
?????????
??????
?????=01
00000001001010000
010*********
Edge 第8章 图
8-1 画出1个顶点、2个顶点、3个顶点、4个顶点和5个顶点的无向完全图。试证明在n 个顶点的无向完全图中,边的条数为n(n -1)/2。 【解答】 【证明】
在有n 个顶点的无向完全图中,每一个顶点都有一条边与其它某一顶点相连,所以每一个顶点有n -1
条边与其他n -1个顶点相连,总计n 个顶点有n(n -1)条边。但在无向图中,顶点i 到顶点j 与顶点j 到顶点i 是同一条边,所以总共有n(n -1)/2条边。
8-2 右边的有向图是强连通的吗?请列出所有的简单路径。 【解答】
判断一个有向图是否强连通,要看从任一顶点出发是否能够回到该顶
点。右面的有向图做不到这一点,它不是强连通的有向图。各个顶点自成强连通分量。
所谓简单路径是指该路径上没有重复的顶点。
从顶点A 出发,到其他的各个顶点的简单路径有A →B ,A →D →B ,A →B →C ,A →D →B →C ,A →D ,A →B →E ,A →D →E ,A →D →B →E ,A →B →C →F →E ,A →D →B →C →F →E ,A →B →C →F ,A →D →B →C →F 。
从顶点B 出发,到其他各个顶点的简单路径有B →C ,B →C →F ,B →E ,B →C →F →E 。 从顶点C 出发,到其他各个顶点的简单路径有C →F ,C →F →E 。
从顶点D 出发,到其他各个顶点的简单路径有D →B ,D →B →C ,D →B →C →F ,D →E ,D →B →E ,D →B →C →F →E 。
从顶点E 出发,到其他各个顶点的简单路径无。 从顶点F 出发,到其他各个顶点的简单路径有F →E 。
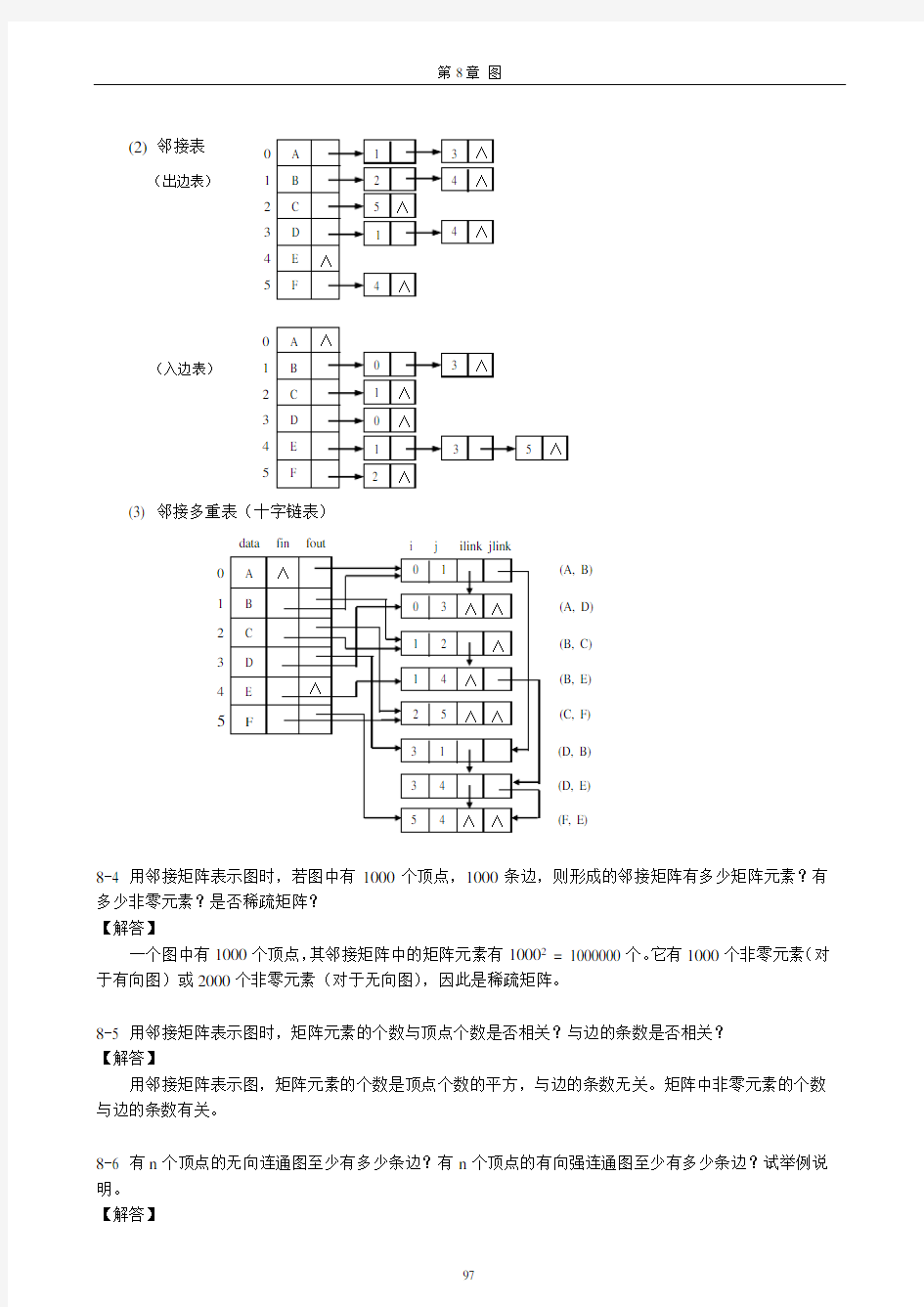
8-3 给出右图的邻接矩阵、邻接表和邻接多重表表示。 【解答】
(1) 邻接矩阵
1个顶点的 无向完全图
2个顶点的 无向完全图
3个顶点的 无向完全图 4个顶点的 无向完全图
5个顶点的 无向完全图
(2) 邻接表 (3) 邻接多重表(十字链表)
8-4 用邻接矩阵表示图时,若图中有1000个顶点,1000条边,则形成的邻接矩阵有多少矩阵元素?有多少非零元素?是否稀疏矩阵? 【解答】
一个图中有1000个顶点,其邻接矩阵中的矩阵元素有10002 = 1000000个。它有1000个非零元素(对于有向图)或2000个非零元素(对于无向图),因此是稀疏矩阵。
8-5 用邻接矩阵表示图时,矩阵元素的个数与顶点个数是否相关?与边的条数是否相关? 【解答】
用邻接矩阵表示图,矩阵元素的个数是顶点个数的平方,与边的条数无关。矩阵中非零元素的个数与边的条数有关。
8-6 有n 个顶点的无向连通图至少有多少条边?有n 个顶点的有向强连通图至少有多少条边?试举例说明。 【解答】
12345
0 1 2 3 4 5
(出边表)
(入边表)
12345data fin fout (A, B) (A, D) (B, C)
(B, E) (C, F) (D, B) (D, E) (F, E)
①
②③
④⑤或
①
②③
④⑤
①
②③
④⑤
①
②③
④⑤
n个顶点的无向连通图至少有n-1条边,n个顶点的有向强连通图至少有n条边。例如:
特例情况是当n = 1时,此时至少有0条边。
8-7对于有n个顶点的无向图,采用邻接矩阵表示,如何判断以下问题:图中有多少条边?任意两个顶点i和j之间是否有边相连?任意一个顶点的度是多少?
