调控,利用甲醇诱导表达任何感兴趣的基因(Ellis等,1985;Koutz等人,1989;tschopp等人,1987A)。
?α-因子分泌信号能够分泌性表达目的蛋白。
?Zeocin抗性基因在大肠杆菌和毕赤酵母都能用于筛选(Baron等人,1992;Drocourt等人,1990)。
?C-端含Myc和His标签,可以用于检测和纯化重组蛋白。
?pPICZ A,B,C三种读码框使得可以将基因克隆入载体而不发生任何移码突变。
pPICZaa载体序列
LOCUS pPICZα\A3593bp DNA circular SYN2-SEP-2003
SOURCE
ORGANISM
COMMENT This file is created by Vector NTI
https://www.doczj.com/doc/6a2889154.html,/
COMMENT VNTAUTHORNAME|https://www.doczj.com/doc/6a2889154.html,|
FEATURES Location/Qualifiers
source 1..3593
/invitrogen="25"
/vntifkey="98"
primer complement(1423..1443)
/invitrogen="1880000"
/vntifkey="27"
/label=3'\AOX1\primer
primer855..875
/invitrogen="1890000"
/vntifkey="27"
/label=5'\AOX1\primer
CDS1320..1337
/invitrogen="1010000"
/vntifkey="4"
/label=6xHis
primer1144..1164
/invitrogen="1900000"
/vntifkey="27"
/label=alpha-factor\primer terminator1341..1682
/invitrogen="2550000"
/vntifkey="43"
/label=AOX1\transcription\terminator CDS1275..1304
/invitrogen="1090000"
/vntifkey="4"
/label=c-myc\epitope
terminator2538..2855
/invitrogen="2560000"
/vntifkey="43"
/label=CYC1\transcription\terminator promoter2095..2162
/invitrogen="2340000"
/vntifkey="30"
/label=EM7\promoter
misc_feature1208..1274
/invitrogen="1460000"
/vntifkey="21"
/label=MCS
rep_origin complement(2866..3539)
/invitrogen="2540000"
/vntifkey="33"
/label=pUC\origin
CDS941..1207
/invitrogen="1280000"
/vntifkey="4"
/label=alpha-factor\signal\peptide
promoter1683..2094
/invitrogen="2300000"
/vntifkey="29"
/label=TEF1\promoter
CDS2163..2537
/invitrogen="1370000"
/vntifkey="4"
/label=Zeo(R)
promoter 1..940
/invitrogen="2160000"
/vntifkey="29"
/label=AOX1\promoter
BASE COUNT892a886c801g1014t
ORIGIN
1agatctaaca tccaaagacg aaaggttgaa tgaaaccttt ttgccatccg acatccacag 61gtccattctc acacataagt gccaaacgca acaggagggg atacactagc agcagaccgt 121tgcaaacgca ggacctccac tcctcttctc ctcaacaccc acttttgcca tcgaaaaacc 181agcccagtta ttgggcttga ttggagctcg ctcattccaa ttccttctat taggctacta 241acaccatgac tttattagcc tgtctatcct ggcccccctg gcgaggttca tgtttgttta 301tttccgaatg caacaagctc cgcattacac ccgaacatca ctccagatga gggctttctg 361agtgtggggt caaatagttt catgttcccc aaatggccca aaactgacag tttaaacgct 421gtcttggaac ctaatatgac aaaagcgtga tctcatccaa gatgaactaa gtttggttcg 481ttgaaatgct aacggccagt tggtcaaaaa gaaacttcca aaagtcggca taccgtttgt 541cttgtttggt attgattgac gaatgctcaa aaataatctc attaatgctt agcgcagtct
601ctctatcgct tctgaacccc ggtgcacctg tgccgaaacg caaatgggga aacacccgct 661ttttggatga ttatgcattg tctccacatt gtatgcttcc aagattctgg tgggaatact 721gctgatagcc taacgttcat gatcaaaatt taactgttct aacccctact tgacagcaat 781atataaacag aaggaagctg ccctgtctta aacctttttt tttatcatca ttattagctt 841actttcataa ttgcgactgg ttccaattga caagcttttg attttaacga cttttaacga 901caacttgaga agatcaaaaa acaactaatt attcgaaacg atgagatttc cttcaatttt 961tactgctgtt ttattcgcag catcctccgc attagctgct ccagtcaaca ctacaacaga 1021agatgaaacg gcacaaattc cggctgaagc tgtcatcggt tactcagatt tagaagggga 1081tttcgatgtt gctgttttgc cattttccaa cagcacaaat aacgggttat tgtttataaa 1141tactactatt gccagcattg ctgctaaaga agaaggggta tctctcgaga