Lecture 08 - Cash Flow Statements
- 格式:pdf
- 大小:967.82 KB
- 文档页数:36

Cash Flow Statements 2(based on Week 10 lecture)Due Week 11 (10 October)1.Questions from Deegan Chapter 20 (14 marks):Question 13. (4 marks)This question can be answered by using either the t-account approach or theequations approach.The following t-accounts are in $000Property, plant and equipmentThe original cost of the asset that was disposed is determined by adding theaccumulated depreciation pertaining to the asset ($40 000, as determined above)to the carrying amount of the disposed asset ($90 000, which was provided in thequestion) to give an original cost of $130 000. Because a gain of $20 000 wasmade on disposal of property, plant and equipment, $110 000 must have beenreceived for the disposed asset ($90 000 + $20 000).If we adopt an equation method approach, cash payments to suppliers of theproperty, plant and equipment would be determined as:Cash payments = Closing balance of plant (650 000) – opening balance of plant(500 000) + original cost of asset sold (130 000) = $280 000Question 14. (10 marks) Complete the Statement of Cash Flows. Show workings.(Note: cash flows from operating activities were prepared for Week 10 tutorial)Cash flows from operations (from Week 10 tutorial – no marks for this in Week 11)Receipts from customers 200 000Payments to suppliers (140 000)Payments for accrued expenses (26 000)Interest payments (20 000)14 000Cash flows from investment activitiesPlant and equipmentThe journal entries for the disposal of the plant and equipment can besummarised as:Dr Accum. depreciation—plant and equip. 20 000Cr Plant and equip. 20 000 As Plant increased by $10 000, $30 000 must have been acquired during the period(this is given in the question), as reconciled below:Accumulated depreciationCash flows from investing, therefore, were:Payment for property plant and equipment (30 000)Cash flows from financingA reconciliation of movements in share capital would show that there havebeen no issues for cash.The only cash flow from financing relates to $20 000 from long-termloans.Hence, the total cash flows for the period can be represented as:Opening cash balance 120 000Cash from operations 14 000Cash from investing (30 000)Cash from financing 20 000Closing cash balance 124 000We are now able to present a statement of cash flows for XYZ Ltd.XYZ LimitedStatement of Cash Flowsfor the year ended 30 June 2013$000 Cash flows from operating activitiesReceipts from customers 200 Payments to suppliers of goods and services, inclusive of labour (166) Interest paid (20) Net cash provided from operating activities (1) 14 Cash flows from investing activitiesPayment for property, plant and equipment (2) (30) Net cash used in investing activities (30) Cash flows from financing activitiesProceeds from borrowings 20 Net cash from financing activities 20 Net increase in cash held 4 Cash at the beginning of the financial year 120 Cash at the end of the financial year 1242.Past Examination Question (12 marks)Mickelson Ltd Cash Flow Statement for year ended 30 June 2011Required:Complete the Statement of Cash Flows for Mickelson Ltd for the year ended 30 June 2011, using the pro forma provided. Show all workings. (Note: cash flows from operating activities were completed for Week 10 tutorial)3.Critical Thinking questions (8 marks)Hooker Corporation collapsed in July 1989, owing hundreds of millions of dollars to various creditors. This occurred in the era before a Cash Flow Statement was required in Australia, although a Funds Statement was required, which provided different sort of information about the movement of funds. It appears that creditors and the market took different views of the company’s success.Read the article ―Hooker Corporation: a case for cashflow reporting?‖ by Jack Flanagan and Greg Whittred. It can be found on Blackboard (Assessment/Weekly TutorialWork/Week 11 Cash Flow Statements 2). It was published in Australian Accounting Review in 1992 (Vol. 1, No. 3), pp. 48 – 52).Required:(a)Outline the indicators of financial performance that may have contributed to thecompany’s reputation and state whether its reputation was deserved, according to the article. (4 marks)Indicators:Return on Assets – This climbed fairly steadily from 1979 (10%) to around17% in 1986, before falling dramatically after 1987.Return on Equity – this was quite volatile between 1979 and 1988, risingsteeply from around 7.5% to 20% between 1984 and 1989. It thenplateaued briefly and then dropped steeply after 1987.Current Ratio – This reached a peak of 3.5:1 in 1987, falling off steeplyafter that.Quick Ratio – This was fairly stable until a peak of 1:1 in 1987 and arapid fall after thatLeverage – This was around 70% in 1979, falling to under 50% in 1987and then rising steeply to almost 75% after thatInterest coverage – Although this was extremely variable, in 1987 it wasat about 1.4, rising steeply to 2.4 by 1988.Was the Hooker reputation deserved?The sudden drop off in many of these ratios in 1988 should have provided an indicator to Hooker’s creditors that things were not good with the company. However, up until that point there may have been no great cause for concern. The article states that while creditors were “over-confident” in relation to Hooker, investors were “rather less optimistic” (Flanagan and Whittred, 1992, p. 50). For those who were financially knowledgeable, Hooker was underperforming relative to its industry.(b)Do you think that if Hooker Corporation had been required to prepare a CashFlow Statement, that its failure might have been avoided? You may find the ICC format (Issues, content, conclusions) useful in structuring your answer.(4 marks) Issue.Before Cash Flow Statements were required, users of financial reports did not have a reliable way of assessing how the cash was flowing, i.e. whether a company was operationally sustainable from a cash point of view. The issue with the Hooker case is whether anybody could have told from its financial reports prior to its collapse, that it was nearing collapse.Content.Some points to be considered:Traditional indicators did not provide much indication of troubles aheadHowever there was a lot of volatility in some of the indicators, which may have indicated troubles, to an astute reader of financial statementsIt is surprising that major creditors were not more aware of the company’sliquidity problems, since presumably big banks would have been able to ask for whatever information they requiredFor people knowledgeable about the real estate industry, Hooker’s performance was not particularly goodThe payment of quite high dividends in the few years before the company’scollapse may have been worth a closer examinationA deeper investigation of borrowings, which were increasing significantly, mayhave provided further information about the company’s soundness (or lack ofsoundness!)It would not have been possible, without a cash flow statement, to pull out some of the figures for cash flows from operations, without detailed analysis of thefinancial statements, and even then, it may not have been possible. The authorshave constructed cash flows from operations (see Figure 4) by going deeper into the reports. This would require a lot of expertise. The cash flow analysis in Figure4 reveals information not able to be known from the other indicators, and shows amuch less attractive performance.Conclusions.Your opinion, based on the content you have discussed!Total marks for Week 11 Tutorial work: 34 (will be scaled back to 5% if collected)。