【解答】
用邻接矩阵表示无向图时,因为是对称矩阵,对矩阵的上三角部分或下三角部分检测一遍,统计其中的非零元素个数,就是图中的边数。如果邻接矩阵中A[i][j] 不为零,说明顶点i与顶点j之间有边相连。此外统计矩阵第i行或第i列的非零元素个数,就可得到顶点i的度数。
8-8对于如右图所示的有向图,试写出:
(1) 从顶点①出发进行深度优先搜索所得到的深度优先生成树;
(2) 从顶点②出发进行广度优先搜索所得到的广度优先生成树;
【解答】
(1) 以顶点①为根的深度优先生成树(不唯一):②③④⑤⑥
(2) 以顶点②为根的广度优先生成树:
8-9 试扩充深度优先搜索算法,在遍历图的过程中建立生成森林的左子女-右兄弟链表。算法的首部为void Graph::DFS ( const int v, int visited [ ], TreeNode
【解答】
为建立生成森林,需要先给出建立生成树的算法,然后再在遍历图的过程中,通过一次次地调用这个算法,以建立生成森林。
te mplate
//从图的顶点v出发, 深度优先遍历图, 建立以t (已在上层算法中建立)为根的生成树。
Visited[v] = 1; int first = 1; TreeNode
int w = GetFirstNeighbor ( v );//取第一个邻接顶点
while ( w != -1 ) {//若邻接顶点存在
if ( vosited[w] == 0 ) { //且该邻接结点未访问过
p = new TreeNode
if ( first == 1 ) //若根*t还未链入任一子女
{ t->setFirstChild ( p );first = 0; }//新结点*p成为根*t的第一个子女
else q->setNextSibling ( p );//否则新结点*p成为*q的下一个兄弟
q = p;//指针q总指示兄弟链最后一个结点
DFS_Tree ( w, visited, q );//从*q向下建立子树
}
w = GetNextNeighbor ( v, w );//取顶点v排在邻接顶点w的下一个邻接顶点}
}
下一个算法用于建立以左子女-右兄弟链表为存储表示的生成森林。
template
//从图的顶点v出发, 深度优先遍历图, 建立以左子女-右兄弟链表表示的生成森林T。
T.root = NULL; int n =NumberOfVertices ( ); //顶点个数
TreeNode
int * visited = new int [ n ];//建立访问标记数组
for ( int v = 0; v < n; v++ ) visited[v] = 0;
for ( v = 0; v < n; v++ ) //逐个顶点检测
if ( visited[v] == 0 ) {//若尚未访问过
p = new TreeNode
if ( T.root == NULL ) T.root = p;//原来是空的生成森林, 新结点成为根
else q-> setNextSibling ( p );//否则新结点*p成为*q的下一个兄弟
q = p;
DFS_Tree ( v, visited, p );//建立以*p为根的生成树
}
}
8-10 用邻接表表示图时,顶点个数设为n,边的条数设为e,在邻接表上执行有关图的遍历操作时,时间代价是O(n*e)?还是O(n+e)?或者是O(max(n,e))?