aaagagaggc 1201tgaagctgaa ttcacgtggc ccagccggcc gtctcggatc ggtacctcga gccgcggcgg 1261ccgccagctt tctagaacaa aaactcatct cagaagagga tctgaatagc gccgtcgacc 1321atcatcatca tcatcattga gtttgtagcc ttagacatga ctgttcctca gttcaagttg 1381ggcacttacg agaagaccgg tcttgctaga ttctaatcaa gaggatgtca gaatgccatt 1441tgcctgagag atgcaggctt catttttgat acttttttat ttgtaaccta tatagtatag 1501gatttttttt gtcattttgt ttcttctcgt acgagcttgc tcctgatcag cctatctcgc 1561agctgatgaa tatcttgtgg taggggtttg ggaaaatcat tcgagtttga tgtttttctt 1621ggtatttccc actcctcttc agagtacaga agattaagtg agaccttcgt ttgtgcggat 1681cccccacaca ccatagcttc aaaatgtttc tactcctttt ttactcttcc agattttctc 1741ggactccgcg catcgccgta ccacttcaaa acacccaagc acagcatact aaattttccc 1801tctttcttcc tctagggtgt cgttaattac ccgtactaaa ggtttggaaa agaaaaaaga 1861gaccgcctcg tttctttttc ttcgtcgaaa aaggcaataa aaatttttat cacgtttctt 1921tttcttgaaa tttttttttt tagttttttt ctctttcagt gacctccatt gatatttaag 1981ttaataaacg gtcttcaatt tctcaagttt cagtttcatt tttcttgttc tattacaact 2041ttttttactt cttgttcatt agaaagaaag catagcaatc taatctaagg ggcggtgttg 2101acaattaatc atcggcatag tatatcggca tagtataata cgacaaggtg aggaactaaa 2161ccatggccaa gttgaccagt gccgttccgg tgctcaccgc gcgcgacgtc gccggagcgg 2221tcgagttctg gaccgaccgg ctcgggttct cccgggactt cgtggaggac gacttcgccg 2281gtgtggtccg ggacgacgtg accctgttca tcagcgcggt ccaggaccag gtggtgccgg 2341acaacaccct ggcctgggtg tgggtgcgcg gcctggacga gctgtacgcc gagtggtcgg 2401aggtcgtgtc cacgaacttc cgggacgcct ccgggccggc catgaccgag atcggcgagc 2461agccgtgggg gcgggagttc gccctgcgcg acccggccgg caactgcgtg cacttcgtgg 2521ccgaggagca ggactgacac gtccgacggc ggcccacggg tcccaggcct cggagatccg 2581tccccctttt cctttgtcga tatcatgtaa ttagttatgt cacgcttaca ttcacgccct 2641ccccccacat ccgctctaac cgaaaaggaa ggagttagac aacctgaagt ctaggtccct 2701atttattttt ttatagttat gttagtatta agaacgttat ttatatttca aatttttctt 2761ttttttctgt acagacgcgt gtacgcatgt aacattatac tgaaaacctt gcttgagaag 2821gttttgggac gctcgaaggc tttaatttgc aagctggaga ccaacatgtg agcaaaaggc 2881cagcaaaagg ccaggaaccg taaaaaggcc gcgttgctgg cgtttttcca taggctccgc 2941ccccctgacg agcatcacaa aaatcgacgc tcaagtcaga ggtggcgaaa cccgacagga 3001ctataaagat accaggcgtt tccccctgga agctccctcg tgcgctctcc tgttccgacc 3061ctgccgctta ccggatacct gtccgccttt ctcccttcgg gaagcgtggc gctttctcaa 3121tgctcacgct gtaggtatct cagttcggtg taggtcgttc gctccaagct gggctgtgtg 3181cacgaacccc ccgttcagcc cgaccgctgc gccttatccg gtaactatcg tcttgagtcc 3241aacccggtaa gacacgactt atcgccactg gcagcagcca ctggtaacag gattagcaga 3301gcgaggtatg taggcggtgc tacagagttc ttgaagtggt ggcctaacta cggctacact 3361agaaggacag tatttggtat ctgcgctctg ctgaagccag ttaccttcgg aaaaagagtt 3421ggtagctctt gatccggcaa acaaaccacc gctggtagcg gtggtttttt tgtttgcaag 3481cagcagatta cgcgcagaaa aaaaggatct caagaagatc ctttgatctt ttctacgggg 3541tctgacgctc agtggaacga aaactcacgt taagggattt tggtcatgag atc
//
