
Python异常处理实例解读
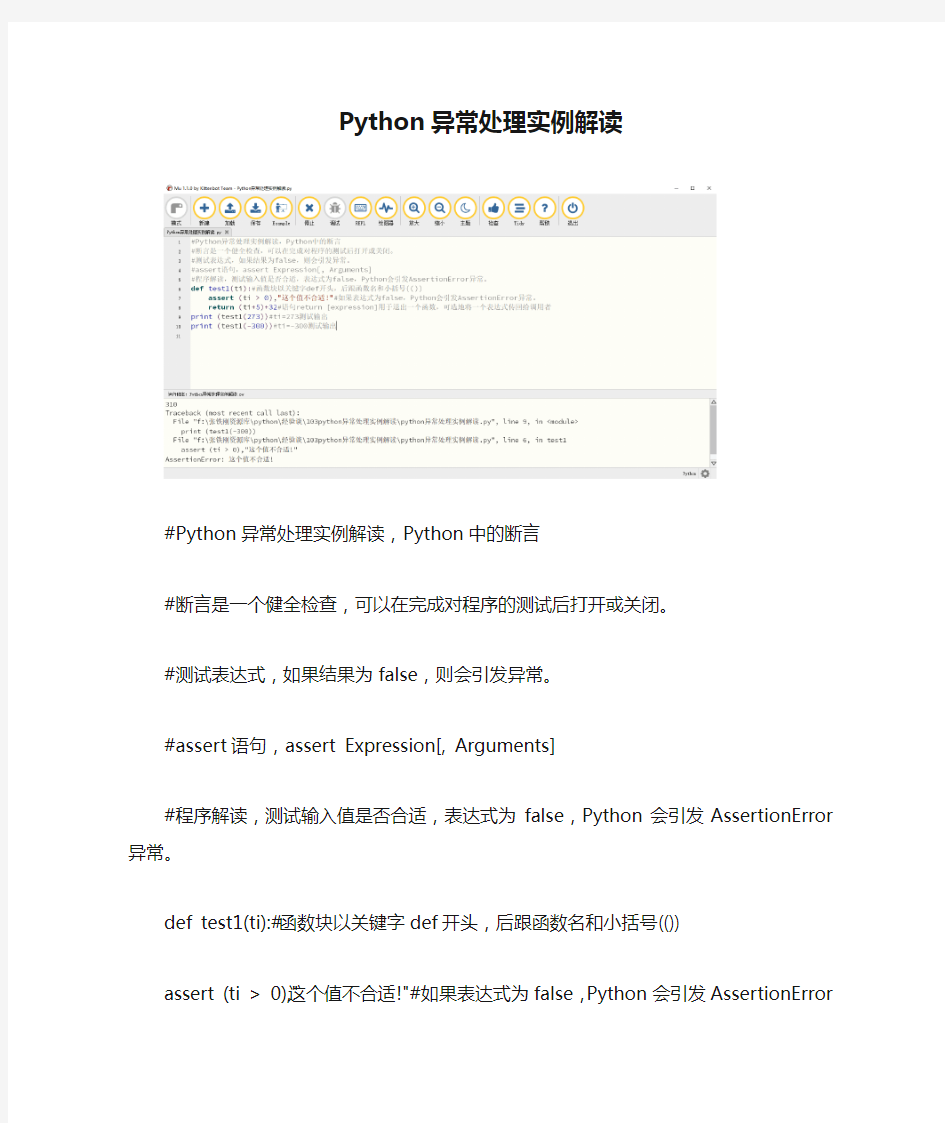
#Python异常处理实例解读,Python中的断言
#断言是一个健全检查,可以在完成对程序的测试后打开或关闭。
#测试表达式,如果结果为false,则会引发异常。
#assert语句,assert Expression[, Arguments]
#程序解读,测试输入值是否合适,表达式为false,Python会引发AssertionError异常。def test1(ti):#函数块以关键字def开头,后跟函数名和小括号(())
assert (ti > 0),"这个值不合适!"#如果表达式为false,Python会引发AssertionError异常。
return (ti+5)+32#语句return [expression]用于退出一个函数,可选地将一个表达式传回给调用者
print (test1(273))#ti=273测试输出
print (test1(-300))#ti=-300测试输出
运行结果!