【解答】
在邻接表上执行图的遍历操作时,需要对邻接表中所有的边链表中的结点访问一次,还需要对所有的顶点访问一次,所以时间代价是O(n+e)。
8-11 右图是一个连通图,请画出
(1) 以顶点①为根的深度优先生成树;
(2) 如果有关节点,请找出所有的关节点。
(3)如果想把该连通图变成重连通图,至少在图中加几条边?如何加?
【解答】
(1) 以顶点①为根的深度优先生成树:⑩①②
③④⑤
⑥
⑦
⑧
⑨
(2) 关节点为 ①,②,③,⑦,⑧
(3) 至少加四条边 (1, 10), (3, 4), (4, 5), (5, 6)。从③的子孙结点⑩到③的祖先结点①引一条边,从②
的子孙结点④到根①的另一分支③引一条边,并将⑦的子孙结点⑤、⑥与结点④连结起来,可使其变为重连通图。
8-12试证明在一个有n 个顶点的完全图中,生成树的数目至少有2n-1-1。 【证明】略
8-13 编写一个完整的程序,首先定义堆和并查集的结构类型和相关操作,再定义Kruskal 求连通网络的最小生成树算法的实现。并以右图为例,写出求解过程中堆、并查集和最小生成树的变化。 【解答】 求解过程的第一步是对所有的边,按其权值大小建堆:
①
② ③
④ ⑤
⑥
11 7
6
8
5
10
9
7
⑩
① ②
③
④
⑤
⑥ ⑦ ⑧
⑨
⑩
① ②
③
④
⑤
⑥ ⑦ ⑧
⑨
加(1, 2), (1, 3),
(2,3)
加(2, 4)
加(3, 4)
加(3, 5) 加(3, 6)
加(5, 6)
求解过程中并查集与堆的变化:
最后得到的生成树如下
完整的程序如下:
#include
template
MinHeap ( int Maxsize = MaxHeapSize ); MinHeap ( Type Array[ ], int n ); void Insert ( const Type &ele ); void RemoveMin ( Type &Min );
void Output ();
private: void FilterDown ( int start , int end ); void FilterUp ( int end ); Type *pHeap ; int HMaxSize ;
int CurrentSize ; };
class UFSets { public:
3 1 -6 3 3 5 1 3 11 3 5 7
2 4 9
2 3 10
3 6 8 ①
② ③
④ ⑤
⑥
6
7
5
7
9
③ ④
选(3,4,5)
③ ④ ⑤ ⑥
选(5,6,6)
③ ④ ⑤ ⑥
选(1,2,7)
① ② ③ ④ ⑤
⑥
选(3,5,7) ① ② 1 3 11
2 4 9 2
3 10
3 6 8
③ ④ ⑤
⑥ 选(3,6,8), 在同一连通分量上, 不加 ① ② 1 3 11
2 3 10 2 4 9
③ ④ ⑤
⑥ 选(2,4,9), 结束
① ②
1 3 11
2 3 10
0 1 2 3 4 5 6
并查集的存储表示
enum { MaxUnionSize = 50 };
UFSets ( int MaxSize = MaxUnionSize );
~UFSets () { delete [ ] m_pParent; }
void Union ( int Root1, int Root2 );
int Find ( int x );
private:
int m_iSize;
int *m_pParent;
};
class Graph {
public:
enum { MaxVerticesNum = 50 };
Graph( int Vertices = 0) { CurrentVertices = Vertices; InitGraph(); } void InitGraph ();
void Kruskal ();
int GetVerticesNum () { return CurrentVertices; }
private:
int Edge[MaxVerticesNum][MaxVerticesNum];
int CurrentVertices;
};
class GraphEdge {
public:
int head, tail;
int cost;
int operator <= ( GraphEdge &ed );
};
GraphEdge :: operator <= ( GraphEdge &ed ) {
return this->cost <= ed.cost;
}
UFSets :: UFSets ( int MaxSize ) {
m_iSize = MaxSize;
m_pParent = new int[m_iSize];
for ( int i = 0; i < m_iSize; i++ ) m_pParent[i] = -1;
}
void UFSets :: Union ( int Root1, int Root2 ) {
m_pParent[Root2] = Root1;
}
int UFSets :: Find ( int x ) {
while ( m_pParent[x] >= 0 ) x = m_pParent[x];
return x;
}
template
pHeap = new Type[HMaxSize];
CurrentSize = -1;
}
template
pHeap = new Type[HMaxSize];
for ( int i = 0; i < n; i++ ) pHeap[i] = Array[i];
CurrentSize = n-1;
int iPos = ( CurrentSize - 1 ) / 2;
while ( iPos >= 0 ) {
FilterDown ( iPos, CurrentSize );
iPos--;
}
}