质粒图谱信息 一.九种表达载体 Pllp-OmpA, pllp-STII, pMBP-P, pMBP-C, pET-GST, pET-Trx, pET-His, pET-CKS, pET-DsbA 二.克隆载体 pTZ19R DNA pUC57 DNA PMD18T PQE30 pUC18 pUC19 pTrcHisA pTrxFus pRSET-A pRSET-B pV AX1 PBR322 pbv220 pBluescript II KS (+) L4440 pCAMBIA-1301 pMAL-p2X pGD926 三.PET系列表达载体 Protein Expression ? Prokaryotic Expression ? pETDsb Fusion Systems 39b and 40b Protein Expression ? Prokaryotic Expression ? pET Expression System 33b Protein Expression ? Prokaryotic Expression ? pET Expression Systems Protein Expression ? Prokaryotic Expression ? pET Expression Systems plus Competent Cells Protein Expression ? Prokaryotic Expression ? pET GST Fusion Systems 41 and 42 Protein Expression ? Prokaryotic Expression ? pETNusA Fusion Systems 43.1 and 44 Protein Expression ? Prokaryotic Expression ? pET Vector DNA Protein Purification ? Purification Systems ? Strep?Tactin Resins and Purification Kits 四.PGEX系列表达载体 T EcoR pGEX-1 I/BAP pGEX-2T pGEX-2TK pGEX-3X pGEX-4T-1 pGEX-4T-2 pGEX-4T-3 pGEX-5X-1 pGEX-5X-2 pGEX-5X-3
如何阅读质粒图谱 最近由于实验需要,需要查阅载体图谱,到园子里搜罗一番,发现虽然有人问载体图谱阅读的问题,也有前辈回答,但都不详细,借自己也在琢磨这个问题的机会,将我学到的东西整理一下,于 大家分享。 载体主要有病毒和非病毒两大类,其中质粒DNA是一种新的非病毒转基因载体。 一个合格质粒的组成要素 #复制起始位点Oril 即控制复制起始的位点。原核生物DNA分子中只有一个复制起始点。而真核生物DNA分子有多个复制起始位点。 #抗生素抗性基因可以便于加以检测,如Amp+l ,Kan+ #多克隆位点MCS 克隆携带外源基因片段l #P/E 启动子/增强子l #Termsl 终止信号 #加poly(A)信号l 可以起到稳定mRNA作用 二、如何阅读质粒图谱 第一步:首先看Ori的位置,了解质粒的类型(原核/真核/穿梭质粒) 第二步:再看筛选标记,如抗性,决定使用什么筛选标记。 (1)Ampr 水解β-内酰胺环,解除氨苄的毒性。 (2)tetr 可以阻止四环素进入细胞。 (3)camr 生成氯霉素羟乙酰基衍生物,使之失去毒性。 (4)neor(kanr)氨基糖苷磷酸转移酶使G418(卡那霉素衍生物)失活 (5)hygr 使潮霉素β失活。 第三步:看多克隆位点(MCS)。它具有多个限制酶的单一切点。便于外源基因的插入。如果在这些位点外有外源基因的插入,会导致某种标志基因的失活,而便于筛选。决定能不能放目的基因以及如何放置目的基因。 第四步:再看外源DNA插入片段大小。质粒一般只能容纳小于10Kb的外源DNA片段。一般来说,外源DNA片段越长,越难插入,越不稳定,转化效率越低。 第五步:是否含有表达系统元件,即启动子-核糖体结合位点-克隆位点-转录终止信号。这是用来区别克隆载体与表达载体。克隆载体中加入一些与表达调控有关的元件即成为表达载体。选用那种载体,还是要以实验目的为准绳。 启动子-核糖体结合位点-克隆位点-转录终止信号 #启动子-促进DNA转录的DNA顺序,这个DNA区域常在基因或操纵子编码顺序的上游,是DNA分子上可以与RNApol特异性结合并使之开始转录的部位,但启动子本身不被转录。 #增强子/沉默子-为真核基因组(包括真核病毒基因组)中的一种具有增强邻近基因转录过程的调控顺序。其作用与增强子所在的位置或方向无关。即在所调控基因上游或下游均可发挥作用。/沉默子-负增强子,负调控序列。 #核糖体结合位点/起始密码/SD序列(Rbs/AGU/SDs):mRNA有核糖体的两个结合位点,对于原核而言是AUG(起始密码)和SD序列。l #转录终止顺序(终止子)/翻译终止密码子:结构基因的最后一个外显子中有一个AATAAA的保守序列,此位点down-stream有一段GT或T富丰区,这2部分共同构成poly(A)加尾信号。
---------------------------------------------------------------最新资料推荐------------------------------------------------------ 质粒图谱的阅读方法 质粒图谱的阅读方法载体主要有病毒和非病毒两大类,其中质粒 DNA 是一种新的非病毒转基因载体。 一、一个合格质粒的组成要素 a. 复制起始位点 Ori 即控制复制起始的位点。 原核生物 DNA分子中只有一个复制起始点。 而真核生物 DNA分子有多个复制起始位点。 b. 抗生素抗性基因可以便于加以检测,如 Amp+ ,Kan+ c. 多克隆位点 MCS 克隆携带外源基因片段 d. P/E 启动子/增强子 e. Terms 终止信号 f. 加 poly(A)信号可以起到稳定 mRNA 作用二、如何阅读质粒图谱第一步: 首先看 Ori 的位置,了解质粒的类型(原核/真核/穿梭质粒)。 第二步: 再看筛选标记,如抗性,决定使用什么筛选标记。 (1) Ampr 水解-内酰胺环,解除氨苄的毒性。 (2) tetr 可以阻止四环素进入细胞。 (3) camr 生成氯霉素羟乙酰基衍生物,使之失去毒性。 (4) neor(kanr)氨基糖苷磷酸转移酶使 G418(长那霉素衍生物)失活(5) hygr 使潮霉素失活。 第三步: 1 / 6
看多克隆位点(MCS)。 它具有多个限制酶的单一切点。 便于外源基因的插入。 如果在这些位点外有外源基因的插入,会导致某种标志基因的失活,而便于筛选。 决定能不能放目的基因以及如何放置目的基因。 第四步: 再看外源 DNA 插入片段大小。 质粒一般只能容纳小于 10Kb 的外源 DNA 片段。 一般来说,外源DNA 片段越长,越难插入,越不稳定,转化效率越低。 第五步: 是否含有表达系统元件,即启动子-核糖体结合位点-克隆位点-转录终止信号。 这是用来区别克隆载体与表达载体。 克隆载体中加入一些与表达调控有关的元件即成为表达载体。 选用那种载体,还是要以实验目的为准绳。 启动子-核糖体结合位点-克隆位点-转录终止信号 a. 启动子-促进 DNA 转录的 DNA 顺序,这个 DNA 区域常在基因或操纵子编码顺序的上游,是 DNA 分子上可以与 RNApol 特异性结合并使之开始转录的部位,但启动子本身不被转录。 b. 增强子/沉默子-为真核基因组(包括真核病毒基因组)