310
Traceback (most recent call last):
File "f:\张铁刚资源库\python\经验谈\103python异常处理实例解读\python异常处理实例解读.py", line 9, in
print (test1(-300))
File "f:\张铁刚资源库\python\经验谈\103python异常处理实例解读\python异常处理实例解读.py", line 6, in test1
assert (ti > 0),"这个值不合适!"
AssertionError: 这个值不合适!
>>>
6. 异常和文件处理- Dive Into Python 6.1 异常处理. Python的异常用 try except finally 来处理. 并且except后还可以跟else . 引发异常用raise 如果抛出的异常没有被处理. 在Python IDE中是显示一些红色的信息. 在真正的Python程序运行时. 会导致程序终止. 在以前我们已经见到过一下几种异常: 在Dictionary 中如果使用的key 不存在. 会引发KeyError异常.如: >>> d = {"a":1, "b":"abc"} >>> d["c"] Traceback (most recent call last): File "
Python的中文处理 一、使用中文字符 在python源码中如果使用了中文字符,运行时会有错误,解决的办法是在源码的开头部分加入字符编码的声明,下面是一个例子: #!/usr/bin/env python # -*- coding: cp936 -*- Python Tutorial中指出,python的源文件可以编码ASCII以外的字符集,最好的做法是在#!行后面用一个特殊的注释行来定义字符集: # -*- coding: encoding -*- 根据这个声明,Python会尝试将文件中的字符编码转为encoding编码,并且,它尽可能的将指定地编码直接写成Unicode文本。 注意,coding:encoding只是告诉Python文件使用了encoding格式的编码,但是编辑器可能会以自己的方式存储.py文件,因此最后文件保存的时候还需要编码中选指定的ecoding 才行。 二、中文字符的存储 >>> str = u"中文" >>> str u'\xd6\xd0\xce\xc4' >>> str = "中文" >>> str '\xd6\xd0\xce\xc4' u"中文"只是声明unicode,实际的编码并没有变。这样子就发生变化了: >>> str = "中文" >>> str '\xd6\xd0\xce\xc4' >>> str = str.decode("gb2312") >>> str u'\u4e2d\u6587' 更进一步: >>> s = '中文' >>> s.decode('gb2312') u'\u4e2d\u6587' >>> len(s) 4 >>> len(s.decode('gb2312')) 2 >>> s = u'中文'
Python基础知识:以九九乘法表实例学循环/字符串/ 列表推导式 九九乘法表可以说是我们每个人小的时候,学数认字以来第一个要背诵的数学口诀,没有人不认识它。 下面我们看看在python中如何实现它吧,实现的打印效果如下图所示: 方法1:常规思维版 定义了一个函数myFunc1,其思路同C/C++语言通用实现方法类似,使用两层for循环,外层控制行的转换,内层控制列的口诀输出,代码如下图所示: 打印结果信息时,使用了format函数转换为字符串。每列中每条口诀之间使用“\t”分割,每行之间使用上图的第15行代码换行。 方法2:优雅简洁版 定义了一个函数myFunc2,使用了join函数和列表推导式的
方法实现,代码如下图所示: 1、对于列表推导式,也可以参考例子: 其通用的书写形式如下: [表达式for 变量in 列表] 或者[表达式for 变量in 列表if 条件] 列表推导式内部也可以嵌套使用,如上面代码的实现。 2、对于join函数,其功能是将序列(如字符串、元组、列表等)中的元素以特定的分隔符连接成一个新的字符串。其使用格式如下: ‘‘sep’’.join(seq) 其中,sep是指分隔符,seq是要连接的元素序列。 完整的测试代码 完整的测试代码如下图所示: 说明:本例中python的运行版本是2.7.14,为实现print函数不换行打印的功能(第14行代码,python3系列可直接支持),所以增加了第9行代码“from __future__ import print_function”,以便python2系列中print函数能够支持end 关键字。
1.请补充横线处的代码,让Python 帮你随机选一个饮品吧! import ____①____ (1) listC = ['加多宝','雪碧','可乐','勇闯天涯','椰子汁'] print(random. ____②____ (listC)) 参考答案: import random (1) listC = ['加多宝','雪碧','可乐','勇闯天涯','椰子汁'] print(listC)) 2.请补充横线处的代码,listA中存放了已点的餐单,让Python帮你增加一个“红烧肉”,去掉一个“水煮干丝”。 listA = ['水煮干丝','平桥豆腐','白灼虾','香菇青菜','西红柿鸡蛋汤'] listA. ____①____ ("红烧肉") ②____ ("水煮干丝") print(listA) 参考代码: listA = ['水煮干丝','平桥豆腐','白灼虾','香菇青菜','西红柿鸡蛋汤'] ("红烧肉") ("水煮干丝") print(listA) 3.