template
Type Temp = pHeap[i];
while ( j <= end ) {
if ( j < end && pHeap[j+1] <= pHeap[j] ) j++;
if ( Temp <= pHeap[j] ) break;
pHeap[i] = pHeap[j];
i = j; j = 2 * j + 1;
}
pHeap[i] = Temp;
}
template
Type Temp = pHeap[i];
while ( i > 0 ) {
if ( pHeap[j] <= Temp ) break;
pHeap[i] = pHeap[j];
i = j; j = ( j - 1 ) / 2;
}
实验2 查找算法的实现和应用?实验目的 1. 熟练掌握静态查找表的查找方法; 2. 熟练掌握动态查找表的查找方法; 3. 掌握hash表的技术. ?实验内容 1.用二分查找法对查找表进行查找; 2.建立二叉排序树并对该树进行查找; 3.确定hash函数及冲突处理方法,建立一个hash表并实现查找。 程序代码 #include cout<<"Not present!"; } return 0; } 结果 二叉排序树 #include 一,实验题目 实验十一:图实验 采用邻接表存储有向图,设计算法判断任意两个顶点间手否存在路径。 二,问题分析 本程序要求采用邻接表存储有向图,设计算法判断任意两个顶点间手否存在路径,完成这些操作需要解决的关键问题是:用邻接表的形式存储有向图并输出该邻接表。用一个函数实现判断任意两点间是否存在路径。 1,数据的输入形式和输入值的范围:输入的图的结点均为整型。 2,结果的输出形式:输出的是两结点间是否存在路径的情况。 3,测试数据:输入的图的结点个数为:4 输入的图的边得个数为:3 边的信息为:1 2,2 3,3 1 三,概要设计 (1)为了实现上述程序的功能,需要: A,用邻接表的方式构建图 B,深度优先遍历该图的结点 C,判断任意两结点间是否存在路径 (2)本程序包含6个函数: a,主函数main() b,用邻接表建立图函数create_adjlistgraph() c,深度优先搜索遍历函数dfs() d,初始化遍历数组并判断有无通路函数dfs_trave() e,输出邻接表函数print() f,释放邻接表结点空间函数freealgraph() 各函数间关系如右图所示: 四,详细设计 (1)邻接表中的结点类型定义: typedef struct arcnode{ int adjvex; arcnode *nextarc; }arcnode; (2)邻接表中头结点的类型定义: typedef struct{ char vexdata; arcnode *firstarc; }adjlist; (3)邻接表类型定义: typedef struct{ adjlist vextices[max]; int vexnum,arcnum; }algraph; (4)深度优先搜索遍历函数伪代码: int dfs(algraph *alg,int i,int n){ arcnode *p; visited[i]=1; p=alg->vextices[i].firstarc; while(p!=NULL) { if(visited[p->adjvex]==0){ if(p->adjvex==n) {flag=1; } dfs(alg,p->adjvex,n); if(flag==1) return 1; } p=p->nextarc; } return 0; } (5)初始化遍历数组并判断有无通路函数伪代码: void dfs_trave(algraph *alg,int x,int y){ int i; for(i=0;i<=alg->vexnum;i++) visited[i]=0; dfs(alg,x,y); } 五,源代码 #include "stdio.h" #include "stdlib.h" #include "malloc.h" #define max 100 typedef struct arcnode{ //定义邻接表中的结点类型 int adjvex; //定点信息 arcnode *nextarc; //指向下一个结点的指针nextarc }arcnode; typedef struct{ //定义邻接表中头结点的类型 char vexdata; //头结点的序号 arcnode *firstarc; //定义一个arcnode型指针指向头结点所对应的下一个结点}adjlist; typedef struct{ //定义邻接表类型 adjlist vextices[max]; //定义表头结点数组 数据结构实验指导书 实验一线性表的顺序存储结构 一、实验学时 4学时 二、背景知识:顺序表的插入、删除及应用。 三、目的要求: 1.掌握顺序存储结构的特点。 2.掌握顺序存储结构的常见算法。 四、实验内容 1.从键盘随机输入一组整型元素序列,建立顺序表。(注意:不可将元素个数和元素值写死在程序中) 2.实现该顺序表的遍历(也即依次打印出每个数据元素的值)。 3.在该顺序表中顺序查找某一元素,如果查找成功返回1,否则返回0。 4.实现把该表中某个数据元素删除。 5.实现在该表中插入某个数据元素。 6.实现两个线性表的归并(仿照课本上P26 算法2.7)。 7. 编写一个主函数,调试上述6个算法。 五、实现提示 1.存储定义 #include typedef int ElemType;//元素类型 typedef struct list{ ElemType *elem;//静态线性表 int length; //表的实际长度 int listsize; //表的存储容量 }SqList;//顺序表的类型名 2.建立顺序表时可利用随机函数自动产生数据。 3.