财金英语教程参考答案Chapter 1: Introduction to Finance1. What is finance?- Finance is the management of money and includesactivities such as investing, borrowing, lending, budgeting, saving, and forecasting.2. What are the three main functions of finance?- The three main functions of finance are planning, acquiring, and managing financial resources.3. What is the time value of money?- The time value of money is the concept that a sum of money is worth more now than the same sum in the future dueto its potential earning capacity.4. How does inflation affect the value of money?- Inflation erodes the purchasing power of money over time, meaning that the same amount of money will buy fewer goodsand services in the future.5. What is the difference between a bond and a stock?- A bond is a debt instrument where an investor lends money to an entity in exchange for interest payments, while a stock represents ownership in a company and offers thepotential for capital gains and dividends.Chapter 2: Financial Statements1. What are the four main financial statements?- The four main financial statements are the balance sheet, income statement, cash flow statement, and statement of changes in equity.2. What is the purpose of a balance sheet?- The balance sheet provides a snapshot of a company's financial position at a specific point in time, showing its assets, liabilities, and equity.3. How is net income calculated?- Net income is calculated by subtracting all expensesfrom the total revenue of a company during a specific period.4. What does the cash flow statement show?- The cash flow statement shows the inflow and outflow of cash within a business over a period of time, categorizedinto operating, investing, and financing activities.5. What is the statement of changes in equity?- The statement of changes in equity shows the changes in the equity accounts of a company over a period of time, including retained earnings, capital contributions, and other comprehensive income.Chapter 3: Financial Analysis1. What are the main types of financial analysis?- The main types of financial analysis are ratio analysis,horizontal analysis, vertical analysis, and trend analysis.2. What is the purpose of ratio analysis?- Ratio analysis is used to evaluate a company's financial health by comparing various financial ratios such asliquidity, profitability, and leverage ratios.3. What is horizontal analysis?- Horizontal analysis involves comparing financial statement items over multiple periods to identify trends and changes in performance.4. What is vertical analysis?- Vertical analysis, also known as common-size analysis,is a method of financial statement analysis where each itemis expressed as a percentage of a base figure, typicallytotal assets or total revenue.5. What is trend analysis?- Trend analysis involves examining the historical data of financial metrics over time to predict future trends and performance.Chapter 4: Risk Management1. What is risk management?- Risk management is the process of identifying, assessing, and prioritizing potential risks to an investment or project, and taking steps to mitigate or avoid these risks.2. What are the types of risks in finance?- The types of risks in finance include market risk,credit risk, liquidity risk, operational risk, and legal risk.3. What is diversification?- Diversification is a risk management strategy that involves spreading investments across various financial instruments, industries, or geographic regions to reduce overall risk.4. What is hedging?- Hedging is a risk management technique used to reducethe risk of price fluctuations in an asset by taking an offsetting position in a related security.5. What is the role of insurance in risk management?- Insurance is a risk management tool that providesfinancial protection against potential losses or damages by transferring the risk to an insurance company in exchange for a premium.Chapter 5: Investment Strategies1. What are the different types of investment strategies?- Types of investment strategies include passive investing, active investing, value investing, growth investing, and income investing.2. What is the difference between passive and active investing?- Passive investing involves a "set it and forget it" approach, typically using index funds, while active investingrequires regular buying and selling of individual securities based on market research and analysis.3. What is value investing?- Value investing is an investment strategy that involves buying stocks that are considered undervalued by the market, with the expectation that their true value will eventually be recognized.4. What is growth investing?- Growth investing focuses on companies that are expected to grow at an above-average rate compared to the market, often investing in companies with strong competitive advantages and high growth potential.5. What is income investing?- Income investing is an investment strategy aimed at generating a steady stream of income from investments, typically through dividends or interest payments.Chapter 6: International Finance1. What is international。


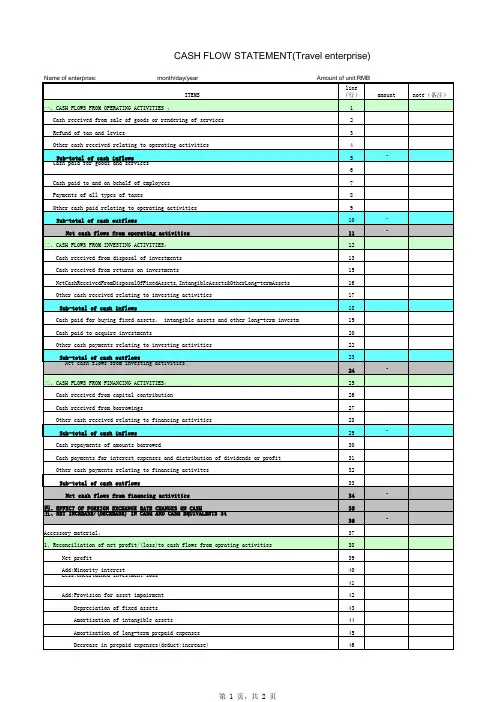