请补充横线处的代码。dictMenu中存放了你的双人下午套餐(包括咖啡2份和点心2份)的价格,让Python帮忙计算并输出消费总额。 dictMenu = {'卡布奇洛':32,'摩卡':30,'抹茶蛋糕':28,'布朗尼':26} ___①____ for i in ____②____: sum += i print(sum) 参考代码: dictMenu = {'卡布奇洛':32,'摩卡':30,'抹茶蛋糕':28,'布朗尼':26} sum = 0 for i in (): sum += i print(sum) 4.获得输入正整数 N,反转输出该正整数,不考虑异常情况。 参考代码: N = input() print(N[::-1]) 5. 给定一个数字123456,请采用宽度为25、右对齐方式打印输出,使用加号“+”填充。 参考代码: print("{:+>25}".format(123456)) 6.给定一个数字.9,请增加千位分隔符号,设置宽度为30、右对齐方式打印输出,使用空格填充。 参考代码:
python语言经典案例(基础级) 案例1: 题目:输入一行字符,分别统计出其中英文字母、空格、数字和其它字符的个数。 程序分析:利用while 或for 语句,条件为输入的字符不为'\n'。 实例- 使用while 循环 #!/usr/bin/python # -*- coding: UTF-8 -*- import string s = raw_input('请输入一个字符串:\n') letters = 0 space = 0 digit = 0 others = 0 i=0 while i < len(s): c = s[i] i += 1 if c.isalpha(): letters += 1 elif c.isspace(): space += 1 elif c.isdigit(): digit += 1 else: others += 1 print'char = %d,space = %d,digit = %d,others = %d' % (letters, space,digit,others) 实例- 使用for 循环 #!/usr/bin/python
# -*- coding: UTF-8 -*- import string s = raw_input('请输入一个字符串:\n') letters = 0 space = 0 digit = 0 others = 0 for c in s: if c.isalpha(): letters += 1 elif c.isspace(): space += 1 elif c.isdigit(): digit += 1 else: others += 1 print'char = %d,space = %d,digit = %d,others = %d' % (letters, space,digit,others) 以上实例输出结果为: 案例2: 题目:一球从100米高度自由落下,每次落地后反跳回原高度的一半;再落下,求它在第10次落地时,共经过多少米?第10次反弹多高? 程序分析:无 程序源代码:
a='helLO' print(a.title()) # 首字母大写a='1 2'
执行结果:1 2 1 2 1 2 00000001 2 1 2 3 4 5 6 7 8 # 3 字符串搜索相关 .find() # 搜索指定字符串,没有返回-1 .index() # 同上,但是找不到会报错 .rfind() # 从右边开始查找 .count() # 统计指定的字符串出现的次数 # 上面所有方法都可以用index代替,不同的是使用index查找不到会抛异常,而find s='hello world' print(s.find('e')) # 搜索指定字符串,没有返回-1 print(s.find('w',1,2)) # 顾头不顾尾,找不到则返回-1不会报错,找到了 则显示索引 print(s.index('w',1,2)) # 同上,但是找不到会报错 print(s.count('o')) # 统计指定的字符串出现的次数 print(s.rfind('l')) # 从右边开始查找 # 4字符串替换 .replace('old','new') # 替换old为new .replace('old','new',次数) # 替换指定次数的old为new s='hello world' print(s.replace('world','python')) print(s.replace('l','p',2)) print(s.replace('l','p',5)) 执行结果: hello python heppo world heppo worpd
# 5字符串去空格及去指定字符 .strip() # 去两边空格 .lstrip() # 去左边空格 .rstrip() # 去右边空格 .split() # 默认按空格分隔 .split('指定字符') # 按指定字符分割字符串为数组 s=' h e-l lo ' print(s) print(s.strip()) print(s.lstrip()) print(s.rstrip()) print(s.split('-')) print(s.split()) # 6字符串判断相关 .startswith('start') # 是否以start开头 .endswith('end') # 是否以end结尾 .isalnum() # 是否全为字母或数字 .isalpha() # 是否全字母 .isdigit() # 是否全数字 .islower() # 是否全小写 .isupper() # 是否全大写 .istitle() # 判断首字母是否为大写 .isspace() # 判断字符是否为空格 # 补充 bin() # 十进制数转八进制 hex() # 十进制数转十六进制 range() # 函数:可以生成一个整数序列 type() # 查看数据类型 len() # 计算字符串长度 format() # 格式化字符串,类似%s,传递值能多不能少
python的try语句有两种风格 一:种是处理异常(try/except/else) 二:种是无论是否发生异常都将执行最后的代码(try/finally) try/except/else风格 try: <语句>#运行别的代码 except<名字>: <语句>#如果在try部份引发了'name'异常 except<名字>,<数据>: <语句>#如果引发了'name'异常,获得附加的数据 else: <语句>#如果没有异常发生 try的工作原理是,当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。1、如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except 子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。 2、如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印缺省的出错信息)。 3、如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。 try/finally风格 try: <语句> finally: <语句>#退出try时总会执行 python总会执行finally子句,无论try子句执行时是否发一异常。 1、如果没有发生异常,python运行try子句,然后是finally子句,然后继续。 2、如果在try子句发生了异常,python就会回来执行finally子句,然后把异常递交给上层try,控制流不会通过整个try语句。 当你想无论是否发生异常都确保执行某些代码时,try/finally是有用的。 这个在打开文件的时候有用finally总是在最后close()文件
本文由我司收集整编,推荐下载,如有疑问,请与我司联系Python:分割字符串,尊重和保留引号[重复] Python:分割字符串,尊重和保留引号[重复][英]Python: Split a string, respect and preserve quotes [duplicate]Using python, I want to split the following string: ?使用python,我想拆分如下字符串: a=foo, b=bar, c=“foo, bar”, d=false, e=“false” This should result in the following list: 这应导致下列清单: ?[‘a=foo’, ‘b=bar’, ‘c=“foo, bar”‘, ‘d=false’, ‘e=“false’”‘] When using shlex in posix-mode and splitting with “, “, the argument for cgets treated correctly. However, it removes the quotes. I need them because false is not the same as “false”, for instance. ?当在posix模式下使用shlex并使用“,”拆分时,clex的参数得到了正确的处理。但是,它删除了引号。我需要它们,因为false和false不一样。 My code so far: ?到目前为止我的代码: ?import shlexmystring = ‘a=foo, b=bar, c=“foo, bar”, d=false, e=“false”‘splitter = shlex.shlex(mystring, posix=True)splitter.whitespace += ‘,’splitter.whitespace_split = Trueprint list(splitter) # [‘a=foo’, ‘b=bar’, ‘c=foo, bar’, ‘d=false’, ‘e=false’] 19 s = r’a=foo, b=bar, c=“foo, bar”, d=false, e=“false”, f=“foo\”, bar”‘ re.findall(e (?: | )+ matches a sequence of non-delimiters and quoted strings, which is the desired result. 将模式2和3组合在一起(?: |)+匹配一个非分隔符和引号字符串序列,这是期望的结果。0 ?Regex can solve this easily enough: ?Regex可以很容易地解决这个问题: ?import remystring = ‘a=foo, b=bar, c=“foo, bar”, d=false, e=“false”‘splitString = re.split(‘,?\s(?=\w+=)’,mystring) The regex pattern here looks for a whitespace followed by a word character and then an equals sign which splits your string as you desire and maintains any quotes.