为每个算法功能建立相应的函数分别调试,最后在主函数中调用它们。 六、注意问题 插入、删除元素时对于元素合法位置的判断。 七、测试过程 1.先从键盘输入元素个数,假设为6。 2.从键盘依次输入6个元素的值(注意:最好给出输入每个元素的提示,否则除了你自己知道之外,别人只见光标在闪却不知道要干什么),假设是:10,3,8,39,48,2。 3.遍历该顺序表。 4.输入待查元素的值例如39(而不是待查元素的位置)进行查找,因为它在表中所以返回1。假如要查找15,因为它不存在,所以返回0。 5.输入待删元素的位置将其从表中删掉。此处需要注意判断删位置是否合法,若表中有n个元素,则合法的删除位 云南大学软件学院数据结构实验报告 (本实验项目方案受“教育部人才培养模式创新实验区(X3108005)”项目资助)实验难度: A □ B □ C □ 学期:2010秋季学期 任课教师: 实验题目: 查找算法设计与实现 姓名: 王辉 学号: 20091120154 电子邮件: 完成提交时间: 2010 年 12 月 27 日 云南大学软件学院2010学年秋季学期 《数据结构实验》成绩考核表 学号:姓名:本人承担角色: 综合得分:(满分100分) 指导教师:年月日(注:此表在难度为C时使用,每个成员一份。) (下面的内容由学生填写,格式统一为,字体: 楷体, 行距: 固定行距18,字号: 小四,个人报告按下面每一项的百分比打分。难度A满分70分,难度B满分90分)一、【实验构思(Conceive)】(10%) 1 哈希表查找。根据全年级学生的姓名,构造一个哈希表,选择适当的哈希函数和解决冲突的方法,设计并实现插入、删除和查找算法。 熟悉各种查找算法的思想。 2、掌握查找的实现过程。 3、学会在不同情况下运用不同结构和算法求解问题。 4 把每个学生的信息放在结构体中: typedef struct //记录 { NA name; NA tel; NA add; }Record; 5 void getin(Record* a)函数依次输入学生信息 6 人名折叠处理,先将用户名进行折叠处理折叠处理后的数,用除留余数法构造哈希函数,并返回模值。并采用二次探测再散列法解决冲突。 7姓名以汉语拼音形式,待填入哈希表的人名约30个,自行设计哈希函数,用线性探测再散列法或链地址法处理冲突;在查找的过程中给出比较的次数。完成按姓名查询的操作。将初始班级的通讯录信息存入文件。 二、【实验设计(Design)】(20%) (本部分应包括:抽象数据类型的功能规格说明、主程序模块、各子程序模块的伪码说明,主程序模块与各子程序模块间的调用关系) 1抽象数据类型的功能规格说明和结构体: #include 重庆文理学院软件工程学院实验报告册 专业:_____软件工程__ _ 班级:_____软件工程2班__ _ 学号:_____201258014054 ___ 姓名:_____周贵宇___________ 课程名称:___ 数据结构 _ 指导教师:_____胡章平__________ 2013年 06 月 25 日 实验序号 1 实验名称实验一线性表基本操作实验地点S-C1303 实验日期2013年04月22日 实验内容1.编程实现在顺序存储的有序表中插入一个元素(数据类型为整型)。 2.编程实现把顺序表中从i个元素开始的k个元素删除(数据类型为整型)。 3.编程序实现将单链表的数据逆置,即将原表的数据(a1,a2….an)变成 (an,…..a2,a1)。(单链表的数据域数据类型为一结构体,包括学生的部分信息:学号,姓名,年龄) 实验过程及步骤1. #include { ElemType elem[MAXSIZE]; /*线性表占用的数组空间*/ int last; /*记录线性表中最后一个元素在数组elem[ ]中的位置(下标值),空表置为-1*/ }SeqList; #include "common.h" #include "seqlist.h" void px(SeqList *A,int j); void main() { SeqList *l; int p,q,r; int i; l=(SeqList*)malloc(sizeof(SeqList)); printf("请输入线性表的长度:"); scanf("%d",&r); l->last = r-1; printf("请输入线性表的各元素值:\n"); for(i=0; i<=l->last; i++) { scanf("%d",&l->elem[i]); } px(l,i); printf("请输入要插入的值:\n"); 图实验一,邻接矩阵的实现 1.实验目的 (1)掌握图的逻辑结构 (2)掌握图的邻接矩阵的存储结构 (3)验证图的邻接矩阵存储及其遍历操作的实现 2.实验内容 (1)建立无向图的邻接矩阵存储 (2)进行深度优先遍历 (3)进行广度优先遍历 3.设计与编码 MGraph.h #ifndef MGraph_H #define MGraph_H const int MaxSize = 10; template #include 实验报告 实验六图的应用及其实现 一、实验目的 1.进一步功固图常用的存储结构。 2.熟练掌握在图的邻接表实现图的基本操作。 3.理解掌握AOV网、AOE网在邻接表上的实现以及解决简单的应用问题。 二、实验内容 一>.基础题目:(本类题目属于验证性的,要求学生独立完成) [题目一]:从键盘上输入AOV网的顶点和有向边的信息,建立其邻接表存储结构,然后对该图拓扑排序,并输出拓扑序列. 试设计程序实现上述AOV网 的类型定义和基本操作,完成上述功能。 [题目二]:从键盘上输入AOE网的顶点和有向边的信息,建立其邻接表存储结构,输出其关键路径和关键路径长度。试设计程序实现上述AOE网类型定义和基本操作,完成上述功能。 