Issue 1 Disclosure: cash flow statements1. General format of cash flow statement:Cash Flow Statementfor the year ended 30 June 2006Cash flows from operating activitiesCash receipts from customers+Cash paid to suppliers and employees-Cash generated from operationsInterest paid-Income taxes paid-Net cash used in operating activitiesCash flows from investing activitiesPurchase of investments-Purchase of property, plant and equipment-Proceeds from sale of equipment+Interest received+Dividends received+Net cash used in investing activitiesCash flows from financing activitiesProceeds from issue of share capital+Proceeds from long-term borrowings+Repayment of borrowings-Dividends paid-Net cash used in financing activitiesNet increase (decrease) in cash and cash equivalents+/-Cash and cash equivalents at beginning of period+Cash and cash equivalents at end of period+2. As cash flow statement is introduced, what is meant by the term ‘cash’?Definition of cash is important because cash cannot generate cash flow in the context of preparing a cash flow statement and cash should be recorded in ‘Cash and cash equivalents at beginning of period’.Cash comprises cash on hand and demand deposits.Cash equivalents are short-term highly liquid investments that are readily convertible into known amounts of cash, and which are subject to an insignificant risk of changes in value.Examples: bank and non-bank bills, money market deposits close to maturity, investment within a term of 3 months or less.Bank overdraft is treated as a financial activity.Account receivable (subject to adjustment by bad debts) and equity securities (highrisk in changes in value) are excluded from the definition of cash.(Note: you need to make clear whether the payment or receipt is for our own company or third parties)4. Preparing the cash flow statementStep 1: Cash flows from operating activitiesThere are 2 methods which can be used – direct method and indirect methodDirect method is based on individual item in income statement. Major classes of revenues are shown as gross cash inflows from operations, and expenses are shown as gross cash outflows from operations. The information necessary to determine the operating cash flows is obtained by adjusting sales, cost of sales and other items in the accrual-basis IS for non-cash items and items not related to operating activities.Under direct method, each item is adjusted from accrual basis to cash basis. Certain items, such as depreciation and amortisation of non-current assets and gains/losses on non-current assets disposed of, are excluded, because they have no effect on cash flow. Indirect method is based on after-tax profit in income statement. The accrual-basis profit is adjustedto a cash-basis profit by making adjustments for non-cash items used in the determination of profit. Added back to profit are the effects of all deferrals of cash inflows (deferred income) and outflows (prepayment), and deducted are all accruals of expected future cash inflows (accrued income) and outflows (accrued expense). The deferrals and accruals of future cash flows are reflected in the changes in the balance of assets and liabilities relating to operating activities. (This method is similar to what is done in preparing tax).Both methods are permitted under IAS7.Bad debts written off is actually A/R written off in UK (Dr Provision for doubtfuldebts/Cr AR)The point is the balance of the allowance for doubtful debts account must not be netted off against the accounts receivable balance. We must use bad debts written off.B. Cash paid to suppliers and employees (and other expenses)For cash paid to employees and other services:Step 2: Cash flows from investing activitiesA. Acquisition and disposal of non-current assetsThis step involves an examination of any changes in these long-term assets in the light of relevant transaction data to determine the effects on cash flows. Hence, you must search the data to check whether the company purchase long-term assets on cash or on credit and sell long-term assets on cash or on credit.Step 3: Cash flows from financing activitiesThe initial step is to analyse the balance sheet and statement of changes in equity for changes in non-current liabilities and equity items. These changes are then assessed in light of additional relevant transaction data to determine changes which resulted in cash flows.Step 4: Ascertain net cash and cash equivalent increase/decreaseStep 5: Reconcile cash and cash equivalent at end with that at the beginningStep 6: Note to disclose the components of cash and cash equivalentsStep 7: Note to reconcile the net cash used in operating activities with profit in the IS by using indirect method.The reconciliation process commences with the accrual-basis profit and adjusting for any non-operating items (e.g. gains/losses on sale of PPE) and all non-cash expenses and revenues.Profit for the periodSubtract: Gains on sale of non-current assets (Profit from investing activities/gains do not affect cash, only sales proceeds affect cash)Subtract: Investment income (Interest and dividends received from investing activities)Add: Depreciation and other write-downs (No reduction of cash)Add/subtract: Changes in current assets and liabilities in BS (Non-current assets and liabilities relate to investment or financing)Step 8: Notes to discuss non-cash financing and investing activities, including acquisition or sale of a subsidiary and of property, plant and equipmentWhy? Since the cash flow statement reports only the effects of transactions on cash and cash equivalents, some material financing and investing activities may be omitted from the statement if such transactions do not affect cash flows.Examples include conversion of long-term debt to equity, the acquisition of other entities by means of a share issue, the acquisition of non-current assets by means of mortgage, and the acquisition of assets by entering into a finance lease.My own thought:The essence of cash flow statement is to turn the accrual-accounting profit to cash-accounting profit (which is also net cash). In order to achieve this goal, there are 2 ways we can choose. The first way is to adjust the accrual-accounting profit, which is called indirect method. Under indirect method, accrual-accounting profit is adjusted by reducing non-cash expenses such as depreciation expense (which means adding it to profit), and gain/loss which does not affect the cash level. Then, we need to adjust the change of current assets and liabilities, which are related to operating activities. Actually, we can subdivide the profit, and this will lead to another method – direct method. Under the direct method, the amount of cash inflow and outflow will be calculated. We can use sales, purchases and other expense together with the change of assets and liabilities to get the cash. Cash generated from operating activities is closely related to current assets and current liabilities; cash generated from investing activities is closely related to non-current assets; cash generated from financing activities is closely related to non-current liabilities and equity.Example:Direct method:Cash outflow = Beginning A/C Payable + Purchases – Closing A/C PayableIndirect method:Net cash = Profit + Increase of A/C Payable= (Revenue –OS –Purchases + CS …) + Ending A/C Payable –Opening A/C Payable= … - (Purchases + Opening A/C Payable – Ending A/C Payable= … - the amount of cash outflow for purchasesDirect method:Cash inflow = Beginning A/C Receivable + Credit Sales – Ending A/C ReceivableIndirect method:Net cash = Profit – Increase A/C Receivable= (Revenue - …) – (Ending A/C Receivable – Beginning A/C Receivable)= Revenue… + Beginning A/C Receivable – Ending A/C Receivable= The amount of cash inflow for sales5. Limitations of the cash flow statement→Past cash flows reported: the statement is useful to the extent that the past cash flow information helps in predicting the future cash flow position. Heavy reliance on the cash flow statement for any one period can be dangerous.