原文链接https://www.doczj.com/doc/614863345.html,/sinchb/article/details/8392827 事先说明哦,这不是一篇关于Python异常的全面介绍的文章,这只是在学习Python 异常后的一篇笔记式的记录和小结性质的文章。什么?你还不知道什么是异常,额... 1.Python异常类 Python是面向对象语言,所以程序抛出的异常也是类。常见的Python异常有以下几个,大家只要大致扫一眼,有个映像,等到编程的时候,相信大家肯定会不只一次跟他们照面(除非你不用Python了)。 python标准异常 异常名称描述 BaseException 所有异常的基类 SystemExit 解释器请求退出 KeyboardInterrupt 用户中断执行(通常是输入^C) Exception 常规错误的基类 StopIteration 迭代器没有更多的值 GeneratorExit 生成器(generator)发生异常来通知退出 SystemExit Python 解释器请求退出 StandardError 所有的内建标准异常的基类 ArithmeticError 所有数值计算错误的基类 FloatingPointError 浮点计算错误 OverflowError 数值运算超出最大限制 ZeroDivisionError 除(或取模)零(所有数据类型)
AssertionError 断言语句失败 AttributeError 对象没有这个属性 EOFError 没有内建输入,到达EOF 标记 EnvironmentError 操作系统错误的基类 IOError 输入/输出操作失败 OSError 操作系统错误 WindowsError 系统调用失败 ImportError 导入模块/对象失败 KeyboardInterrupt 用户中断执行(通常是输入^C) LookupError 无效数据查询的基类 IndexError 序列中没有没有此索引(index) KeyError 映射中没有这个键 MemoryError 内存溢出错误(对于Python 解释器不是致命的) NameError 未声明/初始化对象(没有属性) UnboundLocalError 访问未初始化的本地变量 ReferenceError 弱引用(Weak reference)试图访问已经垃圾回收了的对象RuntimeError 一般的运行时错误 NotImplementedError 尚未实现的方法 SyntaxError Python 语法错误 IndentationError 缩进错误 TabError Tab 和空格混用 SystemError 一般的解释器系统错误 TypeError 对类型无效的操作 ValueError 传入无效的参数 UnicodeError Unicode 相关的错误
字符串处理是非常常用的技能,但Python 内置字符串方法太多,常常遗忘,为了便于快速参考,特地依据Python 3.5.1 给每个内置方法写了示例并进行了归类,便于大家索引。 PS: 可以点击概览内的绿色标题进入相应分类或者通过右侧边栏文章目录快速索引相应方法。 概览 字符串大小写转换 ?str.capitalize() ?str.lower() ?str.casefold() ?str.swapcase() ?str.title() ?str.upper() 字符串格式输出 ?str.center(width[, fillchar]) ?str.ljust(width[, fillchar]); str.rjust(width[, fillchar]) ?str.zfill(width) ?str.expandtabs(tabsize=8)
?str.format(^args, ^^kwargs) ?str.format_map(mapping) 字符串搜索定位与替换 ?str.count(sub[, start[, end]]) ?str.find(sub[, start[, end]]); str.rfind(sub[, start[, end]]) ?str.index(sub[, start[, end]]); str.rindex(sub[, start[, end]]) ?str.replace(old, new[, count]) ?str.lstrip([chars]); str.rstrip([chars]); str.strip([chars]) ?static str.maketrans(x[, y[, z]]); str.translate(table) 字符串的联合与分割 ?str.join(iterable) ?str.partition(sep); str.rpartition(sep) ?str.split(sep=None, maxsplit=-1); str.rsplit(sep=None, maxsplit=-1) ?str.splitlines([keepends]) 字符串条件判断 ?str.endswith(suffix[, start[, end]]); str.startswith(prefix[, start[, end]]) ?str.isalnum() ?str.isalpha() ?str.isdecimal(); str.isdigit(); str.isnumeric() ?str.isidentifier()