阅读质粒图谱的基本方法.txt爱情是彩色气球,无论颜色如何严厉,经不起针尖轻轻一刺。一流的爱人,既能让女人爱一辈子,又能一辈子爱一个女人![转帖] 阅读质粒图谱的基本方法 载体主要有病毒和非病毒两大类,其中质粒DNA是一种新的非病毒转基因载体。一、一个合格质粒的组成要素 a复制起始位点Ori 即控制复制起始的位点。原核生物DNA分子中只有一 个复制起始点。而真核生物DNA分子有多个复制起始位点。 b 抗生素抗性基因可以便于加以检测,如Amp ,Kan c 多克隆位点MCS 克隆携带外源基因片段 d P/E 启动子/增强子 e Terms 终止信号 f 加poly(A)信号可以起到稳定mRNA作用 二、如何阅读质粒图谱 第一步:首先看Ori的位置,了解质粒的类型(原核/真核/穿梭质粒) 第二步:再看筛选标记,如抗性,决定使用什么筛选标记。 (1)Ampr 水解β-内酰胺环,解除氨苄的毒性。 (2)tetr 可以阻止四环素进入细胞。 (3)camr 生成氯霉素羟乙酰基衍生物,使之失去毒性。 (4)neor(kanr)氨基糖苷磷酸转移酶使G418(长那霉素衍生物)失活 (5)hygr 使潮霉素β失活。 第三步:看多克隆位点(MCS)。它具有多个限制酶的单一切点。便于 外源基因的插入。如果在这些位点外有外源基因的插入,会导致某种标 志基因的失活,而便于筛选。决定能不能放目的基因以及如何放置目的 基因。 第四步:再看外源DNA插入片段大小。质粒一般只能容纳小于10Kb的外 源DNA片段。一般来说,外源DNA片段越长,越难插入,越不稳定,转 化效率越低。 第五步:是否含有表达系统元件,即启动子-核糖体结合位点-克隆位 点-转录终止信号。这是用来区别克隆载体与表达载体。克隆载体中加入 一些与表达调控有关的元件即成为表达载体。选用那种载体,还是要 以实验目的为准绳。 启动子-核糖体结合位点-克隆位点-转录终止信号 a 启动子-促进DNA转录的DNA顺序,这个DNA区域常在基因或操纵子 编码顺序的上游,是DNA分子上可以与RNApol特异性结合并使之开始转 录的部位,但启动子本身不被转录。 b增强子/沉默子-为真核基因组(包括真核病毒基因组)中的一种具有 增强邻近基因转录过程的调控顺序。其作用与增强子所在的位置或方向 无关。即在所调控基因上游或下游均可发挥作用。/沉默子-负增强子, 负调控序列。 c核糖体结合位点/起始密码/SD序列(Rbs/AGU/SDs):mRNA有核糖体
基因组序列的差异分析 ----mVISTA的在线使用说明 当然,除了在线版的,我们还可以在网站上填写信息申请离线的软件。但我试用了一下,需要先自己比对,然后要按照一定的格式来制作文件,当然你还必须得安装java才能运行软件;总之,我感觉没有在线版的方便。 1 将数据放入服务器中 在首页,你将被要求确定你想要分析的基因组序列的数量。输入这个数字之后,点击“提交”,将带你到主提交页面。 mVISTA服务器最多可以同时处理100条序列。 1.1主提交页面必填的内容 E-mail 地址 通过E-mail,我们可以提示你的在线处理已经得到结果。
序列 你可以用2种方式来上传你的序列: 1.使用“Browse”按钮从你的电脑上,上传纯文本的Fasta格式文件。如果是一个作为参 考的生物体的DNA序列必须作为一个contig提交(可以进行一定的定向排列将多个片段合并为一个contig),而其他非参考序列可以在一个或多个contig中提交(draft)。 Fasta格式的示例序列(您可以在NCBI站点上找到关于该格式的更多细节): >mouse ATCACGCTCTTTGTACACTCCGCCATCTCTCTCT … !!!注意:序列里面我们只接受字母CAGTN和X。请确保提交序列是作为一种纯文本格式,而不是Word或HTML文件格式。 如果您以FASTA格式提交序列,我们建议您为它取一个有意义的名称(比如直接是你的物种名之类的),因为这些名称将出现在我们生成的图形中。如果您使用的是一个draft草图序列,那么结果中每个contigs的命名都将按照您在“>”符号后指示的命名进行。 2.您可以给出它的GenBank登录号,系统将自动从GenBank数据库里进行检索序列。 在这两种情况下,序列的总大小都不应超过10M,而且任何一条序列都不应超过2M。 1.2主提交页面选填的内容 这些选项允许您自定义您的VISTA分析。您可以使用独立获得的基因注释,选择合适的Repeat Masker选项,给分析的序列指定名称,并改变序列保存分析的参数。如果您没有填写这些选填选项,我们将使用它们的默认值。 比对程序 根据您分析的具体内容(参见“about”-链接中的详细信息),您可以选择以下比对程序之一:1、AVID----全局两两比对。如果您选择使用这个程序,其中一个序列应该被完成比对,其他 所有序列可以完成或以草图draft格式完成。对于集合中所有已完成的序列,AVID生成所有相对所有成对的比对结果,可以使用任何序列作为基础(参考)来显示。如果某些序列是草图格式,AVID将生成它们与最终序列的比对,这将被用作基础(参考)。这是该服务器上唯一可以处理草图序列的比对程序。 (小知识:草图序列与完整序列DNA sequence, draft: Sequence of a DNA with less accuracy than a finished sequence. In a draft sequence, some segments are missing or are in the wrong order or are oriented incorrectly. A draft sequence is as opposed to a finished DNA sequence.)2、LAGAN----完成完整序列的全局两两比对和多重比对。如果某些序列是草图格式,您的查 询将被重定向到AVID以获得两两比对。多重比对将由VISTA可视化,它将计算并显示序列的保守区,以您指示的任何序列作为参考。这是该服务器上唯一能够产生真正的多重
经常在坛子里看到一些人求助质粒图谱,很多时候我发现其实有些质粒图谱还是很容易找到了,刚开始帮忙查找了下,还公布了一些查找质粒图谱比较好的网站,后来看得多了,很多时候,这样的帖子直接跳过了。今天又看到几个求质粒图谱的帖子,因此决定就查找质粒图谱的方法,写个总结帖子,希望对虫子们有些帮助。这些方法,大部分是自己学习的过程中积累的,也许总结得还不够全面,望其他虫友指正。 方法一:安装软件Vector NT 做分子实验,经常和不同的质粒打交道,了解各种质粒的图谱信息是必需的,invitrogen公司的这款软件绝对是分子生物学虫子们的福音,功能强大、界面美观,使用起来很人性化。后面的很多方法都是基于在这款软件的使用之上,因此个人觉得要想对质粒图谱了解更直观,安装这款软件是非常必要的。而且,一旦安装了这款软件,你就发现这款软件的软件包里面会包括invitrogen公司的所有质粒图谱信息和其他比较常见和经典的质粒图谱(不是有虫子求pRS系列质粒吗?帖子链接https://www.doczj.com/doc/6a2889154.html,/bbs/viewthread.php?tid=3103223&fpage=1,如下图,数据库中本身就有很多)。这里就不一一细说,各位虫子可以自己体验下。(这款软件的下载和使用说明书站内很多)