测试数据:教材图7.29 【题目五】连通OR 不连通 描述:给定一个无向图,一共n个点,请编写一个程序实现两种操作: D x y 从原图中删除连接x,y节点的边。 Q x y 询问x,y节点是否连通 输入 第一行两个数n,m(5<=n<=40000,1<=m<=100000) 接下来m行,每行一对整数 x y (x,y<=n),表示x,y之间有边相连。保证没有重复的边。 接下来一行一个整数 q(q<=100000) 以下q行每行一种操作,保证不会有非法删除。 输出 按询问次序输出所有Q操作的回答,连通的回答C,不连通的回答D 样例输入 3 3 1 2 1 3 2 3 5 Q 1 2 D 1 2 Q 1 2 D 3 2 Q 1 2 样例输出 C C D 【题目六】 Sort Problem An ascending sorted sequence of distinct values is one in which some form of a less-than operator is used to order the elements from smallest to largest. For example, the sorted sequence A, B, C, D implies that A < B, B < C and C < D. in this problem, we will give you a set of relations of the form A < B and ask you to determine whether a sorted order has been specified or not. 【Input】 Input consists of multiple problem instances. Each instance starts with a line containing two positive integers n and m. the first value indicated the number of objects to sort, where 2 <= n<= 26. The objects to be sorted will be the first n characters of the uppercase alphabet. The second value m indicates the number of relations of the form A < B which will be given in this problem instance. 1 <= m <= 100. Next will be m lines, each containing one such relation consisting of three characters: an uppercase letter, the character "<" and a second uppercase letter. No letter will be outside the range of the first n letters of the alphabet. Values of n = m = 0 indicate end of input. 【Output】 For each problem instance, output consists of one line. This line should be one of the following three: Sorted sequence determined: y y y… y. Sorted sequence cannot be determined. Inconsistency found. 实验七图的创建与遍历 实验目的: 通过上机实验进一步掌握图的存储结构及基本操作的实现。 实验内容与要求: 要求: ⑴能根据输入的顶点、边/弧的信息建立图; ⑵实现图中顶点、边/弧的插入、删除; ⑶实现对该图的深度优先遍历; ⑷实现对该图的广度优先遍历。 备注:单号基于邻接矩阵,双号基于邻接表存储结构实现上述操作。算法设计: #include . } void EnQueue(int e) { base[rear]=e; rear=(rear+1)%QUEUE_SIZE; } void DeQueue(int &e) { e=base[front]; front=(front+1)%QUEUE_SIZE; } public: int *base; int front; int rear; }; //图G中查找元素c的位置 int Locate(Graph G,char c) { for(int i=0;i 邻接矩阵的实现 1. 实验目的 (1)掌握图的逻辑结构 (2)掌握图的邻接矩阵的存储结构 (3)验证图的邻接矩阵存储及其遍历操作的实现2. 实验内容 (1)建立无向图的邻接矩阵存储 (2)进行深度优先遍历 (3)进行广度优先遍历3.设计与编码MGraph.h #ifndef MGraph_H #define MGraph_H const int MaxSize = 10; template int vertexNum, arcNum; }; #endif MGraph.cpp #include 实验1 (C语言补充实验) 有顺序表A和B,其元素值均按从小到大的升序排列,要求将它们合并成一 个顺序表C,且C的元素也是从小到大的升序排列。 #include 求A QB #include #include 洛阳理工学院实验报告 附:源程序: #include { InsertBST(&((*bst)->lchild),key); return OK; } else if(key>(*bst)->key) { InsertBST(&((*bst)->rchild),key); return OK; } } void CreateBST(BSTree *bst) { int key; *bst=NULL; scanf("%d", &key); while (key!