1 输出你好 #打开新窗口,输入: #! /usr/bin/python # -*- coding: utf8 -*- s1=input("Input your name:") print("你好,%s" % s1) ''' 知识点: * input("某字符串")函数:显示"某字符串",并等待用户输入. * print()函数:如何打印. * 如何应用中文 * 如何用多行注释 ''' 2 输出字符串和数字 但有趣的是,在javascript里我们会理想当然的将字符串和数字连接,因为是动态语言嘛.但在Python里有点诡异,如下: #! /usr/bin/python a=2 b="test" c=a+b 运行这行程序会出错,提示你字符串和数字不能连接,于是只好用内置函数进行转换 #! /usr/bin/python #运行这行程序会出错,提示你字符串和数字不能连接,于是只好用内置函数进行转换 a=2 b="test" c=str(a)+b d="1111" e=a+int(d) #How to print multiply values print ("c is %s,e is %i" % (c,e)) ''' 知识点: * 用int和str函数将字符串和数字进行转换 * 打印以#开头,而不是习惯的// * 打印多个参数的方式 '''
3 列表 #! /usr/bin/python # -*- coding: utf8 -*- #列表类似Javascript的数组,方便易用 #定义元组 word=['a','b','c','d','e','f','g'] #如何通过索引访问元组里的元素 a=word[2] print ("a is: "+a) b=word[1:3] print ("b is: ") print (b) # index 1 and 2 elements of word. c=word[:2] print ("c is: ") print (c) # index 0 and 1 elements of word. d=word[0:] print ("d is: ") print (d) # All elements of word. #元组可以合并 e=word[:2]+word[2:] print ("e is: ") print (e) # All elements of word. f=word[-1] print ("f is: ") print (f) # The last elements of word. g=word[-4:-2] print ("g is: ") print (g) # index 3 and 4 elements of word. h=word[-2:] print ("h is: ") print (h) # The last two elements. i=word[:-2] print ("i is: ") print (i) # Everything except the last two characters l=len(word) print ("Length of word is: "+ str(l)) print ("Adds new element") word.append('h') print (word) #删除元素 del word[0] print (word) del word[1:3] print (word) ''' 知识点:
字符串常用函数 replace(string,old,new[,maxsplit]) 字符串的替换函数,把字符串中的old替换成new。默认是把string中所有的old值替换成new 值,如果给出maxsplit值,还可控制替换的个数,如果maxsplit为1,则只替换第一个old 值。 >>>a="11223344" >>>print string.replace(a,"1","one") oneone2223344 >>>print string.replace(a,"1","one",1) one12223344 capitalize(string) 该函数可把字符串的首个字符替换成大字。 >>> import string >>> print string.capitalize("python") Python split(string,sep=None,maxsplit=-1) 从string字符串中返回一个列表,以sep的值为分界符。 >>> import string >>> ip="192.168.3.3" >>> ip_list=string.split(ip,'.') >>> print ip_list ['192', '168', '3', '3'] all( iterable) 如果迭代的所有元素都是真就返回真。 >>> l = [0,1,2,3] >>> all(l) Flase >>> l = [1,2,3] >>> all(l) True any( iterable) 如果迭代中有一个元素为真就返回真。 >>> l = [0,1,2,3] >>> all(l) True >>> l = [1,2,3] >>> all(l) True basestring() 这个抽象类型是str和unicode的父类。它不能被调用或初始化,但是它可以使用来测试一
Python内置的字符串处理函数整理字符串长度获取:len(str)例:print'%slengt By xuanfeng6666 at 2014-06-01 139 阅读 0 回复 0.0 希赛币 Python内置的字符串处理函数整理 ?字符串长度获取:len(str) 例:print '%s length=%d' % (str,len(str)) ?字母处理 全部大写:str.upper() 全部小写:str.lower() 大小写互换:str.swapcase() 首字母大写,其余小写:str.capitalize() 首字母大写:str.title() print '%s lower=%s' % (str,str.lower()) print '%s upper=%s' % (str,str.upper()) print '%s swapcase=%s' % (str,str.swapcase()) print '%s capitalize=%s' % (str,str.capitalize()) print '%s title=%s' % (str,str.title()) ?格式化相关 获取固定长度,右对齐,左边不够用空格补齐:str.rjust(width) 获取固定长度,左对齐,右边不够用空格补齐:str.ljust(width) 获取固定长度,中间对齐,两边不够用空格补齐:str.center(width) 获取固定长度,右对齐,左边不足用0补齐.zfill(width) print '%s ljust=%s' % (str,str.ljust(20))