方法二:查找质粒图谱的网站: 这个之前有人求助质粒图谱时,我在回应求助帖里面公布过几个我经常用的网址,估计不是专题,很多人没看到,现在在此重新总结下 1.Vector Database 地址:https://https://www.doczj.com/doc/6a2889154.html,/g?a=vdb 这个网站很页面很人性化,直入主题,也是我经常用到一个网站,比如同样这个帖子求pRS类质粒图谱(注意,是一类质粒图谱,没关系,照样能找到),直接在搜索框输入pRS,可以看到,之类质粒一共有三十多个。
一、载体主有病毒和非病毒两大类,其中质粒DNA是一种新的非病毒转基因载体。 一、一个合格质粒的组成要素 复制起始位点Ori,即控制复制起始的位点。原核生物DNA分子中只有一个复制起始点。而真核生物DNA分子有多个复制起始位点。抗生素抗性基因:可以便于加以检测,如Amp+ ,Kan+ 多 克隆位点:MCS克隆携带外源基因片段 P/E:启动子/增强子 Terms:终止信号 加poly(A)信号:可以起到稳定mRNA作用 二、如何阅读质粒图谱 第一步:首先看Ori的位置,了解质粒的类型(原核/真核/穿梭质粒) Ori的箭头指复制方向,其他元件标注的箭头多指转录方向(正向)。 第二步:再看筛选标记,如抗性,决定使用什么筛选标记: (1)Ampr:水解β-内酰胺环,解除氨苄的毒性。 (2)tetr :可以阻止四环素进入细胞。 (3)camr:生成氯霉素羟乙酰基衍生物,使之失去毒性。 (4)neor(kanr):氨基糖苷磷酸转移酶,使G418(卡那霉素衍生物)失活。 (5)hygr:使潮霉素β失活。 第三步:看多克隆位点(MCS)。它具有多个限制酶的单一切点,便于外源基因的插入。如果在这些位点外有外源基因的插入,会导致某种标志基因的失活,而便于筛选。决定能不能放目的基因以及如何放置目的基因。 第四步:再看外源DNA插入片段大小。质粒一般只能容纳小于10Kb的外源DNA片段。一般来说,外源DNA片段越长,越难插入,越不稳定,转化效率越低。 第五步:是否含有表达系统元件,即启动子-核糖体结合位点-克隆位点-转录终止信号。这是用来区别克隆载体与表达载体。克隆
载体中加入一些与表达调控有关的元件即成为表达载体。选用那种载体,还是要以实验目的为准绳。 相关概念: 启动子-核糖体结合位点-克隆位点-转录终止信号 启动子-促进DNA转录的DNA顺序,这个DNA区域常在基因或 操纵子编码顺序的上游,是DNA分子上可以与RNApol特异性结合并使之开始转录的部位,但启动子本身不被转录。 增强子/沉默子-为真核λ基因组(包括真核病毒基因组)中的一种具有增强邻近基因转录过程的调控顺序。其作用与增强子所在的位置或方向无关。即在所调控基因上游或下游均可发挥作用。沉默子-负增强子,负调控序列。 核糖体结合位点/起始密码/SD序列(Rbs/AGU/SDs):mRNA有核糖体的两个结合位点,对于原核而言是AUG(起始密码)和SD序列。 λ转录终止顺序(终止子)/翻译终止密码子:结构基因的最后一个外显子中有一个AATAAA的保守序列,此位点down-stream有一段GT 或T富丰区,这2部分共同构成poly(A)加尾信号。结构基因的最后一个外显子中有一个AATAAA的保守序列,此位点down-stream有一段GT或T富丰区,这2部分共同构成poly(A)加尾信号。 三、载体及其分类 载体:即要把一个有用的基因(目的基因——研究或应用基因)通过基因工程手段送到生物细胞(受体细胞),需要运载工具(交通工具)携带外源基因进入受体细胞,这种运载工具就叫做载体(vector)。 P.S.基因工程所用的vector实际上是DNA分子,是用来携带目的 基因片段进入受体细胞的DNA。 载体的分类 按功能分成:(1)克隆载体:都有一个松弛的复制子,能带动 外源基因,在宿主细胞中复制扩增。它是用来克隆和扩增DNA片段(基因)的载体。(所以有时实验时扩增效率低下,要注意是不是使用的严谨型载体)(2)表达载体:具有克隆载体的基本元件 (ori,Ampr,Mcs等)还具有转录/翻译所必需的DNA顺序的载体。
人类基因组图谱定义 1543年,比利时解剖学家A·维萨里(1514-1564)发表了划时代的著作《人体的构造》,开创了人体解剖学,使人们从宏观上了解了自己。“人类基因组计划”建立的人类基因组图,被誉为“人体的第二张解剖图”,它将从微观上或者说从根本上使人类了解自己。 人类第一个基因组草图 2000年6月26日,美国总统克林顿和英国首相布莱尔联合宣布:人类有史以来的第一个基因组草图已经完成。2001年2月12日中、美、日、德、法、英等6国科学家和美国塞莱拉公司联合公布人类基因组图谱及初步分析结果。 人类基因组计划中最实质的内容,就是人类基因组的DNA序列图,人类基因组计划起始、争论焦点、主要分歧、竞争主战场等都是围绕序列图展开的。在序列图完成之前,其他各图都是序列图的铺垫。也就是说,只有序列图的诞生才标志着整个人类基因组计划工作的完成。 2003年4月15日,在DNA双螺旋结构模型发表50周年前夕,中、美、日、英、法、德六国元首或政府首脑签署文件,六国科学家联合宣布:人类基因组序列图完成。 人类基因组图谱的绘就,是人类探索自身奥秘史上的一个重要里程碑。它被很多分析家认为是生物技术世纪诞生的标志,也就是说,21世纪是生物技术主宰世界的世纪。正如一个世纪前量子论的诞生被认为揭开了物理学主宰的20世纪一样。 全球专家拟绘癌症基因图谱 国际癌症基因组协会4月29日在英国伦敦成立。这一组织计划通过统筹各国和地区专家的合作,耗资10亿美元,历时10年,绘制较为完整的致癌基因突变图谱。目前已有英国、中国和美国等9国加入这一计划。 专家认为,图谱将为癌症预防、诊断和治疗带来一场革命,开辟癌症个案化治疗的新时代。 方法 国际癌症基因组协会计划利用更加先进、快速的基因组测序新技术,详细研究50种不同类别的癌症,希望找到所有与癌症相关的基因突变现象。 英国剑桥韦尔科姆基金会桑格研究所是这一计划的主要参与者之一。 英国《泰晤士报》援引桑格研究所专家迈克·斯特拉顿的话说:“借助更快速的脱氧核糖核酸(DNA)测序新技术,国际癌症基因组协会雄心勃勃,志在为数以千计癌症基因组测序,制作一个涵盖所有DNA变异的目录,绘制完整的癌变图谱。” 越来越多科研成果表明,癌症并非单一类型。而每种癌症都包括大量由不同类型基因突变导致的不同亚种类别,需要分别对症治疗。 国际癌症基因组协会计划在每种癌症的研究中,提取500名病人的细胞并测序基因组,与健康细胞作比对,以期找出导致癌细胞形成和扩散的基因突变。 意义 专家认为,图谱绘制对于癌症治疗具有革命性意义。 如果图谱绘制成功,医生就可准确掌握单个患癌病人的致癌基因突变因素,进而更为轻松地对症下药,寻找对特定病人或特定癌症种类具有针对性的治疗药物。 比如,医学界目前普遍认为,赫赛汀(Herceptin)是特定种类乳癌的治疗药物。 图谱还有助于发明新的癌症治疗药物。 韦尔科姆基金会负责人马克·沃尔波特说,识别致癌基因突变是癌症治疗领域内的一次“大跨步”进展,目的在于实现“对症治疗”。 沃尔波特披露,桑格研究所的斯特拉顿等专家已启动一项致力于研发癌症治疗新药的计划。 合作 国际癌症基因组协会成立的作用还在于促进各国专家合作。 目前已确定加入这一计划的国家为英国、中国、美国、澳大利亚、加拿大、法国、印度、日本和新加坡。 协会计划对每一种类癌症的研究资助2000万美元,因而整个研究项目将耗资约10亿美元。