=ENDKEY) { InsertBST(bst, key); scanf("%d", &key); } } BSTree SearchBST(BSTree bst, int key) { if(!bst) return NULL; else if(bst->key==key) return bst; //查找成功 else if(bst->key>key) return SearchBST(bst->lchild,key); else return SearchBST(bst->rchild,key); 实验六图的应用及其实现 一、实验目的 1.进一步功固图常用的存储结构。 2.熟练掌握在图的邻接表实现图的基本操作。 3.理解掌握AOE网在邻接表上的实现及解决简单的应用问题。 二、实验内容 [题目]:从键盘上输入AOE网的顶点和有向边的信息,建立其邻接表存储结构,输出其关键路径和关键路径长度。试设计程序实现上述AOE网类型定义和基本操作,完成上述功能。 三、实验步骤 (一)、数据结构与核心算法的设计描述 本实验题目是基于图的基本操作以及邻接表的存储结构之上,着重拓扑排序算法的应用,做好本实验的关键在于理解拓扑排序算法的实质及其代码的实现。 (二)、函数调用及主函数设计 以下是头文件中数据结构的设计和相关函数的声明: typedef struct ArcNode // 弧结点 { int adjvex; struct ArcNode *nextarc; InfoType info; }ArcNode; typedef struct VNode //表头结点 { VertexType vexdata; ArcNode *firstarc; }VNode,AdjList[MAX_VERTEX_NUM]; typedef struct //图的定义 { AdjList vertices; int vexnum,arcnum; int kind; }MGraph; typedef struct SqStack //栈的定义 { SElemType *base; SElemType *top; int stacksize; }SqStack; int CreateGraph(MGraph &G);//AOE网的创建 int CriticalPath(MGraph &G);//输出关键路径 (三)、程序调试及运行结果分析 (四)、实验总结 在做本实验的过程中,拓扑排具体代码的实现起着很重要的作用,反复的调试和测试占据着实验大量的时间,每次对错误的修改都加深了对实验和具体算法的理解,自己的查错能力以及其他各方面的能力也都得到了很好的提高。最终实验结果也符合实验的预期效果。 四、主要算法流程图及程序清单 1、主要算法流程图: 2、程序清单: 创建AOE网模块: int CreateGraph(MGraph &G) //创建有向网 { int i,j,k,Vi,Vj; ArcNode *p; cout<<"\n请输入顶点的数目、边的数目"< 附录A 实验报告 课程:数据结构(c语言)实验名称:图的建立、基本操作以及遍历系别:数字媒体技术实验日期: 12月13号 12月20号 专业班级:媒体161 组别:无 姓名:学号: 实验报告内容 验证性实验 一、预习准备: 实验目的: 1、熟练掌握图的结构特性,熟悉图的各种存储结构的特点及适用范围; 2、熟练掌握几种常见图的遍历方法及遍历算法; 实验环境:Widows操作系统、VC6.0 实验原理: 1.定义: 基本定义和术语 图(Graph)——图G是由两个集合V(G)和E(G)组成的,记为G=(V,E),其中:V(G)是顶点(V ertex)的非空有限集E(G)是边(Edge)的有限集合,边是顶点的无序对(即:无方向的,(v0,v2))或有序对(即:有方向的, 无向图中顶点V i的度TD(V i)是邻接矩阵A中第i行元素之和有向图中, 顶点V i的出度是A中第i行元素之和 顶点V i的入度是A中第i列元素之和 邻接表 实现:为图中每个顶点建立一个单链表,第i个单链表中的结点表示依附于顶点Vi的边(有向图中指以Vi为尾的弧) 特点: 无向图中顶点Vi的度为第i个单链表中的结点数有向图中 顶点Vi的出度为第i个单链表中的结点个数 顶点Vi的入度为整个单链表中邻接点域值是i的结点个数 逆邻接表:有向图中对每个结点建立以Vi为头的弧的单链表。 图的遍历 从图中某个顶点出发访遍图中其余顶点,并且使图中的每个顶点仅被访问一次过程.。遍历图的过程实质上是通过边或弧对每个顶点查找其邻接点的过程,其耗费的时间取决于所采用的存储结构。图的遍历有两条路径:深度优先搜索和广度优先搜索。当用邻接矩阵作图的存储结构时,查找每个顶点的邻接点所需要时间为O(n2),n为图中顶点数;而当以邻接表作图的存储结构时,找邻接点所需时间为O(e),e 为无向图中边的数或有向图中弧的数。 实验内容和要求: 选用任一种图的存储结构,建立如下图所示的带权有向图: 要求:1、建立边的条数为零的图; 数据结构教程 上机实验报告 实验七、图算法上机实现 一、实验目的: 1.了解熟知图的定义和图的基本术语,掌握图的几种存储结构。 2.掌握邻接矩阵和邻接表定义及特点,并通过实例解析掌握邻接矩阵和邻接表的类型定义。 3.掌握图的遍历的定义、复杂性分析及应用,并掌握图的遍历方法及其基本思想。 二、实验内容: 1.建立无向图的邻接矩阵 2.图的xx优先搜索 3.图的xx优先搜索 三、实验步骤及结果: 1.