Python如何针对任意多的分隔符拆分字符串操作 本篇文章小编和大家分享一下Python cookbook(字符串与文本)针对任意多的分隔符拆分字符串操作,文中会结合实例形式进行分析Python使用split()及正则表达式进行字符串拆分操作相关实现技巧,对Python开发感兴趣或者是想要学习Python开发技术的小伙伴可以参考下哦。 问题:将分隔符(以及分隔符之间的空格)不一致的字符串拆分为不同的字段。 解决方案:使用更为灵活的re.split()方法,该方法可以为分隔符指定多个模式。 说明:字符串对象的split()只能处理简单的情况,而且不支持多个分隔符,对分隔符周围可能存在的空格也无能为力。 # example.py # # Example of splitting a string on multiple delimiters using a regex import re #导入正则表达式模块 line = 'asdf fjdk; afed, fjek,asdf, foo' # (a) Splitting on space, comma, and semicolon parts = re.split(r'[;,\s]\s*', line) print(parts) # (b) 正则表达式模式中使用“捕获组”,需注意捕获组是否包含在括号中,使用捕获组导致匹配的文本也包含在最终结果中 fields = re.split(r'(;|,|\s)\s*', line) print(fields) # (c) 根据上文的分隔字符改进字符串的输出 values = fields[::2] delimiters = fields[1::2] delimiters.append('') print('value =', values) print('delimiters =', delimiters) newline = ''.join(v+d for v,d in zip(values, delimiters)) print('newline =', newline) # (d) 使用非捕获组(?:...)的形式实现用括号对正则表达式模式分组,且不输出分隔符 parts = re.split(r'(?:,|;|\s)\s*', line)
本文由我司收集整编,推荐下载,如有疑问,请与我司联系 python 字符串操作 2017/08/24 0 name=“My \t name is {name} and age is {age}”print(name.capitalize()) #将name的值首字母大写print(name.count(“a”)) #输出a这个字符的出现的个数print(name.center(50,”-”)) #一共打印50个,其他用-代替print(name.endswith(“ex”)) #结尾是否包含exprint(name.expandtabs(tabsize=30)) #将字符串中的\t 转化为30个空格print(name[name.find(“name”):]) #find查找的意思字符串也可以进行切片,返回的结果为name及后面的一行内容 print(name.format(name=“wang”,age=23))print(name.format_map({“name”:”wang”,”age ”:23})) #字典的格式。。和format的结果一样print(“ab123”.isalnum()) #判断是否包含字母和数字,如果包含则返回为trueprint(“ab124”.isalpha()) #判断是否包含纯英文字符,如果是则返回为true,大小写不区分print(“122”.isdigit()) #判断是否为整数,如果为整数则返回为trueprint(“al1”.isidentifier()) #判断是不是一个合法的标识符(就是判断是不是合法的变量名)print(“aLL”.islower()) #判断是不是小写,是则返回trueprint(“aLL”.isnumeric()) #判断是不是数字,是则返回trueprint(“aLL”.isspace()) #判断是不是空格print(“My Name Is “.istitle()) #判断每个字符串的首字母大写,是的话就为trueprint(“my name is “.isupper())#判断是否是大写print(‘+’.join([‘1’,’2’,’3’])) #将列表的值转变为字符串的形式这个输出结果为:1+2+3print(name.ljust(50,”*”))print(name.rjust(50,”*”))print(“WANG”.lower())#将大写变成小写print(“wang”.upper()) #将小写边城大写print(“\nwang”.lstrip()) #取消左边的空格和回车print(“wang1\n”.rstrip())#去掉右边的空格和回车print(“ \nabng\n”.strip())#将左边和右边的空格和回车都去掉print(“wang han”.replace(‘a’,’A’,1))#将字符串中的a替换为大写的A,只替换其中一个print(‘wang wang’.rfind(‘a’)) #找到最右边的那个字符的下标print(‘1+2+3+4’.split(‘+’)) #以+号为分隔符,输出为列表的格式print(‘wang LI’.swapcase()) #将大写小反转print(‘wang han’.title()) #将每个字符串的首字母大写 ?tips:感谢大家的阅读,本文由我司收集整编。仅供参阅!