如何查找质粒图谱 编者小木虫论坛susizheng 经常在坛子里看到一些人求助质粒图谱,很多时候我发现其实有些质粒图谱还是很容易找到了,刚开始帮忙查找了下,还公布了一些查找质粒图谱比较好的网站,后来看得多了,很多时候,这样的帖子直接跳过了。今天又看到几个求质粒图谱的帖子,突发奇想,就查找质粒图谱的方法,写个总结帖子吧,希望对虫子们有些帮助。这些方法,大部分是自己学习的过程中偶尔发现,也许总结得还不够全面,望其他虫友指正。 方法一:安装软件Vector NT 做分子实验,经常和不同的质粒打交道,了解各种质粒的图谱信息是必需的,invitrogen公司的这款软件绝对是分子生物学虫子们的福音,功能强大、界面美观,使用起来很人性化。后面的很多方法都是基于在这款软件的使用之上,因此个人觉得要想对质粒图谱了解更直观,安装这款软件是非常必要的。而且,一旦安装了这款软件,你就发现这款软件的软件包里面会包括invitrogen公司的所有质粒图谱信息和其他比较常见和经典的质粒图谱(如下图,不是有虫子求pRS 系列质粒吗?如下图,数据库中本身就有很多)。这里就不一一细说,各位虫子可以自己体验下。(这框软件的下载和使用说明书站内很多) 方法二:查找质粒图谱的网站: 这个之前有人求助质粒图谱时,我在回应求助帖里面公布过几个我经常用的网址,估计不是专题,很多人没看到,现在在此重新总结下。 1.Vector Database 地址:https://https://www.doczj.com/doc/6a2889154.html,/g?a=vdb 这个网站很页面很人性化,直入主题,也是我经常用到一个网站,比如这个帖子https://www.doczj.com/doc/6a2889154.html,/bbs/viewthread.php?tid=3103223&fpage=1,这个虫友求pRS类质
基因酷质粒图谱https://www.doczj.com/doc/6a2889154.html,/bbs/forum-38-1.html,收藏了将近800种质粒的图谱及相关信息 特向大家推荐,介绍及使用方法见: https://www.doczj.com/doc/6a2889154.html,/bbs/thread-417-1-1.html 质粒图谱信息 一.九种表达载体 Pllp-OmpA, pllp-STII, pMBP-P, pMBP-C, pET-GST, pET-Trx, pET-His, pET-CKS, pET-DsbA 二.克隆载体 pTZ19R DNA pUC57 DNA PMD18T PQE30 pUC18 pUC19 pTrcHisA pTrxFus pRSET-A pRSET-B pVAX1 PBR322 pbv220 pBluescript II KS (+) L4440 pCAMBIA-1301 pMAL-p2X pGD926 三.PET系列表达载体 Protein Expression ? Prokaryotic Expression ? pET Dsb Fusion Systems 39b and 40b Protein Expression ? Prokaryotic Expression ? pET Expression System 33b Protein Expression ? Prokaryotic Expression ? pET Expression Systems Protein Expression ? Prokaryotic Expression ? pET Expression Systems plus Competent Cells Protein Expression ? Prokaryotic Expression ? pET GST Fusion Systems 41 and 42 Protein Expression ? Prokaryotic Expression ? pET NusA Fusion Systems 43.1 and 44 Protein Expression ? Prokaryotic Expression ? pET Vector DNA Protein Purification ? Purification Systems ? Strep?Tactin Resins and Purification Kits 四.PGEX系列表达载体
利用addgene查找质粒载体图谱 生物工程 杨翔 2012718026 摘要: 现如今的生物实验研究中,细菌质粒是重组DNA 技术中常用的载体。在天然质粒的基础上,为了适应实验室操作而进行人工构建质粒载体。与天然质粒相比,质粒载体通常带有一个或一个以上的选择性标记基因(如抗生素抗性基因)和一个人工合成的含有多个限制性内切酶识别位点的多克隆位点(MCS)序列,并去掉了大部分非必需序列,使分子量尽可能减少,以便于基因工程操作。 做分子实验,经常和不同的质粒打交道,了解各种质粒的图谱信息是必需的,然而如何准确迅速的查找到所需要的质粒图谱,是实验研究的基础工作,这里简单介绍一下应用addgene网站查找质粒图谱的方法。 关键词:质粒图谱,addgene 一.Addgene简介 Addgenen是一个全球科学家质粒共享非盈利组织。它作为一个公益性组织,负责保存和提供质粒。 科学家发表文章如果涉及到质粒,会发一份到Addgene保存,其他科学家如果需要这个质粒,也可以向Addgene索取 二.网站首页界面 https://www.doczj.com/doc/6a2889154.html,/点击此网址,进入addgene首页,可以看到如下界面。 菜单栏包括了:Home(首页),Deposit Plasmids(储存质粒),Find Plasmids(查找质粒),How to Order(如何构建),Plasmid Reference(质粒引用)以及最后一个About Addgene(关于Addgene) 三.查找方法 1.我们以常见的pRS质粒为列,点击菜单栏的Plasmid Reference,进入以下界面。
2.再点击下图中的Vector Batabase,进入载体数据库。 点击后会出现以下界面 3.之后,我们可以根据界面中给出的四种搜素方法查找所需的质粒载体,包括:Plasmid Type(质粒类型) Source(质粒的来源) Bacterial Resistance(细菌抗药性) Selectable Marker(选择标记)