→Non-cash transactions and events, such as debt-equity swaps, non-current asset purchases by long-term debt, the use of financial leases, and barter transactions donot appear in the statement but are appendages by way of note. Hence, in evaluating an entity’s future cash flows, careful attention must be given to information contained in the notes to the statement.→Liquidity/solvency: The entity is solvent when the assets (rather than cash) of the entity, when realised, are sufficient to pay off all debts as they fall due.→Management manipulation: management may wish to make cash flows appear better or worse than they actually were during a reporting period. Ways in which cash flows may be manipulated include prepayment, delaying cash payments, postponing acquisition of large investments, deferring debenture issues, use of barter, and the use of finance leasing.→Cost: most entities opt for the indirect method because it is less costly to implement than the direct method.。
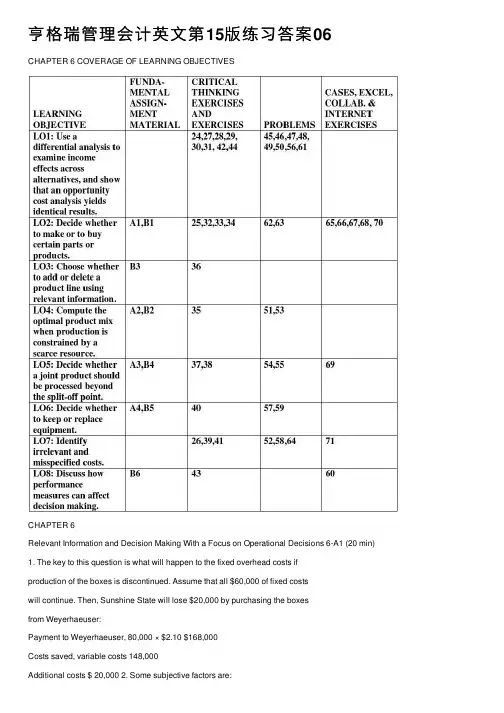
亨格瑞管理会计英⽂第15版练习答案06 CHAPTER 6 COVERAGE OF LEARNING OBJECTIVESCHAPTER 6Relevant Information and Decision Making With a Focus on Operational Decisions 6-A1 (20 min) 1. The key to this question is what will happen to the fixed overhead costs ifproduction of the boxes is discontinued. Assume that all $60,000 of fixed costswill continue. Then, Sunshine State will lose $20,000 by purchasing the boxesfrom Weyerhaeuser:Payment to Weyerhaeuser, 80,000 × $2.10 $168,000Costs saved, variable costs 148,000Additional costs $ 20,000 2. Some subjective factors are:Might Weyerhaeuser raise prices if Sunshine State closed down its box-making facilityWill sub-contracting the box production affect the quality of the boxesIs a timely supply of boxes assured, even if the number needed changesDoes Sunshine State sacrifice proprietary information when disclosing the box specifications to Weyerhaeuser3. In this case the fixed costs are relevant. However, it is not the depreciation onthe old equipment that is relevant. It is the cost of the new equipment. Annualcost savings by not producing the boxes now will be:Variable costs $148,000Investment avoided (annualized) 80,000Total saved $228,000 The payment to Weyerhaeuser is $228,000 - $168,000 = $60,000 less than thesavings, so Sunshine State would be $60,000 better off subcontracting theproduction of the boxes.6-A2 (10 min.)1. Contribution margins:Plain = $70 - $55 = $15Professional = $100 - $75 = $25Contribution margin ratios:Plain = $15 ÷ $70 = 21.4%Professional = $25 ÷ $100 = 25%2. Plain Professionala. Units per hour 2 1b. Contribution margin per unit $15 $25Contribution margin per hour $30 $25 Total contribution for 20,000 hours $600,000 $500,000 3. The plain circular saws are the best use of the scarce machine hours. For a givencapacity, the criterion for maximizing profits is to obtain the greatest possiblecontribution to profit for each unit of the limiting or scarce factor. Moreover,fixed costs are irrelevant unless their total is affected by the choice of products.6-A3 (15 min.) Table is in thousands of dollars.1,2. (a) (b) (a)-(b) (c) (a)-(b)-(c)SeparableSales Sales Costs IncrementalBeyond at Incremental Beyond Gain orSplit-Off Split-Off Sales Split-Off (Loss)A 230 54 176 190 (14)B 330 32 298 300 (2)C 175 54 121 100 21 Increase in overall operating income from further processing of A, B, and C 5The incremental analysis indicates that Product C should be processed further, butProducts A and B should be sold at split-off. The overall operating income would be$44,000, as follows:Sales: $54,000 + $32,000 + $175,000 $261,000Joint cost of goods sold $117,000Separable cost of goods sold 100,000 217,000Operating income $ 44,000Compare this with the present operating income of $28,000. That is, $230,000 + $330,000 + $175,000 - ($190,000 + $300,000 + $100,000 + $117,000) = $28,000. Theextra $16,000 of operating income comes from eliminating the $16,000 loss resultingfrom processing Products A and B beyond the split-off point.6-A4 (30-40 min.)Problem 6-60 is an extension of this problem. The two problems make a good combination.1. Operating inflows for each year, old machine:$910,000 - ($810,000 + $60,000) $40,000Operating inflows for each year, new machine:$910,000 - ($810,000 + $22,000*) $78,000* $60,000 - $38,000Cash flow statements (in thousands of dollars):Keep ReplaceThree ThreeYear Years Years Year Years Years1 2 & 3 Together 1 2 & 3 Together Receipts, inflows from operations 40 40 120 78 78 234 Disbursements:Purchase of "old" equipment (90)* -- (90) (90) -- (90) Purchase of "new" equipment:Total costs less proceedsfrom disposal of "old"equipment ($99,000-$15,000) -- -- -- (84) -- (84) Net cash inflow (outflow) (50) 40 30 (96) 78 60* Assumes that the outlay of $90,000 took place on January 2, 2010, or sometime during 2010. Some students will ignore this item, assuming correctly that it is irrelevant to the decision. However, note that a statement for the entire year was requested.The difference for three years taken together is $60,000 - $30,000 = $30,000. Note particularly that the $90,000 book value can be omitted from the comparison. Merely cross out the entire line; although the column totals will be affected, the net difference will still be $30,000.2. Income statements (in thousands of dollars):Keep ReplaceThree ThreeYears Years Year Years Years1, 2 & 3 Together 1 2 & 3 Together Sales 910 2,730 910 910 2,730 Expenses:Other expenses 810 2,430 810 810 2,430 Operating of machine 60 180 22 22 66 Depreciation 30 90* 33 33 99 Total expenses 900 2,700 865 865 2,595 Loss on disposal:Proceeds ("revenue") -- -- (15) -- (15) Book value ("expense") -- -- 90 -- 90* Loss -- -- 75 -- 75 Total charges 900 2,700 940 865 2,670 Net income 10 30 (30) 45 60 * As in part (1), the $90,000 book value can be omitted from the comparison without changing the $30,000 difference. This would mean dropping the depreciation item of $30,000 per year (a cumulative effect of $90,000) under the "keep" alternative, and dropping the book value item of $90,000 in the loss on disposal computation under the "buy" alternative.Difference for three years together, $60,000 - $30,000 = $30,000.Note the motivational factors here. A manager may be reluctant to replacesimply because the large loss on disposal will severely harm the profitperformance in Year 1.3. The net difference for the three years taken together would be unaffected becausethe item is a past cost. You