原文链接事先说明哦,这不是一篇关于Python异常的全面介绍的文章,这只是在学习Python异常后的一篇笔记式的记录和小结性质的文章。什么你还不知道什么是异常,额... 异常类 Python是面向对象语言,所以程序抛出的异常也是类。常见的Python异常有以下几个,大家只要大致扫一眼,有个映像,等到编程的时候,相信大家肯定会不只一次跟他们照面(除非你不用Python了)。 python标准异常
2.捕获异常 Python完整的捕获异常的语句有点像: 1.try: 2.try_suite 3.except Exception1,Exception2,...,Argument: 4.exception_suite 5....... #other exception block 6.else: 7.no_exceptions_detected_suite 8.finally: 9.always_execute_suite 额...是不是很复杂当然,当我们要捕获异常的时候,并不是必须要按照上面那种格式完全写下来,我们可以丢掉else语句,或者finally语句;甚至不要exception语句,而保留finally语句。额,晕了好吧,下面,我们就来一一说明啦。 语句 try_suite不消我说大家也知道,是我们需要进行捕获异常的代码。而except语句是关键,我们try捕获了代码段try_suite里的异常后,将交给except来处理。 try...except语句最简单的形式如下: 1.try: 2.try_suite 3.except: 4.exception block
Python-字符串操作方法(转) Posted on 2008-09-05 19:22 ∈鱼杆阅读(2111) 评论(1) 编辑收藏网摘所属分类: Python Python-String-Function 字符串中字符大小写的变换: * S.lower() #小写 * S.upper() #大写 * S.swapcase() #大小写互换 * S.capitalize() #首字母大写 * String.capwords(S) #这是模块中的方法。它把S用split()函数分开,然后用capitalize()把首字母变成大写,最后用join()合并到一起 * S.title() #只有首字母大写,其余为小写,模块中没有这个方法 字符串在输出时的对齐: * S.ljust(width,[fillchar]) #输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。 * S.rjust(width,[fillchar]) #右对齐 * S.center(width, [fillchar]) #中间对齐 * S.zfill(width) #把S变成width长,并在右对齐,不足部分用0补足 字符串中的搜索和替换: * S.find(substr, [start, [end]]) #返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索 * S.index(substr, [start, [end]]) #与find()相同,只是在S中没有substr时,会返回一个运行时错误 * S.rfind(substr, [start, [end]]) #返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号 * S.rindex(substr, [start, [end]]) * S.count(substr, [start, [end]]) #计算substr在S中出现的次数 * S.replace(oldstr, newstr, [count]) #把S中的oldstar替换为newstr,count为替换次数。这是替换的通用形式,还有一些函数进行特殊字符的替换 * S.strip([chars]) #把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None * S.lstrip([chars]) * S.rstrip([chars]) * S.expandtabs([tabsize]) #把S中的tab字符替换没空格,每个tab替换为tabsize个空格,默认是8个 字符串的分割和组合: * S.split([sep, [maxsplit]]) #以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符
授课教案
授课教案附页 教学设计说明一、旧课回顾 ?字符串在内存中的存放形式:s = 'Hello World' ?字符串s的长度的获取:len(s) ?字符串中的字符是从0开始编号的,字符串中第一个字符的序号是0,最后一个字符的序号是len(s)-1,所以最后一个字符是s[len(s)-1]. ?字符和编码的转换: ?大小写字母的转换: 大写字母X转小写字母x:ord(‘X’)+chr(ord(‘a’)-ord(‘A’)) 小写字母x转大写字母X:ord(‘x’)-ord(‘a’))+chr(ord(‘A’) ?练习: 对任意一个字符串,将它反向显示。例如:输入字符串‘hello world’,输 出‘dlrow olleh’。 分析: 字符串中的字符是从0开始编号的,字符串显示是从第0个字符开始,一直 到第len(s)-1个字符; 要将字符串反向显示,只需要先显示第len(s)-1个字符,再显示第len(s)-2个 字符,... ,最后显示第0个字符即可。 很明显,使用for循环可以很容易实现。从第len(s)-1个字符开始, start=len(s)-1,到第0个字符为止,stop=0 - 1= -1,步长step = -1.
代码示例: 注意:step>0时,到谁为止,stop = 谁+1;step<0时,到谁为止,stop=谁-1. 二、字符串的比较 ?两个字符串a,b可以比较大小,比较规则是按各个对应字符的Unicode编码,编码大的一个为大。 ?比较a[0]和b[0],如果a[0]>b[0]则a>b,如果a[0]