如何查找质粒图谱之我见——plasmid map, Vector Sequence方法汇总 经常在坛子里看到一些人求助质粒图谱,很多时候我发现其实有些质粒图谱还是很容易找到了,刚开始帮忙查找了下,还公布了一些查找质粒图谱比较好的网站,后来看得多了,很多时候,这样的帖子直接跳过了。今天又看到几个求质粒图谱的帖子,因此决定就查找质粒图谱的方法,写个总结帖子,希望对虫子们有些帮助。这些方法,大部分是自己学习的过程中积累的,也许总结得还不够全面,望其他虫友指正。 方法一:安装软件Vector NT 做分子实验,经常和不同的质粒打交道,了解各种质粒的图谱信息是必需的,invitrogen公司的这款软件绝对是分子生物学虫子们的福音,功能强大、界面美观,使用起来很人性化。后面的很多方法都是基于在这款软件的使用之上,因此个人觉得要想对质粒图谱了解更直观,安装这款软件是非常必要的。而且,一旦安装了这款软件,你就发现这款软件的软件包里面会包括invitrogen公司的所有质粒图谱信息和其他比较常见和经典的质粒图谱。这里就不一一细说,各位虫子可以自己体验下。(这款软件的下载和使用说明书站内很多) 方法二:查找质粒图谱的网站: 这个之前有人求助质粒图谱时,我在回应求助帖里面公布过几个我经常用的网址,估计不是专题,很多人没看到,现在在此重新总结下 1.Vector Database 地址:https://https://www.doczj.com/doc/6a2889154.html,/g?a=vdb 这个网站很页面很人性化,直入主题,也是我经常用到一个网站,比如同样这个帖子求pRS类质粒图谱(注意,是一类质粒图谱,没关系,照样能找到),直接在搜索框输入pRS,可以看到,之类质粒一共有三十多个。
一、如何阅读质粒图谱 载体主要有病毒和非病毒两大类,其中质粒DNA是一种新的非病毒转基因载体。 一、一个合格质粒的组成要素 复制起始位点Ori,即控制复制起始的位点。原核生物DNA分子中只有一个复制起始点。 而真核生物DNA分子有多个复制起始位点。 抗生素抗性基因:可以便于加以检测,如Amp+ ,Kan+ 多l克隆位点:MCS克隆携带外源基因片段 P/E:启动子/增强子 Terms:终止信号 加poly(A)信号:可以起到稳定mRNA作用 二、如何阅读质粒图谱 第一步:首先看Ori的位置,了解质粒的类型(原核/真核/穿梭质粒) Ori的箭头指复制方向,其他元件标注的箭头多指转录方向(正向)。 第二步:再看筛选标记,如抗性,决定使用什么筛选标记: (1)Ampr:水解β-内酰胺环,解除氨苄的毒性。 (2)tetr :可以阻止四环素进入细胞。 (3)camr:生成氯霉素羟乙酰基衍生物,使之失去毒性。 (4)neor(kanr):氨基糖苷磷酸转移酶,使G418(卡那霉素衍生物)失活。 (5)hygr:使潮霉素β失活。 第三步:看多克隆位点(MCS)。它具有多个限制酶的单一切点,便于外源基因的插入。 如果在这些位点外有外源基因的插入,会导致某种标志基因的失活,而便于筛选。决定能不能放目的基因以及如何放置目的基因。 第四步:再看外源DNA插入片段大小。质粒一般只能容纳小于10Kb的外源DNA片段。 一般来说,外源DNA片段越长,越难插入,越不稳定,转化效率越低。 第五步:是否含有表达系统元件,即启动子-核糖体结合位点-克隆位点-转录终止信号。 这是用来区别克隆载体与表达载体。克隆载体中加入一些与表达调控有关的元件即成为表达载体。选用那种载体,还是要以实验目的为准绳。 二、相关概念: 启动子-核糖体结合位点-克隆位点-转录终止信号 启动子-促进DNA转录的DNA顺序,这个DNA区域常在基因或操纵子编码顺序的上游,是DNA分子上可以与RNApol特异性结合并使之开始转录的部位,但启动子本身不被转录。 增强子/沉默子-为真核l基因组(包括真核病毒基因组)中的一种具有增强邻近基因转录过程的调控顺序。其作用与增强子所在的位置或方向无关。即在所调控基因上游或下游均可发挥作用。沉默子-负增强子,负调控序列。 核糖体结合位点/起始密码/SD序列(Rbs/AGU/SDs):mRNA有核糖体的两个结合位点,对于原核而言是AUG(起始密码)和SD序列。 l转录终止顺序(终止子)/翻译终止密码子:结构基因的最后一个外显子中有一个AATAAA 的保守序列,此位点down-stream有一段GT或T富丰区,这2部分共同构成poly(A)加尾信号。结构基因的最后一个外显子中有一个AATAAA的保守序列,此位点down-stream有一段GT或T富丰区,这2部分共同构成poly(A)加尾信号。 三、载体及其分类 载体:即要把一个有用的基因(目的基因——研究或应用基因)通过基因工程手段送到生物细胞(受体细胞),需要运载工具(交通工具)携带外源基因进入受体细胞,这种运载
如何阅读质粒图谱 载体主要有病毒和非病毒两大类,其中质粒DNA是一种新的非病毒转基因载体。 一个合格质粒的组成要素 1. 复制起始位点Ori 即控制复制起始的位点。原核生物DNA分子中只有一个复制起始点。而真核 生物DNA分子有多个复制起始位点。 2. 抗生素抗性基因可以便于加以检测,如Amp+ ,Kan+ 3. 多克隆位点MCS 克隆携带外源基因片段 4. P/E 启动子/增强子 5. Terms 终止信号 6. 加poly(A)信号可以起到稳定mRNA作用 如何阅读质粒图谱 第一步:首先看Ori的位置,了解质粒的类型(原核/真核/穿梭质粒) 所谓穿梭质粒是指一类人工构建的具有两种不同复制起点和选择标记,因而可以在两种不同类群宿主中存活和复制的质粒载体。此概念不仅用于不同的微生物菌群之间,也可以推广到真核生物表达载体的构建,如用于枯草的pBE2、酵母的pPIC9K、哺乳动物表达载体pMT2 和用于植物细胞的Ti 质粒。这些穿梭质粒不仅可以在大肠杆菌中复制扩增,也可以在相应的枯草、酵母、动物或植物细胞中扩增和表达。这样利于对质粒的分子生物学操作和大量制备。 第二步:再看筛选标记,如抗性,决定使用什么筛选标记。 1. Ampr 水解β-内酰胺环,解除氨苄的毒性。 2. tetr 可以阻止四环素进入细胞。 3. camr 生成氯霉素羟乙酰基衍生物,使之失去毒性。 4. neor(kanr)氨基糖苷磷酸转移酶使G418(长那霉素衍生物)失活 5. hygr 使潮霉素β失活。 第三步:看多克隆位点(MCS)。它具有多个限制酶的单一切点。便于外源基因的插入。如果在这些位点外有外源基因的插入,会导致某种标志基因的失活,而便于筛选。决定能不能放目的基因以及如何放置目的基因。 第四步:再看外源DNA插入片段大小。质粒一般只能容纳小于10Kb的外源DNA片段。一般来说,外源DNA片段越长,越难插入,越不稳定,转化效率越低。 第五步:是否含有表达系统元件,即启动子-核糖体结合位点-克隆位点-转录终止信号。这是用来区别克隆载体与表达载体。克隆载体中加入一些与表达调控有关的元件即成为表达载体。选用那种载体,还是要以实验目的为准绳。 启动子-核糖体结合位点-克隆位点-转录终止信号 1. 启动子-促进DNA转录的DNA顺序,这个DNA区域常在基因或操纵子编码顺序的上游,是DNA 分子上可以与RNApol特异性结合并使之开始转录的部位,但启动子本身不被转录。