can substitute any number for the original $90,000figure without changing this answer.For example, examine how the results would change in part (1) by inserting $1 million where the $90,000 now appears (in thousands of dollars):Keep: Replace:Three Years Three YearsTogether Together Difference Receipts, inflows from operations 120 234 114 Disbursements:Purchase of old equipment(1,000) (1,000) 0Purchase of new equipment:Gross price (99)Disposal proceeds of "old" 15 -- ( 84) (84) Net cash outflow ( 880) ( 850) 30 In sum, this may be a horrible situation. The manager really blundered. Butkeeping the old equipment will compound the blunder to the cumulative tune of$30,000 over the next three years.4. Diplomatically, Lee should try to convey the following. All of us tend to indulgein the erroneous idea that we can soothe the wounded pride of a bad purchasedecision by using the item instead of replacing it. The fallacy is believing that acurrent or future action can influence the long-run impact of a past outlay. Allpast costs are down the drain. Nothing can change what has already happened.The $90,000 has been spent. Subsequent accounting for the item is irrelevant.The schedules in parts (1) and (2) clearly show that we may completely ignorethe $90,000 original outlay and still have a correct analysis. The important point is that the $90,000 is not an element of difference between alternatives and,therefore, may be safely ignored. The only relevant items are those expectedfuture items that will differ between alternatives.5. The $90,000 purchase of the original equipment, the sales, and the otherexpenses are irrelevant because they are common to both alternatives. Therelevant items are the following (in thousands of dollars):Three YearsTogetherKeep Replace Operating of machine(3 × $60; 3 × $22) $180 $ 66 Incremental cost of new machine:Total cost $99Less proceeds of old machine 15Incremental cost -- 84 Total relevant costs $180 $150 Difference in favor of buying $ 306-B1 (15-20 min.)1. Make BuyTotal Per Unit Total Per Unit Purchase cost €10,000,000€50 Direct material €5,500,000€27.50Direct labor 1,900,000 9.50Factory overhead, variable 1,100,000 5.50Factory overhead, fixedavoided 900,000 4.50Total relevant costs €9,400,000 €47.00 €10,000,000€50 Difference in favor of making € 600,000 € 3.00The numerical difference in favor of making is €600,000 or €3.00 per unit. Therelevant fixed costs are €900,000, not €3,000,000.2. Buy and LeaveMake Capacity Idle Buy and RentRent revenue -- -- € 1,150,000 Obtaining of components €(9,400,000) €(10,000,000)€(10,000,000)Net relevant costs €(9,400,000) €(10,000,000) € (8,850,000) The final column indicates that buying the components and renting the vacatedcapacity will yield the best results in this case. The favorable difference is€9,400,000 - €8,850,000 = €550,000.6-B2 (15 min.)1. If fixed manufacturing cost is applied to products at $1.00 per machine hour, ittakes $.75 ÷ $1.00, or 3/4 of an hour to produce one unit of XY-7. Similarly, ittakes $.25 ÷ $1.00 or 1/4 of an hour to produce BD-4.2. If there are 100,000 hours of capacity:XY-7: 100,000 hours ÷ 3/4 = 133,333 units.BD-4: 100,000 hours ÷ 1/4 = 400,000 units.Total contribution margins show that BD-4 should be produced, generating$200,000 of contribution margin, which is $66,667 more than would be earned by XY-7.Per Unit Units TotalXY-7 $6.00 - ($3.00 + $2.00) = $1.00 133,333 $133,333BD-4 $4.00 - ($1.50 + $2.00) = $ .50 400,000 $200,0006-B3 (15-20 min.)All amounts are in thousands of British pounds.The major lesson is that a product that shows an operating loss based on fully allocated costs may nevertheless be worth keeping. Why? Because it may produce a sufficiently high contribution to profit so that the firm would be better off with it than any other alternative.The emphasis should be on totals:Replace Magic Department WithExisting GeneralOperations Merchandise Electronic Products Sales 6,000 -600 + 250 = 5,650 -600 + 200 = 5,600 Variable expenses 4,090 -390 + 175a= 3,875 -390 + 100 b= 3,800 Contribution margin 1,910 -210 + 75 = 1,775 -210 + 100 = 1,800 Fixed expenses 1,100 -120 + 0 = 980 -120 + 30 = 1,010 Operating income 810 - 90 + 75 = 795 - 90 + 70 = 790 a(100% - 30%) × 250b(100% - 50%) × 200The facts as stated indicate that the magic department should not be closed. First, the total operating income would drop. Second, fewer customers would come to the store, so sales in other departments may be affected adversely.6-B4 (15 min.)1. Sales ($400 + $600 + $100) $1,100Costs:Raw materials $700Processing 100Total 800Profit $ 3002. Sales ($840 + $850 + $170) $1,860Costs:Joint costs $800Frozen dinner costs 440Salisbury steak costs 200Tanning costs 80Total costs 1,520Profit $ 340Although it is more profitable to process all three products further than it is tosell them all at the split-off point, it is important to look at the economic benefit from further processing of each individual product.3. Steaks to frozen dinners:Additional revenue from processing further ($840 - $400) $440Additional cost for processing further 440Increase (decrease) in profit from processing further $ 0 Hamburger to Salisbury steaks:Additional revenue from processing further ($850 - $600) $250Additional cost for processing further 200Increase (decrease) in profit from processing further $ 50 Untanned hide to tanned hide:Additional revenue from processing further ($170 - $100) $ 70Additional cost for processing further 80Increase (decrease) in profit from processing further $ (10) Only the hamburger dictates that it should be processed further, because it is the only product whose additional revenue for processing further exceeds theadditional cost. You are indifferent about processing further steak to frozendinners, as the incremental profit is 0.4. The resulting profit would be $350:Sales ($400 + $850 + $100) $1,350Costs:Joint costs $800Further processing of hamburger 200Total cost 1,000 Profit $ 3506-B5 (15-20 min.)1. Three Years TogetherKeep Replace Difference Cash operating costs $42,000 $27,000 $15,000 Old equipment, book value:Periodic write-off asdepreciation 15,000 -or lump-sum write-off - 15,000* Disposal value -6,000* 6,000 New equipment, acquisition cost 15,000** - 15,000 Total costs $57,000 $51,000 $ 6,000 *In a formal income statement, these two items would be combined as "loss ondisposal" of $15,000 - $6,000 = $9,000.