建立无向图的邻接矩阵: 1)源代码: #include "stdio.h" #include "stdlib.h" #define MAXSIZE 30 typedefstruct{charvertex[MAXSIZE];//顶点为字符型且顶点表的长度小于MAXSIZE intedges[MAXSIZE][MAXSIZE];//边为整形且edges为邻近矩阵 }MGraph;//MGraph为采用邻近矩阵存储的图类型 voidCreatMGraph(MGraph *g,inte,int n) {//建立无向图的邻近矩阵g->egdes,n为顶点个数,e为边数inti,j,k; printf("Input data of vertexs(0~n-1): \n"); for(i=0;i 数据结构实验 实验四、图遍历的演示。 【实验学时】5学时 【实验目的】 (1)掌握图的基本存储方法。 (2)熟练掌握图的两种搜索路径的遍历方法。 【问题描述】 很多涉及图上操作的算法都是以图的遍历操作为基础的。试写一个程序,演示连通的无向图上,遍历全部结点的操作。 【基本要求】 以邻接多重表为存储结构,实现连通无向图的深度优先和广度优先遍历。以用户指定的结点为起点,分别输出每种遍历下的结点访问序列和相应生成树的边集。 【测试数据】 教科书图7.33。暂时忽略里程,起点为北京。 【实现提示】 设图的结点不超过30个,每个结点用一个编号表示(如果一个图有n个结点,则它们的编号分别为1,2,…,n)。通过输入图的全部边输入一个图,每个边为一个数对,可以对边的输入顺序作出某种限制。注意,生成树的边是有向边,端点顺序不能颠倒。 【选作内容】 (1)借助于栈类型(自己定义和实现),用非递归算法实现深度优先遍历。(2)以邻接表为存储结构,建立深度优先生成树和广度优先生成树,再按凹入表或树形打印生成树。 (3)正如习题7。8提示中分析的那样,图的路径遍历要比结点遍历具有更为广泛的应用。再写一个路径遍历算法,求出从北京到广州中途不过郑州的所有简单路径及其里程。 【源程序】 #include 一,实验题目 实验六堆栈实验 设计算法,把一个十进制整数转化为二进制数输出。 二,问题分析 本程序要求将一个十进制整数转化为二进制数输出。完成此功能所要解决的问题是熟练掌握和运用入栈和出栈操作,实现十进制整数转化为二进制数。 (1)数据的输入形式和输入值得范围:输入的是一个十进制整数,且其为正整数。 (2)结果的输出形式:输出的是一个二进制整数 (3)测试数据:1)9 2)4500 三,概要设计 1.为了实现上述程序功能,需要: 构造一个空的顺序栈s 将十进制整数除以2的余数入栈 将余数按顺序出栈 2.本程序包含7个函数: 1)主函数main(); 2)顺序栈判栈空函数stackempty(seqstack *s) 3)顺序栈置空栈函数seqstack *initstack(seqstack *s) 4)顺序栈入栈函数push(seqstack *s,int x) 5)顺序栈出栈函数pop(seqstack *s) 6)顺序栈取栈顶元素函数gettop(seqstack *s) 7)将十进制数转换为二进制数函数setnum(int num) 各函数间关系如下: 四,详细设计 1,顺序表的结构类型定义: typedef struct{ int data[maxlen]; int top; }seqstack; 2,顺序栈入栈函数的伪代码: void push(seqstack *s,int x){ if(s->top<=maxlen-1&&s->top>=-1){ s->top++; s->data[s->top]=x;} else printf("error");} 3,顺序栈出栈函数的伪代码: void pop(seqstack *s){ if(s->top>=0) s->top--; else printf("error"); } 4,将十进制数转换为二进制数函数伪代码: void setnum(int num){ seqstack s; initstack(&s); while(num){ int k=num%2; push(&s,k); num=num/2;} while(!stackempty(&s)){ int x=gettop(&s); printf("%d",x); pop(&s); } } 五,源代码 #include "stdio.h" #define maxlen 100 typedef struct{ //定义顺序栈的结构类型 int data[maxlen]; int top; }seqstack; int stackempty(seqstack *s){ //顺序栈判栈空算法if(s->top>=0) return 0; else return 1; } seqstack *initstack(seqstack *s){ //顺序栈置空栈算法s->top=-1; return s; } 精品文档数据结构 实 验 报 告 目的要求 1.掌握图的存储思想及其存储实现。 2.掌握图的深度、广度优先遍历算法思想及其程序实现。 3.掌握图的常见应用算法的思想及其程序实现。 实验内容 1.键盘输入数据,建立一个有向图的邻接表。 2.输出该邻接表。 3.在有向图的邻接表的基础上计算各顶点的度,并输出。 4.以有向图的邻接表为基础实现输出它的拓扑排序序列。 5.采用邻接表存储实现无向图的深度优先递归遍历。 6.采用邻接表存储实现无向图的广度优先遍历。 7.在主函数中设计一个简单的菜单,分别调试上述算法。 源程序: 主程序的头文件:队列 #include 数据结构实验十一:图实验
数据结构实验
数据结构实验报告七查找、
数据结构实验答案1
数据结构实验报告图实验
数据结构_实验六_报告
数据结构实验七图的创建与遍历
数据结构实验报告图实验
数据结构实验
数据结构第六章实验
数据结构实验六
数据结构实验六 图的应用及其实现
数据结构实验报告(图)
数据结构图实验报告
数据结构实验四五六
数据结构实验六 堆栈实验
数据结构实验—图实验报告
相关主题
文本预览