pcDNA?3.1(+) pcDNA?3.1(–) Catalog nos. V790-20 and V795-20 Version K 10November2010 28-0104 User Manual
ii
Table of Contents Important Information (v) Accessory Products (vi) Methods (1) Overview (1) Cloning into pcDNA?3.1 (2) Transfection (6) Creating Stable Cell Lines (7) Appendix (10) pcDNA?3.1 Vectors (10) pcDNA?3.1/CAT (12) Technical Support (13) Purchaser Notification (13) References (15) iii
iv
Important Information pcDNA? Vectors This manual is supplied with the following products. Product Catalog no. pcDNA?3.1(+) Vector V790-20 pcDNA?3.1(–) Vector V795-20 Shipping and Storage Vectors are shipped on wet ice. Upon receipt, store at –20°C. Contents The pcDNA?3.1 vector components pcDNA?3.1 are listed below: Item Concentration Volume pcDNA?3.1 Vector pcDNA?3.1(+) or pcDNA?3.1(–)20 μg at 0.5 μg/μl, in TE buffer, pH 8.0 (10 mM Tris-HCl, 1 mM EDTA, pH 8.0) 40 μl Control Plasmid pcDNA?3.1/CAT 20 μg at 0.5 μg/μl, in TE buffer, pH 8.0 (10 mM Tris-HCl, 1 mM EDTA, pH 8.0) 40 μl Product Qualification The Certificate of Analysis provides detailed quality control information for each product. Certificates of Analysis are available on our website. Go to https://www.doczj.com/doc/6a2889154.html,/support and search for the Certificate of Analysis by product lot number, which is printed on the box. v
(转载) 一.九种表达载体 Pllp-OmpA, pllp-STII, pMBP-P, pMBP-C, pET-GST, pET-Trx, pET-His, pET-CKS, pET-DsbA 二.克隆载体 pTZ19RDNA pUC57DNA PMD18T PQE30 pUC18 pUC19 pTrcHisA pTrxFus pRSET-A pRSET-B pVAX1 PBR322 pbv220 pBluescriptIIKS( ) L4440 pCAMBIA-1301 pMAL-p2X pGD926 三.PET系列表达载体 ProteinExpression?ProkaryoticExpression?pETDsbFusionSystems39band40b ProteinExpression?ProkaryoticExpression?pETExpressionSystem33b ProteinExpression?ProkaryoticExpression?pETExpressionSystems ProteinExpression?ProkaryoticExpression?pETExpressionSystemsplusCompetentCells ProteinExpression?ProkaryoticExpression?pETGSTFusionSystems41and42 ProteinExpression?ProkaryoticExpression?pETNusAFusionSystems43.1and44 ProteinExpression?ProkaryoticExpression?pETVectorDNA ProteinPurification?PurificationSystems?Strep?TactinResinsandPurificationKits 四.PGEX系列表达载体 TEcoR?pGEX-1I/BAP
() 一.九种表达载体 Pllp-OmpA, pllp-STII, pMBP-P, pMBP-C, pET-GST, pET-Trx, pET-His, pET-CKS, pET-DsbA 二.克隆载体 pTZ19RDNA pUC57DNA PMD18T PQE30 pUC18 pUC19 pTrcHisA pTrxFus pRSET-A pRSET-B pVAX1 PBR322 pbv220 pBluescriptIIKS( ) L4440 pCAMBIA-1301 pMAL-p2X pGD926 三.PET系列表达载体 ProteinExpression?ProkaryoticExpression?pETDsbFusionSystems39band40b ProteinExpression?ProkaryoticExpression?pETExpressionSystem33b ProteinExpression?ProkaryoticExpression?pETExpressionSystems ProteinExpression?ProkaryoticExpression?pETExpressionSystemsplusCompetentCells ProteinExpression?ProkaryoticExpression?pETGSTFusionSystems41and42 ProteinExpression?ProkaryoticExpression?pETNusAFusionSystems43.1and44 ProteinExpression?ProkaryoticExpression?pETVectorDNA ProteinPurification?PurificationSystems?Strep?TactinResinsandPurificationKits 四.PGEX系列表达载体 TEcoR?pGEX-1I/BAP