**In a formal income statement, written off as straight-line depreciation of $15,000 ÷3 = $5,000 for each of three years.2. Three Years TogetherKeep Replace Difference Cash operating costs $42,000 $27,000 $15,000 Disposal value of old equipment - -6,000 6,000 New equipment, acquisition cost - 15,000 - 15,000 Total relevant costs $42,000 $36,000 $ 6,000 This tabulation is clearer because it focuses on only those items that affect thedecision.3. Benefits of the replacement alternative* $15,000Deduct initial net cash outlay required* 9,000 Difference in favor of replacement $ 6,000 * 3 × ($14,000 - $9,000)** $15,000 - $6,000Also, the new equipment is likely to be faster, thus saving operator time. The latter is important, but it is not quantified in this problem.6-B6 (10 min.)1. The replacement alternative would be chosen because the county would have$6,000 more cash accumulated in three years.2. The keep alternative would be chosen because the higher overall costs ofphotocopying for the first year would be shown for the replacement alternative(under accrual accounting):First YearKeep Replace Cash operating costs $14,000 $ 9,000 Depreciation expense 5,000 5,000 Loss on disposal 9,000 Total costs $19,000 $23,000 Thus, the performance evaluation model might motivate the manager to make adecision that would be undesirable in the long run.6-1 An opportunity cost does not entail a disbursement of cash at any future time, whereas an outlay cost does entail an additional disbursement sooner or later.6-2 The $800 represents an opportunity cost. It is the amount forgone by rejecting an opportunity. It signifies that the value to the owner of keeping those strangers out of the summer house for that two-week period is at least $800.6-3 Accountants do not ordinarily record opportunity costs in accounting records because those records are traditionally concerned with real transactions rather than possible transactions. It is impossible to record data on all lost opportunities.6-4 A differential cost is any difference in total cost or revenue between two alternatives. A differential cost is an incremental cost when one of the alternatives contains all the costs of the other plus some additional costs. The additional costs are the incremental costs – which are also differential.6-5 No. Incremental cost has a broader meaning. It is the addition to total costs by the adoption of some course of action. Another term, marginal cost, is used by economists to indicate the addition to costs from the manufacture of one additional unit. Of course, marginal cost is indeed the incremental cost of one unit.6-6 The decline in costs would be called differential or incremental savings.6-7 Not necessarily. Qualitative factors can favor either making or buying. Often factors such as product quality and assurance of delivery schedules favor making. However, sometimes establishing long-term relationships with suppliers is an important qualitative factor favoring the purchase of components.6-8 The choice in many cases is not really whether to make or buy. Instead, the choice is how best to use available capacity. 6-9 Yes. The costs that make a difference when a product or department is being deleted are the avoidable costs.6-10 Four examples of scarce factors are: (a) labor hours, (b) money (investment capital), (c) supervisory hours, and (d) computer hours.6-11 Joint products are two or more manufactured products that (1) have relatively significant sales values and (2) are not separately identifiable as individual products until their split-off point. Examples of joint products include chemicals, lumber, flour, and meat.6-12 The split-off point is where the individual products produced in a joint process become separately identifiable. Costs before the split-off point are irrelevant for decisions about the individual products. They affect the decision about whether to undertake the entire production process, but they do not influence decisions about what to do with the individual products.6-13 Yes. Techniques for assigning joint-product costs to individual products are useful only for product costing, not for deciding on further processing after the split-off point. The product must be considered separately at that point apart from its joint cost. The proper basis of the decision on further processing is a comparison of incremental revenue versus incremental expense between the alternatives of selling at the split-off point and processing further.6-14 No. Once inventory has been purchased, the price paid is a sunk cost. It is true that selling at a price less than $5,000 would produce a reported loss. However, a sale at any price above $0 is economically beneficial provided that the only alternative is to scrap the inventory.6-15 No. Sunk costs are irrelevant to the replacement decision.6-16 No. Past costs are not relevant because they cannot be affected by a decision. Although past costs are often indispensable for formulating predictions, past costs themselves are not the predictions that are the inputs to decision models. Clear thinking is enhanced by these distinctions.6-17 Only b and c are relevant.a. Book value of old equipment is irrelevant to a replacement decision because itdoes not change under any alternative and cannot be realized.b. Disposal value of old equipment is relevant to a replacement decision because itcan either be realized (by replacement) or forgone (by continued use).c. Cost of new equipment is relevant to a replacement decision because it can beincurred (by replacement) or avoided (by continued use).6-18 Yes. Some expected future costs may be irrelevant because they will be the same under all feasible alternatives.6-19 Yes. The statement is correct in terms of total variable costs.6-20 Two reasons why unit costs should be analyzed with care in decision making are: 1. Most unit costs are stable only over a certain range of output, and care must betaken to see that allowances are made when alternatives are considered outsidethat range.2. Some unit costs are an allocation of fixed costs; thus when a higher volume ofoutput is being considered, unit cost will decrease proportionately, and vice versa. Two other reasons are mentioned in the text:1. Some unit costs are based on both relevant and irrelevant factors and should bebroken down further before being considered.2. Unit costs must be reduced to the same base (denominator) before comparing orcombining them.6-21 Sales personnel sometimes neglect to point out that the unit costs are based on outputs far in excess of the volume of their prospective customer.6-22 An inconsistency between a decision model and a performance evaluation model occurs when a decision about whether to replace a piece of equipment is based on the cash flow effects over the life of the equipment but a manager's performance evaluation is based on the first year's reported income. The loss on disposal of the equipment is irrelevant for decision purposes, but it affects the first year income, hence the performance evaluation.6-23 The wide use of income statements to evaluate performance may overly influence managers to maximize short-run performance that may hurt long-run performance. They may pass up profitable opportunities to replace equipment because of the large loss on disposal shown on the first year’s income statement.6-24 Yes, this statement is generally correct. Accountants record transactions. But opportunity cost is the cost of transactions that do not occur (or have not occurred yet). It is the cost of opportunities forgone. Managers usually have much better information about forgone opportunities than do accountants.6-25 Deciding whether to outsource payroll functions requires estimates of the cost of designing, maintaining, and using a payroll system internally compared to the cost of a contract with an outside supplier. To operate an internal payroll system requires hiring personnel with the needed expertise in both legal/governmental issues affecting payroll and information processing to implement a system. Small companies often find it less costly to outsource payroll to a company that has broad expertise in these areas.6-26 Whenever total costs are unitized by dividing by total units and the resulting unit costs are then used to predict new total costs based on a different level of production, errors are being made if any of the costs are fixed. If the new production level is higher, predicted total costs are overestimated. If the new production level is lower, predicted total costs are underestimated. Never unitize fixed costs if the resulting unit cost will be used for planning purposes!Consider the following simple example:Fixed Cost Variable Cost TotalTotal $100 $100 $200Units ÷10 ÷10 ÷10Unit Cost $10 $10 $20If a new planned number of units is 20, what will be the new, predicted total cost?The correct cost function and cost prediction isTotal Cost = $100 + $10 × Number of units= $100 + $10 × 20 =$300The correct cost function is based on the two amounts that are constant within the relevant range – the total fixed cost and the unit variable cost.The incorrect unitized cost function and incorrect and overestimated prediction isTotal Cost = $20 × Number of units= $20 × 20= $400It is easy to see that the error comes from treating fixed costs as if they were variable.6-27 The amount paid for inventory is a sunk cost. Once a company has the inventory, it cannot change what it paid for it. Thus the only relevant issue is what can be done with the inventory. If there is a choice of selling the inventory for less than what the company paid for it or not selling it at all, it is certainly better to get something rather than nothing for it.6-28 (10-15 min.)1. IndependentPractice Employee DifferenceOperating revenues $350,000 $110,000 $240,000 Operating expenses 220,000 -- 220,000 Income effects per year $130,000 $110,000 $ 20,000Choose Independent Practice Revenues $350,000 Expenses:Outlay costs $220,000Opportunity cost of employee compensation 110,000 330,000 Income effects per year $ 20,000 Each tabulation produces the key difference of $20,000. As a general rule, wefavor using the first tabulation when feasible. It offers a straightforwardpresentation of inflows and outflows under sharply stated alternatives.2. Choice as EmployeeRevenue $ 110,000Expenses:Outlay costs $ 0Opportunity cost of accounting practice 130,000 130,000Income effects per year $ (20,000)If the employee alternative is selected, the key difference in favor of becoming asole practitioner is again $20,000. Bridgeman is sacrificing $20,000 to avoid therisks of an independent practice.6-29 (10-15 min.)Alternatives Under Consideration(1) (2) (1) - (2)Sell, Rent, and HoldInvest in Bonds Present Home DifferenceRevenue $10,000* $ - $10,000 Less: Outlay cost 12,000 6,000 6,000 Income effects per year $ (2,000) $(6,000) $ 4,000 *5%× $200,000Advantage of selling the home is $6,000 - $2,000 = $4,000. Obviously, if rent is higher, the advantage decreases.The above analysis does not contain explicit opportunity costs. If opportunity costs were a part of the analysis, the following presentation applies (whereby the interest on investment in bonds is not listed as a separate alternative but is regarded as a forgone alternative):Alternative Chosen:Hold Present HomeOpportunity cost $(10,000)Outlay cost 6,000Income effects per year $ (4,000)As before, the advantage of selling the home and renting is $4,000. The opportunity cost of home ownership is 5% × 200,000 = $10,000.6-30 (15-20 min.) Opportunity cost is the maximum available contribution to profit forgone by using limited resources for a particular purpose. In this case, the opportunity cost of the machine when analyzing the alternative to produce 12-oz. bottles of Juice Cocktails is $90,000, the larger of the $90,000 contribution margin from additional sales of the 100% Juices or the $75,000 proceeds from the sale of the machine. The $160,000 historical cost of the machine is a past cost and thus irrelevant.6-31 (15-20 min.) The first tabulation is probably easier to understand, but the choiceof a tabulation is a matter of taste:(a) (b) (c)Expand Expand Rent toLaboratory Eye GiftTesting Clinic Shop Revenues $330,000 $500,000 $11,000Expenses 290,000 480,000 0Income effects per year $ 40,000 $ 20,000 $11,000Treating the gift shop as the forgone (rejected) alternative, the tabulation is:(a) (b)Expand ExpandLaboratory Testing Eye Clinic Revenue $330,000 $500,000 Expenses:Outlay costs $290,000 $480,000Opportunity cost,rent forgone 11,000 301,000 11,000 491,000 Income effects per year $ 29,000 $ 9,000The numbers favor laboratory testing, which will generate a contribution to hospital income that is $20,000 greater than the eye clinic's.The numbers have been analyzed correctly under both tabulations. Both answer the key query: What difference does it make? As a general rule, we prefer using the first tabulation. It is a straightforward presentation.6-32 (15 min.)1. It is easiest to analyze total costs, not unit costs.Make PurchaseDirect materials $400,000Avoidable overhead costs:Indirect labor 30,000Supplies 20,000Allocated occupancy cost 0Purchase cost $420,000Total relevant costs $450,000 $420,000The difference in favor of purchasing is $450,000 - $420,000 = $30,000.2. Because the quantitative difference is small, qualitative factors may dominate thedecision. Companies using a just-in-time system need assurance of both qualityand timeliness of supplies of materials, parts, and components. A small, localcompany may not be reliable enough for Bose. In essence, Bose may be willing to "invest" $30,000, the quantitative advantage of purchasing, in order to have more control over the supply of the components.The division manager may have made the right decision for the wrong reason. He incorrectly ignored avoidable fixed costs, leading to a mistaken belief that making the components was less costly by $.20 per unit or $20,000 in total. The $50,000 of avoidable fixed costs makes the purchase option less costly by $30,000. If themanager's decision is to make the component, it should be because forgoingprofits of $30,000 has a long-run qualitative benefit of more than $30,000, notbecause the bid is greater than the variable cost6-33 (20-25 min.)Nantucket Nectars should make the bottles.Make BuyPer PerTotal Bottle Total Bottle Purchase cost $250,000 $.250 Direct materials $80,000 $.080Direct labor 30,000 .030Variable overhead 60,000 .060Avoidable fixedoverhead 60,000 .060Total relevant costs $230,000 $.230 $250,000 $.250 Difference in favor of making $ 20,000 $.0206-34 (15-20 min.)Buy andUse。

Cash Flow Statements♦ 1 FRS 1: Cash flow statementsThe conventional profit and loss account and balance sheet are drawn up according to the rules of accruals accounting. Accruals accounting requires judgment in regard to areas such as:♦stock valuation♦depreciation policy♦provision for doubtful debts.This makes it difficult to interpret a company’s results with confidence. Cash flows are less subject to manipulation. Standard headings an in FRS 1 cash flow statement♦Net cash flow from operating activities♦Dividends from associates (not examinable)♦Returns on investments and servicing of finance♦Taxation♦Capital expenditure♦Acquisitions and disposals (not examinable)♦Equity dividends paid♦Management of liquid resources♦Financing♦Increase/decrease in cash.Proforma cash flow statement for the year ended 31 December 20X4£000 £000Net cash flow from operating activities (note 1) X Returns on investments and servicing of financeInterest received XInterest paid (X)___X Taxation(X) Capital expenditurePayments to acquire intangible fixed assets (X)Payments to acquire tangible fixed assets (X)Receipts from sale of tangible fixed assets X___(X) Equity dividends paid (X) Management of liquid resourcesPurchase of treasury bills (X)Sale of treasury bills X___(X) FinancingIssue of ordinary share capital XRepurchase of debenture loan (X)Expenses paid in connection with share issue (X)___X___Increase in cash X___Three notes are also required by FRS 1.a. Reconciliation of operating profit to net cash flow from operating activities£000 Operating profit XDepreciation charges XIncrease in stocks (X)Increase in debtors (X)Increase in creditors X___Net cash inflow from operating activities X___b. Reconciliation of net cash flow to movement in net debt£000 £000 Increase in cash in the period XCash to repurchase debenture XCash used to increase liquid resources X___Change in net debt* XNet debt at 1 January 20X6 (X)___Net funds at 31 December 20X6 X___*In this example all changes in net debt are cashflows.c. Analysis of changes in net debtAt 1 January Other At 31 December20X6 Cash flows changes 20X6£000 £000 £000 £000 Cash in hand and bank X X X XOverdrafts (X) X X –Long-term debt (X) X X (X)Current asset investments X X X X____________Total (X) X X X____________♦♦ 2 The elements of a cash flow statementNet cash flow from operating activities♦Start with the operating profit shown in the profit and loss account.♦Adjust for transactions not involving the movement of cash.♦This reconciliation from operating profit to operating cash flow can be shown as note 1 to the cash flow statement.•Returns on investments and servicing of finance: include dividends received here whilst equity dividends paid are disclosed separately, lower down the cash flow statement. •Taxation: this is tax paid during the year, not the tax charged in the profit and loss account.The same is true for dividends.•Management of liquid resources: liquid resources are short-term or current asset investments.•Financing will include any or all of the following elements.♦Proceeds of share issues♦Payments to redeem a loan♦Proceeds on taking out a new loan♦Increase/decrease in cash: this includes cash in hand plus deposits repayable on demand, less any overdrafts.3 Preparing a cash flow statementDirect and indirect methods for calculating the net cash inflow from operating activities. FRS 1 permits either the direct method or the indirect method to be used to calculate the net cash flow from operating activities.♦The indirect method begins with operating profit from the profit and loss account and adjusts this figure for non-cash items and for increases and decreases in working capital.♦The direct method uses the actual trading cash flows to arrive at the net cash flow from operating activities. It is less commonly used.FRS 1 questions usually appear in the same format: you are given two balance sheets plus additional information. To tackle these questions, work down the balance sheets identifying the movements between the two and then decide where each movement should be disclosed on the cash flow statement or the notes (or sometimes both).When you have dealt with a line on the balance sheet, tick it off.Note 3 has four columns.♦For each element of net debt, put the opening balance sheet amount in column one,♦the closing balance sheet amount in column four and♦the difference in columns two and three (as appropriate)Note 2 is simply a summary of the information produced in Note 3.The movement or change column is produced first with the cash and overdraft movement being combined and the current asset investment change and long-term debt change being shown separately. Note that all Note 2 figures can be taken from Note 3, so make sure that you prepare Note 3 first.。




Cash flow statement Prof.(FH) Dr. Walter EggerIAS 7• Structure– Operating activities– Investing activities– Financing activities– Change in cash and cash equivalents (up to 3 month)IAS 7• Operating activities– cash flow of the profit of the year– Changes in working capital• Investing activities– Purchase and sale of intangible assets andfixed assets– Purchase and sale of current and non-current financial instrumentsIAS 7• Financing activities– Proceeds from issuing capital– Payments to owners (capital)– Payments of dividends– Proceeds from issuing debentures, loans, notes,bonds, mortgages and other short term borrowings – Repayment of amounts borrowed– Cash payment by a lessee for the reduction of theoutstanding liability relating to a finance leaseIAS 7• Foreign currency cash flows– Average exchange rate of the year– Non cash difference as a single item forreconciliation of cash and cash equivalents • Interest and dividends– Payments have to be disclosed seperately – Allocation to operating or other activitiespossibleIAS 7• Taxes on income– Cash flows to be disclosed seperately– Operating activities• Investments/disposals of subsidiaries – Single item in investing activities (net cash)IAS 7• Non-cash transactions– Acquisition of assets either by assumingdirectly related liabilities or by means of afinance lease– Acquisition of an entity by means of an equity issue– Conversion of debt to equity。